
Abstract
About 20% of individuals with attention deficit hyperactivity disorder are first diagnosed during adolescence. While preclinical experiments suggest that adolescent-onset exposure to attention deficit hyperactivity disorder medication is an important factor in the development of substance use disorder phenotypes in adulthood, the long-term impact of attention deficit hyperactivity disorder medication initiated during adolescence has been largely unexplored in humans. Our analysis of 11,624 adolescent enrollees with attention deficit hyperactivity disorder in the Truven database indicates that temporal medication features, rather than stationary features, are the most important factors on the health consequences related to substance use disorder and attention deficit hyperactivity disorder medication initiation during adolescence.
Keywords
Introduction
An estimated 1 out of 13 Americans (20.1 million) over the age of 12 are struggling with a substance use disorder (SUD), 1 and recently, SUD-related overdose deaths have surpassed the number of deaths attributed to motor vehicle accidents. 2 One of the potential risk factors for the development of SUD is an attention deficit hyperactivity disorder (ADHD) diagnosis. ADHD is one of the most prevalent neuropsychiatric disorders, with 6%–10% of children (aged 2–17) received a diagnosis. 3 Given that 62% of individuals diagnosed with ADHD receive medication therapies, 4 it is critical to systematically assess the long-term association of ADHD medication on subsequent risk of SUD.
The spontaneously hypertensive rat (SHR) model of ADHD has been extensively used to assess the impact of exposure to specific ADHD medications.5–11 Using the SHR model, we have recently reported that never medicated rats with an ADHD phenotype self-administered more cocaine than those without an ADHD phenotype. Moreover, the ADHD medication introduced during adolescence was an important factor associated with a further increase in cocaine self-administration in young adulthood.5–11 These preclinical findings suggest that medication type and age of medication initiation are critical factors in the relationship between ADHD pharmacotherapy and subsequent SUDs. Our hypothesis is:
Hypothesis: The initiation of ADHD medication during adolescence increases SUD risk beyond that associated with ADHD alone.
To test this hypothesis, big healthcare data analyses have been carried out. Healthcare data are a growing source of information that can be harnessed to advance our understanding of factors that increase the propensity for developing SUDs as well as those that aid in the treatment of the disorders. 12 Using healthcare data, two previous studies13,14 analyzed adolescent initiation of ADHD medication. Although both studies leveraged existing data sets, the findings lacked the specificity and sensitivity to assess age of initiation and medication types as factors associated with SUDs due to the inclusion of a heterogeneous study population (a wide range of ages 13–64 years old) and aggregated medication types. A big data analytical approach12,15,16 holds the potential to address such knowledge gaps using retrospectively aggregated data sets in an accelerated (faster), cost-effective (cheaper), and scientifically rigorous (better) manner.
A key limitation of the two studies above is the grouping of ADHD medications into a single variable,13,14 effectively ignoring the fact that large-scale healthcare data can provide detailed temporal medication records for every individual. It is our belief that such temporal data may encode critical information regarding the long-term impact of ADHD medication. To exploit the temporal dynamics in large historical data for improved management of chronic diseases, three classes of predictive models have been developed. First, stacked-temporal models (STMs) separate temporal data into fixed-size windows. From each window, the representation of dynamics is learned using simple statistical models. Finally, the variables from all the windows are concatenated to form the feature space for the prediction task. 17 One of the disadvantages of STM is that the representation features are all obtained within a window. Therefore, any temporal dynamics beyond the window size could be missed using the STM approach. Second, Hidden Markov models (HMMs), or more generally dynamic Bayesian networks, model a recurring probabilistic structure that holds constant over time. 18 However, the basic assumption of HMM that successive observations are independent is rarely held in healthcare data. 19 Third, the recently developed recurrent neural networks (RNNs) models are successful particularly for learning long-range dependency in temporal data. However, RNN could be inefficient if the healthcare data are sparse.
In this article, we address the technical challenges in analyzing temporal medication data and present a new framework to predict the long-term impact of ADHD medication initiated during adolescence. Our framework has three components: (1) data preprocessing, (2) SUD prediction using RNNs, and (3) hypothesis exploration by varying RNN and inputs. Experimental results show that temporal medication features of ADHD medication initiation during adolescence, rather than stationary features (e.g. medication type, age, sex), are the most important factors on the health consequences related to SUD.
Background
RNNs are powerful models in processing longitudinal data. Figure 1 shows a full RNN structure, where the circles represent the network layers and the solid lines represent the weighted connections. 20
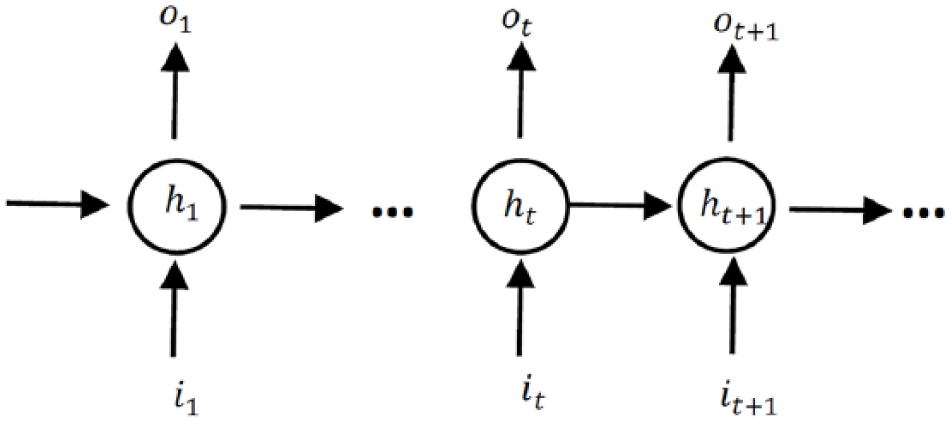
Unrolled structure of RNNs. The circles present hidden layers, it, ot and ht are respectively input, output, and hidden state at time step t.
The long-short term memory (LSTM) model is one of the most powerful RNNs. The LSTM has already been deployed successfully in analyzing temporal data in biomedical applications.21–23 In particular, the LSTM alleviates the vanishing gradient problems 24 and bridges time intervals in a sequence. In a LSTM model, nodes are replaced with a unit called memory cell as shown in Figure 2. 25 A memory cell includes the input gate, output gate, and forget gate. The input gate decides how to update the cell state using the new input and the output gate determines how to filter the output. The forget gate decides which information the LSTM is going to forget; it considers both it and ht and then, utilizing a sigmoid function, it generates a matrix with elements between 0 and 1. The previous cell state will be element wisely multiplied by the numbers generated by the forget gate to determine how much information the LSTM unit wants to keep.
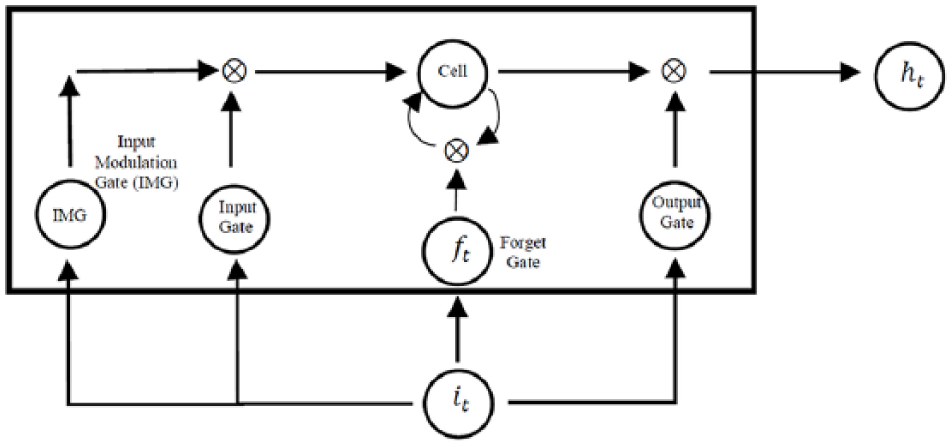
A LSTM memory cell. Each LSTM unit includes the input gate, the output gate, and the forget gate.
Materials and methods
Truven Health MarketScan data
Herein, we analyzed the large-scale administrative records in the Truven Health MarketScan Commercial Claims database (Truven) for the years 2009 to 2015. Data include person-specific clinical utilization, expenditures and enrollment across inpatient, outpatient, prescription drug, and carve-out services. This database contains about 30 million enrollees annually across the United States, and these enrollees are nationally representative of the US population with respect to sex (50% female), regional distribution, and age.
Although the population is disproportionately privately insured and middle class, the very large sample supports well-powered subgroup analysis. The Truven databases link paid claims and encounter data to detailed enrollee information across sites, types of providers, and over time. Historically, more than 20 billion service records are available each year. These data represent the medical experience of insured employees and their dependents for active employees, early retirees, and Medicare-eligible retirees with employer-provided Medicare Supplemental plans.
We extracted all the ADHD-related records from Truven between January 2009 and December 2015. We selected all the 254,996 individuals who had an International Classification of Disease (ICD-9) diagnosis of ADHD (ICD-9 code 314.X); among them, 136,933 are children (6–12 years) and 118,063 are adolescents (13–20 years) onset exposure to ADHD medication. For each of the enrollees with an ADHD diagnosis, all the ADHD medication records between January 2009 and December 2015 were extracted. In total, we extracted 11,778,912 records from Truven. The original format of the prescription and professional service encounter claims in Truven is a table where each row is a visit and columns are enrollee ID, date of visit, and prescription. If an enrollee has multiple visits, each visit will occupy a row in the table. To facilitate further study of the temporal patterns in the data, we converted the Truven format into an enrollee-time matrix X(P, T), where P is the complete set of ADHD enrollees and T is the set of time points between January 2009 and December 2015 (by month); each cell xij records the medications an enrollee pi took at time tj. Figure 3 shows the cohort definition and describes the process mentioned above. Here 12 ADHD medications were considered and categorized into four medication groups, that is, amphetamines, methylphenidate, modafinil, and others, based on the first eight digits of the generic product indicator (see Table 1 for details). Given the monthly subscription records in Truven, the finest temporal resolution of T is by month.
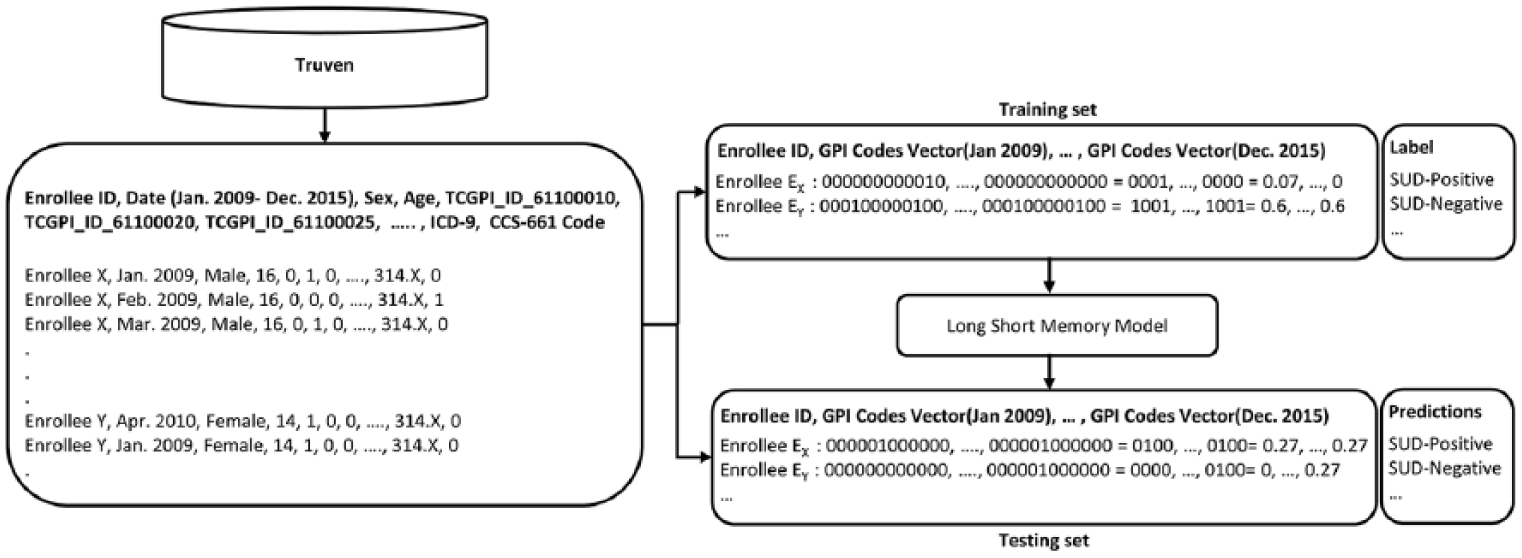
Cohort definition: All ADHD-related records from Truven between January 2009 to December 2015 have been extracted. The SUD-cohort includes ADHD individuals who have been diagnosed as having a SUD for the first time after he or she has received a prescription for an ADHD medication for at least 5 months. The SUD-control cohort includes ADHD individuals without any diagnosis of SUD during the follow-up period.
Generic product indicator of ADHD medications.
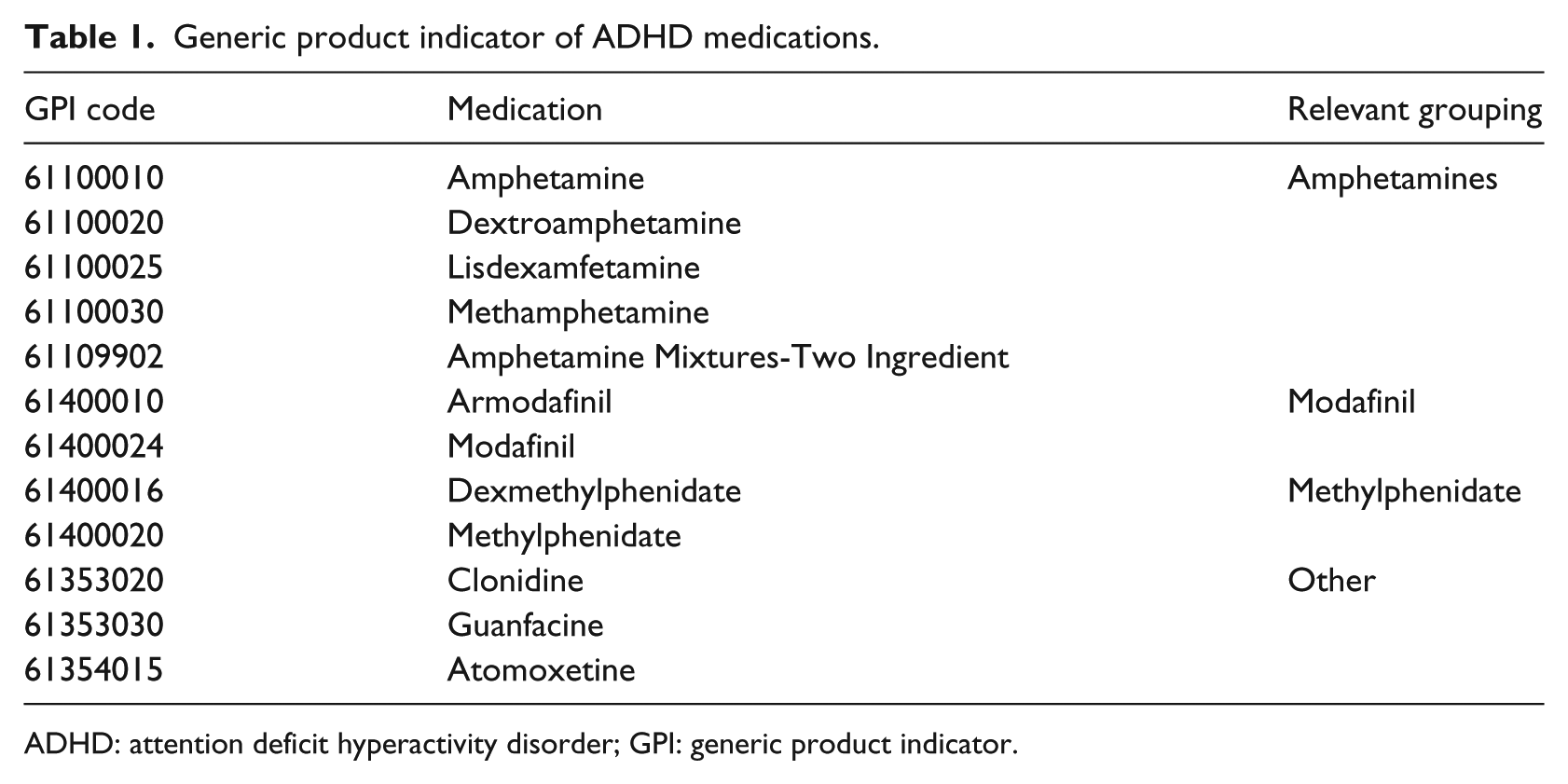
ADHD: attention deficit hyperactivity disorder; GPI: generic product indicator.
We directly plugged enrollee’s demographic information, including age and sex, into the longitudinal ADHD medication records, and then trained the LSTM. Specifically, for enrollee pi at time step tj, we converted the age of pi at tj into to a bit vector, which was then concatenated the vector with the ADHD medication record in cell x(i, j). Similarly, an additional bit was used to incorporate the sex information. This new format allows us to model both temporal and stationary features simultaneously.
We determined if an enrollee in P has been diagnosed as having a SUD for the first time after he or she has received a prescription for an ADHD medication for at least 5 months. If this condition is met, the enrollee is labeled as ADHD-SUD positive (label yi = 1 for enrollee pi) and all the ADHD medications after the first SUD diagnosis will be removed from X(P, T); otherwise, the enrollee is labeled as ADHD-SUD negative (label yi = 0 for enrollee pi). The extracted Truven data include detailed enrollee-level information over time, ready for assessing the long-term impact of ADHD medications. Figure 4 shows a simplified example of the longitudinal medical record data that have been created for an enrollee, and Figure 5 visualizes the entire medical record data. Each row in Figure 5 has a similar format to what is described in Figure 4; each pixel in each row is related to a time stamp (1 month) and its color shows the ADHD medication that an enrollee was prescribed.

A simplified example of the longitudinal medical record data. Each entry corresponds to a time step (a specific month) and shows the ADHD medications that enrollee was prescribed. If the enrollee did not use any medication during a specific month, the entry will be 0.
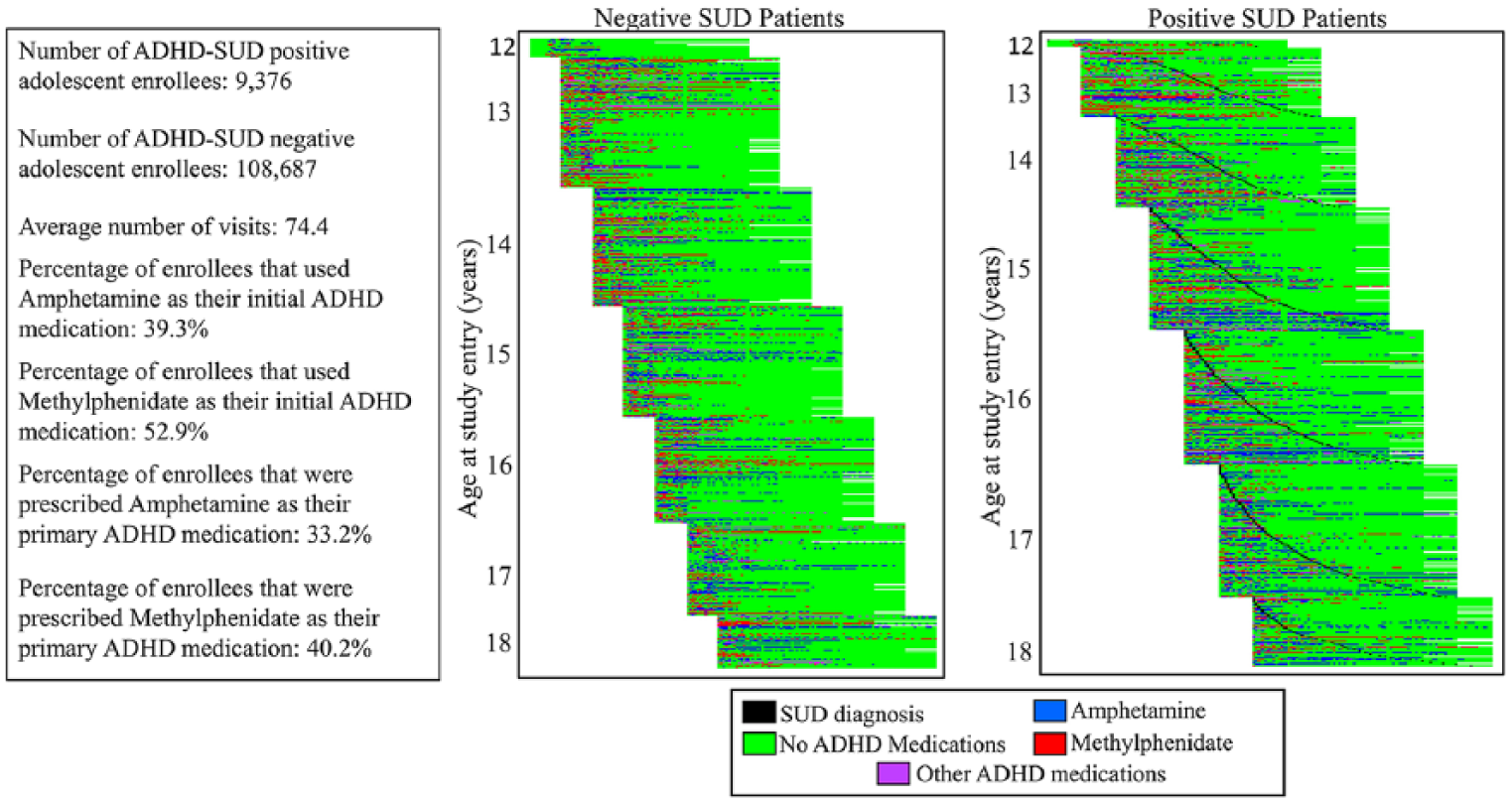
Visualization of the longitudinal data. Left figure describes SUD negative enrollees and right figure describes SUD positive enrollees. Enrollees are sorted based on their ages and in the right figure (SUD positives) they are also sorted based on the SUD diagnosis dates. Note that black dots highlight the time stamp when the ADHD enrollee is diagnosed with SUD.
On average, every enrollee has 74.4 visits and among them, the average number of visits for ADHD-SUD positive enrollee is 61.2. Regarding the type of ADHD medications that enrollees used, 39.3% of enrollees used amphetamine as their initial ADHD medication while 52.9% initiated with methylphenidate. Only a small portion (almost 1%) of enrollees were prescribed both as their first prescriptions. A medication is called the primary medication for an enrollee if the prescriptions for that medication occupy more than 80% of that enrollees ADHD medication prescriptions. Given the definition, 33.2% of enrollees are prescribed amphetamine as the primary ADHD medication and 40.2% of enrollees are prescribed methylphenidate as the primary ADHD medication. According to the above basic statistics, there is no significant bias in the data toward SUD. More sophisticated methods are required to extract knowledge from the Truven data.
Note, although adolescent ADHD medication initiators in the Truven data are represented less than child initiators, for those who are ADHD-SUD positive, data from adolescent enrollees are abundant, whereas data from children are insufficient for this analysis (see Figure 6). Therefore, although we have licensed a limited subset of Truven data, it is still appropriate to study the impact of the initiation of ADHD medication in adolescent enrollees.
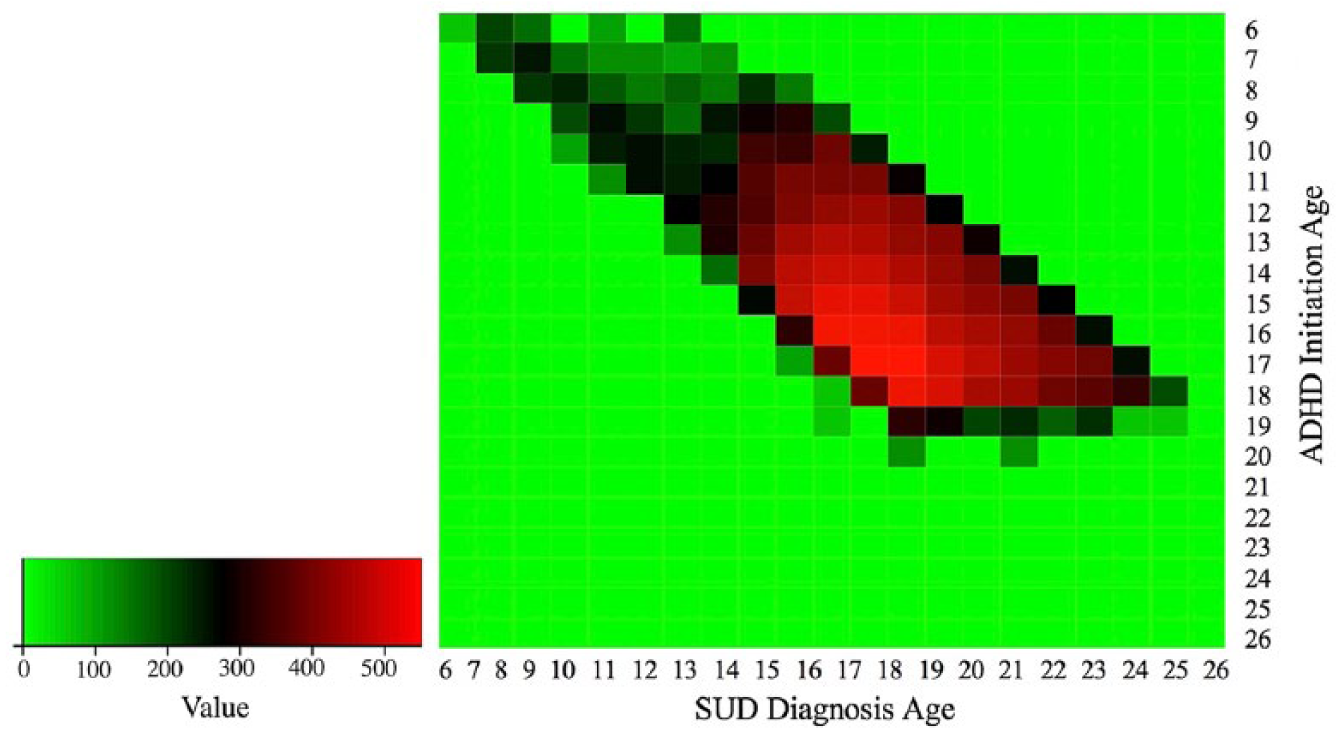
Visualization of data availability in the Truven data. Red indicates abundant medical records, black indicates insufficient medical records, and green means NA. Only the ADHD enrollees who develop SUD are included. Figure shows that in the Truven data, data from adolescent ADHD enrollees are abundant, while data from children with ADHD are insufficient for analysis.
Bayesian statistics
Truven is a complex national biomedical data set. To better understand the data, we explored it using Bayesian statistics. Specifically, we computed and compared the conditional probabilities of SUD given different types of ADHD medications.
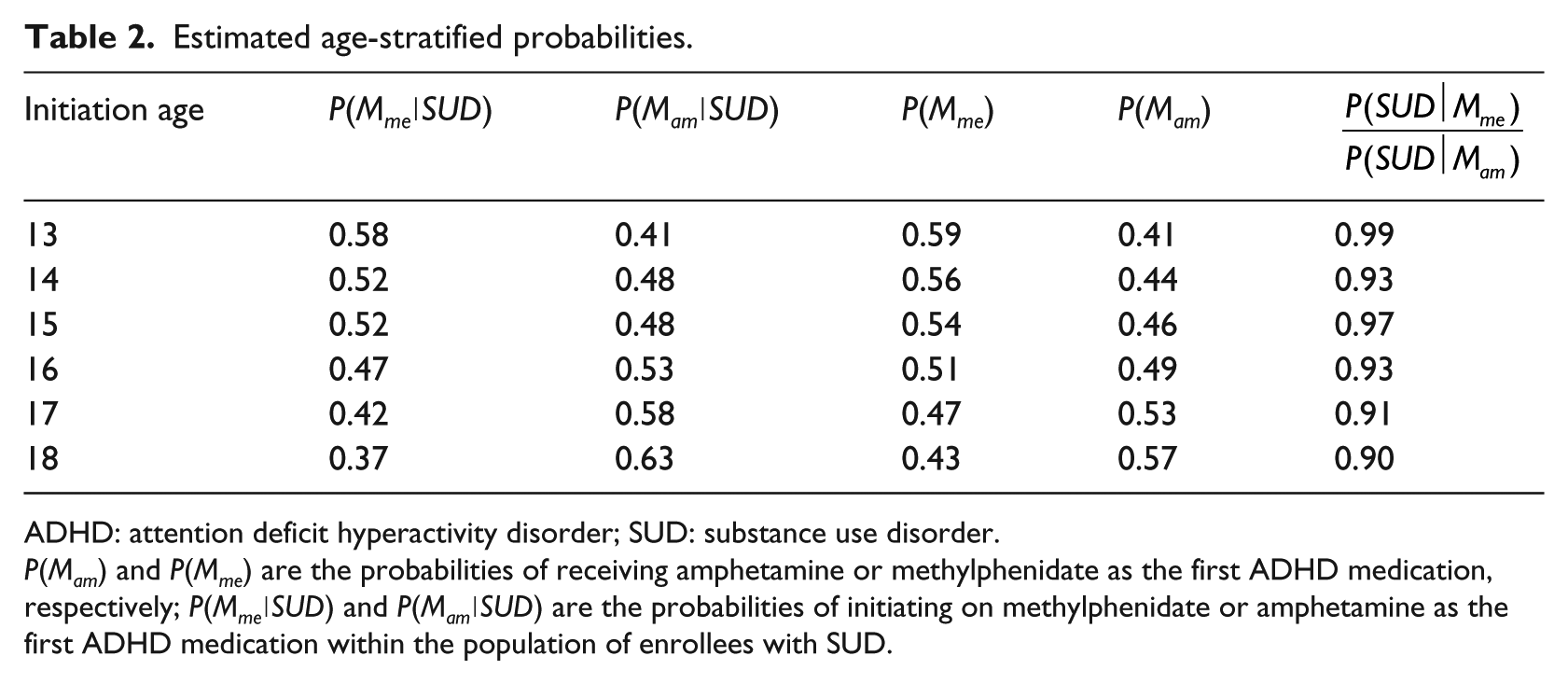
First, based on data availability, we stratified the Truven data into six subsets based on ADHD medication initiation age (13–18 years). For every subset, the probability of the SUD diagnosis for enrollees with ADHD were calculated for two types of initial ADHD medications, that is, methylphenidate, P(SUD∣Mme) and amphetamine, P(SUD∣Mam). These estimated probabilities (prevalence rates) can be included in a ratio to describe the relative probability (prevalence) of SUD for enrollees initiating on these medications. Table 2 shows an observed age-effect where those in the oldest age strata who initiated on amphetamine have elevated probabilities (prevalence) of SUD, relative to those who initiated on methylphenidate (last column provides relative probability ratios or prevalence rate ratios).
Estimated age-stratified probabilities.
ADHD: attention deficit hyperactivity disorder; SUD: substance use disorder.
P(Mam) and P(Mme) are the probabilities of receiving amphetamine or methylphenidate as the first ADHD medication, respectively; P(Mme∣SUD) and P(Mam∣SUD) are the probabilities of initiating on methylphenidate or amphetamine as the first ADHD medication within the population of enrollees with SUD.
However, these estimates are limited by only describing medication at initiation. This summary measure does not encompass a more comprehensive picture of medication utilization, and the over-simplification could miss important relationships between age at initiation, medication patterns, and subsequent SUDs in enrollees with ADHD.
Temporal model
Based on the preclinical studies, we hypothesize that the initiation of ADHD medication in adolescence would increase SUD risk beyond that associated with ADHD alone (see Hypothesis). However, neither the existing big data studies nor our Bayesian statistics are capable of identifying potential temporal relationships between ADHD medication and SUD in adolescent enrollees. This implies either our hypothesis is incorrect or the factors investigated are not simple factors, such as medication type and age of initiation, but may be hidden in the temporal medication data. To discover such advanced factors in the Truven data, we adopted the LSTM model to predict SUD using the temporal ADHD medication records in X(P, T) (see “Background” section for details). If critical information on the subsequent SUDs in adolescent ADHD exposure exists, and such critical information can be captured by a predictive model, then the performance of the model should be significantly higher than baseline models.
Applying a temporal model (such as the LSTM model) on healthcare data is nontrivial due to technical challenges inherent in the data including high dimensionality, heterogeneity, temporal dependency, sparsity, and irregularity. 26 Therefore, data preprocessing is critical to ensure high model performance.
In data preprocessing, we addressed two problems in the Truven data, that is, data sparsity and label imbalance problems. First, we reduced data sparsity. This is an important problem since in the enrollee medication record matrix X(P, T), 96.6% of medication records are simply empty (noted as zero). To address this, we removed all the empty records before the first ADHD medication record or after the last ADHD medication record. In addition, empty sequences, sequences in which the enrollee used ADHD medication for less than 5 months, and enrollees who started using ADHD medication less than 5 months prior to being diagnosed with SUD were all removed to further reduce noise and remove outliers. In the literature, the 3-, 6-, and 12-month break are commonly used as a baseline cut-off value to determine whether the medicine initialization is authentic.27,28 However, long ADHD breaks usually happen during the summer break which is approximately 2.5 to 3 months in the United States. It is clear that 3-month break is too short and 6- or 12-month break is too long. Alternatively, we used the 5-month break based on our previous experiences with SHR model of ADHD.5–11 Using the 5-month break also slightly enlarged the data set size from 10,836 to 11,462 (almost 6% increase) compared with using the 6-month breaks. Second, we addressed the label imbalance problem. The Truven data include in total of 118,063 enrollees with adolescent initiation of ADHD medication, 9376 of them are ADHD-SUD positive, and 108,687 of them are ADHD-SUD negative. The positive and the negative data sets are highly unbalanced and this can significantly affect training and optimization of any type of neural networks.29,30 In this article, we adopted a data level approach called focused under-sampling 31 to deal with the class imbalance problem. We first applied zero-padding to the input sequences so that the sequence lengths are the same, which makes it feasible for sequence comparison. Note that our LSTM model handles variable length sequences and this zero-padding strategy is only used during the preprocessing phase. Then, we applied the cosine similarity 32 to compare these sequences. We defined the cosine similarity between two sequences u and v as (we assumed each timestamp is i.i.d)

For every SUD-positive sample, we select one (or five) of the most similar SUD negative samples from the ADHD-SUD negative enrollee pool using cosine similarity (equation (1)); thus, a balanced (or a slightly unbalanced) data set was generated.
Hypothesis testing method
To predict SUD from the temporal ADHD medication records X(P, T), we adopted the LSTM model. Besides the temporal ADHD medication records, each enrollee has rich stationary features such as sex, ADHD initiation age, and medication type. Such stationary features could be critical factors toward the development of SUD. We used two different approaches to test the functionality of the stationary features. In the first approach, we encoded stationary features, including age and gender, into the longitudinal ADHD medication records. In the second approach, we separated the Truven data using each stationary feature as a partitioning criterion, such as separating enrollees into age groups, changing the granularity of the medication records, or ignoring medication-to-medication differences. Finally, we trained LSTM models on these data sets and compared model performance. If the model performance is significantly different than the model trained using complete data, then the selected enrollees regrouping criteria may be a critical factor toward the development of SUD because it provides an increased power to predict the development of SUD.
Note that an enrollee may be prescribed multiple medications at the same time point. Cell x(i, j) in X(P, T) is a vector of bits, each representing an ADHD medication and a bit is 1 if the corresponding medication is prescribed. Since the LSTM requires the input to be either a word or a value, we convert the vector of bits into an integer and then apply the Min-Max normalization to vanish the effect of scaling and map all values in [0, 1].
Experimental results
All the LSTM models were deployed on the TensorFlow platform 33 and were trained using eight GeForce GTX 1080 GPUs. Batch size, learning rate, number of hidden neurons, and number of epochs were set to be 256, 0.09, 75, and 100, respectively.
Two dummy models named All-Negatives and All-Positives, which label all validation samples as negatives or positives, respectively, served as baseline. Support vector machine (SVM) 34 and random forest (RF) models 35 were also compared with the LSTM models.
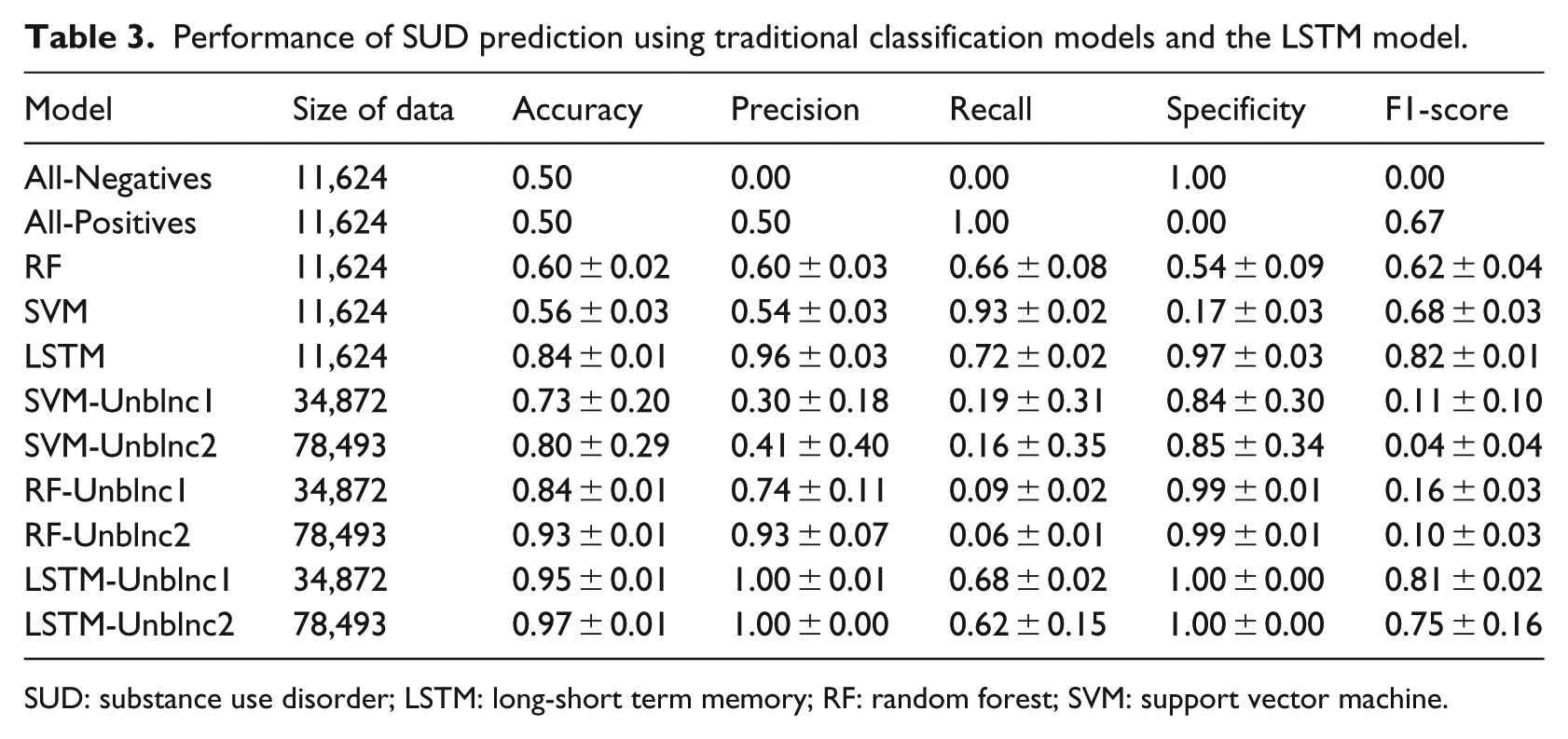
For systematic performance testing, each time we randomly selected 90% of the data as training data and the other 10% as testing data and repeated this process 20 times. Averaged performance on the unseen folds was reported as the final result. Parameters of SVM and RF were tuned using a 20-fold cross-validation and the averages of the best validation performance were reported in Table 3. Note that the performance of the baselines were even poorer than the validation performance. Accuracy, precision, recall, specificity, and F1-score were used to evaluate and compare different models. 36 In all models, we considered ADHD individuals with SUD as the positive samples and ADHD individuals without SUD as the negative samples.
Performance of SUD prediction using traditional classification models and the LSTM model.
SUD: substance use disorder; LSTM: long-short term memory; RF: random forest; SVM: support vector machine.
Experimental results on Truven data
Performance of the LSTM models, dummy models, and traditional classification models (SVM and RF) are provided in Table 3. In Table 3, the models “All-Negatives,” “All-Positives,” “RF,” “SVM,” and “LSTM” are all trained and tested on the balanced data set (refer to the “Temporal model” section to see the focused under-sampling and the cosine similarity that were adopted to create the balanced and the unbalanced data sets). In Table 3, regarding the balanced Truven data, the LSTM model has the highest accuracy (0.84), precision (0.96), specificity (0.97), and F1-score (0.82). The results indicate that LSTM captures important factors in the Truven data providing increased power to predict the development of SUD, while SVM and RF miss such factors.
In addition, we tested model performances on two unbalanced Truven data sets, that is, Unblnc1 (positive–negative ratio being 0.20) and Unblnc2 (positive–negative ratio being 0.08 when the complete Truven data were used). Table 3 shows the model performances on Unblnc1 and Unblnc2; X-Unblnc1 represents a model X trained on Unblnc1 data set. Table 3 shows that LSTM maintains high performance on both unbalanced data sets (LSTM-Unblnc1: precision = 1.00, recall = 0.68 and F1-score = 0.81 and LSTM-Unblnc2: precision = 1.00, recall = 0.62 and F1-score = 0.75). The high performance of the LSTM model indicates that the temporal medication records in the unbalanced Truven data encode critical factors that provide an increased power to predict the development of SUD in adolescent ADHD enrollees, which were captured by the LSTM model.
Figure 7(a) illustrates the robustness of the LSTM model. The performance of the LSTM model on both the training and the validation data sets remains stable when different learning rates were applied. Figure 7(b) shows the model performance over a wide range of number of hidden neurons, and Figure 7(c) shows how the variation of the number of epochs affected the LSTM model performance. In both experiments, the LSTM model performance remained stable.
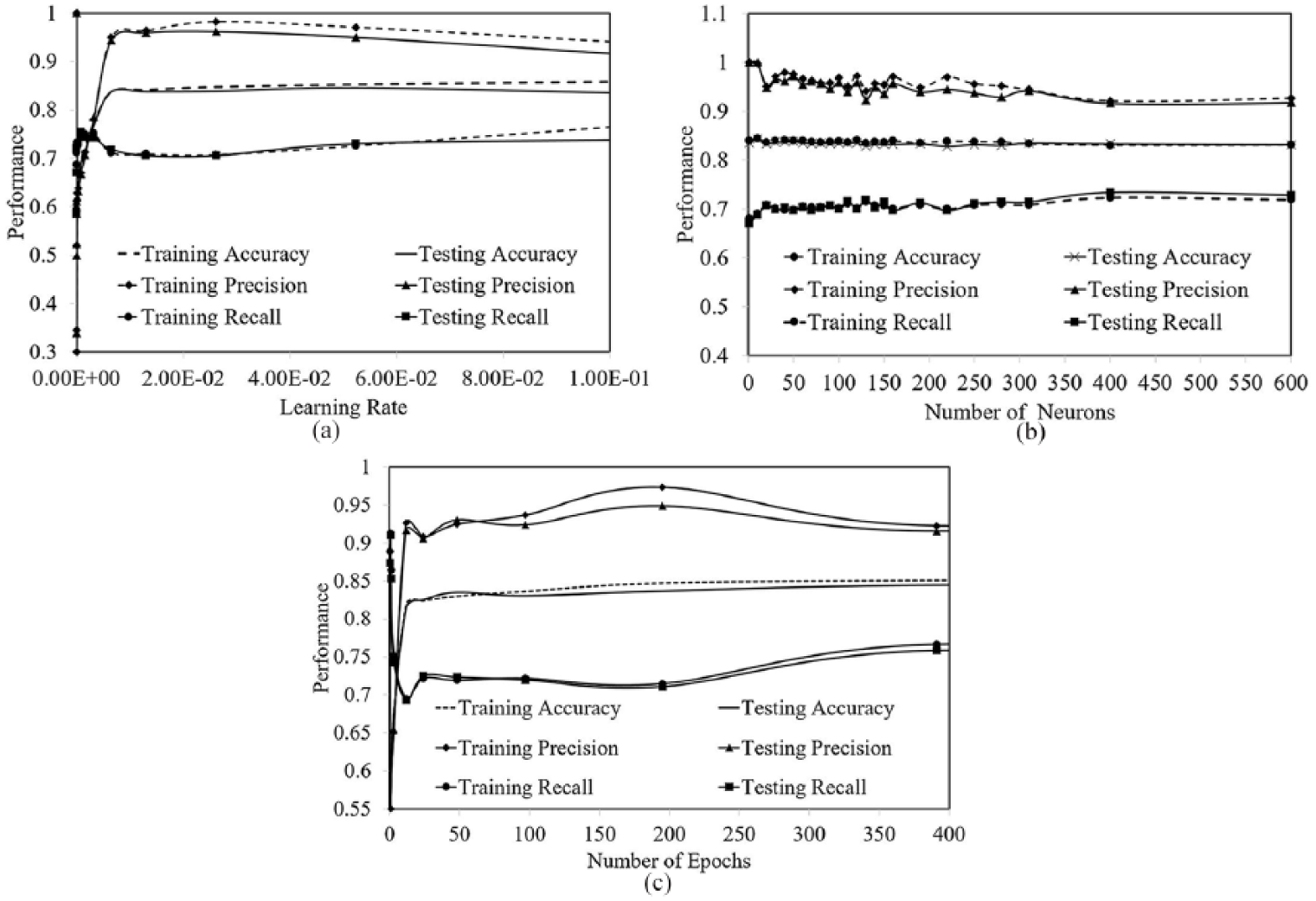
(a) The number of epochs is fixed to be 100. The learning rate varies in a wide range. (b) The learning rate and number of epochs are fixed to be 0.09 and 100, respectively. The number of neurons is changed from 1 to 600. (c) The learning rate and number of neurons are fixed to be 0.09 and 75, respectively. The number of epochs is changed from 0.1 to 400.
Hypothesis testing using Truven data
Knowing that in the temporal medication records, there are critical factors that increase the power to predict SUD in enrollees who initiate ADHD medication during adolescence, the next step is to explore all of the important factors suggested from the literature (such as age of ADHD medication initiation and demographic information). To this end, we encoded demographic features, age and sex, as well as medication types into the temporal medication records. Table 4 shows the performance of a LSTM model trained only using the temporal pattern medication records (LSTM-NoDemo) and a LSTM model trained using additional demographic features (LSTM-Demo). As shown in Table 4, incorporating demographic features into the LSTM model neither increased nor decreased the model performance significantly.
Effect of encoding stationary features on the LSTM model performance on predicting SUD.
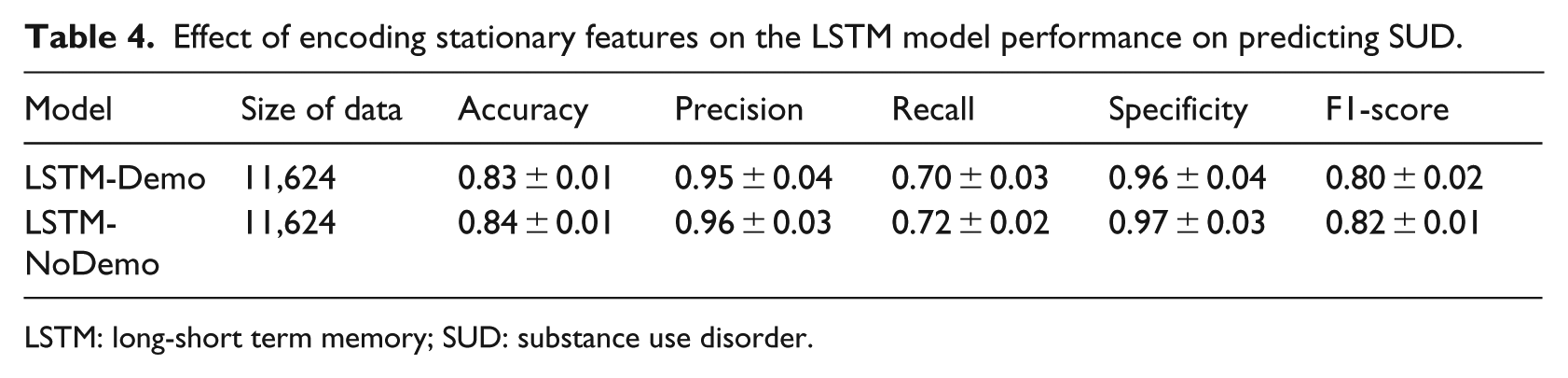
LSTM: long-short term memory; SUD: substance use disorder.
We further tested the effect of stationary features other than the demographic information, such as medication type, initiation age, sex, and temporal pattern of using medications on developing SUD. We separated the Truven data using each stationary feature as a partitioning criterion and then trained the LSTM models on the separated data and compared the model performance.
First, we tested whether the medication application pattern is a key factor for predicting SUD in adolescent ADHD enrollees. Specifically, an enrollee may be prescribed a medication during a few months, stop for a few months, and then start again being prescribed the medication. To test whether the on–off medication application pattern is a critical factor, we generated a new data set by removing all the gaps from the ADHD medication records and trained a LSTM model called LSTM-NoGaps using the newly generated data. For comparison, we generated another data set, in which only the binary on–off medication application patterns were preserved. This data set is used to train a LSTM called LSTM-OnOf. Table 5 shows the performance of LSTM-NoGaps and LSTM-OnOf models.
Effect of medication application patterns.
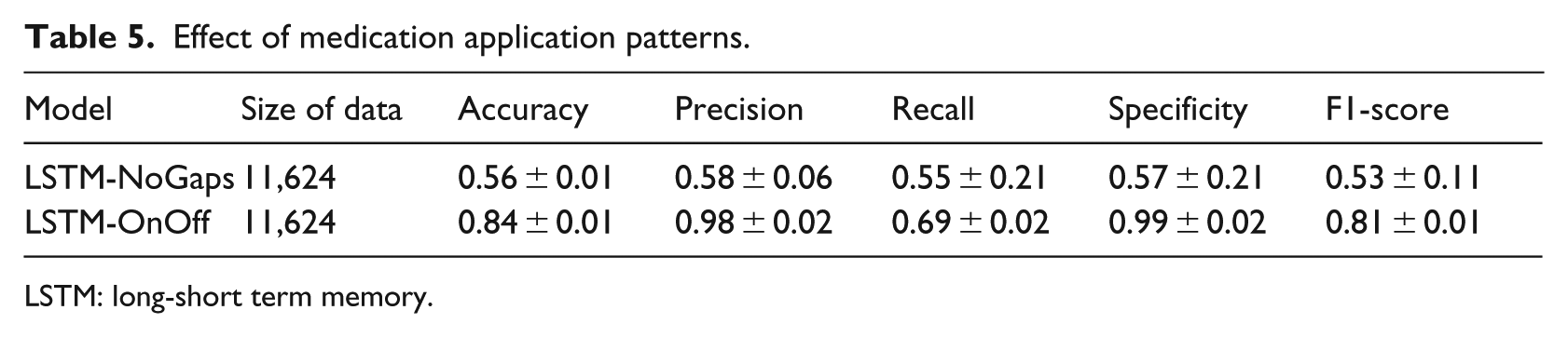
LSTM: long-short term memory.
Table 5 shows that the model performance of LSTM-NoGaps is significantly worse than using the complete data. F1-score drops from 0.81 to 0.53 when the gaps were removed. However, the model performance of LSTM-OnOff is similar to the LSTM model trained using the complete data. These results indicate that the on–off medication application patterns encoded in the temporal data are a critical factor for predicting the development of SUD in adolescent ADHD enrollees.
Second, we tested how long the medication application patterns could be. Since in the Truven data, the longest ADHD medication records span 7 years, we generated a batch of new data sets by only considering the ADHD medication records in the first x years (x varies from 1 to 7). Note, all of these new data sets include the same enrollees, but are across different ranges of time for their medication records. Figure 8 shows LSTM results on these seven data sets. In Figure 8, LSTM-xyr represents a LSTM which is trained using the medication records in the first x years. Figure 8 shows that the F1-score of the LSTM-1yr model is low (average 0.48 and SD 0.27). However, the F1-score of the LSTM-2yr model increases significantly from 0.48 to 0.58 and continued to increase when longer medication records are used. These results indicate that the medication application pattern is a long-term pattern (at least longer than 1 year).
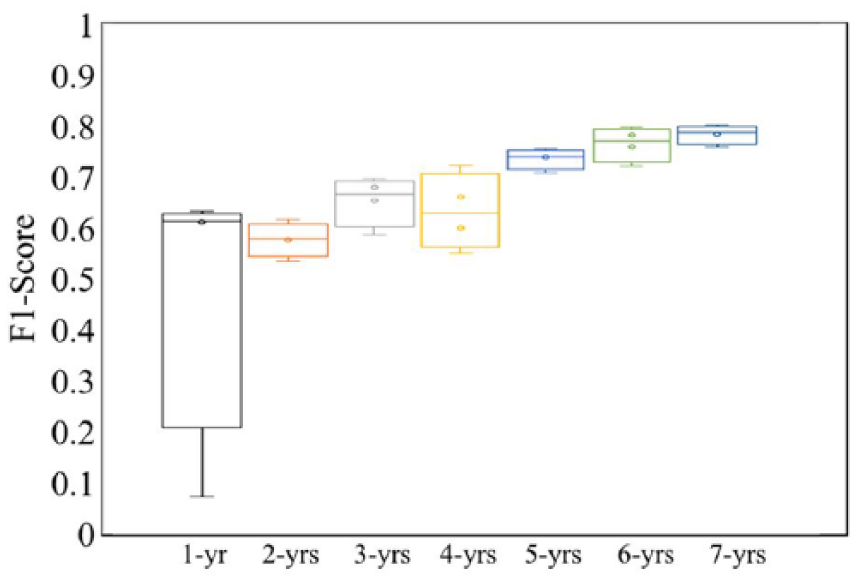
Impact of range of time of ADHD medication on SUD prediction. When the medication record range is increased from 1 to 7 years, the model performance increases.
Since the long-term temporal medication application patterns appear to be a key factor in predicting subsequent SUD in adolescent ADHD enrollees, we test whether this association holds for different ADHD medication types or different sex groups. The LSTM-Methylphenidate model is trained using enrollee’s data where methylphenidate is the primary medication (⩾80%). The LSTM-Amphetamine model is trained using enrollees’ data where amphetamine is the primary medication. Table 6 shows that both models achieve a similar F1-score (0.84 and 0.81) compared to the LSTM model trained incorporating both medications (0.82). These results indicate that long-term temporal medication application patterns exist using different ADHD medication types, but the exact pattern may be different. Table 6 also shows LSTM-Male and LSTM-Female models achieve the same F1 score (0.80), which is similar to the LSTM model trained incorporating both male and female enrollees (0.82). These results indicate that within different sex groups, the long-term temporal medication application patterns constitute important factors captured by the LSTM model.
Performance of LSTM for adolescent ADHD enrollees with different primary medication or sex.
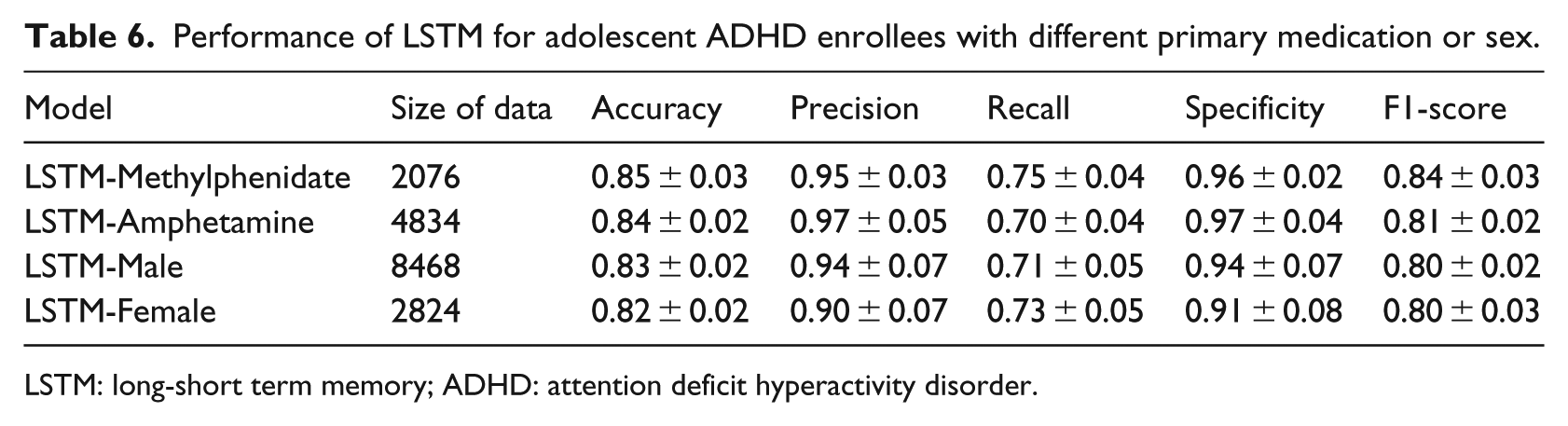
LSTM: long-short term memory; ADHD: attention deficit hyperactivity disorder.
Finally, we tested the importance of the long-term temporal medication application patterns in different age groups. Table 7 summarizes the LSTM model performance when applied to different age groups. All the F1-scores are similar to each other and are similar to the F1-score of the LSTM model trained using the entire data. These results indicate that in different age groups, the long-term temporal medication application patterns constitute the important factors captured by the LSTM model.
Performance of LSTM for adolescent ADHD enrollees separated by age group.
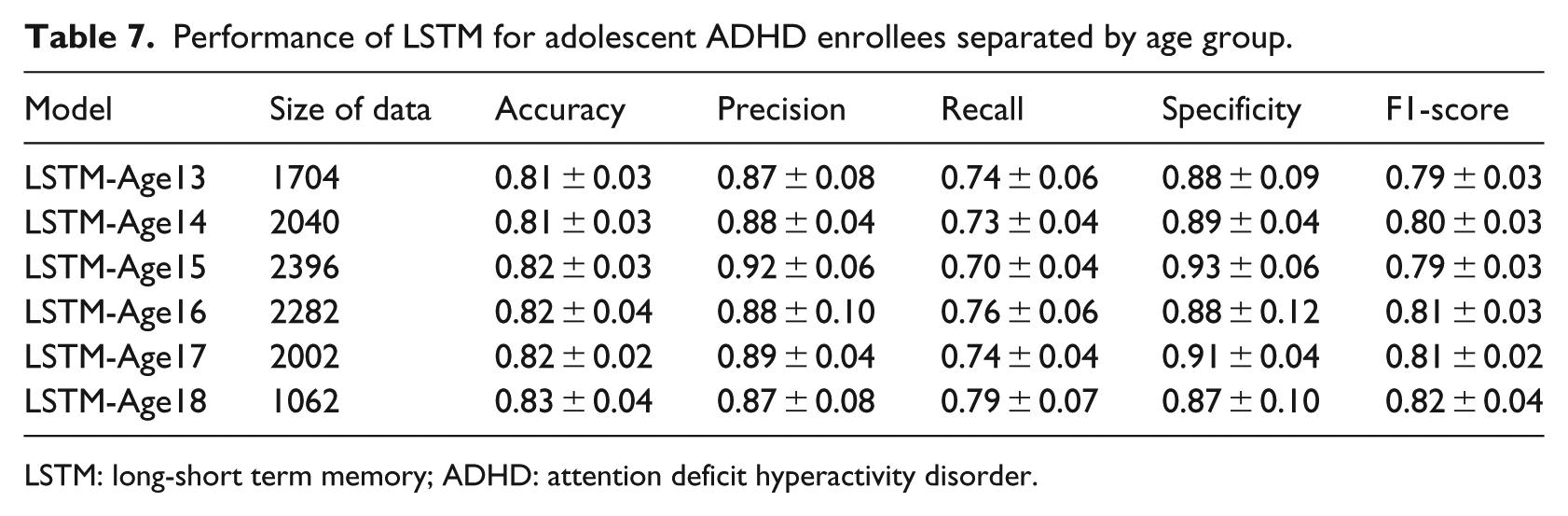
LSTM: long-short term memory; ADHD: attention deficit hyperactivity disorder.
Conclusion
SUD is a public health crisis costing the US an estimated US$740 billion annually in healthcare, lost workplace productivity, and crime. 1 One of the potential risk factors for subsequent development of SUD is an ADHD diagnosis. Leveraging large-scale healthcare data, two previous studies13,14 analyzed adolescent initiation of ADHD medication but results are inconclusive with respect to important questions related to the development of SUD. A key limitation in the previous studies is the grouping of ADHD medications into a single variable.
In this study, we hypothesized that the initiation of ADHD medication in adolescent enrollees would increase SUD risk beyond that associated with ADHD alone. We systematically studied the long-term impact of ADHD medication initiated during adolescence using the LSTM model with various grouping criteria. We discovered that long-term temporal medication application patterns (described as duration and gaps) appear to be key factors that provide increased power to predict the development of subsequent SUD in adolescent ADHD enrollees. These patterns could be universal since they are apparent in both sexes, different ADHD medication types, and across age groups.
There are some limitations in our approach that should be considered before using the results of this study or extending this research project. First, the current model relies only on patient demographic information, ADHD medical types, and medical application temporal sequences. Incorporating more detailed medication information (such as dosage) could be critical to identify the relationship between ADHD medication and SUD. Second, the current approach cannot predict/estimate risks because the medication application patterns that may lead to the increment of SUD risk have not been studied. In the future, we will extend our approach to address the aforementioned problems (such as incorporating dosage in LSTM). The rationale is, given a patient who is constantly on the same type of medication for a while, the variation of the dosage may indicate whether the medication is still effective for the patient. In addition, we will extract long-term temporal medication application features from Truven data and then identify the most important features using the forward backward feature selection method. The selected features may have potential to inform clinical practice to improve ADHD treatment and minimize risk for SUD.