
Abstract
This article focuses on the production side of clinical data work, or data recording work, and in particular, on its multiplicity in terms of data variability. We report the findings from two case studies aimed at assessing the multiplicity that can be observed when the same medical phenomenon is recorded by multiple competent experts, yet the recorded data enable the knowledgeable management of illness trajectories. Often framed in terms of the latent unreliability of medical data, and then treated as a problem to solve, we argue that practitioners in the health informatics field must gain a greater awareness of the natural variability of data inscribing work, assess it, and design solutions that allow actors on both sides of clinical data work, that is, the production and care, as well as the primary and secondary uses of data to aptly inform each other’s practices.
Keywords
Background and motivations
Data work can be defined as any activity that is accomplished on data, such as searching, retrieving, consulting, inscribing, arranging, transcribing, printing, and sending data to accomplish tasks and have work done. Much of the medical literature equates data work to activities for which medical practitioners use expressions like paperwork, deskwork, and desktop medicine.1–3 These expressions are usually associated with a derogatory perspective by comparing the time clinicians spend in clinical care and face-to-face encounters with patients to the time spent on reviewing charts, writing orders, arranging records, producing reports, and signing letters. A recent study 3 analyzed the usage logs of almost one million patients’ electronic records by 471 primary care physicians and found that physicians split time evenly between seeing patients and documenting activities. In the mold of the increasing digitization of hospital work, Chen et al. 4 recently coined the phrase “electronic patient record encounter” (EPRE) to denote medical interactions with a further interlocutor (i.e. the electronic medical record) other than the patient 5 and quantified that residents have approximately 10 EPREs daily, which last little more than half an hour each, for a total of 5 h in data entry and retrieval daily. This finding confirms other recent studies1,2,6,7 that found how medical doctors spend slightly more than one-half of their daily work shift “on the record,” and have to deal with forms and charts even visiting their patients, when data work accounts for approximately one-third of the time spent in the examination room.
However, it is widely known in the health informatics literature that in a work setting, data not only are produced to document work activities and keep a cumulative record to comply with accountability policies and legal norms, but also crucial for cooperative work, enabling the coordination of actors and the articulation of activities across space, time, and business units. This phenomenon was observed in the domain of hospital care and described by Berg 8 in a seminal and oft-cited paper. Thus, although it is analytically easy to distinguish between care and data work, these two kinds of activities are so intertwined that the former could not unfold without the latter. Even isolating “direct clinical face time” 1 in single encounters would neglect the individual doctors’ need to take written notes of encounters so conditions and interpretations can be recalled during future encounters 9 and, in so doing, formulate an understanding of the evolution of the patient’s illness and collaborate with themselves (at least) over time. 10 Decoupling clinical and data work is even more futile in hospital work, which is cooperative by nature. For instance, physicians’ prescriptions cannot be decoupled by order entry since the cooperative effort to administer a treatment to a patient needs specific data to be articulated within a record, which both mediates and enables asynchronous communication and collaboration between physicians and nurses, so as to act as the distributed and working record described by Fitzpatrick 11 and Bardram and Bossen, 12 among others, for example, by Greenhalgh et al. 13
In this article, we will focus on the inscribing side of data work in the medical domain, or data recording work, and in particular on one aspect of the activities in which physicians and nurses make a textual (or anyway coded) representation of some clinically relevant aspect pertaining to the illness of a patient on either paper or an electronic medium, for any of the reasons mentioned above, usually to trigger further action, reflection, and decision-making. One particular aspect we want to shed light on is the multiplicity of data recording work, as this is reflected in terms of data variability. By doing so, we complement the research conducted on the variability of the “reading side” of data work. This latter variability, perhaps because of its ties to interpretation and sense-making, has been already acknowledged in the specialist literature and widely discussed in many studies from Garfinkle’s work in 2008 to more recent ones:14,15 different readers of the same record can depict to themselves different narratives 16 of the patient’s illness trajectory, 17 also according to their knowledge. 18
Multiplicity in data work
This study lies within a research line that has focused on the multiplicity inherent in the work processes by which data are inscribed into artifacts. Multiplicity (in data work) occurs when the same phenomenon observed in the reality of interest is reported more than once in the same textual corpus (such as in a medical record) as either the same representation (data redundancy) or different representations due to the nature of the artifact hosting the representation itself, the situation in which the representation has been produced, or according to different interpretations of the observers of the phenomenon mentioned above (data variability).
Cabitza et al. 19 reported on some studies focusing on data redundancy, which is when multiplicity is reflected in multiple traces left on artifacts by data work. We distinguished “multiplicity by redundancy” according to whether the same or slightly different representations of a clinical condition of interest are either duplicated or replicated across the many components of the medical record. Data work redundancy is, therefore, a kind of redundancy of effort applied to data production. We observed that it is often purposely pursued by health practitioners for a number of reasons, such as to improve cognition in event recall, make data retrieval faster, enrich handing-over conferences across work shifts and professional roles and, although it seems obvious, minimize errors by double-checking. These practices are carried out by practitioners convinced of the value of documenting care from their own perspective at the cost of producing more data than strictly necessary and having to correct the inevitable misalignments and local inconsistencies. 20 For these latter drawbacks (which are perceived as drawbacks according to an engineering-oriented perspective), the digitization of the patient record is advocated by some as a means to eradicate data work redundancy, or to limit this phenomenon to the access of the same data from multiple points in the application and by multiple distributed users at the same time, a position that has been recognized as simplistic at best.13,21
As hinted above, another kind of data work multiplicity regards the multiplicity of the originality of data, that is, information regarding the different actors who could have produced the data and their different situated practices, that is, where and in which conditions they have done it. Also, this characteristic is usually lost in the automation of the means by which health practitioners produce data. In paper-based artifacts, originality is conveyed by penmanship and other subtle signs of individual habits of data recording that may get lost when this activity is transformed into a “robotically checking a bunch of electronic boxes”; 22 unlike a “faceless note,” 22 a handwritten note can indicate to a competent member of a work team who wrote it (from the handwriting) and, in some cases, whether the person was in a frantic and rushed medical situation or completed the “paper work” 9 in a calm and focused manner. Both these elements are important when assessing the reliability of the content of the data (i.e. Who wrote it? A novice or an expert clinician? Someone I respect or an unreliable colleague?) and eventually trigger double-checking and other compensating actions. 23 These factors notwithstanding, although originality is information that is easy to conceive as meta-data and store along with the data (as often it is, in usage logs), this indication is seldom conveyed to the users in the digital counterparts of paper-based records. Thus, it is missing, like other aspects of data work,24,25 the degree of perceived validity or finalization, which is usually related to writings in pencil and side notes in paper-based records.10,26
These brief accounts are aimed at the following point. Proponents and designers of the digitized record tend to underestimate the phenomenon of data work multiplicity, whether it is related to the ostensible inefficient and sometimes unintended routes along which data flow across the parts of the record (i.e. data redundancy) or to the ostensibly interchangeability of the data producers (i.e. data originality). In particular, data producers are not abstract actors that translate an objective reality into a standardized language 27 and are not interchangeable: who records what (and when) affects what data are produced and both their validity and reliability.
For this reason, historically, health care facilities have adopted structured forms requiring practitioners to represent cases in terms of well-defined and limited sets of values and codes. These frames and structures notwithstanding, clinical data recording work is not the orderly representation of an objective reality through the structured lens of the medical record; rather, it is a creative process in which each single physician tells his or her story about the patient by interpreting the same conditions in different ways with respect to colleagues.
In this article, we focus on data work multiplicity not in terms of data redundancy but in terms of data variability. This phenomenon, often termed ‘observer variability’ or ‘inter-rater reliability,’ is well known in the medical literature and does not indicate the extent medical doctors make mistakes in their records; rather, it is an intrinsic and unavoidable uncertainty of clinical conditions and the ambiguity of medical data. As such, this phenomenon is almost completely neglected in health informatics, resulting in information technology (IT) scholars assuming that medical data are reliable for goals other than care, such as accounting, epidemiological research, and decision support design. In what follows, we shed light on this dark side of data work with two field studies undertaken in two purposely different domains: the qualitative interpretation of electrocardiogram (ECG) readings and the more controlled and procedural environment of spine surgery.
Investigating data recording variability
As hinted above, we investigated the dimension of data recording variability by undertaking two different yet complementary studies. The first one regards a single cardiological case (represented by an ECG) that a large sample of cardiologists belonging to different institutions in Italy was to report on an ad hoc structured form. The second study regards a series of six surgical cases, which nine surgeons belonging to the same surgical unit reported on a standard surgery form that is adopted internationally for epidemiological purposes. As such, these two studies were aimed at getting a comprehensive picture of the phenomenon in two extremely different settings: one regarding a single condition that is typically interpreted with acuity and expertise for its intrinsic ambiguities and nuances (the ECG) and the other one concerning the well-defined sequence of actions performed in a series of representative surgical operations. In the former case, the data producers did not share any reporting conventions: not only did they belong to different clinical facilities across Italy, but also the online form they were asked to fill in was unlike any of the forms they used on a daily basis at work. In the other case, the surgeons were colleagues working closely on a regular basis, were well acquainted with each other, and shared a number of habits, surgical practices, and linguistic and reporting conventions. In particular, the nine participants met regularly before the study (and independent of it) to agree and share the best ways to fill in the standard form we adopted for this study, which had been already used for years in their unit to routinely send surgical data to an international scientific association.
Data recording variability is not a new topic within the medical community. In the specialist literature, it is often referred to with terms such as inter-rater reliability, inter-rater agreement, information bias, and observer variability. This phenomenon has been documented since the beginning of the 20th century, studied since the 1940s (especially in the radiological domain of image interpretation), and attracted the greatest interest in the 1970s. 28 The main studies show that the agreement between the physicians that codify (or categorize) the same phenomenon independently (for this reason, they are called raters or coders) is often poor or questionable; less frequently, it is either good or acceptable. In the past 40 years or so, this aspect of medical data work (and practice) has been a minoritarian concern within the medical community. The lack of greater awareness of it, despite its potential impact on any subsequent step in data work and clinical care, has also been traced to the fact that finding suboptimal reliability could “disturb the doctors morale” 29 and perhaps undermine the doctors’ confidence on the objective and scientific side of their discipline.
For instance, Jewett et al. 30 reported submitting plain abdominal radiographies to three different radiologists to detect the presence or absence of residual stone fragments; differences among radiologists were found in 52 percent of the reports and 24 percent when the films were reread by the same radiologist. Even more recently, a multicenter, prospective study on 260 digital images of premature infants was performed to investigate intra- and inter-observer reliability among seven experts in the diagnosis of retinopathy of prematurity. 31 Results showed both an inadequate inter-observer agreement among experts with agreement values (calculated in terms of Fleiss’ kappa) between 0.24 and 0.41 (according to diagnosis of different features in retinal images) and, as expected, a slightly higher (albeit still inadequate) intra-observer agreement for the same features with values between 0.47 and 0.63. In general, excellent concordance is very rare. 32
In this study, to assess the agreement with which the clinicians reported the cases, we chose two common measures from the specialist literature. For the sections of the forms that encompass the mutually exclusive type of multiple choice items (rendered as radio buttons on Web forms), we employed a chance-adjusted measure, Krippendorff’s agreement coefficient alpha. In its most general form, this coefficient is defined as
The cardiological study
For this study, two authors (cardiologists) conceived a reporting task and questionnaire to be administered to a sample of clinician experts in ECG reading. This task regarded the ECG of a 77-year-old woman, randomly extracted from the ECG Wave-Maven (https://ecg.bidmc.harvard.edu/maven/mavenmain.asp) database, an online repository of more than 500 ECGs of various difficulty developed for the self-assessment of students and clinicians in ECG reading proficiency. The selection was limited to cases with difficulty levels ranging from 2 to 4 (on a scale of 1–5), so trivial and excessively difficult cases can be avoided. Although the selected case (no. 26, https://ecg.bidmc.harvard.edu/maven/dispcase.asp?rownum=25&ans=1&caseid=26) had been assigned a difficulty score of 4, the authors agreed that this was due to the diagnostic condition (i.e. a hard-to-detect renal failure), and the ECG signs were suitable for a standard reading and to the task at hand. In this task, the participants were invited to assess 39 ECG features in terms of presence or absence. This was done so to mimic the standard report forms designed with long lists of checkboxes that have been increasingly adopted in cardiological settings to allow for fast reporting and minimal deviation from structured coding. However, to avoid missing important nuances for each reporting decision, we conceived a four-value scale (certainly present, probably present, probably absent, certainly absent), from which dichotomous data could be derived by subsequent aggregation. The aspects considered in the form were the electrical axis of the QRS vector (4 items), the atrioventricular conduction (10 items), and morphological aspects (25 items).
Participants were personally invited by email to complete an online multi-page questionnaire, implemented on the Limesurvey platform. Invitations were personal and the questionnaires tokenized to avoid multiple compilations and allow for one gentle reminder that was sent after 2 weeks after the initial invitation. When we closed the survey two additional weeks later, 75 cardiologists had completed the form (see Figure 1), completing the task in approximately 9 min on average (M = 529, (SD) = 390 seconds, see Figure 2).
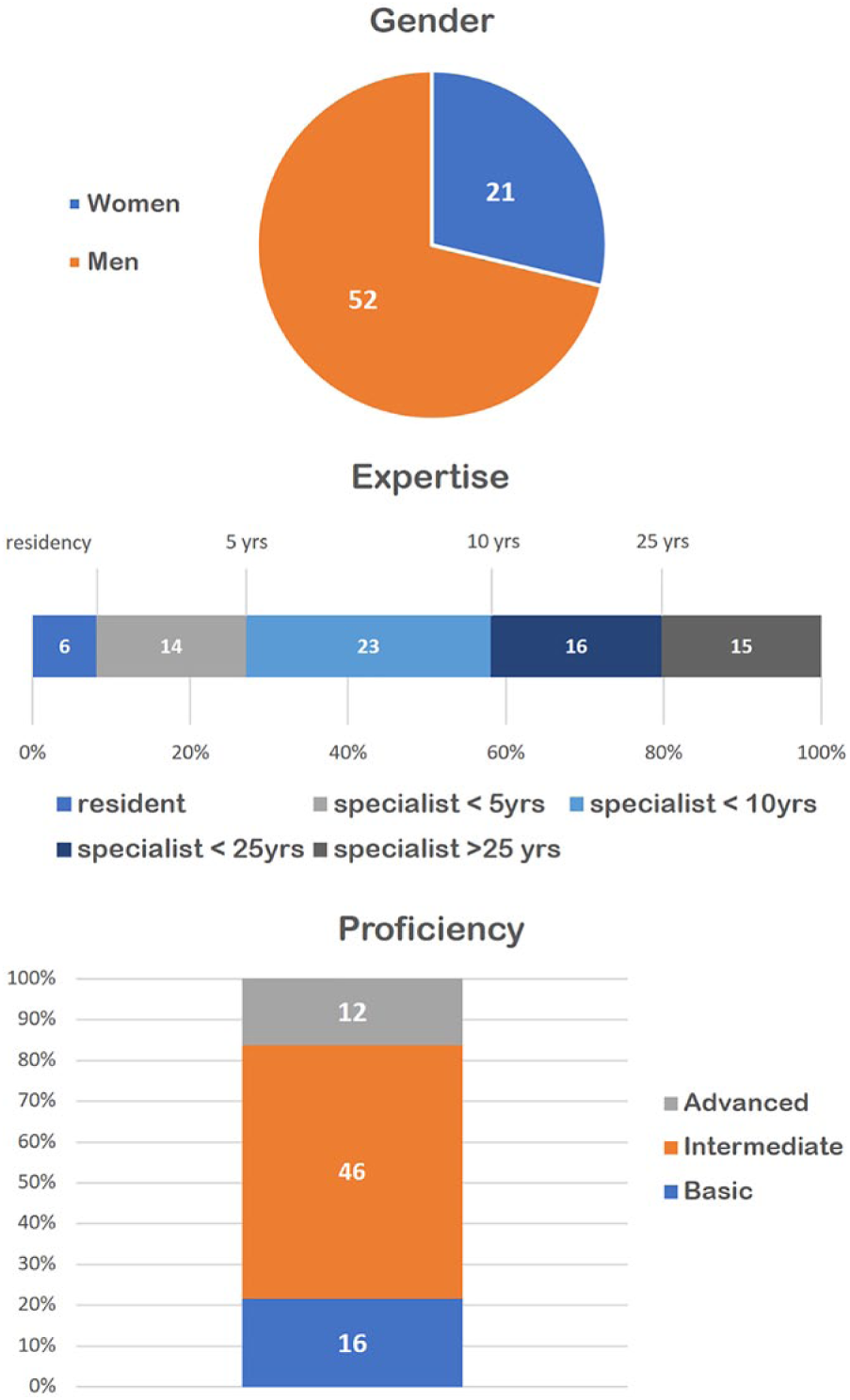
The distribution of the participants of the cardiologic study, with respect to gender, expertise, and (self-perceived) proficiency in ECG reading.
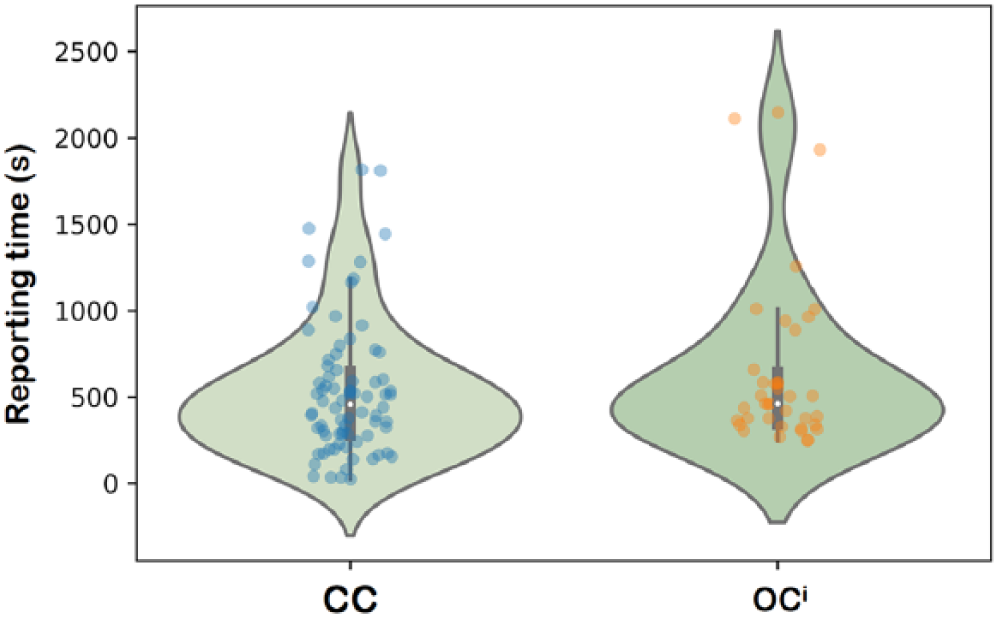
Violin plots of the reporting times for the cardiological study (on the left, the
The results surprised the cardiologists; although they considered the ECG of average complexity, the number of doubts expressed and errors made by the coders were beyond expectations. One-third of the respondents chose either one of the two middle values indicating only a likely answer (27%), or the item indicating they were too unsure to make a decision (the ‘don’t know’ (DK)—option chosen by 4%). For 18 out of 39 conditions, diagnostic errors exceeded the 5 percent threshold, which can be considered acceptable. Worse yet, for 10 items, more than 20 percent of the coders were wrong in their reporting decisions. However, the majority decision was always achieved with statistical significance (i.e. the majority group was clearly above 50 percent as indicated by the confidence intervals in Figure 3).
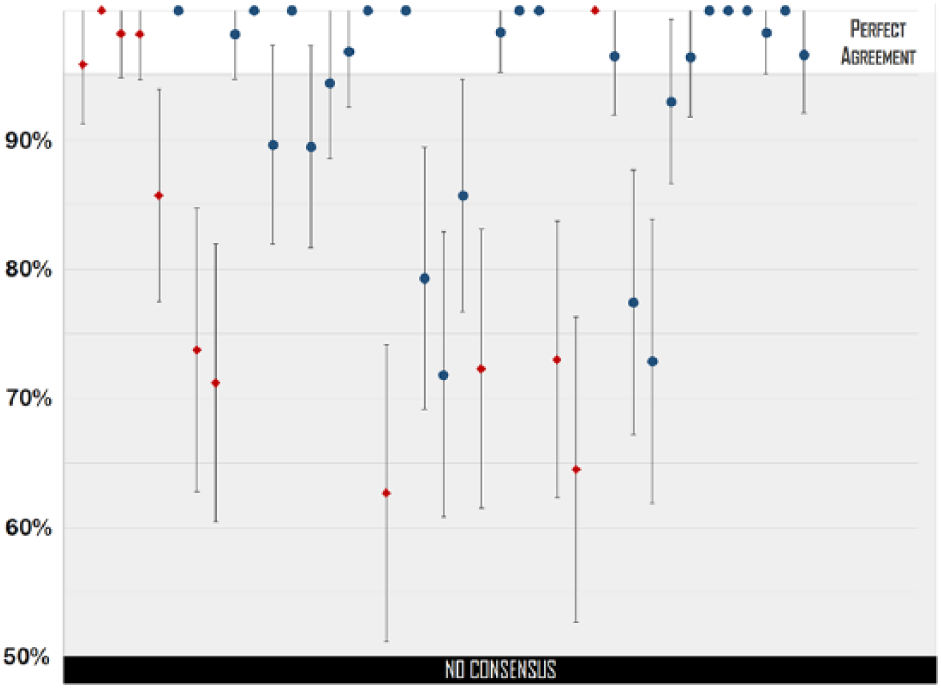
For each item of the cardiological form (39 items—on the horizontal axis from left to right), we indicate the proportions (and their confidence intervals) of coders belonging to the majority who reported either the presence or absence of a condition in the ECG considered. ECG items are indicated as red diamonds and review items as blue circles. Majorities were always statistically significant (i.e. the confidence interval never crosses the 50% border on the left, which is when no univocal answer is collectively expressed by the sample of coders). However, in several cases, majorities were smaller than 95 percent.
To assess the inter-rater agreement achieved by the involved coders in filling in the form, we considered the DK values as missing values and dichotomized the ordinal answers by aggregating certain and likely options together. By doing so, we could treat the data as nominal variables (i.e. as regular checkboxes). Moreover, to reduce the impact of systematic missing values on the agreement score, we also discarded the answers of 24 cardiologists as “lazy coders,” meaning participants who did not fill in at least 90 percent of the form’s items.
As expected, the agreement was low (52%) (all agreement coefficients are expressed in terms of Krippendorff alphas, computed with IBM SPSS, v. 24, and the KALPHA script developed by Hayes and Krippendorff
34
), which means the coders agreed on only half of the overall content of the form (not considering the fields that could match by mere chance), as shown in Figure 4 (the
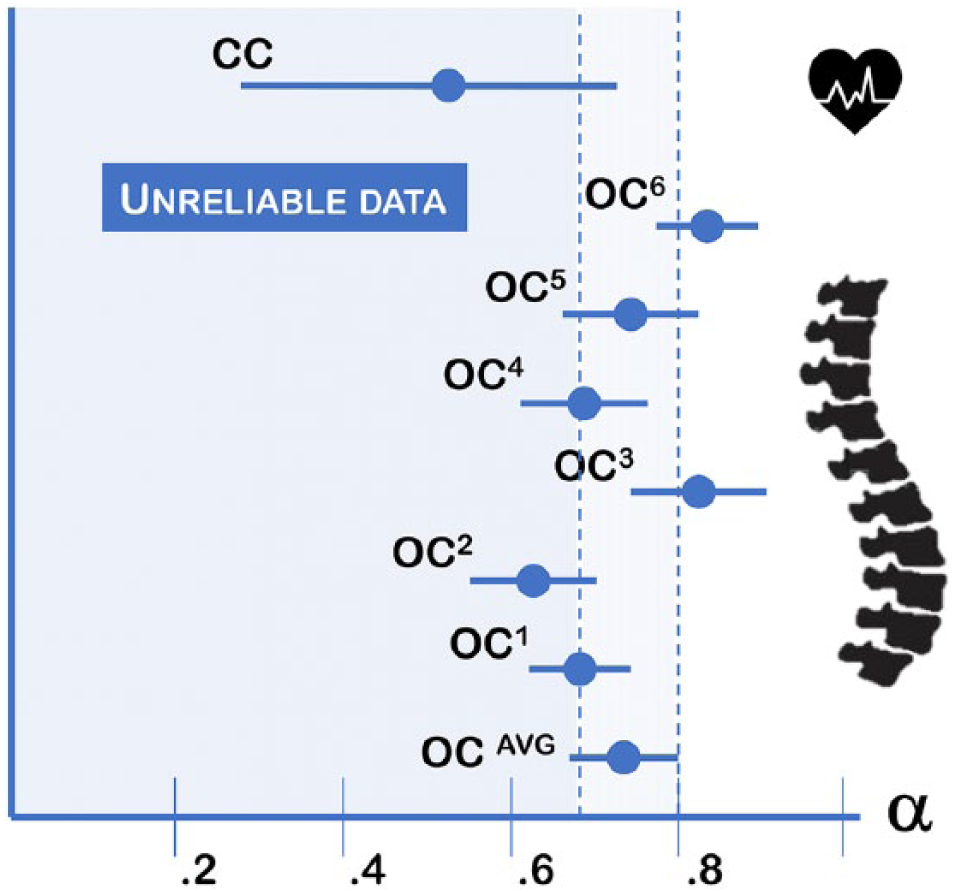
The agreement coefficients
The orthopedic study
The second study was undertaken at the IRCCS Orthopedic Institute Galeazzi (IOG) of Milan, Italy. This is a large teaching hospital specializing in basic and clinical research on locomotor disorders and associated pathologies where almost 5000 surgeries are performed yearly, mostly arthroplasty (hip and knee prosthetic surgery) and spine-related procedures. From this institute, we involved nine surgeons of the GSpine4 unit, which is the largest spine surgery division at the IOG, including 15 stable members and treating approximately 600 patients annually.
This study adopted an existing standard form designed by an international scientific society, Eurospine, to allow its affiliates (i.e. hospitals, spine units, and single surgeons) to collect data from their practice according to a unified model and send the data to a central registry, the international spine registry ‘Spine Tango.’ The form we considered for our study is called the Spine Tango Surgery (version 2011, available at http://www.eurospine.org/cm_data/SSE_PRIM_2011_ENG.pdf). This is the international (i.e. English language) version of a two-page form, available in 10 languages, which encompasses only closed-ended options, either multiple-answer or alternative-option items, to minimize recording variability and hence allow for the aggregation of data from multiple sites across Europe.
Two authors (orthopedic surgeons) designed a reporting task where the members of the GSpine4 unit would voluntarily and anonymously consider six cases of varying types and complexity and then independently report them on an electronic version of the paper-based Spine Tango Surgery form for each case. The six cases were real surgical operations that had been performed in the previous 3 months; these cases are considered a random sample of the typical surgical procedures performed at IOG by the GSpine4 team. More precisely, they were the latest operations to occur which were also representative of three main classes of procedures that are typically performed by this spine unit. One case involved myelopathy surgery; this procedure addresses injuries to the spinal cord due to severe compression and traumas. The other cases involved deformity and degenerative lumbar diseases. Deformity was represented by two cases: one in the idiopathic form in an adolescent and the other in the age-acquired form in adult. Degenerative disease was represented by three cases, including a routine procedure (i.e. a slipped disk) and an intermediate difficult procedure (i.e. spondylolisthesis) to address shifted vertebrae. The third case of this series involved anterior arthrodesis, which is surgery-induced joint ossification between two bones; it is encountered considerably less frequently than the others and considered a more complicated clinical case.
One of the authors then reviewed the medical records and all the available documents regarding each of these six cases and wrote a comprehensive yet concise surgical report (of approximately 700 words) describing the case so that the respondents could recall it (each respondent was likely involved in all of these surgical procedures, although possibly weeks earlier or at different degrees of involvement) and then be supported in the task of completing the surgery form. All the descriptions also included two or three medical high-resolution images and could be consulted by the respondents at all times during the compilation of the form. This form was rendered through a multi-page online questionnaire developed on the Limesurvey platform, adopting a style sheet that would resemble the paper-based form. In addition, no digital support was given to detect and prevent potential inaccuracies in the paper-based format: all the available options were left selectable, even for those fields that were denoted as mutually exclusive choices in the original form.
The team members who were enrolled as participants of the study were told that the study was aimed at evaluating the reporting time and assessing its impact on the team workload. Thus, they were instructed to fill in the forms as carefully as possible but in real-life conditions during their regular work shift, to minimize bias in the conclusions that we could draw from the analysis of the responses.
Nine surgeons filled in the six forms, completing each case in approximately 9 min on average (M = 521, SD = 254 seconds), although most of the cases were reported in approximately 6 minutes (see Figure 2). Agreement levels varied, also according to the relative (and varying) complexity of the cases. The case-wise average agreement scores are reported in Figure 4, while Figures 5 and 6 show the average reliability of each section of the standard form.
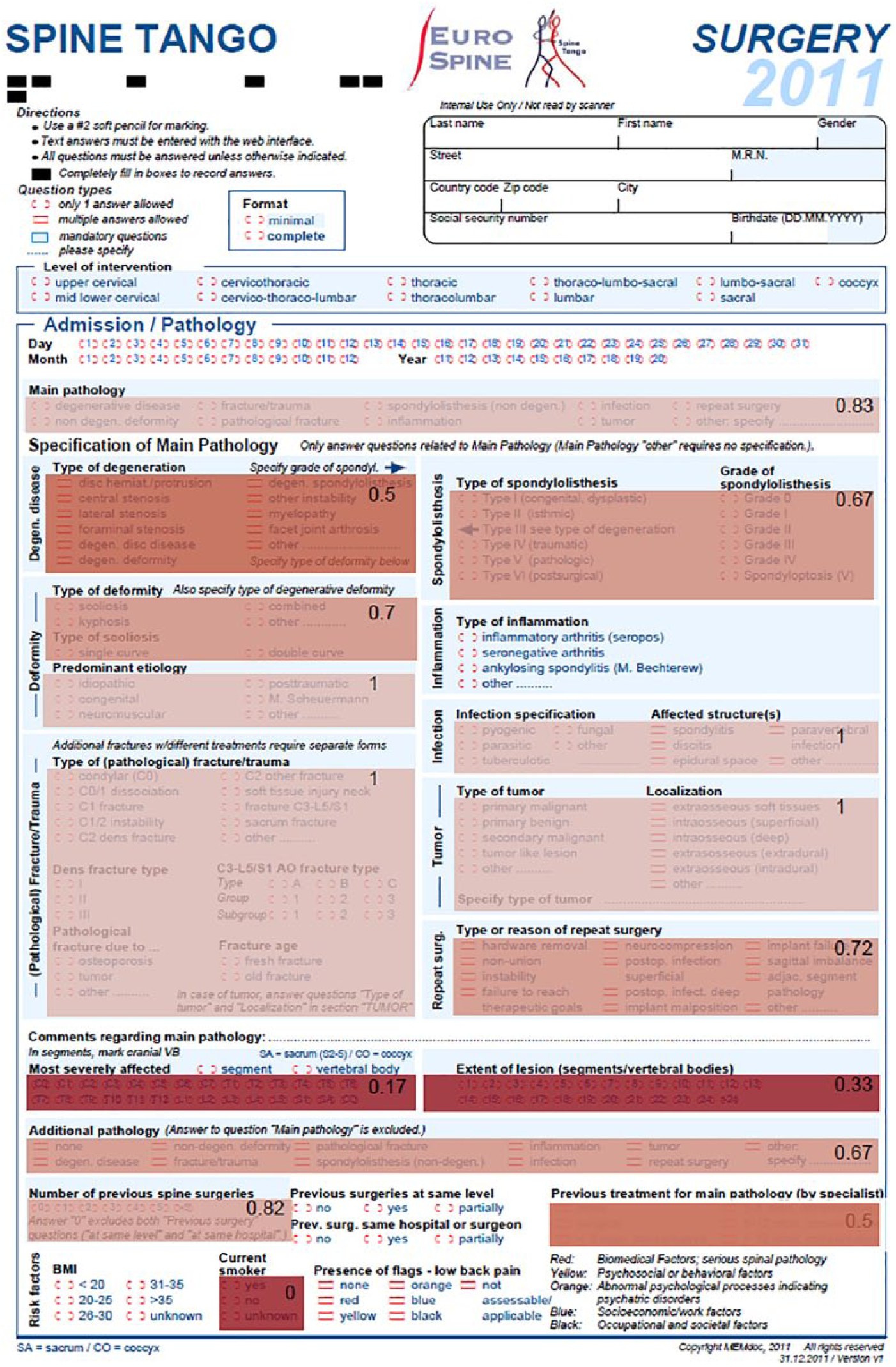
The front side of the Spine Tango Surgery form. Agreement coefficients (
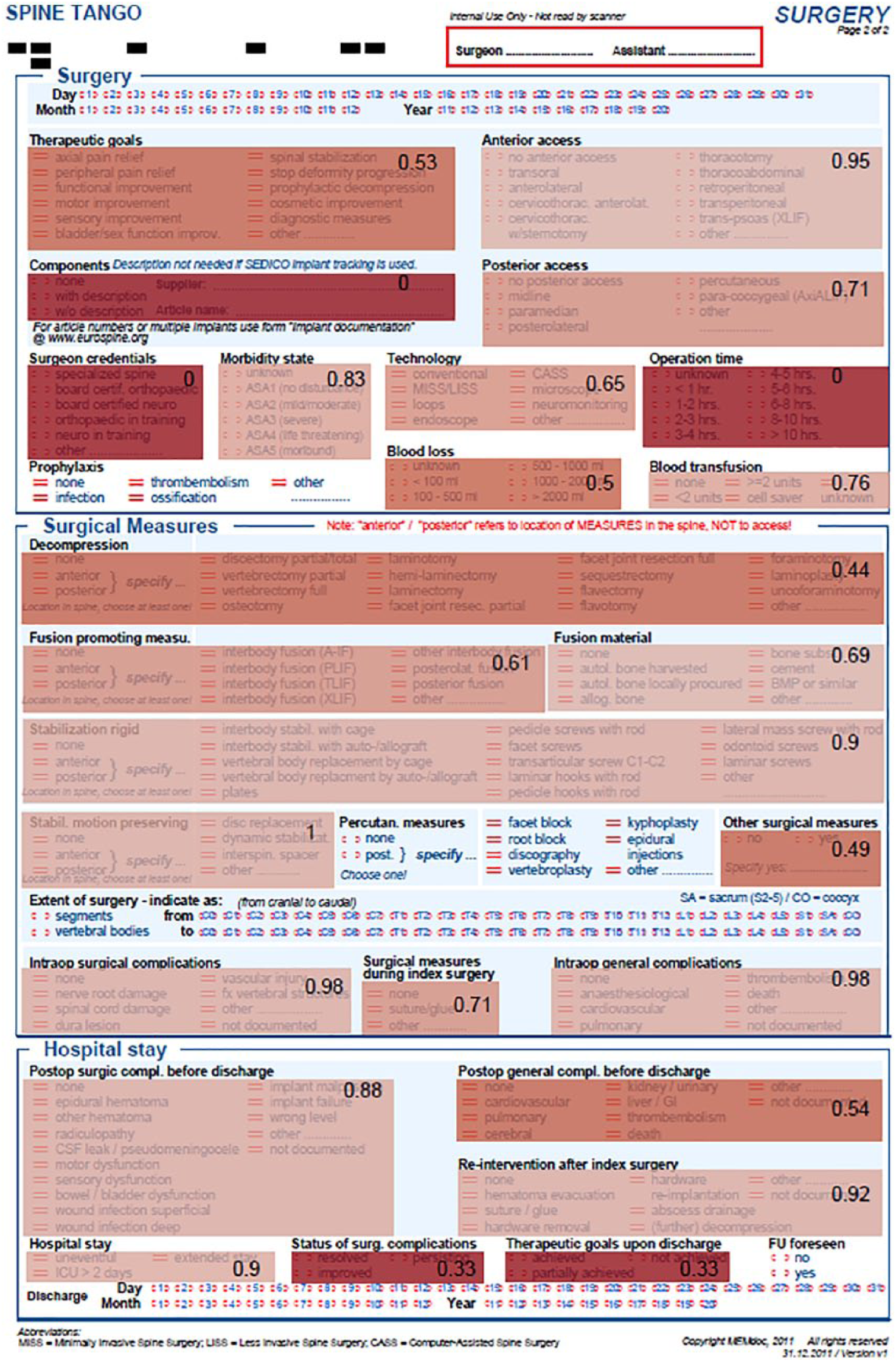
The rear side of the Spine Tango Surgery form (see also Figure 5).
Discussion and implications for design
In this article, we presented two studies aimed at giving a complementary view of the phenomenon of data work multiplicity. In the orthopedic setting, the data work under consideration was the standardized reporting of surgical procedures by those who had performed them (although after a washout period and on the basis of a written account). However, in the cardiological setting, data work focused on how proficiently clinicians could document what they read in some sample ECG tracings. These two studies yielded different results (see Figure 4). The agreement among the orthopedic coders was found to be higher than in the cardiological study but not significantly. This was partly expected due to the nature of the task, the acquaintance of the coders with the reporting tool, and the common background of the coders involved. 18 However, in both cases, the average agreement did not achieve the threshold recommended by Krippendorff 33 for medical data. However, with this contribution, we do not aim to yield “yet further” evidence of the phenomenon of observer (or coder) variability in medicine, which is well known and documented in the literature. Rather, we make a point about the importance of multiplicity in data work (especially in data recording work), which is generally not widely considered in medical informatics and in the design of electronic medical records. This multiplicity is the “elephant” we refer to in the title of this article.
The elephant in the room is an idiomatic expression indicating a matter of concern that is not considered or discussed despite its lumbering and placid existence. We use the phrase elephant in the record to describe the phenomenon of variability in data recording work and how this data multiplicity affects the consequent reliability of the record’s data for other aims than the ones for which the data have been produced (mostly for medical care). This phenomenon is reminiscent of the so-called first law of medical informatics: “data shall be used only for the purpose for which they are collected”
35
and its corollary, which states, “if no purpose was defined prior to the collection of the data, then the data should not be used.” In this multi-site study, we showed that even if data producers know the purposes for which they record data related to their practice (accountability and research), feel genuinely committed to these purposes, and use forms specifically designed to minimize variability and increase the objectivity of judgment, secondary uses of their data (such as statistical analysis for either monitoring or epidemiological research and the statistical optimization of predictive models) can be undermined by the variability among their reports. In this article, we specifically spoke of the multiplicity of their reports instead of considering this variability in terms of unreliability or poor agreement among the coders as it is usually done in the specialist literature. In fact, our point is that the observed multiplicity (i.e. multiple descriptions of the same events and procedures), such as in the orthopedic study, or multiple interpretations of the same health condition, such as in the cardiological study, should not be traced (entirely) to incompetence or reporting errors. While we cannot rule out the existence of reporting and interpretation errors in our studies, in discussing these results with some specialists (including the four medical authors of this article), we concurred that errors had a low impact. Instead, data multiplicity can be traced back to the intrinsic uncertainty, ambiguity, and manifoldness of the medical phenomena being reported by Simpkin and Schwartzstein
36
and, therefore, it is created where data work and interpretation work overlap, as they often do in medicine. Indeed, it is noteworthy here to recall the words of Monteiro about interpretation work. He said, [this] is embodied on two levels: one, when the digital objects [in our case, reports and records] are produced; two, when they are handled in weekly meetings. Meaning about natural phenomena [in our case, medical phenomena] is thus being continually constructed in these various processes.
37
The data work we described in this study is clearly on the former level: the embodiment of interpretation in some written form. However, our observations on data redundancy and the related practices, 38 and the similar work on intertextuality occurring among medical records 39 suggest that data work is also crucial to interpretation work on the second level mentioned above.
Interpretation work makes sense of seemingly incoherent data (by interpolating between them or even transcending them) and reduces the potentially negative impact of data variability on diagnostic accuracy and therapeutic efficacy, which are constantly (yet slowly) improving over time. 40 However, this kind of work usually eludes the abstract models and algorithmic requirements of data quality as these are usually defined for (or imposed by) health information systems.41,42 When automation, rather than human interpretation, creates output from input, the old saying holds true (i.e. if garbage is put into a machine, then garbage goes out 43 ). This simple consideration cannot be overrated, especially in this data-driven age, in which increasingly larger amounts of clinical data are harvested and used for epidemiological research and to create the so-called ground truth for the development of predictive models with machine learning techniques. To these latter aims, medical informaticians usually focus on problems of data quality such as completeness and timeliness 42 and take the reliability of record data for granted, leaving the multiplicity of data recording work and its consequences on automation almost completely unaddressed. 44
However, sweeping data multiplicity under the rug can just contribute to fiction and hence undermine both human interpretation work (by offering data that are flattened into hard-wired codes) and the automation support of real-life care. A more viable alternative could be using automation to detect data multiplicity, assess it, and hence bounce it to the awareness of the practitioners (rather than trying to get rid of it). This is the first and necessary step to make this phenomenon duly recognized and an object of discussion among clinicians and health informaticians. A second step could involve undertaking further research on whether representing data multiplicity could improve the collaborative process of making sense of data (which is another form of data work) and contribute to the achievement of shared decision-making
45
that could be grounded not only on firm and established certainties but also on the unavoidable ambiguities and gray areas of many medical cases (where multiple views and interpretation coexist). Representing multiplicity (i.e. to detect, assess, and display it to the users of the medical record) is a challenging task. For instance, observer variability could be automatically assessed by a system that, for a random selection of cases, would ask two or three physicians (unaware of the others’ assignments) to fill in the same patient record. In so doing, the system would have multiple data for the same patient and compute a reliability measure associated with these attributes. This information could be conveyed at the interface level in terms of
Moreover, the system could extract the mode value (i.e. the value reported in the same field of the same form by most of the respondents, if such a value exists) and determine whether this majority value had been chosen by a significant majority of coders (i.e. higher than 50%). This approach has been found useful to improve the quality of medical records and make their data reliable enough for ground-truthing, 46 at the expense of involving a sufficient number of coders (e.g. 12) on a random basis, if not on a regular one. In our field cases, this kind of consensus data could be extracted for all of the items in the cardiological case (not surprisingly, given the high number of coders involved), but less frequently in the orthopedic study, when mode values extracted from the forms were found to be representative of a team consensus for just two-thirds of the form items (65%).
In conclusion, we believe that the following conjecture is worth further investigation: does a system that exposes data recording work variability help the involved stakeholders discuss this issue and understand whether there is a will (and the necessary resources) to improve concordance in data work? This aim could be addressed through a number of socio-technical interventions, which include gently inviting colleagues to a stricter compliance with compilation rules, 47 as well as by suggesting or promoting the adoption of check-lists; 48 binding incentives to the continuous improvement of average concordance rates; adopting (or requiring) an electronic medical record that implements data checks which prevent further use if anomalies and divergences among multiple coders are detected; planning additional training sessions to improve the coders’ acquaintance with classification schemas, coding standards, and compilation conventions; and, finally, hiring (or asking for) medical assistants, or scribes, 49 who are specialized in data recording work and committed to high-quality record-keeping. Any of the above interventions could have a positive impact on data work and care, as well as unintended consequences, which must be partly envisioned ex ante and duly assessed in post hoc analyses.
With the support of digital IT, the elephant of the variability of recording data work would not (or better yet, should not) be removed from the rooms of medicine and hospital care. Rather, data workers could be made more aware of it and could be provided with some means to coexist with, and possibly leverage, it for the sake of better data, smoother data work, and the respectful observance of the laws of medical informatics.
Footnotes
Author’s Note
Angela Locoro is now affiliated with Università Carlo Cattaneo - LIUC, Italy.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Grant SPINEREG - CC-2015-2365325 funded by the Italian Ministry of Health. Grant CO-2016-02364645 - The influence of baseline clinical status, comorbidity, and surgical techniques on the risks and benefits of spine surgery: use of the registry to supplement the evidence from the cohort study funded by the Italian Ministry of Health.