
Abstract
Today, social media is increasingly used by patients to openly discuss their health. Mining automatically such data is a challenging task because of the non-structured nature of the text and the use of many abbreviations and the slang terms. Our goal is to use Patient Authored Text to build a French Consumer Health Vocabulary on breast cancer field, by collecting various kinds of non-experts’ expressions that are related to their diseases and then compare them to biomedical terms used by health care professionals. We combine several methods of the literature based on linguistic and statistical approaches to extract candidate terms used by non-experts and to link them to expert terms. We use messages extracted from the forum on ‘cancerdusein.org’ and a vocabulary dedicated to breast cancer elaborated by the Institut National Du Cancer. We have built an efficient vocabulary composed of 192 validated relationships and formalized in Simple Knowledge Organization System ontology.
Objective
Controlled vocabularies such as SNOMED, 1 MeSH 2 and UMLS 3 play a key role in biomedical text mining applications. These vocabularies contain solely the terms used by health professionals. For the last 10 years, vocabularies dedicated to health care consumers also called Consumer Health Vocabulary (CHV) have been created. These CHVs link common terms related to health used by laymen to expert terms used by health professionals. Such CHV can be used to extract relevant information from social media.
In this article, we address the challenge of semi-automatically building a CHV in French. For example, we seek to link the term ‘onco’ used by patients for the term ‘oncologue’ (oncologist in English) used by health professionals. The originality of our approach is to use texts written by patients (patient-authored text (PAT)) collected from forums.
The main contributions of this article are twofold. First, we describe a global process from candidate terms extraction to formalization of the relationships in Simple Knowledge Organization System (SKOS). Second, we compare three measures based on different paradigms to link common terms to expert terms. Our method has been validated successfully, automatically and manually on the forum at ‘cancerdusein.org’, which is dedicated to breast cancer.
Motivations and current situation
According to a survey carried out in 2011 by the Health On the Net (HON) Foundation, 4 the Internet has become the second source of information for patients after consultations with a doctor; 24 per cent of the population uses the Internet to find information about their health at least once a day (this can rise to six times a day) and 25 per cent at least several times per week. While maintaining anonymity, social media also allow patients to freely discuss with other users and also with health professionals. They discuss their medical results and their treatment options, but they also receive moral support. Househ et al. 5 explored the range of social media platforms used by patients and examines the benefits and challenges of using these tools from a patient perspective.
In previous work, 6 we were interested in the study of the quality of life of patients with breast cancer in social media. We captured and quantified what patients express in forums about their quality of life. The main limitation of this work is due to the vocabulary in these types of posts which decrease the performances of automatic methods. Indeed, most patients are laymen in the medical field. They use slang terms, abbreviations and a specific vocabulary constructed by the online community, instead of expert terms that can be founded in medical terminologies used by health professionals such as SNOMED, MeSH and UMLS. Most of the text mining methods have shown their limits because of this particular vocabulary. In this work, we therefore propose to build a French CHV specialized for breast cancer.
Initially, the creation of this CHV has been motivated by the need to reduce the vocabulary gap between patients and health professionals. 7 Indeed, literature shows that patients’ understanding of medical terminology is essential to participate in the medical decision-making process. 8 Some researchers used CHV to improve the readability by non-experts of medical documents 9 or patient’s electronic records. 10
Recent methods have been developed to extract consumer health expressions from social media. Doing-Harris and Zeng-Treitler 11 automatically generated candidate terms to be processed by humans for inclusion in a CHV. Jiang and colleagues12,13 used co-occurrences for consumer health expression extraction from social media. Bouamor et al. 14 used a learning-to-rank method, where statistical and linguistic features are combined to determine whether a term is associated with lay or a specialized audience. Keselman et al. 15 extracted consumer health concepts manually from health-focused Bulletin boards. They mapped these concepts automatically to UMLS concepts using MetaMap and manually for the remaining frequently used terms. Patrick et al. 16 manually extracted common terms from e-mail questions submitted by consumers to a health care institution and from enquiries submitted by consumers to a health care information website. They mapped them to expert terms extracted from a corpus of 25,000 family-medicine progress notes created by family physicians. Vydiswaran et al. used Wikipedia as corpus for pair extraction using explicit patterns (e.g. also called, commonly referred to as). They associate expert terms with common terms and also non-expert terms with expert terms. 17 Despite these initiatives, currently, only one CHV is available: Open Access and Collaborative Consumer Health Vocabulary (OAC CHV). 18 This CHV is included in UMLS. To our knowledge, there is currently no CHV in French.
In this article, our goal is to use PAT published on social media to build a French CHV in the field of breast cancer. The volume of texts written by patients in social media, such as forums, is becoming more and more important. 19 Such PAT provides access to many descriptions of patients’ experiences and a wide range of topics. In the past 5 years, there has been a growing interest in the exploitation of these PAT as a tool for public health, for example, to analyse the spread of infectious diseases. 20 In this work, we propose to mine forums to extract common terms by collecting various kinds of patients’ expressions, such as abbreviations, frequently misspelled terms or common terms used by non-experts to talk about their diseases.
The originality of our approach is to combine three types of measurements based on three paradigms in order to reconcile non-expert and expert terms.
The two first measurements are based on co-occurrence paradigm. The envisaged hypothesis is that the patients’ vocabulary evolves when exchanging with the community. Consequently, we retrieved common and expert terms in the same threads in forums or in the same documents indexed by Google. We have implemented traditional measurements to calculate the degree of association between non-expert and expert terms. Such measurements (Dice, Jaccard, Cosine or Overlap) were recently discussed in Pantel et al. 21 and Zadeh and Goel. 22 These measurements are used in many fields such as ecology, 23 medicine 24 and language processing. 25 After preliminary experimentations, we present a modified version of the Jaccard measurement which compares the number of occurrences of two terms independently and together in forum threads. Similarly, we implement the Normalized Google similarity which is based on the number of occurrences of the two terms together and independently in the documents indexed by the web search engine Google. 26
The last measurement is based on the architecture of the collaborative universal encyclopaedia Wikipedia. 27 We exploit the network of links between Wikipedia pages to calculate a metric. The French version of Wikipedia from 25 February 2016 contains more than one and a half million articles. Wikipedia articles have been used successfully in knowledge acquisition, 28 question/answer applications 29 and text categorization. 30 Chernov et al. 31 used links between Wikipedia categories to extract semantic information. Witten and Milne 32 used links between Wikipedia articles to determine the semantic proximity between terms.
In order to benefit from the advantages of the CHV, we formalized the obtained relationships as an ontology. We decided to use SKOS. SKOS is a concept diagram representation language, like thesauri, taxonomies and controlled vocabularies. 33 It allows expressing and managing easily interpretable models by machines in the perspective of the semantic web. SKOS itself being an OWL ontology, the representation of SKOS is based on Resource Description Framework (RDF) graphs. Increasingly, vocabularies are implemented SKOS for health and audiovisual applications, 34 for education and culture, 35 for Food and Agriculture (Agrovoc), 36 for activities of the European Union (Eurovoc), 37 for the environment (GEMET) 38 and for the economy (STW). 39
Material and methods
Relationship extraction
Figure 1 shows the proposed method, structured in six steps. This method uses a medical resource containing expert terms we are willing to match with non-expert terms. We have chosen as a reference resource denoted by the INCa dictionary the vocabulary given on the INCa 40 website composed of 1227 terms, all included in the French version of the MeSH.
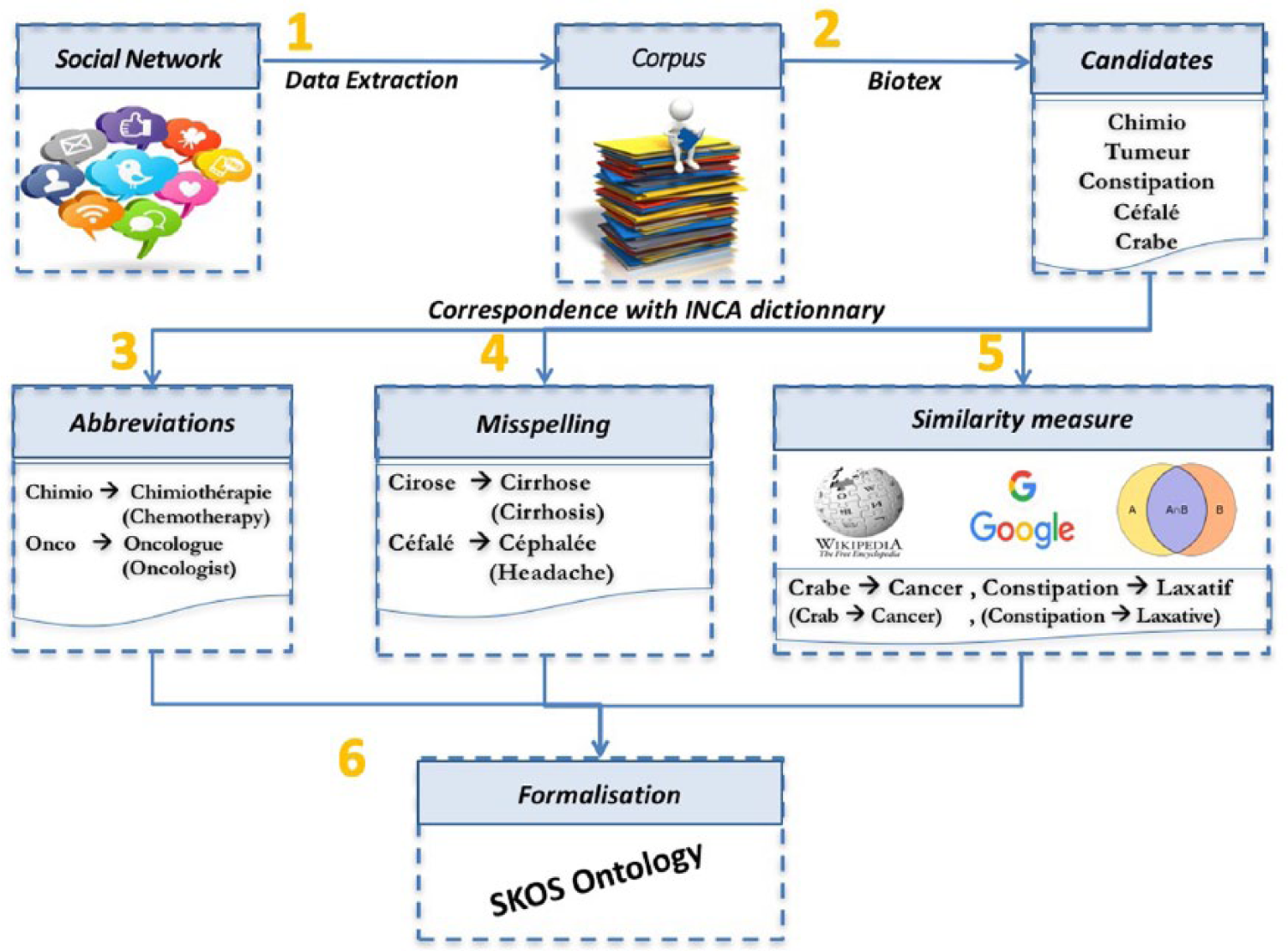
Semi-automatic building of a CHV in six steps.
Step 1: corpus constitution
We use the forum at ‘cancerdusein.org’ dealing with breast cancer. This forum facilitates sharing with other patients. Patients publish updates, photos or documents and send messages to all group members. The dataset contains 16,868 posts from 675 members, which have been collected between 2010 and 2014. Most members are the patients. Just a few posts belong to health professionals or relatives of the patients.
Step 2: candidate extraction
We sought terms from the corpus that have a high probability of belonging to the medical field using a BioTex tool. 41 BioTex implements state-of-the-art measurements for automatic extraction of biomedical terms from free text in English and French. In our study, more than 200 patterns have been used to identify the candidates. The candidates are filtered according to LIDF-value (Linguistic patterns, IDF and C-value information). 42 If BioTex has been trained for biomedical literature, our preliminary experiments show its efficiency on PATs because patients use similar constructions to experts with substitutions and misspelling. These expressions follow the same construction rules and are captured by the patterns (e.g. Noun–Adjective matches ‘Echo mammaire’ – Breast ultrasound in English). As an outcome of this step, we obtain a set T = t1, …, tN of N n-grams (n ∈ [1, …, 4]) that are not listed in the INCa dictionary. We use them at steps 3, 4 and 5 as explained below.
Step 3: spelling correction
In the set of terms identified at step 2, we search for those corresponding to common spelling errors. We seek to match all the terms ti ∈ T, with a correctly spelled term in the INCa dictionary. For this, we use the Aspell software 43 in order to obtain a set M = {m1, m2, …, mm} of m propositions of corrections for the term ti and we only keep the propositions found in the INCa dictionary. Levenshtein distance is used to compare the term ti and each term mj ∈ M. Only the terms whose distance to ti is lower than or equal to 2 are pairing to ti. Three additional conditions are necessary: (1) paired terms must begin with the same letter; (2) the length of matched terms is more than 3 characters and (3) the comparison is case-insensitive. If all these conditions are validated, the term ti is paired with the term mj with a weight(mj,ti) = 1/|M|. Examples of frequent spelling errors are listed in Table 1.
Equivalent between patient and medical terms (abbreviations and spelling errors).

Step 4: abbreviations
Biomedical expressions are often truncated by patients. In the set of terms identified at step 2, we search for those corresponding to abbreviations. For this, we adapted the stemming algorithm Carry 44 using a list of the common suffixes used in the biomedical field (e.g. logie, logue, thérapie and thérapeute in French, respectively, logy, logue, therapy and therapist in English). For a term ti ∈ T, we obtain a set A = {a1, a2, …, ak} of k propositions of abbreviations included in the INCa dictionary. The term ti is paired with each abbreviation aj ∈ A with a weight(aj, ti) = 1/|A|. Examples of abbreviations are listed in Table 1.
Step 5: similarity between two terms
We focus here on all terms produced at step 2 which are neither spelling errors (step 3) nor abbreviations (step 4). We try to match these terms with three approaches: (1) considering a semantically structured resource (Wikipedia), (2) considering the generalists co-occurrences on the web (Normalized Google similarity) and (3) considering the co-occurrences in messages from patients (Jaccard).
Wikipedia similarity
The hypothesis is to use the network of the links between pages of the Wikipedia resource. For this, we query this resource through its Application Programming Interface (API). 45 In this encyclopaedia, a referenced term is described by a page 46 and is linked to other terms which are described by other pages. The terms linked to the considered term are found on a dedicated page. 47 Given Wt = (w1, …, wn), the set of terms linked by Wikipedia to a term ti that belongs to the INCa dictionary. A term ti is associated to a term wj ∈ W according to the two measurements calculated using equation (1). Note that the set W solely contains terms present in the INCa dictionary

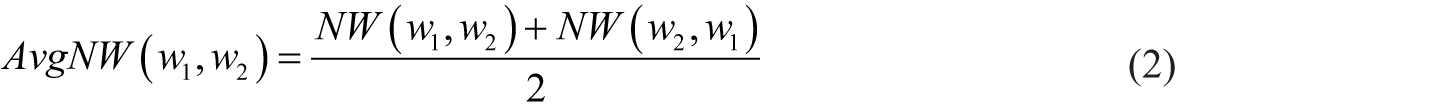
where
Wikipedia provides a knowledge base for computing word relatedness in a structured fashion and with more coverage than WordNet. 48 The intuition is the following one. Two close terms occur in linked pages.
Google similarity
The hypothesis is to exploit the co-occurrences in the documents indexed by the Google search engine. Google search is restricted to French language documents. We use the measurement proposed by Cilibrasi and Vitanyi 26 to compute the semantic similarity between two terms, based on the number of results returned by a Google query. This standard similarity is obtained as follows
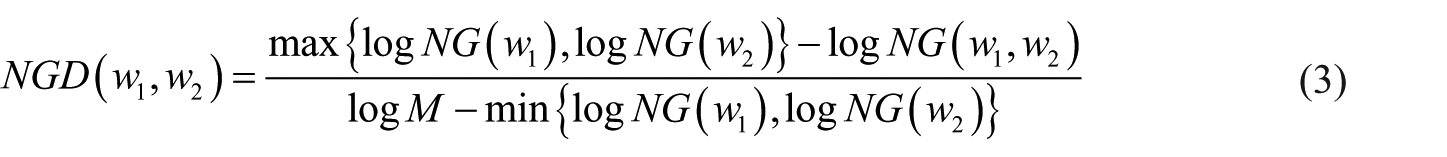
where
The Normalized Google similarity between two terms is derived from Park et al. 49 This similarity is based on the number of results (hints) returned by Google search engine. The intuition is the following one. The more two terms are close, the more the two terms appear together in the documents returned by Google.
Jaccard similarity
The hypothesis is to exploit the co-occurrences not in the Web document as the previous measurements but in the text of the corpus produced by patients. If we consider all the messages of a patient, we often found common terms associated with expert terms. We use a formula similar to the Jaccard measurement to compute the similarity between w1 and w2
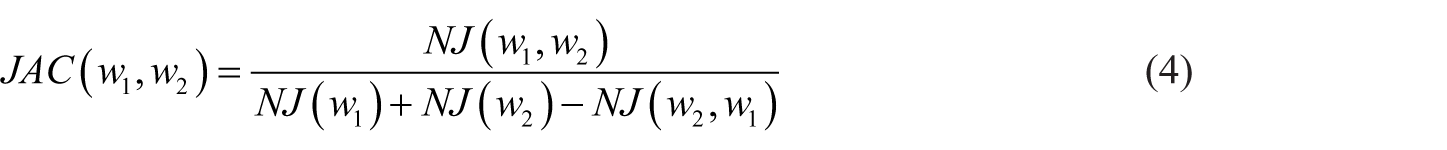
where
Step 6: formalization in SKOS
We use the relationships obtained in steps 3, 4 and 5 to create an SKOS ontology. This ontology links an INCa term to different patient terms: preferential terms are used to define the MeSH term representing the expert term, alternative terms are used to represent abbreviations and hidden terms are used to represent spelling errors. An example of the obtained graph is presented in Figure 2.
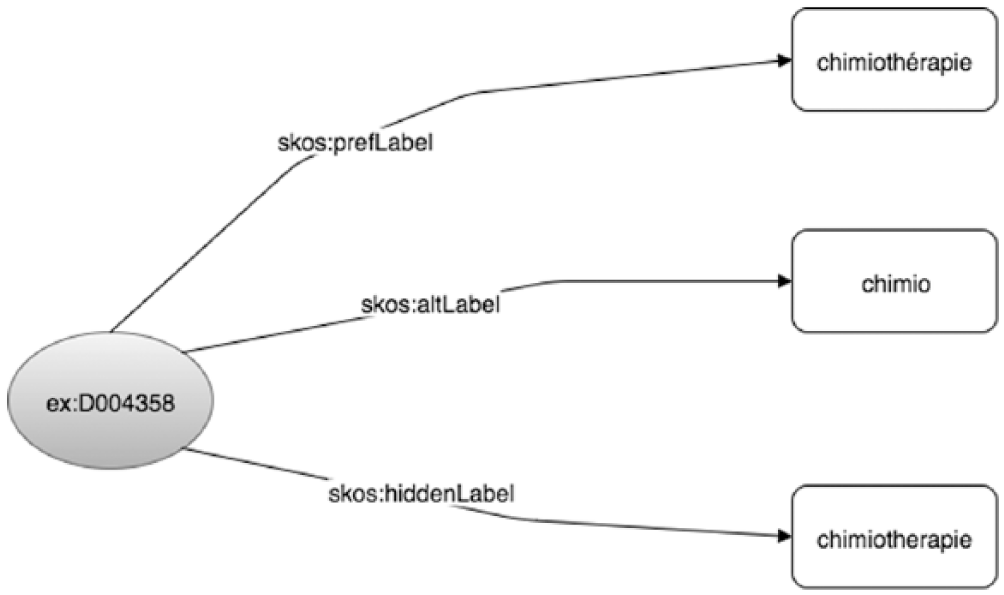
SKOS ontology extract for the term ‘chimiothérapie’ (chemotherapy). ‘Chimiothérapie’ is the expert term, ‘chimiotherapie’ is a spelling error and ‘chimio’ is an abbreviation.
Relationship validation
At the end of step 5, we have k relationships ri with i ∈ [1, k]. Each relation ri connects a common term patj (the term from the corpus) with an expert term biol (the term of the dictionary provided by the INCa). Each relationship is associated with a category type ∈ {spelling error, abbreviation, association}. In this section, we present two methods of validation (automatic and manual). The final manual validation is important to present weaknesses of the associations obtained with the quantitative methods.
Automatic validation
We automatically validate a relationship ri defined by the pair patj–biol, if ri exists in the dictionary of relations with a high confidence level provided by the contributory game – ‘http://www.JeuxDeMots.org’. 50 This Game With A Purpose (GWAP) is used by Internet users not specialized in the medical field. The goal of this game is to build an extensive network of lexical semantic. The graph is composed of nodes. The nodes are linked by different types of relations including 179.578 occurrences of the synonymy relationship and medical vocabularies. 51 This tool has been used efficiently for disambiguation of medical terms and is a reliable source of gold data for medical vocabularies. 52
Manual validation
All relationships ri which could not be validated automatically were presented to five people, including an expert from the medical field. We propose relationships in the form ‘patj – biol – type’ in order to validate the association and its label. Two choices are proposed to annotators: (1) Yes: to validate the relationship and (2) No: to invalidate the relationship. We kept a relation if at least three annotators (including the medical expert) had validated it.
Global validation
As a result, we obtained a set of labelled relationships (patj – biol – type). Because we do not know in advance how many relationships exist for a common term patj, we cannot compute the recall. For this reason, we decided like Doing-Harris and Zeng-Treitler 11 to evaluate our results in terms of precision and used equation (5)
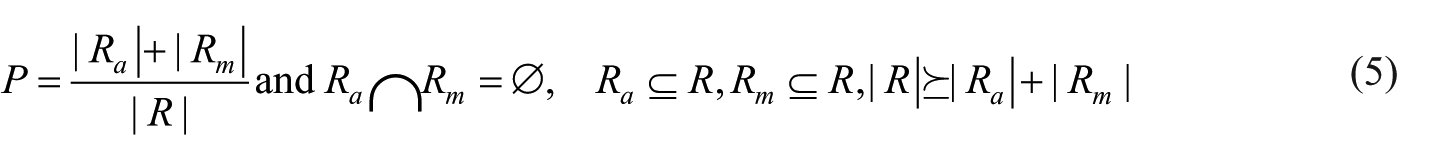
where Ra is the set of relationship automatically validated, Rm is the set of relationships manually validated and R is the set of relationships provided as output by our method.
Results
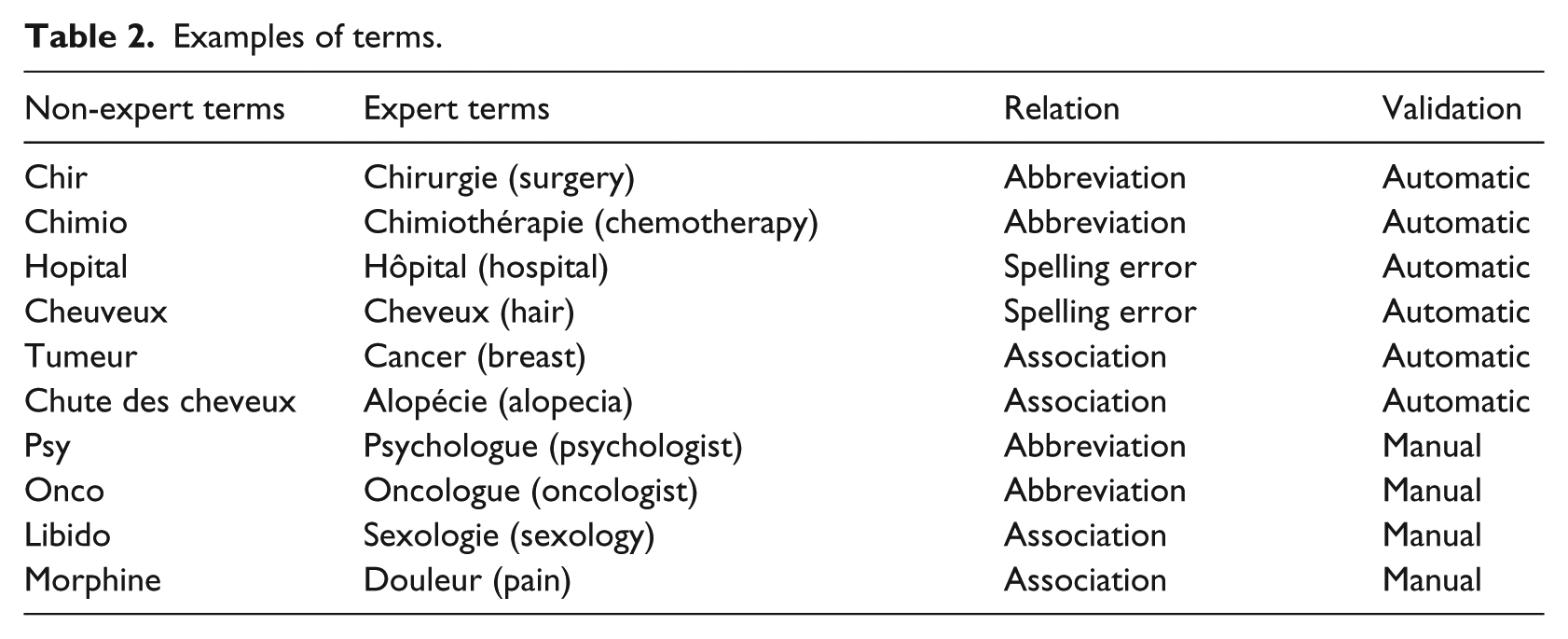
We evaluated our results in terms of precision on the k = 1900 first terms found at step 2; 96 relationships were automatically validated with ‘JeuxDeMots’. Experts evaluated the remaining relationships. A kappa Fleiss coefficient kf was computed to measure the inter-annotator agreement. We obtained kf equal to 0.25. This low agreement is explained by the variability of judgement annotators on the medical value terms. The expert in breast cancer keeps only correct associations in relation with breast cancer and other experts keep all correct relationships even those relationships not linked to breast cancer (e.g. ‘orbite – terre – association’, ‘orbit – hearth’ in English). Consequently, we choose to keep only associations validated by three experts including the breast cancer expert. Examples of validated relationships are presented in Table 2. Statistics about the validation are presented in Figure 3. We discuss these results in section ‘Discussion’.
Examples of terms.
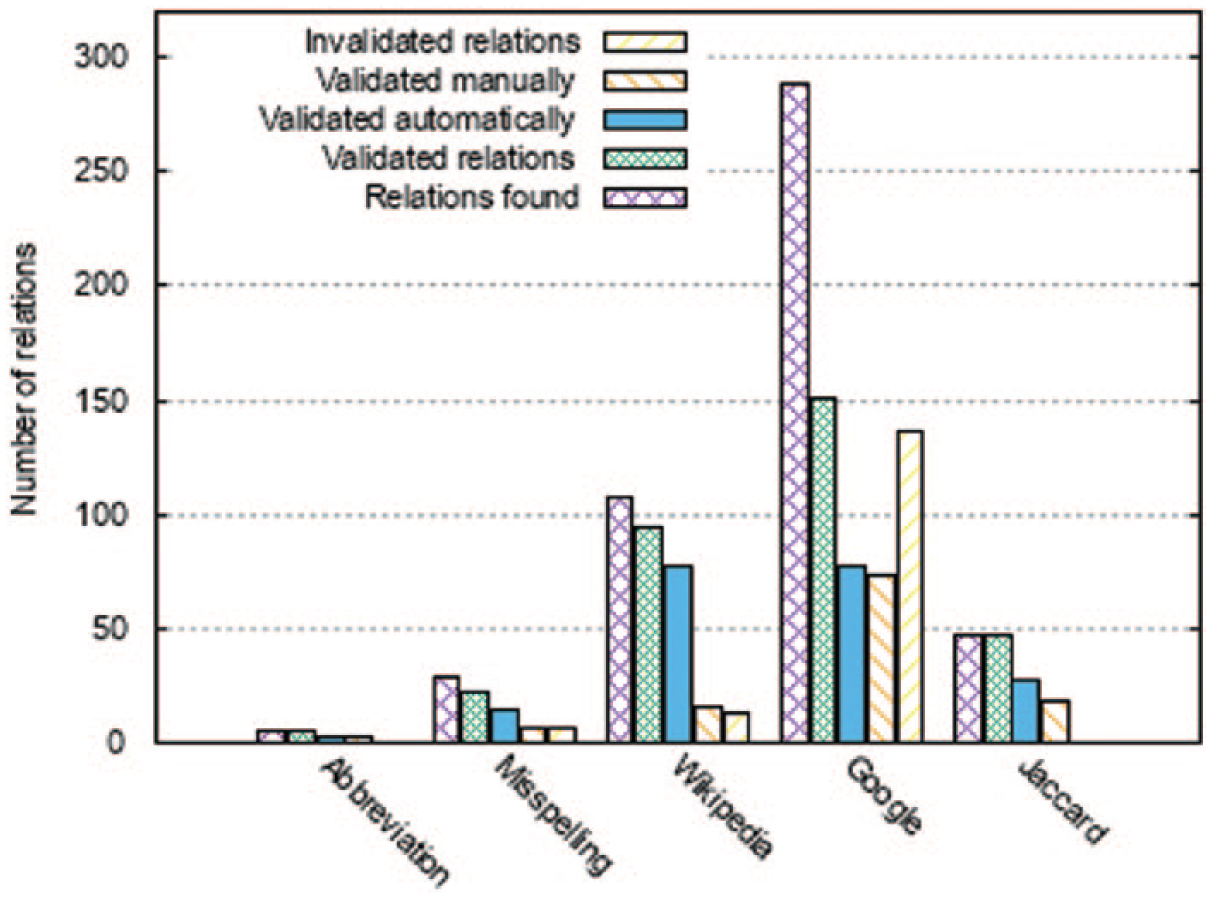
Number of relationships validated automatically, manually and those not validated at all.
For each common term, we keep in the resource the related term having the most important similarity. For example, with the Google similarity, for the non-expert term ‘crabe’, the related terms are (in French) zodiaque, cancer, tabou, hémorragie and biopsie (zodiac, cancer, taboo, haemorrhage and biopsy in English). We keep the closest term to ‘crabe’ which is listed in the INCa dictionary, here ‘cancer’. Thus, we create the relationship ‘crabe–cancer’ which is included in the ontology. However, in the case where two relationships have the same weight, the common term may be linked to several expert terms (e.g. onco – oncology, onco – oncologist) and vice versa.
Figure 3 shows the number of validated relationships on our corpora for each measurement. For spelling errors, we obtain an overall precision P equal to 76 per cent. We have validated 22 relationships on the 29 obtained at step 3; 15 relationships were obtained by automatic validation and 7 by manual validation. For abbreviations, we obtain an overall precision P equal to 100 per cent. We have validated five relationships on the five obtained at step 4; three relationships were obtained by automatic validation and two by manual validation. For the Wikipedia similarity, we obtained an overall precision P equal to 88 per cent. We have validated 94 relationships on the 107 obtained; 78 relationships were obtained by automatic validation and 16 by manual validation. With the Google similarity, we obtained an overall precision P equal to 52 per cent. We have validated 151 relationships on the 288 obtained; 77 relationships were obtained by automatic validation and 74 by manual validation. With the Jaccard similarity, we obtained an overall precision P equal to 100 per cent. We validated the 47 relationships obtained; 28 relationships were obtained by automatic validation and 19 by manual validation.
Finally, considering all types of relationships, we obtain an overall precision P equal to 55 per cent. We have validated 192 relationships out of 346 that were obtained at step 5.
At step 5, we observed an overlap of the relationships obtained with the three similarities. The 47 relationships obtained by the Jaccard similarity are included in the set of relationships obtained by Google and Wikipedia similarity measure. We also found 80 relationships in common between Google and Wikipedia measurements. Excluding the duplicates among the relationships, we keep 165 relationships to be included in the SKOS ontology.
Discussion
Building a CHV can be done in several ways (manually or semi-automatically). In this study, we built a CHV semi-automatically for the breast cancer field in French. The proposed method allows connecting the terms used by patients with those used by health professionals. To build this vocabulary, we only used data extracted from forums and a connection to the Wikipedia API and to the web search engine Google.
We have compared three similarity measures based on different paradigms. We observe that the Wikipedia similarity provides little work for the expert to validate the candidate relationships. However, the Google similarity gives the highest number of validated relationships, but it requires additional effort for manual validation. With the Jaccard similarity, although the set of relationships found is very small and is included in the ones found with the other similarity measures, the relationships are all validated.
Considering the noisy nature of the biomedical textual data we used, the obtained results are very encouraging. Doing-Harris and Zeng-Treitler 11 have conducted a similar work. They built a general CHV in English. Out of 88.994 terms, they found 774 relationships and validated 237, thus a precision of 31 per cent. In our work, out of the 1900 terms, we found 346 relationships and validated 192, thus the global precision is 55 per cent.
One limitation is the number of matches issued from the initial resource. The INCa resource is composed of 1227 terms. Only 117 expert terms (that correspond to 10% of the initial resource) found corresponding common term with our method. This can be explained by the fact that we do not consider the 470 acronyms (that correspond to 38% of the initial resource). Moreover, we have projected the other 640 terms in the forums and have observed that these terms are frequently used by the patients in forum posts and therefore do not have specific substitutes. Finally, we have created a specific resource dedicated to the field of breast cancer and not a general resource.
A second limitation is the type of users, which produced the PAT exploited in this study. Indeed, unless a group has formal gatekeeping of members, it is difficult to know for sure whether people posting to a forum are patients, health care professionals, care providers, family or friends of patients. Consequently, terms extracted at step 2 may have been generated by users who are not suffering from breast cancer. In particular, it has been known for decades that health information seeking is done principally by friends or family members and then after that by patients. 53 In this work, we made the assumption that the vocabulary of relatives is similar to patients vocabulary and must be included in the CHV. However, in a previous work, 54 we have proposed a method to automatically deduce the role of forum user. This method can be used at the beginning of our chain to exclude the posts of health care professionals and care providers.
Finally, we only use ‘cancerdusein.org’ forum because French physicians and INCa recommend this forum to patients. However, there are certainly many other online communities related to breast cancer (e.g. in Facebook and Twitter), and of course, the community studied in this article is not necessarily representative of all patients suffering from breath cancer. In particular, we have used in previous work other social networks such as Facebook 55 to capture and compare the topics expressed by patient in forums and in Facebook. We note that most of the messages in forums focus on medical questions (e.g. secondary effects of treatment, non-medical treatment and observance). We retrieve these topics in Facebook, but the focus is also on encouragement and support request. It is important to note that our method can be easily applied to others corpus. As we do not pre-treat patient corpus, we only need to collect the different types of messages. This would allow us to know how patients express themselves in both types of social media.
Conclusion and perspectives
In this article, we present a method for linking the terms used by patients in social media to those used by health care professionals, which are present in controlled vocabularies. An advantage of this method is that aligned expressions can be composed of several terms. We only solicit experts for validation if the relationships are not retrieved using our gold standard.
We applied this method to the breast cancer field, but it can be applied to many other areas. For this, we need to replace the INCa list with a list of terms specific to the domain of the studied disease and to collect a new corpus of messages dealing with the disease.
We have also experimented with this method for French, but the method can be adapted to other languages with appropriate resources.
We compared three similarity measures to link common and expert terms. Such a resource will be an essential step in the automatic processing of social media content in the medical field.
The resource is now freely available to download for the community at the following address: http://bioportal.lirmm.fr/ontologies/MUEVO. We transformed this resource into human readable and machine-readable formats. To do this, we created an ontology in SKOS format to embed the platform BioPortal. 56
In the long term, we plan to re-use data used to study the quality of life of patients with breast cancer and thus improve our processes similar to the one presented in previous work. 6 We could measure the impact of the resource, for example, on annotation57,58 and classification tasks. 59 Similarly, we will apply our method to social media in English to extend existing CHV. We will also study the development of the vocabulary of patients over time, using a Latent Dirichlet Allocation (LDA) model.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and /or publication of this article: This work was supported by the ANR SIFR (Semantic Indexing of French Biomedical Data Resources) and by a grant from the French Public Health Research Institute (![]() ) under the 2012 call for projects as part of the 2009–2013 Cancer Plan.
) under the 2012 call for projects as part of the 2009–2013 Cancer Plan.