
Abstract
The social identity approach suggests that group prototypical individuals have greater influence over fellow group members. This effect has been well-studied offline. Here, we use a novel method of assessing prototypicality in naturally occurring data to test whether this effect can be replicated in online communities. In Study 1a (N = 53,049 Reddit users), we train a linguistic measure of prototypicality for two social groups: libertarians and entrepreneurs. We then validate this measure further to ensure it is not driven by demographics (Study 1b: N = 882) or local accommodation (Study 1c: N = 1,684 Silk Road users). In Study 2 (N = 8,259), we correlate this measure of prototypicality with social network indicators of social influence. In line with the social identity approach, individuals who are more prototypical generate more responses from others. Implications for testing sociopsychological theories with naturally occurring data using computational approaches are discussed.
Keywords
Online forums are used by millions of individuals every day to seek advice, social support and a sense of community. However, concerns have been raised that online forums contribute to the spread of false information (“fake news”), political polarization and radicalization (Hinds & Joinson, 2017). These concerns have created a heightened interest in understanding social influence online. Social identity theorists have long studied how group identities exert influence over individuals in the offline world (Tajfel, 1974). More specifically, researchers have studied the role of the group prototype and group prototypical leaders in influencing other group members (van Knippenberg & Hogg, 2003). However, little research has sought to explore how prototypical individuals may influence others online. One of the primary barriers to studying group processes online from a sociopsychological perspective has been the lack of methodology for measuring social identity constructs without utilizing self-report survey data. In this article, we build upon a novel method by Koschate et al. (2019) to assess group prototypicality in online text data. This allows us to test whether prototypicality relates to social influence in online forums using naturally occurring behavioral data such as linguistic and social network indicators rather than self-report measures.
Social Identity Approach to Social Influence
Self-categorization theorists suggest that when individuals categorize themselves as a group member, they are influenced by the group’s social norms and therefore tend to behave in group prototypical ways (Turner et al., 1987). The group’s prototype provides a blueprint for how to behave and can provide clarity especially for those experiencing uncertainty (Hogg, 2012). A prototype refers to the quintessential representation of a particular social identity; prototypes define the characteristics, behaviors and attitudes of a particular group, as distinguished from other groups (Hogg, 2001). Thus, when an individual self-categorizes with a group, they evaluate the extent to which they belong within the group by comparing themselves to the prototype (Hogg & Reid, 2006).
The link between leader prototypicality and social influence has been studied in the offline realm for decades (van Knippenberg, 2011); however, this link remains understudied online. Offline research has indicated that leaders derive influence as other group members perceive them to embody and represent what is group prototypical (Hogg, 2001; Hogg & van Knippenberg, 2003; van Knippenberg & Hogg, 2003). In turn, group members are more trusting of those perceived as group prototypical due to the assumption that more prototypical leaders have greater motivation to pursue the interests of the group (Giessner & van Knippenberg, 2008; van Knippenberg & van Knippenberg, 2005). Additionally, leader emergence research has suggested that in groups with no defined leader, individuals who are perceived as more prototypical have a greater likelihood of emerging as leaders (Fielding & Hogg, 1997). This is because other group members turn to those perceived to be prototypical, especially when risky decisions need to be made (van Knippenberg et al., 2000).
Current Online Social Influence Approaches
Whilst there is an abundance of research into the underlying mechanisms of influential leaders offline, this comprehensive understanding of leadership and influence is yet to be applied online. In online studies of social influence and leadership, influence research has focused on understanding how connections and interactions between individuals enable us to gauge which users are most influential (see Peng et al., 2018 for a review). This approach falls into the domain of social network analysis. Metrics included in the computation of influence within this literature are: the number of interactions between users (Yang et al., 2010), novelty of information that a user provides to the network (Song et al., 2007), density of connections between individuals (Zhou & Liu, 2015), and topical expertise (Munger & Zhao, 2015). A large proportion of this literature is also devoted to understanding how the structure and topology of social networks impacts diffusion of information throughout the network (for example, Wang et al., 2013).
However, social network analysis identifies influential individuals from a purely mathematical perspective. Through analysis of the structure of networks and the connections between users, the network-based approach is able to identify key nodes that may impact the diffusion of information through a network (see Razaque et al., 2019 for a review). However, we argue that by taking the sociopsychological reality of individuals into account, we can gain greater understanding into the social dynamics of online groups.
Thus, this research aims to combine group prototypicality research with social network analysis in order to understand whether the relationship between group prototypicality and social influence transfers to the online realm. This research also demonstrates the importance of interdisciplinary work using data sources not commonly utilized within psychological research. By using naturally occurring data, we can observe real-world behaviors from a large number of individuals free from demand characteristics. Further, we also illustrate the value of psychological theory in domains primarily focused on using advanced, data-driven mathematical techniques to model social processes.
Social Identity Theory Online
One theory used to study online behavior through a social identity lens is the Social Identity model of Deindividuation Effects (SIDE; Reicher et al., 1995). The SIDE model posits that individuals communicating online tend to experience greater depersonalization due to the anonymity afforded by the online environment. Consequently, this anonymity results in an overestimation of the perceived similarities between members of an online community (Postmes et al., 2001). This is explained by the limited number of social cues that are available during online interactions. Therefore, individuals are viewed, and view themselves, in terms of their shared social identities as opposed to multifaceted, unique personal identities (Postmes et al., 2001). Further, the SIDE model also comprises a strategic component; this refers to the enactment of social identities or the “purposeful expression (or suppression) of behaviors relevant to those norms conventionally associated with a salient social identity” (Klein et al., 2007, p. 30). This component of the SIDE model is associated with social identity consolidation, namely the process of securing one’s place within a group (Klein et al., 2007). In online settings, it becomes important for individuals to accurately convey their social identity in order to gain acceptance as one of the ingroup. Consequently, based on the idea that individuals conversing online are highly motivated to secure their place within a group, online data become a rich resource for studying social identity processes in a naturalistic environment.
It therefore follows that, based on the idea that individuals are motivated to communicate their social identities online, it will be possible to detect salient social identities using online behavioral data. In research by Koschate et al. (2019), the prototypical linguistic style of group members is used to detect the salience of either a parent or feminist identity. Whilst using forum as a proxy for identity salience, they demonstrate that it is possible to predict which forum a post originated in based only on linguistic style features. Further, they cross-validate this methodology in an offline experiment where identity salience is manipulated, finding that their classifier (trained online) is able to correctly predict which identity was made salient at the point of writing. This research introduces the idea that we can work backwards from context-dependent, homogeneous ingroup behavior in order to study social identities online.
Koschate et al.’s approach combines knowledge from the psycholinguistic tradition, which suggests individuals unintentionally reveal cues about their psychological reality through variations in their linguistic style (Tausczik & Pennebaker, 2010), with knowledge from self-categorization theory, which suggests that the behavior of group members is impacted by the social norms of the groups to which they belong (Turner et al., 1987; Turner & Oakes, 1986). Prior psycholinguistic research has concentrated on determining differences in communication style between different genders (Newman et al., 2008), ages (Löckenhoff et al., 2008) and personalities (Mairesse et al., 2007; Pennebaker et al., 2005). However, for the most part, it is assumed that individuals write in relatively stable and invariable ways based on the groups to which they belong (e.g., male or Democrat) (Newman et al., 2008; Sylwester & Purver, 2015). Yet, the social identity approach to linguistic style appreciates that individuals may identify with many different social groups which influence behavior only when those identities are salient (Turner, 1982). Other than the research of Koschate et al., this dynamism of linguistic style remains under-researched within the psycholinguistic tradition (Nguyen et al., 2016). However, it has long been discussed in variationist sociolinguistics.
Variationist sociolinguists suggest individuals shift their linguistic style due to contextual factors; in contrast to the psycholinguistic approach, they note an individual’s linguistic style is not stable across contexts. There are various theories of when individuals shift their style; some acknowledge the audience as central to shifts to linguistic style (audience design theory; Bell, 1984), others focus on interpersonal relationships (communication accommodation theory; Giles et al., 1991), whilst others view communication purpose as integral to shifts in style (Schilling-Estes, 2002). Whilst all these theories are supported by empirical evidence, the social identity approach to linguistic style suggests identity salience is a key feature that mediates these style shifts. Thus, a change in audience or topic influences which social identity is salient, consequently impacting an individual’s communication style.
The Present Research
This research focuses on two social identities hypothesized to be important to those using darknet cryptomarkets (Munksgaard & Demant, 2016). Cryptomarkets are hidden websites which allow for the anonymous sale of illicit goods. Cryptomarkets have been referred to as “eBay[s] for drugs” (Barratt, 2012, p. 683) – they host multiple sellers, selling multiple products and display customer reviews for each product available (Barratt & Aldridge, 2016). Silk Road was the first cryptomarket to exist on the darknet and was active from February 2011 until October 2013. Since its demise, many other cryptomarkets have risen in its place, with authorities estimating that approximately $300 million worth of drugs were sold online in 2016 (United Nations Office on Drugs and Crime, 2018). According to previous Silk Road research, libertarians and entrepreneurs were both active during the 32 months that the darknet site was active (Maddox et al., 2016; Masson & Bancroft, 2018; Munksgaard & Demant, 2016), and thus these identities are the focus of our research. Whilst there are likely differences between those who believe libertarian ideals and those who enact their libertarian ideals through drug dealing on cryptomarkets, or similarly between entrepreneurs and those who are criminal drug vendors, we hypothesize that we can utilize a broader understanding of non-criminal identity prototypes in order to study more niche cryptomarket identities. In the future, we hope the research conducted into these identities on the clearnet can help to identify influential individuals on darknet websites.
In order to study the link between identity prototypicality and social influence online, we first build a model to detect social identities online. Study 1a involves training a machine learning algorithm to determine the group prototypical linguistic style of our two identities (libertarian and entrepreneurial) on a clearnet website (Reddit). In Study 1b, we validate our prototypicality model by excluding demographic differences as an explanation using a within-person design study. In Study 1c, we use data from the Silk Road darknet forum to exclude local accommodation as an explanation for our results. Finally, we apply our model on unseen Reddit data to study the link between our measure of identity prototypicality and influence (Study 2).
Study 1a – Training and Developing the Model
In Study 1a, we trained and validated a decision tree classifier to detect our two social identities – a libertarian identity and an entrepreneur identity – using Reddit data. We hypothesized that, in line with Koschate et al. (2019), it would be possible to accurately differentiate between two social groups based on a group prototypical linguistic style (H1). We then validated our model by testing (1b) whether it could correctly classify posts where the author is the same person (within-person design), and (1c) whether this finding is more than accommodation to local forum norms using data from Silk Road.
Method
Data Collection
We first collected data from individuals writing with one of our two identities salient. In line with Koschate et al. (2019), we used forum topic as a proxy for identity salience. We assumed that individuals posting in either an entrepreneur forum or a libertarian forum had the respective identities salient at the time of writing. We then trained our classifier to distinguish whether a contribution originated in either of these two forums, thereby creating a model that assesses a group prototypical linguistic style.
After receiving ethical approval from the Departmental Ethics Board, data were collected from the Reddit “Libertarian” and “Entrepreneur” forums, known as “subreddits”. Google BigQuery was used to collate the data.
We collected one year’s worth of posts and comments for both subreddits. We collected the title, text, URL and author of all posts and comments submitted to the Libertarian and Entrepreneur subreddits in 2018. In total, we collected 1,932,334 contributions to the Entrepreneur and Libertarian subreddits. This comprised 41,933 posts and 334,001 comments to the Entrepreneur subreddit (n = 375,934) and 65,048 posts and 1,491,352 comments to the Libertarian subreddit (n = 1,556,400).
Quantification of Linguistic Style
To linguistically analyze the data, we used Linguistic Inquiry and Word Count software (LIWC) (Pennebaker et al., 2015). LIWC uses a bag-of-words language model, so that word order is ignored. It counts the number of words classified into particular linguistic categories, for example affective words, adverbs, future tense words (see Pennebaker et al., 2015 for further detail) and computes a percentage value for each document, reflecting the proportion of a particular feature in a document. The textual data from each Reddit post was converted into a vector with 41 stylistic features (see online supplemental materials). We define style as the part-of-speech categories that are used widely across different contexts and domains regardless of topic (e.g., pronouns and articles) (Schwartz et al., 2013). Conversely, linguistic categories corresponding to message content (such as “work” or “money”) were omitted.
Data Preparation
In order to train our model to predict identity salience, it was necessary to exclude any data that may adversely impact our ability to draw robust psychological conclusions (see Table 1). First, we removed posts containing only URLs. Entrepreneur forum moderators aim to remove any posts that contain only links themselves, and so we only removed one post. In the Libertarian subreddit, URLs are frequent and so we removed 52,767 posts at this stage. We then omitted posts and authors that had been deleted or removed by moderators. 1 Next, we removed posts made by bots. Bots are automated scripts used to provide information to users of a subreddit (Massanari, 2016). We removed all submissions containing the word “bot”, as bots often identify themselves using phrases such as “I am a bot”. We also removed authors with “bot” in their name and the “AutoModerator” in the entrepreneur forum.
Detail of data preparation process.
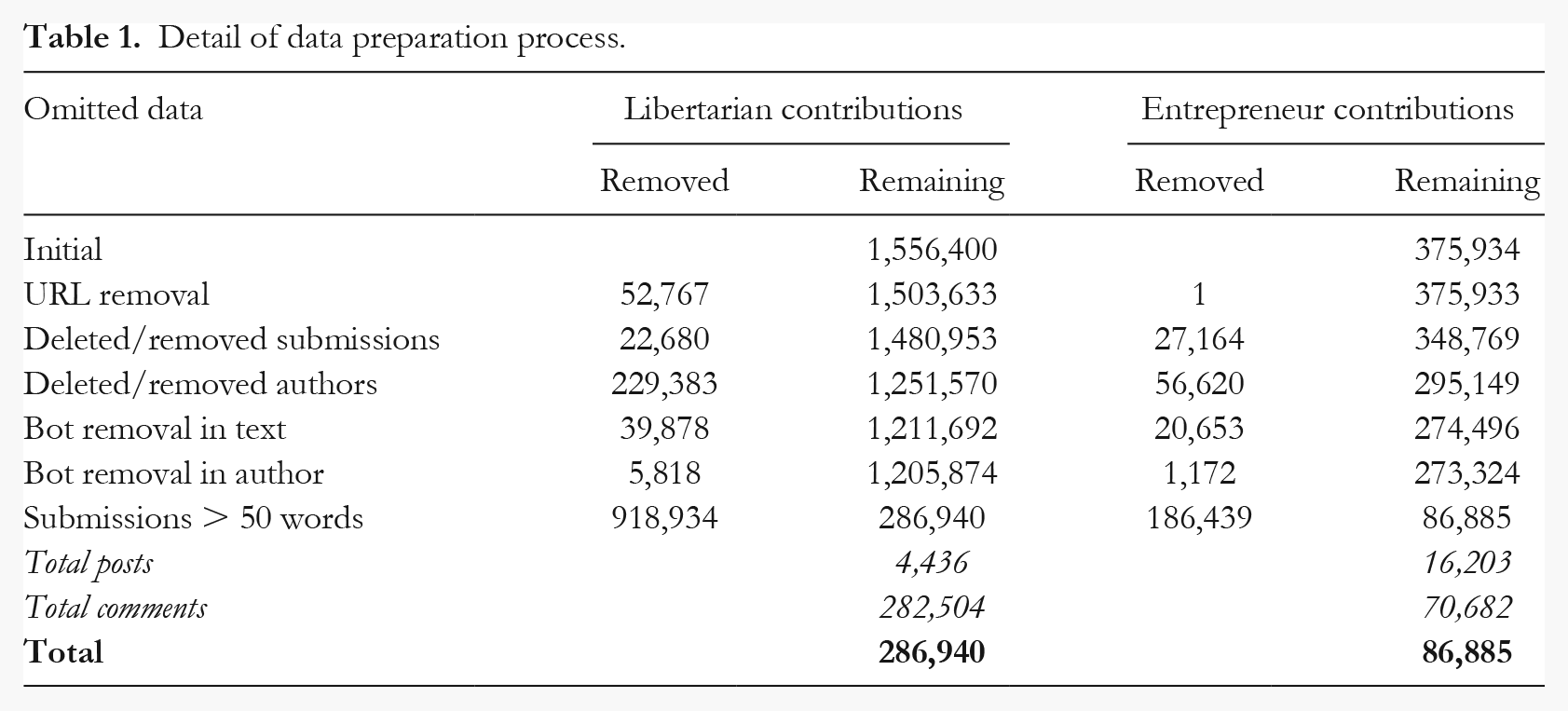
Next, we omitted submissions with fewer than 50 words. As outlined above, the linguistic analysis software used in this research is word count software which uses percentages to determine the proportion of words in a text that belong to a specific linguistic category. Consequently, in texts with low word counts, particular categories may be highly over-weighted; for example, in a text with only 10 words, each word is weighted at 10%. As a result of this, it is accepted within psycholinguistics that texts with higher word counts lead to more robust and reliable psychological conclusions (Boyd, 2017). Further, Chung and Pennebaker (2019), the developers of LIWC, advise using a minimum cut-off of 100 words where possible. In practice, word count cut-offs are often lower than this, especially when using sparser social media data (50 words – Bäck et al., 2018; 25 words – Koschate et al., 2019; 45 words – Nelson et al., 2017; 50 words – Petrie et al., 2008; 50 words – Wilson, 2019). Our choice of 50 words was made in order to keep as much data as possible in our analysis, whilst ensuring that the data could be used to draw psycho-logically meaningful conclusions (Pennebaker Conglomerates Inc., 2017).
After data omission, we had a sample size of N = 373,825 (n = 286,940 from the Libertarian subreddit and n = 86,885 from the Entrepreneur subreddit; see Analytic Strategy for how we deal with this disparity). In total, there were 27,225 individuals posting in the libertarian forum and 25,824 individuals posting in the entrepreneur forum. The mean number of words per contribution was 116 (Med = 85, SD = 102) in the libertarian forum, and 135 (Med = 91, SD = 194) in the entrepreneur forum.
Analytic Strategy
A Random Forest algorithm was used to classify posts as either libertarian or entrepreneur based on patterns in linguistic features. Random Forests are non-parametric, supervised learning methods, comprising multiple decision trees each voting on which class (in our case, forum) a particular datapoint belongs to. Decision trees are trained through repeatedly splitting the dataset into subsets consisting of similar datapoints until each datapoint is classified into pre-specified categories. At each split, the dataset is divided based on the value of one of its features. The resultant model is then tested on previously unseen data in order to gauge how successful the model is at distinguishing between the two classes (forums) based on the features (linguistic style variables).
In traditional Random Forest classifiers, the feature and threshold chosen to split the data are mathematically optimal (see Cutler et al., 2012 for more information). For this research however, we used an Extremely Randomized Trees (“Extra Trees”) classifier which chooses the best feature–threshold combination for each split from a small, randomly chosen set (Geurts et al., 2006). In this way, the Extra Trees model is less likely to overfit the training data through a more efficient method of reducing variance and bias within the dataset. Furthermore, due to the randomized procedure of splitting the data, Extra Trees are less computationally expensive.
Imbalanced class sizes can adversely impact a classifier’s ability, as merely choosing to classify every post as one of the majority class can still achieve an apparently high accuracy. In order to deal with the imbalanced class sizes of our dataset, we undertook random under-sampling of the majority class whereby we ran the classifier on 75,118 randomly chosen posts taken from the libertarian forum in order to match the 75,118 submissions in the entrepreneur forum. We used the same number of comments (n = 70,682) and posts (n = 4,436) in each sample. We repeated this process 10 times to ensure there was no significant variance between each subset of 75,118 libertarian forum submissions.
For the initial analysis, we trained and tested our Extra Trees model using 75,118 posts from both the Libertarian and Entrepreneur subreddits. We entered all 41 LIWC style features into the model. To prevent overfitting and lower the bias of our model, we used k-fold cross-validation with k = 10. In k-fold cross validation, a subset (fold) of the data (1/10 in 10-fold cross validation) is held out of the training set and is used to validate the model (see online supplemental materials for more information). In this way, the model is trained on 9/10 of the data, and then validated on the 1/10 that has been held out. This cross-validation is completed 10 (k) times, until all folds have been held out of the training set and used in validation. Empirical evidence has shown k-fold cross-validation using k = 5 or k = 10 yields test error rate estimates that exhibit neither high estimates of bias nor inflated variance (Kuhn & Johnson, 2013).
Further, we also extracted the importance of each of the 41 features entered into our model in order to ascertain which features may be irrelevant or redundant to the classification process (Figure 1). Using redundant features can lead to models that overfit the training data and therefore perform worse during testing. It is therefore important to select the most predictive features.
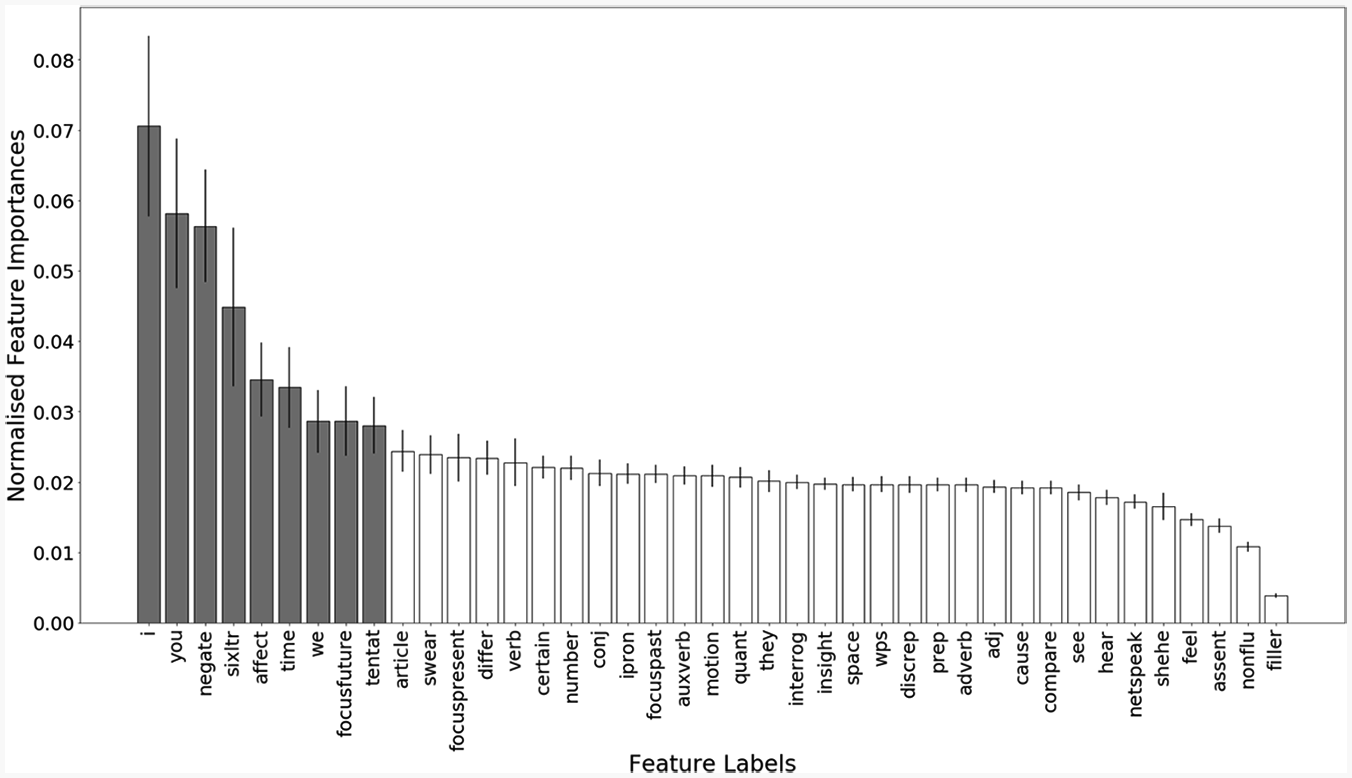
Graph illustrating normalized impurity-based feature importances in classifying forum posts.
Through plotting the importance of each feature, it was possible to identify nine features that were more important than the others in the classification process. We therefore repeated the analysis using only the top nine most important features (for more information see the online supplemental materials).
Results
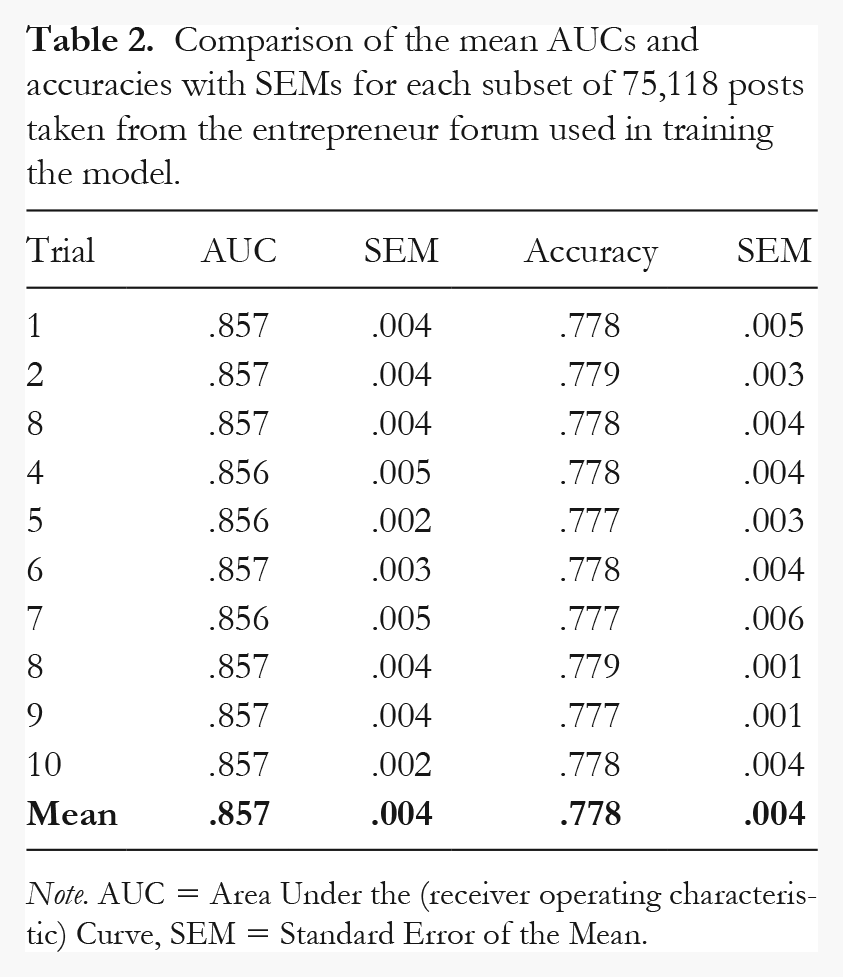
To assess whether random under-sampling was a robust technique to address the imbalanced class sizes, we ascertained how the model performed when a random subset of 75,118 posts was taken from the libertarian forum to match the 75,118 submissions in the entrepreneur forum. Table 2 below indicates the Area Under the (receiver operating characteristic) Curve (AUC) and accuracy scores for the classifier and associated Standard Errors of the Mean (SEMs) on each trial. As evidenced in Table 2, the AUC and standard error of each trial showed little variance, verifying the use of random under-sampling to correct for the class imbalance.
Comparison of the mean AUCs and accuracies with SEMs for each subset of 75,118 posts taken from the entrepreneur forum used in training the model.
Note. AUC = Area Under the (receiver operating characteristic) Curve, SEM = Standard Error of the Mean.
For the main analysis, when training our model on the top nine most important features, the model achieved an AUC of .83 and an accuracy of .76. The confusion matrix below illustrates the percentage of posts that were correctly and incorrectly classified (Figure 2).
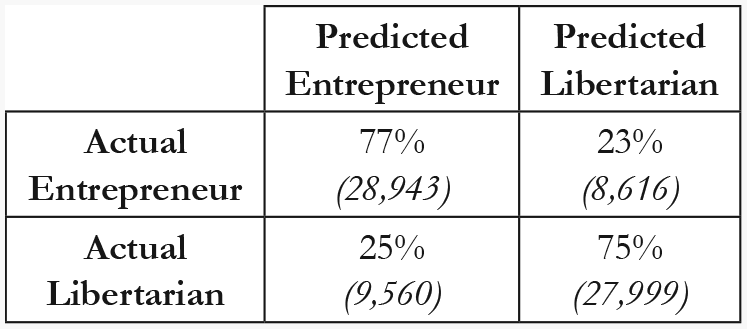
Confusion rate matrix for nine-feature classifier.
Discussion
Our results demonstrate that linguistic style between libertarians and entrepreneurs differs sufficiently enough to detect which group a text stems from, thus finding support for Hypothesis 1. This shows synthesis with Koschate et al. (2019). Moreover, the confusion matrix (Figure 2) indicates that using only nine linguistic features, we are able to correctly classify 77% of entrepreneur posts and 75% of libertarian posts. Thus, the variation in linguistic style between these two identities can be captured ~ 75% of the time using only nine linguistic style features.
However, a possible explanation for this finding is that individuals posting in the libertarian subreddit are demographically different to those posting in the entrepreneurial subreddit. Previous research has highlighted that demographic factors, such as age and gender, may impact linguistic style (Löckenhoff et al., 2008; Newman et al., 2008). In Study 1b, we validate our model by testing it on individuals who have posted in both the libertarian and the entrepreneur forums. By completing a within-person analysis, we are able to exclude stable demographic differences as an explanation for the results of Study 1a.
Further, another possible explanation is that individuals may be accommodating to the style of the forum and thus these results may be platform dependent. Communication accommodation theory (Coupland, 1995; Giles et al., 1991) suggests individuals linguistically converge with those they are in discussion with, and therefore our results may be explained by this accommodation to forum norms. Instead, we propose that individuals have an idea of what is socially normative for their identity (an identity prototype) and thus behave in line with this prototype regardless of the online platform on which they are posting. In order to rule out local accommodation as an explanation for these results, we examine a platform-based explanation in Study 1c.
Study 1b – Excluding Demographic Differences
As outlined above, it is possible that the main driver of linguistic style differences between the libertarian and entrepreneur forums is, in fact, due to demographic differences between the individuals who post in both of these forums. In Study 1b, we hypothesize that our classifier will still differentiate between the prototypical linguistic style of the two social groups even when the text is written by the same individuals (H2).
Method
Test Dataset
To exclude demographic factors, we performed a within-person analysis; we used data from individuals who had posted in both the entrepreneur forum and the libertarian forum. For each individual, we calculated their average linguistic scores from posts in both forums. In total, 441 users contributed submissions of over 50 words to both forums; this gave us a test dataset consisting of N = 882 (441 individuals with two scores each). For the training dataset, we used the remaining submissions from both forums from authors not included in our test set. After random under-sampling, our training dataset consisted of N = 142,320 posts, with n = 71,160 from each forum.
Procedure
We used the nine-feature model outlined in Study 1a on our within-person test dataset.
Results
When training the classifier using nine data-driven features outlined in Study 1a and testing the classifier on posts from individuals who had posted in both the entrepreneur and the libertarian forum, our classifier achieved an AUC of .781 and an accuracy of .724. The confusion rate matrix (Figure 3), indicates that the classifier was approximately equally successful at classifying libertarian and entrepreneur identities.
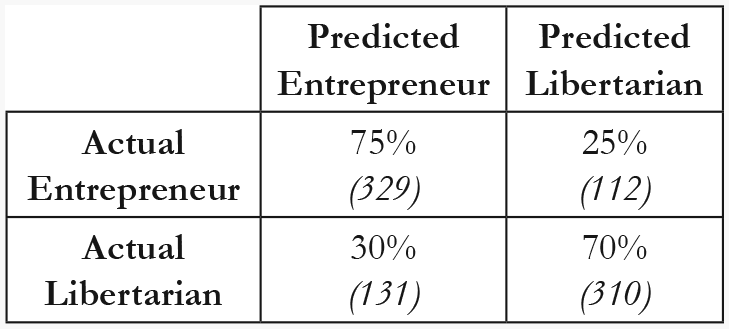
Confusion rate matrix for nine-feature classifier when tested on within-person data.
Discussion
The results of Study 1b indicate that when we exclude demographics as a possible explanation for the findings of Study 1a, our model is still able to correctly identify which of our two identities was salient at the time of writing.
The results from the within-person analysis suggest it is possible to detect intra-individualistic style shifts using only nine linguistic features. This result validates the model as it illustrates that the classifier can distinguish between the linguistic style of libertarians and entrepreneurs even when we exclude demographics as an explanation. In line with findings from Koschate et al. (2019), the within-participant analysis shows that individuals shift their linguistic style according to the social identity that is salient in the social context. This result serves to underline the dynamism and fluidity of linguistic style that is often overlooked.
However, it could still be argued that this finding is just the result of forum users accommodating to local norms. In order to test this possibility, Study 1c examines whether the model is still able to distinguish between identities when tested on data from a different online platform.
Study 1c – Excluding Local Norms as an Explanation
In Study 1c, the primary interest is in understanding whether the results from the previous studies can be explained purely by accommodation to local forum norms. Here, we argue that individuals have a cognitive representation of their social identity which prescribes identity-congruent behavior. More specifically, we hypothesize that our model will still be able to detect prototypical linguistic styles of libertarians and entrepreneurs on a different platform (Silk Road) (H3).
Method
Test Dataset
To exclude local norms as an explanation for the results of Studies 1a and 1b, we used data from Silk Road which has been collated and made publicly available by Branwen and colleagues (2015). Two forums were identified that linked strongly to the libertarian and entrepreneur social identities: the “Vendor Roundtable” forum and the “Philosophy, Economics and Justice” forum (Munksgaard & Demant, 2016). The Vendor Roundtable forum consisted of vendors discussing ideas to improve their business models whilst the Philosophy, Economics and Justice forum consisted of political and philosophical discussion related to libertarian ideas. The initial sample consisted of N = 20,836 posts, with 10,780 originating in the Economics, Philosophy and Justice forum and 10,056 originating in the Vendor Roundtable forum. After removing posts with fewer than 50 words, this left N = 10,494 posts with n = 4,746 posts from 553 users in the Vendor Roundtable forum and n = 5,748 posts from 1,131 users in the Philosophy, Economics and Justice forum.
Procedure
We used the Reddit-trained nine-feature model outlined in Study 1a and tested it on the Silk Road dataset.
Results
When using the model trained on nine features, the classifier achieved an AUC of .65, and an accuracy of .61. Further inspection of the confusion rate matrix (Figure 4) suggests that the classifier is better at classifying entrepreneurs than libertarians; the classifier correctly classifies 69% of entrepreneurs, but only 55% of libertarians.
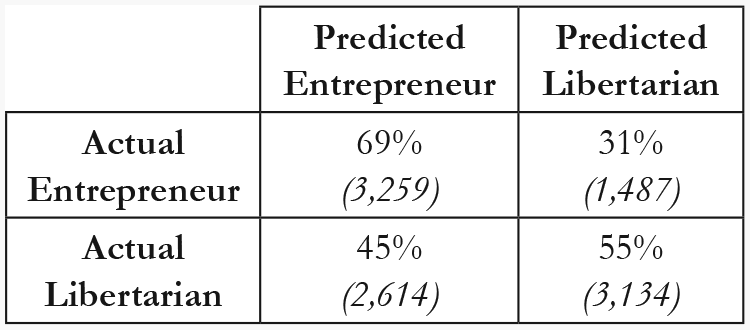
Confusion matrix for nine-feature classifier tested on Silk Road data.
Discussion
By testing our model on data taken from Silk Road, we were able to explore whether the results of Studies 1a and 1b could be explained by accommodation to local norms. The results of Study 1c indicated that when using a Reddit-trained classifier on Silk Road data, the classifier was still able to distinguish between our two identities 65% of the time. However, further inspection of the confusion matrix revealed that a significant proportion of the libertarian posts were being misclassified as entrepreneur.
Nonetheless, the aim of this study was to indicate that the results of Study 1a and 1b are explained by more than just local norms. The fact that the classifier is able to classify both identities at a higher rate than chance (50%), indicates that local norms alone cannot explain the findings in Study 1a and 1b. Nevertheless, one way to improve upon this methodology in future may be to use multiple data sources to distinguish between linguistic features that are locally important and others that are more globally important.
Further, the difficulty in predicting libertarian identities on Silk Road may be because Silk Road libertarians are influenced by a different prototype than the libertarians on Reddit. In this study, we assumed that we could utilize a broader understanding of the identity prototypes in order to classify identities on Silk Road. However, the findings of this analysis suggest that there may be something unique about libertarian identities on Silk Road that our classifier is not currently capturing. For example, it could be argued that libertarians on Silk Road are more extreme in their identities than those using Reddit. This explanation is in line with the interview-based research of Maddox et al. (2016) who found that darknet cryptomarkets “facilitate a shared experience of personal freedom within a libertarian philosophical framework” (p. 111). In this way, being present on Silk Road is a libertarian act of rebellion against the rules of society and thus likely attracts a more “extreme” libertarian than those debating ideas on Reddit.
Nonetheless, the possible discrepancy between Silk Road and Reddit libertarians points to a novel way of comparing the similarity of identity prototypes through language analysis. In order to further understand how libertarians operating on Silk Road may perceive their social identities, we could use classifiers trained on other similar identities, such as anarchists or intellectuals, in order to understand which identity-prototypical communication style is closest to that of the Silk Road libertarians. In turn, this could enable further insight into the social identity prototypes of individuals operating in criminal spaces.
Study 2 – Identity Prototypicality and Social Influence Online
Having determined that our classifier can predict identity between groups, within individuals and is capturing something more than just local accommodation, we then sought to use this classifier to study the link between identity prototypicality and influence online. According to social identity theory, individuals who are more group prototypical can exert a disproportionate amount of influence over other group members (Hogg, 2001). This is because individuals who are perceived as prototypical members of the group are trusted as reliable sources of information about the group identity (Hogg et al., 2012).
In the wealth of literature that has sought to understand the link between the perception of prototypicality and leadership effectiveness (see Barreto & Hogg, 2017 for a meta-analysis), perceptions of prototypicality have been measured through self-report methodologies. In some studies, participants are asked to rate how prototypical they perceive a group leader to be and then to rate leadership qualities such as effectiveness and trust (Hirst et al., 2009; van Knippenberg et al., 2008). In others, individuals are simply told how prototypical a leader is and then asked to rate their leadership qualities (Platow & van Knippenberg, 2001). Whilst these studies demonstrate the link between perceived prototypicality and leadership abilities, it is not clear exactly how an individual comes to their perception of another’s prototypicality. Further, due to the richness of offline interactions, there could be any number of social cues that influence perceptions of prototypicality. In contrast to this, however, social cues in online interactions are much more limited. Thus, whilst we do not have a cognitive understanding of how individuals come to perceive others’ prototypicality, this research looks to examine whether statistical regularities in linguistic style may be used to assess prototypicality.
Previous research has indicated that linguistic style plays a key role in impression formation online. For example, Larrimore et al. (2011) noted that in online peer-to-peer lending environments, use of concrete language (articles and quantifiers) predicted the likelihood of receiving a loan. Additionally, Toma and D’Angelo (2015) found that in online medical communities, forum users were more likely to be perceived as experts if they used more words in their posts, fewer singular personal pronouns and anxiety-related words, as well as more long words and negations.
Therefore, combining the findings that linguistic style plays a key role in impression formation and, secondly, that individuals online strategically enact their social identities to relevant ingroups (SIDE; Reicher et al., 1995), we predict that prototypical group members are recognized by other group members from their linguistic style. Further, we hypothesize that there will be a positive relationship between linguistic prototypicality and influence within the forum, in line with the findings from offline research (Baretto & Hogg, 2017).
For this study, we will quantify influence using basic measures in order to understand whether this idea is worth further exploration. Previous research looking to identify leaders within online communities has suggested that the number of responses that an individual is able to generate is a key indicator of their influence (or at least influential potential) within a forum-based environment (Huffaker, 2010). Based on this quantification of influence, we hypothesize that prototypical individuals will be able to generate more responses from others compared to those who are less prototypical (H5).
Method
Data Collection
For Study 2, we used the classifier outlined in Study 1a to generate prototypicality scores for each individual and then correlated this with measures of influence online. We used the nine-feature classifier from Study 1a to assess the prototypicality of previously unseen Reddit data from March 2019. For the March dataset, we collected the title and text of each post, as well as the author, URL and number of comments. For the comments, we collected the author, text, comment id, parent post id and link id. The link id referred to the id of the top-level post and the parent post id referred to a comment within a thread that someone may be responding to.
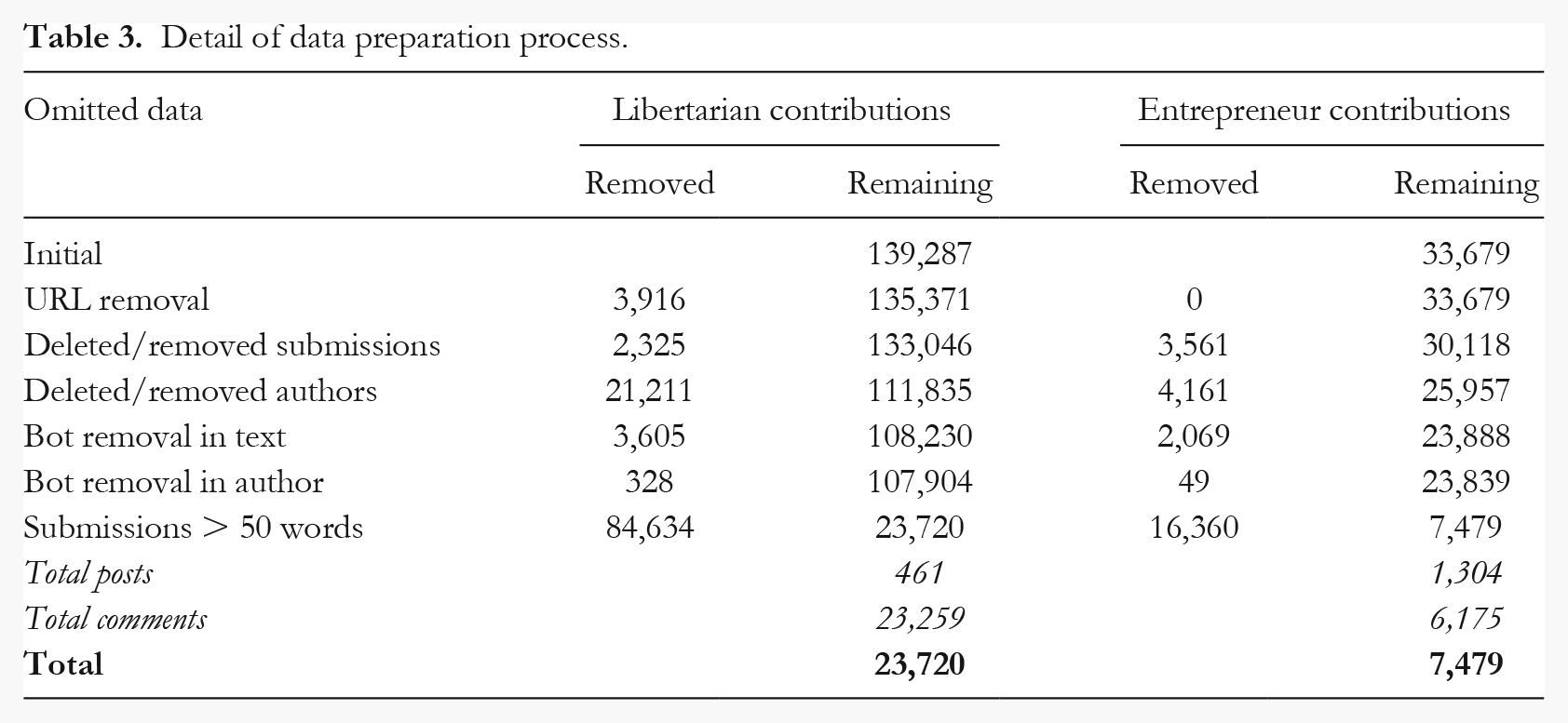
The total sample consisted of N =172,966 submissions, with n = 33,679 from the Entrepreneur subreddit, and n = 139,287 from the Libertarian subreddit. For the linguistic analysis, we applied the same data pre-processing procedure outlined in Study 1 (see Table 3). This left us with a sample size of 23,720 posts from the libertarian forum (4,917 authors), and 7,479 posts in the entrepreneur forum (3,342 authors). The mean number of words per contribution was 217 (Med = 136, SD = 264) in the libertarian forum, and 151 (Med = 101, SD = 186) in the entrepreneur forum.
Detail of data preparation process.
Procedure
To generate prototypicality scores for each individual, we used the classifier outlined in Study 1a. Extra Trees classifiers not only provide a measure of how successfully the model is able to classify posts on aggregate (e.g., AUC/accuracy), but also provide a metric of how strongly each post is classified on a continuous scale. In our model, a score closer to 0 indicates a post is more prototypically libertarian, whereas a score closer to 1 indicates a post is more prototypically entrepreneurial. Using this scale as our dependent variable, we can ascertain whether strongly prototypical individuals are more influential than less prototypical individuals. Having determined a prototypicality score for each post, we calculated the average prototypicality score for each author per forum.
In order to determine how many responses an individual generates, we used the number of comments per post metric provided by Google BiqQuery, as well as centrality measures. To calculate the centrality measures, we derived a network of connections based on who responded to who. In this network, each node represented a user in the forum and an edge between two nodes represented an interaction. We instantiated an edge between two nodes if one user had replied to another user’s post or comment. More specifically, we used a directed network approach which meant that if User A commented on User B’s post, an edge would exist from A to B, but not from B to A. We decided a directed network approach was more appropriate than an undirected network approach (where the same edges would exist between A and B as between B and A regardless of sender and receiver), in order to distinguish between individuals who have more connections because they receive more incoming comments, and those who have more connections because they comment more on other’s posts.
By constructing this network of connected users, we can determine which nodes are most central in the network. An individual’s indegree centrality is the number of replies a user receives on all posts and comments. Whilst it is common to use indegree centrality alone as a measure of response generation (Huffaker, 2010) for the current research, we use an individual’s indegree centrality divided by their total number of contributions to understand how many responses an individual generates whilst taking into consideration their own posting behavior (Mislove, 2009); we refer to this as a “centrality ratio”. For example, a person who has posted once and received four responses would have a centrality ratio of 4, whereas a person who has posted four times and received one response would have a centrality ratio of 0.25. Based on this metric, the higher the centrality ratio the greater the number of responses an individual is able to generate per contribution.
The primary difference between the centrality ratio and number of comments is that the number of comments per post focuses on an individual’s ability to generate responses based only on their posts, whereas centrality measures consider whether an individual’s comments are also likely to generate responses. In forums with longer discussions, indegree centrality may prove more important in understanding whether an individual’s comments are likely to generate further responses. On the other hand, in forums with more of a question–answer format, the number of comments variable may be sufficient for understanding response generation.
To generate centrality measures we used popular software package UCINET (Borgatti et al., 2002). UCINET generates centrality scores by constructing a network of connections and quantifying these connections (for more information see the online supplemental materials). Finally, we calculated the centrality ratio by dividing each author’s indegree centrality by their total contributions.
Results
To assess the relationship between prototypicality and influence, we conducted several Spearman’s rank correlations. First, we reverse coded the libertarian prototypicality score, as scores closer to zero unintuitively referred to higher libertarian prototypicality. We then correlated prototypicality scores with centrality ratios and number of comments per post. Using the prototypicality score determined from the nine-feature classifier, in the libertarian forum a statistically significant relationship was observed between linguistic prototypicality and centrality ratio, rs (4915) = .07, p < .001. The relationship between prototypicality and number of comments was in the predicted direction, although did not reach significance, rs (357) = .10, p = .061. 2
In the entrepreneur forum, we found no relationship between centrality ratio and prototypicality, rs (3340) = –.006, p = .744; however, we did find that prototypical individuals received more comments on their posts, rs (1096) = .11, p < .001.
To explore the difference in significance between prototypicality and centrality ratio and number of comments, we conducted an independent samples t-test to ascertain whether there was a difference in the number of comments per post between the two forums. We found that the number of comments on libertarian threads (M = 22.5, SD = 48.2) was significantly higher than those on entrepreneur threads (M = 13.0, SD = 33.3), t (1763) = 5.79, p < .001. 3
Discussion
The results from Study 2 indicate that individuals who are more linguistically prototypical tend to generate more responses from other group members, thus providing support for Hypothesis 5.
The results showed that prototypical individuals in the libertarian forum had a higher centrality ratio than those who were less prototypical; relative to the number of contributions they made, prototypical individuals received more responses. Whilst there was no relationship between prototypicality and the centrality ratio in the entrepreneur forum, there was a positive relationship between prototypicality and the number of comments generated on posts. Whereas the centrality ratio measures how many responses an individual receives on all contributions (including comments), the number of comments variable consists only of the number of responses an individual receives on their posts. We therefore explored this difference in finding by comparing the average length of discussion thread in each forum and found that the libertarian forum had longer threads (more comments) than the entrepreneur forum. As a result, it can be argued that the centrality ratio becomes a more informative measure of response generation in forums with greater discussion such as the libertarian forum, whereas the number of comments variable is an apt measure of response generation in forums with more of a question–answer format. This is because in forums with more of a question–answer format, the comments (answers) are not aimed at generating further responses. The findings outlined in Study 2 therefore make sense in light of the differing forum structures.
However, this brings us to acknowledge the limitation in using response generation as a measure of social influence within a forum. From a social identity perspective, influential individuals are those who define the group’s identity as well as the normative attributes and behaviors associated with it (Hogg, 2012). Unfortunately, in online forums we do not have direct access to the perceptions of individuals who may have been influenced by a post or person yet decided not to respond. Based on this limitation, we can only consider the explicit responses in order to understand the reaction of other group members. In this study, however, we chose to measure influence via response generation without considering the content of the responses that were generated. This is in line with much of the social-network-based approaches to the study of influence and gives us an approximate understanding of whether identity prototypicality as quantified using linguistic style is an area worth further exploration. Based on the small but significant results within this study, future work should examine this relationship with more robust and psychologically motivated measures of influence.
In order to further this line of inquiry, future research would benefit from directly analyzing the communications of others towards individuals that are more prototypical. This could be completed both qualitatively, by directly assessing how individuals respond to prototypical individuals, but also computationally using linguistic style matching techniques (LSM; Niederhoffer & Pennebaker, 2002). Previous research has highlighted that individuals with a low reputation in forums accommodate towards those with higher reputations (Jones et al., 2014). In Jones et al.’s study, reputation is a forum-specific variable and encapsulates the number of upvotes, length in community and number of posts a user has made. By combining LSM techniques with the measure of prototypicality outlined in this research, we could further test whether users accommodate towards prototypical users.
General Discussion
The findings from this research illustrate the value for social scientists to explore new methods of measuring social psychological constructs and testing social psychological theory in naturally occurring online datasets. In Study 1, we show how measures of linguistic group prototypicality can be developed and validated on naturalistic data using a variety of study designs (between-groups and within-person) and also using different datasets (Reddit, Silk Road). Further, in Study 2, our findings of the relationship between prototypicality and influence serve to criterion-validate the computational methodology, whilst also providing support for theories of social influence that have remained understudied in naturally occurring data. Whilst a plethora of research has utilized self-report survey methodology to study prototypicality and social influence in offline contexts, the primary approach to studying social influence online has focused on the structure and relationships of social groups and the position of members within these groups rather than socio-cognitive processes. In the present research, we develop a method for indirectly measuring socio-cognitive processes using computational methodologies and demonstrate their potential value for future research. More specifically, indirect measures of socio-cognitive processes allow us to better understand the characteristics that make individuals influential in changing social contexts. They also provide us with a means to describe influential individuals online without the circularity of describing them as influential because of their influence. For example, influential users or bloggers online have been defined by their ability to generate responses (Huffaker, 2010), the immediacy with which others respond to them (Yang et al, 2010), content similarity between responses (Huffaker, 2010), contribution of novel content (Song et al., 2007) or the number of times the user’s message is shared (Cha et al., 2010). However, these metrics serve only to describe the behavior of influential users and their followership rather than provide an explanation of their influence based on a testable model or theory.
Interestingly, it is possible to draw parallels between the network approach to influence with how leadership and influence were originally studied within psychology. Both early leadership researchers and current network analysts approach influence research through focusing on the traits of the individuals (Judge et al., 2002) and social exchange relationships between leaders and followers (Graen & Uhl-Bien,1995; Hollander, 1980). Where social exchange theorists study the interpersonal relationship between team members and leaders (Hollander, 1992), network analysts similarly study how influencers are responded to by those around them through shares, likes, Retweets and comments. Thus, in a similar way to how psychologists came to note the importance of the group processes underlying influence, we propose that this understanding of group psychology is needed to extend the current approaches to social influence online. Moreover, in this research we provide a methodology for exploring how social psychological expertise can be used to achieve this goal.
In the present research, we have shown the value that social psychology can contribute to this topic through the creation of new theoretically based computational metrics used to study influence online. In lieu of this, future research should not shy away from creating new psychologically based metrics to better understand the behavioral metrics that have been well-researched within data science. Through gaining greater insight into the “why” of influential users, more so than just the “how”, this will enable the development of more predictive models that are better able to understand online behavior.
In sum, this article provides support for using computational methodologies and naturally occurring online data to test social psychological hypotheses. Whilst it is acknowledged that the effect sizes observed are smaller than those that would be expected in more controlled environments, we nonetheless find statistically significant relationships between prototypicality and social influence in line with findings from offline research (Hogg et al., 2012). However, we contend that there is still much research to be done in exploring how social psychological theories and measures can help to enhance the current approaches to the study of influence online. Further, we also believe that by incorporating data science approaches into psychological research more generally, these novel methodologies will enable researchers to test predictions and theories in completely new ways with real-world data. Naturally occurring online data provide a wealth of opportunity for furthering social psychological research; not only do they provide a way to observe real-world behavior on a mass scale free from demand characteristics, they also allow researchers to study longitudinal processes that may be challenging to study offline. We therefore encourage social psychologists to step forward and embrace this new era of psychological research.
Supplemental Material
Supplementary_Materials_revised – Supplemental material for Using computational techniques to study social influence online
Supplemental material, Supplementary_Materials_revised for Using computational techniques to study social influence online by Tim Hopthrow, Laura G. E. Smith, Mark Levine, Alicia Cork, Richard Everson, Mark Levine and Miriam Koschate in Group Processes & Intergroup Relations
Footnotes
Authors’ note
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Engineering and Physical Sciences Research Council [EP/S001409/1, 1929614].
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.