
Abstract
Is it possible to judge someone accurately from his or her online activity? The Internet provides vast opportunities for individuals to present themselves in different ways, from simple self-enhancement to malicious identity fraud. We often rely on our Internet-based judgments of others to make decisions, such as whom to socialize with, date, or employ. Recently, personality-perception researchers have turned to studying social media and digital devices in order to ask whether a person’s digital traces can reveal aspects of his or her identity. Simultaneously, advances in “big data” analytics have demonstrated that computer algorithms can predict individuals’ traits from their digital traces. In this article, we address three questions: What do we currently know about human- and computer-based personality assessments? How accurate are these assessments? Where are these fields heading? We discuss trends in the current findings, provide an overview of methodological approaches, and recommend directions for future research.
Personality judgments affect many aspects of life, from our choices of friends and whom to date or marry to the way organizations promote their products and services. In physical environments, we judge other people from cues such as their voice, dress, and demeanor, whereas online, we use their Facebook profile, photo albums, tweets, and even the way they write. Often, these online cues (known as digital footprints or digital traces) are the sole information we have to form an impression of someone, particularly when he or she is a stranger, or a “zero acquaintance.”
This can be challenging because individuals may present themselves online in ways that make them appear more appealing than they really are (e.g., more attractive, fitter, happier). On the surface, these cues may be misleading; however, individuals leave other (more hidden) digital footprints whenever they unlock their smartphone, join a Wi-Fi network, or wear devices that track their movement (e.g., accelerometers, gyroscopes). Whereas humans may struggle to make sense of these cues, computers can extract and search for trends in these data. This has led researchers to ask whether computers can accurately predict people’s personality from their digital footprints.
In this article, we outline the mechanisms underlying human- and computer-based personality prediction and describe how future research could address current limitations. We begin by considering what personality is and what “accurate” really means.
What Is Personality?
Personality traits are patterns of thought, emotion, and behavior that are relatively consistent over time and across situations. (Funder, 2012, p. 177)
For years, David Funder’s work on personality has formed the backbone of much psychology research focused on understanding how accurately we perceive ourselves and others. In his realistic-accuracy model, Funder (1995) argued that accurate personality judgments depend on an individual’s (target’s) personality trait and a judge’s (observer’s) correct judgment of that trait. Typically, psychologists measure accuracy using the degree to which observers agree with an individual’s judgment of his or her own personality (called self–other agreement), how much observers agree in their judgments of the same person (other–other agreement), and whether or not a personality judgment can predict behavior (which would imply higher accuracy). To date, psychologists have almost exclusively evaluated personality using self–other and other–other agreement because self-report measures are relatively easy to conduct and to obtain, compared with observing behaviors. However, our digital traces (i.e., digital manifestations of our behavior) can directly address these issues; they are more easily available for analysis and can provide researchers with opportunities to pair personality measures with actual behavior.
These new developments pose some exciting possibilities for researchers, particularly computer scientists (who can develop algorithms to analyze masses of data) and psychologists (who can test theories in new domains), yet cross-disciplinary communication is rare. But with connected devices predicted to outnumber humans 5:1 within the next few years (Nordrum, 2016) and more aspects of our lives leaving digital traces, psychologists risk missing an opportunity to gain unique insights into personality if they ignore the potential of computational methodology, and vice versa (if computer scientists ignore psychology theory, then they may miss valuable insights into human behavior). In the following sections, we critique existing psychological and computational methods and discuss future directions for research.
What Do We Currently Know About Human- and Computer-Based Personality Assessments?
The Big Five model (also known as the five-factor or OCEAN model; McCrae & Costa, 1999) is the most popular theory used in personality assessment (see Table 1 for an overview of each trait, with examples of current findings). In human perception studies of digital footprints, targets and observers both complete questionnaires (on the target’s personality and the observer’s perception of the target’s personality, respectively). In computer-based studies, algorithms are “trained” to predict traits based on preexisting self-report data (obtained from the target) that are associated with their digital footprints. Then, the similarities between target and observer or target and computer are correlated, providing a measure of how accurate the assessments were.
Examples of Platforms and Digital Footprints Associated With the Big Five Personality Traits
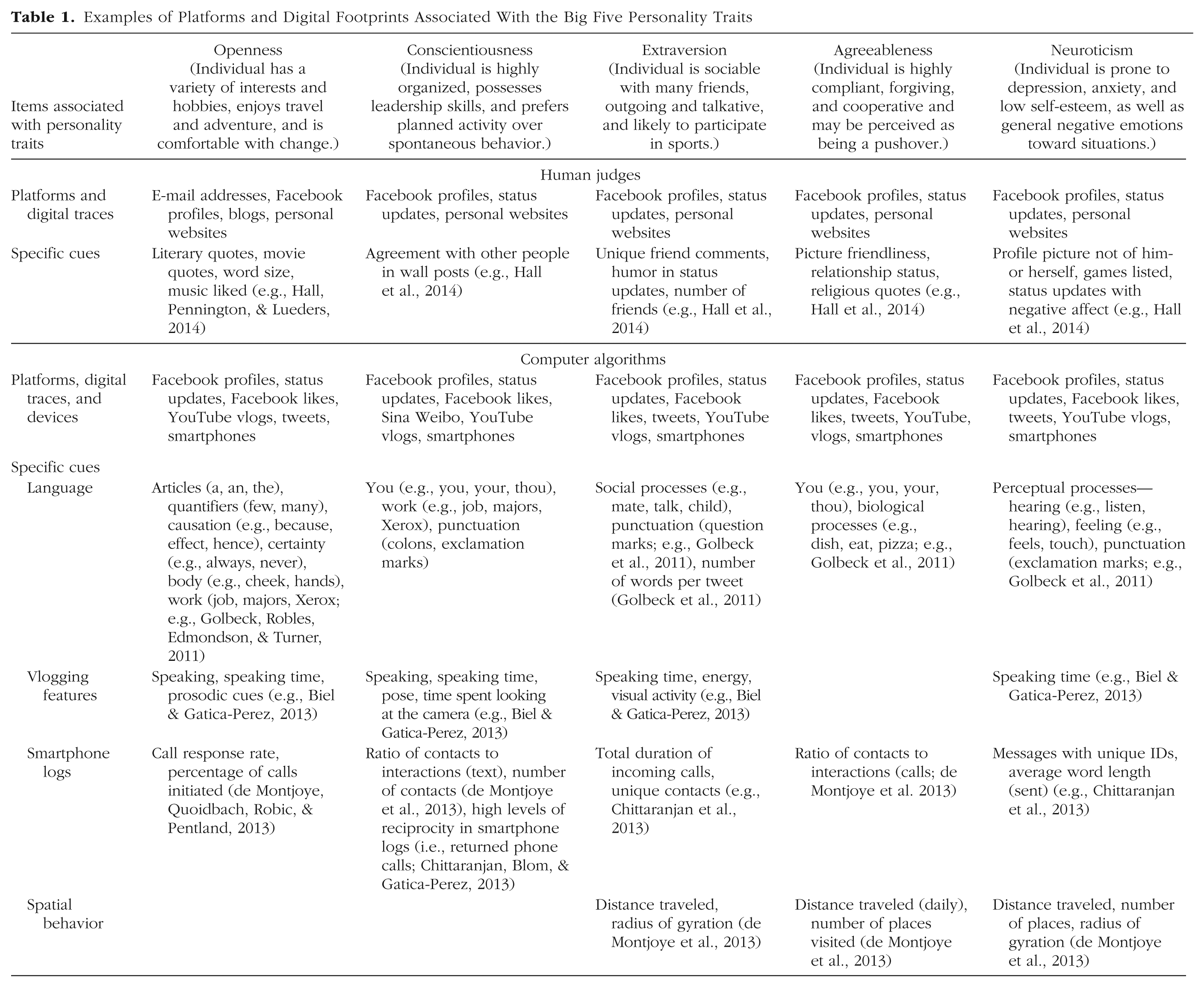
Both human- and computer-based studies have demonstrated that all traits are identifiable in some form or another. For example, human perception studies have demonstrated accurate personality prediction from personal websites (Vazire & Gosling, 2004) and Facebook profiles (e.g., Waggoner, Smith, & Collins, 2009), and computer algorithms have successfully predicted personality from Facebook messages (e.g., Schwartz et al., 2013) and Facebook “likes” (e.g., Youyou, Kosinski, & Stillwell, 2015; Youyou, Stillwell, Schwartz, & Kosinski, 2017). To date, the evidence from two separate meta-analytic investigations suggests that computers are more accurate than humans in predicting personality (Azucar, Marengo, & Settanni, 2018; Tskhay & Rule, 2014). (A meta-analysis involves combining results from multiple studies to establish how strong an effect is.) Figure 1 compares the findings across the two studies for each of the Big Five traits.
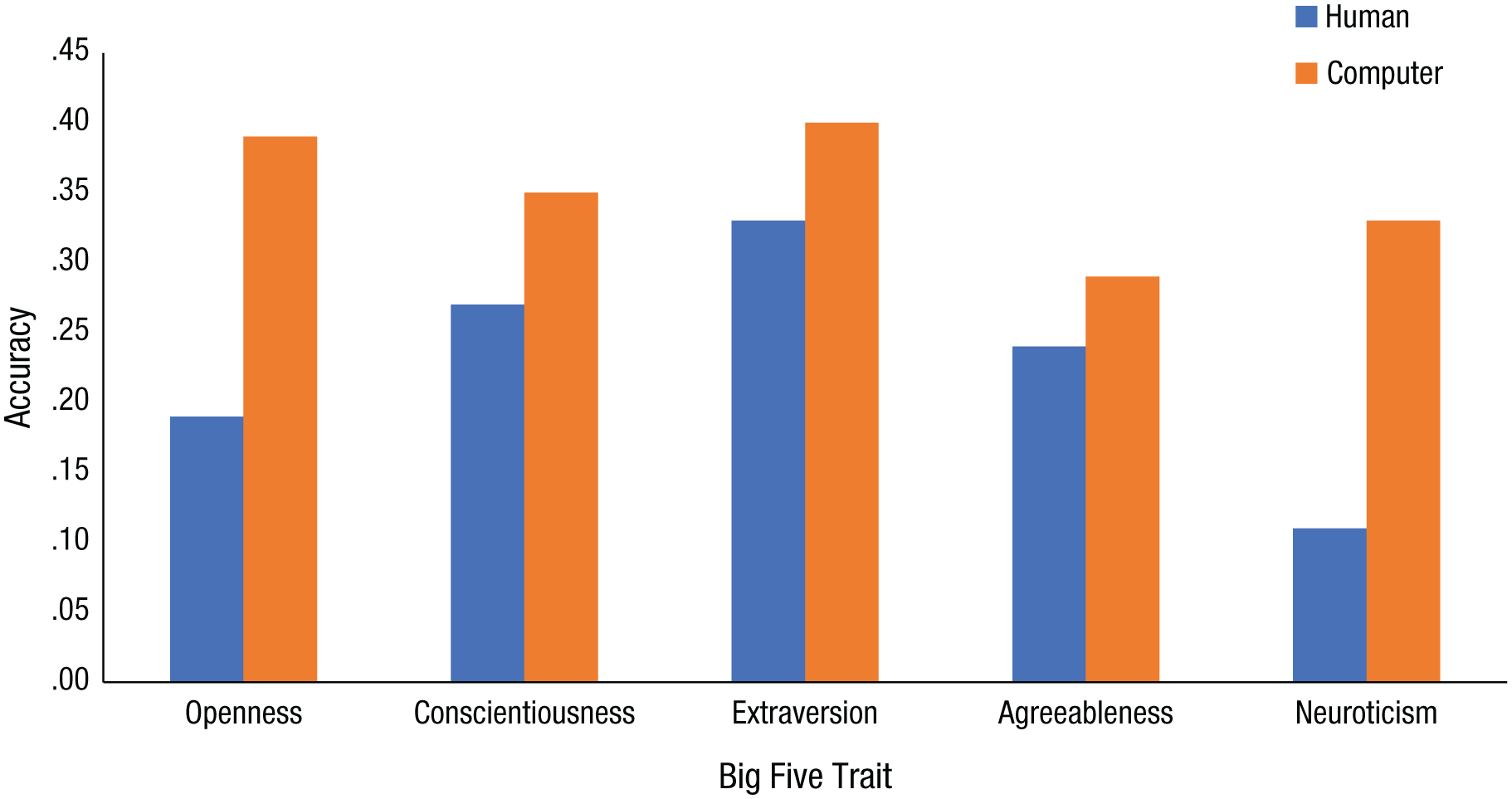
Accuracy of human- and computer-based predictions for each of the Big Five traits, obtained from meta-analyses by Tskhay and Rule (2014; blue bars) and Azucar, Marengo, and Settanni (2018; orange bars). Accuracy represents the meta-analytic correlation between observers’ and targets’ personality scores. Accuracy was measured by Pearson’s correlation (r), where 0 indicates no relationship and 1 indicates a perfect relationship. In these instances, the correlations demonstrate low-to-moderate effects across the Big Five traits.
So why are some traits easier to predict than others? And why are computers (seemingly) more accurate than humans? Unfortunately, neither psychology nor computer science can currently answer these questions. Aside from the lack of communication between the two disciplines, both are limited by their traditions in practice, methods, and theoretical applications. We explain these issues below.
Prediction Versus Explanation
Traditionally, psychology research attempts to explain behavior. For instance, theoretical models developed in relation to off-line personality perception, such as Brunswik’s (1956) lens model and Funder’s (1995) realistic-accuracy model, provide a means for exploring which cues are associated with targets’ personalities and observers’ predictions (e.g., Back, Schmukle, & Egloff, 2008, found that observers’ judgments of openness were associated with targets’ use of fantasy names in their e-mail addresses). Figure 2 provides an example of how cues may be used by targets and observers in Brunswik’s lens model (in line with the findings of Hall, Pennington, & Lueders, 2014).
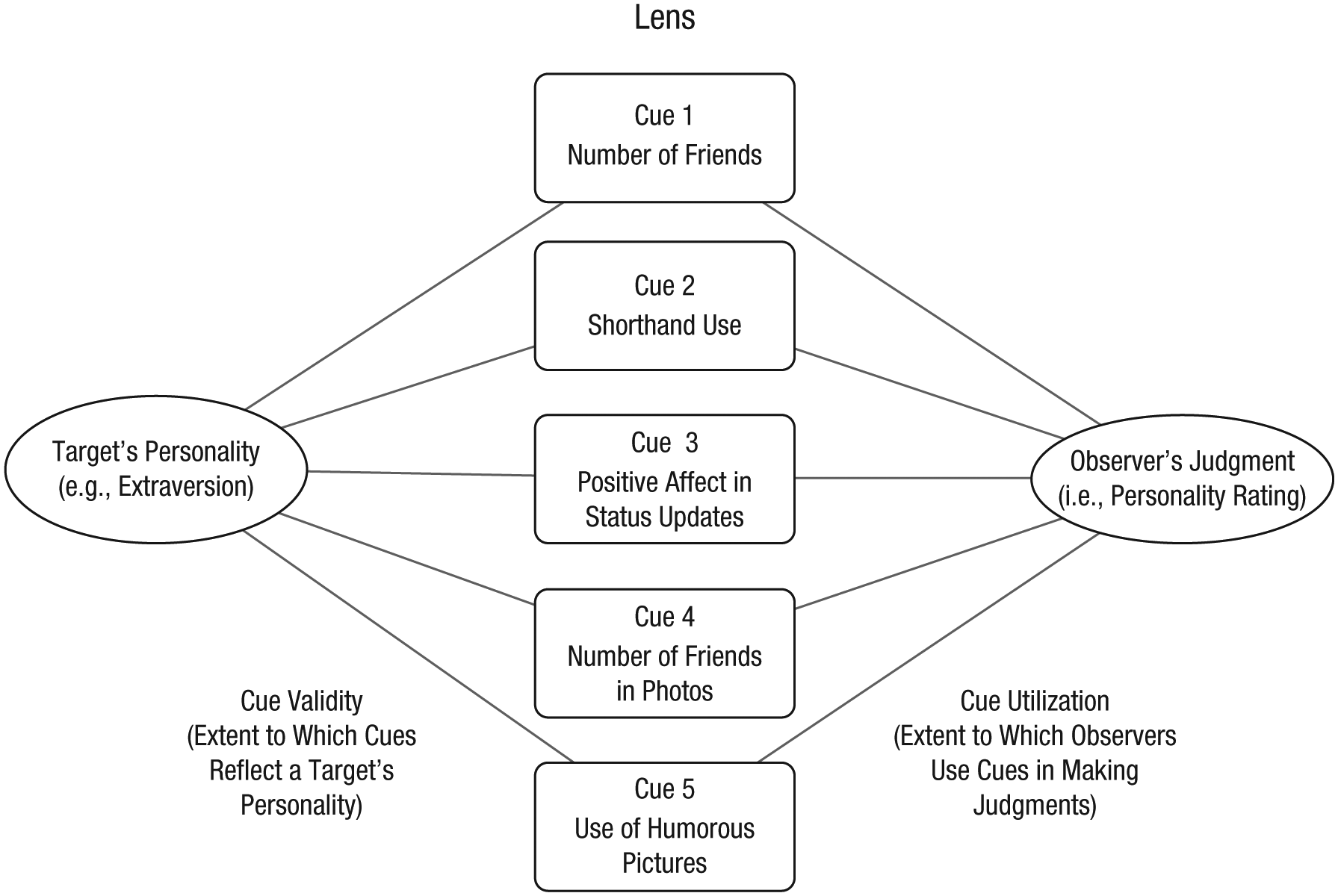
Schematic showing how cues may be used by targets and observers in Brunswik’s (1956) lens model. The model conveys the idea that targets leave digital cues that may reflect aspects of their personality. The target’s personality (represented by the left oval) is made up of digital cues. Cue validity is the extent to which each of these cues actually represents the target’s personality. The observer’s judgment of the target’s personality (represented by the right oval) is based on the same set of digital cues (which form a “lens” that enables observers to formulate their impressions). Cue utilization is the extent to which an observer uses these cues in making a judgment. For example, it may be that Cue 4 (number of friends in photos) is highly associated with the target’s personality, whereas Cue 5 (use of humorous pictures) is not. If an observer heavily focuses on Cue 5 in making his or her judgment, then that impression is likely to be inaccurate.
Although such analyses may provide finer-grained insights into personality perceptions, empirically they are problematic. For instance, such models cannot assure that cues are explicitly related to personalities or judgments. That is, lens-model analyses show only which cues are associated with judgments and personalities (whereas in reality, observers may be using other cues to form judgments that were not measured). The majority of studies also use very few observers (typically under 10), and there is no feedback mechanism to improve their accuracy. Thus, observers are not trained, motivated, or expected to improve their judgments. Finally, some observers are excellent at judging personality accurately, whereas others are weak, and typically, researchers collate ratings to form an overall accuracy measure.
Alternatively, computer models attempt to predict personality from a set of digital cues. The approach is similar, but instead, an algorithm adopts the role of the observer. However, in contrast to researchers conducting human personality-perception studies, computer scientists predetermine which cues (or features) will be collected and used by the algorithm when they design the study. Typically, a computational study involves assembling a data set of digital footprints and then splitting that data set into a training set and a testing set. The training set is used to “teach” an algorithm to predict personality, and the testing set is used to evaluate the accuracy of its predictions. This process, known as cross-validation, enables researchers to estimate how accurately their algorithm may perform in practice.
Computer scientists often experiment with different algorithms and feature sets to evaluate how accurately they can predict personality. The advantage of this approach is that researchers can (a) work from the bottom up and discover patterns in data that were not preconceived, (b) develop complex mathematical models that can make predictions from masses of fine-grained data, and (c) apply advanced statistical techniques, such as Bayesian inference—a method that improves predictions as more information becomes available. The disadvantages are that researchers have no means of explaining their findings empirically. Further, some computer algorithms can be “black box,” meaning that even the creators do not have full access to how their algorithms work. These methods are problematic because researchers understand the algorithm’s inputs and outputs but not what happens internally. Consequently, researchers can be ignorant to hidden biases, and the algorithm becomes “accountable” for taking particular courses of action.
Methodological Approaches and Challenges
Currently, personality assessments are almost entirely dependent on self-reports. The current gold-standard approach for obtaining “true” personality assessments involves aggregating questionnaires completed by individuals and their close acquaintances (informants; e.g., John & Robins, 1994). The process of combining reports mitigates against targets self-inflating or self-deprecating (John & Robins, 1994) and observers judging targets overpositively or overnegatively. While these measures are used in many personality-perception studies in off-line contexts (e.g., judgments of job candidates), they are seldom used in studies of personality perception and digital footprints. For example, Vazire and Gosling’s (2004) study was the only research in Tskhay and Rule’s (2014) meta-analysis that used combined self- and informant reports. This means that current human perception studies are likely to be nonoptimal, as observer accuracy is compared with target reports that are more vulnerable to bias.
Analyzing digital footprints with computer models can remove the requirement for personality questionnaires, so instead assessments may be conducted with real-life behavioral data. However, almost all researchers seek to predict self-report data from digital footprints, risking the possibility that the ensuing computer models are also predicting personality from more biased assessments. While some approaches have circumvented this problem—for example, by assessing personality from language and then associating personality with some other behavioral trace (e.g., Farnadi et al., 2016) or by comparing algorithm performance with informant reports (e.g., Park et al., 2015)—these are rare, and target and informant ratings have still been absent. Future research could therefore consider using aggregate target and informant reports to provide more realistic and accurate personality assessments.
Computer models also provide an opportunity to test psychological theories on real-life data but rarely do. So, could theory and bottom-up computational approaches work together to improve accuracy? Or could psychology theories help inform algorithm design?
For example, Vazire’s (2010) self–other-knowledge-asymmetry model predicts that internalized traits (e.g., neuroticism) are known better to individuals, whereas outwardly observable traits (e.g., extraversion) are more readily recognized by observers. Current evidence suggests that similar asymmetries also exist for computer models (e.g., many studies identify openness more easily than agreeableness). However, the possibility for algorithms to analyze and compute more varied data could help to address these imbalances if researchers account for the data when designing the algorithms. For example, if we assume neuroticism is internalized, then we might hypothesize that it could manifest in individuals’ behavioral residue (traces they do not think about or attempt to control; e.g., number of log ins, e-mail response times) as opposed to self-generated content (e.g., photos and status updates, which may be more indicative of extraversion). Researchers may then want to explore whether such patterns exist and then use these findings when designing an algorithm.
Finally, experience-sampling methods could provide a useful approach for examining personality over time, in different contexts, or across multiple platforms and devices simultaneously. This would extend much of the existing work (across both human and computer-based studies) that tends to focus on one platform or digital trace at a single moment in time. Thus, in human perception studies, Brunswik (1956) lens-model analyses could explore whether the same cues are associated with targets’ personalities and observers’ predictions over different contexts and intervals. And in computer-based studies, analytics of personality assessments could examine behavioral consistency unobtrusively (e.g., movement patterns) and to fine granularities (e.g., time stamps measured in nanoseconds). Such findings could begin to address many of the classic state-trait discussions from the 1970s (e.g., Bem & Allen, 1974; Epstein, 1979), as well as extend more recent explorations of personality judgments in different contexts (e.g., Sauerberger & Funder, 2017; Wall, Taylor, Dixon, Conchie, & Ellis, 2013).
Where is Personality Prediction Heading?
As our interactions with technology continue to grow apace, the opportunities to study personality and predict behavior are unprecedented. So what should (or could) happen to the current gold-standard methods and the Big Five traits? What do these new methodologies mean for personality as we know it? And how can researchers respond to these developments? We offer our thoughts on these questions below.
Many researchers may consider measures such as the Big Five to be too restrictive because they limit individual differences to a few dimensions. However, if self-reports are no longer needed, then computers could identify patterns of behavior that are divorced from personality theory altogether. By analyzing behavior with (potentially) hundreds or thousands of traits and dimensions, algorithms could simply identify clusters of co-occurring behaviors among a set of digital traces. These could include anything from language to facial recognition, or from purchasing habits to electricity consumption, and in aggregate (e.g., Facebook behavior combined with location data). Such clusters could offer new insights into personality traits that were previously unnoticed and even challenge assumptions that personality is anything outside of behavior. Alternatively, these findings could simply reinforce and extend existing assumptions about the Big Five traits. Regardless, such computational power implies that computers will inevitably be better than humans at predicting future behavior.
If researchers embrace these new methodologies, then future work could benefit countless domains: recruitment, criminal investigations, and health and well-being, to name but a few. For instance, Matz, Kosinski, Nave, and Stillwell (2017) recently highlighted the prospect of “psychological mass persuasion” of individuals by personalizing Facebook advertisements in accordance with their personality traits (p. 12714). Matz et al. (2017) found that, compared with unpersonalized advertisements, tailored advertisements increased click rates by 40% and purchases by 50%. Effective persuasion online or via digital devices could therefore offer innumerable opportunities to encourage people to live healthier lives, find support groups, recycle, and so forth. Alternatively, persuasive appeals could exploit individuals in more malicious efforts, for instance, by promoting extremist propaganda or publicizing political agendas. Such techniques were believed to have been used in Donald Trump’s 2016 presidential campaign and the Vote Leave campaign in Britain’s European Union referendum, wherein the data-analytics companies Cambridge Analytica and AggregateIQ attempted to influence people’s voting patterns (Cadwalladr, 2018; Kitchgaessner, 2017).
These new prospects, of course, also pose ethical challenges concerning peoples’ privacy, security, and trust. The ability to collect and analyze masses of data from everyday devices provides more opportunities to use data in coercive or fraudulent ways and raises the question of what true informed consent is. (Cambridge Analytica, for instance, has recently come under scrutiny for using approximately 87 million individuals’ Facebook data without explicit consent.) Researchers should therefore strive for transparency in their use of algorithms, inform individuals about what data they are collecting and what they will do with it, and honor what others have consented to.
Finally, in a recent article that asks whether psychology is still a behavioral science, Doliński (2018) reported that only 6% of articles in a recent volume of Journal of Personality and Social Psychology examined behaviors. In a time when studies of personality (measured by actual behavior) are rare, there is much to be gained from increased interdisciplinary research. Not only can computational methods directly address this, but they can potentially enable us to redefine personality altogether.
Recommended Reading
Azucar, D., Marengo, D., & Settanni, M. (2018). (See References). A comprehensive review of computer-based personality prediction from digital traces.
Tskhay, K. O., & Rule, N. O. (2014). (See References). A comprehensive review of human-based personality perception from digital traces.
Vazire, S., & Carlson, E. N. (2011). Others sometimes know us better than we know ourselves. Current Directions in Psychological Science, 20, 104–108. A comprehensive, highly accessible overview of what is known about human personality perception.
Yarkoni, T., & Westfall, J. (2017). Choosing prediction over explanation in psychology: Lessons from machine learning. Perspectives on Psychological Science, 12, 1100–1122. A comprehensive overview of how machine learning can be used in psychology research.
Youyou, W., Kosinski, M., & Stillwell, D. (2015). (See References). A representative study that illustrates original research about both human- and computer-based personality prediction.
Footnotes
Acknowledgements
The authors would like to thank the anonymous reviewers whose comments have significantly improved this article.
Action Editor
Randall W. Engle served as action editor for this article.
Declaration of Conflicting Interests
The author(s) declared that there were no conflicts of interest with respect to the authorship or the publication of this article.
Funding
This work was funded by the Centre for Research and Evidence on Security Threats (Economic & Social Research Council Award No. ES/N009614/1).