
Abstract
Aims and Objectives:
This study investigates whether Japanese learners of English automatically map English number morphology onto conceptual numbers in both directions. Two research questions guide the study:
RQ1. Mismatch costs: Do L2 learners show reaction-time slowdowns when:
(a) A singular noun is paired with a plural picture?
(b) A plural noun is paired with a singular picture?
L1 speakers serve as a baseline to establish expected mismatch effects.
RQ2. Directional asymmetry: If mismatch costs occur, are they equivalent in both directions, or is there a systematic asymmetry?
Methodology:
The study employed a sentence-picture matching task that crossed noun number (singular vs. plural) with picture condition (match vs. mismatch), extending previous unidirectional designs to test both directions of number mapping in L2 processing. Reaction times (RTs) served as the primary dependent measure.
Data and Analysis:
Thirty-two L1 English speakers and 96 Japanese L2 learners (CEFR B1–B2) each completed 200 trials (80 target items and 120 fillers). Incorrect trials were excluded, and extreme RTs were trimmed before the analysis. RTs were analyzed using inverse Gaussian generalized linear mixed-effects models, with sentence length and trial order included as covariates.
Findings:
L1 speakers showed significant RT slowdowns for both mismatch types, confirming automatic singular–plural mapping. In contrast, L2 learners exhibited a slowdown only when a singular noun was paired with a plural picture, and no effect when a plural noun was paired with a singular picture, revealing a processing asymmetry. For Japanese learners, plural nouns did not consistently activate conceptual plurality.
Originality:
This is the first study to examine both directions of morphological-conceptual number mismatch in L2 processing, extending Jiang et al., which tested only the singular-noun/plural-picture mapping.
Significance:
These findings refine the Morphological Congruency Hypothesis by showing that incongruent L2 morphemes can lead to direction-specific processing weaknesses in learners’ conceptual mapping.
Keywords
Introduction
Among the grammatical features studied in second language acquisition (SLA), number agreement is one of the most widely investigated phenomena due to the complex morphosyntactic processes it entails (Jackson et al., 2018; Jegerski, 2016; Jiang, 2004, 2007; Sagarra & Herschensohn, 2013). Researchers are particularly interested in first language (L1) influence, as some languages lack number agreement entirely. For second language (L2) learners, whose L1 lacks this feature, computing number agreement in the L2 can be especially challenging. Although the sources of difficulty in processing agreement are complex, many scholars attribute it to insensitivity to inflectional morphemes, such as the plural marker -s and third-person singular -s (3PS) (Jiang, 2004; Shibuya & Wakabayashi, 2008).
Japanese learners of English represent an ideal test group due to the typological contrast between Japanese and English. Japanese lacks obligatory plural morphology and number agreement (Kato, 2006), relying instead on optional suffixes to indicate plurality (Kim, 2008; Kurafuji, 2004). This contrast allows for a focused investigation into how L2 learners acquire the obligatory mapping between morphological and conceptual number in English.
Number representation in language involves multiple levels of processing. To understand L2 number processing, it is crucial to distinguish among three levels: conceptual, grammatical, and morphological (Nickels et al., 2015). Conceptual number refers to the speaker’s mental representation of quantity; that is, whether the referent is singular or plural. Morphological number concerns overt inflectional markings (e.g., plural -s), while grammatical number pertains to syntactic properties that control agreement patterns. This tripartite framework facilitates a more precise analysis of form-meaning mappings in L2 learners. While all three levels are important, the present study focuses on the mapping between morphological and conceptual number, which is fundamental to how learners associate linguistic forms with meaning. The psychological validity of these distinctions is well-supported by studies showing that L1 speakers (NS) differentiate these levels in both language production (Bock & Miller, 1991; Vigliocco et al., 1995) and comprehension (Nicol et al., 1997; Wagers et al., 2009).
In English, these levels typically align for regular count nouns (e.g., cat vs. cats). However, certain noun types display dissociation (Corbett, 2000). For example, collective nouns (e.g., family) involve conceptual plurality but grammatical singularity, while zero plurals (e.g., sheep) lack overt morphological marking. Such mismatches complicate not just the morphological level but also the conceptual representation of number.
A crucial factor distinguishing these levels is semantic markedness. According to the weak theory of plurality (Sauerland et al., 2005), the singular carries a presuppositional requirement that its referent be a single atomic entity, whereas the plural possesses no inherent presupposition. In other words, singularity is semantically marked because it must refer to exactly one entity, while plurality is semantically unmarked and can, in principle, refer to any quantity including one. When both singular and plural forms are available, pragmatic principles (specifically, Maximize Presupposition) block the use of the plural in contexts where the singular’s presupposition is satisfied.
This semantic asymmetry appears to have cognitive consequences for conceptual representation. Patson et al. (2014) investigated this issue using a picture-matching paradigm in which participants read sentences containing singular noun phrases (NPs) (e.g., the crayon), numerically quantified plural NPs (e.g., the two crayons), or plural definite descriptions (e.g., the crayons), and then judged whether a subsequently presented picture depicted an object mentioned in the sentence. For singular NPs and two-quantified NPs, participants responded faster when the number of objects in the picture matched the number specified by the NP. However, for plural definite descriptions, no such match effect was observed; response times were similar regardless of whether the picture showed one object or multiple objects. Patson et al. interpreted these findings as evidence that singular NPs trigger relatively specified conceptual representations, whereas plural NPs with underspecified numerosity trigger vague or indeterminate representations. Importantly, these results are consistent with the weak theory of plurality, suggesting that the conceptual representations of unquantified plurals may be no more similar to images of multiple objects than to images of single objects.
Psycholinguistic research on L2 learners has often focused on their sensitivity to plural morphology by examining real-time processing of subject-verb number agreement violations (e.g., Jiang, 2004, 2007; Song, 2015). However, number agreement tasks involve complex syntactic operations and may not isolate the learner’s basic ability to map morphological forms (e.g., -s) to conceptual meanings (“more than one”) (Tamura, 2025). While such studies have provided crucial insights, the foundational form-meaning mapping remains ambiguous. Hence, explicitly adopting a framework that distinguishes between morphological and conceptual number (Nickels et al., 2015) is necessary for a more targeted investigation.
Recent studies show that L2 learners may access conceptual plurality even in the absence of overt morphological cues. For instance, Kusanagi et al. (2015) investigated notional number attraction in subject-verb agreement processing using a self-paced reading task. They found that when Japanese learners processed sentences with collective nouns (e.g., team, family) as local attractors, the notional plurality of these nouns disrupted their sensitivity to number agreement violations, suggesting that learners accessed conceptual number information during online processing. Similarly, Tamura et al. (2019) investigated reciprocal verbs (e.g., hug, kiss), which conceptually require a plural subject. Using garden-path sentences in a self-paced reading task, they found that Japanese English-as-a-Foreign-Language (JEFL) learners avoided the garden-path effect only when reciprocal verbs were combined with conjoined NPs (e.g., the mother and the father) but not with plural definite descriptions (e.g., the parents). This suggests that learners can access conceptual plurality when the constituents of the plural set are explicitly specified. Crucially, in both studies, participants processed English sentences without pictorial stimuli, and conceptual plurality was conveyed through lexical means (collective nouns or conjoined NPs) rather than through the plural morpheme alone. These findings indicate that learners can access and utilize conceptual plurality during online sentence processing. This raises a more specific question: can learners automatically activate conceptual number representations when encountering morphological number marking (e.g., plural -s)?
To investigate this form-meaning mapping more directly, Jiang et al. (2017) employed a sentence-picture matching task. In their paradigm, participants first viewed a picture containing three objects for 1,330 ms, after which a sentence describing the spatial relationship among the objects appeared above the picture. Participants judged whether the sentence correctly described the picture. Crucially, half of the trials included a hidden number manipulation; although the sentence always contained a singular noun (e.g., the tall basket), the picture showed either one or multiple tokens of the critical object. Participants were never informed of this manipulation. The key finding was that L1 speakers of English and Russian, languages with obligatory plural morphology, showed reaction-time (RT) delays when a singular noun was paired with a plural image, even though this mismatch was irrelevant to the task. In contrast, Chinese English as a Second Language (ESL) speakers, whose L1 lacks obligatory number marking, showed no such mismatch effect. Jiang et al. interpreted this result in support of the Morphological Congruency Hypothesis (MCH; Jiang et al., 2011), which posits that when a grammatical feature is absent in the L1, establishing the corresponding form-meaning mapping in the L2 is difficult. While Jiang et al.’s study provided strong evidence for the MCH, its one-directional design tested only the singular-noun/plural-picture mismatch; the reverse mismatch, plural forms with singular concepts, was not examined.
A different approach was taken by Rusk et al. (2020), who used a visual-world eye-tracking paradigm to investigate comprehension in Mandarin-L1 early immersion learners of English in Taiwan. Participants heard singular or plural nouns (e.g., pencil vs. pencils) while viewing a four-picture array containing a singular-object image, a plural-object image, and two distractor images. Eye-tracking data revealed an asymmetry: L2 learners processed plural nouns similarly to L1 speakers, directing their gaze quickly to plural images; however, their processing of singular nouns was delayed compared to L1 speakers. While both groups showed a brief early bias toward plural images, possibly reflecting the greater visual complexity of multi-object displays (cf. Koch et al., 2021; Schlenter, 2019), L1 speakers rapidly redirected their gaze on singular trials, whereas L2 learners did not. Rusk et al. interpreted this as evidence that L2 learners had difficulty using singular morphology to guide referent identification. Importantly, despite their L1-like online performance on plural trials, L2 learners were significantly less accurate than L1 speakers on the offline picture decision task for both singular and plural items, suggesting that online gaze patterns may not fully reflect the robustness of underlying form-meaning mappings.
These studies collectively highlight the challenges of acquiring number marking in an L2. However, a key question remains. While Rusk et al. (2020) examined bidirectional processing, their task measured preference and attention, not whether conceptual mismatch caused processing delays in the way Jiang et al. (2017) did. To date, no study has used a sentence-picture mismatch paradigm to investigate whether L2 learners experience processing slowdowns for both singular-to-plural and plural-to-singular mismatches. The present study aims to address this gap.
Building on Jiang et al. (2017), this study extends the sentence-picture matching task to a bidirectional design, testing both singular-to-plural and plural-to-singular mismatches. The goal is to determine whether Japanese learners exhibit mismatch-related processing slowdowns in both directions and whether these effects are symmetrical. It is hypothesized that the form-meaning mapping may not be symmetrical. This prediction draws on findings from numerical cognition suggesting that singularity is conceptualized more precisely than plurality (Patson, 2016; Patson et al., 2014). A singular noun reliably evokes a specific representation of “one,” whereas a plural noun corresponds to a less-defined concept of “more than one” (Patson, 2016). Thus, singular morphology is expected to trigger a strong conceptual representation, resulting in a robust mismatch cost when paired with a plural image. In contrast, plural morphology may not consistently evoke a clear plural concept in learners whose L1 lacks obligatory number marking (Jiang, 2004, 2007; Jiang et al., 2011).
Accordingly, the present study addresses the following research questions:
RQ1. Do L2 learners, like L1 speakers, show RT slowdowns when:
(a) A singular noun is paired with a plural picture? (b) A plural noun is paired with a singular picture?
RQ2. If mismatch costs occur, are they equivalent in both directions, or is there a systematic asymmetry?
L1 speakers were included to establish baseline mismatch effects against which L2 performance could be interpreted, rather than for direct statistical comparison.
Methodology
Participants
The participants included 32 L1 speakers of English and 96 Japanese L2 learners of English. 1 Both groups were recruited in Japan. The L1 participants were either exchange students (n = 27) or English language teachers (n = 5). Although most L1 participants were from the United States (n = 24), others were from the United Kingdom (n = 3), Australia (n = 3), Canada (n = 1), and Singapore (n = 1). Table 1 summarizes the demographic information of the participants.
Demographic information of the L1 participants.
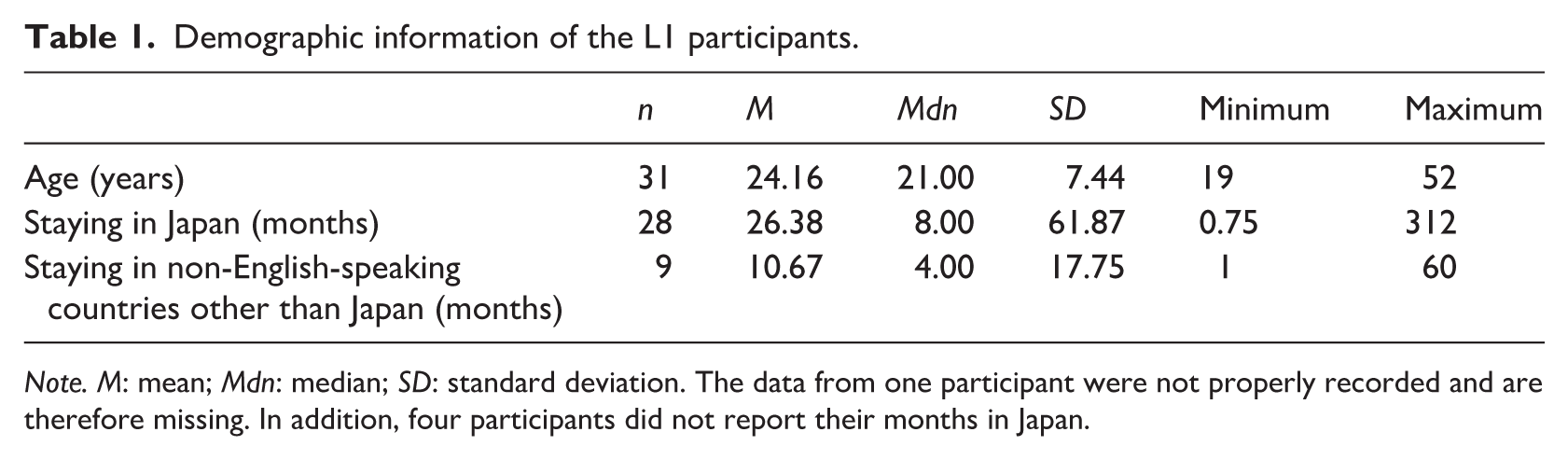
Note. M: mean; Mdn: median; SD: standard deviation. The data from one participant were not properly recorded and are therefore missing. In addition, four participants did not report their months in Japan.
The JEFL were undergraduate or graduate students from various majors, such as education, engineering, psychology, agriculture, economics, and law. Nineteen of the 96 participants had stayed in English-speaking countries for at least 1 month. All JEFL participants took the paper-based Oxford Quick Placement Test (OQPT) to estimate their English proficiency. The mean score was 38.01 (SD = 5.22) out of a maximum of 60, indicating that most participants were at the B1–B2 (intermediate) level of the Common European Framework of Reference (CEFR). Table 2 summarizes their demographic information.
Demographic information of the JEFL participants.
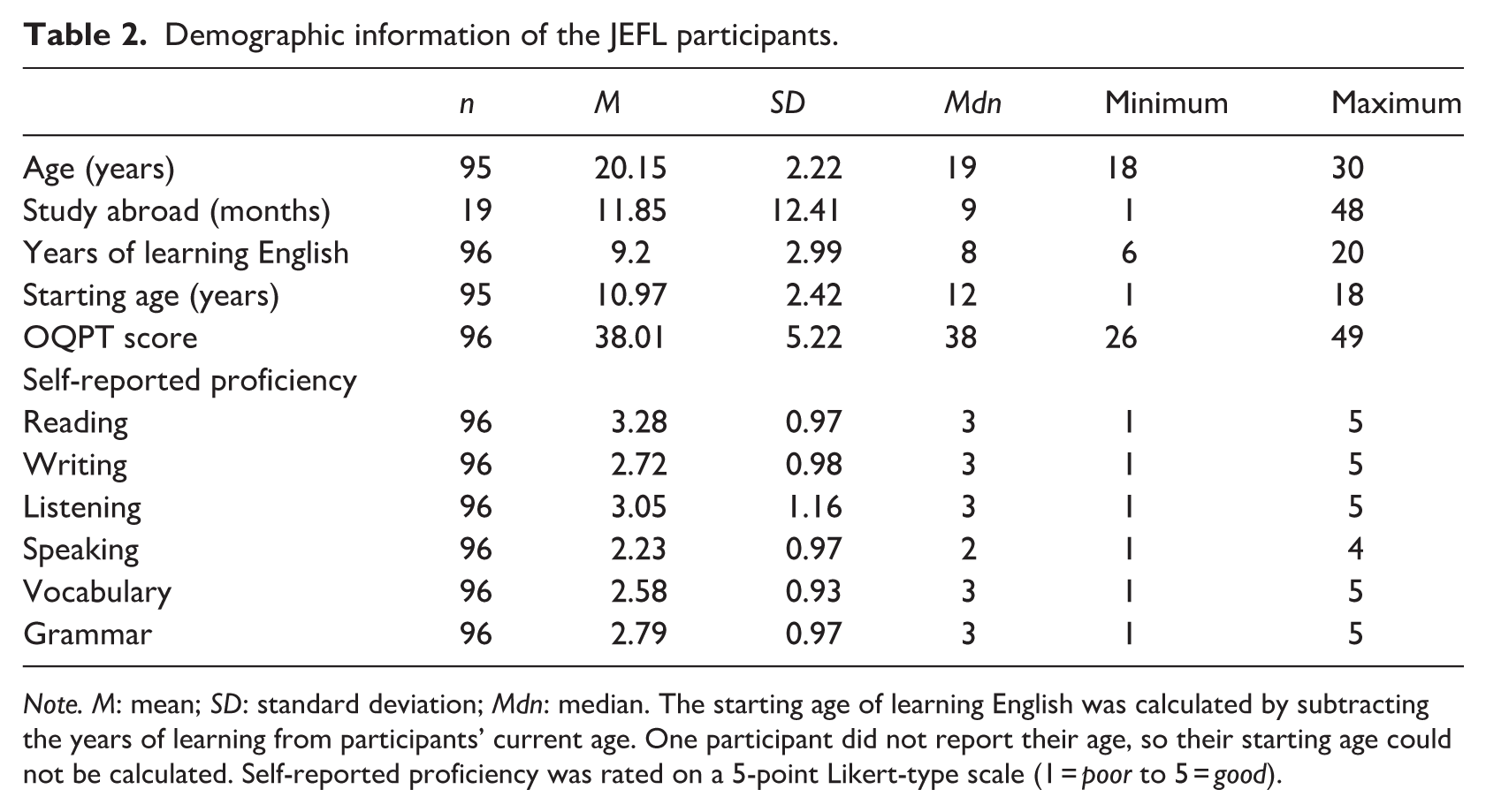
Note. M: mean; SD: standard deviation; Mdn: median. The starting age of learning English was calculated by subtracting the years of learning from participants’ current age. One participant did not report their age, so their starting age could not be calculated. Self-reported proficiency was rated on a 5-point Likert-type scale (1 = poor to 5 = good).
Materials and design
Design
This study employed a 2×2 within-participants factorial design with two independent variables: noun number (singular, plural) and picture condition (match, mismatch). The four resulting experimental conditions are summarized in Table 3 and visually presented in Figure 1.
Experimental conditions and example sentences for the sentence-picture matching task.

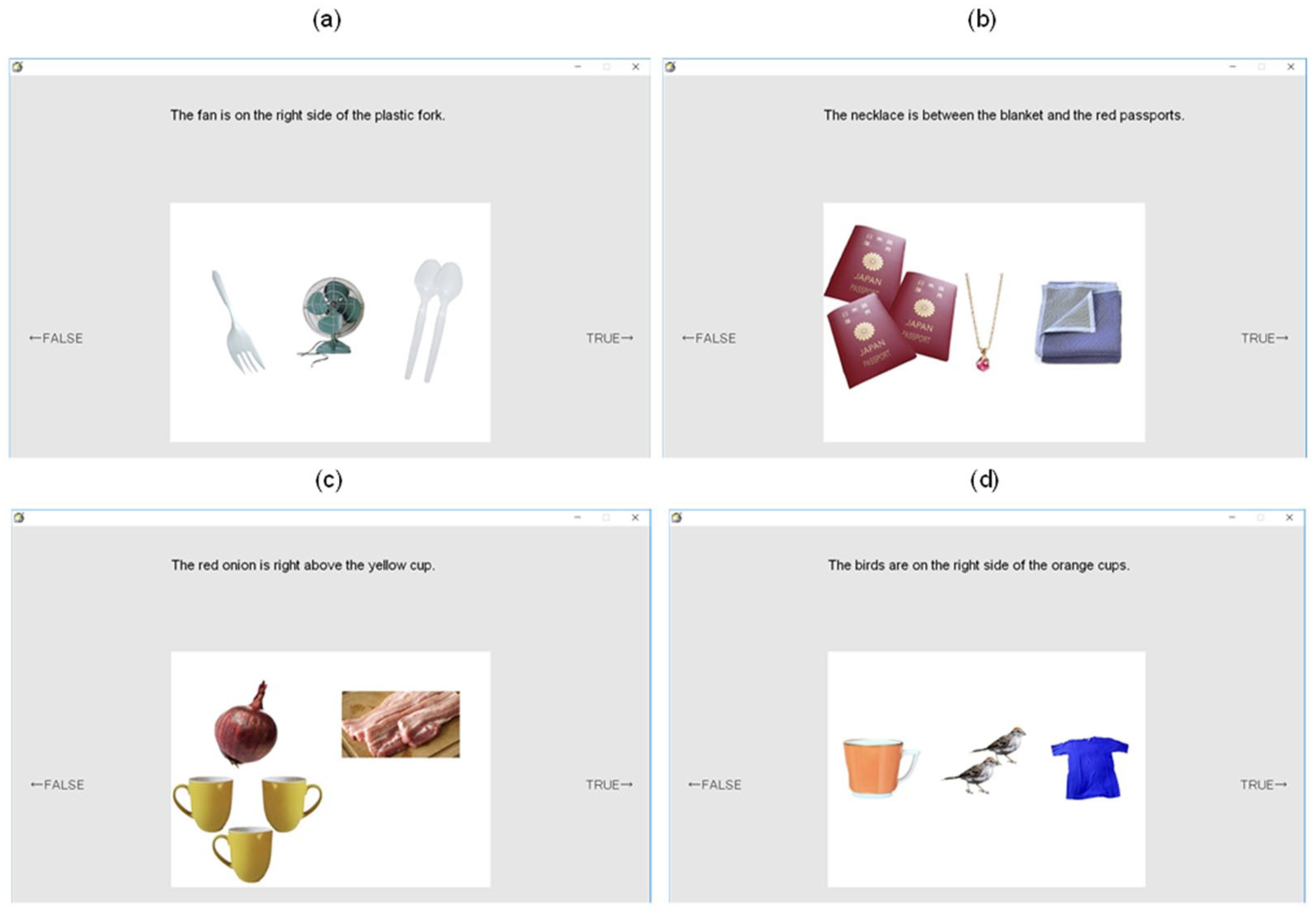
Sample pictures of (a) singular match condition, (b) plural match condition, (c) singular mismatch condition, and (d) plural mismatch condition.
This design builds upon the unidirectional mismatch paradigm of Jiang et al. (2017). By systematically including both a singular-noun/plural-picture and plural-noun/singular-picture mismatches, the design bidirectionally tests the conceptual mismatch cost, allowing a direct comparison of processing difficulties in both directions. The two matched conditions served as baselines for their respective mismatch conditions.
Test sentences
The test sentences were based on the materials used in Jiang et al. (2017). Due to proficiency differences between participants in Jiang et al.’s (2017) study and the present one, some vocabulary was modified based on the JACET 8000 vocabulary list (JACET Committee of Basic Words Revision, 2003). All vocabulary used was within Level 4 of the JACET 8000 list, except for notebook, pizza, necklace, colorful, and vase. These exceptions were confirmed to appear in a vocabulary book for Japanese junior high school students, indicating their familiarity. As a result, 32 of the 80 test sentences from Jiang et al. (2017) were revised (see Supplementary Material for the full list).
To increase statistical power, 40 new target items were added. Furthermore, 80 filler items were created to maintain a 2:3 target-to-filler ratio, resulting in 80 target items and 120 fillers. All 80 target items were semantically matching (i.e., required a “YES” response), regardless of number discrepancies. To ensure an equal number of positive and negative responses across the experiment, 100 filler items were created to require “NO” responses (i.e., no number mismatch but the sentence and the picture differed in meaning), while the remaining 20 filler items required “YES” responses (i.e., no number mismatch and the sentence and the picture matched in meaning). Consequently, the entire session consisted of 100 “YES” and 100 “NO” trials. Twelve additional items were created for the practice session, none involving number mismatches.
To ensure counterbalancing, four presentation lists were created using a Latin-square design. Each list contained 20 tokens per experimental condition (80 total target items) plus 120 filler items. All 200 items were randomly ordered per participant to prevent systematic order effects.
Pictures
All stimuli were edited to maximize clarity and maintain identical visual demands across groups. Non-essential background details were removed unless essential (e.g., water for a “swimming duck”). In plural-picture conditions, the number of objects was fixed at three to control for numerosity effects (Patson et al., 2014). Objects were evenly spaced and not stacked or overlapped.
Pictures were displayed on a 500 × 375-pixel white canvas (Figure 1). Most source images came from Morguefile (royalty-free) or Flickr (CC BY-SA 2.0); 2 others were photographed by the author. The complete stimulus set is publicly available on OSF: https://osf.io/79x2v/overview?view_only=78050f8a86944f3e8f1f4083ef54f623.
Although efforts were made to standardize visual presentation, some variation in the relative size of objects across conditions was unavoidable due to the nature of the images (e.g., three passports occupied more visual space than a single necklace as shown in Figure 1). However, the critical comparison was always within-item across the match and mismatch conditions, minimizing the impact of such variation.
Procedure
Data were collected individually in a quiet room. All stimuli were presented visually (i.e., sentences were displayed on screen, with no auditory presentation). If two participants were tested simultaneously, a partition was installed, and participants used earplugs to minimize distraction. Before the task, participants received an explanation and gave written informed consent.
The experiment was run on a laptop using a program developed with Hot Soup Processor (ver. 3.4). After on-screen instructions (see Supplementary Material), participants could ask questions. Then they clicked a “start” button to begin a 12-trial practice session.
Each trial proceeded as follows: a picture with three objects appeared for 3,000 ms. Then, a sentence appeared above the picture. Participants judged whether the sentence matched the picture in terms of location and/or color (Figure 2). If it matched, they pressed “Enter”; if not, they pressed “TAB.” They were instructed to respond as quickly as possible, using the right hand for “Enter” and the left hand for “TAB.” During practice, immediate feedback was provided, and participants could rest briefly and then press the space bar to initiate the next trial.
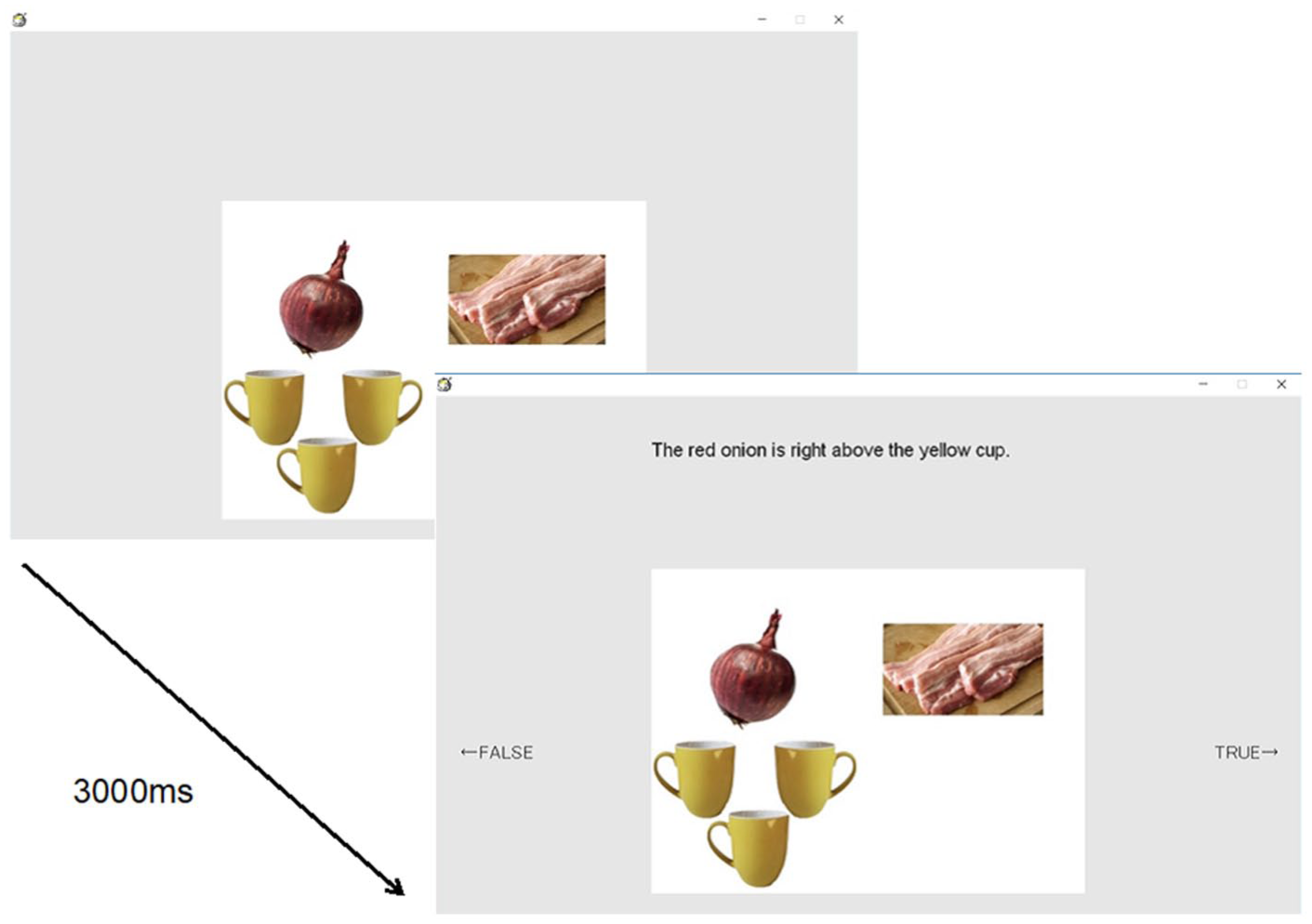
Schematic of the experimental task.
After practice, participants could ask additional questions. The experimenter explained that no feedback would be provided during the main session. Crucially, they were explicitly instructed to focus on the color of the objects and spatial relationships (i.e., whether the sentence correctly described the position of the objects) and to ignore any numerical discrepancies, such as singular–plural mismatches. This explanation was provided in English for L1 participants and in Japanese for JEFL participants.
The main session included 200 randomized trials. Afterward, JEFL participants took the OQPT (α = 0.64 [0.54, 0.74]). All participants completed a background questionnaire. The entire session lasted about 40–50 minutes for L1 participants and 70–90 minutes for JEFL participants. JEFL participants received 2,000 JPY as compensation.
Analysis
Before analysis, RT data were cleaned. Items with accuracy below 70% (6 for L1, 5 for JEFL) were excluded. All participants met the ⩾70% accuracy criterion; no participants were excluded based on this threshold. After removing the low-accuracy items, all the incorrect responses (L1: 7.0%; JEFL: 9.7%) were removed. Among correct responses, outliers above the participant’s mean + 3 SDs and above 6,000 ms (L1) or 7,500 ms (JEFL) were excluded. The 6,000 ms cutoff followed Jiang et al. (2017). A 7,500 ms threshold was data-driven and represented the ~95th percentile of JEFL correct RTs. Responses <1,200 ms were also excluded. Consequently, 5.1% of the correct trials were removed from each group.
Generalized linear mixed models (GLMMs) were fitted to raw RT data using R 4.3.2 (R Core Team, 2023) and the lme4 package (ver. 1.1-34; Bates et al., 2023). Models with inverse Gaussian and gamma distributions, both of which are considered to fit well with the raw RT data (Lo & Andrews, 2015), were compared via Akaike information criterion (AIC). Two null models, which only included by-participant and by-item random intercepts, were fitted to the current data with an identity link function. Inverse Gaussian models yielded lower AICs than gamma models (L1: 33222 vs. 33270; JEFL: 101620 vs. 101652) and were therefore adopted.
Separate models were fitted for the L1 and L2 groups because the primary goal was to examine the presence and directionality of mismatch effects within each group, with the L1 group serving as a reference for expected L1 processing patterns rather than as a factor in direct statistical comparison.
Covariates (sentence length, trial order, and proficiency for JEFL) were evaluated for inclusion using forward model comparison. Sentence length (number of words) was included to control for variation in reading time across items. Proficiency did not significantly improve model fit and was therefore excluded from the final models, which included sentence length and trial order. For random effects, models were initially specified with the maximal structure justified by the design (Barr et al., 2013), including by-participant and by-item random intercepts and random slopes for the fixed effects and their interaction. When models failed to converge, the random effects structure was simplified following Bates et al. (2015). Ultimately, the final models for both the L1 and JEFL groups successfully converged with the maximal random effects structure justified by the design, including by-participant and by-item random intercepts and random slopes for the experimental factors (noun number, number mismatch, and their interaction). All R code and outputs are available on OSF (https://osf.io/79x2v/overview?view_only=78050f8a86944f3e8f1f4083ef54f623).
Covariates were scaled and centered. Categorical variables were contrast-coded (Mismatch: −0.5 = Mismatch, 0.5 = Match; Noun number: −0.5 = Plural, 0.5 = Singular), as recommended by Linck and Cunnings (2015).
Given that the primary focus was the interaction between noun number and mismatch, simple main effect tests were conducted using the emmeans package (Lenth, 2024) when an interaction emerged. It was hypothesized that number mismatches would cause processing delays, reflected in RTs. For example, encountering a singular noun (e.g., book) with a picture showing multiple objects (e.g., three books) or a plural noun (e.g., books) with a picture of a single object would result in delayed processing. These effects would indicate automatic conceptual number activation, despite instructions to ignore number mismatches.
Results
L1 participants
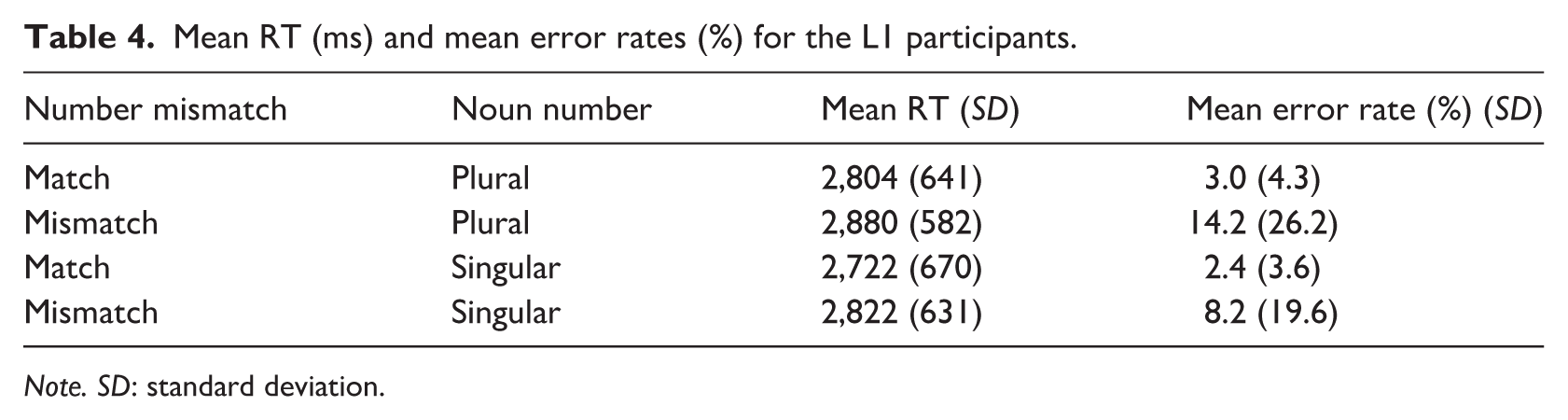
The mean accuracy of the matching judgment was high, at 95.5% (SD = 4.1%) across all items and 93.0% (SD = 10.6%) for target items. This indicates that L1 participants performed the task attentively and appropriately. Table 4 summarizes the L1 group’s error rates and RTs.
Mean RT (ms) and mean error rates (%) for the L1 participants.
Note. SD: standard deviation.
The final GLMM included the main effects of number mismatch and noun number, their interaction, and two covariates (sentence length and trial order). As expected, sentence length showed a significant positive effect (p < .001), indicating that for every additional word in the sentence, RTs increased by approximately 125 ms. There was a significant main effect of number mismatch (p = .022) and noun number (p = .012). However, their interaction was not significant (p = .666). These results demonstrate that L1 participants responded more slowly when there was a mismatch between the number in the picture and the sentence, regardless of whether the noun was singular or plural, and that they responded significantly faster to singular nouns than to plural nouns overall. Table 5 presents the final GLMM results, and Figure 3 illustrates the RT delay associated with number mismatch.
GLMM results for the L1 group.
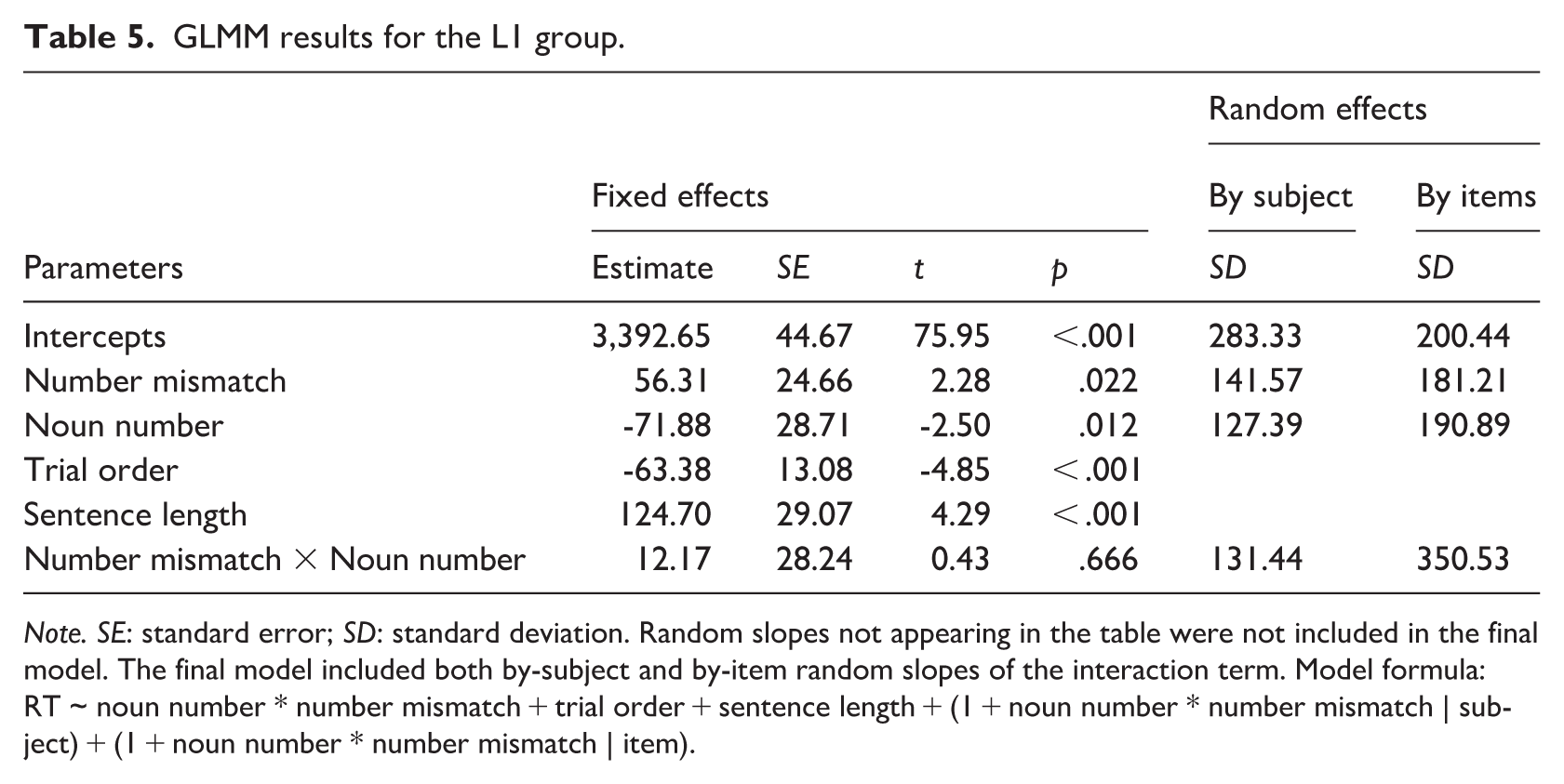
Note. SE: standard error; SD: standard deviation. Random slopes not appearing in the table were not included in the final model. The final model included both by-subject and by-item random slopes of the interaction term. Model formula: RT ~ noun number * number mismatch + trial order + sentence length + (1 + noun number * number mismatch | subject) + (1 + noun number * number mismatch | item).
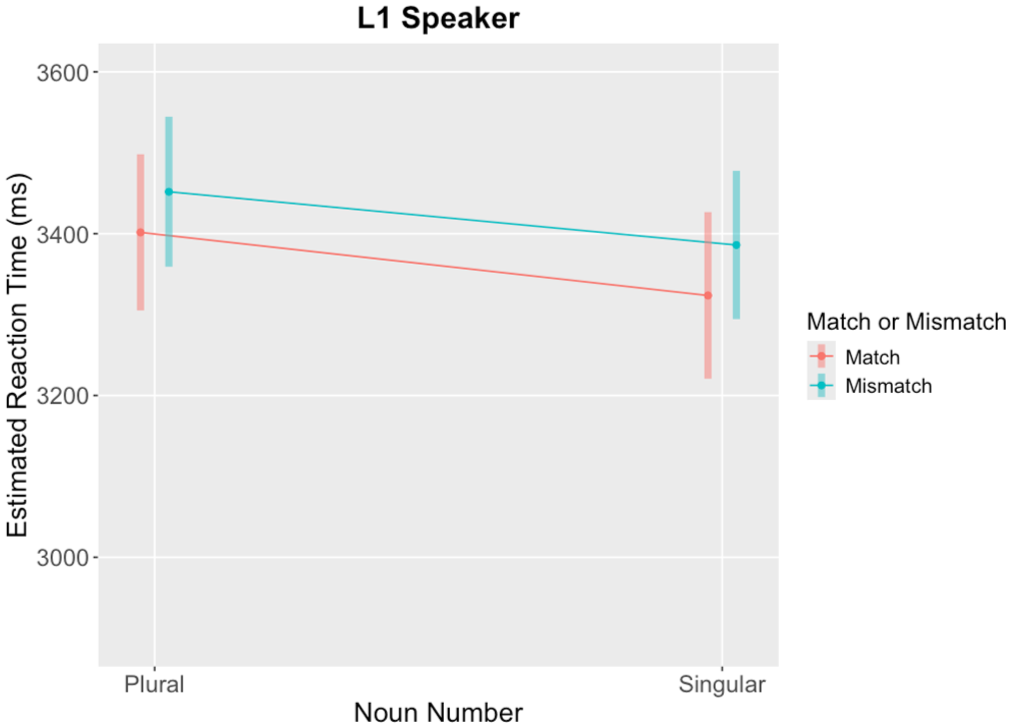
Interaction plot of the estimated RT for the L1 group. Error bars represent 95% confidence intervals.
There were significant main effects of sentence length (p < .001) and the trial order (p < .001), indicating that responses took longer with longer sentences and became faster as the experiment progressed.
Hence, even though the number mismatch should have been disregarded, the L1 group hesitated to judge the sentence-picture match in both mismatch conditions.
JEFL participants
Although the accuracy of the JEFL group was slightly lower than that of the L1 group, it was high enough to infer that JEFL participants were sufficiently and appropriately engaged in the matching task (all items: M = 92.0%, SD = 6.4%; target items: M = 90.3%, SD = 10.6%). The error rates and mean RTs for each condition are summarized in Table 6.
Mean RT (ms) and mean error rates (%) for the JEFL group.
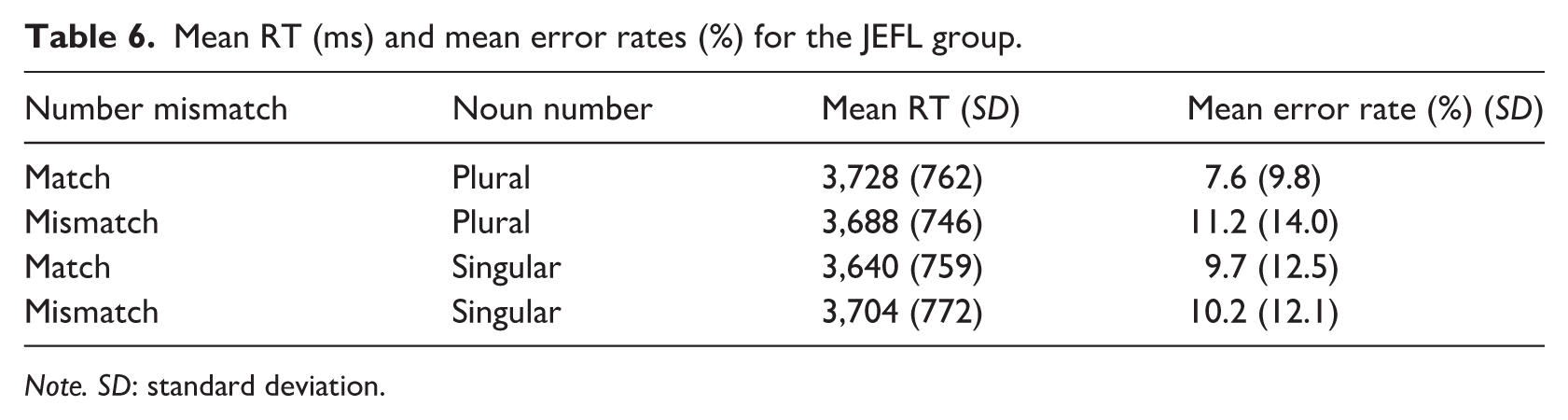
Note. SD: standard deviation.
Descriptive statistics in Table 6 suggest a pattern distinct from the L1 group regarding mismatch effects. Specifically, mean RTs did not appear to increase when the target noun was plural and a single object was presented (i.e., the mismatch condition). This observation was statistically examined in the subsequent analysis.
The final GLMM model for the JEFL group included the main effects of number mismatch and noun number, their interaction, and the two covariates (sentence length and trial order). Table 7 summarizes the GLMM results. Consistent with the L1 group, sentence length significantly predicted RTs (p < .001), with each additional word adding approximately 97 ms to the processing time. In contrast to the L1 group analysis, there was a significant interaction between number mismatch and noun number (p < .001), confirming the contrasting pattern suggested by the descriptive data (see Figure 4). The simple main effects tests revealed no significant RT difference between the match and mismatch conditions when the target nouns were plural (p = .714), 3 in contrast to the L1 participants. Nevertheless, there was a significant mismatch effect in the singular noun conditions (p < .001), consistent with the L1 group’s findings.
GLMM results for the JEFL group in the sentence-picture matching task.
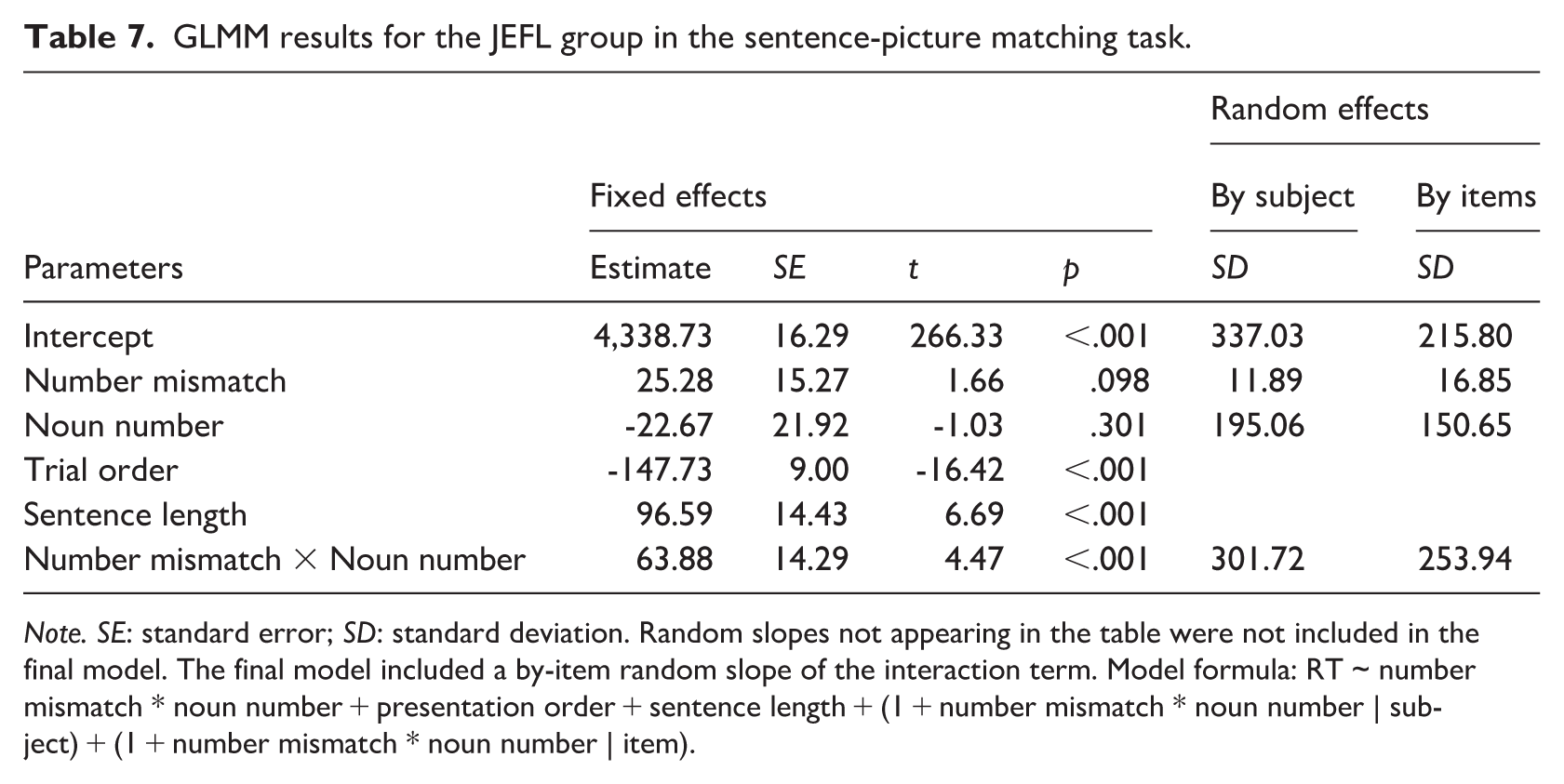
Note. SE: standard error; SD: standard deviation. Random slopes not appearing in the table were not included in the final model. The final model included a by-item random slope of the interaction term. Model formula: RT ~ number mismatch * noun number + presentation order + sentence length + (1 + number mismatch * noun number | subject) + (1 + number mismatch * noun number | item).
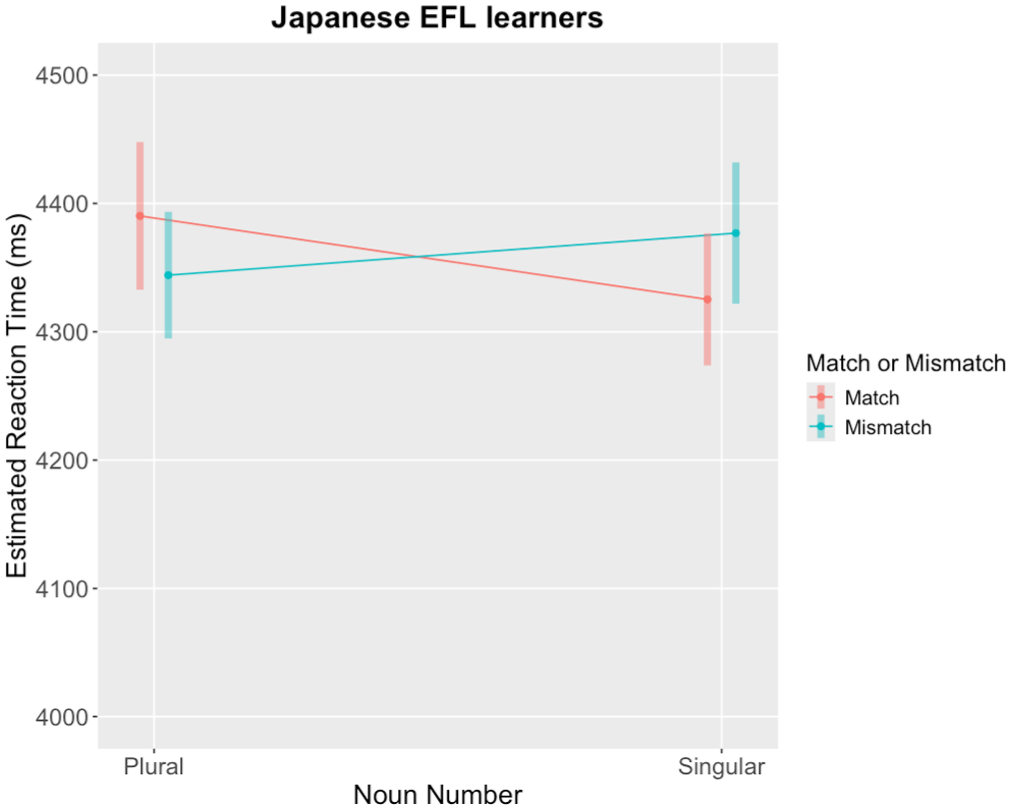
Interaction plot of the estimated RT for the JEFL group. Error bars represent 95% confidence intervals.
These results suggest that the JEFL group successfully processed the singularity of the target nouns and matched them with the number of objects presented in the pictures. However, unlike the L1 group, there was no activation of the plurality of the target nouns, as evidenced by the lack of response to number mismatches between plural nouns and single-object images.
Discussion
Summary and interpretation of key findings
The present study investigated the online processing of English number morphology by JEFL group, focusing on the mapping between morphological forms (singular/plural) and their conceptual representations. The results revealed an asymmetry in the learners’ processing. In line with the L1 control group, the JEFL group showed a significant processing cost when a morphologically singular noun was mismatched with a plural concept (i.e., a picture of multiple objects). However, no such mismatch cost was observed in the reverse condition; that is, the learners did not exhibit a significant processing delay when a morphologically plural noun was paired with a singular concept. This asymmetry suggests that while the form-meaning link for singular nouns is robust enough to trigger an automatic conceptual conflict, the link for plural nouns is not.
The primary explanation for this asymmetry lies in the conceptual markedness of number (Sauerland et al., 2005). Drawing on previous research in linguistics (Sauerland et al., 2005) and psycholinguistics (Patson et al., 2014), it is posited that singularity is the conceptually marked member of the number opposition, as it refers to the precise and specific quantity of exactly one. Plurality, in contrast, is the conceptually unmarked member, denoting a less specified, more ambiguous quantity of more than one. For L1 participants, the mapping between the plural morpheme -s and the conceptually unmarked plural meaning is deeply entrenched through massive experience, which becomes fully automatized, leading to a robust mismatch cost, even for weaker conceptual conflicts. This processing delay reflects the cognitive cost of resolving the conflict between the linguistic input and the visual reality, confirming that L1 speakers automatically activate precise conceptual number information upon encountering the noun.
However, for L2 learners, the situation is different. The mapping for the conceptually marked singular form is strong enough to be processed automatically. In contrast, for the plural form, the combination of its inherent conceptual underspecification and the lack of a congruent obligatory morpheme in their L1 (as suggested by the MCH; Jiang et al., 2011, 2017) results in a form-meaning link that is not robust enough to be automatically triggered in a speeded, online task. The weak conceptual conflict created by the plural mismatch does not reach the threshold necessary to be detected as a processing cost.
Comparison with previous research
The findings both complement and contradict previous studies. The observation of a singular mismatch cost in the JEFL group contrasts with Jiang et al. (2017), who did not find this effect for Chinese L1 learners. This discrepancy may stem from several methodological differences. For instance, this study controlled the number of objects in plural pictures at a fixed quantity of three and ensured that they were distinguishable, which may have facilitated mismatch detection.
A critical divergence from Rusk et al. (2020) is the absence of a mismatch effect for plural nouns in the L2 group, whereas Rusk et al. reported L1-like processing for plurals. This discrepancy can be reconciled by considering both the visual properties and the cognitive demands of the tasks.
First, regarding visual properties, Rusk et al. used a visual-world paradigm where participants viewed singular and plural images simultaneously. Recent research suggests that such displays can introduce a picture complexity effect, where participants’ gaze is automatically drawn to visually complex images (i.e., those with multiple objects) regardless of linguistic input (Koch et al., 2021; Schlenter, 2019). Rusk et al. (2020) themselves noted an early bias toward plural images in both L1 and L2 groups. While L1 speakers could rapidly override this bias when hearing a singular noun, L2 learners may have found it difficult to disengage attention from the salient plural image, creating an illusion of efficient plural processing. In contrast, the present study employed a sentence-picture verification task. This design precludes the influence of visual preference for complex stimuli, as the task required evaluating the semantic consistency between the noun and the image rather than selecting a referent from an array. Thus, the processing slowdowns (or lack thereof) observed in this study likely reflect the learners’ genuine ability (or inability) to map morphology to conceptual number, unconfounded by visual attentional biases.
Second, regarding cognitive demands, Rusk et al.’s paradigm measured a predictive, referential search, where the plural morpheme -s (combined with the visual bias) served as a practical cue to guide the eyes. In contrast, the present study employed a sentence-picture verification task. This design precludes the influence of visual preference for complex stimuli and instead forces learners to verify and resolve a conceptual conflict between the linguistic form and the visual reality. The results imply that while L2 learners may be able to “use” the plural -s as a search cue (as in Rusk et al.), the underlying form-meaning mapping is not robust enough to create a strong conceptual conflict when challenged directly in a verification task.
These findings offer a refinement of the MCH. The difficulty predicted by the MCH may not be an all-or-nothing phenomenon. Instead, L1–L2 congruence may interact with the conceptual properties of the target feature. For features that are conceptually marked and precise (such as singularity), learners may establish a robust form-meaning link despite L1 incongruence. For features that are conceptually unmarked and underspecified (such as plurality), the lack of L1 congruence may present a high barrier to developing an automatic, L1-like mapping.
Limitations and implications
A key limitation of this study is the use of explicit instruction to ignore number mismatches, with debatable potential impact. On one hand, this instruction creates an artificial processing environment. On the other hand, the fact that the L1 group showed robust mismatch effects for both singular and plural nouns suggests that the underlying conceptual conflict was not easily suppressed by such instructions. This validates the interpretation that the asymmetry observed in the learner group reflects a processing difference rather than a task-induced strategy. Nevertheless, it remains plausible that the instruction differentially affected L2 learners, who might have strategically suppressed their attention to the plural morpheme. Therefore, future research should systematically investigate this factor by comparing performance across different instruction conditions to differentiate these possibilities.
Furthermore, an L1 baseline condition for the JEFL group was absent, specifically, testing Japanese speakers in their L1. While establishing such a baseline would be ideal, a direct replication of this study’s bidirectional mismatch paradigm in Japanese is challenging. This is because obligatory plural markers in Japanese (e.g., -tachi) are largely restricted to animate nouns, making it difficult to create stimuli for the plural-noun/singular-object mismatch condition using the same range of inanimate nouns as used in the English task. However, the unidirectional design of Jiang et al. (2017) circumvented this issue. The singular-noun/plural-picture mismatch is possible in classifier languages such as Chinese and Japanese, which enabled them to conduct an L1 baseline experiment. Therefore, a significant challenge for future research is to develop a novel paradigm capable of testing bidirectional mismatch costs within the grammatical constraints of Japanese. Such a study would provide a true baseline for L2 performance and definitively test the hypothesis regarding the robustness of form-meaning mappings.
Finally, the generalizability of the present findings is constrained by the specific typological properties of the L1. Japanese is a classifier language with optional number marking, which contrasts sharply with the obligatory singular–plural distinction in English. Consequently, the asymmetry observed here, driven largely by the conceptual markedness of singularity, may be particularly pronounced in learners whose L1 lacks obligatory plural marking. Caution should be exercised when extending these conclusions to learners from other L1 backgrounds. Future studies should investigate whether similar patterns emerge in learners with different L1 number systems to determine the broader applicability of these findings to L2 morphological acquisition.
Conclusion
This study provides new evidence for singular–plural asymmetry in the online processing of English number by Japanese L2 learners. The results suggest that learners can successfully map singular morphology onto precise conceptual meaning; however, the link between plural morphology and its underspecified conceptual meaning remains non-automatized. This highlights the importance of considering L1–L2 congruence and the inherent conceptual properties of grammatical features when modeling the complex process of L2 development.
Supplemental Material
sj-docx-1-ijb-10.1177_13670069261422017 – Supplemental material for Singular–plural asymmetry in L2 English number processing: A sentence-picture matching study of Japanese learners of English
Supplemental material, sj-docx-1-ijb-10.1177_13670069261422017 for Singular–plural asymmetry in L2 English number processing: A sentence-picture matching study of Japanese learners of English by Yu Tamura in International Journal of Bilingualism
Footnotes
Acknowledgements
This study is based in part on my doctoral dissertation submitted to the Graduate School of International Development, Nagoya University, in 2018. I would like to express my deepest gratitude to my supervisors, Junko Yamashita, Masatoshi Sugiura, and Koji Miwa, for their invaluable guidance and patient support throughout my doctoral studies. Although the publication of this work has taken longer than expected, I am grateful for the opportunity to revise and refine it. I also thank the Editor, Prof. Ad Backus, for accepting this manuscript for publication and for his support throughout the review process.
Ethical approval and informed consent statements
All procedures involving human participants were in accordance with the ethical standards of the Ethical Research Committee of the Graduate School of International Development, Nagoya University, where the research was performed, and the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. All the participants provided written informed consent by signing a consent form before the study began.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by JSPS KAKENHI (grant numbers 20K13123 and 25K00481).
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Supplemental material
Supplemental material for this article is available online.
Notes
Author biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.