
Abstract
This study explores speech processing of English coda laterals (dark L’s) in second language (L2) listeners whose native language does not permit laterals at syllable coda positions. We tested L2 listeners’ (native Mandarin) perception of coda laterals following three Australian English vowels differing in phonological backness, including /iː/, /ʉː/, and /oː/, which represent a front vowel, and central vowel, and a back vowel, respectively. L2 listeners first completed an AX task which tested their ability to discriminate between /iː/-/iːl/, /ʉː/-/ʉːl/, and /oː/-/oːl/, and then they completed an identification task with eye-tracking which tested their ability to distinguish vowel–lateral sequences and bare vowel categories using explicit phonological–orthographical labels. The results show that vowel backness plays a key role in L2 listeners’ perceptual accuracy of English coda laterals, whereas the eye-tracking and identification data suggest some paradigmatic differences between the two tasks. Mandarin listeners show excellent discrimination and identification of coda laterals following a front vowel and poor performance following a back vowel, whereas the central vowel has led to intermediate patterns.
1 Introduction
Decades of psycholinguistic research have shown that nonnative (L2) listeners experience difficulties in perceiving segments due to persistent interference from their native language (L1) phonology, and such interference manifests in L2 listeners’ perception of target language vowels (Escudero et al., 2009; Tyler et al., 2014), consonants (Best et al., 2001; Logan et al., 1991), phonemic tones (Hallé et al., 2004; So & Best, 2014), and segment sequences (Dupoux et al.,1999, 2011). According to one of the prevalent psycholinguistic theories of nonnative speech perception, the perceptual assimilation model (PAM, and its extension for L2 learners, PAM-L2) (Best, 1995; Best & Tyler, 2007), nonnative listeners (naïve or experienced) apprehend articulatory gestures directly from the speech input, and the combination of articulatory gestures can form different levels of phonological units, including phonemes and phonemic sequences. More importantly, nonnative and L2 listeners recognize such units or speech categories based on the affordances of their native language phonology, including but not limited to its segmental inventory, coarticulatory patterns, systematic allophonic variations, and phonotactic restrictions (Best & Tyler, 2007). A well-known example is that Japanese only has one liquid category and adult Japanese listeners are often challenged in discriminating between English /l/ and /ɹ/ sounds because both are perceived as similar to the same native Japanese category (MacKain et al., 1981; Sheldon & Strange, 1982). Some of these perceptual difficulties might be persistent, but research has also shown that experienced L2 listeners (e.g., L2 learners who regularly use the target language) sometimes show better performance than naïve listeners with limited proficiency (e.g., Levy & Strange, 2008). Although the inventory effect has received substantial attention in the past, a growing body of research has highlighted the importance of phonological contexts in L2 segmental perception (Best & Hallé, 2010; Hallé & Best, 2007; Hao et al., 2023; Kilpatrick et al., 2019; Levy, 2009; Strange et al., 2001). For instance, Japanese listeners’ perception of English /s/ and /ʃ/ is influenced by the following vowel context: When the consonant–vowel sequence violates the co-occurrence restriction in the listeners’ native language (e.g., /ʃi/ but not */si/ is a possible syllable in Japanese), L2 listeners show decreased perceptual sensitivity as compared with a context where no violation is expected (e.g., both /ʃu/ and /su/ are attested syllables in Japanese). In an AXB experiment, Japanese listeners discriminated /ʃu/-/su/ with very high accuracy, whereas /ʃi/-*/si/ showed significantly lower accuracy, indicating that consonant perception is influenced by the immediate vowel context and language-specific constraints (Kilpatrick et al., 2019).
This short report is part of a larger study investigating whether native Mandarin listeners can accurately perceive English coda laterals, that is, dark /l/ (phonetically, [ɫ]). In particular, this study investigates whether L2 perception of coda laterals is influenced by the phonological context, especially the preceding vowel. Coda laterals are dark ([ɫ]) in many mainstream English dialects (e.g., British, Australian, and American English), and its articulation involves both a coronal medial constriction and a lingual/dorsal constriction, resulting in a phonetic quality similar to [ɤ], [o], or [ʊ] (Gick et al., 2013; Hardcastle & Barry, 1989; Sproat & Fujimura, 1993). In Mandarin, however, laterals are systematically prohibited in coda positions, as Mandarin syllable phonotactics only permits nasals and glides (in phonetic diphthongs) post-vocalically (Duanmu, 2007, 2011), for example, /CVn/ is a possible syllable, whereas */CVl/ is not. At the same time, onset laterals in Mandarin are always light, that is, its articulation does not involve the dorsal gesture as seen in English dark /l/’s. For native Mandarin listeners, English coda /l/ presents a challenge for L2 speech learning with both a mismatch in gestural implementation (i.e., L1: light vs. L2: dark) and a mismatch in phonotactic regularity (i.e., L1: unattested coda vs. L2: attested coda). It, therefore, raises interesting research questions for speech perception as to whether lateral codas can be accurately perceived by L2 listeners. Evidence from Mandarin loanword adaptation suggests that English coda laterals are often adapted as a rhotic vowel /ɚ/, but they also often undergo deletions, /Vl/ → /V/. For instance, De
2 Method
2.1 Participants
The participants of this study were 16 native Mandarin Chinese speakers residing in Australia (14 females, Mage = 24.0, SD = 3.4), who spoke English as a second/additional language (L2). All participants were originally from PR China, and at the time of testing, they were international students at the University of Melbourne. Their mean age at the onset of the acquisition of English was 6.9 years old (SD = 1.7). Before coming to Australia, the participants had received classroom-based English education in China for 13.7 years, whereas they had an average of 2.0 years (SD = 1.1) of English-mediated education since their arrival. According to their self-report, English was used 72.5% (SD = 18.9) of the time in academic settings and 45.3% of the time (SD = 17.5) in non-academic settings. All participants completed standardized English proficiency tests as a requirement for entering the Australian university, and their IELTS scores ranged from 6.5 to 7.5, indicating an upper-intermediate to advanced level of proficiency overall. Although the participants had different levels of exposure and linguistic command in different regional Chinese dialects, these dialects do not have a different constraint on coda laterals from Standard Mandarin. None spoke a third language fluently, and none reported any speech or hearing disorders. All participants gave written consent to participate, and all were tested in a quiet room.
2.2 Stimuli
The stimuli used in this study were a set of /pVda/ and /pVlda/ pseudowords, produced by a male native speaker of AusE who was phonetically trained. Three AusE high vowels, /iː/, /ʉː/, and /oː/ were chosen to represent three levels of vowel backness, that is, front, central, and back (Cox & Fletcher, 2017; Harrington et al., 1997). It is worth noting that the central vowel /ʉː/ in AusE had a back vowel allophone [u] in pre-lateral contexts, resulting in a phonetic contrast of [ʉː]-[uɫ]. Therefore, the backness labels should be understood as phonological terms rather than phonetic values. Pseudoword carriers were used to minimize the potential lexical biases. The speaker produced each word multiple times in a clear citation style, and we chose two tokens per word as the stimuli based on voice quality and background noise level. The consonant /p/ was used in all stimulus words to generate a controlled onset context, whereas the consonant /d/ was implemented to prevent the drop of the coronal gesture of coda laterals in /pVlda/ words. The acoustic properties of the stimuli are summarized in Table 1, and the set of stimuli was also used in our previous study (Wang et al., 2023). For each target vowel, formant values (F1/F2) were estimated at the mid-point where a relatively steady formant structure can be observed, and the boundary between the vowel and the following coda lateral (in CVLCV pseudowords) was placed at the mid-point of the transition part, which is indicated by a change in amplitude and/or spectral quality. It is worth noting that such annotations do not aim to document the absolute values of the segments in question because this is not a production study, but rather they help ensure that stimuli with the same phonological structure have comparable acoustic properties.
Acoustic Properties of the Stimuli, Including First Two Vowel Formants (Hz), Whole Duration (ms), and Segmental Durations (ms), Averaged for Two Unique Tokens per Word.
2.3 Procedures
This study deployed a series of two tasks to investigate L2 listeners’ cognitive processing pattern of coda laterals in different vowel contexts, including an implicit AX discrimination task and an explicit identification task with eye-tracking. The AX task is one of the standard paradigms for examining the outcome of speech perception (Strange & Shafer, 2008; Werker & Tees, 1984), that is, the discriminability of a given pair of phonological categories. At the same time, the response time (RT) measure in the AX task can indicate the level of cognitive demand in performing auditory discrimination (Strange, 2011). However, the disadvantage of the AX task is also clear: Both discrimination accuracy (%) and RT are opaque measures of speech perception, while the time course of cognitive processing is not available for examination. Therefore, the second task was a forced-choice identification task enhanced with eye-tracking (Chong & Garellek, 2018; Cutler et al., 2004), which allows an examination of the time course during the decision-making process. It is also worth noting that the two tasks had different complexity levels in terms of integrating linguistic representations of different modalities: The identification task but not the AX task requires listeners to categorize perceived speech stimuli using explicit phonological-orthographical labels. Finally, deploying two tasks allows necessary data triangulation. All participants completed the AX task first and then the identification task following a short break.
2.3.1 AX discrimination
The AX task was deployed to test the L2 listeners’ ability to differentiate /Vl/ sequences from the corresponding bare vowel categories, /V/. A total of four contrasts were tested, including /iː/-/iːl/ (front), /ʉː/-/ʉːl/ (central), /oː/-/oːl/ (back), and a control pair with two unrelated vowels, /ɑe/-/əʉ/. All contrasts were served and tested in /pV(l)ba/ pseudowords (see Table 1 for details). On each trial, the listener heard a sequence of two stimuli, and they were required to respond whether the two pseudowords were phonologically identical (“Same” trials, AA or BB), or not identical (“Different” trials, AB or BA), by pressing either the F key or the J key on their keyboard. All four duplet types (AA, AB, BB, and BA) were equally represented, and the presentation order was randomized. Two interstimulus-interval (ISI) values (250/1,500 ms) were used as some previous research suggests that longer ISI values may lead to poorer discrimination performance (Werker & Tees, 1984), but some studies did not find such an effect (e.g., Davidson & Shaw, 2012). Although all stimuli were produced by the same speaker, the task used two sets of recordings, and as a result, the two pseudowords in a pair were always different acoustically, even when they signal the same phonological category. The task was timed, and participants had 2,500 ms for giving a response on a trial. In total, there were 96 trials (4 contrasts, 4 duplet types, 2 ISIs, and 3 repetitions), and self-paced breaks were given every 32 trials to reduce the fatigue effect. At the same time, RT was recorded as a measure of cognitive demand during perceptual processing. The AX task was developed using Psytoolkit (Stoet, 2010, 2017).
2.3.2 Identification with eye-tracking
The second task was a two-alternative-forced-choice (2AFC) identification task, which tested L2 listeners’ ability to accurately perceive and categorize /V/ and /Vl/ categories using phonological-orthographical labels. Two conditions were implemented, including (1) the Competitor condition, where listeners were required to distinguish /Vl/ sequences from the corresponding /V/ categories, similar to the AX discrimination task, and (2) the Distractor condition, where listeners were required to distinguish /Vl/ sequences from an unrelated vowel category, /ɑe/. The procedures of the identification task are illustrated in Figure 1.
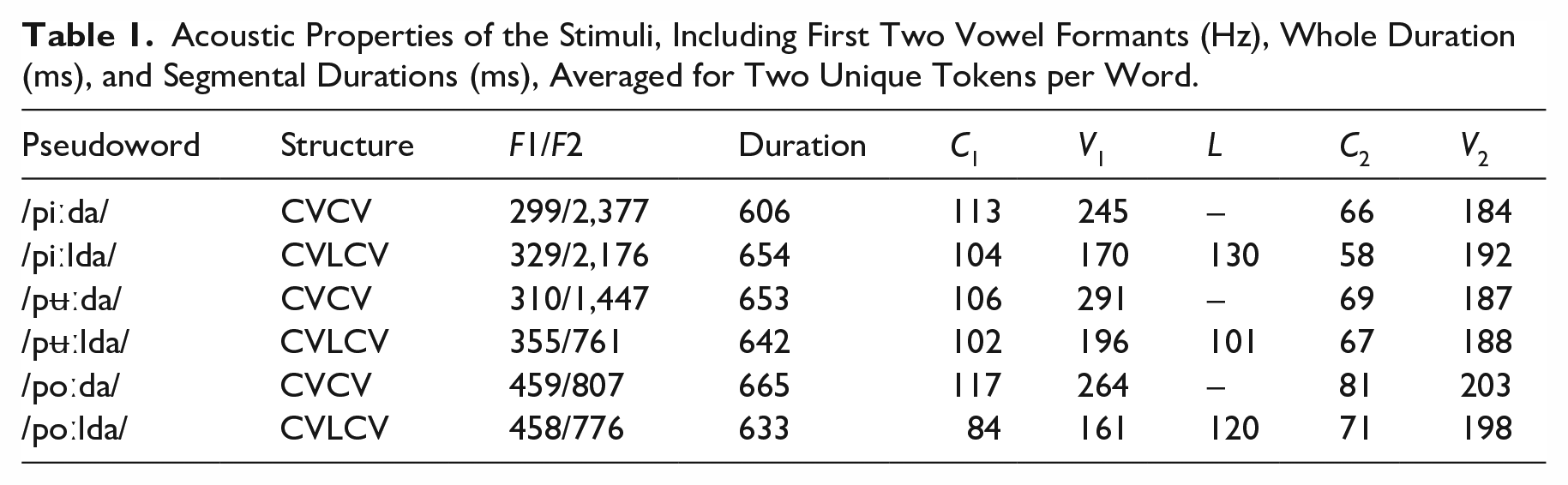
Main procedures of the identification task. In the example, there is a contrast between /iː/ and /iːl/, which represents the front-competitor condition in the task.
At the beginning of each trial, two phonological labels were printed on the screen (e.g., <PIL> for /piːl/, <PUL> for /pul/, <POL> for /poːl/, and <PAI> for /pɑe/), and the participants were instructed to preview the choices for 500 ms before a cross appeared at the center of the screen for 1,000 ms. After that, the labels were presented again, and a stimulus word (e.g., /piːlda/) was simultaneously played. Participants were not required to give a response right away until after a decision period of 2,000 ms when a prompt was presented on the screen asking whether the stimulus matched the left or the right phonological label. The participants were then allowed to give a response by hitting either the F key (“Left”) or the J key (“Right”) on their keyboard. The side of the correct label was counterbalanced. In total, the task had 192 trials (3 vowels, 2 conditions, 2 categories per contrast, 2 positions, 2 tokens per category, and 4 repetitions), and self-paced breaks were given every 48 trials to reduce the fatigue effect.
For examining the listeners’ online processing pattern during the decision-making stage, their eye fixations were recorded during the 2,000 ms critical period shortly before they were prompted to give an identification response. Before that decision period, the cross (i.e., the fixation point) presented at the center of the screen was used to attract visual attention, and thus their initial eye fixation locations were relatively consistent across different trials. The fixation data were recorded using a low-cost eye tracker (Tobii 4C), which ran at a sampling rate of 60 Hz, that is, it was able to detect fixation locations every 16.667 ms. The eye-tracking device was fixed underneath the screen of a Macbook Pro laptop computer, and participants sat at a distance of approximately 50 cm. Nine-point calibration was used for each participant before the task with the help of the software Talon. During the task, listeners were instructed to look at the black cross when it appeared, and they were also instructed not to look outside of the screen or keep their eyes closed for a long time. The task was developed using PsychoPy (Peirce, 2007). Apart from identification accuracy, it was also of special interest to this study to examine the looking behaviors during the decision-making process, especially the frequency and the duration of time when L2 listeners were attracted by the non-target (incorrect) label, that is, a competitor or distractor. For instance, for identifying the category in /puːlda/, <PUL> is the correct label, <PU> is a competitor label, whereas <PAI> is a distractor label. When perceptual confusion occurs, the listener will show more occurrences of looking at the alternative label and will spend more time looking at the alternative label.
2.4 Predictions
The general prediction of this study is that vowel backness can affect L2 listeners’ perception of English coda laterals, and as the gestural overlap between the nuclear vowel and the coda lateral increases, L2 listeners will become increasingly challenged in distinguishing vowel–lateral sequences from bare vowel categories, displaying a case of perceptual deletion (i.e., not perceiving a segment when it is present in the stimulus). More specifically, we first expect that Mandarin listeners will show high discrimination accuracy and low RTs in /iː/-/iːl/, poor performance in /oː/-/oːl/, and intermediate patterns in /ʉː/-/ʉːl/, replicating the finding of our precursor study (Wang et al., 2023). Next, we expect that difficulties in lateral coda perception will also result in different online processing patterns in an eye-tracking identification task. In the early stages of processing, participants may temporarily look toward both labels, as previous research shows (Chong & Garellek, 2018; Weber & Cutler, 2004). During the decision-making process, L2 listeners will have more eye fixations on non-target labels if they experience increased competition between two phonological categories. In contrast, when category competition is minimal, participants should quickly look toward the target label without considering the non-target label for a long time. It is expected that category competition is stronger in the competitor condition than in the Distractor condition, and the specific level of competition in the competitor condition depends on the backness level of the nucleus vowel.
3 AX discrimination results
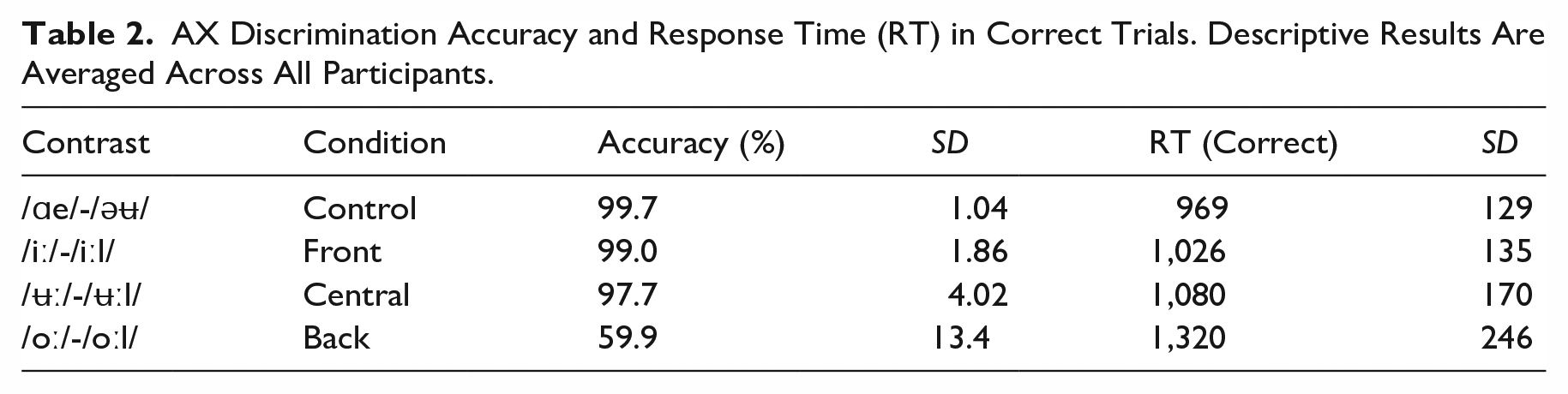
The data analysis was carried out in an R environment with freely available packages (R Core Team, 2023). The descriptive results of the L2 listeners’ AX discrimination performance are summarized in Table 2. For inferential statistics, the accuracy data were analyzed using a generalized linear mixed-effects model (GLMM, binomial link), which took contrast and ISI as fixed factors (the interaction effect is also included), whereas participant was controlled as a random factor. Both contrast and ISI were categorical variables, and they were treatment-coded, that is, the control contrast and the 250 ms ISI condition were set as reference levels. Initially, both a random intercept and a random slope (participant by contrast) were included but the model produced a singular fit, that is, the model was potentially over-fitted, and thus the random slope was removed from the random effect and the model successfully converged. See Supplemental Material for details of the model-fitting procedures (for all analyses in this article). When the model was checked by a Wald Chi-square test, there was a significant main effect of contrast, χ2(3) = 158.45, p < .0001. However, the main effect of ISI was not significant, χ2(1) = 0.06, p = .8099, indicating that the manipulation of the silence interval did not lead to changes in discrimination accuracy. The contrast–ISI interaction effect was not significant either, χ2(3) = 1.89, p = .5959. Next, to compare the mean accuracy measures between different contrasts, we carried out a series of post hoc tests based on estimated marginal means (EMMs) (see Table 3). Noticeably, the participants achieved ceiling-level accuracy in /iː/-/iːl/ (99.0%), /ʉː/-/ʉːl/ (97.7%), and the control pair /ɑe/-/əʉ/ (99.7%), whereas /oː/-/oːl/ showed a low accuracy measure (59.9%). Indeed, the post hoc tests confirmed that the accuracy of /oː/-/oːl/ was significantly lower than the other three pairs (p < .0001 for three comparisons, Bonferroni adjusted).
AX Discrimination Accuracy and Response Time (RT) in Correct Trials. Descriptive Results Are Averaged Across All Participants.
Pairwise Comparison of AX Discrimination Performance. Mean Differences and p Are Obtained From Generalized Mixed-Effects Modeling.
Note. Bonferroni adjustments applied.
p<.05, **p<.01, and ***p<.001.
For examining the cognitive demand in the AX discrimination task, RT data (in correct trials, in AB/BA duplets, see Table 2) were also analyzed using a GLMM (Gamma link), where contrast and ISI were fixed factors, and participant was included as a random factor (random intercept: participant; random slope: participant by ISI, see Supplemental Material for details). A Wald Chi-square test shows that the main effect of Contrast was significant, χ2(3) = 110.35, p < .0001, the main effect of ISI was not significant, χ2(1) = 0.29, p = .5886, and the interaction effect was not significant either, χ2(3) = 3.23, p = .3569. Likewise, the between-contrast differences were checked using a series of post hoc tests (see Table 3). This time, the tests revealed a more gradient pattern as more comparisons became significant. At the participant level, the control pair showed the lowest mean RT (969 ms), followed by the /iː/-/iːl/ (1,026 ms), /ʉː/-/ʉːl/ (1,080 ms), and /oː/-/oːl/ (1,320 ms). All pairwise comparisons were significant after adjustment (p < .023 for 6 comparisons, Bonferroni adjusted). To conclude, the prediction was confirmed that the backness level of the nucleus vowel has a clear role in the discrimination performance of /V/-/Vl/ contrasts: Increased vowel backness is associated with decreased accuracy and increased latency (RT). The only unexpected finding was that the participants showed ceiling-level accuracy when discriminating /ʉː/-/ʉːl/ (97.7%) and therefore its differences from the front vowel pair and the control pair were not significant. At the same time, the RT pattern was completely consistent with the predictions.
4 Identification with eye-tracking results
The identification accuracy measures obtained by the L2 listeners in each condition are summarized in Table 4. Noticeably, all participants achieved 100% accuracy in the Distractor conditions for all three vowels, and the variation was only observed in the competitor conditions. For analyzing the response accuracy in the competitor conditions, a GLMM was fitted (binomial link) which took (vowel) backness as the predictor, whereas participant was kept as a random factor (random intercept only, see Supplemental Material for model-fitting details). A Wald Chi-square test revealed a significant effect of backness, χ2(2) = 59.16, p < .0001. Post hoc tests revealed that all pairwise comparisons were significant at the .0001 level, Bonferroni adjusted, such that the front vowel (99.8%) > the central (78.3%) > the back (61.6%).
Identification Accuracy (%) by Vowel Backness Level and Test Condition, That Is, Whether a Competitor or a Distractor Is Presented. Values are Averaged Across All Participants.
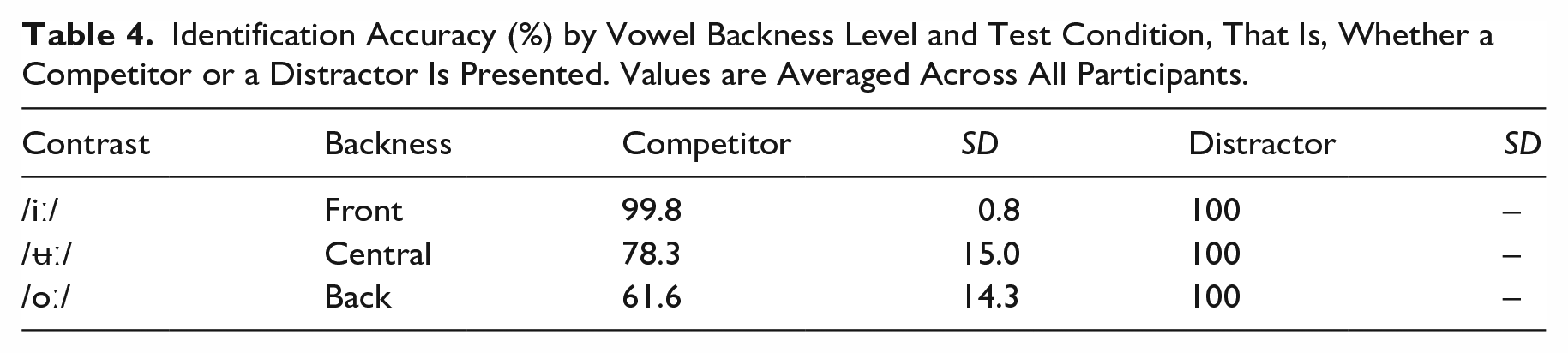
The averaged temporal trajectories of eye fixations within the 2,000 ms time window are summarized in Figure 2. Tracking data from two participants were excluded due to poor recording quality. The participants’ eye fixation rates on the target label (upper panel) and non-target label (lower) were complementary: More fixations on the target label were accompanied by lower fixation rates on the non-target label at the same time point. Therefore, only fixation data on the non-target label were analyzed. Overall, the trajectories in the competitor conditions showed substantial variations across different vowel backness levels, whereas the trajectories in the Distractor condition were relatively stable. In addition, the trajectories revealed at least two sub-stages of cognitive processing within the time window, including a pre-decision stage (0–500 ms) where listeners briefly consider both options in an early-stage visual search and a decision-making stage (500–2,000 ms) where listeners consider the likelihood of the phonological label matching the auditory stimulus. In the Distractor conditions, the proportion of dwell time (y-axis) showed almost exponential decay curves after 500 ms. In the Competitor conditions, such a sharp decay pattern could only be observed for the front vowel (i.e., /iː/-/iːl/); for both the central vowel (/ʉː/-/ʉːl/) and the back vowel (/oː/-/oːl/), the decay of looking time proportion was less steep, indicating that listeners continued considering the alternative labels during the decision-making process.
Averaged proportion of looking time on target and non-target labels during identification. Zero on the x-axis indicates the onset time of stimulus presentation.
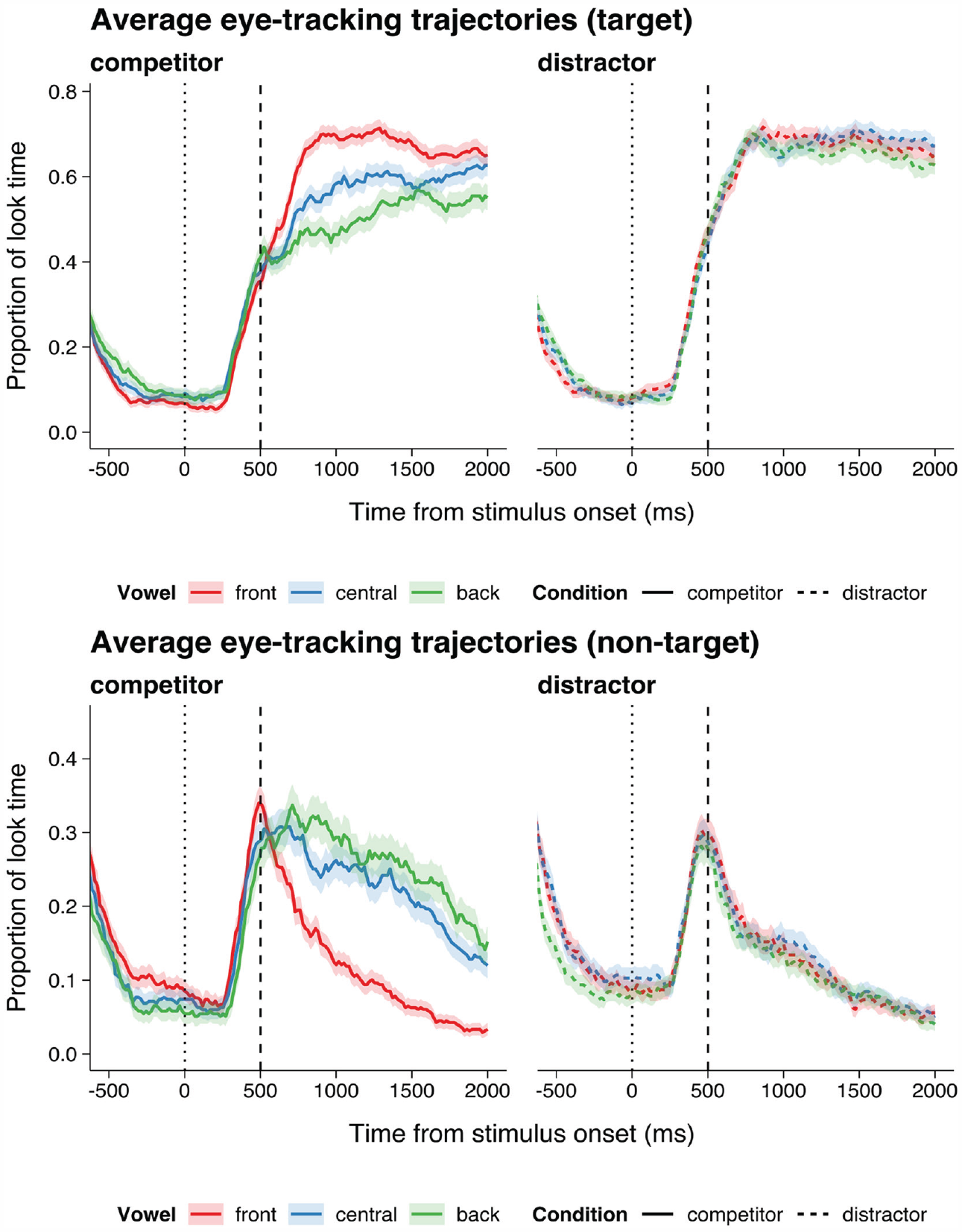
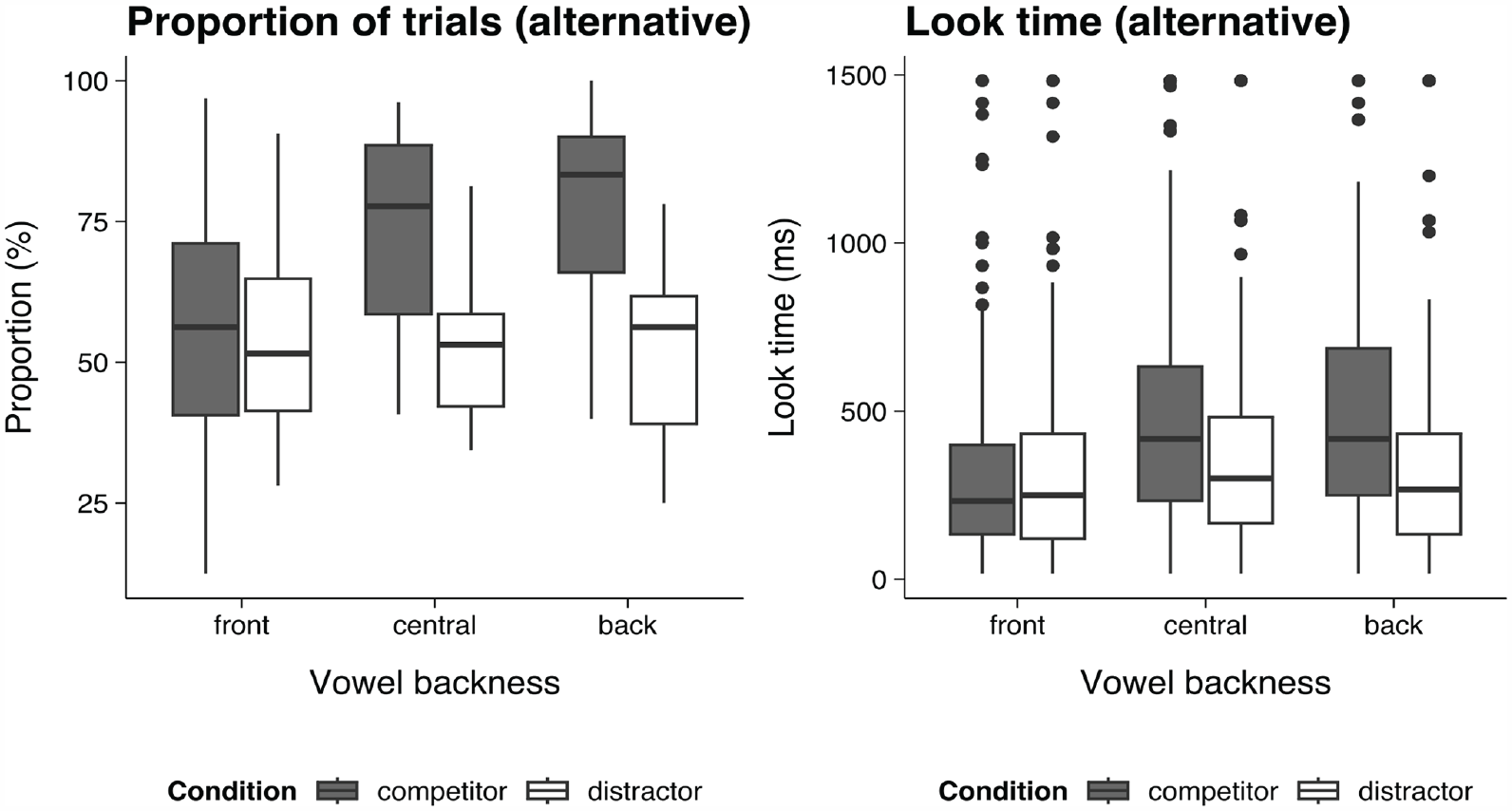
To test these observations, the summative looking time on the alternative label was calculated for each valid trial during the decision stage, that is, 500–2,000 ms from the stimulus onset. First, trials with zero and non-zero looking time on the alternative label were differentiated: Zero looking time indicates that the participant never looked at the alternative label during the whole decision-making process. The proportion of trials with a non-zero looking time would indicate whether the label was likely to be considered as the response, see the left panel of Figure 3. Next, in the trials where participants did look at the alternative label, the total dwell time on the label would indicate the level of cognitive competition (see the right panel of Figure 3). Trial proportion data and looking time data were analyzed similarly using GLMMs (binomial link and Gamma link, respectively), where backness and condition were set as fixed factors and participant was controlled as a random factor (random intercept = Participant, random slope = participant by condition; see Supplemental Material for details), and the significance level of each effect was checked by a Wald Chi-square test. For trial proportions, there was a significant effect of vowel Backness, χ2(2) = 16.47, p = .0003, a significant effect of condition, χ2(1) = 26.70, p < .0001, and a significant backness–condition interaction effect, χ2(2) = 43.21, p < .0001. Similarly, for looking time, there was a significant effect of backness, χ2(2) = 32.03, p < .0001, a significant effect of condition, χ2(1) = 30.29, p < .0001, and a significant backness–condition interaction effect, χ2(2) = 22.16, p < .0001. Therefore, two sets of post hoc tests were carried out between all backness–condition combinations (see Table 5).
Left: Proportion of trials where the non-target (incorrect) labels had a non-zero looking time, averaged across participants. Right: Total looking time at alternative labels, excluding zero looking time trials.
Pairwise Comparison of Looking Behavior During Decision-Making (Time Window = 500–2,000 ms from Stimulus Presentation).
Note. Bonferroni adjustments applied.
p < .01. ***p < .001.
The proportion data and the looking time data showed highly consistent patterns. First, in the Distractor conditions, the proportion data did not show significant differences across three backness levels (p = 1.0000 for three comparisons); the same was true in the looking time data (p = 1.0000 for three comparisons). In the Competitor conditions, both the proportion data and the looking time data showed the participants experienced more perceptual confusion in central and back vowels, indicating that the competitor for the front vowel (e.g., /iː/ for /iːl/) led to less activation and cognitive competition as compared with the competitors for the other two vowels (e.g., /ʉː/ for /ʉːl/ and /oː/ for /oːl/). However, the difference between central and back vowels in the Competitor condition was not significant in either the proportion data or in the looking time data (p = .6958 and 1.0000, respectively), indicating that these two vowels had similar processing patterns (see also Figure 2). To summarize, the predictions of the identification task were also supported by the findings overall, and the discovered patterns were highly consistent with the AX discrimination results, except that the central vowel condition was more similar to the front vowel in terms of discrimination accuracy (see Table 2), whereas its eye-tracking pattern was more similar to the back vowel (see Figures 2 and 3).
5 Discussion
The results from the two tasks in the present study successfully replicated our previous finding that native Mandarin listeners at times show a “perceptual deletion” effect in perceiving coda laterals, especially following a back vowel (Wang et al., 2023). Clearly, this effect cannot be explained solely in terms of cross-language inventory differences, as both English and Mandarin have a lateral consonant in their phonemic inventory. Instead, we argue that the decreased perceptual salience should be explained in terms of the phonotactic differences and the articulatory implementations between the two languages. As Mandarin phonology only permits laterals to occur at syllable-initial positions, English coda laterals lead to violations of the L2 listeners’ native (Mandarin) phonological grammar. It is now well-documented in the literature that nonnative listeners often “repair” illicit phonemic sequences in their speech perception, and a well-known example is illusory vowel epenthesis in consonant cluster perception (e.g., Dupoux et al.,1999, 2011; Kilpatrick et al., 2020). For instance, Japanese listeners persistently hear an illusory vowel between two obstruents and therefore fail to distinguish between [ebzo] and [ebuzo]. This study, together with our previous study, reveals that the opposite repairing strategy also exists: Nonnative or L2 listeners can repair an illicit phonemic sequence by “deleting” a segment that is present in the speech signal.
Such a deletion effect may not be due to any cognitive process that actively deletes a perceived segment before it becomes conscious, but, rather, it is more likely to be rooted in L2 listeners’ failure in interpreting articulatory gestures in speech perception (Wang et al., 2023). As English coda laterals are often velarized and have a phonetic quality similar to [ɤ], [o], or [ʊ] (Gick et al., 2013; Hardcastle & Barry, 1989; Sproat & Fujimura, 1993), L2 listeners may interpret the perceived lingual gesture as signaling part of the preceding vowel, instead of a separate phoneme. Although coda laterals are also produced with a coronal gesture, this gesture might not be salient enough to be recognized as belonging to a new segment. Therefore, a back vowel–lateral sequence might be perceived by L2 listeners as a relatively poor (yet still acceptable) exemplar of a bare vowel category (Wang et al., 2023), and ultimately, Mandarin listeners perceive a back vowel–lateral sequence and the corresponding back vowel category as two exemplars of a single speech category. This pattern is consistent with previous acoustic and articulatory research that back vowels show a high level of overlap with a following coda lateral (Lin et al., 2012; Proctor et al., 2019; Szalay et al., 2021). In contrast, although front vowels are also produced with the lingual gesture, their articulatory gestures are less overlapping with a coda lateral due to tongue backness differences, and therefore the coda must be recognized as a separate phoneme from the preceding vowel. According to PAM/PAM-L2 (Best, 1995; Best & Tyler, 2007), discrimination is difficult when two non-native speech categories are perceived as non-contrastive phonologically, and this explains why coda laterals are more accurately perceived after a front vowel as compared with a back vowel. Although PAM/PAM-L2 has been widely tested for inventory differences, we argue that the principles of perceptual assimilation can be extended to nonnative and L2 perceptions of phonemic sequences.
Furthermore, the eye-tracking (identification) task has revealed rich information about the real-time processing in L2 listeners, which is not available in the AX discrimination task or our previous study. Nevertheless, measuring eye fixations requires visual presentations of response labels in an identification task, which may increase the cognitive demand of the perception task overall. In comparison, the AX discrimination task relies solely on auditory information, and participants are not required to explicitly recognize each perceived category using orthographic-phonological labels. When eye-tracking data are compared with discrimination results, both similarities and differences are observed. First, both tasks showed that the front vowel /iː/ led to an easy condition, whereas the back vowel /oː/ was a difficult vowel condition, as indicated by the accuracy data. However, the two tasks showed slightly different patterns for the central vowel /ʉː/. In the AX task, L2 listeners showed almost a ceiling level of accuracy for /ʉː/-/ʉːl/ (97.7%) at a similar level as /iː/-/iːl/ (99.0%), but only in terms of response latency, /ʉː/-/ʉːl/ showed a significantly longer mean RT (1,080 ms) than /iː/-/iːl/ (1,026 ms). This is slightly different from our previous study which tested Mandarin listeners with only limited L2 exposure (Wang et al., 2023): In native Mandarin speakers residing in China with no overseas experience, participants showed significantly higher AX and AXB discrimination accuracy in /iː/-/iːl/ than /ʉː/-/ʉːl/. At the same time, it was reported that more experienced L2 listeners, as indicated by a larger English vocabulary size, tended to achieve higher accuracy metrics in the discrimination tasks, indicating that lateral coda is learnable in perception. The present study recruited a cohort of more experienced listeners (i.e., international students residing in an English-speaking country), and therefore the similarity between /ʉː/-/ʉːl/ and /iː/-/iːl/ may reflect continuous phonological acquisition. Also, it is likely that L2 listeners have attended to the change in vowel quality between the open-syllable and pre-lateral contexts, that is, /ʉː/ is realized as a central vowel (mean F2 = 1,447 Hz) while a phonetically back vowel preceding a coda lateral (mean F2 = 761 Hz). If that is the case, then the high discrimination accuracy should be attributed to L2 listeners’ sensitivity toward the allophonic variation of the nucleus vowel, but not necessarily their ability to accurately perceive the coda lateral. Other measures from this study also suggest that the Mandarin listeners have not fully mastered coda lateral in /ʉːl/: Apart from the long RT measure, participants showed a relatively low identification accuracy in the second task (78.3%), significantly lower than the front vowel condition (99.8%).
Perhaps more strikingly, the eye-tracking trajectories (especially between 500 and 2,000 ms after the stimulus presentation) suggest that the Mandarin listeners experienced persistent category competition between /ʉː/ and /ʉːl/ (PU vs. PUL, in orthography), at a similar level to that between /oː/ and /oːl/ (PO vs. POL). However, the non-significant difference in eye-tracking metrics between /ʉː/-/ʉːl/ and /oː/-/oːl/ should be interpreted with caution: As this study had a relatively small sample size (N = 16), the null effect could be due to low statistical power, but not necessarily indicating the same level of cognitive confusion. Although it is still possible that L2 listeners rely on allophonic information to make category decisions (e.g., they might think that a back vowel always suggests a coda lateral), the identification task may have directed the participants’ attention toward to coda position. Vowel allophony may provide a reliable cue in discrimination when two stimuli are presented in a sequence, but it may not serve as a reliable cue in coda identification when the stimulus is presented alone in isolation. Furthermore, as /ʉː/ is realized as a back vowel pre-laterally ([uɫ]), the gestural overlap is similar between the /ʉːl/ and /oːl/ sequences (because both are back vowels now), and therefore, it is not entirely unexpected that similar processing patterns can be observed in these two conditions.
In summary, our result suggests that L2 listeners can experience substantial perceptual confusion in processing English coda laterals, even when they achieve ceiling-level discrimination performance for the same contrast. These differences in results between the two tasks also suggest paradigmatic differences between discrimination tasks and identification tasks, and that the two paradigms should be used in combination. When only discrimination tasks are deployed (e.g., in Wang et al., 2023), it is not clear whether successful discriminations reflect mastery of a phonological structure, as one cannot determine which dimension of phonological-phonetic difference is attended to by the participant (e.g., vowel quality change or the presence of coda lateral). In contrast, an identification task can direct the participant’s attention to the key area of interest (e.g., syllable codas) and test whether listeners successfully recognize phonological structures using phonological labels when no paired comparisons are available.
Footnotes
Acknowledgements
We want to thank the Mandarin speakers who participated in the study. A special thanks also goes to Alexander Kilpatrick for his help in generating the test stimuli. The article has also received invaluable comments from Rikke Bundgaard-Nielsen, Brett Baker, Olga Maxwell, and the anonymous reviewers at Language and Speech.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.