
Abstract
Purpose:
Among the first linguistic symptoms of several types of dementia are word-finding problems. Multilinguals with dementia may have stronger difficulties, as multilinguals are found to retrieve words more slowly than monolinguals, possibly due to larger vocabularies and the additional cognitive load of suppressing non-target languages. A deeper insight into the factors that influence word retrieval and trigger word-search sequences in multilingual dementia may inform linguistic theory, improve dementia assessment and help caregivers in overcoming communicative challenges.
Approach:
In this study, we combine a usage-based and a conversation analytic approach to language and communication to explore lexical aspects of word-finding problems in multilingual speakers with dementia.
Data:
The participants are seven multilingual persons with dementia with different first languages, but English and Norwegian in common. They completed a picture-based naming task with nouns and verbs, took part in a semi-structured interview on their language background and went through a cognitive assessment. Naming performance was scored, and conversation analysis was further used to assess the presence of word search sequences.
Findings:
With one exception, the participants scored highest in their self-identified strongest language. Despite long exposure to Norwegian, all seven scored higher in English. Word-search sequences were evenly distributed between these two languages, but notably more successful in English. Higher scores and fewer searches were observed for nouns than for verbs, and for words with high imageability and low age of acquisition. High frequency and cognateness were associated with higher scores.
Implications:
Theoretically, combining frameworks was a prerequisite for investigating word searching and word finding in union, and the approach allowed for a nuanced understanding of the mental and interactional accomplishment of lexical retrieval as gradual and situated rather than binary.
Originality:
The paper proposes a psycho-conversational model of word retrieval as a gradient.
Keywords
Introduction
When we speak, we rely on fast and accurate word retrieval. Cognitive decline, found in most types of dementia, slows down this process, leading to word-finding problems. Multilingual speakers tend to have larger vocabularies than monolinguals and retrieve words somewhat slower. Studying word retrieval among multilingual individuals living with dementia could deepen our understanding of lexical processing and the mental lexicon. This paper combines psycholinguistic approaches and conversation analysis to study the mental processes and the situated behaviour occurring during word-finding problems. We study lexical properties’ influence on word retrieval and investigate whether analyses of word-search sequences may illuminate lexical processing.
Word retrieval within a usage-based view on language
Psycholinguistic properties have a strong influence on word finding. A usage-based view on language processing assumes a mental lexicon with connections based on perceived similarities in form, meaning and use (Bybee, 2010; Langacker, 1987). When retrieving a word, we use these connections, activating the target word as well as words connected to it.
Concerning use, a word is entrenched every time we encounter it (Langacker, 1987), developing stronger network connections with time (Bybee, 2010; Juhasz, 2005). Hence, high-frequency words are more easily activated (Bybee, 2010). Words acquired early have time to strengthen their connections and reach a higher cumulative frequency, making them easier to retrieve than words acquired late (Brysbaert & Cortese, 2011). Turning to meaning, words denoting concepts easy to imagine (see, hear, smell or feel) are more easily activated. Hence, imageability facilitates activation (Paivio et al., 1968). Word class also affects retrieval: Nouns can be conceptualised in isolation, whereas verbs require one or more participants involved in the action or state they denote (Langacker, 1987). As such, nouns should be easier to activate in single-word elicitation than verbs. When it comes to form, a word is easier to activate if it has many phonological neighbours, that is, words differing by only one sound, as the many phonological connections aid facilitation (Vitevitch, 2002). There is an intricate relationship between frequency and phonological neighbourhood density (PND), where highly frequent phonological neighbours will contribute more to activation, but they might also outcompete the target word, leading to production of the wrong word, and subsequent phonological searches.
Multilingualism, ageing and the lexicon
Our vocabularies grow throughout life; we learn new words with new experiences every day. For the same reason, our mental representations of the words we know also grow stronger and richer (Jarema & Libben, 2007; Langacker, 1987; Ramscar, 2022). Simultaneous multilinguals, that is, individuals acquiring more than one language from birth, may have larger total vocabularies than monolinguals already from the very beginning (De Houwer et al., 2014; Pearson et al., 1993). Our vocabularies may increase in all our languages or only in one, depending on context and use. According to Grosjean’s Complementarity Principle, a multilingual individual will use their languages for different purposes, with different interlocutors and in different contexts (Grosjean, 1998). This principle implies that while our vocabularies never stop growing, multilinguals will not know the ‘same’ words in all their languages.
However, while we may use our languages in different contexts, and while patterns of language use may change over time, evidence from experimental psycholinguistics and neurolinguistics indicates that all the languages we know are always active (de Groot & Starreveld, 2015; Libben & Goral, 2015; Misra et al., 2012; Sebastian et al., 2011). Hence, language choice is a matter of inhibiting irrelevant languages (Abutalebi & Green, 2007). It has been suggested that the added mental load of this inhibition and switching between languages gives multilinguals a cognitive advantage, one that may delay symptoms of dementia (cf. Vega-Mendoza et al., 2019). This claim has been an object of debate for over a decade (see e.g., Paap et al., 2024).
While our lexicons expand with age, processing slows down (Salthouse, 1996). Both factors mean retrieving the right word gets harder with age (Connor et al., 2004; Nicholas et al., 1985), and tip-of-the-tongue phenomena become more common (Burke et al., 1991). Furthermore, the vocabulary becomes not only larger with age, but also richer in imagery (Simonsen et al., 2013; Wingfield & Stine-Morrow, 2000).
Seeing the multilingual mental lexicon as integrated (Dijkstra et al., 2019; Libben & Goral, 2015) and assuming complementary use of multiple languages, multilingual individuals will use each of the words they know less often than a monolingual. With larger vocabularies, multilinguals may exhibit slower access particularly to infrequent words (Gollan & Silverberg, 2001). The larger the vocabulary, the more competitors are possibly activated and need to be inhibited to find the target word (Abutalebi & Green, 2007). Words with similar forms and meanings across languages, so-called cognates, tend to be easier to access, possibly because these representations are perceived as so similar that they entrench each other (de Groot & Nas, 1991; Peeters et al., 2013).
Word-finding problems in dementia
Most of the research on lexical retrieval among individuals living with dementia has been conducted on monolinguals, and most studies on multilingual language processing has focused on younger and neurologically healthy adults. The few existing studies on multilingualism and ageing suggest that elderly multilinguals encounter similar problems as monolinguals, although more complex, as changes due to ageing interact with changes in the use of and proficiency in each language (Lerman & Obler, 2017). While older adults exhibit reduced processing capacity and executive control, this effect may be counterbalanced by a ‘bilingual advantage’ in executive control, suggested to stem from the cognitive exercise of inhibiting and switching between languages (Bak et al., 2014; Bialystok et al., 2004, 2006; Bialystok & Sullivan, 2017).
All types of dementia cause memory deficits, although the manifestations vary between types. In Alzheimer’s disease (AD), we commonly see progressive decline of episodic and working memory from the beginning (Manchon et al., 2015), whereas persons with primary progressive aphasia (PPA) show memory deficits only at a later stage (Gorno-Tempini et al., 2011). When it comes to language, word-finding problems is a common and early symptom of both AD (Chen et al., 2001; Nicholas et al., 1996; Salmon et al., 1999) and PPA, particularly the logopenic subtype (Gorno-Tempini et al., 2011; Kempler & Goral, 2008).
For multilinguals with dementia, some of their languages may be relatively spared: Some studies report the first language as better preserved (Ardila & Ramos, 2008; Mendez et al., 1999), others have reported little difference between the languages (Costa et al., 2012; Manchon et al., 2015), while yet others have reported larger deficits in the dominant language, possibly connected to deficits in effortful retrieval (Gollan et al., 2010). Given that word frequency plays an important role for lexical activation, and we are likely to know many low-frequency words in a dominant language, but few in a non-dominant language, retrieval deficits may not be as evident in the non-dominant language (Ivanova et al., 2014). A study by Lind et al. (2018) followed ‘JJ’, a 69-year-old American English/Norwegian person with PPA, over 18 months. They reported lower performance in word retrieval in his L2 than in his L1, but the difference diminished as the disease progressed.
There is little research on how word-finding problems in individuals living with dementia are handled in conversations, but the above-mentioned ‘JJ’ is presented in two case studies of retrieval problems and word searches in connected speech (Lind et al., 2018; Svennevig & Lind, 2016). These studies show that he displayed different types of problems and used different remedial strategies in English, his L1 and Norwegian, his L2. He frequently managed to overcome word-finding problems in his L1 through a variety of word-search strategies.
Conversation analysis provides a framework to study such strategies and the role they play in communication. Broadly, a word search sequence starts by a speaker displaying problems in continuing or completing an ongoing turn at talk. This may be indexed by intra-turn pauses and by speech perturbations such as hesitation markers (uh) and sound stretches (Schegloff et al., 1977), allowing the participant to hold their turn longer. There may also be embodied displays of trouble, for instance, involving gaze (Goodwin & Goodwin, 1986). Speakers may also provide verbal indications that a word search activity is in course (e.g., ‘what’s it called’) or initiate a phonetic or semantic search (Landmark et al., 2024). As such, analyses of word-search sequences carry information that could increase our understanding of lexical processing, particularly when seen in relation to word-finding problems.
This study
In this paper, we combine a usage-based and a conversation analytic approach to investigate word-finding problems in multilingual speakers with dementia. We study a picture-based naming task carried out across languages. Naming scores as well as occurrences of word-search sequences are used as indicators of word difficulty, to allow investigating lexical retrieval as a gradient. We analyse the results across languages before concentrating on the role of lexical properties on word retrieval in Norwegian, an L2 to all participants.
We ask the following research questions:
How do the participants perform in naming tasks across their languages?
Focusing on English and Norwegian, how often do they employ word search strategies in their responses?
Which lexical properties can account for participants’ word finding and word searching?
Methods
Participants
The participants were seven individuals diagnosed with mild to moderate dementia, recruited through a hospital memory clinic, home nursing care services and day care centres: ‘Sven’, ‘Koki’, ‘Gabriel’, ‘Ali’, ‘Rey’, ‘Laura’ and ‘JJ’. All had acquired Norwegian in their late teens or during their twenties. Their age, language background and diagnosis are outlined in Table 1 below. All seven participants are described in the studies by Svennevig et al. (2019) and Landmark et al. (2024). JJ has also been presented in the studies by Svennevig and Lind (2016), Lind et al. (2018) and Malcolm et al. (2019). Diagnosis, subclassification and severity based on the Clinical Dementia Rating Scale (Morris, 1997) were gathered from the national registry NorCog (Medbøen et al., 2022) or given straight from the hospital.
Age, language background and diagnosis for the seven participants (non-assessed languages in parentheses, self-reported strongest language in bold).

Note. AD: Alzheimer’s disease; PPA: primary progressive aphasia.
All participants lived at home. Data collection was carried out here, in a day care centre or at the University of Oslo. JJ and Laura had grown up as monolingual English speakers, while the others had acquired multiple languages either from birth as simultaneous bilinguals (Sven, Koki and Gabriel) or successively from early school years (Ali and Rey). Their self-identified dominant language is marked in bold text in Table 1.
Contact with healthcare providers occurred in Norwegian, in which Ali, JJ and Laura were highly intelligible, with a native-like accent, few morphosyntactic errors and no apparent speech problems. Koki also had a native-like accent and no apparent speech problems, but frequently made morphosyntactic errors. Rey and Gabriel had stronger non-native accents. Sven’s productions when communicating with Norwegian speakers appeared as a mixture of Norwegian and Swedish, both in pronunciation and morphosyntax. Rey and Sven suffered from dysarthria and/or apraxia of speech, and Sven furthermore had general motoric problems, and a slow and monotonous speech, with long hesitations.
Cognitive assessment
The participants completed a set of cognitive tests, including the Rowland Universal Dementia Assessment Scale (RUDAS; Storey et al., 2004), the Flanker test (Eriksen & Eriksen, 1974) and the Pyramids and Palm Trees (PYPAT; Howard & Patterson, 1992). This assessment was carried out in a language that the participants were highly fluent in: Norwegian for Sven; Japanese for Koki; Norwegian for Ali; and English for Rey, Laura, JJ and Gabriel. In RUDAS, the maximum score is 30, with a cut-off at 23 for neurotypical individuals. As shown in Table 2, Rey, Ali and Laura scored at or above this point, whereas Gabriel, Sven, Koki and JJ scored below. Sven’s low score can partly be explained by motoric problems, as the tool includes a figure-copying task as well as hand movements.
Cognitive test results for the seven participants.
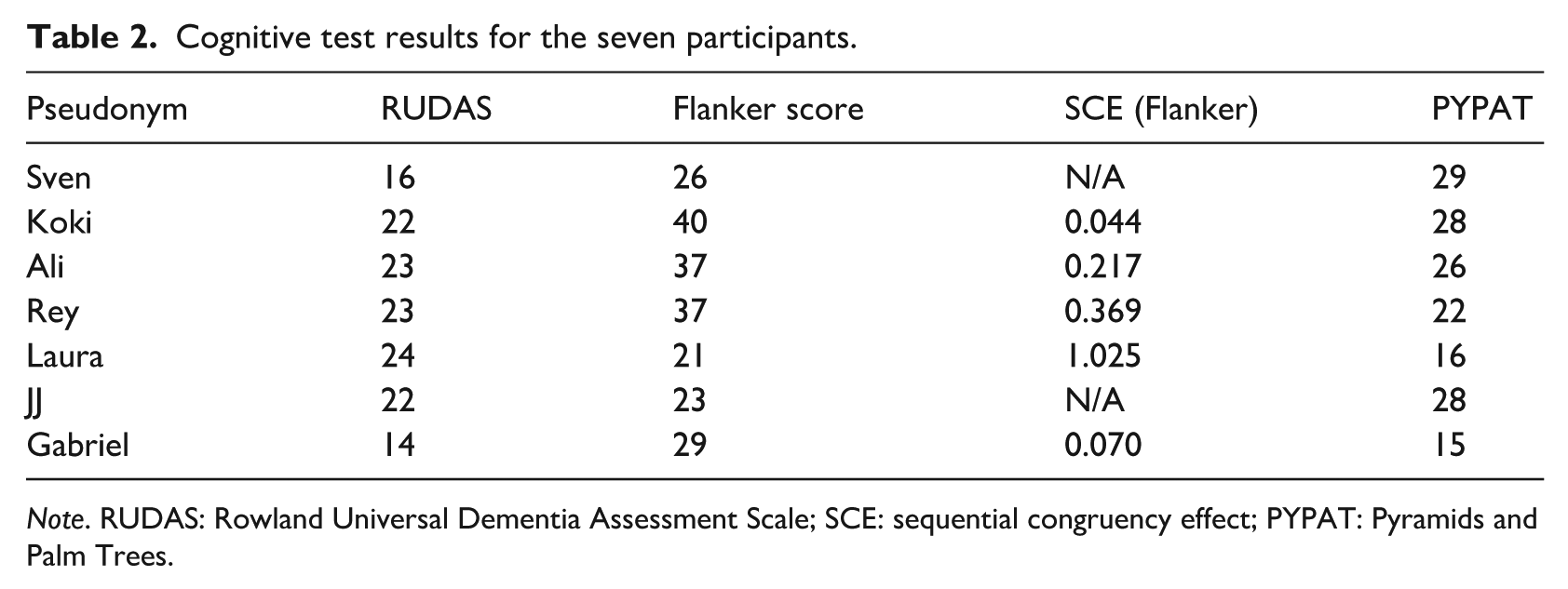
Note. RUDAS: Rowland Universal Dementia Assessment Scale; SCE: sequential congruency effect; PYPAT: Pyramids and Palm Trees.
The Flanker task (Eriksen & Eriksen, 1974) measures inhibitory control. In addition, the sequential congruency effect (SCE), that is, the relative cost of shifting between conditions, can be calculated as a measure of attention (Grundy et al., 2017). A high raw score (max = 40) indicates high control, a low SCE number indicates little shifting cost. Table 2 shows both the raw score and the SCE score. Koki had a perfect Flanker score and the lowest SCE, indicating stronger inhibitory and attention skills. For Sven and JJ, SCE could not be calculated.
The PYPAT (Howard & Patterson, 1992) assesses semantic comprehension by asking the participant to indicate which one of two pictures best matches a third. For instance, in the task giving name to the test, they are asked to indicate if the best match for a pyramid is a pine tree (wrong answer) or a palm tree (correct answer). Preparing for the current project, we carried out a PYPAT pilot on three neurologically healthy migrants to Norway with a non-Western background to identify pairings that rest so strongly on Western cultural cues that they do not translate well to non-Western migrants to Norway. Through this pilot, we excluded 18 tasks, leaving a subset of 34 tasks. The maximum score is hence 34, and Sven was closest with 29. Gabriel and Laura scored at chance level, with 15 and 16 points, respectively.
Naming test
The participants completed a 62-item naming task shown on a computer screen: 31 drawings of objects from the Norwegian version of Psycholinguistic Assessments of Language Processing in Aphasia (PALPA; Kay et al., 1996), and 31 drawings of actions from the Norwegian Verb- and Sentence Test (VOST [Verb- og setningstesten]; Bastiaanse et al., 2006; see Figure 1). We asked the participants to complete the naming tasks in every language in active use, with at least a week between languages. An interpreter or a researcher speaking the given language leads the test session. Due to interpreter unavailability, some languages could not be assessed (Creole for Gabriel, Urdu for Ali). Experimenters were instructed to not give feedback on accuracy, but to remind the participant to answer in the target language if they named several items in a row in a non-target language. The test sessions were recorded (audio or video). The responses were analysed from a psycholinguistic as well as a conversation analytical perspective.
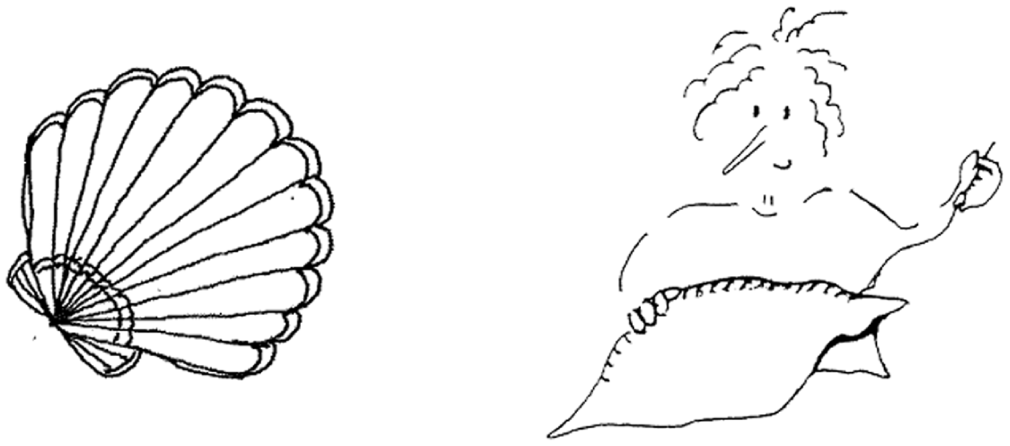
Examples from the naming task, for the target words shell from PALPA and sew from VOST.
Psycholinguistic analysis
The first author scored responses by the categories in Table 3. Synonyms and hyponyms were scored as correct if judged as appropriate for the pictures, while hypernyms were scored as semantic errors. This scoring was carried out in all the languages tested, with help from native speakers for Finnish, Japanese and Tamil.
Scoring system for psycholinguistic analysis.

For Norwegian, the language of the society and the primary focus of this paper, the following psycholinguistic properties were obtained from the online database Norwegian Words (Lind et al., 2015): frequency, imageability and age of acquisition. As outlined in the introduction, these are known to influence word retrieval. While the frequency data (listed as occurrences per million) stem from the NoWaC corpus (Guevara, 2010), the data on imageability and age of acquisition were assessed through online surveys by Lind et al. (2015). In addition to these measures, a frequency-weighted measure of PND based on Luce and Pisoni (1998) was established for this paper and subsequently added to the database. Finally, we used data on cognateness, calculated by phonological Levenshtein distance, from the study by Strangmann et al. (2023).
Two different thresholds for scoring the naming results were used, following the study by Hansen et al. (2017): For the presentation of the participants’ performance and investigations of the relationship between searching and retrieval, a soft scoring regime was used, where synonyms or hyponyms that appropriately described the picture in the language tested, were considered correct responses. In analyses of the effects of lexical factors on retrieval, we are interested in properties of the target words. Hence, only responses including the stem of the target word were considered correct responses within this stricter scoring regime.
Conversation analysis
Drawing on a body of previous conversation analytic research describing characteristics of word search sequences (cf. Goodwin & Goodwin, 1986; Greer, 2013; Hayashi, 2003; Kurhila, 2006; Laakso & Klippi, 1999; Oelschlaeger, 1999; Schegloff et al., 1977; Svennevig & Lind, 2016), together with qualitative analysis of the current dataset, a two-step coding scheme was developed and applied to (1) identify all instances of word-searching and (2) identify and describe the variety of word-search strategies used by the participants during these word-search sequences (see Landmark et al., 2024). For step one (the focus of this study), instances where the participant did not produce an immediate response, but instead initiated a word search, for example, with hesitation, filled pauses or other vocal, verbal or embodied search markers, were coded as a word search. The coding scheme was inductively developed by the second author in collaboration with the first author, taking a bottom-up approach (Stivers, 2015), and coded by a research assistant. Inter-rater reliability measures were not conducted, but cases of doubt were discussed until consensus was reached. Instances with a pause without any other search marker were not coded as searches, as it was not always clear from the recording exactly when the experimenter continued to the next test item.
The following extract is an example of a sequence coded as a word search (cf. Jefferson (2004) for transcript conventions). It is drawn from Laura’s (L) naming session with the experimenter (T2), where the target word is the verb ‘sew’ in Norwegian (sy):
Example word-search: Laura (NO VOST) sy ‘sew’
The search is initiated with a cut-off (marked with (-)), and two pauses, before Laura restarts with a series of phonetic searches, first with a prolonged ‘s::’ before a new attempt, where the vowel ‘o’ is added (‘s:::o’), perhaps projecting the English word ‘sew’, and thus constituting a code-switch. Finally, Laura self-corrects this, and after yet another phonetic search (‘e: s:’), Laura succeeds in producing a complete answer in the target language, although with a slight deviation from the target pronunciation ( ‘hun syer’ rather than ‘hun syr’). Further in-depth analyses of the variety of word-search strategies used can be found in the companion study Landmark et al. (2024).
Statistical analyses
Chi-square tests were used to explore relationships between our two outcome variables (naming score and word search) and word class. For the other lexical factors, Wilcoxon tests were employed. Statistical analyses were carried out in R 4.2.3 (R Core Team, 2023) using RStudio 2023.09.1 (RStudio Team, 2023). Lexical factors that inherently follow a logarithmic (frequency, AoA, PND) or exponential (imageability) distribution were transformed to yield more linear scales.
The lexical factors investigated here are known to be associated with each other, potentially posing challenges for analyses as well as interpretations. Before carrying out the statistical analyses for our third research question, we hence analysed the relationships between properties, identifying significant, yet not strong relationships between them. The nouns were more frequent (W = 17.573, p = .006), more imageable (W = 36.858, p < .001) and acquired earlier than the verbs (W = 13.141, p < .001), residing in denser phonological neighbourhoods (W = 18.049, p = .021), according to Wilcoxon tests. There was no word class difference in cognateness (p = .8). Only weak and medium correlations were found between the four continuous variables, for which Spearman’s correlations are given in Table 4.
Spearman’s correlations between frequency, imageability, age of acquisition, phonological neighbourhood density and cognateness (n.s. = not significant).
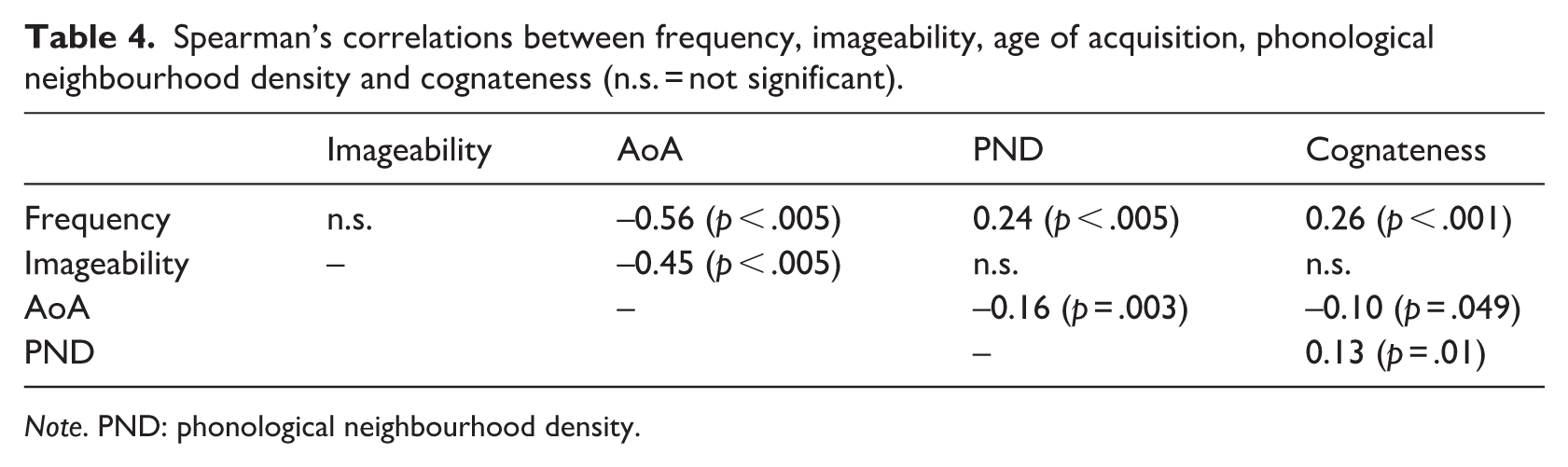
Note. PND: phonological neighbourhood density.
Ethical considerations
The study was endorsed by the municipality and approved by the Norwegian Centre for Research Data, the Regional Committee for Medical and Health Research Ethics and the hospital’s data protection officer. Participants and interlocutors received oral and written information and signed a written consent. To ensure that participation was informed and voluntary throughout the study, we re-obtained oral informed consent prior to every data collection session. Data were stored and processed on the TSD service, operated and developed by the TSD service group at the University of Oslo’s IT department (USIT). As some of our participants belong to very small minorities in Norway, we have omitted details of their educational and occupational histories in this paper, along with details about Gabriel’s Creole, which would identify his ethnicity.
Results
Naming results across languages
All participants had high naming scores in their self-identified dominant language, with the exception of Ali, who scored slightly better in English (53%) than in Norwegian (47%). Gabriel’s English (52%) and Norwegian (45%) scores were similar to Ali’s, whereas Rey displayed a slightly larger difference between his English (61%) and Norwegian (41%) scores. Sven spent a long time, due to his apraxia, but scored higher than anyone else in English (89%) – and even higher in his L1 Finland Swedish (92%). He scored somewhat lower in German (60%), Finnish (58%) and Norwegian (42%). Koki scored high in Japanese (87%), somewhat lower in English (73%) and on group average in Norwegian (50%). Laura scored second highest in English (84%), with JJ a bit behind (68%), while these two received the fewest points in the group in Norwegian (19% for Laura, 32% for JJ). Laura had also used French in her career, and her score here falls between her two other languages (45%).
As discussed in the study by Svennevig et al. (2019), the participants frequently involved other languages than the target language. JJ and Laura used English frequently in their Norwegian test session, and ended at 53% and 32%, respectively, if given credit for these responses. Similarly, Sven relied heavily on Swedish in his Norwegian test session, arriving at 69% if credited for correct Swedish language responses in this test session. A more qualitative discussion of the participants’ naming performance can be found in the study by Landmark et al. (2024).
The scores for English and Norwegian, the two languages all participants had in common, are shown in Figure 2. Interestingly, they all scored higher in English than in the majority language Norwegian, whether it was their first, second or third language.
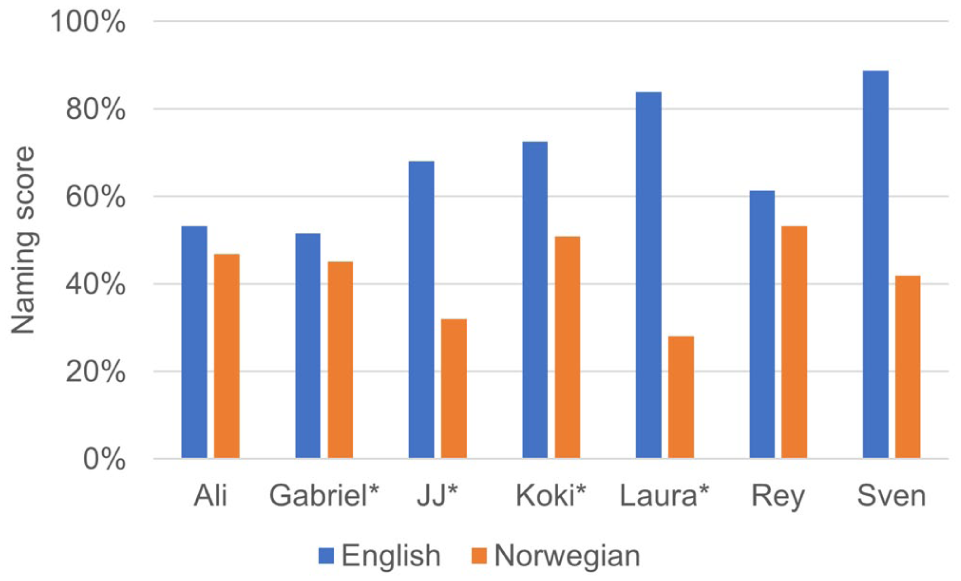
Naming scores in percentages for English and Norwegian (English L1 speakers marked with *).
Prevalence of word-search strategies
While the participants’ scores were consistently higher in English than in Norwegian, we found no clear pattern in the prevalence of search strategies (see Figure 3). For Ali, Gabriel and JJ, there was little difference between the languages. Koki, Rey and Sven searched more in English, while Laura searched more in Norwegian. Comparing Figures 2 and 3, Laura differs from the others by searching the most in the language with the lowest score.
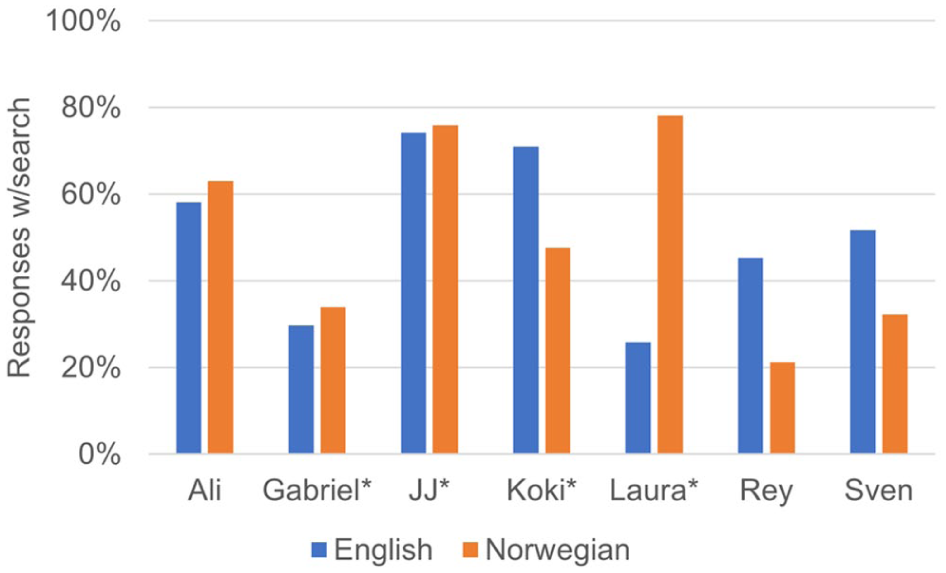
Percentages of responses with a search sequence, for English and Norwegian (English L1 speakers marked with *).
On a group level, the participants searched for words in 51% of their English responses and 50% of their Norwegian responses. Among the 222 times strategies were involved in the search for an English target word, only 50% were successful. In contrast, the target word was retrieved in 83% of the responses involving no search. In Norwegian, the participants scored correctly in 39% of the cases involving a word search, and in 72% of the cases without a search. It might thus look as if searching for a word is unhelpful. However, it is relevant to take word difficulty into account, as we do in the next subsection.
Word properties, word-search and retrieval
Concentrating on the role of lexical properties on word retrieval in Norwegian, we found that word searches occurred more often when the target was a verb (63%) than when it was a noun (36%). This word class difference was significant (χ2(1) = 27.46, p < .001). The words eliciting searches were furthermore less imageable than those that did not (Mdnsearch = 653, Mdnnosearch = 804, W = 25.404, p < .001). They were also acquired later in life (Mdnsearch = 1.41, Mdnnosearch = 1.20, W = 15.170, p = .004). There was no significant difference in frequency (p = .474), PND (p = .47) or cognateness (p = .08) between words eliciting a search and words that did not.
Turning to words successfully retrieved, we found similar patterns. While 50% of the nouns were successfully retrieved, the same was true for only 39% of the verbs. This word class difference was significant (χ2(1) = 4.98, p = .02). The words successfully retrieved were more frequent (Mdnretrieved = 3.0, Mdnnotretrieved = 2.2, W = 13.736, p < .001), more imageable (Mdnretrieved = 800, Mdnnotretrieved = 670, W = 16.386, p < .001), acquired earlier (Mdnretrieved = 1.44, Mdnnotretrieved = 1.63, W = 25.938, p < .001) and had a higher cognateness (Mdnretrieved = 0.25, Mdnnotretrieved = 0.17, W = 11.954, p < .001). There was no significant difference in PND (p = .795).
Discussion
This paper set out to combine conversation analysis and psycholinguistics to study word retrieval and word-search sequences in a naming test. We were interested in the performance across languages, and in connections between scores and word searches. Finally, we investigated relationships between these two measures and a set of lexical variables. Below, we will summarise and discuss our results before turning to theoretical and clinical implications.
Concerning word retrieval, the participants scored highest in their self-identified dominant language, except Ali, who saw Norwegian as his strongest, but still scored higher in English. Unfortunately, we were unable to test Ali in his L1 Urdu. All seven participants scored higher in English than in the majority language Norwegian, even if most had used Norwegian as their main work language for most of their lives.
Moving over to word searching, Koki, Rey and Sven searched more in English, while Laura searched more in Norwegian and Ali, Gabriel and JJ were balanced. On a group level, word searches were evenly distributed between the languages, but notably more successful in English than in Norwegian. Word-search strategies were employed half the time – in both English and Norwegian. Word searches were negatively associated with word finding: The chances of retrieving a target word were higher when no search strategy was employed, indicating that when a word is easy to find, there is no need for a search. We uncovered more searches for the harder words – verbs, low-imageability words, words acquired later in life. A natural interpretation is that our participants employed word-search strategies when needed, and that their scores would have been lower if they had not done so. As further explored and discussed in the study by Landmark et al. (2024), it appears that both the amount of searching and the strategies employed matter for their word-retrieval success.
Diving into lexical properties for Norwegian uncovered interesting patterns: Word searches were more likely for verbs than for nouns and more likely, the lower the imageability, higher the age of acquisition. Hence, the participants tended to use search strategies for words with properties reported to make them harder according to the literature – and according to our findings on retrieval, where word class, imageability and age of acquisition were significant predictors of success. Other lexical factors were associated with target word retrieval, but not with word searches: Frequency and cognateness appeared to facilitate retrieval without searching. Both these factors are assumed to lead to entrenchment and thereby better word retrieval within a usage-based framework (Bybee, 2010; de Groot & Nas, 1991). Below, we will discuss implications of these results from a usage-based and a conversation analytical approach.
The relationship between cognition, multilingualism and word retrieval is complex. We found no clear link between naming scores and degree of cognitive decline, as measured by RUDAS, Flanker score, SCE and PYPAT. To exemplify, Sven scored higher than any of the others in two of his five languages, while scoring low on the cognitive tasks, but high on the semantically oriented PYPAT. Laura, who was just behind Sven in English (her L1), was the only one to score above cut-off on RUDAS, but she scored lower than any of the others on Flanker and at chance level on PYPAT. While this picture seems chaotic, the results combined may provide a useful profile of the individuals: Sven can evoke both the semantic and phonological form of the words he is aiming to produce; he requires time to surpass his motoric difficulties, utilising that time to activate his target words. With his Finland Swedish background, Sven was the participant with the L1 most closely related to Norwegian. As we discuss in more detail in the study by Svennevig et al. (2019), there was a substantial Swedish influence in his Norwegian language production lowering his naming score. His spouse reported him to previously separate clearly between the two languages, so the mixing might be related to issues with inhibition or switching indicated by his low scores on RUDAS and Flanker. Laura appears to struggle with inhibition and attention as well as on a semantic level but compensates with strong English skills. As such, our study reveals substantial variability within participants with the same diagnosis, contrasting with an understanding of dementia where the main linguistic issues are related to deteriorated semantic representations.
Theoretical implications
The novel combination of usage-based theory and conversation analysis allows for new theoretical perspectives into the process of word retrieval. From a usage-based point of view, the facilitatory effects of the words’ age of acquisition, frequency and cognateness on word retrieval can be attributed to properties of the mental lexicon: We assume usage-related factors to strengthen representations, and as such, facilitate retrieval. Incorporating conversation analytical insights allows for a more nuanced approach to retrieval, by also looking at how the participants work towards a response instead of focusing on the end point.
A more nuanced approach could give us new insights into lexical processing. Can we distinguish between words that are quickly and easily accessed and words that are retrieved, but often require some extent of searching? Highly imageable and early acquired, but infrequent nouns could be potential examples of the latter, as they are easy to grasp on a conceptual level and have many connection lines to other words, yet they might be hard to retrieve directly due to their low frequency of use. Looking at word finding and word searching in context, this is precisely what we find.
Drawing on insights from conversation analysis to usage-based theory, the study findings may suggest viewing word retrieval as a four-way gradient in a psycho-conversational model, as illustrated in Figure 4: Direct retrieval (no search), retrieval after search, unsuccessful search and finally no attempt (treating searching as futile). It may thus be more appropriate to see word retrieval as a gradual and situated phenomenon than as an either-or categorical property, as traditional in psycholinguistic approaches. In other words, it is not simply a matter of access, but a ‘process’ of retrieval.
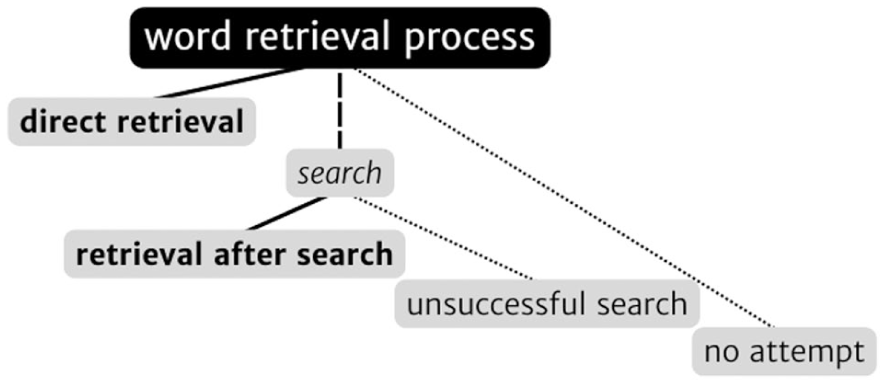
A psycho-conversational model of word retrieval as a four-way gradient, with lines and vertical alignment reflecting degree of lexical access.
The study may also offer insights from usage-based to conversation analytic perspectives: Word search instances do not happen at random; properties of the target words influence whether a search is necessary. Specifically, it can be useful to know that they are more likely when the target word is a verb, a word acquired late in life or a word denoting a concept that is hard to imagine, as found in this paper. Finally, the study findings suggest fruitful empirical and theoretical promise in further endeavours of true interdisciplinarity approaches across established theoretical boundaries.
Clinical implications
One clinical implication from this paper is to look beyond the majority language in multilingual ageing populations. All our participants were stronger in English than in Norwegian despite many years of contact with Norwegian. Self-reports did not always tally with our naming results. Hence, relying on self-reports or testing only the majority language would yield a partial picture and underestimate the participants’ language knowledge. Moreover, with an increasingly diverse ageing population in many Western countries, elderly care may profit from a more inclusive language policy welcoming all shared languages.
Limitations and future directions
This study has a small n, weakening the generalisability of the findings. The diversity in terms of language backgrounds is a strength and a weakness. It gives breadth, reflecting the multilingual ageing population, but complicates assessment and direct comparisons. We have been intentionally vague on details such as education, profession, and for Gabriel also the exact Creol language he spoke, in the interest of confidentiality. While none of these properties are directly identifiable, they could identify some of our participants overall. However, we see that withholding this information limits the generalisability of our results, and makes us unable to address factors that could constitute confounding effects, such as the relationship between education and risk of dementia.
Further studies could explore word-finding difficulties and word searching in other contexts, for instance, everyday conversations. Moreover, while this paper reports on connections between psycholinguistic properties and the ‘presence’ of a search, it would be interesting to look deeper into the word search sequences unfolding in a naming test setting. Our companion study by Landmark et al. (2024) takes steps in these directions.
Conclusion
This paper reports on scores and word searches from a naming task carried out with seven multilingual individuals with dementia. The participants searched less and scored higher when the target word was a noun than when it was a verb. The same was found for words with high imageability and low age of acquisition. High frequency and cognateness were associated with high scores, but not with the prevalence of searches. The participants scored higher in English than in the majority language, Norwegian.
Investigating word searches and word finding in union was possible by combining psycholinguistic and conversation analytical frameworks. This endeavour allowed for a nuanced understanding of the mental and interactional accomplishment of word retrieval seen as gradual and situated rather than a binary question of access. Although research has so far focused on either the path or the endpoint, we believe that the phenomenon in question can be best understood by taking in the full picture.
Footnotes
Acknowledgements
The authors are deeply indebted to the participants taking part in the study. We also want to thank Aafke Diepeveen, Maria Njølstad Vonen, Malene Bøyum and André Nilsson Dannevig for research assistance, and all the others who have contributed as interpreters, or facilitated recruitment and data collection. Ingeborg Sophie Bjønnes Ribu led the data collection from JJ and made highly valuable contributions to our research design, including the piloting of PYPAT on non-Western participants. We want to acknowledge the Norwegian registry of persons assessed for cognitive symptoms (NorCog) and Anne-Brita Knapskog for providing access to patient data. The bridging of disciplines was inspired by Marianne Lind, who also gave crucial contributions to the project that this paper emerged from.
Ethical Considerations
The study was endorsed by the municipality in which it took place, and approved by the Norwegian Centre for Research Data, the Regional Committee for Medical and Health Research Ethics and the hospital’s data protection officer.
Consent to participate
Participants and interlocutors received oral and written information and signed a written consent. As the primary participants were living with dementia and could not necessarily remember us or their consent between sessions, we ensured that participation was informed and voluntary throughout the study by re-obtaining oral informed consent to participate prior to every data collection session, before starting any audio or video recording. Data were stored and processed on the TSD service, operated and developed by the TSD service group at the University of Oslo’s IT department (USIT), a solution approved for sensitive data.
Consent for publication
Written informed consent for publication was provided by the participant. The information letter and consent form from the project are submitted as an attachment.
Author contributions
P.B.H. had the idea for the scope and structure of the paper, led the work with the manuscript, contributed to the recruitment of participants, tested six of the participants in one language, recruited and instructed interpreters or researchers carrying out testing in other languages and managed the technical solutions for recording, storing and processing of data from the project. She also suggested the psycholinguistic scoring system and processed and scored the data according to this system. A.M.D.L. took part in the decisions of scope and structure and all stages of the writing process and contributed to the recruitment. She co-designed the data collection protocols for six of the participants together with P.B.H. She furthermore planned the conversation analytical data scoring, trained research assistants in coding, oversaw the work and resolved issues together with the assistants. P.B.H. and A.M.D.L. designed the model outlined in the paper. H.G.S. was in the leadership group of the MultiLing Dementia project, which this paper was a part of, contributing to securing the funding and to the overall design. She took part in the development of the psycholinguistic part of the project, and also carried out testing in one language in all seven participants. She made decisions on data collection, coding and framing, and also wrote several sections in the introduction and discussion along with P.B.H. J.S. led the MultiLing Dementia project and took leadership in the overall design and formal steps regarding ethics, storage and recruitment. He also took part in the recruitment, the discussions on analyses and the writing process. All authors approved the manuscript before submission.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partly supported by the Research Council of Norway through its Centres of Excellence funding scheme (project number 223265 and project number 250093).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Recordings, transcriptions and scores are stored on the TSD service provided by the University of Oslo’s IT department (USIT). Due to their nature, these cannot be shared openly, but it is possible for other researchers to apply for ethical approval to use the data for future research.