
Abstract
Aims and objectives:
Masked priming lexical decision research involving relatively high-proficient Japanese–English bilinguals suggests that past-tense and present-tense morphological connections (e.g., fell-FALL and looked-LOOK) are represented in their L2 (English) lexicons in a way that is similar to how they are represented in L1 (English) lexicons. The goal of the present research was to determine whether the same is true for low-proficient Japanese–English bilinguals.
Methodology:
Seventy-seven low-proficient Japanese–English bilinguals were tested in the masked priming lexical decision task. We manipulated the morphological or orthographic similarity between L2 English prime-target pairs.
Data and analysis:
We analyzed response latencies and error rates using (generalized) linear mixed-effects models.
Findings:
Although participants responded significantly faster to targets preceded by past-tense primes (e.g., fell-FALL and looked-LOOK) when compared to unrelated primes (e.g., slow-FALL and danger-LOOK), those priming effects were the same size as priming effects produced by orthographically similar primes (e.g., fill-FALL and lonely-LOOK), suggesting that the facilitation from past-tense primes is likely orthographic in nature. Nevertheless, the low-proficient bilinguals showed significant L2-L2 repetition priming (e.g., fall-FALL and look-LOOK), suggesting that, for those individuals, L2 (English) words are at least represented at the lexical level.
Originality:
The present study empirically confirmed a prediction, derived from a post hoc exploratory analysis in our previous research, that masked morphological priming effects are no larger than orthographic priming effects in low-proficient bilinguals. This indicates that a certain level of functional proficiency is required to observe morphological priming effects for Japanese–English bilinguals.
Implications:
Our results suggest that morphological connections in L2 are not yet established for low-proficient bilinguals, even when L2 words are lexically represented in their mental lexicon.
Are representations of L2 words in a bilingual’s lexicon similar to those of L1 readers? Recent studies have suggested that such is not always the case. For example, L2 readers show weaker lexical competition processes than L1 readers, especially when the two languages involve different scripts (Jiang, 2021; Kida et al., 2022; Nakayama & Lupker, 2018; Qiao & Forster, 2017; Wanner-Kawahara et al., 2022). On the other hand, other aspects of L2 representations do appear to be similar to those in L1. For instance, Wanner-Kawahara et al. (2022) found that past-tense inflectional morphological connections in L2—the focus of this article—are similar to those of L1 readers, at least for proficient Japanese–English bilinguals.
Representations in the mental lexicon have often been examined using masked priming lexical decision experiments (Forster & Davis, 1984). In those experiments testing L1 English readers, present-tense verb targets were responded to faster when primed by their past-tense verb form than by unrelated word primes (e.g., kept-KEEP, boiled-BOIL < shoe-KEEP, jump-BOIL, Forster et al., 1987; Silva & Clahsen, 2008) or orthographic controls (e.g., kept-KEEP, boiled-BOIL < keen-KEEP, billion-BILL, Crepaldi et al., 2010; Pastizzo & Feldman, 2002). These priming effects are presumed to reflect connections between the prime and target word representations within the lexicon—a morphological connection in this case. Studies have also shown that priming effects from past-tense primes can be as large as those from repetition primes (e.g., kept-KEEP, boiled-BOIL = keep-KEEP, boil-BOIL < shoe-KEEP, jump-BOIL, Forster et al., 1987; Silva & Clahsen, 2008, but see Morris & Stockall, 2012). As prime–target pairs in a repetition priming condition presumably provide the maximal degree of priming, equivalent size priming effects with past- and present-tense verb pairs suggest a strong morphological connection in the L1 lexicon.
Masked priming lexical decision tasks that have been used to investigate whether morphological relationships in L2 parallel those in L1 have, so far, produced somewhat mixed results. Similar priming patterns for L2 and L1 readers have been observed in some situations, suggesting that morphological relationships are represented in a similar manner in the two lexicons (e.g., Feldman et al., 2010; Voga et al., 2014; Wanner-Kawahara et al., 2022). For instance, Feldman et al. (2010) showed that regular past-tense primes facilitated responses compared to unrelated and orthographically similar word primes (e.g., billed-BILL < careful-BILL; billed-BILL < billion-BILL) for Serbian–English bilinguals. On the other hand, other studies have not found parallel priming patterns (e.g., Clahsen et al., 2013; Silva & Clahsen, 2008). For example, Silva and Clahsen (2008), examining Chinese–English and German–English bilinguals, observed no priming from past-tense forms compared to unrelated primes (e.g., boiled-BOIL = jump-BOIL). This absence of facilitation was not due to the bilinguals’ inability to process the masked primes, as the same participants produced significant repetition priming (e.g., boil-BOIL < jump-BOIL). Note, however, that, using the same critical (English) stimuli as Silva and Clahsen (2008), Voga et al. (2014) did observe significant priming for Greek–English bilinguals (e.g., boiled-BOIL < jump-BOIL). Therefore, even experiments with similar designs and stimuli have yielded inconsistent results.
The present research focuses on two important factors that could have contributed to those mixed results. One factor is the type of control primes used to assess the priming effects. While some studies have used unrelated primes to measure morphological priming effects, those effects should be more appropriately evaluated by using orthographically similar primes. The reason is that orthographically similar word primes facilitate target recognition for different-script bilinguals (e.g., Jiang, 2021; Kida et al., 2022; Nakayama & Lupker, 2018; Qiao & Forster, 2017; Wanner-Kawahara et al., 2022) and past-tense primes are inevitably orthographically similar to their targets. (Note that this priming pattern is the opposite of the inhibitory effect typically found for L1 readers with word primes [Davis & Lupker, 2006; Nakayama et al., 2008; Segui & Grainger, 1990].) Therefore, when priming is measured only against unrelated primes, the high degree of orthographic similarity between past- and present-tense forms in English makes it difficult to discern whether the locus of the priming effect is morphological or orthographic for different-script bilinguals. It is thus crucial to include orthographically similar primes as a control in the relevant experiments. Nevertheless, unrelated primes should also be included as they, together with orthographic primes, establish a better picture of the locus of priming. For instance, because orthographic similarity can have an inhibitory impact not only for L1 readers but also for same-script bilinguals (Bijeljac-babic et al., 1997) when word primes are used, the estimate of facilitation from morphological primes (vs. orthographically similar primes) would be inflated and a more neutral control would help to establish that fact.
The second factor is the impact of participants’ L2 proficiency. That is, proficiency differences across experiments may have contributed to the mixed findings in the literature. Previous studies suggest that L2 proficiency often modulates the pattern of priming effects in bilinguals (e.g., Nakayama et al., 2013, 2016; but see Duyck et al., 2004) and, in fact, L2 proficiency does appear to influence morphological priming effects. For example, as noted earlier, Feldman et al. (2010) found significant morphological priming effects for past-tense prime and present-tense target pairs (e.g., billed-BILL) in their overall analysis. When the data were analyzed as a function of participants’ L2 proficiency level, however, it was found that this priming pattern held only for the high-proficiency bilinguals. Specifically, for low-proficiency bilinguals, past-tense primes did not facilitate target identification, suggesting that the development of representations for morphological relationships in the L2 lexicon may require a reasonably high level of fluency in L2. It is important to keep in mind, however, that in Feldman et al. (2010), L2 proficiency was estimated mainly based on the participant’s speed and accuracy of responding rather than using an objective, independent measure of L2 proficiency. Thus, the apparent proficiency difference may have been caused by factors other than L2 proficiency per se.
With these two issues in mind, Wanner-Kawahara et al. (2022) examined masked morphological priming effects for relatively proficient Japanese–English bilinguals. Following Feldman et al. (2010), the related stimulus pairs were regular and irregular past-tense primes and their present-tense targets (e.g., looked-LOOK, fell-FALL). Both unrelated (e.g., rather, joke) and orthographically similar primes (e.g., locker, fill) were also included. Past-tense primes, irrespective of their regularity, and orthographically similar primes facilitated responses relative to unrelated primes. Notably, the facilitation from past-tense primes was significantly larger than that from orthographically similar primes. Therefore, it was concluded that morphological connections like those of L1 English readers had developed in the participants’ L2 English lexicon.
Critically, post hoc analyses using TOEIC scores (an objective measure of L2 proficiency) revealed different priming patterns for the most and least proficient bilinguals. The most proficient bilinguals (TOEIC score = 965) showed a much larger morphological priming effect than the priming effect in the orthographically similar condition (both effects were measured relative to the unrelated condition). In contrast, the least proficient bilinguals (TOEIC score = 605) showed no significant RT difference to targets primed by morphological and orthographic primes, suggesting that, for those individuals, the facilitation from the morphological primes (using the unrelated condition as a baseline) is essentially entirely orthographic in origin. In essence, these post hoc analyses suggested that there appeared to be, at most, very weak morphological connections in the L2 English lexicon for low-proficient bilinguals: a result that is consistent with Feldman et al.’s (2010) findings.
The present research
The patterns in Wanner-Kawahara et al. (2022), including those in their post hoc analysis, were consistent with previous studies indicating that morphological connections are present in the L2 lexicon for relatively proficient bilinguals while they are not yet established (or are very weak) when L2 proficiency is low. However, this latter conclusion is based on a post hoc, exploratory analysis of an observed data pattern rather than being driven by an a priori prediction. While an exploratory data analysis aids researchers in uncovering unexpected discoveries that could lead to the generation of new hypotheses, its weakness lies in the potential for attributing explanatory power to a particular factor when the data pattern was actually generated by another factor (e.g., see Lipton, 2005; Nosek et al., 2018). Therefore, in order to evaluate our claim that L2 proficiency matters in the development of morphological connections more fully, a confirmatory test is necessary (e.g., Platt, 1964). The present study was, therefore, conducted in an attempt to confirm our conclusion, derived from Wanner-Kawahara et al.’s post hoc analysis, that morphological connections are not yet established in the L2 lexicons of low-proficient bilinguals. That conclusion will be supported if those individuals demonstrate morphological priming effects that are no larger than their orthographic priming effects.
The claim that the representations/processing of L2 morphological relationships differ between bilinguals of different L2 proficiency levels is not an uncommon one. In the declarative/procedural model of Ullman (2001), for example, L2 readers are likely to rely on rule-based morpho-syntactic processing to a lesser extent than L1 readers. As L2 readers become more proficient in their L2 with increased experience, however, they are likely to rely on this rule-based process. Similarly, in Jiang’s (2000) framework of L2 representations, L2 forms initially have no connections with their morphological or semantic representations for novice L2 readers. Such connections develop as the bilingual becomes more experienced in their L2. Although our study does not aim to provide support for any particular framework or model of L2 representations and processing, confirmation of our prediction would be consistent with a commonly held view that L2 representations and processing can develop to mimic those seen with L1 readers.
The participants in the current experiment were Japanese–English bilinguals who were substantially lower in English proficiency than those examined by Wanner-Kawahara et al. (2022). As in prior research, the critical (morphologically related) stimuli were past-tense prime and present-tense verb target pairs. Two additional prime types were also used, orthographically similar primes and repetition primes. As noted, our expectation/prediction based on the post hoc analyses in Wanner-Kawahara et al. was that our L2 readers would show a significant facilitatory orthographic priming effect (vs. unrelated primes) with that effect being the same size as that in the morphological priming condition.
Because our focal prediction was that there would be a null difference between the morphologically and orthographically related conditions, we felt it necessary to also include a repetition priming condition in the present experiment (not present in Wanner-Kawahara et al., 2022). The inclusion of this condition had two purposes. First, a significant repetition priming effect, if observed, would confirm that the low-proficient bilinguals in the present experiment can successfully process masked, briefly presented L2 primes (e.g., Gollan et al., 1997). That demonstration would be important if the reason that there was no difference between the morphological and orthographic priming conditions was that neither condition produced any priming. Second, assuming that there will be priming from both morphologically related and orthographically related primes, contrasting the priming effects in those conditions with that in the repetition priming condition would allow us to better assess the time course of the development of L2 word representations. A fairly sizable repetition priming effect is assumed to reflect lexical-level processing and is typically equal to the prime’s duration plus or minus 10 ms (e.g., Forster et al., 2003). Therefore, if a repetition priming effect of 40–60 ms is observed, we can conclude that the establishment of lexical level connections is essentially complete in our participant population even if the contrast between the morphologically related and orthographically related conditions provides no evidence that morphological connections exist.
It should be noted that the only major difference between the setup of the present study and Wanner-Kawahara et al.’s (2022) was the English proficiency level of participants (although, as described below, it was necessary to use different stimuli in the present study). Studies examining morphological priming effects in L2 typically target different populations (e.g., Chinese–English, German–English, Greek–English, Serbian–English bilinguals) with different experimental designs (e.g., with or without an orthographic control, with or without filler trials), making comparisons among their results across studies somewhat difficult (e.g., see Feldman et al., 2010; Silva & Clahsen, 2008; Voga et al., 2014). Testing the predictions derived from Wanner-Kawahara et al.’s results with a setup that is nearly identical to the one they used enabled us to draw firmer comparisons between the studies’ results concerning the effect of L2 proficiency on morphological connections in the L2 lexicon than allowed by contrasts between other pairs of studies currently in the literature.
Method
Participants
Seventy-seven low-proficient Japanese–English bilinguals were recruited from the National Institute of Technology (NIT), Sendai College (Mean age = 19, SD = 2.04). The participants spoke Japanese as their first language and started learning English at the age of 11 (SD = 2.42) on average. As in Wanner-Kawahara et al. (2022), we used the TOEIC Listening & Reading (hereafter TOEIC) score as the measure of English proficiency. 1 The participants’ mean TOEIC score was 421.82 (SD = 159.65). Therefore, the English proficiency of the participants in this study was much lower than that of Wanner-Kawahara et al.’s participants (e.g., M TOEIC score = 790.76). Participants received a 500-yen gift card (roughly equivalent to US$3.70) for their participation.
Stimuli
Items in the present experiment were newly selected to suit the vocabulary level of the low-proficient bilinguals, rather than using the same items as in Wanner-Kawahara et al. (2022). Care was taken so that the participants would be familiar with all word items, including the past-tense forms of irregular verbs, in order to properly assess the nature of connections of L2 words in their lexicon (if a stimulus word is not contained in a participant’s lexicon, its connections within that lexicon cannot be assessed). First, target verbs were selected from junior high school English textbooks in Japan. The appropriateness of each word was then assessed independently by two experienced English teachers who are familiar with the vocabulary level of the participant population. Only the words that both teachers agreed would be known by the participants in our study were included in the final stimulus set.
Following Wanner-Kawahara et al., two types of verbs (Verb Types) were used as targets: regular verbs (n = 36) and irregular verbs (n = 36). Regular verbs take the suffix “-ed” in their past-tense forms (e.g., looked-LOOK). Irregular verbs do not take the “-ed” suffix in their past-tense forms, and, for the present stimuli, their past- and present-tense forms had the same letter length (e.g., fell-FALL). Regular and irregular verbs were matched on their mean word frequencies, numbers of orthographic neighbors (Coltheart et al., 1977), and word lengths (all ps > .49). Each target was paired with four prime types: Morphological (e.g., fell, looked), Orthographic Control (e.g., fill, lonely), Unrelated (e.g., slow, danger), and Repetition (e.g., fall, look). Where possible, the primes were also junior-high-school-level words. Lexical characteristics of the stimuli are shown in Table 1.
Lexical characteristics (SD) and examples of prime–target (verb) pairs.
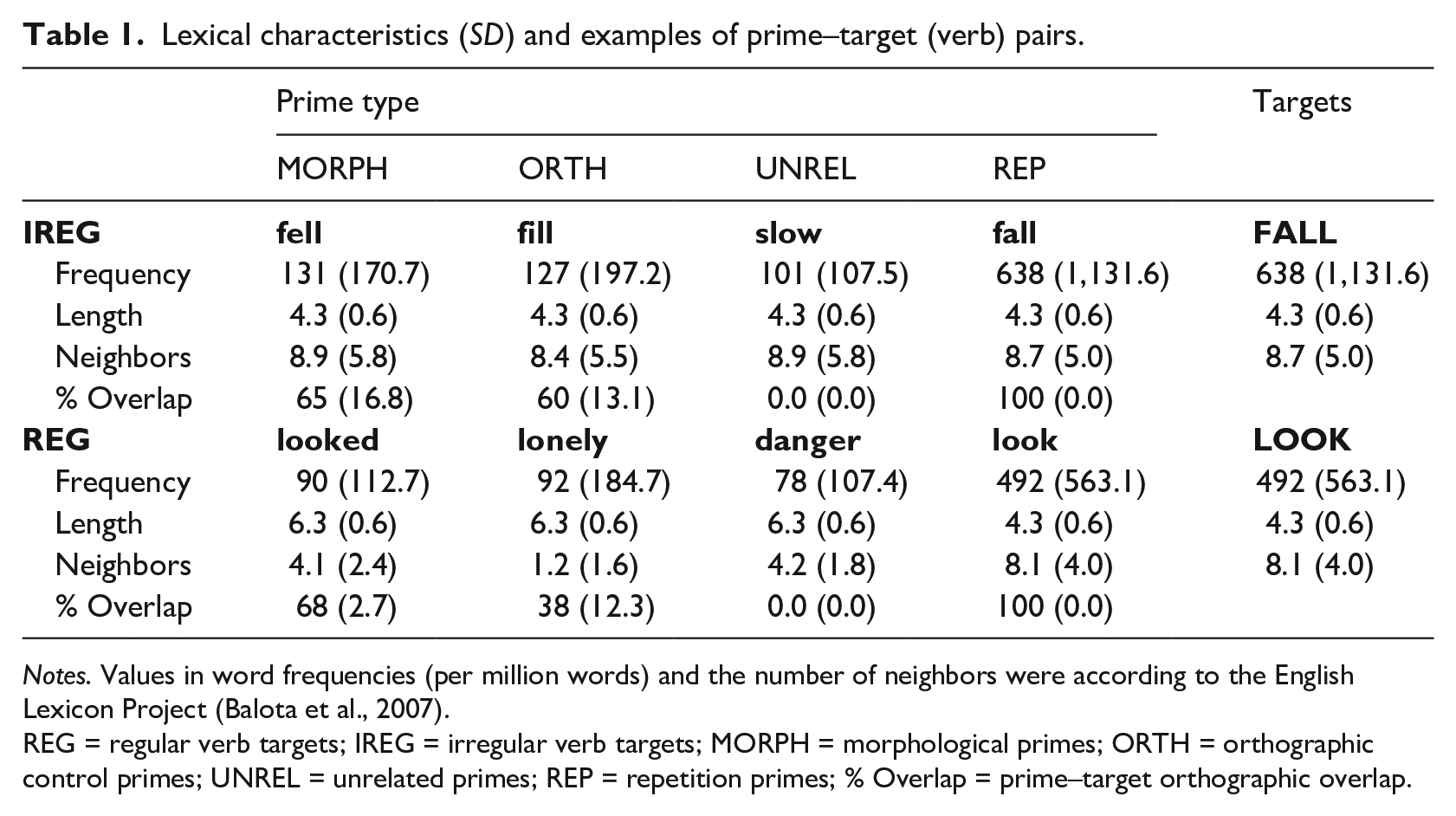
Notes. Values in word frequencies (per million words) and the number of neighbors were according to the English Lexicon Project (Balota et al., 2007).
REG = regular verb targets; IREG = irregular verb targets; MORPH = morphological primes; ORTH = orthographic control primes; UNREL = unrelated primes; REP = repetition primes; % Overlap = prime–target orthographic overlap.
For the Irregular targets, the Morphological, Orthographic, and Unrelated primes were matched on mean word frequencies (Ms = 131, 127, 101, respectively, F < 1). Repetition primes, however, had a significantly higher mean word frequency (M = 638) than the other three prime types (all ps < .05), as our target verbs were of high word frequency (as in Wanner-Kawahara et al., 2022). Across the four prime types, the mean number of neighbors (Ms = 8.86, 8.39, 8.86, 8.67, F < 1) and word lengths (Ms = all 4.25) were matched. Prime–target orthographic overlap was not statistically different between Morphological primes and Orthographic primes (Ms = 65% and 60%, t(35) = 1.13, p = .27). This measure was calculated in the same way as in Wanner-Kawahara et al. (2022): dividing the number of identical letters in the same position between prime–target pairs by the letter length of the prime and multiplying the result by 100. Unrelated primes had no orthographic overlap with their targets (M = 0%). Repetition primes had complete orthographic overlap with their targets (M = 100%).
For the Regular targets, similarly, the Morphological, Orthographic, and Unrelated primes were matched on their mean word frequencies (Ms = 90, 92, 78, respectively, F < 1). Again, repetition primes had a significantly higher mean word frequency (M = 492) than the other three prime types, all ps < .05. Morphological, Orthographic, and Unrelated primes were also matched on their mean word length (Ms = all 6.31); however, Repetition primes were inevitably shorter by two letters (i.e., they did not contain an “-ed,” M = 4.31). Reflecting the fact that shorter words tend to have more neighbors, repetition primes had a significantly larger number of neighbors (M = 8.14) than each of the other three types of primes (M = 4.14, 1.17, and 4.17, for Morphological, Orthographic, and Unrelated, respectively), all ps < .05. The mean numbers of neighbors were matched between Morphological and Unrelated primes, p > .05, but Orthographic primes had significantly fewer neighbors than Morphological and Unrelated primes, ps < .05.
As in Wanner-Kawahara et al. (2022), an effort was made to match the prime–target orthographic similarity for the morphological and orthographic conditions of the Regular verbs. However, it was also a priority that our low-proficient bilinguals would know all the stimulus words used in the experiment. As a result, it was impossible to fully equate the orthographic similarity values due to the limited vocabulary size of the participants (i.e., matching would have forced us to select words as orthographic primes that were likely unknown to our participants). In the end, the degree of prime–target orthographic overlap was significantly higher for Morphological prime–target pairs than Orthographic prime–target pairs (Ms = 68% and 38%, t(35) = 13.03, SEM = 2.28, p < .001) because the prime–target pairs in the Morphological condition shared more letters in the same position than the prime–target pairs in the Orthographic condition. As it was expected that orthographic similarity would facilitate target processing for this population of bilinguals (e.g., Nakayama & Lupker, 2018; Wanner-Kawahara et al., 2022), a further expectation would be that morphological primes would likely produce a slightly larger degree of orthographic priming than the priming effects produced in the orthographic priming condition for Regular verbs. We will return to this issue below.
Four presentation lists were created for word targets. In each list, Morphological primes, Orthographic primes, Unrelated primes, and Repetition primes were each paired with one-fourth of the targets. The pairings were counterbalanced so that across the lists, each word target was primed by all prime types, but for each participant, each target was only presented once.
Seventy-two nonword targets were also selected. These nonword targets consisted of two sets of 36 nonwords, which served as counterparts to the Irregular and Regular verb targets. Word length and numbers of neighbors were matched to those of their verb target counterparts. Within each set of nonword targets, one-quarter of the targets (n = 9) were paired with primes that mimicked the relationship in each of the word target conditions—Morphological primes and their targets (Nonword Morphological: e.g., heal-HEAK, course-COUR), Orthographic primes and their targets (Nonword Orthographic: e.g., wild-WINA, country-COGUE), Unrelated primes and their targets (Nonword Unrelated: e.g., flash-ZONET, mister-JAME), and Repetition (nonword) primes and their targets (Nonword Repetition: e.g., basp-BASP, chan-CHAN). There was only one presentation list for nonword targets, and none of the word primes preceding nonword targets was a critical stimulus.
Apparatus and procedure
DMDX (Forster & Forster, 2003) was used to control stimulus presentation, record responses, and measure latencies. The sequence and timing of stimulus presentation were identical to those of Wanner-Kawahara et al. (2022). Each trial began with a fixation cross presented for 450 ms followed by a 50 ms blank screen. Then, a forward mask (i.e., a series of # signs) matching the letter length of the prime was presented for 500 ms. A prime was then presented in lower-case letters for 50 ms. A target in upper-case letters immediately followed the prime. Participants were asked to respond as to whether the target was an English word or not as fast and accurately as possible by pressing a corresponding button on a gamepad (“YES”: word, “NO”: nonword). The target remained on the screen until a response was made or timed out after 3,000 ms. The inter-trial interval was 1,000 ms. All stimuli were presented in white 18 pt. Courier New font on a black background at the center of the screen. Thirty-two practice trials mimicking the experimental conditions preceded the critical trials and that block of trials was repeated until participants were familiar with the task. None of the critical stimuli were used in the practice trials.
After the masked priming experiment, participants completed a demographic background and vocabulary survey. In the vocabulary survey, participants were presented with a list of stimuli used in the experiment and asked to mark any words they did not know. 2 Approval for the experiments was obtained from the ethics review board for research with human subjects of the National Institute of Technology (NIT), Sendai College, and the Graduate School of International Cultural Studies, Tohoku University.
Results
Data from five participants were removed due to high error rates (>25%). Correct responses with latencies equal to or exceeding 1,500 ms were considered outliers and were removed from further analyses (0.41% of the word data). Individual trial data for specific stimuli were removed if the participant marked either the prime or the target as unknown in the vocabulary survey administered after the lexical decision task. Doing so resulted in removing 4.32% of the data for word trials. Correct responses and error data were then analyzed by (generalized) linear mixed effect (LME) models (e.g., Baayen et al., 2008) using the lme4 package (Bates et al., 2015) available in R (R Core Team, 2021). In order to calculate the p-values with the degrees of freedom based on Satterthwaite’s approximation, we used the anova function of the lmerTest package (Kuznetsova et al., 2017). Post hoc comparisons were carried out using the emmeans package (Lenth, 2022) with Tukey’s honest significant difference (HSD) adjustments when necessary. Mean response latencies and error rates are shown in Table 2. Before the analysis, Verb Type (Regular and Irregular) was contrast-coded, whereas Prime Type (Morphological, Orthographic, Unrelated, and Identity) was treatment-coded, in which the reference was set to the Unrelated condition.
Mean response latencies and (error rates) to irregular and regular verb targets as a function of prime type and priming effects.
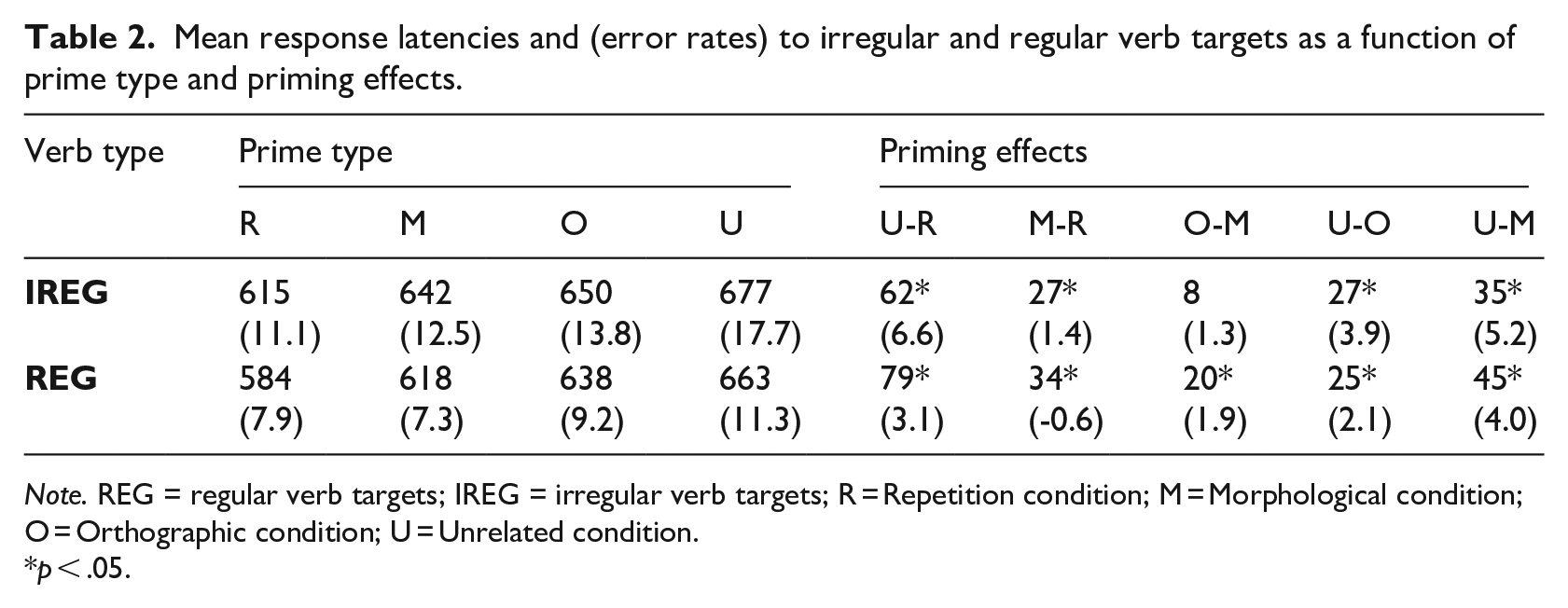
Note. REG = regular verb targets; IREG = irregular verb targets; R = Repetition condition; M = Morphological condition; O = Orthographic condition; U = Unrelated condition.
p < .05.
Response latencies
For the response latency analysis, a reciprocal inverse transformation was applied to the raw RTs (i.e., -1,000/RT; hereafter, invRT). The model used was lmer(invRT ~ Verb Type * Prime Type + (1|Subjects) + (1|Targets) as this random intercept-only model was the most complex model that converged. The main effect of Prime Type was highly significant, F(3, 4231.2) = 98.11, p < .001. The main effect of Verb Type was marginal, F(1, 69.3) = 2.94, p = .09. Numerically, regular verbs were responded to slightly faster than irregular verbs across Prime Type (M = 624 ms vs. M = 646 ms). The interaction between Verb Type and Prime Type was also marginal, F(3, 4230.9) = 2.24, p = .081.
Further analyses were conducted separately for irregular and regular verbs to examine their priming patterns more closely. For Irregular targets, the most complex model that converged was the intercept-only model: invRT ~ Prime Type + (1|Subjects) + (1|Targets). In this analysis, the main effect of Prime Type was significant, F(3, 2032.7) = 34.15, p < .001. Follow-up analyses of the significant main effect showed that, relative to the Unrelated condition (M = 677 ms), responses were significantly faster in the Morphological condition (M = 642 ms), estimated coef. = −0.10, SE = 0.02, t = −5.39, p < .001 and the Orthographic condition (M = 650 ms), estimated coef. = −0.08, SE = 0.02, t = −4.22, p < .001 (i.e., both conditions produced significant priming effects). Responses were not significantly different between Morphological and Orthographic Control conditions, estimated coef. = −0.02, SE = 0.02, t = −1.13, p = .67, indicating that the facilitation in the morphological condition was likely due to orthographic similarity. A significant repetition priming effect was also observed for irregular targets, estimated coef. = 0.18, SE = 0.02, t = 10.05, p < .001. Further, responses in the Repetition condition were significantly faster (M = 615 ms) than responses in the Morphological condition, estimated coef. = −0.08, SE = 0.02, t = 4.61, p < .001, and the Orthographic condition, estimated coef. = − 0.10, SE = 0.02, t = 5.70, p < .001.
As the crucial test concerned the (lack of a) difference between the morphological and orthographic conditions, Bayes factor (BF) analyses were carried out to further analyze this potential difference. In the analyses, we used the Bayes information criterion (BIC) to approximate BFs (Wagenmakers, 2007). Specifically, we compared the model that does not include Prime Type (Morphological vs. Orthographic; H0) and the model that does include the term (H1). The analysis showed that BF was 0.0010, favoring the H0 over the H1, indicating “extreme evidence” for the lack of a difference between these two conditions (Wagenmakers et al., 2018).
For Regular targets, the random intercept-only model, invRT ~ Prime Type + (1|Subjects) + (1|Targets), was used. The main effect of Prime Type was significant, F(3, 2128.9) = 68.81, p < .001. Follow-up analyses of the significant main effect showed that relative to the Unrelated condition (M = 663 ms), responses were significantly faster in both the Morphological condition (M = 618 ms), estimated coef. = −0.13, SE = 0.02, t = −7.50, p < .001 and the Orthographic condition (M = 638 ms), estimated coef. = −0.08, SE = 0.02, t = −4.38, p < .001. In addition, responses were significantly faster in the Morphological than the Orthographic condition, estimated coef. = −0.05, SE = 0.02, t = −2.90, p = .02. The Repetition condition produced significantly faster responses (M = 584 ms) than the Unrelated condition, estimated coef. = 0.23, SE = 0.02, t = 13.98, p < .001, the Morphological condition, estimated coef. = 0.11, SE = 0.02, t = 6.57, p < .001, and the Orthographic condition, estimated coef. = 0.16, SE = 0.02, t = 9.24, p < .001.
Finally, a BF was also calculated for the Regular targets comparing the model that does not include Prime Type (Morphological vs. Orthographic Control; H0) and the model that does include the term (H1). The analysis showed that BF was 3.5754 favoring the H1 over the H0. Thus, the BF showed “moderate evidence” for the presence of a morphological priming effect (Wagenmakers et al., 2018). Recall, however, that this contrast involving the Regular targets is not pure. That is, it is likely that there was some additional orthographically based facilitation for the Morphological prime–target pairs because those pairs were more orthographically similar to each other than the Orthographic prime–target pairs were.
Error rates
The model used was: glmer(error ~ Verb Type * Prime Type + (1|Targets), family = “binomial”). The main effect of Verb Type was marginally significant, χ2 = 3.71, p = .05; error rates were numerically larger in the Irregular condition than in the Regular condition (13.8% vs. 8.9%). The main effect of Prime Type was also significant, χ2 = 20.44, p < .001. There was no interaction between Verb Type and Prime Type, χ2 = 1.20, p = .75.
Follow-up analyses of the significant main effect revealed two significant priming effects: the Repetition condition produced significantly lower error rates than the Unrelated condition, estimated coef. = 0.51, SE = 0.13, z = 3.88, p < .001, as did the Morphological condition, estimated coef. = −0.50, SE = 0.13, z = −3.75, p = .001. No other contrasts, including Morphological vs. Orthographic or Orthographic vs. Unrelated primes, showed a significant difference, all ps > .08.
Discussion
Wanner-Kawahara et al. (2022) have demonstrated that Japanese–English bilinguals can show morphological priming in their L2 when using both unrelated words and orthographically similar words as the control primes. A post hoc analysis involving L2 proficiency (i.e., TOEIC scores) showed that the morphological–orthographic difference existed only for the most proficient bilinguals. For the less proficient bilinguals, however, there was very little difference between the morphological and orthographically similar conditions suggesting that the morphological priming effect was primarily driven by orthographic similarity. These results led those authors to propose that morphological representations have developed in the L2 lexicon of high-proficient Japanese–English bilinguals but not in the L2 lexicon of low-proficient bilinguals. However, because the participants in Wanner-Kawahara et al. were all relatively high-proficient bilinguals, it was not possible to test their hypothesis in a controlled experiment. The present experiment was thus an attempt to provide a confirmatory examination of this hypothesis.
In the present experiment, regular and irregular present-tense targets (e.g., LOOK and FALL) were paired with four prime types: morphological (e.g., looked-LOOK, fell-FALL), orthographic (e.g., lonely-LOOK, fill-FALL), unrelated (e.g., danger-LOOK, slow-FALL), and repetition primes (e.g., look-LOOK, fall-FALL). Based on the post hoc discovery that Wanner-Kawahara et al.’s (2022) lowest proficient bilinguals did not appear to show a morphological priming effect when using the orthographic prime condition as the baseline, we expected that the bilinguals in the present experiment (who were purposely selected to be of low L2 proficiency) would also not show a difference between the orthographic and morphological conditions.
With respect to our pattern of results, note first that a significant and sizable repetition priming effect emerged. This result suggests that these low-proficient bilinguals could process L2 masked primes. Indeed, the large effect (e.g., around 70 ms) was at the higher end of the range of typical repetition priming effects (e.g., Forster et al., 2003). It was also substantially larger than the significant orthographic priming effect (e.g., around 25 ms). Thus, this effect clearly indicates that our participants could process the masked primes to the lexical level.
Against this backdrop, the results generally support our prediction regarding morphological connections: Although morphological primes facilitated target processing relative to unrelated primes, there was little evidence that they produced a larger priming effect than orthographic primes. Therefore, it appears that the facilitation effect in the morphological condition was mainly driven by prime–target orthographic similarity. These results are consistent with those of Feldman et al. (2010), who showed significant morphological priming (relative to orthographic primes) for their high-proficient bilinguals but not for their low-proficient bilinguals.
A potential qualification of our conclusion, however, comes from the fact that, although the overall priming patterns were not significantly different as a function of verb type, when regular verb items were analyzed alone, morphological primes did produce a significantly (20 ms) faster latency than orthographic primes. Assuming that representations develop in a bottom-up manner in the lexicon, this result could be explained by assuming that regular inflectional connections develop earlier than those of irregular inflections (see Crepaldi et al., 2010; Rastle et al., 2015). An alternative account of this difference, however, is that it was due to the regular morphological primes being more orthographically similar to their targets than the orthographic primes (e.g., played-PLAY, M = 68% vs. planet-PLAY, M = 38%). As such, the shorter latency following morphological primes merely reflects greater orthographic facilitation rather than the existence of morphological connections.
Although it doesn’t appear to be possible to tease these two ideas apart based on the present data, in a post hoc regression analysis, we found that the difference in the degree of orthographic overlap for the regular morphological prime–target pairs was not directly related to their morphological priming effect sizes (t < 1, β < .001, n.s.). This result would seem to support the idea that the difference between the Morphological and Orthographic conditions for Regular verbs was not an orthographic priming effect but rather may reflect the beginnings of morphological connections for regular verbs. 3 Needless to say, however, further studies are needed in order to fully resolve this issue.
Regardless of whether the morphological priming advantage for regular verbs is an orthographically based effect or whether it represents the beginning of the development of morphological relationships in the L2 lexicon, our results imply that connections for L2 past-tense and present-tense morphological relationships need time to develop in the lexicons of Japanese–English bilinguals. That is, our results imply that connections for L2 past-tense and present-tense morphological relationships develop slowly in the lexicons of Japanese–English bilinguals. This implication can be understood within the context of the Ontogenesis Model (Bordag et al., 2022), which focuses on how L2 representations develop. According to the Ontogenesis Model, connections between form and meaning in L2 can differ from those for L1 readers of the language in two ways. First, form-meaning connections in L2 are usually created by mapping preexisting L1 meaning representations onto L2 forms and thus are weaker than those in L1 where form and semantic level representations have been developed simultaneously earlier in life. Second, representations for L2 forms are fuzzy or underspecified, which makes it difficult for L2 readers to identify the correct word among similarly spelled words.
Wanner-Kawahara et al. (2022) discussed the idea that L2 morphological connections can be created similarly to how form-meaning connections are created in L1, in that preexisting L1 morphological relationships (past tense–present tense) can be mapped onto L2 word form representations. Their research demonstrated that morphological connections of this sort in L2 can exist even when bilinguals have somewhat fuzzy L2 form-level representations (with that fuzziness being documented by the lack of lexical competition). The significant morphological priming effect in their experiment indicated that higher-level representations, such as morphological level representations, can develop without waiting for the L2 form-level representations to reach their optimal encoding level.
The present results further indicate that even if morphological level connections can be formed when L2 forms are represented fuzzily, a certain level of specificity is nevertheless required before morphological priming can be observed. In the present experiment, low-proficient bilinguals processed morphological and orthographic primes in the same way, indicating that their L2 form representations were not precise enough to differentiate similarly spelled words as would be predicted by the Ontogenesis Model. Relatively high-proficient bilinguals in Wanner-Kawahara et al. (2022), on the other hand, showed greater priming from morphological than from orthographic primes, indicating that their L2 form representations were precise enough to differentiate the alternatives. Taken together, although a preexisting morphological relationship in L1 can be mapped onto L2 forms, the establishment of morphological-based connections becomes possible only after the system is sensitive enough to tell which word form the higher-level relationship should be mapped onto.
Note also that our interpretation that L2 morphological connections develop with increased proficiency is consistent with that of Viviani and Crepaldi (2022), who examined the effect of L2 proficiency on derivational priming with Italian–English bilinguals. It should be noted, however, that despite the weak (or nonexisting) L2 morphological connections of our low-proficient bilinguals, a sizable repetition priming effect was observed in our experiment. That result suggests that, as the stimuli in the present experiment were selected to suit our participants’ low English proficiency level, most L2 word targets are represented lexically for our participants.
In order to further examine how the low-proficient bilinguals represented L2 English words themselves (at least for those stimuli used in the present experiment), we compared the lexical decision performance of the low-proficient bilinguals with that of the high-proficient bilinguals in Wanner-Kawahara et al. (2022). We first examined the speed of lexical decision: The overall mean RT in the present experiment (M = 634 ms, SD = 169) was similar to that in Wanner-Kawahara et al. (M = 653 ms, SD = 175 in Experiment 2). We next computed a measure of processing stability, the coefficient of variation (CV), for the two groups of bilinguals. CV, the ratio of SD to the mean RT in each participant, reflects to what extent processing is automatized (Segalowitz & Segalowitz, 1993; also see Lim & Godfroid, 2015, for review). A smaller CV indicates that cognitive processing is highly automatized and efficient. The results showed that the mean CV was quite similar between our low-proficient bilinguals (M = 0.22) and Wanner-Kawahara et al.’s high-proficient bilinguals (M = 0.21). These findings suggest that there was little difference between how our low-proficiency bilinguals were able to access the L2 target words used here and how Wanner-Kawahara et al.’s high-proficient bilinguals were able to access the L2 target words used in their experiment. This contrast, therefore, further implies that the efficiency of lexical retrieval in L2 does not predict the existence of morphological connections among L2 words.
In summary, the present results support the claim that connections or representations for L2 past-tense inflectional relationships are generally not yet present in the L2 lexicon of Japanese–English bilinguals who are low in English proficiency even when those lexicons contain lexical representations of the relevant words. The fact that L2 proficiency appears to modulate whether morphological priming effects are observed supports the possibility that the previous mixed results regarding this issue may have been at least partly due to differences in L2 proficiency between experiments (also see Viviani & Crepaldi, 2022). Furthermore, because the impact of orthographic similarity on lexical access may well be different depending on the type of bilinguals (same script vs. different script, Bijeljac-babic et al., 1997; Nakayama & Lupker, 2018) and their L2 proficiency (Viviani & Crepaldi, 2022; Wanner-Kawahara et al., 2022), the present results also support the conclusion that the use of both unrelated and orthographic primes would seem to be a preferred methodology to use when attempting to understand underlying morphological representations for bilinguals.
Footnotes
Data availability
The anonymized data supporting this study’s findings are available from the corresponding author. Individual participant data are not available due to the terms of the consent form.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by JSPS KAKENHI Grant Number JP19K14468