
Abstract
Aims/Objectives:
According to Multilink, words from the first (L1) and (L2) second languages share a common store and their access is non-selective. Thus, the presentation of a target word activates in parallel lexical candidates from both languages that share form and semantic overlap. The degree of words’ activation also depends on their resting levels of activation (words that are more used have a higher resting levels of activation). Since non-cognate translations and synonyms share meaning, they may be seen as qualitatively similar lexical representations, and consequently subject to similar processing if their frequency levels are matched. However, whereas masked priming lexical decision studies with synonyms failed to find reliable masked priming effects, the majority of those with non-cognate translations (especially in the forward direction, i.e., from L1 to L2) showed significant effects. The present study extends those findings by directly comparing the processing of synonyms and translations in bilinguals.
Design/methodology:
A masked priming lexical decision task (targets were preceded by a related 50-ms word [an L1 translation or an L2 synonym] or by a 50-ms unrelated word) was conducted. Lexical frequency of usage was higher for primes than for targets.
Data and analysis:
Reaction times and accuracy from 24 sequential (highly proficient) European Portuguese-English bilinguals were analyzed with linear mixed effects models.
Findings/conclusions:
Results showed priming effects for translations, but not for synonyms, indicating a differential processing of synonyms and non-cognate translations.
Originality:
This is the first empirical work that directly compares the processing of synonyms and translations in bilinguals by using the same targets words for both prime types.
Significance/implications:
The findings contradict the Multilink model, since they index a differential representational nature of lexico-semantic links for translations and synonyms. Modifications in the model are needed to account for the data.
Keywords
One of the questions addressed by psycholinguistics research on bilingualism that has attracted great attention over decades concerns the organization and processing of the two languages in the mind. The leading model of bilingual visual word recognition and production, the Multilink model (Dijkstra et al., 2018), claims that words from first (L1) and second (L2) languages are represented in a shared system and co-activated in parallel. Thus, when a given word is presented (e.g., “time”), this activates lexical candidates that share orthographic, phonological, and semantic similarities within (e.g., “lime”) and across languages (e.g., the European Portuguese word “timo,” thyme in English). As such, non-cognate translations (e.g., ache-dor, in English and European Portuguese, respectively) and synonyms (i.e., ache-pain) can be seen as qualitatively similar as they share meaning, and, thus, they might be represented and processed in a similar way, an issue that we wanted to examine with the present research.
Following the Multilink (Dijkstra et al., 2018), the level of words’ activation depends not only on form and meaning overlap within and across languages but also on their resting levels of activation (RLA), which are determined by the frequency of L1 and L2 words’ use. Since L1 words are generally used more on a daily basis than L2 words, they have higher RLAs and, consequently, they are recognized faster, at least by sequential unbalanced proficient bilinguals. If this is so, it is plausible to think that the recognition of a given L2 word would be equally fast if preceded by their L1 (non-cognate) translation than by an L2 synonym, whenever frequency levels of translations and synonyms are matched. However, available empirical evidence on the processing of non-cognate translations and synonym words points to cognitive differences between them. Thus, for instance, phenomena such as that of mutual exclusivity (i.e., the resistance to giving different labels to the same object) and repetition blindness (i.e., the inability to retrieve a repeated word in a rapid serial visual presentation task) seem to be higher for synonyms than for non-cognate translations (see Au & Glusman, 1990, for the former effect; and Altarriba & Soltano, 1996, and Kanwisher & Potter, 1990, for the latter). Additionally, translations lead to greater word recall than synonyms (e.g., Kolers & Gonzalez, 1980; see also Macleod, 1976, and Nelson, 1971); they are characterized by higher intrusion errors in free recall tasks (e.g., Paivio et al., 1988); and they are read faster than synonyms (see Levy et al., 1992; MacKay & Bowman, 1969).
Even though these studies come together to show differences between synonyms and translations, they mostly focused either on translations or synonyms in different populations (bilinguals and native speakers of a given language, respectively). A direct comparison of the L1 and L2 data within the same population would provide clues as to the possible qualitative and/or quantitative differences between L1 and L2 processing, as we intend to do here. Of special interest for the present research are the studies conducted by Ibrahim et al. (2017) and Witzel (2019). Ibrahim et al. (2017) attempted to compare the processing of synonyms and translations via production tasks. Since L1 words have a higher RLA, due to their higher frequency of use comparatively to L2 words (Multilink; Dijkstra et al., 2018), the authors manipulated synonyms’ frequencies in order to emulate the asymmetries found in unbalanced bilinguals when processing the two translation directions (i.e., faster processing translating from L2-L1 than from L1-L2). Thus, in their experiment, native speakers of British English carried out a within-language “translation” task in which they had to produce high-frequency (HF) synonyms after the presentation of low-frequency (LF) ones (emulating the L2-L1 translation direction) versus LF synonyms after the presentation of HF ones (as in L1-L2). Given that the sample was only comprised of monolinguals, any differences in producing synonyms across conditions could not be explained by the existence of multiple lexicons, but rather by general processing principles such as word frequency. The results showed, as expected, faster response times for the production of HF synonyms than for the production of LF synonyms. Extrapolating this result to the bilingual case, different RLA between L1 and L2 words, as well as the frequency of L2 usage that modulates those RLA, may account for the differences in the processing of L1 and L2 words. Although these results are a priori consistent with the Multilink model (Dijkstra et al., 2018), the authors did not compare directly the processing of synonyms and translations in a bilingual population. Bearing in mind the differences found between these two kinds of words in the above-mentioned studies, one may think that both types of words are modulated by frequency but they are not represented and accessed in the same way.
Indeed, when considering studies using masked priming lexical decision tasks (LDTs), which tap into word recognition, masked priming effects are consistently obtained with non-cognate translations in a forward direction (i.e., shorter reaction times when the target word in L2 is preceded by a non-cognate translation prime in L1 [usually presented for 50 ms] than when it is preceded by an unrelated L1 word prime), but weak or absent in the other translation direction (i.e., L2-L1; see Ferré et al., 2017; Wen & van Heuven, 2017, for overviews). As it was said before, these asymmetries fit well with the tenets of the Multilink model as the differences in frequency between L1 and L2 words would affect their access. To be more precise, the processing of HF words, which are usually those from L1, is faster than that of LF words, and hence, the time that is needed for conceptual level activation to arise from these HF words as primes would be sufficient to affect target processing. This would explain the robust masked priming effect observed in the L1-L2 direction. In fact, if bilinguals are very proficient in L2 or balanced, the effects of priming appear in both directions (e.g., Duñabeitia et al., 2010; Nakayama et al., 2018). The same scenario is not observed with semantically related pairs within a language where the results are scarce and mixed (see Witzel, 2019, for an overview), probably because the effect depends not only on their frequency values but also on the semantic relation between the prime and the target. In other words, on their degree and/or type of semantic relationship: associative versus category. Indeed, it seems to be difficult to obtain semantic priming effects within language at less than 66 ms of prime durations (e.g., Bueno & Frenck-Mestre, 2008) with the exception of a few studies. For example, studies using prime durations of 57 ms (Sánchez-Casas et al., 2012) and of 66 ms (Perea & Rosa, 2002) in which the processing of semantically and highly associated words (e.g., cradle-baby) was examined, as well as the processing of words that only share semantic relations (e.g., horse-zebra), found priming effects restricted to words that were semantically and associatively related. In newer studies using prime durations of 50 ms, priming effects were neither observed for semantically related word pairs (e.g., hawk-EAGLE: de Wit & Kinoshita, 2015) nor synonyms (Witzel, 2019).
These studies on semantic priming did not manipulate, however, the frequency levels of primes and targets (a variable signaled as crucial for the Multilink model), with the exception of that developed by Witzel (2019). This author carried out two masked priming LDTs in English with synonyms to test whether these words and translations are similarly represented and processed in the bilingual mind. As Ibrahim et al. (2017), Witzel only examined the processing of synonyms in a sample of native speakers of English (more than a third were monolinguals and the others knew other languages than English) via the manipulation of frequency levels of primes and targets. In the first experiment, HF synonyms primed LF targets (HF-LF) and LF synonyms primed HF targets (LF-HF), emulating L1-L2 and L2-L1 translation, respectively. Both HF and LF words of each synonym pair could be a target, so each word was presented twice to the participant in the same session—once as target and another as prime. Results showed no priming in either of the synonym conditions (HF-LF and LF-HF). Since each word was presented twice, the difference regarding the RLA of HF and LF words could have been minimized explaining the absence of priming effects. For that reason, in the second experiment, only HF words were used as primes to LF targets (condition [HF-LF], emulating the forward translation direction [L1-L2]). Here, 33 native English speakers were recruited (again, almost half were monolinguals and the others knew other languages than English). Results were consistent with those from Experiment 1 as no signs of masked priming effects were found. The author claimed that 50 ms of prime duration could not suffice to impact the semantic processing of the target, as usually happens with L1-L2 translations. Witzel concluded, therefore, that the Multilink model should be amended to account for the existent qualitative differences between the processing of translations (at least in the L1-L2 direction) and synonyms. The aim of the present research was to corroborate these findings by comparing, for the first time, the processing of synonyms and translations directly in a homogeneous sample of highly proficient unbalanced European Portuguese-English bilinguals. This would enable us to rule out the effect of a heterogeneous sample in the absence of masked priming effects. Additionally, we used the same L2 targets across conditions (preceded by HF synonyms vs L1 translations) in an attempt to obtain clues as to the possible mechanisms underlying the qualitative and/or quantitative differences between L1 and L2 processing.
As in the study by Witzel (2019), in the present research, we used a masked priming LDT. Here, the same target (e.g., ACHE) in different lists was preceded by a synonym (pain) or an unrelated English word (moon) and by an L1 word translation (dor) or an unrelated European Portuguese word (som). The frequency of L2 synonym primes was purposefully higher than that of L2 targets to simulate the typical divergences in frequency that characterizes forward translation (L1-L2) and, consequently, to directly compare the effect of priming for L1-L2 translations and HF-LF L2 synonyms. In this way, any observed differences between the processing of synonyms and translations would not be due to differences in RLAs, and thus, the Multilink model (Dijkstra et al., 2018) should be amended to account for the findings. Considering the results of the studies above mentioned, we expected to observe masked priming effects for L1-L2 translations but not for HF-LF L2 synonyms.
General method
Ethics statement
The experiment complied with the ethical standards of the Declaration of Helsinki and was conducted with the approval of the Ethics Committee for Human Research (CEICSH 082/2019) of the University of Minho (Braga, Portugal). Written consent was obtained from all the participants.
Participants
Thirty-seven unbalanced moderate to highly proficient sequential European Portuguese-English bilinguals (20 females) were recruited from the University of Minho, Portugal. All were university students with ages between 18 and 34 years old (Mage = 22, SD = 4), which received course credits in exchange for their participation.
According to the results of the Language History Questionnaire (LHQ 3.0; Li et al., 2019), participants showed high levels of L2 proficiency on reading (M = 6.3, SD = 0.7), writing (M = 5.5, SD = 1.0), speaking (M = 5.4, SD = 1.1), and listening skills (M = 5.9, SD = 1.1), on a 7-point Likert-type scale (from 1 = very poor to 7 = native-like). In addition, LHQ encompasses more specific questions about the language environment and language use. This allowed us to characterize our participants as highly proficient sequential bilinguals. On average, the participants reported spending 24% (SD = 14%) of their daily life speaking English. Additionally, they reported a mean age of acquisition of the spoken English language of 8 years old (SD = 2.4) with reading and writing acquisition roughly at the same time (M = 7.8, SD = 2.0). On average, the sample has dedicated a total of 10 years (SD = 2.3) to the learning of the English language.
Furthermore, we used a version of the lexical test and the spelling test developed by Casalis et al. (2015) to further evaluate L2 proficiency. In the lexical test, participants must translate 150 words from L1 (European Portuguese) to L2 (English), with increasing levels of difficulty (beginner, intermediate, and advanced) according to item frequencies (M = 522, SD = 743; M = 72, SD = 96 and M = 24, SD = 36, respectively) taken from the Children’s Printed Word Database (CPWD) database (Masterson et al., 2003). The maximum score for each level of difficulty is 50 words correctly translated. The participants’ average score for the beginner, intermediate, and advanced translation tasks was 48 (SD = 4), 34 (SD = 10), and 20 (SD = 9), respectively. In the spelling test, participants must choose the correct spelling of 20 words, each with 2 possible candidates. On average, participants chose the correct spelling of 18 (SD = 2) words.
Moreover, the LexTALE (Lemhöfer & Broersma, 2012), a vocabulary test that consists of 60 items (40 words and 20 nonwords), which belong to different syntactic categories to assess the participants’ English vocabulary size, was employed. The participants’ mean score was 61.53% (SD = 28.43%), which confirms our participants’ L2 proficiency.
Stimuli
Ninety English target words were selected from previous studies on synonyms and translation equivalents (e.g., Basnight-Brown & Altarriba, 2007; Finkbeiner et al., 2004; Ibrahim et al., 2017; Locker et al., 2003), from the WordReference.com (2019) English Synonyms dictionary and the Infopedia dictionary of the Portuguese language (Porto Editora, 2019). Each target word was associated both to its European Portuguese translation equivalent (e.g., dor—ACHE) and its synonym in English (e.g., pain—ACHE), which functioned as prime words. Target words had lower lexical frequency (log10) values than synonym and translation primes. The lexical frequency (log10) was chosen over the classical lexical frequency per million to facilitate the stimuli control across languages.
L2 synonym and L1 translation primes were matched on the number of letters, lexical frequency (log10), number of orthographic neighbors, and the mean of the bigram log10 frequency. These values were taken from the N-Watch database for the English words (Davis, 2005), as well as from the P-PAL database for the European Portuguese words (Soares et al., 2018). Besides, unrelated L2 and L1 prime words were also matched to synonym and translation primes, respectively, on the above-mentioned psycholinguistics variables (all ps > .142). The Normalized Levenshtein Distance (NLD), a measure of orthographic overlap, between both primes and targets (taken from NIM: A Web-based Swiss army knife to select stimuli for psycholinguistic studies; Guasch et al., 2013) was also controlled (p = .179). See Table A1 in Appendix 1 for a complete list of the experimental stimuli.
Due to the nature of the LDT, 90 pseudoword targets were created using the Wuggy software (Keuleers & Brysbaert, 2010) from the targets of other previously excluded triplets (target, synonym, and translation) with the same characteristics as the ones used in the experimental set. For each synonym and translation primes paired with the target pseudowords, other unrelated L2 and L1 prime words were also selected, following the method used for the experimental stimuli control reported above.
The stimuli were organized in four lists such that in two lists each target word was preceded by its synonym or by an unrelated English prime (the targets that were preceded by a synonym in one list, in the other they were preceded by an unrelated word and vice versa) and in the other two lists the target was preceded by its L1 translation or by an L1 unrelated prime (again, the targets that were preceded by its translation, in the other list were preceded by an unrelated word and vice versa). In this way, we guaranteed that each target went through all prime conditions.
Procedure
All participants signed the informed consent form. Subsequently, they were tested individually in soundproof booths at the Human Cognition Lab (School of Psychology, University of Minho). The experiment comprised two sessions 1 month apart, each with a masked priming LDT. The order of the sessions was counterbalanced to control for order effects. In this way, if the participant first responded to the LDT in which the list had L2 synonyms and L2 unrelated words as primes, the second time the subject would respond to the LDT with L1 translations and L1 unrelated words as primes, and vice versa. In both sessions, a hash marks mask (############) was presented for 500 ms in the center of the screen. Afterward, a lowercase prime was presented for 50 ms. Following the prime, a target word or a target pseudoword appeared on the screen in uppercase letters. Participants were asked to decide whether the target constituted an English word or a nonword, as fast and as accurately as possible. The target appeared on the screen for 2,500 ms or until the participants responded. According to the instructions presented on the computer screen at the beginning of the LDT, if the letter string was considered an English word, participants were instructed to click on the “M” keyboard key, whereas if they considered that it was not an English word, they should press the “Z” keyboard key.
In the end, participants also answered a word recognition/familiarity task to assure they knew the experimental words (i.e., targets and primes). All words were presented as a list and the participants’ task was to report which words they did not know. Participants did not know on average 20 (SD = 12) words out of 90 used in the experimental task.
Participants took approximately 50 minutes to complete all the procedure (including both LDT sessions). The experiment was run using the DMDX software (Forster & Forster, 2003). Figure 1 shows an example of a given trial for each experimental session.
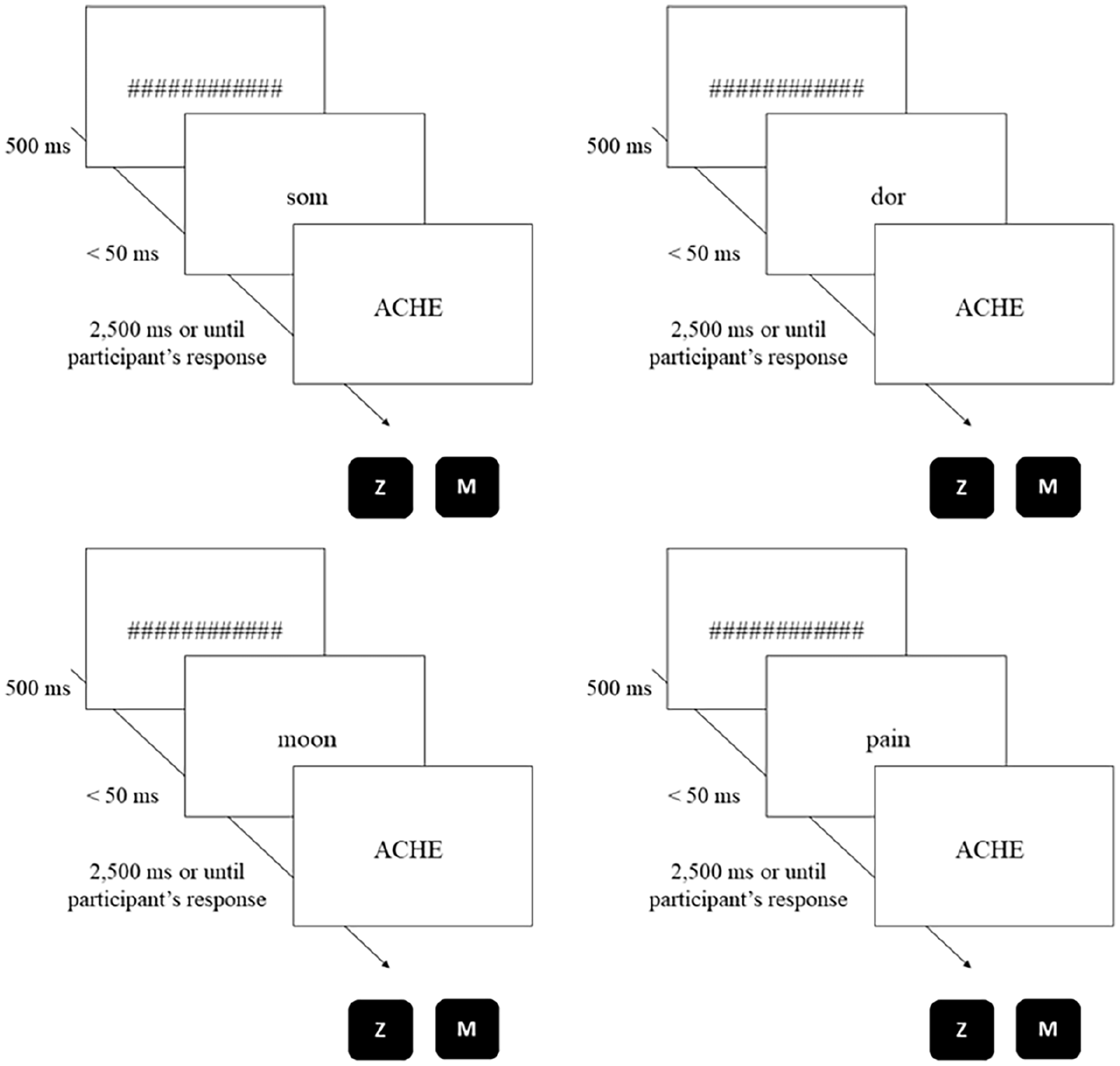
Example of a trial in the translation (above) and synonym (below) experimental session (related primes on the right; unrelated primes on the left).
Results
Subjects who did not complete both LDTs were excluded from the analysis. Twenty-four out of 37 were included in the final analysis. Reaction times (RTs; in ms) and accuracy (proportion of correct responses) were analyzed using linear mixed effects (lme) models with the R software (Bates et al., 2011). A random intercept model with two repeated-measure factors (Prime type: related vs unrelated and Prime-target relation: translation vs synonym) as fixed factors was run. For the accuracy analyses, we used a generalized lme with logistic link function and binomial variance, with a similar model as the latency data. The models were fit using the lme4 R library (Bates et al., 2011) and the lmerTest R library to contrast simple effects with differences of least squares means. For the effects that reached statistical significance, the second degree of freedom of the F statistic was approximated with Satterthwaite’s method (see Satterthwaite, 1941, and Khuri et al., 1998). The p values were adjusted with Hochberg’s method for all the post hoc comparisons equal or below .05 (see Benjamini & Hochberg, 1995, and Hochberg, 1988, for details). Incorrect responses (6.7% of the raw data) and correct responses for unknown words (15.9% of the raw data) were excluded from the data. In addition, RTs shorter than 200 ms and that were below and above 2.5 SDs of the participants’ means in each experimental condition were also removed from the latency data (2.2% of the raw data). Due to the strong positive skewness observed in RT data, a scaled power transformation (box-cox transformation) was carried out to provide normality to the residuals of the linear mixed model to be estimated (Box & Cox, 1964; Fox & Weisberg, 2019; see Soares et al., 2021, for a recent work using the same procedure). The mean RTs (in ms) and accuracy (Acc) rates in all conditions are presented in Table 1.
Mean reaction times (RTs) in milliseconds and accuracy rates (Acc) for each priming condition.

Note. The standard deviation of the means is presented in parentheses.
The lme analysis on the latency data showed a main effect of prime type, F(1, 3130.2) = 5.78, p = .016, indicating that participants were faster responding to the targets when they were preceded by related than unrelated primes (715 ms vs 724 ms, respectively), as expected. The interaction prime type × prime-target relation was also significant, F(1, 3140.2) = 4.28, p = .039. This effect revealed that priming effects were restricted to the translation condition as only in this condition related primes produced significantly faster responses than unrelated primes (p = .001). In the synonym condition, no effects of prime type were observed (p = .83).
On the accuracy data, only a main effect of prime-target relationship was observed, χ2(1) = 4.48, p = .032, showing that participants were more accurate at recognizing target words when preceded by their translation (93%) than synonyms (91%). It is worth noting here that although the most important psycholinguists variables known to affect word processing were controlled for (see the “Stimuli” section), in order to explore any possible effect of those variables in the results, we also run the model considering as covariables either priming or target linguistic properties, as well the metric of semantic-associative relationship acquired from the latent semantic analysis (LSA), but the pattern of results maintained basically the same.
Discussion
The aim of the present masked priming LDT was to test the tenets of the Multilink model (Dijkstra et al., 2018), regarding the representation and processing of non-cognate translations and synonyms. According to Multilink, words from the L1 and L2 share a common store and their access is non-selective. The degree of across-language activation depends on form and semantic overlap, and also on words’ RLA, which is typically higher in L1 than in L2 due to its greater use. Since translations and synonyms share meaning, we hypothesized that they can be seen as similar lexical representations, presenting similar processing whenever the frequency of use in each language is controlled for, as we did here. The results were clear-cut, showing significant priming effects only for L1-L2 non-cognate translations and thus replicating and extending the findings reported by Witzel in 2019 to a homogeneous sample of European Portuguese-English sequential bilinguals. They are also consistent with a substantial body of literature on translation and semantic priming, questioning the suitability of the Multilink model to account for the representation and processing of synonyms and translations. Indeed, while a masked translation priming effect is a well-established phenomenon as Wen and van Heuven (2017) showed with an elegant meta-analysis study, semantic priming effects within language at prime durations equal to or lower than 66 ms (e.g., Bueno & Frenck-Mestre, 2008; Sánchez-Casas et al., 2012; see also Perea & Rosa, 2002, with synonyms) are difficult to find. All in all, two alternative hypotheses can be drawn here: (1) these asymmetries are indexing a differential representational nature of lexico-semantic links for translations and synonyms; or (2) they are quantitative rather than qualitative based, as happens with L1-L2 and L2-L1 translations. Note, indeed, that the overall effect size of masked priming in Wen and van Heuven’s (2017) study was substantially higher for L1-L2 translations than for L2-L1 (0.86 and 0.31, respectively). This means that the number of participants needed to obtain a power of 0.8 with forward translations in a one-tailed paired t-test is of 10 participants with an effect size of 0.86, but of 66 participants with an effect size of 0.31 with backward translations. In fact, from the 33 experiments included in the meta-analysis with backward translation direction (L2-L1), only 13 obtained significant priming effects (most of them had primes with higher frequency than targets). In any case, in the majority of studies that failed to show priming effects in such direction, the tendency was always of facilitation for related versus unrelated targets. The same scenario is not usually found when prime and targets within language are related in meaning such as synonyms. The few studies on masked semantic priming (prime duration equal to or lower than 66 ms) which found a facilitative priming effect showed that this was mainly due to words that were semantically and associatively related (Perea & Gotor, 1997; Perea & Rosa, 2002; Sánchez-Casas et al., 2012). Thus, when prime durations are brief, association seems to provide a priming boost as Lucas pointed out in 2000 (see also Moss et al., 1995, for a similar interpretation with aural stimuli).
This is the reason why we are inclined to think that the first hypothesis, that is, the existence of a differential representational nature of lexico-semantic links for translations and synonyms, is more plausible. Indeed, the above-mentioned studies (Hutchinson, 2003; McNamara, 2005) that showed facilitative semantic priming effects with prime durations equal to or lower than 66 ms advanced two main reasons for such effects: categorical membership (e.g., giraffe and dog) and context association (e.g., monkey and banana). Although synonyms and translations share both, context association could be said to happen for synonyms to a lesser degree since we do not usually use a synonym in the same context. Note that in sequential bilinguals, L2 words are commonly learned via association with L1 translations (see Barcroft, 2009; O’Malley & Chamot, 1990). Therefore, it is likely to be assumed that synonyms share weaker formal and associative links than non-cognate translations, which could explain the asymmetries found in priming when using brief prime durations. In fact, Perea and Rosa (2002) found a positive correlation between the associative strength and the priming magnitude when using shorter stimulus onset asynchronies (SOAs) than 70 ms. More specifically, when synonyms were not associated (Experiment 2), the priming effect started to become negative, that is, faster responses to unrelated than to related pairs. In any case, as a reviewer 1 pointed out, one may still think that the 50 ms prime duration was too short for the L2 synonym prime to impact the processing of the target, but sufficient for the L1 translation prime to do so even when synonyms and translation primes were matched in frequency. The reviewer may be right since frequency values were obtained from normative data taken from native speakers of a given language (i.e., English or Portuguese) instead of from bilingual speakers and, thus, differences between translations and synonyms may be a matter of quantitative rather than qualitative differences. This is a question we wanted to examine in further studies. However, it is important to note that, as we mentioned above, priming studies with synonyms in L1 and similar prime durations as the one used in the present research failed to show priming effects (e.g., Witzel, 2019). This led us to think that differences between synonyms and translations are more a question of qualitative differences.
Leaving aside the differences in processing between translations and synonyms and focusing on the former, the reduced priming effect observed with L2-L1 translations in the literature in comparison to L1-L2 translations is likely due to the fact that L1 words are indeed used more frequently and thus they access meaning more efficiently than L2 words, at least when bilinguals are unbalanced. It is worth noting here that the Multilink integrates the tenets of the revised hierarchical model (RHM; Kroll & Stewart, 1994), and thus, it assumes that the strength of lexico-semantic links varies as a function of translation direction: weaker from L2-L1 than in the other way around. Thus, the reason behind the strong consistent priming with L1-L2 translations might be due to a combination of different factors, as Witzel (2019) pointed out: (1) these translations can be seen as synonyms which are strongly associated and (2) the prime in L1 has higher RLA. This would explain their faster and more efficient access to meaning in comparison to L2 words. Also, it would explain why priming effects with synonyms within languages that are not highly associated are not usually found. If we are correct, and the reason behind the differences between synonyms and L1-L2 non-cognate translations are qualitative due to dissimilarities in the nature of the links between lexical representations and the semantic system (i.e., L1-L2 are more strongly associated than synonyms at least in unbalanced sequential bilinguals), then these differences would be attenuated if bilinguals acquire the two languages simultaneously and used both equally, an issue that we want to examine with early balanced bilinguals. Under such a scenario, synonyms and translations might be similarly represented and processed as the Multilink model (Dijkstra et al., 2018) holds. Bear in mind that the context of L2 acquisition and usage of the two languages seems to impact the nature of lexico-semantic links and, more precisely, the magnitude of conceptual effects (see Comesaña et al., 2009, 2012, and García-Gámez & Macizo, 2020, for more detail). For instance, Comesaña et al. (2009) investigated the conceptual representations of L2 words in children native speakers of Spanish. In their second experiment, participants were taught Basque vocabulary with two different methods: word association (i.e., a pair of an L2 word with an L1 word) or a word-picture method (i.e., the L2 word was paired with a picture), both followed by a backward translation recognition task (L2-L1; to indicate if Basque-Spanish translations displayed were correct or incorrect). Results showed that, even though children learned the L2 words correctly with both methods, those from the word-picture group made more errors for incorrect translations when pairs were semantically related than when they were unrelated (the so-called semantic interference effect). This effect suggests that, as discussed by the authors, children in the word association group did not have (or have a reduced) initial access to the conceptual system, compared to children in the word-picture group. The latter seemed to have developed stronger links between the L2 lexicon and the conceptual system as a consequence of the picture association method which is more based on semantic processing, as opposed to the more lexical processing of word association. As such, it seems that the learning method influences the way in which the links between the lexical representations and the conceptual system are formed. In the same vein, García-Gámez and Macizo (2020) explored the learning of L2 words in isolation and also within sentences while recurring to either lexical-based or semantic-based training. Results showed that learning was similar for both groups. However, in a translation task, individuals in the lexical training group were faster at forward translation (L1-L2) than individuals who followed a more semantic training. The authors suggest that the latter participants used a conceptually mediated processing route for translating, comparatively to their counterparts, giving support to the conclusions reached by Comesaña et al. (2009, 2012). Therefore, it is plausible to hypothesize that when examining early balanced bilinguals, who learn two languages simultaneously and, therefore, in a more semantic manner, no differences should arise between synonyms and non-cognate translations, just as Multilink (Dijkstra et al., 2018) postulates. Future studies should examine this possibility in order to know which amendments the Multilink model needs to incorporate within its structure to account for the results. We recognize that this model was developed based on empirical evidence taken from adult sequential bilinguals. In any way, if asymmetries found in priming with translations and synonyms are indeed qualitative in nature, the model should incorporate different associative and semantic weights for synonyms and translations. For instance, in the form of reciprocal lateral inhibitory connections in semantic memory for semantically related pairs but not for highly associative ones (similarly to inhibition proposed by Anderson & Bjork, 1993). Semantic inhibition may be reduced over time and, therefore, it would only occur during the initial stages of word recognition.
To sum up, the present masked priming lexical decision study was developed to examine whether non-cognate translations are processed like synonyms. This study, which compared for the first time the processing of these two types of words using a within-item design with unbalanced sequential bilinguals of European Portuguese-English, showed clear masked priming effects for L1-L2 translations but null effects for synonyms. Findings underscore the necessity of amendments in the Multilink model.
Footnotes
Appendix 1
Experimental materials used in the LDTs—target and corresponding prime words (synonym, unrelated English [EN] word, translation, and unrelated European Portuguese word).
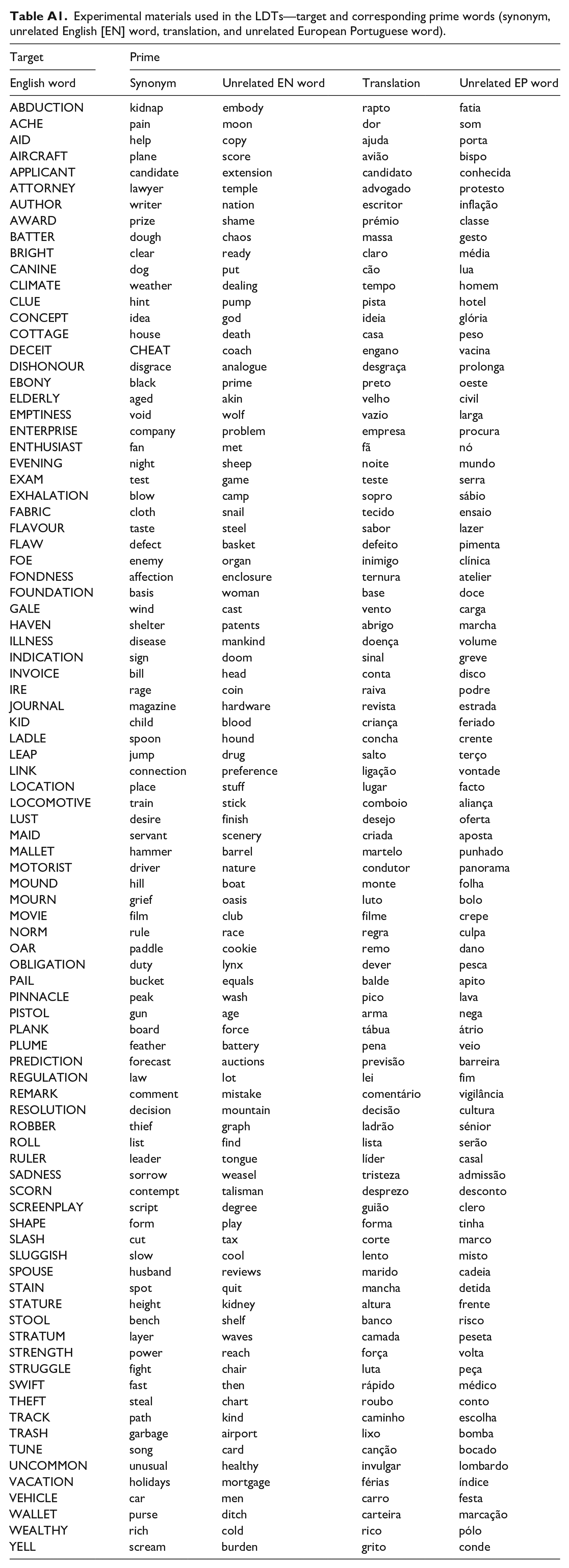
| Target | Prime | |||
|---|---|---|---|---|
| English word | Synonym | Unrelated EN word | Translation | Unrelated EP word |
| ABDUCTION | kidnap | embody | rapto | fatia |
| ACHE | pain | moon | dor | som |
| AID | help | copy | ajuda | porta |
| AIRCRAFT | plane | score | avião | bispo |
| APPLICANT | candidate | extension | candidato | conhecida |
| ATTORNEY | lawyer | temple | advogado | protesto |
| AUTHOR | writer | nation | escritor | inflação |
| AWARD | prize | shame | prémio | classe |
| BATTER | dough | chaos | massa | gesto |
| BRIGHT | clear | ready | claro | média |
| CANINE | dog | put | cão | lua |
| CLIMATE | weather | dealing | tempo | homem |
| CLUE | hint | pump | pista | hotel |
| CONCEPT | idea | god | ideia | glória |
| COTTAGE | house | death | casa | peso |
| DECEIT | CHEAT | coach | engano | vacina |
| DISHONOUR | disgrace | analogue | desgraça | prolonga |
| EBONY | black | prime | preto | oeste |
| ELDERLY | aged | akin | velho | civil |
| EMPTINESS | void | wolf | vazio | larga |
| ENTERPRISE | company | problem | empresa | procura |
| ENTHUSIAST | fan | met | fã | nó |
| EVENING | night | sheep | noite | mundo |
| EXAM | test | game | teste | serra |
| EXHALATION | blow | camp | sopro | sábio |
| FABRIC | cloth | snail | tecido | ensaio |
| FLAVOUR | taste | steel | sabor | lazer |
| FLAW | defect | basket | defeito | pimenta |
| FOE | enemy | organ | inimigo | clínica |
| FONDNESS | affection | enclosure | ternura | atelier |
| FOUNDATION | basis | woman | base | doce |
| GALE | wind | cast | vento | carga |
| HAVEN | shelter | patents | abrigo | marcha |
| ILLNESS | disease | mankind | doença | volume |
| INDICATION | sign | doom | sinal | greve |
| INVOICE | bill | head | conta | disco |
| IRE | rage | coin | raiva | podre |
| JOURNAL | magazine | hardware | revista | estrada |
| KID | child | blood | criança | feriado |
| LADLE | spoon | hound | concha | crente |
| LEAP | jump | drug | salto | terço |
| LINK | connection | preference | ligação | vontade |
| LOCATION | place | stuff | lugar | facto |
| LOCOMOTIVE | train | stick | comboio | aliança |
| LUST | desire | finish | desejo | oferta |
| MAID | servant | scenery | criada | aposta |
| MALLET | hammer | barrel | martelo | punhado |
| MOTORIST | driver | nature | condutor | panorama |
| MOUND | hill | boat | monte | folha |
| MOURN | grief | oasis | luto | bolo |
| MOVIE | film | club | filme | crepe |
| NORM | rule | race | regra | culpa |
| OAR | paddle | cookie | remo | dano |
| OBLIGATION | duty | lynx | dever | pesca |
| PAIL | bucket | equals | balde | apito |
| PINNACLE | peak | wash | pico | lava |
| PISTOL | gun | age | arma | nega |
| PLANK | board | force | tábua | átrio |
| PLUME | feather | battery | pena | veio |
| PREDICTION | forecast | auctions | previsão | barreira |
| REGULATION | law | lot | lei | fim |
| REMARK | comment | mistake | comentário | vigilância |
| RESOLUTION | decision | mountain | decisão | cultura |
| ROBBER | thief | graph | ladrão | sénior |
| ROLL | list | find | lista | serão |
| RULER | leader | tongue | líder | casal |
| SADNESS | sorrow | weasel | tristeza | admissão |
| SCORN | contempt | talisman | desprezo | desconto |
| SCREENPLAY | script | degree | guião | clero |
| SHAPE | form | play | forma | tinha |
| SLASH | cut | tax | corte | marco |
| SLUGGISH | slow | cool | lento | misto |
| SPOUSE | husband | reviews | marido | cadeia |
| STAIN | spot | quit | mancha | detida |
| STATURE | height | kidney | altura | frente |
| STOOL | bench | shelf | banco | risco |
| STRATUM | layer | waves | camada | peseta |
| STRENGTH | power | reach | força | volta |
| STRUGGLE | fight | chair | luta | peça |
| SWIFT | fast | then | rápido | médico |
| THEFT | steal | chart | roubo | conto |
| TRACK | path | kind | caminho | escolha |
| TRASH | garbage | airport | lixo | bomba |
| TUNE | song | card | canção | bocado |
| UNCOMMON | unusual | healthy | invulgar | lombardo |
| VACATION | holidays | mortgage | férias | índice |
| VEHICLE | car | men | carro | festa |
| WALLET | purse | ditch | carteira | marcação |
| WEALTHY | rich | cold | rico | pólo |
| YELL | scream | burden | grito | conde |
Authors’ note
Preliminary results of this paper were published in “Contribuciones a la Lingüística y a la Comunicación Social. Tributo a Vitelio Ruiz Hernández” (2021). In L. R. Ruiz, R. M. Rodríguez, A. Muñoz, L. Chierichetti, M. R. Álvarez (Eds.), Contribuciones a la Lingüística y a la Comunicación Social. Tributo a Vitelio Ruiz Hernández (pp. 70–72). Santiago de Cuba: Ediciones Centro de Lingüística Aplicada. ISBN: 978-959-7174-40-0.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was conducted at the Psychology Research Centre (CIPsi), University of Minho, and supported by the Foundation for Science and Technology (FCT) through the Portuguese State Budget (UID/01662/2020). It has also been supported by the Agence Nationale de la Recherche (ANR) (Reference ANR-16-CE28-0009-01).