
Abstract
Research motivation:
Myers-Scotton’s Matrix Language Framework (MLF) has long been extremely influential, claiming ‘universality of support, no matter which languages are involved’. Support for this model, however, has largely come from language pairs that are typologically different in terms of their clausal word order, or else have vastly different inventories of inflectional morphology. My aim in this work is thus to test the extent to which the underlying principles of the MLF can be applied to Vietnamese–English, that is, two languages that are both subject–verb–object (SVO) and highly analytic.
Approach:
I apply the MLF’s main principles, i.e. the System Morpheme Principle and the Morpheme Order Principle, to Vietnamese–English codeswitching data to determine the extent to which the matrix language of each utterance could be straightforwardly established.
Data and analysis:
Data come from the Canberra Vietnamese English corpus (CanVEC), which contains 45 speakers from both first- and second-generation immigrants. I provide both quantitative and qualitative analyses of the MLF performance on this dataset.
Findings/conclusions:
Results show that MLF model fails to account for the majority of the CanVEC bilingual data, including both first- and second-generation speakers’ production. I further highlight, on empirical grounds, the equivocal nature of assuming speakers’ monolingual code as a basis of comparison, the ‘Composite ML’ notion, and the assumption of null elements in mixed speech.
Originality:
This is the first study that examines Vietnamese–English language contact with respect to the matrix language, using natural language production from the Vietnamese–English bilingual community in Canberra. This is also the first that empirically shows how various parts of the MLF can be both quantitatively and qualitatively problematic.
Significance/implications:
This work addresses a lacuna in the field, where work on minority languages and their speech communities is still much more limited, especially in comparison to English and other Indo-European languages. The data and analysis offered here serve as a modest contribution in this direction, allowing us to address existing biases and to reexamine ‘universal’ assumptions of various kinds.
Introduction
One of the most prominent views in the study of bilingualism is that there exists an asymmetrical relationship between the two languages in any bilingual discourse (Joshi, 1985). That is, in any given combination of two languages, ‘speakers and hearers generally agree on which language the mixed sentence is ‘coming from’’ (Joshi, 1985, pp. 190–191), thereby selecting one ‘main language’ for the utterance. 1 Myers-Scotton (1993) was the first to formalise these ideas into what later became known as the Matrix Language Framework (MLF), which has since enjoyed considerable research attention. Examples (1) and (2) illustrate.

In Example (1), Swahili supplies all the syntactic morphemes and word order and is therefore considered the matrix language (ML). Similarly, Adamme fulfils this role in Example (2) and therefore deemed the ML of this utterance.
Despite being hugely influential, however, support for this asymmetrical model has mainly come from language pairs that are typologically different in terms of their clausal word order, or else have vastly different inventories of inflectional morphology (e.g., Myers-Scotton (1993) on Swahili–English [agglutinative-analytic]; Fuller & Lehnert (2000) on German–English [fusional-analytic]; Deuchar (2006) and Deuchar et al. (2018) on Welsh–English [VSO-SVO]; and Wang (2007) on Tsou–Mandarin [VOS-SVO]). To my knowledge, little to no research has examined the MLF on a language pair that shares the same word order and has limited inflectional morphology. This represents a major shortcoming in the empirical literature, given that the two principles underpinning the MLF – the System Morpheme Principle and the Morpheme Order Principle – heavily depend on these factors. Ultimately, for a model that has claimed ‘universality of support, no matter which languages are involved’ (Myers-Scotton, 2006, p. 248), it is crucial that more diverse evidence is needed.
In this work, I examine the notion of the ML on natural Vietnamese–English code-switching data, produced by the bilingual migrant community in Canberra, Australia. This language pair presents a particularly interesting test case as both Vietnamese and English are SVO and inflectionally limited. It ultimately allows us to ask: ‘To what extent can we straightforwardly identify a Matrix Language in this under-explored bilingual context?’
The rest of the paper is organised as follows. I first introduce the Vietnamese–English code-switching data and the community where it is spoken, followed by a brief background on the MLF and its related work with a particular focus on the model’s predictive power. I then lay out the protocol of how I establish the ML for this dataset, before reporting the results. I conclude with a note on ‘stable bilingualism’ and highlight the implications for future studies of language contact.
Data
Data come from the Canberra Vietnamese–English CS Natural Speech Corpus (CanVEC; L. Nguyen & Bryant, 2020). The community is relatively small in size (1.6% of the total Vietnamese population in Australia), comprising of just over 4,000 speakers reporting speaking Vietnamese at home (Australian Bureau of Statistics, 2021). Canberra attracts the lowest number of recent Vietnamese migrants due to high living costs and more limited job opportunities. The majority is thus well-known for being ‘Canberrans’ for the most part: relatively young, well-paid, and well-educated. They are often employed in education or the public sector (Australian Bureau of Statistics, 2021) and have high English proficiency overall. This contributes to how the Canberra immigrant community is often considered ‘atypical’. Overall, code-switching is also easily and naturally observed (L. Nguyen, 2021; Thai, 2005); conversations within families are on average a mix of half Vietnamese, a quarter code-switching, and a quarter English (L. Nguyen, 2021, p. 54).
Despite a lack of a defined Vietnamese neighbourhood like other cities in Australia, the Canberra community is characterised by a dense social network, regular internal contact, and a high degree of communally shared information and activities. Potential speakers are thus identified as those who share (1) ethnicity as Vietnamese, (2) a base in Canberra, (3) the main languages they speak, that is, Vietnamese and English, (4) cultural events and practices, and (5) an exchange network within the community.
Between June and September 2017, the final sample of 45 Vietnamese–English bilingual speakers living in Canberra and its surrounding regions within the Australian Capital Territory (ACT) was collected. This was a region where I had existing contacts with the community, having lived there for almost a decade, studying and working in Canberra. As Labov (1972, pp. 114–115) recognised, the researcher’s membership of the community offers an important advantage in community-based investigations, as established trust and networks with the speech community enable greater access to natural speech. Participants were sought in two ways: from informal contacts within the community, and via informal advertisements in both English and Vietnamese.
Participants in the study were asked to self-record on their mobile phones one or two conversations totalling at least 30 minutes, with no single recording shorter than 15 minutes. The interlocutor was another Vietnamese-English bilingual whom the speaker would normally speak with casually, for example, a close friend, a colleague, or a family member. Briefing of participants prior to the recording took place to introduce the project. No instruction was given to influence whether participants speak both languages in the recording; instead, they were encouraged to converse as they normally would. No topics or explicit mention of language mixing was given. To maximise data authenticity, I was not present during the recordings. Since speakers had a pre-existing connection with each other, the conversations flowed naturally from the beginning, without no initial awkwardness. I then transcribed the recordings using ELAN, and another bilingual speaker was hired to independently spot check 10% of the transcription.
The final dataset comprises 23 transcribed spontaneous conversations between 45 Vietnamese–English bilingual speakers in Canberra, Australia. First-generation speakers include 15 males and 13 females who are adult acquirers of English and have lived in Canberra for at least 10 years. Second-generation speakers meanwhile include 6 males and 11 females who acquired both English and Vietnamese simultaneously from birth or at a very young age (before 6), and whose parents qualify as first generation. The transcriptions were provided in standard Vietnamese orthography. Table 1 provides some basic statistics.
Basic linguistic statistics of the CanVEC corpus.
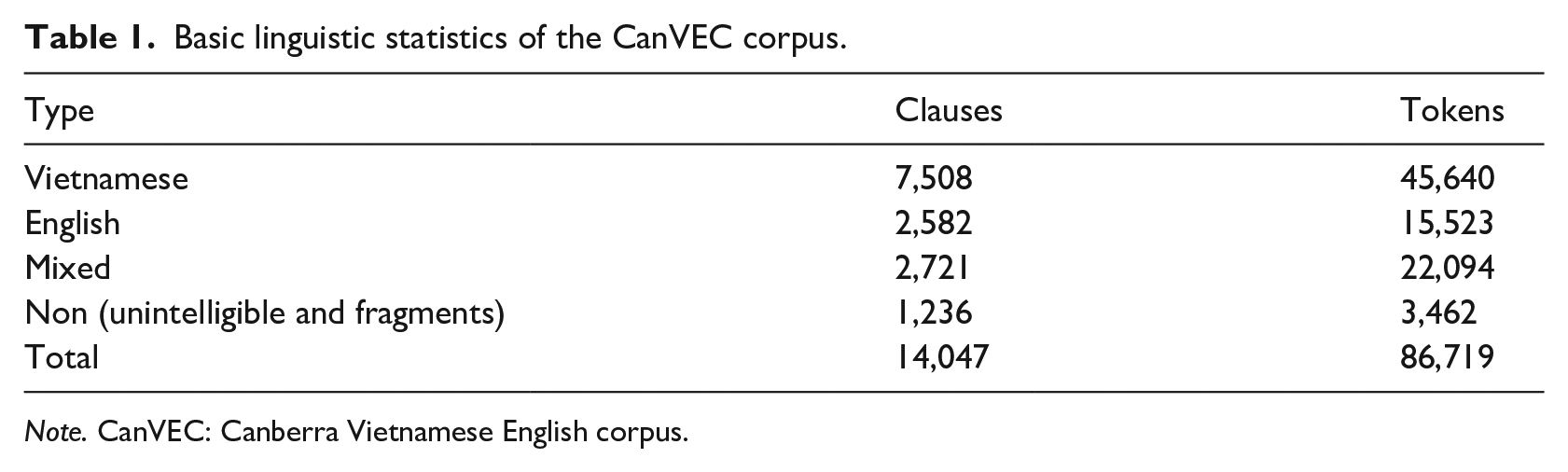
Note. CanVEC: Canberra Vietnamese English corpus.
The MLF
One fundamental aspect of the MLF model is the distinction between Content Morphemes and System Morphemes. Content Morphemes are defined as those that can assign or receive thematic roles, with semantic and pragmatic features, while System Morphemes ‘largely indicate relations between Content Morphemes’ (Myers-Scotton, 2002, p. 15). This distinction is further developed into what she terms the ‘4M model’, which is summarised in Figure 1.
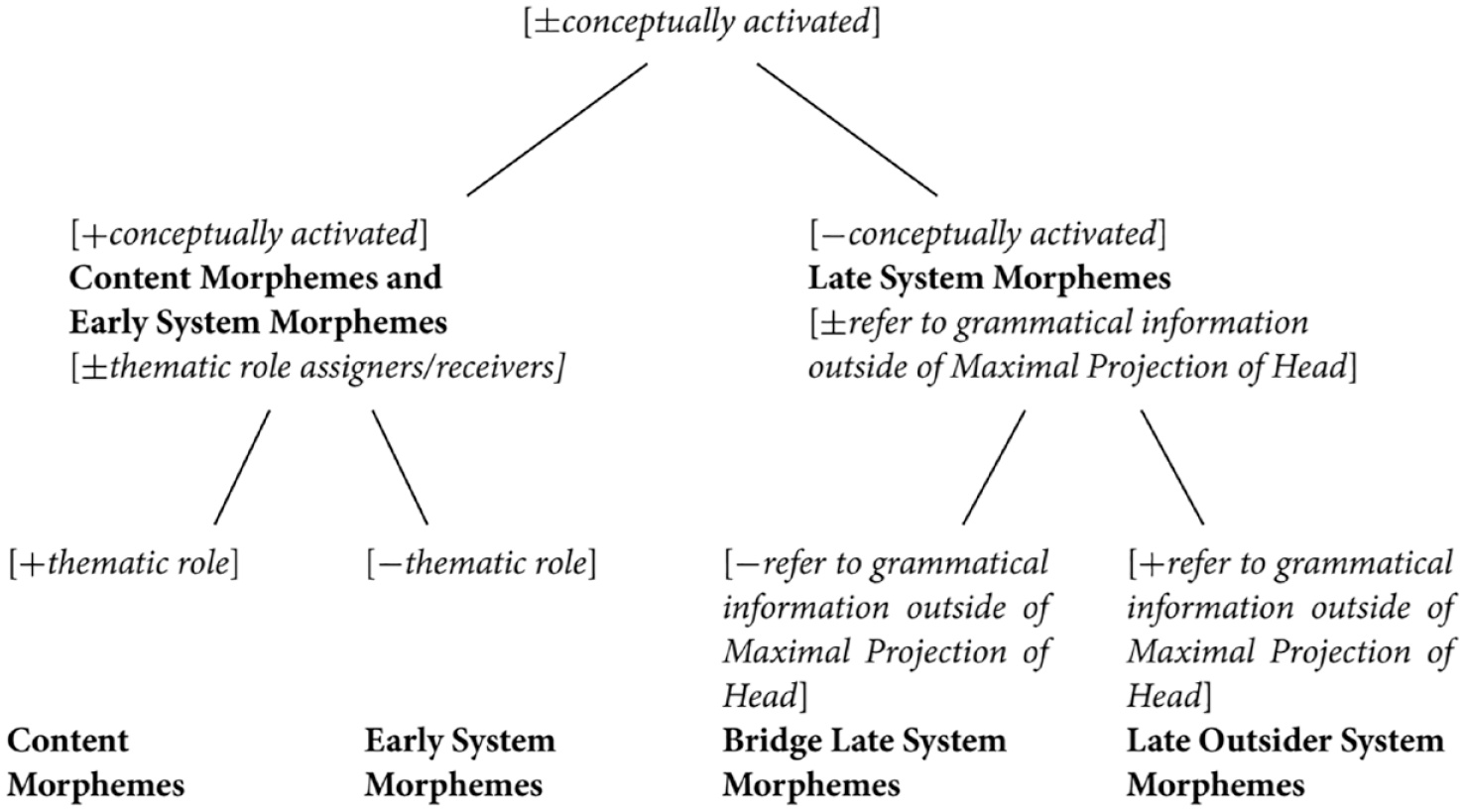
Different types of morphemes in the 4M model, Myers-Scotton (2002, p. 73).
In this model, Early System Morphemes are conceptually activated and index ‘semantic and pragmatic meanings that satisfy speakers’ intention’ (Myers-Scotton & Jake, 2000b, p. 1055) (e.g., determiners and plural markers in English). Late System Morphemes, by contrast, do not require activation at the lemma level (e.g., verbal agreement). Bridge Morphemes, such as possessive ‘of’ and ‘’s’ in English, also belong to this category and are characterised by their ability to ‘unite morphemes into larger constituents’ (Myers-Scotton & Jake, 2000a, p. 4). Nonetheless, as we will shortly see, the most important type of System Morphemes that are central to the identification of the ML are Late Outsider System Morphemes. Following Myers-Scotton and Jake (2000a), Late Outsider System Morphemes are defined as those depending on information outside their immediate maximal projection (i.e., an XP of some kind) for their forms. Typical Late Outsider Morphemes are subject-verb agreement affixes and case affixes.
Another key distinction in the MLF model is that of the ML and the Embedded Language (EL). According to Myers-Scotton (2002), the ML is the language that contributes more by supplying the grammatical structure for a mixed utterance, while the EL is only responsible for inserted materials within the ML frame. To identify the ML, Myers-Scotton proposed two universal principles that can be applied to any language pairs:
1. The System Morpheme Principle:
In ML+EL constituents, all System Morphemes which have grammatical relations external to their head constituent (i.e. which participate in the sentence’s thematic role grid) will come from the ML.
2. The Morpheme Order Principle:
In ML+EL constituents consisting of singly occurring EL lexemes and any number of ML morphemes, the surface morpheme order (reflecting surface syntactic relations) will be that of the ML. (Myers-Scotton, 2002, p. 59)
In Myers-Scotton’s model, both principles are applied simultaneously, meaning both principles must be satisfied in any given code-switching clause. Essentially, the ML is supposed to be the language determining the word order and the language that supplies function words. The ‘constituents’ referred to in the above principles are either an ML+EL mixed constituent, an EL island containing only EL morphemes, or an ML island containing only ML morphemes.
An important point worth stressing is that, while the System Morpheme Principle only refers to a specific subset of morphemes ‘that have grammatical relations external to their head constituent’ (i.e., Late Outsider Morphemes), other types of System Morphemes are also believed to almost always come from the ML. The ‘Uniform Structure Principle’ of the MLF ‘predicts early and Bridge Late System Morphemes from the ML as the unmarked choice – just because it gives preference to keeping structure uniform across the CP’ (Myers-Scotton, 2002, p. 120).
The predictive power of the MLF
Although the MLF has been used as a productive platform to analyse CS data, its predictive power remains debatable. For example, in a study focusing on Arabic diglossic switching between Tunisian Arabic (TA), a dialectal variety of Arabic spoken in Tunisia, and Fushaa, a blanket term for Classical Arabic/Modern Standard Arabic, Boussofara-Omar (2003) put forward counter examples to the two main principles of the MLF (i.e., the System Morpheme Principle and the Morpheme Order Principle), showing that (i) it is possible for both participating languages to contribute System Morphemes to the clause; and (ii) there exist cases where all morphemes come from Fushaa, but word order reflects that of Tunisian Arabic.
Responding to these examples, Myers-Scotton (2004) claims that ‘the MLF model was formulated to cover CS between language varieties that are separate languages (i.e., not mutually intelligible varieties, such as dialects)’ (p.89). However, as Wang (2007) points out, this defence is problematic as the boundary between a language and a dialect can be rather blurry. Varieties are often classified as ‘dialects’ of a particular language merely for socio-political rather than linguistic reasons. Furthermore, not all dialectal varieties are mutually intelligible. Mandarin and Southern Min offers a good example. Although Southern Min is often labelled as a dialect of Chinese and shares most of its morphosyntax with Mandarin, they differ substantially in their lexicon and phonology (Wang, 2007, p. 81). Similarly Auer and Muhamedova (2005) found that ‘a neat separation between Matrix and Embedded Language is impossible’ (p.52), using Kazakh–Russian and Latin–Early New High German data. They specifically show how EL islands are not utterly free from the dictates of the ML, and furthermore, in the opposite direction that the ML can also be influenced by the EL.
Among those sharing the view that code-switched data is not a ‘monolingual mix’, MacSwan (2005) was the pioneer of the generative approach, arguing that a theory of CS does not need to draw on a CS-specific mechanism. He draws on data from multiple language pairs, showing how the MLF principles fail to predict ‘codeswitching grammar’; Example (3) is one of these:

In this example, MacSwan (2005) argues that as the EL (i.e., English) also supplies a System Morpheme for the clause (i.e., English determiner ‘the’), 2 this is a violation of the System Morpheme Principle. Although Myers-Scotton and colleagues have pointed out that this involves a misinterpretation of the MLF in that ‘the’ is an Early System Morpheme and therefore does not need to come from the ML (Jake et al., 2005, p. 272), this creates issues in another part of the model, ‘the Uniform Structure Principle’. Recall that the Uniform Structure Principle is an augmented principle embedded in the theoretical account of the MLF. Specifically, the Principle stipulates that all structural elements are preferably sourced from the ML to maintain the CP’s wellformedness. The occurrence of an English Early System Morpheme in Example (3) thus diminishes the predictive power of the MLF model.
Some other studies have also tested the predictive power of the MLF in comparison to that of the Minimalist Programme (MP). For determiner phrases, for example, the MLF predicts that the determiner is sourced from the ML (i.e., the language of the finite verbs, which form the category of ‘Late System Morphemes’ as described in Figure 1), while the MP predicts that determiners would be sourced from the language with grammatical gender (i.e., Welsh or Spanish, but not English). The results by Herring et al. (2010) on Welsh–English found higher support for the MP in terms of coverage of the data, and no significant differences between the accuracy of the models’ predictions on both language pairs. Similarly, for adjective–noun combinations in several languages, research has found both evidence for (Parafita Couto et al., 2015 – English–Welsh) and against the MLF (Cantone & MacSwan, 2009 – German–Italian, Wyngaerd, 2017 – French–Dutch).
Ultimately, a common characteristic of all the studies so far is that they involve language pairs that have different word orders and/or different inflectional morphology (i.e., the two criteria upheld by the MLF principles). As far as I am aware, only one study to date has tested the predictive power of the MLF on both sets of language combination, that is, Mandarin–Tsou and Mandarin–Southern Min, respectively (Wang, 2007). The finding is particularly telling in that while the MLF model could be straightforwardly applied to Mandarin–Tsou due to their different word orders and morphology, it was found to struggle with Mandarin–Southern Min, a language pair that shares the same surface clausal word order with limited overt morphology. Wang (2007) reported that the MLF principles were only able to account for less than 10% of the Mandarin–Southern Min data (N < 30/300), with success rates ranging from 3% to 8% between groups of speakers. Wang dealt with this problem by suggesting the revival of two additional criteria that had previously been abandoned by Myers-Scotton herself (Myers-Scotton, 2002): the Morpheme Counting Principle (i.e., the language has the higher number of morphemes in an utterance is the ML) and the Uniform Structure Principle (i.e., the language that supplies early and bridge System Morphemes is the ML). I will return to these additional criteria in more detail in the section ‘Findings and discussion’, where I showcase how these criteria remain linguistically arbitrary and are not applicable to Vietnamese–English.
For Vietnamese–English CS specifically, the application of the MLF has only come up very briefly in one study thus far (Tuc, 2003). Set in Victoria, Australia in 1994, the study posed a broad question of how first-generation Vietnamese speakers use CS in their bilingual repertoire. Tuc’s most relevant finding was that within a single NP, when a single attributive adjective is from English, the position of this adjective is ‘always on the right-hand side of the Vietnamese noun’ (p.65), which reflects Vietnamese NP word order and contrasts with English. However, due to lack of information on how the ML was determined, this observation alone cannot show whether or not the structure of these mixed NPs conforms to the constraint prescribed by the MLF (i.e., the language of the finite verb dictates the word order of mixed Adj-N combinations). This finding also only constituted a small part of Tuc’s work, and therefore did not merit any further analysis in his study.
At this point, it becomes apparent that the MLF has been applied to a range of different language pairs, with various degrees of success. However, what seems missing in these studies is the due consideration of an important question that is not often asked: whose ML is it that we are talking about when we ‘assign’ the ML? In these studies, the assumptions seem to be that community’s monolingual ‘norm’ is consistent with ‘standard’ facts of the participating languages. This is particularly problematic, given that it has long been established that language variation is the norm, not the exception (Bolton, 2018; Clark, 2016; de Vogelaer & Katerbow, 2017; Hudson Kam, 2015; Labov, 1995; Mesthrie & Bhatt, 2008; Poplack, 2018; Saraceni, 2010, 2015; Tagliamonte, 2007; Tagliamonte, 2011, 2012). 3 I thus attempt to probe this missing element in this work, using natural conversational Vietnamese–English code-switching data from the bilingual Vietnamese community in Canberra, Australia. The data involve both the speakers’ monolingual and code-switching production, and is therefore particularly suitable to examine this underlying assumption of the MLF. I next apply the MLF’s two main principles, the System Morpheme Principle and the Morpheme Order Principle, to the code-switching subset and demonstrate how the data are coded.
Identifying the ML in Vietnamese–English CS
The System Morpheme Principle
As previously discussed, the System Morpheme Principle specifies that the language of the Late Outsider Morpheme is the ML of any given bilingual CP. The augmented 4M model (Figure 1) further stipulates that Late Outsider System Morphemes include any morpheme under INFL, which cannot be realised without checking with another element in the sentence (i.e., ‘outside of Maximal Projection of Head’.) However, because Vietnamese does not inflect and has neither subject–verb agreement nor case affixes, this presents a significant challenge. This means that the System Morpheme Principle, as it stands, can only be applied to mixed clauses with an English finite verb in this study.
Another issue with the System Morpheme Principle is that even when we have a mixed clause with an English finite verb, subject–verb agreement varies due to a phonological characteristic typical of Vietnamese L2 speakers of English. Specifically, the coda is most often unreleased, as in the following example. Note that whenever CanVEC examples are presented, I use a subscript number at the end of each speaker’s pseudonym (1, 2) to indicate their generation membership. For example, Harry1 signals that Harry is a first-generation speaker.

In this example, it was not possible to determine from the recording whether agreement had occurred or not, because the missing coda /s/ indicating 3SG agreement in ‘lives’ can be interpreted as either being absent or present but phonetically unrealised. Similar examples of deleted codas in speakers’ production are well-represented across the corpus, and can be observed by listening to almost any recording. This observation is in line with previous studies’ discussion of Vietnamese speakers’ phonotactic tendency to delete or reduce final consonants in speech (Lardiere, 1998; Osburne, 1996; Patil, 2008) both in English and in Vietnamese, furthering reducing the applicability of this principle. Ultimately, where there is no phonetic realisation of a Late Outsider Morpheme as in Example (4), we have no basis to determine whether the cause is down to phonology or syntax. Only the latter matters in establishing an ML.
Limited display of overt inflections in both languages thus makes the System Morpheme Principle extremely problematic for a language pair like Vietnamese–English. The problem is further amplified by the fact that, similarly to other analytic languages (e.g., Mandarin, Cantonese, Thai), morphemes in Vietnamese are highly multi-functional; the same element, unchanged in form, can either be a System or a Content Morpheme depending on its distribution. Examples (5) and (6) illustrate:

In Example (5), đã is a Content Morpheme that means ‘satisfying’, which occurs after the clausal subject and acts as the main (stative) verb. In Example (6), however, the same element precedes the main verb làm ‘do’ and is a past tense marker. 4 These ‘đã’ are homonyms with both identical pronunciations and identical spellings but different meanings. Using the System Morpheme Principle in Vietnamese–English mixed speech, then, actually requires consideration of the morpheme position, rather than the form of the morpheme itself. This leads us to the discussion of the Morpheme Order Principle.
The Morpheme Order Principle
The Morpheme Order Principle states that the surface word order of a mixed clause is determined by the ML. The application of this principle assumes that the two languages involved have different word orders at a clausal level, which is not the case for English and Vietnamese, ‘as demonstrated in Example (7).
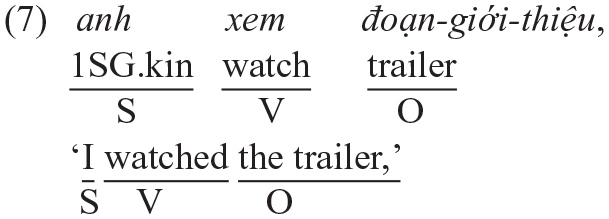
It is thus not possible to attribute the word order identified in a CS utterance like Example (8) below to either English or Vietnamese, given SVO is the default word order in both languages.

It is worth noting, however, that while the Morpheme Order Principle is not applicable in Vietnamese–English code-switching data at a clausal level, it is quite productive in the nominal domain and in the formation of interrogatives. These outward grammatical contrasts have long been known as ‘conflict sites’ (Poplack & Meechan, 1998), i.e. points at which the surface structures of two languages differ. Given limited inflectional morphology in both languages, these ‘conflict sites’ are helpful in identifying the ML of the clauses in this study.
Nominal domain
Vietnamese is a head-initial language, which places all of its modifiers, except for classifiers and numerals, post-nominally (Duffield, 2013). In English, despite a few exceptions (which do not appear in my data), the canonical order for attributive modifiers is pre-nominal. Examples (9)–(11) below provide some illustration:

In Example (9), the mixed NP ‘this sách’ follows English word order, where the demonstrative determiner ‘this’ precedes the Vietnamese head noun sách (book). According to the Morpheme Order Principle, this means English provides the syntactic structure of the NP and is thus the ML. By contrast, in Examples (10) and (11), the word order selected by the NP cái chuyện không ok’ (that ‘not-okay’ story) and ‘clip nó’ (his or her clip) mirrors Vietnamese word order, and so Vietnamese is considered the ML.
Polar questions
The formulation of polar questions is another promising diagnostic that can be used to differentiate between English-ML and Vietnamese-ML clauses. Consider Examples (12) and (13):
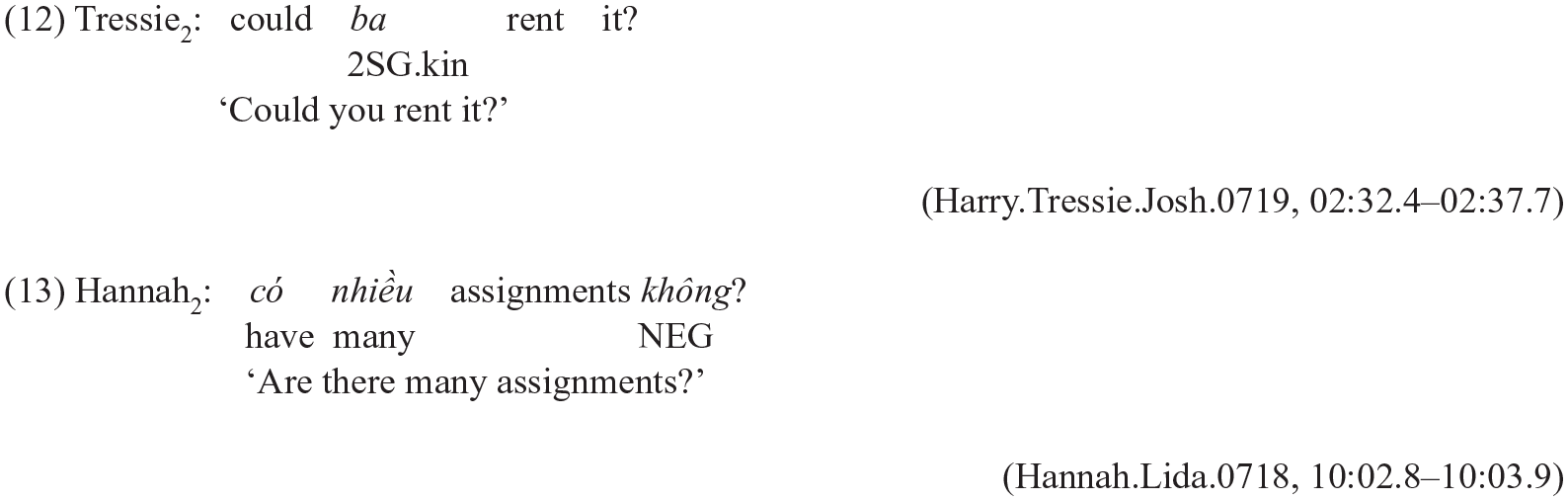
In Example (12), the modal ‘could’ was fronted to form the question and so it is clear that it follows English word order. English is then considered the ML. In contrast, the speaker in Example (13) inserted the negator không at the end of the utterance to form a standard polar question. This mirrors Vietnamese word order and so Vietnamese is considered the ML of the utterance.
Wh-questions
The formation of Wh-questions is another syntactic feature that is not shared by English and Vietnamese. English content questions are typically formed by Wh-movement followed by an auxiliary verb (Erickson, 2001). By contrast, Vietnamese is a Wh-in situ language, which means that Wh-questions follow the same SVO order as a declarative (D. H. Nguyen, 1997). Examples (14) and (15) demonstrate this. In Example (15), an equivalent declarative is also provided in (15b) for clarification.

Such differences in the syntactic structures of Wh-questions suggest that in a mixed content question, the position of the Wh-word could reveal the ML. Consider the following example:
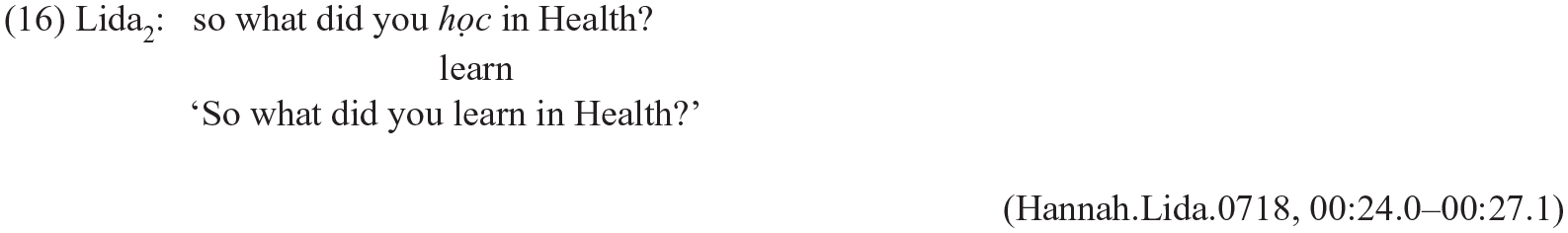
In this example, since the Wh-question was formed based on the English rule; that is, the Wh-word placed at the beginning of the sentence and the movement of the auxiliary ‘did’, English is tagged as the ML of this clause.
Having discussed the universal principles of the MLF and where they can be applied, I next present the outcome of applying these principles to CanVEC.
Findings and discussion
It is clear from our previous discussion that there are only limited instances where the original MLF criteria can be applied to Vietnamese–English. I would also make explicit here that the System Morpheme Principle and the Morpheme Order Principle should be applied simultaneously and the outcomes are expected to converge – that is, the ML identified by the SMP should be the same as the ML identified by the MOP. Figure 2 reports the outcome of applying these universal MLF principles in CanVEC.
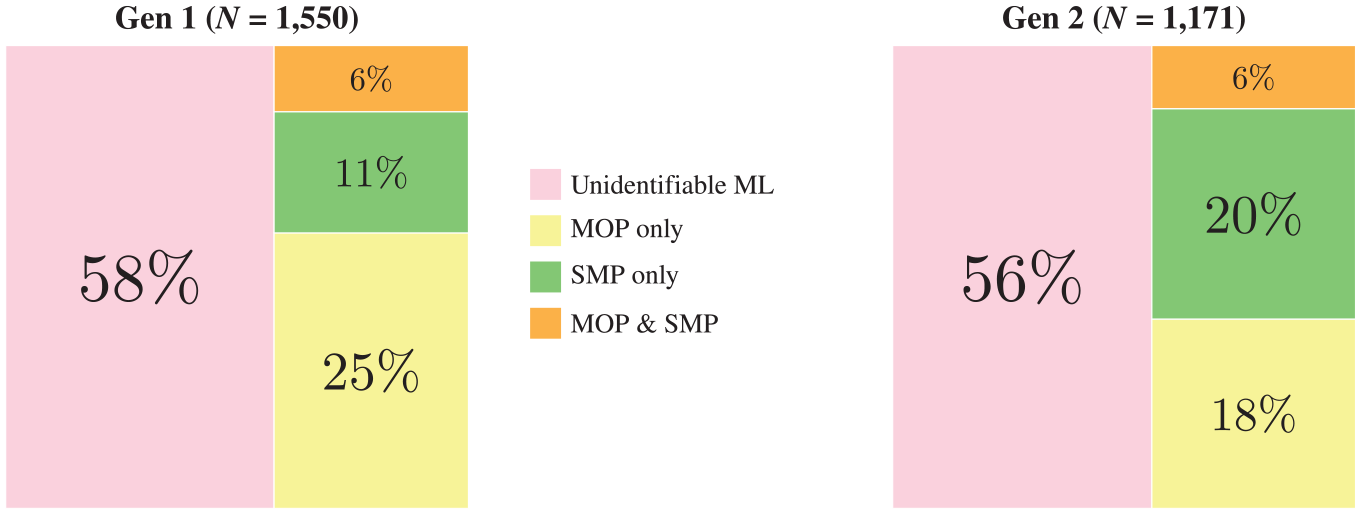
The proportion of mixed clauses captured by MLF principles.
As Figure 2 illustrates, the proportion of mixed clauses where both principles apply accounts for just 6% in each generation. In addition, the System Morpheme Principle seems to be more effective on the second-generation data than on the first-generation (20% vs 11%). This is due to the fact that first-generation speakers’ production display more L2 effects (cf. Example (4)). The fact that the System Morpheme Principle is more productive in second-generation data can also be further explained by the fact that second-generation speakers in the corpus produced more English-ML mixed utterances, where Late Outsider Morphemes (i.e., subject–verb agreements) manifest in a more overt way.
What really stands out in Figure 2, however, is not the difference in individual rates of success obtained with each principle, but the overwhelming proportion of the mixed data as yet unaccounted for. As Figure 2 clearly shows, MLF principles were only helpful in identifying the ML in just over 40% of the corpus, leaving more than half of the mixed clauses’ ML unidentified. This is a striking result, particularly for a model that has been claimed to be universally functional ‘no matter what languages are involved’ (Myers-Scotton, 2006, p. 248). This is furthermore at odds with some previous suggestions that the MLF works unfailingly on genetically distinct languages (such as English and Vietnamese), where ‘there seems to be a universal tendency to select one morpho-syntactic rule’ (or, more precisely, the morpho-syntactic rules of one language) over the other (Chan, 2009, p. 197).
Table 2 provides a breakdown of data types, which remain unaccounted for. As we can see, only roughly 10%–20% of the data without an identifiable ML involved congruent word order. A major proportion of this subset (∼90%, N = 1,555) are characterised by various other features.
An overview of CanVEC data where the ML cannot be straightforwardly determined.
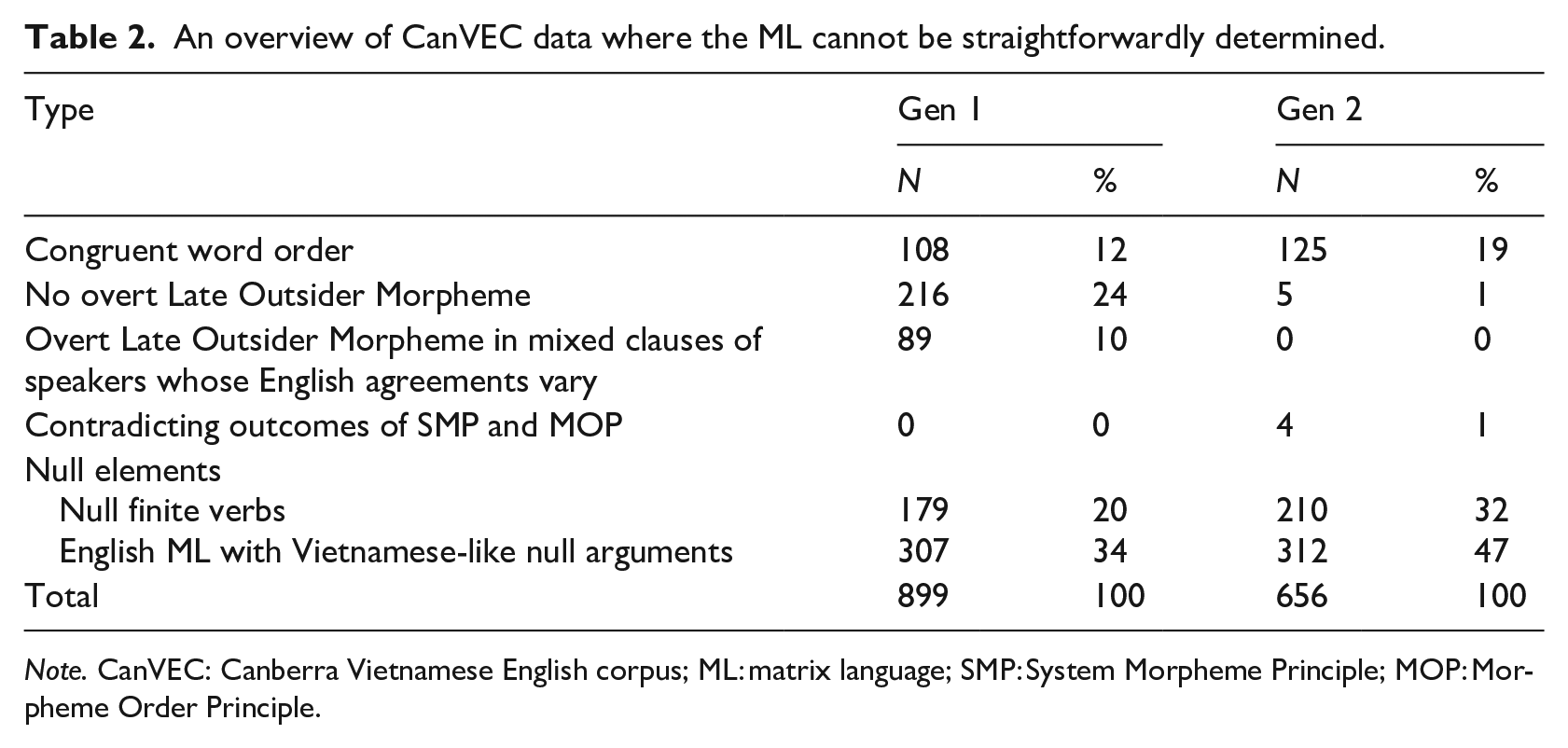
Note. CanVEC: Canberra Vietnamese English corpus; ML: matrix language; SMP: System Morpheme Principle; MOP: Morpheme Order Principle.
A logical next step, then, is to dig deeper into each of these categories and examine what makes them particularly challenging for the MLF?
Whose ML is the ML?
Recall from the section ‘Identifying the ML in Vietnamese-English CS’ that we were only able to apply the System Morpheme Principle to mixed clauses with an overt realisation of English verbal agreement in this study, due to the structural nature of the languages involved. The issue for the first-generation speakers, nonetheless, remains that there is very little overt verbal agreement marking due to their phonotactic characteristics (section ‘Identifying the ML in Vietnamese-English CS’). In cases where there is no overt agreement where it should occur, it is thus difficult to determine whether it is due to the speakers’ phonotactic tendency to delete final consonants, or whether it is because they actually do not have any syntactic agreement in place.
However, as the data also show, even when applying this principle to the limited proportion of mixed clauses with overt English agreement, the determination of ML may still be nowhere near straightforward for some speakers. Consider Example (17) below from Reece, one of the first-generation speakers in the corpus.

In this example, Reece’s mixed utterance follows English subject–verb agreement rules. As English supplies the Late Outsider Morpheme (i.e., agreement ‘-s’), it is thus considered the ML. However, this analysis appears problematic when we consider Reece’s monolingual English variety in the examples below. By way of contrast, overt agreement is marked with underline and unexpressed agreement is marked with

As Examples (18) and (19) illustrate, Reece’s English agreement varies, with the unexpressed variant appearing to be more common. This echoes the dilemma previously described, where an absence of phonetic realisation of Late Outsider Morphemes could either be the result of a phonotactic tendency or a manifestation of a grammatical feature. Only when it is a phonotactic tendency, however, can we reasonably say that speakers follow English grammatical rules (i.e., the grammatical agreement is there, just without phonetic realisation) and therefore that English is the ML. On the other hand, if it is indeed a manifestation of speakers’ grammar, then we have no basis to determine the ML: the speakers’ English variety does not have subject–verb agreement either, just like their monolingual Vietnamese. Unfortunately, there is no easy way to decide which scenario is more likely, especially in a community where speakers are highly bilingual.
In the context of Reece’s speech, one might argue that, though variable, the fact that he occasionally has agreement in his monolingual English may suggest that this feature does exist in his English variety. Given that Vietnamese does not require agreement at all while English does, overt agreement in his mixed clauses can thus only indicate that this grammatical feature comes from English. I would like to point out, however, that even if subject–verb agreement does exist in Reece’s English, data clearly shows that his (and most CanVEC first-generation speakers’) overt realisation and non-overt realisation of English agreements varies to a large extent, with the non-overt agreement being considerably more common in the corpus (N = 212/247). 5 This observation suggests that there might be different factors conditioning overt and non-overt subject–verb agreement in speakers’ English. Until we know precisely what these conditions are, we still do not have a strong basis upon which we can reliably assign English as the ML of the speaker’s mixed utterance. 6 This again amplifies the inherent problematic assumption of a prescriptively sanctioned standard monolingual baseline in interpreting the ML, a point I previously discussed in ‘The predictive power of the MLF’.
Composite ML
Another issue that emerges from this set of challenging data is cases where the System Morpheme Principle and the Morpheme Order Principle each point to a different ML. The MLF states that in any given mixed CP, only one language is the ML, and only this ML can supply the word order and Late Outsider Morphemes for the utterance. On this basis, the System Morpheme Principle and the Morpheme Order Principle are non-hierarchical criteria, and their results should ultimately converge. However, it is apparent from the data that this is not always the case. For example, there is some evidence of word order coming from one language but Late Outsider Morphemes from the other. Consider the following:

As Examples (20)–(23) illustrate, there is a pattern of conflicting evidence for the ML, when the Late Outsider Morpheme comes from one language but the morpheme order comes from the other. Specifically, the finite verbs in these examples all come from English, and the overall clausal word order could be English (or Vietnamese; we cannot tell due to congruent word order), yet the nominal word order follows that of Vietnamese: ‘booklet này’ (N + DET) in Example (20), ‘mistake worst’ (N + ADJ) in Example (21), ‘competition really bự này’ (N + ADJ + DET) in Example (22), and ‘thing khó’ (N + ADJ) in Example (23). Given that both Vietnamese and English contribute to the basic grammatical structure, we are left with no means to determine the ML of these utterances.
We should note here that this ‘hybrid’ scenario has been somewhat addressed in what Myers-Scotton (1998) called a ‘Composite ML’, that is, a situation where the morphosyntactic frame of a CP comes from both participating varieties, and this ‘Composite ML’ fossilises as the main medium of communication. This is hypothesised as the stage in language shift where two languages converge, splitting and recombining abstract lexical structure. This idea of a Composite ML, however, has been particularly subject to criticisms (Auer & Muhamedova, 2005; Boussofara-Omar, 2003; P. Davies & Deuchar, 2010; Gardner-Chloros, 2009), first and foremost for its directly conflicting nature with the fundamental idea of the MLF. That is, if we accept that more than one variety can participate in setting out the grammatical structure of the ML + EL constituents, then the ML–EL hierarchy and the System-Content Morpheme distinction are substantially weakened (Boussofara-Omar, 2003). 8 These theoretical issues, coupled with the empirical data presented here, present serious challenges for identifying a clear ML in bilingual discourse.
Another crucial aspect that is worth pointing out is that, though small in number (N = 4), all of these Composite-ML clauses were produced by second-generation speakers. Given that Myers-Scotton (1998, p. 299) attributes the mechanism of a Composite ML to second language learners (whose ‘imperfect knowledge’ of the target language licences ‘Composite-ML structures’), we would expect that most of the Composite-ML utterances were produced by the first-generation speakers who acquired English as a second language. This is not the case we see in CanVEC. Intriguingly, while this result contradicts Myers-Scotton’s (1998) theoretical proposition, it is consistent with her own empirical findings in a study of the Arab–American community in Columbia (Jake & Myers-Scotton, 2009). In this study, second-generation Arabs produced eight times more Composite-ML clauses than first-generation speakers (N = 34 vs N = 4). The theoretical implication of these findings, however, was not explicated.
Ultimately, the point worth stressing here is that the current MLF model cannot account for cases where the results of the Morpheme Order Principle and the System Morpheme Principle are in conflict. Although the idea of a Composite ML seemingly addresses cases that show the lexical items from one language but the grammar from another, it still cannot offer a principled explanation for cases exhibiting mismatched grammatical outcomes (e.g., Examples (20)–(23)). Simply labelling these instances Composite-ML structures therefore seems like stretching the model to cover data that do not fit.
Clauses with null elements
The majority of the data that were unaccounted for, in fact, are characterised by language-specific constructions that neither of the MLF principles is capable of accounting for, in particular clauses with null elements (N = 1,008). The first to be discussed are dropped English auxiliaries (e.g., ‘

As we can see, auxiliary drop occurs quite frequently in spoken English across different generations. This phenomenon is also prevalent in CanVEC mixed clauses, as shown in Examples (27)–(29).

Given that the System Morpheme Principle relies on the manifestation of a Late Outsider System Morpheme as an indication of the ML, non-standard finite clauses without an overt auxiliary (which is, in most cases, also the finite verb), render the principle problematic. It is worth noting that a similar finding was previously reported for Welsh–English (P. G. C. Davies, 2010), wherein the ML could only be reliably identified in clauses with an overt finite verb. Nonfinite or verbless clauses, in contrast, could only have an identifiable ML where other cues of ‘conflict sites’ are present, for example, an NP with a modifying element, similar to what I previously described for Vietnamese–English in this study.
It should also be noted that while CPs as the proposed unit of analysis can contain null elements, ‘assuming’ the form of such null elements in a CS context is not so straightforward. Specifically, Myers-Scotton (2002, p. 55) cites English ellipses as examples, and argues that CPs such as ‘What?’ or ‘Never!’ are ‘simply monolingual CPs that contain a number of null elements’, and that these null elements can be assumed for the purpose of identifying the ML. This assumption, though, is particularly problematic. In a discourse context where there are at least two languages in play, we cannot straightforwardly determine to which language the null elements belong. Consider the veto on the switch between a subject pronoun and a verb as an example. Despite some cross-linguistic evidence proposing that a switch between a pronoun and a verb is ‘impossible’ (Fuertes et al., 2013; Gumperz, 1977; Lipski, 2019; MacSwan & Colina, 2014; Timm, 1975; van Gelderen & MacSwan, 2008), a study on the Vietnamese community in Australia found that single insertion of Vietnamese pronominal kin terms in otherwise-English discourse is the most common switching pattern (L. Nguyen, 2018). This trend is also reflected in CanVEC: switches between a pronoun and a verb are highly probable (e.g., line f. [finite], or line a., b., c., e., and i. (non-finite) in Example (28)), making it equally plausible for the null elements in these cases to be Vietnamese as they are to be English. This underlines the fact that no linguistic evidence of ‘predictable switching points’ is yet conclusive enough such that we can confidently assume the language of null elements in mixed discourse (Auer & Muhamedova, 2005; Boussofara-Omar, 2003; Chan, 2008; Clyne, 1987; Gardner-Chloros & Edwards, 2004; Malik & Khurshid, 2017; Parafita Couto et al. 2015, i.a.).
Other than null finite verbs, for which the language cannot be determined, some of the data in CanVEC (see Table 2) also feature a structure where the two main MLF principles point to English as the ML, but the arguments are left null largely in Vietnamese-permitted environments. Examples (30)–(33) illustrate this pattern from both generations in the corpus.

As the examples demonstrate, while the MLF System Morpheme Principle and Morpheme Order Principle determine that English is the ML in these clauses, the structures show some Vietnamese-like abstract influence in terms of null arguments. Recall that Composite ML does not only cover conflicting outcomes of the two main principles, but also those exhibiting ‘grammatical features’ of all sorts from both languages. I discussed in the previous section how this concept is problematic. It is even more so in Vietnamese where the predisposition for null arguments is extremely complex (L. Nguyen, 2018, 2021) – different speakers are under different constraints as to when they can and cannot leave elements unexpressed. It thus seems unsatisfactory to classify the clauses under discussion here as either English-ML or Composite-ML clauses based on the current principles.
Considering Wang’s additional principles
Having shown how the original principles of the MLF are not effective on the Vietnamese–English code-switching data, I would like to return to Wang’s (2007, 2016) proposal to extend the MLF model to ‘challenging’ language pairs. Specifically, Wang previously reported the limited applications of the MLF on isolating languages (Mandarin–Southern Min), and proposed the re-introduction of the ‘Uniform Structure Principle and the ‘Morpheme Counting Principle’ as a solution (cf. ‘The predictive power of the MLF’). These principles, however, remain problematic for Vietnamese–English code-switching data.
The Uniform Structure Principle states that Early and Bridge Late System Morphemes come from the ML as the unmarked choice – ‘just because it gives preference to keeping structure uniform across the CP’ (Myers-Scotton, 2002, p. 120). In this sense, the Bridge Morpheme của (possessive marker) in Vietnamese could potentially be used to test this principle; however, it is optional in most contexts. Example (34) demonstrates a typical case in the corpus, where the Bridge Morpheme của is not phonologically realised at all.

In fact, this observed phenomenon reflects the widely permitted omission of the Bridge Morpheme in Vietnamese (D. H. Nguyen, 1997, p. 184): của is only required where the possession is to be emphasised or contrasted. Furthermore, even when Bridge Morphemes do occur, they pattern similarly to the Vietnamese Early System Morpheme cái (Vietnamese generic classifier) in that they are present mostly in monolingual Vietnamese clauses, English clauses with Late Outsider Morphemes already present as shown in Example (35a), or mixed clauses that are already ML-identifiable by the original principles as in Example (35b).
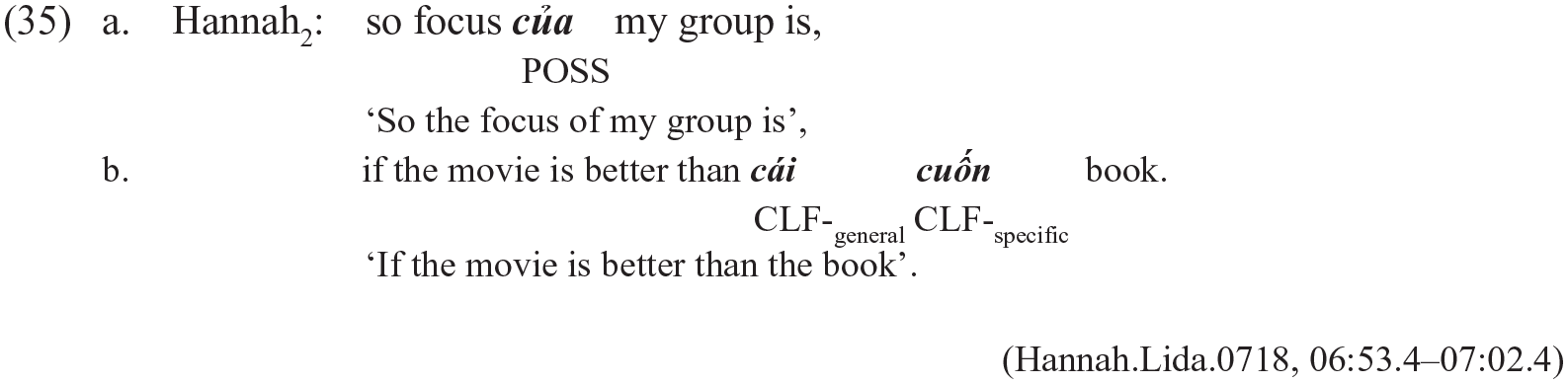
As for the Morpheme Counting Principle, the premise is that ‘the language that is the source of the grammatical frame often supplies more morphemes in a bilingual CP’ (Myers-Scotton, 2002, p. 61). The first issue in applying the Morpheme Counting Principle is that frequency counts cannot be applied to individual clauses. As Myers-Scotton (1993) observes, ‘frequency counts must be based on a discourse sample; they offer no reliable evidence if they are performed on single sentences’ (p. 68). Wang’s decision to apply them at the level of individual clauses for Mandarin–Southern Min is therefore rather puzzling. Furthermore, it is worth noting that the concept of a ‘discourse sample’, in fact, has not been well-defined either. It remains unclear what counts as a discourse sample, and ‘how large is large enough is an unresolved issue’ (Myers-Scotton, 1993, p. 68). On the whole, a more crucial empirical question to ask is whether the language that has the larger total number of morphemes in the entire corpus should be considered the ML, irrespective of the intricacies of word order and system morphemes at a clausal level. If so, this seems to defeat the idea of the ML as a ‘grammatical construct’. If not, we need an explicit explanation of how and under what constraints the principle can operate.
Furthermore, Myers-Scotton (1993) also states that ‘cultural borrowings from the Embedded Language for new objects and concepts are excluded from the count’ (p. 68). Yet the question of what counts as borrowing is already controversial in the CS literature, let alone the distinction between ‘cultural borrowing’ and ‘core borrowing’. 10 According to Myers-Scotton (1993, pp. 168–171), because there is ‘an equivalent’ in the recipient language, ‘core borrowing’ must be used for purposes other than filling a lexical gap. Only in this case is borrowing considered a valid morpheme for the Morpheme Counting Principle. On an empirical basis, this distinction appears unclear as there is no specification of how, or in what aspect, a concept can be considered to have a ‘viable equivalent’ in the other language. This difficulty has been previously reported for Vietnamese–English in a study on the usage of Vietnamese kin terms in bilingual discourse (L. Nguyen, 2016).
Finally, as Muysken (2000) points out, the Morpheme Counting Principle is questionable when applied to language pairs that are typologically disparate with respect to morphology, because it will favour the one with the larger inventory of grammatical morphemes. This point was well-taken by Myers-Scotton (2002), and contributed to her decision to abandon this criterion in later work. Although this was not a problem for Wang (2007, 2016) as he argued that Mandarin and Southern Min are both isolating, it is not the case for Vietnamese–English. Specifically, although both Vietnamese and English are highly analytic, English still has moderate inflection marking person-number, tense and aspect, whereas Vietnamese has no obligatory grammatical device for doing so. As we can see in Example (36), a Vietnamese exact equivalent (Luna, 36c) of a simple English clause (Tressie, 36a) has fewer overt morphemes due to lack of verbal agreement (‘-s’ in the English verb ‘likes’). Similarly, Vietnamese does not overtly mark tense very often (e.g., Examples (36d) and (36e)), hence the range of morphemes in the verbal domain is far more limited.

This, taken together with the fact that Vietnamese broadly allows null arguments (as in Example (36e); cf. also ‘Findings and discussion’), means that applying the Morpheme Counting Principle to a language pair like Vietnamese–English is particularly difficult.
A note on ‘stable bilingualism’
Before concluding the paper, I would like to deal with Myers-Scotton’s (2002) claim in her latest version of the MLF that the MLF is devised to account for ‘stable bilingualism’ only, and that ‘problematic cases’ often do not fall inside this remit (p.111). Specifically, she writes: ‘the MLF cannot account for all the structures in the CS of speakers in those communities where the relative status of the languages – in terms of both speaker proficiency and socio-political prestige – is more fluid than not’, and then goes on to name ‘recent immigrants’ as a case in point (Myers-Scotton, 2002, p. 111). Given that the Canberra Vietnamese bilingual community is a modern immigrant community, one might suspect that the MLF is not applicable to this contact setting to begin with, thereby explaining the lack of success of the model on CanVEC data.
I note, however, that although the modern migration situation is often seen as fluid, the situation in Canberra is quite different. As I have previously described, the community is rather small in size and attracts the lowest number of recent Vietnamese migrants due to its lack of a defined Vietnamese neighbourhood, high living cost, and more limited job opportunities in comparison to other diasporas (Australian Bureau of Statistics, 2021). This has produced a community comprising mostly young, educated speakers who acquired English and Vietnamese at a young age, either simultaneously or subsequently. Second, the fact that all speakers of CanVEC have been in Australia for at least 10 years (cf. Jake & Myers-Scotton, 2009) also means that speakers’ proficiency in both languages is likely to have surpassed the ‘unstable’ learning phase, or in other words, have to some extent ‘fossilised’ into a stable ‘endstate grammar’ (Birdsong, 2004; Hawkins, 2000; Long, 2008). Several acquisition works have addressed this stabilisation in some detail, including longitudinal studies showing virtually ‘no changes’ in speakers’ grammars between the recording sessions conducted nine years or more apart (Lardiere, 2007; Long, 2008). Finally, the community is characterised by a dense social network, regular internal contact, and a high degree of communally shared information. All of these factors have been previously recognised as identifiers of a ‘stable bilingual community’ (Trudgill, 2011), thereby rendering ‘unstable bilingualism’ a weak explanation for the lack of success of the MLF model on the CanVEC dataset. 11
Concluding remarks
This paper re-considered the notion of an ML, using data from the Canberra Vietnamese community in Australia. Specifically, it tested how readily applicable the putatively universal MLF model is to Vietnamese–English in CanVEC, a new dataset that involves languages with homologous word order and limited inflectional morphology. Findings show limited success both quantitatively and qualitatively, thereby laying bare three essential problems with the model:
The problematic nature of taking speakers’ assumed monolingual code as a baseline;
The lack of a principled strategy for cases where outcomes of the Morpheme Order Principle and the System Morpheme Principle are in conflict; and
Its struggle dealing with certain types of modern production data, especially those involving contemporary spoken colloquial features (e.g., zero auxiliary) and non-standard L2 features (which is a given in many bilingual contexts).
Although these issues may not be confined to just Vietnamese–English (cf. Auer & Muhamedova, 2005; Berruto, 2005), I have shown, on specific empirical grounds, the extent to which the model’s assumptions can be both quantitatively and qualitatively problematic. Quantitatively, the MLF model fails to account for the majority of the Vietnamese–English bilingual data, including production from both first- and second-generation speakers (58% and 56%, respectively). Qualitatively, the application of the model highlights the thorny issues around assuming speakers’ monolingual code as a basis of comparison, the ‘Composite ML’ notion, and the assumption of null elements in bilingual discourse.
I further demonstrated how Wang’s (2007) approach for establishing the ML in isolating languages remains linguistically challenging. While the Uniform Structure Principle and the Morpheme Counting Principle may work to some degree for Mandarin–Southern Min (both isolating languages), they are not particularly helpful for Vietnamese–English (one isolating, one inflectional). The significant difference in terms of morphemes available in the verbal domain (tense, aspect, agreement) between these two languages, together with the fact that Vietnamese also broadly allows null elements while English does not, means that applying these two extra principles to Vietnamese–English data remains unfruitful.
Ultimately, I agree with Auer and Muhamedova (2005) in that the study of code-switching must take the syntactic structure of the data as the starting point rather than the monolingual ‘codes’, which the MLF components seem to refer to. Although Myers-Scotton (2002) insists that the ML is not identical to any single ‘monolingual’ language but is just an abstract construct, it is unclear how we can identify an ML if it cannot be equated with the monolingual description. In any case, the conclusion seems transparent: the definitions of the component parts of the MLF are insufficiently clear, and even if one tries to sensibly flesh out these components, the predictions do not seem to reflect what we see in Vietnamese–English.
On a broader scale, this work addressed a lacuna in the field, where research on minority languages and their speech communities is still much more limited, especially in comparison to English and other Indo-European languages. My hope is that the data and analysis offered in this work – focussing on a lesser-described language pair such as Vietnamese-English, in a stable but atypical community such as Canberra – have served as a modest contribution towards progress in this direction.
Footnotes
List of abbreviations
CLF: classifier.
COMP: complementiser.
COP: copula.
DEM: demonstrative.
DM: discourse marker.
LOC: locative.
NEG: negation.
PL: plural.
POSS: possessive.
PRG: progressive.
PST: past.
SG: singular.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was originally funded by the Cambridge International Trust.