
Abstract
Aims and objectives:
Previous research has revealed much about the syntactic and social variables conditioning code-switching (i.e., the alternation between two or more languages in a discourse or utterance); however, little is known about the phonological effects. Our work explores this area by asking two main questions: (1) Does lexical tone affect code-switching between a tonal language and a non-tonal language? and (2) Is this effect (or lack thereof) observable cross-linguistically?
Methodology:
We examine natural code-switching production between Cantonese and English, Mandarin and English, and Vietnamese and English. We use a semi-automatic natural-language processing method to process and extract relevant variables, including tonal categories at switch points.
Data and analysis:
Data include transcribed natural speech from three bilingual corpora: the HLVC corpus (Cantonese/English, 25 speakers), the SEAME corpus (Mandarin/English, 20 speakers), and the CanVEC corpus (Vietnamese/English, 45 speakers). We use logistic mixed-effects models to examine tonal effects, taking into account other factors such as frequency and grammatical category.
Findings/conclusion:
We found a robust tonal effect in Cantonese/English, a less robust effect in Mandarin/English, and no effect in Vietnamese/English. This indicates there is a tonal effect in code-switching between a tonal and a non-tonal language, but this effect is language-dependent. We also found a specific T3 ‘step-up’ pattern at Cantonese-English switch points and offered some possible phonological explanations.
Originality:
This is the first study that systematically investigates tonal effects in code-switching across different language pairs, using comparable data and methods. Our finding of a Cantonese-English T3 ‘step-up’ pattern is also a novel discovery that hitherto has not been documented.
Significance/implications:
Theoretically, our findings support Clyne’s ‘facilitation theory’ in code-switching at a prosodic level. Empirically, we nevertheless emphasised the complexity of different prosodic features and social variables in play, thereby rejecting the idea of ‘predicting’ code-switching solely based on linguistic factors.
Keywords
Introduction
Code-switching (CSw) is a phenomenon whereby language users combine two or more languages in a single discourse or utterance. This linguistic behaviour has been widely documented in a variety of language-contact scenarios, from computer-mediated interaction (Laroussi, 2011; Lynn & Scannell, 2019; Papalexakis & Doğrüoz, 2015; Siebenhaar, 2006; Winata et al., 2022), language teaching and learning (Ahmad & Jusoff, 2009; Carstens, 2016; Daniel et al., 2019; Nguyen et al., 2022; Wang, 2019) to natural production in multilingual communities where two or more languages coexist (Clyne, 2003; Nagy, 2011, 2018; Nguyen, 2018; Torres Cacoullos & Travis, 2018; Tse, 2019). Examples (1)–(3) provide some illustration.
Ceol alainn ar @johncreedon
music beautiful on
‘Lovely music on @johncreedon on @RTERadio1 now’
(Adapted from Lynn & Scannell, 2019)
2.
当 下 倾 盆 大 雨 时,
when downfall pour basin big rain time
‘When it is pouring (basin-like big rain), we will stay at home’
(Write & Improve submission, Nguyen et al., 2022)
3.
cái
CLF DET AUX Q
‘Was that concert more than what you expected?’
(CanVEC corpus; Nguyen & Bryant, 2020)
Within linguistics, most studies to date have focussed on the syntactic and social variables conditioning code-switching; for example, Poplack (1980) et seq., Myers-Scotton, (1993) et seq., Muysken (2000) et seq., Torres Cacoullos and Travis (2018); Nguyen (2018, 2021). We still know relatively little about the phonological variables, however, despite previous evidence suggesting a link (Antoniou et al., 2011; Balukas & Koops, 2015; Fricke et al., 2016; Olson, 2013; Piccinini & Garellek, 2014). In this work, we thus explore the relationship between a particular phonological feature, namely lexical tone, and natural CSw production, in the context of three tonal languages (Cantonese, Mandarin, and Vietnamese) and a non-tonal language (English). Our research questions are therefore two-fold:
Does lexical tone affect code-switching between a tonal language and a non-tonal language? and
Is this effect (or lack thereof) observable cross-linguistically?
We attempt to answer these questions using three CSw corpora: the HLVC corpus (Cantonese/English) (Nagy, 2011), the SEAME corpus (Mandarin/English) (Lyu et al., 2010), and the CanVEC corpus (Vietnamese/English) (Nguyen & Bryant, 2020). All three datasets consist of transcribed, natural speech and are therefore highly comparable. Together, they represent a diverse range of linguistic and social scenarios where tonal and non-tonal languages come into contact.
The remainder of this paper is organised as follows. We first provide a brief description of the contact settings and tonal systems of the language varieties in question (§Background). We then move on to discuss our corpora and data processing (§Methods), before presenting our findings (§Results) and analysis (§Discussion). We finally conclude with a summary and offer recommendations for future research (§Conclusion). It is important to note that throughout this paper, we use a forward slash (/) between a pair of languages to indicate general code-switching, and a hyphen (-) to indicate a particular direction. For example, Cantonese/English implies code-switching between Cantonese and English in general, whereas Cantonese-English implies switching from Cantonese into English.
Background
The language varieties of interest in this study are Cantonese/English spoken in Hong Kong and Toronto, Canada, Mandarin/English spoken in Singapore and Malaysia, and Vietnamese/English spoken in Canberra, Australia. In what follows, we first introduce the contact settings in these areas, then describe the tonal systems of Cantonese, Mandarin, and Vietnamese, respectively. We then consider the relevant prosodic features in these varieties of English, before finally discussing how they might manifest in a code-switching scenario.
It should be noted that the contact situations in these communities are extremely complex, and it remains difficult to provide a comprehensive overview. We thus only focus on three key aspects that we deem most relevant in the contact landscape section: community formation, language use, and language attitude of the communities in question.
The contact landscape
The language contact situation in Hong Kong is a little different. Cantonese has always been the predominant language in daily life, although it only became an official language along with English from 1974 onwards. While English was the sole official language before that, the English-speaking population was rather small, and it was not until the 1980s when compulsory education was institutionalised and university places were greatly expanded that the number of people who were proficient in English began to rise sharply (Joseph, 2004). This increase in educational opportunities contributed to the emergence of a distinctive English variety, known as ‘Hong Kong English’. In this variety, the stress system of British English is to some extent re-interpreted as a tonal system, which corresponds to a subset of tone patterns of Cantonese (Gussenhoven, 2012; Luke, 2000; Wee & Liang, 2016). Cantonese with English insertion also became a new norm, distinguishing itself from other Cantonese varieties spoken in mainland China (Y. S. Cheung, 1985; Gibbons, 1987; Li, 2000).
Like Hong Kong English, English spoken in Singapore has been influenced by extensive, long-term language contact with indigenous languages and has taken on a distinctive form. There are generally two varieties of Singapore English: a relatively standard variety used mainly for formal purposes of communication, referred to as Standard Singapore English, and an informal colloquial variety, called Singapore Colloquial English, or Singlish. While the standard variety generally shares similar linguistic features with other established standard varieties of English such as British or American English, the colloquial variety has undergone more substantial substrate-influenced restructuring. There is still considerable inter- and intra-ethnic variation across speakers as a result of varying effects of individual bilingualism (e.g., speaking a different first languages [L1], having a different language dominance) and differences in cultural affiliation or orientation (Sim, 2019). Within the Chinese community, in particular, the shift to English is also concurrent with the shift to Mandarin from other Chinese languages. Specifically, the ‘Speak Mandarin Campaign’ launched in 1979 promoted the use of Mandarin as a lingua franca for all ethnically Chinese people, resulting in the decline of other Sinitic heritage languages (commonly referred to by locals as ‘Chinese dialects’) spoken in Singapore such as Cantonese, Teochew and Hakka.
In Malaysia, ethnic Malays make up 70% of the population. Since the 1960s, Malay has been adopted as the main (and later sole) medium of instruction and English became a second language in the education system (Ng & Cavallaro, 2019). This results in the predominance of Malay over other languages. English, however, continues to be used in the civil service and trade contexts and developed its own features (Hashim, 2020). Generally speaking, Malaysian English shares many features with Singaporean English, including the division of formal and colloquial sub-varieties. Although the substrate languages are similar, Malaysian English has more lexical borrowing from Malay, whereas Singaporean English has more from Hokkien (Low, 2012). Within the Malaysian Chinese society, various Chinese varieties are still actively spoken today in addition to Malay and English, including Hokkien, Cantonese, and Mandarin (Khoo, 2017; Wang, 2012).
In Canberra, however, the situation is slightly different. Contrary to the other densely populated cities such as Sydney or Melbourne, in which Vietnamese speakers cluster in neighbourhoods and are employed in family business, the majority in Canberra work in education or the public sector, or have a partner doing so (Australian Bureau of Statistics, 2017). While official numbers are difficult to obtain, this group is well known for being ‘Canberrans’ for the most part: relatively young, well paid and well educated. This also means that they have high English proficiency in general, and code-switching within the community is more easily and naturally observed (Nguyen, 2021; Thai, 2005). Conversations within families are on average a mix of half Vietnamese, a quarter code-switching and a quarter English (Nguyen, 2021, p. 54).
In summary, the language contact situations in these three communities are clearly diverse, with different social circumstances, linguistic histories and demographic make-ups. What they all have in common, however, is an environment where language contact is ubiquitous, most of which involves a majority, (mostly) non-tonal language (i.e., English) and a heritage tonal language (i.e., Cantonese, Mandarin, Vietnamese, respectively). Together, this represents a unique collection of datasets that allow us to systematically investigate tonal effects across different contact scenarios. In what follows, we briefly introduce the tonal systems of these language varieties.
The tonal systems
Despite all being tonal languages, Cantonese, Mandarin, and Vietnamese differ noticeably in their tonal inventories. Figure 1 provides an illustration.
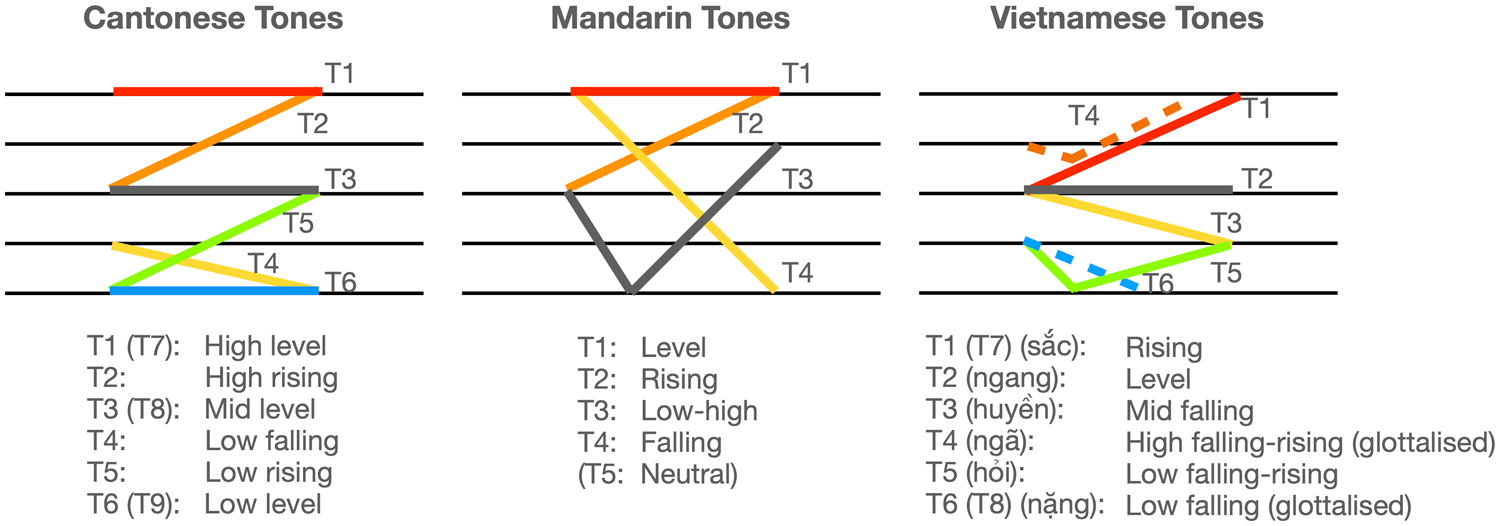
Tonal inventories in Cantonese, Mandarin, and Vietnamese. The shape of each tone is represented schematically using lines in colour. The dashed lines indicate that glottal constrictions are involved (a glottal stop in the middle of Vietnamese T4, and at the end of Vietnamese T6). Tones in brackets are tones with stop codas and can be merged into the same category of the previous tones.
As we can see, the tonal systems in Cantonese, Mandarin and Vietnamese differ both in terms of quantity and quality. Specifically, Cantonese has six tones, three of which are level tones (T1: high level, T3: mid level, T6: low level) and three of which are contour tones (T2: high rising, T4: low falling, T5: low rising). There are also three checked tones (high checked T7, mid checked T8, and low checked T9) that can be grouped with T1, T3, and T6, respectively, due to the matching pitch levels. The difference is that the syllables bearing checked tones end in stop consonants and are shorter in duration (compared to syllables with non-checked tones). In recent years, certain tones in Cantonese are reported to be undergoing merging (T2/T5 and T3/T6 in speech production), and this sound change is found among both native speakers in Hong Kong as well as heritage speakers in Toronto (Fung & Lee, 2019; Mok et al., 2013; Nagy et al., 2020; Zhang, 2019).
In contrast, there are five tones in Mandarin. In addition to the four tones shown in Figure 1 (T1: level, T2: rising, T3: low-high ‘dipping’, and T4: falling), there is also a neutral tone (T5), which is not shown graphically since it does not have a tonal target and its phonetic realisation is entirely determined by the surrounding tonal contexts. Mandarin spoken in Singapore and Malaysia largely follows the pronunciation of standard Mandarin spoken in the mainland China. There are a few deviations in the tonal systems; however, most of them are associated with the influence of other southern Chinese dialects (e.g., Hokkien, Cantonese) spoken in the region. First, the distribution of neutral tone is limited to fewer words compared to that in standard Mandarin (Choo, 2015). Second, T2 displays a low-level stretch in the f0 contour before it starts to rise, which is different from standard Mandarin (L. Lee, 2010). Finally, there is a ‘fifth tone’, which is a special category reserved for a group of characters that have checked tones in Hokkien and Cantonese, and is pronounced with a shorter duration and a falling pitch (Chen, 1983). This category is less popular among young speakers, however, due to the declining presence of the dialects in Singapore and Malaysia (Choo, 2015).
In Vietnamese, tones are more commonly referred to by their ‘tone names’ instead of a numeric category as in Cantonese or Mandarin. We adopt Tuc (2003)’s assignment of numeric categories to facilitate comparison. The tonal system described here is the standard variety. There are four tones with modal phonation (T1: rising, sắc, T2: level, ngang, T3: mid falling, huyền, T5: low falling-rising, hỏi), and two tones with glottal constriction (T4: high falling-rising with mid-glottalisation, ngã, T6: low falling tone with ending glottalisation, nặng). Like Cantonese, there are two more tones, T7 and T8, which occur only in syllables with stop codas and can be grouped with T1 and T6, respectively. Unlike Chinese languages, the tonal contrast in Vietnamese not only relies on pitch and duration differences, but also tends to involve laryngeal features, such as breathiness and creakiness (Brunelle, 2009b; Pham, 2003).
Finally, English is typically classified as a non-tonal language, although some English varieties in contact with tonal languages have been known to develop tone-like features (Gussenhoven, 2012; Lim, 2009). In these contact situations, tonal categories are assigned to syllables in English words in a similar fashion as they are assigned to Chinese syllables, mostly making use of the contrast in pitch register but not pitch contours. In Hong Kong English and Singaporean/Malaysian English in particular, the exact tonal assignment also bears specific characteristics. For example, the tonal assignment in Hong Kong English seems to be reminiscent of the stress in British English in which a high tone (H) is assigned to the syllable that would bear stress in English. A mid tone (M) is assigned before the high tone and a low boundary tone (L) is assigned to the utterance-final position (W. H. Y. Cheung, 2009; Wee, 2016). This is slightly different in Singaporean/Malaysian English, where a high tone (H) is assigned to the final syllable of a content word, resulting in a series of rising melodies on the utterance level (Chong & German, 2015; Ng, 2012). This tonal development occurs in tandem with the replacement of lexical stress in the language system (Tan, 2015, 2016; Wee, 2016). Although Vietnamese-English has not been formally proposed as an established English variety, studies have suggested that Vietnamese speakers may produce and perceive English stress as corresponding to Vietnamese tones (Nguyen, 2004; Nguyen et al., 2008). In aggregate, this seems to indicate that tonal transfer might be a strong tendency across English speakers whose L1 is a tonal language.
Tonal facilitation in code-switching
In code-switching research, one of the most relevant and influential ideas is the concept of facilitation introduced by Clyne (2003). Built on his earlier, widely known ‘Triggering Hypothesis’ (Clyne, 1967, 1980). Clyne stipulates that certain forms of lexical, semantic, phonetic/phonological, prosodic, tonemic, graphemic, morphological, and syntactic (or any combinations of these) similarities between the languages involved might facilitate a switch (Clyne, 2003, p.76). He specifically draws on bilingual and trilingual data from different migrant communities in Australia to show how code-switching is a matter of strong tendencies and probabilities rather than of absolute constraints as in previous works (e.g., the Equivalence Constraint, the Free Morpheme Constraint, the Government Constraint, the Conjunction Constraint, etc.). These strong tendencies are believed to be a result of one or more principles of facilitation at lexical, tonal/prosodic, or syntactic levels.
For the purpose of our research, the most relevant principle in Clyne’s work is the facilitation principle at the tonal/prosodic level. This principle suggests that ‘lexical items in a tonal language whose tone is identified with the pitch and stress of the non-tonal language in contact are liable to facilitate (though not necessarily cause) transversion’ (Clyne, 2003; Principle 2, ‘tonal facilitation’, pp. 175–177). Using data from Mandarin and Vietnamese in Australia, Clyne showed how items in the same tonal range substantially increases the likelihood of a transversion (a term he prefers to code-switching). In the Vietnamese/English bilingual community, for example, he pointed out that more than 85% of switches to English occurred immediately after a Vietnamese word of a mid-to-high pitch tone (Tuc, 2003). According to Clyne, these are the tones that Vietnamese are most likely to associate with English pitch and stress (unstressed syllables with mid tones and stressed syllables with high tones). Words with these tones take speakers into an overlapping tonal zone between the two languages, thereby facilitating a switch. Similarly, most switches (96.49%, N not available) from Mandarin to English were also found to correlate with falling tones, which correspond to English intonation (Zheng, 1997).
While Tuc (2003) and Zheng (1997)’s studies above (i.e., the only two studies we know so far that have specifically examined tonal effects in CSw) provide some illuminating results, one essential caveat is that they did not take into account other contributing factors such as grammatical categories or frequencies in establishing the effects. There is thus a high chance that their results may be biased by the effect of certain tokens occurring more frequently at switch points and are not truly representative of tonal category effects. Furthermore, since their datasets are quite different, it is difficult to compare findings and establish whether the reported effects generalise beyond their focus. Our study thus aims to contribute in this direction by examining tonal patterns in large-scale corpora across different language pairs and applying statistical models to account for the effect of other linguistic and social variables.
Methods
Corpora
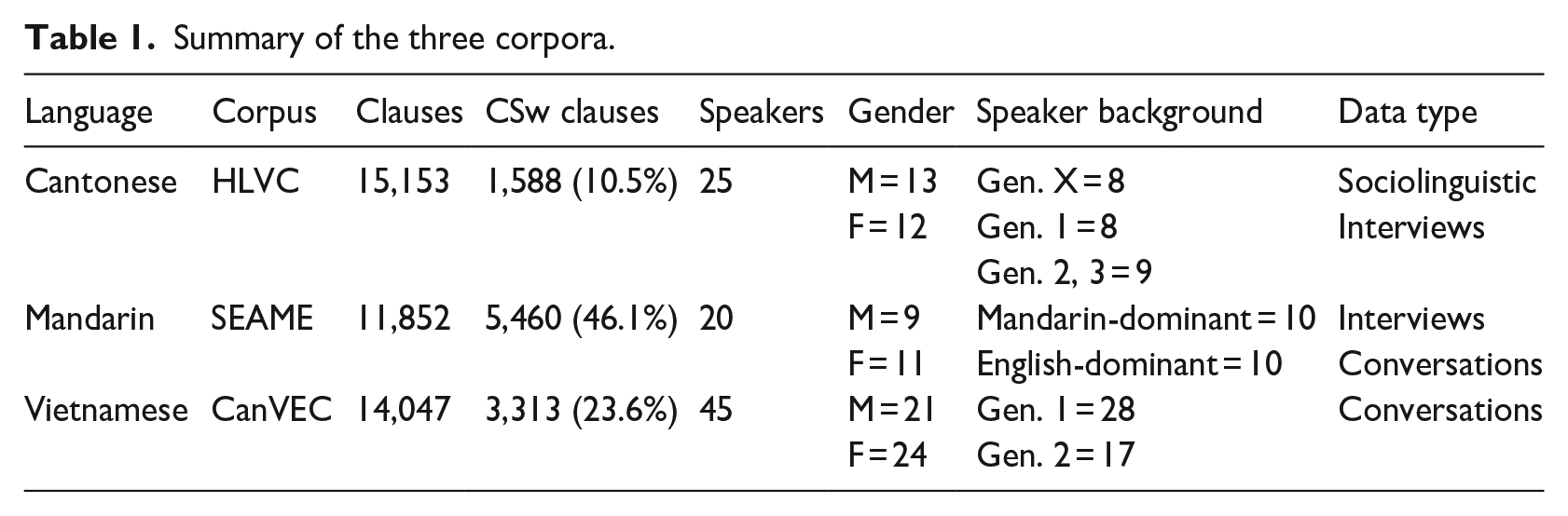
Our data comes from three corpora: the HLVC corpus for Cantonese/English, the SEAME corpus for Mandarin/English, and the CanVEC corpus for Vietnamese/English. Each of these corpora is described in more detail below and summarised in Table 1.
Summary of the three corpora.
Data processing
Having selected our corpora, we next applied the semi-automatic natural language processing (NLP) methodology, previously developed for the CanVEC corpus (Nguyen & Bryant, 2020), to all three datasets. Since the transcription convention of HLVC and SEAME differed from CanVEC, we needed to do some pre-processing to standardise the data format. For example, in HLVC, we discarded any Cantonese clauses that contained redacted information or digits, since we did not know which language these items were in, and removed most punctuation, with the exception of apostrophes (e.g., don’t), hyphens in compounds (e.g., T-shirt) and incomplete words (e.g., f. . .). We also removed whitespace and non-speech mark-up (e.g., laughs). Similarly, in SEAME, we removed non-speech mark-up (e.g., <v-noise>) and the whitespace between Chinese characters.
After standardisation, we developed a pipeline for processing each clause in the HLVC and SEAME corpora as described below:
Based on character encoding (Chinese characters or English letters), we divided the strings into the largest contiguous sequences of Chinese only or English only. There could be multiple switches in one clause.
Each sequence was processed by the relevant word tokeniser and POS tagging toolkit: PyCantonese (J. Lee et al., 2022) for Cantonese, Jieba and SpaCy (Honnibal & Montani, 2017; Sun, 2020) for Mandarin, and SpaCy for English. 3 In addition, Cantonese and Mandarin strings were converted to Romanisation to extract tonal information (Cantonese was converted to Jyutping by PyCantonese, Mandarin to Pinyin by Pypinyin) (Huang et al., 2023). 4
We assigned three language labels to tokenised data: English, Chinese, and language-neutral. Since language-neutral items refer to those not exclusive to any language (Riehl, 2005), they are not considered valid points for code-switching. The language-neutral labels were assigned to words that were POS-tagged as ‘INTJ’ (interjections) such as ‘um’ and ‘okay’, ‘PROPN’ (proper nouns) such as place names, as well as those belonging to a manually compiled list including filler words (e.g., ‘eh’) and sentence-final particles (e.g., ‘aa3’ and ‘lah’). 5
CSw points were identified based on language labels, marked as either English-Chinese or Chinese-English. If we considered any of the top 50 most frequent words at switch points to be a language-neutral word, we added this word to the language-neutral wordlist described in the previous step and iteratively re-ran this step.
We extracted tonal categories at switch points based on the automatic Romanisation. For multi-syllabic tokens, TONE was extracted from the syllable adjacent to English tokens. For example, in the sentence ‘send keoi5dei6 email’, T5 was extracted when counting English-Cantonese CSw, and T6 was extracted when counting Cantonese-English CSw. 6
We extracted all the tokens along with the relevant information for regression analysis, including their frequency, POS-tags, speaker information, and whether they are switch points or not.
For CanVEC, only steps 4–6 were implemented as the corpus had already been tokenised, language tagged and POS tagged following steps 1–3 (Nguyen & Bryant, 2020).
Statistical analysis
We focussed on the tonal tokens (i.e., Cantonese, Mandarin, Vietnamese tokens) in the datasets to examine whether lexical tonal categories influence the probability of a token becoming a switch point, either to English or from English. To determine the tonal effect while taking into consideration other contributing factors, we used R Studio software (R Studio Team, 2020) to conduct logistic mixed-effects regressions, using the glmer function in the lme4 package (version 1.1.31, Bates et al., 2015) and lmerTest package (version 3.1.3, Kuznetsova et al., 2017). Pairwise comparison with Tukey adjustment was conducted using the emmeans package (version 1.8.3, Lenth, 2022). To validate the models, we used the check_collinearity function in the performance package (version 0.10.2, Lüdecke et al., 2021) to make sure there is no multicollinearity problem among the independent variables. We further used the DHARMa package (version 0.4.6, Hartig, 2022) to ensure there are no significant issues in the residual patterns.
The variables of interest are listed in Table 2, with TONE being the main fixed effect and treatment-coded. There are six tones in HLVC (T7, T8, and T9 are merged with T1, T3, and T6, respectively), five tones in SEAME (including the neutral tone T5), and six tones in CanVEC (T7 and T8 are merged with T1 and T6, respectively, see Figure 1).
Regression variables.
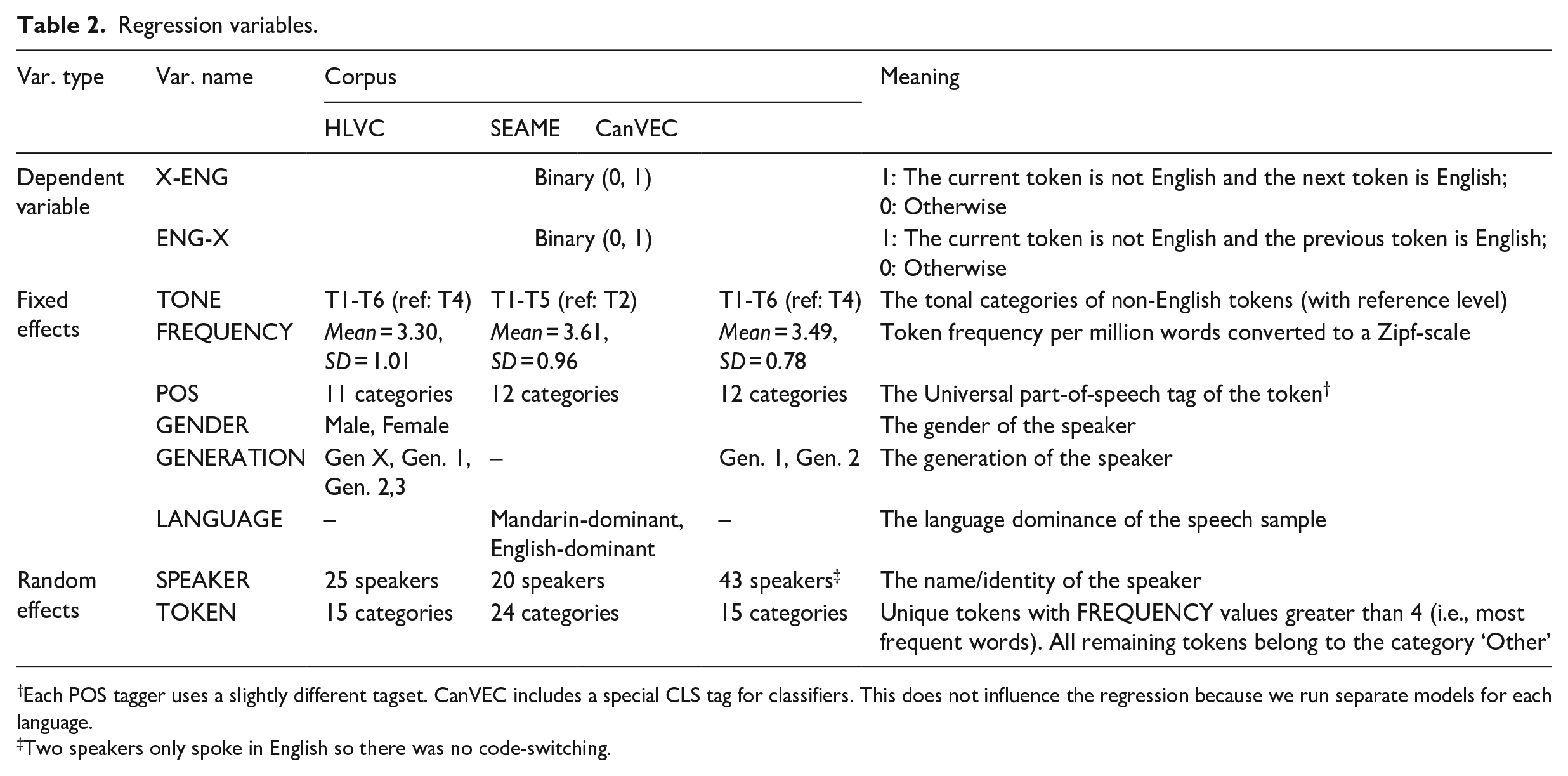
Each POS tagger uses a slightly different tagset. CanVEC includes a special CLS tag for classifiers. This does not influence the regression because we run separate models for each language.
Two speakers only spoke in English so there was no code-switching.
Other fixed effects include frequency (FREQUENCY) and part of speech (POS) of each token, as well as GENDER and GENERATION of the speakers. POS tags were defined according to the set of Universal POS tags (de Marneffe et al., 2021). The FREQUENCY of each token was calculated as frequency per million words and then converted to Zipf scale (van Heuven et al., 2014). The scale normally ranges from 1 to 6, with the upper half (4–6) representing high-frequency words. In the Mandarin model, we had no information about the GENERATION of speakers, so we instead included a LANGUAGE variable indicating whether the speech was characterised as Mandarin-dominant or English-dominant. Results from the check_collinearity function in the performance package suggest no multicollinearity among the independent variables (all VIFs < 3) (cf. James et al., 2013). The details of model results and validations are provided in the Supplemental material.
For random effects, we included a random intercept for TOKEN and SPEAKER, and a by-speaker random slope for TONE. The TOKEN variable was generated to further control the influence of a few highly frequent tokens. Specifically, tokens with a Zipf frequency less than 4 were merged into one category, whereas those larger than 4 were treated as one category on its own. Because each token is associated with a unique tone (i.e., no variation of tone within each token), we did not include a by-token random slope for TONE. 7
Results
We report our results in two parts. In the first part, we compare the raw frequencies of each tone appearing at switch points, similar to previous studies. In the second part, we present the results of mixed-effects logistic regression where other contributing factors are taken into consideration.
Raw frequency
Table 2 reports the raw frequency, the distribution (i.e., the percentage of each tone relative to the total number of switches), and the proportion (i.e., the percentage of each tone relative to the total occurrences of that tone in the corpus) of each tone across all switch points. In other words, the distribution highlights how different tones are spread across the switch points, while the proportion measures how often a certain tone appears at a switch point compared to a non-switch point, that is, the preference for switch points across different tones. More formally, distribution and proportion are calculated according to Equations 1 and 2, respectively.
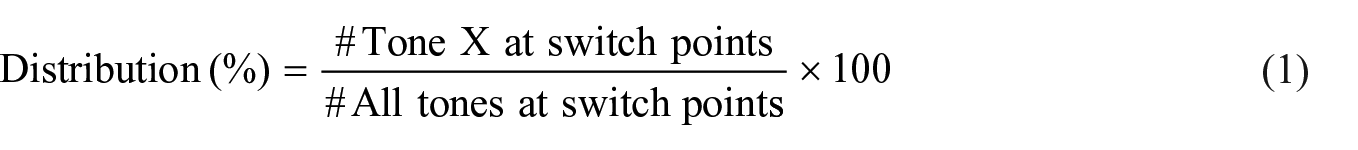
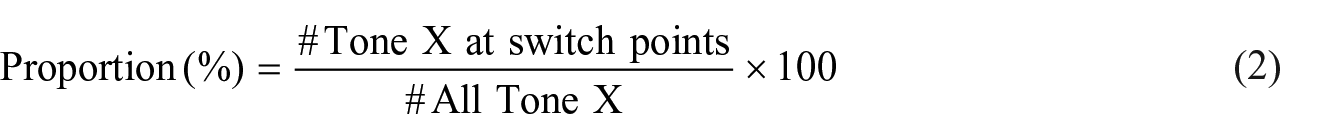
Raw frequency and distribution of tones at switch points, and their proportion relative to global tone frequency. The largest numbers of distribution and proportion in each row are highlighted in orange, and the smallest numbers are in teal.
At this point, the general impression from raw rates seems to suggest that there exists a preference for a certain tone at switch points in each direction for each language pair. For X-Eng, these facilitating tones are identified as T3 (mid-level tone) in Cantonese, T3 (dipping tone) and T5 (neutral tone) in Mandarin, and T1 (rising tone) in Vietnamese. For Eng-X, these are T3 (mid-level tone) and T5 (low-rising tone) for Cantonese, T3 (dipping tone) and T5 (neutral tone) for Mandarin, and T1 (rising tone) and T5 (low falling-rising tone) for Vietnamese. We should emphasise, however, that the most frequently occurring tones at switch points are not necessarily the same tones that are most likely to appear at switch vs. non-switch points. For Mandarin-English, for example, while T4 is the most frequent tone at switch points compared to all other tones (accounting for 44.55% of the distribution), T5 has the strongest preference for switch points compared to other tones (14.74% of the time when it appears). This again highlights the complexity of measuring tonal effects and underscores the need to go beyond raw distribution.
Logistic regression
We next report results from our mixed-effects logistic regression models. Since we are mostly interested in the tonal effect, we focus only on the post hoc pairwise comparisons between all different combinations of tone pairs. 8 Tests of the differences were performed on the log scale and back-transformed to the odds ratio (OR) to facilitate interpretation. In all the tables that follow, an OR larger than 1 indicates a higher probability of the first tone occurring at switch points relative to the second. SE represents the standard error of the estimate OR (the higher the number, the more uncertain the estimate), and z-ratio measures the deviation of the estimate OR from 1. The statistically significant results (with ps < .05) are highlighted in bold.
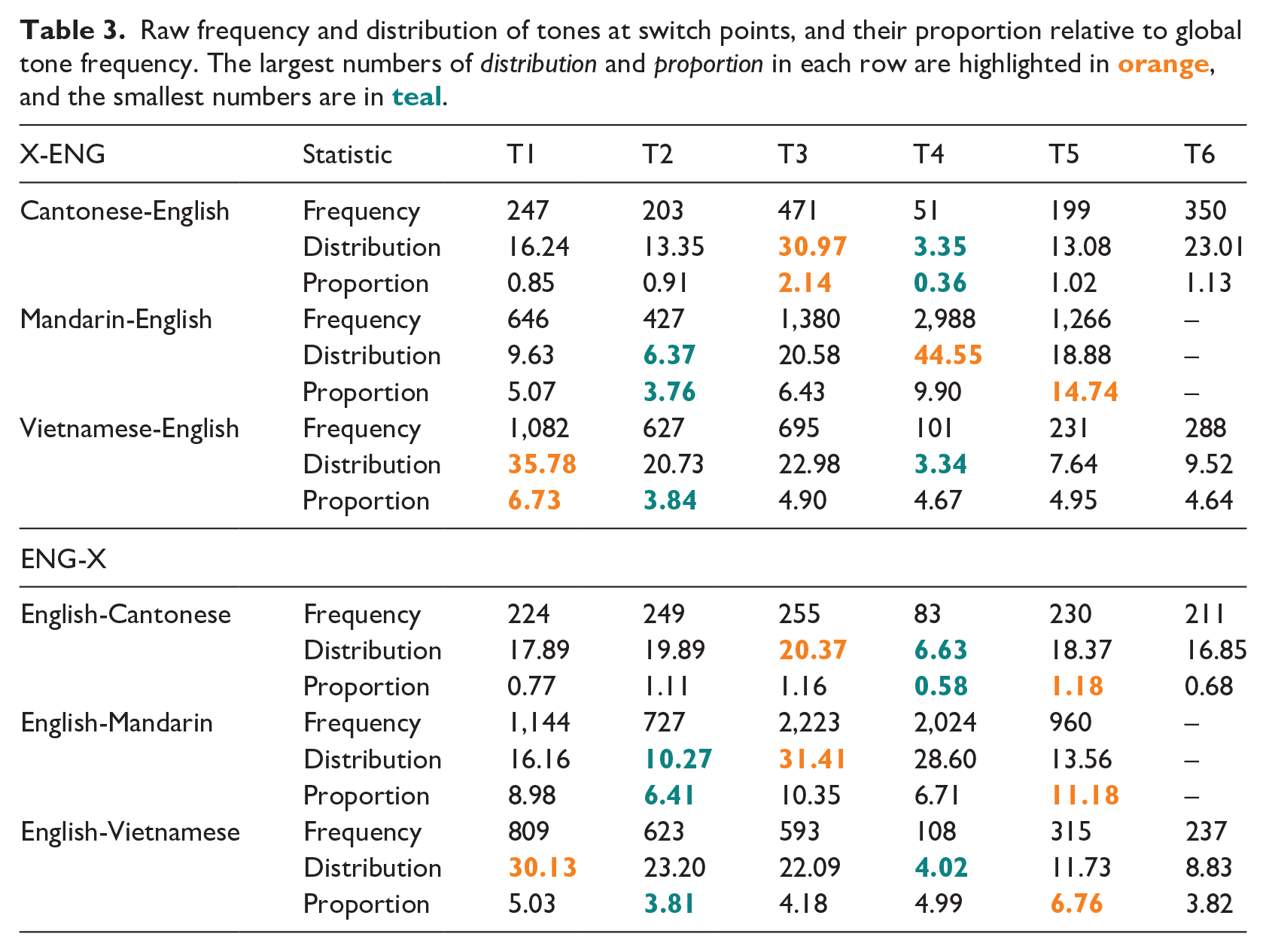
Post hoc comparisons in Cantonese. We begin with T4 as it is taken as the reference level in the regression model.
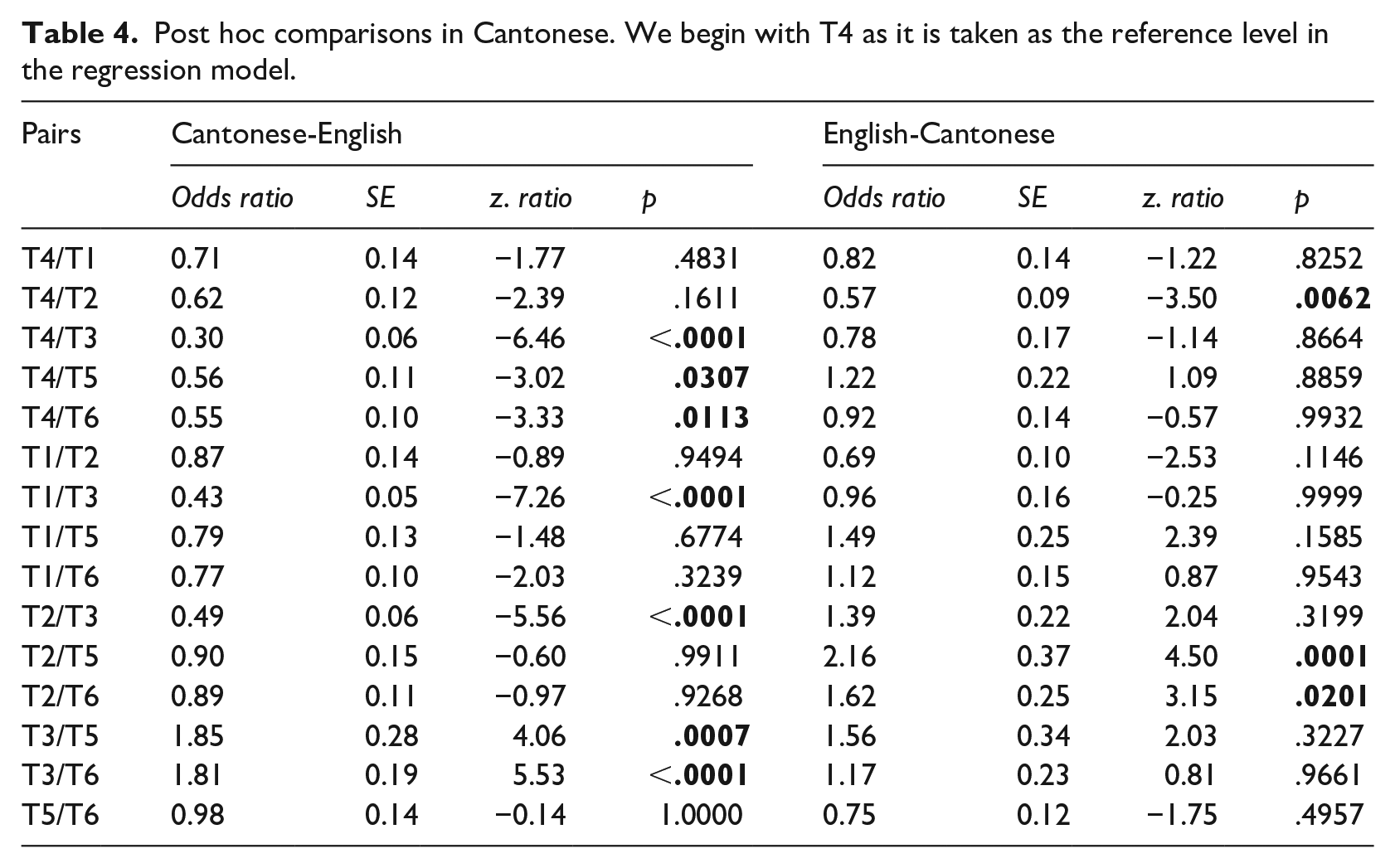
Post hoc comparisons in Mandarin. We begin with T2 as it is taken as the reference level in the regression model.
Post hoc comparisons in Vietnamese. We begin with T4 as it is taken as the reference level in the regression model.
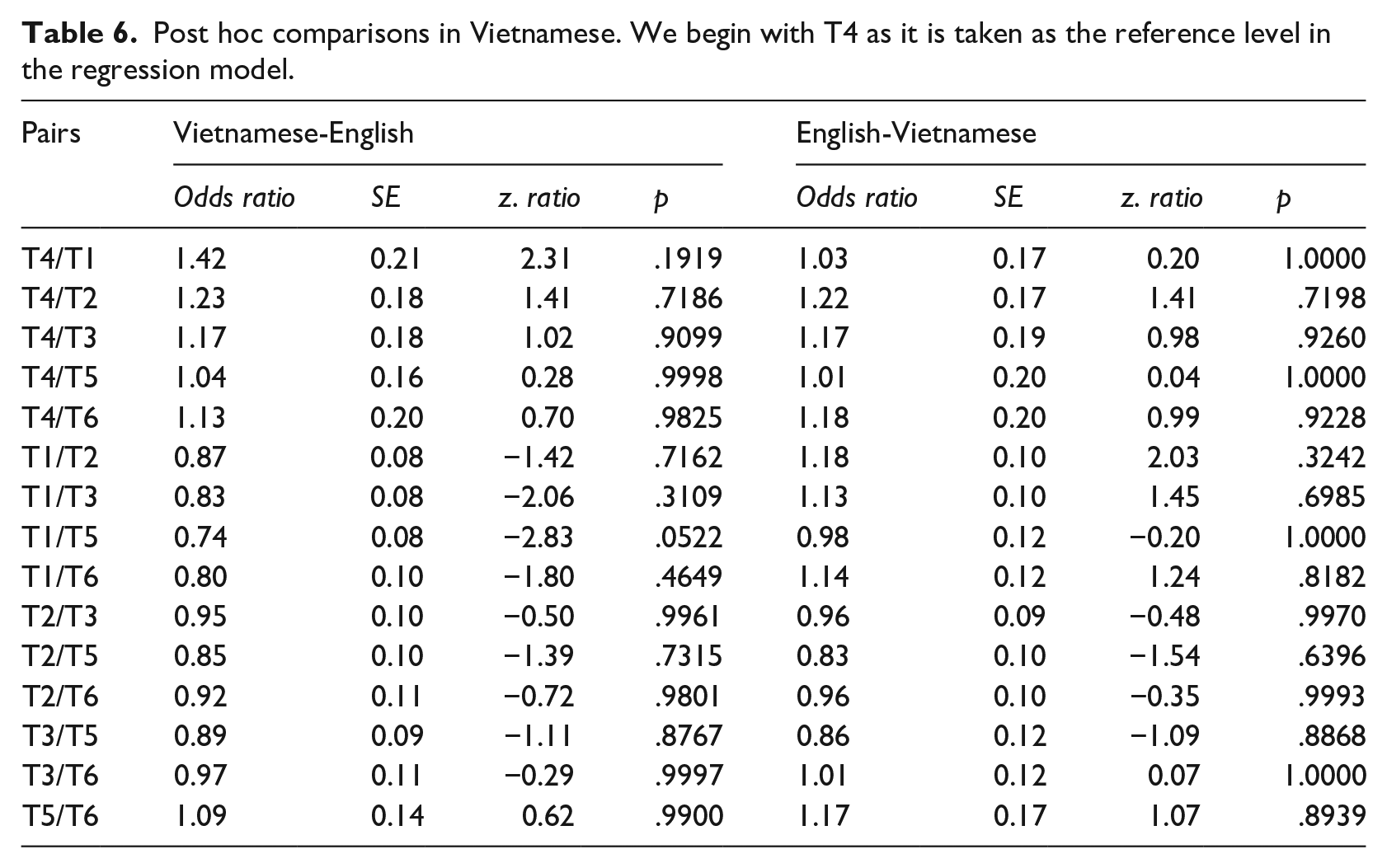
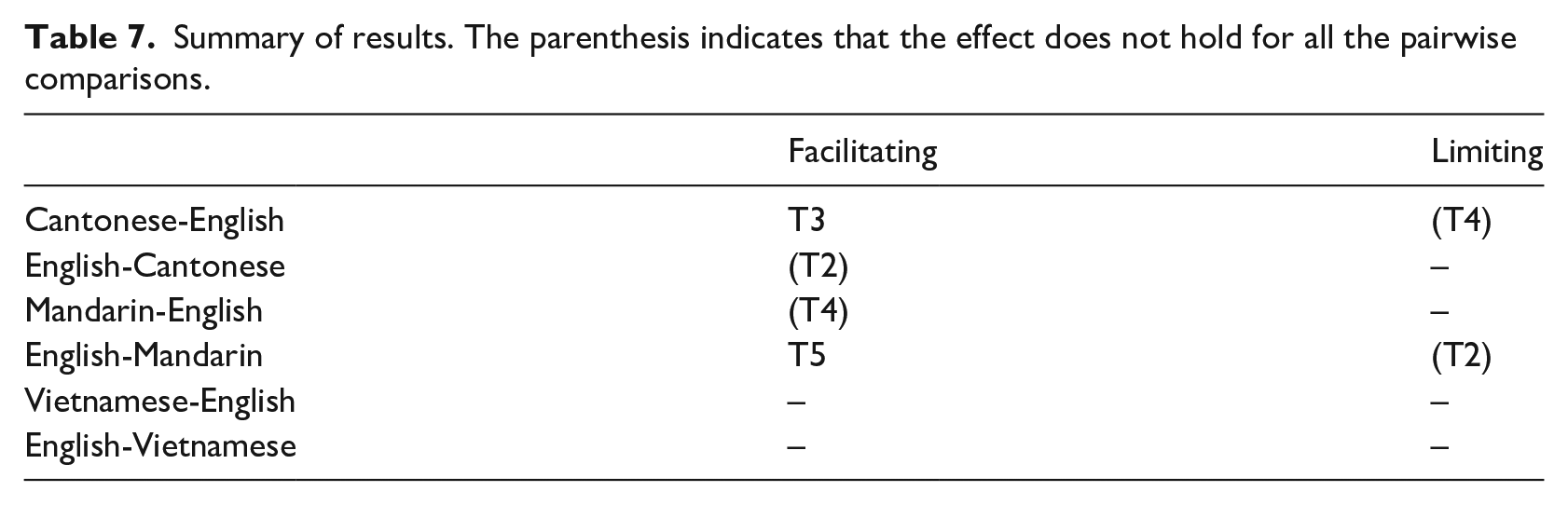
Table 7 summarises the logistics regression results across the three contact settings in this study. As we can see, results show some positive evidence for tonal effects in Cantonese/English and Mandarin/English but not for Vietnamese/English. This indicates that there exists a tonal effect in code-switching between a tonal and a non-tonal language, but this effect is language-dependent. In what follows, we focus on the effects found in Cantonese/English and Mandarin/English and discuss their implications.
Summary of results. The parenthesis indicates that the effect does not hold for all the pairwise comparisons.
Discussion
Tonal effects in CSw: evaluating evidence for prosodic facilitation
The most robust tonal effect found in this study is that of Cantonese-English code-switching, where T3 (mid-level tone) was unanimously identified as exhibiting clear facilitating effects, as reflected in both sections ‘Raw frequency’ and ‘Logistic regression’. Situating this in the context of the Cantonese communities in question, we suspect that this might be due to the tonal assignment of Hong Kong English, 10 in which either a high (H) or a mid (M) tone (i.e., level tones) is assigned to English syllables (§The tonal systems). This means that compared to contour tones, a Cantonese level tone at a switch point would bear more resemblance to the prosody of subsequent English syllables and therefore be more conducive to a switch to English. This is further supported by the fact that there appears to be a limiting effect of T4 – a contour tone – on the other end of the spectrum. Ultimately, the pattern accords with Clyne’s tonal facilitation hypothesis (§Tonal facilitation in code-switching), thereby reaffirming the role of overlapping prosodic conditions in code-switching. A natural question which may emerge at this point is that if level tones in Cantonese (T1, T3, T6) are indeed preferred over contour tones (T2, T4, T5) at switch points, why does only T3 demonstrate a facilitating effect? We will return to this in the later discussion. For now, the key point to note is that T3, a mid-level tone which shares some prosodic features with Hong Kong English, displayed robust facilitating effects in Cantonese-English code-switching.
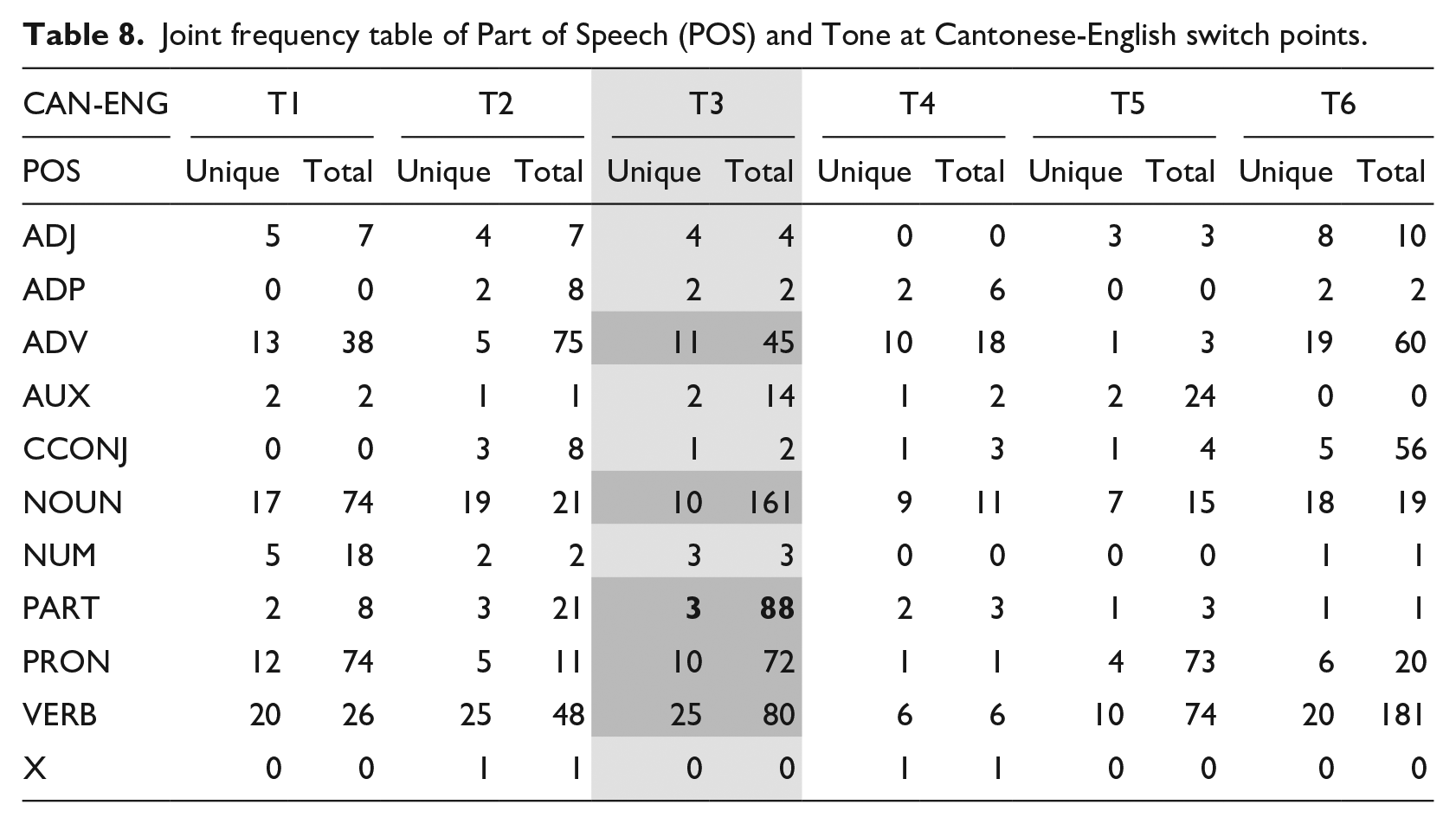
It is reasonable to suspect that the effect of T3 is not directly related to tone, but rather to certain POS or specific words that happen to carry that tone. Indeed, as Table 8 illustrates, there are only 3 unique particles (PART) with T3 that appeared at Cantonese-English switch points, but they have very high frequency (N = 88). While this might suggest some kind of overlapping effect between tone and POS/specific token, it is clear from the table that T3 is also well spread across a range of unique words and many other POS. This means that even though we cannot completely tease the effect of tone and POS apart, we can be reasonably confident that T3 is indeed a strong contributing factor to a switch from Cantonese to English. 11
Joint frequency table of Part of Speech (POS) and Tone at Cantonese-English switch points.
For Mandarin/English, we also identified some evidence for the facilitating role of T5 (neutral tone) in English-Mandarin CSw and T4 (falling tone) in Mandarin-English CSw, but the interpretation is less conclusive. Specifically, the occurrence of T5 at English-Mandarin CSw is limited to six words, with two particles taking up a large portion (de: 77%, N = 735/960; le: 17%, N = 165/960). This is in significant contrast with T3 at Cantonese-English switch points, where the occurrences are distributed among 65 different words. It is thus less clear whether the facilitating role of T5 at English-Mandarin switch points can be solidly attributed to the tonal effect. Similarly, while we found a facilitating effect of T4 for Mandarin-English code-switching, this effect is not entirely robust. Zheng (1997) previously attributed the facilitating effect of T4 in Mandarin/English code-switching to the similarities between Mandarin falling tones and the English falling intonation contour. Although this explanation fits with Clyne’s (2003) hypothesis as well as what we proposed for Cantonese/English, it may not satisfy the Mandarin/English data we have at hand. In particular, the intonation contour in Singaporean/Malaysian English mainly consists of a series of rising melodies across an utterance, and a falling contour can only appear on the last syllable of the content word in an intonation phrase (Chong & German, 2015; German & Chong, 2018). This unique intonation pattern leads us to believe that the tonal effects in Mandarin/English code-switching observed here are less likely to be attributed to the similarity between Mandarin falling tones and (Australian) English intonation as suggested in Zheng (1997).
Furthermore, we should take note that the speakers of the SEAME corpus come from a more linguistically diverse environment than the bilingual children in Australia as in Zheng (1997). The SEAME speakers’ speech is thus likely, to a larger extent, subject to the influence of other languages in contact. For example, Singaporean/Malaysian Mandarin contains traces of other southern Chinese languages such as Hokkien and Cantonese (Chin & Cavallaro, 2021), while Singaporean/Malaysian English is often influenced by Malay (Ng, 2012). The extent of these influences further differs depending on the presence/dominance of various dialects in different sub-regions.
Finally, it is worth mentioning that we found no facilitating or limiting tonal effect for Vietnamese/English, contrary to what we have seen in the other language pairs. Given that Vietnamese T2 is similar to Cantonese T3 (Figure 1), this finding may seem to run counter expectation. It should be noted, however, that the presence of a mid-level tone is not the sole determining factor in facilitating a switch to English. There remain some non-trivial distinctions in the Cantonese and Vietnamese tonal systems that should be taken into account. For example, the Vietnamese tonal system involves more glottalisation features, while the Cantonese tonal system relies more on pitch. This means that a level tone in Cantonese may have different statuses in the system compared to a level tone in Vietnamese. Furthermore, the prosody in Vietnamese-English may not resemble that in Hong Kong English, thereby contributing to different phonological interactions in a code-switching context.
In all cases, further examination of the acoustic data and speakers’ language background is needed to arrive at a more robust conclusion.
Tonal effects in Cantonese-English: T3 step-up pattern
Having discussed the tonal effects in all the language pairs, we now return to a question previously raised in relation to the results for Cantonese/English. Namely, if level tones in Cantonese (T1, T3, T6) are indeed generally preferred over contour tones (T2, T4, T5) at switch points, why does only T3 demonstrate a facilitating effect? Thanks to the availability of the HLVC audio data, we were able to cast some light in this direction.
First, we observe that there exists a specific ‘step-up’ pattern at Cantonese-English switch points; that is, the pitch of the English word starts at a higher level than the previous Cantonese syllable, as illustrated in Figures 2 and 3. These graphs represent some typical examples of the f0 pattern at Cantonese-English switch points where T3 is present on the Cantonese syllable. As we can see, the f0 contours show a ‘step up’ from the Cantonese mid-level T3 to the English monosyllabic words ‘break’ and ‘self’ (which are associated with an H tone). This ‘step-up’ pattern can be consistently observed for T3 throughout the corpus. Although the f0 difference identified in the ‘step up’ is not huge compared to the overall tonal space of Cantonese (the difference is about 20 Hz in both Figures 2 and 3), this level of pitch raise is perceptually clear to native speakers.
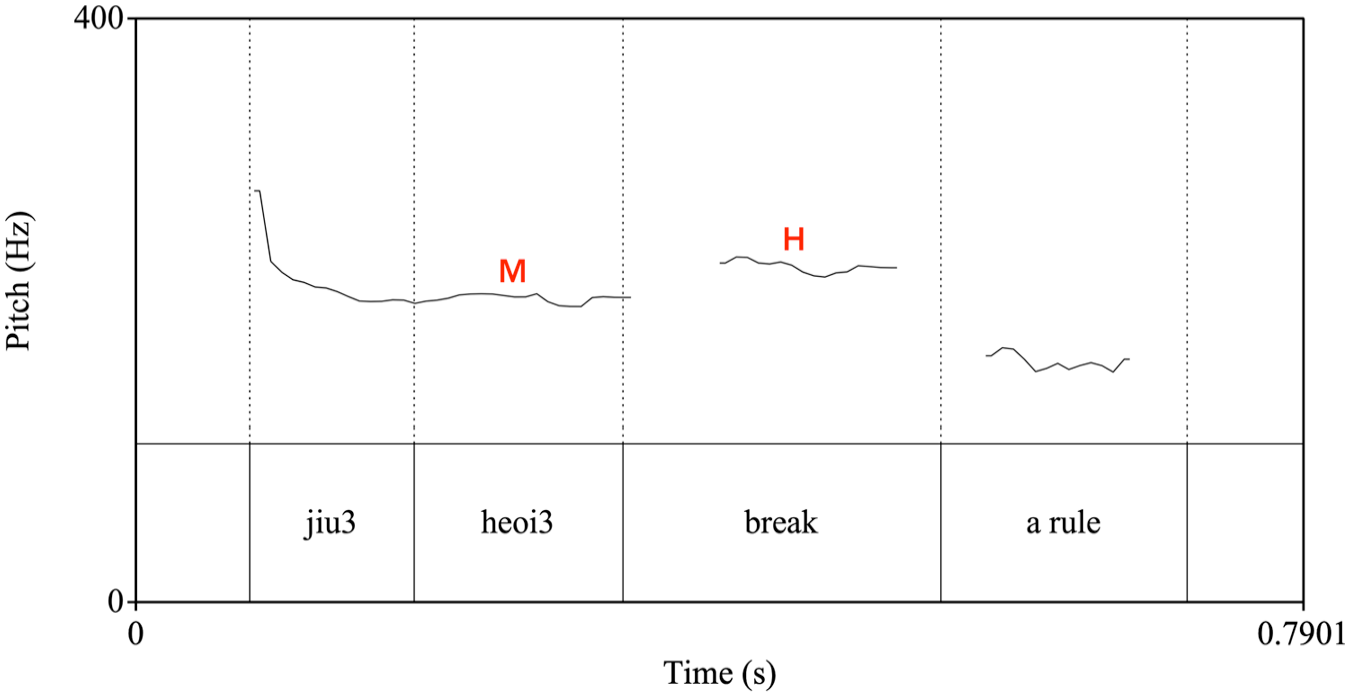
F0 contour of a Cantonese-English CSw at Cantonese T3. Translation of the sentence: ‘(. . .) is going to break a rule’.
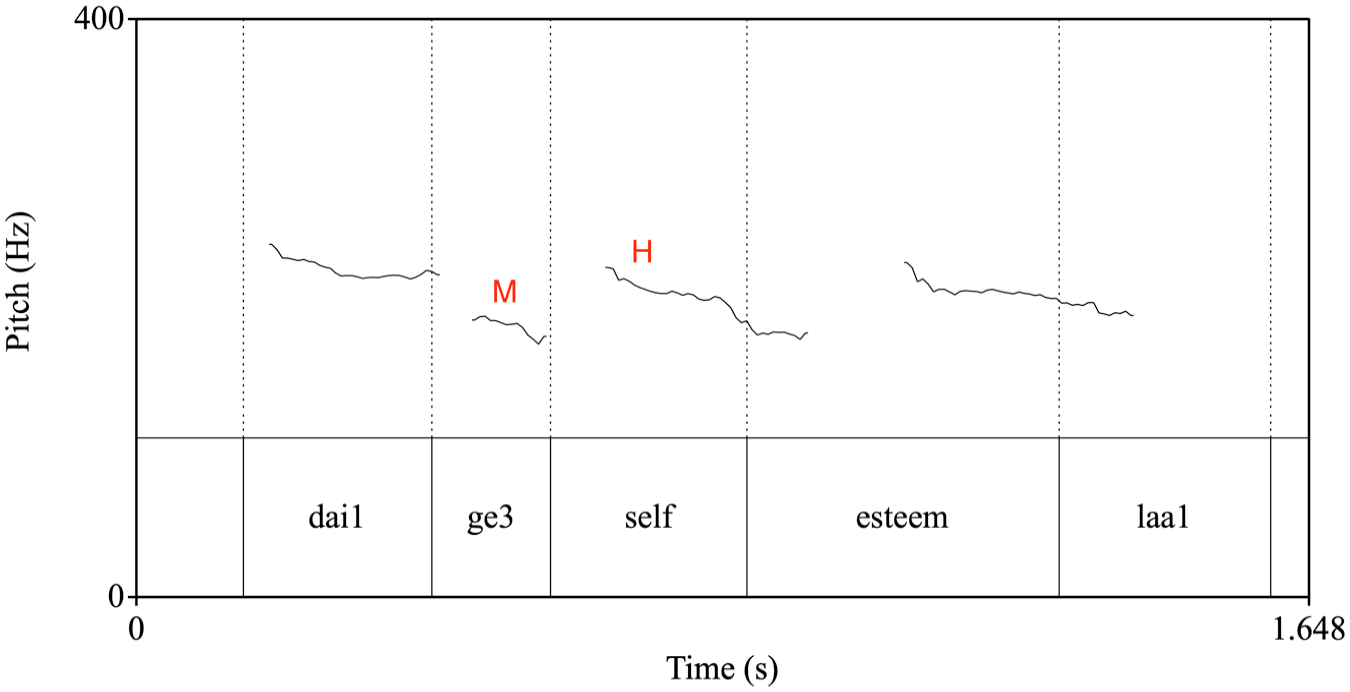
F0 contour of a Cantonese-English CSw at Cantonese T3. Translation of the sentence: ‘(It is) low self-esteem la (sentence-final particle)’.
Previous research has suggested that in Hong Kong English, tones are specified underlyingly for syllables that usually bear stress in British English, and M tones are associated with any word-initial syllables that do not have underlying H tones (Wee, 2016). In other words, an M tone is the unmarked default choice in tonal assignment, unless a H tone is specified in the lexicon. When an English word after a switch point has an initial H tone, which is a common scenario, a preceding M tone would best fit the tonal pattern of English words. In Cantonese, T3 has in fact been found to be associated with an M tone in terms of the pitch pattern (Wee & Liang, 2016). T1, on the other hand, is associated with H tones, and T6 is associated with neither H nor M tones in Hong Kong English. We illustrate in Figure 4, for example, that the ‘step-up’ pattern observed at T3 switch points is not borne out at the less frequently occurring T1 switch points. This exclusive resemblance between T3 and M tone possibly explains why only T3, but not other level tones, has a facilitating effect in Cantonese-English CSw.
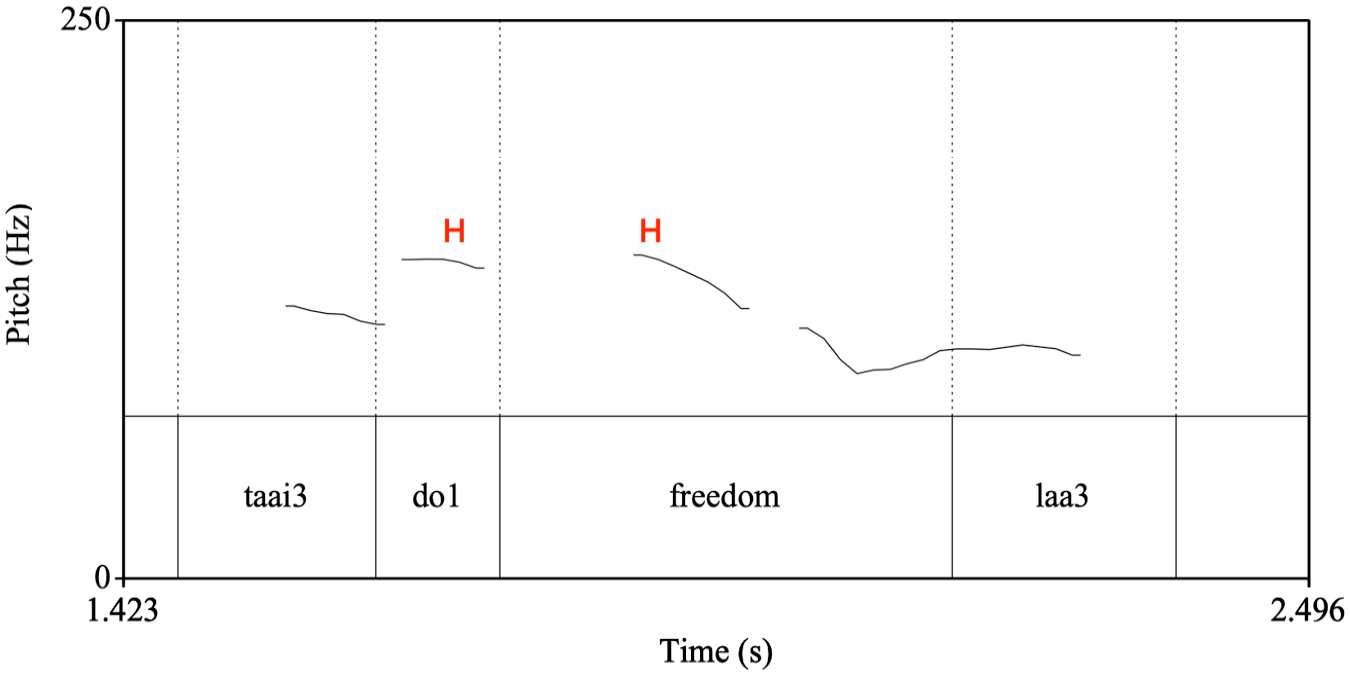
F0 contour of a Cantonese-English CSw at Cantonese T1. Translation of the sentence: ‘Too much freedom’.
Conclusion
We began this study by asking whether lexical tone has an impact on code-switching between a tonal language and a non-tonal language, and whether this effect (or lack thereof) is observable cross-linguistically. Our research has found some positive evidence that lexical tone indeed has an effect on Cantonese/English and Mandarin/English but not on Vietnamese/English. This suggests that although such an effect exists, this effect is language-dependent. For Cantonese/English specifically, we observed the most robust finding, where T3 (mid-level tone) plays a clear leading role in facilitating a switch from Cantonese to English. We explained this in reference to Clyne’s concept of prosodic facilitation (Clyne, 2003), and furthermore observed a specific ‘step-up’ pattern occurring at this particular switch point. We ultimately highlighted the prosodic similarity between Cantonese T3 and Hong Kong English M tone in facilitating their code-switching behaviour.
As for Mandarin/English and Vietnamese/English, although the previously reported tonal effects were not (fully) confirmed in our study, we should keep in mind the complex contact background of these communities when drawing conclusions. This lack of effect could be a result of other factors being captured in our study (e.g., grammatical categories, token frequency, etc.), but could also equally be a result of factors NOT being captured (e.g., regional variation, individual linguistic background, etc.). In any case, what is ostensibly clear is that even if there might be tonal effects in CSw for these language pairs, they were not robust enough to rise above interactions with other variables in play and thus stand as significant.
Looking forward, we rely on future research to address some of the limitations that we were not able to address in this study. Specifically, we hope the specific acoustic features of these varieties can be more accurately captured using audio data. This will allow a more detailed and comprehensive phonological analysis of tonal effects at both social and individual levels. The more limited distribution of neutral tone (T5) in Singaporean/Malaysian Mandarin (Choo, 2015), the ongoing tone merger in Cantonese (Cheng, 2017; Nagy et al., 2020), or the regional tonal variation in Vietnamese (Brunelle, 2009a), for example, can be more effectively reflected using the f0 data from the audio recordings. Furthermore, the extent to which the ‘step-up’ pattern is prevalent in Cantonese/English CSw needs to be more systematically examined. Future investigations could also look at tonal effects between two tonal languages, or between a tonal language and another non-tonal (i.e., non-English) language to offer a more comprehensive understanding of this matter.
Finally, we would like to emphasise that although the lack of consistent effects across all language pairs in this work hints towards an absence of coarse generalisation, it has opened up possibilities for more fine-grained categorisation; for example, which TYPE of tonal systems might be more conducive to a switch to and from English (or other languages in future work). This line of enquiry should be of interest to researchers not only in tonal languages, but also in language typology more broadly. Ultimately, we hope to have shed some light on the intriguing question of tonal effects in language contact, thereby encouraging further interest in this area.
Footnotes
Appendix 1
Appendix 2
Acknowledgements
The authors are grateful to Naomi Nagy for granting access to the HLVC corpus.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was funded by Language Sciences Incubator Fund and Issac Newton Trust (PI: L.N.).