
Abstract
Aims:
This study provides new insights into Arabic-English code-switching with particular reference to verb insertion. It aims to identify (1) patterns of English verb insertion into Arabic; (2) factors affecting them. We offer an alternative to previous studies’ conclusions regarding a supposed lack of English verbs integrated morphologically into Arabic, which is claimed to result from incongruence between Arabic and English verb systems.
Methodology:
We employ the Matrix Language Frame (MLF) model and the 4-M model.
Data and analysis:
The data comprise 14,414 clauses obtained from interviews with students at the American University in Cairo. Data were analyzed quantitatively.
Findings:
Most (80.17%) of inserted verbs were inflected with Arabic tense, gender, and number prefixes showing morphological integration into Arabic. We distinguished four recurrent patterns in verb insertion: (1) complete morphological integration in the present tense; (2) incomplete assimilation of forms requiring the use of the plural suffix -u; (3) lack of morphological integration in the past tense; and (4) lack of suffixation of Arabic clitics to English verbs.
Originality:
This is the first study focusing on verb insertion in Arabic-English code-switching based on empirical data collected in Egypt. It offers different findings on verb patterns and their explanation compared with other quantitative studies based on the MLF model. We propose to look beyond incongruence between Arabic and English as a factor determining verb patterns to include linguistic convention. Thus, we hypothesize that verb insertion might be controlled by linguistic norms accepted and perpetuated in a given speech community.
Significance:
Contrary to previous claims, our results show that patterns of verb insertion in Arabic-English code-switching are consistent with the MLF model. Hence, the study contributes evidence for the MLF model and its explanatory value.
Aim of the study
Previous studies on bilingual code-switching (CS) with Arabic have mostly analyzed their findings using Poplack’s structural constraints and the Matrix Language Frame (MLF) model. The universality of Free Morpheme and Equivalence constraints (see Poplack, 1980) has been falsified by all studies investigating CS between Arabic and French (Bentahila & Davies, 1983), Arabic and Dutch (Nortier, 1990), as well as Arabic and English (Alhazmi, 2016; Al-Khatib, 2003; Atawneh, 1992; Bader, 1995, 1998; Bader & Minnis, 2000; Mustafa & Al-Khatib, 1994; Youssef, 2016). Some studies have also questioned the validity of the MLF model (Aabi, 1999; Al-Enazi, 2002), claiming that CS with Arabic constitutes a unique case which is not subject to current theoretical concepts. Studies that confirm its validity (Alenezi, 2006; Al-Rowais, 2012; Okasha, 1999) report two atypical phenomena—an unusually large number of English inflectional phrase (IP) islands and a lack of English verbs inflected with Arabic suffixes. Both these phenomena are explained as resulting from incongruence between Arabic and English.
This study aims to provide new insights into Arabic-English CS with particular reference to verb insertion within the MLF model. The study’s central claim is that patterns of verb insertion in Arabic-English CS are not exceptional compared to the patterns seen with other language pairs. Our research shows that psycholinguistic factors, especially the manner and time of exposure to English and Arabic-English CS, may substantially impact on linguistic behavior. We suggest that (1) the number of IP islands recorded in previous studies may be overestimated due to the method of data classification—particularly regarding conjunctions of the inn/ann-type; (2) the lack of mixed verbs results from conventional patterns perpetuated within the investigated communities. Thus, CS patterns are influenced more by linguistic habits and socialization rather than by purely structural factors.
Data
This study is based on data obtained from interviews with students at the American University in Cairo (AUC) in 2015. The whole corpus comprises 87,801 words. The interviews were conducted in Arabic in the form of informal conversations, each lasting 45 to 170 minutes, with two or more participants discussing topics intended to engage them in conversation such as, for example, the linguistic situation in Egypt, CS, education, social inequalities, culture, religion, economy, sexual harassment, hobbies, and family life. In total, 28 students were interviewed.
Most participants were competent bilinguals raised with exposure to American culture. Some, especially those who were born from mixed marriages or spent most of their lives abroad, were raised in a natural bilingual environment. Others acquired English in Egypt in either international schools, wherein the whole education was conducted in English with Arabic as a non-compulsory subject, or in private schools providing bilingual Arabic-English education. Only a few participants graduated from state schools and were subject to intensive language instruction after their admission. For all participants, Arabic-English CS serves as their natural form of verbal communication and is difficult to control, even when conversing with monolinguals. They are perfectly aware of their linguistic behavior, which they see as a consequence of their cultural references and educations in private schools with instruction in English. As a result, CS is the most prevalent and hence unmarked form of communication among AUC community members. Monolingual Arabic discourse is marked and commonly perceived as a trait of state school graduates.
The matrix language frame model
In this section, we introduce crucial assumptions of the MLF hypothesis and its application in previous studies on Arabic-English CS with particular reference to morpheme classification. Against this background, we explain how we categorized data used in this study. All examples provided come from our data unless otherwise stated.
The MLF model of CS is insertional and assumes an asymmetrical relationship between the languages involved. The main premise is the existence of a dominant language, i.e. the matrix language (ML) that determines the grammatical framework. It provides system morphemes and the morpheme order in mixed constituents. The contribution of the other language—the embedded language (EL)—is mostly confined to content morphemes.
In early studies on the MLF model (Myers-Scotton, 1993, 1997; Myers-Scotton & Jake, 1995; Myers-Scotton et al., 1996), a frequency criterion was proposed to differentiate between the ML and the EL. This assumed that the ML provides more of the morphemes at the discourse level. Eventually, this criterion was replaced by a distribution of system versus content morphemes (Myers-Scotton, 1997), which is deemed crucial for determining the ML.
The ML may change in the course of interaction. Therefore, the unit of analysis in the MLF model is a complement(izer) phrase (CP). The term refers to S-bar in generative grammar, being a phrase/clause headed by a complementizer. For this reason, Myers-Scotton and Jake (1995, p. 982) find it more precise than a clause or sentence. In (1), we can see one bilingual sentence consisting of two CPs; the first one—I assumed—is monolingual; the second one has Arabic as the ML and an English insertion.
(1) I assumed INNU HUWWA BYA‘RIF YIKALLIM English KWAYYIS I assumed that he ASP.3ms.know 3ms.speak English well “I assumed that he spoke English well.”
The 4-M model (see Jake & Myers-Scotton, 2009; Myers-Scotton, 2002, 2013; Myers-Scotton & Jake, 2000, 2001, 2009, 2017), elaborating on the system versus content distinction, divides morphemes into content and three types of system morphemes: one type of “early” system morpheme and two sub-types of “late”—bridge morphemes and outsider morphemes. While both EL early and bridge morphemes may appear in mixed constituents, all outsiders must come from the ML (Jake & Myers-Scotton, 2009; Myers-Scotton, 2013). This makes the occurrence of outsiders a decisive test of the MLF hypothesis.
Content morphemes assign and receive thematic roles. They include nouns, adjectives, most verbs and prepositions, and discourse markers. Early system morphemes—that is, definite articles, verbal prepositions, and plural markers—modify the meanings of content morphemes. In CS with Arabic, the most regularly used English early system morpheme is the plural marker, which appears with all inserted nouns. The definite and indefinite articles, on the other hand, are virtually absent. This is exemplified in (2) where lifeguards is modified by -s instead of the Arabic plural marker -īn and defined by the Arabic article -il.
(2) WA ’ABILNA WAḤDA MIN IL-lifeguards and met.1pl someone.FEM from the-lifeguards “And we met someone from the lifeguards.”
Late system morphemes—bridges and outsiders—constitute larger linguistic units. One difference is that the former depend on the information inside the phrase in which they occur, while the latter must look outside their maximal projections to participate in well-formed constituents since they “coindex relations that hold across phrase and clause boundaries” (Jake & Myers-Scotton, 2009, p. 225). Bridges are usually invariant forms (e.g. of) whereas typical outsiders are verb affixes, such as for subject-verb agreement, and case markers; they typically have more than one allomorph and are subject to declension or conjugation (Myers-Scotton & Jake, 2009, p. 345). The classification of lexical categories may differ across languages. For example, in English, the preposition of in genitival constructions shows no variation. As a bridge morpheme, it might be inserted into the Arabic frame. Its Egyptian Arabic equivalent bitā‘ is always marked for gender and number to agree with the proceeding item. In (3), it appears in a singular feminine form since the Arabic equivalent of “quality”, gūda, is feminine. Thus, bitā‘ is an outsider. The same applies to verbs. In both languages, they are content morphemes. However, Arabic verbs have no infinitives and always occur with verb affixes. Since verb affixes are outsiders, Arabic verbs cannot be inserted into the English frame.
(3) FĪH FAR’ KBĪR TAB‘ AN FI L-quality BITĀ‘IT education NAFSAHA there.is difference big of.course in the-quality of education herself “Of course, there is a big difference in the quality of education itself.”
Incongruence between ML and EL
Except for outsiders, all EL items are allowed in mixed constituents provided they are sufficiently congruent with their ML equivalents. Incongruence between ML and EL results in two compromise strategies if the EL element better satisfies the speaker’s intentions than its ML equivalent: bare forms and EL islands (Jake & Myers-Scotton, 1997; Myers-Scotton & Jake, 1995; Myers-Scotton et al., 1996).
Bare forms lack the system morphemes necessary for them to be well-formed within the ML. When Arabic is the ML, this primarily applies to inserted adjectives, which always lack Arabic gender and plural markers. In (4), alāqa (“relationship”) is feminine; hence the modifying adjective requires the suffix -a in Arabic; in (5) selfish should be in plural which is marked by the suffix -īn in Arabic.
(4) MAFĪŠ ‘ALĀQA personal There.is.no relationship personal “There is no personal relationship.” (5) INN IḤNA selfish that we selfish “That we are selfish.”
EL islands are monolingual constituents containing only morphemes from the EL. Hence, they are well-formed according to the EL grammar. However, as part of the whole CP, they are always framed by the ML. In (6), the phrase closed community observes the English word order; however, it is framed by Arabic since the Arabic equivalent of “very” follows the phrase according to the Arabic word order. While English adjectives are often inserted as bare forms, as it is in (4), two types of noun phrases are always used as EL islands. These are phrases containing numerals and possessive determiners, as in (7), which results from incongruence between the languages. In Arabic, the syntax of numerals is more complex, including different forms of numerals depending on the noun; possessive determiners are clitic pronouns.
(6) IS-SA’UDIYYA ZAMĀN KĀNIT closed community ’AWI the-Saudi-Arabia once was. “Saudi Arabia was once a very closed community.” (7) IL-BANĀT YIḤAWLU YIḤAFẒU their virginity LI MUGARRAD SABAB WĀḤID the-girls try.3pl protect.3pl their virginity for merely reason one “The girls try to protect their virginity for only one reason.”
Verb system incongruence
Verbs, as content morphemes, are regarded as among most frequently code-switched items. Considering the main assumptions of the MLF model, we could predict that EL verbs should be inserted into the morphology of the ML. In practice, their integration differs across languages. The same occurs in the process of borrowing. Wichmann and Wohlgemuth (2008) elaborating on loan verbs distinguish four patterns listed in hierarchical order according to the degree of their integration with the target language: the light verb strategy, indirect insertion, direct insertion, and paradigm transfer. Direct insertion relates to the “model” pattern in the MLF model wherein a bare form takes the ML morphology. This, however, according to the MLF model, implies grammatical congruence for verb systems in the languages involved.
When verb systems are insufficiently congruent, besides bare (non-finite/uninflected) forms, inflectional phrase (IP) islands and “do verb” constructions, 1 referred to as the light verb strategy in Wichmann and Wohlgemuth (2008), may be used as an additional strategy. While bare forms and the light verb strategy are found in other CS data (e.g. for Turkish-Dutch CS, see Backus, 1996), IP islands are claimed to be more typical of Arabic-English CS.
An IP includes abstract categories such as tense and agreement, i.e. it merges lexical categories into a well-formed clause. In other words, an IP is part of a CP. It is composed of all the necessary elements of the clause except a complementizer. Thus, IP islands are well-formed embedded clauses.
Studies on bilingual CS with Arabic report two patterns of verb insertion into the Arabic ML. The first one is direct insertion found in Arabic-French CS (i.e. French verbs are integrated morphologically either by adapting the Arabic conjugation—see Boumans & Caubet, 2000; Caubet, 1998; Heath, 1989; Ziamari, 2007, 2009—or by inflecting French infinitives with Arabic suffixes—see Aabi, 1999; Bentahila & Davies, 1983, 1992). The latter is also found to happen in Arabic-Spanish CS (Vicente & Ziamari, 2008). The second pattern—the light verb strategy—is typical of Moroccan Arabic-Dutch (Boumans, 1996, 1998) and Nigerian Arabic-English CS (Owens, 2007).
Arabic-English CS reveals no direct insertion nor light verb strategy. Previous studies designed to test the MLF hypothesis (Alenezi, 2006; Okasha, 1999) record an unusually large number of English IP islands framed by Arabic and a lack of English verbs inflected with Arabic suffixes, which is explained as a result of incongruence between Arabic and English verb systems (Jake & Myers-Scotton, 1997; Myers-Scotton, 2010; Myers-Scotton & Jake, 2001; Myers-Scotton et al., 1996).
Although Myers-Scotton (2013) and Myers-Scotton and Jake (2014) revised their position, assuming no congruence checking between the two languages’ verbal systems, Myers-Scotton (2013, p. 46) still claims that English verbs do not accept Arabic inflections. This assumption, however, is based on one data set collected by Okasha (1999) and supported later by Alenezi (2006). While the numbers of inflected verbs in each study—four in Alenezi (p. 130) and five in Okasha (p. 99)—are indisputable, this study argues that English IP islands are overestimated due to two factors related to the method used in these previous studies to determine the identity of the ML.
Defining the ML in previous studies on Arabic-English CS
The first issue concerns the application of the frequency criterion in a way that sets the ML in advance, instead of strictly adhering to the distributions of morpheme types in particular CPs. Accordingly, Alenezi (2006, p. 143) states that in (8), you can’t believe is an English IP island whereas it is, in fact, a well-formed monolingual English CP:
(8) ğāt hina wa sHafitah / you can’t believe it “She came here and saw it; you can’t believe it.”
Secondly, probably all CPs with Arabic conjunctions followed by English IPs in the studies mentioned above are automatically interpreted as CPs with Arabic as ML, even if the Arabic conjunction is the sole Arabic morpheme in the CP. For instance, Okasha provides an example (9) where Arabic bass ‘but’ connects two monolingual English CPs, stating that “Arabic frames what is otherwise English structure” (1999, p. 111):
(9) I would like to wear this dress BASS (but) my parents won’t let me (Okasha 1999, p. 112)
However, Jake and Myers-Scotton (2009, p. 229) treat coordinators along with adverbial subordinators (e.g. because, but) as content morphemes, which means that bass is considered a content morpheme. If the ML is the sole source of word order and outsider system morphemes in bilingual CPs, English should be recognized as the ML in (9).
We encountered similar examples in our data. In some of them, bass is the only Arabic morpheme appearing in a larger chunk of speech, for example:
(10) he’s really bad at Arabic BASS he’s so good at vernacular, which is weird, he’s bad at grammar, he’s bad at the literature BASS he’s really good at vernacular
In example (11), besides bass, the only Arabic insertions are discourse markers ya‘ni (lit. “it means”) and masalan (“for example”):
(11) bass ya‘ni (but I mean) if I’m like masalan (for example) sitting, have like a very serious conversation, it’s not easy for me to do it in Arabic, I mean I can do it bass ya‘ni (but I mean) it takes me a lot of efforts
Such elements, due to their frequent use in vernacular Arabic, are easily accessible, even for those less proficient in Egyptian Arabic who therefore prefer English as a ML. The unmarked patterns of their CS usually include Arabic discourse markers with almost monolingual English CPs. A similar pattern is found in Moroccan Arabic-French CS, where it is used for symbolic purposes (Bentahila & Davies, 1995, p. 45). Thus, it is very likely that less proficient Arabic users resort to such “insertions” to make their speech sound more Arabic since they are not grammatically dependent on the ML. As such, they are not genuine insertions, but rather intra-sentential alternations, as defined by Muysken (2000).
The only conjunctions that cannot be classified unambiguously are of the inn/ann-type. Inn/ann is basically a complementizer “that” but it also appears in compound subordinators, as in ma‘a inn (“despite that,”) and li-inn (“because”). These conjunctions usually include pronoun clitics, that is, outsider system morphemes. Myers-Scotton and Jake (2001) categorize such multi-morphemic elements as outsiders (for more details of conjunction typology, see Jake & Myers-Scotton, 2009; Myers-Scotton, 2013).
Multi-morphemic conjunctions are typical of Arabic due to its dichotomous pronoun system. Personal pronouns in subject position are independent whereas as object complements, in constructions with prepositions and conjunctions of inn/ann-type are suffixed as clitics. When attached to conjunctions, clitic pronouns are often coindexed with the subject of the subordinate clause (and sometimes the main clause as well) and become outsiders. Thus, according to Jake and Myers-Scotton (2009, p. 230), the subordinators li-annuhum and li-annu in the examples (12) and (13) from Okasha’s corpus establish Arabic as the ML:
(12) HUMA BYIDFA‘ŪLI KUL HĀGA LI-ANNUHUM they can afford it
2
they HAB.IMP.3PL.pay.1SNG every thing because.3PL they can afford it “They pay for everything because they can afford it.” (13) HUNĀK BINIḤKI AKTAR LI-ANNU we get in the mood BASS HŪNI it is difficult there HAB.IMPF.1PL.speak more because.1PL (sic!) we get in the mood but here it is difficult “There we speak more because we get in the mood but here it is difficult.”
Similarly, Alenezi (2006) states that inn/ann-type conjunctions like (14) are “abundant evidence that ML, which is Arabic in this case, provides late system morphemes” (p. 140):
(14) He said innu (that) he will be here.
Nonetheless, not all inn/ann-type conjunctions are genuine multi-morphemic forms. li-annuhum in (12) differs significantly from li-annu in (13) and innu in (14), although they all include clitics. The glossing in (12) and (13) suggests that in both examples clitics refer to the subject of the following IP. While this is valid for (12), the clitic -u in (13) indicates the third-person masculine singular (lit. “his”). The pronoun is mostly attached to inn-type conjunctions without any reference to the subject. It may be followed by a different personal (independent) pronoun, e.g. innu ana (“that I”). Thus, it is a frozen form, used without (pro)nominal reference.
In the present data, such frozen forms and content morpheme conjunctions (e.g. bass) are used in a similar manner. The conjunction inn/innu is also used by speakers who feel more comfortable in English. In excerpt (15), only the second CP is clearly framed by Arabic:
(15) Fa (so) I stayed with him šwayya (a bit) / kān huwwa ḥāsis (he felt) / inn (that) I’m having a hard time in class
In the rest of this excerpt, Arabic is the source of easily accessible adverbs and conjunctions. Inn-type conjunctions appear four times, once after an Arabic CP and three times after English CPs. There is no rationale for claiming that Arabic frames those CPs, especially when inn conjunctions join two monolingual English CPs. We state that such frozen forms should be considered content morphemes incorporated into a CP framed by English.
Pronoun doubling
Another atypical pattern observed in Arabic-English (Eid, 1992), Arabic-French (Bentahila & Davies, 1983) and Arabic-Dutch (Nortier, 1990) CS, which affects data classification, is pronoun doubling, involving two personal pronouns before the verb. The first pronoun is Arabic, followed by a pronoun and verb of the other language. Myers-Scotton and her collaborators (Jake, 1994; Myers-Scotton, 2010; Myers-Scotton et al., 1996) see this as a consequence of incongruence between Arabic and English pronoun systems: Arabic supplies a topic pronoun which appears in a specifier position, followed by an English one to satisfy the grammatical requirements of English, which means that Arabic is the ML. Thus, in previous studies CPs such as (16) from Okasha (1999, p. 116) are classified as CPs with Arabic as the ML:
(16) Huwwi (he) he likes it ana (I) I don’t that is the difference
This approach only considers structural factors to explain the phenomenon. As topicalization and left dislocation frequently occur in vernacular Arabic for emphasis, pronoun doubling might be regarded as a pragmatic tool that has become part of bilinguals’ repertoire. Boumans (2000) argues that clause-initial emphatic pronouns in Arabic, due to their pragmatic function, should be considered discourse markers—that is, content morphemes. Considering that pronoun doubling occurs overwhelmingly in CPs, where all late system morphemes originate from the other (non-Arabic) language, we state that they should be analyzed as EL insertions or intra-sentential alternations.
Data classification
In previous studies, the ML is mostly defined at the discourse level. We state that in the community under investigation, where CS itself is an unmarked choice and speakers tend to change ML, strict differentiation between the four types of morphemes is the only way to determine the ML of particular CPs. This is how the data in this study were classified. Thus, English IPs introduced by Arabic conjunctions that are content morphemes and frozen forms (innu), as well as CPs with pronoun doubling, are treated here as CPs with English ML. The data were classified into four types of CPs: monolingual Arabic, monolingual English, CPs with Arabic as the ML, and CPs with English as the ML.
Results
Table 1 shows the overall distribution of CP types in the data and the numbers of inserted constituents in mixed CPs. AR_M stands for monolingual Arabic CPs, AR_ML—CPs with Arabic as the ML, ENG_M—monolingual English CPs, and ENG_ML—CPs with English as the ML. There are 2693 inserted constituents in mixed CPs with Arabic and 1914 CPs with English as the ML.
Overall distribution of monolingual and bilingual CPs.
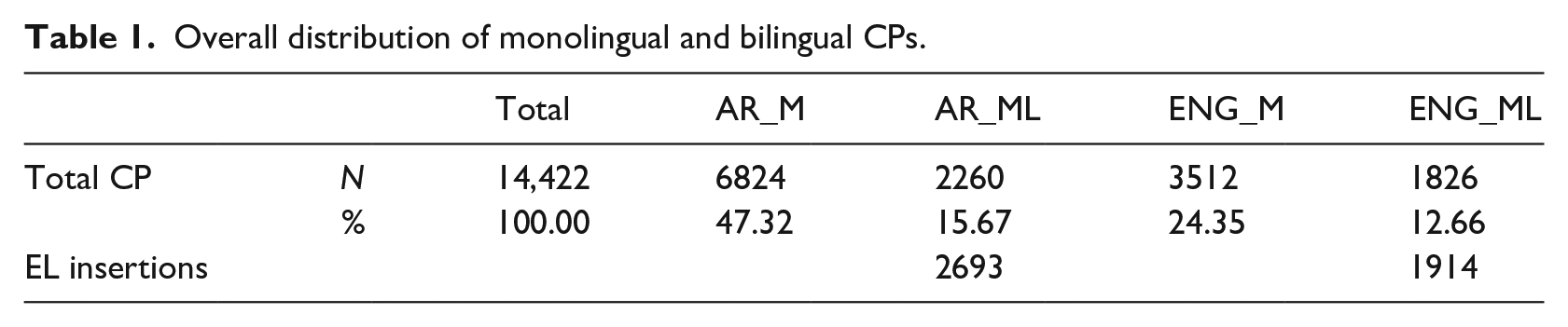
We should stress that interviews differed in their distributions of CP types. The smallest number of CPs framed by English in one interview was eight (five monolingual and three mixed), being 0.83% of all CPs in that interview. The highest percentage of CPs controlled by English in any interview was 59%. A quantitative data analysis shows the participants’ preference for monolingual CPs. Out of the total number of 14,422 CPs, 10,336 (71.66%) were monolingual Arabic (6824) or monolingual English (3512). Mixed CPs numbered 4086 (2260 with Arabic and 1826 with English as the ML), being 28.33% (15.67% and 12.66% for Arabic and English, respectively).
Table 2 displays the types and frequencies of inserted constituents in CPs with Arabic as the ML, ranked by frequency.
The overall distribution of insertions in CPs with Arabic as the ML.
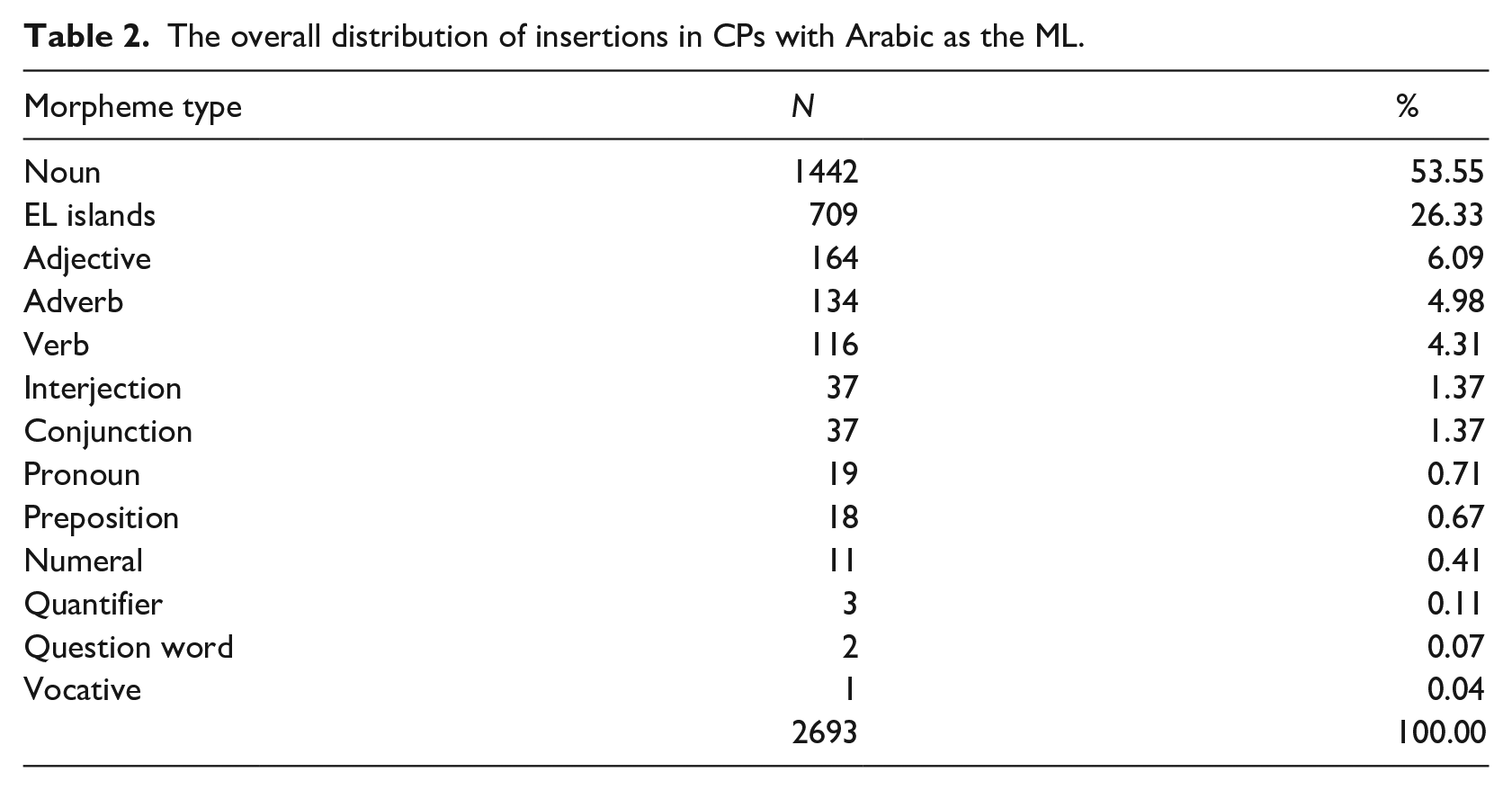
Inserted English verbs come after nouns, EL islands, adjectives, and adverbs. They form 4.31% of all insertions and 5.85% of lone insertions. Table 3 displays the types of inserted verbs recorded.
Patterns of English verb insertion.

Out of 116 verbs, 92 (80.17%) were morphologically integrated with Arabic. Their assimilation was usually complete; they were inflected with tense, gender, and number affixes. For example:
(10) in-nās bit-relate il-English bi l-upper social class the-people ASP.3fem-relate the-English to the-upper social class “People relate English to the upper social class.”
The only exceptions were third-person plural verbs. Five out of eight plural forms showed partial integration, lacking the plural suffix -u. For example, in (17) the predicate of the main clause byiḥawlu “they try” is a well-formed Arabic verb. The following verb, yi-accommodate (lit. “he accommodates”), is a singular form used with a plural meaning. This inconsistency is difficult to explain due to the scarcity of the plural forms encountered. Fully and partially integrated forms appear in similar grammatical contexts. In (18), we find a fully integrated verb mix after the same verb as in (17). The available examples indicate that the phonological context should also be excluded as a factor in this matter.
(17) professors byiḥawlu yi-accommodate li everyone professors ASP.try.3pl 3ms-accommodate to everyone “Professors try to accommodate to everyone.” (18) BYIḤAWLU YI-mix-U L-ITNĒN ASP.try.3pl 3ms-mix-pl the-two “They try to mix both of them.” Phrasal verbs were usually inserted with their English satellites (verbal prepositions), as in, for example: (19) MUMKIN YI-relate to ḤAGĀT MU‘AYYANA maybe 3ms-relate to things specific.FEM “It may relate to specific things.”
Interestingly, only 14 verb forms (11.21%) were indisputably bare forms. In (20), the verb help lacks the third feminine prefix ti-. However, it introduces a well-formed Arabic predicate in the subordinate clause:
(20) ‘AŠĀN DAYMAN BYIB’A IL-‘ĒLA help TI-DFA‘ IL-FILŪS because always AUX the-family help 3f-pay the-money “Because the family always help to pay the money.”
No verb was morphologically integrated in the past tense. In four out of six examples recorded, past forms occurred. For example:
(21) IN-NIẒĀM IL-MAṢRI, YAʿNI, failed the-order the-Egyptian, meaning, failed “The Egyptian order, I mean, failed."
The lack of assimilation in the past tense deserves attention. In Arabic, past-tense verb forms are inflected with suffixes. In non-past forms, suffixes are only required in the second and third-person plurals. As mentioned before, most plural examples recorded lacked the obligatory -u. This suggests that English verbs tend not to be cliticized, which is also supported by the lack of Arabic clitic complements after English verbs. Instead, English pronoun complements are always used, as in (22), for example:
(22) KULL WĀḤID BYI-justify it B-ṬARIʾTU every one ASP.3ms-justify in-way.his “Everyone justifies it in their own way.”
Since Arabic clitics seem unacceptable with English items, speakers resort to other strategies to denote the past tense. Apart from past forms, two bare forms appeared in VPs with the Arabic auxiliary kān. In such examples as (23), kān seems sufficient as a marker to express the past meaning of the embedded bare verb form:
(23) ILLI HUWWA KĀN reconcile ID-DĪN BI L-modern who he was reconcile the-religion with the-modern “Who reconciled the religion with modern.”
The use of integrated versus bare forms seems highly dependent on context. Integrated verbs occur after personal pronouns (except in one example) and immediately following auxiliaries, modals, and verbs that require verbal complements. Bare forms (or infinitives) are mostly used when other elements occur between the two verbs; as in example (24), where only the verb “relax,” which directly follows the modal, is integrated, although “zone out” would also require the prefix a- to be well-formed in Arabic:
(24) ‘AZYA A-relax KIDA U zone out Wanting.FEM 1sg-relax at.last and zone out “I want to relax at last and zone out.”
Likewise, in (25) and (26), two different verb forms occur after the same verb—ḫalla (“to allow” or “to cause sb to do sth”):
(25) ILLI HAT-ḪALLI T-facilitate my movement BA‘D KIDA which FUT.3fs-allow facilitate my movement after that “Which will let facilitate my movements after that.” (26) WI BA‘DĒN DA BYI-ḪALLI N-NĀS KAMĀN to know And besides this ASP.3ms-make the-people to know “Besides, this makes people know.”
The verb “facilitate” in (25) is inflected with the prefix t-, while “know" in (26) appears in the infinitive form. However, although these data supports the above-described hypothesis of context-dependent integration, due to the scarcity of data, generalizations in this matter would be premature.
Discussion
A comparison of this study’s results with those obtained in Okasha (1999), Alenezi (2006), and Jake and Myers-Scotton (2002)—summarized in Table 4 below—shows certain discrepancies as well as similarities. The differences relate to (1) types of bilingual CPs used, in terms of ML; and (2) the numbers of embedded English verbs morphologically integrated with Arabic. The greatest similarity is the high proportion of monolingual and bilingual CPs with Arabic as the ML.
Generational differences in CS patterns. a

The tables do not include CPs with a Composite Matrix Language distinguished in the cited works. Thus, the percentages do not add up to 100%.
The studies above focus on generational differences in CS patterns, showing a clear distinction between generation I (raised in the Arab world) and generation II (raised in the United States) in the distribution of monolingual CPs; English CPs occur more frequently with generation II, Arabic CPs in generation I. Another characteristic is an insignificant number of bilingual CPs with English as the ML. The authors conclude that both generations maintain Arabic as the ML.
Arabic also appears to be the dominant language in the present study since monolingual Arabic CPs constitute 47.32% of recorded CPs. However, the high number of Arabic CPs is probably partly attributable to the interviews having been conducted in Egyptian Arabic, influencing the participants’ linguistic performance. In the initial phases of conversations, more Arabic monolingual utterances were produced, showing linguistic accommodation to the interviewers. The highest proportion of CPs framed by English (monolingual or bilingual) appear in the longest interviews. As a rule, the longer the interview, the higher the proportion of CPs framed by English.
The present study reveals a higher proportion of bilingual CPs with English as the ML and a more balanced distribution between bilingual CPs—15.67% with Arabic as the ML versus 12.67% with English ML. However, the number of bilingual CPs with Arabic as ML in previous studies may have been overestimated, since the authors appear to classify all English CPs with Arabic conjunctions and pronoun doubling as Arabic ML CPs, as well as categorizing at least some monolingual English CPs as EL islands. The fact that English monolingual CPs outnumber other CP types in generation II data may indicate that English is the ML, at least at the discourse level, for people raised in the U.S.
Generational differences in CS patterns have also been observed in other CS data with Arabic. In Bentahila and Davies’s (1992, 1995) study on Moroccan Arabic-French CS, balanced bilinguals from older generations tended to resort to inter-sentential, while young people—Arabic-dominant bilinguals—to intra-sentential CS. This also applies to verb insertion. In the older generation, mixed verbs constitute 2.2% of all switches as opposed to 9.3% in generation II (1992, p. 448; 1995, p. 81). A change towards verb integration is also found in Moroccan Arabic-Dutch CS, where ‘do constructions’—according to Boumans (1996, 1998)—are currently a typical pattern of verb insertion. In Nortier’s (1990) study, based on data collected a few years earlier (1986), occurrences of “do constructions” numbered only five.
The data examined herein also differ in terms of verb insertion from those obtained by Okasha (1999), Alenezi (2006), or Jake and Myers-Scotton (2002). In our data, inserted English verbs show a higher occurrence (4.31%), and most were morphologically integrated. In Okasha (1999, p. 140), lone EL verbs were more frequently inserted as bare forms (18 in generation I, and 8 in generation II). In contrast, in our data they number 14—a significant difference given the sample sizes of the studies.
The proportion of embedded verbs in the data is not substantial. However, we believe that their number is substantially smaller than their actual use in the community. While collecting data, we constantly heard English verbs morphologically integrated into Arabic. We suppose the interviewers’ linguistic performance significantly minimized such verb insertion in the interviews. Other data—including Rouchdy (1992) and Atawneh’s (1992), which Myers-Scotton and her associates did not incorporate into their analysis—imply that verb insertion is more widely accepted in Arabic-English CS than has been claimed.
In Atawneh’s (1992) data, collected in the United States from three children aged 9–11, verbs and verb phrases occur second most frequently to nouns and noun phrases, comprising 18.3% of all switches (Atawneh, 1992, p. 223). There are still twice as many single nouns as verbs, but compared with other data sets, the difference is less significant. Atawneh does not elaborate on patterns of code-switched verbs. However, in the examples given, all verbs are inflected with Arabic suffixes.
Since English verbs with Arabic inflections have been recorded elsewhere, we claim that verb insertion is not restricted by linguistic incongruence between Arabic and English. The idea of looking beyond syntactic constraints in explaining CS patterns has been raised in several studies on CS with Arabic. Each has proposed its interpretation. Boumans and Caubet (2000, p. 166) hypothesized that the disparity between patterns of Algerian Arabic-French and Moroccan Arabic-Dutch CS might result from different sociolinguistic situations in the Netherlands versus North Africa. Algerian Arabic-French CS reveals patterns similar to CS in other former French colonies. The Moroccan community in the Netherlands, on the other hand, shows similar patterns to those of the Turkish community, especially in terms of ‘do constructions.’ The authors assume that the latter pattern might be “characteristic of migrant bilingualism in modern industrialized societies” (Boumans & Caubet, 2000, p. 171). Owens (2007), however, proposes an areal norm explanation regarding “do constructions.” In his data set, collected among Nigerian Arabs, two different patterns of verb embedding appear. Standard Arabic verbs are usually morphologically integrated into Nigerian Arabic while English verbs are introduced through “do constructions,” a pattern also found when Hausa is the ML (and English the EL) as well as for other language pairs in the area. However, areal explanations might be valid only for particular communities since data from Arabic-English CS collected in the United States show substantial variation regarding verb insertion.
Bentahila and Davies (1992, 1995, 1998) relate generational differences in CS patterns to a change in speakers’ linguistic competencies, stressing other extra-linguistic factors that might affect their linguistic choices and communicative strategies, e.g. how each of the two languages was acquired (at home versus through formal education), social attitudes towards them, their symbolic values, and the distribution of language dominance (see Bentahila & Davies, 1998). This interpretation, however, is difficult to apply to the results of the present study.
Firstly, the majority of our participants were competent bilinguals. Some (usually those raised abroad) were English-dominant bilinguals. This certainly influences their predominant choice of English as the ML. The most characteristic pattern of their CS was what Bentahila and Davies (1998) term “leaks,” involving inserting Arabic conjunctions and discourse markers for symbolic reasons. However, most other participants, unlike Moroccan bilinguals, were accustomed to using both languages since infancy. Their exposures to English were not confined to formal settings, but rather supported and sustained by English-dominant media, such as music, films, and websites. As a consequence, both codes can be found in complementary distribution in the speech of the majority of AUC community members. While communicating with their parents, they mainly use Arabic. At the same time, Arabic cannot satisfy all their communication needs, particularly in communication with peers of similar linguistic backgrounds. Thus, CS is not confined to discussing education-related issues but has become an unmarked form of communication in certain types of speech events. This is partly because, in Egyptian society, especially among the AUC community, CS is considered an essential hallmark of the privileged, while monolingual performance is usually stigmatized and associated with graduates of state schools. Hence, bilingual CS is used for two reasons—to confirm membership in a particular speech community and to fulfill communication needs not achievable through monolingual discourse. Their linguistic competencies allow them to choose linguistic tools and strategies from their bilingual repertoires that best facilitate the achievement of their conversational aims.
That is not to say that linguistic competence does not affect CS patterns. However, if we compare verb insertion in Arabic-French versus Arabic-English CS, the results would seem inconsistent. In Bentahila and Davies’s data, Arabic-dominant bilinguals embed French verbs in Arabic matrices, while balanced bilinguals switch between whole CPs. In our data, balanced bilinguals tend to insert English verbs in CPs with Arabic as the ML (using inter-sentential CS as well). In this respect, our findings are more consistent with the hypothesis made by Wichmann and Wohlgemuth (2008). The authors suggest that “direct insertion implies a relatively high degree of bilingualism” (p. 111). Increased bilingualism translates into a tendency to replace the light verb strategy, i.e. the pattern of the lowest degree of integration, by insertional patterns showing morphological integration. Given the linguistic background of the participants in this study and the fact that direct insertion is the strategy most commonly used in our data, Wichmann and Wohlgemuth’s predictions might explain the results obtained herein. However, they do not explain why morphological integration is not found in Okasha (1999), Alenezi (2006), and Jake and Myers-Scotton (2002) in generation II data. If increased bilingualism, which certainly applies to generation II, was a decisive factor, we should observe a shift from bare forms towards direct insertion. We also have to keep in mind that not all verbs in our data show complete integration. This relates to past-form verbs as well as non-past plural forms, most of which lack the plural suffix -u. Thus, we may infer that English verbs do not accept Arabic clitics as a result of the incongruence between the languages, which is also confirmed by the lack of clitized pronoun complements attached to English verbs. However, data from Alhazmi (2016) and (Atawneh, 1992) contradict this assumption. In both data sets, fully integrated verbs in the past form as well as cliticized complements are observed, as in example (27) (Atawneh, 1992, p. 237).
(27) HĀDA ILLI ANA spellYET-U this that I spell.1PST-it “This that I spelt.”
The occurrence of cliticized forms in Atawneh (1992) may be explained by the fact that the data came from children. In private conversations with Egyptian parents, this type of insertion was often mentioned to be present in their children’s linguistic performance at an early age to become absent later. Nevertheless, the same pattern is found in Alhazmi (2016) from radio and Facebook data in Australia. The author provides examples of English verbs with Arabic present- and past-tense verb markers, and clitic pronouns, remarking at the same time that forms cliticized with certain affixes were judged as unacceptable by participants in his study.
Thus, data sets from Arabic-English CS prevent any ultimate conclusions from being drawn. What we can conclude is that CS patterns are not determined solely by syntactic factors, including structural incongruence. Generational differences may indicate that CS patterns used by individuals are adjusted to conventional patterns in speech communities. It is currently impossible to investigate generational differences in Arabic-English CS in Egypt, as it is a relatively new phenomenon. The majority of our participants’ parents do not speak English. However, a diversity of results obtained in various studies corroborate conventional explanations of verb insertion patterns as far as Arabic-English CS is concerned. This diversity is not confined to morphological integration or its lack but also relates to its completeness. Thus, it is highly likely that the way verbs are inserted in Arabic-English CS reflects and largely depends upon changing community patterns of CS, its acquisition through socialization, and the adoption other code-switchers’ performance patterns.
Conclusion
This study focused on verb insertion in Arabic-English CS with reference to the MLF model. 80.17% of embedded English verbs recorded were morphologically integrated into Arabic. This substantially contradicts the results reported in other quantitative studies on Arabic-English CS, in which English verbs were mostly inserted as bare forms. Our research indicates that verb insertion in Arabic-English CS is not atypical compared to other language pairs and does not contradict the MLF model.
The results obtained allow to specify four recurrent patterns of verb insertion: (1) in non-past tense inserted verbs are morphologically integrated with Arabic, i.e. they are inflected with tense, gender, and number affixes; (2) most third-person plural verbs in non-past forms show incomplete assimilation lacking the plural suffix -u; (3) past forms are inserted as either past forms or bare forms with the Arabic auxiliary to mark the tense; (4) English verbs are never cliticized with Arabic pronoun complements; instead, English pronouns are used. This suggests that morphological integration of English verbs constitutes a linguistic norm as long as embedded verbs are not suffixed with Arabic clitics. However, as other studies report cases that seem to be unacceptable in ours, this generalization can only be applied to the community under investigation—in this case, to AUC students.
Regarding factors affecting CS patterns, we agree that grammatical incongruence between the languages involved and the degree of bilingualism constitute a basic frame providing speakers with available means. However, the differences in the results found in a variety of data from Arabic-English CS suggest that they cannot be seen as decisive in this matter. Thus, we would rather hypothesize that the ultimate determinant is convention. That is, linguistic norms perpetuated in a given speech community acquired through socialization, which may translate into how incongruence is perceived. Testing our hypothesis needs further investigation of diverse speech communities in the Arab world. This includes short-term studies to find similarities and differences in the linguistic performance of various communities as well as longitudinal studies focused on particular participants that will allow us to observe possible changes in their behaviors at different stages of their lives that may also verify whether increasing degree of bilingualism at the individual level influences CS patterns.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was financed by the National Science Center in Poland based on decision number DEC-2013/11/D/HS2/04524. Also this article is made open access with funding support from the Jagiellonian University under the Excellence Initiative – Research University programme (the Priority Research Area Heritage).