
Abstract
Aims/objectives/research questions:
Heritage speakers have been shown to use multiword units, which merge structural elements of both their languages, which do not conform to the combinability patterns of the monolingual variety. However, it is not clear to what extent heritage speakers actually have the knowledge of the corresponding monolingual sequences. The present study on Russian heritage speakers in Germany addresses the question of whether heritage speakers have receptive knowledge of monolingual multiword units that they do not command in production.
Design/methodology/approach:
The study followes a mixed methods design by combining corpus and experimental methodology.
Data/analyses:
First, language production data of heritage speakers from two corpora were analysed for nontypical multiword units with prepositional phrases. In the second step, these nontypical multiword units as well as their typical monolingual equivalents served as test items in an acceptability judgement task performed by 53 Russian-German heritage speakers and 56 Russian native speakers.
Findings/conclusions:
The results show that heritage and native speakers rate nontypical multiword units as less acceptable than their monolingual equivalents. However, the acceptability of typical and the unacceptability of nontypical expressions were more salient for native speakers, whereas heritage speakers in many cases tended to equally accept typical and nontypical items. Acceptability ratings varied according to test items in both groups, but there was no overlap between nontypical multiword units most acceptable to monolinguals and those most acceptable to heritage speakers.
Originality:
Our paper applies an innovative mixed method approach in investigating the receptive knowledge of monoloigual multiword units in heritage speakers. Additionally, it is one of the first studies looking at the reactions of native spekaers to novel multiword units produced by heritage speakers.
Implications:
The findings support the idea of a unified multilingual construction, suggesting that heritage speakers do have some receptive knowledge of monolingual multiword units but this knowledge differs from that of monolingual speakers.
Keywords
Introduction
It is now an established fact that a large part of native speech is made up of formulaic sequences or multiword units (MWUs), that is, combinations of words that represent the habitual phrasings of a speech community (Coulmas, 1979; Erman & Warren, 2000; Fillmore et al., 1988; Pawley, 2001). They come in a variety of different types including idioms (e.g., hit the sack), collocations (e.g., widely known), multiword terms (e.g., blind spot), pragmatic formulas (e.g., Have a good day!), and usual sequences (e.g., at the expense of X or in the middle of X). Performing two crucial functions, processing enhancing and socio-interactional, MWUs are argued to be a part of language competence in all types of speakers, irrespective of their grammatical and lexical proficiency (Wray, 1999). Whereas much research has been conducted on MWUs in native speakers and second language learners, little is known about MWUs in heritage speakers (HSs), a group of language users that has recently become important in linguistic research.
An HS is ‘an early bilingual who grew up hearing (and speaking) the heritage language (L1) and the majority language (L2) either simultaneously or sequentially in early childhood (that is, roughly up to age 5), but for whom L2 became the primary language at some point during childhood (at, around, or after the onset of schooling)’ (Benmamoun et al., 2013, p. 133). Due to the language shift, HSs’ first language development is interrupted and often results in incomplete acquisition, especially of the features acquired late by monolinguals (Albirini & Benmamoun, 2012; Montrul, 2008). In addition, HSs experience attrition as their language use is typically limited to the home environment (Montrul, 2008; Polinsky, 2011). In spite of tremendous variability in the outcomes of heritage language acquisition, all HSs have a common characteristic of informal exposure to language in childhood, which results in their best-developed language skill being oral comprehension (Polinsky, 2015).
HSs have been considered a unique population allowing researchers to identify naturally resilient and vulnerable areas of language, thus arriving at a better understanding of language faculty (Benmamoun et al., 2013). Surprisingly little research, however, has been conducted on MWUs in HSs. The question remains open of what knowledge about MWUs of the monolingual variety does and does not get acquired through the type of limited exposure which characterizes HSs. Regarding productive knowledge, available corpus studies have shown that HSs often use MWUs that combine features of the heritage and the dominant language and are not typical of the monolingual variety. Studies addressing receptive knowledge of MWUs in HSs are few and their results are controversial, that is, whereas some argue that HSs’ recognition of MWUs is native-like, others show an almost complete lack of even receptive skills.
In this article, we focus on the receptive knowledge of MWUs in HSs based on the data from Russian HSs in Germany and ask two questions. First, do HSs have receptive knowledge of the MWUs of the monolingual variety, which they seem not to command in production and for which they create novel MWUs? Second, how are these novel HS-MWUs perceived by monolingual speakers? To answer these questions, we first collected examples of novel MWUs in HS corpora and then tested how HSs and NSs perceive these novel expressions and their monolingual equivalents via an acceptability judgement task. Before presenting the study, we will discuss some theoretical points regarding the concept of the MWU and its application to HSs.
Theoretical background
Defining and identifying monolingual MWUs
MWUs are singled out as a particular group of linguistic expressions based on the criterion of formulaicity, which refers to several words having a strong relationship to one another in jointly creating meaning (Wray, 2008). MWU is not a monolithic construct and specific definitions of it vary according to a linguistic field. Traditional phraseological research (e.g., Burger et al., 2007; Cowie, 1998) emphasizes semantic idiomaticity and syntactic fixedness. From the perspective of language processing, MWU is defined as a preconstructed sequence of words, which is stored and retrieved from memory as a whole (Sinclair, 1991; Wray, 2002). Finally, the distributional approach focuses on conventionality of language use (Brunner & Steyer, 2007; Bybee, 2010; Pawley, 2001). MWUs here are viewed as ‘combination[s] of at least two words favoured by native speakers in preference to an alternative combination which could have been equivalent had there been no conventionalization’ (Erman & Warren, 2000, p. 30) or as ‘phrases that are conventional pairings of form and unit of meaning in a speech community’ (Buerki, 2016, p. 18).
Within the distributional approach, which we will follow in this study, MWUs are considered to emerge through frequency-based repetition (Bybee, 2006, 2010), that is, the more a chain of words is used together, the more entrenched it becomes as one unit. Consequently, an ideal MWU is ‘an expression that is frequent and evenly dispersed in a corpus and where at least one part attracts the other strongly (but where ideally both parts attract each other and/or are highly predictive of each other)’ (Gries, 2022, p. 6). Focusing on conventionality of language use, the distributional approach has extended the scope of MWUs beyond such classical types as idioms, compounds, and collocations to units of various sizes and complexity levels representing the most frequent, recurrent, semantically compositional multiword sequences termed lexical bundles (Biber & Conrad, 1999), institutionalized phrases (Sag et al., 2002), or usual sequences (Buerki, 2016). Large-scale corpus investigations have shown that conventional, nonidiomatic sequences outnumber idiomatic MWUs (Jones & Sinclair, 1974; Renouf & Sinclair, 1991). Buerki (2016) found that usual sequences represent the most common category of MWUs in the analysis of a 29 million words corpus of English-language Wikipedia texts.
Depending on the definition, MWUs have been identified in a number of different ways including psycholinguistic measures, acoustic analysis, statistical analysis, and native speaker judgements (see Wood, 2019 for an overview). Here we will briefly discuss only the last two, as they are relevant to the present research. In statistical analysis, a minimal length of a word combination and a minimal token frequency in a corpus (mostly between 10 and 40 occurrences per million) or a measure of word association (such as mutual information) is usually set up and the corpus is then searched for word combinations satisfying these criteria. Currently, more sophisticated statistical techniques are proposed that additionally cover type frequency and dispersion (Gries, 2022). The statistical procedure can only be applied to a very large corpus of millions of words, which makes it problematic for smaller data sets. In addition, applying statistical measures does not solve the problem of determining the boundaries of MWUs (Wray, 2002).
An alternative way to identify an MWU is the use of native speaker judgements with a checklist of criteria. The standard procedure here is asking judges to study the criteria of a checklist and search a corpus for expressions that satisfy the criteria (Wood, 2019). For example, among the nine criteria for formulaicity used by Coulmas (1979, p. 32) are “at least two words long”, “individual elements are not used concurrently in the same form separately or in other environments”, “repeatedly used in the same form”, and “coheres phonologically”. Summarizing available checklists, Wood (2019) notes that phonological coherence and structural complexity are the most commonly used features. Overall, the identification of MWUs even in monolingual data remains a challenging issue and requires a combination of measures.
To summarize, an MWU is a heterogeneous concept with a definition varying according to research perspective. In general, MWUs are understood as semantically nondecomposable and syntactically fixed word combinations in phraseological research, as units stored and retrieved from the mental lexicon as a whole in the processing approach, and as the most conventional ways to formulate some aspects of language in a community in the distributional approach. MWUs exist in various types, with usual sequences possibly being the most frequent ones. Several means have been applied to identify MWUs, including statistical measures and native speaker judgements.
MWUs in HSs: productive skills
The definition of MWUs as developed for monolinguals has to be modified when applied to multilinguals. As Wray (1999, p. 213) notes, formulaic language used by multilinguals cannot be reduced to the subset of that used by adult NSs. Multilinguals use their own sets that partially overlap with that of adult natives. In addition to native-like formulaic sequences, learners use MWUs, which contain nonnative language forms or meanings. Some of these nonnative expressions remain stable and fossilize; some disappear after a short time (Wray, 1999).
Kopotev et al. (2020) discuss a similar instability problem with regard to MWUs in HSs. Due to the limited size of bilingual corpora, word combinations found in the heritage data are difficult to identify as MWUs on the basis of positive statistical criteria because they are ‘single occurrences, which may be interpreted as either ad hoc decisions of a speaker or as a new ‘‘fixed’’ feature of the heritage language’ (Kopotev et al., 2020, p. 2). The authors suggest defining HSs’ MWUs based on negative statistical evidence, that is, nonconformity to statistical expectations of the monolingual variety. The nonconformity is in place when HSs produce novel word combinations instead of expressions statistically expected in the monolingual variety (Kopotev et al., 2020, p. 3). Consequently, heritage collocations are defined as ‘linear co-occurrences produced by heritage speakers, whose frequency in a native Russian corpus equals to zero and is thus in contrast to colloquial and frequently used native collocations with the same meanings’ (Kopotev et al., 2020, p. 7).
In available corpus studies, heritage collocations have been identified either based on judgements of linguistically trained native speakers (Rakhilina et al., 2016; Vyrenkova et al., 2014) or by a frequency approach comparing word combinations in an HS corpus with a monolingual reference corpus (Kopotev et al., 2020). Heritage collocations were then classified into three types according to the hypothesized reason for their emergence: calques, semicalques, and decompositional structures.
Calques are copies of the structure of the dominant language by structures of the heritage language at different linguistic levels. Calques are found in word formation as in svobodnyj bassejn ‘free pool’ and mamin den’ ‘mothers’ day’ in Russian–German speakers, calqued from the German Freibad and Muttertag (Karl, 2012, p. 160), or in collocations, such as in the collocation brat’ lekarstvo ‘take medicine’ instead of prinimat’ lekarstvo ‘accept medicine’ calqued from the German collocation Medikament nehmen by Russian–German speakers. There are also calques at the level of idiomatic expressions as in ne vsjo že v žisni možno imet’ ‘one cannot have everything in life’ calqued after the German idiom man kann nicht alles haben (Karl, 2012, p. 164). Although calques have received the most attention in research, corpus studies show that they are less frequent in the production of HSs than semicalques (Kopotev et al., 2020; Rakhilina et al., 2016).
Semicalques, or amalgams, are ‘newly created expressions that rely simultaneously on the two linguistic systems available to a bilingual speaker’ (Rakhilina et al., 2016, p. 12). For example, the phrase pered glazami detej ‘in front of children’s eyes’ produced by Russian HS in the United States combines two structures, a standard Russian expression na glazax u detej ‘on the eyes of the children’ and the English expression in front of the children. Rakhilina et al. (2016, p. 15) believe that semicalques are novel expressions that result from semantic decomposition of the original MWU and the reassemblance of its meaning by means of the most semantically transparent and frequent elements of both languages.
A similar strategy of semantic decomposition is at work in the third type of HS-MWUs, that is, in decompositional structures. Such structures result from the HS ‘breaking the concept into simpler semantic items, each one of which is lexicalized by a separate word’ (Rakhilina et al., 2016, p. 10). Decomposition is most evident with idioms and with set expressions such as sdelat’ to že samoje ‘to do the same’ or načat’ novuju žizn’ ‘to start a new life’ transformed by HSs into sdelat podobnye dejstvija ‘to do similar actions’ or načat’ novyj obraz žiszni ‘to start a new way of life’ (Rakhilina et al., 2016, p. 11).
The generalized finding from corpus studies is that the HSs’ access to and active knowledge of monolingual MWUs is restricted. However, this restricted access is compensated in production by calquing from the dominant language and semantic decomposition visible in specific HS-MWUs nontypical of the monolingual variety.
MWUs in HSs: receptive skills
Very few studies have been conducted on the receptive knowledge of monolingual MWUs in HSs and the results of available research are controversial. For example, Zyzik (2021) tested if Spanish HSs in the United States have receptive (recognition) and productive (recall) knowledge of Spanish verb–noun collocations. The results show that while participants recognized most collocations, they recalled much fewer, which suggests a high degree of receptive knowledge but limited production ability.
In other studies, it has been argued that HSs do not have even receptive knowledge of monolingual MWUs. Kim (2013) tested collocational knowledge of low-proficiency Korean HSs in the United States by means of a word association task and found that HSs produce fewer collocation-based associations (e.g., wedding photo, married life) than NSs. Although it was a production task, the authors interpreted the result as evidence for deficits in the receptive knowledge of collocations, stemming from the fact that HSs tend to learn words individually and therefore have fewer chunks in the lexical network.
Karl (2012) also argued for the lack of receptive collocational knowledge in at least some HSs based on the results of a grammaticality judgement task. She asked both early and late Russian–German bilinguals to judge sentences containing calques found in the bilingual Russian–German production data. Calques at four levels served as testing material: word-formation, polysemy, collocational calques, and idiom calques. The findings show that collocational calques were much more acceptable both to bilinguals and to monolinguals than the three other types of calquing. Among bilinguals, there were two groups: the ones whose judgement behaviour was very similar to the native group, and others, who showed a tendency to use the middle part of the evaluation scale for both sentences with calques and those without. To explain such avoidance of categorical judgements, the author suggested that the second group was apparently aware of the fact that the modified sentences were based on German expressions, and therefore did not completely accept them. However, due to the lack of knowledge of the corresponding structure in Russian, these bilinguals could not completely reject the calques either (Karl, 2012, p. 294). Although the two bilingual groups in the study were not formed on the criterion early versus late bilingual, it turned out that the second group showing nonnative behaviour is largely made up of HSs, that is, participants with an early age of exposure to the second language who are dominant in it and have little formal education in the first language. Therefore, the study of Karl (2012) suggests that HSs’ use of calques is likely to result from a lack of receptive knowledge of collocations in the monolingual variety.
The three studies tapping into HSs’ receptive knowledge of MWUs of the monolingual variety produce heterogeneous findings because they use different methodologies and different types of HSs. In addition, their results are largely limited to one type of monolingual MWUs (collocations) and one type of HS-MWUs (calques). Given that corpus studies have revealed calques being less numerous in HS production than semicalques and semicalques being constructed of the structures of both languages of an HS, a question arises: do HSs have receptive knowledge of monolingual MWUs corresponding to semicalques in HS production? This is the first question we will address in the present study.
Perception of nontypical MWUs by native speakers
The second issue we will explore is how monolingual speakers perceive semicalques, which are word combinations nonconforming to statistical expectations of the monolingual variety. To our knowledge, there are very few studies addressing the question of how native speakers perceive and process these nontypical MWUs. Millar (2011) focused on nontypical collocations produced by L2 Japanese learners of English and asked how learners’ deviations from conventional collocations affect collocation processing by NSs. The findings of a self-paced reading task show that NSs read unconventional words in learner collocations (e.g., cheap instead of low cost, or culture instead of cultural background) significantly slower than in conventional collocations, indicating that nontypical word combinations require additional processing effort compared to MWUs typical of the monolingual variety.
Whether MWUs produced by HSs also involve higher processing efforts from the monolingual speakers is an open question. The only relevant study here is Karl (2012) as introduced above. The results indicate that at least at the level of judgements, calques produced by bilinguals tend to be noticed by NSs and judged as something foreign. Importantly, however, the degree of acceptability varied according to the level at which calquing occurred. Collocational calques turned out to be less disturbing to monolingual speakers than word formation, polysemy, and idiom calques. One-third of collocational calques were judged by monolinguals as completely natural. Moreover, even within collocations, there were varying degrees of acceptability from completely normal to completely unacceptable. Finding out what types of nontypical MWUs are most disturbing to NSs and why is of high theoretical and practical interest. The present study will contribute to its understanding by testing the acceptability of semicalques produced by HSs to monolingual speakers.
To summarize, HSs have been shown to produce word combinations of three types, each of which does not conform to the combinability patterns of the monolingual variety. It is not clear whether these nontypical MWUs result from the lack of receptive knowledge of the equivalent MWUs of the monolingual variety, or from the inability to apply this knowledge in production. Research also suggests that nontypical MWUs might require additional processing effort from monolingual speakers and the degree of processing difficulty is different for various nontypical MWUs. The question of what makes some unconventional MWUs more difficult to process than others remains open.
Goals and research question of the study
The present study has two aims. First, we want to know whether nontypical MWUs produced by Russian–German HSs result from their lack of receptive knowledge of equivalent MWUs in the monolingual variety, or instead from the limited ability to use this knowledge in speech production. Second, we aim to tap into the perception of nontypical MWUs by Russian NSs.
We follow Kopotev et al. (2020) and define nontypical, that is, HS-MWUs as linear sequences used by HSs in place of word combinations statistically expected in the monolingual variety. Adhering to the understanding of monolingual MWUs within the distributional approach, we focus on one type of MWUs, namely usual sequences defined as frequent word sequences that are compositional in semantics but have semantic unity typical of words and structurally complete phrases (Buerki, 2016, p. 269). We are specifically interested in usual sequences containing prepositional phrases as the nonconventional use of prepositions or nouns in prepositional constructions is often mentioned in corpus studies of heritage language but has so far not been investigated in detail (Lehnhard, 2021). Furthermore, we will limit our study to those monolingual usual sequences with prepositional phrases that have been replaced with semicalques in HSs’ production. Semicalques are particularly suitable for our purpose because, as mentioned above, they represent the most frequent type of nontypical MWUs in HSs’ corpora and are considered evidence of HSs having the knowledge of both their dominant and their heritage languages.
To summarize the focus of our study, we are interested in semicalques used by HSs in place of usual sequences with prepositional phrases in monolingual variety. To give an example, the monolingual usual sequences echat’ na mašine ‘go by car’ and s moej točki zrenija ‘with my point of view’ have been replaced with echat’ s mašinoj ‘go with car’ and s moej perspektivy ‘with my perspective’ in an HS variety.
Based on this type of MWU, the study was designed to answer two questions:
Do Russian NSs and Russian HSs in Germany perceive HSs’ semicalques as nontypical MWUs?
Do Russian–German HSs recognize the conventionality of usual sequences of the monolingual variety that are equivalents of the semicalques found in HSs’ production?
If HSs perceive semicalques as nontypical and their monolingual equivalents as typical word combinations of Russian, then we might expect them to have receptive knowledge of MWUs of the monolingual variety, which they cannot access in a native-like manner during language production. Differences in the acceptability between NSs and HSs are likely to imply HSs’ lack of receptive knowledge of monolingual MWUs.
A two-step procedure was utilized to answer these questions. First, a corpus analysis was conducted to identify semicalques in spontaneous spoken and written production of Russian–German HSs. In the second step, an offline acceptability judgement task was designed with the identified semicalques and their equivalents in standard Russian as stimuli. The task was meant to provide insights into the receptive knowledge of MWUs, that is, rules of word combinability in the internal grammar of HSs and NSs. These abstract rules cannot be measured directly but can be accessed by observing to what extent an individual accepts an MWU as being formed according to their internal grammar.
The use of judgement tasks as a metric of grammatical knowledge for nonnative populations, that is, HSs and L2 learners, has often been criticized (e.g., McDonald, 2006; Polinsky, 2015; Tokowicz & MacWhinney, 2005). Tokowicz and MacWhinney (2005) point out that judgement tasks are based on the initial detection of a structural violation arising directly from the natural comprehension process. ‘However, when these judgments are rendered offline, the initial comprehension-based processes become intermingled with additional explicit processes derived from both reflection and formal grammaticality training’ (Tokowicz & MacWhinney, 2005, p. 178). Polinsky (2015) argues that this kind of task requires metalinguistic awareness that usually develops in the formal education system and is the opposite of the NSs’ natural intuition about language. She considers this task foreign to HSs, as they are not used to thinking critically about their heritage language.
Being aware that due to its metalinguistic nature, the judgement task cannot be treated as a direct reflection of HSs’ competence, we decided to use it for two reasons. First, our goal was to obtain comparable data from many speakers on the same narrow set of word combinations. Second, we consider the ability to make acceptability judgements a part of one’s language competence both in L1 and L2, allowing insights into the linguistic knowledge that speakers might not display in spontaneous production.
Methodological approach
Corpus analysis
The goal of the corpus analysis was to collect examples of HSs’ semicalques with prepositional phrases, that is, word sequences that (1) represent a blend of the structures of the heritage and dominant languages, (2) deviate from usual sequences of the monolingual variety of Russian, and (3) contain a prepositional phrase either in the function of an adjunct or an argument of a verb, adjective, or noun.
Two corpora, the Russian–German subcorpus of the corpus RUEG-RU_0.2.0 (Wiese et al., 2019) and the Russian–German HS subcorpus of the Russian Learner Corpus, further RLC (Rakhilina et al., 2016), were used as a data source. Both subcorpora contain around 12,000 tokens each. The RUEG-RU_0.2.0 corpus includes narrations of a video clip about a car accident from 20 Russian–German HSs, adolescents and young adults aged 15–28 who were either born in Germany or immigrated to Germany before the age of 6. All speakers had literacy skills (reading and writing) in Russian and considered themselves proficient Russian speakers. Keeping the conditions on language production stable, these data allow identifying nontypical MWUs that are used by several speakers. To enlarge the thematic scope of the word combinations, we analysed essays on various topics written by advanced Russian–German HSs from the RLC. These HSs are university students born in a Russian-speaking country and brought to Germany as children or born in Germany and raised in a Russian-speaking family. In the RUEG corpus, we manually analysed written transcripts. The RLC was searched automatically because it is error-annotated, including errors in word combinations.
A word combination was considered nontypical if: 1) it was not attested in the Russian National Corpus (henceforth RNC), and 2) it was judged by two linguistically trained Russian NSs as nontypical. To illustrate this procedure, let us discuss example (1) from the RLC.
‘
The word combination dva časa pozže occurred two times, once in the RUEG corpus and once in the RLC. It was not attested in the RNC and was judged as nontypical by two linguistically trained Russian NSs. It is a word combination, which contains structural elements of both German and Russian. Superficially, it is a direct calque of the German construction zwei Stunden später but if we consider its constructional equivalents in Russian, we can see that they could have served as a reference point for the HSs’ word combination as well. In monolingual Russian, there are three possible constructions to express this meaning. The first one is the expression čerez dva časa ‘through two hours’ built of a preposition and a noun phrase in the accusative. With the frequency of 2,356 tokens (7 i.p.m.) in the RNC, it is the most conventional form for this meaning. Two alternatives, although less frequent, constructions are dva časa spustja (60 tokens, .18 i.p.m.) and dvumja časami pozže (59 tokens, .18 per million). Both can be glossed as two hours later and are based on a preposition postponed to the noun phrase. In the former, the noun phrase is in the accusative case, in the latter it is in the instrumental case. In addition, standard Russian has a related construction na dva časa pozže (26 tokens) literally glossed as on two hours later. Semantically, it strongly implies a comparison with some expected time point. Structurally, pozže is not a preposition that determines the case of the noun phrase but an adverb. The accusative case is assigned by the preposition na. The presence of these four constructions in Russian that are partially similar to the German structure might have motivated the HSs’ word combination dva časa pozže additionally to the transfer from German. Therefore, this word combination qualifies for an HS semicalque, that is, an MWU not typical for monolingual Russian.
Based on the procedure just described, 20 nontypical word combinations with prepositional phrases were chosen from the HS production data. Their equivalents in monolingual Russian were identified based on the intuitions of the NSs and the RNC. If several semantically equivalent constructions existed in monolingual Russian (see the example discussed above), the one with the highest frequency in the corpus was taken to exemplify the typical combination.
It is important to note that since we aimed to test the acceptability of the HSs’ semicalques without considering the linguistic properties of each word combination, we did not control for various factors related to the component words such as part of speech or length, and to the properties of the word combinations such as semantic transparency, frequency, or strength of word association. However, nontypical MWUs identified in the data can be classified according to two criteria, the syntactic status of the prepositional phrase within the MWU and the type of difference between monolingual and HS-MWU. The classification is presented in Table 1. Half of the selected prepositional phrases are syntactically independent, functioning as an adjunct to the whole utterance as in examples (2) and (3). In another ten of the examples, a prepositional phrase is an argument of a verb, noun, or adjective as in (4) or in (5).
Classification of HS-MWUs according to the function of the prepositional phrase and the type of divergence between the HS-MWU and its monolingual equivalent.

Note. HS-MWUs: heritage speakers multiword units; PP: prepositional phrase.
The second classification criterion is the type of divergence between the HS-MWU and its monolingual equivalent. First, a distinction can be drawn between lexical and grammatical differences. Grammatical differences between the HS-MWU and the corresponding monolingual MWU occurred in our data only in two examples, both in independent prepositional phrases. In (2), HSs use the dative case of the adjective and noun instead of the expected accusative case in the monolingual MWU.
(2)
‘
(3)
‘
(4) Povest’ i ekranizacija
‘The narration and its film adaptation are
(5) Nado
‘One should
In (3), HSs use the demonstrative in the genitive case in postposition to the noun, whereas in the monolingual MWU, the demonstrative in the accusative precedes the noun. Apart from these two grammatical modifications, all other differences between monolingual and HS-MWUs were lexical. Lexical deviations can be subdivided into addition of a lexical item to the monolingual sequence and replacement of an item in a monolingual sequence. In our data, there were four cases of additions, exemplified by (6), where a possessive pronoun moj ‘my’ was inserted between the preposition and the noun in the monolingual usual sequence s roždenija ‘since birth’.
(6) Ja razgovarivaju po-russki
‘I speak Russian
The most frequent type of deviation of HS-MWUs from monolingual MWUs in our data is item replacement. There were 10 preposition replacements, eight of them in prepositional phrases functioning as arguments as in (5), where the preposition u ‘at’ was replaced with ot ‘from’ in the HS-MWU. Preposition substitution also occurred twice in prepositional phrases functioning as adjuncts as in (7), where the temporal preposition čerez ‘through’ was replaced with the adverb pozže ‘later’ in the HS-MWU.
(7)
‘
In two examples, the noun of the monolingual MWU was replaced with another noun in the HS-MWU as in (8), where the monolingual MWU po intuicii ‘by intuition’ was changed into the HS-MWU by selecting the noun čuvstvo ‘feeling’ instead of intuicija ‘intuition’.
(8) Poėtomu my pošli v les i
‘That’s why we went to the woods and,
Finally, there were two examples with replacements of an adverb modifying the prepositional phrase as in (9), where the adverb točno ‘right’ was used in the HS-MWU instead of the kak raz ‘just’ in the monolingual MWU.
(9)
‘At this very time, she was about to leave’.
To summarize the corpus analysis, we identified 20 HS-MWUs with prepositional phrases that represent a blend of the structures of both the heritage and the dominant language and are not typical of monolingual Russian. In one half of these nontypical sequences, prepositional phrases function as adjuncts and in the other half as arguments of a verb, an adjective, or a noun. The HS-MWUs represent four types of modifications of the corresponding monolingual usage sequences: grammatical modifications of the component word forms, additions of a lexeme absent in the monolingual sequence, and replacements of a preposition, a noun or an adverb in the monolingual sequence. The most frequent type was preposition replacement in prepositional phrases functioning as arguments.
Acceptability judgement task
Materials
Twenty HS-MWUs identified in the corpus analysis served as items in the acceptability judgement task. Each item was presented in two conditions: nontypical (the one found in the HS production) and typical (the most frequent semantic equivalent in monolingual Russian). This resulted in 40 experimental items.
Each item was embedded in a sentence context that was modelled on the broader context in which the nontypical unit occurred in the HS corpora. We chose two versions of sentence context for each item. Each participant received each item in both conditions (nontypical, typical), but paired with a different context version. The pairing of the type of construction and sentence context was counterbalanced across participants. For example, (10a) represents a sentence in which the nontypical sequence orpravit’sja na putešestvie ‘set out on the journey’ was used by an HS. (10b) and (10c) are two versions of the sentence in which this test item was presented to participants. (10d) and (10e) are the versions with the typical equivalents of the construction. For example, a participant could have received this item in a nontypical condition (10b) and in a typical condition (10e).
(10a) Odnaždy ja figural’no
‘Once I figuratively
(10b) My
‘We set
(10c) Oni
‘They
(10d) My
‘We set out in the journey around the city’.
(10e) Oni
‘They set out in the journey around the island’.
Items were assigned to two blocks with 20 experimental items each. Within both blocks, items were presented in random order. Item equivalents were presented in different blocks. The order of the blocks was counterbalanced. This resulted in four different lists. Participants were randomly assigned to one of the four lists.
In addition to experimental items, we also included 10 filler items to control whether participants performed the task correctly. The filler items were half grammatical and half ungrammatical Russian sentences. Each of the ungrammatical sentences contained a very salient error in case, gender, or number agreement, and verbal aspect. Half of the 10 filler items were presented in block 1 and half in block 2.
Participants
Russian–German HSs were recruited through mailing lists at several German universities. All of them were students but only a few studied Russian as a subject. To qualify for the status of an HS, participants had to be born in Germany with at least one Russian speaking parent, or have immigrated to Germany from a Russian-speaking country before the age of 7. The mean age of arrival in Germany for HSs as a group was 5.2 years. Russian NSs were recruited through personal networks. At the time of the study, either all of them had a university degree or were students. This makes the bilingual and the monolingual groups roughly comparable in terms of education, which is important given the metalinguistic nature of the task. In the HS group, there were 53 participants (mean age = 22.5, SD = 5.0, range 18–53, 67% females). In the NS group, there were 56 participants (mean age = 39.1, SD = 12, range 14–72, 83.9% females).
Procedure
The acceptability judgement task was conducted online via SoSci survey. 1 In the first part, all participants were asked to answer demographic questions and bilingual participants were additionally invited to answer 14 questions about their language biography. These factors might be important in explaining potential individual variation in the acceptability judgements, which however cannot be considered here and is a topic for a separate study. The questions and instructions were provided in both Russian and German to make sure that all participants understood them well.
In the second part, participants were instructed to read the sentences and rate their acceptability on a 5-point Likert-type scale. The wording of the task was as follows: ‘We are interested in how Russian is used by different people. In the following, you will see several sentences. Please read each sentence carefully and rate it from 1 meaning “completely natural” to 5 “completely unacceptable”. “Natural” means that it can be said by an ordinary Russian native speaker’. The points of the Likert-type scale were labelled as ‘completely natural’ – ‘a little strange’ – ‘strange’ – ‘very strange’ – ‘completely unacceptable’. Sentences were presented one at a time with a Likert-type scale placed below the sentence.
Data coding and analysis
We analysed acceptability ratings using the statistical software R including the packages tidyverse, ordinal, performance and lsmeans (Christensen, 2022; Lenth, 2016; Lüdecke et al., 2021; Wickham et al., 2019). Based on our hypothesis, we fitted cumulative link mixed effect models with the interaction of condition and speaker as a fixed effect to predict acceptability ratings (cf. Taylor et al., 2023). We included random intercepts and slopes for participant and item (e.g., Baayen, 2008), model formula: acceptability ~ condition * speaker + (1 + condition|participant) + (1 + condition|item). In addition, we conducted a qualitative analysis of individual test items.
Results
Quantitative findings
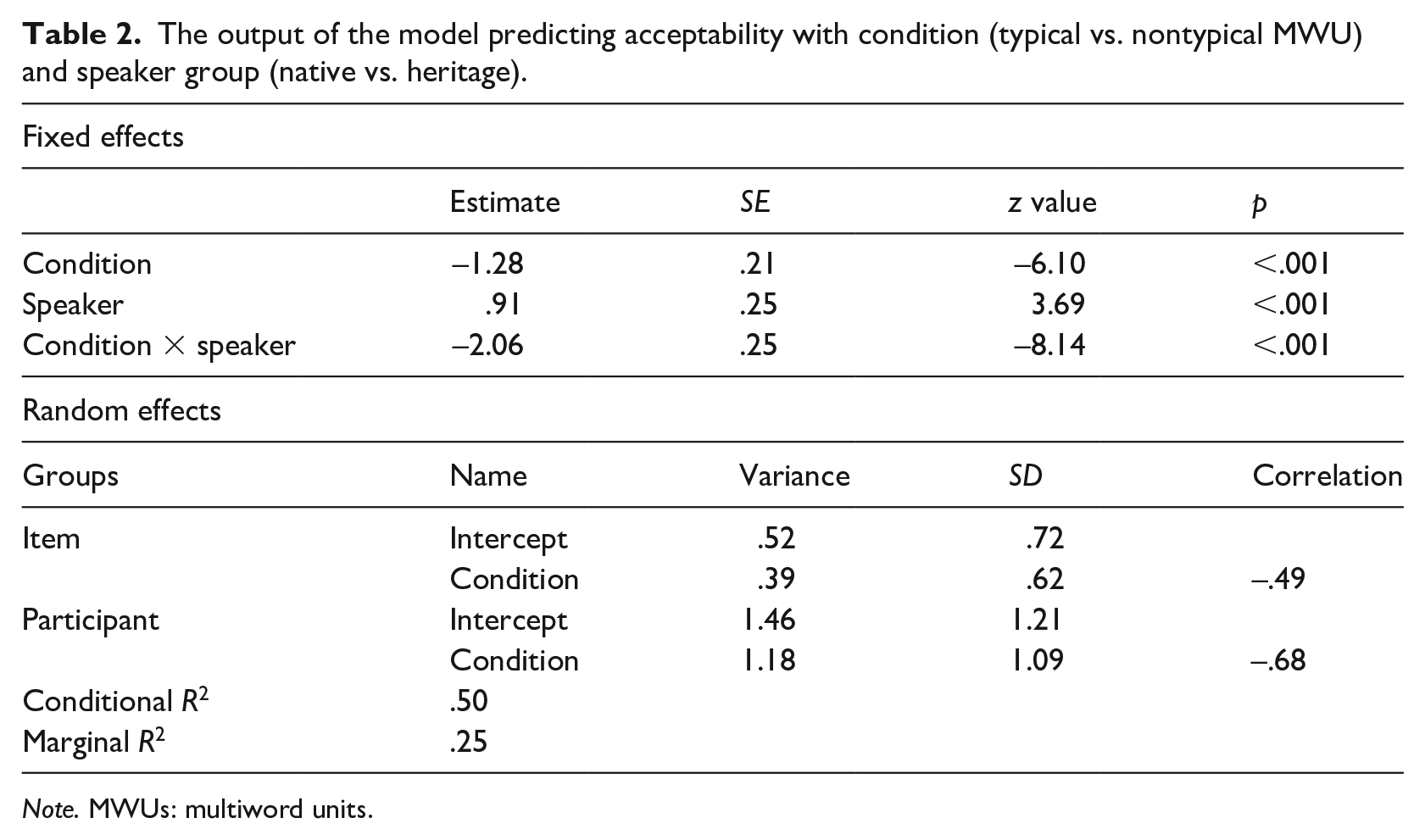
The output of our cumulative link mixed model predicting acceptability with condition and speaker is given in Table 2. The fixed effects part of the model shows an interaction of condition and speaker, indicating that the effect of condition differs between both speaker groups. To examine this interaction, we conducted a post hoc Tukey test. It revealed that first, both speaker groups rated typical items as more acceptable than nontypical items (HSs: z = −6.10, p < .001; NSs: z = −15.31, p < .001).
The output of the model predicting acceptability with condition (typical vs. nontypical MWU) and speaker group (native vs. heritage).
Note. MWUs: multiword units.
Second, typical expressions were rated as more acceptable by NSs than by HSs (z = −5.40, p < .001), whereas nontypical expressions were rated as more acceptable by HSs than by NSs (z = 3.69, p = .001). Thus, the results indicate that both speaker groups show differences in acceptability for typical and nontypical items, but this effect is more pronounced in NSs.
Figure 1 visualizes the distribution of ratings according to condition and speaker group. The box plot gives us details about the middle value of the ratings in the HS and NS groups, as well as about the spread of the middle value, the highest and the lowest ratings. The thick horizontal line indicates the middle value (median). We see that for typical items, the median ratings in both the HSs and NSs groups are 1, which means that typical items are in general considered completely natural. However, the distribution of responses (indicated by the boxes above and below the middle line) suggests that HSs show a larger variation in acceptability ratings for typical items than NSs. 75% of the HSs’ ratings cover values 1 (completely natural) and 2 (a little strange) and another 25% are situated between values 2 (a little strange) and value 3 (strange). In the NSs’ group, there is a narrow distribution of ratings (there are no boxes surrounding the median line) indicating consistency in judging typical items as completely natural. However, the dots in the graph indicate that there are outliers, that is, cases when some typical items are not rated as natural by some NSs.
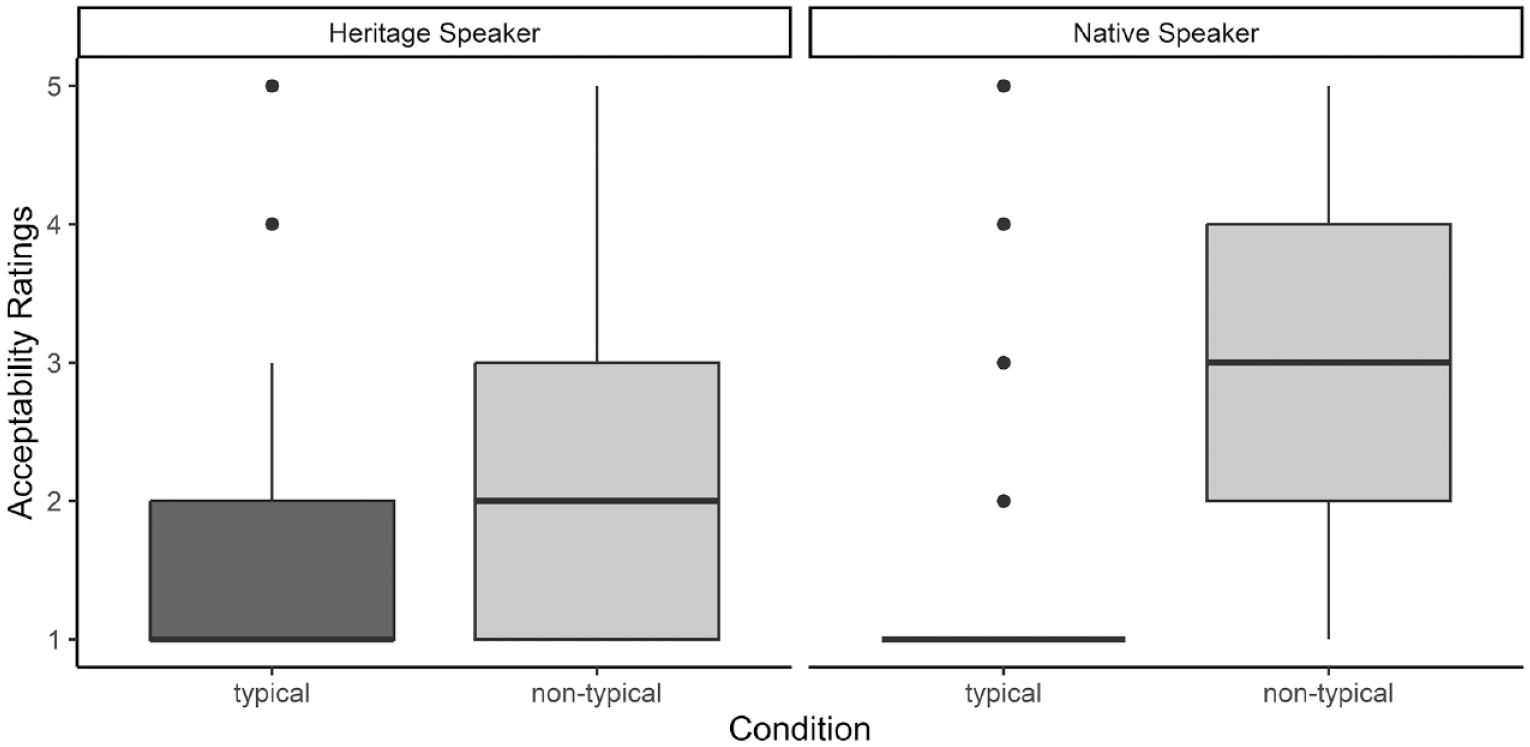
Acceptability ratings of HSs and NSs according to the type of MWU.
With regard to nontypical items, the graph shows a difference in the median ratings between the HS (median 2 = a little strange) and the NS groups (median 3 = strange). The distribution of ratings between the groups is also different. 50% of the NSs’ ratings lie between values 2 (a little strange) and 4 (very strange), 25% cover value 5 (completely unacceptable) and another 25% cover value 1 (completely natural). In the HSs’ group, 75% of the ratings lie between 1 (completely natural) to 3 (strange), and 25% of the judgements are situated between 3 (strange) and 5 (completely unacceptable). However, the graph also reveals a high degree of variability in the ratings of nontypical items within both the HS and the NS groups, visible in the long vertical line (the top of this line represents the maximum and the lowest point represents the minimum ranking) and the long box surrounding the median. We see that in both the NS and HS groups, the vertical line stretches from value 1 to value 5 indicating that nontypical items are evaluated by ratings from completely natural to completely unacceptable. 50% of the NSs’ judgements are situated between values 2 (slightly strange) and 4 (unacceptable) and 50% of HSs’ judgements are between values 1 (completely natural) and 3 (strange). This means that although HSs as a group more readily accept nontypical items than NSs, individual NSs and HSs hold quite different opinions about the naturalness of particular nontypical items.
Confirming this variation, the random effects part of our mixed model (the lower part of Table 2) reveals sizable random effects of item and participant, whereby variation around the fixed intercept and slope is numerically larger between participants than between items. The model’s total explanatory power is substantial (conditional R2 = .50), and the part related to fixed effects alone (marginal R2) is .25.
Summing up the quantitative analysis, we see that the direction of the effect of condition on the acceptability of an MWU is the same in HSs and in NSs but the effect size is larger in NSs than in HSs. In addition, there is a large variation between individual items and, even more significantly, between individual participants.
Qualitative findings
A detailed analysis of interspeaker variability lies beyond the scope of the current paper, and here we will focus on variability in ratings according to items.
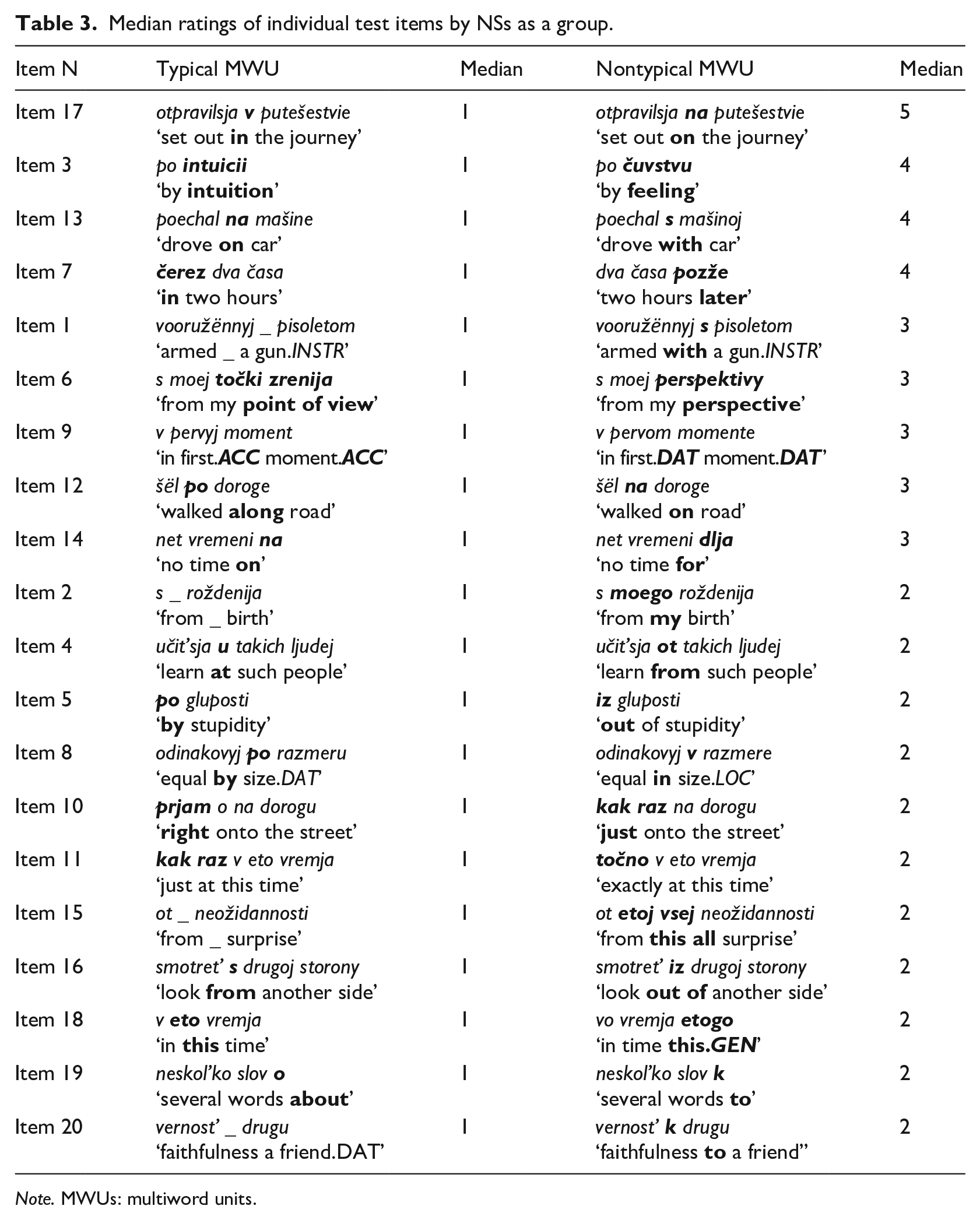
Tables 3 and 4 show the median ratings of each of the 20 test items in NSs’ and HSs’ judgements correspondingly. The data in the tables are ordered in descending order of the median ratings for the nontypical items, that is, the items at the top of the right-hand column were rated as most unnatural. The data are split into two parts by a thick horizontal line: the nontypical items in the upper part received the median rating from strange (value 3) to completely unacceptable (value 5). The nontypical items in the bottom part were rated as natural (value 1) or a little strange (value 2).
Median ratings of individual test items by NSs as a group.
Note. MWUs: multiword units.
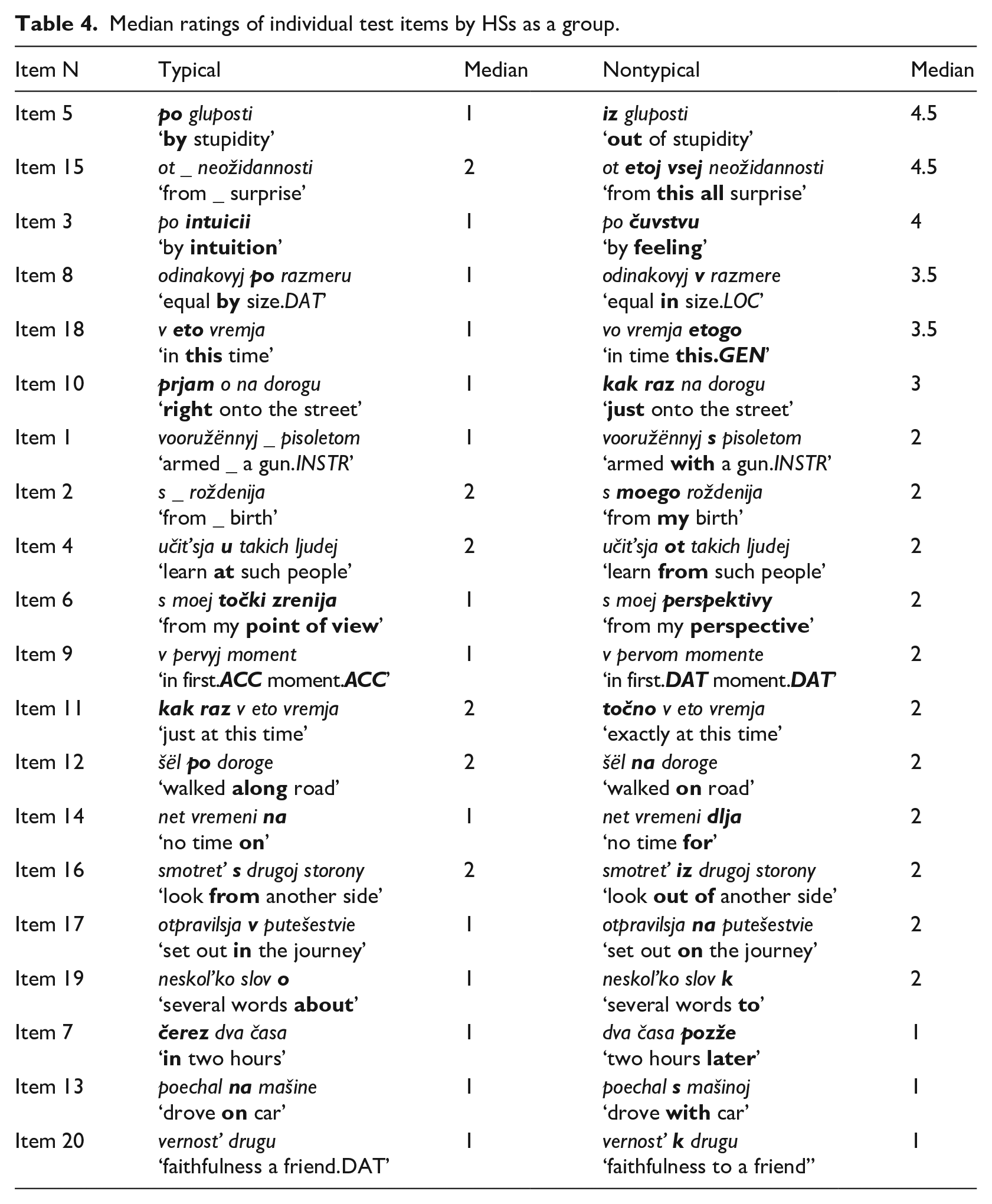
Median ratings of individual test items by HSs as a group.
As seen from the second column of Table 3, the median value given by Russian NSs to all items exemplifying monolingual equivalents of the HS-MWUs is 1, which indicates that all typical constructions are considered completely natural. On the other hand, none of the nontypical items has 1 as a median rating, telling us that none of them is totally acceptable to NSs. At the same time, the median rating of 2 for half of the nontypical constructions (the bottom part of Table 3) indicates that they were considered as only slightly deviating from the typical ones. In the other half of the nontypical constructions (nine items in the upper part of Table 3), one item was rated as completely unacceptable (Item 17), three were rated as unacceptable (Items 3, 7, and 13) and five items were considered strange (Items 1, 6, 9, 12, and 14).
Table 4 shows that in contrast to NSs, HSs rated only 14 of 20 typical items as completely natural (median 1) and judged six typical items as a little strange (median 2). Regarding nontypical items, HSs’ ratings also differed from those of NSs. HSs accepted three nontypical items as completely natural (median value 1). In addition, they rated eight items as equally acceptable in the typical and nontypical conditions. Three items (7, 13, and 20) received a median value of 1, suggesting both typical and nontypical word combinations being completely natural to HSs, and five items (2, 4, 11, 12, and 16) were judged with 2, indicating that both their typical and nontypical variants sound slightly strange to NSs. If we compare the upper parts of Tables 3 and 4, we see that there is only one test item (Item 3) occurring in both lists, meaning that only for this item, the nontypical variant was similarly unacceptable for NSs and HSs. Otherwise, there is no overlap between the two lists. For example, the nontypical variant of item 17 is considered by NSs as completely unnatural, whereas HSs rate it as slightly strange. Similarly, the other way around, HSs consider items 5 and 15 close to completely unacceptable, whereas NSs evaluate them as slightly strange.
If we now compare the bottom parts of the tables, we see that the ratings of HSs and NSs coincide with regard to five nontypical constructions (Items 2, 4, 11, 16, and 19). However, in four of these items, HSs rate the typical and nontypical variants equally, which is not the case for NSs. It means that the judgements of HSs match those of NSs only in one item (Item 19).
Let us now have a closer look at the ratings of nontypical items representing different types of divergence from the typical MWUs identified in the corpus analysis above. To recall, we singled out grammatical modifications, additions, and replacements. Table 5 gives a percentage of items within each group (and corresponding raw numbers in brackets) that were judged with an indicated median acceptability rating. The first thing we see is that median acceptability ratings are not consistent within each category, that is, not all additions and not all grammatical changes are evaluated as strange. In the grammatical modification category, represented by only two items, both HSs and NSs rated one item as a little strange and another one as strange. In the addition category, both NSs and HSs considered three nontypical items as a little strange and one as strange. In the replacement category, ratings of both NSs and HSs reveal much variation. NSs evaluate half of the replacements as a little strange and another half in a range from strange to completely unacceptable. HSs more readily accepted replacements varying their judgements from natural to unacceptable.
Percentage of native speakers (NSs) and heritage spekaers (HSs) specified median acceptability ratings for items according to the type of deviation of the nontypical variant from the typical one.
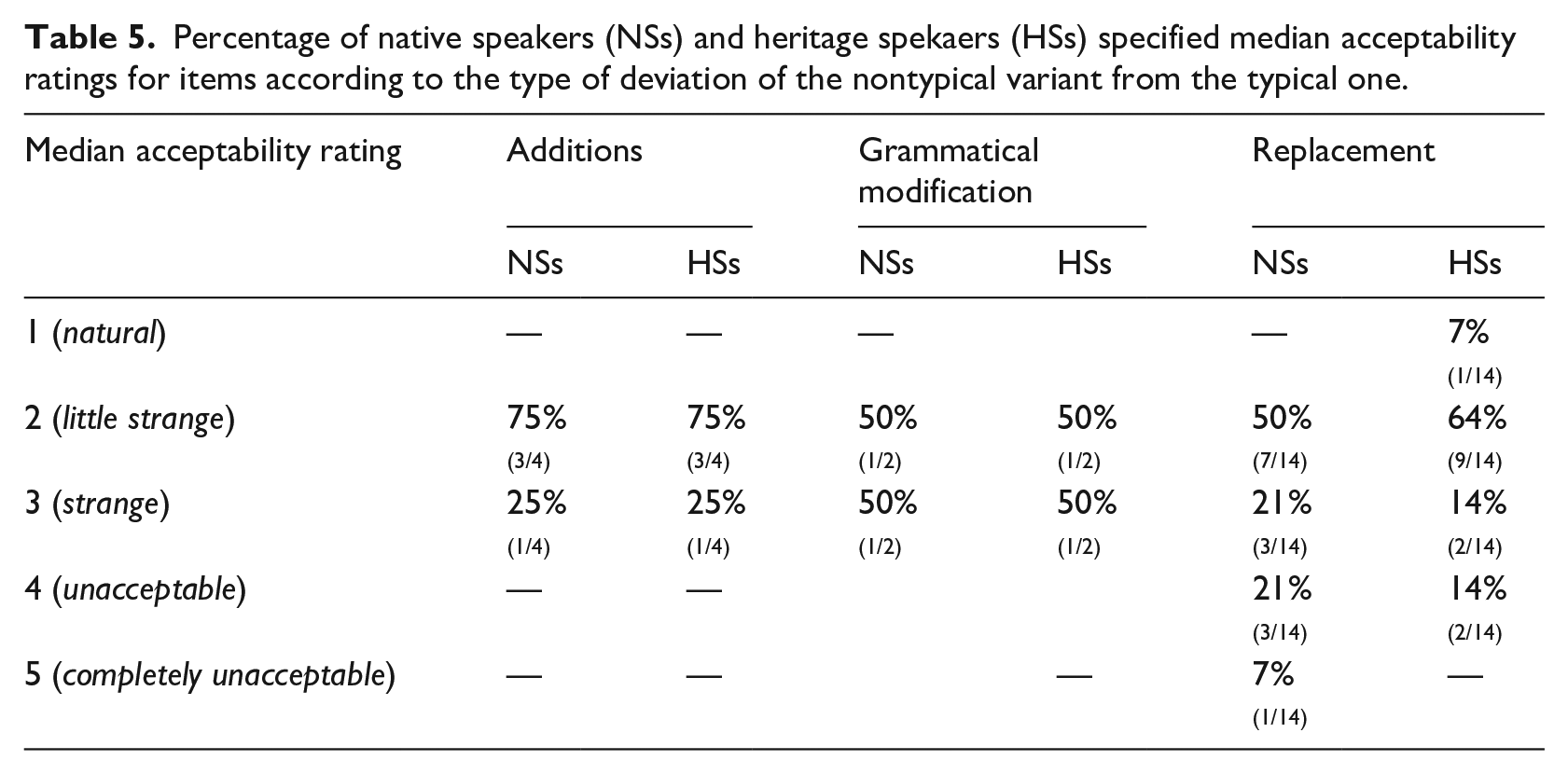
Regarding particular items in each category, there is no overlap between NSs and HSs. For example, NSs consider the addition of the preposition c ‘with’ in vooružёnnyj pisoletom ‘armed a gun.INSTR’ as less acceptable than other additions, whereas HSs consider the addition of pronominal adjectives in ot etoj vsej neožidannosti ‘from this all surprise’ as least acceptable. The grammatical modification of case in the sequence v pervyj moment ‘in the first moment’ is less acceptable to NSs than the grammatical modification of the sequence v eto vremja ‘at this time’, whereas for HSs it is the other way around. In the replacement category, NSs found the replacement of the preposition v ‘in’ with na ‘on’ in otpravilsja v putešestvie ‘set in the journey’ completely unacceptable and HSs considered it only slightly strange. At the same time, HSs rejected the replacement of the preposition po ‘along’ with iz ‘from’ in po gluposti ‘by stupidity’ completely unacceptable, although, for HSs, it sounded only a little strange.
To summarize, both HSs and NSs vary their acceptability judgements according to individual items. Crucially, there is no overlap between the ratings of individual items in both groups. Those items that are considered completely unacceptable by NSs are rated as slightly strange by HSs and vice versa. For HSs as a group, there was a tendency to equally accept the typical and nontypical variants of almost half of the test items.
Regarding the type of modification of a monolingual MWU, additions of a lexeme seem to be tolerated more than grammatical modifications and item replacements by both HSs and NSs, although there is large variability within each modification type.
Discussion
In this study, we aimed to answer two questions. First, do nontypical MWUs of the semicalque type in the HS corpora result from insufficient receptive knowledge of the corresponding word combinations of the monolingual variety of Russian, or from an inability to apply this knowledge in speech production? Second, do Russian NSs notice the nontypicalness of HS-MWUs? We applied a judgement task in which Russian NSs and Russian–German HSs were asked to rate the acceptability of HSs’ semicalques and their monolingual equivalents. We hypothesized that HSs’ judgements corresponding to NSs’ judgements would suggest HSs having developed receptive knowledge of monolingual MWUs. Differences between the judgements of HSs and NSs would indicate the lack of receptive knowledge in HSs.
Our results revealed both similarities and differences in the judgements of NSs and HSs. First, both speaker groups judged nontypical MWUs as less acceptable than typical MWUs. However, this effect was more pronounced in NSs, that is, NSs were more likely to accept typical constructions and to reject nontypical constructions than HSs. Furthermore, qualitative analysis revealed that HSs tend to equally accept a typical and a nontypical variant of the same MWU for 40% of the items. Second, the judgements of all participants across both speaker groups varied a lot according to individual items. However, nontypical items least acceptable for NSs did not overlap with those considered least acceptable by HSs.
The judgement behaviour of HSs in our study, especially the tendency for undifferentiated judgements, corresponds to the results of Karl (2012). However, given the fact that typical MWUs overall were judged by HSs as more acceptable than nontypical MWUs, we cannot conclude that HSs lack the receptive knowledge of monolingual MWUs. Rather, we argue that HSs might have a ‘wider grammar’ including representations for both typical and nontypical MWUs resulting from convergence between MWUs of their heritage and dominant languages. This explanation is consistent with previous research on the bilingual mental lexicon and on bilingual syntactic representations. The shared (distributed) asymmetrical model (Dong et al., 2005) emphasizes that the conceptual system of a bilingual contains both common elements (conceptual components that are equivalent across translations in the two languages) and language-specific elements, but the link between form and meaning is stronger for common than for language-specific elements. Along the same line, research on syntactic representations in bilinguals revealed that whereas structures that differ between languages might be represented separately, representations of similar structures are shared (Hartsuiker et al., 2004; Hartsuiker & Pickering, 2008; van Gompel & Arai, 2018). Language contact research has demonstrated that in areas of linguistic systems where the two languages already had similar features, differences tend to collapse and a bilingual’s two languages become uniform with respect to a property that was initially merely similar (Bullock & Toribio, 2004).
The idea of a ‘wider grammar’ in bilinguals is also in line with the Diasystematic Construction Grammar (Höder, 2018). Here, multilingual speakers are suggested to have a unified multilingual construction, which is a network of both language-specific and language-unspecific constructions, whereby language-specific constructions are linked through language-unspecific, general, highly schematic constructions. Language-unspecific constructions are formed in course of multilingual language acquisition in two ways. First, there are highly schematic constructions like syntactic patterns that are observable in both languages, and they will be acquired as language-unspecific from the start. Second, there are constructions that are first acquired as language-specific and later turn into language-unspecific through interlingual identification, that is, abstraction and generalization of similar constructions in both languages.
In our case, HSs might have developed some representations for the Russian-specific constructions, which were later modified through interlingual identification with the German equivalents. Associated processes of semantic decomposition and re-assemblance of the semantic meaning probably result in a representation of a language-unspecific construction that accommodates the corresponding units of both languages.
The likelihood of Russian-specific constructions turning into language-unspecific constructions is high in the immigration settings like the one of Russian as a heritage language in Germany, where the power status of the heritage language is low and the proficiency of HSs in another language is high. Under such conditions, bilinguals are likely to use the L2 type of bilingual optimization strategy ‘use as much as possible of the L2, i.e., the grammatical and lexical properties of the second language, as the matrix or base language’ (Muysken, 2013, p. 714). Consequently, the kind of change typical of heritage languages is an enhanced congruence between translation equivalents in both languages, affecting the structure of the heritage language more than the structure of the dominant language. Structures resulting from such convergence tend to represent options licenced albeit not preferred in the monolingual variety (Indefrey et al., 2017).
This is a very important point supported by two findings from our study. First, our corpus analysis confirms that many nontypical MWUs used by HSs in production are partially based on a pattern existing in monolingual Russian. For example, in the HS construction iz glupostu ‘out of stupidity’, the preposition po ‘along’ in the conventional construction was replaced with iz ‘out’. In monolingual Russian, both prepositions (and some others) can be used in the construction indicating a reason for doing something and the selection of a particular preposition with a particular noun is difficult to predict. Thus, we have po gluposti ‘along stupidity’ po junosti ‘along being young’ but iz ljubvi ‘out of love’, iz nenavisti ‘out of hate’, iz lubopytstva ‘out of curiosity’. The preposition chosen by HSs is therefore one of the possible prepositions in this construction, although not the one conventionalized in combination with this noun. The second argument in support of HSs’ MWUs being logical extensions of patterns existing in the monolingual variety is the fact that more than half of the nontypical constructions in our study (11 out of 20) were rated by NSs as only a little strange. This converges with the results of Karl (2012), where one-third of collocational calques were judged by NSs as acceptable. Some tolerance to the modifications of MWUs is predicted from the construction grammar view of MWUs emphasizing their schematicity (Buerki, 2016) and is supported by a psycholinguistic study of collocation processing by Sonbul (2015).
An important result of our study is the variability of judgements regarding specific MWUs. We found that both NSs and HSs consider some nontypical MWUs more natural than others but that the structures most acceptable to NSs were not the same as for HSs. Explanations of what makes a nontypical MWU acceptable to NSs should cover an interaction of multiple factors related to the properties of the MWU in the monolingual variety on the one hand, and to the type of divergence between the monolingual and heritage speaker MWU, on the other. The former group of factors includes measures of frequency and association (Gries, 2022) indicating the representational strength (entrenchment) of the MWU. It is logical to expect that the more frequent a particular MWU is in the monolingual variety and the stronger the association between its constituents, the more noticeable its modification will be to NSs and HSs. We see these effects in our data for NSs judgements: the preposition replacement in the monolingual MWU otpravitsja v putešestvie ‘set in the journey’ with a strong association between the verb and the preposition (binomial-likelihood of 98 605 and mutual information of 22.90 in the RNC) was completely unacceptable to NSs, whereas preposition replacement in the sequence učit’sja u takich ljudej ‘learn at such people’ with a weaker verb-preposition association (binomial-likelihood of 14 005 and mutual information of 19.23 in the RNC) was rated by NSs as only slightly strange. Regarding token frequency, preposition replacement in the MWU po gluposti ‘from stupidity’ with a token frequency of 2 i.p.m. was more acceptable to NSs than the preposition substitution in the MWU čerez cas ‘in hour’ with a frequency of 27 i.p.m. Our results thus suggest that the frequency of an MWU and the association strength between its constituents affect acceptability judgements of nontypical MWUs in NSs.
In contrast, frequency and strength of association in a monolingual MWU seem not to affect the judgements of nontypical MWUs by HSs. The reason for this is probably connected to the fact that the representations of MWUs in HSs are shaped by the characteristics of the equivalent MWU in the dominant language in addition to the features of an MWU in the monolingual variety. It is plausible to suggest that a higher frequency and a stronger association between elements of the equivalent MWU in the dominant language lead to a higher acceptability of the corresponding semicalqued MWUs to HSs. For example, in our data, we observe that the HS-MWU iz gluposti ‘from stupidity’, partially based on the German pattern aus Dummheit ‘from stupidity’ with a frequency of .09 i.p.m. (GermanWeb 2020 deTenTen 2 ), was unacceptable to HSs, whereas the HS-MWU dva časa pozže ‘two hours later’ based on the German pattern Stunde später ‘an hour later’ with a frequency of 2.03 i.p.m. was rated by HSs as completely natural. Further research should be conducted to uncover how the frequency and strength of word association in both the heritage and the dominant language of HSs interact to influence the perception (and production) of MWUs by HSs.
Regarding the type of divergence between typical and nontypical MWUs, our results indicate that additions of an element to an MWU might be more acceptable than grammatical modifications and replacement of an element within a sequence to both NSs and HSs. Some tolerance towards addition of an item to an MWU is expected from the construction grammar view of MWUs (Buerki, 2016) and has also been found in a processing study of Vilkaité (2016) showing that adjacent (e.g., provide information) and nonadjacent collocations (e.g., provide some of the information) show similar processing advantages for entire phrase reading times. Future studies could work on this issue, testing what types of modifications in MWUs are most and least acceptable to NSs and HSs.
Finally, our study has shown that the acceptability of nontypical MWUs varies between individuals not only within the HS group but also within the NS group. This finding underscores the importance of individual experience with particular MWUs for the native speakers’ knowledge and processing of MWUs (Verhagen, 2020). The influence of language experience should be even larger in HSs, given the variation in their language learning and using trajectories. It is a task of further research to define the factors determining the degrees of variation in the knowledge and processing of MWUs between individuals, both native speakers and HSs.
Summary, limitations, and future directions
Our study has shown that both native speakers and HSs consider typical MWUs as more acceptable than nontypical MWUs found in HSs’ production. However, HSs considered typical items less natural and nontypical items more natural than native speakers did. Moreover, HSs tended to rate some typical and nontypical items as equally acceptable. This result suggests HSs having some receptive knowledge of the monolingual MWUs albeit different from that of a monolingual speaker, which lends support to the idea of language-unspecific constructions in the multilingual repertoire.
Overall, the acceptability of nontypical MWUs varied according to item and participant for both native speakers and HSs. We have observed that the type of divergence of a nontypical MWU from its typical equivalent might be one of the multiple factors determining the acceptability of individual items. Additions of an element to an MWU were more acceptable to both native speakers and HSs than grammatical modification and replacement of an element. For native speakers but not for HSs, the acceptability of a nontypical MWU seemed to depend on the frequency and association strength of its equivalent in the monolingual variety. The acceptability of a nontypical MWU for HSs might be partially determined by the frequency of the underlying equivalent in the dominant language.
The generalizability of our findings is limited due to several reasons. First, our operationalization of an MWU was broad and covered constructions with different properties. Further research based on narrower specified types of MWUs might give us a clearer picture of what features are crucial to their acceptability by mono- and multilingual speakers. Second, the format of acceptability judgements might only reveal speakers’ conscious reflections about their underlying representations and might not be an ideal instrument to test speakers’ unconscious receptive knowledge. Further research would certainly benefit from other formats that better differentiate between explicit and implicit receptive knowledge. Third, we focused on group results in the quantitative analysis and were not able to go into details of interindividual variation, which has been identified as an important predictor in the mixed model. The influence of speaker-related variables remains an important point for further research.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.