
Abstract
This paper presents an exploratory study on the use of frequency-based probabilistic word combinations in Heritage Russian. The data used in the study are drawn from three small corpora of narratives, representing the language of Russian heritage speakers from three different dominant-language backgrounds, namely German, Finnish, and American English. The elicited narratives are based on video clips that the participants saw before the recording. Since the current study is based on a relatively small corpus, we conducted a manual corpus-based analysis of the heritage corpora and an automated analysis of the baseline (monolingual) corpus to investigate the differences between the heritage and monolingual language varieties. We hypothesize that heritage speakers deploy fewer probabilistic strategies in language production compared with native speakers and that their active knowledge of and access to ready-to-use multiword units are restricted compared with native speakers. When they cannot access a single lexical item or a collocation, heritage speakers are able to tap both into the resources of the dominant language and the resources of their home language. The connection to the dominant language results in transfer-based non-standard word combinations; when heritage speakers tap into the resources of their home language, they produce unattested in the monolingual variety, “heritage” collocations, many of which are nevertheless grammatically legitimate.
Introduction
Heritage language is commonly defined as an individual’s first (home) language that is acquired in the context of another dominant language (Benmamoun et al., 2013; Kupisch & Rothman, 2016; Polinsky & Kagan, 2007; Scontras et al., 2015). Heritage speakers are effectively unbalanced bilinguals—some simultaneous, some sequential—whose weaker language corresponds to the one acquired in the family. To illustrate, a heritage speaker of Somali, who lives in Sweden, acquires the Somali language at home, typically from first-generation Somali-speaking immigrants in Sweden. The language of the parent generation serves as input to heritage learners in the home, and this language (which in its own right undergoes change in the contact environment) is referred to as the baseline variety, in relation to the language of the homeland (e.g. the Somali language spoken in Somalia). 1 Heritage languages have been subject to extensive research in recent years, with the main focus being placed on differences between the heritage language, the language of the baseline, and the homeland variety of the baseline language.
Serious strides in research of the heritage language have been made in the area of phonology and phonetics (Chang et al., 2008; Kupisch et al., 2014), morphology (Montrul, 2004; Polinsky, 2006), syntax (Laleko, 2010; O’Grady et al., 2001; Polinsky, 2008), and pragmatics (Dubinina, 2011; Sorace & Serratrice, 2009). When it comes to heritage lexicon, however, the volume of research is significantly smaller, and the range of differences in the lexical knowledge of the heritage speakers and baseline/homeland speakers is still poorly understood. Understanding the lexical properties of heritage languages is also harder: phonology, morphology, and syntax demand acquiring closed classes of categories and operations, whereas lexical semantics and lexical knowledge more generally have to do with much more broadly defined, often open, classes.
One important domain of inquiry to which researchers have turned their attention is the domain of multiword expressions, which includes a wide range of (semi-)fixed word combinations from truly idiomatic, such as to eat crow or at the drop of a hat, to more transparent combinations that betray a tendency to co-occur together rather than true non-compositionality, such as strong tea, take a train, apply for a job, and so on. The components in the latter type expressions are rarely fully predictable, and, within a given phrase, the choice between several lexical items is possible, for instance, to apply for a [job/position]. When the choice is available, what is chosen is probabilistic: for instance, in the expressions to apply for a X, the word job is five times more likely than the word position (according to the Contemporary Corpus of American English data, COCA; see Davies, 2010). This may result in a greater “fixedness” of the phrase ‘to apply for a job’ and its function as a single unit.
Linear probabilistic co-occurrences of lexical items illustrated above are known as frequency-based collocations. In corpus linguistics, such collocations are understood as “recurrent and predictable word combinations, which are a directly observable property of natural language” (Evert, 2008); thus, they are extractable statistically without the need of deeper linguistic analysis (see also, among others, Biber, 2009; Hunston & Francis, 2000; Sinclair & Mauranen, 2006) and do not necessarily presuppose semantic non-compositionality as opposed to lexical collocations or idioms (Evert, 2008; Nesselhauf, 2005; Nunberg et al., 1994). In the remainder of this paper we will be concerned with frequency-based collocations, regardless of their compositional or non-compositional nature in terms of deeper semantic analysis.
Let us note that the word combinations found in our heritage data cannot be defined as collocations in the strict sense of this term; since we are working with a small pool of data, many of the items chosen for analysis are single occurrences, which may be interpreted as either ad hoc decisions of a speaker or a new “fixed” feature of the heritage language. Nonetheless, we suggest that our data demonstrate negative statistical evidence, that is, non-conformity to statistical expectations of the monolingual variety. This non-conformity is evident in the situation where the heritage speakers produce linguistic items non-attested in the monolingual corpus instead of frequently used colloquial expressions, which are statistically expected in the monolingual language variety. We refer to these non-attested items as heritage collocations.
Collocations are extremely pervasive in language (Wray, 2002), yet they have proven to present a considerable difficulty for language learners even at advanced levels (Meunier & Granger, 2008; Wray, 2002). Few studies have considered the collocational abilities of heritage speakers. No work to date has tested heritage speakers’ comprehension of collocations, and the few studies that do exist focus on select groups of collocations and suggest that heritage speakers differ both from monolinguals and second-language learners in their knowledge of these items (Doğruöz & Backus, 2009; Rakhilina et al., 2016; Treffers-Daller et al., 2015).
The study of collocational patterns is a promising endeavor for heritage language research for at least two reasons. First, the probabilistic nature of a collocation suggests that its degree of syntagmatic fixedness (specifically, the degree of a perceived fixedness in the mind of the speaker) largely depends on the amount of input that the speaker of the language receives. For an association between tea and strong (as opposed to something like dark) to take hold, the speaker of English must encounter the combination a reliable number of times. Given the limited amount of input that the heritage speakers receive compared with that of the native speakers of the language, the focus on collocations can help researchers better understand the role input plays in the development of a speaker’s linguistic structure. Second, since some multiword combinations are more transparent than others, they are a good testbed for exploring heritage speakers’ control of their linguistic creativity (cf. Doğruöz & Backus, 2009; Rakhilina et al., 2016 for the latter aspect of lexical-collocational knowledge in heritage speakers).
The current paper aims to add to the literature exploring heritage speakers’ collocational strategies. Using quantitative and descriptive qualitative methods, we investigate heritage collocations produced by three groups of speakers of Russian dominant in American English, Finnish, and German, respectively. We specifically focus on those word combinations that do not have an equivalent in the monolingual Russian spoken in the homeland and provide a systematic description of the types of such heritage collocations unattested in the monolingual data. Based on the analysis, we discuss possible linguistic mechanisms that result in the development of such collocations in the heritage language.
Our paper is structured as follows: the next section presents the heritage language corpora used in this study and describes the extraction procedures. This is followed by a quantitative analysis of those items that are not attested in the baseline. We then provide a detailed analysis of the main collocational patterns that emerge from our data and describe a classification of the observed patterns. Finally, conclusions, as well as a discussion of limitations and future directions, are presented. Based on the analysis of the heritage collocations, we argue that although dominant languages undeniably impact collocational patterns in the language production of heritage speakers, dominant language influence is not the only or even the main force that drives changes in the heritage lexicon. Numerous heritage collocations in the speech of our speakers have no traces of dominant language influence; instead, they appear to be a result of “borrowing from within the language” (Doğruöz & Backus, 2009); 2 that is, operating with resources available in the heritage language repertoire.
Study
Corpora collection and participants
The data for the study were three small corpora, originally compiled for other research projects; all three, however, were collected from heritage speakers of Russian and in a similar fashion, in other words, by asking the participants to produce a narrative of the details of a video clip they had just seen. The narrative elicitation procedure is a well-established method in language studies; in addition to providing a meaningful context for the task, elicited speech samples result in comparable data: since all participants describe the same video, the corresponding narratives allow for a more systematic comparison across such formal parameters as length (size) of a narrative (as measured in the number of words), words per minute (for oral mode), words per sentence (for written mode), as well as lexical and syntactic complexity.
The three corpora were collected from three different groups of heritage speakers of Russian, one group residing in Germany and Switzerland, one in Finland, and one in the United States. For the purposes of this study, we call the corpus produced by Finnish-dominant Russian heritage speakers FIN-H, the corpus produced by German-dominant Russian heritage speakers GER-H, and the third corpus, produced by English-dominant Russian language speakers from the United States, ENG-H. All L1 examples are marked as RUS, FIN, GER, and ENG, respectively.
Russian-Finnish data: FIN-H corpus
The FIN-H corpus was collected in 2010 for the project entitled “F+R=X: How effective is multilingual education?” (Kopotev & Sammalkorpi, 2012). Participants in this project were 74 fifth- through ninth-grade students (ages 11–15) from a Finnish-Russian school in Helsinki; 47 (63.5%) of the participating students were living in families where Russian was spoken by both parents, while the rest were from families with a Russian-speaking mother and a Finnish-speaking father. In this study, the participants watched a five-minute fragment from the cartoon Pingu (BBC production), a dynamic story in which characters speak in gibberish. The participants then individually typed up a retelling of the plot on the computer. Below is a sample narrative (1) produced by one of the participants (words marked with an asterisk are incorrect forms or usage; these include spelling, word choice, word order, gender agreement, and inflectional errors): (1) V fil’me Pingu *pošol v *školi, *tamon vljubilsja v mal’čika. Mal’čik ne ljubil Pingu, *potomišta on *xatel sidet odin v klasse. No Pingu *saravno sel k mal’čiku. kogda škola zakončilas’, Pingu xotel *potružitsja s *mal’čikam, no on ne *xatel. Potom Pingu rasstroilsja i kinul snežok, potom mal’čik kinul i *papal v okno. Potom *sprjatalis’ v bočku i *vljubilis’. Kogda im *nadila *iti *damoj, oni *poculivalis’. ‘In the film, Pingu went to school, there he fell in love with a boy. The boy didn’t love Pingu, because he wanted to sit alone in the class. But all the same, Pingu sat with the boy. When school was over, Pingu wanted to befriend the boy, but the boy didn’t want to. Then Pingu got upset and threw a snowball; the boy threw a snowball too and hit the window. Then they hid in a barrel and fell in love. When they had to go home, they kissed.’
Russian-German data: GER-H corpus
The data from the Russian-German speaking participants were collected by Elena Denisova-Schmidt (2014). Fourteen Russian-German heritage speakers from Germany and Switzerland (nine females and five males, of ages varying from 7 to 35) participated in this study. The participants were shown an episode from a Soviet animated cartoon Nu, Pogodi! (produced by Soyuzmultfilm) and were asked to retell the events they saw in the clip. Below is a sample (2) of a retelling by a Russian-German heritage speaker: (2) vot volk on šël po ulice i vot musorku *pinal. I potom kogda *ved’ i milicija proexala. On potom ostanovilsja i potom opjat’ *pivnul *ètot *ètot musorku. Ii potom kušat’ zaxotel. Ii da potom vzjal otkuda *to verëvku i da,*kinul na kryšu ii potom uže *odel vot *naverx da. I potom zajac vidit verëvku i potom da *razrjazaju, potom on upal. I prjamo vot v *milicejskuju mašinu da.
3
‘So the wolf he walked along the street and so trash can kicked. And then when and even the police drove by. Then he stopped and then again kicked that…that trash can. Ah-and then he got hungry. Ah-and yeah then he got from some place a rope and yeah, threw on the roof a-and then put it up there yeah. And then the hare sees the rope and then yeah cuts, then he fell. And right into the policemen car, yes.’
Russian-English data: ENG-H corpus
ENG-H corpus was collected in a similar fashion to the German corpus, with the help of another cartoon from the Nu, Pogodi! series. Thirty-four interviews with Russian-English heritage speakers from the United States were collected and transcribed by Tanya Ivanova-Sullivan (2014). The age of the informants in this corpus varied from 18 to 30 years. A sample (3) of an oral narrative from Ivanova-Sullivan’s data is presented below: (3) I zajac opjat’ ubežal i teper’ v ètom…v *zale krivyx zerkal. I volk tože za nim tuda zaxodit. I oni tam smejutsja, tam smotrjat v zerkala, i vse tak stranno vygljadjat: u nix muskuly bol’šie, to oni očen’ korotkie, to dlinnye. Potom oni prixodjat i tam zerkalo *pokazyvaet…pokazyvaet èto ix *istinu, nu kak oni po-nastojaščemu vygljadjat. I zajac ponimaet, čto èto volk i, konečno že, panikuet, vyključaet svet. Volk èto tože pytaetsja najti zajca vse ravno. I beret to, čto on dumaet èto # zajac, ego èto uši, a okazyvaetsja èto nosorog. V èto vremja zajac uže ubežal, poët i idet po tropinke. Govorit, A nam vse ravno, a nam vse ravno…
‘And the hare ran away and now he is in this…in a hall of crooked mirrors. And the wolf also him follows there. And there they laugh, like look in the mirrors and they look so strange: they have lots of muscle, and here they look short, and there they look tall. Then they come and there the mirror shows them…shows like their truth, like what they actually look like. And the hare realizes that it’s the wolf, and, of course, he panics and switches off the lights. The wolf like he also attempts to find the hare nonetheless. And he takes what he thinks is this…hare, his like ears, but it turns out it’s a rhinoceros. In the meanwhile, the hare has left, he sings and walks along a trail. And says: It’s all good, it’s all good.’
We are aware of the fact that the differences in language proficiency levels and age among the speakers in the three groups may result in certain qualitative differences in the resulting texts (Long et al., 2012; Swender et al., 2014). The level of proficiency is known to impact the rate of speech, the number of errors, and the length of language production. It is conceivable that the native-like collocational abilities of the heritage speakers also correlate with the general language proficiency; however, this consideration will have to remain outside of the scope of the current study for future research.
In investigating collocations in heritage language, we are, of course, limited by the data available, and the data used here represent both written and spoken language. However, for our purposes the differences in the modes of production (oral vs. written) are not prohibitive and may have little impact on the collocational strategies of the heritage speakers. Heritage speakers who can write are likely to represent higher proficiency or, at the very least, a more motivated group, given that they have taken it upon themselves to acquire literacy; nevertheless, deviation from the baseline can be observed in both written and spoken production and can thus inform our understanding of collocational strategies in heritage language production. Given the dearth of research in heritage collocations we would like to assess similarities across groups, so that—despite the variability observed in the data—we take into account all the heritage collocations produced in all three groups and propose an explanation for underlying mechanisms based on the best data available.
To summarize, this article focuses on heritage collocations that surface across all data available, regardless of other structural and functional linguistic differences evident in the data, in order to investigate more general principles that underlie co-occurrence of words in different language varieties and to develop a general classification of the phenomena.
General characteristics of the corpora
Below, we present two parameters that characterize the overall features of the collected texts: corpus size and lexical diversity.
Corpus size
Table 1 provides the information on the average length of a narrative in each corpus. The median within each set of texts in our study is quite close to the mean, which suggests that texts included in each corpus are relatively equal in size. However, the average size of а narrative (both in mean and median of tokens) varies from corpus to corpus: thus the texts in the FIN-H corpus (in which only narratives longer than 50 words have been included) are the shortest on average, which is likely the result of the written mode used during data collection compounded by the factor of age (high school students) and linguistic level. The smaller length of texts in the GER-H corpus than in the ENG-H corpus is most likely the result of relatively lower average language proficiency level of the Russian-German speakers compared with the Russian-English speakers in our study.
Corpora size in number of words (mean and median).

Lexical diversity
Lexical diversity can be estimated using the type-token ratio (TTR), that is, the number of word tokens (the raw word count) in relation to the number of word types (the number of unique word forms). The closer the obtained figure is to 1, the more varied is the vocabulary. An important caveat here is the fact that this measure is relative: TTR depends heavily on the text size, with shorter texts exhibiting larger TTR (Chipere et al., 2004).
4
For example, if the shortest story consisted of just one sentence (4), its TTR would naturally be 1, since none of the words is repeated: (4) Nu pingu podružilsja s *novjam *učenika. FIN-H well Pingu ‘So Pingu befriended a new pupil.’
To avoid misleading TTR results caused by differences in the lengths of the texts, we opted for using standardized TTR (sTTR), which is less dependent on corpus size. 5 The results of the sTTR test are presented in Table 2.
Lexical diversity.

For comparison, TTR counts for texts produced by Russian monolingual children vary from about 44 in a dialogue to 68 in monologue (Galyashina, 2002). The TTR counts of heritage texts are expectedly lower: for instance, Anstatt (2006) found that five-year-old Russian-German bilingual children produce Russian texts with а lower TTR—one of 36—than their monolingual counterparts. To compare our results with the numbers reported by Anstatt (2006), the Finnish and American speakers in our study are comparable with respect to lexical diversity (see Table 2). The lexical variation of the German-Russian bilinguals is comparatively poorer at 27.20. These results again point to the fact that the general level of proficiency of the participants who contributed to the GER-H corpus is lower than that of their American and Finnish counterparts.
The data
As a reminder, we define heritage collocations in accordance with the statistical approach; in line with this approach, these collocations are linear co-occurrences produced by heritage speakers, whose frequency in a native Russian corpus equals to zero and is thus in contrast to colloquial and frequently used native collocations with the same meanings.
In order to cull the data, two coders, both native speakers of Russian and trained linguists, worked through the heritage corpora described above and extracted all noun phrases (NPs) and verb phrases (VPs). Note that all phrases that included mixed codes were excluded from further analysis. First, it is not a methodologically straightforward issue to distinguish between code-switching (switching into another linguistic code) and borrowing (when only some units, most often words but sometimes morphosyntactic features are transferred into one language from another). Additionally, in the oral data we cannot always separate phonologically adapted borrowings from direct borrowings of dominant language words. One such problematic instance (5) is shown below, where the noun aploz was transcribed in Cyrillic; however, it can equally be a researcher’s transcription of the Russian adopted pronunciation [ʌˈplos] or of borrowed American English [əˈplɑːz]. (5) *davat’ give. ‘to applaud’
Although mixed code collocations may present material for a fruitful analysis and discussion of heritage collocational strategies, such examples are left outside current analysis.
Following the extraction of heritage collocations, we subjected them to an analysis based on the framework known as Contrastive Interlanguage Analysis (CIA). First proposed in 1996 by Sylviane Granger (1996), CIA relies on the idea that a comparative approach to learner data that juxtaposes two or more distinct language varieties in order to identify the similarities and differences between these language varieties may yield interesting results and reveal aspects of these linguistic varieties that would not have been available to researchers if these data had been treated in isolation (Granger, 2015).
Initially CIA was intended to be used in corpus linguistics for comparisons between corpora of the second language and mother tongues, and for the comparison across second language data, especially those produced by speakers with different first languages. We suggest that such an approach to data analysis can be successfully applied to the study of heritage languages as well, given their well-demonstrated divergence from the respective standard or baseline variety. The full procedure of CIA comprises several stages, which we briefly explain below (see Granger, 2015, for a detailed account).
Selection of data
One of the main principles of CIA is the selection of comparable data. Complete parallelism in the types of data representing different language varieties within a project is not always realistic, given the labor- and resource-intensive nature of data collection and processing in corpus studies; yet, to ensure text-type comparability special attention is paid to task, mode, genre, and other text characteristics that heavily impact language production. Traditionally, the learner language varieties are compared with “reference” corpora, either large national corpora (such as the British National Corpus) or smaller more specialized corpora that are more suitable for the context and the goals of a study (such as the Louvain Corpus of Native English Essays). “The word ‘reference’ makes it clear that the corpus does not necessarily need to represent a norm” (Granger, 2015, p. 17); it is to serve as a point of reference and a foundation for the discussion of the linguistic differences observed in different language varieties under analysis.
Thus, the three heritage corpora that were used as data in our study (Section Corpora collection and participants) were collected through a similar task (retelling a video clip) from a specific group of speakers (heritage speakers of Russian); they also represent the same genre (narrative). We utilized the Russian National corpus (RNC) as our “reference” corpus to which the heritage data were compared. The Russian National corpus, like any other national corpus, is meant to represent maximally a national language in all its varieties. We have restricted our “reference” corpus to an RNC sub-corpus which included texts dated only from 1945 to 2016 (approximately 150 million words). We suggest that this period will most accurately represent the possible input that the heritage speakers in our study may have received.
Identification of differences in learner data and reference data
Many CIA studies generally focus on the comparisons of linguistic features that are easily identifiable through automated corpus procedures, such as the frequencies of certain lexical items, grammatical forms, or clause types. CIA studies and learner corpus research more generally have made a notable contribution to the study of learner lexical knowledge. Given that the governing view of the lexicon in CIA is phrasal, the studies of collocations, colligations, and lexical bundles are quite numerous (although most of this work is carried out in relation to English as a second language, ESL). Typically, researchers compare the frequencies of given structures or patterns in the learner and in the native variety and capture their potential differences in terms of overuse, underuse, and alternative use (all three being neutral, non-evaluative terms) of the structures in question in the learner data. In keeping with this approach, our study focuses on lexical knowledge, and specifically on nominative and verbal word combinations. Accordingly, at this stage of the analysis, we extracted all NPs and VPs from the heritage data and then searched for each of the extracted phrases in the reference corpus. This step included one important modification. All phrases are naturally presented in the data as a sequence of two word-forms, as, for example, in (6): (6) *lomal steklo ENG-H break. ‘(he) broke the glass’
Since Russian allows for morphological modifications of both word forms (specifically, alternations in number for both forms and tense for the verb), to take into account all possible alternations, we searched not only for the given sequences of word forms but for combinations of lemmas lomat’ ‘to break’ and steklo ‘glass’. That means that we included all possible paradigmatic forms of the verb and of the noun in the query. The example (7) captures the essence of it: (7) lomal / lomajem / budu lomat’ / lomaja break. stëkla / steklo glass. ‘he broke /we are breaking /I will break /breaking the glasses /glass’
Classification of the linguistic differences identified in learner data
CIA emphasizes the importance of linguistic analysis of forms in the mother tongue of the learners parallel to those they produce in the target language, since this comparison may illuminate the potential sources of differences between the two language varieties. Although this step is often omitted in the CIA studies that are available, we find it crucial to our agenda: the point of our analysis is not simply to identify the differences between the heritage and the monolingual collocations, but to identify those from the heritage data that have frequently used colloquial counterparts in the monolingual corpus. At this stage of analysis, the NPs and VPs that were not attested in the RNC sub-corpus were considered heritage collocations and were taken up for further qualitative analysis. This analysis was guided by considerations of the possible nature of the heritage collocations: Could we identify traces of influence of the dominant language? Could we identify the influence of other structures of the heritage language that impact the production of a collocation at hand? Did the dominant language features and the heritage language features appear to mutually influence a creation of a novel construction? A detailed account of the procedures and the analysis included in this step is presented in the “Data analysis” section, below.
To provide a fuller illustration to the CIA procedures, consider the following example. The heritage collocation in (8a), attested in the ENG-H corpus, was checked against the RNC data, and since the expression was not found in the massive corpus of the Russian data, we ran a check search for standard collocations denoting the intended meaning, namely (8b) and (8c). Thus, the collocation in (8a) is considered a heritage collocation by contrast to native collocations in (8b) and (8c). (8) a. *VS
6
na mikrofone in microphone. b. VS v mikrofon in microphone. c. VS čerez mikrofon through microphone. ‘to VS using the microphone’
Figure 1 shows the overall numbers of heritage collocations, culled from the data by manual extraction and analysis against the RNC corpus data. The RNC data illustrate the relative frequency of three collocations, where govorit’/skazat’ v mikrofon (8b) is the most frequently used, with Freq=0.26 ipm, 7 govorit’/skazat’ čerez mikrofon (8c) occupies the second place, with Freq=0.01 ipm, and govorit’/skazat’ na mikrofone (8a) is not attested in the RNC at all. In contrast, the heritage collocation (8a) has the frequency of 1740.14 ipm in the heritage data. Note that the high ipm values in the heritage data are not directly comparable to the RNC data because of significant differences in the sizes of the corpora. These values demonstrate only two simple facts: first, there is a heritage collocation with frequency more than zero in heritage data and, second, the frequency of this collocation in RNC is zero, while other collocations that denote the intended meaning are used.
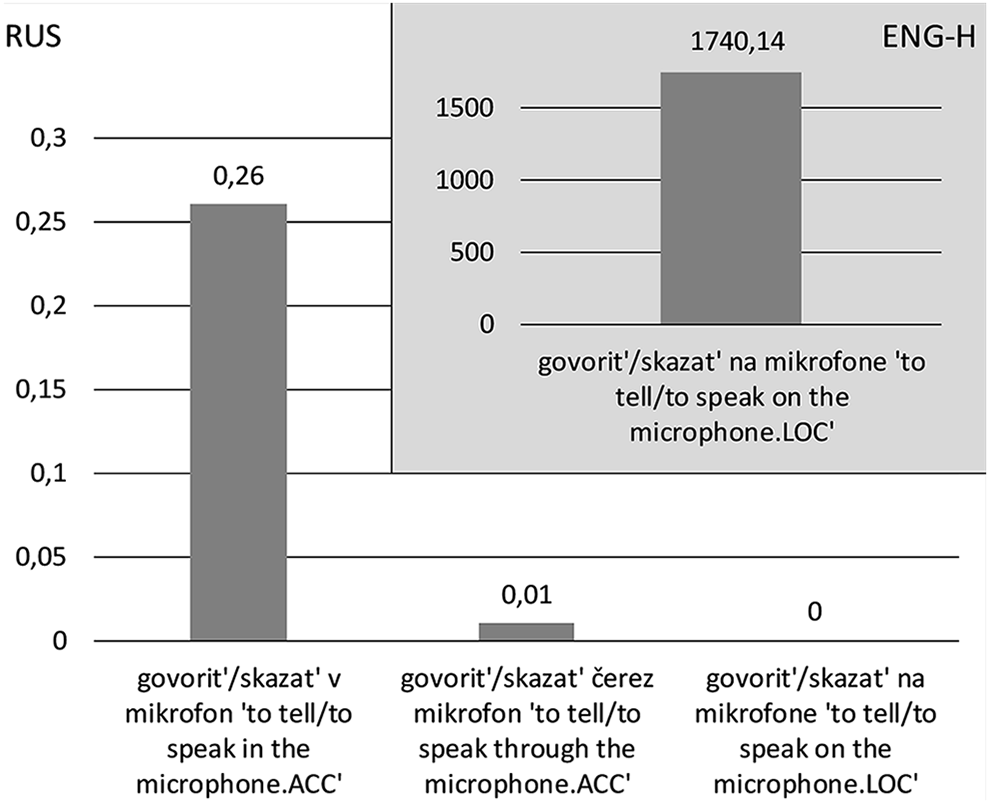
Collocations ‘VS using the microphone’.
All word combinations extracted from the heritage data in our study using this method were then subjected to a thorough qualitative analysis, illustrated below.
Data analysis
Although the differences in the counts of the heritage collocations may be revealing, the averaged numbers do not have the same generalizable power one expects when dealing with normally distributed phenomena. More importantly, each individual item presented a unique challenge in identifying its structural properties and the possible factors driving the divergence from the corresponding structure attested in the RNC.
To illustrate our approach, we will now discuss three different cases that call for three different techniques. The first case is an example of a direct borrowing from English where analysis relies on a simple comparison of the frequencies in heritage data and the monolingual data. In the second case we need to extend the analysis both to dominant language collocations (in that case those of German) and to target-language collocations in order to confirm the complex origin of the item produced by a heritage speaker. In the third case we discuss cases where collocations—that technically exist in the monolingual data—are placed into a wrong discourse frame; such cases demand a more sophisticated analysis beyond raw frequencies and sentence-level syntax.
Heritage collocations for ‘break a mirror’
Let us first consider a set of heritage collocations that were used to describe the action of breaking mirrors in the ENG-H corpus: the participants produced such items (9a–d; Figure 2). Although the Russian verb lomat’ can indeed be translated into English as ‘to break’, a different verb is expected in this phrase, namely, the verb razbivat’ ‘to shatter’. These two verbs in Russian differ in relating the degree of affectedness, such that fragile objects such as glass, mirrors, or china tend to collocate with the verb razbivat’ ‘shatter, smash’ and not lomat’ ‘break’. The heritage speakers in our data often fail to make this distinction: as shown in Figure 2, they use four different verbs to recount the scene with broken mirrors or glass, 8 none of which conforms to native-like selection according to the RNC. 9
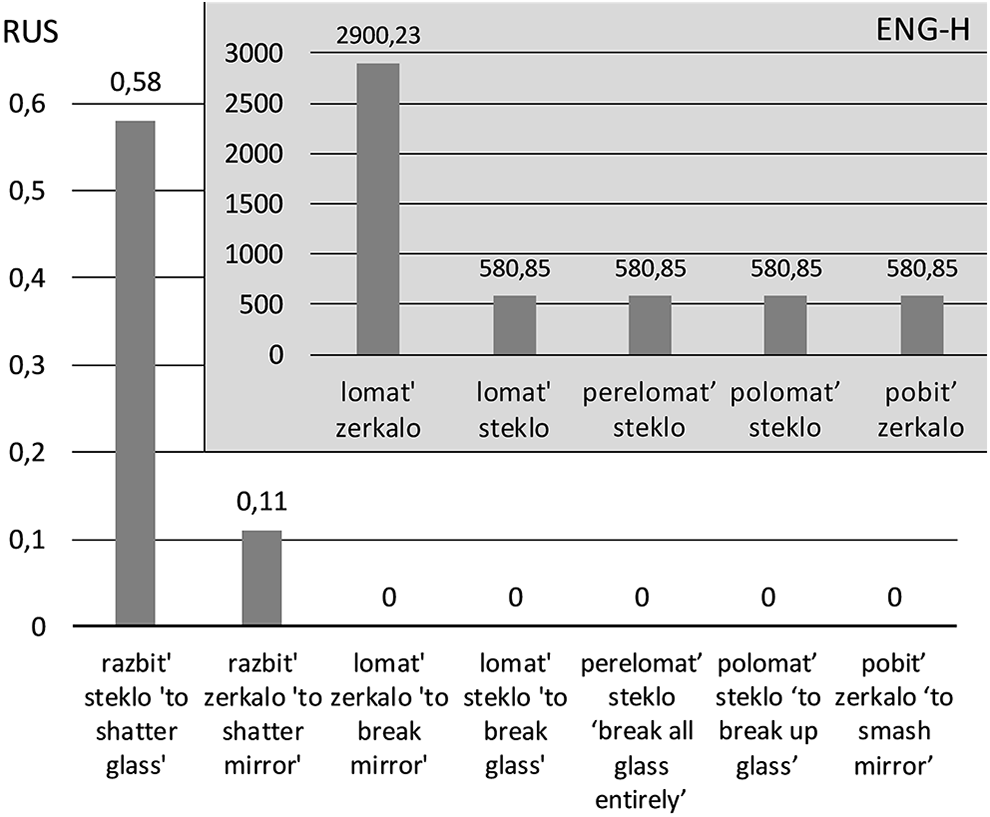
Collocations for ‘break a glass/mirror’.
(9) a. *lomat’ steklo/zerkalo ENG-H break. ‘to break glass/mirror’ b. *pere-lomat’ steklo ENG-H over-break. ‘break all glass entirely’ c. *po-lomat’ steklo ENG-H on-break. ‘to break up glass’ d. *po-bit’ zerkalo ENG-H on-smash. ‘to smash mirror’
Collocations for ‘light a cigarette’
If we consider another set of heritage collocations, this one from the GER-H corpus, describing lighting a cigarette, we see a different picture in terms of structural properties of each and the likely mechanism that drives combining of the words. To describe the concept of lighting a cigarette, the Russian-German speakers in our study produce a number of verbal heritage collocations (10a) and (11a), whereas the collocation zakurit’ sigaretu ‘to light a cigarette’, which is attested in the RNC, is found only once in the GER-H data (Figure 3).
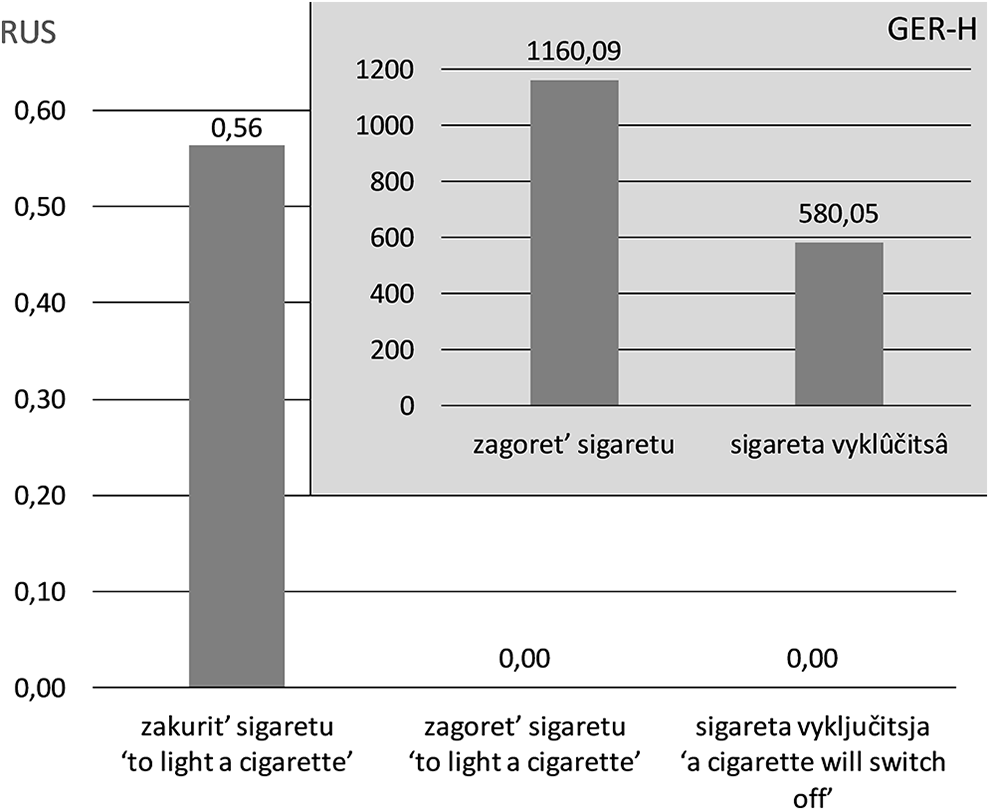
Collocations for ‘light a cigarette’.
(10) a. *sigareta vy-ključitsja GER-H cigarette. ‘a cigarette will switch off’ b. die Zigarette aus-macht GER ‘a cigarette will switch off’ (11) a. *za-goret’ sigaretu GER-H up-burn. ‘to light a cigarette’ b. die Zigarette an-zünden GER ‘to light a cigarette’
It becomes clear that the heritage collocations (10a) and (11a) are of different natures. Both can be traced to German standard collocations. However, whereas (10a) appears to be a direct word-by-word transfer (cf. 10b), the case of (11a) may be more complex. On the one hand, it appears to be influenced by a frequent German collocation (cf. 11b). Yet, the use of this expression may be compounded by two facts: a similar German collocation Licht anzünden ‘to turn on the light’ has a direct equivalent in Russian: (zažigat’ svet ‘to turn on the light’). Additionally, the perfective causative prefix za- ‘CAUSE’ is commonly used with other Russian verbs:
Collocations for ‘in response’
A more challenging case of a non-attested pattern is when a collocation per se can appear in the baseline but is used by the heritage speakers in a wrong discourse frame. Consider the collocation produced by Finnish heritage speakers, shown in (12). A phrase v otvet ‘in response’ is typically used in Russian with verbs denoting speech and other communicative acts like ‘to say’, ‘to get’, ‘to smile’, ‘to hear’. The heritage collocation (12) is not attested in the RNC, while other collocations with the same meaning are found (see Figure 4).
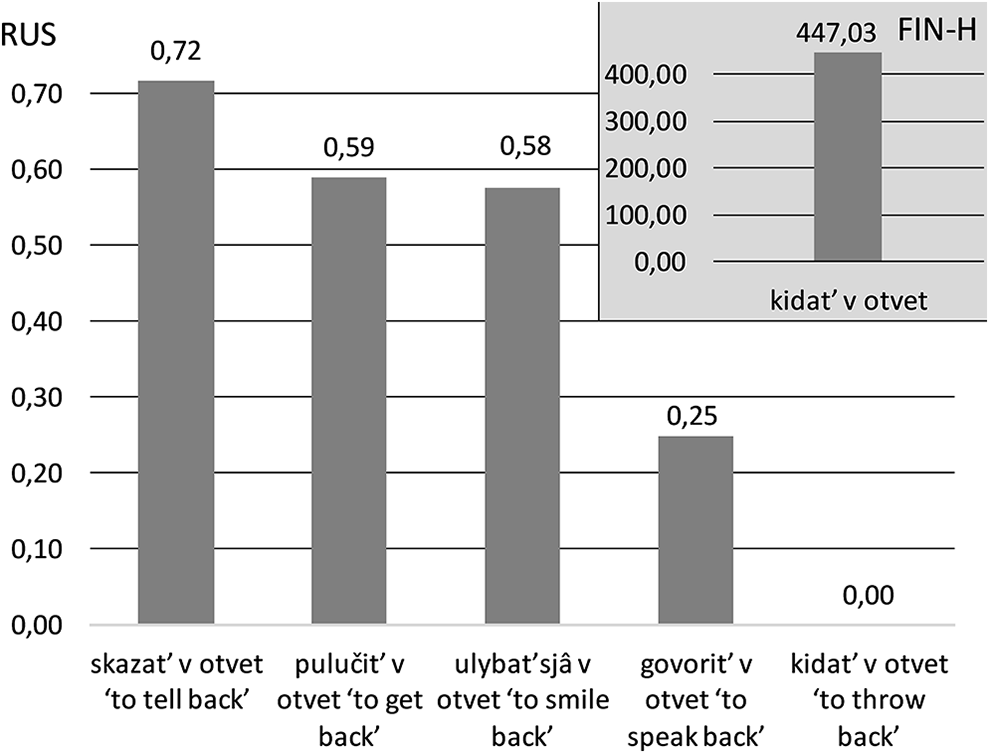
Collocations for ‘in response’.
(12) *kidat’ v otvet FIN-H throw. ‘to throw back’
In sum, a close analysis of the structures found in the heritage language compared with the corresponding structures in the dominant language and in the baseline shows that heritage speakers are aware of collocations as a general concept; however, they lack the relevant items in their heritage language. In that sense, they appear different from L2 speakers whose “collocational needs” seem more modest (Rakhilina et al., 2016). In the next section we address the ways heritage speakers introduce collocations or substitutes thereof into their language.
Heritage collocations: A quantitative summary
The numbers in Table 3 show that Russian heritage speakers dominant in German produce around one and a half as many VPs as the English- and Finnish-dominant speakers. The situation with NPs is somewhat different: although it appears that the Russian-English participants use more nominal heritage collocations than the Finnish- and German-speaking heritage speakers, the fact of the matter is that nominal collocations, which effectively represent complex nominal phrases, are in general far less common in the heritage corpora than the verbal ones. The German and Finnish heritage speakers in particular avoid complex nominal phrases, opting for simple phrases expressed by a noun or a pronoun without governed groups. Extended nominal groups in the FIN-H corpus are extremely rare—for example, novaja devočka ‘new girl’—and German data contain no structures of interest. The American heritage speakers of Russian in our study, on the other hand, use a larger number and a larger variety of nominal constructions and hence provide us with more data to analyze. These differences in the use of nominal and verbal structures are likely to result from the differences in the level of heritage language proficiency, and although these observations are worth pursuing further, they are largely outside the scope of the current project. Here both types are taken into account together.
Frequency of heritage collocations.

The questions that arise from this complexity are most pertinent to our discussion: Do the differences stem from the gaps in the linguistic knowledge of heritage speakers, and if so, what are some strategies that the heritage speakers employ to navigate those gaps? Are the differences in the collocational strategies between the heritage language and the baseline a result of the influence from the dominant language, and if so, how does that influence play out? More generally, what do the patterns of differences in collocations tell us about the nature of the heritage language production compared with monolingual variety?
Heritage collocations: Main types and the motivation for these types
As we discussed in the “Data analysis” section, there is no methodologically straightforward way to distinguish types of heritage collocations because they might be built using competing strategies. However, to anticipate the discussion in this section, three main strategies deployed by heritage speakers in combining words give rise to infelicitous collocations: transfer from the dominant language, convergence of mechanisms from both languages, and non-transfer novel formations in the heritage language. We will examine these three categories here in turn.
Having analyzed the non-attested collocations found in our data, we do find that at least some of these collocations fit in the categories of linguistic transfer such as calques. Yet, the bulk of the deviations in the heritage data do not seem to stem from a direct transposition of the rules of the dominant language into the heritage language, even when some interaction between the two languages is evident. Thus, based on the analysis of our data, we distinguish three categories of non-attested collocations in our data. We call these calques, amalgams, and non-transfer collocations. Below, we discuss and illustrate each category separately.
Transfer from the dominant language: Calques
The first plausible explanation for the collocational behavior that we observe in our data is cross-linguistic influence or linguistic transfer; that is, an adaptation of semantic or syntactic structures from one language into the other language. The transfer phenomenon has been extensively studied in the field of second language acquisition. Odlin (1989), for instance, identifies three types of what he calls “production errors”: substitutions, calques, and alterations of structures. Substitutions (i.e. the use of native language forms in the target language) and calques (adaptations of dominant language structures in the target language) are thought to reveal a direct influence of L1 on L2 (or of the more dominant language on the weaker language, as might be the case with heritage speakers). Alterations, on the other hand, may or may not be directly triggered by the L1. Pavlenko and Jarvis (2002) identify somewhat similar categories of transfer in their study on the types of transfer in Russian-English bilinguals: semantic extension, lexical borrowing, and loan translations. 10 By definition, Odlin’s substitutions appear to be similar to Pavlenko and Jarvis’s lexical borrowings, which the latter authors define as a transfer strategy of adapting words phonologically, morphologically, or orthographically from one language to the other. Loan translations (calques) are defined as literal translations of collocations, idiomatic expressions, or compound words. Semantic extension is conceptualized in Pavlenko and Jarvis (2002) to be a form of negative transfer through which L2 words are used in the meaning of their perceived equivalent in the L1.
In the study of Turkish heritage speakers from the Netherlands, Doğruöz and Backus (2009) distinguish four types of transfer from Dutch into heritage Turkish, namely replacement, omission, addition, and semantic gap. Although these mostly describe structural properties of the unconventional constructions described in the paper, these types largely conform to the transfer categories reviewed above. Thus, replacements (i.e. a replacement of a whole construction or a part of a construction with an element from the dominant language) and semantic gaps (word-by-word translations of culturally specific concepts) are similar to loan translations (or calques), whereas additions and omissions of elements may be described as alternations. 11 An important note on Doğruöz and Backus’s (2009) approach is that the authors interpret L1 influence as “a creative process” (42), whereby elements from both languages are combined, resulting in a hybrid structure.
Although calquing is often found in second language learner data, the strategy of direct transfer of structures from the dominant language into the weaker one is not the most frequent strategy for the heritage language speakers in our study (a similar observation is made in Rakhilina et al., 2016). Nonetheless, calquing is relatively well represented in the data and is worth the attention and discussion.
A calque can involve a word-by-word borrowing or a more abstract transfer of syntactic structure. In both cases, some type of transfer from the dominant language may be evident to a naïve native speaker. We call such calques “transparent”; once again, their transparency may be at a different level of abstraction. There are also less apparent calques, ones whose nature as calques may become obvious only with a more sophisticated linguistic analysis; we call such calques “oblique.”
Transparent collocational calques
These calques represent an obvious and basic part-by-part transposition of elements from one language to another. Some may represent an occasional or online calquing, as in (13a) and (14a): (13) a. *vy-ključit’ sigaretu GER-H off-switch. ‘to switch off the cigarette’ b. die Zigarette /Kerze aus-machen GER ‘to put out a cigarette / a candle’ c. potušit’ sigaretu RUS extinguish. ‘to stub out the cigarette’ (14) a. *motocikl ot milicionera GER-H motorcycle. ‘motorcycle of the policeman’ b. Motorrad vom Polizisten GER motorcycle. ‘motorcycle of the policeman’ c. motocikl milicionera RUS motorcycle. ‘motorcycle of the policeman’
Others appear to have become a more systematic feature of the heritage language variety. Consider multiple examples of delat’+Action Noun ‘to do+Action Noun’ in the ENG-H corpus (17 occurrences). See (15) and (16):
12
(15) *delat’ tanec ENG-H do. ‘to do a dance’ (16) *delat’ malen’kij šou ENG-H do. ‘to do a small show’
These are likely to reflect a systematic transfer of a typical and frequent English syntactic pattern of light-verb constructions that utilize light (semantically bleached) verbs such as to do, to get, to take that form a predicate when accompanied by an additional expression, usually a nominal phrase denoting an action (Doğruöz & Backus, 2009). Such structures are far less frequent in standard Russian, which prefers semantically full verbs like tancevat’ ‘to dance’, pokazyvat’ fokusy ‘to show magic tricks’.
Oblique collocational calques are less straightforward and may be harder to identify at first glance. For illustration, consider the heritage collocation *brosit’/kinut’ obratno ‘to throw back.’ In the standard Russian expression brosit’/kinut’ obratno ‘to throw something back’, the object should be co-referential with that one previously mentioned; one can only throw (17) odin iz nix kinul FIN-H one snižoki v togo pingvina <…>,
snowball. no tot but ‘One of them threw a (18) Irina vzjala Irina neskol’ko sekund few ‘Irina picked up the phonei and threw iti back a few seconds later.’
Again, Russian allows to throw something back, if the object remains the same, as is the case with the phone in (18), where trubka ‘phone’ and [pro] are coreferential. In the animation that the narrative retells, the scene is quite different: a penguin threw one snowball, and his friend threw back a different one (17). Thus, the heritage collocation brosit’ obratno ‘to throw back’ in (17) is perfectly grammatical in Russian, but it breaks the rules of coreference that hold in the Russian language, aligning the item with the Finnish rules, where an object governed by a transitive verb + takaisin ‘back. (19) Matti heitti lunta Matti päälle ja Pekka heitti [proj] takaisin towards. ‘Matti threw
Given that the heritage collocation “throw [the same snowball/it] back” is attested five times in the Finnish heritage texts, we believe this structure is calqued from the standard Finnish.
Language convergence: Amalgams
As mentioned above, a sizeable number of the heritage collocations in our data are influenced by the dominant language only to some extent. Since they cannot be defined as pure lexical or syntactic calques, we refer to these structures as amalgams, that is, combinations of structures present in the heritage and the dominant language. A clear-cut example of an amalgam is exemplified in (20), produced by a Russian-American heritage speaker: (20) *pered glazami detej ENG-H in-front-of ‘in front of the children’s eyes’
This expression combines two structures, a standard Russian expression na glazax u detej (literally, on the eyes of the children) and the English expression in front of the children. While this transfer is supported by the fact that the collocation pered glazami ‘before someone’s eyes’ is grammatically correct in Russian, that collocation only appears in certain other contexts, such as (21) found in the RNC: (21) U menja pered glazami est’ RUS by primer example. ‘I have an example in front of me.’
More so than is the case with calques, amalgams prove to be driven by complex linguistic rules. Consider (22) below: (22) a. *dostat’sja na balkon GER-H reach-up. ‘to climb (to) the balcony’ b. klettern auf den Balkon GER reach. ‘to climb (to) the balcony’ c. zabrat’sja na balkon RUS climb. ‘to climb (to) the balcony’
This heritage collocation in (22a) consists of a well-formed prepositional phrase (PP) and a verb that pair up to produce an infelicitous collocation. This combination of words cannot be explained by direct calquing from German, because in this case we would expect the verb zabrat’sja/zabirat’sja na + NP (Ger. klettern auf + NP ‘to climb onto + NP’). Instead the speaker selected a verb, which might be motivated by the German verb erreichen + NP ‘to reach + NP’ (cf. dostat’ + NP ‘to reach + NP’), and added the Russian suffix -sja, subsequently combining it with a PP that belongs to another construction (which would have been appropriate here, cf. Rus. 22c). 13
A heritage collocation produced by a Finnish-Russian speaker below (23a) may have been considered a case of pure calquing (cf. 23b) save for the fact that the speaker makes one small—but important, in our opinion—concession to the Russian grammar. In the Finnish expression heittää läppää (literally ‘to throw joke. (23) a. *kidat’ anekdoty FIN-H throw. ‘to trade jokes’ b. heittää läppää FIN throw. c. perekidyvat’sja anekdotami RUS throw. ‘to trade jokes’
We suggest that such and similar structures are built when a heritage speaker relies on collocational preferences available in both of their languages, the home (heritage) language and the dominant language.
Non-transfer heritage collocations
The items in this category do not appear to be a result of dominant language influence. This category consists of heritage collocations that are built using linguistic resources of the heritage language; conceivably, the reduced input that the heritage speakers receive may be insufficient to adhere to the statistical preferences of the baseline norm but enough to manipulate parts of the system in constructing novel expressions. In the process, the heritage speaker may expand selective preferences of the language and create a combination that is grammatical but violates statistical preferences and thus sounds “unnatural.” These types of heritage collocations often do not break selective restrictions of the language, but the choice of the co-occurring items is by no means in line with the probabilistic tendency found in a monolingual corpus.
We propose that the non-transfer heritage collocations fall into two types. The first are items created by relying on a transparent conceptual description, even when a formulaic (and often more succinct) expression exists in the baseline: cf. English ‘We are
Conceptual descriptions in heritage collocations
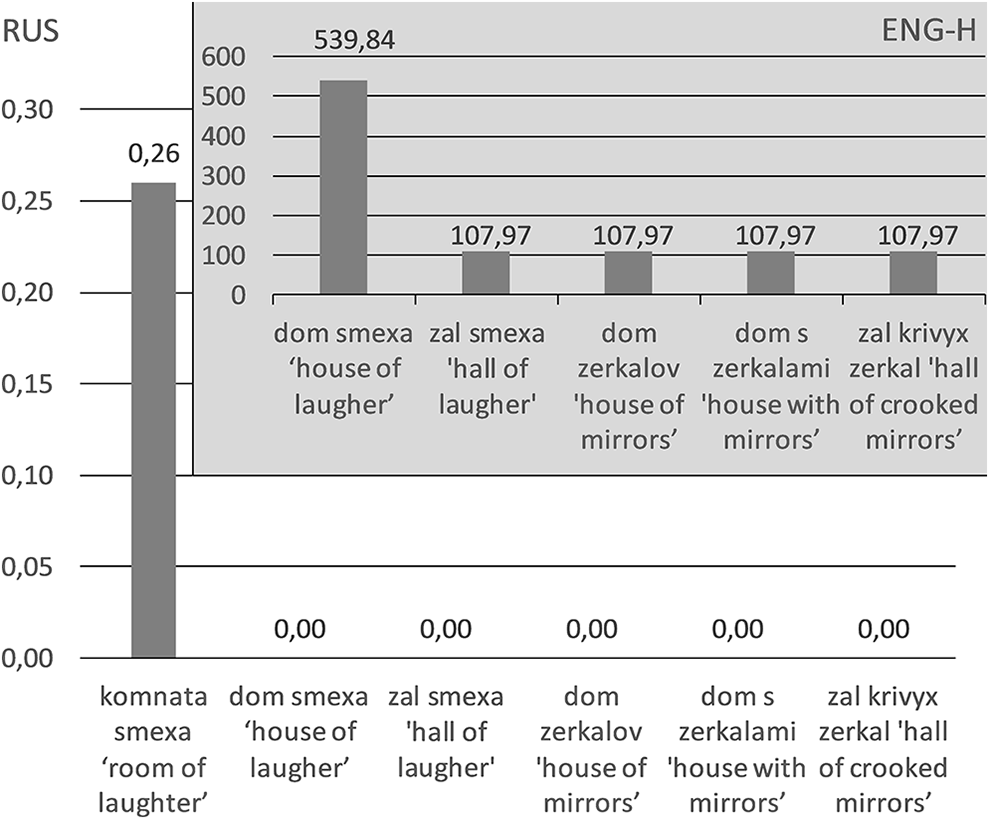
To illustrate the first type, many Russian-English heritage speakers had difficulties with the description of the concept of ‘house of mirrors’ in their narratives. In the Russian conceptual sphere, the term komnata smexa ‘room of laughter’ is used, which necessarily includes a reference to crooked or funny mirrors. Although a significant number of Russian-English speakers produced an RNC attested collocation komnata smexa (lit. ‘room of laughter’) (24d), a number of English-based variations on this collocation were found in the heritage speaker data (Figure 5).
Collocations ‘room of laughter’.
These include, for example, grammatical but non-formulaic (24a-b), where a learner chooses a near-synonym such as ‘house’ or ‘hall’ for the idiomatic ‘room’, and non-grammatical (24c), which contains a wrong form, which is not used in this collocation.
(24) a. *dom smexa ENG-H house. ‘house of laughter’ b. *zal smexa ENG-H hall. ‘hall of laughter’ c. *dom zerkalov
15
ENG-H house. ‘house of mirrors’ d. komnata smexa RUS room. lit. ‘room of laughter’
Although these combinations are non-formulaic and, thus, non-standard, they transparently—and effectively—describe the concept of the hall of mirrors as a place (house, hall) where people laugh (house of laughter). According to Rakhilina et al. (2016), such semantically transparent novel collocations are based on structures that are universally available across languages and are frequent in the language production of heritage speakers (unlike foreign language learners, who seem to rely on the structures of their first language). Although Rakhilina et al. (2016) report that the majority of innovative constructions in their data are such semantically transparent structures, we find few instances of these in our three corpora. The bulk of non-transfer collocations in our data belong to other types.
Overgeneralizations
To reiterate, we understand overgeneralization as the use of a superordinate term in a heritage collocation that requires a more specific item; recall the hypothetical English *make results discussed above. One of the motivating factors here could be that a given superordinate lexical item is more frequent in the input received by heritage speakers compared with the hyponymic lexical item that is called for by the lexical selectional restrictions. Heritage speakers are not aware of the selectional restrictions (and may not even know the hyponymic lexical item), so they pick the lexical item that is common and whose general meaning is reasonable. In other words, if speakers do not know or have trouble accessing a more specific lexical item, they tend to use the more frequent, hence more generic, item in their own repertoire that is somewhat similar in meaning.
To illustrate, consider the example (9a) above: *lomat’ steklo/zerkalo ‘break glass/mirror’ from the ENG-H corpus, where the verb lomat’ ‘break’ replaces the word razbivat’ ‘shatter’ needed in relation to glass objects (see Figure 2). The speaker may not be aware of the existing lexical specification calling for the verb razbivat’ and uses a more general term lomat’ ‘break’, thus overriding the collocational preferences of the noun steklo ‘glass’.
A similar instance is found in the GER-H corpus, *bit’ musorki ‘to hit garbage bins’, which is not attested in the RNC data. Here, the heritage speaker may not be aware of the verb pinat’ ‘to kick’ that tends to collocate with an inactive object like musorka ‘garbage bin’; the speaker simplifies the collocational preferences and uses a more frequent but less semantically-specified bit’ ‘to hit’ over a more specific pinat’ ‘to kick’.
Many non-transfer heritage collocations rely on some combination of structural parts of Russian word formation, but are nevertheless infelicitous. At least two types of such exemplars relate to a particular linguistic feature of the Russian language, that is, its affixal properties. The Russian language presents a rich system of prefixes and suffixes, whose role in word-formation is typically twofold. Verbal prefixes, for instance, can fulfill both lexical and grammatical functions, in other words, prefixes often have lexical meaning that modifies or specifies the meaning of the verb, and that also signifies an aspectual form, that is, the perfective aspect (Wade, 1995, among many others). We describe two cases (25–26) that engage with prefixes and verbal lemmas in different ways. (25) a. * out-pull. ‘switch off the light’ b. out-switch. ‘switch off the light’
In (25a) the speaker produces a verb form in which the prefix of a verb vy- ‘out’ and the word svet ‘light’ (roughly out…the light) belong to the native-like collocation (cf. 25b), but the middle part, a verbal lemma, is inappropriate for the context. We suggest that the meaning of prefixes (which constitute a small, closed class of frequent items) is transparent to the heritage speaker and is used to build an approximation of a structure where all elements are essentially native-like, while their combination is unattested in monolingual Russian.
In cases as in (26a), the opposite situation holds: the speaker produces the right verbal lemma -xvatit’ ‘grab’ but fails to produce the prefix s-, which is appropriate to the collocational context, using the prefix za- instead:
16
(26) a. * ‘occupy the horn’ b. ‘grab at the horn’
It is likely that a deviation in these cases is driven or compounded by the Russian construction in which the verbal prefix is doubled with a verbal preposition that has the same form and etymology and a close meaning, as in (27): (27) do-jti do stola RUS up-to-come. ‘come up to the table’
There are no strict rules governing the duplication of prefix and preposition, but rather a complicated set of conventions regulating usage (see Ferm, 1990). It seems that a heritage speaker tries to extend (to overgeneralize) this probabilistic tendency and to use a phonetically similar prefix. In fact, prefixes are so often an object of concern, that this question needs to be elaborated in a further study. Our preliminary conclusion is that collocations are not only word-by-word combinations but may also be constituted by items on different levels, for instance, Prefix and Preposition (za.Pref + za.Prep) or Prefix and Noun (vy.Pref + light) (cf. Stefanowitsch & Gries, 2003).
A heritage speaker may also generalize a grammatical rule in a way that oversimplifies non-prefix derivation in cases where a circumfix is needed, cf. *ljubit’-
In addition, heritage speakers appear to overgeneralize the rule of forming the perfective aspect with prefixation. In Russian, a perfective form is often formed by adding a perfective prefix (thus, the imperfective delat’ ‘make’ becomes the perfective s-delat’). However, obtaining the imperfective forms from the perfective by simply dropping the prefix does not always result in a grammatically correct form, since not all prefixed verbs in Russian are derived from an imperfective non-prefixed stem. If heritage speakers do not follow a complex set of conventions of formation of imperfective/perfective verb pairs, they might conceivably generalize the set of conventions to a simple rule “if you need to signal aspect, add a prefix to mark Perfective or drop it to mark Imperfective Aspect,” as illustrated in (28a). The native set of rules is more complicated, including modifications in both prefixes and suffixes and changes in verb government (cf. 28b–28c): (28) a. *ljubit’sja v nego FIN-H fall-in-love. ‘to fall in love with him’ b. in-fall-in-love. ‘to fall in love with him’ c. ljubit’ ego RUS love. ‘to love him’
General discussion
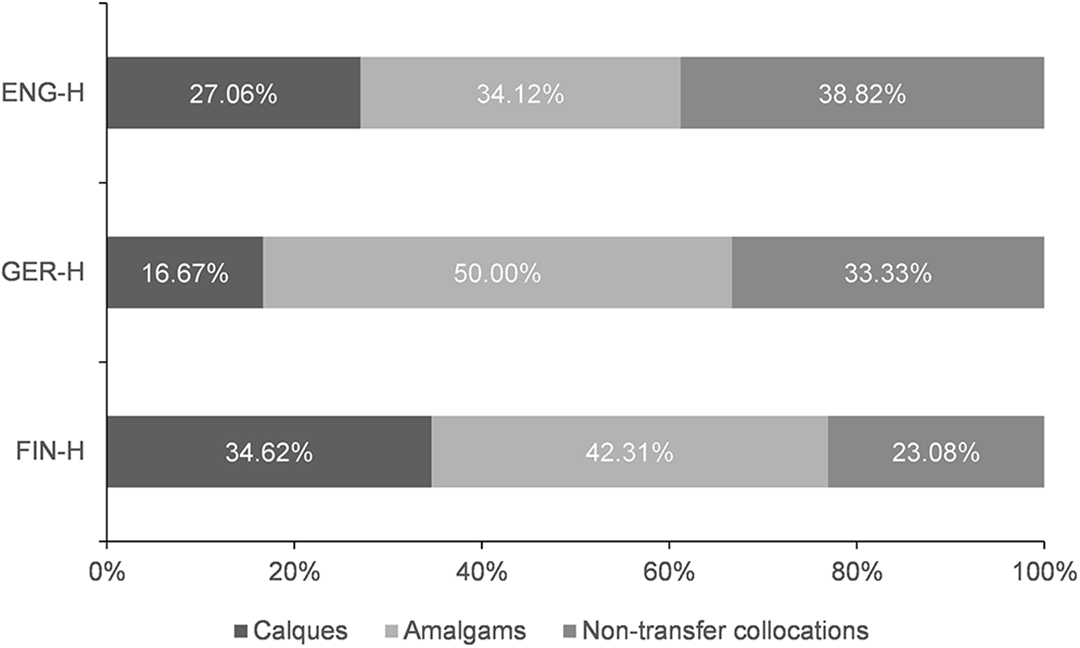
The goal of this study was to explore the use of heritage collocations in heritage Russian. Although we pooled from three different Russian heritage language corpora produced by heritage speakers with three different dominant languages, the goal of the initial analysis was to establish the commonalities in the heritage collocational strategies, rather than to explore the differences between the dominant language groups. Conducting a manual corpus analysis of the heritage corpora and automated analysis of the reference corpus (the RNC), we investigated the issue of heritage speakers’ access to probabilistic collocations when the speakers faced a language gap. The analysis of the heritage collocations showed that although the heritage speakers’ collocational knowledge may in some cases be comparable to that of native speakers, their lexical strategies are malleable, betraying the near-nativeness of the heritage speakers rather than full conformity to the native monolingual baseline. The heritage speakers can tap into the resources of the dominant language (copying the collocations from the dominant language, for instance), but they can also create novel structures that either represent a mixture of the structures from the two languages or involve resources of the heritage language only. Based on these observations, we may classify the heritage collocations taken for the analysis in this article into the following types, according to the likely mechanism of production: calques, amalgams, and non-transfer heritage collocations, with further subdivisions within these categories (Figure 6).
Types of heritage collocations.
In particular, calques can be subdivided into two types. First, there are transparent calques, which represent basic, piece-by-piece transposition of elements from one language to another, as in (29): (29) *vy-ključit’ sigaretu GER-H off-switch. ‘to switch off the cigarette’
And then there are oblique calques, or combinations of words that can be grammatical, but that in the baseline require a different context or a different set of presuppositions. An example of the latter is (30): (30) *brosit’ [pro] obratno FIN-H throw. ‘to throw [it] back’
Non-transfer heritage collocations can also be broken down into two subtypes: (a) conceptual descriptions, created using a transparent expression, even when a formulaic (and often more succinct) one exists in the baseline vocabulary, as in (31) below; and (b) heritage-language-based overgeneralizations created by overgeneralization or extension of a semantic or grammatical pattern in the heritage input, as in (32): (31) *dom zerkalov ENG-H house. ‘house of mirrors’ (32) *lomat’ steklo ENG-H break. ‘to break glass’
We acknowledge that the classification that we propose is not strict: some samples of heritage collocations in our data may be considered true or typical representatives of a particular class while others are so close to the periphery as to blur the lines between the classes that we distinguish for the purposes of this analysis. Some word combinations are a result of the influence of several factors and have traces of a combination of strategies (such as calquing from the dominant language that is compounded by an overgeneralization of a rule in the heritage language); such “mixing” makes it difficult to assign each collocation to a separate class. For example, the line between calques and amalgams is especially fluid, and classification of many structures belonging to these classes was tentative.
Nonetheless, we maintain that our classification provides a useful perspective on the mechanisms employed in the production of the innovative heritage collocations: it allows us to make inferences about the heritage speakers’ preferences in dealing with language gaps. Thus, when posing the question of whether the innovative heritage collocations are largely a result of contact-induced change or a result of intra-linguistic processes, our data analysis suggests that both factors are at play. On the one hand, numerous examples of calques and amalgams suggest that the heritage language is susceptible to contact-induced change, while at the same time the overall preponderance of amalgams—that is, structures that contain elements from both languages available to the speaker—indicate that COPYING of structures from one language to another (to borrow the term from Doğruöz & Backus, 2009) is the result of interaction between languages, rather than of the dominance of a single language. In other words, contact-induced change is never a straightforward or random transposition of elements of the dominant language to the receiving language but a complex interplay of the structures of the two languages. Additionally, many heritage collocations in our data were produced by manipulating the resources of the heritage language only.
Studying word combinations is a good way to get at questions such as whether heritage learners tend to use probabilistic strategies less than native speakers because they do not get the frequency of patterns in their input in the same amount as native speakers. Indeed, the full range of collocational features appears to be less available to the heritage speakers, and they are subject to different demands than rules of grammar. Grammatical rules are more constrained and finite than collocational preferences. A limited variation at a point in the language system (e.g. tense forms) demonstrates morphological generalizations typical for monolinguals even if the input is limited. A broader variation across collocational preferences leads to more errors in production. However, the cognitive strategies used by heritage language speakers are common with those of L1 speakers, including generalization (albeit exaggerated) and conceptualization (albeit less idiomatic).
The study presented in this paper opens a number of follow-up questions and in effect suggests a line of inquiry. An important piece of data that was left outside the current discussion included multiple samples of word combinations that contain code-switching. By default, heritage collocations that consist of elements of heritage and dominant language are not attested in the L1 variety, and the analysis of such structures may significantly add to the discussion of the collocational strategies of heritage speakers. On the one hand, lexical borrowing and the calquing of whole structures are deeply intertwined: it is conceivable that a borrowed lexical item may trigger the choice of a non-standard multiword combination or structure. A calqued structure may also trigger the choice of, or a need for, a borrowed item. And yet we notice examples where code-switching is incorporated into native-like structures. The issue of differences in the collocational strategies between the heritage speakers and L2 speakers in general is of great interest—comparative studies may illuminate many discussions, including that concerning the effects of reduced input. This line of inquiry will necessarily add the dimensions of age of exposure and level of language proficiency to the picture. Finally, experimental studies of comprehension of collocations in speech and writing may also greatly add to the fuller picture of the collocational abilities of speakers whose language developed (or continues to develop) in the context of limited input.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was partly supported by the ASLA-Fulbright Research Grant for a Senior Scholar Program, USA.