
Abstract
Objective:
The objective of this article is to discuss the pedagogical and practical need for automated assessment tools that enable teachers, researchers, and other language practitioners to relatively quickly and automatically assess the general proficiency of second language (L2) speakers according to a number of different linguistic parameters, specifically the use of collocations.
Introduction:
The Introduction discusses existing approaches to the concept of collocation and its role in L2 corpus studies.
Methods:
In the main part, Toward the automatic detection of collocational strength, we describe an approach to assessing collocations in Russian L2 written production, which is based on the corpus-driven contrastive analysis. In brief, this approach proposes ranking L2 collocations in accordance with the “collocational scores” of bigrams extracted from a reference (L1) corpus, with the assumption that the greater number of native-like bigrams in an L2 text and the higher collocational scores associated with them, the more proficient is the learner who created the text. To test this hypothesis, we conducted a series of experiments based on an L1 reference corpus and split the L2 datasets into four proficiency groups (Beginner, Intermediate, Advanced, and Superior).
Results and evaluation:
The findings, presented in the section Results and evaluation of the methods, established an empirical minimum and maximum of mean reciprocal rank (MRR) values, and the variation of the MRR across the four proficiency levels. In the last sections, we discuss shortcomings of the methods and propose further steps for overcoming them. We believe that the proposed method for assessing the collocational skill of Russian L2 writers can be successfully integrated into a bigger system capable of multifaceted automatic assessment of Russian learner texts.
Keywords
Introduction
As a linguistic field, phraseology has gone through significant changes in recent decades, largely due to the increased availability of computer-aided technologies for language analysis (Granger, 2021). Original ideas developed in the works of J. Firth (1957), M. Halliday (1973), and then J. Sinclair (1991), which put lexis, including a variety of phraseological expressions, firmly at the center of linguistic research, have gained much support in more recent corpus-based research. In addition, although contemporary thinking sees phraseology as being at the interfaces of morphology, syntax, and discourse, the original focus on lexis continues in much contemporary research, as reflected in the terminology used to apply to formulaic language: multi-word expressions, lexicalized phrases, collocations, lexical bundles, and so on. (Wray, 2013).
The proliferation of terms reveals a robust research agenda; however, it also betrays a certain degree of conceptual overlap and methodological issues that continue to characterize the field. Moreover, much research on phraseology continues to struggle to find the best approaches to defining, extracting, and automatically assessing formulaic expressions in a variety of texts and for a variety of research and practical purposes.
One area of linguistic research that has seen a growing volume of phraseology studies is foreign language (L2) linguistics. In fact, this field may have been the first to deal with the practical issues of formulaicity in language (Herbst, 2011; Stubbs, 2009). Indeed, any attempt by a learner to achieve a degree of native-like language ability inevitably results in the realization that languages have multiple conventionalized ways of stringing words together and that these are unpredictable, based on traditionally understood “grammar rules.” The need to identify, and subsequently, teach conventionalized (read formulaic) sequences was recognized as early as the 1930s (see Stubbs, 2009 for references). Much contemporary research in L2 phraseology is represented by corpus-based investigations of the phraseological abilities of language learners, an area to which we hope this article will contribute.
From the wide range of formulaic units (Wood, 2015; Wray, 2013), we focus on collocations, which may be the most studied units in learner corpus research thus far (Granger, 2021). We first review the general approaches to defining collocations and discuss the methodological aspects of extracting and assessing them, with a focus on learner data. We then present our study, which explores a novel approach to the automatic extraction and assessment of collocations in learner texts created by L2 learners, with the ultimate goal of exploring the role of collocations in placing learner texts on a proficiency scale.
Defining collocations: Phraseological versus statistically oriented approaches
Collocations belong to a wide class of formulaic sequences (Bartsch, 2004; Moon, 1998) and despite their long history in the field, they continue to be a challenging notion to define (Wray, 2013). Nonetheless, to provide a clearer definition and operationalization of collocations, two general approaches can be distinguished: the “significance-oriented” or “phraseological” approach (Hausmann, 2004; Herbst, 2011; Jackendoff, 1995; Nesselhauf, 2005 inter alia) and the statistically oriented approach (Biber, 2009; Evert, 2005 inter alia).
The significance-oriented approach is rooted in the traditional study of phraseology—a branch of linguistic studies that belongs to lexicology and lexicography. One of the most comprehensive classifications of idiomatic units within this approach was developed by Mel’čuk (2023) who aggregated both Western and Eastern European traditions in the study of phraseology. His classification takes into account several aspects, such as the linguistic levels at which idiomatization occurs; the degree of idiomaticity; and the pragmatic implications at play. The phraseological unit in this paradigm is the phraseme, defined in Mel’čuk’s (2023) latest paper as follows: A complex linguistic sign is called a phraseme iff 1. it is not free – that is, iff the selection of at least one of its constituent elements by the Speaker is constrained (by an individual linguistic item), and 2. if the constrained selection concerns only one sign within the phraseme, this sign is not a grammatical lexeme. (p. 36)
Based on this definition, the concept of collocation is rather straightforward: a collocation can be deconstructed, both semantically and formally, but its usage has constraints, most often in the form of a mutual co-occurrence of its part: for example, the adjectives in English heavy accent, Russian: sil’nyj akcent lit. “strong accent,” or French accent à couper au couteau lit. “accent to cut with the knife.” 1
The alternative approach, known as the statistically oriented approach, to defining collocations has been largely developed in the field of corpus linguistics, where a collocation is understood as any statistically significant cooccurrence, including all forms of multiword expressions <. . .> and compositional phrases which are predictably frequent (Sag et al., 2002, p. 9).
Importantly, within this paradigm, collocations are identified through corpus-driven procedures, with no criteria for formulaicity pre-set by researchers. Since they are calculated on the basis of frequency measures, they are not required to be “grammatically complete” or “idiomatic” (Biber et al., 2004, p. 371 2 ), their only raison d’être being statistical salience. Thus, the examples of purely frequency-based collocations include grammatically complete expressions such as on the one hand, as well as “incomplete” but not statistically random sequences such as as shown in figure, in the context of, percent of the, and even I don’t think he 3 —insofar as the last is a statistically significant sequence in, for example, oral academic discourse.
Not all researchers working with the statistically oriented approach consider sequences that cross clause boundaries or do not complete an argument structure to be collocations, arguing that the syntactic relationships of the elements involved in a collocation play a significant role in its identification (Nesselhauf, 2005). Thus, such English combinations as hold tight and holds tight 4 (if statistically diverging) should not represent two different collocations. In other words, the two approaches handle the question of whether a collocation is a relationship between word forms (tokens) or lemmas somewhat differently, with the phraseological approach mostly focusing on the semantics of the lemma and the statistical approach mostly dealing with word forms. This question is especially relevant in case of, for example, the Slavic or Uralic languages with their highly inflectional morphology. In the Russian language, for example, a lemma sequence that includes an adjective and a noun may conceivably appear in 12 token realizations (although the actual distribution may be skewed).
Despite their different epistemological positions, the two approaches described above are not contradictory. Both are grounded in the cognitive paradigm (as opposed to the generative approach), both recognize the importance of the usage frequencies of particular “fixed” expressions, with a shared understanding that “they might appear to be analysable into segments” (Sinclair, 1991, p. 105). In fact, a gradient inclusive approach, which suggests conceptualizing collocations on a continuum from more paradigmatic to more syntagmatic, appears to successfully bridge the two above-mentioned approaches; in this gradient view, lexical sequences are closer to the “nuclear sequence” (an abstracted gestalt) and contain more paradigmatic information, whereas word-form sequences include more syntagmatic information and provide frequency and probabilistic information (Evert & Kermes, 2003; Newman, 2008).
In our study, we utilize a statistically based, corpus-driven approach, which has several advantages in our view: it is not only “methodologically straightforward” with high “face validity” (Ellis et al., 2013, p. 89), it is also supported by psycholinguistic research (Durrant & Doherty, 2010), and importantly for our long-term goals, is suitable for developing an automated multifaceted algorithm of language assessment.
Collocations in L2 corpus studies
Collocations have become the focus of a wide range of research on language acquisition and language pedagogy, especially in recent decades (Ellis et al., 2013; Meunier & Granger, 2008; Wray, 2013; inter alia). Language educators and language pedagogy researchers have long shown an interest in formulaic language for immediate instructional reasons. On the one hand, conventionalized language patterns have been understood as indispensable for fluent and target-like language production and to mark higher levels of language proficiency (Herbst, 2011; Nesselhauf, 2005; Paquot & Granger, 2012). At the same time, earlier studies of the role of formulaic language in L2 do not seem to have yielded systematic results (Schmitt & Carter, 2004), and many scholars have thus argued that formulaic language is a performance phenomenon independent of a developing grammar system (e.g., Bohn, 1986). Contemporary thinking on the nature of language and the evidence of the pervasiveness of patterning in language, however, has led most linguists to believe that the ability to manipulate formulaic language is at least developmentally significant (e.g., Bardovi-Harlig, 2002; Schmitt & Carter, 2004) or fundamentally crucial (Ellis, 2012; Eskildsen et al., 2007; Herbst, 2011).
Collocations in corpus studies
Investigations of learner corpora conducted with the help of corpus analytics have begun to contribute to a better understanding of the L2 phrasicon and the phraseological abilities of L2 learners at different levels of proficiency. Granger (2021) provides a comprehensive summary of research questions that has arisen in learner corpus investigations of L2 phrasicon, including but not limited to: investigating the differences between L1 and L2 speakers’ use of phraseological expressions; the under-use, over-use, and appropriateness of use of formulaic sequences in learner language; variations in the use of phraseological expressions in learner groups distinguished by L1, proficiency levels, and type of instruction/exposure, and so on.
In one such study, Crossley and Salsbury (2011) utilized a frequency-based measure and tracked the use of two-word collocations (or lexical bundles in their terminology) in the oral production of six L2 speakers of English over the course of a year. By comparing the overlap between the normalized counts of lexical bundles in the L2 speaker texts and the L1 reference corpus, the authors found that some learners showed stable growth in the number of native-like MWEs, while other learners exhibited non-linear progression or no growth in frequencies of native-like expressions. Bestgen and Granger (2014), on the other hand, tracked the development of the use of multiword expressions (MWEs) by measuring the strength of collocational association in the L2 learner essays over the course of a semester. They also found no significant increase in association strength but did find a significant relationship between the strength of association score and the essay quality scores. Interestingly, there was no significant relationship between the t-scores (a frequency-based collocational measure, see Section “Methods: Toward the automatic detection of collocational strength” for more information on this) and the essay quality scores in this study. The authors suggest that although phraseological competence advances slowly, association measures generally serve as a good developmental measure. Combining the frequency and strength of association measures, Yoon (2016) investigated the use of verb–noun combinations in the writing of L2 English learners over the course of one semester. Although the learners showed no dynamic association strength in verb–noun combinations, a comparison between the learner and native speaker groups revealed a significant difference in association strength in argumentative writing; and a comparison between the learner and native speaker groups also revealed that the L2 writers under-used low-frequency verb–noun combinations in their writing.
It is safe to conclude that a combination of approaches achieves the best results. To illustrate this point, O’Donnell et al. (2013) explored how different measures of formulaicity may affect the results of a comparison of the use of these formulaic sequences in different learner groups (novice vs. expert academic writers, and native vs. non-native). The authors chose four measures in their analysis: n-gram frequency, Mutual Information (MI), p-frames, and native forms (based on the Academic Formulas List (AFL), Simpson-Vlach & Ellis, 2010) and found that different measures led to different patterns of results. Thus, clear differences between expert and novice writers emerged in the frequency- and MI-based measures, but no differences emerged between the L1 and L2 writers; for p-frames, no expertise or native language status effects were found. For formulas defined by native norms based on the AFL, clear expertise effects were found, with expert writers using significantly more formulaic sequences than both graduate and undergraduate writers, but no effect of native language status was observed. The authors concluded that investigations into formulaic language are not methodologically simple and that “much depends on the design of the corpus, the mix of participants, the variability of prompt, task, and genre, and the statistical definition of formulaicity” (O’Donnell et al., 2013, p. 103).
The methodological aspect of research is no less important in formulaic language. O’Donnell et al. (2013) argue that “measurable operationalizations” (p. 87) of formulaic sequences, that is, the methodological procedures used to extract and compare the sequences, are intrinsically connected to the very essence of the phenomena. We address this question in Section “Methods: Toward the automatic detection of collocational strength,” where we further develop an approach that leans on comparisons between L1 and L2 data, and also propose an automatic assessment protocol that can be used as the component of a more comprehensive assessment tool.
Collocations in automatic proficiency assessment
The ultimate goal in computer-assisted language testing (CALT) is to create a tool capable of non-human processing, and many such tools are already available for analyzing English (Cobb, 2013; Graesser et al., 2004; Kyle & Crossley, 2015), Swedish (Pilán et al., 2016), German (Bernius & Bruegge, 2019), and other well-resourced languages. As regards the Russian language, we are aware of several related projects: Revita (Katinskaia et al., 2018), Tekstometr (Laposhina et al., 2018), Visualizing Russian (Clancy et al., 2019), DeepRus (Kor-Chahine et al., 2022). To the best of our knowledge, none of these had provided the user with a tool for assessing collocations at the time of writing this paper.
The majority of CALT systems that provide some assessment of language proficiency are based on text-internal measurements such as sentence length, word length, type/token ratio, which in turn are based on features extracted from the text itself (Heift, 2021). The text-internal approach presents an impassable barrier when dealing with collocations, as they cannot be measured on the internal parameters of an L2 text. An alternative approach to assessing collocational skills may utilize a list of collocations (some pre-developed phrase list), from which a quiz, a fill-in-the-blanks exercise, or similar pedagogical tasks may be constructed. Nowadays, the best practices in collocational skill assessment presuppose a corpus-based list or dictionaries (Gyllstad, 2007). Fewer systems rely on assessing the collocations presented in an L2 text (Treffers-Daller et al., 2013). The most promising approach, which we advocate in this article, is aimed at comparing texts produced by L2 students with reference data, or a standard, L1 corpus. Such attempts were recently discussed in Lenko-Szymanska (2014) and Qin (2014), who used a larger reference corpus to attest multi-word sequences in L2 English learner texts. The assessment was based on a calculation of how many native-like collocations were found in a learner text, but it did not take into account collocational strength. This approach differs from that which we present in the next section.
Methods: Toward the automatic detection of collocational strength
The extraction of collocations from a text is by definition a frequency-based process. However, an individual learner text is generally too short for any statistical methods. In our previous work (Kopotev et al., 2020), we circumvented this challenge by evaluating L2 texts against a large enough corpus of native texts, the Russian National Corpus (RNC) in that particular case. The approach appeared to be promising; in the current article, we further strengthen it by utilizing a bigger corpus and adopting an algorithm that opens up possibilities to automatically evaluate learner collocations against corpora in order to place an L2 text on a proficiency scale.
The key idea of our approach is as follows. As calculating inter-textual collocational strength is not inherently feasible, we propose the extrapolation of collocational features from a reference corpus. Initially, the learner text is split into bigrams—a chunk of two sequential tokens—for each of which the collocational strength is ascribed from a large L1 reference corpus. The assumption regarding learner collocational proficiency is as follows: if the learner uses a greater number of bigrams attested in the reference corpus and if the collocational strengths of these bigrams is higher, we consider the collocational proficiency of the learner to be higher. Naturally, non-attested collocations are assigned a zero, which means they are not found in a large L1 corpus. To accomplish these operations, we utilize (a) a corpus of learner texts, (b) a large reference corpus of the Russian language, and (c) two collocational measures, which we explain below.
Of the great number of different methods proposed for collocation extraction (Pecina 2010, e.g., observed 80), the majority of studies on collocations utilize the following measures: t-score, Log-Likelihood (LL), (Pointwise) Mutual Information ([P]MI), and Dice. Applying these, one can obtain overlapping yet different results depending on the focus of each measure: whereas t-score ranks the most frequent collocations higher (e.g., despite of), Dice favors words that are infrequent yet highly attracted to each other (e.g., lo and behold). In this study, we utilize these two measures, PMI and Dice, whose results have proven to be complementary when applied to Russian data (Pivovarova et al., 2019).
Data
The data used in this research consisted of two sets: written learner texts collected from L2 speakers (hereinafter L2 data) and a large reference corpus (hereinafter L1 data).
The L2 data were collected in the summer of 2019 at an 8-week-long immersive intensive Russian language program at a well-known US-based language school. Unlike traditional college courses in the United States, the immersive mode of the program makes the conditions similar to those when studying abroad (see Merrill et al., 2021 for more information). In the program, students are expected to speak only Russian, the so-called “language pledge” is maintained throughout the duration of the program. The number of instructional hours is 21 per week, or approximately 168 per summer term. In addition, the students were exposed to Russian through extra-curricular and daily routine activities.
The program had seven curricular levels, ranging from Low to Superior (see Table 1). The placement decisions were made on the basis of entrance exams, which consisted of two grammar tests, an oral proficiency interview (OPI), and a writing proficiency test (WPT). To assess final proficiency, the students were tested at the end of the program, using the same procedures. The WPT, which specifically assesses the writing proficiency level, was conducted in the following manner: learners were asked to write one narrative and two argumentative essays in the span of 90 minutes, with no access to additional resources. The essays were then graded according to the American Council on the Teaching of Foreign Languages (ACTFL) guidelines, with two trained raters grading each learner text. If the raters’ scores differed, a third ACTFL-certified tester made the final decision regarding the proficiency level assignment. All texts were written by hand and later digitalized for research purposes, with the university’s approval.
Number of texts and words in proficiency categories.
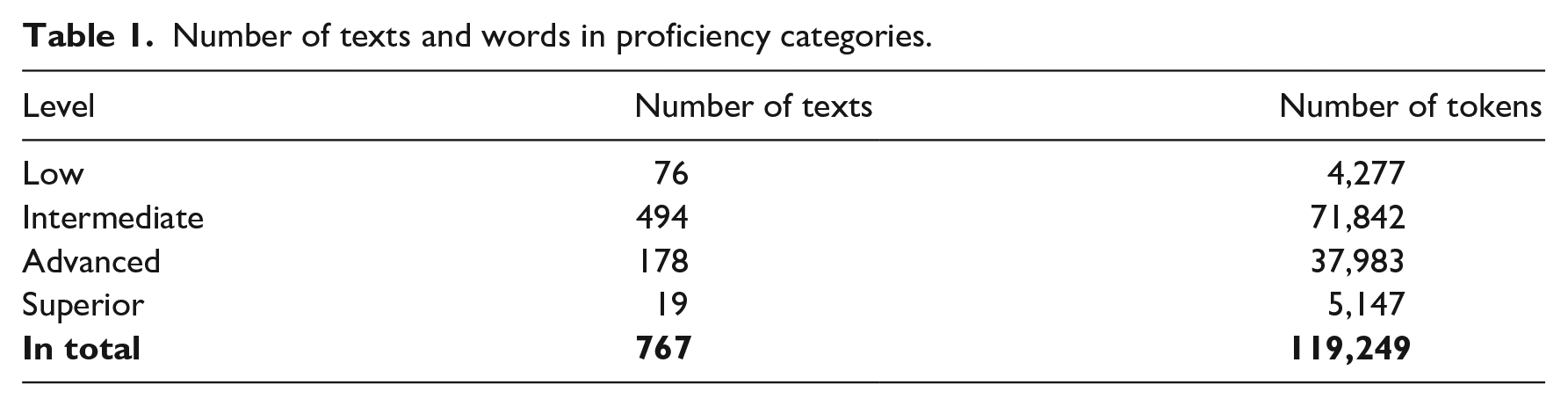
A total of 137 students participated in the study. We selected the texts of 133 participants (127 L1 English speakers, one L1 Chinese Mandarin speaker, one L1 German speaker, one L1 Portuguese speaker, and one L1 Spanish speaker). The texts by the only heritage Russian language student were excluded because language learning background is known to influence the dynamics of instructed language acquisition. Essays that contained more than 50% misspelled or unclear tokens were also excluded from the analysis, as these orthographic issues rendered the meaning of the essays indecipherable. Eleven texts were excluded on the basis of this criterion. Finally, 26 essays of under 25 words were excluded from the analysis to enable meaningful computational analysis (Verspoor et al., 2012). The final L2 dataset included 767 essays, 119,249 running words in total.
All the handwritten essays were typed up by a Russian-speaking research assistant with experience in teaching Russian as an L2, and then cross-checked by a second assistant with similar training. Next, all the essays were standardized for spelling; orthographic standardization was required to properly lemmatize and parse the data. All digital files were saved as plain text in UTF-8 encoding.
As the L1 dataset, we utilized the Taiga corpus (Shavrina & Shapovalova, 2017), which, unlike the RNC, is freely available for downloading. The size of the corpus is ca 400 mln running words, it is morphologically annotated, and it represents five thematic domains: poetry, social media, film subtitles, news, and magazines.
Data prepossessing
Both the L1 and L2 datasets were first split into tokens and bigrams, that is, two-word sequences; duplicates within the L2 texts had been removed. For the L1 dataset, the frequencies of each token and each bigram were then calculated and stored. This step allowed us to further calculate the collocational strength of the bigrams extracted: for each L1 bigram, the Dice and t-score were calculated on the basis of the formula below:
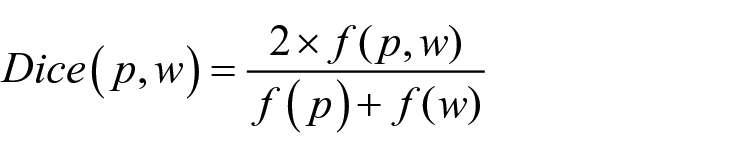
and
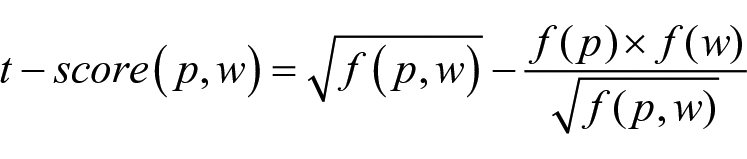
where (p,w) is a bigram, p and w are its fillers, f(p) and f(w) are their frequencies in the L1 corpus, and f(p,w) is the frequency of their co-occurrence in the L1 corpus.
We ranked the calculated Dice- and t-scores, and ascribed the ranks to the L2 bigrams if the match was found in the L2 data. If an L2 bigram was not attested in the L1 dataset, the Dice and t-score values were assigned zero. Thus, the final database for the analysis consisted of bigrams from the L2 dataset enriched with data from the L1 dataset, such as word frequencies, bigram frequencies, Dice and t-score and their ranks, and, finally, the mean reciprocal rank (MRR) measures, which we describe in the next section.
Methods
This section focuses on the method we propose and addresses the issues of automatic extraction and assessment. To measure the collocational strength of the collocations found in the L2 texts, we used the MRR, a measure traditionally applied in the evaluation of machine translation (Guzmán et al., 2019), information retrieval (Shah & Croft, 2004), and question-answering quality (Voorhees & Tice, 2000). In brief, the MRR takes into consideration the rank of a correct response in relation to all responses: The higher the rank, the higher the MRR and the (assumed) quality of translation or information retrieved.
Computationally, the MRR is the average of the multiplicative inverse of the ranks of the first correct answers to a set of queries:
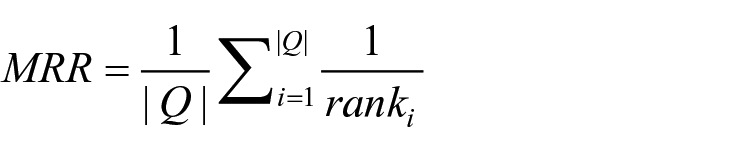
where ranki refers to the rank position of the first relevant document for the i-th query Q.
Generally, to calculate the MRR, one needs to create a table of responses produced by the machine to a stimulus—be they translations or querying results. All responses are ranked, and the rank of the first correct response is written out. For example, the English sentence A dog is playing with a toy may be translated into Russian as presented in Table 2.
Data for MRR calculation.
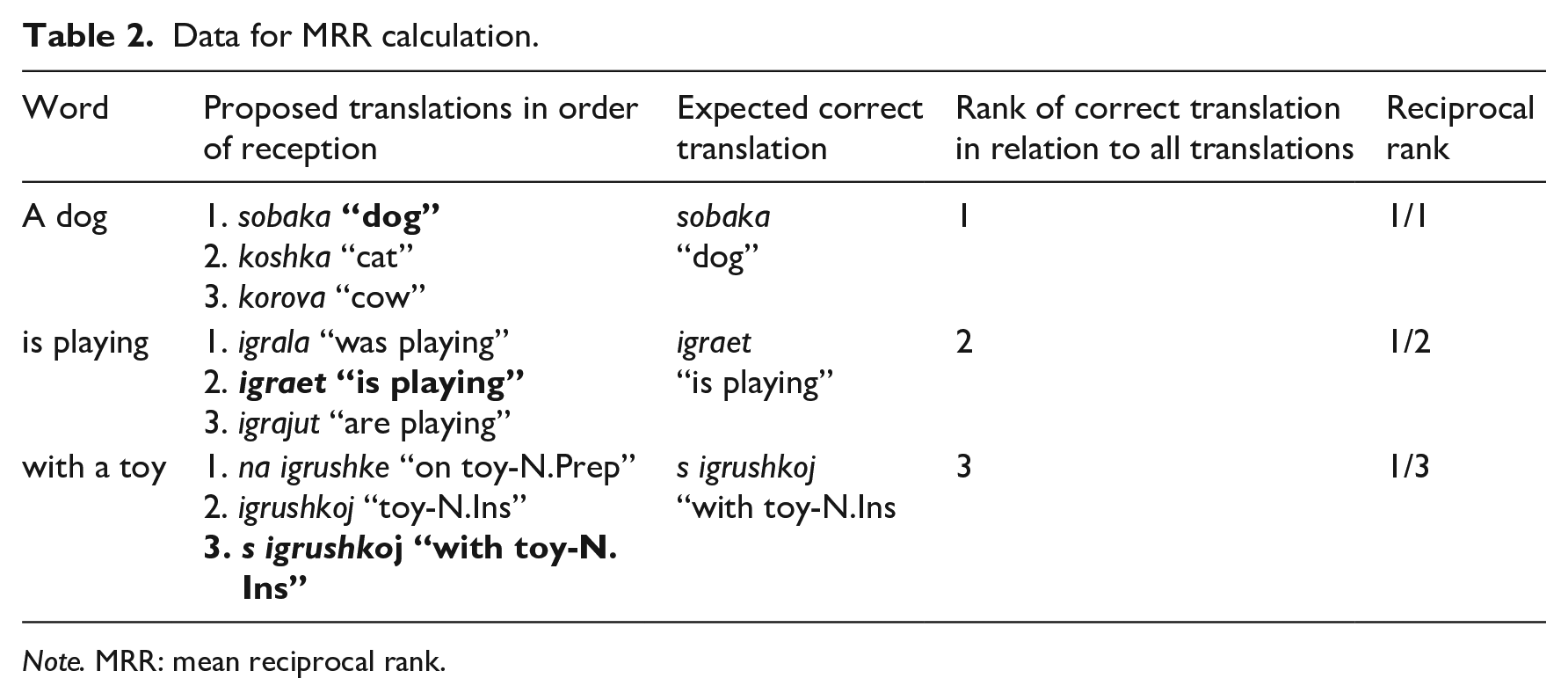
Note. MRR: mean reciprocal rank.
The rank of the correct translation (given in bold) in relation to all translations is counted and converted reciprocally as 1/x. Based on this, the MRR is counted as an average: (1 + ½ + ⅓)/3~.61. This is the value of the “quality” of the translation, which can be from 0 to 1, where a higher MRR score indicates a better result.
The adaptation we propose here is as follows: we consider the first correct answer to be the rank of the corresponding bigram in the L1 dataset. Therefore, for every L2 bigram, a reciprocal rank of the corresponding L1 Dice or t-score values is ascribed; “reciprocal” meaning 1 divided by the value of the respective rank. The rest of the calculation remains intact.
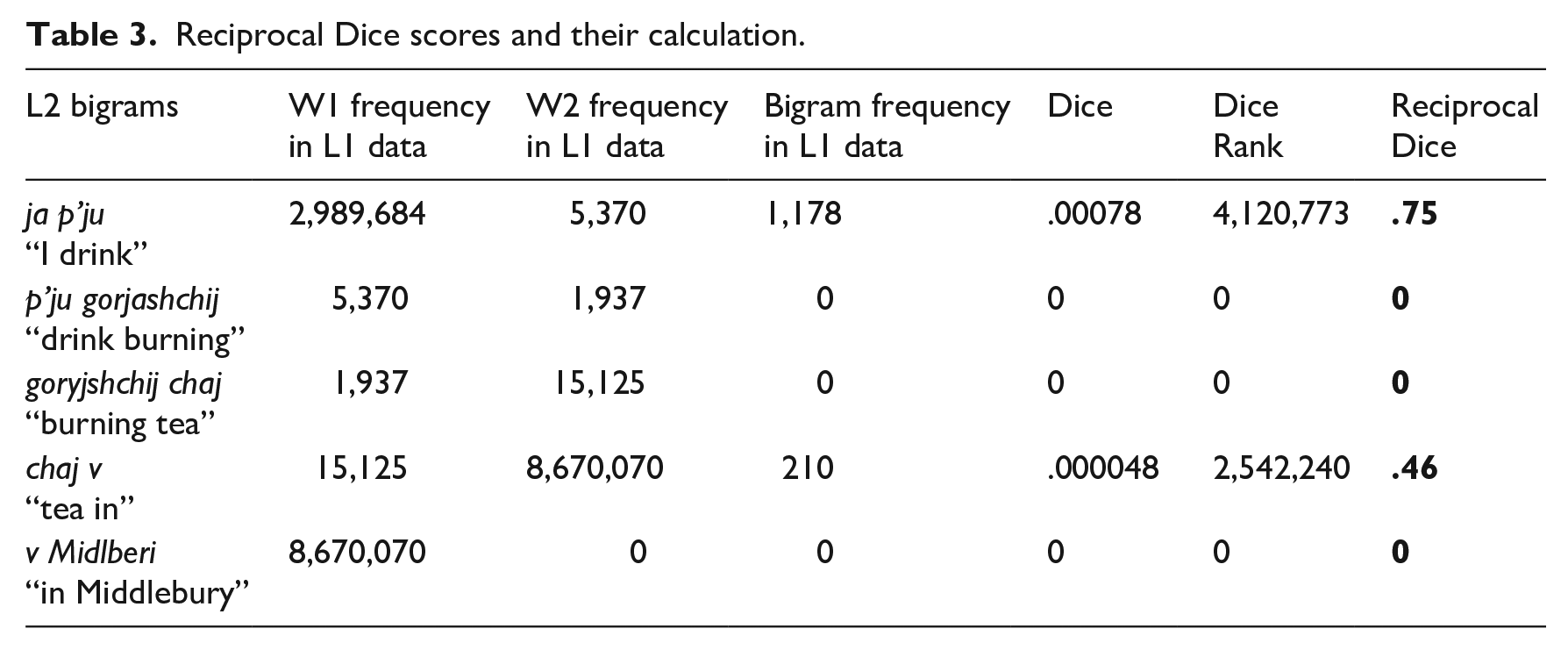
To reiterate, the Dice and the t-score ranks are based on a comparison of L2 and L1 data. To do this, we take a bigram from the L2 data and search for it in the L1 list; if found, we reciprocally accredit the rank of the Dice or t-score to the L2 bigram. In other words, each L2 bigram obtains a rank if it has the corresponding L1 collocation. Naturally, if an L2 bigram is not found in the list, its rank is zero. In the final step, we calculate the reciprocal rank of every bigram, as a division of x/y, where x is a sum of the reciprocal ranks and y is the number of the ranks. The MRR is then the average of the reciprocal ranks in the text. Table 3 presents an example of the calculated data.
Reciprocal Dice scores and their calculation.
(1) Ja p’ju gorjashchij chaj v 1.SING drink-PRT.1.SG burning -ACC.SG tea-ACC.SG in
Midlberi
Middlebury-LOC.S “I am drinking a burning tea in Middlebury”
From the table above, the Dice MRR can be calculated as (.75 + 0 + 0 + .46 + 0)/5 = .242. The MRR for the t-score is calculated in the same way.
An inescapable drawback of our approach is connected to non-attested collocations, which have a score of zero. This issue may arise if the bigram is either completely erroneous, for example, *gorjashchij chaj “*burning tea,” or acceptable but non-attested in the corpus, for example, v Midlberi “in Middlebury.” We address this problem in Section “The lowest MRR of pseudo-collocations.”
Results and evaluation of the methods
Although the MRR can theoretically take a value from 0 to 1, in this section, we examine the empirical MRR as it appears on the basis of our data. To do this, we calculate the lowest (Section “The lowest MRR of pseudo-collocations”) and the highest (Section “Top-100 collocations”) observed MRR values, as well as the MRR values of learner (Section “Learner data”) texts.
The lowest MRR of pseudo-collocations
First, we created a list of about 120 thousand pseudo-collocations, which means a random concatenation of any two words taken from the corpus. This way, we produced a list of word pairs with no intended semantic meaning. Naturally, most pseudo-collocations are unattested in the L1 corpus, although some accidentally reflect real ones: 279 appeared as attested, thus providing us with specific Dice and t-score ranks (see Table 4).
List of generated pseudo-collocations.
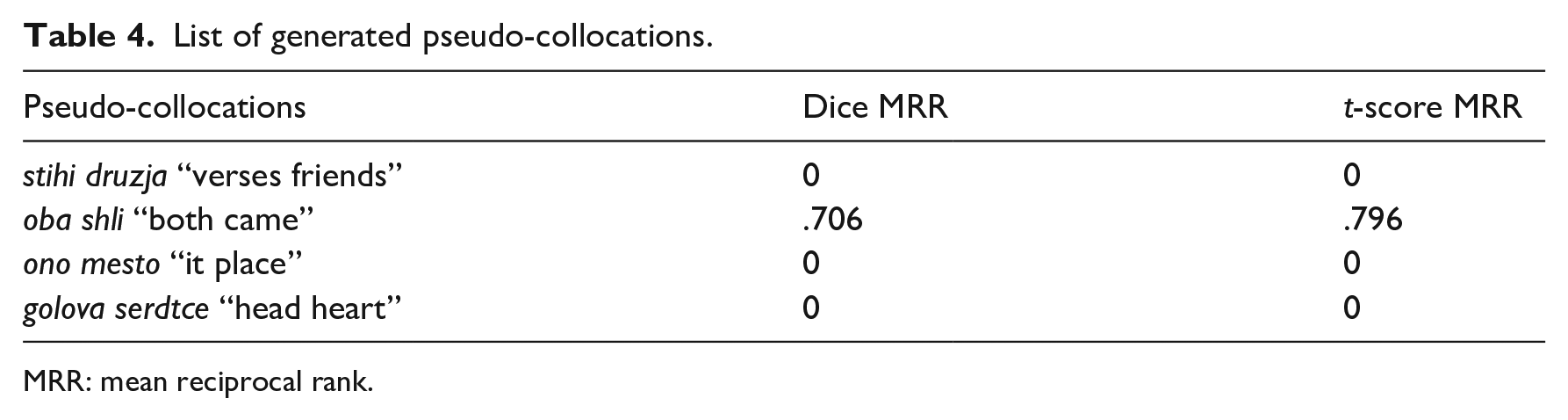
MRR: mean reciprocal rank.
Before presenting the results, we would like to highlight that pseudo-collocations provide us with a great opportunity to test how zero values affect the results. Our initial hypothesis was that zeros are considered either a completely incorrect L2 bigram or a correct bigram that is not found in the L1 reference corpus. To test this assumption, the MRRs for pseudo-collocations are counted twice: first, completely excluding non-attested bigrams, and second, taking both attested and non-attested bigrams into account. In the first scenario, the Dice MRR has a value as high as .61; but if the non-attested bigrams are also considered, the Dice value drops dramatically to .0015. The t-score MRR repeats this tendency: .218 with attested bigrams only; .0005 with all bigrams. This experiment leads us to two conclusions: (a) zero-value bigrams have a great influence and should thus be included in the calculation and (b) an empirical minimum MRR is independent of the scores and tends toward zero. A practical consideration leads us to a similar conclusion: if one considers pseudo-collocations, which have non-zero values, the result is close to that of low-level students, which is counter-intuitive, as the list of pseudo-collocations is complete nonsense. Although 73% of a random student text is attested bigrams, the list of pseudo-collocations is reversed: only a small amount of these, less than .01%, corresponds to authentic collocations. To conclude, excluding zeroes makes the data biased toward the existing, rather than the unattested in an L1 corpus, bigrams.
Top-100 collocations
As the next step in the analysis, we tested a theoretical maximum MRR. To do this, the top-100 authentic collocations were extracted and their MRRs were calculated (see examples in Table 5). The simple means, based on the top-100 collocations, are .976 for Dice MRR and .732 for t-score MRR, which makes it possible to set upper thresholds for both metrics.
Top-100 bigrams and their MRRs.
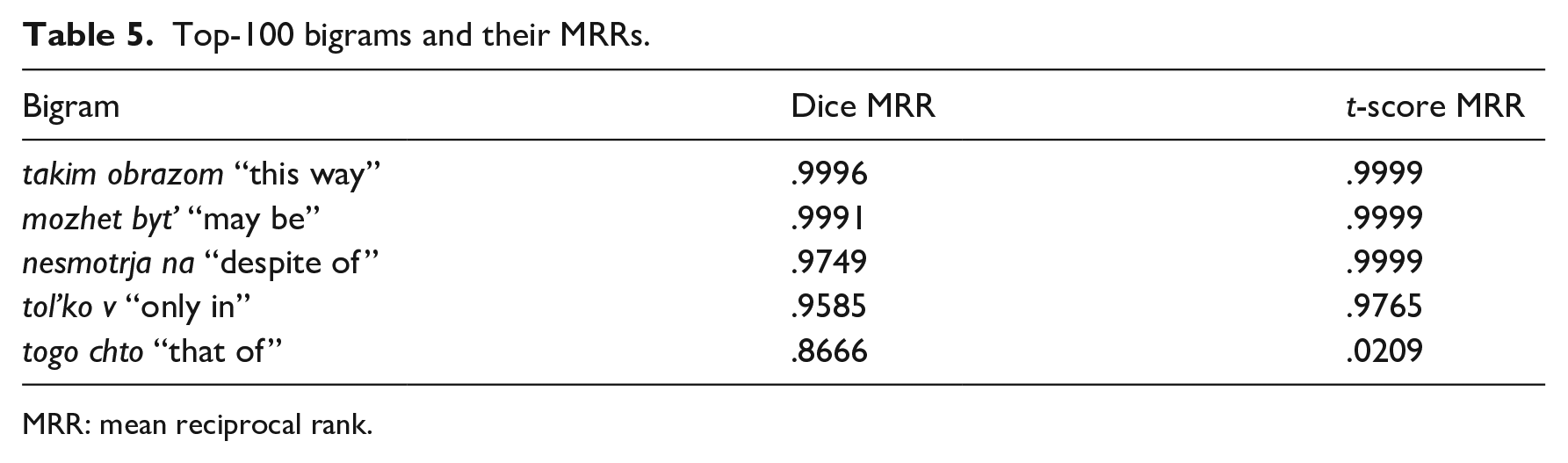
MRR: mean reciprocal rank.
Learner data
Once the extremes were established we could take the final step and find the differences between the learner texts. The list of L2 bigrams consists of ca. 120,000 items, of which about 87,000 were attested in the L1 data. Below are some examples—from non-attested (2) to well-attested (4)—from our L2 data.
(2) *delat’ balet (3) ?lomal steklo (4) zanimajus’ jazykom “to do ballet” “(he) broke glass” “[I] study a language”
Table 6 presents the associated MRRs for both the Dice and t-score. For easy reference, the empirical extremums are also presented.
Dice and t-score MRRs for each proficiency level.
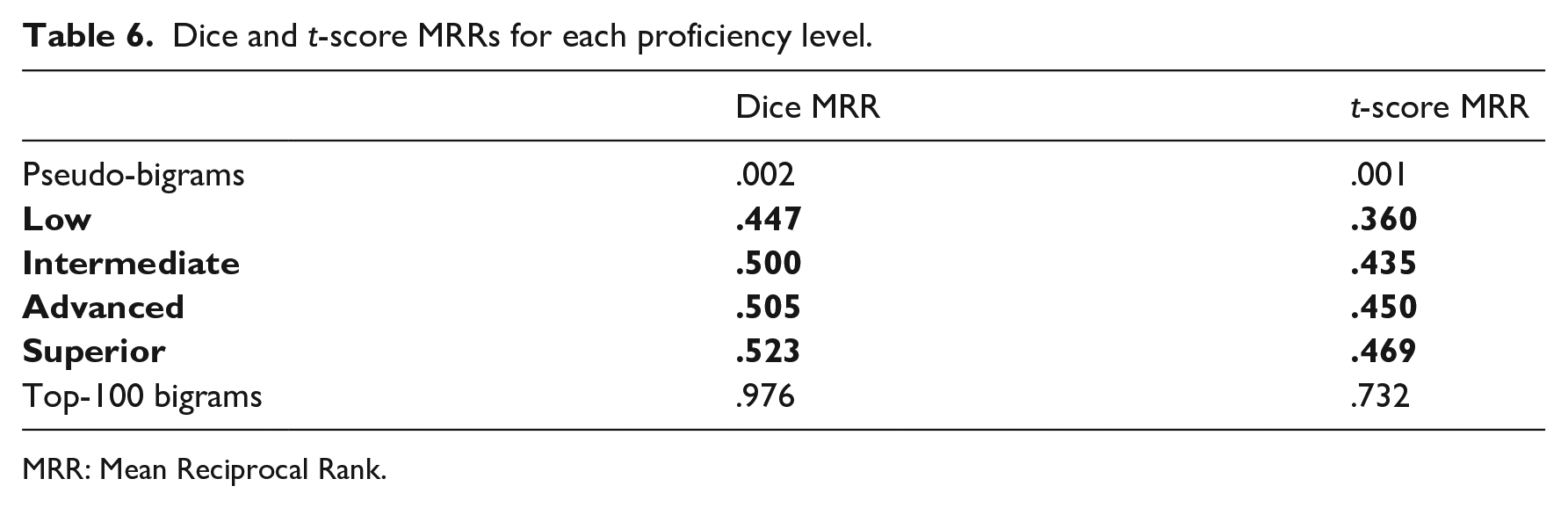
MRR: Mean Reciprocal Rank.
Several conclusions can be made on the basis of these calculations. First, both the Dice- and t-score-based MRRs develop linearly, in an up-trending direction, whereas the pseudo-collocations represent the lowest values, and the top-100 collocations represent the highest values. However, a clear drop is evident at both ends. Second, the actual L2 data disposes between .45 and .52 for the Dice MRR and between .36 and .47 for the t-score MRR, which may be considered narrow, but is clearly measurable. Third, Kendall’s correlation between the Dice and t-score MRRs are as high as .997, which means that both measures are developed equally throughout the proficiency levels. Figure 1 illustrates these conclusions more clearly.
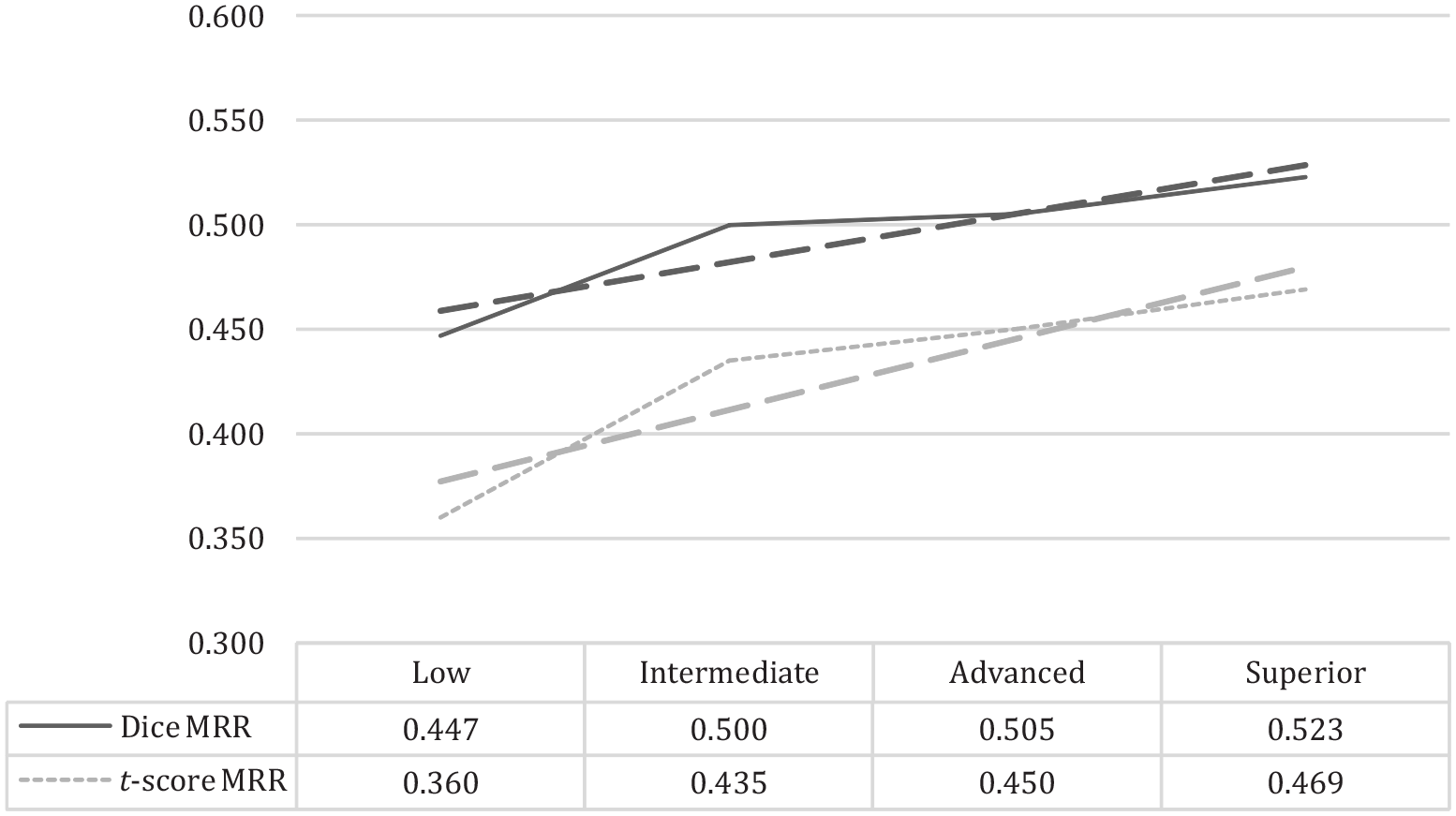
Dice and t-score MRRs for each proficiency level.
Discussion
Referring to Section “Collocations in L2 corpus studies,” many previous studies have been based on preplanned lists of collocations (either dictionary- or corpus-based), which have shown only minor or even no collocational development. In this article, we advocate an approach that aims to compare the whole text—or more precisely, all L2 bigrams—with the reference L1 data. Our approach also adds collocational strength to previous studies measured by MRRs, which enables more authentic, coherent assessments.
The narrow range of MRRs
The difference between the proficiency levels in our data becomes distinct if the number is accurate to three decimal places. From this perspective, the assumption presented in the introductory section should be discussed further. Some previous research has shown that beginners tend to use phraseology as un-analyzed chunks that they have learned by heart, so their production can be highly conventional, even if extremely limited (Eskildsen et al., 2007). Thus, one should not expect the MRRs to be low, even among beginners. In contrast, Figure 1 shows more development from low to intermediate than from intermediate upward, regardless of the measures used. Although this observation needs to be investigated further, we can speculate that beginners tend to spend more effort on memorizing specific phrases and on utilizing them more actively in speech production, whereas more advanced students focus more on grammar. The angle we are exploring here is narrow in nature because the communicative approach, widely adapted today, highlights the development of communication skills from the very beginning. This means—first and foremost—not acquiring perfect grammar, but mastering conversation, thus memorizing phrases to use.
Dice versus t-score MRRs
The observable MRRs based on the Dice and t-score are inevitably smaller than the theoretical maximum of 1; Dice MRR has slightly larger values, but both are equally suitable for calculation. To explain the difference between the two measures, we highlight the fact that their results essentially overlap (Kendall rank correlation for L1 Russian is .75; see Pivovarova et al., 2019, p. 153), although they focus on slightly different types of collocations. The t-score is, put simply, a fine-tuned projection of raw frequencies. Thus, the items that are ranked higher by the t-score are the most frequent consequences, regardless of whether they are fixed expressions, that is, fast food, or just frequently used co-occurrences, that is, fast train. On the contrary, the Dice score extracts rarer but more stable fixed expressions that entail an idiomatic shift in semantic meaning, that is, fast talk. Dice is a more practical measure (Daudaravicius, 2010); it serves educational purposes better, as it more effectively captures the phraseological items, on which attention primarily focuses in class. The t-score MRR reflects a parallel development, although it captures collocations that are outside the main focus in class to a greater extent, for example, compound prepositions or conjunctions. Thus, while the two are, in fact, strongly correlated, we believe that Dice MRR is more aligned with the tasks a student tends to accomplish during their studies, which is to learn collocations as they are understood in phraseology rather than in corpus linguistics. Referring to Section “Introduction” of this article, we can say that Dice is better for paradigmatic items, while the t-score works better for syntagmatic ones.
Non-attested bigrams
In the previous section, we discussed results with zero values or collocations that are unattested in the L1 reference corpus. This issue leads to a bidirectional conclusion. On the one hand, bigrams that have zero values may not represent real collocations at all, being the result of a learner error. On the other hand, some bigrams are well-formed but still unattested in the L1 corpus, especially those that include toponyms (v Midlberi “in Middleburry”) or names (s Dzhejsonom “with Jason”). The solution to this issue is obvious: a bigger and even more representative reference corpus must be used—a task that we plan to accomplish in the future. Nonetheless, even at this stage, the results presented in Section “The lowest MRR of pseudo-collocations” indicate a clear difference between the two approaches to data with zero values, either excluding or including them; it appears that incorporating non-attested bigrams into final counts provides more accurate results and should thus be included.
Conclusion and further directions
In a sense, our result is opposite to that achieved before. Whereas previous studies have used a precompiled list of native collocations or selected learner collocations, we looked at the texts holistically, aiming to establish an inherent difference, however tight. We also see how the algorithm could be improved: in brief, it should take into account not only the quantitative but also the qualitative features, making the whole approach more sophisticated.
First, in its current form, the algorithm does not take into account duplicate collocations; they are simply removed, if appeared in a learner’s text. However, we expect the numbers of repeated collocations to be higher at the low proficiency level, because beginners seek to perpetually use the expressions they have just learned. More advanced learners, in turn, do not reuse collocations so often, as they possess a richer phrasicon. By analogy with the Type/Token Ratio (TTR), we propose—and will test in the future—the Collocation/Type Ratio (CTR), aimed exactly at this problem. The second solution is inspired by previous studies, which have demonstrated how the L2 phrasicon depends on the course books used in class. We believe that adding this information would distinguish between the collocations that draw special attention during class, and those acquired in free communication. Finally, we share the view expressed earlier, that a collocation’s position in a text should also be considered (Kermes & Teich, 2012). Usually, at the beginning of a text, a learner demonstrates their best capabilities by using the phrasicon they possess. The longer a text is, the more difficult the task of keeping the same level of idiomaticity becomes. The more advanced a learner is, the more equally the collocations are distributed throughout the text. These directions enable further assessment of proficiency levels: Whereas beginners are presumably trapped within a limited repertoire that they perpetually reuse, advanced students show more diversity and steadiness in collocational competence. This is a natural development of the approach, which we will address in the future.
To conclude, we emphasize that the approach we present, although also valuable in itself, is a part of the holistic assessment service on which we are working (Kisselev et al., 2021, 2022; Klimov et al., 2021). Language proficiency level is a multifaceted phenomenon with many parameters to be assessed. We believe that the tool for measuring it should include at least three levels of evaluation—grammatical, lexical, and collocational—and take into account all three dimensions together.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.