
Abstract
Aims:
Within the current multilingual paradigm shift, transfer is increasingly conceptualised not only as an unintentional mechanism of “interference”, but also as an intentional mechanism used as a learner strategy. However, very little is known from an empirical perspective about (un)intentionality in transfer. This article builds on an exploratory study which suggested that background language words that fit well within the morphological constraints of the target language are highly activated during target language use and, consequently, likely to transfer unintentionally. The present study tests whether the correlation between morphological similarity and unintentionality in lexical transfer is statistically significant
Methodology:
A quasi-Poisson regression analysis was employed to test the significance of morphological similarity on the amount of unintentional transfer in the written production of Spanish by 78 highly multilingual school students, when tested together with additional variables (number of languages known, proficiency in the target and source languages, frequency of use, first language/second language status and psychotypology) that have also been proposed to affect lexical activation and transfer.
Data and analysis:
A picture-story description task was used to elicit written transfer. When a learner reported – introspectively or retrospectively – a word to have been transferred from a background language, this word was coded as an instance of intentional transfer. Reversely, non-target-like words traced back to a background language by the authors that were not commented on by the learner were coded as instances of unintentional transfer.
Findings:
A strongly significant (p < 0.001), positive correlation was found between the amount of unintentional transfer and morphological similarity. A negative trend (p < 0.1) was also found between amount of unintentional transfer and number of languages known by learners. Theoretical implications are discussed.
Originality:
This is one of few studies shedding light on (un)intentionality in transfer. It is also one of few studies to employ regression analysis to investigate the effect of several variables on transfer.
Significance:
The study provides empirical evidence to substantiate theoretical accounts of lexical activation. First, the results show that morphological similarity indeed seems to be the primary variable leading to high levels of cross-lexical activation and, second, the results show how highly activated words are more likely to be transferred unintentionally, further supporting these theoretical accounts.
Keywords
Introduction
Conceptualised as an unintentional or unconscious mechanism of “interference”, transfer has traditionally been the most frequently provided explanation for the alleged “failure” of second language (L2) learners to learn the new language “successfully” (i.e., in a monolingual first language (L1)-like manner) (see Cook, 1997; Ortega, 2019). For language education, a long-standing implication of this perspective has been to forbid any use of non-target languages in the classroom as an attempt to minimise interference between students’ languages (Cenoz & Gorter, 2014). Within the multilingual paradigm shift in the 21st century, however, the multilingual individual is no longer seen as two fractioned monolinguals in one person, but as a speaker who moves across languages and employs competencies that are not necessarily comparable to those of monolinguals (see, e.g., Cook, 2016; Grosjean, 2010; Meier, 2017). In line with this perspective, transfer is increasingly conceptualised as an intentional mechanism that language learners can use as a strategy. On the one hand, the conceptualisation of transfer as an intentional mechanism is reflected in theoretical accounts, which note that transfer may be used as a “conscious strategy” or “intentionally” (Herdina & Jessner, 2002; Jarvis, 2009). On the other hand, this conceptualisation is also reflected in the recent model of pedagogical translanguaging (e.g., Cenoz & Gorter, 2014, 2020), which implies that raising (cross)linguistic awareness will help learners identify opportunities to use transfer creatively or intentionally. This idea is also referred to as “teaching for transfer” by Cummins (2008) and has been discussed in various studies as a pedagogical implication of research studies (e.g., Otwinowska et al., 2020; Ringbom & Jarvis, 2010; White & Horst, 2012).
Despite these theoretical advances, however, very little is known from an empirical perspective about the difference between unintentional and intentional transfer. Jessner (2006) and Tullock and Fernández-Villanueva (2013) used think-aloud protocols to examine the scanning mechanisms underlying word choice in multilinguals’ written production. Although these studies did not focus on transfer that made it into the text, the meta-comments during the think-aloud protocol illustrate how transfer can be produced intentionally, as a strategy to overcome gaps in lexical knowledge. More recently, expanding on these studies, Fuster and Neuser (2020) used think-aloud protocols and recall interviews to explore the proportion of intentional versus unintentional lexical transfer in the written production by four adult multilingual learners of Catalan. Employing descriptive statistics, (un)intentionality was found to relate to types of lexical transfer (e.g., borrowing and foreignising) (see “Regression analysis on unintentional transfer” subsection) in different ways. Moreover, of the main factors (proficiency, frequency of use, L1/L2 status, and morphological similarity/typology and psychotypology) shown to affect the predominance of one source language (SL) of transfer over another (see Neuser, 2017; Falk & Bardel, 2010), morphological similarity appeared to be the most important variable affecting (un)intentionality in transfer. Whereas 90% of transfer from typologically distant SLs was produced intentionally, 63% of transfer from typologically close SLs occurred unintentionally. Given that words from typologically distant languages will generally not fit well within the morphological constraints 1 of the target language (TL), Fuster and Neuser (2020) suggested that learners use these words very selectively or consciously. By contrast, words from typologically close languages will often fit relatively well within the morphological constraints of the TL and, therefore, be strongly connected to morphologically similar words in the TL. Due to such strong cross-lexical connections, these words will be highly activated during TL use and, consequently, be more prone to be transferred unintentionally, without requiring conscious effort for them to be selected.
Research aims
The present study tests whether the correlation between morphological similarity and unintentionality in the use of transfer is statistically significant, testing it alongside other variables (number of languages known, proficiency, frequency of use, L1/L2 status and psychotypology) that have also been proposed to affect the activation level of words in theoretical accounts of lexical activation (see “Models of multilingual lexical activation” section) and which might, thereby, also affect unintentionality in transfer. The focus is on the amount of unintentional written lexical transfer exhibited by multilingual school students of Spanish as a foreign language. The data are part of Fuster’s (forthcoming, 2022) doctoral monograph, which focuses on the implications of the study of (un)intentionality in lexical transfer for pedagogical translanguaging. In the next section, we turn to psycholinguistic models of lexical activation, which offer a theoretical framework for unintentional transfer.
Models of multilingual lexical activation
Transfer is a by-product of the cohabitation of various languages in the mind and, as such, constitutes a rich source of information about multilingual lexical organisation and the process by which knowledge is accessed. Whereas a dichotomy developed in the literature as to whether different languages belong to one unitary system in the mind or whether they are separate, there is evidence for both integration and separation, and today the mainstream view is that languages are partly separate and partly integrated (see Neuser, 2017).
One of the first models advocating such a view of partly integrated and partly separate lexicons is the Subset Hypothesis by Paradis (1987, 2009). According to this model, the languages in the mind belong to the same overall system. Yet, in this overall system, words are organised by language category as well as by other characteristics such as formal register versus informal register. Building on Weinreich’s (1953) seminal proposal of various lexical representations, where forms (or “lexemes”) in different languages are directly connected to their concepts, many authors have adopted models that include the addition of the “lemma” and “tags” (or “nodes”) (e.g., De Bot, 2003; Levelt, 1989; Lowie, 2000; Woutersen, 1997). The lemma mediates between the form and its concept and is defined by many different tags that are attached to it, each containing information such as semantic, syntactic and pragmatic features of the word or what language the word belongs to (for overviews, see Neuser, 2017; Jarvis, 2009). As illustrated in Figure 1, Paradis (1987, 2009) posits that when words are tagged for the same characteristics (e.g., “formal register” and “English”), they develop connections between them, forming networks or subsets. In the early stages of L2 acquisition, L2 words will have strong connections with their L1 translation equivalents, which will cause them to be highly co-activated and, consequently, likely to transfer during L2 processing. As L2 proficiency increases, a stronger network within L2 items will build and connections between L1 and L2 words become looser, with the L2 developing into a more independent network. Nevertheless, morphologically similar L1 and L2 words, such as cognates, are expected to retain a strong connection.
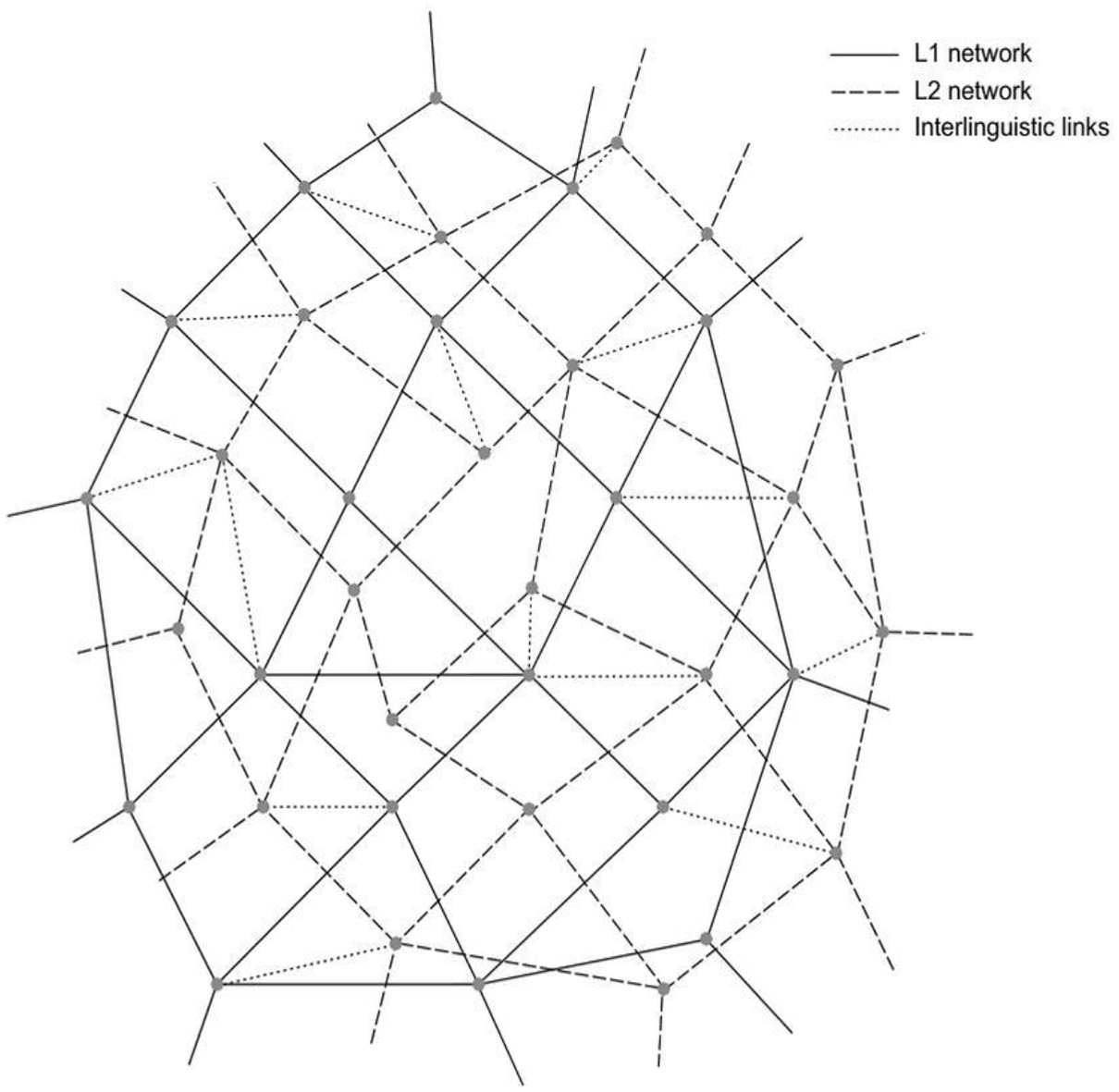
Paradis’ (1987) subset hypothesis (from Herwig, 2001, p. 117).
Within such a network approach to lexical organisation, activation of either whole language subsets or activation of individual words from different language subsets has developed as the most prominent proposition for lexical processing and transfer in particular.
Most models of lexical activation conceptualise language as a system that is either active or in some way inhibited. It is argued that the language tag helps activate one language subset while inhibiting another, thus allowing the speaker to distinguish between the languages (e.g., De Bot, 2004; Green, 1986; Lowie, 2000). The idea is that highly activated language subsets are more difficult to inhibit, which, it is argued, explains greater amounts of transfer from strongly activated languages into less strongly activated languages than vice versa. Interestingly, the main factors proposed to affect the activation level of a language are the same as the aforementioned (see “Introduction” section) factors found to influence the predominance of one SL of transfer over another: frequency of use; proficiency; L1/L2 status and typology (De Bot, 2004, p. 26). Other models zoom in onto individual words with the aim of explaining how certain words from languages being inhibited may still transfer to the TL. The Parasitic Model of L2 and L3 [third language] Vocabulary Acquisition by Hall and Ecke (2003) posits that when an L3 word is registered, it will develop a connection with the closest and most highly activated words in the L1, L2 and/or L3 based on morphological similarity. Alternatively, if no matching form representation is found in terms of morphological similarity, it will be connected to the nearest translation equivalent. An L3 word that is not well known or that has not been sufficiently used and which has connections with L1/L2 words will thus behave parasitically, being retrieved via its links with those L1/L2 words. The L3 German “tschüss” (English: “bye”), for instance, may be connected to the similar-sounding L2 English form “choose” and accessed via this (Ecke & Hall, 2014, p. 363). As L3 proficiency increases, L3 words will, in general, become more segregated into their own L3 network, becoming less dependent on their links with L1/L2 words, which will result in less transfer from L1/L2. Still, even when an L3 word has abandoned its connection with an L1/L2 form and established a connection within the L3 network, if it is not used frequently, its access route will be weak and occasionally subject to influence from a morphologically similar L1/L2 word. Although the model thus emphasises the role of morphological similarity, Ecke and Hall (2014) note that connections may also be modulated by psychotypology, linguistic awareness, L1/L2 status, proficiency and frequency of use. Morphological similarity is also the main factor argued to affect the activation level of words in the Bilingual Interactive Activation Model by Van Heuven et al. (1998). In this model, words have a number of words they are attached to, both intra-linguistically and inter-linguistically, based on morphological similarity. When the English “wind”, for instance, is encountered, orthographic neighbours from the same language (e.g., “kind”, “wild”) and from other languages (e.g., Swedish “kind” [English: “cheek”], “vind” [English: “wind”], “vild” [English: “wild”]) will also be active and, consequently, more likely to transfer, while less similar words will be inhibited. In the Activation Threshold Hypothesis, Paradis (1997) suggests that a further primary factor affecting the activation level of a word is frequency of use. When a word is regularly activated through frequent use, its activation threshold is lowered and the word becomes more readily available for selection.
Thus, the picture that emerges is that more highly activated words are more likely to transfer, and that the main factors potentially affecting their levels of activation are proficiency, frequency of use, morphological similarity/typology, psychotypology, L1/L2 status and linguistic awareness (De Bot, 2004; Ecke & Hall, 2014). Moreover, the assumption is that transfer due to high levels of activation occurs unintentionally, not intentionally. This seems to be suggested, for example, in De Bot’s well-known metaphor of ping pong balls, where words may still “escape and jump [i.e., on their own, automatically] to the surface” (De Bot, 2004, p. 26) during language-general inhibition. Ecke explicitly stresses this, writing that it is “automatic word retrieval and its failure, reflected in or accompanied by unintended intrusions of various kinds”, rather than “intentional switches [. . .] that are part of the speaker’s communication strategy repertoire”, that tell us about “the cognitive mechanism underlying lexical retrieval” (Ecke, 2015, p. 146) (see also Jarvis, 2009, p. 103). Similarly, Fuster and Neuser (2020) argue explicitly that those L1/L2 words which fit well within the morphological constraints of the L3 develop strong connections with L3 words and therefore attain high levels of activation during L3 production, which, they argue, likely leads to unintentional transfer. The present study therefore examines unintentional transfer data with the aim of providing empirical evidence for the models discussed above.
Methodology
Participants
The participants were 78 multilingual teenagers studying Spanish at a heterogeneously multilingual upper secondary school in Stockholm, represented by learners with different language backgrounds. Most of the students had a foreign background, with 29% using Swedish as an L1 and 71% as an L2. A total of 15 languages (L1s and L2s) were represented in the sample: English and Swedish, which all students knew at higher levels of proficiency; Spanish, which they were studying as a foreign language; and Aramaic, Arabic, Serbo–Croatian–Bosnian–Montenegrin, Turkish, Russian, Armenian, Italian, Portuguese, Persian, Chechen, Polish and Rumanian, which were mainly used at home. A language used at home since infancy was operationalised as “L1” – 33% reported using one L1, while 41% reported using two L1s and 26% reported using three L1s. With regards to proficiency in TL Spanish, 28% of the students were beginners in their first year of studying Spanish at school, while 51% were in their fourth year and 21% were in their fifth year.
The first author is fluent in Spanish (as well as Swedish and English) and conducted the data collection and analyses. Whenever a non-target word was found that could potentially have been transferred from a language not known to the author, a speaker of this language was consulted. However, of these languages, only a few instances of orthographic transfer from Arabic were found, where /p/ was produced as /b/.
Data collection
Empirical task
The data collection was carried out in the students’ regular school setting during their Spanish classes. In a first phase of the study, only 14 students participated. They individually joined the researcher in a dedicated room to perform the empirical task. This task consisted of three aspects:
(a) describing a picture story in writing (20 minutes);
(b) a think-aloud protocol, in which participants were thinking aloud while writing the picture story description; and
(c) an immediate recall interview, in which the researcher prompted the students to reflect on what they had written immediately after they had completed the task (10 minutes).
The written picture story description task was used to elicit transfer data. The picture story employed for this task was the book Frog where are you? (Mayer, 1969), which has been used satisfactorily in many previous studies (e.g., Neuser, 2017; Kellerman, 2001). The students were given 20 minutes to describe (in writing) as many pictures from the book as possible. The participants were instructed to focus on trying to convey the story to a speaker of Spanish in any way possible, without worrying too much about making mistakes. These instructions were given in Swedish (a high-proficiency language) in order to ensure that the students would fully understand the task. A potential limitation is that giving the instructions in Swedish might have heightened the level of activation of Swedish and thus induced a disproportionate amount of transfer from this language. The authors felt this potential effect to be negligible, however, as Swedish was the dominant language in the school setting and, consequently, was highly activated already prior to the instructions being given.
The think-aloud protocol was used in order to gain insight into which instances of transfer were produced intentionally and unintentionally. The students were instructed to think aloud and verbalise any thoughts they might have while writing. The students alternated mostly between TL Spanish and Swedish when thinking aloud. If a student paused their think-aloud protocol for more than 5 to 10 seconds, the researcher would prompt them by asking in TL Spanish “What are you thinking?” When a student reported to have transferred a word from a background language (BL) (e.g., “taken it from Lx”, “adapted the Lx word”), this word was coded as an instance of intentional transfer.
Finally, a recall interview was conducted immediately after the completion of the picture description task (10 minutes). The goal of the recall interview was to detect instances of intentional transfer that might not have been commented on during the think-aloud protocol due to any number of reasons, such as time constraints imposed by the task, despite their intentional nature. The students were asked to go through their text and orally comment on any words that they had been unsure of at the time of writing it. The recall interview was conducted in Swedish in order to ensure that the students could offer a more detailed account. If a student reported to have been unsure of a word but did not provide any further comments, the researcher would prompt them by asking “Why were you unsure of this word?” or “In what way were you unsure of this word?” Again, any word the students reported to have been transferred from a BL during the recall interview was coded as an instance of intentional transfer. Reversely, any non-target-like word that could be traced back to a BL by the authors (i.e., negative transfer) that was neither commented on during the think-aloud protocol, nor during the recall interview was coded as an instance of unintentional transfer.
Verbal reports from think-aloud protocols and recall interviews provide deep insights into the decision processes underlying instances of intentional transfer (e.g., why a student decided to foreignise a specific word in a certain way and not in another) (see Fuster & Neuser, 2020). However, they are very time-consuming and, given the relatively large sample of this study and time limitations, a faster procedure was tested in a second phase of the study. The two data collection procedures were compared in order to determine whether the faster procedure yielded the same results and could be used for the remainder of the study.
In the second phase of the study, 14 students participated simultaneously during their regular Spanish class, instead of doing the task individually in a separate room. They did not conduct individual think-aloud protocols or recall interviews, but, instead, were asked to write their descriptions in the classroom (20 minutes) and, once they had finished writing, to conduct a self-reflection and underline those words they had been unsure of (10 minutes). Those transfer words that were underlined were considered to represent intentional use, while those that were not underlined but were identified as negative transfer by the authors were considered to represent unintentional use. A t-test found no significant differences between the two groups with regards to the total amount of transfer (p = 0.56), the amount of unintentional transfer (p = 0.08) and the amount of intentional transfer (p = 0.92) (the students from these two groups were in their fourth year of TL Spanish). Therefore, the remaining 50 students underwent the latter, faster procedure.
Given the notion that it is unintentional transfer, rather than intentional transfer, that is related to lexical activation (see “Models of multilingual lexical activation” section), the current study focuses exclusively on the unintentional transfer items identified in the data (thus ignoring all instances of transfer identified by the participants introspectively or retrospectively).
Questionnaire
After the aforementioned tasks, the students were given a questionnaire in Swedish eliciting information on five of the seven variables to be included in the analysis: number of languages; L1/L2 status of each BL; proficiency in each BL; frequency of use of each BL; and perceived level of lexical similarity between TL Spanish and each BL (psychotypology). The variable of TL proficiency was operationalised as the level of Spanish class a learner attended. The variable of typological closeness was operationalised at three levels of closeness: Romance languages were considered the closest to TL Spanish (value “3”); followed by Germanic languages (value “2”); and non-Indo-European languages (value “1”) (see “Variables” subsection, for a description of the variables). The students were given 15 minutes to fill in the questionnaire.
The questionnaire was based on Neuser’s (2017) questionnaire, which is publicly available online. However, the number of questions related to each variable had to be reduced considering time limitations and the relatively high number of languages each student knew (between three and six). For example, whereas Neuser (2017) included questions related to age and mode of acquisition (“How did you learn Lx? a) at home, b) at school. . .”) in order to code L1/L2 status, the present questionnaire only asked “What is/are your mother tongue(s)” (including a definition of “mother tongue”) and any BL not reported to be a mother tongue (L1) was coded as an L2. Similarly, Neuser (2017) included more detailed can-you questions for the variable of BL proficiency (e.g., “I can introduce myself and answer simple questions about myself”), the present questionnaire included more general can-you questions for speaking, listening, reading and writing (e.g., “Overall, how well can you read in Lx?”). Questions for other variables were similarly simplified. The questionnaire can be found in Fuster’s (forthcoming, 2022) doctoral monograph.
Data analysis
Regression analysis was used to test the significance of morphological similarity on the amount of unintentional transfer exhibited by the students, when tested together with the other main variables proposed to affect the activation level of words (proficiency, frequency of use, L1/L2 status morphological similarity/typology and psychotypology) (see “Models of lexical activation” section). In previous studies, transfer variables have predominantly been investigated in a qualitative manner and often remained confounded (see Neuser, 2017; Ecke, 2015). Regression analyses are a type of inferential statistical analysis that can help disentangle variables through their ability to test the predictive power of each variable when holding the other variables constant. Since the response variable is a count variable – that is, how many instances of unintentional transfer each learner produced – Poisson regression analysis, in particular, lent itself as the most appropriate type of analysis for the present study (Legler & Roback, 2019).
For Poisson regression analysis to be reliable, the mean of the dependent variable needs to be equal to its variance (Legler & Roback, 2019). However, this characteristic often does not hold in practice (Zeileis et al., 2008), as was also the case in this study. The variance in the response variable was higher than the mean. Given this over-dispersed count variable, we employed a quasi-Poisson analysis, which, like Poisson analysis, uses mean regression and variance, but estimates the dispersion parameter from the data instead of assuming it to be fixed at 1 (Zeileis et al., 2008). Quasi-Poisson regression analysis yields the same coefficient estimates as a Poisson analysis, but the precision in the inference is adjusted for over-dispersion.
Variables
Information regarding most of the independent variables was elicited through the questionnaire (see “Questionnaire” subsection). Another characteristic of Poisson regression is that the data points need to be independent from each other (Legler & Roback, 2019). This is why individual transfer items could not be used as data points, as some come from the same learner and thus are not independent. Therefore, rather than using each transfer item as a data point, with its associated variables (e.g., whether it comes from an L1 or L2, or whether the proficiency level of its SL is high or low), each individual student acts as a data point, which, in turn, means that there can only be one associated value for each variable (e.g., one value for L1/L2 status, or one value for SL proficiency). This was problematic, however, for those variables with values that vary across a student’s transfer words. For example, one transfer word from a student may come from an L1, while another transfer word from the same student may come from an L2 word, but the regression analysis only allows us to use one value for the L1/L2 status of a student. For this reason, an average value was calculated for the following variables: L1/L2 status; SL proficiencies; SL frequencies of use; SL psychotypological beliefs; and typological distances. This was not necessary for the remaining three variables: number of unintentional transfer instances; number of languages known by the learner; and TL proficiency. The following list provides a description of the dependent variable and the seven independent variables:
(a) Dependent variable. Number of unintentional transfer instances (
(b) Number of languages (
(c) Target language proficiency (
(d) L1/L2 status in the source languages of transfer (
(e) Proficiency in the source languages of transfer (
(f) Frequency of use in the source languages of transfer (
(g) Morphological similarity in the source languages of transfer (
(h) Psychotypological assumed or perceived similarity in the source languages of transfer (
The average values thus represent continuous variables, reflecting, for example, how much “L2-status-ness” in the SLs of transfer was present in a student’s transferred items, and how this amount of “L2-status-ness” in the SLs correlates with the amount of unintentional transfer produced by a student.
It should be noted, moreover, that only types, not tokens, of words in a student’s transfer count were included in the analysis. In the picture description task, a student may borrow the word “frog”, for example, multiple times, as many of the images depict a frog. In this case, only one instance of “frog” was included in that student’s transfer count. This was decided in order to avoid exaggerating the effect of those variables related to the specific words being transferred multiple times.
Results
Data exploration
There were 299 distinctive transfer words in the dataset. On average, 8% (standard deviation (SD) 6) of the total number of words produced were transferred, a similar percentage to those found in previous studies (e.g., 5.3% in Lindqvist, 2006; 7.7% in Neuser, 2017). 32% of all transferred words were transferred unintentionally. The upper rows in Tables 1 and 2 show the students’ counts of unintentional and intentional transfer observed in the data, with the lower rows giving the percentage of students in each of these counts. For the purposes of this study, the regression analysis focuses only on unintentional transfer, but the frequency distribution of intentional transfer is nonetheless given here in order to provide a broader overview of the data.
Counts and percentages of unintentional transfer.

Counts and percentages of intentional transfer.

91 % of the students produced between 0 and 2 instances of unintentional transfer, while the remaining 10% of students were dispersed between counts 3 and 16, which contributed to a considerable degree of inter-subject variation (mean (M) 1.24, SD 2.31). In the case of intentional transfer, 86% of the students produced between 0 and 4 instances, while the remaining 14% were dispersed between counts 5 and 10 (M 2.58, SD 2.00). Thus, students, on average, use more intentional transfer than unintentional transfer. These numbers show that transfer is not only an unintentional mechanism, as traditionally conceptualised in the notion of “interference”, but also an intentional mechanism used as a learner strategy (see “Introduction” section). As also illustrated in Figure 2, the percentage of students not transferring any instance of unintentional transfer (46%) is considerably higher than any of the other counts. This relatively low rate of unintentional transfer might in part be due to the instructions given during the data collection. Previous studies show that L2 learners can report on various kinds of word retrieval products that occurred unintentionally but were recognised in retrospect (e.g., Ecke, 1999, 2009). Similarly in the present study, the possibility of participants potentially identifying unintentional transfer as intentional remains a limitation. However, the fact that the goals of the study were clearly stated, the environment was positive and supportive, students were aware that the study was anonymous and the results would not be shown to their teacher or in any way influence their grade should have contributed towards mitigating this tendency. The fact that the majority of participants conducted the stimulated recall task by themselves in writing rather than orally in interview format (see “Empirical task” subsection) should further limit the extent of this issue, as their possible embarrassment when discovering unintentional transfer may have been greater in a face-to-face interview. In future studies, it could be useful to ask participants to be mindful to distinguish between words they were unsure of at the time of the production and words they had become unsure of in retrospect.
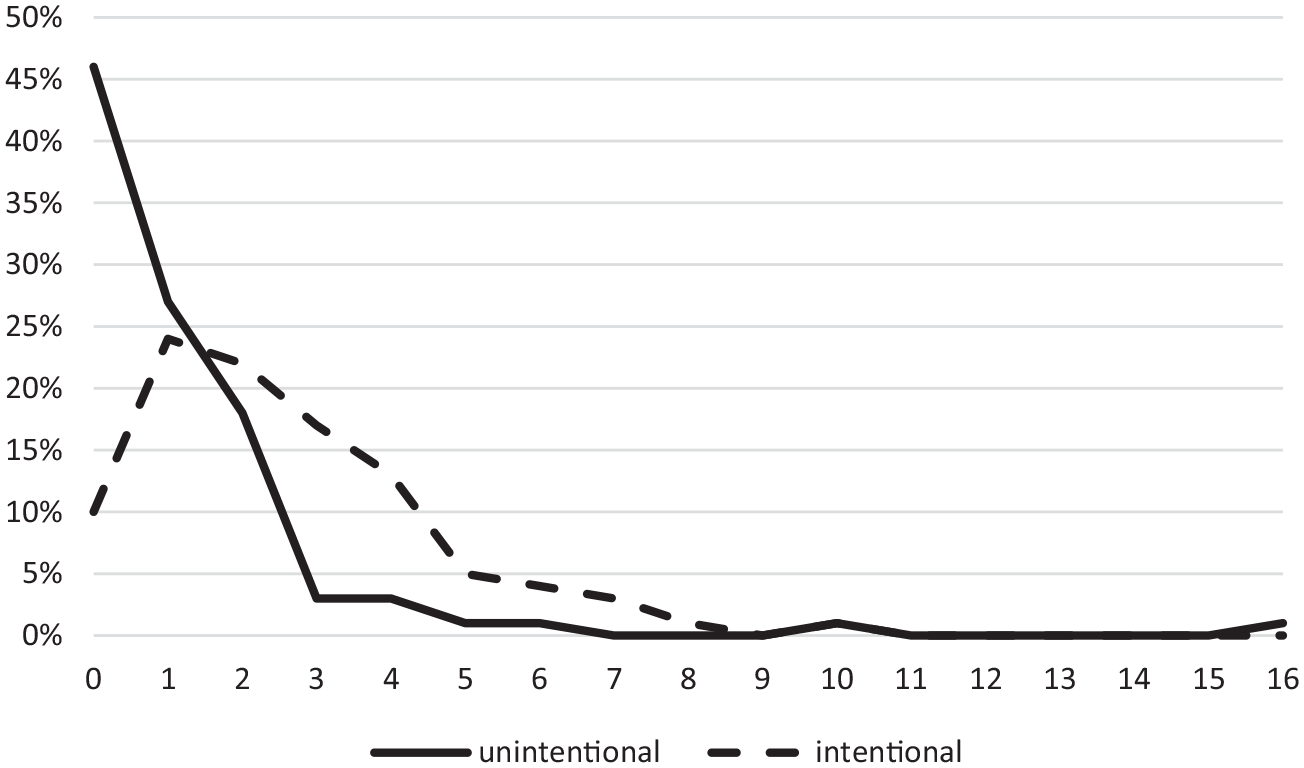
Counts (x-axis) and percentages (y-axis) of unintentional and intentional transfer.
Table 3 shows the means and SDs for the SLs of transfer and for the seven independent variables.
Means (Ms) and standard deviations (SDs) for the source languages (SLs) of transfer and the independent variables.
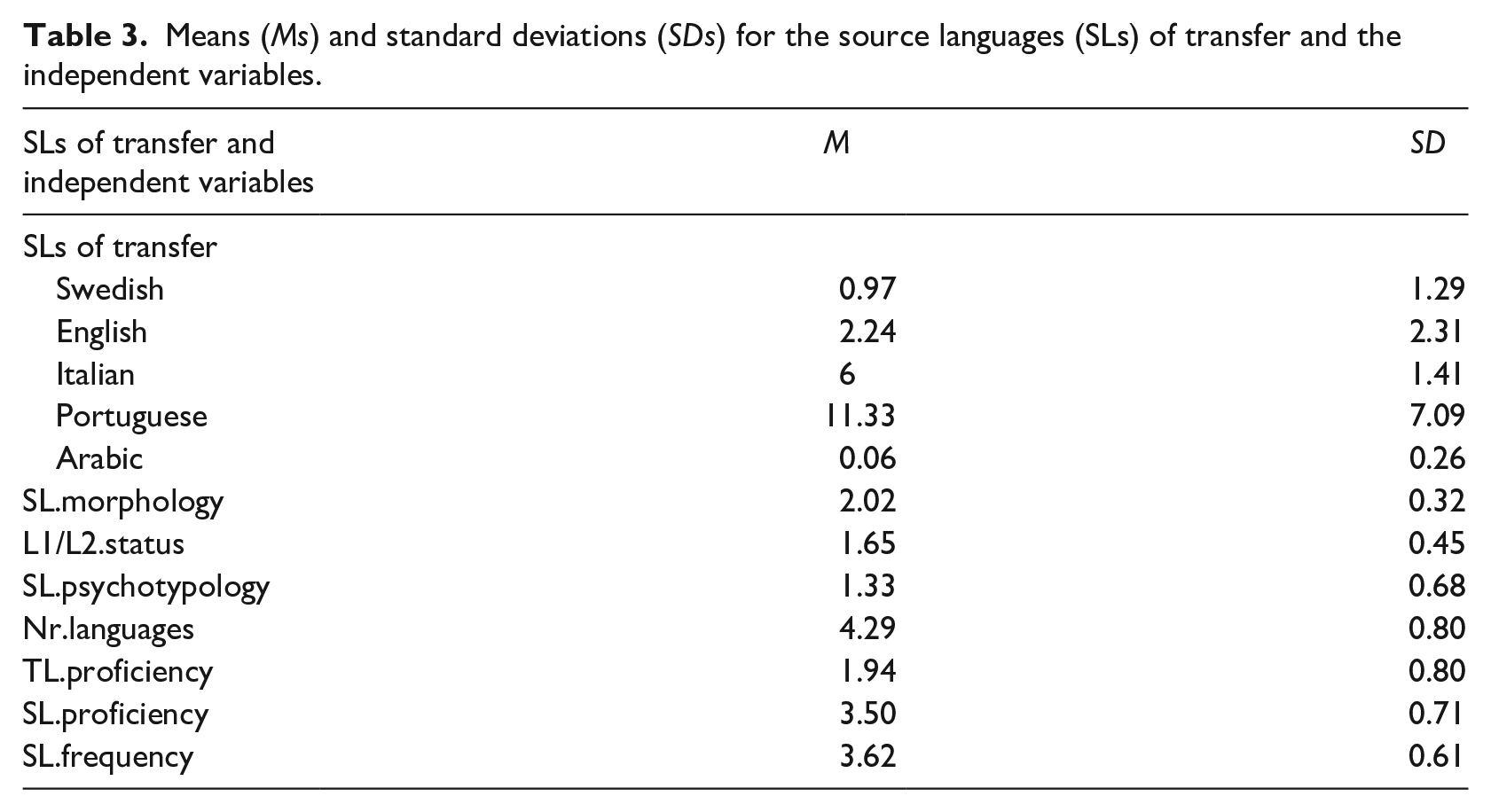
The mean for
Before running the regression analysis, a bivariate analysis was conducted for each pair of the variables in order to ensure lack of serious multicollinearity between the predictors. No serious multicollinearity – that is, r > 0.7 (Dormann et al., 2013) – was found, with the largest correlation coefficient between two predictors being r 0.62 (
Regression analysis on unintentional transfer
The quasi-Poisson regression analysis on students’ number of instances of unintentional transfer was found to have a good fit. The median deviance residual was close to 0 (−0.27), indicating the coefficients were not seriously overestimated or underestimated. Moreover, the drop-in-deviance was 112.57 (null deviance 210.013 – residual deviance 97.441), with a difference in degrees of freedom of 7 (78 − 71). This difference was significant (p < 0.001), suggesting that the model contained at least one variable that predicts the data significantly better than the intercept model. The results of the analysis are summarised in Table 4. The first column shows the estimated regression coefficients with their standard errors in the second column. We discuss the results in terms of the exponentiated values (or odds ratios) of these, in the third column, as is usually done in generalised linear models. The significance codes are given in the fourth column, with the 95% confidence intervals for the exponentiated coefficients in the fifth column.
Results of the quasi-Poisson regression analysis for the students’ amount of unintentional transfer.
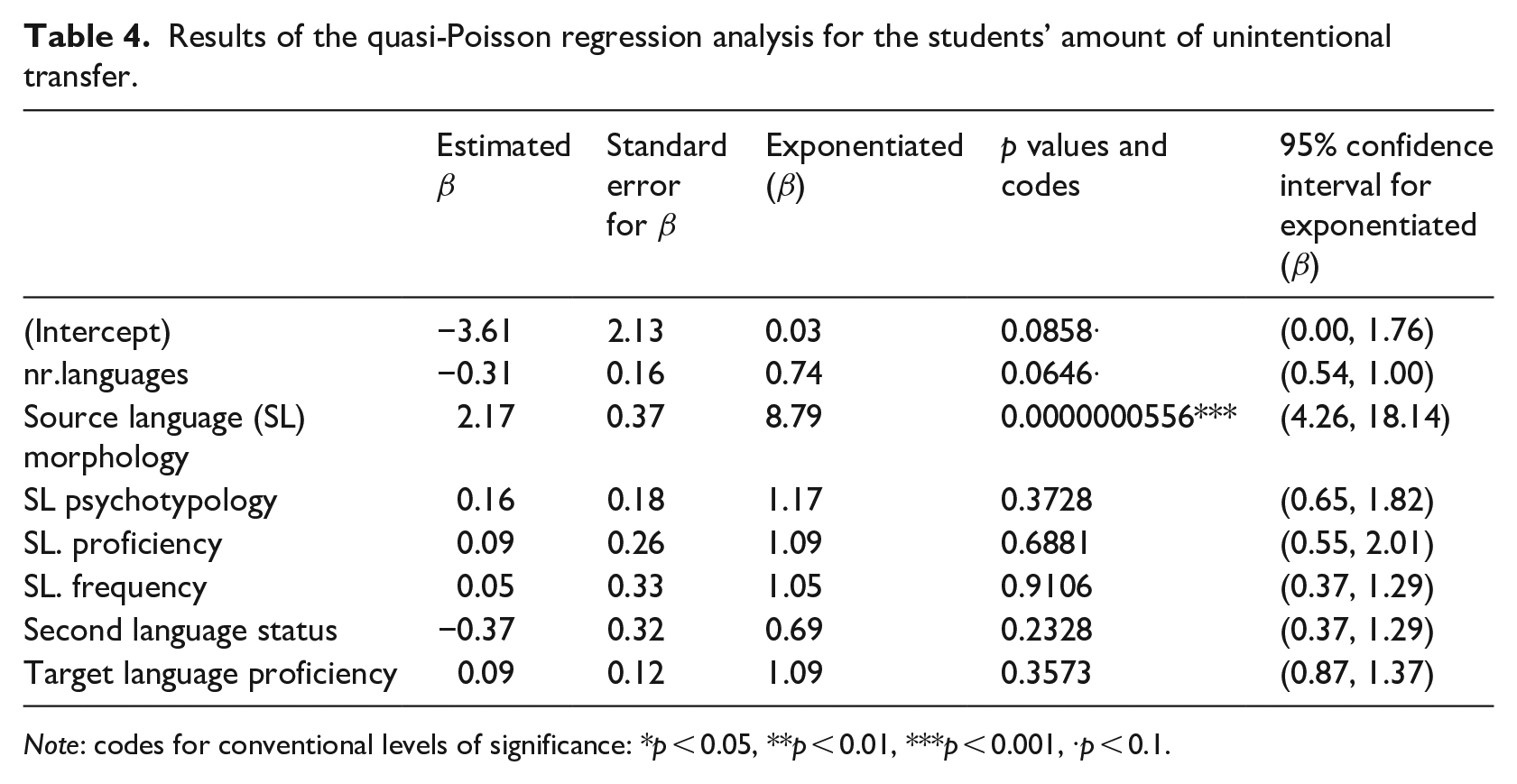
Note: codes for conventional levels of significance: *p < 0.05, **p < 0.01, ***p < 0.001, ·p < 0.1.
No significant effect was found for number of languages known, psychotypology, SL proficiency, frequency of use, L1/L2 status and TL proficiency at the conventional level of p < 0.05. A considerable negative trend between
The most important predictor was the amount of morphological similarity in the SLs of a student’s count of unintentional transfer. All other variables held constant, a student with one additional score in
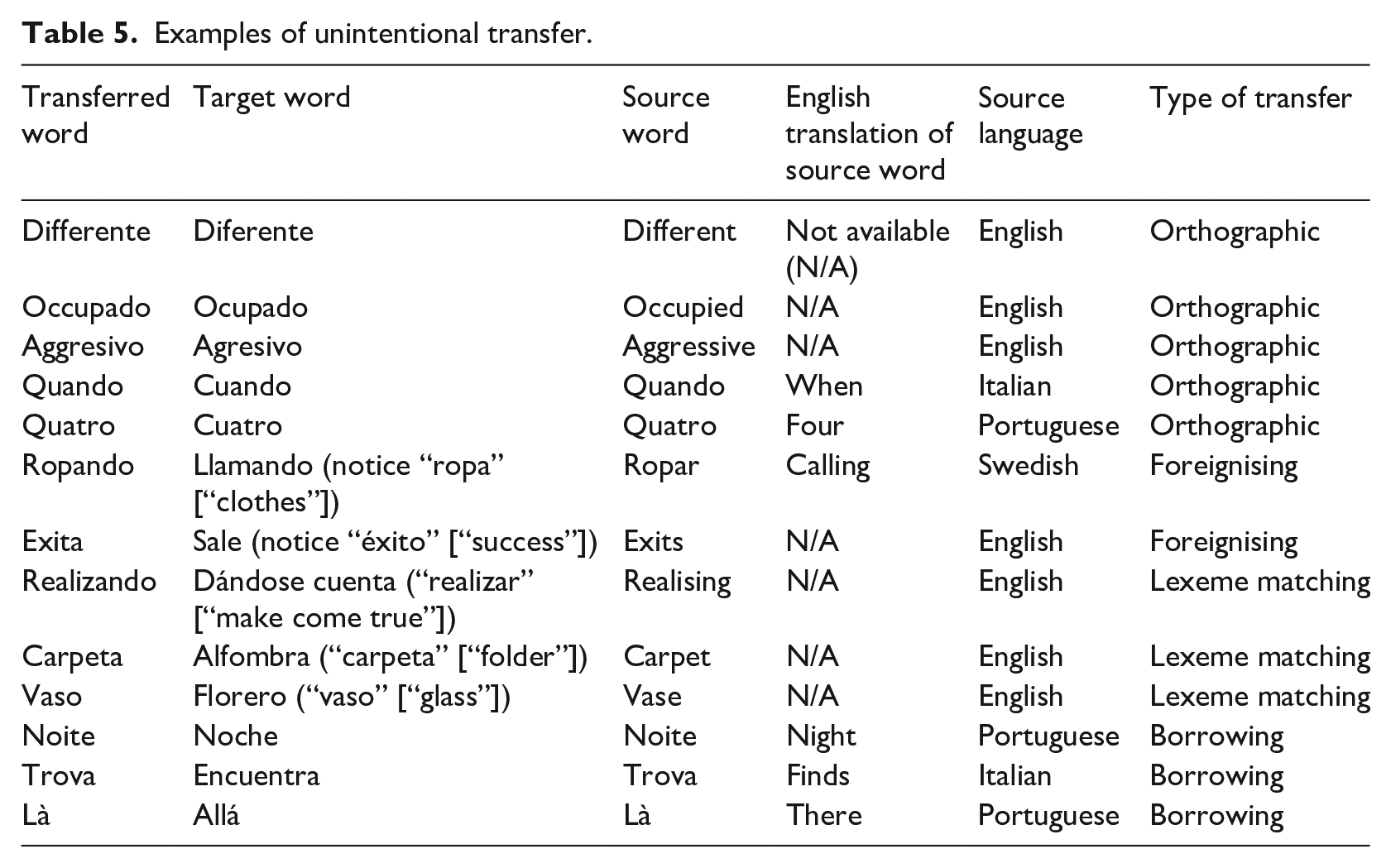
The regression analysis, nevertheless, demonstrates the importance of morphological similarity at a language-general level in unintentional transfer. Interestingly, analysing the data at an item-specific level, we find the same pattern in transfer from Swedish and English. Even in these typologically more distant languages, we find that unintentional transfer predominantly occurs on specific SL items that already fit TL morphology. As seen in the examples in Table 5, some of these unintentionally transferred words do not violate the morphological constraints of Spanish, such as the verb root of ropando (i.e., ropar), based on Swedish “ropa” (“to call”), a false friend with Spanish “ropa” (“clothes”). A great number of them are, moreover, cognates, such as ocupado – occupied or diferente – different. A considerable number are otherwise false friends, such as realizando – realizing, carpeta – carpet or vaso – vase. Items were categorised as follows: borrowing refers to transferring a BL word without adaptations; foreignising refers to transferring a BL word after having adapted its morphology; in orthographic transfer, a TL word is misspelled due to influence of the spelling of a BL word; and Lexeme matching refers to using a TL word that is morphologically similar to a BL word (usually a so-called false friend) as though it had the meaning of the latter (for overviews of types of lexical transfer, see Neuser, 2017; Bardel, 2015). The most common types of unintentional transfer were borrowings (35%), orthographic transfer (almost exclusively in cognates) (30%) and direct translations (22%). Direct translations are not included in Table 5 because they are semantic types of transfer, occurring due to semantic rather than morphological reasons. Examples of lexeme matching are provided instead, as the reason for transferring the meaning of the source word into the target word is morphological similarity.
Examples of unintentional transfer.
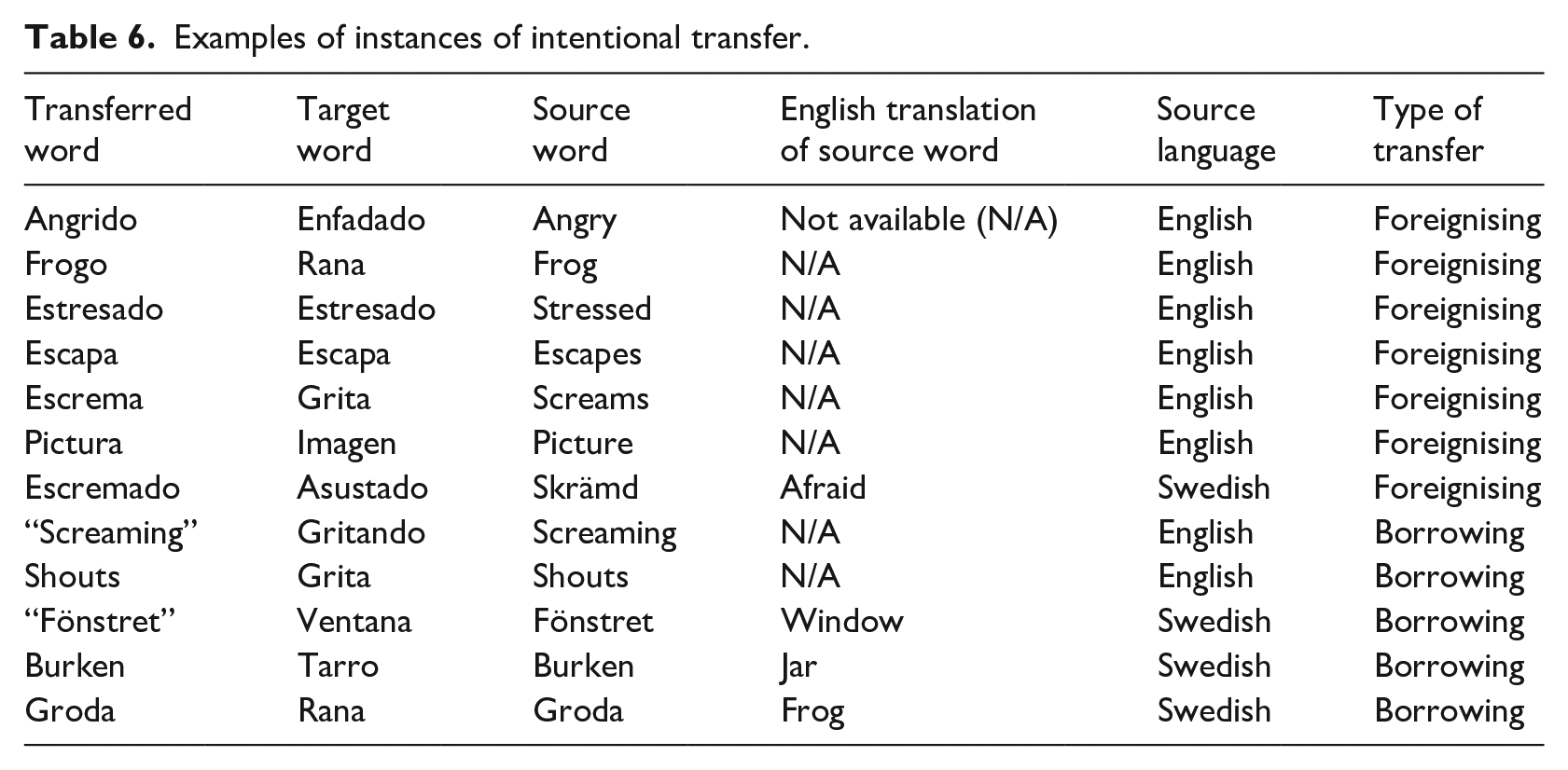
By contrast, intentional transfer predominantly occurs on SL items that require more difficult adjustments in order to fit TL morphology. As seen in the examples in Table 6, intentionally transferred words from Swedish and English often do not fit as well within the morphological constraints of TL Spanish and students even express their awareness of this by using quotation marks in some cases, for instance “fönstret”. The most common type of intentional transfer, indeed, was foreignising (52%), followed by borrowings (46%). That foreignising is so common in intentional transfer reflects their lack of target-like morphology, which makes it necessary for them to be adjusted (i.e., foreignised). As also observed in Fuster and Neuser (2020), the fact that intentional transfer predominantly occurs on SL items that do not fit TL morphology and therefore require more difficult adjustments is also in the differences between unintentional foreignisings and intentional foreignisings. As in the previous study, in the present study the changes made in unintentional foreignisings consisted exclusively of exchanging SL suffixes for TL suffixes (e.g., Swedish “ropa
Examples of instances of intentional transfer.
Discussion
The present study aimed to provide statistical evidence in support of a previous exploratory study (Fuster & Neuser, 2020) which found that BL words that fit TL morphology relatively well seemed to be more highly activated and, consequently, more likely to transfer unintentionally. Employing a quasi-Poisson regression analysis, the significance of morphological similarity on amount of unintentional transfer was tested when considered together with other relevant variables (number of languages known, proficiency, frequency of use, L1/L2 status and psychotypology) that have been proposed to affect the activation level of words in theoretical accounts of lexical activation.
No significant effect was found for number of languages, proficiency, frequency of use, L1/L2 status and psychotypology. These variables have been shown to affect other aspects of transfer, such as the predominance of one SL over another SL, but do not seem to significantly affect the occurrence of unintentional transfer in our study. Still, future studies should test whether they might be significant in other learner configurations, such as in older learners or in more homogeneous samples. It may also be that these variables affect the occurrence of intentional transfer, rather than unintentional transfer. We would like to note, however, that while the p values for most of the non-significant variables were above 0.1, the variable of number of languages known had a p value of 0.06. While not a significant result, it nevertheless shows a considerable negative trend between the number of languages a student knows and the amount of unintentional transfer they produce. The trend for more multilingual students to exhibit less unintentional transfer seems to be in line with studies on language learner strategies and linguistic awareness in bilinguals/multilinguals, which have often found that more multilingual individuals perform more strategically, presumably due to an increased level of linguistic awareness (see, e.g., Cenoz, 2003). More multilingual students may notice more differences and similarities between the TL and their BLs and have thereby developed a strengthened control of their transfer use, being more capable of inhibiting the transfer of words that are highly activated but which they do not intend to use. It would be interesting for future studies to examine the effect of number of languages known on transfer control in a more detailed manner.
The regression analysis found a strongly significant (p < 0.001) and positive correlation between morphological similarity and unintentional transfer. The amount of unintentional transfer from typologically very close SLs (Portuguese and Italian) was much higher in speakers of these languages than in speakers of typologically less close SLs (Swedish and English), as well as in speakers of typologically very distant SLs (Arabic). Analysing the data at an item-specific level, this association between morphological similarity and unintentional transfer also holds for transferred items from Swedish and English. Unintentional transfer from these two SLs predominantly occurs on SL items that fit TL morphology (e.g., occupado, from English “occupied”; realizando, from English “realizing”). Intentional transfer, by contrast, tends to occur on SL items that do not fit TL morphology and therefore require more difficult adjustments (e.g., escremado, from Swedish “skrämd”; or escrema, from English “screams”). This result thus provides statistical evidence for the suggestion in Fuster and Neuser (2020) that BL words that fit TL morphology are more highly activated and more likely to be transferred accidentally. Among the characteristics posited to modulate cross-lexical connections and to affect the activation levels of words, our data suggest that morphological similarity is the most important variable. We find this result aligns especially with the Parasitic Model of L2 and L3 Vocabulary Acquisition (e.g., Ecke & Hall, 2014; Hall & Ecke, 2003). The Parasitic Model predicts that L3 words – at least while they are not well known or have not been sufficiently used – will be connected to and accessed via morphologically similar L1/L2/L3 words whenever such similarity is detected. This is also posited by the Bilingual Interactive Activation Model (e.g., Van Heuven et al., 1998). The Parasitic Model further predicts that if no matching form is available based on morphological similarity, the new L3 word will be connected to its nearest translation L1/L2 equivalent. The fact that most transfer instances produced by our students, who were at lower levels of proficiency in TL Spanish, was form-related, rather than meaning-related, supports the prediction that morphological similarity will be the primary variable modulating cross-lexical connections at initial stages of vocabulary acquisition. The frequent instances in our data of borrowing (e.g., Portuguese noite, for Spanish “noche” [“night”]), lexeme matching (e.g., using the Spanish carpeta [“folder”] with the meaning of the English “carpet” [Spanish: “alfombra”]) and orthographic transfer (e.g., misspelling the Spanish “diferente” as differente, due to influence from the English “different”) evidence that new L3 words are connected to morphologically similar BL words and accessed via these connections. In the instances of foreignising, we see, moreover, that when there is a lexical gap of knowledge in the L3, its nearest L1/L2 translation equivalent will be transferred if it is morphologically similar to L3 words. For example, when a learner does not know the TL Spanish form for “to go out/to exit” (Spanish: “salir”), they are more likely to foreignise the English translation equivalent “to exit” than “to go out”, as it is morphologically the most similar to L3 Spanish words, for example, “éxito” (English: “success”), “excita” (English: “[s/he] arouses”) or “existir” (English: “exist”). This is in line with Bouvy’s (2000) study, which focused on the formal aspect of lexical transfer and found that her L1 Dutch speakers were more reluctant to transfer “bezuinigen” than “sparen” (synonyms for “to save money”) into L2 English, presumably due to the latter’s greater morphological similarity to English words such as “to spare”.
The goal of this study was to provide empirical evidence in support of theoretical accounts of lexical activation, as well as to offer a first exploration of factors affecting unintentionality in lexical transfer employing regression analysis. It has offered a number of new and exciting insights, but more studies are needed to validate these results and to broaden this emergent field of empirical exploration of theoretical accounts of lexical activation. For example, more studies are needed exploring the cognitive differences between unintentional transfer and intentional transfer. Studying (un)intentionality in transfer provides a window into the intricate organisation of the multilingual lexicon. Better understanding the difference between unintentional and intentional transfer will also have important pedagogical implications for making use of students’ BLs as a resource. Our results around morphological similarity and linguistic awareness suggest that teachers should raise students’ awareness not only about similarities (e.g., the existence of cognates), but also about differences in similarities (e.g., different spellings in cognates and false friends). This may help students to avoid transferring erroneous aspects that are highly activated but which they do not mean to transfer.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.