
Abstract
This article reports a quasi-experimental study which compared the effectiveness for multiword item learning of three listening-based activities: dictation, dictogloss, and answering text comprehension questions. In a dictation, students write down segments of text immediately after listening to them, whereas in dictogloss students try to reconstruct the text from memory. Chinese learners of English (N = 142) first engaged in one of the three activities, then received the transcript of the text and used a different colour to make corrections to what they had written. The learners were given an unannounced immediate and a two-week delayed posttest concerning 10 expressions from the text. Both dictation and dictogloss led to better scores than answering comprehension questions in the immediate posttest, but the advantage diminished in the delayed test, and this most markedly so for the dictation activity. Items that were successfully retrieved during the text-reconstruction stage of the dictogloss activity rather than rectified by the students afterwards with the aid of the transcript stood the best chance of being recalled in the posttests. This suggests that dictogloss could be made more effective if it were implemented in ways that promote accurate retrieval at the text-reconstruction stage.
I Introduction
Evidence has accumulated over the past few decades that second language (L2) learners benefit considerably from mastering a large repertoire of multiword items, such as collocations, idioms, and other formulaic phrases (Bestgen, 2017; Boers et al., 2006; Crossley, Salsbury & McNamara, 2015; Hou, Loerts & Verspoor, 2018; Kremmel, Brunfaut & Alderson, 2017; Saito, 2020; Tavakoli & Uchihara, 2020). Recognizing the importance of this phraseological dimension of language, many pedagogy-minded applied linguists have started evaluating diverse classroom interventions that promote L2 learners’ acquisition of multiword items (for a review, see Pellicer-Sánchez & Boers, 2018). Some interventions engage learners in the deliberate, often decontextualized, study and practice of multiword items (henceforth MWIs) and show varying degrees of efficacy depending on how this was implemented (Alali & Schmitt, 2013; Boers, Dang et al., 2017; Ferguson, Siyanova-Chanturia & Leeming, 2021; Laufer & Girsai, 2008; Peters & Pauwels, 2015; Zhang, 2017). Other studies have investigated how well learners pick up MWIs incidentally (i.e. without a deliberate intent to learn MWIs) from reading and/or listening activities (Pellicer-Sánchez, 2017; Vu & Peters, 2021; Webb & Chang, 2020; Webb, Newton & Chang, 2013) and from exposure to audio-visual materials such as television programs and video-recorded lectures (Dang, Lu & Webb, 2021; Majuddin, Siyanova-Chanturia & Boers, 2021; Puimège & Peters, 2019; Puimège, Montero Perez & Peters, 2021). The study we report in this article is situated within this second broad strand of inquiry (i.e. incidental acquisition of MWIs).
Written input generally fosters incidental vocabulary better than spoken input (Hatami, 2017; Vidal, 2011). There are several explanations for this. One is that, during reading, it is possible to linger on a new word before moving on, while this is not feasible in real-time listening. Another is that learners can find it hard to discern or recognize words in continuous speech (Carney, 2021; Goh, 2000), whereas in written text the words are presented as distinct units, separated by blank spaces. Giving learners access to the written version or transcript of a text while they listen to it helps them to overcome this second obstacle (Charles & Trenkic, 2015), and this leads to faster word-learning rates compared to listening alone (Brown, Waring & Donkaewbua, 2008; Malone, 2018; Montero Perez et al., 2014; Peters, 2019; Teng, 2018; Vu & Peters, 2020). When it comes to the acquisition of MWIs, however, there may be less need for concurrent assistance from written text (Webb & Chang, 2020). This is because MWIs are often made up of words that a learner is already familiar with. If so, the challenge is not to discern new words but to appreciate the phraseological behaviour of known words. Additionally, spoken discourse includes prosodic cues as to what word sequences constitute a semantic unit (Lin, 2012), something that is absent from written input (unless it is indicated by means of punctuation). If MWIs stand a relatively good chance of being picked up from spoken input, then it must be worth exploring listening activities that could harness this potential. In this article, we examine two candidates – dictation and dictogloss. Before discussing these activities, it is useful to discuss some of the factors that hinder incidental acquisition of MWIs, as this will help to appreciate how activities such as dictation and dictogloss might address them.
One factor that can hinder incidental MWI uptake is that some MWIs can be understood without paying attention to all their constituents. For example, tell the truth and make a mistake can be understood without much attention to the fact that it is tell (rather than say) that precedes the truth and that it is make (not do) that precedes a mistake. Similarly, in other words and dependent on can be understood without making a mental note of the prepositions in (not with) and on (not of), respectively. This is problematic because attention is believed to be a necessary step in the learning process (Schmidt, 2001). Furthermore, L1 speakers tend to produce MWIs fast and often with reduced articulation (Bybee, 2002), because they tend to retrieve these word sequences from the mental lexicon as prefabricated chunks (Wray, 2002). Although prosody may help learners to realize that a certain word string constitutes a unit, discerning its precise makeup can be challenging, especially regarding closed-class words (e.g. prepositions) which do not receive prosodic stress. Activities such as dictation and dictogloss at least require learners to listen carefully to aural input, since they are expected to produce a corresponding transcript. As learners are also normally presented with the ‘model’ transcript afterwards, this gives them an additional opportunity to notice (constituents of) MWIs which they failed to recognize in the spoken text. Another factor hindering MWI acquisition is a lack of repeated encounters with the same MWI. As a class, MWIs abound in discourse (e.g. Erman & Warren, 2000), but few individual MWIs occur numerous times in a single text (unless the text is deliberately flooded with instances). A solution is to expose learners to the same text more than once, which is a feature of the activities we examine in this article.
II Dictation and dictogloss
1 Dictation
Dictation can be implemented in various ways (e.g. Davis & Rinvolucri, 1988), but one common way is as follows. The students first listen to a short text (read aloud by a teacher or audio-recorded) at a natural pace. The students are asked to listen for overall comprehension of the text and do not take any written notes at this stage. Then the text is dictated in segments with pauses for the students to write down what they have heard. Then they listen to the text a third time, now divided into longer parts (typically full sentences) with brief pauses in between, so the students can verify and amend their written version of the text. After this, the students’ version of the text is compared to the transcript of the original text.
The use of dictation in language teaching has a long history (Deyes, 1972; Morris, 1983; Stansfield, 1985), but there appear to be only a few empirical studies on the learning outcomes it generates (Jia & Hew, 2019; Kiany & Shiramiry, 2002; Siegel & Siegel, 2015). Instead, dictation seems to have attracted more attention from researchers interested in its usefulness for language testing (Fouly & Cziko, 1985; Natalicio, 1979; Oller & Streiff, 1975; Savignon, 1982), although this interest appears to have waned in recent decades.
As to the potential usefulness of dictation specifically for MWI learning, this was already pointed out many years ago by Nation (1991, p. 12): Dictation will be most effective when it involves known vocabulary that is presented in unfamiliar collocations and constructions . . . The unfamiliar collocations and constructions are the learning goal of dictation.
Because dictation requires students to produce an accurate transcript of a listening text, they are not very likely to ignore the constituents of MWIs. Further learning of MWIs may happen if, during the third listening, the learners notice they have missed or misheard some of the words (although for evidence that learners’ often stay committed to their initial interpretation, see Carney, 2021). Remaining discrepancies may be noticed by the students as they compare their version to the transcript of the original text at the end of the procedure. Another reason for expecting MWI learning to happen through dictation is that learners listen to the same text more than once. The first listening stage will familiarize them with what is said, so that more attentional resources can subsequently be allocated to how it is said.
In sum, there appear to be good reasons for expecting dictation activities to be beneficial for MWI learning. However, we know of no empirical study that has directly examined this.
2 Dictogloss
Repeated listening to the same text is also a feature of dictogloss (Wajnryb, 1990). Like dictation, dictogloss can be implemented in various ways (e.g. Prince, 2013), but it is usually done along the following lines (e.g. Vasiljevic, 2010; Wilson, 2003). The students first listen to a text presented at a natural pace and are asked to listen for comprehension, without taking any notes. Then, the text is listened to a few more times, but, unlike dictation, without pauses for the students to write down short segments. Instead, the students note down key words that will help them to reconstruct the whole text afterwards. After the final listening, the students recall the content of the text, assisted by their notes, and try to produce a text that resembles the original. This text-reconstruction stage is often implemented as pair work, so the students can pool their resources (Kim, 2008; Kopinska & Azkarai, 2020). Because dictogloss is quite challenging, the students’ version of the text will almost inevitably deviate from the original text. If so, the learners may become aware of certain target language features at the final stage of the procedure, when they compare their own version with the original text (Thornbury, 1997).
Dictogloss accords well with Swain’s Output Hypothesis (Kowal & Swain, 1994; Swain, 1995; Swain & Lapkin, 1995). In fact, text-reconstruction activities were used in the studies by Swain and her colleagues which helped shape the Output Hypothesis. Dictogloss has a precursor called dicto-comp (Ilson, 1962; Riley, 1972), which also used listening texts as prompts for writing, but which put less emphasis on reconstructing the original text. Although dictogloss does not have as long a history as dictation, and although the latter is probably better known by teaching professionals around the world, it is easier to find published studies which implemented dictogloss. In many of these, the researchers were interested in the language-related episodes triggered by the activity (Fortune, 2005; García Mayo, 2002; Leeser, 2004; Malmqvist, 2005). Only a few have examined learning outcomes from dictogloss and these tend to concern grammar features 1 (e.g. Gorman & Ellis, 2019; Khezrlou, 2021; Li, Ellis & Zhu, 2016). 2
We know of no studies that have examined the merits of the dictogloss procedure as described above for MWI learning, although Lindstromberg, Eyckmans & Connabeer (2016) explored procedures that show similarities. Advanced EFL students first read a 120-word text and then listened to it being read out four times by their teacher, during which they could take notes. One group of students was given a blank sheet for them to write notes and then reconstruct the text (in pairs), but another group was given a worksheet where text segments (close to 40% of the text) were already provided, and so their text-reconstruction task was made less demanding. The latter activity resembles what has been called partial dictation (Thornbury, 1997; for an example, see Niu & Helms-Park, 2014) and could thus be labeled partial dictogloss. The segments that were provided on these students’ worksheet included 14 MWIs that had been selected as target items. The students were asked to hand in their text-reconstruction work and were subsequently asked to reconstruct the text anew from memory. The students who had been provided with the worksheets that included segments of the text (including the MWIs) were found to be more successful at this and they also reproduced more of the MWIs than their peers who had done the more demanding variant of dictogloss. Both procedures tried by Lindstromberg et al. (2016) clearly differ from the way we described dictogloss earlier. Most importantly, the students were not given an opportunity to compare their own initial versions with the original text. As mentioned above, this comparison could have helped them notice discrepancies, which regarding the target MWIs would logically have occurred only for the students whose worksheets did not provide these. In any case, the use of dictogloss was not the independent variable of interest in Lindstromberg et al. (2016) since both treatments were dictogloss-like activities. 3 It is thus still not clear if dictogloss fosters MWI learning better than other listening-based activities.
3 Dictation versus dictogloss?
We have found only one published study that directly compared these two activities. In a small-scale classroom experiment, Reinders (2009) used dictation and dictogloss to help ESL students acquire subject–verb inversion after negative adverbs (e.g. Never had he seen . . .), and found a marginal (non-significant) advantage for dictogloss. However, the report does not include information about how well the learners performed their respective tasks, and so it is unclear how much noticing happened. It is conceivable that participants failed to produce the target pattern (e.g. *Never he had seen) and overlooked it when they checked their work against the model text. This is plausible because this pattern of subject–verb inversion is neither structurally nor semantically salient. As we discussed previously, the same can be said of certain elements of MWIs. In the study we report below, we therefore examined not only the learning outcomes, but also how the participants performed their respective tasks.
III Research questions
The questions addressed in the study are (a) whether dictation and dictogloss are equally effective for MWI learning, in comparison to a baseline condition where learners are not required to reproduce a text, (b) whether it is accuracy during dictation rather than noticing discrepancies afterwards that best predict learning, and (c) whether it is accuracy during dictogloss rather than noticing discrepancies afterwards that best predict learning.
It is difficult to predict whether learning outcomes will be better after dictation or after dictogloss. On the one hand, dictation might be more beneficial than dictogloss because the students are less likely to write down inaccurate word strings which subsequently need to be supplanted by the appropriate MWIs. On the other hand, dictogloss requires more retrieval effort than dictation, and successful retrieval is known to be beneficial for knowledge retention (e.g. Candry, Decloedt & Eyckmans, 2020). On the downside, dictogloss entails a greater likelihood than dictation of multiple discrepancies between the students’ reconstructed version and the original text, which potentially makes it challenging for the students to take notice of all these discrepancies (including discrepancies regarding MWIs) at the stage when they check their work against the model text. We therefore tentatively hypothesize that dictogloss is more effective than dictation for MWI retention provided the students reproduce the MWIs accurately during the actual task (benefiting from the retrieval effort) but we make no predictions regarding MWIs noticed afterwards at the verification stage.
IV The study
1 General design
This quasi-experimental study used a between-participant design with three treatment conditions. One group of participants did a dictogloss, the second did a dictation and the third listened to the same text to answer content-related questions. Any learning gains attested in the latter condition (which does not require verbatim text reproduction) would serve as a baseline with which to compare the gains resulting from dictation and dictogloss. To gauge the learning gains, a test about MWIs from the text was administered a week before the listening-based activities, again shortly after completion of the activities, and two weeks later. The worksheets which the students wrote on during their respective activities (e.g. dictogloss) were collected to examine students’ task performance, that is, whether the MWIs were reproduced correctly before or after they checked their work against the transcript of the original text.
2 Participants
A total of 142 Chinese first-year university students learning English as a foreign language (EFL) took part in this study, which was presented to them as an extracurricular opportunity to practise English. Participation was voluntary. The participants were non-English majors between the ages of 17 and 20. They had had approximately 10 years of English learning experience at school. They were recruited from five classes that were taking the same general English proficiency courses in parallel. Students from two of the classes were assigned to the dictation condition (n = 58), students from another two classes were assigned to the dictogloss condition (n = 56), and students from the remaining class (n = 28) were assigned to a content-focused listening condition. The assignment to treatment conditions was done by existing classes because the three activities involved working in pairs, and it was preferable that the students in these pairs were acquainted with each other. Written consent to use their data was obtained from all the participants. The same instructor (the first author) took charge of all the activities.
3 Materials and instruments
The same text, about a general-interest topic (Appendix 1), was used with all three groups. It was adapted from https://www.cbc.ca/natureofthings/m_features/are-you-a-supertaster-here’s-why-you-should-know-and-how-to-find-out. Because it is recommended that texts used for activities such as dictation consist of words that the students understand (e.g. Deyes, 1972; Morris, 1983; Nation, 1991), we took the following steps. A week before the experiment, all the participants were given the Updated Vocabulary Levels Test (Webb, Sasao & Ballance, 2017), which is organized by word-frequency levels, with 30 test items per level. On the first two levels together, that is, items from the 2,000 most frequent words of English, the participants obtained a mean score of 56/60. The mean scores on the third and fourth level were 21/30 and 17/30, respectively. These scores suggest that these students had good knowledge of the 2,000 most frequent words of English and fair knowledge of the next frequency band. According to the vocabulary profiler on Cobb’s (n.d.) Lexical Tutor website (https://www.lextutor.ca/vp/comp/), 92.3% of the running words in the text belong to the 2,000 most frequent word families of English (based on the COCA–BNC 1,000–25,000 lists), and 95.9% coverage is reached when words from frequency band 3 are included. One low-frequency word, supertaster(s), occurs five times in the text, but this is the subject of the text, and its meaning is explained in the introduction. Excluding this item, 98.3% of the running words belong to the 3,000 most frequent word families of English. To further assist comprehension, a Mandarin translation of remaining potentially unfamiliar single words (e.g. fiber, overwhelmed) was given to the students before the listening activity.
Three versions were made of an English native speaker’s audio-recorded reading (at a pace of on average 3.45 syllables per second) of the text: an uninterrupted version (71 seconds long), a version with pauses between short segments (10 minutes in total, with segments on average 5 words long), and a version with pauses between longer segments (2 minutes in total, with segments on average 13 words long). The text was divided into two roughly equal parts. Each group listened to the first half (86 words) according to the procedures outlined below, before tackling the second half of the text (98 words) according to the same procedures. Dealing with the two parts of the text sequentially was intended to make the tasks (especially dictogloss) more manageable.
Ten MWIs which each occurred once in the text served as target items: increased risk, responsive to, when it comes to, obsessed with, lead to, overwhelmed by, have an impact on, too . . . for [one’s] liking, tend to, and chances are. All are included in one or more of the following dictionaries: http://www.macmillandictionary.com, https://www.oxfordlearnersdictionaries.com and http://www.ldoceonline.com/dictionary. They thus appear to be considered by lexicographers to be conventionalized phrases. Originally, 13 MWIs were selected as target items, but 3 were excluded from the analyses because the pretest indicated most students already knew them.
The pretest was a cued form-recall test, consisting of separate sentences with blanks for the missing words of the target MWIs, but with the first letters of all the missing words provided to constrain the options. The Mandarin translation of the target items was given as an additional hint. For example: Those who smoke have an i____________r___________ of heart disease. (2 words; a rise in the chance that something bad or dangerous may happen; 增加风险)
The posttests used the same format with the exception that only the first letter of the first word of each MWI was provided (Appendix 2). For example: Those who smoke have an i_______________________ of heart disease. (2 words; a rise in the chance that something bad or dangerous may happen; 增加风险)
Since the students had by now been exposed to the MWIs several times, and the test clearly related to the text-based activities they had just completed, it was no longer considered necessary to give as many cues as in the pretest. We acknowledge that using slightly different formats hinders a precise evaluation of learning gains. However, we wanted the posttests to capture the students’ recall of complete MWIs instead of their recall of the content words (e.g. obsessed, tend, impact) supplemented by successful guessing of very short function words such as prepositions (e.g. with, to, on) based on first-letter cues. The students were given 10 minutes to complete each of the tests.
4 Procedures
One week after the pretest, the instructor introduced the topic of the listening text and briefly engaged the students in brainstorming about what a text entitled ‘supertasters’ might be about. She then explained the listening-task, which differed for the three treatment conditions.
The students assigned to the dictation group first listened twice to the uninterrupted recording without taking notes. They then listened to the recording where the text was divided into short segments followed by pauses, so they could write down the segments. They then listened once more to the text, this time divided into the longer segments, so they could amend what they had written previously. The students were next asked to work in pairs and consult each other about parts of the text they felt unsure about. After this, they were shown the transcript of the text and asked to make corrections to their own version, using a different colour to indicate the changes. Total time on task was 49 minutes.
After the same introductory steps as above, the dictogloss group also listened twice to the uninterrupted recording without taking notes. They then listened to the version divided into long segments with short pauses and took notes. A fourth listening to the uninterrupted version followed, so the students could make additions to their notes. Then they were asked to share notes and reconstruct the text in pairs. The teacher explained that the objective was to produce a text that resembled the original wording as closely as possible. The last step was for the students to compare their version with the transcript of the original text and make amendments, using a different colour (for an example of a worksheet, see Appendix 3). Total time on task was 49 minutes.
The students assigned to the ‘baseline’ listening condition, which did not require reproducing the text, also first listened twice to the uninterrupted recording. They were then given a list of open comprehension questions to answer. They subsequently listened twice more to the uninterrupted recording to make any amendments to their answers, after which they compared their answers in pairs. Finally, they read through the transcript of the recording and used a different colour to make any changes to the responses on their worksheet. Altogether, this activity also took 49 minutes. Note that in all three conditions, the text was listened to the same number of times (4).
At the end of the respective activities, the students’ worksheets were collected. The immediate posttest (which was not announced beforehand) followed shortly afterwards. The delayed posttest (also unannounced) followed two weeks later.
5 Analysis
Responses on the MWI gap-fill tests were scored dichotomously (correct or incorrect). No point was awarded if participants failed to provide a constituent word or provided an incorrect word, such as an incorrect preposition. No points were given either when participants made spelling mistakes. The students went over the print version of the text at the end of their respective listening activities, and so could be expected to verify appropriate spelling. As regards inflectional morphology, a distinction was made between totally fixed phrases, such as when it comes to and chances are, and phrases with variable inflection, such as tend to / tends to / tended to. No point was awarded if a mistake was made in the former case (*when it come to), but a point was given if an inflectional mistake was made in the latter case (on condition that everything else was correct). Leniency in the latter case seemed justified because the test was meant to assess participants’ knowledge of phraseology rather than their mastery of morpho-syntax. To check the reliability of the scoring protocol, the first two authors independently scored 10% of the test sheets. As there were no instances of disagreement, the first author scored the remaining test sheets.
As to the MWIs written (or missing) on the worksheets collected at the end of the session, a distinction was made between the MWIs that students wrote down before they checked their work against the transcript of the listening text and the amendments they made afterwards. These data served to answer the question whether it is successful task performance (successful retrieval in the case of dictogloss) or rather post-facto noticing that best predicts learning outcomes.
To answer the question whether the three activities bring about different learning gains for MWIs, two multilevel logistic regression models with test-item responses nested within participants were used to analyse learners’ performance on the immediate posttest and the delayed posttest, with treatment condition as a fixed factor. Any items for which a student had supplied a correct response in the pretest were excluded. 4 The analyses were run in Jamovi using the GAMLj models (Gallucci, 2019).
To answer the question whether it is accuracy at the listening-and-writing stages or correction during comparison with the transcript of the listening text that best predicts learning, the successfully recalled MWIs in the posttests were traced back to the worksheets in the three conditions. Six separate multilevel logistic models were run in Jamovi (three treatment conditions * two posttest). The models controlled for items that according to the pretest were already known by students.
V Results
Research question 1: Comparing learning gains
Table 1 shows the descriptive statistics for the MWI pretest and posttest scores. On average, the participants produced 2.5 of the 10 target MWIs in the pretest. Recall that the pretest provided the students with the first letter of every missing word, and so the average test score may reflect some lucky guesses. 5 Although we treated correct pretest responses as indicative of prior knowledge of the target MWIs in the statistical modeling, it cannot be ruled out that prior knowledge was slightly overestimated owing to lucky guesses and consequently that the learning gains are slightly underestimated.
Means and standard deviations for the multiword items (MWI) tests.
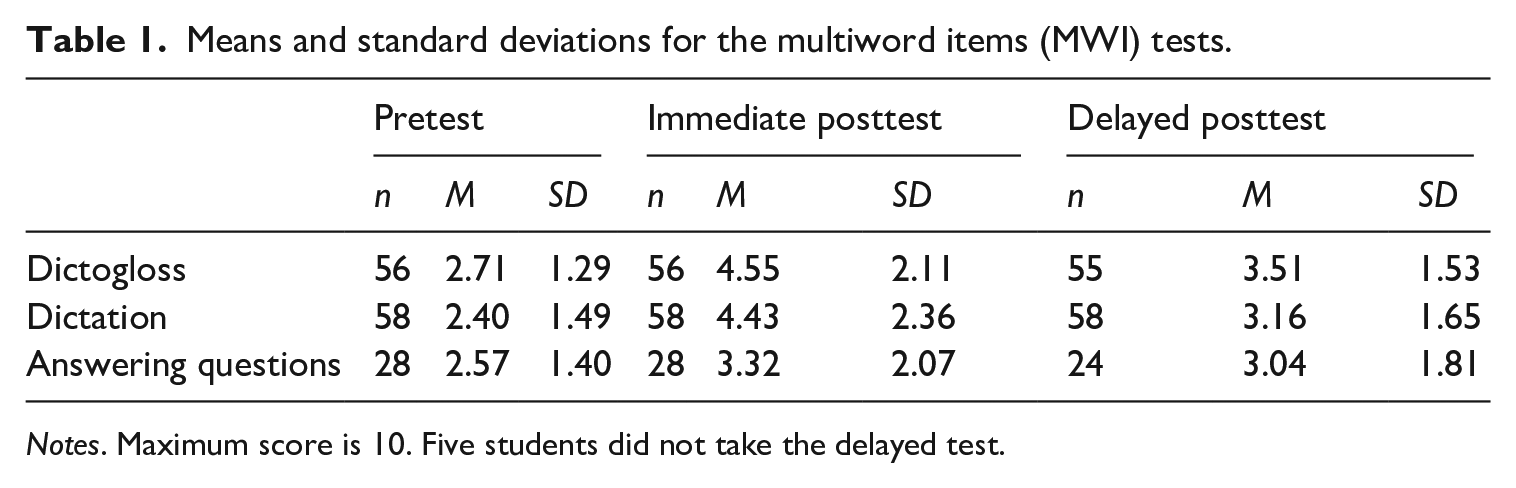
Notes. Maximum score is 10. Five students did not take the delayed test.
Multilevel logistic regression revealed no differences between the three treatment groups’ pretest scores (p = .561). In the immediate posttest, the dictogloss and dictation group both outperformed the ‘baseline’ group that just answered comprehension questions, but the difference diminished considerably two weeks later. The multilevel logistic regression models indicated that treatment was a significant predictor of learning gains on both the immediate and the delayed posttest (p < .001 and p = .035, respectively). According to Tables 1 to 3, dictogloss led to slightly better MWI recall than dictation, but the post-hoc pair-wise comparisons reveal no statistically significant difference between the dictogloss and dictation groups in either the immediate (z = 0.33, p = .744) or the delayed posttest (z = ‒0.88, p = .377). Post-hoc pair-wise comparisons confirm that both the dictation and the dictogloss activity led to better recall of MWIs than answering content-related questions in the immediate posttest (z = ‒4.65, p < .001, and z = ‒4.42, p < .001, respectively). However, the difference shrank in the delayed posttest, where the pair-wise comparisons indicate that the dictation group no longer outperformed the baseline group (dictogloss vs. answering questions: z = ‒2.59, p = .029; dictation vs. answering questions: z = ‒2.02, p = .086).
Learning gain in the immediate posttest: Estimates of fixed and random effects.
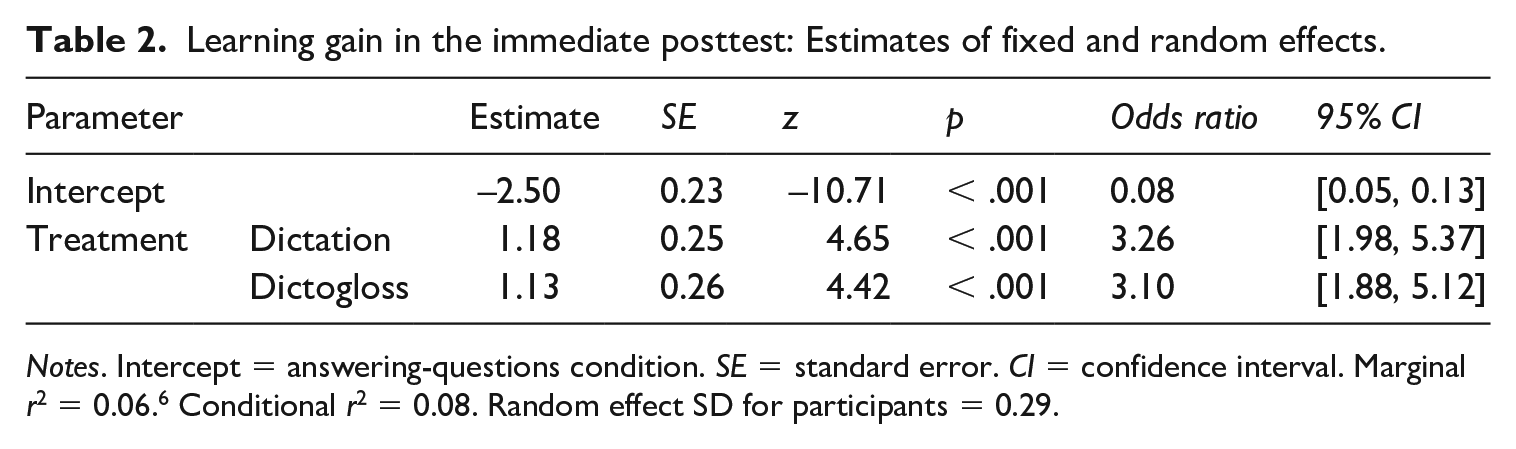
Notes. Intercept = answering-questions condition. SE = standard error. CI = confidence interval. Marginal r2 = 0.06. 6 Conditional r2 = 0.08. Random effect SD for participants = 0.29.
Learning gain in the delayed posttest: Estimates of fixed and random effects.
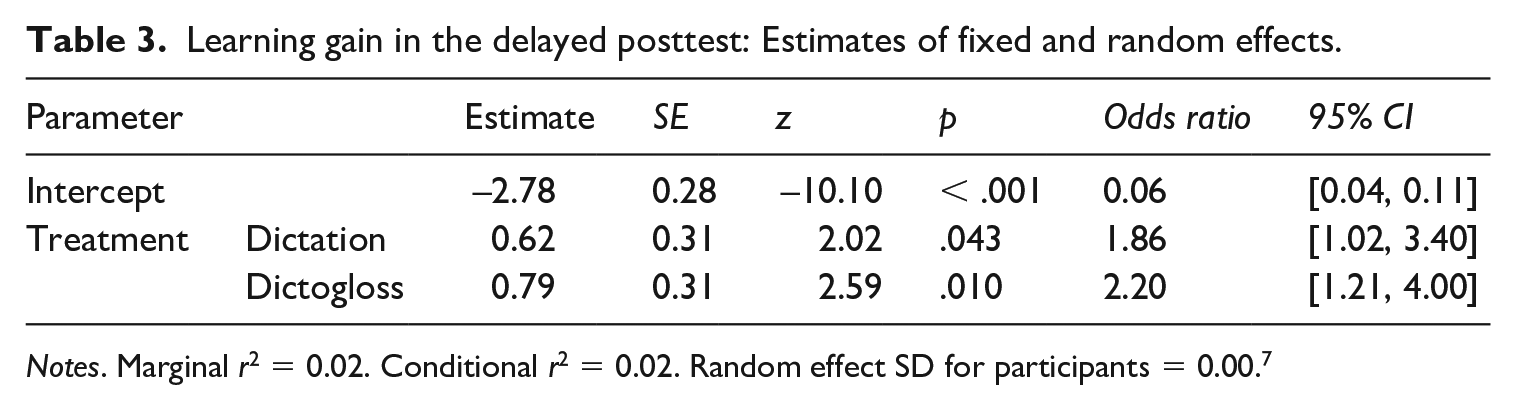
Notes. Marginal r2 = 0.02. Conditional r2 = 0.02. Random effect SD for participants = 0.00. 7
It is worth noting that even in the treatment conditions which – according to the background literature – could be expected to be relatively effective for MWI learning (i.e. dictation and dictogloss), the posttest scores were low if the amount of time spent on the respective activities (close to 50 minutes) is taken into consideration.
Research question 2: Does it matter if you do not get it right from the start?
In all six multilevel regression models, pretest performance was, as expected, a significant predictor of posttest successes (z [7.05, 12.40]). In other words, items already known at pretest were also known at posttest. Also as expected, the tallies of correct and amended MWIs on the students’ worksheets before and after comparison with the transcript show different proportions across the three treatments (see Table 4). A chi-square test of independence confirms that there was a significant relation between these tallies and the treatment conditions: χ2(4, N = 1420) = 595.13; p < .00001. The students who did the dictation activity were the most likely to write down the MWIs on their worksheets at the listening-and-writing stage of their activity, although what they wrote was not always correct. Their errors were typically spelling errors (e.g. *inpact instead of impact) and occasionally a misheard preposition (*impact in instead of on). By comparison, the students doing the dictogloss activity needed to make many more amendments when they compared their reconstruction of the text with the model transcript and at that stage copied the missing (parts of) MWIs onto their worksheets (e.g. adding for their liking to something tastes too strong). These students also needed to correct more diverse prepositional errors (e.g. *obsessed of).
Worksheet analysis: Tallies of missing/wrong and correct multiword items (MWI) instances per treatment.
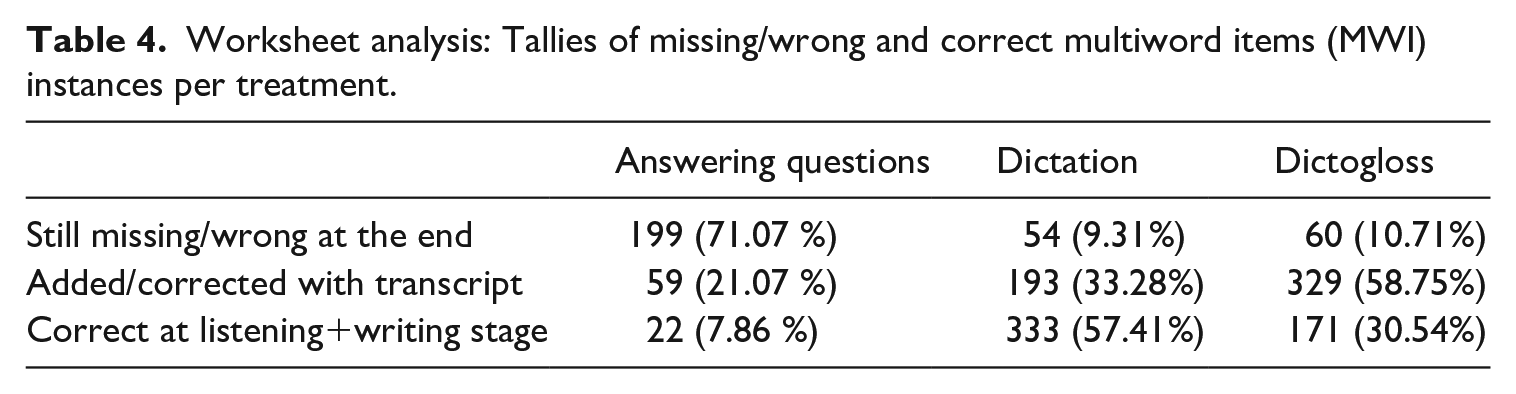
The worksheets of the students who were asked to answer content-related questions showed little use of target MWIs altogether. This accords with earlier research suggesting that learners are not likely to ‘mine’ texts for items beyond single words (Hoang & Boers, 2016).
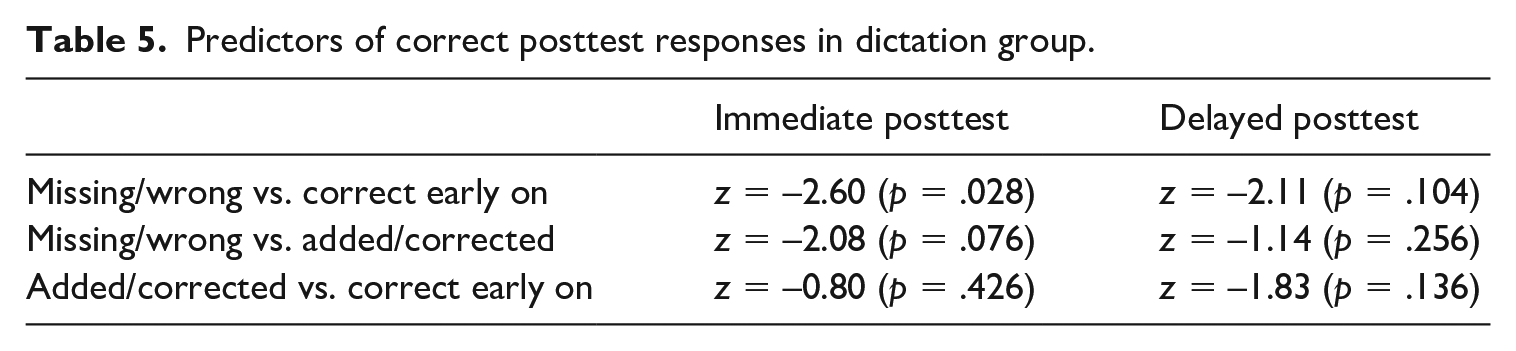
In the dictation condition, writing the MWIs correctly on the worksheets at the listening-and-writing stage was a predictor of successful recall in the posttests, but statistical significance was reached only for the immediate posttest when compared to MWIs which remained wrong or missing after comparison with the transcript of the listening text (see Table 5). Interestingly, MWIs that were corrected at this comparison stage were not recalled more successfully at a statistically significant level than MWIs which were overlooked altogether.
Predictors of correct posttest responses in dictation group.
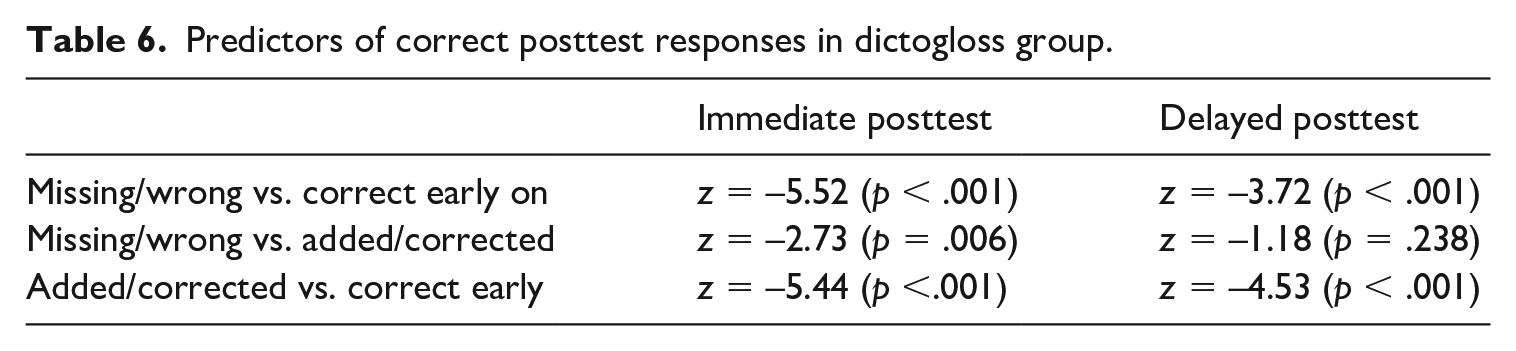
When students reproduced MWIs correctly during the text-reconstruction stage of dictogloss, then these MWIs stood a very good chance of being recalled in the posttests. In comparison, MWIs corrected or added afterwards, at the stage when the students compared their reconstructed version to the transcript of the listening text, were not as likely to be recalled. Unsurprisingly, MWIs which were overlooked altogether stood the poorest chance of being recalled in the tests (see Table 6). Interestingly, self-corrected MWIs were no longer better recalled at a statistically significant level in the delayed posttest than overlooked ones.
Predictors of correct posttest responses in dictogloss group.
As regards the group that was asked to answer content-related questions, there were probably too few correct MWIs on the worksheets (< 8%) for a statistical trend to emerge.
VI Discussion
Because they invite attention to the language code, we hypothesized that both dictation and dictogloss would lead to better MWI learning than a purely content-focused listening activity, albeit for slightly different reasons. In the case of dictation, we assumed that students would take notice of the MWIs in the text since they needed to write these down immediately after hearing them. We reasoned that MWIs which were nonetheless missed during the dictation would subsequently be noticed during the comparison with the original text. In the case of dictogloss, we reasoned that the effort invested in retrieving MWIs from memory would be beneficial. If retrieval failed, we assumed the students would nonetheless learn as they compared their text with the original version, since they had been instructed to reproduce the original wording. As expected, both dictation and dictogloss brought about better learning gains than the content-focused activity, at least according to an immediate recall test. The advantage of the dictogloss group was less pronounced in the two-week delayed test, and the dictation group did not even outperform the baseline group at this point. It needs to be acknowledged that even in the immediate posttest neither the dictation nor the dictogloss activities showed great promise for MWI acquisition if time investment is taken into consideration.
Analysis of the students’ worksheets allowed us to distinguish between instances of MWIs that were reproduced successfully during the listening-writing activity and ones that were added or rectified during subsequent comparison with the transcript of the listening text. Interestingly, the benefits of self-correction – a manifestation of post-facto noticing – were found to be rather marginal. Instead, it was MWIs that were reproduced accurately early on that stood the best chance of being recalled in the posttests, and this was particularly noticeable in the case of dictogloss. (To reiterate, this analysis controlled for instances of correctly reproduced MWIs that according to the pretest were already known by students.) We may therefore speculate that dictogloss could have emerged as a more effective activity had the rate of successful retrieval during text reconstruction been higher. If so, then it is vital to implement dictogloss in ways that increase the likelihood of successful retrieval, while nonetheless preserving a desirable level of difficulty (Bjork & Bjork, 2014).
One possibility is to create a worksheet on which segments of the transcript are provided (i.e. partial dictogloss). This is what was done in Lindstromberg et al. (2016), but in that study it was the target MWIs that were provided on the worksheet. It would be interesting to compare this with a dictogloss implementation where the given text segments exclude the target MWIs, so the students can benefit from retrieving them from memory. Another feature of the way Lindstromberg et al. (2016) implemented dictogloss was to present the print version of the text first before moving on to the listening activity. This is another way of reducing trial and error.
While self-correction at the stage of comparison with the model transcript turned out a weaker predictor of posttest successes, it stands to reason it is nonetheless better than overlooking MWIs altogether. It is worth noting that a fair number (about 10%) of MWIs remained incomplete or inaccurate on both the dictation worksheets and the dictogloss worksheets even after students compared their texts with the transcript. Typographic enhancement of the target MWIs (e.g. using bold font) in the transcript could therefore be helpful to direct learners’ attention to the MWIs at the stage when they compare their version to the model text (e.g. Boers, Demecheleer, et al., 2017; Choi, 2017; Vu & Peters, 2021).
VII Conclusions and limitations
We examined the usefulness of two activities for fostering incidental MWI learning, notably dictation and dictogloss, which have in common that they (a) are based on listening input, (b) require learners to reproduce (in writing) a text they listen to a few times, and (c) stimulate noticing of language features when learners subsequently check their output against the model transcript. While there are theoretical grounds (discussed in the first part of this article) for expecting these activities to be effective for MWI acquisition, the learning gains observed in this study can hardly be described as spectacular.
We did find evidence that retrieval from memory, which is a defining feature of dictogloss, is a strong predictor of learning success – in accordance with dozens of studies on retrieval practice, including second language vocabulary (e.g. Barcroft, 2007; Candry et al., 2020). This suggests that implementing dictogloss in a way that ensures a good level of success at the text-reconstruction stage can make it a more effective activity than a standard dictation.
Several limitations to this study need to be acknowledged. One is the small number of target items. It may be worth examining learning gains from a series of similar activities to increase the total number of target items. This might then also provide an opportunity to examine if there are any characteristics that make some MWIs more amenable than others to being acquired through these activities. We also need to recognize that we only used a productive recall test. More differences in learning might have been discernable had we included a less demanding format, such as a multiple-choice test, or if we had retained the same number of first-letter cues in the posttests as in the pretest. A methodological contribution of this study, we believe, is its demonstration that tracing posttest responses back to task performance can shed light on what mechanisms predict learning outcomes. This is useful, because rather than determining whether a given task ‘works’ for a certain purpose, it may inform ways of making it work better.
Footnotes
Appendix 1
Appendix 2
Appendix 3. An example of a dictogloss worksheet
Appendix 4
Acknowledgements
We would like to express our gratitude to the students who volunteered to participate in this study, and to the teachers and Deans at Beijing International Studies University, China, for their support.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.