
Abstract
This study investigates whether re-thinking the separation of lexis and grammar in language testing could lead to more valid inferences about proficiency across modes. As argued by Römer, typical scoring rubrics ignore important information about proficiency encoded at the lexis–grammar interface, in particular how the co-selection of lexical and grammatical features is mediated by communicative function. This is especially evident when assessing oral versus written exam tasks, where the modality of a task may intersect with register-induced variation in linguistic output. This article presents the results of an empirical study in which we measured the diversity and sophistication of four-word lexical bundles extracted from a corpus of French proficiency exams. Analysis revealed that the diversity of noun-based bundles was a significant predictor of written proficiency scores and the sophistication of verb-based bundles was a significant predictor of proficiency scores across both modes, suggesting that communicative function as well as the constraints of online planning mediated the effect of lexicogrammatical phenomena on proficiency scores. Importantly, lexicogrammatical measures were better predictors of proficiency than solely lexical-based measures, which speaks to the potential utility of considering lexicogrammatical competence on scoring rubrics.
Introduction
Recently, there have been calls to re-think traditional divisions between “vocabulary” and “grammar” that have been typical in models of language ability used in language testing (e.g., Alderson & Kremmel, 2013; Kremmel et al., 2017; Römer, 2017). As argued by Römer (2017), language proficiency rating scales often fail to acknowledge the fact that lexis and grammar interact in meaningful ways. This is evident in corpus linguistic data showing that certain words and grammatical structures demonstrate patterns of co-occurrence and recurrence (Biber, 2009; Römer, 2009; Sinclair, 1991; Stefanowitsch & Gries, 2003), that is, they appear together more often than would be “expected on the basis of chance” (Gries, 2008, p. 6) or they are very often repeated together (Biber et al., 1999; Paquot & Granger, 2012). Importantly, these studies also show that associations between lexical items and grammatical structures often serve specific communicative functions (see Biber et al., 2004), which means that associations between lexis and grammar also need to be considered within the specific communicative context in which they occur. The problem with strictly separating lexis and grammar on scoring rubrics is therefore twofold.
First, it ignores important information about linguistic competence encoded at the lexis–grammar interface, information which has shown to contribute to holistic evaluations of learner productions. For example, Paquot (2018) found that the association between words in specific grammatical structures (e.g., arouse + curiosity in a direct object structure) was a significant predictor of the proficiency scores assigned to advanced learner texts in a corpus of research papers. Importantly, no significant differences were found regarding the lexical or syntactic complexity of the texts, suggesting that the most important information about proficiency was not lexical or grammatical but rather lexicogrammatical. Similarly, Kyle and Crossley (2017) found that the association strength of verbs and the constructions in which they appear (e.g., subject-
The second problem with separating lexis from grammar on scoring rubrics is that it ignores the way that both lexis and grammar interact together with communicative function. That language varies according to context of use is certainly not news to language assessment specialists (see Bachman, 1990). What is less clear, however, is how functional differences between tasks relate specifically to the lexicogrammatical features exhibited in exam performances and how those lexicogrammatical features, in turn, relate to the proficiency scores attributed to such exams. For example, in a study comparing oral and written TOEFL iBT tasks, Biber and Gray (2013) observed that collocational patterns differed not only with respect to task type, but that such patterns were reflected in the scores attributed to the exams. As Paquot, Gries, and Yoder (2021) highlight, “there is a need for more research into how lexicogrammatical competence interacts with foreign language proficiency and development across modes, tasks, registers and other linguistic, contextual and or situational characteristics” (p. 229). In particular, relatively little research has examined the linguistic differences between oral and written production tasks on language exams (Biber et al., 2016). The current study, therefore, represents an attempt to complement the discussion about the division between lexis and grammar in language testing by investigating the extent to which lexicogrammatical characteristics are predictive of proficiency scores in oral versus written exam tasks.
Background
One way to capture complexity at the lexis–grammar interface is through phraseology. Phraseology looks beyond single words to examine the way that words combine together. Psycholinguistic research has shown that both learners and native speakers are sensitive to patterns of co-occurrence and recurrence but in different ways. Ellis et al. (2008), for example, found that for learners of English, the processing of three-, four-, and five-word phrases is primarily a function of the frequency of the phrases in large reference corpora. For native speakers, however, it is not frequency but rather association strength of the phrases that has the strongest effect on processing. Phrases containing words that occur more exclusively together (and rarely with other words) were the fastest to process. These receptive differences are also found in production data. Durrant and Schmitt (2009) compared written texts produced by native and non-native writers of English and found that compared to the native writers, the non-native writers used more highly frequent collocations and fewer infrequent but strongly associated collocations. Similarly, as learners increase in proficiency, they tend to decrease their use of highly frequent bigrams (adjacent word pairs) and increase their use of infrequent but highly associated bigrams, both when learners are compared cross-sectionally across proficiency levels (Granger & Bestgen, 2014) as well as when individual learners are followed longitudinally (Bestgen & Granger, 2018).
Paquot (2019) termed this aspect of linguistic competence phraseological complexity, which she defined as the diversity and sophistication of phraseological units in learner production, following Ortega, (2003). Phraseological diversity refers to the extent to which a learner uses a large number of different phraseological units. Phraseological sophistication, on the contrary, refers to the extent to which a learner is able to select more specific or informative phraseological units (i.e., those which may be more appropriate to a specific topic or register). In a series of studies focusing on second language (L2) English, French, and Dutch, measures of phraseological complexity have been found to be predictive of L2 proficiency, even when lexical and syntactic complexity measures were not (Paquot, 2018, 2019; Rubin et al., 2021; Vandeweerd et al., 2021). While these studies speak to the relevance of phraseological complexity to L2 proficiency in general, they are limited by the fact that they have focused exclusively on written production.
Writing and speaking differ in a number of important ways including the presence (or absence) of an audience, the degree of online planning required, and control over output (Ravid & Tolchinsky, 2002). The fact that speaking occurs online and in real time also means that learners have less time to conceptualize, formulate, and monitor linguistic output as compared to writing (Skehan, 1998). Even the most pressured writing conditions (e.g., timed language exams) still offer more opportunities for planning and revising compared to speech. As a result, L2 speech generally exhibits less lexical complexity as compared to writing (e.g., Granfeldt, 2007). The constraints of real-time production and the lack of online planning may also lead to the use of more frequent (and, therefore, more accessible) phraseological units, as suggested by the results of Biber and Gray’s (2013) study of the collocations used in oral and written TOEFL iBT tasks.
In addition to the overall differences outlined above, speech and writing often serve different communicative purposes. As a result, oral and written productions tend to be associated with the use of different linguistic features (Biber, 2019). For instance, the fact that speech is often interactive means that it tends to have a more personal or involved focus. Linguistically, this is associated with a greater use of pronouns, modal verbs, lexical verbs, adverbs, and discourse markers. In contrast, writing tends to be more informational in purpose and is marked by the use of nouns, nominalizations, attributive adjectives, and prepositional phrases. These differences have been observed across several languages and different text types (Biber, 2014) and even extend to the level of phraseology, with speech associated with the use of verb-based phraseological units and writing associated with noun-based phraseological units (Biber et al., 2004).
From a developmental perspective, linguistic features associated with speech are also hypothesized to be acquired early because they are necessary for almost all types of conversation. Linguistic features common to writing (e.g., complex phrasal embedding), on the contrary, are hypothesized to be acquired later and only in the context of formal education (Biber et al., 2011; Halliday & Matthiessen, 2006). This suggests that although tasks may require different linguistic features, there may be developmental patterns within tasks whereby more advanced language users incorporate more nominal complexity features, regardless of task type. For example, in their study comparing oral and written TOEFL iBT tasks, Biber et al. (2016) found that although written tasks were indeed associated with the use of phrase-level linguistic features and oral exams were associated with clause-level linguistic features, within each task, there was a positive relationship between the use of phrasal features and holistic proficiency scores given by raters.
With regard to French, the target language of the learners in our study, phraseological complexity has also been found to increase with proficiency both in oral production (Forsberg, 2010), and in written production (Vandeweerd et al., 2021). Only one study thus far has directly compared phraseological complexity across modes, however. Vandeweerd et al. (2022) compared the diversity and sophistication of direct objects (verb + noun) and adjectival modifiers (noun + adjective) across oral and written tasks collected from university-level learners of French over a period of 21 months. While the design of the corpus made it difficult to isolate the precise effects of task characteristics (e.g., modality, interactivity) from register, comparison of the learner group and a first language (L1) group seemed to indicate that the extra planning time afforded by the written task had a positive effect on the phraseological complexity in learner productions but that this effect was somewhat mediated by the functional requirements of the task, as seen by the fact that the complexity of the noun-based units (adjectival modifiers) and verb-based units (direct objects) differed across tasks. However, the applicability of these findings to the language testing context is somewhat limited given that the study involved a relatively small and quite advanced sample of learners (n = 29) and the fact that the learners were not directly impacted by the results of their linguistic performance.
The current study, therefore, aims to determine the extent to which measures of phraseological complexity are predictive of oral versus written French proficiency scores in the context of a high-stakes language assessment exam. In line with previous research, we expect that measures of phraseological complexity will be predictive of proficiency even when controlling for the lexical complexity of a text (Vandeweerd et al., 2021). This would suggest that raters are sensitive to complexity not just at the level of lexis but also at the lexis–grammar interface (i.e., that phraseological measures are not simply a subset of lexical complexity measures) as argued by Paquot, Gries, and Yoder (2021). We also aim to determine the extent to which various measures of phraseological complexity (e.g., those targeting diversity vs sophistication and noun-based vs verb-based units) differ in their ability to predict proficiency scores in the two modes. We expect to find that verb-based measures will be more predictive of proficiency in the oral task and that noun-based measures will be more predictive of proficiency in the written task due to the register-induced differences between the two tasks (in line with Biber et al., 2016) but that the constraints of online production will have a mediating effect on the complexity of speech (Skehan, 1998).
Methodology
Data
This study uses a sample of 545 oral and written productions from the Test d’évaluation de français (TEF, Chambre de commerce et d’industrie de Paris, 2010), a French proficiency exam recognized by the French Ministry of Education for the admittance of non-native speakers to higher level education in France. Because the exam is also recognized by the federal government of Canada for immigration purposes, many of the candidates who take the exam are themselves native speakers of French. The distinction between native and non-native speakers, however, often has much more to do with identity and national politics than linguistic performance (Davies, 2004; Holliday, 2017). We therefore decided to include both candidates who self-identified as native speakers of French and those who identified their first language as a language other than French and used L1 background as a control variable in the statistical analysis, in light of previous research showing an effect of L1 background on phraseological competence (e.g., Durrant & Schmitt, 2009; Ellis et al., 2008).
As discussed previously, the communicative function of a task tends to be associated with the use of specific linguistic features. For this reason, we selected two tasks with a similar function:
Written Production Task B asks candidates to write a “letter to an editor” (minimum of 200 words) in which they respond giving their opinion on a controversial topic. The prompts for this task are randomly distributed to candidates prior to starting the exam and consist of sentences extracted from newspaper articles (e.g., “Television advertisements should be abolished”). Candidates are asked to develop at least three arguments to defend their point of view. They have an hour to complete this task as well as another written production task. Both tasks are completed via computer without access to reference materials.
Oral Production Task B asks candidates to make a telephone call to a close friend. They are provided with a visual prompt (e.g., an advertisement promoting a vacation to Quebec), which they must present to the examiner and convince them to participate. Candidates have 10 minutes to complete the task.
While letters and telephone calls differ in more than just modality (e.g., stylistics, structural conventions, formality), they both require candidates to express their personal attitudes and their certainty about propositions in order to persuade the addressee (i.e., the newspaper editor in the case of the written task and the “friend” in the case of the oral task). Functionally, this tends to promote the use of linguistic elements such as first-person pronouns and dependent clauses (e.g., À mon avis, c’est vrai que . . ., “In my opinion, it’s true that . . .”), especially relative to more narrative- or descriptive-type tasks (e.g., Lu, 2011; Michel et al., 2019). This functional similarity makes these two tasks more comparable than the other TEF tasks, which are more narrative or descriptive in nature (e.g., newspaper article, telephone inquiry to request information).
The evaluation of the exams was done externally by raters at the Chambre de commerce et d’industrie de Paris. Pairs of raters judged each production on a scale of 0–6 for each of the following criteria: presentation of ideas, quality of argumentation, grammatical precision, vocabulary control, elocution (in the case of the oral task), and orthography (in the case of the written task). Although inter-rater reliability scores are not available for these texts specifically, reliability has previously been reported to be moderate (r = .652) for the written production section of the TEF exam (Casanova & Demeuse, 2016) and high (r = .94) for the oral production section (Artus & Demeuse, 2008). A proprietary formula was used to transform the individual scores into a normed score out of 699 for the entire section of the exam. According to Artus and Demeuse (2008), this was done so that raters remain unaware of how the global score for each competence is calculated (to prevent them from simply assigning scores based on an a priori estimation of a candidate’s global proficiency). The normed scores out of 699 are indexed to the Common European Framework of Reference for Languages (CEFR, Council of Europe, 2001), with 100 point increments corresponding to the six CEFR levels. 1
The sample of exams used in the study (Table 1) was made according to several criteria. First, we made an initial selection of exams where the written section was at least 100 words in length because complexity measures have been shown to be unreliable for texts shorter than that. Second, given that topic can have a significant effect on phraseological complexity (Paquot, Naets, & Gries, 2021), we wanted to ensure that differences observed between oral and written sections of the exam were not simply due to topic differences. We, therefore, manually categorized the prompts into overarching themes (e.g., environment, travel, language) and then made an initial selection of exams with a match between the theme of the oral and written sections. The audio from the oral exams was then transcribed and the written exams were manually spell-corrected in order to ensure comparability with the oral transcriptions (which by definition did not have any orthographic errors). Letter headings (e.g., addresses, signature lines) were also removed from the written productions. R scripts were then used to clean the texts (e.g., remove stylized apostrophes, standardize spelling) and part-of-speech (POS)-tag them using TreeTagger (Schmid, 1994). TreeTagger has previously been shown to have a high level of accuracy (96.12%) on L1 data (Denis & Sagot, 2012) and has also been shown to perform well (89.67%–93.52% accuracy) across various different task types (e.g., oral conversations, online reviews, literature and law texts; Mattiuzzi, 2021). We did not carry out an evaluation of the reliability on the POS annotation directly given that POS-taggers have been shown to perform generally well on learner data, provided that texts are manually spell-corrected before being tagged (De Haan, 2000; van Rooy & Schäfer, 2002), which was the case here. Jarvis and Hashimoto (2021), for example, report F-scores above 0.90 for all POS categories in a corpus of L2 English narrative texts, indicating a high level of reliability when compared to human annotation.
TEF sample.
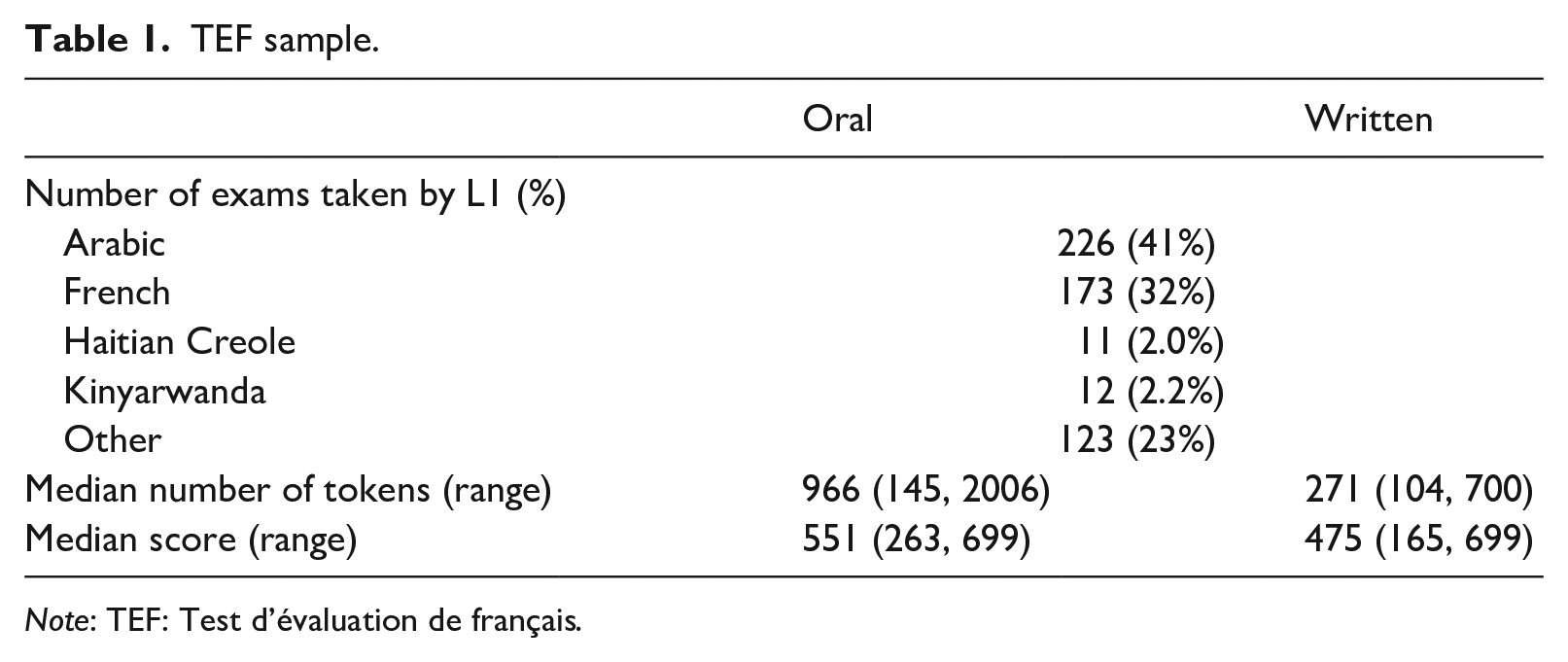
Note: TEF: Test d’évaluation de français.
Following pre-processing, we used topic modelling as an additional method of controlling for topic differences. Topic modelling is a bottom-up method whereby texts are grouped together into computer-defined topics according to their common vocabulary (see Murakami et al., 2017). For each text in the corpus, the model outputs a probability distribution for each topic. This allows the differences between texts to be quantified in terms of their overlapping probability distributions using similarity metrics such as Jensen–Shannon divergence (JSD) (Wang & Dong, 2020). In this study, we used the JSD scores between the oral and written sections of the exams to control for topic differences in the statistical analysis. The smaller the JSD between two sections of the exam, the more similar they are in terms of shared vocabulary. For example, in one exam, where the written prompt was Il faut modifier nos comportements alimentaires pour préserver la planète (“It is necessary to modify our dietary behaviour to preserve the planet”) and the oral prompt related to an advertisement for installing a backyard windmill, both tasks were classified as belonging to the same theme by the model and the JSD value for the two texts was found to be 0.004, indicating a high level of overlap in vocabulary.
Complexity measures
This study focuses on the complexity of four-word lexical bundles. This diverges somewhat from previous studies of phraseological complexity that have primarily focused on two-word co-occurrence phenomena (e.g., adjective + noun, verb + noun, adverb + verb collocations). While such phenomena have been shown to be relevant to L2 development (see Altenberg & Granger, 2001; Durrant & Schmitt, 2009; Laufer & Waldman, 2011; Nesselhauf, 2005), they represent only a small part of a learner’s possible phraseological repertoire. Equally important to L2 phraseology are recurrence phenomena, such as lexical bundles, defined as “sequences of words that commonly go together in natural discourse” (Biber et al., 1999, p. 990). Like co-occurrence phenomena, lexical bundles also exist at the interface between lexis and grammar (Römer, 2009) and have been shown to be relevant to the development of L2 proficiency (e.g., Biber & Gray, 2013; Zheng, 2016).
Unlike collocations however, which by definition contain only two linguistic items, lexical bundles can be of any length. This is especially important when it comes to French because as noted by Vinay and Darbelnet (1995, p. 126), French has a tendency to modify nouns and verbs with prepositional phrases rather than adjectives or adverbs. For example, the French equivalent of comment ironically would be s’exprimer en termes ironiques (lit. “express oneself in ironic terms”). Looking only at two-word collocations would ignore this type of verbal modification (as argued in Vandeweerd et al., 2021). In addition, the number and type of lexical bundles have both been shown to be different across registers and text types (Biber et al., 1999, 2004), a characteristic which makes them particularly suited to comparing oral and written tasks.
As to the length of the lexical bundles, while previous research has investigated bundles ranging in length from 3 to 7 words in French (see, for example, Granger, 2014), there is an upper limit constraining the length of units, given the computational power required to calculate association measures. Initial experimentation revealed that four word-bundles represented a fair balance between expanding construct representation (e.g., to capture important aspects of French as described above) on the one hand and computational feasibility on the other hand. 2
We did however make some modifications to the way that lexical bundles are traditionally extracted. Whereas lexical bundles are typically composed of inflected surface forms, in our approach we used POS-tagged and lemmatized lexical bundles. Using POS-tagged lexical bundles allowed us to filter the units we extracted in order to account for possible cross-modal register differences (Biber, 2019). We focused on two types of lexical bundles in particular: those starting with verbs (verb-bundles) to tap into phraseological complexity at the clause level and those starting with nouns (noun-bundles) to tap into phraseological complexity at the phrase level. Admittedly, this is a rather crude operationalization, but given that this is the first study to investigate phraseological complexity in this way, we felt that it represented a fair balance between a strictly bottom-up approach and imposing too much of our own intuition on the units extracted. The decision to use the lemmas instead of the surface forms was due to the highly inflected nature of French and follows the suggestion of Treffers-Daller (2013) to use lemmas in the calculation of complexity measures in French. In addition, this protects against a possible confound of accuracy in the calculation of our phraseological complexity measures because all inflected forms are treated equally. This is especially important when comparing oral and written French because many grammatical inflections are only encoded orthographically but not phonologically (see Blanche-Benveniste & Adam, 1999). On a practical level, collapsing inflected forms together also makes it possible to calculate association measures in cases where an exact inflected form may not be attested in a reference corpus but another inflected form, representing a different tense or mode is attested, thereby increasing the coverage of our phraseological complexity measures. Another difference from traditional lexical bundle approaches is that we included bundles that crossed punctuation (but not sentence) boundaries (cf. Biber & Barbieri, 2007). This was done because the oral transcriptions contain no punctuation (other than the segmentation into C-units) so we wanted to ensure comparability across modes.
All lexical bundles were extracted using R scripts. Following extraction, the list of units was filtered to remove any verb-bundles starting with the auxiliary verbs être and avoir (so that the focus was on lexical verbs) and any bundles containing lemmas unknown to TreeTagger. For example, the abbreviation H24 (“24/7”) was not recognized by TreeTagger, resulting in the following bundle: ouverture_NOM unknown_ADJ du_PRP magasin_NOM (“unknown opening of the store”). Bundles containing unknown lemmas such as these only accounted for 2.073% of all bundle tokens and 2.196% of all bundle types. Following filtering, we then collapsed all proper nouns and determiners within the bundles. All proper nouns were re-coded as “NAM” (the TreeTagger POS tag for proper nouns) and all determiners as “DET.” For example, the surface form, “Monsieur Dupont, mes sincères . . .” (“Monsieur Dupont, my sincere . . .”) was re-coded as “monsieur_NOM NAM DET sincère_ADJ.” Without collapsing proper nouns, many of the units are not found in the reference corpus (simply because the specific names are not attested). Collapsing determiners was done out of practical necessity because otherwise indexing all variations of units in the reference corpus was not feasible.
The frequency of each bundle was then checked in a large reference corpus and those that appeared fewer than 10 times were excluded from analysis. The use of a frequency threshold ensures that all bundles that are included in the analysis have at least some degree of conventionalization as phraseological units in L1 usage and is in line with previous studies of lexical bundles (e.g., Biber & Barbieri, 2007; Biber et al., 2004). The reference corpus used was the FRCOW16 corpus (Schäfer, 2015; Schäfer & Bildhauer, 2012): a 10 billion word web-scraped corpus of French. An obvious disadvantage of this corpus is that it only contains written texts. As such, it may not be exactly representative of the tasks completed by TEF candidates. That being said, the size of the corpus means that a majority of the lexical bundles extracted from the TEF exams are attested, in comparison to smaller oral-specific corpora in which many of the extracted lexical bundles were simply not found (for a similar argument, see Paquot, Naets, & Gries, 2021). As a precaution, we checked whether there was a significant difference in coverage of lexical bundles from the oral and written tasks, and this was not found to be the case. Table 2 shows the most frequent bundles extracted from the learner corpus.
Most frequent bundles extracted from the TEF corpus.
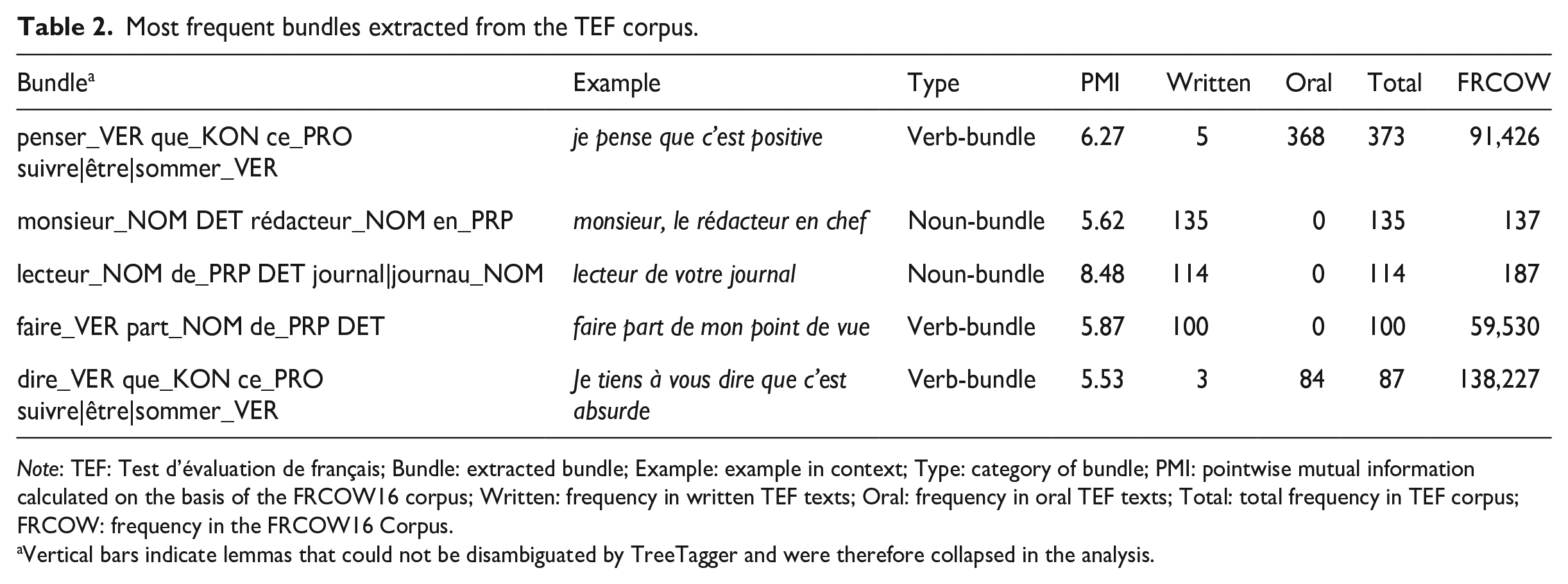
Note: TEF: Test d’évaluation de français; Bundle: extracted bundle; Example: example in context; Type: category of bundle; PMI: pointwise mutual information calculated on the basis of the FRCOW16 corpus; Written: frequency in written TEF texts; Oral: frequency in oral TEF texts; Total: total frequency in TEF corpus; FRCOW: frequency in the FRCOW16 Corpus.
Vertical bars indicate lemmas that could not be disambiguated by TreeTagger and were therefore collapsed in the analysis.
Following Paquot (2019), we defined phraseological complexity in terms of the diversity and sophistication of the bundles. Whereas previous phraseological complexity research has operationalized diversity using transformations of type-token ratios, the length of the phraseological units in the current study mean that very few of them are repeated verbatim more than once in a given text. As a result, type-token-based measures are not very informative. Instead, we operationalized diversity as the ratio of bundle types to the number of different POS structures. For example, imagine a hypothetical text containing the following four verb-bundles:
faire_VER part_NOM de_PRP DET (“share the”);
prendre_VER effet_NOM avant_PRP DET (“take effect before the”);
pouvoir_VER te_PRO aider_VER à_PRP (“can help you to”);
trouver_VER que_KON ce_PRO être_VER (“find that it is”).
In this text, there are four unique verb-bundles but only three unique verb-bundle POS structures (verb + noun + preposition + determiner, verb + pronoun + verb + preposition, and verb + conjunction + pronoun + verb).

As shown in the above formula, this text would receive a value of 1.33, which reflects the fact that this learner used more than one surface realization of the POS structure verb + noun + preposition + determiner.
The logic behind this measure is that a learner who has a relatively small lexical repertoire will consistently use the same words in the same grammatical structures (resulting in a value of 1), whereas a learner with a larger lexical repertoire will show more variation in the words they use to fill grammatical structures (i.e., each POS structure will be realized with multiple different lexical realizations). The main difference with this measure and previous operationalizations of phraseological diversity is that instead of focusing on one single structure at a time (e.g., the type-token ratio of verb + noun collocations), this measure takes into account the diversity exhibited within all grammatical structures (i.e., verb + noun + preposition + determiner, verb + pronoun + verb + preposition).
Phraseological sophistication was operationalized as the pointwise mutual information (PMI, Church & Hanks, 1990) between the first word in the bundle (e.g., faire_VER) and the rest of the sequence (e.g., part_NOM de_PRP DET). This represents the extent to which the first word (the noun or the verb) selects the rest of the sequence (Dunn, 2018). PMI highlights associations that are highly exclusive. Because of this exclusivity, units with a higher PMI tend to serve specific discursive functions (Ellis et al., 2008). For example, salutation_NOM DET plus_ADV distingué_ADJ (“most distinguished salutation;” PMI = 18.5) is used as a greeting in formal letters. In contrast, bundles with a lower PMI tend to be more general and part of everyday use by virtue of the fact that the noun or verb is often found in other structures (e.g., trouver_VER que_KON ce_PRO suivre|être|sommer_VER; “find that it is;” PMI = 4.5).
Both phraseological complexity measures were calculated using a random sampling method. This was because simply calculating measures based on entire texts would introduce a confound of text length. This is particularly problematic given that the median text length of oral productions was over three times longer than that of written productions (see Table 1). To avoid this, measures of phraseological complexity were calculated as the average over 10 random samples of 5 bundles. 3 This method is similar to one that is used to control for text length when calculating morphological complexity (see Brezina & Pallotti, 2019). Visual inspection of the data revealed that the diversity measures exhibited positive-skew, which was addressed by applying a Box-Cox transformation to both measures.
In addition to the phraseological complexity measures, we also calculated two measures of lexical complexity. This was done to determine the extent to which measures of phraseological complexity provide an additional benefit over and above measures that target single words. If phraseological complexity measures are predictive of proficiency, even when controlling for lexical complexity, it would suggest that lexicogrammatical knowledge indeed represents “a different construct” (as suggested by Paquot, Gries, & Yoder, 2021). Lexical diversity was operationalized using MTLD (McCarthy & Jarvis, 2010), and lexical sophistication was operationalized as the number of words on the 3000, 4000, and 5000 frequency bands of the FRCOW16 corpus (i.e., those that are not within the 2000 most frequent words) (as in Lu, 2012). To control for text length, this measure was computed as the average over 100-word moving windows.
Analysis
We built a mixed effects regression model using the nlme package (Pinheiro et al., 2020) in R in order to predict the proficiency scores of the exams as a function of the lexical and phraseological complexity measures. Texts with fewer than five noun-bundle or verb-bundle types (n = 15) were excluded because they did have enough bundles to calculate the phraseological complexity measures. Exams where the topic could not be conclusively assigned by the model (i.e., where there was a tie between the most highly predicted topics) were also excluded to ensure that the categorical variable “topic” was truly characteristic of the vocabulary in a given text (n = 37). Data were split into a training set (67%) for model building and a test set (33%) to evaluate the generalizability of the model on unseen data.
The following variables were included as controls in the model: L1 of the candidate, JSD (the topic similarity between the oral and written sections of exams), and the total number of words (tokens) to control for text length. Because each candidate contributed two productions to the data set, the model included random intercepts per candidate ID. We initially began with a fully specified model with all levels of L1 and topic (the 7 model-generated topics) and where each of the lexical and phraseological complexity measures was allowed to interact with both mode (written/oral) and topic. We then used backward step-wise model selection in order to determine whether all levels of L1 and topic were necessary to the model and whether the interactions between mode and topic were necessary for each complexity measure (i.e., whether they significantly improved model fit). After simplifying interactions, non-significant predictors were retained in the model if they either acted as a control variable (i.e., JSD) or if they were necessary to answer the research questions (in which case a non-significant result would indicate that the null hypothesis that the given measure is not predictive of proficiency could not be rejected). All numeric predictors were standardized and centered prior to modelling. Initial models revealed problems with homoscedasticity which were resolved by weighting variance according to mode.
Following the model selection process, only five levels of L1 (French, Arabic, Haitian Creole, Kinyarwanda, and other) and two levels of topic (travel and other) were retained in the model. We also tested whether second- and third-degree polynomial transformations of the complexity measures would improve model fit in order to determine whether any of the measures had non-linear relationships with proficiency. This was only found to be the case for MTLD, for which a second-degree polynomial significantly improved model fit.
The supplementary materials for this article are provided on the Open Science Framework (OSF) repository. 4 These include the transcription guidelines, topic-modelling procedure, the full model-selection process, as well as all R scripts mentioned in the preceding sections. The descriptive statistics for all measures are provided in Appendix 1.
Results
The summary of the multiple regression model is provided in Table 3. The model was able to explain 47.21% of variance in proficiency scores overall (conditional R2) and 33.66% of the variance was explained by the fixed effects in the model (marginal R2). On unseen data, the model was able to explain 36.81% of the variance in proficiency scores. Both the residual mean squared error (73.23) and mean absolute error (58.90) indicated that when the model was off, it was usually off by less than one hundred points (i.e., less than one CEFR level). Model diagnostics did reveal some non-linearity of residuals, but this was largely due to data scarcity at the lower end of the proficiency scale. For this reason, the accuracy of the model for proficiency scores lower than 400 (CEFR B2) should be interpreted with caution. In the two sections that follow, we present the results of the model concerning the lexical and phraseological complexity measures. As a reminder, these results show the effects of each measure, while controlling for L1 background, text length, and topic similarity between the oral and written components of exams.
Model summary.
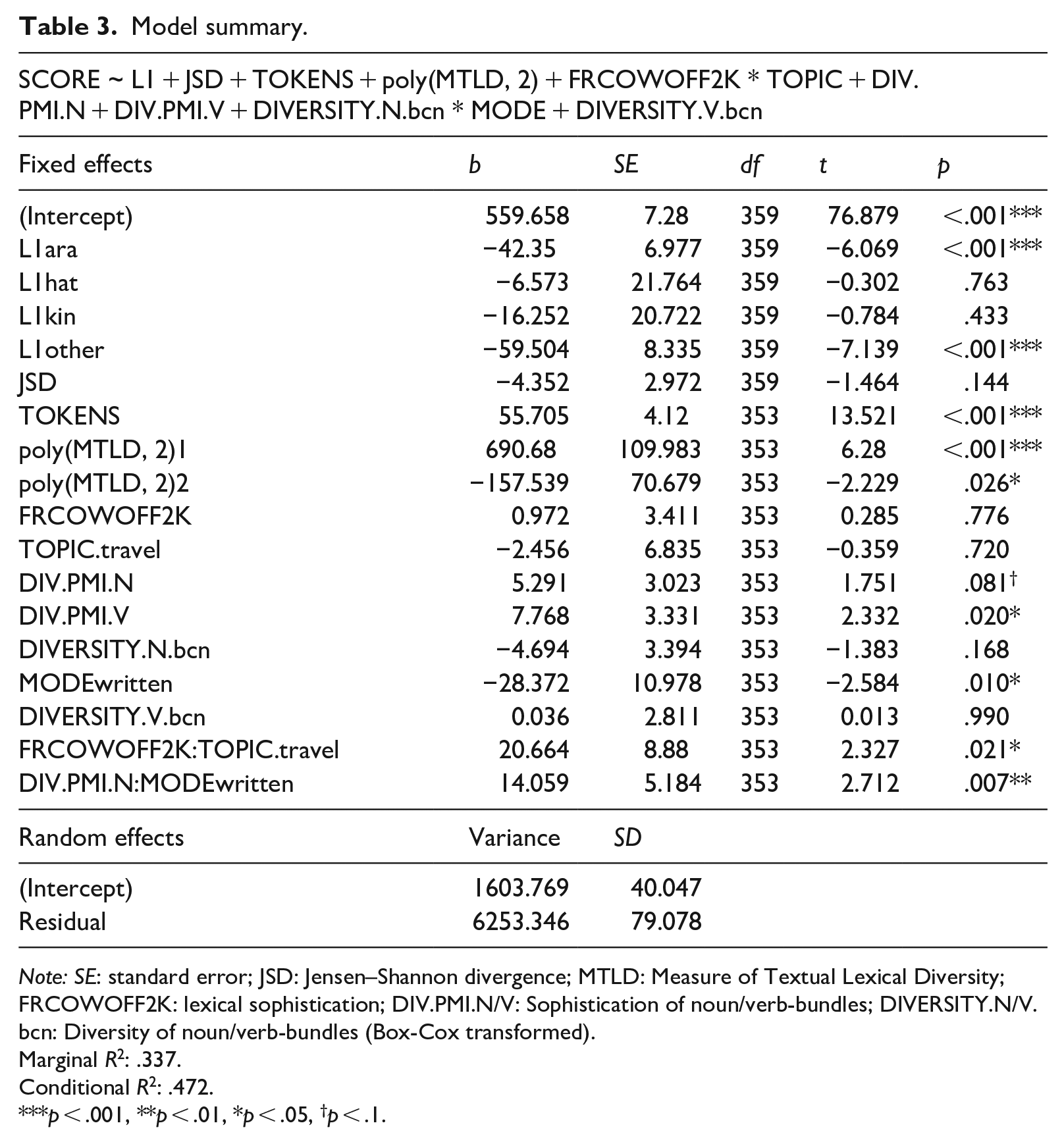
Note: SE: standard error; JSD: Jensen–Shannon divergence; MTLD: Measure of Textual Lexical Diversity; FRCOWOFF2K: lexical sophistication; DIV.PMI.N/V: Sophistication of noun/verb-bundles; DIVERSITY.N/V.bcn: Diversity of noun/verb-bundles (Box-Cox transformed).
Marginal R2: .337.
Conditional R2: .472.
p < .001, **p < .01, *p < .05, †p < .1.
Lexical complexity measures
As shown in Figure 1, there was a significant curvilinear effect of lexical diversity (MTLD) on exam scores whereby an increase in 1 standard deviation of MTLD was found to be associated with 27.26 (95% confidence interval [CI] = [19.5, 35.01]) extra points on the exam. However, this plateaued at z > 1, after which an increase in lexical diversity was no longer associated with an increase in test scores. Lexical sophistication (FRCOWOFF2K) was not found to be positively correlated with test scores except for texts classified as belonging to the topic of travel (as shown by the significant interaction between lexical sophistication and topic). For texts on the topic of travel, an increase in one standard deviation was associated with an increase of 21.64 (CI = [1.09, 42.18]) points on the exam. The lexical sophistication of texts not classified as belonging to the topic of travel was found to be associated with an increase in 0.97 (CI = [−7.23, 9.18]) points (n.s.).
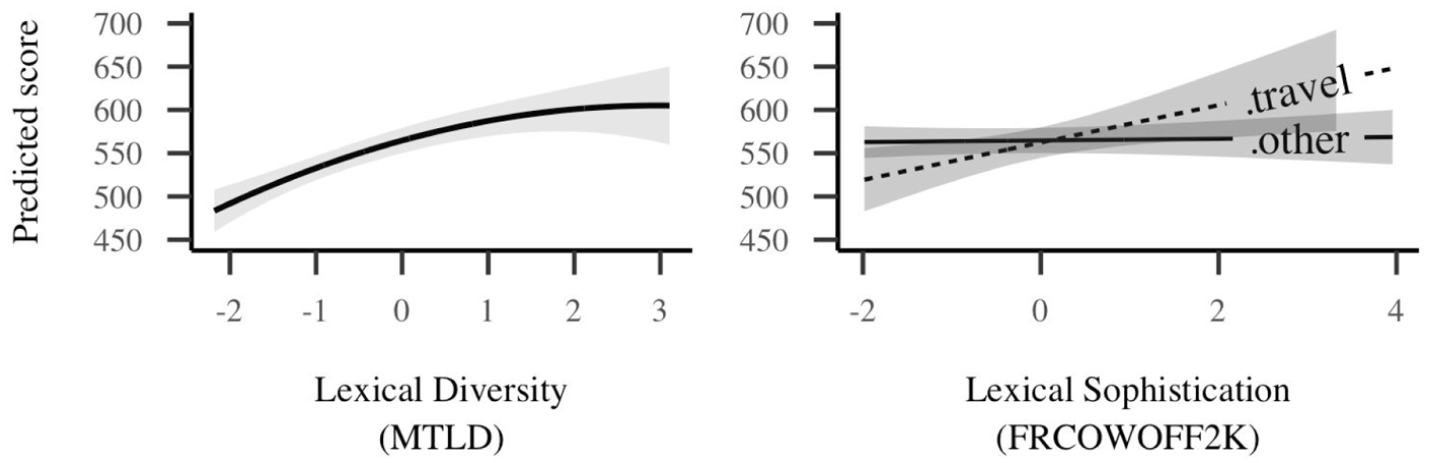
Effects plots for lexical complexity measures.
Phraseological complexity measures
The effects plots for all phraseological complexity measures are shown in Figure 2. None of the phraseological complexity measures were found to interact significantly with topic and only one of the phraseological complexity measures was found to interact significantly with mode: the diversity of noun-bundles (DIVERSITY.N.bcn). In the written task, a one standard deviation increase in the diversity of noun-bundles was associated with 9.36 (CI = [−0.16, 18.89]) extra points on the exam, but in the oral mode, this was associated with 4.69 (CI = [−12.86, 3.47]) fewer points on the exam. The diversity of verb-bundles (DIVERSITY.V.bcn) was found to be slightly positively correlated with proficiency scores, but this was not significant (EMM trend = 0.04, CI = [−5.49, 5.57]). In terms of sophistication, positive correlations were found with proficiency for both noun-bundles (DIV.PMI.N) (EMM trend = 5.29, CI = [−0.65, 11.24]) and verb-bundles (DIV.PMI.V) (EMM trend = 7.77, CI = [1.22, 14.32]) in both modes but only the correlation with the sophistication of verb-bundles was found to be significant at an alpha level of 5%.
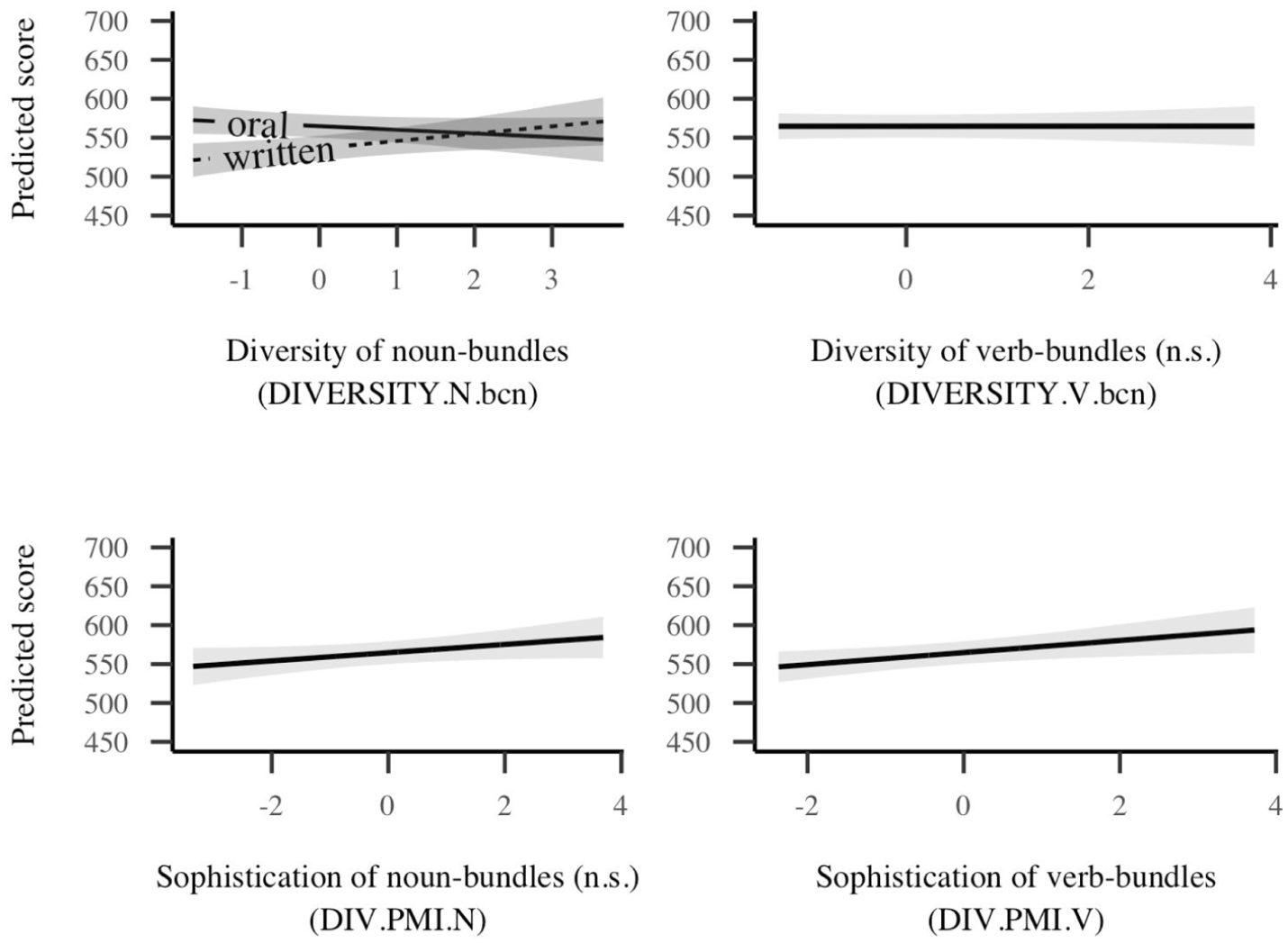
Effects plots for phraseological complexity measures.
Discussion
This study aimed to determine (1) the extent to which measures of phraseological complexity are predictive of oral versus written proficiency scores and (2) the extent to which various measures of phraseological complexity differ in their ability to predict proficiency scores in the two modes.
Phraseological complexity and proficiency scores
A mixed-effects regression model revealed that two of the four phraseological complexity measures were predictive of proficiency scores, namely the diversity of noun-bundles (in the case of the written productions) and the sophistication of verb-bundles (in both the written and oral productions). Importantly, these correlations held even when controlling for the lexical diversity and sophistication of texts. As a comparison, we also built a model that included only lexical complexity measures. This model performed significantly worse than the model with the phraseological complexity measures (Akaike information criterion [AIC] = 8318.00 vs 8310.25, p < .001) and explained slightly less variance in the proficiency scores (Marginal R2 = .31 vs .34), indicating that the lexical complexity measures did not increase their explanatory power once the phraseological measures were removed from the model.
In addition, phraseological measures were found to exhibit two characteristics that made them especially useful as indicators of proficiency. First, unlike with lexical diversity, there was no plateau in the relationship between phraseological complexity and proficiency scores. Increases in phraseological complexity continued to contribute to proficiency scores even at the highest levels of proficiency. Second, none of the phraseological measures were found to interact significantly with topic (cf. Paquot, Naets, & Gries, 2021, who found a significant effect of topic on phraseological sophistication). This was not the case for lexical sophistication, for which a significant positive relationship with proficiency was found only for texts on the topic of travel. Looking at the texts themselves, it seems that relative to other topics, travel seems to have allowed candidates to mobilize a broader range of semantic categories from very general, frequent vocabulary describing common vacation activities (e.g., ski = 25.38/million words; nager, “to swim” = 9.20/million words) to more specific and thus relatively infrequent vocabulary (e.g., moustiquaire, “mosquito net;” 0.97/million words). The fact that such a topic effect was not found for phraseological complexity measures suggests that measures based on the PMI of four-word lexical bundles may be more robust to variations in topic than measures based on the frequency of single words.
It is important to highlight, however, the fact that the contribution of phraseological complexity to exam scores amounted to fewer than 10 extra points on the exam for every one standard deviation increase in phraseological complexity (holding all other variables constant). While this is a rather modest contribution, it is still much larger than that of lexical sophistication, which for texts not on the topic of travel, only amounted to an increase of about 1 extra point (n.s.) for every one standard deviation increase in lexical sophistication. This is despite the fact that examiners are explicitly asked to evaluate vocabulary use in the scoring rubric for the TEF exam.
According to Kane (2006, p. 144), when scoring keys include inappropriate criteria or omit some important relevant criteria, this constitutes a threat to the inferences that can be made on the basis of such scores. Specifically, the results here suggest that intentionally or not, raters were sensitive to the phraseological complexity of the TEF productions, as evidenced by the significant relationship between test scores and phraseological complexity measures. It is not clear from these results precisely how raters took this into account however, given that there is no mention of phraseology or idiomaticity in the scoring rubric. In the case of the TEF, this is especially problematic because the total score is calculated using a formula that takes into account the differences in scores between each sub-criterion (e.g., syntax, lexis, coherence/cohesion). It is therefore crucial that the scores attributed to each sub-criterion actually reflect what they are intended to reflect. If some raters considered phraseological complexity a part of lexis but others considered it a component of syntax, this could lead to differences in the final score given to exams that are objectively similar in terms of global proficiency.
On the basis of the results in this study alone, it is not possible to elaborate further on exactly how lexicogrammatical/phraseological phenomena should be taken into account on scoring rubrics (e.g., as part of existing sub-criteria or as a completely new one?), but future work would do well to explore this question more systematically. What does seem to be important though is that raters receive more explicit instructions as to how such aspects of linguistic competence should be evaluated, in light of the fact that lexicogrammatical competence constitutes an important aspect of proficiency from a theoretical level (Biber, 2009; Römer, 2009; Sinclair, 1991; Stefanowitsch & Gries, 2003) and that raters appear to be sensitive to such phenomena even when they are not included in scoring rubrics.
Differences between phraseological complexity measures
The results of this study also showed that measures of diversity and sophistication differed in their ability to predict proficiency scores for the two types of phraseological units that were extracted. For noun-bundles, diversity was more predictive of proficiency than sophistication. When it comes to verb-bundles however, it was sophistication rather than diversity that was most predictive of proficiency scores. These two findings are each discussed in more detail below.
The diversity of noun-bundles
In the case of written productions, using a diverse set of noun-bundles was associated with higher proficiency scores. This is likely because noun-bundles tap into the phrasal complexity features typical of academic, written discourse (Biber, 2019; Halliday & Matthiessen, 2006). A candidate who uses a variety of noun-bundles in written production therefore demonstrates both knowledge of the functional requirements of the register (e.g., the use of nominalizations and post-modification of nouns) and shows evidence of a broad lexicogrammatical repertoire. In oral productions, on the contrary, greater noun-bundle diversity was associated with lower proficiency scores. This may be because phrase-level complexity features are less important in speech, which tends to have a more personal or involved focus.
Another possibility is that the “diversity” of oral productions is actually due to the repetition of a small set of semi-fixed units, in line with Römer’s (2017) finding that spoken corpora are made up of highly frequent but variable expressions (e.g., I think/mean/thought/know/suppose it) and Leech’s (2000, p. 697) claim that speech relies on a “restricted and repetitive lexicogrammatical repertoire” due to the constraints of real-time processing. For example, in one low-scoring oral production (CEFR B1), a candidate used the following two noun-bundles within the same utterance: temps avec tes enfants (“time with your children;” PMI = 4.5) and sport avec tes enfants (“sport with your children;” PMI = 3.05). The two bundles are technically unique and thus contribute to a higher value for noun-bundle diversity, despite only differing by one word. To check if this might the case more broadly, we calculated the number of noun-bundles in each text that differed by only one word from another noun-bundle in the same text. As suspected, noun-bundles were repeated with only a one-word difference 0.55 (SD = 0.94) times on average in oral productions, compared to 0.18 (SD = 0.45) times in written productions. Of course, this is only a very crude estimate (and there is a large amount of variation), but it provides more evidence that speech may indeed be less lexicogrammatically diverse than writing overall and suggest that when it comes to lexicogrammatical diversity, simplistic descriptors such as the more . . . the better are not necessarily accurate for oral production. These results also hint at the potential usefulness of looking at patterns of lexicogrammatical “fixedness” in French, that is, the use of fixed, invariable expressions compared to “slot-and-frame” expressions with variable internal components (along the lines of Biber’s, 2009, study of such patterns English).
The sophistication of verb-bundles
Although we had expected that verb-based measures would be more predictive of proficiency in the oral productions than in the written productions, we found no significant interaction effect of mode. The sophistication of verb-bundles was positively associated with proficiency to the same extent in both written and oral productions. In retrospect, this finding is actually quite logical because both tasks require argumentation: an opinion about a controversial topic in the case of the written task and reasons why a friend should participate in an activity in the oral task. As shown by Biber et al. (2004), lexical bundles that are used to express attitudes or assessments of certainty (what the authors refer to as “stance bundles”) tend to be composed of dependent clauses and verb phrases (roughly equivalent to the verb-bundles in the current study). This means that the requirements of both tasks (persuading the addressee) require the use of clause-level syntactic features and so the major factor differentiating candidates is therefore the sophistication of the verb-bundles. Candidates who use more sophisticated verb-bundles show evidence of having a larger lexicogrammatical repertoire (all other things being equal) because they are able to draw on more specific or appropriate phraseological units.
This finding is consistent with the longitudinal results of Vandeweerd et al. (2021), who found that the sophistication of verb + noun collocations increased significantly over a 21-month period in both written and oral tasks produced by university-level learners of French but that no significant change was observed for adjective + noun collocations. Together with the findings of Vandeweerd et al. (2021), our results suggest that because verb-bundles tap into communicative functions that are common to both oral and written registers, they may be more useful as broad measures of lexicogrammatical competence when comparing across modes.
Taken together, the results of this study suggest that lexicogrammatical complexity represents a separate construct from that of lexical complexity and provide more evidence in favour of including lexicogrammatical criteria within language testing rubrics (Paquot, Gries, & Yoder, 2021). At the same time, it is important to be cautious of descriptors that are too simplistic and ignore the functional differences between tasks. In Europe, proficiency tests such as the TEF are indexed to the Common European Framework of Reference (CEFR, Council of Europe, 2001). As Paquot (2018) points out, the CEFR promotes a rather traditional understanding of phraseology and does not do justice to the ways that both lexis and grammar interact with communicative function, especially at the higher proficiency levels. As an example, in both the original descriptors and the revised version (Council of Europe, 2018), the use of “prefabricated expressions” is listed as an indication of lower proficiency. This contrasts somewhat with the results here, which found that certain lexical bundles are actually quite sophisticated by virtue of their exclusivity (PMI) and the fact that they demonstrate knowledge of the characteristics and linguistic requirements for certain registers (e.g., the use of je me permets de réagir in formal written letters). To be fair, the most recent version of the CEFR does acknowledge the importance of co-occurrence and recurrence phenomena but this is only within the description of vocabulary control in general, not within the descriptor scales: “as competence increases, such ability is driven increasingly by association in the form of collocations and lexical chunks, with one expression triggering another” (Council of Europe, 2018, p. 134). However, as shown by the results of this study, reducing the relationship between lexicogrammatical competence and proficiency to a simple linear association, as has previously been done in phraseological complexity studies, does not do justice to the complex ways that lexis and grammar both interact with register, modality and proficiency.
Conclusion
In the introduction to this article, we argued (in line with Römer, 2017) that conceptualizing lexis and grammar as solely separate phenomena may lead to invalid inferences about a candidate’s linguistic competence given evidence from target language use. We also discussed the ways in which phraseological phenomena are likely to differ between written and spoken exam tasks. Specifically, we hypothesized that the association between phraseological complexity and proficiency would be mediated by constraints of online processing (Skehan, 1998) and register (Biber, 2019). In order to investigate this, we carried out a study in which we compared the complexity (diversity and sophistication) of two types of phraseological units (noun-bundles and verb-bundles) between oral and written productions from the TEF exam. The results of this study showed that phraseological complexity measures were significant predictors of the proficiency scores assigned to texts by raters, even when controlling for lexical complexity. As it turned out, these measures were even better predictors of proficiency than measures of lexical diversity or sophistication. The results also spoke to the interplay between phraseological complexity, modality, and register when it comes to evaluating proficiency.
The advantage of the measures presented here is that they allow vague descriptors of linguistic competence (e.g., “as competence increases, such ability is driven increasingly by association . . . ”) to be objectively quantified and measured more accurately than may be possible with human raters (Clauser et al., 2010; Williamson et al., 1999). However, it is important to point out that just because the complexity measures employed in this study are correlated with proficiency scores attributed by professional raters, it does not automatically follow that they perfectly represent the construct they are intended to measure (see Pallotti, 2015). Moving forward, it will be important to further evaluate the extent to which these measures really capture the construct of phraseological complexity (e.g., by grounding them in human judgements of phraseological competence and not just proficiency). Such evidence would contribute to understanding the validity of phraseological complexity measures as indices of linguistic proficiency more broadly (see Chapelle & Chung, 2010) as well as their potential usefulness to language assessment (e.g., in automatic scoring).
It is also important to highlight the limitations of the current study. For one, in sampling the TEF exams, we made a decision to prioritize cross-modal topic similarity but this came at the expense of a less diverse sample of proficiency levels. This meant that the data that was used to build the model was skewed towards higher proficiency levels so the applicability of these findings to lower-level learners (below CEFR B2) will need to be investigated in future studies. In addition, our rather broad focus on all noun- and verb-bundles in this study may be criticized for lack of linguistic precision. While it is certainly the case that not all units that were extracted were necessarily equally as informative about proficiency, this study does represent a good first step in broadening the scope of phraseological complexity measures beyond co-occurrence phenomena to include recurrence phenomena such as lexical bundles. In future studies, it may be fruitful to explore the differences between different noun- or verb-bundle structures and to evaluate the usefulness of other aspects of recurrence (e.g., fixedness as in Biber, 2009).
Finally, it is important to acknowledge that although lexicogrammatical complexity was shown to be relevant to the evaluations of proficiency in this study, there are of course many other pragmatic and linguistic factors that raters take into account when scoring an exam. Future studies would do well to explore the extent to which lexicogrammatical complexity works in combination with other aspects of proficiency (e.g., accuracy, fluency) as well as how both factors contribute to the ability to accomplish the exam tasks.
While we realize that a complete description of the complicated relationship between phraseological complexity, register, and modality is probably beyond the scope of most scoring rubrics, the results of this study show that if descriptors are too simplistic, they risk painting an inaccurate picture of linguistic competence, which constitutes a threat to inferences about a candidate’s proficiency made on the basis of exam results. At best, ignoring lexicogrammatical competence may under- or over-estimate a candidate’s proficiency. At worst, scoring rubrics may suggest associations between linguistic features that are actually negatively correlated with proficiency. Considering the results of this study, it seems clear that scoring rubrics should, at the minimum, make reference to lexicogrammatical competence, in addition to lexis and grammar because as argued by Paquot, Gries, and Yoder (2021, p. 229), lexicogrammatical knowledge is not simply the “sum of lexical and grammatical knowledge.” That being said, we agree with Römer (2017) that as corpus linguists, we do not have the relevant expertise to provide advice about the precise way that these findings should be applied. We do hope however that the results of the current study can help to inform a more empirically grounded approach to the lexis–grammar interface in language testing.
Footnotes
Appendix 1
Descriptive statistics for data used in model building.
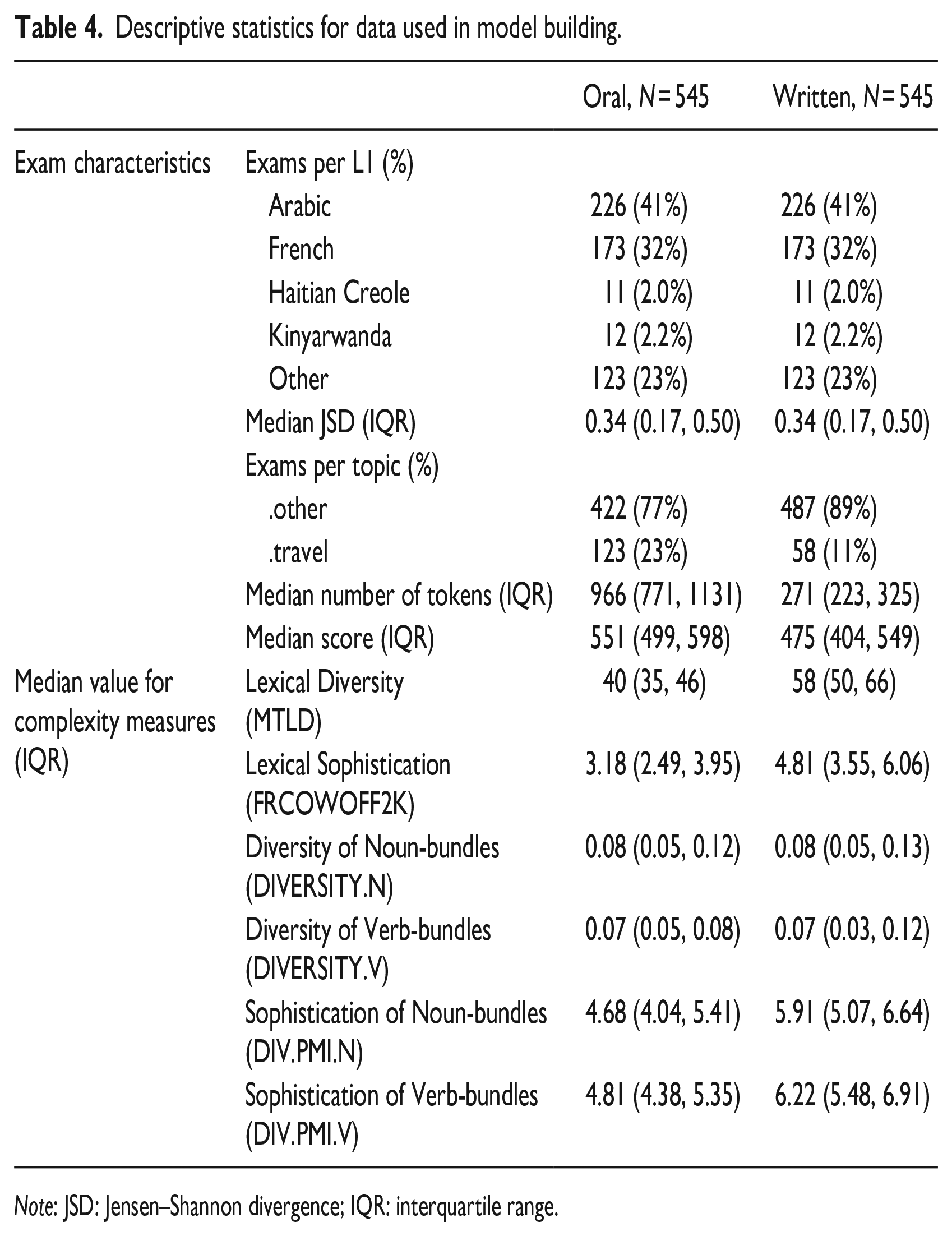
| Oral, N = 545 | Written, N = 545 | ||
|---|---|---|---|
| Exam characteristics | Exams per L1 (%) | ||
| Arabic | 226 (41%) | 226 (41%) | |
| French | 173 (32%) | 173 (32%) | |
| Haitian Creole | 11 (2.0%) | 11 (2.0%) | |
| Kinyarwanda | 12 (2.2%) | 12 (2.2%) | |
| Other | 123 (23%) | 123 (23%) | |
| Median JSD (IQR) | 0.34 (0.17, 0.50) | 0.34 (0.17, 0.50) | |
| Exams per topic (%) | |||
| .other | 422 (77%) | 487 (89%) | |
| .travel | 123 (23%) | 58 (11%) | |
| Median number of tokens (IQR) | 966 (771, 1131) | 271 (223, 325) | |
| Median score (IQR) | 551 (499, 598) | 475 (404, 549) | |
| Median value for complexity measures (IQR) | Lexical Diversity |
40 (35, 46) | 58 (50, 66) |
| Lexical Sophistication |
3.18 (2.49, 3.95) | 4.81 (3.55, 6.06) | |
| Diversity of Noun-bundles |
0.08 (0.05, 0.12) | 0.08 (0.05, 0.13) | |
| Diversity of Verb-bundles |
0.07 (0.05, 0.08) | 0.07 (0.03, 0.12) | |
| Sophistication of Noun-bundles |
4.68 (4.04, 5.41) | 5.91 (5.07, 6.64) | |
| Sophistication of Verb-bundles |
4.81 (4.38, 5.35) | 6.22 (5.48, 6.91) | |
Note: JSD: Jensen–Shannon divergence; IQR: interquartile range.
Acknowledgements
We are extremely grateful to the Chambre de commerce et d’industrie de Paris for their participation in this project, and in particular, to Dominique Casanova. We would also like to thank Héloïse Copin, Anthonya Delfosse, and Thibaut Mareschal for their work transcribing and annotating the exam data.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Fonds de la Recherche Scientifique (FNRS) under Grant no. T0086.18.