
Abstract
Attempts to visually represent the human face in various media forms have a long history. Fairly recent examples can be found in techniques that are used in animated films and video games (performance capture) or in the controversial phenomenon of “deep fakes”. The article looks at the relationship between faces, the media forms that are used for their representation and simulation and the knowledge that is (re)produced about emotions and their communicative effects. It reveals a peculiar contradiction: the quest to create a synthetic digital face that would be universally recognisable in terms of emotional readability and response homogenises our understanding of emotion while disguising the challenging cultural barriers to this recognisability. The simulated face caters to a two-fold and hence paradoxical aesthetic aspiration that places it between uniqueness and universality. By elaborating on the somatic, affective dimension of communication via faces, the article compares culturally specific modes of producing and reading emotions. A Euro-American tradition of thought regards them as artefacts, constructed as antagonists of rationality, that can be controlled and objectively modelled and measured. The idea of the face as the locus of emotions, which can be represented in distinct expressions, contrasts with more ambiguous and relational meanings in East Asian, particularly Japanese contexts. The epistemological genealogy of the facial display of emotions, however, does not conform to a clear West/East divide and is at the same time highly interwoven with specific media forms of their representation. In order to deepen this dynamic understanding of artificial faces, the article looks at different examples of Japanese traditions and art forms. Examples such as portraiture and photography, the subtle illusions created in Nō theatre and the less subtle ones evoked by robotic faces shed a light on the complex meanings but also the affective reactions to artificial faces.
Keywords
Introduction
The relationship between the human face and various media forms such as masks or portraiture has a long history. 1 It is also a complex one, since the human face plays such an essential role in interpersonal communication. The face is strongly linked to ideas of the self and social identity and is regarded as the central site associated with affect, emotion or physical attraction. At the same time, historically and culturally specific media forms are also instrumental in shaping our understanding of the human face. This relationship flickers between representation when the ‘real’ human face is acknowledged as a reference object in art forms such as portrait photography or painting and simulation, when the medium disguises or altogether rejects the necessity of an actual human face, as it is the case with masks or especially with digital media practices. The different cultural techniques used to produce various instantiations of an artificial face simultaneously create the notion that the human face, in effect, can be treated as an independent signifier. Somewhat paradoxically, they remind us that the qualities of an actual human face defy replication.
This centuries-old relationship is being rethought in the current discussions on fairly recent variations of digital faces that are not stills but moving images capable of simulating nuanced changes in facial expressions. The heightened degree of verisimilitude is particularly associated with an ability to effectively and persuasively communicate emotional states. Besides being featured in animated films and video games, the simulated faces in motion are also tied to so-called ‘deep fakes’. This controversial phenomenon describes the use of machine learning (‘deep learning’) to create simulated content that pretends to truthfully depict the face and sometimes also the voice of a real person.
The increasing relevance of simulated faces is also reflected in digital communications technologies, where the depiction of a human face has become the prime marker for an individual’s online self. The creation of purely ‘virtual models’ that are represented by their own social media accounts embeds the simulated face into a social context. 2 While it has often been argued that that the mere increase in ‘accessibility’ and ‘believability’ of simulation technologies makes the ‘fake’ audio-visual content a singular and disconcerting phenomenon (Kietzmann et al., 2020), it is also this direct connection to notions of authenticity, identity and reality that makes the perfection of artificial faces so controversial. They are associated with the communicative intention to deceive and potentially manipulate viewers or users while being seen as instrumental in the problematic rise of misinformation. One major reason for the uncanniness of the digitally perfected artificial face – meaning the uncertainty about the strange in the familiar in a Freudian sense – is that it ‘speaks’ to us on an affective level, even triggering a somatic response: we feel attracted or repulsed, amused by the deception, and we are invited to project social or emotional meanings onto the empty simulation. It is the same effect that makes human-like robots or emotion-sensitive computer interfaces both appealing and unsettling.
These technologies of simulated emotions are rooted in much older ideas that the human face is a medium itself, communicating emotional states that can be broken down into independent analytical units. The sequence from representation to recognition to analysis to simulation of emotions is an epistemological practice of knowledge production, with the digitally perfected artificial face just being its latest instantiation. It is crucial to remember that, even though the glossy audio-visual perfection insinuates otherwise, the current forms of facial simulation are nothing but a continuation of specific histories of representation. Still they continue to foster the narrative that once emotions can be described and codified, each analytical element can be understood independently. The human face, in this reading, is reduced to a production site for meaningful communicative units that seem easily reproducible and susceptible to being digitised, datafied and synthesised. The illusion that is created here is much more consequential and far-reaching, and yet it is much less debated than the bemoaning of the mere ‘fake’ character of simulated faces.
For this reason, it is important to emphasise that despite the attempts to create a universally recognisable notion and representation of an artificial digital face, the underlying epistemological premises and practices are strongly linked to a specific historically, culturally and regionally defined moment. As will be argued, the artificial face is embedded in an aesthetics that mediates between uniqueness and universality and is interwoven with and shaped by certain media forms. The digitally perfected artificial face reproduces epistemological models that mainly account for analytical perspectives, which single out and focus on defined units and are limited to the face (object-oriented approaches). To a large degree, these approaches marginalise other models that take into account a relational and situational dynamic, which is strongly based on implicit forms of knowledge that are much harder to render computable. The analysis of examples taken from an East Asian, mainly Japanese context shows that the relational, contextual or affective meanings of emotion can be meaningfully expressed in other media forms, challenging assumptions of universality originating and globally reproduced in the model of Euro-American discourses. In a broader sense, the argument highlights the implicit epistemological assumptions that are inscribed into technologies that are mainly designed to reproduce object-oriented approaches. The conceptualisation, production, advertising and use of these technologies consequently reproduce a particular (mediated) history and understanding of emotion that is distinct from – and quite easily challenged by – other media forms, their histories and meanings. These marginalised perspectives matter, especially in an age where seemingly universal (media) technologies are becoming instrumental in (often very subtly) establishing a specific but dominant knowledge as universal knowledge.
To address these questions, the article will first focus on the aesthetic aspects that make the digital face in motion different from previous media forms. In particular, it will argue that the suggestive power of audio-visual media and of the moving image are effectively combined with the affective dimension of communication to which the human face is central. In other words, these representations evoke an extraordinary suggestive power by simulating human faces in action. This suggestive power is particularly associated with specific somatic effects. The face, which is regarded as the prime site where human emotions are represented, can for this reason – even in this simulated form – trigger particular perceptions of trustworthiness, attraction and sympathy or feelings of anxiety and disgust. The relationship between faces, the media forms that are used for their representation and the knowledge that is produced about emotions and their communicative effects reveals a peculiar contradiction: the quest to create a synthetic digital face that would be universally recognisable in terms of emotional response homogenises our understanding of emotion while disguising the challenging cultural barriers to this recognisability. The paradoxical aesthetic aspiration of the simulated face places it neatly between uniqueness and universality (Section 1).
Elaborating on the somatic, affective dimension of communication via faces, the article will take a perspective that compares culturally specific modes of reading emotions. As will be argued, the Euro-American tradition of thought regards emotions as artefacts, quasi-objects seen as antagonists of rationality, that can be controlled and objectively modelled and measured. Findings from cognitive science on the differences in perceiving and representing emotions in faces make it clear that this idea of the face as the locus of emotions, which can be represented in distinct expressions, contrasts with more ambiguous and relational meanings in East Asian, particularly Japanese contexts. The epistemological genealogy of the facial display of emotions is highly interwoven with specific media forms of their representation (Section 2).
In order to deepen the understanding of non-European and non-American representations of faces and their affective dimension, the concluding section looks at different examples of Japanese traditions and art forms. Their different ways of conveying emotions will highlight an ambivalence that is heavily contingent on cultural conventions. Examples such as portraiture and photography, the subtle illusions created in Nō theatre and with robotic faces will shed a light on the complex social norms and cultural traditions that shape the meanings but also the affective reactions to artificial faces (Section 3).
Aesthetic characteristics of simulated faces – between uniqueness and universality
It is close to impossible to simply distinguish the presence of a ‘real’ human face from its visual representation. Belting (2017), in his ‘double history’ of the face and mask, interweaves the presence of the face with a common media form used to represent it. The fact that the human face is firmly situated and grounded in specific cultural and social contexts, conventions and restraints, makes it impossible to have a neutral, unbiased and non-judgemental look at it. At the same time, as Belting (2017: 5) points out, ‘the living face produces an expressive or masklike representation in order to show or conceal the self. Human beings engage in the representation of their own faces. Thus, we all embody a role in life’. As a consequence, it can be argued, the face is always to be regarded as both material presence and representation. This is also why the ‘history of the face’ (histoire du visage; Courtine and Haroche, 1988) can be understood as ‘a social history of emotions in the modern period in the West’, one that is characterised by ‘different varieties of individuality’ and in which ‘self-expression (the will to show one’s own emotions) collided with self-control (the desire or compulsion to regulate the emotions)’ (Belting, 2017: 4). This link to emotions is intensified by the affective reactions that are triggered in us when we see a face that we regard as beautiful, attractive, unusual or repulsive.
Despite these specificities of how faces are culturally and socially situated, the idea of universality – translated into expectations of universal meanings that are associated with universal facial expressions – has a long tradition that, as will be argued, is also articulated in practices involving the creation of digital faces. The experiments of the French neurologist Guillaume-Benjamin Duchenne (1806–1875) on the ‘the mechanism of human facial expression’ (Duchenne, 1862) combined electrical stimulations of facial muscles, which were meant to trigger specific expressions that would in turn be photographed in order to create a taxonomy of human emotions. According to Delaporte (2008), the idea of a cognitive-emotional face does not exist prior to Duchenne. Starting with his reflections on the face it could be seen as a major site of revealing an inner life, a universal ‘anatomy of the passions’ (Delaporte, 2008). This link between facial expressions and the usually hidden world of mental states was taken up by Charles Darwin in his work on ‘the expression of the emotions in man and animals’ (1872). These approaches, which singled out individual facial muscles as serving one specific function that “encoded” a particular emotion, were instrumental in shaping the Euro-American understanding of the face as a universal system of signification.
Looking at the ways in which this influential knowledge was produced, there is an interesting link to current discourses on the digital face that are central to the argument pursued here. The experiments are based on simulating specific expressions (via electric stimulation) in the face, caught with and represented in a contemporary state-of-the-art medium (analogue photography) to be associated with certain meanings. It is obvious that the relationship between faces, their expressions, the modalities of the media forms and the artificiality of their creation has a long tradition, with digital faces only being the latest instantiation.
The same is true for technological practices of digitally simulated content (e.g. computer-generated imagery, CGI; ‘photo realism’ in virtual reality etc.) that have long been applied in the creative industries (e.g. Bode, 2017). With the rise of other media technologies – in particular digital photography – questions about the loss of authenticity and auctorial authority were habitually raised (Lister, 2004). These historical predecessors to simulated content speak for the idea of continuity that does not regard the rise of simulated faces, deep fakes in particular, as potentially disruptive. While these analogies are certainly worthwhile, they fail to acknowledge today’s radically different media environments, most notably the major role of platforms, which effectively create fragmented publics that follow their own rules (Poell et al., 2019) and hence provide an ideal ground for fake content to flourish. This contradictory interpretation of newness and continuity is also reflected in analyses of the deep fake phenomenon that often feature two very familiar tropes: on the one hand, you have dramatic accounts of what is new and dangerous about the evolving technology (e.g. Greengard, 2020) 3 ; they are put into perspective by other approaches which emphasise that there is ‘nothing new here’ and instead demand a shift in focus to the underlying social structures (Burkell and Gosse, 2019).
Yet, there are distinct characteristics of simulated digital faces (such as performance capture or animation) defining their specific aesthetic qualities. In addition, these qualities are shaped by contextual and discursive meanings – particularly in the debates on deep fakes – that also ascribe a certain deceptive power to them.
(1) Most straightforwardly, simulated faces in motion constitute a multimodal form that combines both audio and visual characteristics. Particularly looking at deep fakes, Kietzmann et al. (2020) provide a typology that follows different media modalities: photographic – making changes to a face, replacing or blending the face (or body) with someone else’s face (or body); audio – for example, changing a voice or imitating someone else’s voice; video – e.g. face swapping or full body puppetry; and the combination of video and audio – for example, changing the mouth movements and words spoken in a talking head video. What at first sounds like a straightforward feature that distinguishes them from misrepresentations in written text or manipulated still pictures becomes the basis for the much more important aesthetic quality. (2) The suggestive power of audio-visual media and the moving image has even been legally recognised for televisual mass media in particular as giving the appearance of high authenticity (e.g. German Constitutional Court, 2007). Text-based media are usually received more critically by media literate readers – an awareness that increasingly extends to users of social media platforms and video sharing sites. This degree of media literacy, however, is challenged by the depiction of faces, especially those that are already known from other contexts. In aesthetic terms, and particularly as a commentary on deep fakes, the ‘uncanniness of these photos and videos is not because of their lack of relation to reality, but because of their incorporation of partial traces, some of which are visual, some of which are kinaesthetic. Deep fakes are concerning because of the connection they have to reality, not the absence of that connection’ (Bollmer, 2019b: 24; cf. Floridi, 2018). (3) Faces are central to affective modes of communication and give pre-reflexive cues about emotional and mental states. The human face can even be regarded as the prime site of trust, empathy and understanding, as well as of truth and authenticity; its physical presence thus emanates a unique quality (Lévinas, 1986). The idea of faces as indicative of a metaphysical depth below surface appearances on the one hand fuels the aesthetic effect of digital and simulated faces while at the same time destroying its uniqueness by converting it into the realm of consumable (reproducible or even artificial) goods (cf. Han, 2017; Agamben, 2007). The simulated face cites a void.
Of particular importance regarding the consequences for individuals is the somatic dimension of the technology, which can be directly linked to the provided simulated content. A person’s real face and voice, for example, can be integrated into pornographic videos, evoking real feelings of being violated, humiliated, scared or ashamed (cf. Chesney and Citron, 2019: 1773). This somatic dimension and the psychological effects of simulated faces clearly hint at a complex relationship between technology, affect and emotion that is further complicated with the use of deep fakes. 4 In a larger context, the content provided and the interactions facilitated on social networks are regarded as ‘social reality’ per se, as part of a highly mediatised social life. The digital self is a dynamic project, continuously co-authored by other users. This is why digital images and videos affect both the individual idea of the self as well as the social persona of the public and/or publicised self, along with its communicative effects and collaborative construction (McNeill, 2012; cf. Rotman, 2008). Both appear to be part of a space that is open and hence in principle is vulnerable. Identification with digital representations of the self can evoke somatic reactions to ‘virtual’ harm, such as rape or violence that is committed against avatar identities (cf. Danaher, 2018). Both the communicative and the somatic effects can be assumed to be even stronger with deep fakes, since they provide a seemingly accurate representation of the portrayed self. For this reason, it is hardly surprising that, on a discursive level, the debates around deep fake videos clearly express enormous social and individual anxieties concerning online reputation and the manipulation of individuals’ identities and social personae.
Paradoxically, these somatic effects are triggered by images that prioritise the face over the body. In the majority of cases, the body is even absent from the representation altogether. This unlinking of embodied appearance from motion, voice and action involving the whole body (its gestures, movements and position) that is characteristic of performance capture and deep fakes generates an additional uncanny uncertainty about what we are actually seeing. 5 With regard to the affective dimension this again underscores the assumption that facial expressions are in fact the sole arena of emotions, a notion that has also been promoted by preceding media forms such as cinematic film.
In essence, these paradoxical characteristics of simulated faces lead to a contradictory aesthetics, a double logic of uniqueness and universality: On the one hand, it strives for a perfected simulation that is capable of providing unique representations, while on the other hand it aims to create a synthetic digital face that would be universally recognisable (especially in terms of an emotional response), generally negating the cultural barriers to this recognisability.
Bollmer's (2019b) discussion of performance capture is a case in point here. He argues that realism in video and computer games relies on ‘embodied motion’ (kinaesthetic), ‘because kinaesthetic indices serve as the grounds from which digital animation in games represent “real bodies” via abstracted movements rather than visual verisimilitude’ (Bollmer, 2019b: 3). Performance capture can be used in video games to make characters speak and gesture in different languages ‘without any obvious disjuncture between animated facial expression and dialogue’, in order to accommodate markets ‘beyond the hegemony of Anglophone countries’ (Bollmer, 2019b: 5). In particular, Bollmer (2019b: 5) discusses an example, in which the performance of a female Japanese actor is ‘copied in a digital model of a completely different, seemingly white body’; underneath the facade of inclusion promoted by the production company, we witness the erasure ‘of the visual presence of the actor, abstracting out her gestures and speech to place them into another body – one that appears to be white’.
Bollmer (2019b: 6) aptly concludes that the technique of performance capture used in this instance – a variation of the simulated face – ‘appears to push digital animation in two contradictory directions. First, towards an increased cultural specificity. […] But, second, towards a greater sense of universality. Singular character models can be remade in any context through a set of tools that assume all human beings share the same set of emotions and facial gestures at an anatomical and neurocognitive level […]. This fragments the bodies of actors, placing particular gestural, kinaesthetic traces linked to specific, physical bodies into generic, “universal” models – while employing a normative model of facial expression that assumes, at some level, all bodies express and interpret facial expression equivalently’.
The simulated face, it seems, is able to capture universal expressions. The body and its movements, the relative position it takes and its posture, however, are crucially important for communicating affective meanings. The focus on the face overlooks gestures and the kinaesthetic qualities of the body. For East Asian (especially Japanese) contexts, it must be added that this layer of meaning is essential for understanding and adequately interpreting social settings and situations. This is why, in the following section (Section 2), the analysis will focus on the socio-cultural particularities of expressing and reading emotions – especially the hegemonic Euro-American conventions – in order to highlight these contradictions. Finally, Section 3 will discuss examples from the Japanese context of how emotions and the affective dimension of communication are meaningfully produced with a particular emphasis on the body and its contexts, defying a reductionist approach that solely focuses on the face.
Media forms and epistemologies of (artificial) faces – culturally specific modes of en/decoding emotion
The most prominent and most often used model to encode and decode emotion expressed in human faces is the so-called emotional facial action coding system (EMFACS), which regards distinct facial expressions as indicative of internal emotional states, represented by the relative position of 42 muscles on each half of the face (Ekman et al., 2002; Ekman and Friesen, 1984). 6 The model also assumes that so-called basic emotions – happiness/joy, fear, surprise, anger, disgust, sadness – are universal and communicated and understood across cultures through facial expressions. Regarding the simulation technologies discussed in the previous section, FACS is often used to synchronise digital textures with 3D models in performance capture and as the basis for the software used to adjust and manipulate faces. This practice relates to FACS as a technical system that identifies where facial muscles attach to bones and joints below the skin.
The EMFACS model, which relates these muscular points to specific movements that are presumed to be universal, is used to identify emotions in facial expressions. It has – also via the popularity of the FACS taxonomy – become an almost hegemonic model that is used for this purpose in information and computer science, since it produces data that is perfectly and universally machine-readable. 7 EMFACS relies on a broader genealogy 8 going back to Duchenne 9 (see above) with a strong association with contemporary media technologies. Bollmer (2019a) traces back how the model of discrete emotions assumed by Ekman was created earlier in American psychology to determine if people even could identify what emotions actors were performing. In particular, he shows that ‘the identification of “affect programs”, as employed in technologies of emotion detection’ can be ‘linked with a particular media history, one of books of faces used in psychological research from the late 1800s to the 1960s’. The algorithms that are currently used for visual emotion detection recur to the ‘serial images of the same human face, either bound in book form, printed in the pages of academic journals, or organised in unbound photographic folios’ (Bollmer, 2019a: 126–127). The main point of this argument is precisely that the differentiation and categorisation of emotions always depends on the specific media that are developed and applied for this purpose. 10 This approach fundamentally contradicts the primary claim of affect program theory, which is ‘that each of the “basic emotions”, which include emotions such as fear or anger, has a specific, unique neural ‘circuit’ or ‘signature’ (or ‘program’) that is triggered based on a response to a particular stimulus’ (Bollmer, 2019a: 127). This claim is also the basic assumption of the EMFACS model introduced by Ekman and Friesen.
A particular irony regarding the idea of simulated faces is that the taxonomy of ‘universal’ emotions that are referenced in this model were originally performed by white North American actors, often of Ekman himself and his students. These images included varied degrees of emotion, which corresponded specifically to the movement of particular facial muscles, and were also meant as training material for psychologists. Despite the ‘situatedness’ of the visual representations used in this model, cultural differences in the understanding of emotions are an aspect that is accounted for in the development of FACS and even helped it to gain popularity.
One of the most prominent pieces of research in this regard is Ekman’s (1972) work on ‘Universals and cultural differences in facial expressions of emotion. This emphasised the universality of facial expressions by comparing the reactions of US and Japanese students. 11 Usually, the experiment is reported as follows: 12 participants were shown ‘stress-inducing’ films and while being alone showed identical facial expressions, in essence abandoning cultural norms of emotional display and showing emotions in alignment with the EMFACS model. In the presence of other persons, however, US and Japanese students applied social rules differently, with diverging facial expressions governed by a distinct and culturally specific impression management. While this study – and EMFACS generally – upholds the assumption of a universality that is characteristic of expressing emotions, it nonetheless suggests that the face is actively used as a means of communicating emotion and also takes into account the idea of differences depending on cultural and social contexts.
Even though there are obvious differences that have also been subject to the debates on emotions, the context dependence of expressing and reading them cannot be reduced to a simple East (East Asian) vs. West (Euro-American) divide. Dharwadker (2015), for example, identifies how the discrete emotions presumed by Ekman and others in the ‘affect program theory’ tradition are long preceded by the Natyashastra, an Indian Sanskrit text probably written sometime between 400 and 1200 CE. Attributed to Bharata, it is a prominent and early example of a comprehensive theory of emotion that includes a taxonomy of their meanings and how they are performed (cf. Nō theatre, Sec. 3). Dharwadker (2015: 1381) shows the striking similarities between this centuries-old text and classics of Euro-American modernity, such as Charles Darwin’s Descent of Man (1871), as well as in the much more recent emotion theory of Silvan Tomkins’s Affect Imagery Consciousness (1962–92), which is still an influential force for our present understanding of emotion. 13 This is far from being a coincidence, as Dharwadker (2015: 1381) points to the many linguistic intersections between Sanskrit and modern European languages. Bharata’s theory of emotion is not foreign in this sense, rather his ‘concepts and categories have been domesticated in European culture for a long time, in the intertextures of word and idea beneath the visible tissues of textuality’ (Dharwadker, 2015: 1381).
While a clear-cut divide between Western and Eastern thought on emotions and affect cannot and should not be upheld, it is the current convergence between cognitive science and artificial intelligence models that constructs emotions as distinguishable units as part of larger anthropological concepts shaped by Euro-American AI imaginaries (see also Suchman, 2007: 233–236). Dharwadker (2015) illustrates this with reference to Tomkins’s approach and his quest for the codes of affect. A major difference in conceptualising affect and emotion between Tomkins and Bharata is that Bharata’s pragmatic – performative – model emphasises that no two emotions are ever the same. The ways in which emotions are understood as the effect of combinatorial composition contrasts starkly from Tomkins’s model, which articulates the principles of his – and our – contemporary logic of computation. This quest for ways to convert emotion and affect into algorithms effectively reduces them to digital code: ‘this is the hard division between context-sensitive combinatorial logic and context-insensitive binary logic, or between if-then and either-or’ (Dharwadker, 2015: 1394). Intriguingly, it is exactly this distinction that is rearticulated in current models, which mobilise and correspond to differences between Euro-American (code-prone) and East Asian (context-sensitive) approaches to explain the ways in which emotions carry and communicate meaning (see below, also cf. Section 3).
Despite its inadequacies and deficits, EMFACS was established as a powerful model to provide an orderly system of signifiers and in doing so define and establish an interpretation of emotion expression as a supra-cultural constant, even though it stands in a strong Euro-American genealogy. One reason why the EMFACS model has retained its high level of popularity and influence is its simple formula for generating a social reality in ICT-ready form by providing a code system that feeds into automated data analysis through the recognition of visual data patterns. 14 It lives on, for example, in the SHORE software, which promises – besides identifying an individual’s gender and age – to estimate ‘four facial expressions: happy, sad, surprised, angry’ (Fraunhofer IIS, 2020). 15
The most important – and most problematic – effect of this model is that the face is constructed as a signifier that communicates emotions, which in turn are regarded as objects that are unambiguously signified by code represented in facial expressions. Emotion is one signifier among many, homogenising the signified ‘object’. It is reduced to a symbolic character, stripping it of its phenomenological quality. The premise of machine-readability falsely promises a reliable way to gain objective knowledge about emotions. While the reductionism of the purely visual EMFACS model has been widely recognised, its machine-readability assumption lingers on with more recent technological solutions that widen the scope of emotion recognition to include their perceivable multimodality. 16
In these approaches, the face is understood as ‘one of the most powerful tools in social communication’, with social communication defined as ‘the act of sending information that affects the behavior of another individual’ (Jack, 2015). This understanding of sending and receiving information reflects very classical and basic models of communication, shaped by behaviourist ideas and mirroring prototypically technical – and dated – approaches (Shannon and Weaver, 1949). Jack (2015) elaborates that ‘the sender encodes a message (‘I feel angry’) into an information bearer (e.g. a facial expression) and transmits it to a receiver (e.g., a human visual system). The receiver must first detect then decode the transmitted information using prior knowledge […]. For example, if the wrinkled nose and bared teeth in a face corresponds with the receiver’s prior knowledge of “anger,” he/she will perceive that “he/she feels angry”’ (see Figure 1). The idea of the face as a communication tool can be traced back to powerful misconceptions about emotions, the epistemological effects of which serve to consolidate ideas that were predominantly shaped by European and North American histories of thought. The face construed as a communication tool: ‘Communication is a dynamic system of information transmission and decoding’; figure taken from Jack and Schyns (2015), quoted in Jack (2015).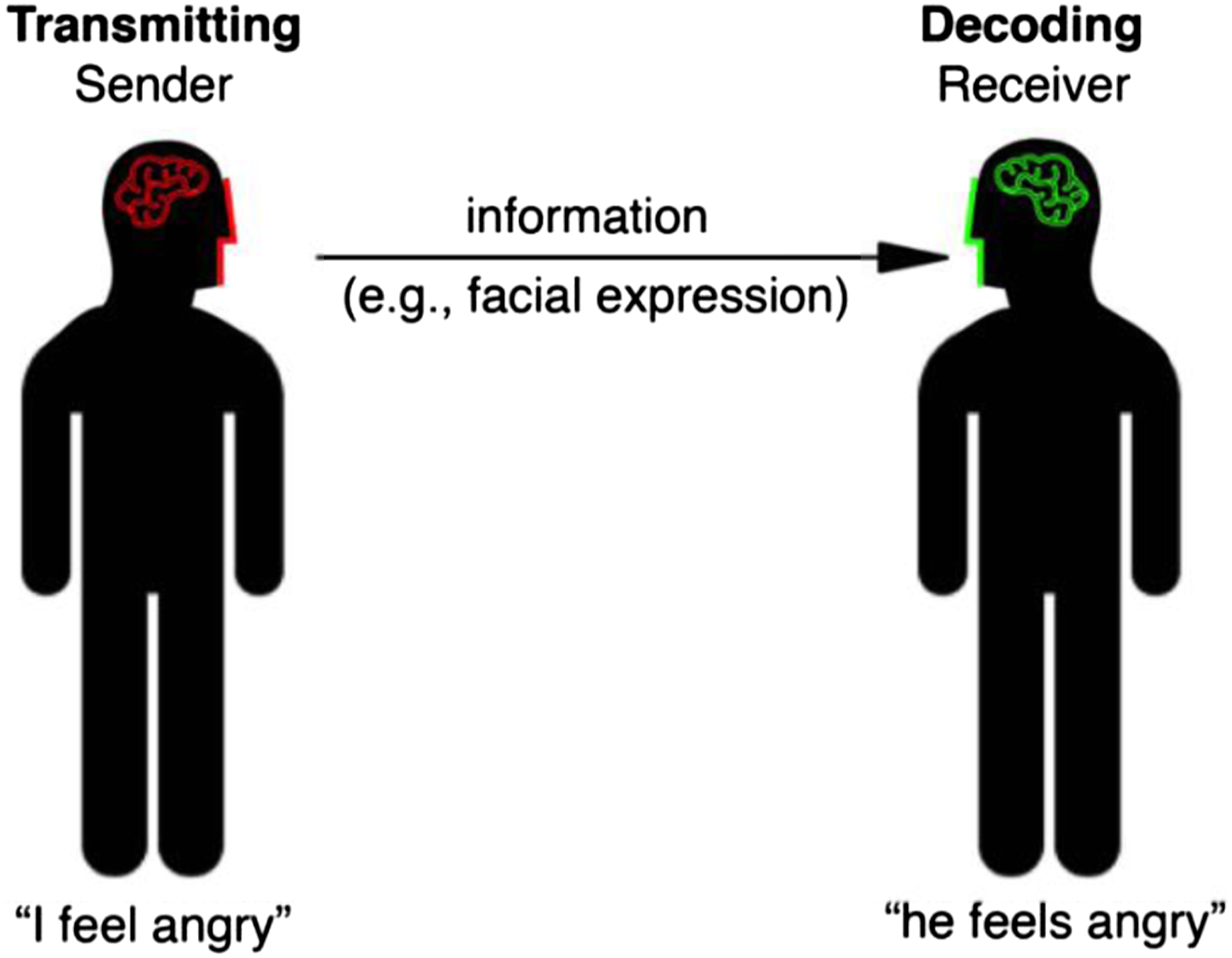
(1) Emotion vs. Cognition & Ratio: Conceptualising emotions as accessible to cognitive tools of rational interpretation – through acts of observation, identification, contextualisation or learning conducted by people or machines alike – weaves them into ancient philosophical assumptions that understand them as self-evident and natural antagonists to rationality. These assumptions fuel beliefs about mental faculties that are divided into ‘categories for thinking (cognitions), feeling (emotions) and volition (actions, and in more modern versions, perceptions)’ and at the same time ‘symbolize a cherished narrative about human nature in Western civilization: that emotions (our inner beast) and cognitions (evolution’s crowning achievement) battle or cooperate to control behaviour’ (Barrett, 2017: 1). Cognitions are not only distinct from emotions but are also capable of measuring and understanding them with the prime objective of control. In this ‘classical view’ (Barrett, 2018: 3) emotions are understood to be an evolutionary residue, a reflection of an innate and uniform structure universally shared. This is also where the idea of emotions as constitutive of communicative processes originates. This view envisages a stimulus that triggers an emotion, which is subsequently transmitted to others by putting them ‘on display’ via facial expressions. The essential factor – also found in the discourses of ‘emotion analytics’, ‘affective computing’ or ‘emotion AI’ – is the stereotypical conception of emotion = pattern = sign. This conception is represented in cultural texts such as cartoons, films, commercials or more recently through emoticons or emojis, all of which help to establish supra-cultural semiotic systems in an attempt to communicate corporeal sensations as easily as possible.
(2) Emotion as a semiotic system: This idea of a supra-cultural semiotic system enabling us, for example, to accurately ‘read’ emotions in commercials or employ emojis in everyday communication is consistent with the general conceptual premise of regarding emotions as subject to ‘interpretive acts’, an operation that in principle is regarded as computable (McStay, 2018: 4). The various technological efforts for decoding and measuring emotions can be seen as an intelligible endeavour if predicated on these premises. As emotions – in both the ways they are described and analysed as well as the ways in which they are individually experienced – depend on social and cultural conventions, practices and media texts, it might at first glance make sense to search for the meaningful patterns in their representation, in order to grasp the experience that is referred to behind the representation. This, however, is yet another narrativistic proposition: emotions and affects can be accurately understood as part of a communicative process within a particular semiotic system. A culturally grounded semiotics bestows on us as knowledge of emotions and how they are subsequently construed as objects that can be computationally processed and interpreted. 17
(3) Emotions as an analytical object: The act of interpreting emotions conditions their formation as epistemic artefacts, that is, as predefined entities that are ascribed an object status in the act of analysing and measuring them. The produced reference objects can be both intelligibly experienced and described. Paradoxically, this confirms that the individual sensation may not be directly accessible to observation, while their suggested machine-readability insinuates that they can now nonetheless be uncovered (cf. Yonck, 2017). This gives rise to the promise that machines have a superior knowledge about how a given individual feels than the person themselves. The strong link between the computation of emotions and practices of surveillance and manipulation is even suggested in the definition of so-called affective computing as ‘computing that relates to, arises from and deliberately influences emotion’ (Picard, 2015: 3).
These assumptions on the measurement of emotions based – primarily, though not exclusively – on facial expressions have come in for some strong criticism. In contrast, Barrett’s theory of ‘constructed emotion’ (Barrett, 2017, 2018) emphasises that emotions are not universal, but rather vary in different cultures. They are not simply ‘triggered’ as primal atavism but sensed uniquely by each individual according to their previous experiences and the specific cultural conventions of the society they live in. In her criticism of the EMFACS model, Barrett (2018: 9) points out that its basic assumptions have never been empirically validated (Leys, 2017 also offers a comprehensive critique). She emphasises that emotions – both as sensations and in terms of their interpretation – always depend on their specific social and cultural contexts, including the expectations of those who interpret or feel them. More recent approaches in cognitive science emphasise that facial displays ‘are not fixed, semantic read-outs of internal states such as emotions or intentions, but flexible tools for social influence. Facial displays are not about us, but about changing the behavior of those around us’ (Crivelli and Fridlund, 2018: 388).
Both the epistemological assumptions about emotion and faces and the media forms of their representation are strongly rooted in Euro-American thought. Crivelli and Fridlund (2018: 389) emphasise that the origins of basic emotions theory (BET) are ‘distinctly Western, with early approaches by Aristotle, but they owe especially to Descartes’s continuation of the Hellenic view of emotion as set against reason’; this essentialist approach contends that facial expressions of emotion are ‘generated and understood pan-culturally’. 18 Regarding the specific aesthetics – the media forms – of the simulated face and its emotions, the body is usually secondary in representations (see above). This reproduces a particularly European visual order, the genre of portraiture, that focuses on the face, often even stripped of its context. Belting (2017: 9) states that ‘where other cultures use the mask, Europeans have developed the portrait in its place’. While East Asian cultures also feature examples of portraiture, this visual genre ‘is unlikely to emphasize the individual at the expense of the context’ (Masuda et al., 2008b: 1263; cf. Kenmochi, 1992).
These epistemological and aesthetic aspects are obstacles to the creation of a digital face that is associated with claims of universality. They become evident when analysing the individual perceptual processes that are shaped by socio-cultural factors, indicating ‘that perception can no longer be regarded as consisting of processes that are universal across all people at all times’ (Nisbett and Miyamoto, 2005: 467). In particular, this has been typically found when comparing ‘Western’ modes of perception, which have the tendency to be ‘context-independent and analytic’ while ‘focusing on a salient object’, with ‘Eastern’ or ‘Asian’ ‘context-dependent and holistic perceptual processes by attending to the relationship between the object and the context in which the object is located’ (Nisbett and Miyamoto, 2005: 467). As far as emotions and their meanings are concerned, the social context of a displayed emotion interpreted in an individual’s facial expressions has been found to be much more dependent on the social context in the ‘context-sensitive East’ with empirical data ‘suggesting that Westerners see emotions as individual feelings, whereas Japanese see them as inseparable from the feelings of the group’ (Masuda et al., 2008a: 365).
This general distinction between Western object-oriented and Eastern context-oriented perception is commonly explained by the more restrictive social structure in East Asian societies, ‘which are based on a web of complex and restrictive social relationships’ and ‘have become sensitive to social relationships and have learned to refer to both social relationships and contextual information in their efforts to understand the world’ (Masuda et al., 2008b: 1272). The ‘Western’ readings, on the other hand, can be traced to a tradition of thought that primarily focuses on ‘discrete objects without being overly concerned with relationships among objects or with field information’, emphasising that ‘Westerners historically have developed object-oriented attention’ (Masuda et al., 2008b: 1272). Even though these generalisations can be criticised as overly homogenising and borderline simplistic tropes distinguishing European and East Asian – in particular Japanese – histories of thought, they clearly reflect actual tendencies (Davis, 2019: 46).
To sum up, emotion cannot simply be excavated as an unambiguous meaningful object from its culturally specific social context. Faces – in their actual, represented or digitally simulated form – are not universal signifiers of emotional states, as their meanings rely on the relations and contexts. These socio-cultural contexts are also characteristic of the specific conventions in representing emotions in faces. To elaborate on this, the next section looks at examples taken from the Japanese context.
Japanese conventions and traditions of visually representing (artificial) faces and their emotions
As has been argued so far, the ability to interpret and ‘read’ emotions cannot be reduced to a simplistic sender-receiver model of information transmission that is based on universal symbols. The ability to read emotions is necessarily based on the social and cultural contexts and is hence dependent on particular conventions. This applies to both interpersonal contexts and the conventions of representing emotions in cultural texts, such as films, advertisements, literature, television, comics or more recently emoticons and emojis.
Regarding interpersonal emotion recognition, Yuki et al. (2007: 2) emphasise that ‘depending on an individual’s cultural background, facial cues in different parts of the face are weighted differently when interpreting emotions’. More specifically, ‘individuals in cultures where emotional subduction is the norm (such as Japan) would focus more strongly on the eyes than the mouth when interpreting others’ emotions’ (Yuki et al., 2007: 2). Another assumption confirmed in this study was ‘that people in cultures where overt emotional expression is the norm (such as the U.S.) would tend to interpret emotions based on the position of the mouth, because it is the most expressive part of the face’ (Yuki et al., 2007: 2). It is the specific ‘cultural norms for the expression of emotions’ that will ‘impact the predominant facial cues individuals use to recognize emotions, with the eyes being a more diagnostic cue for Japanese, and the mouth being a more diagnostic cue for Americans’ (Yuki et al., 2007: 6). Fittingly, the emoticons :) and :( in Western contexts and ( ^_^ ) and (; _ ;) in Japanese contexts denote a happy and a sad/crying face, respectively, putting the focus on either the mouth or the eyes. In other words, the particular conventions in interpersonal communication when recognising emotion are also reflected in the representations of faces in digitally mediated communication.
Portraiture and photography
A similar pattern of how people, their faces and their expressions are represented differently in Western and East Asian contexts can be found in other media forms, such as landscape paintings, portraiture and portraiture photography. Correlating with the object/context difference, Masuda et al. (2008b: 1264) found that ‘East Asian paintings are more likely than Western paintings to depict field information’ in landscape paintings. This corresponds with the formalised genre of portraiture, which particularly features depictions of the human face and has been a distinct visual order in European cultures for centuries. The function of portraits in the European context may be to ‘mark the occasion of a particular success or can record the existence of an individual for posterity’, which is why, ‘Western portraiture seeks to make the subject salient – the intention, in other words, is to distinguish the figure from the ground. For this reason, the model occupies a major fraction of the space’ (Masuda et al., 2008b: 1264). East Asian portraiture, on the other hand, ‘is unlikely to emphasize the individual at the expense of the context. For this reason, the size of the model is relatively small, as if the model is embedded in an important background scene’ (Masuda et al., 2008b: 1264). An open space is sometimes also ‘intentionally left empty so viewers can enjoy the sense of ma (space) as a softening factor of salient visual representation, which has been strongly appreciated in the East Asian arts tradition’ (Masuda et al., 2008b: 1264).
In their experimental study, Masuda et al. (2008b: 1266) showed that these visual patterns of representing the human face in portraiture were also dominant in the different ways study participants photographed a person: ‘East Asians tended to place the model in the background as if the model were part of a context, whereas Americans tended to prioritize the figure at the expense of the ground’. The ratio of the size of the face to the entire frame tended to be smaller in East Asian modes of visual representation. The study participants ‘produced visual images that generally correspond to the modes of artistic expression traditional to their respective cultures’, an effect the authors explain in part by the fact that any given culture ‘exposes people to dominant modes of visual imagery’, which become internalised ‘patterns of artistic expression’ (Masuda et al., 2008b: 1266; cf. Gombrich, 2000, quoted in Masuda et al., 2008b: 1266).
The holistic structure in Japanese representations of the face, emphasising contexts, is distinct from the European and American, more analytic visual orders. The acts of creating and interpreting the representations of faces are contingent upon cultural conventions that resonate well with the patterns of recognising and expressing emotions in these respective cultures. In Western representations the face is more likely to be isolated as an object and signifier of emotion.
A particularly interesting example is the highly differentiated system of symbols used in manga which is used to make mental states visible and readable. Cohn and Ehly (2016: 17) argue in this context that specific ‘graphic schemas’ belong to a ‘larger “visual vocabulary” of a “Japanese Visual Language” used in the visual narratives from Japan’, including, for example, ‘how characters in Japanese manga get bloody noses when lustful or have bubbles grow out their noses when they sleep’. Other conventions include a cruciform symbol that is displayed on a Manga character’s forehead that denotes anger and the use of different colours that encode personality traits (see Abbott and Forceville, 2011; Shinohara and Matsunaka, 2009 for more details).
Nō theatre
A stark contrast to the flashy manga symbolism is the performance art of Japanese Nō theatre. Nō (能, literally: ability, skill, talent) is ‘the oldest surviving theatrical art in Japan’ and ‘includes both music and dance’ (Nakamura and Hunter, 2019: 23). Performed since the 14th century and taking ‘its present form in the mid-Edo period’ (1603–1867), it is said to be a highly evolved art, ‘leaving it in a classic, unchanging, “perfected” form’ (Nakamura and Hunter, 2019: 23).
Seeing this Japanese art form in relation to Greek drama, Keene notes that the ‘use in both of masks, a chorus, song, stately dances and poetry of an elevated nature provides some basis for comparison’; but the Greek and Nō dramas ‘are essentially different despite surface resemblances’ (Keene and Kaneko, 1990: 9). Most notably, the characters in Greek plays, ‘though larger than ourselves and confronted by problems far more terrible than any we are likely to face, are recognizably like us’; the characters in the Nō plays, on the other hand, are ‘hardly more than beautiful shadows, the momentary embodiments of great emotion’ (Keene and Kaneko, 1990: 9).
Central to the performance and to achieving this effect of embodying emotion is the mask: ‘Nō begins with a mask, and within the mask the presence of a god’ (Keene and Kaneko, 1990: 13). All the actors are male and the masks – usually representing the non-living – are about 21 cm in length; they are ‘too small to cover the actor’s entire face, but generally leave a disillusioning sallow or reddish fringe of jowls around the lovely contours of the painted wood’ (Keene and Kaneko, 1990: 63). Their smallness as well as the ‘extraordinarily high foreheads of the masks of young women’ originate in particular aesthetic ideals that adhere ‘to models created in the fifteenth century’ (Keene and Kaneko, 1990: 63). Even though the masks are static, they can still convey different expressions: ‘A lowering of the mask (kumorasu, “clouding”) casts shadows suggestive of grief, a raising of the mask (terasu, “shining”) lightens it, giving an expression of happiness’ (Keene and Kaneko, 1990: 62). But the conventions of the performance are much subtler and also comprise elements such as the gentle lateral moving of the head ‘in the gesture known as “seeing a voice”’ with the actors refraining from any obvious gestures (Keene and Kaneko, 1990: 62).
This art form is remarkable, and almost paradoxical, in that it strives to create the embodiment of emotion by keeping the means to achieve this goal to the minimum. The mask – as a simulated face – covers the actor’s face, with its low key movement constraining most of the information that could be communicated via facial expressions. The real face, of the individual, would even be regarded as a distortion. 19 This subtle form of communicating emotion in simulated Nō faces has given rise to a number of empirical studies, which set out to pinpoint the particular viewpoints and angles that can be identified to convey the desired meanings. One study found that – contrary to the conventions of the performance – happiness was attributed to a downward tilted mask and sadness to an upward tilted one, not only by Japanese but also by British study participants (Lyons et al., 2000). Another (Nishimura et al., 2010, quoted in Miyata et al., 2012: 2) argued that ‘emotions expressed by the whole body postures had stronger effects than those by a Noh mask alone, and that the actor’s initial movements may have determined the labels of emotions in both these conditions’.
After identifying the individual elements in the ‘mysterious’ Nō masks and determining to what extent they contribute to the interpretation of emotion, Miyata et al. (2012: 4) found ‘that the judgment of emotional expressions of a Noh mask is predominantly made based on the shapes of the mouth, with the mouth of an upward/downward tilted Noh mask expressing sadness/happiness, respectively’. Their findings also suggest that the upward and downward movements of the masks are read in a way that runs contrary to the aesthetic Nō rules of kumorasu/terasu. The study participants – all Japanese and without knowledge about the performing skills of Nō – primarily focused on the mouth as the major element, which also contradicts the expectation of the region around the eyes being the major region of emotional expression in the Japanese context (Figure 2). Ko-omote mask, a prototypical mask for representing a young woman, tilted upward and downward, hence encoding different emotion states (taken from Miyata et al., 2012: 3).
Miyata et al. (2012: 4) explain the dominance of the what they call ‘biological factors’ (the interpretation of the mouth) by highlighting that ‘Noh drama has many stylistic rules other than those regarding the Noh masks, including inclination and successive movements of the actor’s body as well as the background chorus and instrumental music […]. Consequently, during the actual performance of the Noh drama, these multiple conventional rules may holistically play a major role in the appreciation of emotions’. While the authors further speculate on the ‘mysterious qualities’ of the masks that ‘with any given head inclinations possess different composite expressions, each of which involves multiple emotions at a time’ (Miyata et al., 2012: 6), their findings essentially stress the importance of contextual information when producing particular meanings. In the case of Nō theatre, it is the subtle rules of the performance that put the artificial faces at the centre of complex conventions to signify emotions (see also Vollmann, 2010).
Robotic faces and bodies
Two starkly differing examples from the field of robotics in Japan highlight the gap between an analytical, object-oriented and symbolic approach to faces and emotions as messages on the one hand and faces and bodies as a contextual, performative presence, evoking a somatic response on the other. The Emotion Expression Humanoid Robot WE-4RII (see Figure 3), developed in 2004, ‘has 59 DOFs [degrees of freedom, T.C.B.] (Hands: 12, Arms: 18, Waist: 2, Neck: 4, Eyeballs: 3, Eyelids: 6, Eyebrows: 8, Lips: 4, Jaw: 1, Lungs: 1) and a lot of sensors which serve as sense organs (Visual, Auditory, Cutaneous and Olfactory sensation) for extrinsic stimuli’ (Takanishi Laboratory, 2020). Emphatically designed as an engineering problem, the robot was created to express ‘Six Basic Facial Expressions of Ekman in the robot’s facial control’ and the developers ‘have defined the seven facial patterns of “Happiness,” “Anger,” “Disgust,” “Fear,” “Sadness,” “Surprise,” and “Neutral” emotional expressions’ with ‘the strength of each emotional expression’ being ‘variable by a fifty-grade proportional interpolation of the differences in location from the “Neutral” emotional expression’ (Takanishi Laboratory, 2020). Emotion Expression Humanoid Robot WE-4RII (Waseda Eye No.4 Refined II), illustration kindly provided by Atsuo Takanishi, Waseda University, Tokyo. Erica, a humanoid robot capable of having ‘natural interaction with persons by integrating various technologies such as voice recognition, human tracking, and natural motion generation’ (Ishiguro, 2020b).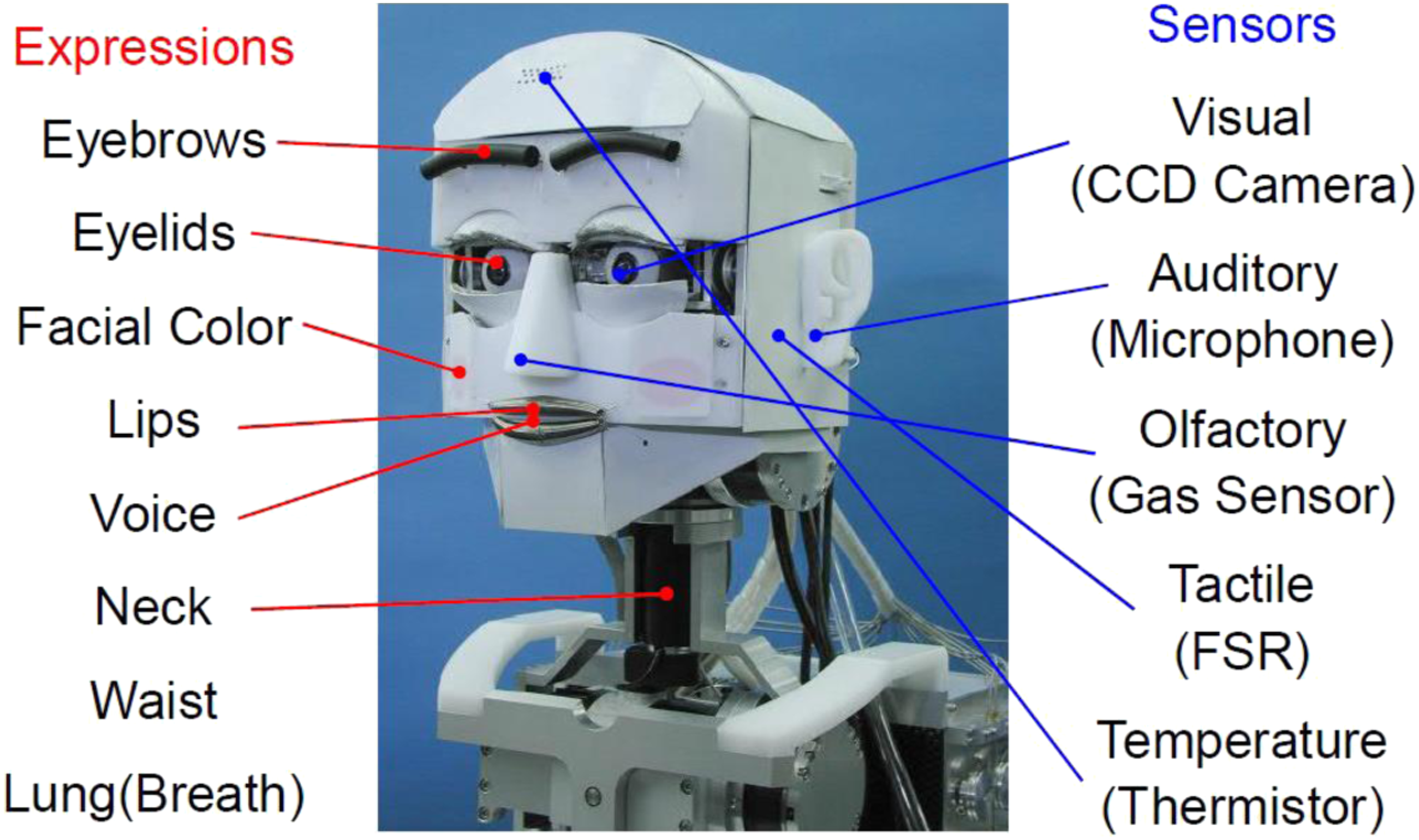

In accordance with the (EM)FACS model and articulating its symbolic order, the technical face and body of the WE-4RII are a prototypical example of conceptualising emotions as code. They are regarded as part of a more or less unambiguous language that requires a particular mechanical interface.
The mechanical face and body of a humanoid and social robot, however, should not be misunderstood as a mere tool to produce a particular non-verbal language of gestures or facial expressions. They can potentially also create a psychosocial quality that cannot be expressed through other medial forms (Bächle, 2020): the human-like design invites people to attribute human qualities and makes them assume that the robot is ‘looking at someone’ or ‘seeing something’ and helps human interaction partners to intuitively understand the interface (Siciliano and Khatib, 2016). The physical presence of the embodied robot itself already makes a difference, for example, when compared to artificial bodiless communication agents that are only represented via video display rather than being materially present (Bainbridge et al., 2011). Humanoid robots have in their entirety been described as ‘ideal interfaces’ (Ishiguro, 2006). In addition, cultural identity markers can be included in inscriptions on the robotic body that indicate sex, race, age or gender; these are not reduced to appearance but include identifiers such as vocal timbre or habitus.
Ishiguro’s gynoid Erica (Figure 4), which is equipped with a full mechanical life-like body, can be regarded as a prototypical example of a performative presence that would trigger a somatic reaction. The effect of the artificial face and body is not reducible to symbolic expressions generated in verbal or non-verbal expressions. It is the presence of the artificial human itself that creates the unique quality. The fact that Erica resembles a beautiful young woman is no coincidence, and not just in the sense of a Pygmalion effort; it is a deliberate design decision: Attractiveness and beauty are essential criteria for Ishiguro as these aesthetic factors enable a more effective performative quality and bodily and facial presence, albeit artificial (Ishiguro, 2020a: 67). One major aesthetic goal of creating humanoid robots in this approach is to evoke the feeling of a human presence, known in Japanese as sonzai-kan, 存在感, a presence as it is felt by another being (Sumioka et al., 2014). As White and Katsuno (2021: 227) also emphasise in their compelling anthropological study, that the idea of animacy that is ascribed to a robot is not just based on the verisimilitude of the artefact itself but on a ‘feeling’ – namely ‘amusement, a cultivated sense of openness to treating robots as alive that incorporates aspects of play and enchantment’. Essential for this quality to be felt are the interactions with the robot, that is its embeddedness in social contexts, in which it is treated as more than a mere technical object.
The abstract and schematic WE-4RII robot that produces codes of emotion via an intricate mechanical system differs sharply from the intriguing presence of Erica that triggers a unique affective response – as this paper’s author thanks to Hiroshi Ishiguro and Katsumi Watanabe could once experience himself – that is astonishingly similar to the one caused by another human being.
Conclusion
The artificial face in its digitally perfected simulated form is no longer just a matter for specialised realms such as art (‘digital effects’) or engineering. With the ubiquitous use of automated image processing and augmented reality filters on smartphones and social media platforms, artificial faces have become part of our day-to-day media cultures and experiences. Given their strong association with notions of self, social status, attractiveness, authenticity and reality, a critical assessment of the range of different practices and technologies utilised in the simulation of faces is essential.
The quest for a universal artificial face prioritises already dominant histories of representation and modes of knowledge production, while marginalising others, under the guise of universally applicable technologies. These hierarchies become even less apparent, since one of the major effects of faces – and their artificial or fake counterparts – lies in the somatic reactions they trigger. This suggestive power that is inherent in the moving image and sets it apart from content such as text and images is substantially reinforced by the affective dimension of communication that is conveyed by facial expressions, the voice and the mere presence of human face. As was shown, the specific meanings created by seemingly universal artificial faces are far from self-evident or ‘natural’.
Dominant interpretations of emotions regard them as objects that can be represented and communicated via particular codes, which are just waiting to be adequately deciphered. These assumptions have a complex genealogy – one that is not entirely Euro-centric – and they are currently reinforced by models applied in computer science that nonetheless provide them with an almost hegemonic status. As this paper highlighted by drawing on East Asian (particularly Japanese) examples, they are being challenged by context-sensitive interpretations of emotions that tie their specific meaning to differing social norms and aesthetic conventions. According to them, the meanings that faces offer should be understood in a highly relational fashion, depending on the socio-cultural context they appear in. These relational interpretations do not follow a simple logic of object representation.
The examples of Japanese conventions and forms of depicting and creating human faces illustrate the dynamic, ambiguous and sometimes contradictory effects they can have, the denotations that are ascribed to them, the performative contexts that shape them and the somatic reactions they potentially trigger. The East Asian aesthetics offer alternative readings of the artificial face that have the potential to challenge and complement the hegemonic American and Euro-centric meanings. These discursive frictions and sometimes inconsistent meanings of (fake) faces widen our understanding of a complex relationship between the human face and its representations, between the face’s presence and its simulation.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Japan Society for the Promotion of Science (PE19032).