
Abstract
Multiple sclerosis (MS) is a progressive demyelinating and degenerative disease of the central nervous system with symptoms depending on the disease type and the site of lesions and is featured by heterogeneity of clinical expressions and responses to treatment strategies. An individualized clinical follow-up and multidisciplinary treatment is required. Transforming the population-based management of today into an individualized, personalized and precision-level management is a major goal in research. Indeed, a complex and unique interplay between genetic background and environmental exposure in each case likely determines clinical heterogeneity. To reach insights at the individual level, extensive amount of data are required. Many databases have been developed over the last few decades, but access to them is limited, and data are acquired in different ways and differences in definitions and indexing and software platforms preclude direct integration. Most existing (inter)national registers and IT platforms are strictly observational or focus on disease epidemiology or access to new disease modifying drugs. Here, a method to revolutionize management of MS to a personalized, individualized and precision level is outlined. The key to achieve this next level is FAIR data.
Keywords
Multiple sclerosis (MS) is a progressive demyelinating and degenerative disease of the central nervous system with symptoms depending on the disease type and the site of lesions and is featured by heterogeneity of clinical expressions and responses to treatment strategies. An individualized clinical follow-up and multidisciplinary treatment is required. Transforming the population-based management of today into an individualized, personalized and precision-level management is a major goal in research. However, a complex and unique interplay between genetic background and environmental exposure in each case likely determines clinical heterogeneity. To reach insights at the individual level, extensive amount of data are required. Here, a method to revolutionize management of MS to a personalized, individualized and precision level is outlined. The key to reach this next level is FAIR data. FAIR is a fairly recent concept that stands for Findable, Accessible, Interoperable and Reusable. 1
Imagine any type of data being ‘Findable, Accessible, Interoperable and Reusable’ by both humans and machines. ‘Findable’ does not mean ‘for everyone to find’, ‘accessible’ does not mean ‘open access’, ‘interoperable’ does not mean ‘for everyone to operate on’ and ‘re-usable’ ‘for everyone to use’. However, it creates the possibility to find, access, interoperate and re-use data when necessary. In other words, it gives data the opportunity to have maximal impact. The possibilities to discover new insights multiplies manifold. But before we get there, many hurdles have to be overcome. Here, a 4C plan is proposed to reach this goal (Collect-Connect-Complete-Construct). An intuitive representation of this plan is represented in Figure 1.
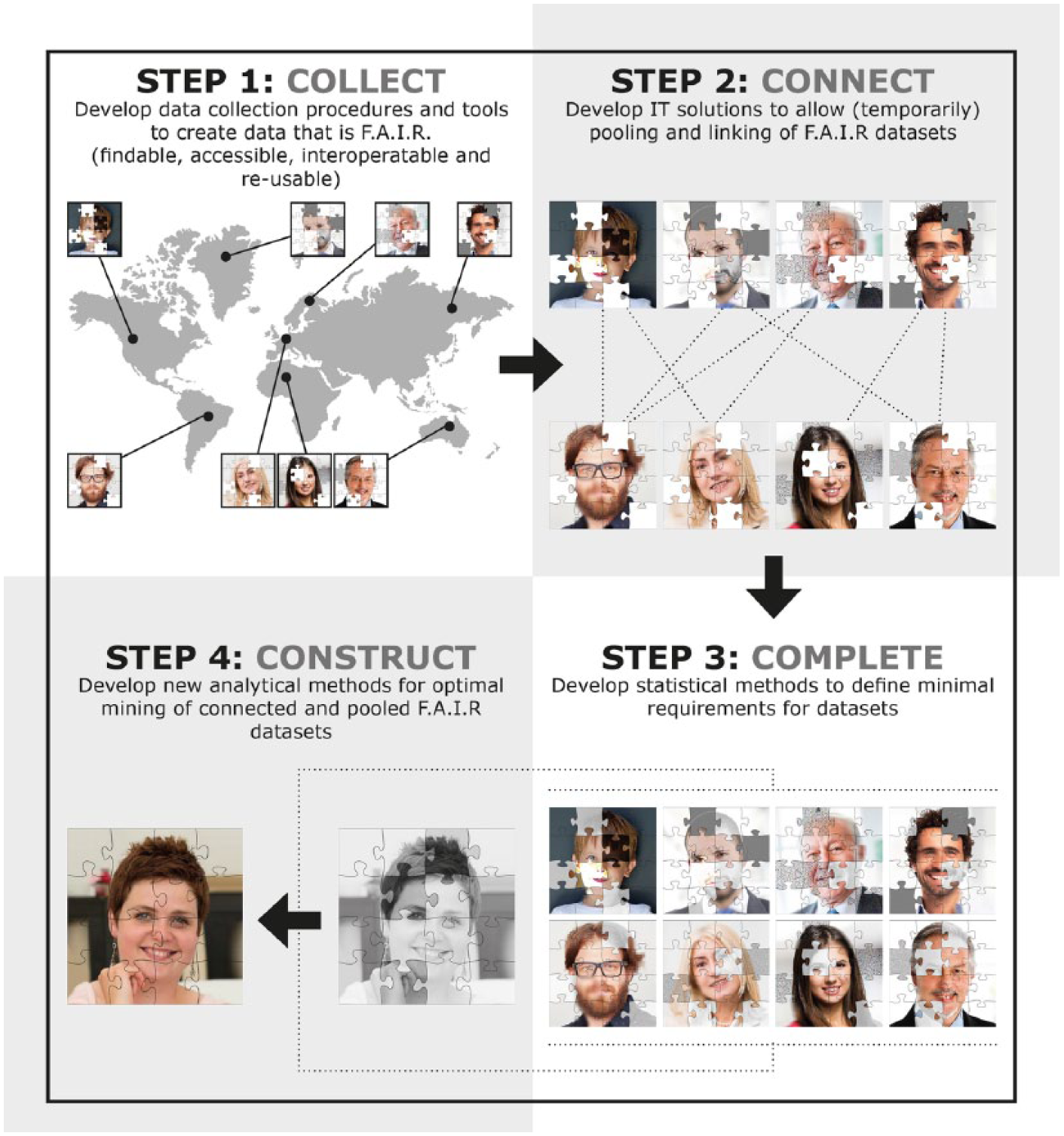
An intuitive representation of a 4C plan towards next-generation management.
Data are collected all over the world by different stakeholders resulting in many datasets, represented by puzzles of a face (step 1: COLLECT). Every dataset has its own weaknesses and strengths. For example, existing and emerging MS-specific data initiatives resulted in international pooling of observational clinical data (e.g. MSBase Registry, 2 Big MS Data Group, European register for MS (EuReMS 3 )), clinical trial data (e.g. Sylvia Lawry Centre for Multiple Sclerosis Research (SLCMSR 4 )), magnetic resonance images (e.g. magnetic resonance imaging in multiple sclerosis (MAGNIMS 5 )), genetic data (e.g. International Multiple Sclerosis Genetic Consortium (IMSGC 6 )), functional and patient-reported outcomes (e.g. iConquerMS, North American Research Committee on Multiple Sclerosis (NARCOMS 7 )) and patient-centred outcomes (e.g. iPCO initiative of the Multiple Sclerosis International Federation). In addition, there is international interest in rehabilitation repositories (MSREHABREP 8 ). Imperfect and inaccessible ‘data silos’ are also present on a local level, since data on the same patients are collected by different data collectors. Indeed, every variable is ideally collected by the expert involved. For example, neurologists are the best candidate to collect diagnosis date, medication strategy and so on. However, when it comes to patient-reported outcomes, patients should be included directly in the data collection process. The same is true for nurses (e.g. weight and blood pressure), rehabilitation specialists (e.g. physical and daily functioning), psychologists (e.g. tests for cognition and depression), speech therapists (e.g. swallowing tests and speech recognition), researchers (e.g. genetic-, immunological- and lipid metabolism) and so on. Although none of these datasets are perfect (nor will they ever be), many insights could be discovered when these datasets could be pooled and connected (step 2: CONNECT). Indeed, in a recently approved Horizon2020 project ‘MultipleMS’ (www.multiplems.eu), universities and companies across Europe and the United States are connecting their datasets to tailor the development and application of therapies to the individual MS patient. Still, sometimes the existing data are insufficient to investigate a certain question and additional data are required. Because collecting data is expensive and time-consuming, efforts should be as focused as possible and methods to identify the minimal requirements for common datasets are required (step 3: COMPLETE). For example, when it comes to personalized prediction of disease progression, information on different levels is required. Collecting all these data for every patient is not feasible. But what if we could mine existing datasets to formulate guidelines for a minimal core dataset? When sufficient overlap between the databases involved is secured and powerful analytical methods are developed to cope with the imperfections of datasets featured by different layers of missing data, these datasets can be optimally mined to create new insights for MS management (step 4: CONSTRUCT).
More specifically, the following steps are formulated:
COLLECT: develop data collection procedures and tools to create FAIR data. Ideally, data collection procedures should be using open-source IT codes, permit visit-entry or automation. The term ‘visit-entry’ implies the direct entry of variables by the experts involved in gathering the data, and automation refers to the fact that automatic import of data that is digitally collected should be possible. Working with open-source IT codes enables a low-priced implementation of IT platforms and the possibility to meeting local needs. Next to this, procedures should be legal, ethical and practical consequences of data sharing and re-use. Currently, there are a lot of insecurities around extensive data sharing initiatives (e.g. what about informed consents? how should we handle pseudo-anonymization? and how can data be shared respecting security and privacy?).
CONNECT: develop IT solutions to allow (temporarily) pooling and linking of FAIR datasets. IT solutions that allow local collection, storage and management of data, and enable (research) question-based pooling are necessary. Today, when data need to be pooled, a lot of time, efforts and costs are necessary for data processing before pooling is possible. Some concrete solutions to simplify pooling are (1) using unique patient identification strategies (e.g. use of national identification number), (2) using database catalogues clearly defining the variables involved and (3) standardization where possible (CDISC labels 9 and Human Phenotype Ontology (HPO) classifications 10 ).
COMPLETE: develop statistical methods to define minimal requirements for datasets. Many insights can be reached using existing data. However, focussed prospective of retrospective data collection will often be required. Therefore, there is a need to develop statistical methods to define minimal requirements for datasets. Being able to objectively define these minimal requirements will make it much easier to motivate people involved in data collection to collect data that are not necessary for their initial intent. Motivating or giving incentives for the collection and storage of biological samples could already be one step forward because this makes retrospective retrieval much easier and less time-consuming.
CONSTRUCT: develop analytical methods for optimal data mining. We lack proper analytical tools for optimal mining of datasets that are featured by different layers of missing data. New insights in building decision-support systems using a combination of imperfect datasets are required. Different research questions should be investigated here (e.g. what is the power of machine learning techniques for these applications? and how can we better handle missing data?).
Table 1 summarizes some concrete recommendations on how we could implement this 4C plan in the MS data arena. Our research project MS DataConnect (www.msdataconnect.com) aims at providing proof-of-concept of this 4C plan to enhance MS research. The MS DataConnect Consortium and the Belgian healthdata.be platform will collaborate to set up a multidisciplinary MS register connecting information collected by care givers, patients and researchers. User-friendly, sustainable FAIR data collection tools and procedures are developed for MS-relevant data striving towards ‘the only once’ – principle referring to (1) data capture from primary (operation) sources of health care actors and (2) re-use of previously collected data.
Recommendations for MS-specific implementation of the 4C plan.
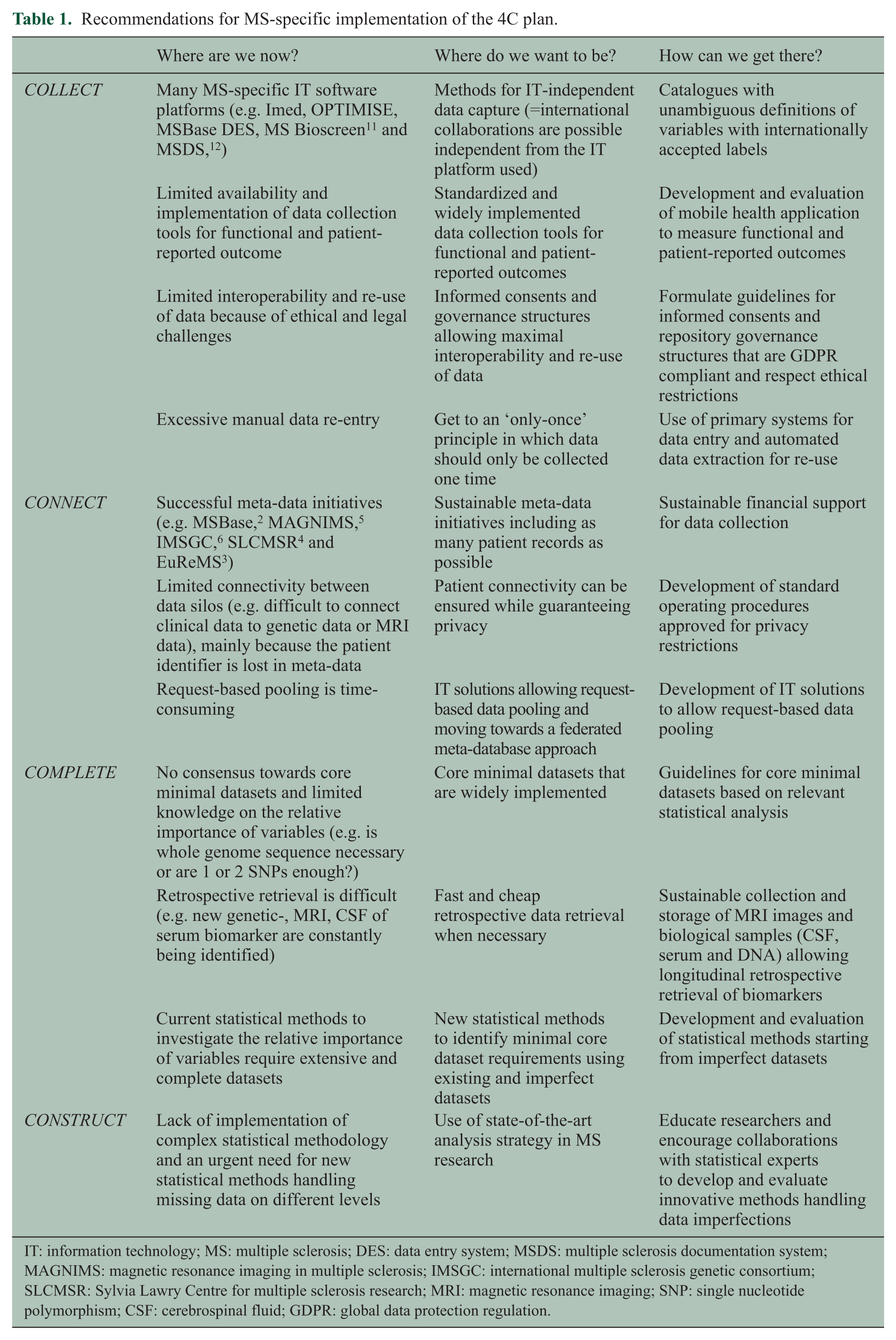
IT: information technology; MS: multiple sclerosis; DES: data entry system; MSDS: multiple sclerosis documentation system; MAGNIMS: magnetic resonance imaging in multiple sclerosis; IMSGC: international multiple sclerosis genetic consortium; SLCMSR: Sylvia Lawry Centre for multiple sclerosis research; MRI: magnetic resonance imaging; SNP: single nucleotide polymorphism; CSF: cerebrospinal fluid; GDPR: global data protection regulation.
Data collection is extremely expensive and time-consuming. Enabling data to achieve maximal impact is our duty on a social and ethical level, but also greatly decreases financial costs associated with data collection and management. Making data available to peers incentivizes researchers to better manage their data and ensure their data are of high quality. This is recognized by several authorities, resulting in new legislations, guidelines and international calls for proposals pushing and supporting the implementation of these FAIR principles (e.g. global data protection regulation (GDPR), European Commission guidelines on FAIR data management in Horizon2020 projects, Innovative Medicine Initiatives calls for the establishment of European Health Data Networks, the rise of organizations and projects that solely focus on improving data management in life sciences, for example, the ELIXIR project (www.elixir-europe.org/)). But implementing the FAIR principles is not only about generating value for the community. It benefits the initial researcher, research sponsor, data repositories, the scientific community and the public. In a time of reduced monetary investment for science and research, data sharing is more efficient because it allows researchers to share resources. Collaboration between scientists is facilitated, enabled and encouraged, resulting in larger and more expansive datasets. This results not only in new insights and better results for the community (e.g. enhanced clinical decision-making/best practice and increased efficiency for identification of research gaps) but also benefit the researcher in many other personal ways as well (e.g. networking, increased number and impact of publication). This will lead to more motivation to contribute to the data collection and quality of the data as well, a win-win situation. 8
The future perspectives of this 4C plan are endless and depend on the stakeholders involved. Indeed, regulators need data for life-cycle assessment of medicinal products, health technology assessment bodies want to incorporate data from clinical practice into the drug development process and researchers want to build personalized decision-support systems. To truly capture the potential of this ‘4C plan’, please reflect on the following question: ‘what would YOU investigate, if you had all the data in the world to your disposal and the analysis tools to optimally mine this data?’ This can only be achieved when efforts towards this ultimate common goal are combined and synchronized.
Footnotes
Acknowledgements
The author would like to thank all the members of the MS DataConnect Consortium (![]() ). MS DATACONNECT operates in a very strong national and international interdisciplinary network. This network connects partners involved in MS care, rehabilitation and research with partners involved in IT development, database management, data sharing procedures, statistics, machine learning and prediction modelling, and this network is expanding very fast. Currently, the following partners are involved: (1) partners involved in MS care, rehabilitation and research: the Biomedical Research Institute (BIOMED) and Rehabilitation Research Center of BIOMED (REVAL), PXL University College Hasselt, the Rehabilitation and MS Center Overpelt (RMSC), MS liga and University Biobank Limburg (UbiLim); (2) partners ensuring the technical expertise: the Center of Statistics (CENSTAT), the IT department of PXL University College Hasselt and the Data Science Institute of Imperial College London. In particular, the author thanks his supervisor Prof. Niels Hellings for his support, guidance and textual suggestions. In addition, the author would like to thank Johan Van Bussel, coordinator of the Belgian healthdata.be platform, and his team for his technical expertise and insights on e-health. Finally, the author would like to thank Hans Constandt and Filip Pattyn (Ontoforce, Belgium) for inspiring her towards using FAIR data in health care.
). MS DATACONNECT operates in a very strong national and international interdisciplinary network. This network connects partners involved in MS care, rehabilitation and research with partners involved in IT development, database management, data sharing procedures, statistics, machine learning and prediction modelling, and this network is expanding very fast. Currently, the following partners are involved: (1) partners involved in MS care, rehabilitation and research: the Biomedical Research Institute (BIOMED) and Rehabilitation Research Center of BIOMED (REVAL), PXL University College Hasselt, the Rehabilitation and MS Center Overpelt (RMSC), MS liga and University Biobank Limburg (UbiLim); (2) partners ensuring the technical expertise: the Center of Statistics (CENSTAT), the IT department of PXL University College Hasselt and the Data Science Institute of Imperial College London. In particular, the author thanks his supervisor Prof. Niels Hellings for his support, guidance and textual suggestions. In addition, the author would like to thank Johan Van Bussel, coordinator of the Belgian healthdata.be platform, and his team for his technical expertise and insights on e-health. Finally, the author would like to thank Hans Constandt and Filip Pattyn (Ontoforce, Belgium) for inspiring her towards using FAIR data in health care.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: L.P. was supported by Interuniversity Attraction Pole (IUAP, no IAP VII/39), the MS network Limburg, the Biomedical Research Institute of Hasselt University and the ELIXIR project.