
Abstract
Background:
Atrial fibrillation (AF) is the most prevalent arrhythmia and a significant cause of morbidity. Artificial intelligence (AI)-based language models represent a novel tool for searching for medical information; however, there is still uncertainty regarding their reliability and readability in different languages.
Objective:
To assess the reliability and readability of information provided by AI-based models for patients with AF.
Methods:
A cross-sectional study was conducted to assess the reliability and readability of the responses generated by ChatGPT, YouChat, Gemini and Perplexity on AF in English and Spanish. Thirty standardised questions were posed in both languages. The quality of the responses was then assessed by 2 independent reviewers via a standardised tool. Readability was assessed via the Flesch–Szigrist formula. The results were then compared by tool and language.
Results:
ChatGPT demonstrated the highest interrater agreement (PA = 0.73 in Spanish, 0.80 in English), followed by Gemini in English (PA = 0.66). In Spanish, ChatGPT generated the highest percentage of complete responses (80%), followed by Perplexity (73%) and Gemini (47%). In English, Perplexity demonstrated the strongest performance, with a score of 93%, followed by ChatGPT, with 73%, and Gemini, with 53%. A readability analysis revealed significant differences between the models (P < .01). The ChatGPT demonstrated the highest performance, although its content was moderately challenging in Spanish and highly challenging in English.
Conclusion:
ChatGPT and Perplexity emerged as the most reliable models, although readability remains a concern. There is a clear need for improvements to optimise the accuracy and accessibility of AI-generated medical information.
Introduction
Atrial fibrillation (AF), the most prevalent type of sustained arrhythmia, has been determined to be a substantial risk factor for adverse events, including mortality, cerebrovascular disease, and heart failure. 1 In 2020, approximately 50 million individuals worldwide were estimated to be affected by this condition.2,3 This increase is influenced by multiple factors, including an ageing population, increased case detection, and its association with various cardiovascular diseases.1,4 Given the impact of AF, providing patients and their caregivers with clear, accurate, and accessible information that allows them to understand the disease and actively participate in its management is essential.
Furthermore, ChatGPT, developed by OpenAI in 2022, was designed with reinforcement learning with human feedback to deliver more useful, confident and conversational responses, marking a milestone in natural language processing.5,6 Other artificial intelligence (AI) platforms, such as YouChat, Perplexity and Gemini, were subsequently introduced. These AI tools are capable of generating text, translating languages, producing creative content and providing answers to questions in an informative manner.7 -9
Moreover, the utilisation of AI in the domain of medical information seeking has markedly increased, with language models such as ChatGPT, YouChat, Gemini and Perplexity7 -9 attaining a notable degree of popularity. Nevertheless, the reliability and readability of the medical information they provide remains a matter of debate, especially in chronic diseases such as AF.
Reliability is defined as the veracity and consistency of information on the basis of scientific evidence, whereas readability is measured as the level of understanding of the general public.10 -12 Studies have highlighted concerns regarding the quality of online medical information, which can influence clinical decisions and the doctor–patient relationship. Besides, this has been shown to result in deficiencies in communication and the critical evaluation of sources.11,12 The aim of the present study is to evaluate the reliability and readability of the AF information generated by 4 AI models (ChatGPT, YouChat, Gemini and Perplexity) in both English and Spanish.
Methods
Design, Setting and Data Collection
A cross-sectional, analytical observational study was conducted to assess the reliability and readability of the information provided by ChatGPT, YouChat, Gemini and Perplexity in English and Spanish. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) checklist for cross-sectional studies was used to guide reporting. Informed consent was not required given the nature of the study.13,14 The study was considered safe and was approved by the ethics committee of the Pontificia Universidad Javeriana (CIE-319-2024).
Sample Size and Question Formulation
We computed the sample size required to detect discordant proportions of 0.1 and 0.4 (delta = 0.3) via a 2-sample paired-proportions test, with 80% power, a 2-sided approach, and a 5% significance level. The resulting calculation indicated a minimum of 30 questions. In line with this, our study employed 30 questions (15 in English and 15 in Spanish), which were distributed evenly across the 4 AI models.
The patients’ most frequently asked questions about AF were subsequently identified from queries made at various search engines. These were compiled from information sites and documents primarily aimed at patients, including Fundación Española del Corazón, 15 Mayo Clinic, 16 the Division of Cardiothoracic Surgery (WashU Medicine), 17 the AFIB Clinic, 18 UChicago Medicine, 19 the American Heart Association factsheet, 20 and the guidelines of AF for patients of the Spanish Society of Cardiology 21 (Appendix 1).
For the selection process, the ‘frequently asked questions’ (FAQ) sections and doubt-oriented chapters in patient guides and leaflets were reviewed.15 -21 These sources were chosen for their accessibility to the general public, relevance, and wide dissemination in the field of health education. On the basis of these criteria, the adjustment, modification and formulation of 15 FAQs were guided, directly reflecting the most common concerns regarding definition, symptoms, causes, diagnosis, treatment options, lifestyle, complications, and prognosis.
These questions were formulated in simple language, and in the first person where possible, as this is the way patients tend to express themselves. The inclusion of the question about heart transplantation was considered relevant owing to the clinical importance of the topic and the frequency with which it arises in forums and consultations with patients with advanced heart failure and AF.
Questions that were ambiguous, contained unverifiable information or lacked clear and objective answers were excluded. Questions were considered ambiguous if their wording allowed for multiple interpretations. Questions were defined as unverifiable if there was no single or standardised answer supported by scientific evidence, or if they depended exclusively on individual clinical assessment, making it difficult to verify them against recognised sources. Finally, 15 standardised questions were selected by the researchers in each language, which were classified into 6 categories: (1) general information about the disease; (2) diagnosis; (3) nonpharmacological treatment; (4) pharmacological treatment; (5) prognosis; and (6) complications.
Response Generation
The formulation of the questions was conducted via the free research versions of ChatGPT, Perplexity, YouChat and Gemini. For the purposes of the study, a user was created in ‘incognito mode’. The questions were posed individually, with the options ‘New Chat, New Thread or New Conversation’ available. Importantly, only the initial response generated by the chatbot was taken into consideration during the evaluation process, without the need for further response generation.
Response Evaluation
These responses were then analysed independently by 2 specialists in internal medicine and cardiology (EJ and JB). To ascertain the reliability of the data, a scale that had previously been used in research to evaluate information generated by AI tools for patients with various diseases was employed.22,23 This scale classifies the answers into 4 categories: (1) Complete: equivalent to the answer of an expert in the subject; (2) Correct but insufficient: accurate but with incomplete information; (3) Partially correct: with correct and incorrect elements; and (4) Completely incorrect. 24
Furthermore, the readability of the responses was analysed via the Flesch formula adapted to Spanish and the Flesch–Szigrist formula,25,26 which is designed to assess the readability of health information for patients. In addition, to assess the quality of the responses generated to questions about AF, the simplified DISCERN scale was used together with the Global Quality Scale (GQS). 27
Statistical Analysis
The distribution of the data was examined via the Shapiro–Wilk test. Given that the assumption of normality was not satisfied, quantitative variables are presented as medians and their corresponding interquartile ranges (IQRs). Absolute and relative frequencies were used to describe categorical variables. Fisher’s exact test was employed to compare them, given that the expected frequencies were less than 5. To ensure consistency in the evaluation of the questions among the researchers, 3 questions were randomly selected and evaluated independently by 2 researchers. The group engaged in a thorough discussion of the discrepancies until a consensus was reached.
The reliability of responses was measured via the proportion of agreements (PA), 28 an extension of the simple agreement ratio, with the aim of correcting for potential biases introduced by chance or by the structure of the data (such as ties). The levels of agreement were categorised in accordance with the methodology established by Landis and Koch. 28
The Mann–Whitney U test was used to compare the medians obtained in the readability assessment between pairs. The Kruskal–Wallis test was used to compare the medians of more than 3 groups. A P-value of P < .05 was used as the criterion for statistical significance. The statistical analysis was conducted using R software, version 4.3.3.
Results
A total of 30 responses (15 in Spanish and 15 in English) were analysed for each AI model.
Interrater Agreement
Table 1 presents the interrater agreement in the assessment of the reliability of the AF information for each model, which was discriminated by language. The agreement was substantial for both ChatGPT (PA = 0.73 in Spanish and 0.80 in English) and Gemini (PA = 0.66 in English). The other models presented lower values.
Interrater Concordance for the Assessment of the Quality of Patient Information on Atrial Fibrillation in English and Spanish.

Proportion of agreements (PA).
Reliability of Information
In the reliability assessment in Spanish, significant differences were observed between the models evaluated (P = .01). As demonstrated in Table 2, ChatGPT obtained the highest percentage of complete responses, with 12 responses (80%), followed by Perplexity, with 11 complete responses (73%), Gemini, with 7 responses (47%), and finally YouChat, with 5 complete responses (33%). The YouChat model was the only model that recorded responses classified as ‘some correct and some incorrect’, with 4 responses (27%). It was evident that none of the models produced completely incorrect responses (Figure 1).
Assessment of the Reliability of Patient Information on Atrial Fibrillation in Spanish and English Languages.
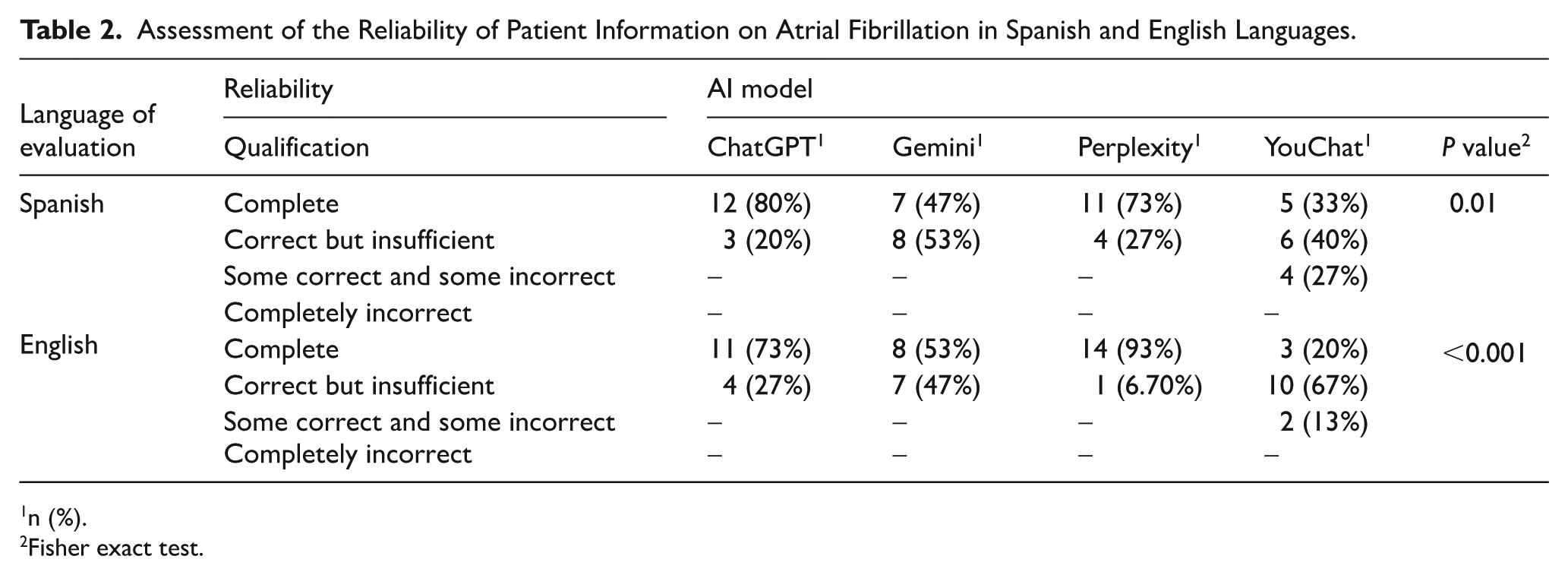
n (%).
Fisher exact test.

Assessing the reliability of Spanish-language information for patients on atrial fibrillation.
In the English language, the disparities between models were even more pronounced (P < .001). Perplexity was identified as the model with the highest level of performance, achieving 14 complete responses, equivalent to 93% of the total. In second place was ChatGPT, with 11 responses, representing 73% of the total. In third place was Gemini, with 8 responses, equivalent to 53% of the total. Finally, YouChat obtained only 3 complete responses, equivalent to 20% of the total. YouChat was the only model that produced responses classified as ‘some correct and some incorrect’, with 2 responses (13%; Figure 2).

Assessing the reliability of patient information on atrial fibrillation in the English language.
Table 3 provides an overview of the reliability of the AF information generated in English by ChatGPT and Perplexity, categorised by completeness level.
Reliability Assessment of Patient Information on Atrial Fibrillation in English Language.

n (%).
Fisher exact test.
Although Perplexity was associated with a greater percentage of complete responses (93% vs 73% for ChatGPT), this difference was not statistically significant (P = .3). Both tools avoided completely incorrect or seriously flawed responses, which is positive in terms of information security. However, ChatGPT had a greater proportion of responses considered ‘correct but insufficient’ (27% vs 6.7% for Perplexity), suggesting that it may provide more conservative or less detailed content. Therefore, although both models offer an acceptable level of reliability, Perplexity could be more effective in providing complete information, which could be important for patient education.
The following study compares the reliability of the responses that were categorised as ‘comprehensive’ across the most accomplished models. As demonstrated in Table 4, ChatGPT and Perplexity in English for AF. Despite the fact that Perplexity demonstrated a greater percentage of complete responses in all the categories evaluated (93% in total vs 73% in ChatGPT), the differences were not statistically significant in any of the categories, according to Fisher’s exact test.
Reliability: Comparison of ChatGPT and Perplexity-Generated Responses Rated as ‘Comprehensive’ in Atrial Fibrillation in English Language.

Fisher exact test.
Notably, both tools provided complete responses for 100% of the diagnosis-related questions. The most significant disparities were observed in nonpharmacological treatment (50% in ChatGPT vs 100% in perplexity). The findings of this study indicate that while Perplexity demonstrates a propensity to furnish more comprehensive responses, particularly in less structured domains such as nonpharmacological treatment, both models exhibit acceptable reliability. Nevertheless, the absence of statistical significance may be attributable to the limited sample size within each category, which compromises the analytical power. This underscores the necessity for subsequent studies to employ larger sample sizes, thereby substantiating the reliability of the observed trends.
Readability
In the Spanish language readability assessment, the AI models demonstrated significant disparities in their performance (P = .009). ChatGPT obtained the highest median score of 55.8 (range: 47.5-65.1; moderately difficult rating), followed by Gemini with 53.4 (43.2PA = 0.73-61.5). The differences between ChatGPT and Gemini were not significant (P = .54), whereas the differences between ChatGPT and YouChat (P = .03) and between Gemini and Perplexity (P = .02) were statistically significant (see Table 5 and Figure 3).
Readability Assessment of Patient Information on Atrial Fibrillation in English and Spanish Languages.
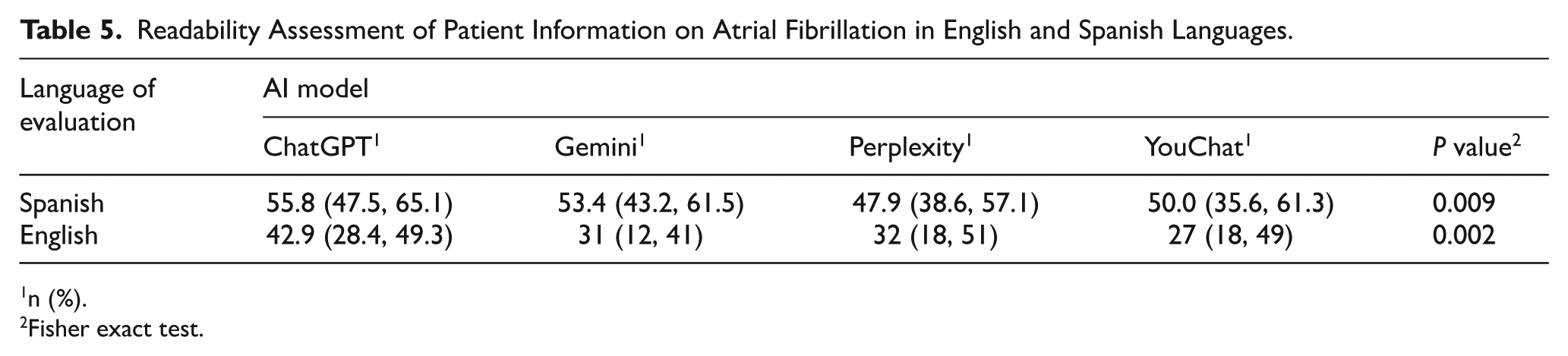
n (%).
Fisher exact test.

Readability assessment of the information for patients on atrial fibrillation in Spanish language.
Furthermore, a significant discrepancy was identified between the models evaluated in the English language (P = .002). Once more, ChatGPT attained the highest median score, with a value of 42.9 (28.4-49.3; hard rating). YouChat clearly obtained the lowest score, with a total of 27 points (out of a possible 49). The differences between Gemini and Perplexity were not significant (P = .35), but notable differences were identified between ChatGPT and Gemini (P = .0032), as well as between ChatGPT and YouChat (P = .0023; Figure 4).

Readability assessment of patient information on atrial fibrillation in English language.
Figure 5 shows the comparison of the readability scores obtained by the ChatGPT and Perplexity models in English. Although the ChatGPT model obtained a visibly higher median score than the perplexity model did, this difference did not reach statistical significance (P = .13). This finding suggests a tendency for ChatGPT-generated responses to be more readable. However, it cannot be stated with statistical certainty that there is a real difference between the 2 models.

Readability comparison between ChatGPT and Perplexity models for patients on atrial fibrillation in English language.
Of particular significance is the observation of outliers in Perplexity, which are indicative of heightened variability in the quality of readability of responses. This, in turn, has the potential to adversely impact the user experience. These findings could have implications for the practical use of these tools, especially in clinical settings where the clarity of language is crucial for patient comprehension. However, it is imperative to acknowledge the need for a more substantial sample size to substantiate these trends with greater certainty.
Quality
In the Spanish language, according to the DISCERN scale, 27 a moderate degree of answer quality was obtained from evaluations of both reviewers (EJ and JB; median = 3, IQR 3-3). In addition, in English, both reviewers give a moderate degree of quality for the answers (median = 3, IQR 3-3), according to the DISCERN scale. 27
Discussion
This study provides an inaugural comparative evaluation of the information generated by 4 AI-based language models for AF patients in both Spanish and English. The study’s objective is to compare the accuracy of responses generated in English and Spanish for medical information.
Our findings demonstrate significant variations in the reliability of information provided by disparate AI models on AF in both English and Spanish. ChatGPT and Perplexity demonstrated superior performance in the provision of complete and accurate information, whereas Gemini and YouChat exhibited greater variability in the quality of their responses.
In the Spanish language, ChatGPT emerged as the model that provided the most complete responses (80%), followed by Perplexity (73%). In contrast to Gemini and YouChat, which exhibited significant disparities and inaccuracies, they presented a higher frequency of responses classified as ‘correct but insufficient’. Notably, 27% of the YouChat platform responses contained partially incorrect information, indicating reduced reliability in providing information in Spanish.
Conversely, in the English language, Perplexity demonstrated exceptional performance, with a 93% complete response rate, surpassing those of ChatGPT (73%) and Gemini (53%). Moreover, YouChat resulted in a lower percentage of complete responses (20%) and a higher percentage of correct but insufficient responses (67%). These findings underscore discrepancies in the performance of AI models, particularly in the context of health-related information.
The analysis revealed significant discrepancies between the models in both languages. In the English language, the difference was statistically significant (P < .001), suggesting that the discrepancies in the quality of information provided by the different models are consistent and not due to chance.
The utilisation of Perplexity and ChatGPT within the models clearly engenders a greater degree of reliability, particularly within the context of the English language. Conversely, it is important to acknowledge the limitations inherent in YouChat and Gemini, which should be duly considered by patients requiring AF information. In addition, the presentation of erroneous answers by models necessitates the supervision of medical personnel to prevent the dissemination of misinformation, which could influence patients’ clinical decisions.
The results of the evaluation of the readability of AF information generated by the different AI models show statistically significant differences in both languages, with p values of .009 in Spanish and .002 in English. In the Spanish context, ChatGPT emerged as the most readable option, with a median score of 55.8, closely followed by Gemini (53.4), YouChat (50.0), and Perplexity (47.9). Conversely, in the English language, considerably lower values were observed, with ChatGPT (42.9), Gemini (31), Perplexity (32) and YouChat (27) demonstrating explanations and answers that were more challenging for nonmedical staff to comprehend.
Considering the aforementioned points, it is posited that the comprehension of AF information generated in the Spanish language is superior to that produced in English. The lower readability of English-language texts has been demonstrated to impede the comprehension of medical information, thus emphasising the necessity of adjusting such texts to the reading level of patients to facilitate health education and informed decision-making.
Finally, considering our findings, several recommendations can be made. First, for those seeking reliable information on AF in Spanish across these AI models, ChatGPT 3.5 appears to provide the most reliable responses. Moreover, if information that is easier to read and understand is desired, ChatGPT also seems to offer the most accessible content. However, if reliable information is desired in English, perplexity may be the most reliable AI tool; however, for those seeking easier-to-read answers, ChatGPT could be the most useful AI tool.
Limitations
The present study is subject to certain limitations. One of the issues that has been identified is that the interpretation of the responses generated by the AI models was carried out from the perspective of health personnel, which may differ from patients’ perceptions. The levels of health literacy vary between individuals. Consequently, patients may have divergent interpretations of the information. To address this limitation, responses were selected on the basis of a broad population and discussed as a team to ensure that they reflected a comprehensive view of information quality.
In addition, factors such as age, educational attainment and technological literacy may influence patients’ comprehension and utilisation of these tools. However, given that the assessment concentrated on overall reliability and readability, the results offer a comprehensive and representative perspective of the population under study.
A further limitation is that ChatGPT does not provide references to information sources unless explicitly requested, which places it at a disadvantage in comparison to other models that do cite their sources. In addressing this limitation, the analysis acknowledged it, thus indicating the necessity for subsequent iterations of these models to provide references in a more accessible manner.
Moreover, it should be noted that the AI models utilised in this study represent evolving technologies; consequently, the responses generated by these models may vary depending on the specific version of the model, the context of the query, and the manner in which the questions are articulated. Nevertheless, to minimise these variations, the responses of each model should be evaluated in its most recent version available at the time of the study. Furthermore, the evaluation was limited to the initial response generated by each model, thus restricting the analysis by excluding the potential for regenerated responses that could have corrected or complemented the initial information. This limitation should be considered, and additional responses should be evaluated in future studies to obtain a more complete picture of the consistency and accuracy of the responses over time.
A salient aspect of this study pertains to the interrater agreement observed in select AI models, as evidenced by the values presented in Table 1. While ChatGPT demonstrated higher levels of consistency in the evaluation of information quality in both Spanish (0.73) and English (0.80), alternative models exhibited lower degrees of agreement. This variability suggests the presence of inconsistencies in responses between raters, which may be attributable to differences in natural language processing algorithms. These findings underscore the necessity of developing more standardised assessment methods, which will yield more robust results in future research.
Conclusions
The present study revealed variations in the reliability and readability of AI-generated AF information. ChatGPT and Perplexity demonstrated the highest levels of accuracy, whereas YouChat exhibited lower accuracy and the presence of erroneous responses. In terms of readability, ChatGPT demonstrated the highest score, although its content was found to be moderately challenging in Spanish and highly challenging in English. These findings underscore the necessity of enhancing the precision and accessibility of these instruments for utilisation in educational and clinical contexts.
Footnotes
Appendix 1
Acknowledgements
To the Pontifical Xavierian University for promoting research.
ORCID iDs
Ethical Considerations
This study was approved by the institutional ethics committee (CIE-319-2024).
Author Contributions
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This article has been funded by the Pontifical Xavierian University.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request and in compliance with the General Data Protection Regulation.