
Abstract
This study aimed to develop an effective forecasting model for daily average PM2.5 concentration using a multilayer perceptron (MLP) neural network. The model was applied to 3 air quality monitoring stations in Mashhad, Iran—Sajjad, Torogh, and Vila—representing different urban land use types. A separate network was trained for each station. The optimal network architecture was determined by tuning the number of neurons in the hidden layer, using input variables such as the previous day’s meteorological parameters (wind speed, temperature, precipitation, solar radiation, and relative humidity), PM2.5 concentration, and temporal indicators (day of the week and month). Data standardization and early stopping were used to enhance generalization. The model performed best at Sajjad station, with an R2 of .79 and MAE of 5.54 µg/m3. Performance at Torogh was acceptable, while Vila showed weaker results. The model detected PM2.5 exceedance events with a true positive rate of 66% to 74% and a false alarm rate as low as 0.18 at Sajjad. Differences in topography, pollution sources, and microclimate conditions influenced spatial variability in accuracy. These findings suggest that MLP neural networks are effective tools for daily air pollution prediction and can support localized early warning systems.
Plain Language Summary
Air pollution, especially tiny particles known as PM2.5, poses serious risks to human health. This study evaluated the ability of a machine-learning model to predict next-day PM2.5 concentrations at three monitoring sites in Mashhad, Iran. A multilayer perceptron (MLP) neural network was trained using previous-day observations of PM2.5 and meteorological variables (temperature, humidity, wind speed, and precipitation), together with temporal categorical features (day-of-week and month). Model performance was compared across sites with different local conditions. Forecast accuracy was higher at locations with more stable emission patterns and lower at sites affected by complex topography and mixed sources. The results indicate that site-specific, properly preprocessed MLP models can provide useful next-day PM2.5 forecasts to support local early-warning and exposure-mitigation measures.
Introduction
One of the critical factors affecting public health is air quality, which is largely influenced by the concentration of particulate matter. Among these, fine particulate matter with a diameter of less than 2.5 micrometers (PM2.5) has been widely recognized for its direct association with adverse health effects.1,2 Elevated levels of PM2.5 have been linked to changes in lifestyle, reduced life expectancy, and increased mortality rates. Numerous studies have demonstrated a statistically significant correlation between atmospheric PM2.5 concentrations and negative health outcomes. 3 Consequently, various air quality standards for PM2.5 have been established based on hourly, daily, and annual exposure limits. According to the latest guidelines of the World Health Organization, the recommended annual and 24-hour average limits for PM2.5 are 5 and 15 µg/m3, respectively. 4 In Iran, based on the national air quality standard approved in 2016, these thresholds are set at 12 and 35 µg/m3, respectively. 5
Meteorological factors such as wind speed and direction, temperature, precipitation, and planetary boundary layer height significantly influence the variability of PM2.5 concentrations in the atmosphere. 6 Severe air pollution episodes typically occur in regions where geographical features and atmospheric stability inhibit natural ventilation, leading to the accumulation of pollutants like PM2.5. 7 These particles, primarily emitted from combustion sources such as urban traffic and industrial activities, remain suspended in the atmosphere for extended periods due to their ultrafine size and can rapidly reach critical concentration levels. 8 Under such conditions, immediate interventions—such as traffic restrictions, school closures, or the suspension of polluting activities—are often required. Accordingly, both national and international air pollution control regulations mandate the implementation of automated operational procedures to prevent pollutant concentrations from exceeding predefined alert thresholds. Here, automated operational procedures denote pre-programed, rule-based response protocols that are activated automatically by real-time monitoring data or short-term forecasts when predefined conditions are met.4,5 These protocols implement explicit decision rules (eg, if forecasted daily PM2.5 reaches or exceeds the action level, then trigger the predefined mitigation measure) and commonly include automated public and institutional alerts (SMS, mobile apps, variable-message signs), traffic-management measures (temporary restrictions, adaptive signal control), notifications to industrial operators to curtail emissions, and rapid deployment of dust-suppression and street-cleaning operations to reduce resuspension of road and construction dust, which contribute to ambient PM concentrations. Automation ensures a rapid, coordinated, and consistent response that reduces delays and human-decision variability.
Mashhad, one of Iran’s major and densely populated metropolitan cities, exhibits both urban and semi-industrial characteristics due to its religious, touristic, and industrial significance. A substantial portion of PM2.5 emissions in Mashhad originates from mobile sources, including older vehicles, diesel buses, and motorcycles. While household heating in most areas of the city is primarily supplied through natural gas systems, in suburban districts such as Toos, Torogh, and surrounding villages, the use of liquid fuels—such as kerosene and diesel—remains prevalent. This reliance on liquid fuels, particularly during colder months, can lead to localized increases in PM2.5 concentrations. In addition to anthropogenic sources, natural contributors such as windblown dust from nearby desert regions also play a role in elevating ambient PM2.5 levels. 9
Given the health impacts associated with PM2.5, this pollutant has become a major public concern in the city of Mashhad. Forecasting PM2.5 concentrations prior to pollution episodes can facilitate more effective interventions to protect public health. A wide range of operational early warning systems—based on statistical and hybrid modeling approaches—have been developed to enable proactive and real-time responses to air pollution events. In this context, predictive models have been increasingly utilized as supportive tools for air quality management in various regions around the world.
Artificial neural networks (ANNs) have been widely applied to forecast the concentrations of various pollutants over different time scales, yielding promising results.10,11 In air quality prediction studies, methods such as ANNs, multiple linear regression (MLR), and stepwise regression (SWR) are among the most commonly used approaches. 12 Due to the complex and nonlinear relationships between meteorological parameters and pollution levels, ANNs have demonstrated superior performance compared to traditional statistical models. 13 Since their initial application in modeling atmospheric pollutant concentrations, 14 ANNs have been regarded as a reliable method in this field.
Although forecasting particulate matter concentrations is more complex than modeling gaseous pollutants—due to the intricate processes involved in aerosol formation, transport, and removal 15 —neural networks have demonstrated high accuracy owing to their ability to identify and model nonlinear relationships. 16 Feedforward neural networks with error backpropagation (FFNNs) are among the most commonly used neural network architectures for predicting pollutants such as PM2.5, PM10, O3, SO2, and CO, due to their capacity to model complex nonlinear interactions. 17 In one study, several machine learning methods were used to predict PM2.5 exceedance events, and FFNNs exhibited superior performance. 18 In other studies, various machine learning approaches—including FFNNs, pruned neural networks (PNNs), and lazy learning (LL) techniques—have been applied for PM2.5 concentration prediction, with FFNNs consistently outperforming the alternatives. 19 Another study analyzed multiple methods for forecasting daily average PM2.5 concentrations. The results of 2 types of multilayer perceptron (MLP) networks—an important subclass of FFNNs—and a radial basis function (RBF) network were compared with 2 classical models, and the MLP model demonstrated superior predictive performance. 20
In the present study, a model was developed to predict daily PM2.5 concentrations based on air pollution data collected from 3 monitoring stations—Sajjad, Vila, and Torogh—in the city of Mashhad. These stations represent diverse urban conditions: the Sajjad station is located in a densely populated, high-traffic area; the Vila station is situated in a region with moderate population density; and the Torogh station is positioned on the southeastern outskirts of the city, where air quality is influenced by industrial activities and heavy-duty vehicle traffic.
An MLP neural network was employed to predict the daily average PM2.5 concentrations at the selected monitoring stations. Model inputs included the previous day’s average PM2.5 concentration as well as the previous day’s meteorological parameters, such as mean wind speed and direction, precipitation, solar radiation, temperature, and relative humidity. Additionally, to account for variations in traffic patterns across different days of the week and throughout the year—due to Mashhad’s religious and touristic nature—variables such as the day of the week (1 -7) and the month of the year (1 -12) were incorporated into the model as input features. The primary objective of this study is to protect at-risk populations by providing accurate and timely information on air quality.
The novelty of this study lies in the development and application of ANN models to predict daily PM2.5 concentrations in Mashhad, one of Iran’s most polluted metropolitan areas. Unlike previous studies that have mainly focused on descriptive assessments of air quality or conventional statistical approaches, our work integrates meteorological variables with traffic-related temporal factors (day of the week and month of the year) to build robust predictive models tailored to the local conditions of Mashhad. By evaluating the performance of multiple ANN training algorithms and comparing prediction accuracy across different urban monitoring stations with diverse land uses, this study provides new insights into the spatial and temporal variability of PM2.5 in the city. The outcomes not only advance the methodological framework for air pollution forecasting in developing countries but also offer practical implications for automated early-warning systems and evidence-based air quality management.
Materials and Methods
Design and Training of MLP Neural Networks
In this study, 3 MLP neural networks were developed to predict the daily average concentration of PM2.5 at 3 air quality monitoring stations in Mashhad: Sajjad, Torogh, and Vila. Each network was independently designed and trained for a specific station—ANN1 for Sajjad, ANN2 for Torogh, and ANN3 for Vila.
The initial dataset comprised several years of hourly pollutant concentrations and meteorological parameters. These data were preprocessed using the Python programing language, with the aid of the pandas library for structured data manipulation and NumPy for numerical computations. During preprocessing, the data were time-indexed by date and aggregated into daily values (24-hour averages) to enable the prediction of next-day PM2.5 concentrations. In instances where one or more input variables were missing for a given day, the corresponding row was removed from the dataset to avoid errors associated with imputation of missing values. Ultimately, approximately 80% of the daily data for each station remained complete and was deemed suitable for model development.
The general architecture of each network consisted of 3 main layers: an input layer, a hidden layer, and an output layer. The input layer incorporated the modeling variables, including meteorological and air quality parameters. The hidden layer comprised several neurons that computed the weighted sum of the inputs and passed the results through a nonlinear tangent sigmoid activation function. The final output was produced in the output layer by combining the weighted outputs of the hidden layer neurons using a linear activation function.
The use of the tangent sigmoid function in the hidden layer enables the network to capture nonlinear mappings and model complex relationships, while the linear activation function in the output layer ensures the generation of continuous outputs without additional nonlinear transformation. This combination of activation functions provides an efficient modeling framework for predicting PM2.5 concentrations. 21
To identify the most appropriate training algorithm for each station, initial neural networks with 10 neurons in the hidden layer were designed and trained using several algorithms. The performance of each algorithm was evaluated on the training, validation, and testing datasets using statistical performance metrics. The algorithm yielding the best overall performance was selected for further modeling.
Once the optimal training algorithm was identified, the process of determining the optimal number of neurons in the hidden layer for each network began. Networks were initially trained with 10 neurons, and the number of neurons was then gradually increased to assess different network configurations. For each configuration, statistical performance indicators were recorded and analyzed for the training, validation, and testing sets. This process continued until the most efficient network structure—based on performance metrics—was identified for each monitoring station.
To prevent overfitting, network structures that exhibited decreased training error but increased validation or testing error were excluded. Network training was performed using the backpropagation algorithm, aiming to minimize the discrepancy between predicted and actual outputs. This process involved a forward pass for signal propagation and a backward pass for updating the connection weights through error backpropagation.
The modeling process was conducted using MATLAB software. The dataset for each station was randomly shuffled and split into training (70%), validation (15%) and test (15%) subsets to mitigate overfitting. The total number of daily data points was 1771 for Sajjad, 1706 for Torogh, and 1641 for Vila; accordingly, the independent test sets comprised 266 (Sajjad), 256 (Torogh), and 246 (Vila) daily samples. The early stopping method was employed to further reduce the risk of overfitting. Additionally, to enhance the stability and reliability of the results, each network was independently trained 3 times.
Study Area
This study was conducted in the metropolitan city of Mashhad, located in northeastern Iran. With a population exceeding 3.5 million, Mashhad is the second most populous city in the country after Tehran. Due to its religious and touristic significance, the city attracts over 20 million domestic and international pilgrims and tourists annually. These characteristics have led to high urban traffic density, increased fossil fuel consumption, and the expansion of commercial and service activities—major sources of PM2.5 emissions.
Topographically, Mashhad is situated on a plain at an average elevation of approximately 980 m above sea level. It is surrounded by the Hezar-Masjed Mountains to the north (with elevations exceeding 2800 m) and the Binalood Range to the southwest (reaching approximately 3211 m). This complex terrain gives rise to specific climatic phenomena such as mountain-to-plain breezes, nocturnal temperature inversions during cold nights, and convective airflows in warmer seasons. These conditions can contribute to elevated pollutant concentrations or the persistence of pollutants near the surface, particularly during winter when thermal inversion events are more intense.
The average annual temperature in Mashhad is approximately 12.4 °C, and the mean annual precipitation is reported to be around 248.6 mm. The prevailing winds in this region typically blow from the west and northwest, with an average speed of about 3 m/s. 22 On average, approximately 86 days per year in Mashhad are classified as having unhealthy air quality for sensitive groups—including children, the elderly, and individuals with respiratory illnesses. This condition is primarily attributed to combustion-related sources such as heavy traffic congestion, domestic heating, industrial activities, and regional climatic factors. 23
In this study, data from 3 air quality monitoring stations were used, each located in areas with distinct environmental characteristics and pollution sources. The Sajjad station was selected to represent urban background pollution associated with PM2.5. This station is situated in the city center at an elevation of approximately 1000 m above sea level, near Falasteen Square, and within less than 100 m of major roads such as Sajjad and Ahmadabad Boulevards. This area is among the busiest traffic zones in Mashhad and is significantly influenced by emissions from both light and heavy vehicles.
The Torogh station, located in the southeastern part of Mashhad at an elevation of approximately 1020 m above sea level, lies about 15 km from the city center and near the Torogh Industrial Zone. This station reflects the combined impact of pollution from high diesel vehicle traffic, industrial activities, and emissions from heavy-duty transportation sources.
The Vila station is situated in a mixed residential-commercial area with moderate traffic density in the southwestern part of the city, at an elevation of approximately 970 m. It is located about 5 km from the city center and is relatively distant from direct sources of industrial emissions. Therefore, this station is considered representative of areas with lower background pollution levels.
The geographic coordinates of the monitoring stations used in this study are as follows: Vila Station (36.31681°N, 59.48475°E), Sajjad Station (36.31854°N, 59.55464°E), and Torogh Station (36.21007°N, 59.66678°E). Additionally, the meteorological station is located at 36.25452° N, 59.61774°E. These coordinates were used to accurately plot the spatial distribution of the monitoring sites on the topographic map of Mashhad, enabling a clearer understanding of their positions in relation to surrounding emission sources and land use patterns.
Figure 1 presents the topographic map of Mashhad, illustrating the locations of the 3 PM2.5 monitoring stations (Sajjad, Vila, and Torogh) as well as the meteorological station. To enhance spatial interpretation, the map also indicates major potential sources of PM2.5 emissions, including 2 large industrial zones on the city’s outskirts, Mashhad International Airport, adjacent desert regions, densely populated residential neighborhoods, and central business districts (CBDs). These features are schematically represented based on their approximate locations relative to the monitoring stations.

Topographic map of Mashhad showing the locations of PM2.5 monitoring stations (Sajjad, Torogh, Vila) and the meteorological station, along with major sources of PM2.5 emissions (industrial zones, airport, desert areas, central business districts, and residential zones).
Data Preparation
Daily datasets for the 3 monitoring stations in Mashhad (Sajjad, Vila, and Torogh) were compiled for 2018 to 2023, including meteorological parameters—air temperature (°C), relative humidity (%), average wind speed (m/s), wind direction (degrees), and precipitation (mm)—and PM2.5 concentrations. Meteorological data were obtained from the Khorasan Razavi Meteorological Organization, while PM2.5 data were provided by the Khorasan Razavi Department of Environment.
PM2.5 concentrations were recorded hourly using online beta attenuation monitors. In this method, an airstream passes over a filter, and the resulting decrease in beta radiation intensity is used to calculate PM2.5 mass concentration. Although beta attenuation monitors are semi-reference methods, 24 data were corrected using adjustment coefficients derived from comparisons with gravimetric reference methods when necessary. Data coverage over the study period was approximately 80% for each station. To maintain analytical integrity, no extrapolation or interpolation was performed to replace missing data.
Annual average PM2.5 concentrations ranged from 35-38 μg/m3 at Sajjad, 26-32 μg/m3 at Torogh, and 20-28 μg/m3 at Vila, reflecting variations in local emission sources such as traffic, industrial activity, and domestic heating.
To provide an overview of the statistical characteristics of the dataset used in this study, descriptive indicators—including range, mean, and standard deviation—were calculated for the main parameters (PM2.5 concentration, temperature, humidity, wind speed, and precipitation). The results of this statistical analysis are presented in Table 1. These indicators help identify data variability and offer insights into the distribution of variables over the study period.
Descriptive Statistics of Meteorological Variables and PM2.5 Concentrations Over the 6-Year Period (2018-2023).
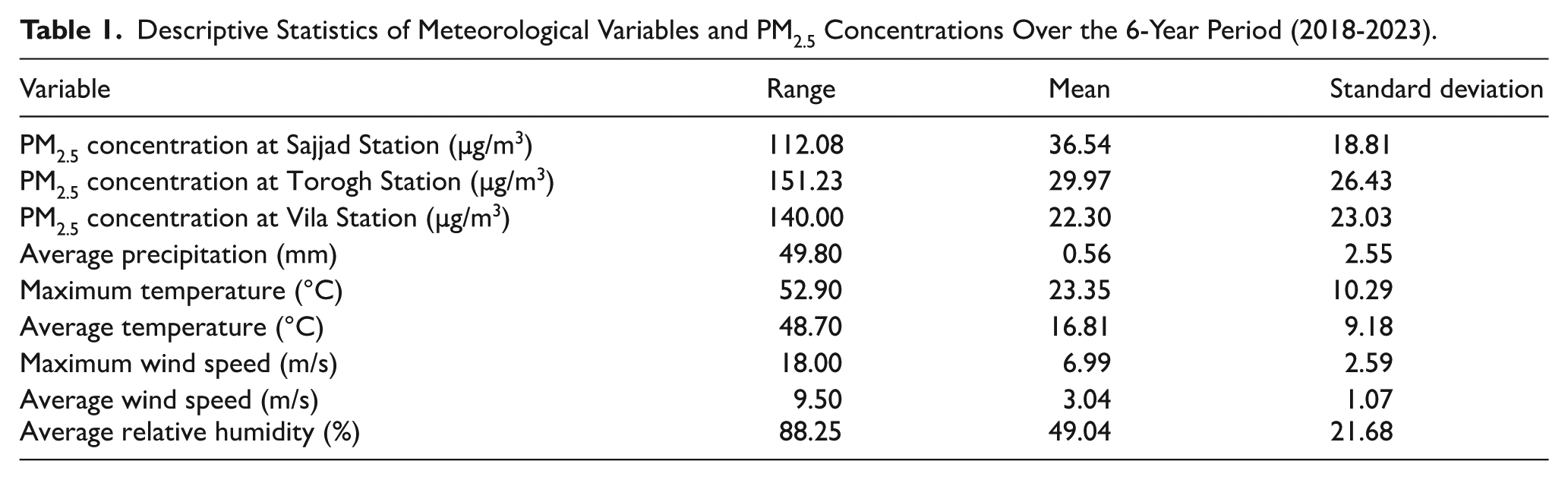
These values indicate considerable variability in both pollutant concentrations and meteorological conditions, which is crucial for understanding the dynamics of PM2.5 behavior and its interaction with environmental parameters in the urban context of Mashhad.
As shown in Table 1, the variables under investigation exhibit different numerical ranges. For example, PM2.5 concentrations at the Sajjad station have a range of 112.08 µg/m3, while the average wind speed varies over a range of 9.50 m/s. These wide disparities in variable ranges highlight the necessity of standardization. Without it, variables with larger numerical ranges—such as PM2.5—may lead to unbalanced learning, reduced convergence speed during model training, and numerical instability.
To address this issue, this study employed a standardization approach in which the input data were transformed to have a mean of zero and a standard deviation of 1 (equation (1)). This process promotes a more stable and uniform gradient flow, reduces numerical instabilities caused by large input values, and accelerates convergence in gradient-based optimization algorithms. It also enhances the effectiveness of activation functions. Additionally, centering the features around the mean and bringing them onto a comparable scale improves model interpretability and contributes to more efficient learning and better generalization to unseen data. 25
Furthermore, to incorporate temporal categorical features such as the day of the week and the month of the year, one-hot encoding was applied. In this method, each category (ie, each weekday or month) is represented as a distinct binary vector, thereby preventing the erroneous imposition of ordinal or numerical relationships between categories. The use of one-hot encoding eliminates numerical bias and enables the model to capture temporal patterns more accurately, ultimately improving its predictive performance.

where
Input Variables
The selection of variables examined in this study was based on a review of relevant literature and the availability of existing data. To assess the appropriateness of the selected variables and evaluate the relationships among them, Pearson correlation analysis was employed. This widely used statistical technique measures the strength and direction of a linear relationship between 2 continuous variables. 25 The correlation coefficient ranges from –1 to +1, where +1 indicates a strong positive relationship, –1 signifies a strong negative relationship, and 0 denotes the absence of a significant linear association. The aim of this process was to identify the most influential variables affecting the dependent variable and to eliminate irrelevant or redundant features.
In this study, a Pearson correlation matrix was constructed—a symmetric structure in which each cell represents the correlation coefficient between a pair of variables. Analyzing this matrix enables the identification of highly correlated variables—those with an absolute correlation coefficient greater than 0.8. Such high correlations indicate multicollinearity and redundancy of information; in these cases, the associated variables are excluded to prevent adverse effects on model stability and accuracy. Additionally, variables showing a weak correlation with the output variable (absolute value less than 0.1) are removed, as they have minimal explanatory power for the dependent variable and do not significantly contribute to model performance. 26 A careful application of Pearson correlation analysis enhances the precision of variable selection, improves model generalizability, and reduces unnecessary complexity.
Results
Correlation Analysis Between Input Variables and PM2.5 Concentration
Prior to designing the neural network model, the Pearson correlation matrix was calculated to assess the relationships between PM2.5 concentration and other measured parameters at each station. As shown in Figure 2, some variables exhibit significant correlations with PM2.5 concentrations, while others show negligible influence on this pollutant. Among the examined parameters, relative humidity demonstrated a moderately strong negative correlation with PM2.5 (correlation coefficients ranging from −.38 to −.45 across different stations), indicating a decrease in particle concentration with increasing humidity. This inverse relationship can be attributed to enhanced wet deposition and reduced atmospheric residence time of particles. 27

Combined Spearman correlation matrix between PM2.5 and meteorological variables at Sajjad (S), Torogh (T), and Vila (V). Cell color shows the mean Spearman correlation across the 3 stations.
Air temperature showed a moderate positive correlation with PM2.5 (correlation coefficients between .30 and .36 across stations). This association most likely reflects several interrelated and partly indirect processes rather than a single direct thermodynamic effect. Warmer, drier conditions are typically associated with lower relative humidity and reduced wet scavenging efficiency, 27 while dry surfaces enhance the resuspension of dust and mechanically generated particles. In general, higher temperatures and increased solar radiation can also enhance photochemical activity and gas-to-particle conversion, thereby promoting secondary aerosol formation; however, in Mashhad’s dry and semi-industrial climate, our results indicate that this mechanism plays only a minor role compared with primary emissions and dust resuspension. Moreover, changes in human activity and energy use (eg, greater electricity consumption for cooling) may further modify emission patterns. Conversely, during winter, the dominant meteorological conditions—such as high relative humidity, stratiform cloud cover, and light precipitation—contribute to lower temperatures and enhanced wet deposition, thereby reducing PM2.5 levels. 27
The role of temperature in PM2.5 dynamics is also mediated through its control of atmospheric stability and boundary-layer structure. Under low-level temperature inversions or a shallow mixing layer, vertical dispersion is strongly suppressed, leading to pollutant accumulation near the surface. 28 Climatic assessments for Mashhad indicate inversion-base heights of approximately 500 to 1000 m from June to September and 100 to 500 m from October to May, with mean minimum inversion heights around 120 m in March.29,30 Persistent, low-altitude inversions, particularly during transition seasons, are associated with the most severe pollution episodes in our records. Thus, temperature influences PM2.5 concentrations through multiple, seasonally dependent pathways—including modifications to atmospheric stratification, secondary aerosol formation, emission/resuspension behavior, and removal processes—that cannot be disentangled by simple bivariate correlations and require multivariate or process-based modeling for quantification.
The analysis of the Pearson correlation matrix revealed a weak negative correlation between precipitation and PM2.5 concentration across the monitored stations, with coefficients ranging from −.12 to −.18. Although this correlation is statistically weak, its influence should not be entirely disregarded. Precipitation contributes to the temporary reduction of airborne particulate matter through the wet deposition process, which removes particles from the atmosphere and transports them to the ground. In the semi-arid climate of Mashhad, where the average annual precipitation is reported to be approximately 220 to 260 mm, 22 not only is the number of rainy days limited, but the intensity and persistence of rainfall are also generally insufficient to cause a significant and sustained reduction in particle concentrations. 31 Therefore, on short-term timescales (daily or weekly), precipitation cannot be considered a major determinant in explaining PM2.5 concentration variability, and its impact is mainly confined to intense or exceptional rainfall events. These findings are consistent with previous studies, which have demonstrated that the effect of precipitation in arid and semi-arid regions is significantly weaker than in humid climates due to lower rainfall frequency and intensity. 32
Based on the correlation matrix results, the mean wind speed showed a moderate negative correlation with PM2.5 concentration, with correlation coefficients ranging from −.28 to −.36 across different stations. This suggests that higher wind speeds are generally associated with lower PM2.5 concentrations. Wind plays an essential role in ventilating polluted air through processes such as dilution, horizontal and vertical dispersion, and the transport of pollutants across the lower atmospheric layers, particularly under conditions with strong regional airflow. 33 However, in this study, the most frequent mean wind speed was observed in the range of 2.0 to 3.88 m/s, indicating that for most days of the year, Mashhad experiences relatively low wind speeds, and strong wind events are rare. Consequently, the moderate level of observed correlation can be attributed to these typically low wind speeds. If stronger winds were more common, the impact of wind on reducing PM2.5 concentrations would likely be more pronounced.
The analysis revealed that although westerly winds are predominant in the region, their low speeds, along with local obstructions such as terrain irregularities and dense urban structures, significantly limit their effect on the dispersion of PM2.5 particles. As a result, wind direction showed no statistically significant correlation with PM2.5 concentrations. Therefore, to avoid incorporating low-impact variables, reduce statistical noise, and enhance model accuracy, wind direction was excluded from the ANN input parameters.
Although solar radiation can contribute to the formation of secondary PM2.5 through photochemical reactions under certain conditions, in Mashhad’s dry and semi-industrial climate, PM2.5 concentrations are predominantly influenced by primary sources, including vehicular traffic and wind-induced resuspension of surface dust. Moreover, due to the strong correlation between solar radiation and air temperature, and the absence of a meaningful relationship between solar radiation and the model output, this variable was also excluded from the model inputs to reduce multicollinearity and simplify the model structure.
The analysis of temporal variables revealed a weak but positive correlation between PM2.5 concentrations and both the day of the week and month of the year. Spearman’s rank correlation coefficients for the relationship between day of the week and PM2.5 ranged from .18 to .25, and for month of the year, from .21 to .28 across the 3 studied stations. Although these correlations are statistically weak, they reflect the influence of temporal patterns in human activity, such as traffic volume and commercial operations, on particulate matter distribution. Additionally, time-related variables may indirectly affect pollutant behavior by influencing meteorological conditions like temperature and atmospheric stability.34,35
Further examination of individual stations showed that this correlation was strongest at the Sajjad station, compared to the Vila and Torogh stations. This variation is primarily attributed to differences in the type and intensity of human activities surrounding each monitoring site. The Sajjad district, as a major administrative-commercial hub in Mashhad, frequently experiences non-local traffic flows. Traffic patterns in this area fluctuate significantly during weekends, public holidays, and religious or social events, which in turn influence pollutant concentrations. These temporal fluctuations lead to greater sensitivity of PM2.5 levels to time-related variables at the Sajjad station.
In contrast, the Vila station is more influenced by local activities and relatively stable traffic conditions, while the Torogh station is situated near industrial zones and heavy transportation corridors, which are less affected by temporal variations such as holidays or special events. Consequently, temporal variability in air pollution patterns is less pronounced at these 2 stations compared to Sajjad.
These findings are consistent with previous studies in other metropolitan areas, which have shown that administrative-commercial zones and urban attraction centers are more susceptible to fluctuations in PM2.5 concentrations due to unstable traffic volumes. 34
Neural Network Structure
To identify the optimal training algorithm for neural network modeling, an MLP was independently designed for each station using a fixed architecture comprising a single hidden layer with 10 neurons. The hyperbolic tangent sigmoid function was applied as the activation function in the hidden layer, while a linear activation function was used in the output layer. Five commonly used training algorithms available in MATLAB—Levenberg–Marquardt (LM), Bayesian Regularization (BR), Scaled Conjugate Gradient (SCG), Resilient Backpropagation (RP), and Gradient Descent (GD)—were evaluated. Among these, the LM algorithm consistently outperformed the others across all 3 stations and was consequently selected as the optimal training algorithm. This algorithm was employed in subsequent stages to refine the network architecture and enhance prediction accuracy.
In this study, an independent neural network was developed for each monitoring station. The selected LM algorithm was used to train an MLP with a single hidden layer of variable size. Starting from 10 neurons, the number of neurons in the hidden layer was gradually increased to assess changes in the model’s performance metrics, including the coefficient of determination (R2) and root mean square error (RMSE), across the training, testing, and validation datasets. The performance results for near-optimal configurations are summarized in Table 2.
Optimization of the Hidden Layer Neuron Count for the 3 Monitoring Stations.

The results presented in Table 2 indicate that increasing the number of neurons in the hidden layer consistently enhances model accuracy on the training dataset. However, this trend does not uniformly extend to the test and validation datasets. For instance, at the Sajjad station, increasing the number of neurons from 15 to 16 improved the correlation coefficient (R2) on the test data from .784 to .793, while the RMSE decreased from 7.12 to 6.77 µg/m3. Nevertheless, further increasing the neuron count to 17 yielded only a marginal improvement in training performance, accompanied by a decline in test set accuracy, indicating the onset of overfitting. This behavior was also observed at the Torogh and Vila stations, suggesting a consistent pattern regarding the impact of increasing network complexity. These results underscore the importance of avoiding unnecessary increases in model parameters, which may elevate the risk of overfitting.
It is worth noting that, during the model training process, the early stopping technique was employed to prevent overfitting. In this study, early stopping was implemented by halting training when the validation error failed to improve over 6 consecutive epochs. This approach effectively mitigates the risk of the model becoming overly fitted to the training data. However, despite the use of early stopping, an excessive increase in the number of neurons in the hidden layer can still lead to overfitting due to the model’s elevated capacity. In such cases, the network becomes excessively complex, and its generalization ability diminishes. As a result, instead of learning generalizable patterns, the model begins to memorize specific fluctuations in the training dataset, leading to reduced performance on the test and validation sets.
Based on the results presented in Table 2, the optimal neural network architectures for each monitoring station were identified as follows: ANN1 for the Sajjad station with 16 neurons, ANN2 for the Torogh station with 11 neurons, and ANN3 for the Vila station with 19 neurons in a single hidden layer. All models utilized the hyperbolic tangent sigmoid activation function in the hidden layer and a linear activation function in the output layer. The final model architectures and training settings are summarized in Table 3.
Compact Summary of MLP Model Features and Training Settings.

The variation in the optimal number of neurons across the stations can be attributed to the distinct statistical characteristics of each dataset. Factors such as data variance and coefficient of variation, the presence of nonlinear patterns of varying complexity, and the signal-to-noise ratio at each station significantly influence the model capacity required for effective learning. Specifically, stations like Vila, which exhibit more severe fluctuations or more complex temporal patterns in PM2.5 concentrations, require a larger number of neurons in the hidden layer to adequately capture the intrinsic structure of the data. This finding underscores that the optimal neural network architecture cannot be uniform or universally applied across all datasets; rather, it must be individually determined based on the statistical properties and inherent complexity of the data at each location. In this context, the trade-off between bias and variance is particularly important. Increasing the number of neurons enhances model capacity, which may reduce bias but increase variance, potentially leading to overfitting. Conversely, too few neurons may result in high bias and underfitting. Therefore, determining the optimal number of neurons should strike a balance between these 2 factors, ensuring that the model maintains sufficient generalization capability while accurately capturing complex data patterns. 36
Neural Network Performance
The performance of the neural network at the 3 air quality monitoring stations in Mashhad—Sajjad, Torogh, and Vila—is illustrated in Figure 3. This figure presents the statistical performance indicators for the training, validation, and testing phases. Based on these results, the model exhibited strong learning capability during the training phase and maintained satisfactory performance in both the validation and testing stages. These findings demonstrate the model’s adequate generalization ability in predicting PM2.5 concentrations for unseen data.
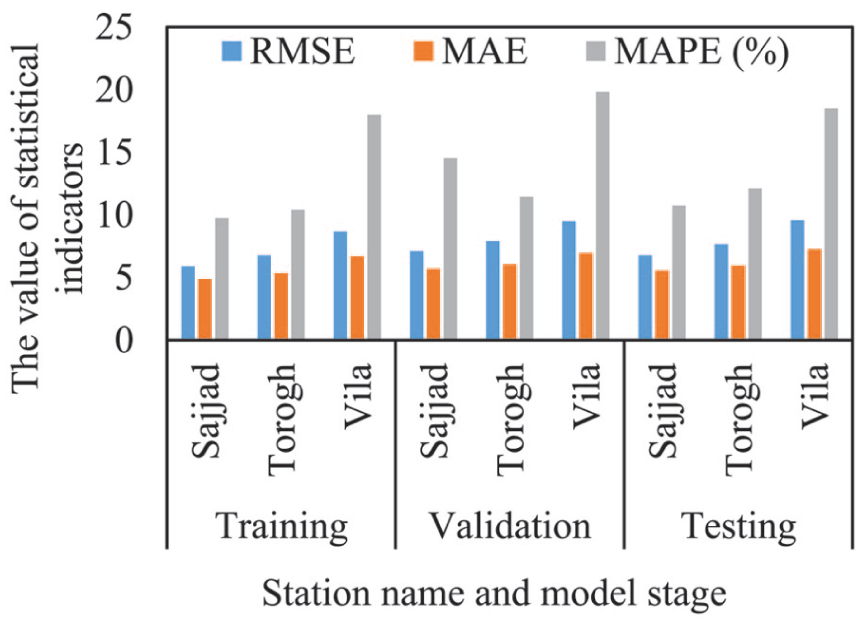
Comparison of MLP model performance indicators during the training, validation, and testing phases at the 3 monitoring stations.
The Sajjad station, located in 1 of the most traffic-congested urban areas of Mashhad, demonstrated the highest predictive performance. This outcome can be attributed to the relatively stable pattern of traffic-related pollution, spatial and temporal consistency in pollutant dispersion, and the absence of diverse or complex emission sources. The model’s statistical performance during the testing phase at this station included an R2 of .79, an RMSE of 6.77 µg/m3, a Mean Absolute Error (MAE) of 5.54 µg/m3, and a Mean Absolute Percentage Error (MAPE) of approximately 10.73%, indicating good agreement between observed and predicted concentrations.
At the Torogh station, despite its peripheral location, high pollution levels were recorded—primarily due to industrial activities, the movement of heavy-duty diesel vehicles, soil erosion, and transboundary pollutant transport from neighboring regions. In this case, the model achieved a testing-phase R2 of .78, an RMSE of 7.65 µg/m3, an MAE of 5.94 µg/m3, and a MAPE of approximately 12.09%. Although the predictive accuracy at Torogh was slightly lower than at Sajjad, the model’s performance remains within an acceptable range. 37
The Vila station, located in a moderately urbanized area near the Binalood mountain range, exhibited the weakest performance in predicting daily PM2.5 concentrations. Nevertheless, even at this station, the model demonstrated an acceptable ability to capture the general data patterns. During the testing phase, the statistical indicators included an R2 of .65, an RMSE of 9.56 µg/m3, an MAE of 7.24 µg/m3, and a MAPE of approximately 18.49%.
The reduced accuracy at this station can be attributed to the high spatiotemporal variability of multiple pollution sources—such as dispersed residential, commercial, and traffic-related activities—which, unlike the Sajjad and Torogh stations, lack spatial and temporal coherence. Furthermore, the station’s geographical location near mountainous terrain influences the formation of meteorological phenomena such as temperature inversions, regional airflows, and specific wind patterns. These factors lead to reduced atmospheric stability and nonlinear pollutant transport, thereby complicating accurate prediction. The interplay of these conditions has diminished the model’s capacity to precisely simulate pollutant concentration behavior in this area.
Figure 4 illustrates the regression results between observed and predicted daily PM2.5 concentrations for the training, validation and test phases. Each subplot (a-i) is annotated with R2, RMSE (µg/m3), MAE (µg/m3) and the number of samples (n). As shown, a strong correlation between observed and predicted values is evident at all 3 monitoring stations.
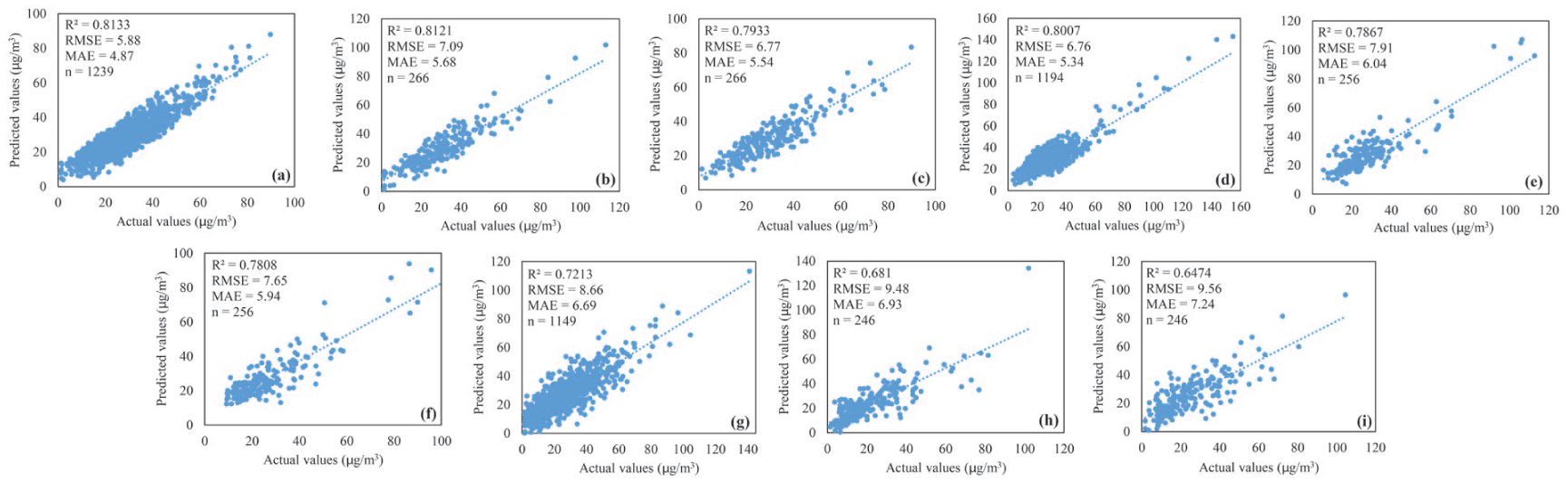
Regression plots comparing the actual and predicted daily PM2.5 concentrations using the MLP neural network model at the 3 monitoring stations. Sajjad Station—(a) training data, (b) validation data, (c) testing data; Torogh Station—(d) training data, (e) validation data, (f) testing data; Vila Station—(g) training data, (h) validation data, (i) testing data. Each subplot reports R2, RMSE, MAE, and the number of data points (n).
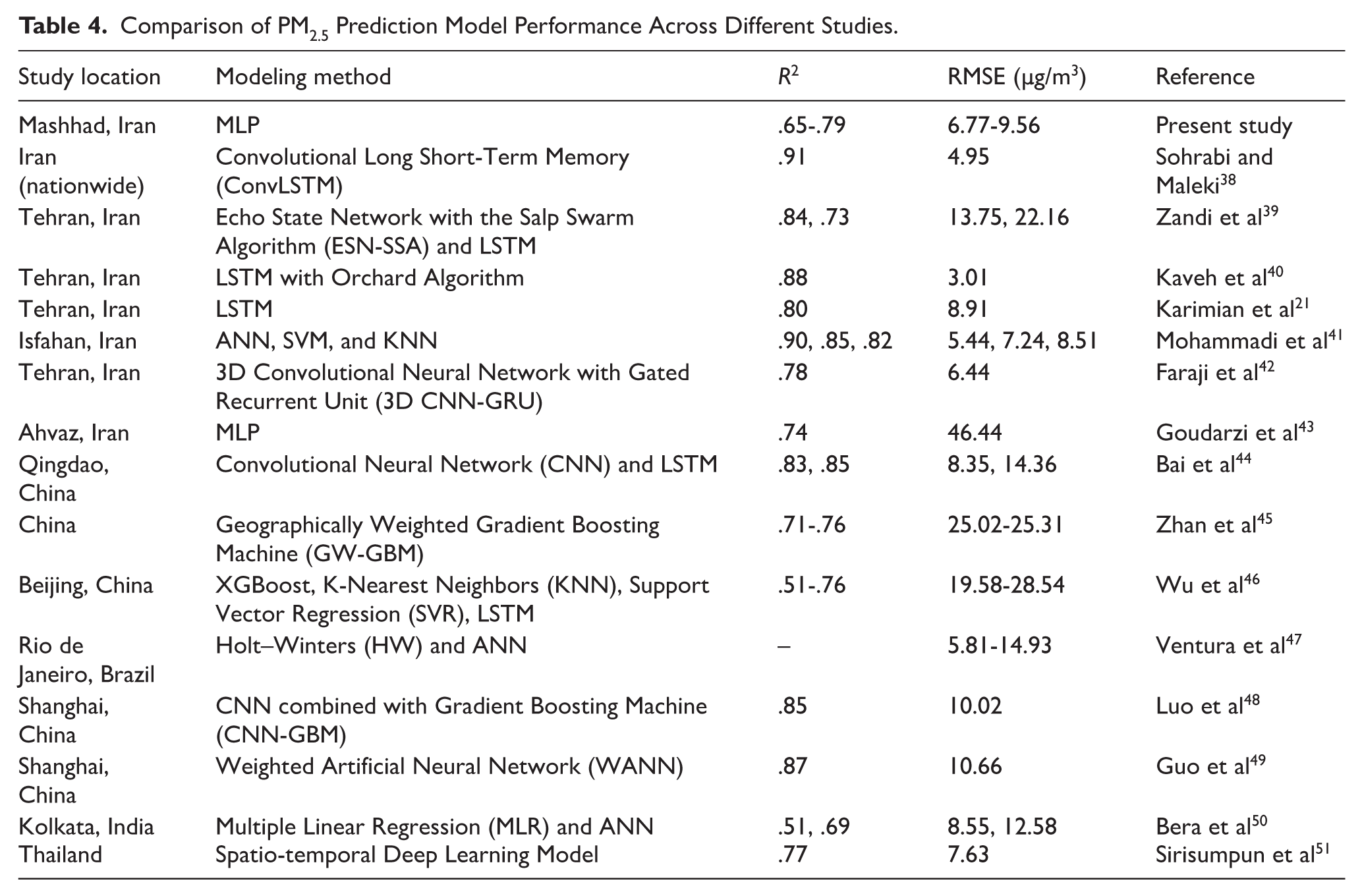
Based on the results presented in Figures 3 and 4, the neural network model demonstrated higher accuracy in areas with more consistent pollution patterns, such as the Sajjad station, while its performance declined in regions characterized by diverse pollution sources or distinct climatic conditions. For further validation, the findings of this study were compared with those of previous research, as summarized in Table 4, which corroborates the accuracy and effectiveness of the modeling approach employed in the present study.
Comparison of PM2.5 Prediction Model Performance Across Different Studies.
Model Performance Evaluation in Predicting Daily PM2.5 Exceedances
To assess the performance of a prediction system, various evaluation metrics can be employed. One of the most critical indicators is the system’s ability to accurately predict exceedances of the daily air quality standard. According to the Iranian National Ambient Air Quality Standard, the permissible daily limit for PM2.5 is set at 35 µg/m3. 5
To analyze the model’s effectiveness in forecasting exceedance events, 3 key statistical indicators were used: True Positive Rate (TPR), False Alarm Rate (FAR), and F1-score. These metrics were calculated by comparing the predicted values against observed data for instances where daily PM2.5 concentrations exceeded the threshold of 35 µg/m3.
The parameters used to compute these performance indicators include: A, the number of correctly predicted exceedance events; F, the total number of predicted exceedances (both true and false); M, the total number of actual exceedance events; and N, the total number of days analyzed (ie, total data points). In this context, the ratio of true positive predictions to all predicted exceedances (A/F) represents the precision of the model in identifying exceedance cases.
The TPR, as defined in equation (2), reflects the model’s ability to correctly identify days with actual exceedances and is considered a measure of the model’s sensitivity.

The FAR, as defined in equation (3), indicates the proportion of predicted exceedance events that did not actually exceed the threshold.

The F1-score (equation (4)) represents the harmonic mean of precision and sensitivity (TPR). This metric is particularly useful in imbalanced classification problems, where the number of exceedance and non-exceedance cases are unevenly distributed. The F1-score effectively balances the model’s ability to correctly detect exceedances while minimizing false alarms. A value closer to 1 indicates superior model performance. In environmental applications, F1-scores greater than 0.70 are typically considered acceptable.

Table 5 presents the performance metrics of the ANN model in predicting exceedance events of the daily PM2.5 threshold (35 µg/m3) at 3 air quality monitoring stations in Mashhad during the period 2018 to 2023. The results indicate notable spatial differences in model performance. Specifically, the ANN model demonstrated superior predictive accuracy at the Sajjad station, while a marked decline in performance was observed at the Vila station.
Performance Metrics of the ANN Model for Predicting Daily PM2.5 Exceedance Events (>35 µg/m3) at Air Quality Monitoring Stations in Mashhad.

At the Sajjad monitoring station, the model’s performance indicators demonstrate considerable success in identifying pollution events characterized by daily PM2.5 concentrations exceeding the regulatory threshold. A TPR of 0.74 indicates that 74% of actual exceedance events were correctly identified. Moreover, a FAR of 0.18 reflects the model’s ability to minimize false positive predictions. The F1-score, a composite metric balancing precision and recall, was calculated as 0.78, indicating a favorable balance between sensitivity and precision in detecting critical pollution events. The model’s superior performance at the Sajjad station can be attributed to the relatively lower density of unpredictable pollution sources—such as construction activities and episodic public events—which often reduce forecasting accuracy. Additionally, the relative consistency of pollution patterns in this area likely enhances the model’s generalizability.
The ANN model’s performance in predicting PM2.5 exceedance events aligns well with findings from similar studies conducted in regions characterized by stable pollution patterns. For instance, F1-scores ranging from 0.77 to 0.88 have been reported in Isfahan 41 ; an F1-score of 0.62 was observed in Jakarta 52 ; and TPR values between 60% and 75% were documented in the western United States. 53 Furthermore, in Athens, the TPR and FAR were reported as approximately 0.78 and 17.9%, respectively. 54
The Torogh monitoring station, located on the southeastern outskirts of Mashhad and adjacent to industrial zones, exhibited relatively stable performance comparable to that of the Sajjad station. The F1-score and FAR at this station were calculated as 0.75 and 0.19, respectively, indicating acceptable accuracy in predicting pollution events and a low rate of false alarms. The presence of relatively consistent pollution patterns stemming from industrial activities, along with the spatial distance from the city center—which reduces the diversity of pollution sources—are key factors contributing to reduced data noise and improved model performance. The findings of this study are consistent with results reported in other industrial regions. For instance, ANN models achieved F1-scores of approximately 0.76 in the Shah Alam Industrial Area, Malaysia, 55 and F1-scores ranging from 0.74 to 0.80 in the Puli Industrial Zone in Taiwan. 56
In contrast, at the Vila station, the F1-score dropped to 0.68, indicating a decline in model performance. This station is situated in the southwestern part of Mashhad, in an area characterized by specific topographic features, including proximity to southern highlands and urban green spaces. Such conditions cause significant variability in wind flow and pollution dispersion patterns. Furthermore, temperature inversion phenomena—especially during early morning hours or colder seasons—can lead to the accumulation of pollutants in the lower atmospheric layers, complicating their dispersion patterns. These dynamics are often overlooked in models that lack vertical atmospheric data. Additionally, the meteorological data used in the modeling process were derived from synoptic stations, which mainly provide generalized representations of regional atmospheric conditions and are insufficient for capturing fine-scale local variations. This mismatch between input data and real-world conditions has likely reduced the model’s predictive accuracy at this station.
Therefore, the integration of high-resolution mesoscale meteorological models, such as the Weather Research and Forecasting (WRF) model, can enhance the accuracy of local input data—particularly in regions with complex terrain and heterogeneous climatic conditions—thereby improving prediction performance. Similar studies have also highlighted the adverse effects of topographical complexity and climatic variability on the performance of air pollution forecasting models. For example, research conducted in Thailand 50 and India 51 reported that in mountainous or valley regions, ANN models experienced significant performance declines, with mean F1-scores ranging between 0.58 and 0.65. These findings are consistent with the performance observed at the Vila station.
Overall, the analysis of Table 5 reveals that the ANN model performs significantly better at stations located in areas with well-defined emission sources, stable dispersion patterns, and relatively simple topographic conditions. This underscores the importance of spatial adaptability in model design, the necessity of high-resolution meteorological data, and the inclusion of local geographic characteristics in the development of air quality forecasting and early warning systems. Given the model’s satisfactory performance at selected stations, it can serve as a foundational component for the implementation of localized air pollution alert systems.
Conclusions
The results of this study indicate that MLP neural network models, when individually designed and optimized for each monitoring site, can provide reliable next-day PM2.5 forecasts across different urban and semi-industrial environments. Quantitatively, the final models achieved test-phase performance as follows: Sajjad—R2 = .79, RMSE = 6.77 µg/m3, MAE = 5.54 µg/m3 (n = 266); Torogh—R2 = .78, RMSE = 7.65 µg/m3, MAE = 5.94 µg/m3 (n = 256); Vila—R2 = .65, RMSE = 9.56 µg/m3, MAE = 7.24 µg/m3 (n = 246). These results reflect higher predictive accuracy at sites with more homogeneous emission sources and stable dispersion patterns (Sajjad), and lower accuracy at locations with complex topography and more variable source contributions (Vila).
The applied preprocessing and training choices substantially contributed to model performance: input features were standardized (z-score), temporal categorical variables were one-hot encoded, early stopping (patience = 6 epochs) was used, and network architectures were optimized per site (16 hidden neurons for Sajjad, 11 for Torogh, and 19 for Vila). Feature selection based on correlation analysis supported the inclusion of air temperature, relative humidity, and average wind speed as the most influential predictors, whereas wind direction and solar radiation showed negligible predictive value and were excluded to reduce multicollinearity and simplify the models.
Taken together, these findings demonstrate that properly configured MLPs can serve as effective components of localized air-quality forecasting and early-warning systems. For operational deployment and further improvement, recommended next steps include increasing the spatial resolution of meteorological inputs, testing alternative deep-learning architectures at sites with strong temporal variability, and maintaining ongoing model validation with updated observational datasets.
Footnotes
Acknowledgements
The authors would like to thank the Khorasan Razavi Meteorological Organization (Iran) for providing access to meteorological data used in this study. We also gratefully acknowledge the Khorasan Razavi Department of Environment (Iran) for supplying the PM2.5 concentration data. This research was conducted during a sabbatical leave as part of the Faculty–Industry and Society Collaboration Program, and the authors appreciate the support of the University of Birjand (Iran) in this regard.
Author Contributions
Conceptualization, MJZ; methodology, MJZ and ADA; software, MJZ; validation, MJZ and SJR; formal analysis, MJZ; investigation, MJZ; data curation, MJZ and ADA; writing—original draft preparation, MJZ; writing—review and editing, MJZ, ADA, SJR and MRMD; visualization, MJZ; supervision, MRMD; project administration, MJZ; resources, ADA and SJR. All authors have read and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.