
Abstract
Genetic variations such as single nucleotide polymorphisms (SNPs) can cause susceptibility to cancer. Although thousands of genetic variants have been identified to be associated with different cancers, the molecular mechanisms of cancer remain unknown. There is not a particular dataset of relationships between cancer and SNPs, as a bipartite network, for computational analysis and prediction. Link prediction as a computational graph analysis method can help us to gain new insight into the network. In this article, after creating a network between cancer and SNPs using SNPedia and Cancer Research UK databases, we evaluated the computational link prediction methods to foresee new SNP-Cancer relationships. Results show that among the popular scoring methods based on network topology, for relation prediction, the preferential attachment (PA) algorithm is the most robust method according to computational and experimental evidence, and some of its computational predictions are corroborated in recent publications. According to the PA predictions, rs1801394-Non-small cell lung cancer, rs4880-Non-small cell lung cancer, and rs1805794-Colorectal cancer are some of the best probable SNP-Cancer associations that have not yet been mentioned in any published article, and they are the most probable candidates for additional laboratory and validation studies. Also, it is feasible to improve the predicting algorithms to produce new predictions in the future.
Introduction
Cancer has a significant impact on human mortality. It stands among the leading causes of death worldwide. The number of cancer cases is increasing at an alarming rate annually. It is believed that some behavioral and environmental triggers can lead to cancer, including diet, lifestyle, chronic, and viral infection. Increasing life span is another leading cause of cancer, and the researchers estimate that about two-thirds of the increase is due to aging. Although thousands of genetic variants (including single nucleotide polymorphisms [SNPs]) have identified to associate with different cancers, the molecular mechanisms of cancers have remained unknown. Therefore, researchers are continuing to explore this field.1-4
Genetic variations like SNPs can cause susceptibility to cancer. For example, the SNPs in a promoter site can affect the gene expression, and even in some tumors, it can affect the patient’s overall state of health and mortality risks.5,6 Most recent, genome-wide association studies (GWASs), show relations between some of the known cancers with the specific SNPs.5,6 For example, Guo et al 7 reviewed 45 SNPs involved in prostate cancer. Also, Zhang et al 8 studied the effect of rs920778 in the HOTAIR gene on esophageal cancer, and Li et al’s 9 study of the effect of rs13252298 SNP in the PRNCR1 gene showed a relation to gastric cancer. A recent case 10 identifies the link between SNP rs10800708 and breast cancer. There are also numerous examples of the relationships between different SNPs and cancers.
However, GWAS studies have several limitations. First, at least one-third of the known variants are in non-coding regulating regions, which affect the transcription factor binding. Second, many GWAS studies show heterogeneity in allele frequencies in different populations.11,12 So, more studies are needed to identify the relationships between cancers and SNPs. Computational methods can facilitate finding and predicting cancer-SNP relationships. There are some algorithmic studies for predicting cancer-SNP relationships. Those researches are mostly based on machine learning algorithms such as classification that need SNP profile data of case and control groups to predict the relationships.13-15 The challenges of these studies are simultaneous need to case and control data, limitation to one or few numbers of the cancers in each study, computational complexity, and so on. So, there is a tangible need for a general low complexity computational solution with few pre-requirements to predict cancer-SNP relationships. To the best of our knowledge, there is no study based on link prediction forecasting cancer-SNP relationships.
Link prediction and its importance
Link prediction, as a technique to analyze the graphs, dates back to the emergence of social networks. 16 Later, it was applied to other networks such as biological ones. 17 The primary purpose of link prediction in its basic definition is to find connections in the network that are missing or may be formed in the future, although it is possible to use link prediction to remove weak or spurious relations from the network. 18 Even in some recent articles, it is practicable to predict the addition and removal of links in the network at the same time. 19

To use the link prediction algorithms, it is first necessary to present the problem network with graph structure. In a graph, entities or elements are considered as vertices or nodes and their relationships as links or edges. The modeling graph may be one of the common types, such as simple, bipartite, weighted, or directed graphs, and the link prediction algorithms have been customized and utilized for all of these graph types. For the computation, the graph can be stored in the computer memory as an adjacency matrix. Link prediction ranks the zero entries of the associated adjacency matrix to find the best promising relationships in the graph to establish. 18 The link prediction algorithm for proposing the most probable edge in a simple graph is as follows:
Self-loop for the nodes is not allowed in the simple graph used by the link prediction algorithm. This means that N(i, i) should always be zero. In addition, because of the symmetry of the corresponding adjacency matrix with respect to the main diagonal, it is enough to calculate the score for only half of it, because the calculated score for (i, j) is equal to the calculated score for (j, i). Also, the score (i, j) function in the above algorithm can be calculated in a variety of ways; one of the simplest methods is based on network topological properties such as the properties of neighbor nodes. 20 Table 1 consists of the most popular topological scoring methods.
Link prediction score functions for topology-based node neighborhood metrics.

Abbreviations: AA, Adamic and Adar; CN, common neighbors; JC, Jaccard; PA, preferential attachment.
Method
Network construction
To study and predict the SNPs associated with various cancers in human, a list of SNPs should be provided at first. For this purpose, the SNPedia database (www.snpedia.com) was used. In this database, information of each SNP, including its effects on cancers, has been gathered from the valid journals. The total number of SNPs in SNPedia reaches 109 530. Also, to determine the relationship between SNPs and cancers, we need a complete list of all cancer names. We extract this list from the Cancer Research UK online database (www.cancerresearchuk.org). It has been active since 2002 in the field of cancer research and information. Each cancer usually has some subgroups that have not always been explicitly mentioned in the articles, so there are many challenges to create an SNP-Cancer network such as the following:
Sometimes the articles refer only to the main category and general name of cancer.
Occasionally, in the articles on the relationship between cancer and the SNPs, associated SNPs are found for all subtypes of a cancer.
Sometimes in the papers, the SNPs associated with cancer are present only for some of the subtypes of that cancer, and no evidence is found for other subtypes.
In some cases, in various articles, specific cancer is mentioned with several names.
In some cases, cancerous tissue is mentioned without the determination of the exact cancer name.
Every so often, there are no data about one cancer on the SNPedia website and no articles showing associated SNP.
For this reason, the authors of the article were forced to extract and check the data manually for each cancer. First, the information on the Cancer Research UK website was studied for all cancers. Next, for each cancer, a variety of different names and different types were examined and categorized. Then each cancer was searched manually on the website (www.snpedia.com), with both the main name and its subtypes. The output was the SNPs, whose association with cancer has been reported. So the list only included the cancers, primary cancer name, or subcategory, which their SNP was found in the search.
In the second step, a Java code was implemented to connect the website (www.snpedia.com) and automatically detect the SNPs associated with the cancers that were categorized in the previous step. In cases in which an SNP was found for the primary cancer name, and there were no data about its associativity for the cancer subtypes, we considered it linked to all subtypes and not for primary cancer name. In cases where SNP was found only for a few subtypes of the main type, the SNPs associated with subtypes were generalized to the main types, and only the name of the main type was entered into the final list of cancers, and the name of the subtypes was not included, for uniformity of the cancer names. In cases where there were several names for a cancer, a name was chosen, and the SNPs found for other alias cancer names made united to only the selected name, and just the selected name entered to the final list. For instances of cancerous tissues that there were some associated SNPs, we neglected them because of the ambiguity of the cancer name, and we avoided to incorporate these data into the final list.
Thereupon the SNP-Cancer network was constructed. Steps performed to prepare the data are shown in Figure 1. The created network is a bipartite one, with 7599 edges or relations, 50 cancers, and 4723 SNP vertices (Figure 2). As the representation of the whole network cannot be informative due to existence of a large number of non-labeled overlapping nodes, we presented only a sub-network regarding a selected subset of cancers in Figure 3 to make the representation more understandable—a bipartite graph demonstration with nodes labeled that would be a complement representation here. In case the network is still enormous in this case, the number of SNPs has also been limited (31 cancers, 33 SNPs, and 222 relationships).

SNP-Cancer network construction steps. SNP indicates single nucleotide polymorphism.

Visualization of SNP-Cancer bipartite graph. Red circles are cancers surrounded by SNPs. SNP indicates single nucleotide polymorphism.

An alternative representation for the SNP-Cancer network. A sub-network with 33 SNPs, 31 cancers, and 222 relationships is presented in the bipartite form to make a better view of the real network. SNP indicates single nucleotide polymorphism.
Bipartite link prediction
After creating a bipartite graph of links between SNPs and cancers, we have a network that identifies which SNPs are associated with which cancers and vice versa. From here onward, the discovery of hidden links in the bipartite graph will be the result of calculations and link prediction algorithms. But, we only introduced the link prediction in its basic form for simple graphs earlier in the “Introduction” section. So, it is necessary to adopt the ranking scores for bipartite networks.
The bipartite network does not involve self-loop relations. Also, the scoring function, which ranks the probable links in the bipartite graph, is different. Because none of the nodes in each part has relationships with the nodes in the same part, direct relation between SNP pairs or cancer pairs is not important here in this research. In this graph type, only the links between the vertices of one part and the vertices from the other part are important. Thus, we chose the scoring functions based on reference.
21
To clarify the customized formulas, it is necessary to define its elements first. If x node is in the first part and y node is in other part of the graph,
Link prediction score function for topology-based node neighborhood metrics in bipartite graphs.

Abbreviations: AA, Adamic and Adar; CN, common neighbors; JC, Jaccard; PA, preferential attachment.
Consequently, we are willing to know which of the scoring methods has the best prediction accuracy for the SNP-Cancer bipartite network, and then we would like to know what new connections between SNPs and cancers are discovered and suggested according to the best edge scoring method. Next, we should prove these findings computationally, and finally, we should be able to validate the proposed results based on the evidence we find on the scientific databases or pass it on to new in vitro experiments.
The accuracy of predictions depends on the properties of the examined networks, such as scale-free or small-world attributes, 22 and none of the scoring algorithms have complete superiority over the others in advance. Therefore, the calculations will be done for each of the scoring methods in Table 2, and after the accuracy evaluation, the best method is introduced for more practical investigation of the results.
Evaluation criteria
To compare the efficiency of the link scoring functions, it is computationally common to measure the performance based on the known network information, ie, the edges that already exist. It is recommended to apply one of the area under the receiver operating characteristic curve (AUC) or precision measures for evaluation. 23 In our work, AUC is used for quantifying the accuracy of the prediction method. To do so, if the set of edges in the network is E, we divide it into 2 distinct parts, ET and EV, which their intersection is an empty set, and their union includes all the edges in the network. ET stands for a training set of edges as existing information, and EV is validation set of edges which we delete from the network randomly and provide no information on them to the scoring functions, and we are going to predict them accurately. To ensure that all validation links are tested, we will use the 10-fold cross-validation process, which does the prediction 10 times for 10 disjoint sets. Each set includes 10% of the randomly removed edges of the network, EV. After that, we report the AUC of the prediction for each score function as the average of the values of 10-fold cross-validation for each function, and larger percentage of the AUC will show the better performance of the scoring method for link prediction. Here, the AUC means the probability that a randomly chosen missing connection is given a higher score by our algorithm than a randomly chosen pair of unconnected vertices. Thus, the degree to which the AUC exceeds 0.5 indicates how much better our predictions are than chance. 24 Therefore, calculating the average score is as follows
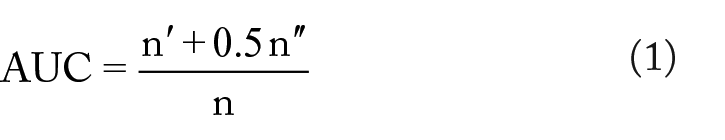
where n is the total number of the random edge selection,
Of course, the real data of related researches can also be used for further validation. For this purpose, we will search online scientific databases, Google Scholar and PubMed, for the predicted links that are not currently available on the SNPedia website, and if we find evidence in research papers and articles, we have another proof for the accuracy of the operation of the algorithms.
Results
Based on the AUC evaluation results among link prediction scoring functions, the PA method is more effective in predicting potential links between SNPs and cancers (Table 3). Accordingly, the most likely 15 predicted links between SNP and various cancers are as follows for PA method, first 2 columns of Table 4.
AUC of different node neighborhood similarity–based link prediction scores over bipartite SNP-Cancer network.
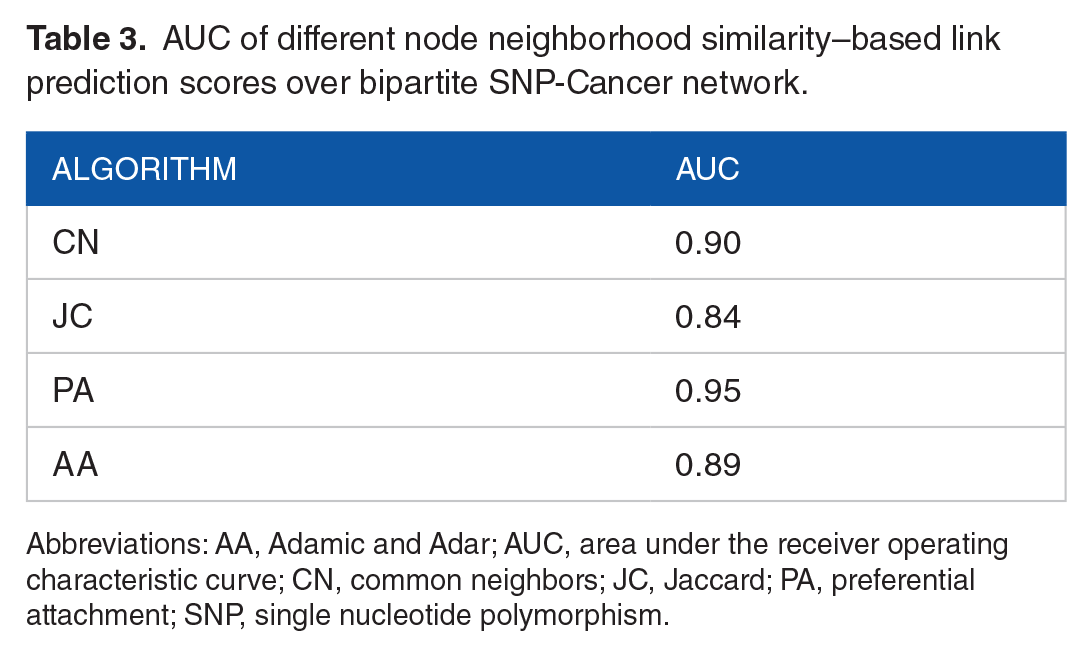
Abbreviations: AA, Adamic and Adar; AUC, area under the receiver operating characteristic curve; CN, common neighbors; JC, Jaccard; PA, preferential attachment; SNP, single nucleotide polymorphism.
Top 15 SNP-Cancer relationships predicted by PA, CN, JC, and AA scoring link prediction approach.

Abbreviations: AA, Adamic and Adar; CN, common neighbors; JC, Jaccard; PA, preferential attachment; SNP, single nucleotide polymorphism.
Because of the novelty of the idea of predicting unknown links between cancer and SNP and for more investigation and better comparison, the results of other scoring functions are also summarized in Table 4.
Discussion
Single nucleotide polymorphisms in the human genome are of the most common genetic variations and are located in different positions of genes such as exon, promoter, intron, 5′-UTR, and 3′-UTR. Due to their position in the genes, SNPs have different levels of control in various diseases, such as cancer, and the results of studies have proven the role of SNPs in cancer in terms of regulation, repair, DNA mismatch, metabolism, cell cycle, and immunity.25-27 Our understanding of the role of SNPs in cancer susceptibility depends on our molecular understanding of the pathogenicity of cancer. 28 In clinical trials, people are usually identified in the advanced stages of the disease, and the main goal is to prevent the progression of disease in patients, and the SNP biomarker data are essential for predicting and screening individuals that are at hazard.
Checking the validity of the AUC results was also done through search in the popular scientific databases, Google Scholar and PubMed, to confirm the probable relationships based on reported pieces of evidence. Type of the reported relations between SNP and cancer is also noted as positive or negative associativity effects, with Yes or No in Tables 5 to 8. Results of the investigation of the evidence affirm the computational link prediction calculation.
Validation of the prediction results for new SNP-Cancer relationships in PA scoring method.
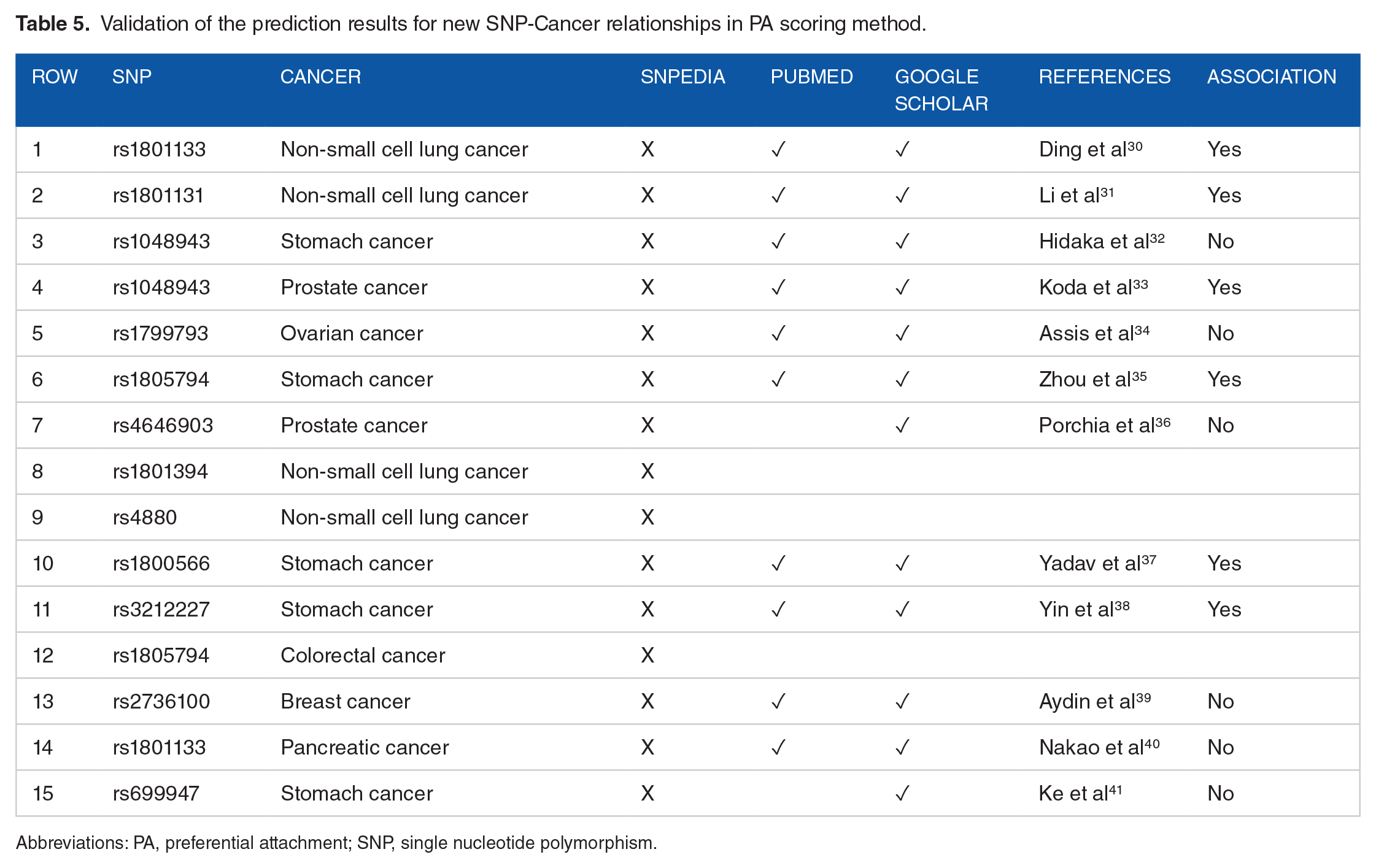
Abbreviations: PA, preferential attachment; SNP, single nucleotide polymorphism.
Validation of the prediction results for new SNP-Cancer relationships in CN scoring method.

Abbreviations: CN, common neighbors; SNP, single nucleotide polymorphism.
Validation of the prediction results for new SNP-Cancer relationships in JC scoring method.

Abbreviations: JC, Jaccard; SNP, single nucleotide polymorphism.
Validation of the prediction results for new SNP-Cancer relationships in AA scoring method.

Abbreviations: AA, Adamic and Adar; SNP, single nucleotide polymorphism.
Of the 15 not included links in SNPedia, that has been predicted by the PA link prediction algorithm, 12 cases have been addressed in the papers; 6 were confirmed by the experiments, 6 were rejected, and the other 3 were not yet declared. While other link prediction methods, which have fewer points than PA in terms of AUC (CN, Jaccard [JC], and Adamic and Adar [AA] methods), have fewer predicted positive associations than PA in literature survey. In particular, JC, which has the weakest predictability power in link prediction researches, 29 has also least positive findings and returned more results that have not been verified at all in the literature (Tables 5-8).
However, in the 3 methods, AA, PA, and CN, there are 2 common couples of rs1801133-Non-small cell lung cancer and rs1801131-Non-small cell lung cancer that all of them confirm but with different score and positions in their sorted, ranked list. Rs1801133 and rs1801131 are also popular and have many related studies and have links to several cancers, while the most frequent cancer in the predictions is Non-small cell lung cancer. AA and CN results are almost identical except in the last position, row 15.
Consequently, there are different confirming publications for many of the SNP-Cancer predicted relationships. We briefly mentioned the latest published paper in column 7 of Tables 5 to 8, to show the recent findings of the studies. The last published paper also integrates all the previous studies and final findings of the type of association (Yes or No) between SNP and cancer.
Several factors such as sparsity or completeness of the network can affect the evaluation results. For example, the network density, number of the existing edges divided by the total possible edges, is 0.032 here, and we have a relatively sparse network. The denser the network will be, the better the performance of link prediction algorithms will get. Also, the completeness of the investigated dataset affects the accuracy of the calculations and results. SNPedia is not fully up-to-date and ideal, as we will demonstrate in the next section and our computations show. Furthermore, the AUC criterion chosen for the evaluation is not the only criterion. It can be completed by verifying the availability of the results in the literature, which is well known as domain knowledge evaluation and will be discussed further.
Another notable point is that there are several predicted relationships here, which have been studied in the literature, but the result of the researches reports no association between SNP and cancer. This is also significant because it has attracted the researchers and approves the importance and directionality of our computational prediction methods for more in vitro investigations.
Conclusions
Based on the promising results of the PA scoring method, to predict new links between SNP and cancer, we suggest examining and verifying below relationships in vitro because, to the best of our knowledge, such links have not yet been reported in scientific publications. If one or more of the following links are verified, one can consider more of these PA predictions to find new SNP-Cancer associations:
rs1801394-Non-small cell lung cancer
rs4880-Non-small cell lung cancer
rs1805794-Colorectal cancer
Numerous unreported predictions of SNP and cancer links on the SNPedia reference website indicate that this database is incomplete and can be completed using literature reviews, in vitro tests, or other methods that can also be used to validate the result of the link prediction method. This is also true for many other biological networks, and they can be enriched with the help of link prediction algorithms, or even their hidden or incomplete relations can be discovered. Also, the precision of the link prediction depends on how the network is created, network properties, and the preprocessing of the network constructor data. The more reliable and accurate the work is, the better the results will be.
Only a small number of the basic existing algorithms for link prediction are used in this research. There were unsupervised node neighborhood-based link prediction algorithms. Other methods, such as path-based or supervised machine learning–based, can also be used to increase the accuracy of the results. In particular, machine learning–based methods can take into account different related features of the network and not just network topology. 18
Link prediction is not used only to predict new or missed relations. Its newer versions can be used to remove noise or misconnections. This version of the link prediction is known as the Negative Link Prediction (NLP) 17 and can be used to identify and eliminate the weak associations between SNP and cancer. The effectiveness of such a method in noise elimination has been proven on experimental data extracted from high-throughput methods for protein networks. 52 Finally, link prediction can also be used to develop and predict links between SNP and other non-cancerous diseases.
Footnotes
Funding:
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests:
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Author Contributions
SB gathered the data and carried out the calculations. SS gave the idea of the research and designed the structure of the work and prepared the draft of the manuscript with SB. MT did the analysis and search for confirmations and filled the tables accordingly. KK participated in analysis and interpretation of the results and final edit of the manuscript’s writing. All authors read and approved the final manuscript. SS managed the teamwork and cooperation.