
Abstract
From tumor to tumor, there is a great variation in the proportion of cancer cells growing and making daughter cells that ultimately metastasize. The differential growth within a single tumor, however, has not been studied extensively and this may be helpful in predicting the aggressiveness of a particular cancer type. The estimation problem of tumor growth rates from several populations is studied. The baseline growth rate estimator is based on a family of interacting particle system models which generalize the linear birth process as models of tumor growth. These interacting models incorporate the spatial structure of the tumor in such a way that growth slows down in a crowded system. Approximation-assisted estimation strategy is proposed when initial values of rates are known from the previous study. Some alternative estimators are suggested and the relative dominance picture of the proposed estimator to the benchmark estimator is investigated. An over-riding theme of this article is that the suggested estimation method extends its traditional counterpart to non-normal populations and to more realistic cases.
Keywords
Introduction
One of the most typical characteristic of malignancy is the disturbance in the balance within cell multiplication. The proliferative activity of the tumor cell population is responsible for the uncontrolled tumor growth. Oncogenic cells are characterized by the continued renewal in their growth and by inhibiting their differentiation. A spatial analysis of the tumor cell growth exhibits a differential rate of growth and may be important in accessing the oncogenic status of the tumor as well as its potential to become malignant.
Braun and Kulperger (1993) and Braun and Kulperger (1995) have introduced an estimator to estimate the growth parameter of an interacting particle system which is discussed in detail by Schürger and Tautu (1976). The interacting particle system theory is also dealt with comprehensively by Liggett (1985) for modeling the proliferation of cells in cancer tumors. They view this interacting particle system as a refinement of the linear birth process which more closely resembles the actual growth of the tumor.
Estimation of the growth rate parameter for linear birth, exponential growth, and Gompertz models has been well-studied. However, the Braun-Kulperger estimator is the first growth rate estimator being proposed for an interacting particle system given the actual tumor data.
The data arises from tumor measurements in mice, for example, at various times following injection of carcinogens. In animal sacrifice experiments, it is only possible to take measurements of the growing tumor at one time point, but several different types of measurements can be taken from the tumor. In longitudinal studies, measurements may be taken at more than one time point, but not as much information can be collected in this case. Usually, only an estimate of tumor volume can be obtained each time. In this paper, we will consider only the former situation. Such data should be considered as coming from an in vivo experiment. In particular, we assume that measurements of the total number of cells and the number of boundary cells can be obtained, but at only one time point for each tumor. Boundary cells are defined here as those cells which still have proliferative potential; cells which are in the interior tend to stop proliferating, because of crowding and other effects. Each boundary cell is assumed to split after an exponentially distributed amount of time, with rate λ independent of all other cells, and independent of the history of the process (a Markov assumption).
In this paper, we consider the situation in which the measurements come from different populations. For example, an experimenter may wish to consider data for several populations of animals on different diets, to obtain a potentially more precise estimate for the growth rate. The experimenter is now at risk, since the growth rate may differ depending on the type of diet. A similar situation arises in the case of testing the effectiveness of different radiation treatments on the reduction of tumors, where controlling for the physical presence of the radiation seed is a common practice. Often, the experimenter will conduct a prior experiment to determine if there is such a physical effect by surgically planting a dummy seed in the growing tumor and comparing the resulted growth with a control group which has no seed. Ultimately, the experimenter may want to pool the growth rate estimates from the two populations to obtain a more precise growth rate estimate.
In order to model this type of situation, we suppose that there are k possibly different populations of tumors evolving with time and denote the growth rate of the lth population by λ l .
The model is a continuous time Markov chain whose state space is the set of all possible configurations of cells existing at the vertices of a regular lattice Zd. To each site

where ±
At the time of exposure to carcinogen, an initial configuration of tumor cells arises from mutation of normal cells. The cells in the initial configuration each waits an independent exponential time, λ l , before starting fission to produce two offspring. One of the offspring stays at the original site, while the other chooses a site at random from the unoccupied sites of the nearest-neighborhood of the original site. If the nearest-neighborhood is completely occupied, then the new offspring does not survive. In this latter case, we may interpret the cell in the process of fission as hypoxic – cut off from the blood supply by the surrounding layer(s) of cells. The process continues with each of the new offspring waiting and undergoing fission in the same manner.
Braun and Kulperger (1993) have shown that, for a large class of such Markovian models and for tf > to, the growth rate is given by
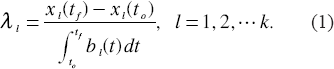
where xl (t) is the expected number of cells at time t and bl(t) is the expected number of boundary cells at time t in a tumor from the lth population. We let Xl (ti) be the observed number of cells and Bl (ti) be the number of boundary cells at time ti, where i = 1,2, …,nl, and the ti's are assumed to be equally spaced apart. Multiple measurements are required at to = tl and tf = tn. Measurements taken from different animals can be assumed independent, but Bl(ti) and Xl(ti) are dependent random variables if taken from the same animal.
If ml independent observations are available at to and tf, then an estimator of λ l is given by

where
In the following theorem, we summarize some useful properties of
where

We now consider the simultaneous estimation of rate parameter vector
Our interest here is to estimate
In this paper simultaneous estimation of rates from independent Markovian distributions is considered. Assume that X1, X2, …, Xk are independent variables following Markovian models with rate parameters
Linear Shrinkage Estimator
We first propose a linear shrinkage estimator (LSE) of

Binary Choice Estimator
The binary choice family of estimators is defined as

where T is the normalized distance between

where I(A) is the indicator of the set A. Note that we have replaced π by I(T < To) in (3) to obtain (5) with a random dichotomous weight. However,

where

and demonstrated that for k > 2 this estimator dominates the MLE. Further, making use of Stein-type estimator, Sclove and Radhakrishnan (1972) demonstrated the non-optimality of the preliminary test estimation. Hence, here we are confined with Stein-type estimation. However, for k < 3, the preliminary test estimation may be a useful choice to tackle the estimation problem at hand.
Non-linear Shrinkage Estimator
Now using the Stein-like base, we propose the following non-linear shrinkage estimator (NLSE) for the parameter vector,
Define

where

The NLSE is defined by

where

The estimator
Positive-part Non-linear Shrinkage Estimator
In the spirit of Sclove and Radhakrishnan (1972), the PNLSE may be defined as
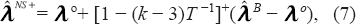
where [·]+ = max(0, ·). The positive part estimator is particularly important to control the over-shrinking inherent in

It is interesting to note that the proposed strategy is similar in spirit to the Bayesian model-averaging procedures. However, the main difference is that the Bayesian model-averaging procedures are not optimized with respect to any particular loss function. The present investigation is stimulated by prediction offered by Professor Efron in RSS News of January, 1995.
“The empirical Bayes/James-Stein category was the entry in my list least affected by computer developments. It is ripe for a computer-intensive treatment that brings the substantial benefits of James-Stein estimation to bear on complicated, realistic problems. A side benefit may be at least a partial reconciliation between frequentist and Bayesian perspectives as they apply to statistical practice. ” It may be worth mentioning that this is one of the two areas Professor Efron predicted for continuing research for the early 21st century.
Shrinkage and likelihood-based methods continue to play vital roles in statistical inference. These methods provide extremely useful techniques for combining data from various sources.
In this section, we showcase our main results by providing the large-sample expressions for the quadratic bias and risk of the estimators. It is straightforward to show that for large samples,


Lemma
Under the sequence in (9) and the model assumptions of Section 1, as m+ → ∞,
Now, we present the expressions for the asymptotic distributional bias (ADB) of the estimators as follows. First, the notation ψ
k
(x; Δ) stands for the noncentral chi-square distribution function with non-centrality parameter Δ and k degrees of freedom. Then we can write


Now, we transform these functions in a scalar (quadratic) form to obtain a simple yet meaningful interpretation. Define

as the quadratic bias of
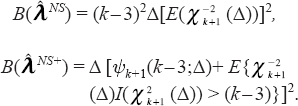
Note that the quadratic bias of
To appraise the risk performance of the estimators, we use the quadratic loss function:

The sequence {C(m+)} in (9) will be used to compute the asymptotic distributional quadratic risk(ADQR) defined below. First, the asymptotic distribution function of
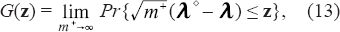
for which the limit in (13) exists. Further, define
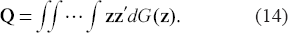
Finally, the ADQR is defined by



Proof. By Lemma the above relations are obtained using the same arguments as given in Ahmed and Braun (2000).
The large sample properties of the proposed estimators are discussed in the light of the quadratic loss function. We now investigate the comparative statistical properties of the Stein-type estimators. When Ho is true,

is a positive quantity. Hence, we conclude that

where emax(.) means the largest eigenvalue of (.).

where emin(.) means the smallest eigenvalue of(.) and
We note that the above lower and upper bounds are equal to the infimum and supremum, respectively, of the ratio
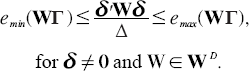
Thus, under the class of matrices defined in relation (18) we conclude that
Based on relations (16) and (17), it is seen that

with strict inequality hold for some δ. Therefore,
Numerical Risk Output
In order to facilitate numerical computation of the risk functions, we consider the particular case
We have numerically computed

Table 1 provides the estimated relative efficiency of
Relative Efficiency of

Relative Efficiency of A

Seemingly, the magnitude of relative efficiency increases as the value of & increases. On the contrary, efficiency decreases with the increasing of Δ.
The Stein-type estimation strategies are asymptotically superior to strategies based on sample information only. Further, the usual Stein-type estimator is asymptotically dominated by its truncated part. However, we must stress that the important issue here is not the improvement in sense of lowering the risk by using the positive part of the
In this research we continue the search started four decades ago by Lindley (1962) for new strategies to think about combining estimation problems. In the context of several models, we consider methods for optimally combining the data from various sources. Although the estimation and inference implications of shrinkage estimator are encouraging, some interesting questions remain. For example, we have used the unbiased estimator and the initial value in the proposed estimation methodology. Perhaps one can use biased estimator to further improve the risk-performance of the estimator. Research on the statistical implications of these and other estimators combining possibilities for a range of statistical models is ongoing.
Footnotes
Acknowledgement
This research was supported by Natural Sciences and Engineering Research Council of Canada. The authors would like to thank Drs. J. Braun and R.J. Kulperger for useful discussions. We would also like to thank the editor for helpful comments.