
Abstract
The utility of the matrix representation with flipping (MRF) supertree method has been limited by the speed of its heuristic algorithms. We describe a new heuristic algorithm for MRF supertree construction that improves upon the speed of the previous heuristic by a factor of n (the number of taxa in the supertree). This new heuristic makes MRF tractable for large-scale supertree analyses and allows the first comparisons of MRF with other supertree methods using large empirical data sets. Analyses of three published supertree data sets with between 267 to 571 taxa indicate that MRF supertrees are equally or more similar to the input trees on average than matrix representation with parsimony (MRP) and modified mincut supertrees. The results also show that large differences may exist between MRF and MRP supertrees and demonstrate that the MRF supertree method is a practical and potentially more accurate alternative to the nearly ubiquitous MRP super-tree method.
Keywords
Introduction
There is increasing interest in supertree methods for phylogenetics (see Bininda-Emonds et al. 2002; Bininda-Emonds, 2004). Supertree methods combine phylogenetic trees with incomplete taxonomic overlap into a comprehensive phylogeny that incorporates all taxa from the input trees. Since the ultimate aim of many supertree analyses is to build large phylogenies, an effective supertree method must be fast as well as accurate. Therefore, the development and implementation of fast algorithms is a critically important part of establishing useful supertree methods.
The most popular supertree method by far is matrix representation with parsimony (MRP; see Bininda-Emonds, 2004). MRP performs a maximum parsimony analysis on a binary matrix representation of the set of input trees (Baum, 1992; Ragan, 1992; Baum and Ragan, 2004). Therefore, MRP analyses can use fast maximum parsimony heuristics (e.g. Nixon, 1999; Goloboff, 2000) and popular phylogenetics programs that implement maximum parsimony like PAUP* (Swofford, 2002) or TNT (Goloboff, 2000). Still, MRP has been criticised for its performance and properties (e.g. Purvis, 1995; Pisani and Wilkinson, 2002; Gatesy and Springer, 2004; Goloboff, 2005; Wilkinson et al. 2005). For example, MRP may have a size bias, in which the size of the input trees affects how MRP resolves conflicts (Purvis, 1995). There is also evidence that MRP may have a shape bias, in which input tree shape affects the resulting supertree (Wilkinson et al. 2005). Furthermore, the validity of using parsimony on a matrix representation of input trees has been questioned (Slowinski and Page, 1999; Eulenstein et al. 2004; Gatesy and Springer, 2004). Thus, there is a need to investigate alternate supertree methods.
The matrix representation with flipping (MRF, or minimum flip) supertree method, like MRP, uses a matrix representation of the input trees (Chen et al. 2003; Chen et al. 2004; Burleigh et al. 2004; Eulenstein et al. 2004). While MRP seeks trees that minimize the parsimony score of the matrix representation of input trees, MRF seeks the minimum number of flips, character changes from 0 to 1 or 1 to 0, that will make the matrix representation of input trees consistent with a phylogenetic tree (see Chen et al. 2003; Burleigh et al. 2004; Eulenstein et al. 2004). The resulting phylogenetic trees are MRF supertrees. Like the parsimony problem, the minimum flip problem is NP-hard (Chen et al. 2006), and therefore, estimating an MRF supertree requires heuristic algorithms when the input trees contain more than approximately 20 taxa. Simulation experiments (Eulenstein et al. 2004; Piaggio-Talice et al. 2004) indicate that MRF supertrees retain more of the relationships from the input trees than MinCut (Semple and Steel, 2000), Modified MinCut (MMC; Page, 2002), and quartet supertree methods (Piaggio-Talice et al. 2004). Also, MRF supertrees retain relationships from the input trees at least as well as MRP supertrees, with MRF appearing to slightly outperform MRP as the taxon overlap among input trees decreases (Chen et al. 2003; Burleigh et al. 2004; Eulenstein et al. 2004). Though these results suggest that MRF is a promising supertree method, the characteristics of the simulated data sets likely differ greatly from those of empirical data sets. Furthermore, the first MRF heuristics were slow (Eulenstein et al. 2004; Goloboff, 2005), and consequently the performance of the MRF super-tree method on large empirical data sets has been largely unexamined.
We describe improvements to existing MRF heuristics that increase the speed of the heuristics by a factor of n, where n is the total number of taxa represented in the input trees. These improvements make it feasible to estimate MRF supertrees for large data sets. Furthermore, they allow the first comparisons of the performance of MRF with other supertree methods using empirical data sets containing many more taxa than were in the simulated data sets. The results of these analyses demonstrate that MRF may perform better than MRP or MMC supertree methods. The analyses also demonstrate notable differences between results of MRF and MRP supertrees that were not observed in small simulation studies.
Definitions
Let S = {s1, …, s n } denote a set of n taxa and ℒ(T) denote the leaf set of a rooted tree T.
A directed phylogenetic tree, or phylogeny for short, over set S is a rooted binary tree T such that every internal node of T has two children and ℒ(T) = S. (The assumption that the phylogenies are binary is made only for simplicity and can easily be dropped.) Let ν be a node of a phylogeny T. Then, Tν denotes the subtree rooted at ν, and T – Tν denotes the tree T with the subtree Tν removed. The set ℒ(Tν) is the cluster of T at ν.
A profile is a multiset τ of phylogenies. The elements of τ are called input trees. A supertree for a profile τ is a phylogeny T such that
A character matrix for S is an n × m matrix M = [aij] over {0, 1,?}, whose i-th row corresponds to taxon si. The j-th column of M is called character J. The set of all s i such that a ij = 1 is the 1-set of character j and is denoted by O j ; the set of all si such that aij = 0 is the 0-set of character j and is denoted by Z j .
Let τ be a profile such that
The matrix representation of trees is the basis for MRP (Baum, 1992; Ragan, 1992; Purvis, 1995) and MRF (Chen et al. 2003; Burleigh et al. 2004; Eulenstein et al. 2004) supertree methods. We note that there are numerous different matrix representations of trees (e.g. Farris et al. 1970; Purvis, 1995; Wilkinson et al. 2004). In this paper, we use a standard binary matrix representation (Farris et al. 1970; Baum, 1992; Ragan, 1992) which is the most commonly used one in supertree studies and was also used in the formal definitions of the MRF method (Chen et al. 2003; Burleigh et al. 2004; Eulenstein et al. 2004). MRF is based on the notion of flip distance from a character matrix M to a tree T(Chen et al. 2003; Eulenstein et al. 2004). This quantity equals the smallest number of 1 → 0 and 0 → 1 changes (flips) that must be made to M so that the 1 -set of each character of M corresponds to some cluster in T. An MRF supertree for M is a tree T that has minimum flip distance to T. We now define the above notions precisely.
Let T be a phylogeny over some subset of S, ν be a node of T, and M be a character matrix for S. Let z
j
(ν) denote the number of taxa that are in the 0-set of character j and also in the cluster at ν; that is, z
j
(ν) = |Z
j
∩ℒ(Tν)|. Similarly, let oj(ν) denote the number of taxa that are in the 0-set of character j as well as in the cluster at ν; that is, o
j
(ν) = |O
j
∩ ℒ(Tν)|. The flip distance of character j to ν is defined as

Note that f j (ν) is the number of changes needed to make character’ correspond to the cluster at node ν. The first term in the right hand side of the above equation is the number of 0 → 1 changes and the second term equals the number of 1 → 0 changes.
The flip distance of character j to T is

The flip distance of character matrix M to T is


The minimum-flip problem is: Given a character matrix M over S, find a phylogeny T over S such that fM(T) is minimum. The fixed-tree minimum flip problem is: Given a character matrix M for S and a phylogeny T for S, compute fM(T).
Heuristics for MRF
The MRF supertree problem is defined only for rooted trees (Chen et al. 2003; Burleigh et al. 2004; Eulenstein et al. 2004), and the rooting of a tree can affect its flip distance from a character matrix. Thus, unlike MRP, MRF supertree heuristics cannot use existing unrooted tree search algorithms. The details of the original MRF heuristic algorithm were not described by Eulenstein et al. (2004), which has led to some apparent confusion in critiques of MRF (e.g. Goloboff, 2005). Therefore, we fully describe the accelerated MRF heuristic.
Like its predecessor, the new MRF heuristic uses a hill climbing strategy that is similar to the one used for unrooted tree searches in PAUP* (Swofford, 2002). The initial tree is obtained through greedy taxon addition using a randomly-chosen order (in practice, several initial trees are usually generated). After the initial tree is obtained, the search proceeds iteratively. At each step it locates the best tree (the tree with the lowest flip distance) that can be obtained from the current tree by a branch swap. Each tree that can be generated by a single branch swap is called a neighbor of the current tree. If no neighbor has a lower flip distance, the search stops and the current tree is returned as the estimate of a MRF supertree. Otherwise, the current tree is replaced by its best neighbor. The improved run times reported here, compared to the run times in the previous MRF heuristic, are due to changes in the implementation of the branch swapping operations.
We consider three rooted branch swapping operations.
The earlier MRF heuristic found the best neighbor by computing the flip distance of each such neighbor from scratch (Eulenstein et al. 2004). This failed to exploit the similarities between the current tree and its neighbors, and, consequently, was quite slow. The running times to find an optimal neighbor tree of a given n-taxon tree for rNNI, rSPR, and rTBR were O(n 2 m), O(n 3 m), and O(n 4 m), respectively. The new algorithms reduce these times by a factor of n, giving execution times of O(nm), O(n 2 m), and O(n 3 m), respectively. In all three cases, the key is to preprocess the tree to allow evaluation of the flip distance of each neighbor in O(1) time per character. Our procedures share some ideas with recently described parsimony heuristics (Ganapathy et al. 2003).
In the remainder of this section, we first describe a bottom-up assignment algorithm that is used in all our branch swapping procedures. We then describe the new rSPR and rTBR algorithms. Finally, we explain the implementation of greedy taxon addition, which relies on rSPR. We have experimentally determined that rNNI tends to produce trees with higher flip distances than rSPR and rTBR; nevertheless, for completeness, we describe the rNNI algorithm in the Appendix. Since the flip distance fM(T) can be obtained by computing f j (T) independently for each character j and adding up the results (see Equation (3)), the descriptions of all the algorithms to follow focus on the computation of f j (T) for a single character j.
Bottom-up assignment
The algorithm traverses the input tree T in post-order, computing four quantities for each node ν: z j (ν), o j (ν), f j (ν), and f j (Tν). Before the traversal starts, it computes the values of |Oj| for every character j; this takes O(nm) time.
Consider a node ν of T. If ν is a leaf, we can easily compute z
j
(ν), o
j
(ν), f
j
(Tν), and f
j
(Tν) in O(1) time. Now, suppose ν is an internal node with children u and w, such that zj(x), o
j
(x), f
j
(x), and fj (Tx) are known for x = u, w. Obviously,


Given z
j
(ν), o
j
(ν), and |O
j
|, the value of f
j
(ν) follows from Equation (1); f
j
(Tν) is given by

When the bottom-up assignment is finished, f j (T) = f j (Tν), where ν is the root node of T, and fM(T) can be computed in O(m) time via Equation (3).
Finding the best rSPR neighbor
The algorithm considers all possible prune nodes; for each such node, it computes the optimum regrafting node. A prune node ν is processed in two steps. First, apply the bottom-up assignment algorithm to Tν and T – Tν. Thus, for each node w of each tree and each character j we have z j (w), o j (w), f j (w), and f j (Tw). Second, traverse the nodes of T – Tν in preorder. Let the k-th node in the preorder sequence be uk; thus, u1 is the root of T – Tν. At step k, we compute the flip distance of the tree T (k) obtained by regrafting Tν at uk. We now explain how to obtain f j (T(1)) in O(1) time and how to compute f j (T(k)), k > 1, in O(1) time using the information computed for T(k −1).
Let pk denote the parent of ν and uk in the k-th rSPR neighbor tree. Let
Note that p1 is the root of the first rSPR neighbor tree (Figure 1(a-b)) and that


(
The value of f
j
(p1) can be computed in O(1) time using Equations (1) and (5) and the information stored at the roots of Tν and T – Tν. Note that
Assume that T(k–1), k > 1, has been processed. We now describe how to process T(k) (Figure 1 (c-d)). Let wA and wB denote the left and right children of uk–1 in T(k–1) and let
Assume that we know

Since, the cluster at uk-1 in T(k) is the same as the cluster at pk-1 in T(k–1), the above expression can be evaluated in O(1) time. Now,
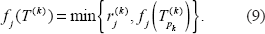
Note that
Finding the best rTBR neighbor
rTBR differs from rSPR in that it may re-root Tν before attaching it to T – Tν. To handle rerouting efficiently, we use a three-way assignment approach, similar to the one used for parsimony by Ganapathy et al. (2003). We now outline the main ideas of this method.
Consider an internal node u as shown in Figure 2. The subtrees of u change, depending on whether the new root is in the direction of edges 1, 2, or 3; the subtrees of u are {Tx, Ty}, {Ty, Tz}, or {Tx, Tz}, respectively. A three-way assignment is a labeling of each vertex u with three lists of values 〈zj(u),oj(u), fj(u), fj(Tu)〉, one for each possible rooting. Such an assignment can be obtained in O(n) time per character by doing a bottomup assignment to find the assignments for the first rooting, and then doing a top down preorder traversal to update the assignments for the other two rootings.

Internal node u and the three possible pairs of subtrees it may have, depending on the rooting. Each requires a different assignment.
After computing a three-way assignment for the pruned subtree Tν, we have, for every possible re-rooting t of Tν, the information needed to find the best possible regrafting of t into T – Tν, using the method earlier described for rSPR. This takes O(n) time per character for each fixed re-rooting t. Since there are O(n) possible re-rootings of Tν and O(n) choices for ν, the time required to find the best rTBR neighbor is O(n 3 ) per character and O(n 3 m) total.
Greedy taxon addition
The greedy search begins with a unique initial tree formed from the first two taxa in the input data set. The third taxon is inserted into every possible branch of the initial tree to form all possible three-taxon trees. The three-taxon tree with minimum flip distance is chosen. Each successive taxon is added in this way until a complete tree is obtained.
To find the best place to add the k-th taxon to the (k – 1)-taxon tree, we use our optimum rSPR neighbor algorithm. In this case, the tree being grafted has a single node containing taxon k and there are 2k – 3 ways to add this taxon to the (k – 1) -taxon tree. The time per regraft is O(km), yielding a total running time of O(n 2 m) for the entire addition sequence. We note that the performance the MRF heuristic may be improved by repeating the greedy taxon addition using different permutations of the taxa and thus generating multiple starting trees.
Data Sets and Results
We examined the performance of MRF, and compared it to two other supertree methods, MRP and MMC, using three large, empirical data sets. MRF supertree analyses, implemented in HeuristicMFT2 (Chen, 2005), used rSPR and rTBR branch swapping on three random addition sequence replicates and saved a maximum of ten trees. MRP supertrees were constructed using PAUP* (Swofford, 2002), and used TBR branch swapping on three random-addition sequence replicates and saved a maximum of 100 trees. MMC supertrees were constructed with a program supplied by Rod Page (Page, 2003). The data sets (see Table 1) were taken from large, published supertree studies of marsupials (Cardillo et al. 2004), mammals (Price et al. 2005), and legumes (Wojciechowski et al. 2000).
Supertree data sets. The second column lists the total number of input trees in each data set, and the third column lists the number of taxa that are found in the set of all input trees. The last column lists the number of characters in the binary matrix representation of the set of input trees.

The performance of each supertree method was evaluated by measuring the degree to which the supertrees agree with the input trees (e.g. Eulenstein et al. 2004). Two measures were used for this purpose: 1) the average MAST-fit between the supertree and the input trees and 2) the average triplet-fit from the supertree to the input trees. The MAST-fit between a supertree and an input tree is the number of leaves in their maximum agreement subtree (Gordon, 1980; Kubicka et al. 1992) divided by the number of leaves in common between the two trees. This was calculated using PAUP* (Swofford, 2002). The triplet-fit from a supertree to an input tree is 1 – (d + r)/(d + r + s), where s is the number of rooted triplets that are identically resolved in the supertree and the input trees, d is the number of triplets resolved differently in both trees, and r is the number of triplets resolved in the input tree but not in the supertree (Page, 2002). The triplet-fit, unlike the MAST-fit, is an asymmetric similarity measure. If there was more than one optimal supertree, we present the average score of all optimal supertrees to each of the input trees. In addition to measuring the quality of the supertrees, we also compared the CPU-time for each supertree method to provide a rough estimate of the computational requirements for each method. All the analyses were conducted on a Linux platform with a 3.0 GHz Pentium IV processor.
In the analyses of each of the three data sets, the MRF supertree had an equal or higher average MAST-fit and triplet-fit to the input trees than MMC or MRP supertrees (Table 2). In the marsupial and Cetartiodactyla data sets, the MAST and triplet-fit scores for the MRP supertrees were very similar to the scores for the MRF supertrees, while the scores for the MMC supertree were lower (Table 2). However, in the supertree analyses of the legume data set, the MAST and triplet-fit scores of the MRF supertree were noticeably (≥6%) higher than for the MMC or MRP supertrees. Also in the analyses of the legume data set, the triplet-fit score for the MRP supertree was higher than that of the MMC supertree, but the MAST-fit score of the MMC supertree was higher than that of the MRP supertree (Table 2). There was little if any difference in the performance of rSPR or rTBR algorithms in MRF analyses, though rTBR analyses required more CPU time than rSPR analyses (Table 2). In the analyses of the marsupial and Cetartiodactyla data sets, MRF with rSPR still required the most CPU time of the three supertree methods, but in the analysis of the legume data set, MRF with rSPR branch swapping used less CPU time than the MRP heuristic (Table 2).
Results of the supertree analyses of three empirical data sets. The triplet-fit and MAST-fit columns show the average triplet-fit or MAST-fit distances of the input trees to the supertree. The Pars. score column shows the parsimony score of the supertree based on the binary matrix representation of input trees, and the Flip dist. column shows the minimum flip distance of the supertree based on the binary matrix representation of input trees. CPU time is the computational time for each supertree algorithm.

Discussion
The new heuristic algorithm makes MRF analyses feasible for large empirical data sets. The previous MRF algorithm was not only slow, its performance and implementation were questioned (Goloboff, 2005). Eulenstein et al. (2004) reported that the previous rSPR heuristic performed better than the rTBR heuristic for MRF. Goloboff (2005, p 289) interpreted this to mean that “SPR usually produced a better agreement with the model [true] tree.” However, Eulenstein et al.'s (2004) statement only referred to an anecdotal observation that rSPR was faster than rTBR and that the flip distances of rSPR and rTNR trees were very similar if not identical. In this study, we again observed that the MRF heuristic with rSPR branch swap ping is much faster than the heuristic with rTBR branch swapping, and that both algorithms yield trees with similar flip distances (Table 2). The similarity between the performance of rSPR and rTBR may seem intuitively surprising (e.g. Goloboff, 2005), but it likely results from the nature of rooted branch swapping. rSPR and rTBR differ in that the latter may reroot the pruned subtree before regrafting. In most situations, it appears that rerooting does not reduce the flip distance. That is, the best rSPR and rTBR neighbors usually have the same flip distance. The implementation of the new heuristic also fixes a bug in the implementation of the previous MRF heuristic that caused the program to save suboptimal trees with rTBR and rNNI branch swapping (see Goloboff, 2005). Both rSPR and rTBR heuristics generally produce supertrees with lower flip distances than supertrees produced with rNNI heuristics (not shown). Though there appears to be little benefit in using the rTBR as opposed to rSPR heuristic in a quick MRF analysis, a thorough MRF analysis should include rTBR branch swapping.
The speed of the new heuristic makes it possible to assess the performance of the MRF supertree method using data sets that would have been too computationally demanding for the previous heuristic method. In fact, these are among the first reported MRF analyses using empirical data sets (but see Burleigh et al. 2004). In all three analyses, MRF appears to perform at least as well and often better than MMC and MRP (Table 2). The results also emphasize the differences that may exist between MRP and MRF supertrees. In previous simulation and empirical studies that used small input trees, the average similarity scores of MRP and MRF supertrees to the input trees were nearly identical (Chen et al. 2003; Burleigh et al. 2004; Eulenstein et al. 2004). However, this does not necessarily mean that MRF and MRP supertrees are similar to each other. In the analyses of the marsupial and Cetartiodactyla data sets, there is a notable difference in flip distance and parsimony scores of the MRF and MRP supertrees, even though the similarity of MRF and MRP supertrees to the input trees appears nearly identical. In the analysis of the legume data set, the difference in the parsimony scores and flip distances of the MRF and MRP supertrees is much larger (Table 2). These examples also demonstrate that the parsimony score of a supertree based on its binary matrix representation may not be a good indicator of the similarity of the supertree to the input trees. MRF trees with higher (worse) parsimony scores resemble the input trees more than the optimal MRP trees (Table 2). In these cases, minimizing the flip distance appears to be a better optimality criterion than minimizing the parsimony score. The legume supertree analyses also demonstrate that the MMC supertree method, which uses no true optimality criterion, can produce supertrees that appear more similar to the input trees than MRP. Thus, it may be unwise to rely solely on an MRP supertree analysis.
A good supertree method must balance computational speed with accuracy. For example, the MMC supertree method has a fast polynomial time algorithm (Page, 2002), but it often results in low quality supertrees (Table 2; Eulenstein et al. 2004). Conversely, the MRF supertree method appears to be accurate relative to other supertree methods, but previously its heuristics were too slow for large supertree studies (Eulenstein et al. 2004). However, the availability of heuristics should not dictate one's choice of supertree methods. Rather, the properties of a supertree method should motivate the development of useful heuristics. Though a number of supertree methods have been proposed (see Bininda-Emonds, 2004), there has been much less focus on developing fast implementations of these methods. This study demonstrates that such work can benefit supertree analyses. We do not suggest that MRF is now the optimal supertree method. In some cases, MRF may exhibit undesirable properties (e.g. Goloboff, 2005; Wilkinson et al. 2005), and the speed of the new heuristics may still be a limitation for building supertrees with many thousand taxa or for implementing supertree bootstrapping replicates (e.g. Creevey et al. 2004; Philip et al. 2005; Burleigh et al. 2006). Still, with the new heuristics, MRF is, in many cases, a viable supertree method that should be considered along with other methods.
Footnotes
Acknowledgements
We thank Olaf Bininda-Emonds and Marty Wojciechowski for providing empirical data sets and Sagi Snir and Mike Sanderson for valuable discussions. This research was supported by National Science Foundation grants EF-0334832, CCR- 9988348, and 0431154.
Appendix: Finding the Best rNNI Neighbor
A rNNI operation on an internal node ν of T resulting in a neighbor tree T′ is depicted in Figure 3. Observe that T and T′ have the same clusters, except that T′ does not contain cluster ℒ(Tν) = ℒ(Tx) ∪ ℒ(Ty) and that T′ has a cluster ℒ(T′ν′) = ℒ(T′ z ′) ∪ ℒ(T′ y ) not present in T.
Prior to starting the search for the best rNNI neighbor, we execute the bottom-up assignment algorithm. Next, we traverse T in preorder, computing f
j
(T – Tν) for each node ν of T as follows. If ν is the root of T, then T – Tν is an empty tree, denoted by Ø, and we define f
j
(Ø) = +∞. Now, suppose ν has parent p and sibling z and assume that f
j
(T – T
p
) has been correctly computed. Then,
Thus, we have zj(ν), o j (ν), f j (ν), and f j (T – Tν), and f j (T – Tν) for each node ν and every character j. We now show how this information can be used to obtain the flip distance of each neighbor tree in constant time per character.
By Equation (2),
The values of f j (Tz) and f j (T y ) are known, while fj(ν′) can be obtained in constant time using the precomputed values of zj and oj for nodes z and y, and Equations (1) and (5). Thus, f j (T′ν′) can be obtained in constant time.
On the other hand,
The values of f j (T – T p ) and f j (Tx) are known, while, like f j (ν′) above, f j (p′) can be obtained in O(1) time from the pre-computed information.
Hence, for each rNNI neighbor T′ of T, f j (T x ) can be computed in O(1) time and f M (T′) can be computed in O(m) time for a matrix of m characters. Thus, the best rNNI neighbor can be found in time O(nm).