
Abstract
Objectives
The present study aimed to evaluate the inter-observer reliability of three feline pain scales commonly used in clinical practice.
Methods
Twenty cats undergoing elective neutering surgery were assessed both pre- and postoperatively by three independent assessors (a board-certified anaesthetist, a veterinary anaesthesia nurse and a final-year veterinary student) using three different pain scales: the Glasgow Feline Composite Measure Pain Scale (CMPS – Feline), the Colorado State University Feline Acute Pain Scale (CSU – FAPS) and the Feline Grimace Scale (FGS). Reliability statistics was used to evaluate the level of agreement between assessors.
Results
Twenty-seven groups of paired observations were evaluated, of which 16 (59%) showed fair agreement, eight (30%) showed none to slight agreement and the remaining three (11%) showed moderate agreement based on Cohen’s weighted kappa statistics. Based on Cronbach’s alpha statistics, 12 (44%) of the 27 groups of observations showed moderate reliability, 12 (44%) showed poor reliability and the remaining three (11%) showed good reliability. No scale was superior to the others in terms of inter-rater reliability (P = 0.179); however, the pair composed of the final-year veterinary student and anaesthesia nurse showed better agreement than the two other pairs of assessors, both of which included the board-certified anaesthetist (P = 0.015).
Conclusions and relevance
Despite the usefulness of behavioural pain scales as clinical tools, their users should bear in mind their limitations, particularly the intrinsic subjectivity and potential variability of outcome between assessors with different backgrounds and level of expertise.
Introduction
Pain assessment in cats is notoriously challenging for veterinarians as a result of the intrinsic characteristics of this animal species.
During the past decade, a number of methods, the majority of which are based on behavioural observations, have been developed, refined and validated with the purpose of quantifying pain and analgesia in feline patients.1 –15 Of these, the Glasgow Feline Composite Measure Pain Scale (CMPS – Feline), the Colorado State University Feline Acute Pain Scale (CSU – FAPS) and the Feline Grimace Scale (FGS) are often regarded as user-friendly, reliable and useful in the clinical setting.15–18 The CMPS – Feline has been validated for post-surgical pain as well as for other pain syndromes, including trauma, and the findings of a recent report suggest that training may not even be necessary for the users to obtain reliable results.16,19 The FGS was initially validated in a cohort of cats mostly affected by abdominal pain, but it may be used in the clinical setting to assess acute pain resulting from various conditions.7,8 The CSU – FAPS is currently in the process of initial validation, with promising results and is particularly appreciated for its ease of use and visual impact, and because it is potentially quicker to apply than other scales in a clinical setting. 17 Recent research appears to support the use of these scales and suggests that they are reliable and may be used by clinical personnel with different backgrounds.18,19
Despite their clinical usefulness, one potential intrinsic limitation of behavioural pain scales is a certain degree of subjectivity depending on the individual assessor and on their level of expertise in pain assessment.
The present study aimed to evaluate the inter-observer reliability of three feline pain scales commonly used in clinical practice.
It was hypothesised that the three scales would show a fair to moderate level of agreement between assessors with different background and level of expertise in pain assessment, namely a board-certified veterinary anaesthetist, a veterinary anaesthesia nurse and a final-year veterinary student.
Materials and methods
Study population
The study population was represented by client-owned cats admitted to the Queen’s Veterinary School Hospital of the University of Cambridge for routine neutering surgery (either spay or castration) between October 2022 and May 2023. The study was conducted under permission of the Ethics and Welfare Committee of the Department of Veterinary Medicine of the University of Cambridge (licence number: CR586-2022) and with signed informed owner consent.
Pain assessments
Three assessors, namely a board-certified veterinary anaesthetist (assessor A: CA), a veterinary anaesthesia nurse (assessor B: KS) and a final-year veterinary student (assessor C: CJ), assessed the study cats independently, and were blinded to the scores generated by the other assessors. They used three feline pain scales commonly used in practice: the CMPS – Feline, the CSU – FAPS and the FGS. Assessors A and B were familiar with the use of the scales, and assessor C received some basic training based on two pilot cats prior to commencing data collection. The cats were assessed both preoperatively, after at least 1 h of acclimatisation in the hospital ward, and postoperatively, as soon as they were fully recovered from anaesthesia and sufficiently conscious to undergo behavioural assessment (ability to lift the head up, to respond to verbal stimulation and to eat and drink if food was offered). For each cat/assessment, the three assessors examined the cats within 30 mins of each other. To increase the chance that the assessors evaluated the cats while in a comparable analgesic status, care was taken to ensure that the 30-min period did not occur at a time when the previously administered analgesic drugs were expected to wear off. The order of the assessors was based on their availability at the time of the assessment and not randomised. Exclusion criteria were aggressive/defensive demeanour, presence of diagnosed comorbidities and administration of rescue postoperative analgesia between assessments/assessors. In case of unavailability of one of the assessors during an assessment, the cats were not excluded from the study, but pairwise evaluations were conducted on the available observations. Each assessor remained blinded to the scores generated by the other two until the end of data collection.
Statistical analysis
A sample size calculation was performed based on the hypothesis that the pairwise agreement between independent assessors would be fair to moderate. Variables were set as follows: statistical test, pairwise inter-class correlation (two-sided test); alpha (α) value, 0.05, power, 0.8; beta (b) value, 0.2; standard normal deviate for α (Zα), 1.960; standard normal deviate for b (Zb), 0.842; expected correlation coefficient, 0.5. This resulted in a minimum number of pairwise assessments equal to 29.
Descriptive statistics was used for demographic variables, and the data distribution was analysed with the Shapiro–Wilk normality test. Reliability statistics was performed with both the Cohen’s weighted kappa (k) test and the Cronbach’s α method with calculation of the inter-class correlation coefficient (ICC).
Inter-rater agreement was classified as follows: for k values below 0.01, no agreement; for k values between 0.01 and 0.20, none to slight; for k values between 0.21 and 0.40, fair; for k values between 0.41 and 0.60, moderate; for k values between 0.61 and 0.80, substantial; and for k values between 0.81 and 1.00, almost perfect agreement. 20 Inter-class reliability was classified as follows: for ICC values below 0.5, poor; for ICC values between 0.5 and 0.75, moderate; for ICC values between 0.76 and 0.90, good; and for ICC values above 0.90, excellent. 21
To determine whether the inter-observer agreement differed between scales or between pairs of observers, the proportions of different categories of agreement were analysed with a χ2 test.
Commercially available statistical software (SigmaStat 3.5 and SigmaPolt 10; Systat; SPSS, version 28; IBM Corp.) was used. P ⩽0.05 was considered statistically significant.
Results
Data are presented as either the mean ± SD or median (interquartile range), depending on the data distribution. Twenty client-owned cats weighing 3.2 (2.6–4) kg and aged 6 (5–24) months, of which 12 were females and eight were males, were included in the study.
The cats were premedicated intramuscularly with a combination of medetomidine (0.015 [0.01–0.015] mg/kg) and methadone (0.2 [0.2–0.3] mg/kg). Following intravenous catheter placement, general anaesthesia was induced with either intravenous alfaxalone (2 [1–2] mg/kg) or propofol (4 [2–5] mg/kg) titrated to effect and maintained with isoflurane in oxygen delivered through a modified T-piece connected to an appropriately sized endotracheal tube. Intra-testicular lidocaine (2 [1.5–2.0] mg/kg) was administered to the male cats before the beginning of surgery. Rescue perioperative analgesia was administered at the discretion of the anaesthetist in charge of each case. All cats received subcutaneous meloxicam (0.2 [0.1–0.2] mg/kg) and buprenorphine (0.02 mg/kg) postoperatively; buprenorphine was administered at 4 h from premedication or earlier if it was deemed necessary based on postoperative pain scores. All surgeries were performed by the same surgeon assisted by a final-year veterinary student.
Preoperative and postoperative assessments were missing in seven and six cats, respectively, as a result of the unavailability of one of the three observers at the time of evaluation.
The outcomes of each of the three scales were analysed separately per pairs of assessors (A and B, A and C and B and C) and per category (preoperative and postoperative values analysed both separately and together) (Tables 1 to 3). This resulted in a total of 27 groups of paired observations (Table 4). The order of assessors was A, B, C in 10/27 (37%), A, C, B in 7/27 (26%), B, A, C in 6/27 (22%), C, A, B in 2/27 (7%) and B, C, A in 2/27 (7%) observations.
Summary of reliability statistics findings of all (preoperative and postoperative) independent assessments performed by three investigators (A, B and C) using three different feline pain scales

*Significance for Cronbach’s α test
†Significance for Cohen’s reliability statistics test
The numbers in bold indicate statistical significance
A = board-certified veterinary anaesthetist; B = veterinary anaesthesia nurse; C = final-year veterinary medicine student; CMPS–Feline = Glasgow Feline Composite Measure Pain Scale; CSU – FAPS = Colorado State University Feline Acute Pain Scale; FGS = Feline Grimace Scale; n = number of assessments; ICC = intra-class correlation coefficient
Summary of reliability statistics findings of preoperative independent assessments performed by three investigators (A, B and C) using three different feline pain scales

*Significance for Cronbach’s α test
†Significance for Cohen’s reliability statistics test
The numbers in bold indicate statistical significance
A = board-certified veterinary anaesthetist; B = veterinary anaesthesia nurse; C = final-year veterinary medicine student; CMPS–Feline = Glasgow Feline Composite Measure Pain Scale; CSU – FAPS = Colorado State University Feline Acute Pain Scale; FGS = Feline Grimace Scale; n = number of assessments; ICC = intra-class correlation coefficient
Summary of reliability statistics findings of postoperative independent assessments performed by three investigators (A, B and C) using three different feline pain scales

*Significance for Cronbach’s α test
†Significance for Cohen’s reliability statistics test
The numbers in bold indicate statistical significance
A = board-certified veterinary anaesthetist; B = veterinary anaesthesia nurse; C = final-year veterinary medicine student; CMPS–Feline = Glasgow Feline Composite Measure Pain Scale; CSU – FAPS = Colorado State university Feline Acute Pain Scale; FGS = Feline Grimace Scale; n = number of assessments; ICC = intra-class correlation coefficient
Based on Cohen’s weighted k statistics, of 27 groups of observations, 16 (59%) showed fair agreement, eight (30%) showed none to slight agreement and the remaining three (11%) showed moderate agreement; none of the pairwise assessments showed substantial or almost perfect inter-rater reliability (Table 4). The χ2 test showed no difference in the proportions of different categories of agreement between pain scales (P = 0.251).
Inter-observer reliability of three different feline pain scales, used independently by three assessors, analysed with two statistical methods

A = board-certified veterinary anaesthetist; B = veterinary anaesthesia nurse; C = final-year veterinary medicine student; CMPS–Feline = Glasgow Feline Composite Measure Pain Scale; CSU – FAPS = Colorado State University Feline Acute Pain Scale; FGS = Feline Grimace Scale; IRA = inter-rater reliability based on Cohen’s weighted k statistics; ICR = inter-class reliability based on Cronbach’s α statistics
Based on Cronbach’s α statistics, of 27 groups of observations, 12 (44%) showed moderate reliability, 12 (44%) showed poor reliability, and the remaining three (11%) showed good reliability; none of the pairwise assessments showed excellent inter-class reliability (Table 4). The χ2 test showed no statistically significant difference in the proportions of different categories of agreement between pain scales (P = 0.179).
The proportions of fair-to-moderate (with respect to k value) and moderate-to-good (with respect to ICC value) categories of agreement were significantly higher for the pairwise assessments B–C than for the pairwise assessments A–B and A–C (P = 0.015).
The preoperative and postoperative scores recorded by the three assessors are summarised in Figures 1 to 3.
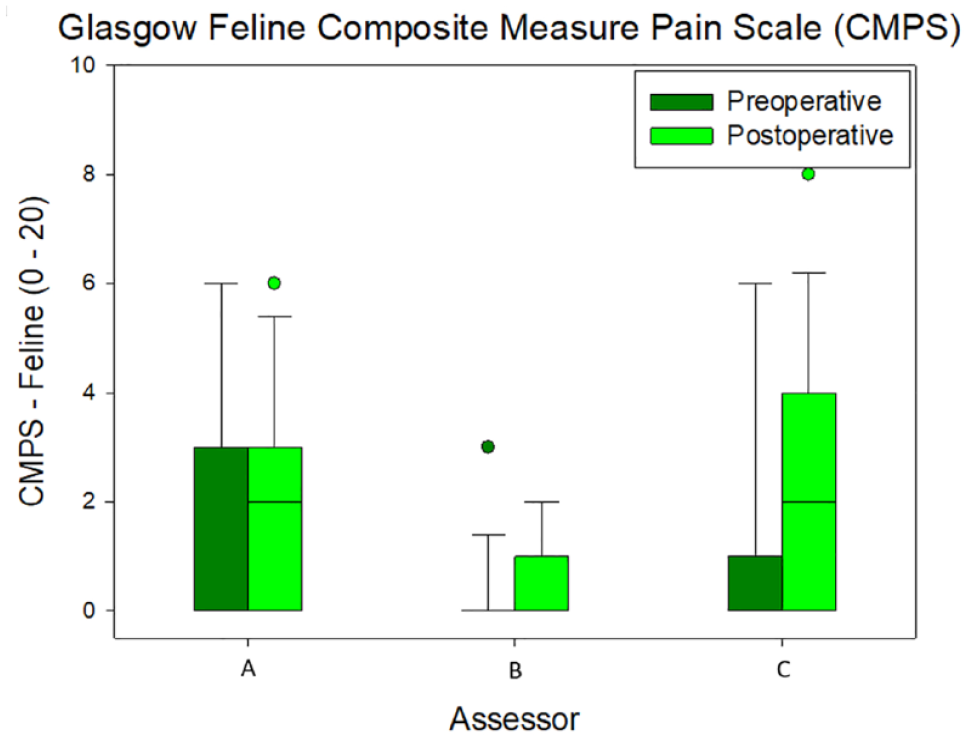
Preoperative and postoperative scores obtained with the Glasgow Feline Composite Measure Pain Scale (CMPS – Feline) by three independent assessors: A (board-certified veterinary anaesthetist), B (veterinary anaesthesia nurse) and C (final-year veterinary student). The boxes represent the second and third quartiles, with the horizontal line inside each box indicating the medians. The lower (25%) and upper (74%) quartiles are shown as vertical lines either side of each box. The dots represent the outliers
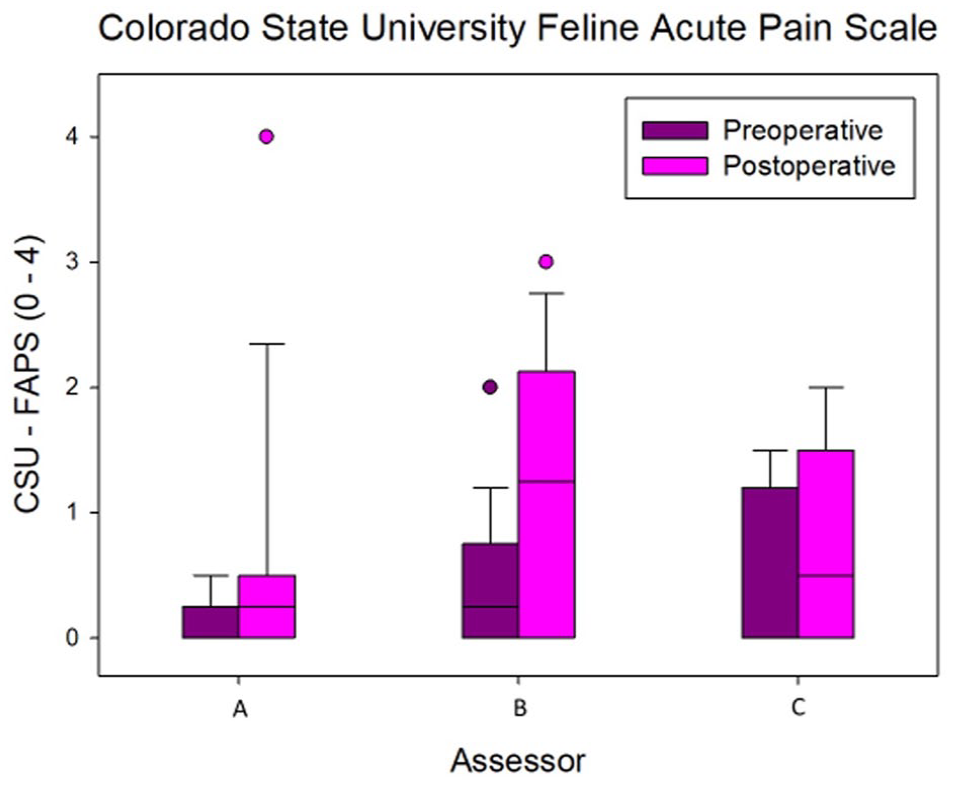
Preoperative and postoperative scores obtained with the Colorado State University Feline Acute Pain Scale (CSU – FAPS) by three independent assessors: A (board-certified veterinary anaesthetist), B (veterinary anaesthesia nurse) and C (final-year veterinary student). The boxes represent the second and third quartiles, with the horizontal line inside each box indicating the medians. The lower (25%) and upper (74%) quartiles are shown as vertical lines either side of each box. The dots represent the outliers

Preoperative and postoperative scores obtained with the Feline Grimace Scale (FGS) by three independent assessors: A (board-certified veterinary anaesthetist), B (veterinary anaesthesia nurse) and C (final-year veterinary student). The boxes represent the second and third quartiles, with the horizontal line inside each box indicating the medians. The lower (25%) and upper (74%) quartiles are shown as vertical lines either side of each box. The dots represent the outliers
Discussion
The main finding of the present study is that the inter-observer reliability of the three pain scales object of the investigation ranged in most cases from poor to fair/moderate, suggesting that subjectivity is a considerable limitation of these tools specifically designed to quantify pain in cats. Our findings are partially in contrast to those of a previously published investigation that identified the FGS as a reliable tool for assessment of acute pain when used by individuals with different background and level of expertise. 19
Although the present study failed to identify differences in reliability between the three scales or superiority of one of the scales, the results show that the level of agreement was not the same between different pairs of assessors. Namely, the veterinary anaesthesia nurse and the final-year veterinary student had better levels of agreement than the other two pairs of assessors, both of which included the board-certified anaesthetist. This finding is interesting, although difficult to interpret. Considering that the anaesthetists and the nurse were both familiar with the use of the scales while the student was not, it would have been reasonable to expect similar scores between assessors A and B instead. As a general consideration, part of the subjectivity of behaviour-based pain scales is considered to be generated by a tendency of the assessors to subjectively interpret certain behaviours rather than observing them and recording their observation. As an example, a stressed, supposedly pain-free cat may growl or vocalise in the hospital setting without this necessarily being a sign of pain. 22 Some assessors may score this specific descriptor in the CMPS – Feline scale, while some others may not, assuming that growling or vocalisations would be most likely unrelated to pain, particularly prior to elective surgery. A different approach to the scale – with some of the observers applying it more literally and others allowing more interpretation – may be the reason for the variability observed in the preoperative pain scores. In supposedly pain-free cats, the scores were expected to trend more consistently towards the lower end of the scale range for all three assessors. While common sense suggests that some degree of interpretation – based on the ‘whole clinical picture’ and on the information on a specific patient – is necessary and unavoidably a part of the clinical assessment of every patient, scale items that are not subject to interpretation should be preferred as they are more likely to produce objective outcomes.
Regarding the postoperative scores, irrespective of the assessor, these tended to be skewed towards the lower end of each scale range, indicating an overall good level of postoperative analgesia. It is worth considering that the pain scales investigated in the current study may perform differently in the presence of a more severe degree of pain.
The present study has some limitations. Although it was interesting and relevant to analyse the preoperative and postoperative scores both together and separately, it should be emphasised that, based on the sample size calculation, statistical tests performed on sub-groups of the study population may be underpowered and their results should be interpreted cautiously.
Ideally, the order of the three scales should have been randomised for each assessment with either a simple randomisation method or a computer-based program. This would potentially have improved the methodology, considering that the results of the first assessment with one of the scales may have represented a source of bias for the subsequent evaluations performed by the same observer on the same cat. Regarding the order of the assessors, this could not be randomised owing to the need to adapt the study design to the clinical flow of a busy veterinary hospital. All cats underwent surgery and were discharged during working hours when the assessors were potentially busy with other clinical work and not necessarily available. Assessing the cats at different time points could have resulted in changes in the level of analgesia – and therefore of pain – in the cats. Therefore, the assessments were restricted to the same 30-min period; however, this resulted in a number of missed assessments due to the inability of some assessors to make themselves available when their evaluation was due.
Conclusions
The present study highlights that, despite their clinical usefulness to assess perioperative pain in feline patients, behavioural pain scales are limited by intrinsic subjectivity. The users of these scales should bear in mind that the outcome may significantly vary depending on both the person performing the assessment and their personal interpretation of how to apply and use the scale.
Footnotes
Conflict of interest
The authors declared no potential conflict of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Ethical approval
The work described in this manuscript involved the use of non-experimental (owned or unowned) animals. Established internationally recognised high standards (‘best practice’) of veterinary clinical care for the individual patient were always followed and/or this work involved the use of cadavers. Ethical approval from a committee was therefore not specifically required for publication in JFMS. Although not required, where ethical approval was still obtained, it is stated in the manuscript.
Informed consent
Written informed consent was obtained from the owner or legal custodian of all animal(s) described in this work. No animals or people are identifiable within this publication, and therefore additional informed consent for publication was not required.