
Abstract
Objectives
The Karnofsky score (KS) modified for cats, a scoring system to rate health and quality of life (QOL) in cats, is used in clinical trials, but its reliability and validity are yet to be determined. The present study aims to evaluate the scientific robustness of the KS when adapted for use in a hospital setting.
Methods
A list of variables to consider during the physical examination, which informs the clinician’s score (CS) part of the KS, was added and clinicians were allowed to choose a score anywhere between 0 and 50. The Karnofsky QOL questionnaire was adapted for use in a hospital setting. F-tests with Bonferroni correction and Spearman rank correlation coefficients were used to evaluate reliability and validity of the KS to assess the health and wellbeing of cats in a hospital setting. The records of 54 feline immunodeficiency virus-positive cats, which were recruited for a clinical trial and hospitalised for 6 weeks, were reviewed. Four veterinarians scored the CS, and one veterinarian and a veterinary nurse assessed the QOL score.
Results
Mean absolute difference between observers was significantly larger for the CS than for the QOL score (P <0.001) and two veterinarians scored significantly higher than the remaining two veterinarians (P <0.001). Inter-observer correlation ranged from 0.45–0.75 for the CS. For the QOL score, the absolute difference between observers was small, no significant difference was found between observers and a high degree of inter-observer correlation was noted (r = 0.91).
Conclusions and relevance
The results indicate low inter-observer reliability for the CS, requiring additional modifications to this part of the KS. The QOL score seems more reliable, and the questionnaire may serve as a reliable tool in the assessment of QOL in cats in a hospital setting. Consequently, further adaptation of the KS is mandatory when simultaneous assessment of both the cat’s clinical health and perceived wellbeing is required.
Introduction
Due to a growing demand for evidence-based veterinary research, there is a need to assess an animal’s physical and psychological wellbeing in a valid and reliable manner.1–4 In feline medicine, scoring scales are often used to quantify clinical signs characteristic for the studied diseases; for example, oral disease or respiratory tract infections.5–10 Other conditions, such as cancer, systemic inflammatory or infectious diseases, demonstrate a complex symptomatology and require a broader approach.11–13 Medical care for such non-curable, chronic conditions typically aims at alleviating pain and discomfort, rather than at cure. Therefore, it is insufficient to express possible treatment effects in terms of overall survival or in terms of reducing a limited number of clinical signs.11,14,15 Notwithstanding the necessity of a thorough clinical examination, the importance of including variables reflecting the quality of life (QOL) should not be disregarded when monitoring a disease or treatment effect, as such information is often lacking in clinical records.2,3,11,16,17
In human medicine, questionnaire-based outcome measures are well accepted.11,16 In animals, however, QOL assessment is challenging owing to the impossibility of self-reporting and as a result of species differences.1–3,14,16 It can thus prove very difficult to make an accurate assessment of something as complex and subjective as QOL.3,13 Behavioural changes are potential indicators of pain and discomfort and therefore owner-perceived, behaviour-based QOL questionnaires can help in evaluating the impact of a disease or of a treatment effect.1,17 Disease-specific assessments have been developed for cats with diabetes mellitus, cancer, and cardiac and degenerative joint disease.13,18–21 Two non-disease-specific feline QOL questionnaires have been suggested in the scientific literature, but their reliability and validity remain to be evaluated.2,22
In an attempt to design an assessment tool for use in cats that encompasses both health and wellbeing aspects, Hartmann and Kuffer modified the Karnofsky performance status scale. 14 This scale is commonly used in human medicine to evaluate disease progression and treatment effect in patients with cancer and in individuals infected with HIV, by measuring the ability to carry on normal daily activity and the occurrence of symptoms.23–26 The proposed Karnofsky score (KS) modified for cats consisted of two parts: a score given by a clinician, determining the cat’s physical condition or health; and a questionnaire to be filled out by the owner, with behaviour-based questions related to the QOL of their cat. 14 Although the KS has been used in cats as an assessment tool in several studies,14,27–33 research on the reliability and validity of the scoring system is lacking. Therefore, the objective of the present study was to assess the inter-observer reliability of the KS further adapted for use in hospital setting.
Materials and methods
Subjects
The data reported in this study were collected during a double-blinded, placebo-controlled clinical trial, which was approved by local and national ethical committees and authorities. Clinically ill client-owned cats naturally infected with feline immunodeficiency virus (FIV) were recruited and enrolled onto the trial if they appeared to be in a clinically stable condition; that is, there was no evidence of clinical or systemic disease requesting immediate veterinary care or likely to request critical care within 6 months. For the clinical trial, cats were hospitalised for a period of 6 weeks, which provided the opportunity to perform multiple observations on each cat. The test product for the clinical trial was administered every 3 days and consisted of a subcutaneous injection with a volume of 0.1 ml/kg. In total, the records of 54 cats were evaluated. In addition, six cats were re-hospitalised after discharge, providing supplementary data.
Adapting the clinician’s part of the KS
The KS proposed by Hartmann and Kuffer describes the clinician’s assessment of the general condition of the cat. 14 The assessor is given the possibility to assign one of six discrete values (Figure 1). However, variables on which to base the assessment were not defined. Therefore, in the present study a list summarising the relevant variables of a physical examination was added (Figure 2). A score sheet was created, which showed the list of variables and the request to take all parameters into account. Furthermore, this form mentioned that clinicians were allowed to give any continuous score between 0% and 50%. The resulting score is referred to as the clinician’s score (CS).

Clinician’s scores for the general condition of a cat according to the Karnofsky score modified for cats by Hartmann and Kuffer 14

Summary of a physical examination, to accompany the clinician’s score of the Karnofsky score modified for cats.
Adapting the KS questionnaire
The questionnaire of the Hartmann and Kuffer KS included questions on behavioural aspects that are impossible to assess in hospitalised cats (eg, ‘your cat is catching mice’, ‘your cat is fighting or having sexual activities as often as normal’). 14 Hence, only behaviours pertinent to hospital settings were identified, leading to the retention of 13/22 questions for evaluation. These questions covered different behavioural domains, such as eating, excretion, sleeping, comfort and playing. A discrete value of 1, 2, 3 or 4 was attributed by the assessor of each question (Figure 3), and aimed at comparing the current frequency of a cat’s behaviour with the normal frequency of this behaviour; that is, when the cat was in a healthy condition. To allow observers to assess the abnormal behaviour for each cat during hospitalisation, owners were thoroughly interviewed pretrial and the questionnaire at baseline was completed collectively (owner and observer). To distinguish the importance of certain behavioural aspects, each score was multiplied by a corresponding impact or weighing factor. Impact factors as suggested by Hartmann and Kuffer were maintained. 14 The discrete values assigned to each of the 13 questions and multiplied by the respective impact factor were summed to a maximum total of 36 and recalculated by cross-multiplication to 50. The resulting score is referred to as the QOL score (Figure 3). The recalculation to 50 enabled an easy comparison between the clinician’s score and the QOL score.

Owner-perceived behaviour-based questionnaire to assess the quality of life of a cat in a hospital setting. The respondent has to give a score from 0–4, comparing the current condition with previous, normal behaviour. These scores are multiplied by the respective impact factor, summed to a maximum total of 36 and recalculated to 50. The resulting score is the quality-of-life score, part of the Karnofsky score
Time schedule for clinical and QOL assessments
Assessments were performed on two different occasions: period 1 covered observations after approximately 1 week of hospitalisation; and period 2 after approximately 6 weeks of hospitalisation. A concise explanation on the use of the scoring systems was provided to all observers, who were blinded to and unaware of each other’s scores. The physical examination, to assess the CS, was performed within the same room as where the cats were housed. Appointments were made with the differentclinicians during the assessment period and cats were placed in their familiar housing in between ratings. The goal was to have a minimum of three assessments per occasion per cat. For QOL scoring, cats were observed and eating and playing behaviour was tested within the cat’s housing environment. Efforts were made by the observers to assess the QOL simultaneously, to avoid distress bias. To allow a reliable assessment of the QOL, it is necessary to be familiar with a cat’s behaviour. Therefore, the aim was to have a minimal but reliable number of two observers completing the QOL questionnaire.
Statistical methods
To evaluate inter-observer reliability, ANOVA was conducted using the absolute score difference between observers and the mean scores per observer as response variables; F-tests were used to evaluate the effect of the method, period and observer. The agreement between two observers per method was assessed using the Spearman rank correlation coefficient.
To assess validity of the used methods, ANOVA was conducted using the mean cat scores as response variables; F-tests were used to evaluate the effect of the method and period. To assess agreement between methods a Spearman rank correlation was calculated between the mean CS and QOL score per cat. Allanalyses were performed using SAS (version 9.2;SAS Institute) at the 5% significance level and the Bonferroni technique was used to adjust for multiple comparisons.
Results
CS
Four different veterinarians participated in the clinician’s assessment of the cats.
Table 1 shows the number of observations and the maximum time lapse between observations for the CS. For the first assessment period (period 1), the mean ± SD time between the clinician’s assessments for each individual cat was 1.3 ± 1.5 days. On 44 occasions, three veterinarians were able to assess one cat within the same period, while on 16 occasions only two veterinarians did.
Number of observations and maximum time lapse between assessments per period for the clinician’s score (CS) and quality-of-life (QOL) score

For the second assessment period (period 2), the mean ± SD time between the clinician’s assessments for each individual cat was 1.0 ± 2.0 days. Three veterinarians assessed the same cat on 22 occasions, while on 20 occasions only two veterinarians assessed the same cat.
QOL questionnaire
One veterinary nurse and one veterinarian (veterinarian 3), both responsible for the day-to-day care of the cats and thus spending sufficient time with the cats to allow for evaluation of behavioural changes, completed the owner’s questionnaire. Table 1 shows the number of observations and the maximum time lapse between observations for the QOL score. For period 1, mean ± SD time between two assessments was 0.13 ± 0.52 days, while for period 2 all assessments took place on the same day.
Reliability
Mean absolute difference between two observers per cat was significantly larger for the CS when compared with the QOL score (Table 2; P <0.001). The period during which the assessments were performed did not have a significant influence on the difference between observers.
Descriptive statistics on the absolute difference between two observers per cat
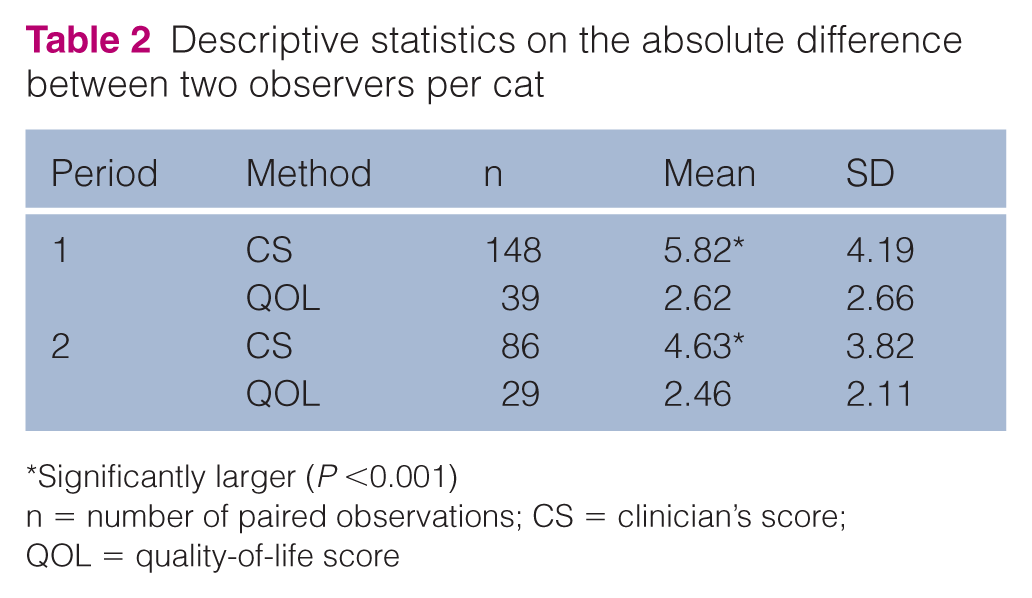
Significantly larger (P <0.001)
n = number of paired observations; CS = clinician’s score; QOL = quality-of-life score
Figure 4 depicts box plots and mean scores per observer, in this case all veterinarians, for the CS. Veterinarian 1 scored significantly higher than veterinarians 2 and 3 (P <0.001), whereas veterinarian 2 scored significantly higher than veterinarian 3 (P <0.001).

Box plots and mean scores per observer for the clinician’s score (CS). Maximum score is 50. When observers share the same superscript letter this indicates a significant systematic difference (P <0.001)
In contrast, no significant difference in the mean QOL score was found between the veterinarian (mean ± SD score 34.23 ± 1.23) and the veterinary nurse (mean ± SD score 34.35 ± 1.23).
Table 3 shows the Spearman rank correlation coefficients for the CS between veterinarians. All four observers correlated significantly (P <0.05), although with a moderate correlation coefficient ranging between 0.62 and 0.75. Only veterinarians 2 and 4 showed a remarkably lower, although not significant, level of agreement (r = 0.45, P = 0.15). No correlations could be calculated for veterinarians 3 and 4 as these clinicians did not assess the same cat during the same period.
Spearman correlation coefficients between observers for the clinician’s score

n = number of paired observations
For the QOL score, observers showed a significant and high Spearman correlation coefficient (r = 0.91, P <0.001).
Validity
Box plots and mean scores per method (CS and QOL score) and period are depicted in Figure 5. There was no significant difference between the CS and the QOL score.
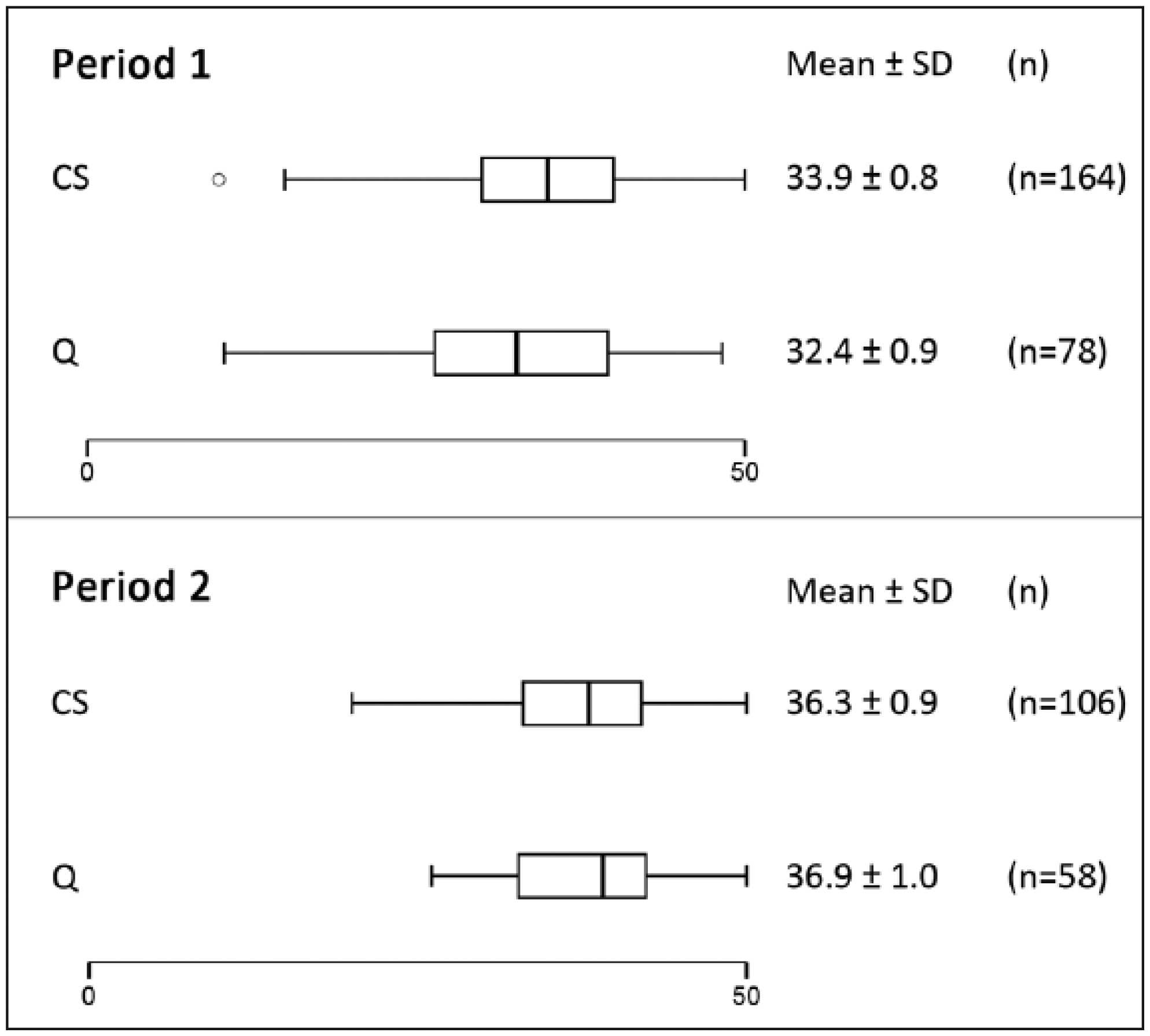
Box plots and mean scores per method (clinician’s score [CS] and quality-of-life [Q] score) for both assessment periods. Maximum score for both scales is 50
Spearman rank correlation coefficient between the CS and the QOL score was significant but low (r = 0.45, P ⩽0.001).
Discussion
The present study evaluated scientific robustness of the KS further adapted it for use in a hospital setting. 14
When multiple observers evaluate a cat’s condition, it is imperative to keep in mind that the cat’s health and wellbeing may vary over time. Therefore, all cats were prescreened for diseases that might cause an acute change in their condition and, if needed, cats were not enrolled into the study. Moreover, 95% of all assessments on the cats were performed within 3 days. Hence, it is assumed that changes in the cat’s condition over time did not meaningfully influence any scoring difference observed between the participating assessors.
Interpretation of inter-observer reliability depends on the ultimate purpose of the measurement. If a single value is to be interpreted by an independent observer, variation between observers should be avoided and inter-observer consensus (ie, the agreement between observers), should be high.1,4,34 Absolute differences between two observers per cat for both methods were calculated and appeared significantly higher for the CS than for the QOL score. In other words, veterinarians gave a wide variety of scores when evaluating the health of the same cat. Consequently, inter-observer consensus was low. Owing to the subjective nature of the CS, it is likely that observers do not share the same opinion on how to judge this scale.
However, when several different cats need to be scored by the same observer, inter-observer consistency becomes more important than inter-observer consensus. In other words, as long as each observer is consistent in classifying observations according to his or her own perception of the scale, different scores or ratings can be interpreted correctly and do not have to agree exactly between observers. 34 Therefore, the systematic differences and correlation coefficients between observers were calculated.
One observer systematically assigned higher CS ratings than two other veterinarians. The lack of a significant difference between this observer and observer 4 was most likely due to the low number of observations of the latter. When one observer consistently assigned higher scores than the others did, this might have contributed to the poor inter-observer consensus for the CS reported above. However, this does not automatically indicate a bad inter-observer consistency. When a systematic difference between observers is present, it is important to know whether observers consistently evaluate in the same way; that is, if one clinician gives a cat a higher score, the other clinician has to do the same and vice versa. Therefore, correlation coefficients between observers were calculated and these appeared only moderate for the CS, with one remarkable and very low outlier.
However, as a result of the low number of observers participating in this study, it cannot be excluded that the low inter-observer consensus and consistency of the CS do not reflect the actual reliability of the scoring system. A larger number of veterinarians could potentially have provided more reliable results. However, simultaneous assessments by more than four veterinarians appeared logistically difficult to organise in the hospital environment and could have been stressful for the cats. Hence, as for the present study, it can only be concluded that the CS did not reach high levels for inter-observer reliability, neither for inter-observer consensus nor for its consistency.
Any scoring scale consisting of subjective elements is vulnerable to observer error and bias. 2 For the CS, assessors had to record a global yet subjective score for the cat’s physical condition. Absence of guidelines and operational criteria creates a further degree of unreliability when using such scales, while a consistent approach is reported to improve reliability.15,35 Although an attempt was made to minimise variability by providing a summary list of elements to examine when attributing the CS, its addition proved insufficient. Moreover, and despite knowledge of its existence, none of the veterinarians had any previous experience in using the clinician’s part of the KS for cats. Even though some explanation was provided pretrial, a more in-depth training on how to complete the CS is mandatory to maximise its inter-observer reliability. A standardised, detailed approach with appropriate criteria combined with more specific training on how to use the scale may improve inter-observer consensus and consistency.
In contrast, inter-observer consensus and consistency were high for the QOL score. Animals have to rely on the perception of a caretaker to assess their QOL. Hence, it is imperative for owners, veterinarians and veterinary nurses to interpret animal behaviour correctly. 1 An extensive interview with the owner aimed at getting a good impression of ‘normal behaviour’ for the included cats. However, this may not have been sufficient, as subtle behavioural disturbances may not seem apparent to someone who is not very familiar with the animal. 1 Nevertheless, for the QOL score no large absolute difference or a systematic difference between observers was observed. Moreover, an excellent correlation between the veterinarian’s and the veterinary nurse’s QOL score was observed. It is encouraging to achieve high levels of reliability for the QOL score, although, admittedly, the apparent correlation may have been biased. Firstly, there were only two observers. Secondly, although both observers scored cats independently and in a blinded manner, they were responsible for the day-to-day care of the animals and thus frequently interacted with each other to discuss the animal’s wellbeing. This could have contributed to aligned opinions and interpretations of both assessors on the cat’s QOL. Consequently, it is advisable to test the reliability of the QOL score using a larger number of observers.
The validity of a measurement tool, in this case the KS, is defined as the degree to which the tool measures what it is designed or claimed to measure. 4 Owing to the lack of a ‘gold standard’ for both the CS and QOL score, their validity is difficult to assess. Nonetheless, a construct validity approach can be taken to estimate the validity of a method in the absence of validated tests. Such an approach explores the difference between two populations that are expected to have different properties, which are assessed by the method. 4 In other words, construct validity for this study can be estimated by comparing results from clinically ill, FIV-positive cats with results from healthy cats. If the expected relationship between both groups is observed, the measurement tool can be considered sound or valid. 4 Alternatively, psychometric methods, such as principle component analysis, can be applied to validate measurement tools for QOL scoring,18,36,37 but these require a substantial dataset, considerably larger than the one available in the present study.
Although the CS and the QOL score were designed with different measurement intentions, a deteriorating physical condition is expected to result, at least to some extent, in a lower QOL for a cat. Therefore, when comparing the CS and the QOL score, an initial estimate of their validity might be obtained. The presented analysis showed no systematic difference between the CS and the QOL score, but a low correlation coefficient between the scores was seen, which may indicate that validity of one or both of the scoring systems might be compromised.
Conclusions
This study in clinically ill, FIV-positive cats evaluated the scientific robustness of the modified KS, adapted for use in a hospital setting. The clinician’s part of the KS showed a systematic difference and a moderate-to-poor correlation between observers, indicating low inter-observer reliability. Consequently, the modified KS is an unreliable tool when the simultaneous assessment of both health and wellbeing aspects is required. Clinicians should be aware of the limitations of the KS, and further research may be needed to add extra guidance and objectivity to the CS. Furthermore, more systematic training of staff would be beneficial prior to the use of the CS. The other part of the KS, the behaviour-based QOL score, shows encouraging inter-observer reliability. The modified questionnaire may thus serve as a reliable tool to measure QOL objectively in cats in a hospital setting.
Footnotes
Acknowledgements
We thank Ms B Weyn for her participation in this research.
Conflict of interest
Nesya Goris has a financial interest in Aratana Therapeutics NV. None of the other authors have any affiliation with this private company.
Funding
The data described were gathered during a study funded by Aratana Therapeutics NV. This work was also supported by the Agency for Innovation by Science and Technology in Flanders (IWT) [IWT-100381].