
Abstract
Artificial intelligence (AI) applications in customer-facing settings are growing rapidly. The general shift toward robot- and AI-powered services prompts a reshaping of customer engagement, bringing machines into engagement conceptualizations. In this paper, we build on service research around engagement and AI, incorporating computer science, and socio-technical systems perspective to conceptualize human-machine engagement (HME), offering a typology and nomological network of antecedents and consequences. Through three empirical studies, we develop a typology of four distinct forms of HME (informative, experimenting, praising, apprehensive), which differ in valence and intensity, underpinned by both emotional (excitement) and cognitive (concern, advocacy) drivers. We offer empirical evidence which reveals how these HME forms lead to different cognitive and personality-related outcomes for other users (perceived value of HME, perceived risk, affinity with HME) and service providers (willingness to implement in services, perceived value of HME). We also reveal how outcomes for service providers vary with the presence and absence of competitor pressure. Our findings broaden the scope of engagement research to include non-human actors and suggest both strategic and tactical guidance to service providers currently using and/or seeking to use generative AI (GenAI) in services alongside an agenda to direct future studies on HME.
Keywords
Introduction
AI is transforming customer-firm interactions and growing remarkably, with Forbes predicting a 37 percent annual growth rate until 2030 (Haan 2024). This rise is matched by a growing interest in service and marketing research (Hollebeek et al. 2024; Wetzels, Grewal and Wetzels 2023). Innovations such as voice assistants (e.g., Siri), chatbots across various sectors (van Doorn et al. 2017; Wirtz and Pitardi 2023), and robots like “Spencer” at Amsterdam Schiphol Airport underscore AI’s potential to enhance competitive advantage for service providers (Huang and Rust 2024; Le et al. 2024). Technological advancements are also increasingly replacing human-to-human interactions with human-to-machine, as seen with integrated GenAI like ChatGPT in robots such as LG’s Rosie and Samsung’s Ballie (Engelfield 2024; Kelly 2020). This shift spans the multidisciplinary field of “machines,” encompassing human-robot interaction, human-computer interaction, AI and robotics disciplines (Ke et al. 2018), opening avenues for research into human-machine engagement (HME).
However, while service research primarily focuses on AI and robot characteristics and their adoption (Belanche et al. 2021; Schepers et al. 2022), there is increasing demand to explore the broader impacts of AI in service settings (Mende et al. 2024; Wirtz et al. 2023). In particular, engagement with machines and subsequent effects on users, customers, and providers remains underexplored. Although engagement research includes non-human actors as engagement objects (Brodie et al. 2019; Storbacka, 2019), studies typically center on brands or firms as engagement objects (Azer, Blasco-Arcas and Alexander 2024). Unlike human-centric engagement studies, interactions with machines may introduce unique typologies and nomological elements due to their distinct nature as engagement objects.
Human-machine engagement is likely to differ significantly from human-human engagement due to structural asymmetries across cognitive, emotional, and psychological levels (Fortunati and Edwards, 2020; Ke et al. 2018). In addition, the automation of human tasks within socio-technical systems by AI necessitates exploration of its impact on engagement (Pasmore et al. 2019)—vital for firms seeking to leverage AI insights for organizational success (Akbarighatar et al. 2023; Storbacka, 2019).
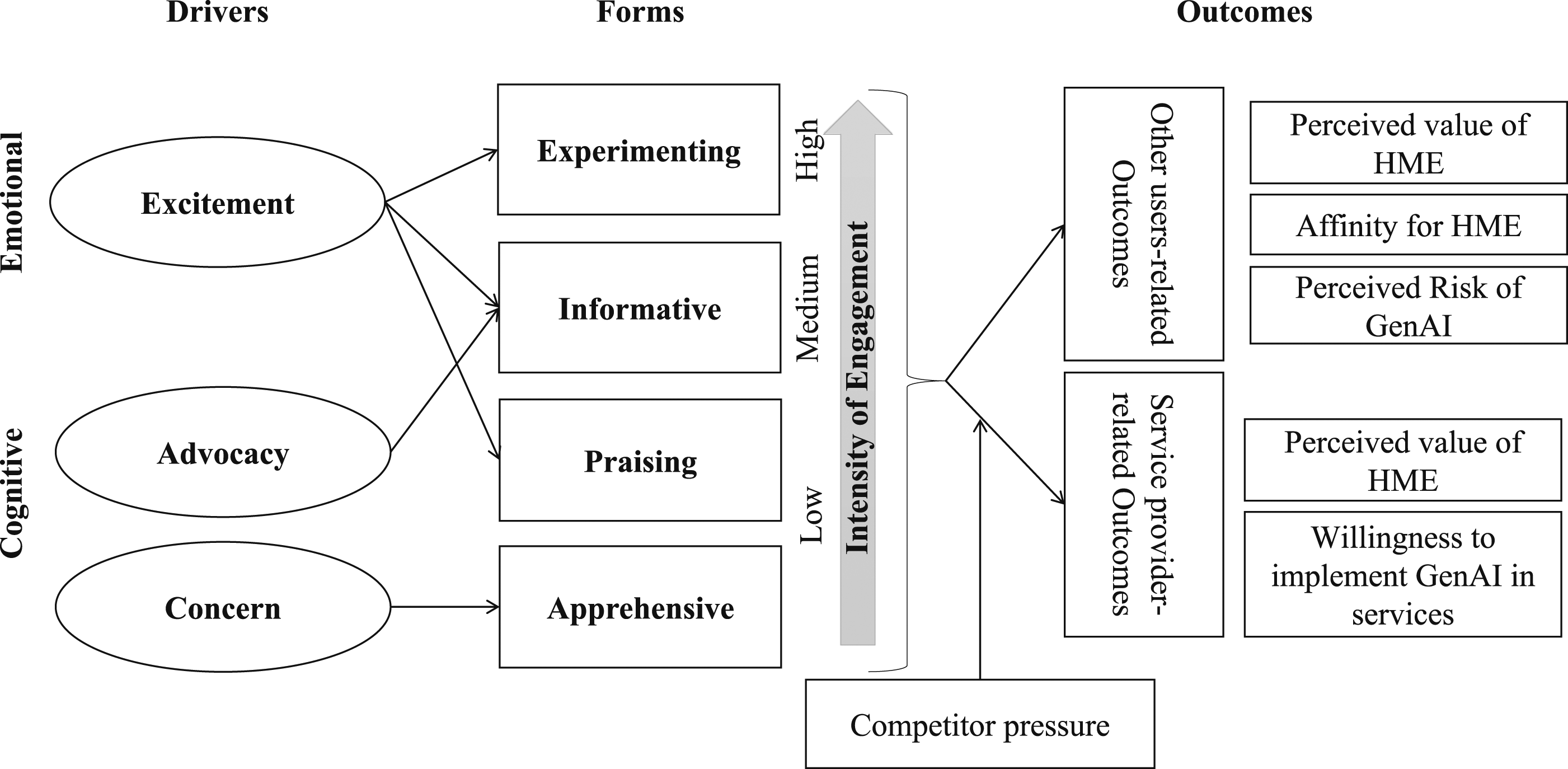
Building on prior research in engagement, AI in service, and socio-technical systems, we define HME as actors’ voluntary contribution of resources (e.g., time, experience, skills, knowledge or labor) that have a machine focus, occur in interactions with other actors and result from drivers. Through qualitative (netnography) and quantitative (experiments) studies, we address the identified research gaps, offering a comprehensive understanding of HME (Figure 1). The paper contributes by (1) introducing HME and its nomological network, (2) presenting a typology of four HME forms (informative, experimenting, praising, apprehensive) distinguished by valence and intensity, driven by cognitive (concern, advocacy) and emotional (excitement) drivers, (3) examines changes in the prevalence of these forms since ChatGPT’s launch, and (4) provides evidence of HME outcomes relating to both customer response and competitive pressure. Overview of studies.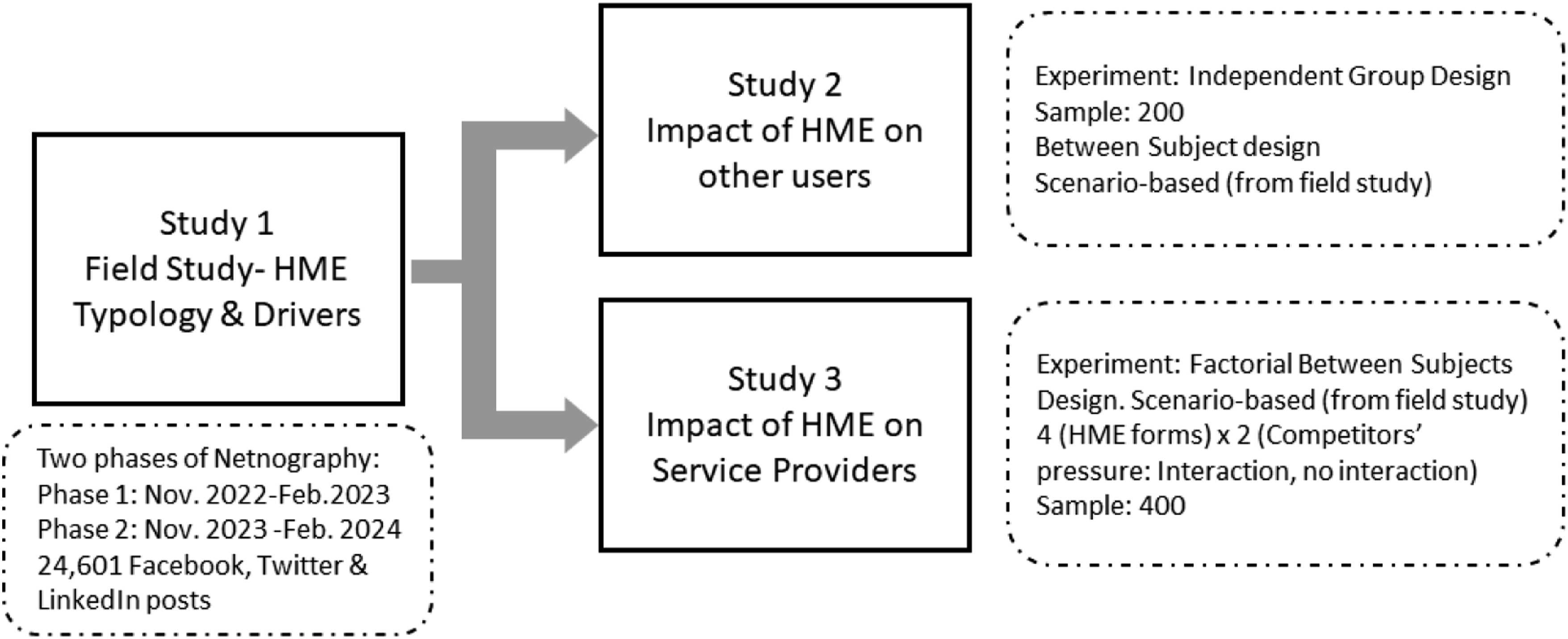
Theoretical Background
Artificial Intelligence (AI) in Services
Research on AI in services is expanding, influencing sector performance through economic growth, cost savings, service quality improvements, and even well-being (Huang and Rust 2024; Makridis and Mishra 2022). Current research with an engagement focus concentrates on cognitive outcomes like acceptance, satisfaction, preference, and compliance (El Halabi and Trendel 2024), with some attention on emotional responses, such as customer reactions to AI’s human-likeness (Belanche et al. 2021) and AI intelligence types (Schepers et al. 2022). While different AI types offer particular advantages—such as thinking AI enhancing customer spending (Schepers et al. 2022) or feeling AI supporting care services (Huang and Rust 2024)—engagement here typically centers on brands or services, not the AI itself.
Research on the actual AI-human engagement interface (Hollebeek et al. 2024) or how AI strategies and customer co-creation impact performance (Wu and Monfort 2023) is therefore limited. Most studies examine how AI enhances engagement with service providers rather than how humans engage directly with AI. For example, AI assisting patient interactions in healthcare (Batra and Dave 2024), personalized AI solutions boosting customer brand investment (Hollebeek et al. 2024), or AI-driven data analysis and marketing personalization enhancing engagement (Babatunde et al. 2024).
Service research on AI also largely focuses on conversational AI, like chatbots or voice assistants, which lack advanced Generative Pre-training Transformer (GPT) architecture, limiting their contextual understanding (Wirtz and Pitardi 2023). In contrast, GenAI represents a more advanced “feeling AI” capable of identifying emotions in prompts, providing service interactions which more closely resemble human employees (Huang and Rust 2024). This shift toward GenAI highlights the need to explore human-machine engagement (HME), a topic hitherto under-researched (Hollebeek et al. 2024).
Human-machine Engagement (HME)
Actor engagement (AE) is a dynamic, iterative process where actors invest resources in interactions with other actors (Brodie et al. 2019). Investments are expressed through diverse engagement behaviors, which vary in their antecedents, intensity, and valence (Azer, Blasco-Arcas and Alexander 2024; van Doorn et al. 2010). The magnitude of resource investment (e.g., time, energy, and knowledge) determines AE intensity and makes behaviors more or less likely to influence others (Fehrer et al. 2018; Wang et al. 2023). Intensity and valence are interconnected and span low to high-intensity levels with varying outcomes (Azer and Alexander 2020; Do and Bowden 2023).
AE extends beyond humans and organizations to include machines (Hollebeek et al. 2024; Storbacka, 2019). Understanding human behavior is essential when implementing new technologies in socio-technical systems, as it shapes the reciprocal relationship between humans and technology (Sony and Naik, 2020). In parallel, computer science research emphasizes the importance of considering human cognitive and emotional drivers when creating more effective, human-centered technologies (Sasi et al. 2024).
This paper, therefore, aims to investigate HME by exploring how and why humans engage with GenAI, identifying HME behaviors and their nomological network. Beyond engagement research focused on customer/organization relationships (e.g., Brodie et al. 2019; Jaakkola and Alexander 2014), there is increasing interest in engagement with technology, such as social media (Dolan et al. 2016)—however, here technology is typically treated the context for, rather than the object of engagement. As AI continues to evolve in customer-business interactions, more studies urge an expansion of engagement research to include non-human actors (Azer and Alexander, 2022; Storbacka, 2019).
Our research, thus, identifies several gaps within the existing literature on AI in services. First, while existing research captures cognitive or emotional responses to AI, it overlooks direct HME, particularly where AI is the focal object of interaction rather than a tool for facilitating engagement with a brand or service. Additionally, while thinking and feeling AI types are acknowledged for their impact on service performance, limited attention has been paid to the interface between human behavior and advanced AI systems, especially with the advent of LLMs like GenAI. Our gap is further underscored by existing engagement research typically focusing on human-to-human or human-to-brand interactions—not how humans engage directly with AI, which our study seeks to reveal.
Study 1: Forms and Drivers of HME
Field Study: Netnography
To explore the HME phenomenon, we utilized netnography. To ensure relevance of the selected sites to our research focus (Kozinets 2010), social media platforms that have seen extensive user engagement around ChatGPT since its launch were utilized (Mollick 2022). Social media interactions make up 80 percent of online engagement (Zote 2024), and to ensure diverse and unbiased sampling, Facebook, Twitter, and LinkedIn were selected for their distinct purpose and audience: Facebook for broad social networking, Twitter for real-time communication, and LinkedIn for professional connections (Kim 2017). The three platforms are active, have recent and regular communications, and are among the largest social networks worldwide (Kozinets 2010), with 2.9 billion (Facebook), 450 million (Twitter), and 310 million (LinkedIn) active users monthly (Statista.com 2023).
To enhance the stability and validity of the findings and provide evidence of user sentiment over time, we conducted two data-collection phases. The first phase captured posts from November 2022 to February 2023, and the second from November 2023 to February 2024. Using NVivo Pro software’s NCapture feature, we extracted 24,601 Facebook, LinkedIn, and Twitter posts featuring popular hashtags: #ChatGPT, #OpenAI, #NLP, #AI, and #MachineLearning (OpenAI.com 2023). Following netnography guidelines, we copied publicly shared posts and filtered them for relevance (Kozinets 2010). Publicly available online content is accessible to researchers as users elect to share information (Langer, Elliott, and Beckman 2005). Only public posts in English were included, and NVivo’s filtration excluded retweets. We manually excluded firm-generated posts and advertisements, focusing on individual users, resulting in 5,990 relevant posts for analysis (Facebook: 1,195, Twitter: 2,179, LinkedIn: 2,616).
Thematic analysis was conducted using open and axial coding. Open coding breaks data and considers all possibilities before applying conceptual labels, while axial coding crosscuts and relates concepts to each other (Corbin and Strauss 2008). Engagement can be positively or negatively valenced (van Doorn et al. 2010), and its intensity can range between high, medium, and low levels (Wang et al. 2023). Hence, themes that initially emerged using open coding were linked to valence and intensity during axial coding. Our two phases of data collection and analysis allowed coding between different data sets, confirming consistency of themes and validity of findings and, therefore, more accurately reflecting the phenomenon under investigation (Denzin 1978). The two phases allowed corroboration of both forms and drivers and the emergence of a new driver (advocacy) within 1 year of the ChatGPT’s launch; thus, theoretical saturation was achieved (Corbin and Strauss 2008).
Key AI in Services Studies.
Key Engagement Studies Offering Typologies & Nomological Elements.
Forms of HME: Definitions and Examples—Study 1.

Study 1: Forms of HME
Informative
Informative HME refers to actors’ voluntary contribution of resources that have a GenAI focus and raise others’ awareness of GenAI. This form, found in 27.7 percent of all posts, sees users sharing illustrations and step-by-step explanations of how to use and benefit from the various capabilities of GenAI. Phrases such as “I will show you’,” “I will explain how/what …,” “I will teach you,” or “If you want to know how …” are typically used. The QTA captured terms such as “explain,” “tell,” “inform,” “improve,” and “prompts.” These posts indicate a users’ expertise and knowledge and ability to explain information in simple terms, using step-by-step templates to make it easily understood by novice users. For example: I will show you how to use AI drawing syntax: 1. Memorize the syntax. 2. Insert several prompts with a preference for your desired style. 3. Create a description of X. 4-a mix between tomato and cucumber, or ask it to illustrate your favorite song, or the concept of global warming. As always, you will need to correct ChatGPT until you like the output (XY, Facebook).
Usage of informative HME has increased significantly over time (34 percent in phase 2) from the initial launch of ChatGPT (21.4 percent). GenAI users appear keen to ensure others gain maximum benefit from their GenAI experience through appropriate prompts and explanations of customization features. For example: If you want to get more reliable answers from ChatGPT, add a prompt at the end of your question asking for reliable sources to be used. For example, after asking “Who is the current president of South Africa?” you can add a prompt like “Answer using only reliable sources and citing them.” After this, Chat GPT will provide you with URLs of sources it used to answer your question, and you can check their accuracy (BB, LinkedIn).
Informing others about prompting requires only explanatory techniques, which require AI expertise but less effort than other behaviors (see below) (Chung 2014). Consequently, informative HME represents medium-intensity engagement.
Experimenting
Experimenting HME refers to actors’ voluntary contribution of resources that have a GenAI focus and which provide examples of their GenAI interactions. These accounted for 21.8 percent of posts. Posts usually include “I asked ChatGPT about something,” “I asked ChatGPT to do something,” “I tried ChatGPT,” or “I used ChatGPT as an experiment.” The QTA captured words such as “experiment,” “example,” “ask,” “try,” “suggest.” Most importantly, users share the outcome of their experimentation in their posts, for example: I recently asked ChatGPT to recommend 10 must-watch movies from Hollywood and Bollywood that offer valuable lessons and learnings for HR professionals. I was blown away by the diverse and inspiring films ChatGPT recommended along with a brief summary and the top HR lessons to be learned from it. From leadership and teambuilding to diversity and inclusion, there’s something for everyone in this ChatGPT suggested list (KL, LinkedIn).
When a new AI application emerges, there is always increased interest in exploring its functionality (Perez-Vega et al. 2021). Since ChatGPT’s release, people have shared examples on social media of experimentation, such as weight-loss plans, poems, children’s books, songs, or even paintings (Mollick 2022), and this was reflected in our data: I asked ChatGPT to write a Valentine’s Day card for my girlfriend (BK, Facebook). Within a year, engaging in experimenting HME also increased (25 percent) compared to the initial launch (18.6 percent). This behavior continues to evolve with examples expanding beyond more fun topics to include travel plans and job interviews: I wanted to plan my next trip to Europe. I asked ChatGPT to act as a travel expert and ask me questions so that it can develop a personalized itinerary for me aligned with my travel interests (BB, Facebook). I asked ChatGPT to act like a professional job interview coach to help me prepare for my next job interview (BW, Twitter).
Experimenting HME differs from informative HME in two respects. Firstly, it adds real-life experience to the contribution. Users of informative HME do not offer examples of the output; they only offer steps to operate. Secondly, informative HME appears to be driven more by expertise or advanced knowledge of AI technology; hence, it most likely takes less time and effort (Wang et al. 2023) compared to experimenting HME users with less expertise but exerting more effort to “try out” GenAI, and share the results of their efforts. Trialability (e.g., experimenting) is crucial for individuals seeking to incorporate new innovations into their lives (Lehtonen 2003). Experimenting, therefore, requires additional engagement (e.g., learning to prompt, generating, and refining content). Thus, compared to informative HME, experimenting represents high-intensity engagement.
Praising
Praising HME refers to actors’ voluntary contribution of resources that have a GenAI focus and which commend GenAI. Praising accounted for 26.4 percent of posts, where users praise GenAI for its advanced capabilities, enormous potential and contribution to success, using phrases such as “super cool,” “spectacular,” “amazing,” “brilliant,” “revolutionize,” “astonishing” and “marvelous.” The QTA captured words such as “opportunity,” “super,” “fan,” “potential.” For example: This super cool language model from OpenAI is a game-changer (UI, Facebook). I want to give a shoutout to ChatGPT for its contribution to this success. What an amazing tool! (QE, LinkedIn).
In engagement literature, users often recommend brands based on favorable experiences (Alexander, Jaakkola and Hollebeek 2018; Azer and Alexander 2022). In this study, however, praising HME is more general and involves society, work (any industry), social life or gaming, for example: With its marvelous capability to generate human-like interaction to various inputs, it is valuable for businesses and individuals alike (EW, Twitter).
Over time, utilizing praising HME has remained fairly constant (26.8 percent) since launch (26 percent). Individuals continue to commend ChatGPT, not only its potential but also its transformative effect, for instance, on social media: This transformative year marked the beginning of a significant shift in the realm of social media platforms, GenAI takes over social media, from silly photos to smart stars! (MM, Facebook).
Unlike informative and experimenting HMEs, praising requires no evidence of output or “how to use” guidance; thus, praising represents low-intensity engagement compared to the other two forms.
Apprehensive
Apprehensive HME refers to actors’ voluntary contribution of resources that have a GenAI focus and which express anxiety or unease about GenAI. Users express anxiety in 24.1 percent of the posts, using words such as “anxiety,” “fear,” “anticipate,” “worry,” “unease,” “dangerous,” “disastrous” or “threat” or posing concerned questions, a typical response to uncertain situations and normal characteristic of human behavior (Azer and Alexander 2022). Apprehensive comments focus on anticipated detrimental consequences of GenAI on life, jobs and education. The QTA captured words such as “jobs,” “fake,” “distrust,” “dangerous,” “threat” and “stop.” For example: Any application that is a threat to human effort is to be stopped ... Einstein said I gave the power of God to apes ... here also we may face disastrous results (PW, Twitter). From fake news to fake intelligence. Despite AI power as the primary source of information, it can be misleading and extremely dangerous to a new generation (YR, Twitter).
Apprehensive HME presents as the opposite of praising HME: users spread concern about GenAI without specific details, and unlike experimenting and informative HMEs, apprehensive HME does not reflect GenAI usage. Hence, apprehensive HME represents low intensity. Across phases, engaging in apprehensive HME significantly decreased (14.2 percent) compared to when it was first launched (34 percent). This decrease likely relates to increased experience and clarity around ChatGPT. Yet, individuals continued to spread doubt and concern about GenAI, now not only about jobs, education and life but also about cybersecurity, legal issues, and the protection of user information. For example: As technology continues to dominate our daily lives, one crucial aspect that demands our attention is cybersecurity (WT, LinkedIn). Dark web posts discuss use of #ChatGPT and other LLMs for illegal activities (XM, Facebook). GenAI carries all sorts of risks—bias, violation of privacy and impersonation (LM, Twitter).
Study 1: Drivers of HME
Excitement
The excitement driver was captured in 65 percent of data and centered on enthusiasm and eagerness for the advanced abilities of GenAI. Over time, users’ excitement marginally increased (66.5 percent) compared to initial launch (63.7 percent). Excitement, amongst other effects, is common in users of new technology (Jayawardhena and Wright 2009), and our QTA supports this through terms such as “excited,” “exciting,” “thrilled,” “fascinated,” “stunned,” “advanced” and “amazing.” Existing research suggests that excitement is an emotional driver and an antecedent of positive behaviors associated with high levels of pleasure and arousal (Ahn and Shin, 2015; Azer and Alexander, 2018). Excitement drives informative, experimenting, and praising HMEs (Web Appendix–Table 3): What an exciting time we live in! With the help of cutting-edge technology, we were able to produce an amazing video from start to finish. First, we got a script created by Chat GPT, an AI language model. Then, we used Di-D, an AI video creator, to bring the script to life with incredible visuals. Finally, we used 11labs to synthesize a voiceover that perfectly matched the video (Informative - VM, Facebook). I created this math lesson plan in just 10 seconds using ChatGPT! If that is not exciting, I don’t know what is (Experimenting - KW, Facebook). AI is one of the most exciting and fast-growing technologies of our time, and a new tool called ChatGPT could change the way we interact with AI (Praising - PR, Twitter).
Concern
The concern driver appeared in 26.1 percent of the data and was captured in two facets: reliability of outputs and uncertainty over GenAI implications. Over time, users’ concern significantly decreased (16.1 percent) compared to launch (36.3 percent). Psychologically, individuals often experience worry, uncertainty or lack of knowledge regarding the impact of innovations or phenomena on their lives (Azer and Alexander 2022). However, after a year, levels of knowledge around ChatGPT had increased, with a commensurate lowering of concern (Borzekowski et al. 2021). Concern was revealed in the QTA in words such as “concern,” “threatening,” “flaws,” “misinformation,” “manipulation,” “uncertainty,” and “unreliable.” Concern is a cognitive driver as it requires an assessment of the reliability of outputs set against expectations of potential benefits (Azer and Alexander 2018). Concern drives apprehensive HME (Web Appendix – Table 3): ChatGPT was able to generate text that was nearly indistinguishable from that written by humans. It was able to produce long, complex sentences that contained accurate grammar, spelling and punctuation. It was rated as human-written in over 90 percent of the tests. This is concerning given the potential for AI-generated text to be misused. It could be used to spread misinformation or be used as a tool of manipulation (BR, LinkedIn).
Advocacy
The advocacy driver only emerged in our second data-collection phase, appearing in 8.9 percent of the data. Advocacy offers opportunities to defend and correct what is deemed wrong (Bhattacharya and Sen 2003; Sweeney et al. 2020). Brand advocacy represents active customer support, facilitating proactive resilience to negative comments about a brand (Pai et al. 2015). Although advocacy is often associated with brands, it appeared as GenAI advocacy in this study. Here, individuals are motivated by advocacy to rectify misconceptions associated with ChatGPT, such as misconceptions about treating GenAI as humans, job replacement, or the nature of LLMs. Advocacy is revealed in the QTA in words such as “use,” “instead,” “replace,” “learn,” and “future.” Like concern, advocacy is a cognitive driver and drives informative HME (Web Appendix – Table 3). Advocacy driver causes users to contribute knowledge and expertise by clarifying what GenAI can and cannot do. HME posts driven by advocacy involve informing others about focal misconceptions about GenAI and step-by-step explanations of capabilities. For example: I’ve heard a lot of people say that AI content is robotic. While that’s not entirely untrue, getting better responses from GenAI like ChatGPT depends on how you prompt. Writing good prompts is not about how long your prompt is. Most often, the shorter the better. Here I will tell you 5 tips for writing better ChatGPT prompts (VS, LinkedIn). No, ChatGPT is not designed to replace data analysts. While these models can assist with certain tasks related to natural language understanding, they lack the specialized skills, domain. Here are some of the analysis prompts to achieve that (MM, Facebook).
In summary, study 1 reveals user engagement with GenAI driven by excitement centering on informative, experimenting, and praising HMEs. These forms vary in intensity, with experimenting (high intensity) providing actual GenAI outputs, informative (medium intensity) offering step-by-step explanations and praising GenAI capabilities without any detail. Both experimenting and informative increase significantly after ChatGPT’s launch, praising remaining stable. Concern over GenAI’s potential harm led to apprehensive HME (low intensity), which decreased over time as advocacy drove people to engage in informative HME. Table 3 provides an overview of the forms and how they differ in valence, intensity, and evidence. However, while Study 1 reveals differences in intensity and valence between forms of HME, the impact these have on other users and service providers is less clear. The following section now sets the scene for two additional empirical studies which address these impacts on other users (study (2) and service providers (study 3).
Impact of Human-Machine Engagement (HME)
The Impact of HME on Other Users
New technologies require both user adaptation and learning (e.g., Blaurock, Büttgen and Schepers 2024), with personality often serving as a coping mechanism for successful human-technology interaction (Le et al. 2024). A key dimension of user personality is an individual’s approach to new technology—that is, affinity for HME (Franke, Attig and Wessel 2019). Affinity for HME is crucial for determining whether users will engage with new technologies or avoid them. In addition, the distinctiveness of HME forms necessitates understanding how they variously impact users’ affinity for GenAI.
Customers interacting with AI also derive perceived value from interactions (Huang and Rust 2021). As AI increasingly mimics human thinking and feeling processes, customer-perceived value should increase (van Doorn et al. 2017). Previous studies have investigated AI users’ perceived value, specifically assessing AI’s utility based on perceptions of what is received and invested (Hollebeek et al. 2024). When customers perceive AI interactions as valuable, their perceived value from experiences will be positive (Prentice et al., 2020). However, it remains unclear how users’ perceived value might be affected by our different HME forms.
Previous research indicates that the advancement of AI offers both value and potential risks (Heller et al. 2020). Individuals are often conflicted: craving AI’s intellectual benefits but concerned about confidentiality, control of personal data, or data theft and misuse (Huang and Rust 2024; Yu, Xu and Ashton 2022). Thus, understanding how HME forms affect the perceived risk of GenAI is important.
Concerning informative HME, novelty can prompt a desire to educate the public (Mitroff 2004), increasing thought processing about GenAI (Heller et al. 2020). Informative resources boost other users’ awareness and information processing about an engagement object (Azer, Blasco-Arcas and Harrigan 2021). Therefore, informative HME (medium intensity) may have more favorable perceived value outcomes than praising HME (low intensity).
Praising HME is lower in intensity and, therefore, while it might potentially spark users’ interest to seek additional information (Lutkevich 2024) and foster affinity, it is less likely. To counter perceived risks as effectively as informative HME (medium intensity). Research shows that higher-intensity engagement forms have a greater impact on other actors (Azer and Alexander 2020). Additionally, lacking information, praising HME may reduce perceived value and increase perceived risk, as panic overrides positive emotions and dominates the brain (Sen, Hongm and Xiaomei 2022).
Experimenting HME (high intensity), unlike informative and praising HMEs, demonstrates actual outputs, requiring more resources and enhancing understanding of GenAI’s capabilities. Examples promote learning by aiding transferability and retention (Bouwer et al. 2018). According to computer science, real outputs show AI model variability, helping users grasp diverse responses to similar prompts (Ribera and García 2019). This approach offers context missing in informative explanations and fosters interactive learning. Therefore, experimenting HME is expected to yield more favorable outcomes, providing transparency, and honest communication about GenAI, which can dispel misconceptions and reduce perceived risks (Ribera and García 2019).
Finally, apprehensive HME, lacking functional details or examples (low intensity), spreads negativity about GenAI’s impact. Despite its lower intensity, shared apprehension can diminish enthusiasm and provoke uncertainty (Warren et al. 2005). Research shows that negative engagement can yield unfavorable responses even when paired with high-intensity positive engagement (Azer and Alexander 2020). Additionally, ChatGPT’s human-like writing can cause eeriness and human identity threats (Mende et al. 2019), leading to an unfavorable affinity with HME. Fear can make people pessimistic and risk-averse (Ahn and Shin 2015), resulting in lower perceived value and higher perceived risk of GenAI compared to other HME forms.
The Impact of HME on Service Providers
The influence of HME on service providers’ decisions to implement GenAI can be significant. Socio-technical systems research suggests that AI’s perceived complexity can hinder adoption, as service providers may find it difficult to understand and operate (Yu, Xu and Ashton 2022). Experimenting HME, with its trialability-related opportunities, can enhance perceived value and willingness to implement GenAI (Chung 2014). Transparency achieved through formalized procedures, visual aids, or actual GenAI outputs can help decision-makers understand GenAI (Akbarighatar, Pappas and Vassilakopoulou 2023). The transparency offered by experimenting HME (high intensity) makes GenAI more trustworthy and accountable (Herrmann and Pfeiffer 2022), countering resistance from apprehensive HME (low intensity).
Computer science research suggests that AI models should be structured for explainability to meet the needs of end-users, decision-makers, and stakeholders (Meske et al. 2022). In socio-technical systems, explainability involves making AI models interpretable through technical methods, such as identifying how inputs affect outputs (Akbarighatar, Pappas and Vassilakopoulou 2023). Our informative HME form provides this explainability, suggesting a more favorable influence compared to, for example, praising HME, which lacks explainability.
A firm’s business activities include responses to the external environment, influencing operations and decision-making (Herrmann and Pfeiffer 2022). Socio-technical systems research highlights competitor pressure as crucial in shaping organizational actions regarding AI application (Yu, Xu and Ashton 2022). Competitor pressure affects AI adoption decisions across business functions, surpassing even expectations of profit (Bughin and Seong 2018). Competitor pressure is also a driver of innovation diffusion and prompts organizations to develop AI adoption strategies (Yang et al. 2015). Fear of losing competitiveness thus motivates firms to accelerate AI adoption to enhance operational efficiency and maintain market advantage (Oliveira and Martins 2011).
To remain competitive, businesses regularly examine and interpret competitor plans (He, Zha and Li 2013). Other firms’ interactions with HME forms in the market can offer valuable insights into their intentions and strategies regarding GenAI. Observing how competitors and peers react to different forms of HME might help businesses gauge competitors’ attitudes toward AI. This information can inform strategic decisions on adopting and implementing GenAI effectively within their operations. By understanding competitor behaviors and responses to AI-related engagements, businesses can improve competitor positioning and adapt approaches accordingly to leverage the benefits of AI technologies.
Drawing on others’ actions relates to notions of social proof (Cialdini 2001), a powerful influence when decisions are uncertain, and information comes from similar others (Pálfi et al. 2024). Social media “likes,” for example, serve as cues for social proof (Shearman and Yoo 2007) and can influence the outcomes of HME. A firm might accelerate technology adoption to maintain competitiveness if competitors adopt innovative technology (Volkman and Gabriels 2023). However, how competitor pressure, exemplified by “liking” specific HME forms, interacts with the impacts of various HME forms on service providers is unclear.
Study 2: Impact of HME on Other Users
Study 2: Design and Procedures
We used an independent-group, experimental, between-subjects design to investigate differences in impact for the four forms of HME. The experiment was carried out in July 2023, eight months after the launch of ChatGPT (in November 2022). The stimulant material (Web Appendix B) was developed using real posts from field Study 1 simulated as a social media page to ensure realism and ecological validity. Names and profile pictures of users were blank to ensure no extraneous effects. Due to the novelty of the forms, it was decided to examine their impact without other effects of additional social media engagement, so “likes,” comments and reposts were left blank. Following the recommendations of Hair et al. (2010) regarding sample size requirements (α = 0.05, statistical power = 0.8, and large effect size), a sample of 200 participants (cell size = 50; 57 percent female; average age = 23.2; M = 1.67, SD = 0.95) was recruited through Prolific. The generalizability of the experiments was ensured by using a representative sample, as suggested by Shadish, Cook and Campbell (2002), which reflects the characteristics of the target population and thereby increases the validity of the results (White and McBurney 2013). Prolific’s subject pool offers a reliable source of data that is representative of the general population (Azer, Blasco-Arcas and Alexander 2024). Since OpenAI is freely accessible, anyone within the target population could be included. Additionally, the sampling methods ensured that participants were familiar with GenAI, and familiarity checks were conducted using items adopted from Flavián et al. (2021), with results confirming this (M = 5.19, SD = 1.21). Participants were assigned randomly to four scenarios using the randomization facility provided by Qualtrics. Scenario realism was measured using items adapted from Gelbrich, Gäthke and Grégoire (2015), and results indicate realistic scenarios (M = 5.36, SD = 1.13). Manipulation checks indicate different answer patterns between manipulations (
Based on previous research, we controlled for technology discomfort using items adapted from Belanche et al. (2021). After exposure to the scenarios, the participants completed a questionnaire comprising items to measure the perceived value of HME adapted from Pelau et al., 2021; Song et al., 2022; and Zhang et al. (2023), affinity for HME adapted from Franke, Attig, and Wessel (2019), and perceived risk of GenAI adapted from Song et al. (2023). Factor loading and reliability of scales were above the recommended threshold of 0.7 (Hair et al. 2010) (see Appendix B – Table 1). Tests were undertaken to confirm convergent (AVE > .5) and discriminant validity, and both maximum and average shared variance were less than AVE (Bagozzi and Yi 1988). Discriminant validity, confirmed as the square root of AVE for each construct, was greater than the correlations between them and all other constructs (see Appendix B – Table 2). Correlations among the study constructs showed no threats of multicollinearity (R < 0.80) (Hair et al. 2010). Finally, we examined CMV bias using Harman’s single-factor test. The results from this test showed that the greatest variance explained by one factor was 25 percent, indicating that common-method bias is not likely to have contaminated the results (Podsakoff et al. 2003).
Study 2: Results
After satisfying preliminary checks on the assumption of homoscedasticity (Levene’s test, p > .05) for all dependent variables and equality of the entire variance-covariance matrices (Box’s test, p = .211), MANOVA was conducted. The results revealed a significant difference between the four forms (Wilk’s lambda = 0.407, F(9, 469) = 23.34, p < .001); any effects of the control variable were non-significant. The difference in impact was significant for perceived value (F(3,195) = 84.16, p < .001), affinity (F(3,195) = 23.35, p < .001), and perceived risk (F(3,195) = 4.73, p = .003). As shown in Figure 2 and Appendix B – Table 3, experimenting HME shows the highest favorable impact, while apprehensive HME had the lowest and most negative score for both perceived value and affinity. Importantly, while the three positive forms had favorable impacts, impacts differed between forms. For example, experimenting HME (high intensity) increased both affinity (Mexp = 5.89) and perceived value of HME (Mexp = 5.67) compared to praising GenAI (low intensity) (Affinity: Mpra = 4.74; perceived value: Mpra = 3.97) or offering information about how to use GenAI without examples of its outputs (medium intensity) (Affinity: Minf = 4.20; perceived value: Minf = 4.49). Effect of HME forms on dependent variables—Study 2.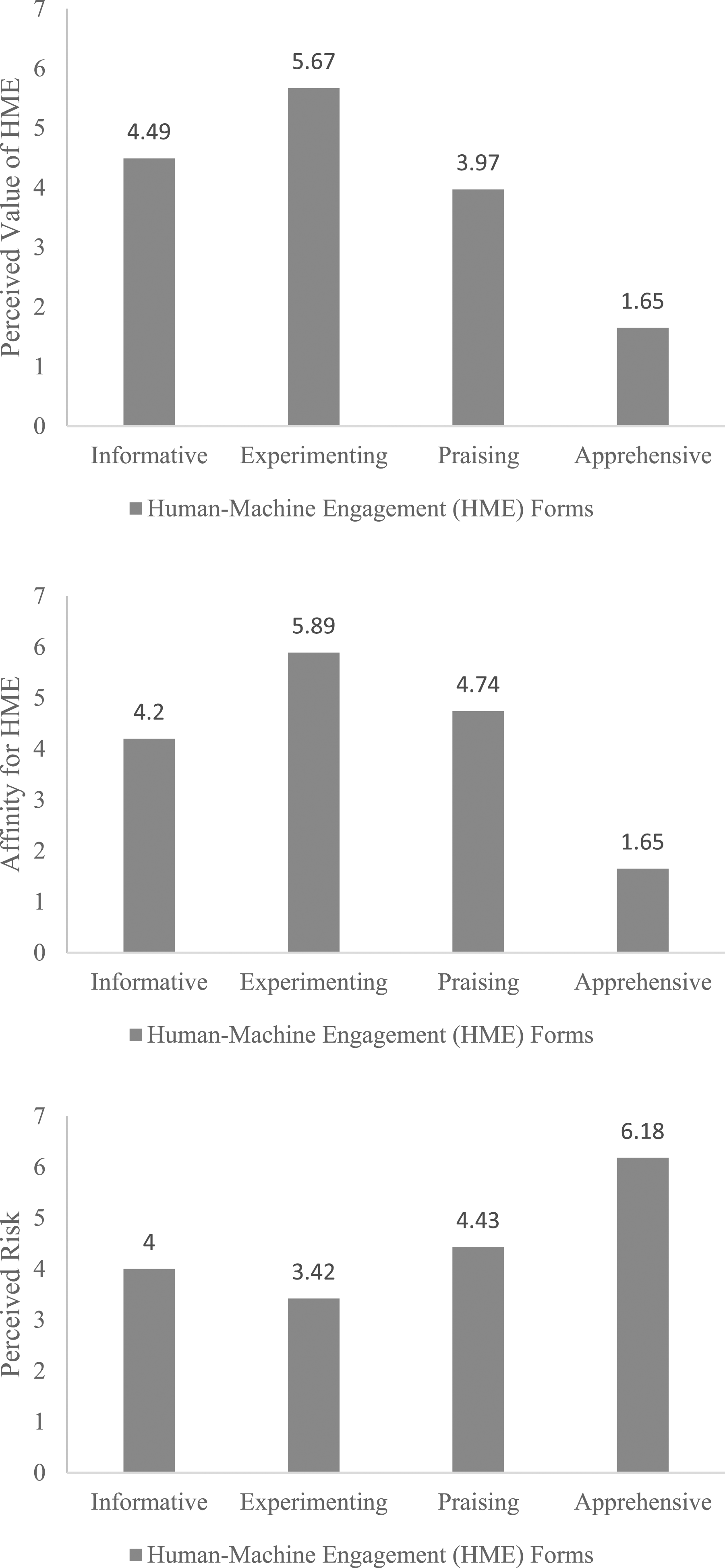
Interestingly, although informative HME revealed a more favorable perceived value of HME than praising HME (Minf = 4.49, Mpra = 3.97; p < .001), praising HME had a stronger impact on affinity than informative HME (Minf = 4.20, Mpra = 4.75; p < .001). This effect could relate to the functional aspects of informative HME, demonstrating its value to other actors (Azer, Blasco-Arcas and Alexander 2024). However, praising HME offers no detail and, thus, may illustrate a knowledge gap, hence, other users’ desire to increase interaction with GenAI (Franke, Attig, and Wessel 2019; Lutkevich 2024). In addition, praising HME (low intensity) scored higher on perceived risk than the two more intense HME forms, with experimenting HME (high intensity) scoring lowest compared to informative HME (medium intensity) (Minf = 4.00, Mexp = 3.42, Mpra = 4.43; p < .001). Finally, results show that individuals recognized the value of HME and affinity for it despite perceived risks, specifically with more intense positive forms, such as experimenting HME (Affinity: Mexp = 5.89; perceived value: Mexp = 5.67; perceived risk: Mexp = 3.42).
Study 3: Impact of HME on Service Providers
Study 3: Design and Procedures
We used a 4 (HME forms) × 2 (competitor pressure: interaction via “likes,” no interaction) factorial, experimental, between-subjects design to investigate the impact of HMEs on service providers. The experiment was conducted in July 2023, eight months after the launch of ChatGPT (in November 2022). Stimulant material (Web Appendix B) was developed using posts from study 1 and simulated a social media page to ensure realism and ecological validity. Some of the posts analyzed in Study 1 mentioned specific brands, companies’ apps and competitors, and we used these posts in this experiment to match the sample. We removed firm names from interactions to avoid any extraneous effects of familiarity.
Following the recommendations of Hair et al. (2010) regarding sample size requirements, a sample of 400 service providers (cell size = 50; 44 percent female; average age = 25.8; M = 1.87, SD = 0.926) was recruited through Prolific. In addition to the procedures followed in Study 2 (web Appendix B – Tables 1 and 2), we specifically requested a sample of service providers. To ensure a representative sample—and thus the generalizability of the experiment and validity of the results (Shadish, Cook and Campbell 2002)—each participant was asked to identify the service sector they worked in. Responses came from customer services (28 percent), hospitality services (25.2 percent), care/health services (23.5 percent), financial services (13.3 percent), and retail services (10 percent). The sample was familiar with GenAI (M = 5.93, SD = 1.23), scenario realism results revealed a realistic scenario (M = 5.78, SD = 1.17) and manipulation checks indicated different response patterns between manipulations for HMEs (
Study 3: Results
Future Research Agenda on HME Forms.
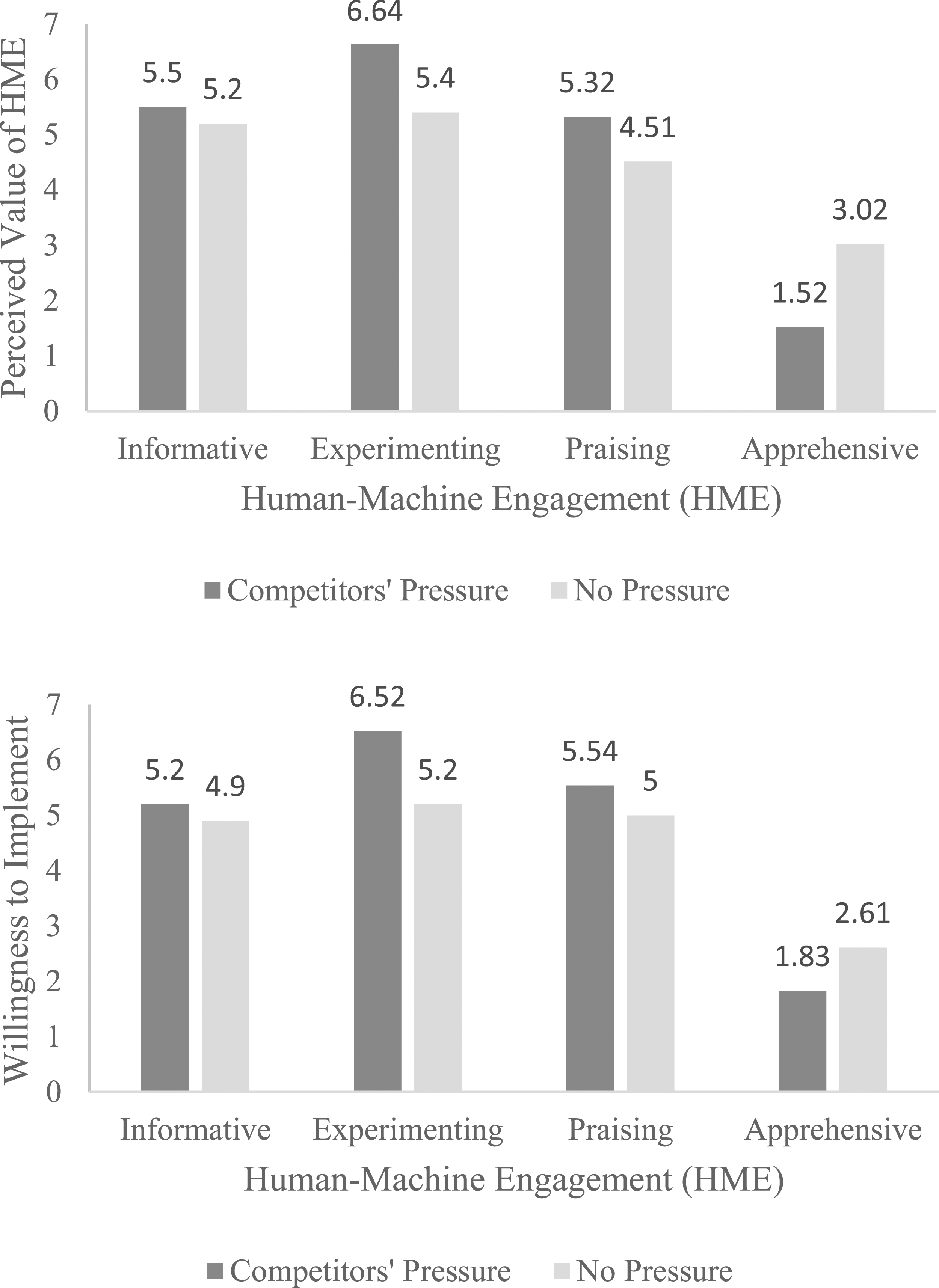
Interaction effect on dependent variables—Study 3.
General Discussion
Theoretical Implications
Research on both AI and Engagement are central to recent developments in service research (Wetzels, Grewal and Wetzels 2023), and by introducing HME, which also draws on computer science and socio-technical systems, we contribute via the first typology and nomological network of the concept (Figure 4). Our four forms vary in intensity and valence, and we provide evidence of both cognitive and emotional drivers and changes in the prevalence of the forms since the launch of ChatGPT. Evidence of the impacts of HME is provided through studies 2 and 3 on both service users and providers. HME: drivers, forms, and outcomes.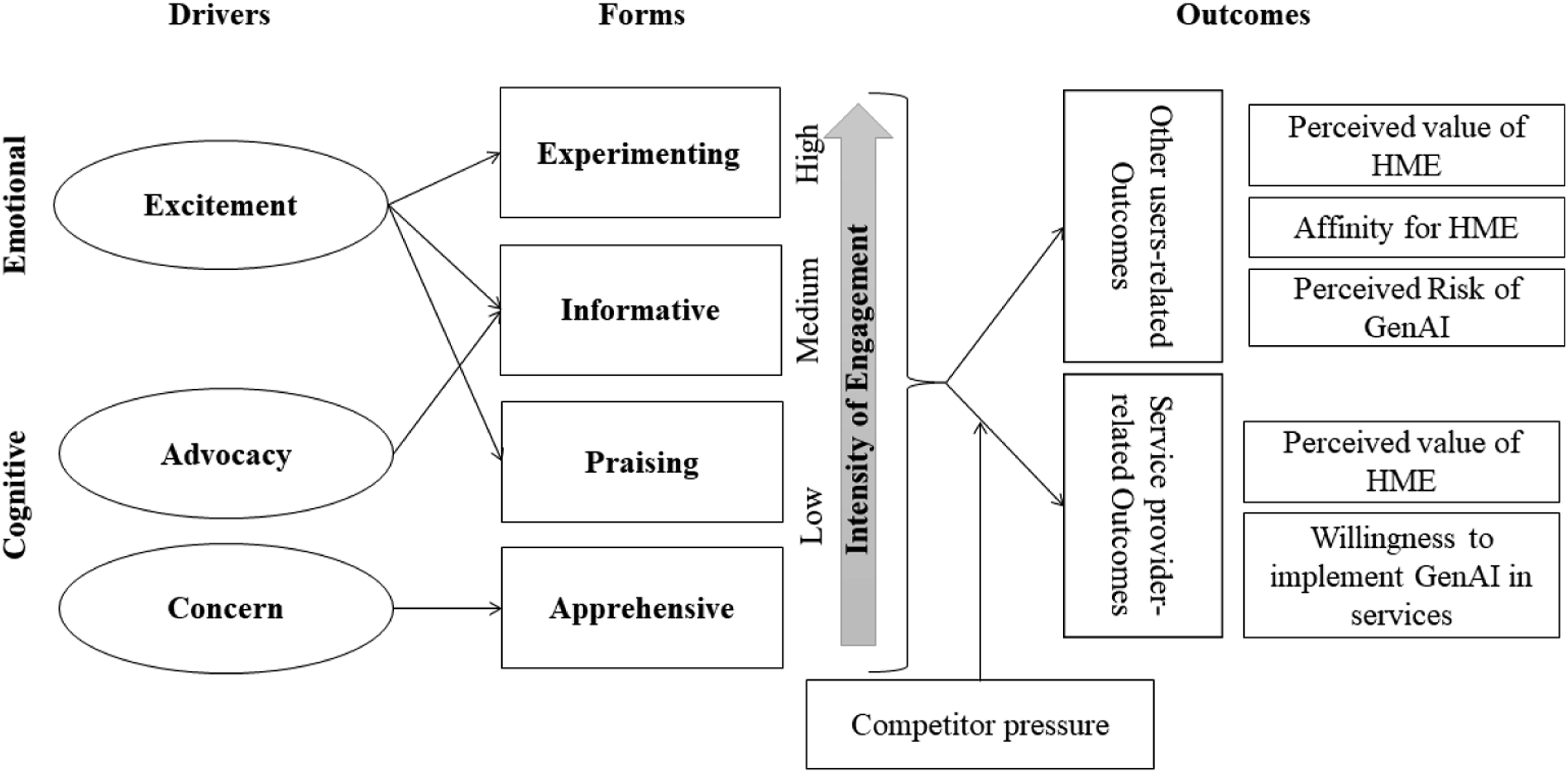
By incorporating machines into engagement conceptualizations, we contribute to service research which, hitherto, has focused on engagement with service providers (Brodie et al. 2019; Storbacka, 2019), thus broadening the scope of AI in service research amid the rapid growth of intelligent machines in service interactions (Hollebeek et al. 2024).
This paper contributes to service research on AI and engagement in two further ways. Firstly, while service research suggests different AI types should be used for customer engagement (Huang and Rust 2021; Schepers et al. 2022), there is a paucity of research on the actual AI and engagement interfaces (Hollebeek et al. 2024). By emphasizing the impact of human engagement with GenAI rather than using AI to facilitate engagement with brands/firms (e.g., Babatunde et al. 2024; Batra and Dave 2024) we also provide one of the first studies with empirical evidence of the impact of feeling AI (Huang and Rust 2024). This extends existing service research, which has focused, hitherto, on customer responses to AI services (e.g., Belanche et al. 2021; El Halabi and Trendel 2024; Han, Deng, and Fan 2023), but not the impact of engagement with the machine as engagement object.
Secondly, by measuring personality-related outcomes of HME, we extend previous service research, which focuses mainly on customers’ cognitive (Hsu and Lin 2023) and emotional responses to AI in services (Schepers et al. 2022). User personality (captured by affinity) is significant in shaping user engagement with AI and provides a focal point in tailoring AI interactions to meet users’ emotional and cognitive needs (Franke, Attig and Wessel 2019). Thus, we offer new insights into how personality-related outcomes relate to different engagement patterns, which is novel for service research.
We also offer contributions to socio-technical systems and computer science research. In relation to the former, we reveal the role of both other users (Study 2) and competitor pressure (Study 3) in shaping firms’ actions (Yu, Xu and Ashton 2022), thus capturing the important influence of competitor pressure on service providers’ willingness to implement GenAI. Although a firm’s business activities include responses to the external environment (Herrmann and Pfeiffer 2022), the interaction between competitor pressure and HME forms has been unclear. Concerning computer science research, we expand the current understanding of human-technology interaction, which has been traditionally focused on human-AI differences (Fortunati and Edwards, 2020) or interfaces (Ke et al. 2018), by offering insights on humans’ engagement with machines, we enable the development of more intuitive, adaptive, and trust-building AI technologies.
Managerial Implications
The rapid growth of AI implementation by organizations (Haan 2024), accompanied by a dramatic reduction in the cost of computing (Coyle and Hampton 2024), means that the importance of understanding and managing HME for service organizations will only increase. Our two-phase netnography provides insight for organizations attempting to introduce AI-based service innovations and a need for planning and implementation teams to account for various stakeholder responses. Firstly, the presence of both positively and negatively valenced forms means that organizations cannot simply rely on technological optimism from early adopters and should, instead, develop strategies for all stakeholders including users that might be more skeptical.
In the initial phases, organizations can consolidate positive responses while attempting to mitigate the worst effects of negative forms. As engagement with the innovation develops, key influencers who can advocate on behalf of the organization can be identified and incentivized. Ultimately, implementing AI into customer-facing settings will require the ability to address user perspectives captured across the various forms of HME. In the following section, we offer some actionable insights to implement GenAI more effectively in customer-facing roles via four key areas that could enhance GenAI and robot-powered experiences while addressing customer concerns.
Explainability and Transparency
To ensure effective integration of GenAI or robots, service providers should prioritize explainability, allowing clear communication of actions and decisions. For instance, Amazon enhances explainability in AI-driven product recommendations by showing users the rationale behind suggestions (Amazon.com 2024). This highlights the importance of balancing social dynamics with technological innovation, fostering more user-friendly GenAI systems (Herrmann and Pfeiffer 2022). Additionally, experimenting HME advises service providers to transparently display GenAI outputs to customers. Hilton’s AI-powered concierge, “Connie,” exemplifies this by showing decision-making processes based on guest preferences, improving engagement and transparency (PRNewswire.com 2016). Thus, AI developers should focus on algorithms that offer clear reasoning for outputs.
Social Sharing and Diverse Use Cases
Experimenting HME suggests that service providers should enhance social sharing capabilities in GenAI-enabled robots, allowing customers to share outputs across platforms. For example, Penny Lane Café in Tokyo uses AI-powered robots to offer personalized menu recommendations based on customer preferences and past orders, improving the dining experience (Newo.ai 2024). Patrons could share these personalized dining suggestions and experiences on social media, showcasing innovative services (Martin et al. 2024). Demonstrating diverse use cases also highlights robot versatility; in healthcare, robots assist with diagnostics, personalized treatment plans, and post-operative care. IBM Watson Health, for instance, provides AI-assisted diagnosis tools that justify suggestions using relevant data like symptoms and medical history and promote AI understanding and adoption (IBM.com, 2022).
Interactive Guidance and Awareness
Informative HME suggests interactive robots guiding users through GenAI systems can lead to positive outcomes. For example, KLM’s robot Spencer offers step-by-step assistance for booking and check-in (KLM.com 2016). Service providers should also run education campaigns to inform customers about GenAI’s potential and limitations, as demonstrated by JPMorgan’s “COiN,” which explains credit decisions using clear factors like credit score (Medium.com 2024). Such campaigns could emphasize GenAI’s role in personal finance while highlighting human collaboration. From a socio-technical perspective, this fosters trust and engagement (Volkman and Gabriels 2023), and from a computer science view, the focus on clear communication highlights the importance of user-friendly interfaces to improve human-AI interaction (Meske et al. 2022).
Community Forums and Concerns
Community forums provided by service providers enable customers to share experiences and feedback on GenAI features, such as UPS’s “ORION” system for route optimization and tracking (Patel 2023). These platforms encourage customer input, fostering positive feedback and praising HME. Service providers should also implement real-time AI monitoring and quality assurance tools to ensure accurate outputs in frontline services. From a socio-technical perspective, forums and AI monitoring strengthen the human-technology relationship. For instance, Kira Systems, used in legal services, lets clients track progress and manage information securely, enhancing trust in GenAI (Meske et al. 2022) and countering apprehensive HME.
Limitations and Future Research
This study introduces a typology of HME which should motivate future investigations into how user characteristics, psychological factors, and cultural traits influence HME. This paper focused on conceptualizing HME and offering its nomological network; however, HME outcomes were limited to short-term effects. Future research can explore HME dynamics across various customer journey touchpoints (Jaakkola and Alexander 2024) and longer-term outcomes (e.g., loyalty and financial performance).
The study defines HME broadly to encompass all forms of intelligent automation, suggesting applications in studying engagement with robots and the metaverse (Wirtz and Pitardi 2023). Future research may further investigate the HME typology across different applications and automation, hence the potential to expand the typology with additional forms, drivers, and differentiation across contexts and applications.
This paper presents the consequences of HME on other users and service providers. Future studies could test the impact of HME on governments, public institutions or more complex service environments such as health services. Additionally, the study underscores competitor pressure’s significant role in GenAI adoption and suggests exploring its nuances across different competitive contexts.
This study provides a foundational understanding of HME, focusing on the behavioral dimension; future research may replicate the study, emphasizing its emotional dimension. While lab experiments demonstrated HME’s impact, further external validation is needed through field experiments, such as analyzing data on clicks, impressions, and user demographics. As this research expands engagement beyond human-firm interactions, it opens new avenues for studying HME’s role in both human-machine interactions and GenAI development (Table 4).
Supplemental Material
Supplemental Material - Human–Machine Engagement (HME): Conceptualization, Typology of Forms, Antecedents and Consequences
Supplemental Material for Human–Machine Engagement (HME): Conceptualization, Typology of Forms, Antecedents and Consequences by Jaylan Azer and Matthew Alexander in Journal of Service Research
Supplemental Material
Supplemental Material - Human–Machine Engagement (HME): Conceptualization, Typology of Forms, Antecedents and Consequences
Supplemental Material for Human–Machine Engagement (HME): Conceptualization, Typology of Forms, Antecedents and Consequences by Jaylan Azer and Matthew Alexander in Journal of Service Research
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research received funding from the University of Glasgow (Award number: 201762-01).
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.