
Abstract
Systematic review techniques are about to become the “new normal” in reviews of management research. However, there is not yet much advice on how to organize the sample selection process as part of such reviews. This article addresses this void and analyzes this vital part of systematic reviews in more detail. In particular, it offers a critical review of systematic literature reviews published in the Academy of Management Annals and the International Journal of Management Reviews between 2004 and 2018. Based on this methodological literature review, the article presents issues to consider in the most critical choices during the sample selection process. Furthermore, this review identifies several descriptive features such as the mean number of research items included in systematic reviews, the mean number of databases used, and the mean coverage period of such reviews. These numbers may be used as benchmark figures in future reviews.
Critical components of systematic literature reviews include a structured execution of the review and a high degree of transparency in the review methods applied. These measures enable the readers and reviewers of such studies to trace and understand better the review results compared with more traditional approaches to literature reviews (Booth et al., 2016; Jesson et al., 2011; Tranfield et al., 2003). In particular, higher transparency applies to a review study’s selection of prior academic work (Adams et al., 2017): systematic literature reviews are expected to report in a detailed manner on the steps taken to arrive at the sample of reviewed literature (Booth et al., 2016; Petticrew & Roberts, 2012; Williams et al., 2020). This article refers to this process as a sample selection in systematic literature reviews.
In particular, in the field of management research, insights into how researchers can conduct such sample selection and what pitfalls there are to avoid remain scarce (Paul & Criado, 2020; Williams et al., 2020). A sign that such insights would be desirable is that many review articles in management research refer to prior review articles for certain methodological choices in sample selection (e.g., Mueller-Seitz, 2012; Pillai et al., 2017; Savino et al., 2017) but, due to unavailability, cannot refer to advice based on more evidence than just single applications of such choices. Important questions that need answering in sample selection include the choice of conducting a keyword search in databases versus focusing on articles published in selected journals, quality assessments, and the period of research to be covered. Prior methodological works on systematic reviews in management research do offer general advice on these questions (e.g., Denyer & Tranfield, 2009; Rousseau et al., 2008; Short, 2009; Tranfield et al., 2003). Recently, guidance on the treatment of gray literature in sample selection has also been offered (Adams et al., 2017). There are narrower and broader definitions of such gray literature (Adams et al., 2017), but general definitions suggest that it includes research items 1 other than peer-reviewed journal articles such as books, book chapters, conference papers, working papers, or official reports (e.g., Lawrence et al., 2014). However, none of these works offer detailed guidance on sample selection.
The present methodological literature review (cf. Aguinis et al., 2020) addresses this void and aims to identify the dominant approaches to sample selection and provide insights into essential choices in this step of systematic reviews, with a particular focus on management research. To follow these objectives, I have critically reviewed systematic reviews published in the two most prominent outlets exclusively devoted to literature reviews in management research (cf. Kunisch et al., 2018), the Academy of Management Annals (AMA 2 ) and the International Journal of Management Reviews (IJMR).
My analyses show that most recently, the overwhelming majority of review articles published in AMA and IJMR have adopted systematic review approaches. At the same time, I found several instances where the sample selection in systematic reviews could be made even more structured, transparent, and comprehensive. In addition, this article presents data on the mean numbers of research items included in the review samples of published AMA and IJMR articles and on other aspects of sample selection. These numbers may serve as reference points for management scholars when contemplating or conducting their next systematic review.
The following section reviews methodological literature on undertaking systematic reviews and the relevance of sample selection therein. Three desired attributes and three main steps of such sample selection are identified. Afterward, I detail the methods I applied for analyzing prior systematic reviews published in AMA and IJMR. The following findings and analysis section identifies four major approaches to sample selection in systematic reviews and highlights several options for inclusion and exclusion criteria. For each of the three main steps, this section includes some reflections on how the found choices adhere to the three desired attributes of sample selection. I conclude the article with implications for future systematic reviews of management research and acknowledge the article’s limitations.
Relevance and Objectives of Sample Selection in Systematic Reviews
Traditional and Systematic Reviews
Systematic reviews have a relatively long tradition in the medical sciences (Moher et al., 2009; Tranfield et al., 2003) but have only been adopted more frequently in management research since the turn of the millennium. In earlier days, review articles, which are now often referred to as traditional literature reviews (e.g., Briner & Denyer, 2012; Jesson et al., 2011), were the norm. Such traditional reviews do not disclose how the reviewed research items were selected or how they were analyzed to arrive at the presented conclusions (Cronin et al., 2008; Tranfield et al., 2003). Consequently, from traditional review studies, it usually remains unclear whether their authors have taken sufficient care to identify and review the relevant—or at least, the most important—research items in their field of analysis, which is why traditional reviews have faced substantial criticism. For instance, Mallett et al. (2012) noted that traditional literature reviews “are all too often restricted to literature already known to the authors, or literature that is found by conducting little more than cursory searches” (p. 447).
Systematic reviews tackle such criticism. That is, although not fully agreeing on the exact ingredients of such a review (e.g., Borrego et al., 2014), authors of methodological pieces on systematic reviews usually agree that a structured and transparent sample selection that enables a comprehensive review of a given field is a cornerstone (e.g., Tranfield et al., 2003; Williams et al., 2020).
Three Desired Attributes of Sample Selection in Systematic Reviews
Existing advice on systematic reviews has identified the overall objectives of such reviews (e.g., Denyer & Tranfield, 2009; Moher et al., 2009; Rojon et al., 2011; Rousseau et al., 2008; Tranfield et al., 2003). The exact wording of these objectives differs slightly between the sources, but as of my reading of the literature, the desired attributes of systematic reviews—including sample selection—can be summarized into the following three widespread and accepted features: (a) structured, (b) transparent, and (c) comprehensive.
Structured
As suggested by Rousseau et al. (2008), systematic reviews should be “structured.” That is, they should be conducted in “an ordered or methodical way” rather than a “haphazard or random way” (Jesson et al., 2011, p. 12). For sample selection, this infers that all the steps taken need to be well explained, founded, and not arbitrary. Tranfield et al. (2003) added that a structured search should be based on a clearly defined research question(s) to be answered by a systematic review, followed by the “identification of keywords and search terms, which are built from the scoping study, the literature and discussions within the review team” (p. 215).
Comprehensive
The second desired attribute of systematic reviews is delivering a synthesis of the reviewed research field that is as comprehensive as possible (Adams et al., 2017; Cronin et al., 2008). That is, a systematic review should cover all relevant research items (Briner & Denyer, 2012; Petticrew & Roberts, 2012; Rousseau et al., 2008; Williams et al., 2020). A research item’s relevance is usually judged by (a) its contribution to answering the review’s aforementioned, predefined research question(s) and (b) its adherence to the set inclusion and exclusion criteria (see the following; Booth et al., 2016; Jesson et al., 2011; Petticrew & Roberts, 2012; Tranfield et al., 2003).
Transparent
Making the sample selection process transparent refers to disclosing the final review sample and the methodological steps taken to arrive at this sample (Rojon et al., 2011; Rousseau et al., 2008; Torraco, 2005; Tranfield et al., 2003). Although a transparent reporting of the research methods applied should probably be a quality criterion for every management research article (Aguinis et al., 2018, 2020), many earlier and traditional review articles in management research have received particular criticism due to their methodological opacity (Briner & Denyer, 2012). Ideally, the researcher should describe sample selection in a published systematic review study so transparently that it allows other researchers to trace the sample selection fully (Pussegoda et al., 2017).
A Review’s Research Question(s) and Author Discretion
As argued by Petticrew and Roberts (2012), the research question(s) guides the subsequent identification of research items to be included and is therefore of paramount importance in a systematic review. Defining such a research question involves the discretion of the authors and can be defined more narrowly or more widely (Petticrew & Roberts, 2012; Rojon et al., 2011). For instance, a researcher can phrase a question to only address research published in a certain period (e.g., the last 10 years) or on a specific type of organization (e.g., family firms). So by defining the review’s research question(s), the researcher can influence the scope of the review and thus the number of research items relevant to a given research question.
Besides the central research question(s), the review can define more detailed inclusion and exclusion criteria. These criteria should disclose the exact reasons why a particular piece of research would be included in or excluded from a review (Rousseau et al., 2008). For instance, a reviewer may choose to review only articles that have been published in certain journals, that are accessible via keyword searches in databases, or that have received a minimum number of citations. Another choice often made in systematic review articles is that gray literature is ignored (Adams et al., 2017).
What these examples show is that for reviewing any specific field, there is not one definite list of research items that comprehensively captures the field (cf. Gond et al., 2020). Consequently, the label comprehensive cannot necessarily be equated with just “all research items” but only with “all relevant research items,” where the question of what is relevant is defined by the review authors in wording their research question(s) and choices on inclusion and exclusion criteria.
Not least, the time and resources available for a specific systematic review likely influence these choices (Booth et al., 2016). For instance, all else being equal, the workload for conducting a systematic review can be expected to be lower when focusing only on peer-reviewed journals or even some specific journals in comparison with reviewing all sorts of publication outlets, including books and working papers. Likewise, limiting the time period of research items will likely lower the number of these items. So, given the usual restrictions of research time and other resources, many review authors may need to make trade-offs when defining their review’s research question and inclusion/exclusion criteria (cf. Adams et al., 2017; Welch et al., 2013).
Despite such discretion, the resulting review sample should enable the review authors to depict the current state of knowledge on a certain topic in an unbiased way (Mallett et al., 2012; Tranfield et al., 2003). This maxim is similar to large-scale quantitative empirical research, where questions are often addressed with the help of probability samples that need to be unbiased and representative subsets of a given population (Bell et al., 2019). So, while keeping the review authors’ discretion in mind, to be comprehensive, a review sample needs to be an unbiased and representative sample of the existing body of research regarding a specific research question(s).
Similarly, although a systematic review’s research question(s) and inclusion and exclusion criteria are subject to discretion, these need to be clear, and it must be transparent why they are in place and how conforming to them was achieved (Booth et al., 2016; Hulland & Houston, 2020; Jesson et al., 2011; Petticrew & Roberts, 2012). Thus, clear definitions help to base inclusion or exclusion decisions on objective criteria—in particular, by defining the inclusion and exclusion criteria before the actual search for potentially relevant research items (Denyer & Tranfield, 2009; Mallett et al., 2012; Rojon et al., 2011). As part of author discretion, the same criterion may either be framed as an inclusion criterion or as an exclusion criterion. For instance, some of the articles I reviewed only included articles published in journals ranked by the Chartered Association of Business Schools (CABS). Researchers can frame this criterion as inclusive (“only include articles published in CABS-ranked journals”) or as exclusive (“exclude articles published in journals not ranked by CABS”). Therefore, in the rest of this article, I use the summary term inclusion and exclusion criteria if it is not entirely clear whether a criterion is inclusive or exclusive.
Three Steps of Sample Selection in Systematic Reviews
There are several guidelines, especially in the medical sciences, on the process of conducting and reporting systematic reviews. For instance, the statements on the Quality of Reporting of Meta-Analyses (QUOROM) and on Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) are among the most frequently applied guidelines (Pussegoda et al., 2017). These statements include steps to be taken in the sample selection as part of systematic reviews (Moher et al., 1999, 2009). Although these steps show slight differences to the recommendations developed in management research (e.g., Denyer & Tranfield, 2009; Gaur & Kumar, 2018; Rousseau et al., 2008; Sharma & Bansal, 2020; Tranfield et al., 2003), they are broadly in line with each other. So, the exact labels and the number of steps differ marginally, but the tasks mentioned in the aforementioned sources can be clustered into three overarching steps of sample selection in systematic reviews, which are detailed in the following and drawn on to organize my findings: (1) identification, (2) screening, and (3) disclosure of the review sample (see Figure 1).
Note that it is also part of a review author’s discretion whether a certain inclusion or exclusion criterion is applied in the identification step or in the screening step (Booth et al., 2016; Jesson et al., 2011), and the AMA and IJMR articles reviewed in the following indeed show variance in the order of the applied criteria. However, some criteria such as the publication year or the publication outlet can already be assessed without an analysis of the research items’ contents. This is why such non-content-related criteria are discussed as part of the identification step in the following. In turn, the content-related criteria require a more in-depth analysis of the potentially relevant research items and are thus discussed in the screening step in the following.
Regardless of specific inclusion or exclusion criteria, Figure 1 visualizes that all three steps should be in line with the three desired attributes discussed previously as much as possible. Moreover, Figure 1 highlights that a systematic review’s guiding research question(s) informs all subsequent steps of the review, including the three steps of sample selection.
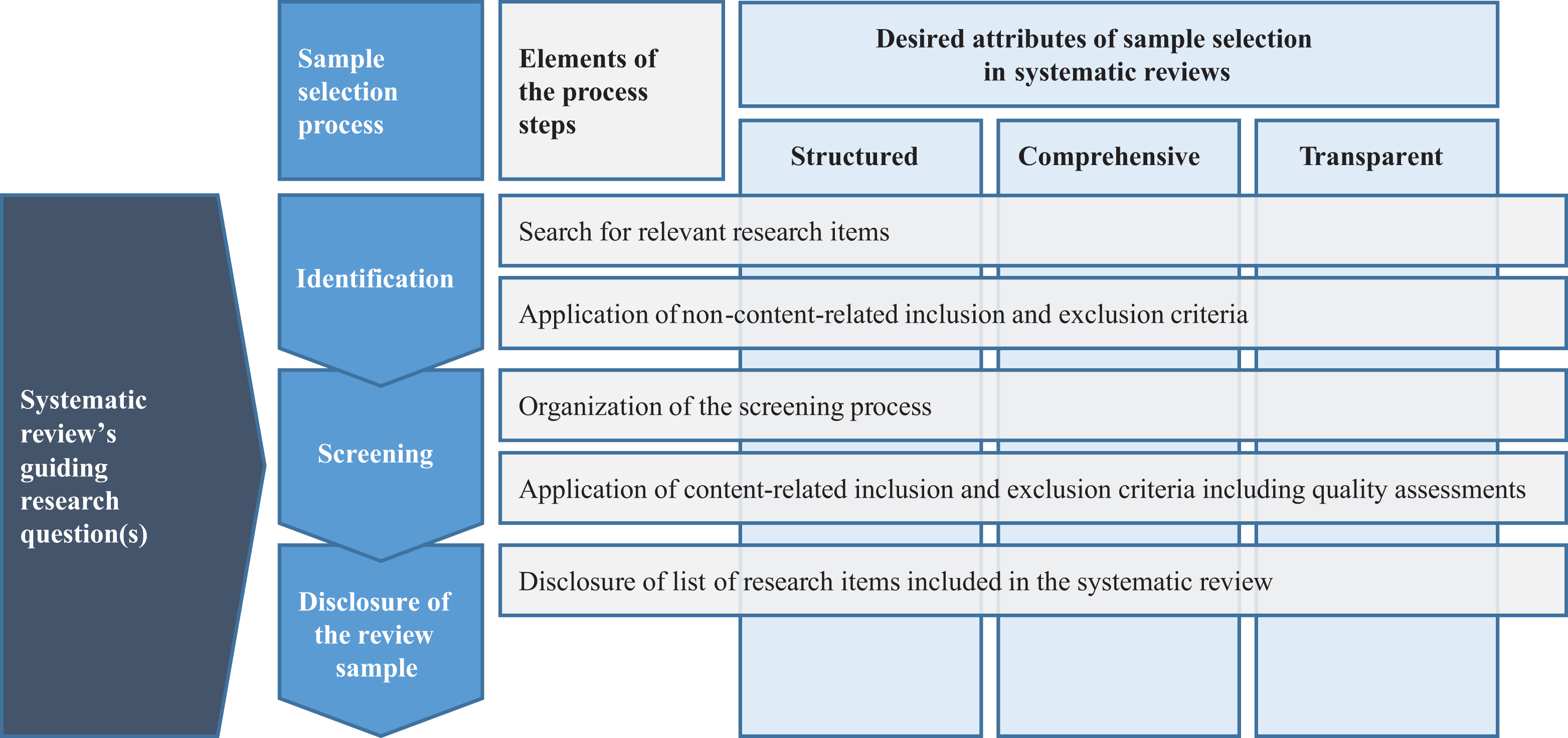
Steps and desired attributes of sample selection in systematic literature reviews.
Identification
The identification step encompasses the search for research items that are potentially relevant to the predefined research question(s). This step results in a list of such items (Booth et al., 2016; Vassar et al., 2017). I use the term potentially here because the final clarification of the content fit of a particular research item for answering a review study’s research question(s) is only made in the screening phase.
When identifying potentially relevant research items, a structured search should not only cover the research already known to the review authors but also be free from preexisting beliefs (e.g., Briner & Denyer, 2012; Mallett et al., 2012; Sharma & Bansal, 2020). This includes the identification of so-far unknown research from other fields, which can foster interdisciplinary knowledge flows (Jones & Gatrell, 2014). Such openness in the identification step is important because only when based on an unbiased and representative review sample can the systematic review generalize about the state of a particular research field or on a specific research question (cf. Wang & Chugh, 2014).
Nevertheless, as indicated previously, review authors may define non-content-related inclusion and exclusion criteria to restrict the identification of potentially relevant research items to certain types of publication outlets, a specific time period covered by the review, or the way research items are to be found. Regarding the latter, systematic reviews are often based on keyword searches in electronic databases to arrive at a comprehensive review sample in a structured and transparent way (Tranfield et al., 2003). There are some recommendations in management research and adjacent fields regarding what databases to choose for such purposes (e.g., Adams et al., 2017; Jones & Gatrell, 2014; Massaro et al., 2016; Webster & Watson, 2002). Some authors from other fields generally suggest a minimum of two databases to alleviate the effects of differing coverage between individual databases (Green et al., 2006). Other authors conclude that researchers often use too few databases, which may endanger the generalizability and validity of review results (Vassar et al., 2017). Although these insights may give management researchers indications on database choices in systematic reviews, the problem remains that database selection very much depends on the studied subject (Thielen et al., 2016). Consequently, a more structured overview of which databases are usually accessed in systematic reviews of management research is missing but detailed in the following.
Even if database searches feature sufficient breadth and depth, keyword-based searches may miss research items potentially relevant to the set research question. For instance, although journal articles are usually easily identifiable via database searches, other research items such as gray literature are often not (Adams et al., 2017). Many existent systematic reviews have therefore excluded such gray literature from their sample selection procedures even though such exclusion necessarily leads to smaller review samples and thus potentially to questions regarding the comprehensiveness of these reviews (Adams et al., 2017).
However, keyword searches may still miss potentially relevant research items. Based on personal experience, Randolph (2009) estimated that “electronic searches lead to only about ten percent of the articles that will comprise an exhaustive review” (p. 7). Others report that researchers only identified 30% of relevant articles through keyword searches in databases while identifying the remaining 70% of articles through “snowballing” techniques, personal knowledge, or personal contacts (Greenhalgh & Peacock, 2005). In this context, snowballing refers to the search of the reference lists of initially identified research items for further potentially relevant items. This approach is sometimes also referred to as going backward because it only identifies research items that are older than the initially identified items. Backward searches can be complemented with forward searches, which look into younger research items citing the initially identified items (Webster & Watson, 2002). For this purpose, also, electronic databases such as the Web of Science or Google Scholar can be used, rendering snowballing techniques useful in working toward a comprehensive review. At the same time, however, snowballing techniques may also lead to less transparency in systematic reviews. Although many such reviews disclose keywords, search engines, and search strings in great detail, the reporting of snowballing techniques is often opaque (Horsley et al., 2011) and free from giving details as to exactly which initially found research items have been referenced or cited by the research items identified through snowballing.
Screening
In the screening phase, the list of potentially relevant research items is analyzed for content that fits the predefined research question(s) (Booth et al., 2016; Petticrew & Roberts, 2012). Content-related criteria often applied in the screening phase include the selection of research items following certain study designs (Petticrew & Roberts, 2012; Pussegoda et al., 2017) or research conducted on certain populations (Booth et al., 2016). Further important kinds of screening criteria are quality assessments (Briner & Denyer, 2012; Macpherson & Jones, 2010; Sharma & Bansal, 2020; Tranfield et al., 2003). According to Tranfield et al. (2003), “individual studies in systematic review are judged against a set of predetermined criteria and checklists” (pp. 215–216) to assess whether their quality is sufficient to be included in the review sample. Tranfield et al. acknowledged that in management research, an article’s quality tends to be assessed by the quality rating of the journal in which the article is published. 3 To avoid such journal-rating-based quality assessments, Tranfield et al. provided a list of criteria to assess an article’s quality but concluded that in systematic reviews of management research, quality assessments remain a “major challenge” (p. 216); this is not least because research quality is a much debated and controversial issue in management research, and a generally accepted view of what constitutes quality research is not yet foreseeable (e.g., Denyer & Tranfield, 2009; Sousa & Hendriks, 2008).
In general, content-related inclusion and exclusion criteria such as quality assessments involve the problem that they may be applied differently between authors of systematic reviews. In particular, during the screening phase, it may therefore be valuable to have more than one reviewer conducting the analysis of potentially relevant research items and reviewers discussing disagreements in the broader review team, which should further contribute to a structured sample selection procedure (Tranfield et al., 2003). Despite such measures, diverging epistemic norms in management research and subjective assessments of whether an article does or does not fulfill specific content-related inclusion or exclusion criteria impedes the reproducibility of systematic reviews of management research (Denyer & Tranfield, 2009; Tranfield et al., 2003). So, although full replicability may not be achievable, proponents of systematic reviews in management research posit that the reporting on the review process should be as transparent as possible (Adams et al., 2017; Rojon et al., 2011; Rousseau et al., 2008; Tranfield et al., 2003).
Disclosure of the Review Sample
After having applied all inclusion and exclusion criteria, the final review sample is rendered. A transparent disclosure of a full list of research items included in this sample is necessary because otherwise, readers do not know which research items exactly build the basis for the review study’s results (e.g., Torraco, 2005; Tranfield et al., 2003).
There are some recommendations in the literature on the minimum number of research items to be included in a review sample so that the publication of a review article is warranted. For instance, Short (2009) suggested that an ideal topic for a review article in management research is a topic where “a number of conceptual and empirical articles have amassed without previous review efforts or a synthesis of past works” (p. 1312). For the field of family business research, Short et al. (2016) provided even more specific guidelines and mentioned 50 articles as the minimum number of research items to be covered in a review article. However, reconsidering the importance of a review’s research question(s) and review author discretion, minimum numbers such as 50 seem arbitrary. As argued by Petticrew and Roberts (2012), a systematic review can also highlight “the absence of data” (p. 35) and the need for further primary research. A systematic review can therefore be useful as a precursor of most primary research to assess the state of the field before adding to it (Linnenluecke et al., 2020; Rojon et al., 2011).
At the same time, systematic reviews that only cover a small number of research items may not be published as a separate article. That is, premier journals focused on publishing review studies such as AMA and IJMR usually require that a review article is broad enough in its scope to be of general interest to management researchers. For instance, in their IJMR editorial, Macpherson and Jones (2010) mentioned that the first principle of a “state of the art” literature review is that it covers a field that is “mature enough to warrant a literature review” (p. 110). In line with the subjectivity involved in scoping a systematic review as explained previously, Macpherson and Jones and other AMA and IJMR editorials leave minimum numbers of research items to be covered unmentioned, but the following analyses shed some light on the past practice regarding the review sample sizes of published AMA and IJMR articles.
Methods
Sample Selection
To present insights into the sample selection as part of systematic reviews of management research, this article focuses on reviews published in AMA and IJMR. These two journals can be considered the most prominent and most cited outlets that are exclusively devoted to publishing review studies of management research. As stated in Clarivate’s Journal Citation Reports 2019, AMA and IJMR are among the top five journals in the management category with the highest two-year impact factors (out of 226 journals listed in this category, with AMA obtaining the first and IJMR obtaining the fifth rank). Also, both are ranked highly in international journal rankings such as the Australian 2019 ABDC Journal Quality List (AMA: A*; IJMR: A) or the CABS Academic Journal Guide 2018 (AMA: Grade 4; IJMR: Grade 3). Although journal rankings can and probably should be discussed critically (e.g., Rowlinson et al., 2015; Tourish & Willmott, 2015; Willmott, 2011), these rankings show that AMA and IJMR are regarded highly in the international scholarly community. Considering such high esteem and the two journals’ high standards for rigor and quality (Elsbach & van Knippenberg, 2018; Jones & Gatrell, 2014), it can be assumed that a review article published in one of these two journals can be considered high quality. At the least, an analysis of AMA and IJMR articles allows for insights into the sample selection practice of well-published systematic reviews of management research.
To select such systematic reviews, I manually went through all 523 articles published in AMA and IJMR between 2004 and 2018. This time frame includes all AMA volumes up to 2018 but excludes the earlier IJMR volumes from 1999 to 2002 4 because the seminal paper by Tranfield et al. (2003) was published in 2003, and so the likelihood of systematic reviews being published in IJMR before 2004 was low (see also Adams et al., 2017). An electronic full-text search of the IJMR articles published between 1999 and 2002 confirmed that none of these articles mentioned the terms systematic literature review or systematic review.
I used somewhat relaxed inclusion criteria to avoid excluding many of the earlier systematic reviews that did not necessarily refer to the Tranfield et al. (2003) article or did not use the term systematic literature review. That is, I used the question of whether the articles disclosed their inclusion or exclusion criteria as my overriding inclusion criterion. Although most of the included articles meeting this criterion mentioned the term systematic literature review and referred to key methodological works such as Tranfield et al., not all authors of the included articles considered their articles pure systematic reviews. Some authors stated that they had used the guidelines by authors such as Tranfield et al. as a “guiding tool” (Wang & Chugh, 2014, p. 26) and did not use the systematic review recommendations as an “orthodox method” (Wang & Chugh, 2014, p. 26). That is, based on some tenets of systematic reviews, they adapted their sample selection strategy to the individual characteristics of the literature they reviewed. Some refer to this strategy as “fit for purpose” (Macpherson & Jones, 2010). These observations necessitated the aforementioned outlined relaxed strategy for identifying systematic reviews from AMA and IJMR. In the following, all included articles are referred to as systematic reviews.
In this selection process, I excluded articles geared toward bibliometric analyses of the literature (e.g., Vogel & Guettel, 2013). Although such bibliometric analyses, too, regularly draw on structured sample selection techniques, they cannot be adequately compared with systematic reviews reported in a more narrative way because the numbers of included articles in bibliometric analyses are usually much higher than those of systematic reviews, and the associated depth of checking inclusion and exclusion criteria is often lower (Zupic & Čater, 2015). For other excluded articles, I know from private communication that they were based on a highly structured review process (e.g., Kunisch et al., 2017). However, to treat all candidate articles equally, I have omitted articles from the sample if the published version or publicly available appendices do not clearly disclose their inclusion or exclusion criteria, as noted previously.
Following these criteria, I identified a total of 232 systematic reviews: 56 from AMA and 176 from IJMR (for a full list, see Appendix Table A1 in the Supplemental Material available in the online version of the journal). Among all included AMA and IJMR articles published in the last analysis year (i.e., 2018), the share of systematic reviews was already more than 80%, which may indicate that systematic approaches have become the new normal when it comes to methods for creating review samples in management research (for details, see Appendix Table A2 in the Supplemental Material available in the online version of the journal).
Analytical Approach
I coded each included review article along 50 dimensions (cf. Aytug et al., 2010; Vassar et al., 2017), which resulted in a total of 11,600 codings. Twenty-one of the 50 codes are based on the main steps and desired attributes of sample selection, as discussed previously (for details, see Appendix Table A3 in the Supplemental Material available in the online version of the journal). These codes include whether the article discloses the keywords used in electronic database searches, the number and names of databases searched, the application of quality assessments, or the usage of snowballing techniques. The 29 remaining codes emerged inductively from reading the identified review articles. For instance, some articles deviated from the usual keyword-based search strategies, whereas others limited their review to empirical studies. So the sum of codes represents a mix of deductively and inductively generated categories, which renders this study’s analytical approach abductive (Lukka & Modell, 2010). The codings were then used to offer descriptives on the entirety of the 232 reviewed articles. Wherever patterns and relationships between categories could be identified, they are reported in the following findings.
To validate the coding, I went through the articles at two separate points in time: first in November 2018 and then again in February 2019. In the second coding trial, I revised 2% of the prior coding. Moreover, in July and August 2019, a research assistant experienced in bibliometric analyses coded all articles independently. In 48 cases (i.e., 0.4% of all codings), his codings differed from mine. This translates into an intercoder agreement 5 of 99.6%—as defined by Neuendorf (2017), an acceptable level of agreement. We then discussed the 48 differing codings and resolved our different assessments of them.
A limitation of this approach is that it relies on the information presented in the reviewed articles and—in some cases—on information provided in the additional data made available online on the publishers’ websites (e.g., in online appendices). Consequently, I could only code publicly available data, excluding potential additional, unreported methodological steps. Therefore, this article may not adequately represent the methods applied in some of the reviewed articles. However, because transparency is one of the critical objectives of systematic reviews, it can be assumed that most authors adhering to systematic review guidelines have reported most—if not all—steps taken to arrive at their review samples (cf. Moher et al., 2009).
Findings and Analysis
Identification
Time Period Covered
A central choice in the identification of relevant research items is the question of whether the time period covered should be limited. Several of the analyzed review articles report that the research focus and views on key constructs within a topic field have shifted or changed over time (e.g., Cardinal et al., 2017; Korica et al., 2017; Saggese et al., 2016). Hence, limitations of the time period covered may omit research (typically earlier work) and thus affect the systematic review’s findings. Consequently, if the time period covered is limited, a disclosure of exact and well-structured reasons for this limitation is necessary for a systematic review to be transparent.
However, 41 (18%) of the articles do not disclose the time period covered, which renders these reviews not fully transparent. Thirty-six (16%) further articles do disclose that they have limited the time period covered to particular years but do not give a reason why, which limits the structured nature and transparency of such reviews. The remaining 155 (67%) articles disclose reasons for their time periods covered, which I grouped into eight categories (see Table 1). For articles mentioning two reasons for their time periods covered, I assigned the reason that appears more prominent in the published article as of my reading.
Time Periods Covered and Review Sample Size.
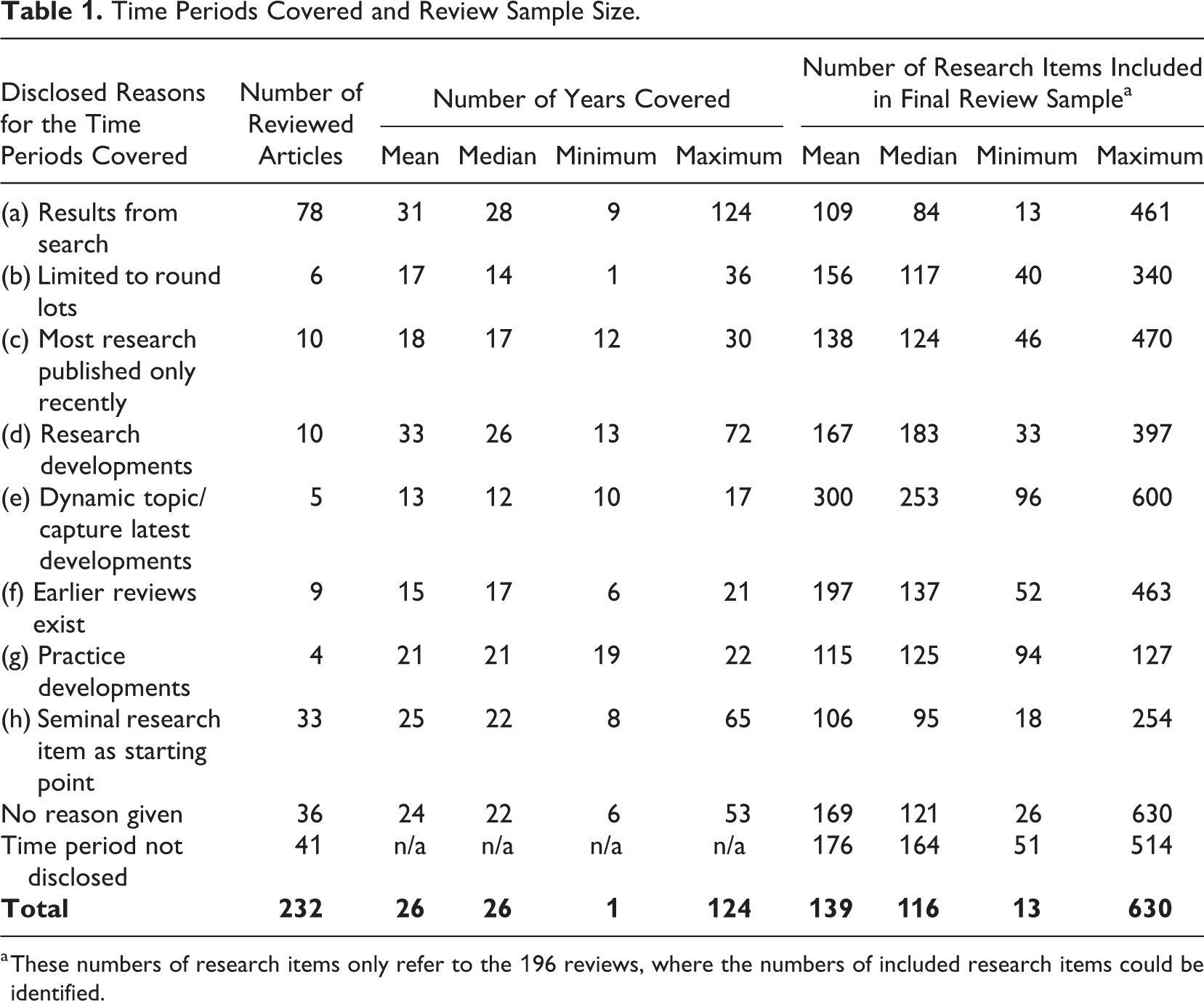
a These numbers of research items only refer to the 196 reviews, where the numbers of included research items could be identified.
The most frequently found reason is that the time period covered results inductively from the search process, referred to as category (a) in Table 1. Such articles aim to cover relevant research items irrespective of their publication date up to the time the manuscript had been submitted or accepted at AMA or IJMR. Such articles cover a mean time period of 31 years. As argued by some reviewed articles, this approach is particularly suitable for topics where there has not been a review published before and where the resulting number of research items is still manageable. The mean number of research items included in the review sample for category (a) amounts to 109 and may thus be regarded as sufficiently “manageable” (cf. Bres et al., 2018) because it is below the overall mean number of included articles, which amounts to 139.
Although most articles do not openly refer to the manageability of review samples, some further reasons for limiting a review’s time period may be covert measures to keep the review sample size manageable. For instance, six articles referred to as category (b) in Table 1 have chosen to limit their time period covered to round lots such as the last 10 or 25 years without giving reasons why these time periods would make sense. Some articles in category (b) have also chosen the year 2000 as the starting point of their reviews, again without giving reasons why. So, this approach conflicts with the previously explained objectives that all decisions in systematic reviews should be well structured and transparent.
Similarly, 20 further articles, categories (c) and (d) in Table 1, limit their search to recently published research (category (c)) or a longer time period that often coincides with the start of new decades in the 20th century (category (d)). Such articles reviewed a mean period of the past 18 years (c) or 33 years (d) before the review, mostly suggesting that before their time period covered, not much research had been going on in the review’s topic. If this latter notion would apply, however, then the question arises as to why such review studies have limited their time period covered in the first place and why they did not aim to address more comprehensively their research question(s) and integrate the few research items published earlier—in particular, when considering that the mean sample size in category (c) reviews is just below the overall mean sample size and thus not extraordinarily high. Consequently, categories (c) and, to some extent, (d) also raise doubts regarding the comprehensiveness and structured nature of such reviews. Five other reviews have suggested that the topic they reviewed was particularly dynamic or that they aimed to capture the latest developments in this topic, category (e) in Table 1. Although this argument, too, might be classified as arbitrary, the mean number of research items covered in this type of review (300 items) is relatively high. Arguably, even if “manageability” of the sample size may not be the best reason for limiting the covered time frame, integrating more than 300 research items in a narrative systematic review article may not be feasible.
Other approaches better reflect a structured and comprehensive sample selection. One such reasoning, referred to as category (f) in Table 1 and as also suggested by Short (2009), is that an earlier review of the same topic exists and that the later review excludes the coverage period of the prior review (e.g., Josefy et al., 2015; Schilke et al., 2018). With 15 years, the mean time period covered in this type of review is below the overall mean time period covered (26 years), but given that this type of approach has a mean review sample size of 197 research items, it should comply with Short’s suggestion that such follow-up reviews are warranted when a critical number of research items have amassed since the prior review. Although only based on nine articles here, the mean coverage period of 15 years may also serve as an indication of the time that usually elapses before warranting a follow-up review in management research.
Another well-structured reason for limiting the time period covered was developments in practice; see category (g) in Table 1. Although only applied in four reviews, this approach allows for comprehensive coverage of the phenomenon studied and a structured (i.e., well explained and founded) decision on the start of the coverage period. For instance, Boiral et al. (2018) limited their review on the adoption and outcomes of ISO 14001 to the years between 1996 and 2015 because 1996 “was the year in which ISO 14001 was launched” (p. 414).
Finally, the second most frequently mentioned reason for limiting the time period covered was seminal research items central to the review topic. The 33 articles falling into this category (h) started their coverage period in the year where one or the first of several seminal research items had been published. For instance, Leibel et al. (2018) selected 1983 as the starting point for their literature search on the dynamics of field formation in institutional research because in this year, “DiMaggio and Powell introduced the term ‘field’” (p. 155). In this approach, the identification of one or several seminal research items can be operationalized with the help of high citation rates or other bibliometric methods (e.g., Linnenluecke, 2017).
Four Principal Search Approaches to Identifying Relevant Research Items
From my analyses, there emerged four principal search approaches for the identification of potentially relevant research items: (a) the journal-driven approach, (b) the database-driven approach, (c) the seminal-work-driven approach, and (d) combined approaches. The first three approaches are driven by a focus on specific journals, databases, or seminal works, which warrants the naming of these approaches. The four approaches, their main pros and cons, as well as implications for future applications are summarized in Table 2 and detailed in the following four sections. Table 3 reports their application within the overall sample of the 232 analyzed articles.
Four Principal Search Approaches in Systematic Literature Reviews.

Note: MOS = management and organization studies.
Principal Search Approaches in the Identification of Research Items in AMA and IJMR.

Note: AMA = Academy of Management Annals; IJMR = International Journal of Management Reviews.
a The totals do not add up to 232 but only to 231 because for one article (Renwick et al., 2013), the principal search approach could not be identified due to missing information.
Journal-driven approach
The journal-driven approach is characterized by the selection of a list of journals before the actual search. Also, this approach usually draws on databases and keywords, but in contrast to the database-driven approach (see below), databases are not the primary organizing logic of the search; journals are. Although the exact selection of journals varies considerably between the reviewed articles, many such journal-driven reviews included searches of the Academy of Management Journal, Academy of Management Review, Administrative Science Quarterly, Journal of Applied Psychology, Journal of Management, Management Science, Organization Science, and Strategic Management Journal.
Given that the journal-driven approach focuses on a predefined set of such journals, it comes with the advantage that the search can be rather easily reported in a transparent and traceable way. My review results underpin this notion: 91% of the 65 journal-driven review articles disclosed the number and names of the reviewed journals, and 85% disclosed a list of the specific research items included in the review sample. A further advantage of this approach is that if a well-regarded journal publishes an article, then the article is presumably built on sufficiently rigorous research methods (e.g., Ahuja & Novelli, 2017; Ravasi & Canato, 2013; Rawhouser et al., 2017), which can clear the quality assessment as required by Tranfield et al. (2003). This focus on the most regarded journals of a field can also make sure that research published in such outlets—often viewed as key literature—is covered in the review. Additionally, journal-driven reviews can represent a very cost-efficient approach to systematic reviews because skimming through a predefined list of journals should be less strenuous than analyzing a virtually endless amount of available other journals (Pittaway et al., 2004; Radaelli & Sitton-Kent, 2016; Vaara & Whittington, 2012; Wang & Chugh, 2014).
A downside of the journal-driven approach can be that the selection of (a small number of) journals to be searched may predetermine the narrowness of review studies. Many analyzed journal-driven reviews posed broad research questions and aimed to generalize about the status quo of a certain topic in management and organization studies (MOS). For instance, Hällgren et al. (2018) aimed to review the contributions from extreme context research to MOS. They reviewed nine well-regarded MOS journals and acknowledged that this choice of journals may have potentially “excluded some excellent studies of extreme contexts” (p. 115). Although the choice of the principal search approach and the specific journals remain at the discretion of review authors, it may at least be debated whether reviews of such narrow sets of journals enable authors to answer comprehensively a systematic review’s research question for the entirety of MOS because it leaves research published in other outlets uncovered that may be relevant to MOS. Several reviewed articles tried to circumvent this limitation by not drawing solely on MOS journals but also on top journals from other fields relevant to their research question(s) (e.g., Ahuja & Novelli, 2017; Jang et al., 2018). Although these measures contribute to reducing the narrowness of journal-driven reviews, such reviews could still miss research items that are potentially relevant to answering the review’s research question and that may have also been published in very well-regarded outlets that, however, have not been covered by the predefined set of journals.
One measure to address this limitation is an increased use of snowballing techniques in journal-driven reviews. Most (78%) of the 65 journal-driven reviews exclusively drew on keyword searches in the selected journals but did not use snowballing techniques. A benefit of snowballing techniques is that they may also identify research items that use different terms for capturing the phenomenon in question rather than those entered in the keyword search (e.g., Niesten & Jolink, 2015; O’Mahoney, 2016) or that have not been published in the predefined set of journals. So, snowballing techniques could support future systematic reviews following a journal-based approach by more comprehensively addressing their research questions. Such snowballing could consider only additional references from the predefined set of journals or even from beyond (i.e., those published in further journals or the gray literature) while ensuring a more transparent reporting on the snowballing procedures (see above).
Another limitation is that only eight (12%) of the 65 journal-driven reviews included some gray literature in their review samples, mostly books or book chapters. The focus on peer-reviewed journals and the belief that such content can primarily be regarded as valid is a built-in feature of journal-driven reviews (cf. Adams et al., 2017). However, concerns with the gray literature could be alleviated while upholding rigorous standards—for instance, by including gray literature only when a certain number of the relevant articles found in the predefined journals (e.g., five) cited a specific research item from the gray literature (for a similar approach, see Shepherd & Challenger, 2013). Then, assumedly, this piece of gray literature is important and should hold sufficient quality to be included in a review of the respective literature. The same logic could also be applied to include well-cited journal articles published in journals beyond the predefined set.
Database-driven approach
The database-driven approach usually starts with the identification of keywords from a scoping study and then applies these keywords to a search in one or multiple electronic databases. As reported in Table 3, of the 133 database-driven reviews, 25 (19%) only considered the title, abstracts, and author-provided keywords for the inclusion of articles, whereas 62 (47%) considered the full text (as well as the title, abstract, and author-provided keywords). Remarkably, the remaining 46 (35%) database-driven reviews did not give any information as to which parts of the research items were searched, which does not add to the transparency of these reviews. Given that the number of research items found in academic databases significantly varies between searches with only the title, the abstract, and the author-provided keywords compared with searches including the full text, it seems desirable that future systematic reviews more consistently disclose their application of keywords to different parts of the research items.
Usage of Databases in Database-Driven Search Approaches (N = 133).
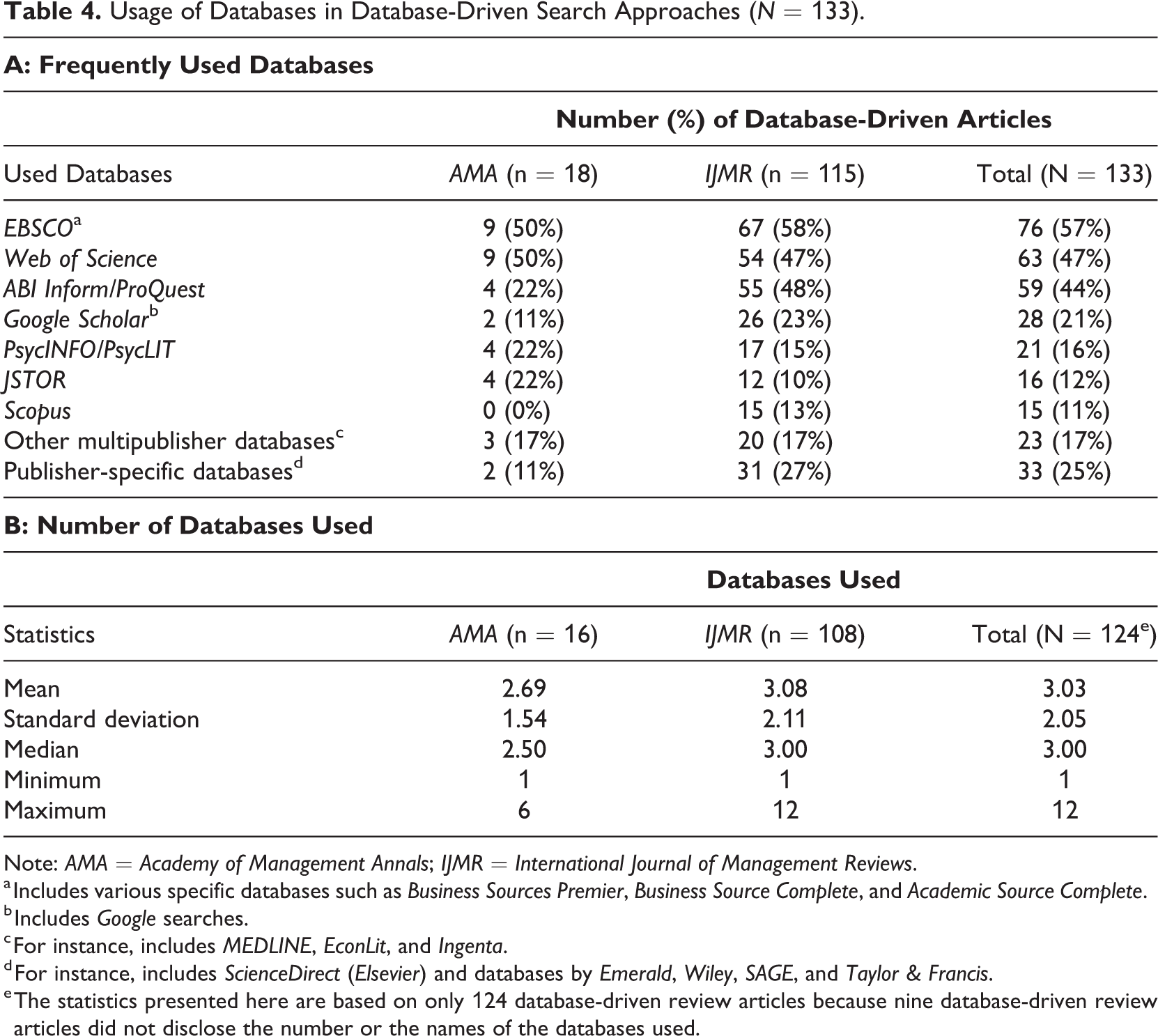
Note: AMA = Academy of Management Annals; IJMR = International Journal of Management Reviews.
a Includes various specific databases such as Business Sources Premier, Business Source Complete, and Academic Source Complete.
b Includes Google searches.
c For instance, includes MEDLINE, EconLit, and Ingenta.
d For instance, includes ScienceDirect (Elsevier) and databases by Emerald, Wiley, SAGE, and Taylor & Francis.
e The statistics presented here are based on only 124 database-driven review articles because nine database-driven review articles did not disclose the number or the names of the databases used.
The analyzed database-driven reviews were more transparent in terms of database choice: 124 (93%) of the 133 database-driven reviews disclosed the databases used in their search. As displayed in Table 4, the overall median and mean numbers of databases used amount to 3, with a standard deviation of 2. So, a rough benchmark for the number of databases to be used might be 3. These numbers include both multipublisher databases that cover the material by many publishers—the three most often used in my sample being EBSCO, Web of Science, and ABI Inform/ProQuest—and databases that only cover one publisher’s content, such as Elsevier’s ScienceDirect. Given that publisher-specific databases will usually deliver less hits than multipublisher databases, one cannot conclude that any three databases would suffice for a comprehensive database search.
In addition, as argued in the methods literature (Thielen et al., 2016), the choice of specific databases should be in line with the review’s guiding research question(s). For instance, for topics at the intersection of management and psychology, the review articles I analyzed often drew on PsycINFO in addition to other multipublisher databases (e.g., Anseel et al., 2007; Atewologun et al., 2017; Xiao & Nicholson, 2013). In turn, if a review aims at integrating gray literature in a structured way, then Google Scholar would be an attractive complement to other multipublisher databases (Gusenbauer & Haddaway, 2020) because Google Scholar currently covers more nonjournal content than the other multipublisher databases named in Table 4 (Bar-Ilan, 2010; Gusenbauer, 2019; Harzing & Alakangas, 2016).
It seems safe to assume that the likelihood of missing relevant research items is lower when as many as possible of the widely used multipublisher databases listed in Table 4 are used (cf. Rojon et al., 2011; Vassar et al., 2017). 6 If several such multipublisher databases are used, most contents from publisher-specific databases will be covered. Searching such publisher-specific databases, too, may nevertheless make sense because they also include in-press articles, which are usually not yet indexed by multipublisher databases such as EBSCO (cf. Wood & McKelvie, 2015). Alternatively, Google Scholar and its built-in “cited by” function can be used to identify younger, in-press articles citing the initially identified articles.
It seems as if such functions and the generally broader coverage of gray literature in databases make the database-driven approach better equipped to draw on gray literature and snowballing techniques: 62 (47%) of the database-driven reviews included some gray literature in their review samples, and 71 (53%) applied snowballing techniques. Although there are no compelling reasons why journal-driven approaches, too, could not draw more intensively on snowballing techniques, these numbers clearly exceed the comparative numbers of journal-driven reviews (see above).
However, as indicated previously, a limitation of database-driven approaches is that a fully transparent and traceable reporting of the search operations in the individual databases is not often seen among the reviewed articles. Such reporting would not only require the disclosure of the keywords and the databases but also of the exact search strings and the chosen filters available at the individual databases. Such details require space, which has long been considered scarce in peer-reviewed journals but is now less of an issue thanks to online appendices, which are offered by an increasing number of journals (Aguinis et al., 2018; Costello et al., 2013; Mallett et al., 2012). Accordingly, more recent entries among the 133 database-driven reviews (e.g., Stumbitz et al., 2018; Theurer et al., 2018) made use of online supplements offering more detailed information on the database search process.
Another limitation is the high number of initial database hits, which often amounts to several thousand in the reviewed articles. What follows is a labor-intensive screening process, even if carried out by not only one but several researchers. Such a process also requires significant resources (e.g., access to electronic databases; see Pittaway & Cope, 2007), which makes systematic reviews expensive (Thielen et al., 2016). Although journal-driven approaches are work-intensive too, getting access to only some journals may be less cost-intensive compared with accessing several multipublisher databases and the found research items.
A measure to narrow the large numbers of initial database hits is the application of non-content-related quality criteria to the preliminary list of research items. For instance, 23 of the 133 database-driven articles only included articles in their sample if the journals publishing them were included in rankings such as the CABS Academic Journal Quality Guide (seven articles) or Clarivate’s Journal Citation Reports (15 articles) or had obtained a minimum rank or score in these rankings. However, the standards for inclusion differ widely between the reviewed articles. Some articles required the respective articles to be published in journals awarded a two-year impact factor by Clarivate 7 of at least 1.0 (e.g., Schmitt et al., 2018), others required a five-year impact factor of at least 1.5 (Perri & Peruffo, 2016), whereas still others only considered the top 30 journals by five-year impact factors in the respective Journal Citation Reports categories (Pindado & Requejo, 2015). The nonexistence of widely accepted standards of such ranking-based quality criteria may thus provide a lever for either enlarging or limiting the review sample size. In particular, choosing ranking criteria geared toward higher ranked journals may lead to a focus on general interest journals, which tend to be ranked above specialist journals (e.g., Hoepner & Unerman, 2012; McKinnon, 2017).
Finally, akin to the journal-driven approach, the selection of specific databases or filters within these databases may also lead to a focus on research items from the management discipline or closely related fields. For instance, Web of Science searches can be restricted to specific “Web of Science Categories” such as “management,” “business,” or “business finance.” Most of the analyzed reviews that used the Web of Science did not disclose such restrictions within this database (but see exceptions such as Ma et al., 2015; Pindado & Requejo, 2015). However, from the reported number of found research items, it seems likely that several further included articles did so but did not report such restrictions. Similarly, 17 of the 76 articles that drew on EBSCO databases specifically reported their usage of EBSCO Business Source Premier and thus restricted their search to business-related content. However, even when incorporating such restrictions, the usual scope and literature coverage of database-driven approaches is still wider than journal-driven approaches.
Seminal-work-driven approach
The seminal-work-driven approach was only applied in five of the reviewed articles (Hopkinson & Blois, 2014; Jarzabkowski & Spee, 2009; Peltoniemi, 2011; Waller et al., 2016; Williams et al., 2018), but its main idea is clearly different from the previously discussed approaches: First, identify one or several research works that can be regarded as seminal for the review’s central research question(s) and then identify the research items that have cited the seminal works. In addition to the direct citations of the seminal works, Peltoniemi (2011) also considered the further “citing paths” (i.e., the citations’ citations, etc.). In general, this approach allows for the comprehensive coverage of a research stream that was founded by one or several seminal works and the structured inclusion of citing works irrespective of their publication outlet (Hopkinson & Blois, 2014). For instance, Hopkinson and Blois (2014) not only considered journal content from the base discipline of their seminal work (i.e., marketing) but also citations from other disciplines.
Whereas two papers following this approach (Hopkinson & Blois, 2014; Waller et al., 2016) only focused on one seminal work, Williams et al. (2018) drew on the citations of 14 seminal works. The existence of seminal works and their transparent and structured identification are essential here. Two review studies (Peltoniemi, 2011; Williams et al., 2018) gave a rather detailed account of how they identified the seminal works, but the other three (Hopkinson & Blois, 2014; Jarzabkowski & Spee, 2009; Waller et al., 2016) only posited that the work they focused on was seminal. This latter procedure cannot be regarded as well structured and transparent because it fails to disclose the identification of seminal works.
Hopkinson and Blois (2014) and Peltoniemi (2011) reported that they used the Web of Science for identifying the citations of their seminal works, whereas the other three articles did not report how they identified such citations. However, the coverage of various databases in terms of citations varies considerably. For instance, Bar-Ilan (2010) found that Google Scholar covers different citing works than the Web of Science or Scopus. Consequently, the choice of the used citation databases may significantly determine the search results in the seminal-work-driven approach and needs to be made transparent.
Combined approaches
Finally, 28 articles combined two of the aforementioned three approaches. In all but one case, these articles combined elements of the journal-based approach with elements of the database-driven approach. The articles that followed such a combined approach feature a mean of 17 specific journals and 2.64 searched electronic databases. These numbers are below the respective numbers of the “pure-play” journal-driven and database-driven approaches and potentially leave room for larger numbers of journals and databases to be covered, but the combination of the two approaches may be able to alleviate some of the downsides of the pure-play approaches. For instance, combining the search of a predefined set of (elite or most important) journals with an open keyword search in electronic databases may help to identify further relevant research items beyond the potentially narrow scope of the selected journals. Thus, a combined approach may contribute to higher chances of not missing relevant research items. The relatively high shares of combined-approach articles that drew on elements of the gray literature (68%) or snowballing techniques (50%) further reflect this focus of combined approaches. Consequently, combined approaches may be regarded as the first choice for presenting an unbiased and comprehensive sample of the relevant literature. The realization of these advantages, however, depends on the mobilization of the substantial resources needed to follow this approach (cf. Mallett et al., 2012) because two of the aforementioned approaches and their associated workloads are incorporated.
Identification of Research Items Based on Individuals’ Knowledge and Manual Searches
Thirty-two articles complemented one of the four principal search approaches with so-called manual searches or an inclusion of articles that were personally known to the authors or their colleagues (e.g., Endres & Weibler, 2017; Saggese et al., 2016). Further studies (e.g., Siebels & zu Knyphausen-Aufseß, 2012) also reported that the journal reviewers had recommended additional items for inclusion during the review process. Others also drew on manual, less structured searches of the Internet and other sources to complement their structured search.
Besides snowballing, such drawing on prior knowledge of the field and manual searches may help to arrive at a more comprehensive coverage of the literature relevant to the preset research question(s) (Greenhalgh & Peacock, 2005). However, this approach comes with the limitation that the review sample’s construction cannot be fully tracked by readers and reviewers. Such limited transparency is particularly apparent if a relatively large number of research items has been identified through prior knowledge or manual search because these two sources are usually not documented in a structured way. It would thus be necessary to disclose how many and which items within the review sample were identified through such procedures to safeguard the traceability of at least the rest of the sample selection. Also, whether structured search approaches, including sufficient snowballing, leave much uncovered remains a question. Consequently, it seems advisable first to draw extensively on the aforementioned approaches and then cross-check the selection made with the authors’ own and their colleagues’ knowledge of the field. Such an approach would likely limit the share of research items included due to individuals’ knowledge or due to manual search and would thus benefit a more structured and transparent identification of potentially relevant research items.
Selection of Most Cited Research Items
Fourteen articles used citation rates of the potentially relevant research items as non-content-related inclusion or exclusion criteria. 8 Most of these articles (11) followed a database-driven search approach and used citation rates to narrow down their extensive lists of potentially relevant items. Several authors justified this choice with their focus on the “most influential” research items (e.g., Barley et al., 2018; Endo et al., 2015; Keupp et al., 2012). Arguably, however, this choice may also be due to many of these reviews focusing on vast topics such as management research on Japanese firms (Endo et al., 2015) or the state of knowledge management research (Barley et al., 2018).
Although citation rates may be instrumental in limiting the review sample size, some methods to identify the “most influential” articles seem arbitrary and not well structured. For instance, Barley et al. (2018) selected the 10 most cited journal articles on knowledge management for each year between 1996 and 2015. This procedure involves the problem that the 11th most cited article in a given year may have been much more “influential” than the most cited article from another year. However, the influential 11th most cited article would not be included in the review sample, which does not comply with the self-set objective of reviewing the most influential articles on knowledge management. Although not intended to discard the overall quality of the article by Barley et al., this example shows that inclusion or exclusion criteria based on citation rates need to be well aligned with the review’s research question(s). Additionally, the length of time since the publishing of a specific research item needs to be incorporated because more recent research items usually have fewer citations than those published long ago (Barley et al., 2018; Keupp et al., 2012). Methods to tackle this issue include comparing relevant research items only to others that have been published in the same decade (Endo et al., 2015) or dividing total citations by the years since the publication of the respective research item.
Another limitation of such citation-based filtering is a lack of transparency. Although the aforementioned three articles (Barley et al., 2018; Endo et al., 2015; Keupp et al., 2012) reported on their choices and the cutoff numbers for citations transparently, many other articles did not do so, which leaves room for more transparent reporting on applying citation rates in future systematic reviews.
Reflections on the Identification Step
All four of the identified principal search approaches come with their own advantages and disadvantages (see Table 2). Most journal-driven review studies adhere to the desired attribute “transparent,” whereas many database-driven and seminal-work-driven review studies did not make their search process transparent. For these latter two approaches, transparent reporting may require more space than for journal-driven reviews, but the online appendices now offered by many journals offer a route toward more transparency. Similarly, more transparent reporting on research items identified based on individuals’ knowledge or based on citation rates seems desirable. In turn, database-driven and seminal-work-driven approaches may be better equipped to address comprehensively a review’s research question(s). Unlike the journal-driven approach, these two approaches are more open to research items beyond a predefined set of journals and may thus be more likely to identify all relevant research items.
Regarding the desired attribute “structured,” none of the four principal search approaches seems per se more structured than others. However, several individual choices in the analyzed articles were not well founded or not in line with the set research question(s). This includes the citation-based selection of research items and some definitions of the time period covered. For instance, review studies that do not disclose the time period covered or those that do not disclose their reasons for limiting the time period covered cannot be regarded as fully transparent or structured because the reader is left in the dark as to which time period has been covered and whether the coverage is in line with the review’s research question(s). Even if made transparent, many review studies provided arbitrary cutoff points for their time periods covered and can thus not be regarded as well structured. Authors of future systematic reviews may therefore consider more structured reasons why the time period covered may be limited, as discussed previously. Conversely, not limiting the time period covered may render a systematic review more comprehensive and seems particularly suited for topics lacking a prior review. Some of these reviews did not explicitly discuss their choice to keep the time period covered unlimited (e.g., Cardinal et al., 2017). However, this nonmentioning may be less problematic because this choice—unlike most others regarding the time period covered—does not result in the exclusion of any potentially relevant research items.
Screening
Organization of the Screening Process
The screening of initially identified research items was mostly organized in the reviewed articles by first scanning titles, abstracts, and author-defined keywords for content fit with the review’s research question(s). As indicated previously, database-driven review studies in particular report on the identification of thousands of potentially relevant research items. A mentioned time-saving strategy to narrow down such large numbers of research items is first to skim only through research items’ titles for content fit before moving onto analyzing abstracts and keywords where a content fit could not yet be assessed (e.g., Ordanini et al., 2008; see also Rojon et al., 2011). Such screening may still not deliver sufficient information needed for a content-based inclusion/exclusion decision to be made. For such articles, a skim or complete reading of the full text will be necessary (e.g., Iqbal et al., 2015; Wilson et al., 2017).
A technique for a structured and transparent examination of the content fit of initially identified research items is the A/B/C logic suggested by Pittaway et al. (2004) and applied similarly in several reviewed articles (e.g., Aguinis et al., 2018; Kauppi et al., 2018; Leseure et al., 2004; Thorpe et al., 2005). Following this logic, every research item is classified as either A (particularly relevant items), B (potentially relevant items), or C (items with little or no relevance). In most of the reviewed articles, only the A-rated research items eventually made it into the final review sample.
The A/B/C logic seems particularly powerful if several researchers are involved in the sample selection process, which is usually feasible only in the case of author teams and not in the case of solo authors. 9 When two or more authors classify articles as A, B, or C, intercoder agreement and similar statistics can be calculated (e.g., Aguinis et al., 2018). Discrepancies between authors in their A/B/C classification may also be used to discuss and develop a refined common understanding about the specific review focus and inclusion/exclusion criteria (Kauppi et al., 2018). Alternatively, a points-based approach may be used where the mean points given by each reviewer to a research item for content fit are calculated and only the research items surpassing a certain points threshold are left in the review sample (e.g., Keupp et al., 2012).
Focus on Empirical or Nonempirical Research Items
Fifty-six reviewed articles exclusively focused on empirical research items, three articles only included nonempirical research items, and the remaining 173 included both empirical and nonempirical research items. Although the three articles focusing on nonempirical research items (Adams et al., 2017; Aguinis et al., 2018; Symon et al., 2018) disclosed the reasons for focusing on nonempirical research in a very transparent fashion, the articles only including empirical research have mostly not disclosed such reasons but only stated that they would exclusively focus on empirical work. Such disclosure would, however, be desirable for future reviews of empirical research to justify all choices made in a transparent manner. Also, most articles that included both empirical and nonempirical research items did not report their reasons for this choice. In this case, the missing reporting seems less problematic because they did not exclude articles, but a full disclosure on such choices could still increase transparency.
Quality Assessments
Many methodological works view quality assessments as an integral part of systematic reviews (e.g., Petticrew & Roberts, 2012). However, only 57 (25%) review studies in my sample discussed quality assessments in the screening process, and 36 of them used journal rankings as inclusion criteria. As discussed previously, the preselection of certain (elite) journals in journal-driven search approaches may be regarded as an implicit measure to secure quality but is not focused on here if not explicitly associated with assuring the quality of the included research items. Approaches relying on journal rankings are often viewed critically (e.g., Tranfield et al., 2003; Williams et al., 2020), for instance, because they transfer the quality assessment for a specific review to the authors of such rankings. So, studies that are highly relevant for a review’s research question(s) and well executed may be excluded just because they were published in a journal with a low or nonexistent ranking. Review authors may therefore need to reflect more critically on the consequences and rationality of journal rankings as a means of quality assessment.
The other 21 articles explicitly mentioning quality assessments either left their operationalization of quality unexplained or referred to other forms of quality assessment—some of them in a very structured and transparent way (e.g., Nguyen et al., 2018; Pittaway et al., 2004). For instance, Nguyen et al. (2018) rated the potentially relevant research items’ quality along five dimensions (theory, methodology and methods, analysis, relevance, contribution) from “Level 0 = absent” to “Level 3 = high quality.” To be included in their review sample, a research item had to show content fit with the research question and achieve a Level 3 rating at least in one quality dimension. This multilevel quality assessment and further points- and level-based examples in the management literature (e.g., Reay et al., 2009; Wong et al., 2012) exemplify the availability of approaches beyond unexplained quality assessments and journal rankings. However, Pittaway et al. (2004) acknowledged that such in-depth quality assessments are a “challenge” (p. 140), which likely points to the additional workload resulting from these assessments. Although the quality-related inclusion criteria in articles such as that of Nguyen et al. were made transparent, none of these articles disclosed a list of excluded research items based on quality considerations. To increase transparency, such a list could, for instance, be included in the review articles’ online appendix. 10
Another way to assess quality in some reviewed studies was the criterion that the included research items had to be published in “peer-reviewed journals” (without reference to any journal ranking), which should assure some minimum quality of the selected items due to the peer-review process (e.g., Radaelli & Sitton-Kent, 2016; Soederlund & Borg, 2018). However, the self-declaration of journals as being “peer-reviewed” may no longer serve as a useful quality criterion because thousands of so-called predatory journals have emerged (Beall, 2012). These journals ostensibly offer a standard peer-review process, yet in reality, they publish anything based on a “pay for publication” approach (cf. Bartholomew, 2014; Bell et al., 2019). Some of the predatory journals have even found their way into popular electronic databases such as EBSCO Business Source Premier. So, for future systematic reviews, it may be useful to not only rely on ostensible peer-review processes but to complement this criterion with further quality checks.
Reflections on the Screening Step
For the screening step, my review also identified several options to make sample selection in reviews of management research more structured. This includes the A/B/C logic and points-based approaches, which were only applied in a handful of review studies but would allow for a structured analysis of the content fit of the identified research items with the research question(s) at hand. These approaches also provide frames for more transparent reporting on the screening step. Such transparency could be further enhanced by disclosing the research items excluded during screening and the reasons for their exclusion, such as the low fit with the research question(s), underlying research design (e.g., empirical vs. nonempirical), and quality assessments. Such information will be produced by review authors anyway when they conduct a structured screening of the initially identified research items (e.g., in the form of spreadsheets), but their disclosure would increase transparency. Again, such detailed reporting requires space, which could be helped by online appendices—if available at the respective publication outlet.
Finally, my review also identified frameworks and checklists that enable quality assessments beyond journal rankings. Review authors could consider these approaches to ensure that quality research items are not excluded from the analysis due to being published in an outlet that does not carry a sufficient ranking. These considerations could also be used to make a review sample more comprehensive by working toward the inclusion of all relevant research of sufficient quality irrespective of journal rankings.
Disclosure of the Review Sample
Disclosure of Included Research Items and Sample Sizes
As reported in Table 5, a full list of research items was disclosed in only 50% of the analyzed articles. For the other 50%, the transparency of the sample selection process was limited. In the earlier parts of the time covered in my analyses (i.e., between 2004 and 2010), length restrictions of journal articles may have been a valid excuse for why researchers could not report a full list of the reviewed articles in the article. However, thanks to online appendices, such arguments are no longer as valid as some years ago. Indeed, 45 analyzed articles, all of them published between 2012 and 2018, offered full lists of the reviewed research items and additional information in online appendices. Alternatively, the full list of research items can be disclosed by marking them in the reference list of the respective review article (e.g., with an asterisk), which was also used by somewhat older articles (e.g., Bakker, 2010; Delarue et al., 2008). Regardless of the specific method, the disclosure of the list of research items included in the review sample can be regarded as a must for presenting a transparent systematic review.
Included Research Items in Final Review Samples.
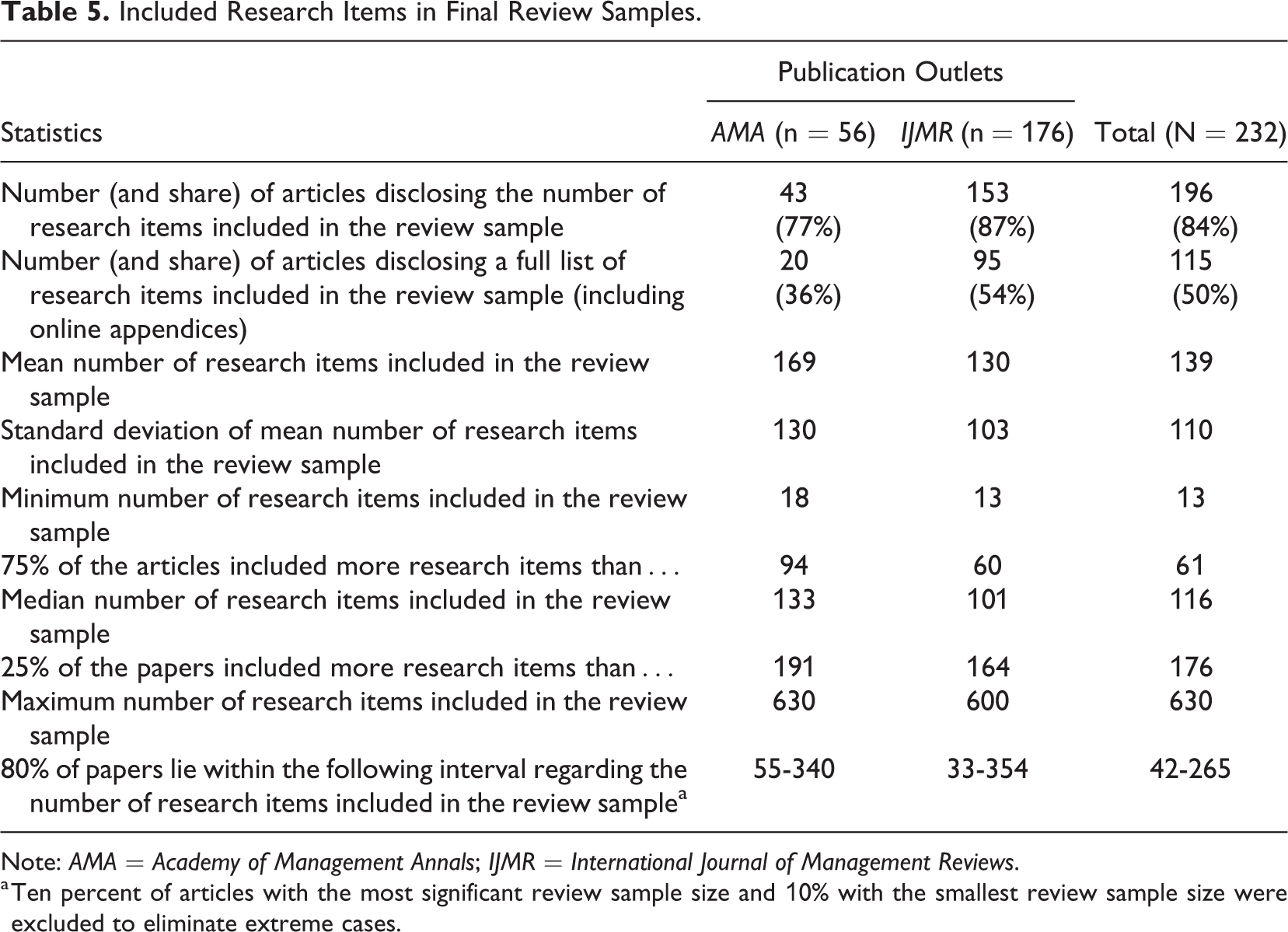
Note: AMA = Academy of Management Annals; IJMR = International Journal of Management Reviews.
a Ten percent of articles with the most significant review sample size and 10% with the smallest review sample size were excluded to eliminate extreme cases.
A high share of the analyzed articles (84%) disclosed the size of the final review sample. As indicated in Table 5, the overall mean review sample size amounts to 139 and the median to 116. When excluding the 10% of articles with the largest and the 10% with the smallest review sample size (which may be regarded as extreme values), the remaining 80% of the analyzed articles have final review samples encompassing between 42 and 265 research items (see Table 5). When using the 80% interval for AMA and IJMR as a benchmark, one could also infer that the critical mass needed to warrant a separate systematic review article in management research (cf. Short, 2009) starts at 33 to 55 research items.
Reflections on the Disclosure Step
The disclosure of the review sample is mainly geared toward making a systematic review transparent. Regarding this desired attribute, however, my analyses showed that future systematic reviews could be made more transparent by disclosing both the size of the review sample and a full list of research items in this sample.
Discussion and Concluding Comments
Implications for Future Systematic Reviews of Management Research
The high and growing share of published systematic reviews indicates that this form of review is, at the time of writing, about to become the new normal in review methods in management research. At the same time, because specific research questions and inclusion/exclusion criteria guide systematic reviews, there is no one “right” way of selecting relevant research items. In contrast, there are several choices to be made by review authors in the sample selection process, which regularly come with specific issues to be considered. These are summarized in Table 6.
Sample Selection Choices in Systematic Reviews of Management Research.

Overall, the aforementioned findings imply that future systematic reviews of management research could be made even more structured, transparent, and comprehensive. More structured reviews could be realized by stringently aligning the sample selection processes with the review’s central research question(s). For instance, future review authors using journal-driven search approaches may need to reflect on whether searches of certain journals could be complemented with further ways of identifying relevant research, which could better enable them to comprehensively address research questions on the entirety of MOS. Likewise, my results suggest that future authors of systematic reviews may need to consider more closely how limitations to the time period covered, the identification of seminal works in seminal-work-driven reviews, the application of citation-based inclusion criteria, the usage of quality assessments, and the application of the A/B/C logic for examining the content fit of initially found research items can be aligned with their reviews’ research question(s) and thus the structured nature of such reviews increased.
Another implication from this article is that more stringent disclosure could raise the transparency of future systematic reviews of management research. As explicated in Table 6, potential ways to increase such transparency include disclosing reasons for limiting a review’s time period, disclosing lists of research items included in review samples and how these items were found (i.e., through structured searches or individual knowledge and manual searches), and disclosing reasons for focusing on empirical or nonempirical research items.
Finally, my results imply that for future authors of systematic reviews, there remain potential choices how the likelihood of a comprehensive coverage of the relevant literature can be increased—for instance, by refraining from imposing unexplained limitations of the time period covered or the usage of combined search approaches when sufficient research resources are available.
In addition to these implications, the data offered in this article on the time periods covered and the mean numbers of research items included in systematic reviews of management research may serve as benchmarks for scholars wondering whether publishing a systematic review as a standalone article is warranted or have questions about the time periods covered in their systematic reviews. Hopefully, the present article can serve as a reference point for such questions, although it must be stressed again that based on a review’s research question(s), there may be valid reasons why a deviation from these reference points is warranted in individual review projects.
Limitations
My analyses and the developed implications are subject to some limitations. First, a systematic review is not always appropriate when performing a literature review (Petticrew & Roberts, 2012; Rojon et al., 2011). When skimming through the AMA and IJMR articles, I also found several reviews leaning toward theory development (e.g., Knights & Clarke, 2017) instead of presenting a synthesis of prior research. For such, and potentially further, review articles, the development or redirection of theory is of primary interest, which may warrant why they do not focus so much on the rationale for the selection of informing articles (cf. Breslin & Gatrell, 2020; Cronin & George, 2020).
Second, an overemphasis on sample selection could risk the mechanical aspects of a systematic review dominating more creative aspects such as synthesizing the literature and developing new insights (cf. Palmatier et al., 2018). As argued by Hulland and Houston (2020), a rigorous sample selection is a necessary condition for a systematic review, but the primary value resulting from such reviews is often the usefulness of the insights generated. Hence, a structured, transparent, and comprehensive sample selection is important but not sufficient and will not necessarily result in a good systematic review.
Finally, there are further highly regarded outlets that frequently publish systematic reviews beyond AMA and IJMR—for instance, the periodic review issues of the Journal of Management, the Journal of International Business Studies, or the Journal of World Business. The two journals I focused on are exclusively devoted to reviews and have published several editorial pieces (e.g., Elsbach & van Knippenberg, 2018; Jones & Gatrell, 2014; Macpherson & Jones, 2010) indicating the expectations from AMA and IJMR toward systematic reviews, including expectations relating to sample selection. The other mentioned outlets have mostly not issued similarly detailed expectations on systematic reviews. Consequently, the methods applied in review articles published in AMA and IJMR may more closely follow these expectations and are thus reported on in more detail and with higher transparency. Although this may limit my findings’ generalizability, I remain confident that the sample selection choices discussed in this article are of interest not only to AMA and IJMR authors but to authors of systematic reviews of management research more generally.
Conclusion
Sample selection is an integral part of systematic literature reviews and includes three steps: (a) the identification and (b) screening of potentially relevant research items and (c) a disclosure of the review sample. These three steps should be conducted in a way that ensures the overall sample selection adheres to three desired attributes: (a) structured, (b) transparent, and (c) comprehensive. Based on an analysis of past reviews published in AMA and IJMR, I have identified several choices where future systematic reviews of management research could adhere even more closely to these three desired attributes in their sample selection procedures. Among these choices, my analyses revealed four principal search approaches for identifying potentially relevant research items. In addition, this article reports data on the mean time periods covered and numbers of research items included in prior systematic reviews, which may serve as benchmarks for future systematic reviews. These more detailed insights into sample selection and the aforementioned implications complement existing methodological advice on conducting systematic reviews in management research (e.g., Adams et al., 2017; Rousseau et al., 2008; Sharma & Bansal, 2020; Tranfield et al., 2003; Williams et al., 2020). I hope that this advice will prove useful for fellow researchers when crafting their next systematic review of management research.
Supplemental Material
Supplemental Material, sj-pdf-1-orm-10.1177_1094428120986851 - Sample Selection in Systematic Literature Reviews of Management Research
Supplemental Material, sj-pdf-1-orm-10.1177_1094428120986851 for Sample Selection in Systematic Literature Reviews of Management Research by Martin R. W. Hiebl in Organizational Research Methods
Supplemental Material
Footnotes
Acknowledgments
I gratefully acknowledge numerous valuable suggestions and comments by Jean M. Bartunek, Laura B. Cardinal, David Denyer, Sven Kunisch, and Markus Menz (the guest editors) and three anonymous reviewers that greatly helped me to improve earlier versions of this article. I also thank David I. Pielsticker for excellent research assistance.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.