
Abstract
The four-parameter logistic Hill equation models the theoretical relationship between inhibitor concentration and response and is used to derive IC50 values as a measure of compound potency. This relationship is the basis for screening strategies that first measure percent inhibition at a single, uniform concentration and then determine IC50 values for compounds above a threshold. In screening practice, however, a “good” correlation between percent inhibition values and IC50 values is not always observed, and in the literature, there seems confusion about what correlation even to expect. We examined the relationship between percent inhibition data and IC50 data in HDAC4 and ENPP2 high-throughput screening (HTS) data sets and compared our findings with a series of numerical simulations that allowed the investigation of the influence of parameters representing different types of uncertainties: variability in the screening concentration (related to solution library and compound characteristics, liquid handling), variations in Hill model parameters (related to interaction of compounds with target, type of assay), and influences of assay data quality parameters (related to assay and experimental design, liquid handling). In the different sensitivity analyses, we found that the typical variations of the actual compound concentrations in existing screening libraries generate the largest contributions to imperfect correlations. Excess variability in the ENPP2 assay above the values of the simulation model can be explained by compound aggregation artifacts.
Keywords
Introduction
High-throughput screening (HTS) is typically performed as a stepwise process, starting with a primary screen of compound libraries ranging from 100 000 to 1–2 million compounds at a single concentration. After data normalization, percent inhibition (“activity”) values are obtained for the compounds at the specific screening concentration.1,2 In a second step, the primary hits (i.e., the compounds passing a fixed threshold or having a larger than 3–6 standard deviation distance from the zero effect level) are selected for concentration-response curve (CRC) validation experiments.2,3 The determination of an IC50 (“potency”) value is based on fitting the four-parameter logistic Hill equation4,5 to the data, although more sophisticated models are sometimes used in detailed pharmacological investigations. 6 The basic assumption of this stepwise HTS design is a reasonable correlation between the percent inhibition and IC50 values, as can be expected from the Hill equation for ideal inhibitors. In screening practice, different sources of variability accumulate and blur this correlation. In addition, in discussion with HTS practitioners, we noticed confusion about what curve such a correlation should be expected to follow. This has led to accounts in the literature where the predictive power of primary, single-concentration screening has been called into question. For instance, McFadyen et al. 7 at Wyeth describe for a set of 118 compounds a “flat” correlation between percent inhibition data determined in the primary HTS and IC50 values determined in a subsequent step. More dramatically, Spencer 8 describes the lack of predictive power of primary activity for a set 1200 known actives included in a Pfizer screen. Depending on assay format and quality, primary screening can yield significant numbers of false positives and false negatives. Inglese et al. 9 have therefore promoted a titration-based approach that they termed quantitative HTS (qHTS), which allows one to confirm hits through replicates and identify CRCs of unusual shape (e.g., bell shaped) directly from primary screening data. With library sizes exceeding 1 million compounds, however, this approach reaches boundaries where logistics, number of data points, and reagent cost become prohibitive. The majority of HTS labs therefore follow the stepwise primary screening model.
Despite these discussions, to our knowledge, the correlation between single-concentration screening data and IC50 values that can be expected both from theoretical considerations, as well as from parameters that influence experimental reality, has not been described in the literature.
We used HTS data sets to examine the correlation between percent inhibition values and IC50 values, using the individual concentrations of the CRC as surrogates for a single concentration experiment. This allowed us to look at the correlation at different concentrations, independent of plate-to-plate and other experimental variability. We then compared these findings with the correlation of CRC results and single-concentration data from the primary screen, thus including all sources of variability one would encounter in real-life screening.
Next, we explored the influence of typical sources of variability, such as compound concentration, on the correlation. To this end, we executed computational simulations to perform a sensitivity analysis of the theoretically expected relationship on the different parameters and to compare the results of these simulations with real-life HTS data.
For the simulations, the general four-parameter logistic Hill equation was used as a definition of the theoretical relationship between percent inhibition data and log10(IC50) data. This allowed investigating the influence of the various Hill curve parameters and also variations in the effective screening concentration and variations in readout scale and data normalization. With these simulations at hand, we were able to explore the boundaries of the current HTS paradigm and essentially derive values for the “best possible” correlations that can be expected given a few basic characteristics of the assay data and of typical compound stock solution libraries. Importantly, we were able to distinguish assays in which the data variability was adequately described by the simulation from types of assays in which additional sources of variability have to be considered. We feel that there is value in clarifying some key relationships in this context, especially since the widespread adoption of screening as a research tool in academia means that scientists will be exposed to these questions beyond a relatively small group of expert users.
Methods
HDAC4 and ENPP2 Assays
The principles and methods of the two assays that are used as illustrations in this article are described in the Supplemental Material.
The Four-Parameter Hill Equation and the Simulations
The four-parameter logistic or Hill slope equation (1) is in practice the most frequently used model expression to describe the sigmoid CRCs. It describes the ideal relationship between the inhibition value y at some screening concentration x with a total of four parameters—namely, IC50 (inflection point), the Hill coefficient n (slope), and the asymptotic plateau values A0 and Ainf at low and high concentrations.
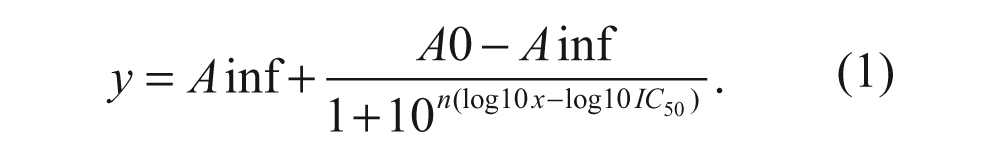
Several alternative but mathematically equivalent expressions are in practical use.4,5,10 We have performed Monte Carlo simulation experiments that were designed to obtain a better quantitative understanding of the expected correlation between inhibition values at some constant concentration and the experimentally derived IC50 values from the same experiment (within-curve correlation) and also from independently performed experiments. The latter will mirror the situation encountered when comparing single data point primary screening results with the corresponding IC50 determinations based on different stock solutions or fresh solutions prepared from powder. In most cases, the simulations will represent the “best possible” correlations that can be expected in a screening assay with the same variability as included in the calculations. Uncorrected systematic plate response errors, additional erratic behavior in some assay execution step, or some compound-related distortion effects will increase the observed scatter. A “tighter” correlation of the experimental data than observed in the simulations with given assay quality parameters can occur if the distribution of the effective solution concentration is entered in a too pessimistic way. We think the calculations are useful for the screening practitioner to gain insight into the relationships of the primary percent inhibition results and the IC50 values of the follow-up screen and their possible degree of variation. The simulation studies were all performed using the R statistical computing system. 11
In contrast to the standard use of equation (1), we determine the relationship between the inhibition y and log10(IC50) at a certain constant screening concentration x. Due to the symmetry of the equation between the log10(x) and log10(IC50) terms, it is obvious that the relationship between y and the varied factors has a sigmoid shape in both cases.
To perform the simulations in the most realistic way, we base the whole procedure on the generation of suitable “raw data” and subsequent data reduction and data analysis steps in the same way as in a real screening campaign, including normalization and dose-response curve fitting for the derivation of “experimental” IC50 parameters. A graphical outline of the simulation procedure, main parameters, and data-processing steps is shown in Figure 1 .
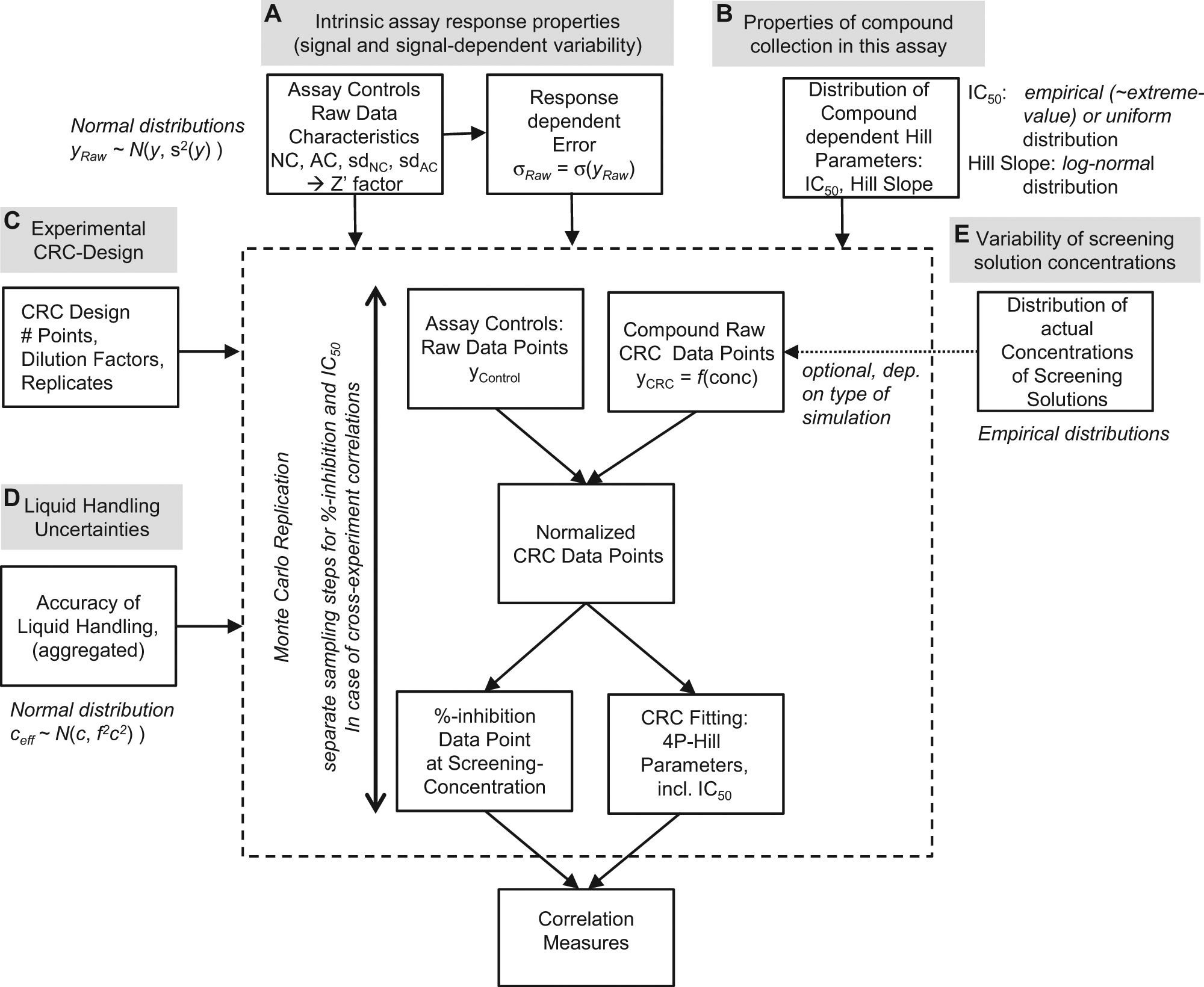
High level overview of the Monte Carlo simulation setup. Experimental factors and simulation parameters A to E are described in more detail in the text and in the Supplemental Material. CRC, concentration-response curve.
The input parameters to the simulation model as outlined in this figure can be categorized as follows: (A) characterization of the raw signal amplitudes y and the signal-dependent uncertainties σ(y) of the various types of control samples, where the continuous response-dependent error is taken as
Simulated raw data for controls, percent inhibition, and concentration-response series data are generated in a Monte Carlo procedure, normalized, and fed into a curve-fitting function (R concentration-response curve fitting package “drc” 10 ) for the estimation of the four parameters of equation (1). These derived parameters are the equivalents of the experimentally derived values, whereas the model input parameters described in (B) above can be considered as the “theoretical” underlying characteristics of the compound effects in the particular assay. The simulation output thus reflects the influence of the different stochastic factors, experimental design aspects, and the CRC parameter estimation procedures. The calculations allow us to assess the influences of the various sources of uncertainties on the correlation parameters. Experimental variability not accounted for in our generic model of common factors of uncertainty in screening processes (e.g., additional compound aggregation effects) will lead to further widening of the distribution and lower the correlation measures accordingly. In this sense, we are able to derive the “highest possible” degree of correlation in the absence of additional “unknown” distortion factors. Further comments and details on data handling in the simulation procedure can be found in the Supplemental Material to this article.
Since the relationship between percent inhibition values and IC50 or log10(IC50) values is nonlinear, as per equation (1), the “usual” linear (Pearson) correlation coefficient
15
should not be used to measure the degree of association. If the data range is restricted to about ±30% around the 50% effect, the approximate linearity of the relationship can still be assumed,
16
but this is no longer the case outside of this range. Examples of the use of the simple linear correlation coefficient over a wide range of concentrations to represent the relationship between inhibition and potency data can be found in the screening literature,
17
but its use is not appropriate. Instead, we use Spearman’s R
18
and Kendall’s τ
19
—both characterizing and summarizing monotonic relationships between two variables—and Joe’s δ*,20,21 an information-theoretical measure for monotonic or nonmonotonic association, as the preferred alternative summaries for association and correlation between our two quantities of interest. δ* is based on the entropy-based mutual information measure but transformed and normalized in such a way that it is equivalent to more “classical” correlations. All these quantities are nonparametric and do not depend on assumed linear relationships. The practical calculation of δ* is based on 2D binning of data, and its value depends to some degree on the number of bins chosen.
21
We use either a fixed value (nbin = 10) or nbin =
It is possible to create an alternative linearized view of the relationship between the initial primary and follow-up CRC experiments by plotting the experimental percent inhibition value and the calculated percent inhibition value at the particular screening concentration using the four Hill equation parameters. This representation has the disadvantage that data points in the transition region around the primary screening concentration, where the variability is usually the largest, are smeared over a wider area of the correlation plot due to the nonlinear nature of the transformation. Furthermore, due to error propagation from the three other Hill equation parameters, the correlation measures can be changed (albeit usually only slightly) by this back-transformation.
Results and Discussion
Observed Experimental Relationships between Percent Inhibition and IC50 Values
The logistic Hill slope model is used to describe the relationship between a screening concentration and the resulting percent inhibition value. The model, however, can also be used to describe the relationship between an IC50 value and the expected inhibition at a fixed screening concentration. Transformation of equation (1) allowed us to generate Figure 2A , describing the effect of varying the screening concentration from 0.01 to 10 µM for IC50 values ranging from 0.1 µM to 1 mM and assuming A0 = 0 and Ainf = -100 with n = 1. The expected sigmoid relationships are observed, with inflection points at the screening concentration. With decreasing screening concentration, the curves exhibit a left shift, always intersecting the -50% line at the screening concentration. The influence of a possibly varying Hill slope on the given ideal relationship is most pronounced in the region of the bend points 16 of the curves see ( Fig. 2B ).
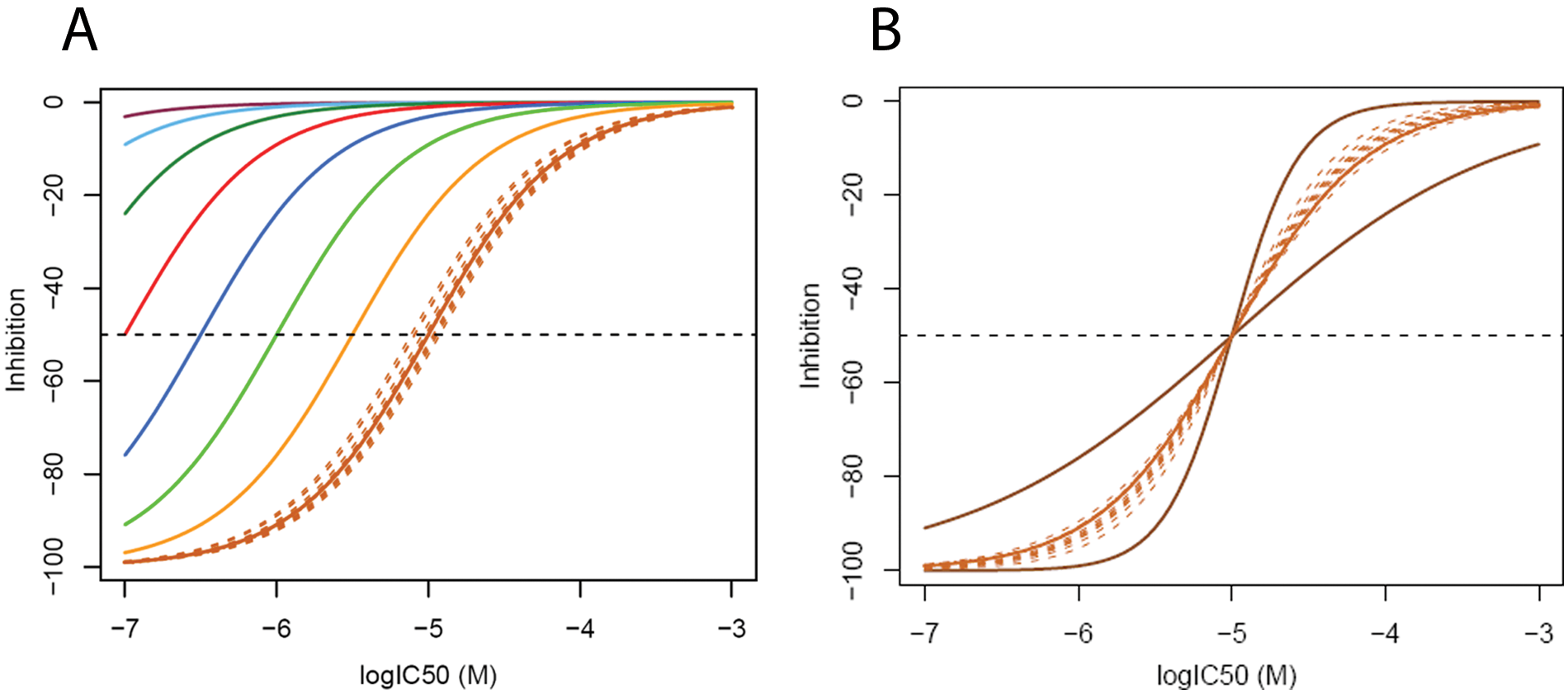
(
This sigmoid relationship can be observed in experimental HTS results despite the variation that is associated with such data. Sources of variability in HTS have been reviewed2,3,25 and include technical errors (instrument malfunction, i.e., pipetting errors), biological errors (i.e., reagent stability and concentration), and statistical errors. We used an enzymatic assay that measured the activity of the histone deacetylase HDAC4. The enzyme removed a trifluoromethyl group from a lysine in a tripeptide substrate. This revealed a trypsin cleavage site, and treatment with trypsin liberated the fluorogenic dye Rh110. Inhibitors of the detection enzyme trypsin were removed in a counterscreen that did not contain HDAC4. However, the impact of compound interference by the choice of a red-shifted fluorogenic dye Rh110 and the removal of nonspecific (e.g., “aggregator”) inhibitors in a counterscreen were designed to minimize the impact of compound interference with the assay.
Of the 3749 compounds that had shown >20% inhibition, 1138 showed >50% inhibition in a 1.4 million primary screen in our test set for this study. Eight concentrations were arrayed in quadruplicates on the same plate to avoid effects from plate-to-plate variability and other random and systematic factors. A total of 1956 compounds did not allow the determination of an IC50 value and were classified as IC50 >10 µM. A further subset of 1283 compounds did not allow the determination of Ainf, or the unconstrained parametric fit failed for other reasons, and therefore the concentration at which the 50% inhibition line was crossed was taken as its IC50 (absolute IC50). The absolute IC50 is a reasonable surrogate value in these cases, as we found a median of 1.02 and a median absolute deviation (MAD) of 0.13 for the ratio of (relative) IC50 to absolute IC50 for the cases where complete curves were obtained. The remaining 510 compounds allowed a fully unconstrained parametric fit to the Hill equation, with IC50 values ranging from 7 nM to 10 µM. Overall, we have obtained 785 IC50 values from the complete primary hit list (20% inhibition cutoff) and 656 IC50 values for compounds initially exhibiting more than 50% inhibition, which corresponds to a 58% validation rate of this set of primary hits.
In Figure 3A , the measured CRC inhibition values were plotted against the log10(IC50) value for all concentration points, so this plot shows the within-curve relationships of these quantities.
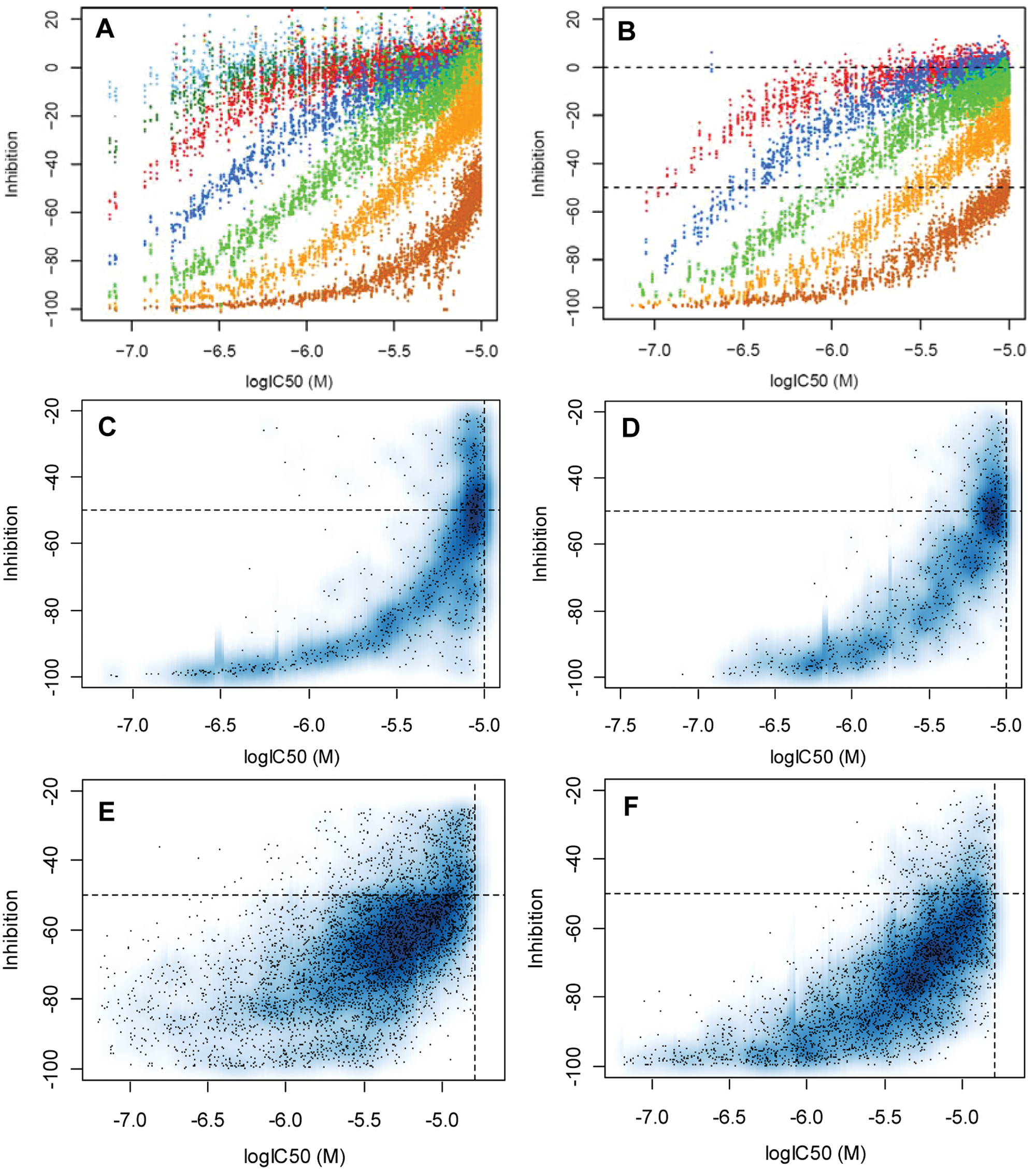
(
The equivalent relationship can also be observed in a “real-life” screening situation, that is, by plotting the percent inhibition values obtained during primary screening against the IC50 values ( Fig. 3C ). The spread of the data increased, especially for lower potency compounds, and the sigmoid relationship is truncated by the highest concentration of the CRC, as well as by the cutoff at 20% inhibition that was used for hit selection in the primary screen. As expected, the region of highest point density passes through -50% at the primary screening concentration of 10 µM.
A semi-logarithmic plot as in Figure 3C allows an immediate judgment on a question that is frequently asked by project teams—that is, if the IC50 values are in accordance with the primary screening data and if the primary screen is predictive of compound potencies as measured in the IC50 experiment. A simple plot as used and proposed here gives immediate confidence in the data quality but, to the best of our knowledge, has so far not been used in literature to give a visual and very intuitive representation of the relationship of the main results of a typical HTS campaign.
Clearly, values will often deviate from the ideal sigmoid curve in real screening data. Differences in compound concentrations, Hill slope values other than 1, and many other factors can affect the correlation. To understand the influence of the major different sources of variability, we built a phenomenological mathematical model that allows the determination of the influence of the most important assay characteristics and parameters on the correlation.
Calculated Relationships between Percent Inhibition and IC50 Values
The computational experiments allow us to perform a quantification of the expected relationship and variability between single-point inhibition data and estimated IC50 values. A quantification of the relationships (joint or conditional parameter density distributions, correlation summaries) from the simulation results is easily accomplished. Also, rough estimates of expected false-negative and false-positive probabilities for single-point primary data, based on a fixed inhibition threshold (e.g., 50%) and on an upper limit setting on the empirical compound potency in the validation screen (e.g., 10 µM), can be made. In actual screening situations, factors that are not taken into account in the simulations might come into play and modify the overall picture somewhat.
An underlying assumption in the simulation procedure for “separate experiment” runs is that the assay quality in the single-point primary screen is the same as in the serial dilution validation screen. The results derived from such simulation studies are usually “best-case” results under the assumptions mentioned above, but as such they are valuable for getting more quantitative insight into the highest possible degree of correlation that can be expected between primary and validation experiments in an assay with a particular design (concentration range, number of replicates, number of concentrations), quality characteristics (dynamic signal range and assay error law, indirectly measured by Z′ factor), process-related factors (concentration variability, liquid-handling reproducibility/variability), and finally also the range and distribution of IC50 values in the assay.
In Figure 3B , we show the within-curve correlation plots of the simulated data based on the key characteristics of the actual HDAC4 screen that can be compared with the experimental situation as displayed in Figure 3A .
The resulting within-curve correlation of the simulated and the actual assay data at 10 µM with the respective fitted IC50 values is shown in Table 1 . The ranges of values are derived from 10 independent repetitions of the simulation runs. In addition, as previously described, the δ* values also depend on the number of data bins chosen for the calculations.
Comparison of Correlation Measures for the Within-Curve (Same Experiment) Relationship between Inhibition and log10(IC50) Values at 10 µM Screening Concentration
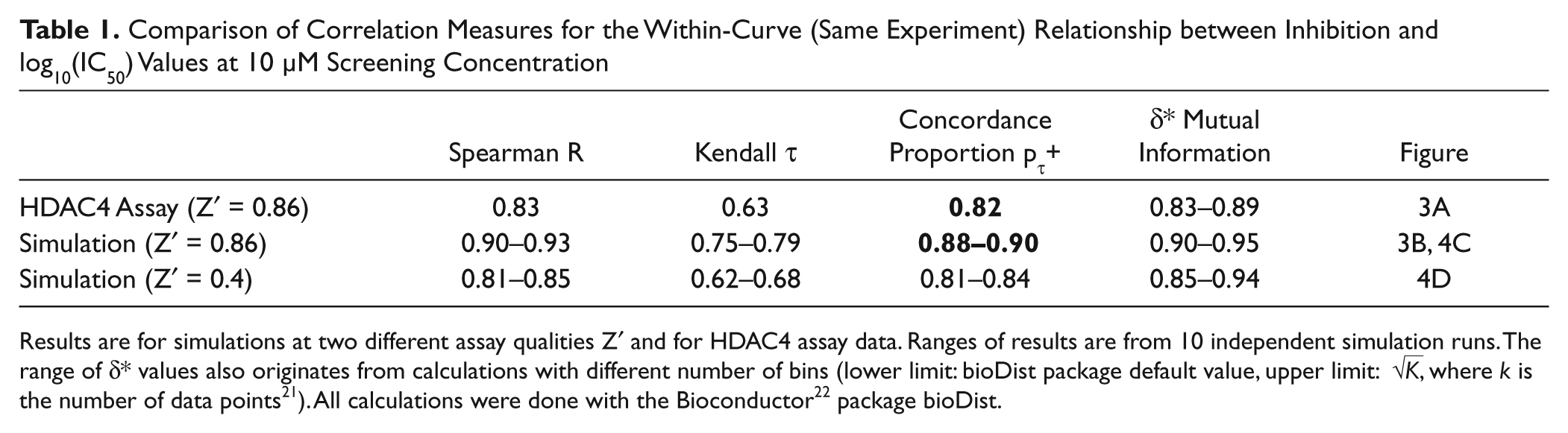
Results are for simulations at two different assay qualities Z′ and for HDAC4 assay data. Ranges of results are from 10 independent simulation runs. The range of δ* values also originates from calculations with different number of bins (lower limit: bioDist package default value, upper limit:
We observe that the different experimental within-curve correlation measures are slightly smaller than the results of simulation runs with the Z′ = 0.86 parameters, but in both cases, the sigmoid relationship (right-truncated at the screening concentration) is clearly discernible, and the correlation measures are all highly significant (p < 10−16). When comparing Figure 3A and 3B , we can see that at 10 µM (brown data), a slightly higher fraction of HDAC4 assay data points lies further away from the bulk of the sigmoid-shaped distribution than is the case for the simulated data set. Such “outliers” are not captured and modeled in the present simulation setup. Often, groups of two or more points of a quadruplicate are outliers in this sense, and this then leads to the observed lowering of the correlation measures. We have not incorporated such “systematic” errors (i.e., comprising whole groups of data points) and outlier contributions in our simulations because too many ad hoc tuning parameters would have been needed, and our primary aim was to represent the main characteristics of a reasonably well-behaved assay setup and the resulting percent inhibition-log10(IC50) relationships in an approximate quantitative way.
The data in Figure 3D were calculated with the same characteristics as the (10 µM, brown) data in Figure 3B , but an additional factor—namely, a probability distribution that describes the possible differences between the effective screening solution concentrations in the primary and validation runs—was introduced. 14 The corresponding correlation measures are shown in Table 2 . When comparing Figure 3C and 3D , we observe that the most prominent part of the experimental relationship (left) is more discernible (has higher point density) and less “washed out” than in the simulated correlation plot (right). On the other hand, a slightly wider small background distribution is observed in Figure 3C . Possible explanations for these differences are the following: (1) The ratio of the effective concentration between primary and validation runs is less random and more highly correlated (i.e., likely more compound dependent) than what sampling from the empirical distribution derived from a broad range of different compounds suggests, 14 and (2) uncontrolled and random experimental factors (e.g., differences in assay reagent batches, occasional differences in reagent stability, changes in the dynamic range of responses, changes in liquid handler calibrations and stability, and dropouts of single pipettor needles) that we already had observed in Figure 3A to some degree may play an even larger role in the primary screening situation than in the validation screen and the corresponding within-curve relationship. Clear outliers and possibly resulting bad curve fits are more easily detectable in the IC50 estimation phase, and such data or curves will more likely be eliminated, whereas this is not possible in nonreplicated primary screening. In this sense, the final IC50 result collection is much less influenced by remaining random experimental variations than the single primary inhibition data. Nonetheless, in reasonably well-behaved and quality-controlled assay runs, this should not be a large problem.
Comparison of Correlation Measures for the Relationship between Inhibition and log10(IC50) Values at 10 µM Screening Concentration for Independent Experiments
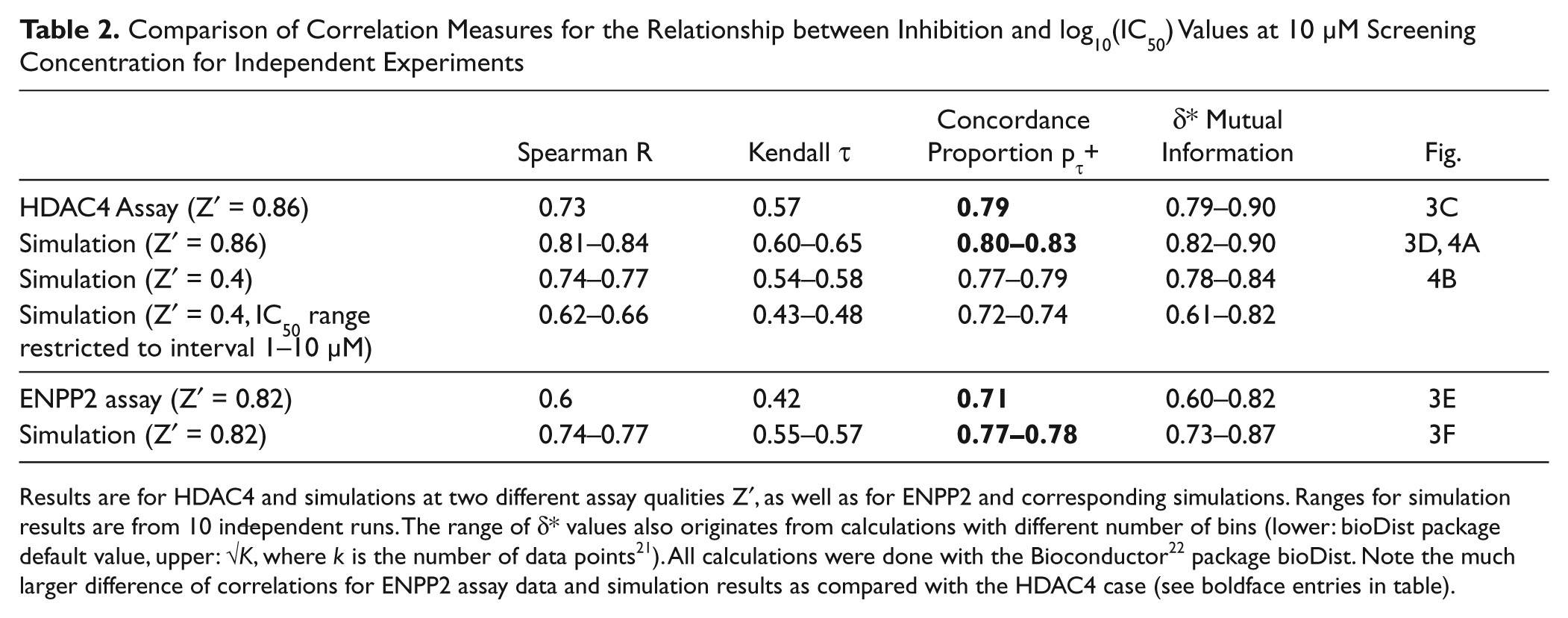
Results are for HDAC4 and simulations at two different assay qualities Z′, as well as for ENPP2 and corresponding simulations. Ranges for simulation results are from 10 independent runs. The range of δ* values also originates from calculations with different number of bins (lower: bioDist package default value, upper:
Similar to the previous within-curve correlation coefficients, we observe here also somewhat smaller values for the actual assay data than for the corresponding simulation with Z′ = 0.86. As previously discussed, the slightly broader background in the real assay data ( Fig. 3C ) as compared with the simulation ( Fig. 3D ) is not completely surprising. So it is again the comparatively larger set of “outlier” data that lowers the degree of association and concordance in the HDAC4 data. It is easy to show, for example, that a 10% random contamination (a homogeneous background of random inhibition values) of a data set with the same characteristics as our Z′ = 0.86 example with τ = 0.7, pτ+ = 0.85 will lower these values to approximately τ = 0.6, pτ+ = 0.8 and exhibit similar shifts for the other correlation measures. From τ = 0.6, pτ+ = 0.80, the reduction is on average down to τ = 0.55, pτ+ = 0.78, so roughly what we observe as shifts between the “optimistic” Z′ = 0.86 simulation and the actual assay data for the within-curve correlations ( Table 1 ) and for independent experiments ( Table 2 ), respectively.
The general assay data quality characteristic can be derived more directly than the solution concentration differences between the single-point and the concentration-response screens. The latter can be accommodated in an average and approximate way by integrating historical information on the distribution of the effective concentrations of screening solutions into the calculation. Other random factors leading to “outlier” data can be considered in a summary fashion, as mentioned in the previous paragraph. Both these “noise” contributions will lead to some degree of lowering of the correlation measures. Because both of these phenomenological factors cannot be determined experimentally in the context of a particular assay (for purely practical and economic reasons), we are taking them into account via the described summary approaches (empirical concentration distributions and estimates of correlation reduction factors in the presence of “background” noise).
In summary, a comparison of experimental and simulated data ( Fig. 3C , D ) showed that typical data characteristics of HTS experiments combined with factors such as concentration variation of stock solutions were sufficient to account for the observed data variability. For several other biochemical assays, we see similar degrees of agreement of primary and secondary IC50 screening results (data not shown), and we can conclude that the main factors of variability in HTS experiments are captured by our procedure.
A similar data set from an ENPP2 screen was analyzed as an example for a more challenging assay ( Fig. 3E , F ). The assay is based on cleavage of the quenched substrate FS-3. FS-3 is an analogue of the endogenous substrate lysophosphatidylcholine (LPC).26,27 During assay development, we found the assay to be quite sensitive to compound aggregation, which could partially be controlled by addition of detergents in the assay buffer (see Supplemental Material). A primary screen of 1.4 million compounds was run with a Z′ factor of 0.82, and after a confirmation run, 5262 compounds were selected for IC50 determination. To minimize interference by fluorescent compounds, we determined IC50 values from slope changes of reaction progress curves rather than from end-point measurements. The experimental data set in Figure 3E and the corresponding simulated experiments in Figure 3F clearly show that in this case, sources of data variability are at play that are not included in the basic simulation. These factors are likely assay specific, and in this case, compound aggregation and readout differences between the primary end-point format and the kinetic measurement format for the IC50 determination phase are likely causes for the discrepancy.
In Figure 4 , we show a set of scatter plots to compare the general appearance of the calculated inhibition-log10(IC50) relationship based on HDAC4 assay data characteristics but varying Z′ for the two cases of independent experiments and within-curve correlations. The corresponding correlation measures are shown in Tables 1 and 2 . The Z′ = 0.4 example case ( Fig. 4B , D ) corresponds to a 4.5-fold increase of the standard deviations of the controls as compared with the simulated data set with Z′ = 0.86 ( Fig. 4A , C ). We can see that the influence of the inclusion of the differences in the effective screening concentration ( Fig. 4A , B ) is visually dominating the scatter plot (wider scattering of data), much above the effect of the change in assay data quality. This contrast in appearance is also reflected in the larger average difference of the correlation measures between the different types of experiments (i.e., between Tables 1 and 2 or between the upper and lower rows of plots in Fig. 4 ) than is found between the different Z′ values (i.e., between left and right plots in Fig. 4 ). The contrast difference is most pronounced in δ* when taking the upper value range limits (which are calculated with the “optimal” number of bins) because the mutual information measure 21 is estimated from the occupation numbers of the 2D scatter plot (2D histogram) and thus quite directly related to its visual appearance.
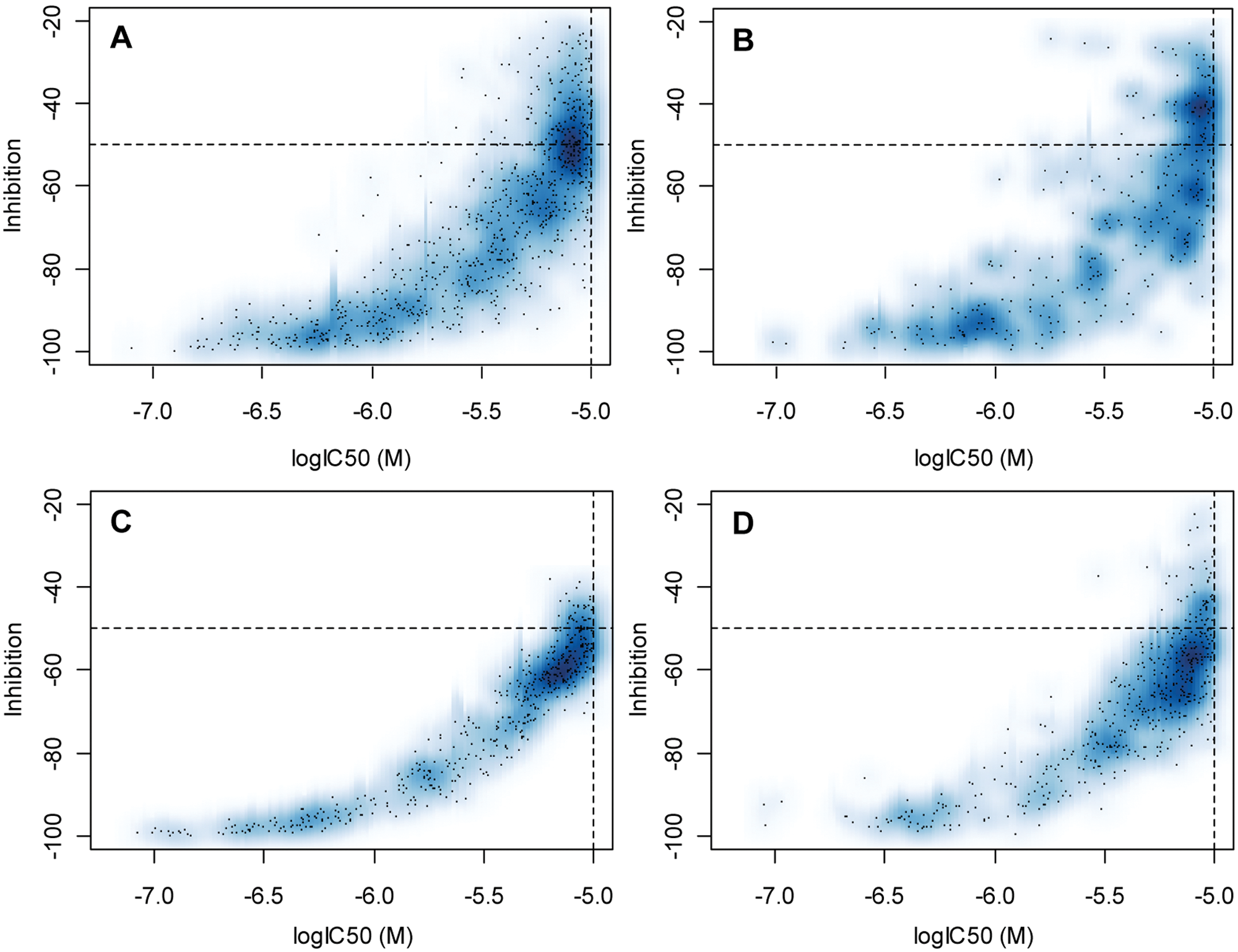
Illustration of the simulated inhibition-log10(IC50) relationships in independent and identical experiments with varying assay quality. For the independent experiments, the effective screening concentration for inhibition and IC50 determinations was independently varied based on empirical solution concentration distributions. (
When looking at a more restricted range of IC50 values, the correlation measures will naturally tend to become smaller, as for any underlying increasing relationship between two quantities. We show an example of this effect for the Z′ = 0.4 simulation results in Table 2 . When only considering the IC50 range from 1 to 10 µM (half the initial logarithmic data range), then all correlation values become considerably smaller, but the corresponding p-values are still <10−16, and thus all correlations continue to be statistically highly significant also for the smaller data range.
A more extensive comparison of correlation data with the basic HDAC4 characteristics but varying assay data quality (Z′ factor) and the influence of the solution concentration uncertainties is shown in Figure 5 .
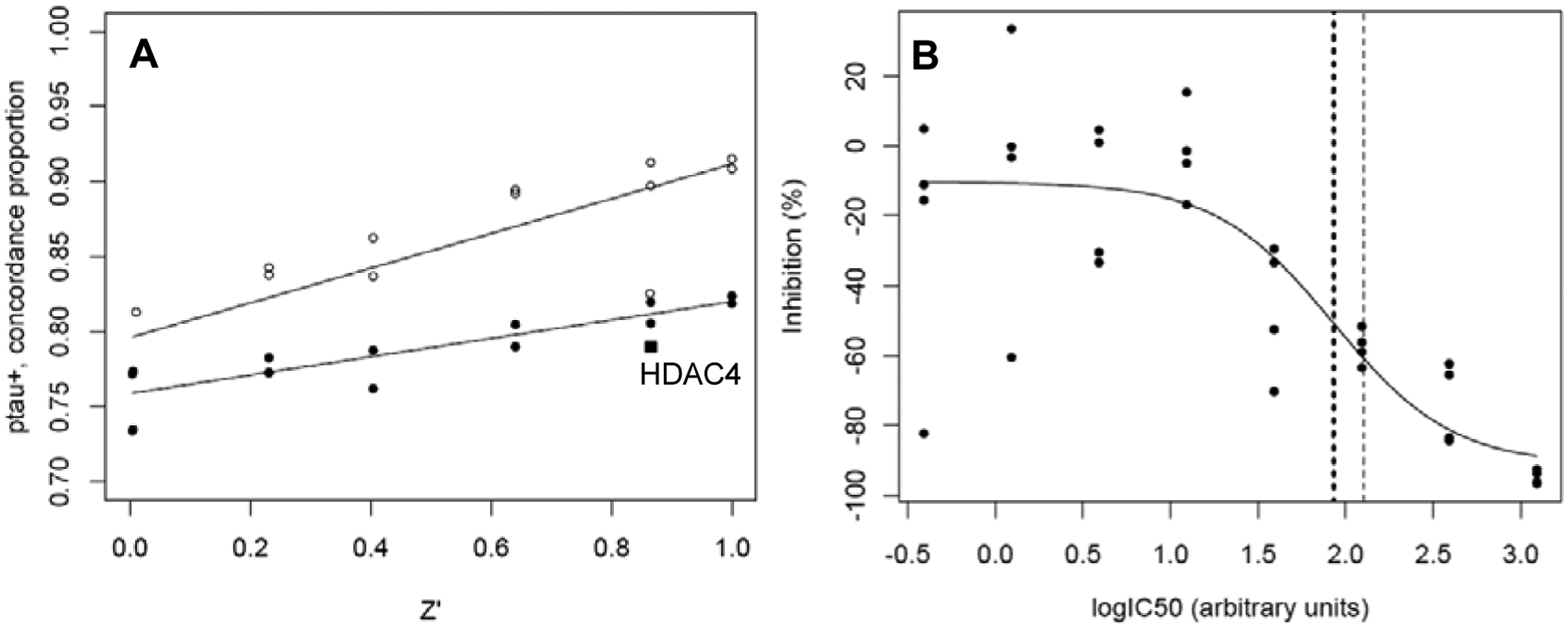
Illustration of the dependence of correlation measures on assay data quality (Z′ factor). The concordance proportion pτ+ can be interpreted as the probability of preserving the activity rank order between any two pairs of data points in the inhibition versus IC50 scatterplots. (
We have performed a series of simulation experiments with varying Z′ factor for two different situations—namely, with and without inclusion of the solution concentration distribution factor. Both result sets are shown in Figure 5A . A particular Z′ factor can be generated by multiple differently sized standard deviation (SD) values of the two types of controls when their respective means are constant. In the calculations, we have chosen to proportionally increase both control SD values, and for the Z′ = 0 case, we have also explored the more extreme “symmetric” error situation where the SD value of both controls is equal in size. This creates a wider distribution for values with “full inhibition” and then results in the lower pτ+ value for both types of relationships shown in Figure 5A . We again observe highly significant correlations between primary and IC50 data for this much wider range of the Z′ data quality indicator than we have previously shown in Tables 1 and 2 .
In Figure 5B , we show an arbitrary example of a simulated CRC data set, which was generated with the asymmetric control error distribution resulting in Z′ = 0. Curve fitting and the derivation of reasonably accurate IC50 values (as judged by the two vertical IC50 markers for model value and “experimental” result) are still possible even with such “low” data quality because of replicated measurements and the presence of data at multiple different concentrations. This will largely offset the uncertainties of single data points in the CRC data.
Another type of calculation allows us to determine the likely variation of inhibition values in different regions of activity values. These simulations are based on a uniform distribution of log10(IC50) values over a larger numerical range than in the previous calculations. An example of such a calculation (IC50 range from 0.1 µM to 1 mM, 10 µM primary screening concentration) using the same basic system parameters as used for the ones in Figure 3D or Figure 4A is shown in Figure 6A .
The smooth local regression line provides the basis for calculating the approximate standard deviation. The individual absolute values of residuals based on the local regression curve are shown in Figure 6B . They allow the derivation of a smooth estimate for the locally varying median absolute residuals and, subsequently, a robust standard deviation measure. 23 The line in Figure 6B represents this varying standard deviation. The asymmetry in the curve position between strong inhibitors (left) and inactive compounds (right) is clearly visible. This is a direct reflection of the respective response variability of the full-inhibition and zero-effect controls or samples, respectively. The significantly larger variability for samples with an IC50 around the screening concentration is readily visible and reaches the 4- to 5-fold value of the zero-effect samples. A concomitant strong increase in false-positive and false-negative rates for samples with such “borderline” potencies above estimates that are based only on control sample response variability is obvious. The increase of the error in the center region is of course related to the rate of change of the inhibition-log10(IC50) relationship—largest around the inflection point—and is expected on these grounds, but the simulation allows us to provide a rough quantification of the increase due to factors that are not directly tractable through a formal mathematical analysis, which is simply based on equation (1).
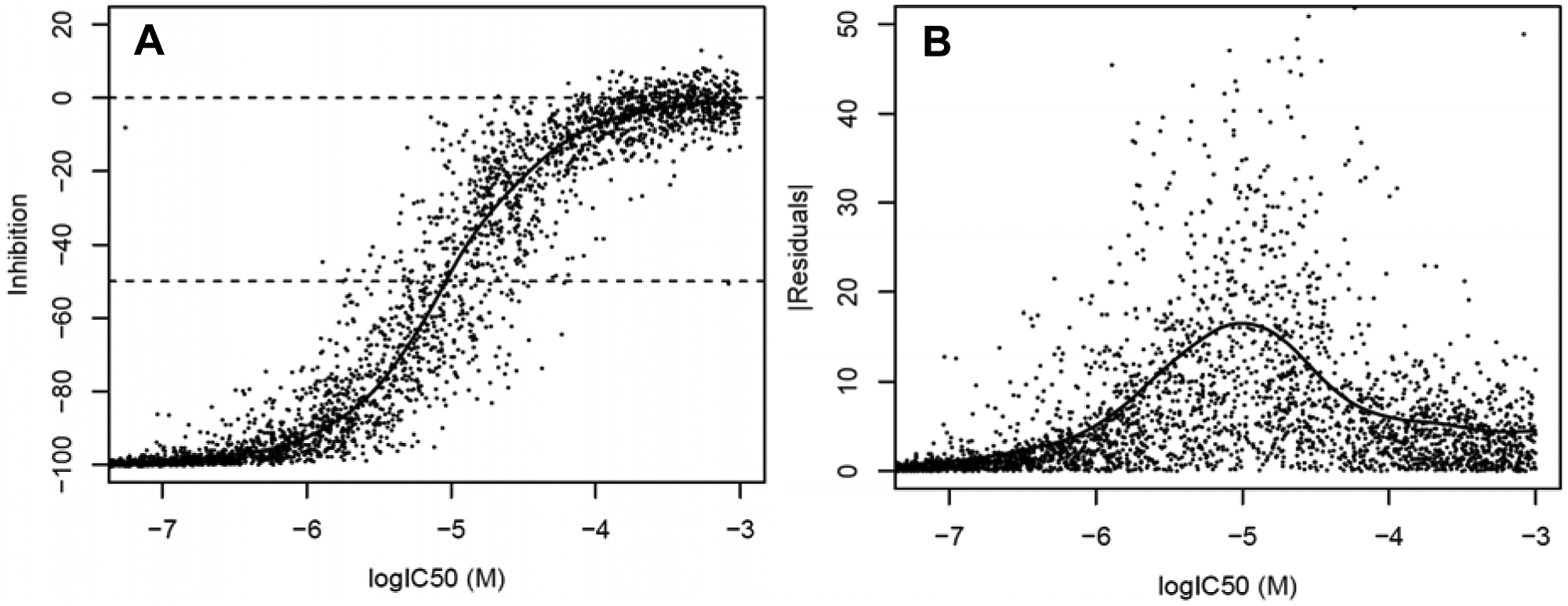
Illustration of the relative increase of percent inhibition variability for values between the bend points of the nominal theoretical relationship based on equation (1). (
The question of whether primary screening data are predictive of IC50 values is encountered frequently in lead-finding projects. Through a transformation of the Hill equation, we have generated plots that show the correlation of percent inhibition values with IC50 values under ideal conditions. Using an example of a typical biochemical assay of HDAC4 activity, we were then able to show that this ideal behavior can be observed under real screening conditions, despite the many factors that contribute to data variability in screening data. We then moved on to examining the influence of typical sources of data variability on the quality of the percent inhibition versus IC50 correlation. Building a mathematical simulation that models the influence of experimental sources of variability, we found that choosing typical values for distribution of compound concentration, statistical assay quality, and distribution of Hill coefficients, for example, resulted in result distributions that are very similar to the experimental data. This confirms that these common factors are largely sufficient to explain variability in experimental data that is observed, for example, in the HDAC4 assay, which possesses a good statistical quality (Z′ = 0.86).
In addition to sources of variability that are common to all screens, there may be sources of variability that are assay specific. For example, the influence of non-stoichiometric inhibition through compound aggregation is highly buffer dependent. In a second example of an ENPP2 screen, these factors resulted in a noticeable discrepancy between the experimental and the simulated data. It should be noted that this discrepancy is not reflected in the statistical quality of the ENPP2 assay as described by Z′ = 0.82.
In an attempt to quantify the deviation from ideal behavior for experimental data, we calculated different correlation coefficients. These coefficients allow judging the relative influence of different sources of data variability. We have found that the distribution of compound concentration in screening decks is the largest single common contributor to data variability in an HTS setting and influences the variability of primary screening data stronger than the assay quality measured by the Z′ factor. In addition, the correlation coefficients, together with the plots, allow researchers to spot assays that are influenced by assay-specific sources of variability, in addition to the general boundary conditions of the HTS experiment, which are mirrored by the simulation results. Derived in pilot screening, they may be useful in triggering additional efforts in assay development.
In this contribution, we hope to provide lead-finding scientists with a practical framework to discuss and judge the predictiveness of their primary screening data. As we find adequately large correlation measures even for the more problematic assay that we have investigated (pτ+ > 0.7), we conclude that for robust assays with good Z′ factors, the HTS paradigm of single-concentration screening followed by concentration-response curves is a valid and cost-efficient approach to detect active compounds and compound families.
Footnotes
Acknowledgements
Drs. Peter Fürst and Adam W. Hill are acknowledged for various discussions and support. We thank Sandrine Ferrand, Aline Tirat-Boeuf, and Lukas Leder for experimental work. We also thank the anonymous reviewers for their comments and some suggestions for improvement.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.