
Abstract
The theorization of multimodality in academic scholarship is disconnected from how it is conceptualized by children. To bridge this gap, we analyzed 75 interviews with children about their digital video making. Analysis of their responses demonstrates children's socially-embedded, age-specific understandings of how modes operate, as well as when and why to employ them. In many cases, children's ideas ran counter to formal semiotic grammars and metalanguages of design. Bridging Systemic Functional Linguistics and social semiotics approaches with work in transliteracies, we argue for the need to advance age-centric social semiotic theories that center children's voices, purposes, and capacity to generate theory.
Introduction
So, I’m just interested in this, that sometimes you write stuff here [on the image on the screen] that you’re not actually directly talking about, right?
No, but I’m writing about what the picture is.
That's right, that's what it is.
Like, it could be just a random picture if you don't label it, but if you label it, then you know.
While coding this transcript of an interview with third grader Skylar (all names are pseudonyms), David wrote an analytic memo titled “Little Gunther Kress” in honor of the semiotician (1940–2019) well known for his contributions to the study of multimodality and visual communication. The memo described Skylar behaving like a semiotician, discussing labels and cues of salience in her digital video, much as a literacy researcher studying multimodality might. That memo was the seed of this article on children's theorizing of multimodality
In this article, we highlight children's perspectives on multimodal composing. We examine how they interpreted the properties and purposes of the semiotic modes with which they designed videos, and we attend to how child-led theorizing aligns with, and may complicate, academic theories. Our inquiry is guided by two research questions:
How do children explain their modal choices in the videos they make in school? When children talk about their video-making, what relationships exist between modes, design elements, and authorial purposes? Which modes and which design elements co-occur with which authorial purposes?
To answer these questions, we analyzed interviews with children ages 8 to 10 about their digital videos as artifacts and their video-making processes and design choices. The interviews (N = 75) were conducted as part of a design-based, qualitatively oriented four-year study in which children made videos on iPads in their language arts and social studies classes. We identified a range of children's context-specific comments about multimodality, from the communicative and aesthetic effects of modes to children's reasons for employing or not employing particular design elements in their videos. Across our data set, children exhibited seven purposes for choosing and using modes. As part of our analysis, we explored how each purpose co-occurred with the use of visual imagery, aural effects, spoken language, and written text. Our goal is not to propose new grammars for analyzing children's multimodal texts, but to learn from children their reasons for composing as they do, reasons that in many cases do not conform to what formal semiotic grammars can capture.
Literature Review: Children and the Generation of Multimodal Theories
While the topic of multimodality is well established in literacy scholarship, children's perspectives about multimodal design are less articulated (Low et al., 2021). Examining how children understand semiosis as it pertains to making videos (Gilje, 2010; Ranker, 2008) would allow us to ground theory-building in their lived realities and authorial purposes. In this section, we begin by exploring children's ability to construct theories and then move into a review of relevant work in the area of multimodal literacy.
Children's Agency, Voice, and Right to Theorize
When are children extended the right to theorize? Appadurai (2006) noted that “all human beings are, in a sense, researchers” (p. 167), and the capacity to generate knowledge should be recognized as a basic right. Children are often portrayed as passive movers within formal institutions, although a number of scholars have commented on children's agency to act upon the social worlds they traverse (Campano et al., 2016; Morrow, 2011; Olwig & Gulløv, 2003). As Dyson (2013) wrote, “Adult-designed institutions do not dictate children's lives. Children have agency in the enactment of their own childhoods; this is a structured agency, shaped in response to the relational and power dynamics of everyday practices” (p. 404). Failure to attend to children's perspectives may reify the notion that they are powerless and deprive them of the right to theorize within everyday spaces and discourses regulated by adults (Yoon & Templeton, 2019).
Here the concept of children's voice becomes critical. Kellett (2009) wrote that voice represents “the right to express one's views freely—including an entitlement to be listened to” (p. 237). In order for children to influence the spaces they occupy, their voices must “transcend the cultural boundaries of childhood and negotiate a shared understanding in the adult world” (p. 238). Developing pedagogical and epistemological frameworks within which to honor children's voices (Campano et al., 2016; Ghiso, 2015; Murris, 2013; Paley, 1986; Yoon & Templeton, 2019) is vital to fostering meaningful inquiries with young learners that can result in the formation of new theoretical knowledge.
We might conceive of approaches to children's perspectives as phenomenological, studying children's perspectives themselves as the unit of analysis or phenomenon under examination, or as methodological, using interviews or other methods to elicit children's voices in order to understand other, related phenomena. An example of the former approach, which we take in this article, is Shultz and Cook-Sather’s (2001) effort to describe children's perspectives on writing by authoring and editing book chapters with them (for similar work, see Weinstein, 2004). In terms of the latter methodological approach, ethnographic studies of children's spaces lend themselves to emic understandings of what children are doing and why (cf. Dyson, 1989). These studies frequently include in-depth interviews, observations, and artifactual data to elicit children's voices and viewpoints (Pahl & Rowsell, 2010), and explore how children and their families perceive in and out-of-school literacy practices (Cañas et al., 2018). Through these phenomenological and methodological lenses, we have set out to discover what we can learn about children's understandings of, and purposes for, multimodal design (cf. Chen, 2020).
Overlaps and Divergences in Multimodality Research
Many literacy researchers attend to the multiplicity of representational modes through which people make and communicate meaning, including image, spoken and written language, sound, object, spatial arrangement, and gesture (Kress, 2010; New London Group, 1996), as well as synergistic ensembles of numerous modes (Hull & Nelson, 2005). New Literacy Studies explores people's use of modes within situated social practices of meaning-making (Mills, 2016; Street, 2013). Multiliteracies research examines the variability of semiosis across sociocultural and linguistic contexts, as well as via new media and technologies (New London Group, 1996; Yeh, 2018). Studies with roots in Hallidayan systemic functional linguistics (SFL) often use extralinguistic approaches to examine how designers choose modes, transmediate across sign systems, and orchestrate semiotic resources (Mills, 2011; O’Halloran, 2004; Rowsell, 2013), as well as semiotic conventions (affordances and constraints) endemic to a mode (Eisenlauer & Karatza, 2020; Gibson, 2014). These three approaches are not exhaustive—other schools of thought include Peircian semiotics, Bakhtinian psychology, art history, and iconography—nor are they mutually exclusive (Anderson, 2013). Theoretical intersections abound in the work of individual researchers who follow more than one approach, sometimes in service of the same argument or larger body of work. This is evident in the oeuvre of Gunther Kress, who appears in each paragraph of this section.
Taking what we would consider an extralinguistic approach, Kress (2009, 2015) proposed that all modes offer distinct potentials for representing meanings, but share some communicative principles and functions that designers orchestrate when composing multimodally. A great deal of related scholarship endeavors to identify particular communicative affordances, modal densities, and functional loads of signs, semiotic systems, and multimodal arrays (Anstey & Bull, 2018; Kress, 2010; Siegel & Panofsky, 2009; Stein, 2004). This work often touches on modal properties such as salience, indexicality, and focalization. Campano et al. (2020) posited that having roots in SFL explains why proponents of extralinguistic multimodality research “have not simply used the term [‘multimodality’] to denote descriptive studies of semiotic practice, but have developed elaborate frameworks or ‘grammars’ for organizing and analyzing multimodal artifacts” (p. 139). Indeed, for decades, researchers have developed structured vocabularies, grammars, and tool kits for analyzing and theorizing multimodal communication in and across texts, genres, and media (Baldry & Thibault, 2006; Bang, 2000; Kress & van Leeuwen, 2002, 2006; Norris, 2004; Rowsell, 2013; Serafini, 2013; van Leeuwen, 1999; Wang, 2014).
Semiotic grammars and tool kits are used in classrooms to teach children to discuss modal properties like color, shape, and layout (Kress & van Leeuwen, 2002, 2006). Teaching children to develop a metalanguage of design is a key component of the pedagogy of multiliteracies (New London Group, 1996), meant to open up the possibilities of multimodal design to individual learners and the classroom community. Here, teachers introduce terminologies with the goal of developing children's dispositions and awareness of multimodal resources (Cope & Kalantzis, 2009; Kress, 1997). It is a top-down approach, beginning with semioticians before being transmitted to teachers and then finally to children via overt instruction.
Semiotic grammars are effective at producing interpretations of modal ensembles but have drawn critiques; classifying modes is a contested domain (Mills, 2016). Grounded in and extending Street’s (2013) overarching critique of autonomous literacies, critiques challenge the implication that semiotic meanings are universal and fixed, rather than socially embedded, mutable, and connected to identities (Ajayi, 2015; Flewitt, 2011; Kachorsky, 2018; Low & Pandya, 2019; Ohito, 2021). While SFL is concerned with linguistic and extralinguistic grammar (Mills & Unsworth, 2017), one of its offshoots, the social semiotic theory of multimodality (Hodge & Kress, 1988), provides an alternative. From a social semiotic perspective, modes are “socially shaped and culturally given resources for making meaning” (Kress, 2009, p. 54). Paralleling Street's (2013) critique of autonomous literacies, social semiotics holds that the use of modes differs according to the cultural and ideological contexts in which modes take on and change meanings through community use.
Rather than focusing on modal affordances as free-floating, a social semiotic perspective elevates social practices; meaning-making is seen as constituted dialogically through modes (Jewitt, 2009; Jewitt et al., 2001; Kress, 1997, 2009; Mills & Unsworth, 2017; van Leeuwen, 2005). Researchers aligning with a social semiotics approach emphasize that modal meanings shift through their interactions with other modes and in how they are used across contexts and indices of power. As Bezemer and Kress (2016) explained, social semiotics asks “about meaning and meaning-making, about the resources for making meaning, about social agents as meaning-makers and about the characteristics of the environments in which they act” (p. 16). Put simply, social semiotics theories place less emphasis on modes in isolation and more on designers and designing contexts.
Writ large, multimodality studies in education have taken a social turn and yet remain occupied, at some level, with identifying affordances and constraints of modes. In many cases, both types of research are undertaken by the same researchers. When the latter is systematized and distilled into a metalanguage of design used to teach children what modes mean and how to talk about them, it depends on modes being defined autonomously and sacrifices the sorts of emic meaning-making explored through social semiotic approaches. This seems to us a contradiction, and one that we ultimately try to reconcile by using a transliteracies approach (Stornaiuolo et al., 2017). Transliteracies hold that literacy practices (and our understandings of them) are always in motion, always contingent on other factors. Because our decision to invoke transliteracies as a way to shuttle among contradictory theoretical approaches was dependent on insights raised in our analysis of children's interview responses pertaining to their authorial purposes, we put aside further exploration of SFL and social semiotics until the Discussion section.
Methods
This inquiry stems from a larger qualitative study examining the language and literacy practices in which children engaged as they made digital videos in school (Pandya, 2018). In this article, we analyze interviews with children about their compositional processes and design choices. We begin by describing the research context before detailing the methods.
Research Site and Participants
Jessica conducted a four-year design-based study (Cobb et al., 2003; Design Based Research Collective, 2003) at the Esperanza School in California, helping make iMovie videos with 180 children aged 8 to 10. Esperanza was a dual immersion charter school, and children composed videos in English and Spanish, depending on the assignment (see Pandya & Low, 2020). Among the student body, seventy percent of students were Latinx, 13% white, 10% Black, 2% “two or more races,” and 1% Asian American. We provide this demographic information as a frame; our larger goal is to center children's voices and thoughts, which we do in detail below. All videos were part of larger curricular units, and because of the schooled nature of the projects, children most often drafted written scripts to work from as they composed on iPads.
Of the nine teachers with whom we worked in the course of this project, only three had studied educational technology beyond their credentials, and few had any extant knowledge of multimodal composing. The research team began each cycle of video production with group lessons on storyboarding, scripting, or other foci, depending on what teachers requested us to start with that was connected to the curriculum. For example, we started with scripts when children were making videos based on essays they had already written for school; we started with photos and images when teachers wanted students to bring in images from home to use in autobiographies. Music and aural effects were provided by the school's music teacher and within the iMovie app. The research team then worked with children on various video production and image/sound editing techniques, but deliberately provided little direct instruction on multimodal design.
We wanted to see what children discussed without having been taught to apply a metalanguage of design to talk about modes. We wanted to learn about children's own ways of talking about design in school—those they developed through play, dialogue, and experimentation. Children may not possess a semiotician's metalanguage of design (what Kress in 1997 called a “theorist's theory”), but they do have ways of interpreting and communicating design ideas to others—what Kress (1997) called their “practical theories” (p. 87). Thus, ours was a different process than the direct instruction on the affordances of modes documented by various researchers (Cope & Kalantzis, 2009; Mills, 2011; Shanahan, 2013). Our aims were related, but were focused on video production techniques rather than expressly being about modal design.
Data, Coding, and Analysis
Jessica's research team collected several kinds of data throughout the project, including field notes (214), children's videos (358), children's written scripts (400 + ), and 21 group and 284 individual semi-structured interviews with children, conducted after five of the nine cycles of video production. While the content and purpose of children's videos changed in each cycle, based on teachers’ shifting curricular foci, the team always used the same protocol for postproduction interviews. Protocols were designed to elicit reflections on choice and purpose: why children had chosen their topic or focus, why they used certain images, and why they had chosen the music they used; all modes were addressed. Interviews were conducted as soon as possible after videos were completed, within several days at most. (We acknowledge the limitation of not asking children to explain their design choices during the composing process.) Each interview lasted approximately 15 min and consisted of questions designed to elicit children's perspectives about their composing processes.
The project yielded 284 interviews over four years, but we did not analyze all 284 transcripts for this inquiry. We randomly selected 75 interview transcripts—15 from each of five video production cycles with no child repeated, to ensure responses were not connected to any one curricular unit, and to hear the voices of multiple children. We then performed a reflexive thematic analysis (Terry & Hayfield, 2020) of the 75 transcripts, focusing on children's responses to the following interview questions:
What did you do/say/show in your movie that you could not have done with a piece of writing? How would it affect your viewers if you had only read them your story instead of showing them your movie? What writing (script) did you use to make your movie? How did you choose that image? How did you choose the music/sound effect? Why did you make your titles like this? Why did you put that (picture/music/voiceover/text) in that spot in the movie? Why did you wave at the camera there?
During each interview, the interviewer and interviewee watched the child's digital movie together twice, first viewing it the whole way through and then frame by frame. During the second viewing, the interviewer asked specific questions about children's modal decisions, such as the following:
The reflexive thematic analysis emphasizes theoretical flexibility, researcher reflexivity, and the guiding presence of the research questions. We began our analysis by inductively coding interview transcripts separately and writing analytic memos. We used Dedoose, an online coding platform that enables multiple researchers to code the same data set, and we coded at the utterance level. To foster intercoder reliability, we came together to consolidate codes, map out subsequent rounds of coding, and resolve any differences through consensus. Guided by our first research question, “How do children explain their modal choices in the videos they make in school?,” we grouped interview responses into three initial codes: “Design Choices,” “Modal Supremacy,” and “Voice and Writing Relationship.” The first code included interview responses in which children explained why they made their video look or sound a certain way. The second (“Modal Supremacy”) featured children discussing their reasons for using one mode instead of another. In many instances, children compared the communicative affordances of different modes to convey their intended meanings, explaining, for instance, why an image was preferable to a voiceover. The third code (“Voice and Writing Relationship”) included instances when children addressed connections between writing their video scripts and voicing their narration.
After coding 75 interviews, we decided our initial three codes were too broad and porous, necessitating an additional round of coding. For instance, we saw children talking about design elements and modes in the same segments but for different reasons. We also saw children discussing the purposes of their compositional choices while referring to modes or design elements. For our second round of coding, we recoded the same 75 transcripts and generated 17 secondary codes. We reached a saturation point midway through the second round of coding, generating no new secondary codes after that point.
The 17 secondary codes fit into three main groups, which we call code families. These are Design Element, Mode, and Purpose (see Table 1). The Design Element code family contains six codes, including “Color” and “Sound/Music.” We use the term “design element” to refer to the constituent semiotic resources that are organized into larger modes (Jewitt, 2009). For example, as Kachorsky (2018) summarized, “writing, speech, image, gesture, and music are all examples of modes…. Speech, for example, is a communicative mode that consists of several semiotic resources (e.g., words, grammar, volume, tone, etc.)” (p. 11). It is these sorts of semiotic resources that we refer to in this article as design elements. We also include under that heading media formats (e.g., still photos, drawings/paintings) that are subsidiary to modes. The six codes that compose our Design Element code family are far from exhaustive, but they are the ones named by children in our data set. This explains why we do not have codes for design elements such as typeface, line width, shape, layout, framing, volume, or tone; they simply were not invoked by these children.
Codes in the Design Element, Mode, and Purpose Families From Our Second Round of Coding of 75 Interviews.

The Mode code family contains four codes that refer to larger sign systems: “Use of Visual Imagery,” “Use of Aural Effects,” “Use of Spoken Language,” and “Use of Written Text.” Finally, the Purpose code family contains seven codes pertaining to children explaining their reasons for using one or more modes or design elements to convey meaning. These comments revealed to us how children thought about their design choices and why they made them, and, as we discuss in the coming sections, offer us novel ways to think about children's purposes for choosing and using modes as they make videos.
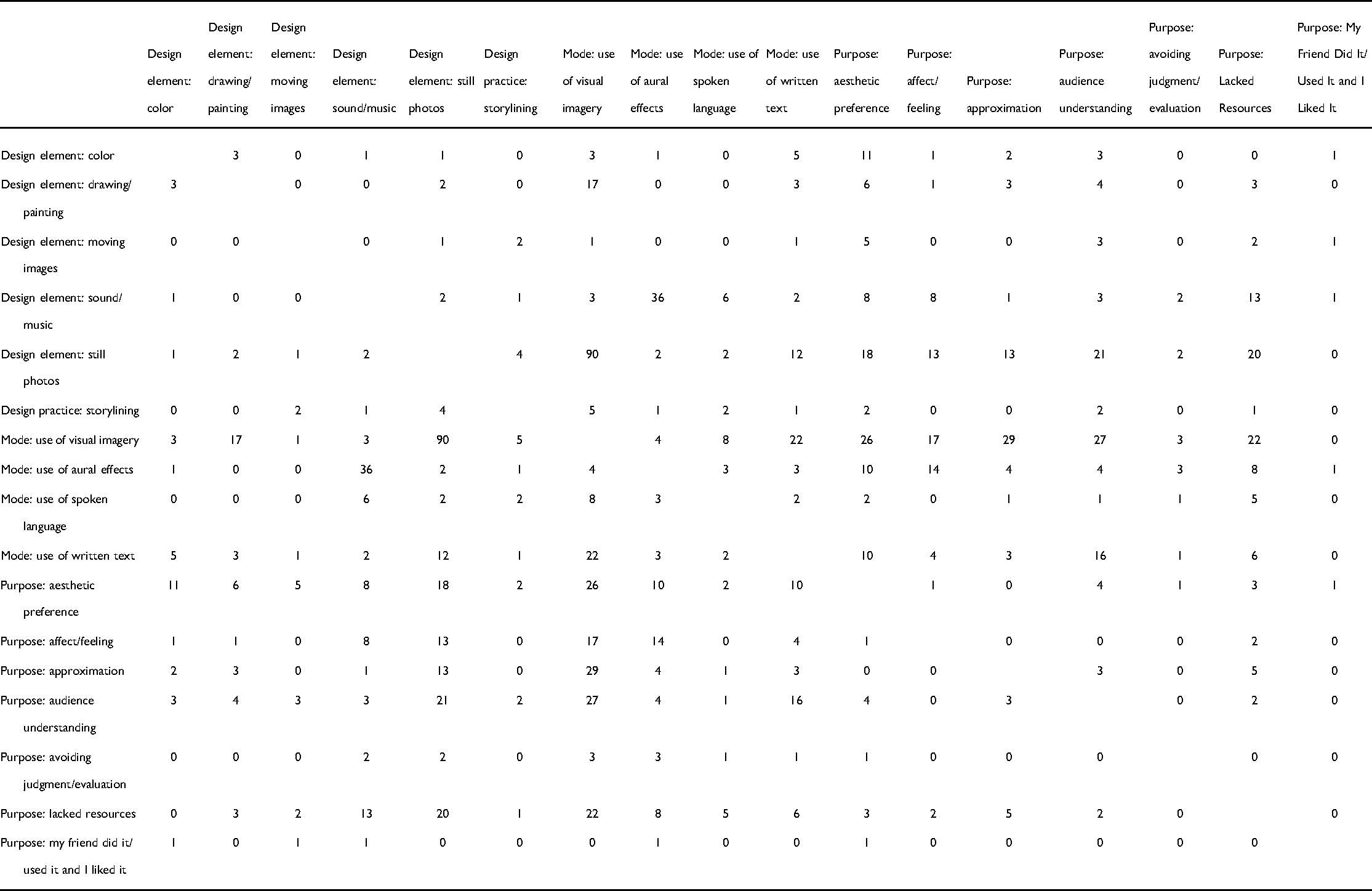
Following our second round of coding, we decided we needed to be able to look at each code family in relation to the others to co-articulate children's authorial purposes with the actual modes and design elements they used in their videos. This need prompted us to pose our second research question: “What relationships exist between modes, design elements, and authorial purposes? Which modes and which design elements co-occur with which authorial purposes?” Using Dedoose, we identified co-occurrences of codes across each of the three code families by generating a co-occurrence matrix, a symmetric, code-by-code accounting of how each tag was used across all data excerpts (see Table 2). Such displays can expose expected and unexpected patterns. For obvious examples, the design element “Sound/Music” co-occurred with the use of aural modes; the design element “Color” co-occurred with visual modes. In other instances, co-articulating children's purposes with their use of modes and design elements was quite revealing, as we discuss ahead. As Siegel (2012) suggested, when modes are combined, researchers should ask questions such as: “How do the different modes relate to one another—for example, as representational, or ironic, each carrying different meanings of knowledge?” (p. 678). This is what we endeavored to do by examining co-occurrences across the three code families, although we do not imply that co-occurrences equate to correlative modal relationships without further exploration of the qualitative context. We grounded our attempts to account for modal relationships primarily in the explanations children provided.
Co-Occurrence of Second-Round Codes Across Three Code Families (Design Element, Mode, and Purpose).
Findings
Our aim was to better understand children's perspectives and purposes for utilizing modes and design elements in their video-making at school. To that end, here we use the Purpose family of codes as the fulcrum of our descriptive analysis, and write about the frequency and consistency of those seven Purpose codes within our data, as well as their co-occurrence with the Design Element and Mode code families. As we discuss each Purpose code, we share examples of children's voices to help illustrate what each code sounded like to us. We organize the Findings section from most to least occurring of the Purpose codes, although we note the number of occurrences does not necessarily mean the ideas contained in the code are more or less powerful.
Children Choose Modes That Are Aesthetically Pleasing to Them
Many children explained they used a particular mode or design element because they liked some aesthetic aspect of it. In 75 interviews, children named this purpose 117 times. Few children provided any additional information beyond aesthetic preference. They used a color because it was their favorite. They used an image or song because they “liked it.” Joaquin told the interviewer he used an image “because it looks pretty and I like the beach.” When asked why he used a color in a certain way, Aidan responded, “‘Cause I liked it.” Lucia explained that she chose to include songs “that I kinda liked.” While it may seem children are not telling us all that much in their responses, it is important to note what they are not saying. Children did not tell us they used red because it is well known to symbolize love or anger (Bang, 2000; Kress & van Leeuwen, 2002). Their reasons were their own, echoing a child in Kress' (1997) study who explained he used a drawing technique “because I like it like that, it has to be like that” (p. 24). As Kress (1997) went on to explain, “It is of course notoriously difficult to extract from anyone their reasons for doing things which were done below the level of consciousness…. [T]he ‘I like it like that’ is quite likely to include much greater complexity than that phrase suggests on the surface” (p. 24).
Code co-occurrences in Table 2 show that “Aesthetic Preference” is co-articulated with numerous Design Element and Mode family codes. As a compositional purpose, “Aesthetic Preference” is the most consistent reason children gave for making any modal or design choice. To clarify: “Aesthetic Preference” is both the Purpose code with the highest total frequency (117) and also the most consistently invoked reason across modes and elements of design. Whereas some Purpose codes co-occurred with only one or two Mode or Design Element codes, “Aesthetic Preference” was given as a reason why children made any modal or design choice, with the exception of the use of spoken language. Whether they used a still photo, a drawing, a song, or a sound effect in their video, we could count on children justifying their decision with some variation of “I did it because I liked how it looked or sounded”
Children Choose Modes to Help Their Audience Understand and Feel
Many of the “Audience Understanding” Purpose codes co-occurred with the Mode codes “Use of Visual Imagery” (27) and “Use of Written Text” (16); rarely did children use aural effects to help their audiences understand (4), but it did happen. Some images were used to inform the audience and set the stage for yet more information, as when Serena used an image of a ship while she was talking about a ship, “so they can see the ship”; she then explained, “After the picture, I wanted to tell them what it was and … about it.” We have written elsewhere on children's perceptions of their digital audience (Pandya & Low, 2020) but have not focused on children's use of modes to help their audiences understand the messages they want to convey.
The “Audience Understanding” code often doubly co-occurred with two Mode codes. In these instances, children told interviewers their reason for doubling up on modes, often to the point of redundancy, was to ensure their intended meaning was conveyed. For instance, Serena used a song for a particular length of time “on purpose” so her “picture could sink in” with the audience. Skylar included a series of images in her video that she had not addressed in her voiceover, and she used titles on the photos. When asked about the titles, Skylar said, “I’m writing about what the picture is,” and explained, “Like, it could be just a random picture if you don't label it, but if you label it, then you know.” Alex used a specific design from the iMovie app with a lot of white space on which he superimposed subtitles. When asked why, he said it was in case his audience could not hear him or had their “volume down, so they can just read it.” Pedro used informative images of himself labeled with his name and age so his audience would not have to guess. Overall, many children used written text to help clarify the meaning of a visual artifact. In nearly every case, clarity was given as the rationale for using labels.
In several instances, children doubled up on modes not to clarify meaning, but to enhance feeling (and hence, communicate their intended message to their audiences). There was definite overlap with the “Affect/Feeling” Purpose code (see below), but in these instances, “Audience Understanding” took precedence. Skylar used an image of herself as a baby with the word “aww” written on it as a title. When asked why she had written the word “aww,” she replied, “Because that's a really cute picture.” When the interviewer subsequently asked, “Is this here because you want people to say that or you think they’ll say that?,” she told us, “I think they’ll think that.” Joaquin told his interviewer he used a particular song in his video “because it was like calm, [then] the music started to go faster …. It goes with the story.” At another point in the interview, Joaquin explained that he used a turquoise background “because it goes with the writing.” In these instances, Skylar and Joaquin combined modes to produce moments of modal density or gestalt (Hull & Nelson, 2005), and to guide audiences to feel what they wanted them to feel. These comments suggest children's awareness of how their modal choices might affect audiences, and show a complex design sensibility.
Children Choose Whatever Modes They Have on Hand
Children's pragmatism is pronounced in the case of the “Lacked Resources” Purpose code (96 total instances). Pedro told his interviewer he used drawings instead of photos because the printer was out of paper. Lucia used the same picture of herself twice because “I didn't really have another picture.” When Maria was asked why she did not include music in her video, she explained that she would have liked to, but “there was like three or four more kids in the room when we were doing this. I didn't really ask.” Her video did not have music. In some cases, children were limited less by material resources than by technical know-how. Oscar couldn't fit all of his words on the iPad screen, so he decided to shorten his script. Belinda and Olivia separately expressed that they wanted to alter their voices to create different effects, but did not know how to use the software to do so. Belinda created drawings because she did not know how to type. Pedro did not write any of his friends’ names in his digital story because of spelling uncertainties; he told us, for example, “I never know how to write Marisol.”
There are 22 instances of co-occurrence between “Lacked Resources” and “Use of Visual Imagery” (see Table 2), and far fewer between “Lacked Resources” and “Use of Aural Effects,” “Use of Spoken Language,” and “Use of Written Text” (eight, five, and one, respectively). This suggests that children favored the use of images—still photos in particular—when making autobiographical videos, but that these images were difficult to come by for various reasons. In these circumstances, as in others, children used whatever artifacts they had on hand. This Purpose code differs from the next, “Approximation,” in which children made choices that were good enough for them, not from a lack of resources, but in consideration of realism or tonal appropriateness.
Children Choose Modes to Approximate Their Intentions
Children's modal and design choices were sometimes pragmatic, such as using Internet photos to stand in for their own and others’ experiences. Much of our coding in this area (67 total instances) involved children using the visual mode to approximate actual people, animals, and objects. They drew family members to the best of their ability. They used stock photos to approximate pets and automobiles. One child, Luna, told the interviewer her photo of a rabbit was found on the Internet: “I just saw a picture that looked just like my bunny.” Noemi included a photo of a woman and man in her video, over a voiceover about how her “parents met in a coffee store.” Only later, when interviewing Noemi, did we learn the photo was of her grandparents, not her parents, because Noemi had no pictures of her parents together (Pandya et al., 2015). As an approximation, a photo of her grandparents would have to suffice. (This example was also coded as “Lacked Resources.”) In other instances, children used images to represent abstract concepts. Anna included a close-up shot of hands with rings on them and explained the photo represented “that they [her parents] love each other.” Anna had asked her parents to pose for the photograph; their hands signified their love. While symbolic representation is not the same as an approximation, such instances fit better in this Purpose code than anywhere else.
The bar for determining if an image was “good enough” to serve as an approximation differed from child to child and sometimes from image to image. Some children weighed the concerns of accuracy and availability. Keisha found a painting on the Internet of a ship that she used in her video response to a book about 15th-century explorers. A painting felt more tonally appropriate to the book's context than a photograph: “It just seemed more…like it was like back then. Now, you can take pictures with cameras.” However, Keisha accompanied her response to the book with a photograph of a random boy, found on the Internet, to represent a member of the crew. Her rationale was that “I just picked the best pictures that made sense.” For a different video project, Alejandra struggled to find a stock image to represent her morning routine. She “needed [a photo] of women because me and my mom get ready together. I couldn't find another picture of people getting ready. And the other ones were of men getting ready.” Alejandra ultimately opted to use a picture of men getting ready; it was deemed good enough.
In Table 2, as in the examples we have shared, “Approximation” bears a strong co-occurrence with the “Use of Visual Imagery.” There are 29 instances of co-occurrence between “Approximation” and the visual mode, and only four, one, and three between “Approximation” and “Use of Aural Effects,” “Use of Spoken Language,” and “Use of Written Text,” respectively. In terms of aurality, Octavio decided to include the sound effect of a door closing when he showed a moving door in his video, telling us that without sound, “it looks like they’re closing by itself.” Octavio felt this would be unrealistic. Another child, Ramona, used a thunder sound effect in her video about the Fourth of July. When asked why she included thunder, Ramona explained, “It sounded like fireworks.” These two examples notwithstanding, children primarily used images for the purpose of approximating realities, including their own, their families’, and book characters’. We see these approximations, decisions about quality of image, and correspondence with a particular perceived reality as critical to the work of any designer: Children, like adults, do the best with what they can find, and make complex choices about when to use what is at hand and when to try harder to find the right effect.
Children Choose Modes for Affective Purposes
Children often told their interviewers (66 instances) that the modes they used contributed to a feeling, either their own (i.e., “it made me happy”) or their potential future audience's, although audience-related comments about multimodality tended toward the informative, as we discussed above. In some cases, children talked about the feelings they were trying to evoke in relation to the overall mood of their videos, whether humorous or scary. For instance, Joaquin noted that he had chosen a particular “scared” face because “if he [the character in the video] was scared then he should go like this.” At other times a child's affective purpose was aimed at the entire mood of the video; Soraya chose a specific song for a video she had made about her birthday “because on my birthday it's playful and the music is playful.” As these snippets suggest, although the “Use of Visual Imagery” Mode code co-occurs much more often with the “Approximation” and “Audience Understanding” Purpose codes (29 and 27 times, respectively), we identified 14 “Use of Aural Effects” co-occurrences with “Affect/Feeling” and 17 co-occurrences for “Use of Visual Imagery.” That is, although the visual was used much more with other purposes than with “Affect/Feeling,” we saw almost even uses of the visual and aural modes for affective purposes.
Songs were often used to evoke or suggest affective responses. Aidan chose a particular song for background music because it was “kind of sad,” and then clarified, “It's a little bit—it's not that sad but I like that one.” Manuel chose a song for his Halloween video because “it was like, scary.” Children were aware of the moments when they used images to evoke certain feelings. Marcus used a “pumpkin pie happy face” photo he found online at the start of his video (which had little to do with Thanksgiving or any pie-related events) “because it was funny” and a good way to start the video. The urge to be funny could be framed within “Affect/Feeling” too: Tom included a photo of his cat on his mom's bed “because it's really funny. And it's still my cat.” Finally, children sometimes included images or words on-screen for fun. For example, Junior had included a “special thanks” slide to himself as the “Movie producer” in the credits “just to be silly.” The feelings children experienced while making and watching videos, and the feelings they elicited in their audiences, matter (e.g., Lenters, 2016).
Children Choose Modes in Anticipation of Evaluation
This Purpose code is related to the “Audience Understanding” code, to be sure, but it brings a unique valence to children's sense of audience awareness. Among data we coded as “Avoiding Judgment/Evaluation,” children brought their knowledge of various modes’ affordances and constraints to bear on their knowledge of audience expectations. In this case, children were less concerned about their audiences understanding them and more concerned about their audiences judging them. For example, if a child doubted they could spell “Columbus” using written language (and believed accurate spelling mattered to their viewer), they might opt to show a picture of Columbus or speak his name instead to insulate themselves from judgment. As Lana explained, “When I talk, I don't have to worry about spelling.” This Purpose code is not only about spelling, however. Some children anticipated other types of judgment, and used specific modes and design elements to sidestep it. Clarissa preferred writing about herself to showing pictures of herself. She was “embarrassed” to imagine what her viewers would think of how she looked in photos. By using words instead of images, Clarissa allayed her own potential feelings of embarrassment. Tatiana and Tom both discussed making modal choices intended to make their videos less “boring,” reflecting their perception that a bored audience might judge their content as dull.
While there is an agency in children strategically choosing and shuttling between modes to avoid evaluation and judgment, we do not want to oversell this finding. The “Avoiding Judgment/Evaluation” code had the second-lowest frequency of our purpose code family (14 instances). Nevertheless, we continue to be struck by children's savvy decision-making about modes and design elements they used to preempt judgment. In Table 2, “Avoiding Judgment/Evaluation” co-occurs with each code in the Mode family with no clear spike anywhere. “Use of Visual Imagery” and “Use of Aural Effects” each co-occur three times with this Purpose code; “Use of Spoken Language” and “Use of Written Text” each co-occur once. There is no indicator in our data set that children privilege the use of any particular mode or design element to mitigate whatever judgment they anticipate from their audience.
Children Choose Modes That Worked Well for Others
Of the seven codes in the Purpose family, “My Friend Did It/Used It and I Liked It” was the least frequently applied, with only five total instances noted in our coding. Nevertheless, we felt it was distinct from other codes and warranted consideration. The name of the code is self-explanatory; sometimes children's design choices were made because they observed the same worked well for a peer. When asked why he used a blue background, Ramon told the interviewer he “had seen it when [his classmate] Juan did this.” Similarly, Lucia discussed the composition of her video by explaining that her classmates “gave me the idea…so then I used it.” There was no particular mode or design element that co-occurred with children voicing this rationale. The visual mode (with the design elements of color and moving images) and the aural mode (with the design element of sound/music) were each noted once in relation to this purpose.
Discussion
Our analysis surfaced numerous instances in which children expounded upon their use of modes when describing videos they made in school. During interviews, they spoke about how they selected and used modes in ways that foregrounded their own shifting interests, preferences, and purposes. They discussed indexicality, synergy, and modal intensity, but with their own language and emphases. (e.g., A painting of a caravel indexed an intended era; a background color paired well with written language; an accompanying song allowed a salient image to sink in.) In many cases, children's ideas ran counter to multimodal grammars of academic provenance, evincing compositional purposes that were often neither overtly semiotic nor rhetorical in nature. With no formal instruction in semiotic theories or a metalanguage of design, children demonstrated socially embedded and age-specific understandings of how modes operate and when and why to employ them.
From children's points of view, orchestrating modes was related first to aesthetic preferences and then to addressing an audience. Children considered modes and design elements in relation to other modes and design elements, and composed in ways intended to be pleasing to them first and to relay a message to others second. Our findings also indicate children made design decisions based on fluid and loose definitions and needs, approximating where they wanted to, doing without when they had to, and borrowing friends’ ideas when they felt like it (Souto-Manning & Yoon, 2018). Children were often aware of audiences’ potential judgments and made efforts to avoid them by choosing design elements they thought would have favorable reactions.
We can learn a great deal about children's purposes for selecting modes and design elements by examining and interpreting the co-occurrence matrix (Table 2). Within our data set, children used images and written text (as opposed to aural effects and spoken language) to help their audiences understand their intended meanings. Further, if an image was the thing children felt needed explanation, written text in the form of labels was the mode they used to provide it. Further still, children used images, but never written text, to approximate the realities they wanted to present to their viewers. For other purposes, such as avoiding an audience's judgment, there was no clear co-occurrence with any particular mode. Depending on the situation, children were just as likely to transmediate from one mode to any other mode to avoid judgment.
In our data set, there were instances in which a single piece of interview data could be assigned more than one Purpose code. For example, there were overlaps among the Purpose codes “Avoiding Judgment/Evaluation” and “Audience Understanding” because the former necessarily implies awareness of audience. Similarly, the “Approximation” and “Lacked Resources” Purpose codes share some common ground. During coding, we attempted to assign the Purpose code that best fits a student's response. On fewer occasions (22 total), we double-coded the same datum as having two purposes. To us, the possibility of overlaps among authorial purposes speaks to the complexity, and potential incongruity, of children's multimodal composing processes.
Two codes from the Purpose family—“Approximation” and “Audience Understanding”—co-occurred often with the “Use of Visual Imagery” Mode code. Conversely, the “Use of Aural Effects” Mode code most often co-occurred with the Purpose codes “Aesthetic Preference” and “Affect/Feeling.” What do these co-occurrences mean, exactly? Based on our analysis, we found children's stated purposes for making compositional choices in their videos were modally segmented and modally specific. Children were likelier to connect aurality to matters of aesthetics and affect, and visuality to matters of representational accuracy and approximation. This is not to say that children never brought aesthetic or affective considerations into their thinking about the visual mode, but that children rarely invoked the aural mode for purposes other than aesthetics and affect. For those conducting research on children's multimodal literacies, these findings will hold a great deal of significance.
Bridging Multimodal Theories
While we are generally amenable to social semiotics approaches to multimodal literacy research, there is a sticking point for us. The social semiotic theories with which we are familiar, and which we discussed above, do not cohere with the ways children themselves talked about modes and design elements. Thus, although we agree with Street (2013) that multimodal literacy research should be “careful not to grant too much autonomy to the individual modes themselves” at the expense of social actors (paraphrased in Campano et al., 2020, p. 139), if we are committed to multimodality research that honors emic perspectives and children's voices, we must place some emphasis on the individual modes and design elements children connect to their authorial purposes.
By affirming individual modes’ and design elements’ autonomous possibilities, it may seem we are aligning with SFL approaches to multimodality research. This is not the case. Children's descriptions of their multimodal authoring often did not fit within established semiotic grammars, frameworks, or tool kits advanced by extralinguistic research. While we appreciate structured grammars and have made use of them ourselves, it was rare in our data set for children to discuss color, shape, layout, or tone in ways that mirrored how these semiotic resources are defined in SFL-informed scholarship and transmitted via metalanguages of design. Thus, we find ourselves without a straightforward path, and ultimately argue there is a need to reconcile elements of SFL with social semiotic theories that emerged and diverted from SFL. To examine how children talk and think about composing using multiple modes, it is necessary to inhabit a position informed by social semiotics, and by the perspectives social semiotics problematizes. We are not the first researchers to work this dialectic, but we may be the first to locate our reasons for doing so within children's stated purposes. As a guide for shuttling among scholarly approaches to multimodality research, we draw on recent work in transliteracies.
As multimodality researchers, we require heuristics that are not overly in the thrall of structure, that are not impervious to children's agency, that do not neglect culture or power relations, and that are not deterministic of the pragmatic purpose-driven choices made by young composers (Ghiso, 2015). Rather, we need theoretical legends that can be navigated—around their contours, within their gaps, and especially in their tensions. Transliteracies scholarship offers overtures to such movements. In Stornaiuolo et al.'s (2017) transliteracies framework, the contingency and instability of literacy practices across time, space, and social groupings are paramount. Context plays a pivotal role in meaning-making, and literacies are mediated by flows of power that interweave and are distributed across social relationships, texts, and bodies (Leander & Boldt, 2012; Low & Rapp, 2021).
Because purposes, identities, and childhoods are contextual and fluid, a transliteracies framing allows us to reconcile what children said they did as they designed using multiple semiotic modes with the attendant multimodal theories and frameworks we have at hand to analyze meaning and meaning-making. If social semiotic theories focus less on modes in isolation than on designers and design contexts, then incorporating transliteracies into social semiotics can better emphasize how designers and design contexts change over time and across space. Rather than aligning with an SFL-informed or social semiotic approach, literacy researchers might recognize in children's dynamic semiosis our own need to stay moving, using extralinguistic approaches that match children's stated purposes and setting aside those that do not.
Conclusion: Children as Multimodality Theorists
To close, we return to the question of how we might extend Appadurai’s (2006) declaration that all human beings are researchers to children's ability to generate knowledge about the purposes and functions of semiotic modes. As adult academicians, when and how will we listen? How will our methods evolve? Shipka (2016) implored researchers to commit to: altering our pedagogical and research practices—to consider how concretely engaging with different modes, genres, materials, cultural practices, communicative technologies, and language varieties impacts our abilities to make and negotiate meaning, how it impacts both what and how we come to know, and perhaps most importantly, how it might provide us with still other options for knowing and being, and for being known. (p. 251)
We support children in “representing their meanings [and] their knowledge of things and how they function in the world” (Nelson, 2007, p. 101). When heard and acted upon by educational theorists, children's voices may serve as a destabilizing force to the status quo. Indeed, a transliteracies perspective implies that “inequitable relations of power can be dismantled and reconfigured, affording equal access, value, and representation to all participants” (Hawkins, 2018, p. 65). Rather than seeing children as needing overt instruction to develop dispositions and awareness about modes or metalanguages of design, we advocate for taking seriously children's organic perspectives and purposes—their “practical theories” (Kress, 1997, p. 87)—as an initial axiom of working with young people.
The field of multimodality has in recent years done better at prioritizing culture and identity, placing greater emphasis on communities of social interactants. If modes are socially shaped and culturally embedded resources recognizable to members of groups (Kress, 2009), then multimodal literacy research must center on community, even while acknowledging that culture and community are neither static nor monolithic (Hawkins, 2018). To that end, age must be recognized in multimodal literacy research as a crucial, constitutive element of children's cultures and social relationships.
Childhood is distinct from other periods in the lifespan, riddled with questions of knowledge, power, and agency (Dyson, 2013; Yoon & Templeton, 2019). Hawkins (2018) posited that social and cultural capital “shape what modes are used and hold sway, how modes and meanings are represented and interpreted, and how people (and groups of people) are positioned vis-á-vis one another” (p. 63). How are we as literacy theorists to understand relationships among multimodality, childhood, and cultural capital? This is a question we leave for future researchers, including ourselves, to take up. We believe navigating the complementarity of SFL, New Literacy Studies, multiliteracies, and other approaches will yield key insights on the matter.
We have attempted to understand and honor children's perspectives and purposes regarding multimodal composing. With digital design projects appearing more frequently in elementary curriculums, it is crucial that children be provided opportunities for shaping researchers’ and educators’ understandings of whether, how, and why multimodal composing is significant to them. Not all will be little Gunther Kress, but they honor the legacies of theorists who came before them by adding their voices to an ever-evolving discussion.
Footnotes
Acknowledgments
The authors acknowledge Cassie Brownell for her generous commentary on an earlier version of this article. We also thank our anonymous reviewers for their feedback on previous drafts and Aria Razfar for his capable editorship throughout the review process.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article. The research for this article was supported by the Foundation for Child Development [Young Scholars Cohort 10].
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.