
Abstract
We introduce “AI Voice,” a qualitative research methodology using collaborative artificial intelligence (AI) image generation to explore sensitive topics with young people. Building upon photovoice traditions, participants collectively create and interpret AI-produced images rather than photographing directly. This disrupts artificial/authentic distinctions, reconceptualizing voice and representation in qualitative methodology. AI-generated images function as “epistemic foils”: their photorealistic yet emotionally unrealistic character creates productive distance enabling reflexive discussion. Through our pilot study (ages 18–24), participants engaged in “affective projection” while maintaining analytical safety, identifying gaps between AI outputs and personal experience. AI Voice enables collaborative meaning-making, positioning participants as critical curators.
Intro and Background: GenAI in/and Social Research
Generative Artificial Intelligence, henceforth GenAI, has become an increasingly visible and widespread aspect of a growing range of digital interactions. Google, Amazon, WhatsApp, and many other digital media providers now include GenAI “assistants” as a default component of the search services and functionalities. Major GenAI platforms, like ChatGPT, xAI’s Grok, Microsoft’s Copilot, and Meta AI’s Llama are expanding their capacities for text, image, video, and audio generation at a seemingly exponential rate. Such technologies have become imbricated into the fabric of everyday life with a rapidity and degree of spread that is arguably historically unprecedented (Atkinson, 2025). Perhaps unsurprisingly, the implications and longer-term consequences of such developments have created concerns for various fields across the social sciences (Jacobsen, 2025; Joyce & Cruz, 2024; Solaiman et al., 2023).
Contemporaneous with developments in which GenAI has emerged as an increasingly significant topic of research are a parallel set in which its affordances as a technology for use in research have come to be explored. In the social sciences, a burgeoning literature has examined the potential for artificial intelligence (AI) to be used in the compilation of literature reviews (Bolaños et al., 2024; Mostafapour et al., 2024), the design of research and research questions (Bail, 2024) and hypotheses (Banker et al., 2024), the analysis and management of data (Haber et al., 2025) and the drafting of research outputs (Salvagno et al., 2023). Such developments have immediately presented a range of related concerns regarding the ethics of these applications, acceptable and unacceptable usage practices, and safeguards relating to academic integrity, transparency and honesty that must be established (Hong & Soulière, 2025; Porsdam Mann et al., 2024).
In qualitative social research, discussions of the potential application of GenAI are in their relative infancy. Nonetheless, key contributions have been made exploring, inter alia, how GenAI can be used in qualitative data analysis (e.g., Chubb, 2023; Hitch, 2024; Morgan, 2023), facilitate theory development from qualitative data (e.g., Christou, 2023), assist in the compilation of systematic reviews and evidence synthesis (e.g., Blaizot et al., 2022), and conduct semi-automated interviews at an unprecedented scale (Geiecke & Jaravel, 2024). These and other similar contributions share a cautious and qualified possible embrace of the affordances of GenAI, noting its enormous potential rapidly to process large volumes of qualitative data, and potentially aid in data visualizations and renderings not previously feasible (Christou, 2023). However, a consistent refrain in these discussions is that GenAI should be treated as at best a kind of assistant to human researchers, not a replacement (Chubb, 2023), with the ease and rapidity of AI also a detractor as it might facilitate a reduction in researcher data immersion, impeding the interpretative work normally involved in human analysis of qualitative data (Sinha et al., 2024). Furthermore, AI involves persistent machine biases, themselves indicative of the historical training data corpora informing large language models, which may perpetuate tropes and stereotypes aligned with specific hegemonic interests (see, for example, Ashwin et al., 2025; Noble, 2018).
Further scholarship has moved beyond examining specific applications of GenAI to pose more foundational ontological and epistemological questions, including whether AI should be employed in research at all (Lester et al., 2025). Such critical perspectives variously draw attention to AI’s entanglement with oligopolistic power structures (Dolata & Schrape, 2025), surveillance capitalism (Zuboff, 2019), algorithmic tyranny (see Benasayag, 2021), colonial epistemological frameworks of the global north (see de Sousa Santos, 2024), and more generally explore how AI technologies are entangled with inherently exploitative labor practices (Crawford, 2021). From this perspective, AI systems inevitably reproduce existing power asymmetries embedded in their training data (Benjamin, 2019; Noble, 2018), making ethical use fundamentally impossible regardless of methodological safeguards. These concerns are particularly acute given AI’s documented role in amplifying surveillance of marginalized communities (Eubanks, 2018) and its dependence in certain cases on precarious, often invisible labor from the global south (Crawford, 2021). Conversely, a further seam of critical scholarship explores how AI technologies may hold emancipatory potential when developed through participatory frameworks that foreground marginalized communities (Costanza-Chock, 2020), and that algorithmic tools can also expose previously hidden forms of discrimination while enabling new forms of democratic participation and counter-hegemonic forms of organization (D’Ignazio & Klein, 2020; McQuillan, 2022).
While acknowledging the profound structural concerns raised by AI, we contend that the widespread integration of GenAI technologies into social, educational, and research contexts renders purely oppositional stances increasingly untenable. Rather than advocating for wholesale rejection or disengagement, our approach seeks to cultivate the conditions for reflexive engagement that enhances rather than diminishes human interpretive authority and critical capacity. This position recognizes that meaningful protection from AI’s potential harms emerges not from avoidance alone, but from developing reflexive practices that preserve human discretion over technological deployment and interpretation.
Our approach in this respect aligns with Messeri and Crockett’s (2024) analysis of the role of AI in scientific research who demonstrate how AI tools, while promising enhanced productivity and objectivity, may paradoxically generate “illusions of understanding” whereby researchers develop inflated confidence in their comprehension of phenomena, potentially fostering “scientific monocultures” that constrain rather than expand knowledge production. Their critique, though focused on natural scientific contexts, highlights dynamics equally relevant to social research: the risk that AI’s apparent sophistication may mask rather than illuminate the interpretive work essential to genuine understanding. Rather than dismissing such concerns, we propose that these require cautious engagement, particularly when conducting research with young people who will necessarily inherit the consequences of contemporary technological trajectories.
Indeed, the starting point for our own consideration of how GenAI might be leveraged to support qualitative research is that there are immediately two problems with the term “artificial intelligence.” The first of these is the term “artificial,” and the second is “intelligence.” The very term “artificial” suggests something other than what is “natural,” and here we employ the term in an ethnographic sense of “naturally occurring data.” The latter term, “natural,” methodologically is used by ethnographic researchers to refer to human activities, interactions, reflections, etc. that occur spontaneously in authentic settings, as opposed, for example, to those that are deliberately orchestrated for the purposes of research (see Kiyimba et al., 2019). Though this distinction too is not without its issues (see, for example, Hughes et al., 2020), it serves here to highlight a problem with the term “artificial”: it risks positioning GenAI as somehow external to the social world and thereby partially immune from the everyday biases, politics and materiality of the language models, algorithms and data through which its inferences and derivations are generated. In effect, this term “dehumanises” GenAI lending it an “illusion of objectivity” (Messeri & Crockett, 2024) when it is, paradoxically, entirely dependent on human documents as training data, and thus inevitably reproduces human biases and social patterns, though with systematic distortions (Ferrara, 2024).
Conversely, the term “intelligence” is also potentially misleading in its anthropocentric invitation to approach GenAI as comprising a form of cognition akin to human intelligence. At its current stage of development, GenAI is arguably best understood not so much as a form of “intelligence” in the anthropocentric sense than as a highly sophisticated modality of pattern recognition, autoregressive next-token prediction, and probabilistic generation from a given corpus of training data (Crawford, 2021). Finally, extending these points further, we might also take issue with the term “generative” in the notion of “generative” AI in that while GenAI can generate new content that did not previously exist, such content always derives from existing material, and is in this sense more derivative than creatively generative. As we shall discuss, however, this distinction, while heuristically useful, ultimately proves overly reductive, even when extended to conventional forms of creative endeavor. Indeed, our application of GenAI to qualitative research has prompted us to rethink and revisit aspects of co-creation, knowledge generation, authenticity, and voice in social research more fundamentally (see also Hughes et al., 2020).
Our underpinning concerns regarding the language of GenAI are of significance when considering its potential in research with young people since they relate to how these technologies might variously be framed, treated, and approached within such encounters. Moreover, as we shall consider later, GenAI technologies are not simply external tools that might be “brought into” research encounters with young people; they are already integral aspects of their everyday lives and meaning-making practices which, we anticipate, are set to greatly expand in their significance throughout their biographical futures. As such, understanding how young people engage with and make sense of GenAIs is likely to become increasingly important, both in terms of how such tools might be harnessed for the purposes of research, and how they are increasingly becoming a “natural” part and parcel of young people’s social worlds. It is from this theoretical foundation that we have developed what we term “AI Voice” methodology—an approach that permits an empirically-grounded reflexive engagement with GenAI precisely in relation to contexts of its use by young people.
GenAI, Young People and Social Research
Recent debates concerning AI and digital media reflect growing anxieties about the benefits and challenges such technologies engender for children and young people. Specific concerns have prompted stakeholders to develop new safeguards for young people’s use of internet-mediated tools (European Commission: Joint Research Centre, et al., 2025), leading, for example, to a specific U.K. bill to protect people online (UK.Gov, 2023). However, to continue our arguments from above, these protective responses typically fail fully to acknowledge that for young people today, AI and digital technologies are not simply external impositions, but integral aspects of their life worlds—they form crucial facets of the cultural universe through which they navigate and mediate identity, relationships, and meaning-making.
Such a disconnect becomes especially pronounced in the context of social research where long-standing concerns about young people’s vulnerability interplay with contemporary anxieties about GenAI. Research has historically been a site of tension regarding, on the one hand, the growing recognition of the need to include children and young people’s perspectives on the issues that relate to them, and, on the other, the need for additional safeguards governing their role in the generation of knowledge, particularly in relation to sensitive topics (O’Reilly and Parker, 2014). This duality of protectionism and the recognition of young people as competent social beings (James & Prout, 2015) creates both challenges and opportunities for researchers seeking innovative ways to promote genuine inclusion, empowerment, and age-appropriate ways of communicating with their young participants.
Thus, to manage concerns about using GenAI in qualitative research, especially with children and young people, care and attention need to be paid to how this is undertaken, in relation to both ethics and methods. Our approach, which we outline in more detail below, has been to balance empowerment and safeguarding through creating spaces where young people can exercise a critical engagement with AI systems while operating within appropriate ethical safeguards. This approach recognizes that meaningful protection and safeguarding comes not simply from excluding young people from GenAI technologies, but from supporting their capacity for critically reflexive participation in systems that will increasingly come both to mediate and constitute their social lives.
The Origins of a New Methodology: AI Voice
The origins of our own use of GenAI grew out of a discussion of the possible approaches we might take to facilitate a discussion of “coping and adjustment behaviours” with young people. The latter forms part of a PhD study of the different ways young people conceptualize coping and how they respond to potentially stressful situations (such as through substance using behaviors) that Homan is undertaking, and for which Hughes, J and O’Reilly are the supervisors. That study aims to explore how contemporary youth describe and communicate with others regarding encountering and managing stressors, and the various positive and negative ways this might be approached. In much of the existing literature on that topic, there is an assumption that (a) substance use can be seen as a negative adjustment to stressful and traumatic life episodes, and (b) that it forms part of a coping strategy on behalf of young people. Homan’s intention in the first phase of that study was to explore with young people their understandings of “coping” and “adjustment,” and to consider the extent to which substance use might be part of this. In doing so, her central aim was to bring young people’s “voices” into discussions of this topic in a field where they are somewhat neglected and/or downplayed.
Given the possible sensitivity of the topic area, and the inclusion of young people who may have experienced life challenges, methods for Homan’s study needed to be mindful of such concerns and to allow for the balance of participant-centeredness and protectionism alluded to above. Focus groups offered distinct advantages in this respect as they facilitate collective conversations where participants can share experiences, insights, and perspectives in a supportive group environment (Adler et al., 2019). This approach is particularly valuable when working with young people who may be marginalized/minoritized or whose voices are seldom heard, as the group dynamic can provide mutual support while enabling authentic expression of experiences and viewpoints (Onwuegbuzie et al., 2009).
To enhance the focus group method, we considered a range of techniques particularly well suited to exploring sensitive personal issues and facilitating discussions of feeling/affect. Significantly, key methodological contenders included photo elicitation—where researchers select or generate photographs or other images to elicit reflection and depth narration from interview participants (see, for example, Harper, 2002)—and photovoice—where participants generate their own photographs/images as a means of articulating and documenting experience, visually “framing” perspectives and priorities, and capturing details or reflections that might be irreducible to textual or verbal representation (see, for example, Wang & Burris, 1997; Hughes, 2012; Tarrant and Hughes, 2019).
We ruled out the possibility of using a conventional model of photovoice where we might have, for example, distributed digital cameras to young people asking them to take photographs documenting their experiences and aspects of their lives relating to the key foci of Homan’s study (or using their own smartphones). Doing so would have raised resource, practical, and above all, ethical concerns—particularly given the sensitive character of the topic, the age of participants, and the issues relating to privacy, etc.—that fell beyond the scope of the study. Exploring photo elicitation, we discussed how we might source ethically and epistemically suitable images to use as a basis for discussions of “positive” and “negative” forms of coping, including some that might or might not include substance use. As we drew up the checklist of everything such images should and should not contain, the brief became more complex and the chances of our finding images that were apposite to the task greatly diminished. We then experimented with ChatGPT’s image-generation functionality as a possible source of visual elicitation materials to use in focus groups with the young people. We soon were able to produce some remarkably photorealistic images that, we felt, might be suitable for the purposes of the research. Image 1 below provides an example of the kinds of images we were able to obtain via this process.

ChatGPT image of “a young person who is not coping well with a distressing life episode”.
This kind of image had potential because of its scope for interpretive polysemy. A potential reading is that the person depicted has had an exchange over the phone that has been distressing, that they are feeling alone, and are simultaneously in touch digitally and personally isolated. One possibility for using this kind of image was to invite participants collaboratively to generate a narrative—a backstory—of the person depicted. What has happened? How did it happen? What will happen next? We could structure the discussion to lead into considerations of coping and adjustment behaviors. Perhaps subsequent images could more directly reference substance use (a cigarette in hand, pills in the background, etc.), avoiding visually “priming” participants toward certain kinds of association while steering the discussion toward topics that were central foci of the study.
In the process of generating these images, we noted that how we instructed ChatGPT had an important bearing on how the image was depicted. To obtain the image included above, we instructed ChatGPT to Create a photorealistic image of a young person who is not coping well with a distressing life episode. Perhaps they are using substances. Leave the image open to a range of possible interpretations. Do more to suggest than depict what’s happening so that the image is open to discussion. Accordingly, we found that how we prompted and interacted with the GenAI was in and of itself a crucial part of this process, and was a form of algorithmic co-production. Given that a key principle of Homan’s research approach was the co-production of knowledge via qualitative research, we soon arrived upon a different methodological possibility: of asking our participants to co-generate images themselves and to use these as a basis for reflection and discussion. This approach was much closer to the photovoice than the photo elicitation type model, hence our coinage of the working term “AI Voice.”
The focus for the remainder of this discussion is on our early piloting phase of AI Voice methodology—how it operated in practice, the unexpected insights it yielded, the ethical and substantive concerns it raised, and the lessons we carried forward to subsequent work (Homan et al. in preparation). What began as a pragmatic opportunity for engaging young people in doctoral research developed into something more significant: the recognition of an emerging methodological approach requiring its own theoretical framework. Through iterative development, we moved from considering AI as merely a potential tool for elicitation to recognizing it as requiring—and generating—its own methodological vocabulary and framework. This paper, therefore, serves a dual purpose: mapping the fieldwork journey through its key developmental phases while also articulating the distinctive methodological terrain that emerged through our engagement with AI Voice in qualitative research.
Questions of “Voice” in AI Voice Methodology
In addition to being an homage to the notion of photovoice, the term “AI Voice” immediately serves to problematize who or what is “voicing” and being voiced in the generation of images and other outputs via AI. In photovoice methodologies, where images are typically self-generated by participants (Wang & Burris, 1997), this direct form of authorship is key to the method as lens, framing, and perspective are simultaneously epistemic and pictorial. “Voice” in photovoice methodologies is facilitated through the affordances of images, particularly in relation to reflections and depictions that might otherwise be emotionally difficult to discuss and/or to articulate verbally or textually. In the case of AI voice methodology, depictions are co-created through an interaction between participants and a GenAI model. The images thus produced, as we have suggested above, are in certain respects better understood as derivations more than original creations. However, this distinction ultimately obscures more than it reveals. In the case of photovoice, too, the images produced are not simply simon-pure creations. A camera (of whatever kind) has its own technological capabilities and constraints that have an important bearing on the images it can be used to generate. Cameras must be operated—a picture framed, an exposure made—and photos must be processed (digitally or otherwise), selected, and interpreted to be “produced.” The act of photographic creation is a socio-material interaction that inevitably forms part of an ongoing “dialogue” of culturally available images, conventions, tropes, and visual standards. Just as no verbal utterance stands outside of language, photographic voice must be understood as part of an ongoing “conversation,” however unique, original, or distinctive the images generated (Hughes et al., 2022).
Similarly, the idea of interviews as social encounters in which an authentic voice is allowed to speak, unencumbered is equally problematic (Hughes et al., 2020). Indeed, all forms of data are mediated, what varies is how this mediation occurs, and how researchers treat such data: how they are read and rendered as particular kinds of evidence (Hughes et al., 2020). In the case of AI voice, the mediation centers on the interaction between human participants and a non-human model, and in that, an interaction that draws upon a stock of cultural tropes, and all the artificial—and here we are using the term in the more technical sense of, somewhat paradoxically, meaning “made or produced by humans”—interests, biases, distortions and narrations that are involved. Indeed, as we shall argue, the “artificiality” of AI voice has potential facility and utility precisely in highlighting the mediation of its own depictions, opening a safe epistemic distance from which to discuss sensitive experiences and their narrations, often in the critical disjuncture between what is prompted and what is depicted.
We wanted to investigate how these differences from photovoice might be leveraged in qualitative research. To explore the potential strengths of the method in practice, as well as to account for ethical concerns and practical considerations in how such a method might be further developed and utilized in co-productive qualitative research projects, we designed a pilot project incorporating the use of AI-generated images to facilitate discussions with young people. The fundamental orientation of our pilot was toward the dialogue and mediation involved in the co-production of GenAI images —the entire iterative process of production and generation, and not simply the “outputs” as “representations.” Put simply, in AI Voice, control over pictorial framing is replaced with control over prompting and critical narrative reframing: “voice” is realized more through reflexive and dialogic critique and iteration than direct photographic representation.
Methods
We obtained ethical approval from the University of Leicester, to recruit a small group of young people (aged 18–24 years) who would be provided with information about the pilot study and its methodology, and who consented to participate. To ensure ethical protocols were appropriate, and to enhance ethical insights and safeguards, a youth panel originally convened for Homan’s PhD study was consulted to examine the participant information and consent forms to ensure the aims of the study were as clear as possible for young people taking part. Limits to confidentiality were clarified and anonymity in publication assured.
To recruit participants, we emailed media, games and art creation students, and latterly social work and sociology cohorts, from seven different U.K. universities drawn from our own scholarly networks. These subject areas were chosen as they included students who, we anticipated, would have some prior knowledge and possible experience of AI-based image generation and/or might have an interest in its potential and the issues relating to its use in research. Ultimately, we recruited four participants from social science and design backgrounds. As our aim was principally to pilot the method and approach, we deemed this small sample to have sufficient information power potential (Malterud et al., 2016) to obtain direct experience of using our approach in practice and of co-developing it such that it might subsequently be employed in the study of young people’s coping and adjustment behaviors (outlined earlier in this paper).
A 2-hr online focus group and workshop was conducted via Microsoft Teams. This platform was chosen as it has been widely adopted in teaching environments from primary to university level and, as such, was accessible and one with which participants were likely to be familiar. In addition, previous research (e.g., Keemink et al., 2022) have found MS Teams to be a platform well suited to online focus groups, whose “benefits of increased accessibility and representation significantly outweigh the limitations related to online social communication” (Keemink et al., 2022, p. 1). In advance, all participants were sent information and informed consent sheets, were told that their participation would involve the use of GenAI to create images, and were guided to create quasi-anonymous “burner” ChatGPT accounts for use in the session. Our aim was to avoid using participants’ personal accounts as these might present data protection issues (e.g., in user histories), all of which were discussed with participants as part of the informed consent process. The session was recorded and transcribed using Teams’ in-built auto transcription feature. This transcript was later reviewed for accuracy. Images created in the session, chat exchanges, plus the text-based prompts used by researchers and participants for the interactions with ChatGPT were also collated and stored in a secure digital repository. Finally, the research team met together after the focus group for a debrief, whereupon we shared experiences of, and reflections upon, the pilot, recording these as written notes.
Data were analyzed using reflexive thematic analysis (Braun & Clarke, 2019): an approach which recognizes the active role of researchers in constructing themes and not simply “discovering” patterns that are intrinsic to the data. The multimodal character of the data collected—GenAI images, text prompts, discussion transcripts, researcher notes—necessitated analytical attention to both process and content dynamics of participant interactions. All aspects of the research engagement were treated as “data” (Hughes et al., 2026) with the potential to afford insights into what might constitute AI Voice, how it might be conducted as a method, and what sorts of research insights it might yield.
Team analyses involved a multiphased approach: initial familiarization with the data through the repeated review of transcripts, images, prompts and notes was followed by systematic coding in which we collectively focused on discussing and resolving differences, both within the data and between our coding decisions, and, in a final phase, thematic generation. Each of these phases was iterative, bringing emergent interpretations of our data into “analytic conversation” (Hughes et al., 2022) through reflexive “dialogue” with other scholarship, concepts, and evidence, and between team members. Our focus was upon how participants engaged with the method, the specific tasks undertaken, the interactions with each other and the GenAI, the reflections on the images that were generated, and the ethical, practical, and substantive concerns that arose from these.
Session Format
The pilot focus group centered around a workshop that was designed and structured according to the following format:
Part 1: Introductions. Researchers introduced themselves and briefly outlined the session aims and objectives. Participants were also asked to introduce themselves and talk briefly about their experiences (or lack thereof) of using GenAI for image generation or other purposes.
Part 2: Reflecting Upon Key Terms. In introducing the topic, researchers asked what participants understood by key terms through using questions such as, “If I was to use the term ‘coping’ what would you understand by that?” Or, “What does the term ‘traumatic’ mean to you? Can you give some examples of what that might mean?” Discussing key terms proved to be an important undertaking since using “emic” terms—those that had currency and utility among participants—were essential to later stages of the workshop. For example, participants preferred the phrasing “dealing with” to our “coping”; similarly, “traumatic” was rephrased as “brutal.” Such clarifications were important both to researchers setting out the task for participants to undertake, and in participants’ discussions of how to prompt GenAI in the process of image generation.
Part 3: Demonstration. In this phase of the workshop, we provided a demonstration of how the GenAI interface (in this case, ChatGPT) can be used to generate images from text-based prompts. Here we were conscious of balancing the need to clarify and demonstrate the task to participants without “priming” them to interact with the AI model in a particular way and using particular kinds of instructions. Our interest was in exploring the different modes and registers through which participants would interact with one another and the AI interface, and so our aim was to minimize presenting our approach as a model of how the task should be completed. To this end, we used a contrasting example (a scenario from which we created images of a middle-aged person who had won the lottery; and another of images of someone who had met a stray dog on their way home) both to demonstrate the interface and its capabilities, and to clarify the process of image generation.
Part 4: Participant Briefing. Participants were provided with the following brief: “A person your age has had a difficult, traumatic, or upsetting experience or period in their life. Create an image or a short video that depicts: a) someone who is responding in a way that is a healthy/positive/beneficial adaptation; b) someone who is responding in a way that is unhealthy/negative/potentially destructive.” Note, in practice, we adapted the language here to reflect emic terms of participants. For example, “traumatic” was changed to “brutal,” “adaption” or “coping” became “deal/ing with.”
In the pilot study we asked the group to generate images for both scenarios (a) and (b). However, in successive workshops we split a larger group into two rooms, with one focusing more on positive “adjustments” to traumatic life episodes; and another focusing on more negative ones. 1
Part 5: Observation. After clarifying the brief with participants. We asked for a volunteer from the group to act as scribe: to become the primary point of interface with the GenAI model, working with their group as a whole to agree on prompts, and entering these into ChatGPT for image generation. After ensuring no private or personal information was visible, we then arranged for that individual to share their screen depicting the ChatGPT window of their burner account. Once we were sure the group understood the task, the researchers switched off their cameras and microphones for the duration of the task, participating in the group only where clarification was requested or guidance was needed. Because image generation can take a long time, the group-generated prompts were also cut-and-pasted into the chat window of the conferencing platform (Teams) so that each participant could use the same prompt in their own “burner” account, to see if they obtained an image more rapidly, and to compare the images they generated.
As researchers, our initial aim here was to observe how participants prompted ChatGPT to create their images: what prompts they used, how they addressed and approached the GenAI, how they arrived at prompts, what terms they used and so forth. However, in addition to this, we also observed how participants reacted to, discussed, critiqued, and re/framed the images generated; how prompts were revised and images regenerated; how various iterations were agreed upon; and, most significantly, how participants critically interrogated the form and content of the images. Particularly significant here were participants’ discussions of the authenticity, realism, accuracy or otherwise of the images: “That’s not right because. . .” or “It should be more like. . .” type observations. Researchers kept a record of their own observations, of the prompts that participants used, and the images they generated:
Part 6: Narration. Members of the group were asked to create a “backstory” regarding the images they created. Here we were interested in what participants “made” of/with what they had collaboratively “made.” Again, our plan for successive workshops was to have two subgroups each presenting to the other these backstory narratives.
Part 7: Exchange and Reflection. The images, the backstories, and the more general narrations were discussed and reflected upon. Researchers acted as facilitators to prompt reflections on the stories and images—to what extent are they fanciful, how far are they realistic? Can participants identify with them? What do the stories tell us about positive or negative adaptations to challenging life circumstances? What can they tell us about AI and AI-generated images?
Part 8: General Discussion and Conclusion. Researchers drew together the main themes of the discussion and facilitated a more general exchange further exploring the range of views, observations and reflections that were made on the substantive concerns of the research topic (in this case, young people’s coping strategies). The discussion was then concluded.
Part 9: Debrief. Researchers debriefed and followed up with participants over email. As part of the debrief, we had a safeguarding protocol to direct participants toward support if it became apparent (either in the session or via subsequent contact) that any of the issues raised had been particularly sensitive, distressing and/or of a personal nature to those involved. In this pilot, there were no such cases.
Findings
Based on our pilot workshop and subsequent focus group sessions, several key themes were identified regarding the practical implementation and methodological considerations of AI Voice as a qualitative research method. The findings reveal both the potential and the challenges of this approach, while highlighting fundamental differences from traditional photovoice methodology. We have assigned pseudonyms to all participants consistent with their gender and ethnicity: Kendra, Melissa, Ravi, and Greg.
Technical and Practical Considerations
Running the focus group workshop brought to the fore an array of technical challenges that both constrained and enabled the research process. The most immediate issue was the sluggishness of image generation. The workshop was conducted during a time of the day during which ChatGPT typically experiences high traffic, and images would sometimes take up to 10 minutes to render, some failed to render at all. This significantly impacted the flow and timing of focus group discussions. Participants experienced considerable frustration with wait times, particularly when attempting to iterate on prompts to refine images. Platform limitations also proved restrictive, with participants limited to generating only three images per day on the free version of ChatGPT, which set limits to the iterative character of the method. Part of the way we mitigated this issue was to ask all participants to run the same, agreed upon, prompts on their own individual “burner” accounts. In addition, members of the research team ran the same prompt on their accounts across different GenAI platforms. We found that Google’s Gemini was typically one of the fastest, most reliable, and best quality alternatives to ChatGPT, and it has since this pilot study become our default choice for AI Voice work.
The technical challenges also highlighted digital equity issues, with participants questioning whether internet speed affected generation times. The need for reliable internet access and basic digital literacy became apparent barriers to participation that require careful consideration in research design. Participants themselves identified potential solutions, with Ravi suggesting alternative platforms and discovering “Ideogram,” which generated multiple images simultaneously and proved significantly faster than ChatGPT:
So, I was searching for like free image generators and I found this one. And it like it’s basically the same thing. You enter the prompt, and it generates this event: these images; and it’s much faster . . .
Ravi’s Ideogram images (included below) contained multiple images from the same prompts. Participants found these useful, but perhaps significantly, more difficult to discuss than singular images, which (as we explore below) allowed for greater depth of reflection. Such issues serve to highlight that technical and technological concerns are not simply matters of process and procedure; they are simultaneously substantive concerns, with different platforms offering distinct affordances and epistemic possibilities. When it comes to GenAI image creation, more is not necessarily more: the pace at which images are produced, the number of images considered, and the character of images produced all have significance for the practice of AI Voice.
Language, Prompting and Collaborative Meaning-Making
A crucial finding concerned the collaborative negotiation of language and the collective work of translating emotional experiences into prompts. Participants demonstrated sophisticated understanding of how their language choices affected AI outputs, leading to extended discussions of authentic expression versus effective prompting.
Participants’ first prompts described a specific scenario in which someone had moved school and was finding it difficult to cope without their former friends. Interpreting our brief, they agreed this would be a good example of a “brutal” life episode, and an example that would present particular difficulties for adjustment. Their specific prompt was as follows: Create Image: I’ve moved school and I’m feeling quite lonely. I’m not doing well without my friends.
This generated Image 4, below:
Participants commented on the style of the image, noting it was not what they had initially anticipated. Having not stipulated they wanted the image to be photorealistic, ChatGPT automatically selected a charcoal-style drawing format. The expression on the subject’s face, the framing of the image, plus the blurring of others in the background were all discussed as of potential significance. As Kendra commented,
. . . it seems like she’s not really in that position. She’s imagining it. It [the GenAI] really took up the image of being isolated: feeling small while you’re isolated. She’s kind of crumpled against herself. Not comfortable.
Here Kendra’s narrative and interpretative work demonstrates considerable analytical skill: that the other people are not fully depicted, that they are partially formed figures in cross hatch, could be suggestive of an external rendering of the main subject’s imagination. Following from such reflections, participants felt that more apt images could be derived if the prompts to the GenAI were more consistent with authentic teenage expression. Melissa articulated this concern directly:
I think we have to write it in like a teenage way as well. Not like my mother, you know, like “I’ve moved to school. I feel really. . .” Do you know what I mean? “I feel really lonely.” It should be “I hate my life!,” kind of thing. “I’m not coping..” . . Just put “no one, no one gets me.”
This observation led to a collective refinement of language, with participants working together to find appropriate expressions. This collaborative language work became a form of knowledge production in and of itself, providing a way into participants’ understandings of how young people actually communicate emotional distress. However, the subjective character of prompting also proved problematic, generating challenges amplified by the GenAI’s potential for misinterpretation. As we have seen, participants found that even seemingly straightforward prompts could produce unexpected outcomes, and, they conjectured, may have compounded technological challenges and delays. Kendra reflected on this complexity:
Maybe because we’re really specific and we have kind of conversational language. It’s making it more difficult to generate it. I’m not really sure.
Nonetheless, the collaborative process of prompt development revealed how participants negotiated not only what to represent but how to represent it. When considering how to depict isolation, participants moved from individual scenarios to shared understanding, with Kendra observing:
I think everybody to some extent, sometimes even if you’re not seeing like your actual friends doing something, you’re just seeing people online that you follow—like certain influencers, or just someone travelling that you follow—doing something that you want to achieve and it makes you feel a certain way.
Inferred in that “certain way” of feeling was something more than just isolation. Kendra here was conveying a simultaneous sense of being both “together and alone” through being connected digitally but simultaneously remote from those others who are seemingly “doing something” that you want to achieve. From a researcher perspective, this shows some of the potential of the AI Voice methodology to elicit reflexive discussions of experience not only through reflections upon outputs—here, the images collaboratively generated—but in determining inputs: the prompts to provide to GenAI, and the scenarios that they convey, which might best capture and convey those experiences.
Cultural and Representation Issues
Cultural considerations emerged as a significant concern, with participants expressing sophisticated awareness of how different cultural backgrounds could influence both input and output in AI-generated imagery. Ravi articulated this concern particularly powerfully through personal experience:
Like I. . . come from a different culture and I don’t know, like what specific thing that makes other people tick, and I don’t want to do that subconsciously. So, I’m very concerned about me saying something bad, so you know. . . that thing also kind of makes me feel isolated. And depressed.
This personal reflection prompted empathetic response and methodological adaptation, with Kendra suggesting ways to incorporate these feelings into the research process: “First of all, I’m sorry. I’m sorry that you’ve experienced that. But so maybe in this we could, input like ‘I’m afraid of doing anything wrong or I feel misunderstood maybe.’” Ravi confirmed the relevance of this approach: “Yeah, misunderstood is a key point, yeah.” This exchange was notable for its emotional richness, highlighting some of the potential for this method to facilitate an exploration of the affective dynamics of shared experiences in a manner that is led by young participants.
The AI system consistently demonstrated cultural bias in its imagery, defaulting to American cultural references despite U.K. participants. When participants prompted scenarios involving “new school” settings, the AI-generated American high school–style lockers, which became a productive point of discussion regarding how AI training data shape representational possibilities. Participants reflected on cultural assumptions embedded in the technology, noting the absence of school uniforms and presence of personal clothing that characterizes American rather than British educational settings.
This is a seemingly innocuous example, but it once again serves to demonstrate that the stock of representations from which GenAI images are derived is not neutral. We also noted through this pilot that there are evidently some attempts in the GenAI coding of different platforms to decenter representations: not to default to white, male, etc. subjects when no specific gender or ethnicity is prompted. In addition, as Images 2 and 3 above help to illustrate, representations would sometimes be open to interpretation regarding gender, sexuality, ethnicity, perhaps through programming to purposively avoid stereotypical imagery. Notwithstanding such points, of particular interest to the research team was participants’ reflexivity regarding the cultural specificity of certain images and, more significantly, how, as the extract from Ravi serves to illustrate, critical reflections on this led to specific discussions of representation, cultural exclusion and inclusion, and the feelings and experiences participants expressed in relation to these.
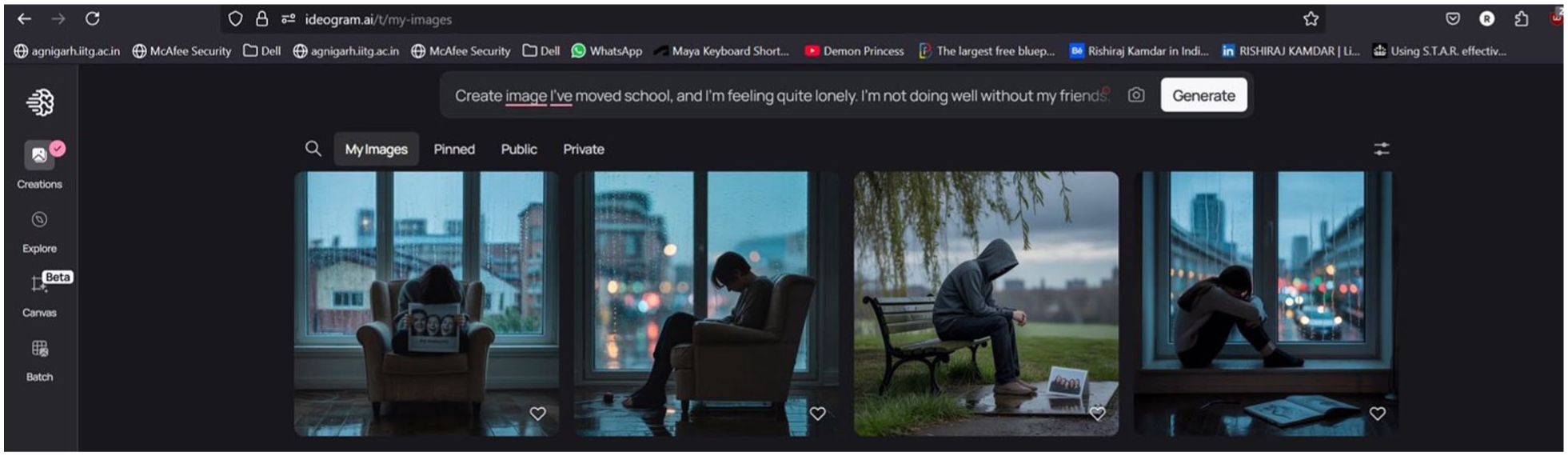
Ideogram generated image of young person who has ‘moved school and is feeling quite lonely’.
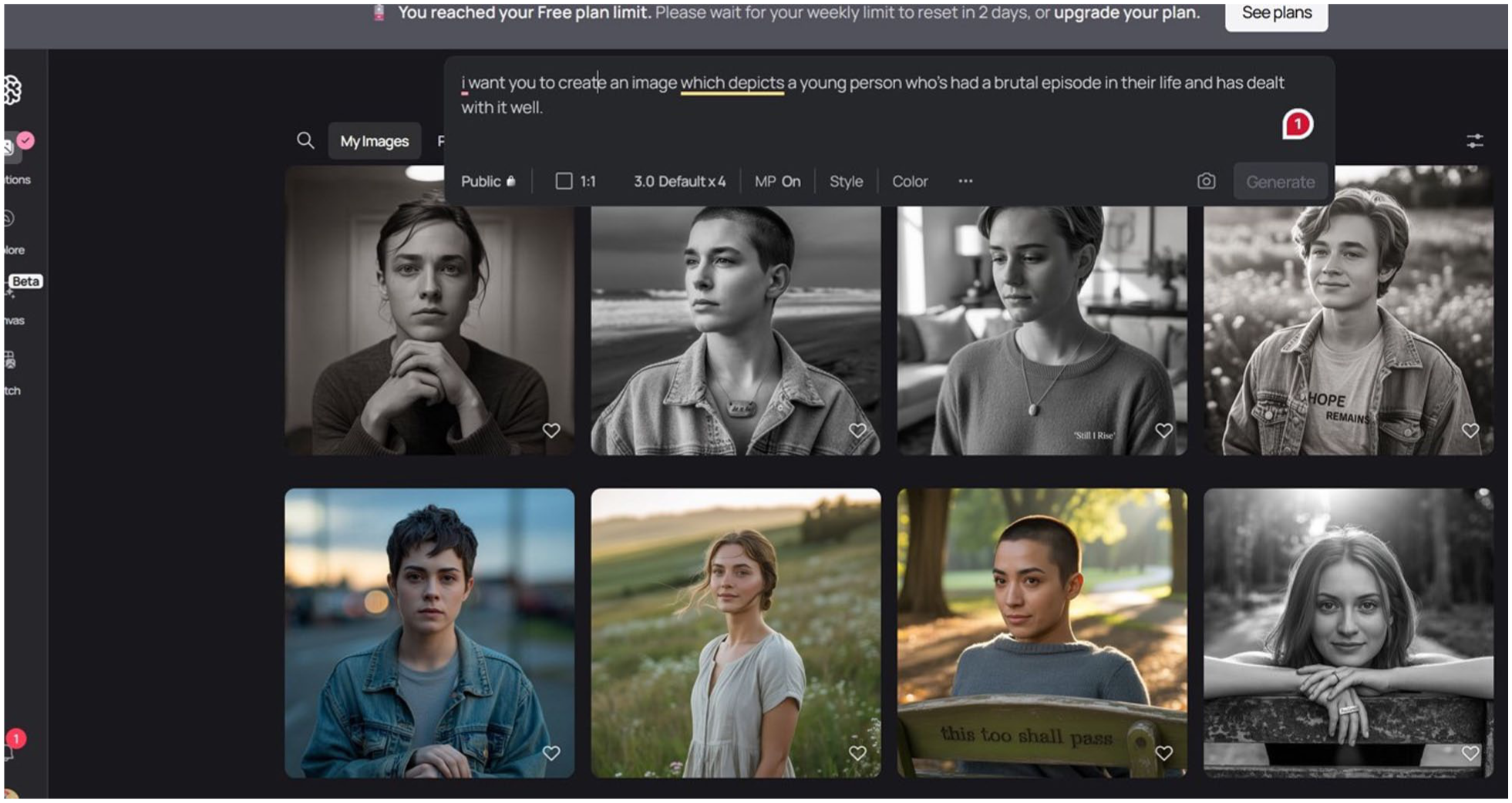
Ideogram generated image of young person “who’s had a brutal episode in their llife and has dealt with it well”.
An Epistemic “Foil”: The Productive Distance of “Artificial” Representation
Following on from the above, perhaps the most significant finding concerned how AI-generated images functioned as what might be termed an “epistemic foil”—creating a productive distance that enabled reflexive discussion precisely because the representations were clearly “artificial.” Here we can observe a key difference between AI Voice and Photovoice: the images generated are not, and were not treated as, of the self or, in this case, of the group in any simple sense as they might have been in the case of Photovoice. They are not approached as “real” artifacts that capture or somehow fix an aspect of someone’s lifeworld. They are, at least in the case of our pilot workshop, consistently understood and approached as “unreal,” even when they are photorealistic. However, rather than seeking AI-generated images directly and authentically to represent aspects of lived experience, participants used the gap between AI outputs and their own understandings of that which these images were intended to depict as a discursive space within which to articulate “how things really are.” Ravi’s critique of Image 4, above, exemplified this process:
I don’t know why the people in the background are fighting. It looks, like . . . they are fighting . . . like, they should be happy in the background because you know this girl in the middle is the one who is sad.

Chat GPT generated image of “I’ve moved school and I’m feeling quite lonely. I’m not doing well without my friends”.
This critical distance enabled detailed analysis of representation itself. Kendra demonstrated analytical sophistication when interpreting the images:
Like the first one, she might be imagining her friends talking in the hallway without her. And the second one is just several images flashing by, maybe of her family being happy, and her realising that she’s not, and being amongst her peers, and realising she doesn’t feel like she belongs there.
These interpretations revealed how participants could use AI representations as vehicles for discussing complex emotional and social dynamics without requiring direct personal disclosure. The safety afforded by this distance became apparent in participants’ ability to cover serious topics with a degree of analytical detachment alloyed with identificational involvement. That is to say, participants could identify with the feelings and mood states depicted in particular images while simultaneously holding these at a distance from themselves. That potential—to engage in affective projection while maintaining analytical distance—enabled participants to explore emotionally charged experiences in a “low stakes” environment. This served to diminish the vulnerability of direct personal disclosure. Such potential was particularly apparent in relation to participants generating “back stories” for the images they co-created. For example, in relation to one of the images, Melissa created a biographical vignette that revealed a sophisticated understanding of social dynamics and cultural displacement:
This is Emma, and Emma’s just moved from. . . America to, you know, a small American town. And she’s from the big city. And this is completely different to her. You know, everybody knows everybody. Whereas she was quite popular at her old school, and you know, now she’s come along, and, you know, she dresses differently and, you know, she speaks differently. And this is. That’s why she’s been left out.

Chat GPT generated image of “someone in their 40s who’s won the lottery … [who has] some trepidation about the possibile futures that lie ahead”.
Emotional Complexity and Methodological Sophistication
From an early stage in experimenting with AI Voice, we became aware that GenAI systems sometimes struggled with the depiction of emotional nuance. A key example is in our demonstration phase (Part 3 of the workshop outlined earlier) where we generated images of a lottery winner. Here our aim was to show how the system worked, and to give an idea of how ChatGPT could be prompted to create images conveying particular scenarios. The first prompt was as follows: Create an image that shows someone in their 40s who’s won the lottery. Life is about to change for this person, likely for the better. But there’s some trepidation about the possible futures that lay ahead. I want the image to be photorealistic and capture the full range of emotions involved.
This image introduced a fair bit of levity into our demonstration. It did so precisely because, as participants various observed, the character depicted looked rather miserable at having won the lottery. One of the participants speculated that it was perhaps because he had only won a few dollars. The image was also very literal in its depiction of a lottery winner. To address these shortcomings, we prompted ChatGPT as follows: This time I want the image to cover the same topic, but to be less literal—maybe they’ve won a house or something like that. The last image looked a bit miserable and looked like the prize wasn’t that great!.
As these images serve to demonstrate, GenAI images typically struggle with the depiction of nuanced emotions, often defaulting to binary representations—misery or ecstasy—rather than capturing complex, more ambiguous or ambivalent emotional states. Partly in relation to this, we sometimes found the images to be culturally-centered. For example, our lottery winner was white, male, and likely American—we inferred the latter from his dress, and from the kind of house depicted in Image 6. When we prompted ChatGPT to regenerate the image, but this time in a more culturally diverse way, it again, interpreted the instruction rather literally and with similarly photorealistic but emotionally unrealistic results:

Chat GPT generated image of “less miserable” lottery winner.
Perhaps significantly, the GenAI systems coped better with some scenarios than others. In hindsight, our first scenario of the winning lottery ticket holder facing a future about to change presented an extremely challenging brief. It may be simply that we were asking for a single image to do too much representational work. Another scenario that we also used to demonstrate the process of image generation fared rather better in the sense that the image seemed more plausible, more realistic in both a pictorial and affective sense. Here our prompt was as follows: Create an image that captures some of the emotional complexities of finding a stray dog on the way home. The image needs to be photorealistic, provide some context, and leave open a range of different narrative possibilities.

Chat GPT generated image of “more culturally diverse” lottery winner.
This image too conveys certain tropes and, again, draws from a distinct cultural stock of imagery. However, it is somehow more believable, perhaps precisely because the composition, lighting and visual storytelling have a cinematic quality. It does not have the quality of a “real” photograph—it feels staged, deliberately sentimental. However, the visual narrative it conveys is rather more believable than the images of the lottery winners above.
Our participants seemed able very quickly, and often precisely, to make judgments regarding the accuracy, authenticity, and realism of specific images. They were especially tuned in to discrepancies and disjunctures between affective and pictorial realism. However, these limitations to particular GenAI images also presented opportunities for often sophisticated, depth discussions regarding emotional experiences and social relationships. For instance, reflections on a GenAI image depicting conflict in the background of school scenes led participants to develop nuanced analyses of how isolation and friendship dynamics actually operate. The method’s “failures” thus became methodologically productive, enabling discussion of emotional complexity through critique of oversimplified representations.

Chat GPT generated image of “finding a stray dog on the way home”.
Kendra’s reflections on the body language depicted in Image 4, above, is one such example:
Her body language. Oh, like she’s literally closing herself off physically boxing herself in. So, opening herself up. Even just kind of standing at her locker. Or kind of just walking past, could be more inviting for, like, her peers to be, like, hey, are you OK? Or a teacher to come up to her to say, “Do you need help? What’s wrong?” But she’s completely closed herself off: the looking down, the scowl.
Similarly, participants demonstrated awareness of how GenAI images’ potential for depicting complex emotions was very much dependent upon the precise terms used in prompts. In reflection upon an image participants generated to depict teenage depression (Image 9 below), Michaela observed,
I think had we said just “sad,” it might have given various different images of being sad. Because we said depressed . . . It’s more specific too, and yeah.

Gemini generated image of “depressed teenager”.
Ultimately, participants recognized there were limits to how far GenAI images could depict emotions. Greg, in particular, took a firm stance on this issue, proposing that GenAI can never truly capture human feeling, precisely because it is not human:
AI will always be without emotion it’ll never capture what anyone truly feels just use information it’s told on what these emotions are, which differ from person to person. Meanwhile actual art will have emotion; it’ll be unique to the person and is accessible for anyone in many forms.
Discussion and Conclusion
Our pilot study reveals that AI Voice operates through fundamentally different routes and channels than traditional photovoice methodology. In doing so, it challenges conventional assumptions about authenticity in qualitative research. Rather than seeking direct representation of lived experience, AI Voice harnesses what we term the “epistemic foil” created by the productive gap between AI-generated imagery and participants’ actual experiences.
This approach—to reflexively leverage the shortcomings, limitations and biases of AI, rather than seek to minimize them—parallels similar developments in the burgeoning field of qualitative GenAI research. Pink’s (2022) work with AI-generated “broken futures” stories reveals similar dynamics where participants used the limitations of such narratives to articulate corrective visions of possible work futures. Taken together, our approaches point toward an emergent methodological direction wherein the distinctive capacity of qualitative research to elucidate human meaning-making, interpretation, and lived experience becomes precisely what is needed to productively engage with AI’s constraints and vice versa.
In our case, this direction found expression through participants consistently engaging in a critical dialogue regarding how AI-generated images failed fully to capture their understanding of emotional experience, using this disjuncture as a discursive space to articulate “how things really are or should be.” The method’s emphasis on collaborative interpretation of clearly mediated representations enabled discussion of sensitive topics through what we identified as affective projection while maintaining analytical distance. Our use of the method also disrupts the notion that voice is something participants simply “have.” Through examples such as those that we have presented here, we were able to observe how participants strived toward “voice”: articulations that have emotional connection to the felt, not just the expressed. AI Voice effectively created a productive space through which to foreground particular forms of reflexive affective engagement by participants in a way that kept them at once connected and at a safe “remove” (Hughes, Hughes and Tarrant, 2022).
Beyond Individual Voice: Collaborative Knowledge Production
Unlike photovoice’s emphasis on individual visual narratives, AI Voice emerged as fundamentally collaborative. Participants negotiated not only prompt content but the very language through which emotional experiences might be articulated. This collective work of translating feelings into prompts became a form of collaborative knowledge production that extended beyond individual reflections.
The collaborative negotiation of appropriate language—particularly evident in participants’ discussions of authentic teenage expression—demonstrates how AI Voice captures emic understandings and experiences while maintaining a degree of emotional safety. It should be “I hate my life!,” kind of thing . . . Just put ‘no one, no one gets me. This translation work not only presented potential insights into how young people actually communicate distress, it also prompted participants to reflect upon their own experiences of particular scenarios.
The Productive Limitations of “Artificial” Representation
We found that GenAI systems often struggle with the presentation of emotional nuance. However, rather than proving solely restrictive, these also offered considerable potential methodological value. The tendency of GenAI toward binary emotional representations—defaulting to polarized archetypes rather than capturing complex, ambivalent states—presented opportunities for participants to articulate the subtleties missing from GenAI outputs.
This tension between technological capability and human experience proved to be a way in to discussing broader questions about AI’s role in meaning-making and its increasingly pervasive influence within young people’s lifeworlds, plus the possible issues that might stem from this. Greg articulated this tension powerfully: When I was 16 and doing bad mentally, art was an outlet, and if given the option to use AI, I would immediately ask “why”? A machine will never express how I’m feeling, just steal other artwork, cause environmental issues, harm the creative industry and not ever be able to understand or ever comprehend the emotion I am feeling; it cannot feel, only copy.
Greg’s critique captures the fundamental limitation that is also, in part, AI Voice’s methodological strength: precisely because AI “cannot feel, only copy,” it creates a safe distance from which human participants can explore and articulate what authentic feeling actually involves. That said, these issues also highlight the limitations to AI-generated content to be treated as, in itself, a form of “voice.” Indeed, the issues that Greg points toward bear out some of the findings from recent academic literature. Wu (2024), for example, has explored how AI’s pseudo-emotional capabilities fundamentally differ from those of genuine human emotional experience; similarly, Marrone et al. (2024) argue that while AI can simulate creative outputs, it lacks the authentic human experience that underlies genuine creativity. This serves to reinforce a central point: GenAI images do not in themselves “voice” particular aspects of experience and feeling. Rather, “voice” is facilitated through the dialogic critical reflection, (re)iteration, and (re)interpretation of such outputs.
The broader concerns that Greg raises—particularly regarding environmental costs and impacts on creative industries—warrant serious consideration, and return us to some of the more fundamental concerns relating to the use of AI that we discussed in the opening sections of this paper. It is first worth noting that traditional photovoice methodologies, particularly those involving the distribution of disposable and/or digital cameras, or extensive use of participants’ digital devices for image creation, carry their own environmental overheads that are rarely acknowledged in methodological discussions. Current estimates suggest that generating a single AI image requires energy roughly equivalent to partially recharging a smartphone, indicating that environmental comparisons between AI Voice and traditional visual methods may be more complex than initially apparent, particularly as GenAI energy efficiency continues to improve. Wang et al. (2024), for example, present a nuanced analysis of the considerable environmental impact of GenAI, including a discussion of the conditions under which AI might achieve greater environmental efficiencies (though under somewhat idealized implementation scenarios). Similarly, a range of recent studies (e.g., Anantrasirichai & Bull, 2022; Bender, 2025; Erickson, 2024) highlight a complex relationship between AI technologies and creative labor, suggesting possibilities for both displacement and augmentation of existing creative jobs, and noting the enduring significance and value of human creativity despite advances in GenAI. While ultimately, these issues are beyond the scope of our current discussion, our methodological approach seeks partly to address these concerns by fostering the kind of critical reflexivity that Greg himself demonstrates. Rather than encouraging unreflective consumption of AI-generated content, AI Voice promotes careful consideration of when, how, and why AI image generation might be appropriate, including within ethically sensitive research. Through collaborative interpretation and iterative dialogue, participants can develop greater awareness of AI’s limitations and possible harms, potentially leading to more thoughtful and judicious use of such technologies. This includes developing practical strategies for when AI image generation serves legitimate research or creative purposes versus when existing images, participant-created artwork, or other alternatives might better serve their needs while reducing environmental impact. This critical stance toward AI consumption aligns with our broader argument for maintaining human discretion and interpretive authority in research encounters with AI systems. Ultimately, we intend our methodology to harnesses and facilitate this critical capacity, transforming concerns about AI’s limitations into productive spaces for developing considered reflexive exchanges.
Implications for Research With Young People
Notwithstanding such ethical concerns, as we have argued throughout this paper, AI is becoming increasingly ubiquitous, profoundly shaping the social worlds occupied by young people. As such, AI Voice methodology reflects broader changes in how young people navigate meaning-making within increasingly digitally mediated and algorithmically-governed environments. Our participants demonstrated nuanced understandings of how these technologies shape representation, suggesting that methods that incorporate them may be particularly well suited for research with populations who daily negotiate, and perhaps are learning to mitigate the gap between algorithmic outputs and their own experiences.
Significantly, AI Voice positions young people as critical curators of AI-generated content—a capacity that may become increasingly central to their biographical and generational futures. As generative AI technologies ostensibly democratize the creation of sophisticated visual, audio, and textual content, young people face a fundamental question about their relationship to creative production. To employ something of an analogy: the widespread use of electronic calculators in primary and secondary schools may, overall, have diminished young people’s capacity for mental arithmetic; however, it arguably may also have facilitated greater access to higher-level mathematical problems, equations, and formulas. In a similar manner, AI tools may alter, perhaps transform, rather than simply replace human creativity. The critical curation skills demonstrated by our participants—their ability to prompt, critique, and iteratively refine AI outputs—suggest new forms of creativity that emerge from human-AI collaboration rather than solely competition or displacement.
Nonetheless, this raises profound questions about the character of creative work and human productive capacity within what Bourdieu (1984) termed the “field of cultural production.” Stated boldly, if everyone possesses the capability to generate professional-quality images, films, or texts through AI prompts, what then happens to traditional notions of creative skill and artistic value? Do GenAI technologies democratize creativity by making powerful tools accessible to all, or do they fundamentally alter, perhaps erode, the basis of cultural distinction itself? When cultural production tools become universally accessible, the traditional mechanisms through which cultural capital operates—through scarcity, specialized knowledge, and technical mastery—may be refigured rather than simply redistributed. Our findings suggest that the answer may partly lie not in the technical capability to generate content, but in the distinctly human capacities for critical (re)interpretation, collaborative meaning-making, and emotional expression that AI Voice methodology reveals and may indeed be used to develop. In such ways, AI Voice offers radical potential for reworking, rewriting, and resisting algorithmic bias through collective engagements by young people in research—thereby not only informing on research agendas, as pointed out earlier, but potentially rewriting them.
Methodological Contributions and Future Directions
In such ways, AI Voice methodology contributes to ongoing theoretical discussions about authenticity and representation in qualitative research by demonstrating how “artificial” representations can enable “authentic” discussion. Indeed, the method problematizes binary distinctions between real and artificial, authentic, and mediated that have long influenced qualitative methodology (Hughes et al., 2020; Hughes, Hughes and Tarrant, 2012).
The method’s transparency—making visible the ordinarily invisible processes of interpretation through collaborative prompt formulation and critical evaluation—offers both methodological and epistemic advantages and challenges. For participants, particularly young people, it provides opportunities to develop critical algorithmic literacy while engaging in reflexive consideration of how technology mediates understanding.
Future research might explore comparative outcomes between AI Voice methodology and traditional visual methods, examine its applicability across different populations and sensitive topics, and investigate how engagement with AI Voice offers pedagogic value in developing participants’ algorithmic reflexivity and critical thinking skills. As generative AI technologies continue to develop rapidly, AI Voice methodology will require ongoing refinement to address emerging ethical and methodological considerations while harnessing new technological possibilities. At the time of writing, a key shift in GenAI technologies is for them increasingly to be positioned as “agents” not simply “assistants.” For AI Voice, it is precisely their assistive not agentive affordances that offer value. Indeed, the method highlights the current limits, and potential future dangers, of that kind of transition.
The development of AI Voice ultimately suggests new possibilities for qualitative research to harness collaborative reflections while maintaining a degree of individual privacy and emotional safety. We would suggest that this might be particularly valuable when working with young people on sensitive topics where the productive gap between artificial representation and lived experience opens methodologically rich spaces for exploration and understanding.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.