
Abstract
This study examines how well individuals in Switzerland can distinguish high-quality deepfakes from real videos and whether a brief literacy intervention improves detection. In an online experiment with 1,361 participants, we tested the deepfake detection skills and how prior exposure and experience with deepfakes and various forms of media literacy relate to performance. Participants struggled to identify deepfakes when attending to visual features of 10-s clips and the literacy intervention showed no direct effect. However, prior deepfake experience and media literacy moderated the intervention’s impact. Findings highlight the need for comprehensive digital literacy strategies to address deepfake-related challenges.
Encouraging individuals to embrace new technologies while also educating them about potential risks is a key challenge for modern societies (Huessy, 1979). While technological literacy is typically developed over time through schooling or professional education, new technologies often emerge and integrate into daily life at a much faster pace (McCosker, 2022). Consequently, there is an ongoing debate about how best to educate individuals on technology’s opportunities and risks. With the rapid pace of digitization and advancements in artificial intelligence (AI), there is an urgent need to build literacy around new information and communication technologies, including social media, mobile phones, and, more recently, deepfakes (Appel & Prietzel, 2022; Hwang et al., 2021; Koltay, 2011).
Deepfakes are a relatively new phenomenon on the internet (Westerlund, 2019) and belong to the broader category of synthetic media, which includes text, images, video, and audio content generated by various machine-learning models (de Seta, 2024). While deepfake technology offers promising applications in education and entertainment, it also poses potential threats to democratic societies (Ahmed, 2021; Fallis, 2020; Hameleers et al., 2022; Vaccari & Chadwick, 2020). Deepfake technology can be used to manipulate existing media or generate entirely new content to deceive viewers, for example, a fake video of a politician or celebrity appearing to say or do something they never did. As a result, the ability to recognize and differentiate synthetic or manipulated media from real content is becoming an essential skill, complementing general internet and media literacy (Hwang et al., 2021; McCosker, 2022; Shin & Lee, 2022).
With the rapid advancement of AI and deepfake technology, individuals are increasingly confronted with new applications that present both opportunities and risks (Jungherr et al., 2025; Rauchfleisch et al., 2025). Many individuals are still unfamiliar with the term deepfake, have little firsthand experience creating deepfakes, and possess limited knowledge of the technology (Vogler & Rauchfleisch, 2024; Sippy et al., 2024). To address these shortcomings, literacy initiatives and short-term interventions have been proposed, similar to measures against disinformation in online media environments (Guess et al., 2020; Hameleers et al., 2020; Pennycook et al., 2021; Van Der Meer et al., 2023). However, there is still limited research on people’s ability to recognize synthetic media, the effectiveness of literacy interventions, and the role of (digital) media literacy and internet skills in this process. In this study, we address this gap in research by analyzing deepfake discernment based on the visual dimension.
In our online experiment, we investigate the capability of the Swiss population to discern deepfakes from real videos based on visual features and whether a short on-site literacy intervention, consisting of basic image-related cues, affects people’s ability to recognize deepfakes. We also investigate if news media literacy, social media literacy, and internet skills, as adjacent skills, as well as prior experience and exposure to deepfakes, moderate the intervention’s effectiveness. Drawing on transfer learning theory (Perkins & Salomon, 1992), we propose that existing knowledge and experience can be more effectively connected to the new information provided in the literacy intervention. For our study, we used a wide range of existing deepfakes and real videos of well-known politicians and celebrities, which were of good quality (i.e., no cheapfakes, cf. Hameleers, 2024). The deepfakes were tested from a larger pool of videos with a prestudy and grouped into three difficulty levels. Overall, our study gives a comprehensive picture of people’s ability to discern deepfakes, the efficacy of an on-site literacy intervention, and the influence of different types of literacy.
Literature Review
Recent advances in AI have made it possible to create high-quality deepfakes that are nearly indistinguishable from real images. As this technology evolves, discerning real from synthetically generated media will become increasingly difficult (Fallis, 2020; Godulla et al., 2021). While deepfake technology has beneficial applications, such as in the film and gaming industries or for personal recreation, it also poses significant risks, particularly in spreading disinformation and causing harm to individuals through deepfake pornography (Birrer & Just, 2024; Hameleers et al., 2022; Vaccari & Chadwick, 2020). To address the risks associated with deepfakes, three key measures are discussed in the literature: state regulation through restrictions or bans, technological detection methods, and (digital) media literacy (Birrer & Just, 2024; McCosker, 2022). To successfully tackle the threat posed by the harmful use of deepfakes, a combination of regulation, technological measures, and literacy is essential. However, large-scale regulations and bans are complex to implement legally, may create economic disadvantages for individual countries, and are often viewed as restrictions on freedom of speech (Bareis & Katzenbach, 2022; Birrer & Just, 2024). Technological detection tools can help, but remain underdeveloped and, like fact-checking for disinformation, often lag behind advances in deepfake production (Bray et al., 2023; Sharma et al., 2024).
This makes literacy measures particularly important to address the risks of emerging AI technologies and deepfakes for individuals and society (McCosker, 2022). Media and information literacy are shown to benefit not only individuals but also society as a whole (Leaning, 2019) and increasingly contain individual skills and social practices for navigating new media environments (McCosker, 2022). Such skills are not static and cannot be learned at a single point in time, such as in school. In dynamic digital media environments, individuals must continuously develop and adapt their media literacy skills in response to new technological innovations, such as deepfake technology or emerging social media platforms (Cho et al., 2024; Leaning, 2019). As a result, digital media literacy is a complex, dynamic, and multi-dimensional concept. Therefore, the literature has begun to explore deepfake literacy, with initial frameworks emerging (Ali et al., 2021; McCosker, 2022; Shin & Lee, 2022; Wagner & Blewer, 2019).
Although challenging to implement (Wagner & Blewer, 2019), deepfake literacy equips individuals with the skills to navigate the risks and opportunities of deepfakes. Strengthening deepfake-related literacy enhances resilience against the misuse of deepfakes for disinformation (Shin & Lee, 2022) and promotes responsible use of the technology. But what does it mean to be deepfake literate? From an operational perspective, this refers to the individual ability to discern false from real content. However, this operational aspect is embedded within a broader context, one that involves understanding and making sense of deepfakes, as well as the digital and cultural environments in which they are produced and circulated (McCosker, 2022). Therefore, deepfake literacy includes critically evaluating information, verifying sources and contextual details, knowledge of sociocultural aspects of new media, and understanding the potential, limitations, and production processes of deepfakes. Key competencies, such as knowledge of algorithms and AI, align with broader internet and new media skills (Hargittai & Hsieh, 2012; Hargittai et al., 2019; Koc & Barut, 2016; Tandoc et al., 2021).
Literacy Intervention
Building up literacy takes time and often collides with the fast development of technology. Therefore, related to the potential threats of deepfake on-site literacy interventions are being discussed as short-term measures to educate individuals and strengthen their literacy (Hwang et al., 2021; Iacobucci et al., 2021). Such interventions include simply raising awareness of the existence and risks of deepfake technology (Iacobucci et al., 2021; Ternovski et al., 2022), explaining how the technology works (Hwang et al., 2021), or providing strategies and specific hints on how to discern deepfakes from real videos (Bray et al., 2023). A key advantage of these interventions is their ability to reach a wide audience and be implemented on platforms where users commonly encounter deepfakes, such as social media or video-sharing sites. However, their short- and long-term effectiveness is debated, with concerns about potential backfire or downstream effects. First, the dynamic and fast-paced development of deepfake technology has raised doubts about the effectiveness of interventions that rely on specific visual cues (McCosker, 2022). Image-based strategies for detecting deepfakes can quickly become outdated, potentially giving individuals a false sense of security. Thus, timely, adaptable interventions that can be regularly updated may offer an advantage over fixed, once-learned approaches. Second, individuals exposed to literacy interventions may become overly skeptical of visual content online, leading them to misidentify real videos as deepfakes (Ternovski et al., 2022). Indeed, research has shown that warnings, such as labels, generally lower trust in information, which can negatively affect the credibility of true content as well (Freeze et al., 2021; Van Der Meer et al., 2023). Ternovski et al. (2022) tested the effect of such warnings in the context of deepfake videos, finding that they did not improve detection ability and instead increased distrust in real videos. Similarly, de Seta (in press) described how consistent platform warnings on synthetic media do not seem to impact the critical evaluation of content, as most users do not pay attention to them or actively seek AI-generated content for enjoyment. Most critically, Hameleers and Van der Meer (2023) demonstrated that general misinformation literacy interventions could, under certain circumstances, backfire.
Despite skepticism about the effectiveness of interventions and warnings, research on disinformation suggests that even brief literacy interventions can significantly improve recognition skills (Guess et al., 2020). It is also crucial to distinguish between different types of interventions, as Van Der Meer et al. (2023) also show that literacy interventions, unlike general misinformation warnings, do not produce adverse spillover effects.
To test the effect of a literacy intervention, we conducted a survey experiment to assess whether a short on-site literacy intervention (cf. Potter, 2013) enhances deepfake detection abilities. We hypothesize that individuals who receive brief instructions on recognizing deepfakes based on visual clues will be better at identifying them than individuals who did not receive such an intervention (Hwang et al., 2021):
As a competing alternative, the intervention may instead trigger generalized skepticism and lead to misclassifications. As already mentioned, recent debates in the literature indicate that some forms of interventions might backfire (Guay et al., 2023; Hameleers & Van der Meer, 2023). The most prominent concern is that interventions will increase skepticism and lead to real content being mistakenly classified as false. In the worst case, a literacy intervention triggers generalized doubt: people become more likely to identify deepfakes at the expense of increased suspicion toward authentic material (Guay et al., 2023). Therefore, we also test the following competing hypothesis:
As we gave one group of participants instructions on identifying deepfake videos, we were interested in how participants explained their decision to categorize the videos as real or false. Hameleers et al. (2025) and Jin et al. (2025) show that qualitative and quantitative content analysis of open-ended questions delivers in-depth insights into people’s strategies and reasoning when confronted with assessing the plausibility and authenticity of deepfake videos. We therefore ask,
Prior News Media Literacy, Social Media Literacy, and Internet Skills
Literacy related to deepfakes is a multi-dimensional concept encompassing the general understanding of media, data, algorithms, and internet skills (McCosker, 2022). Most exposure to and ongoing learning about deepfake technology occurs online, in social and news media environments, where people can gain experience and develop knowledge of the technology (Hameleers et al., 2022). Drawing on Perkins and Salomon’s (1992) high-road transfer framework, we anticipate that participants will draw on their broader literacies when tackling deepfake detection. However, we do not expect this to unfold as an automatic, low-road transfer of existing skills. Instead, our targeted literacy intervention should activate high-road transfer. We expect that those with stronger adjacent literacies, namely, news media literacy (Ashley et al., 2013), social media literacy (Tandoc et al., 2021), and general internet skills (Hargittai et al., 2019; Hargittai & Hsieh, 2012), will benefit more from the intervention than those with weaker foundational skills. Indeed, Hwang et al. (2021) show that general disinformation literacy education “can be as effective as and, in some cases, even more beneficial than deepfake-specific literacy education” (p. 191). We assume that individuals who already possess high literacy skills related to media can better connect and implement the provided deepfake literacy intervention in the experiment. Therefore, we investigate if there are interaction effects between deepfake discernment and participants’ prior news media literacy, social media literacy, and internet skills:
Exposure and Individual Experience
As an additional exploratory analysis, we investigate the role of prior exposure and experience with deepfakes. Many people have little to no experience with deepfake technology or may not even know it exists (Vogler & Rauchfleisch, 2024; Sippy et al., 2024). Therefore, the first step in adapting to new technology and developing literacy skills is understanding how the technology works and how to use it. Research indicates that knowledge of deepfakes and prior exposure to them enhance people’s ability to recognize such content (Shin & Lee, 2022). Furthermore, we anticipate that individuals with firsthand experience of deepfakes, and thus greater familiarity with the technology, will benefit more from the literacy intervention due to transfer learning (Perkins & Salomon, 1992). However, as there is no clear evidence on the interaction between prior experience or exposure and literacy interventions when it comes to deepfake discernment, we pose the following research question:
Method
Prestudy
We first conducted a prestudy in June 2023 (n = 753) with a Swiss online panel from Respondi-Bilendi, which was also used for the main study. In the prestudy, we assessed the difficulty of correctly discerning each video by calculating how far the average rating (on a scale from 1 = clearly real to 7 = clearly a deepfake) was from the correct end of the scale. Videos with mean scores closer to the correct endpoint were considered as easier (see Supplemental Appendix D for more information). We selected a deepfake and a real video of politicians and celebrities. We used short videos of Tom Cruise, Elon Musk, Barack Obama, Hillary Clinton, Volodymyr Zelenskyy, and Vladimir Putin. For each person, we identified one deepfake and one real video that was approximately 10seconds long. The videos featured individuals in neutral speaking settings, either positioned behind a desk or lectern (in the case of politicians) or recorded as selfie videos. All clips showed only the upper body and included no significant gestures beyond natural, coordinated speaking movements. The videos were implemented as Graphics Interchange Format (GIF) without any audio features. We exported all GIFs at a standard-definition size (around 640 × 440) that preserves key facial and contextual details while keeping file sizes manageable. This format was chosen to foreground purely visual features of authenticity, making it more likely that people could participate in the study as the GIF format ensured quick loading and broad compatibility across devices and browsers. In the pretest, participants had to rate with the same scale as in the main study if a video was a deepfake or a real video (1 = clearly real; 7 = clearly a deepfake). We ran the pretest with these videos at the end of another study, which allowed us to use a large sample size of 753 participants and around 376 observations for each video. We selected six videos for our main study based on the pretest results.
Each participant in the pretest was randomly assigned either the deepfake video or the real video for each of the six people. We selected videos for our main study based on three criteria. First, we chose clips spanning varying difficulty levels (see Supplemental Appendix D for more information). Second, we wanted to select three fake and three real videos, each featuring one of six different celebrities or politicians. Third, we measured familiarity (on a 7-point scale) and asked whether people believe they know the video already (binary). Each participant then viewed one randomly assigned video per public figure. We used regression models to identify and exclude videos where familiarity was a significant predictor. We then added prior exposure as a predictor: in almost all cases, it was nonsignificant, and where significant, the effect was in the opposite direction. Thus, prior knowledge did not confound our test set.
Main Study Sample
Our main study was approved by the Ethics Committee of the Faculty of Arts and Social Sciences of the University of Zurich and preregistered (https://aspredicted.org/9z6s-gfx9.pdf). For our online experiment, we recruited participants from the online panel (Respondi-Bilendi). Participants are people living in Switzerland who are above 16 years. Participants from the pretest sample were not invited to this study. The sample includes participants from both the French and German language regions. The surveys were both programmed using Unipark software. As we sampled without quotas, specific age brackets are overrepresented by female participants. We thus calculated survey weights based on the Swiss population and estimated the models using these weights. The results are identical to those without survey weights. More importantly, all of our strata are saturated, which is the most crucial factor when examining correlational relationships (see Supplemental Appendix C.3 for complete age distribution and models with survey weights).
Before we started our main study, we estimated the required sample size to have enough statistical power to test our hypotheses and research questions. Our power simulations indicated a power of 97% for the more complex hypotheses and 100% for the main hypotheses with a sample size of 1,200 (see Supplemental Appendix B). The main study took place in September 2023. Our final sample size was 1,361. 3 Initially, people were randomly assigned to either the literacy intervention or the control group. We then asked them basic socio-demographic questions about their general social media use. After that, we measured the different literacy and skill scales. Then we asked about prior experience and exposure to deepfakes. We also included two attention checks in the first part of the questionnaire before the treatment. The first, placed at the beginning, tested whether participants could view GIFs on their device using a multiple-choice question. The second was an instructional manipulation check that asked participants to select a specific response. Inattentive participants were directly filtered out when they failed one of them. Participants who were assigned to the literacy intervention group then received the literacy intervention before starting to rate the six videos, which were always shown in randomized order to each participant. Participants had to stay 20seconds on the page with the literacy intervention before they could continue with the test. Participants in the control group proceeded to the videos without receiving the intervention. As in the pretest, each of the six test clips was shown as a controlled, ten-second visual excerpt in GIF format without any audio features, standardized in size and resolution, so participants’ judgments relied on visual markers alone. In contrast to the pretest, the participants rated all six videos.
Analytical Strategy
The literature presents various approaches to testing interventions. Guay et al. (2023) showed that it is crucial to include both true and false headlines in the same model as an interaction term with the treatment, rather than evaluating only one type (e.g., fake news). This approach is still rare in communication science. However, it allows us to see whether an intervention improves discernment or merely heightens skepticism at the expense of correctly identifying real headlines. For example, Pennycook et al. (2021) applied this design when testing the impact of accuracy prompts on fake-news sharing.
Independent Variables
The literacy intervention provided guidance on identifying deepfake videos based on visual features, emphasizing movements, depicted details, and contextual clues as the three key factors for detection. Drawing on the MIT Media Lab’s (2023) deepfake detection guidelines, we structured our intervention around three visual-dimension factors—movement, details, and context. This tip-driven approach mirrors the style of Guess et al. (2020) and Hameleers (2022) and aligns closely with how literacy interventions are offered today (AI for Education, 2024). For each factor, we provide two specific cues (“fixed eye gaze” and “floating facial features” for movements, “unrealistic fine details” and “blurred backgrounds” for depicted details, and “unfamiliar appearance” and “unexpected behavior” for context). To maintain a real setting, the instructions did not include specific hints directly related to any of the deepfake videos used in our experiment (see Supplemental Appendix A.2 for the exact wording of the literacy intervention).
For
Media literacy as variable for
Prior experience with deepfakes as variable for
Descriptive Statistics of All Variables.
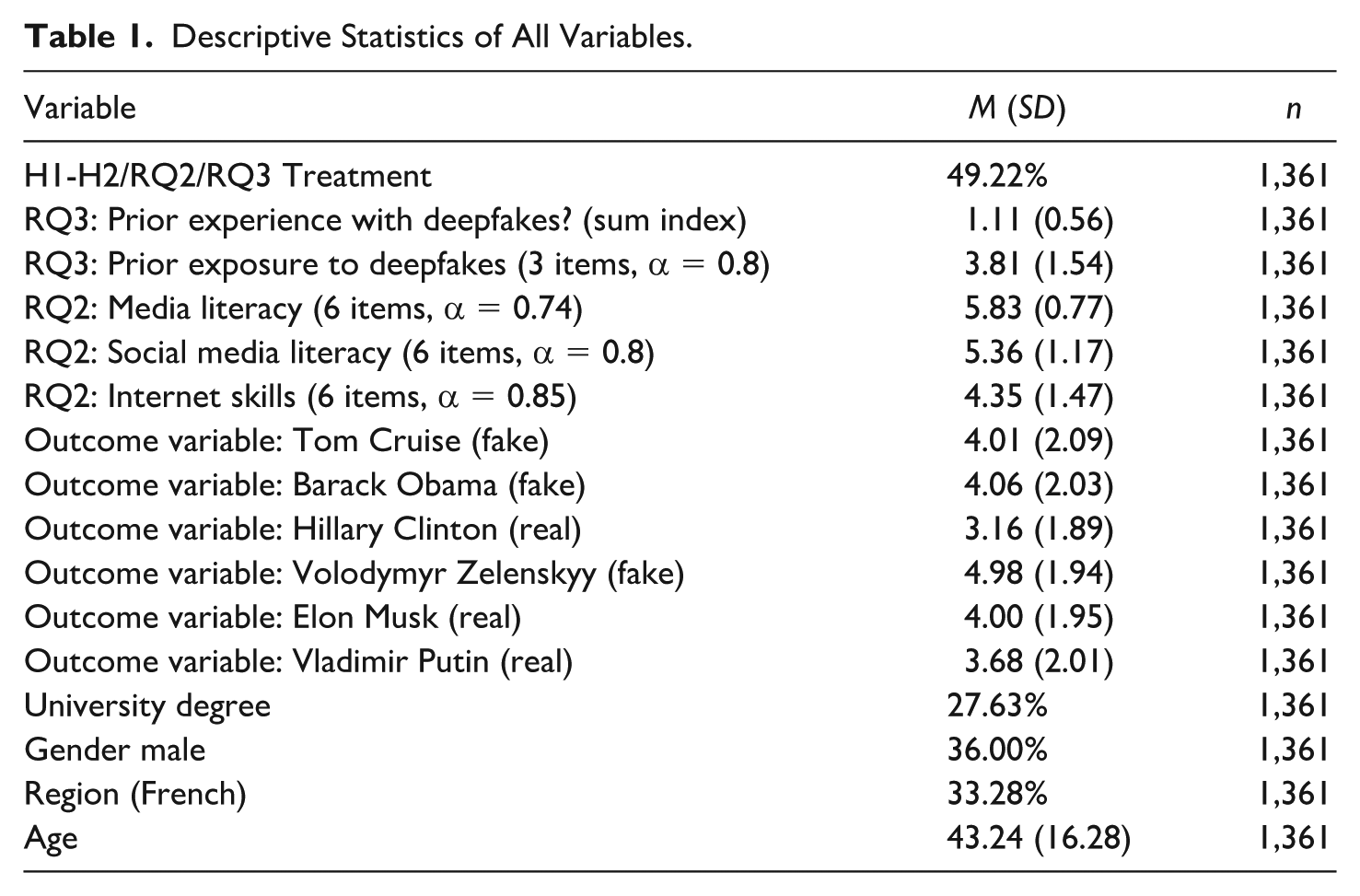
We added gender (male vs. other), age, educational attainment (university degree vs. other), and language region (French vs. German) as covariates to all of our models.
Dependent Variable
As the outcome variable for all hypotheses and research questions, we used participants’ evaluations of each video, asking them to rate it on a scale from 1 (clearly real) to 7 (clearly a deepfake). To assess the effect of the literacy intervention on discernment, the extent to which individuals distinguish between real and deepfake videos, we included an interaction between a dummy variable indicating if someone has received the literacy intervention and a dummy variable indicating video type (real vs. deepfake). The coefficient on this interaction term then reflects participants’ ability to discriminate between real and deepfake videos. As our data are nested, we used a linear mixed-effects model with varying intercepts for participants and videos. The discernment ability was then tested as an interaction term with video type (real or deepfake). For all models except the one for
Results
Overall, our test with the real and the deepfake videos showed that participants had difficulties distinguishing real from deepfake videos. With an average rating of 4.00 (SD = 1.95), the most difficult real video (of Elon Musk) had almost the same rating as the most difficult deepfake (of Tom Cruise), with an average rating of 4.01 (SD = 2.09). The other videos received average ratings between 3.16 and 4.98. While these scores indicate that videos were, on average, not clearly identified, there is an overall difference, t-Welch (8,147.8) = 16.39, p < .001, between the average rating for real (M = 3.61, SD = 1.98) and fake videos (M = 4.35, SD = 2.07).
To test our first hypothesis, we used a multilevel model with varying intercepts for videos and participants (see Supplemental Appendix C.1 for the complete models reported in the main paper).
5
Our data show no effect of the literacy intervention (b = −0.06, 95% confidence interval [CI] = [–0.22, 0.10], p = .452). Respondents who received the intervention did not perform better in discerning deepfakes from real videos than those who did not (see Figure 1). Thus,
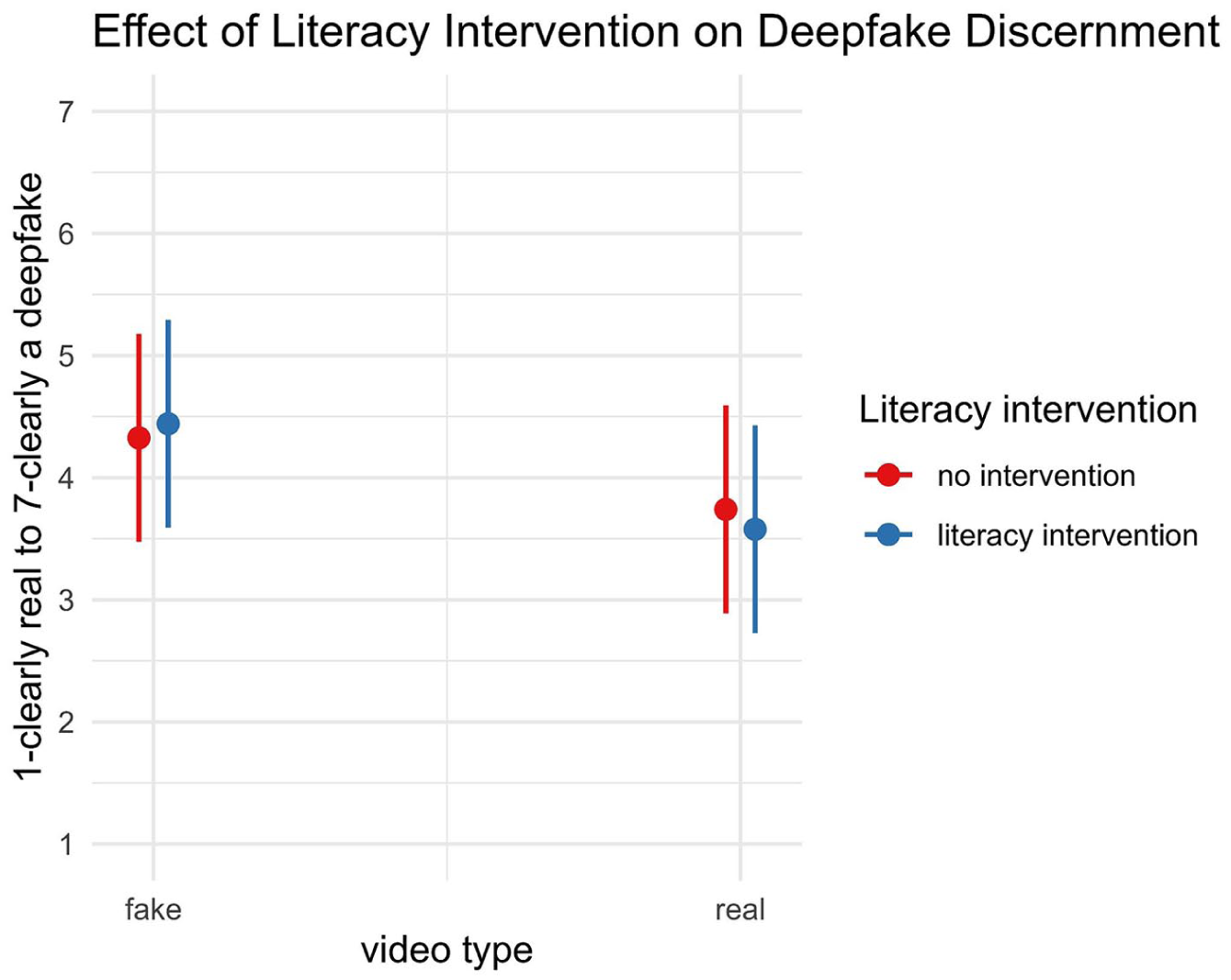
Interaction Between Video Type and Literacy Intervention. The Interaction Effect Is Not Significant.
For
For
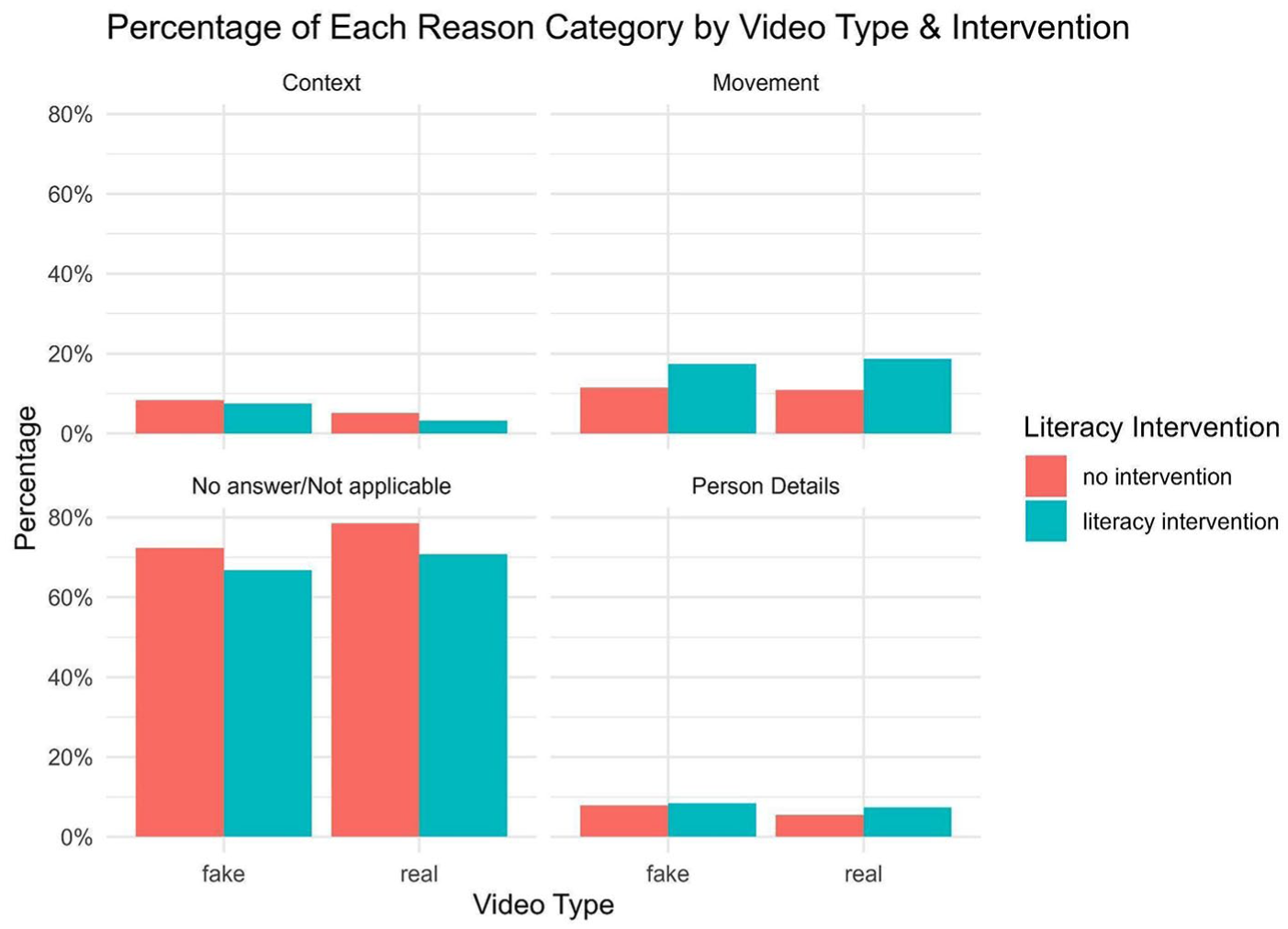
Comparing Video Type and Intervention With How Often No Answer or Nothing Applicable Was Provided.
The Role of Different Literacies in Combination With the Literacy Intervention
As stated in
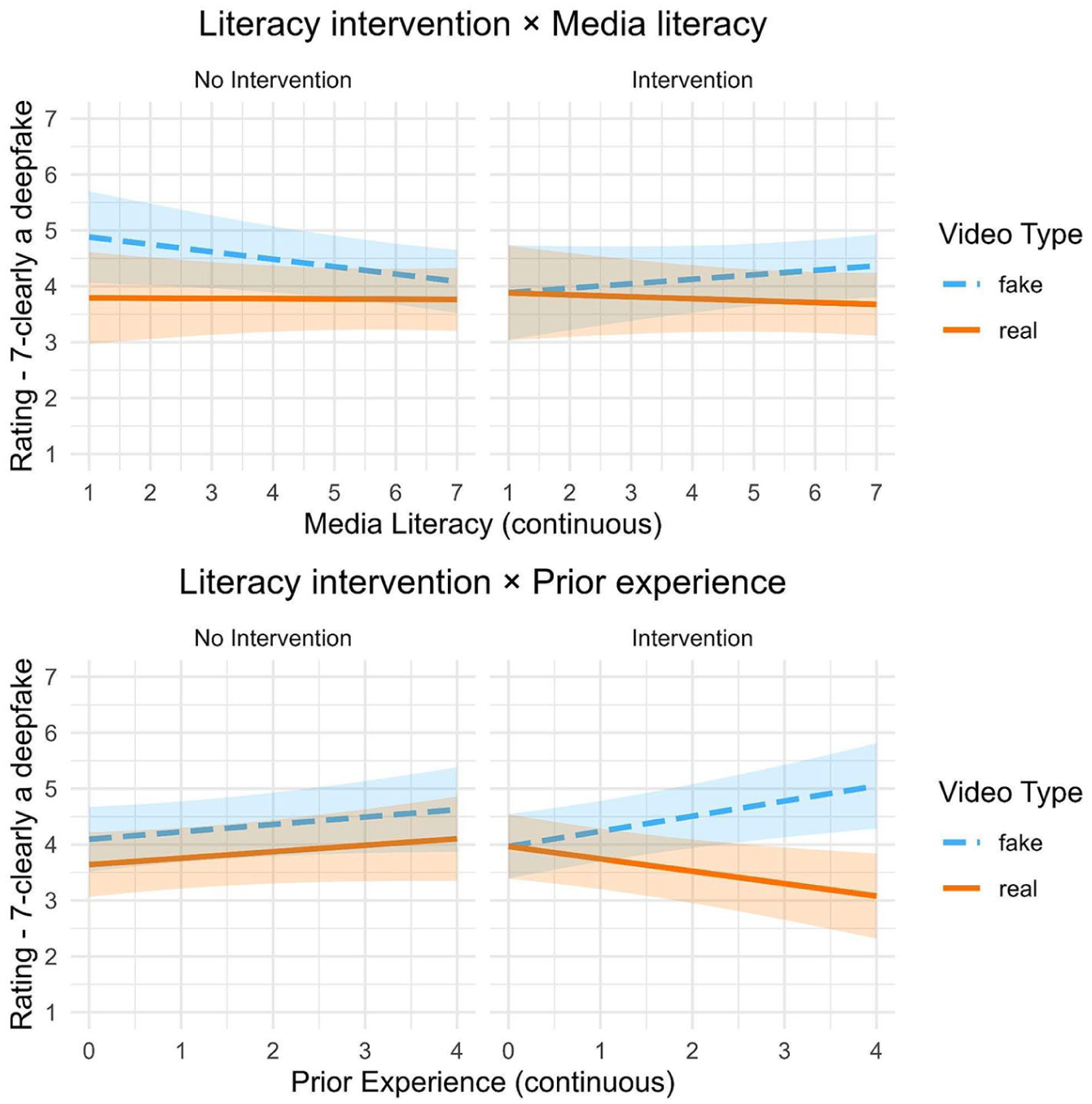
Interaction Between Literacy Intervention, Video Type, and News Media Literacy (Top) and Prior Experience (Bottom).
The Role of Prior Experience and Exposure in Combination With the Literacy Intervention
In
Additional Analyses With Knowledge of Video and Familiarity With the Person in the Video
We also conducted two non-preregistered follow-up analyses (for the model with these additional analyses, see Supplemental Appendix C.1.2). We asked participants whether they had seen the video before the study. For 8.9% of the observations, people indicated that they knew the video. The observations for videos people believed they knew are equally distributed for false and true videos, χ2(1, N = 8,166) = 0.256, p = .613. Therefore, we tested whether people who indicated they knew the video could correctly identify it. Knowing the video did not influence the discernment ability (b = −0.04, 95% CI = [–0.33, 0.24], p = .778). While some people might have seen one of the deepfake or real videos before, and thus more likely correctly rated it, our results indicate that it is also very likely that many of the 8.9% observations, where people indicated they knew the video, was a misperception.
As a second additional analysis that we have not preregistered, we added familiarity with the depicted person as an additional predictor to the model. Our analysis shows that with higher familiarity, the discernment ability increases. Thus, fake and real videos are more likely to be correctly classified (b = −0.06, 95% CI = [–0.10, –0.01], p = .016).
Discussion
Using an online experiment, this study investigated the ability of people in Switzerland to discern deepfake videos and tested whether a situational literacy intervention could improve this ability. Furthermore, the study examined whether people’s news media literacy, social media literacy, and internet skills, as well as their prior exposure and experience of deepfake technology, affect the effect of the literacy intervention. Our experimental study shows that people in Switzerland can hardly distinguish high quality deepfake videos from real videos. Similar results were found in other studies, for instance, by Bray et al. (2023), who concluded that “overall detection accuracy was only just above chance” (p. 1). Age was the only covariate affecting discerning ability, with younger participants being better at correctly identifying real and deepfake videos. As we used well-made deepfakes for our experiment and not low-quality videos or so-called cheapfakes (Hameleers, 2024), our task for participants was difficult. In addition, the stimuli in our experimental setup excluded audio features and focused only on the persons’ upper body. Therefore, the participants only had access to a limited set of visual cues both for the fake and real videos, making them very similar. Overall, the results indicate that with the right quality, a deepfake is hardly distinguishable from a real video, highlighting the need for new strategies to educate users on navigating this emerging internet phenomenon.
Our literacy intervention, which consisted of a brief assistance for recognizing deepfakes based on visual cues given to participants immediately before showing the videos, had no effect on discernment skills. This finding aligns with the study by Bray et al. (2023), who did not find any effect of a literacy intervention similar to ours, that is, providing specific hints related to abnormalities, asymmetries, and the background of the videos. In contrast to other studies (e.g., Ternovski et al., 2022), we found no evidence of a negative downstream effect of the intervention. The literacy intervention did not cause respondents to become overly critical or mistakenly identify real videos as deepfakes. This may be due to the different focus of our intervention, which emphasized image-specific aspects without including initial warnings (priming) about the dangers of deepfakes, as in Ternovski et al. (2022) or the general warning literacy intervention by Hameleers and Van der Meer (2023). Therefore, future research could explore how different types of interventions influence deepfake discernment. In addition, the explorative analysis of the open-ended question on participants’ reasons for classifying a video as real or fake shows that a literacy intervention can at least direct people’s attention to specific details, thereby also showing that people received our intervention and tried to apply it for their decision-making.
Our study further shows that participants’ self-reported firsthand experience with deepfakes (i.e., in our case, heard of, saw, shared, or created a deepfake) and people with high prior news media literacy benefited more from the intervention. At least for some people, short literacy interventions could thus be helpful for deepfake discernment, possibly through a form of transfer learning (Perkins & Salomon, 1992) where existing knowledge could be connected with the new information provided in the literacy intervention. This idea is also supported by the finding that prior experience increased the effect of the literacy intervention. As we did not find any negative downstream effects, literacy interventions might still be worthwhile pursuing, even if they only work for specific groups. However, only
The interaction effects of media literacy and prior experience reveal noteworthy patterns in the control group (see Figure 3). For prior experience, we observe an increase in ratings for both true and false videos as experience grows. Thus, participants with higher experience are more inclined to rate any video as deepfake, though their ability to distinguish between real and fake remains constant across experience levels. Looking at media literacy, the detection of fake videos decreases as media literacy increases in the control group, resulting in poorer overall discernment. The most plausible explanation is that participants with high media literacy skills focused heavily on contextual cues without guidance from the literacy intervention. However, context was not a reliable cue for identifying fakes in most of the videos used for this study. This may have led to misjudgments as participants applied their media literacy skills via low-road transfer. This tendency only reversed into a positive effect when supplemented by the literacy intervention.
Overall, these results suggest that an intervention to improve deepfake discernment focused solely on visual cues may be insufficient; a more holistic approach that enhances adjacent literacies, such as general media literacy, could foster greater skepticism without producing negative downstream effects. A recent study by Jin et al. (2025) highlights the role of specific visual literacy, which consists of the ability to interpret and create visual content, for deepfake discernment. Future studies could investigate the role of visual literacy in combination with literacy interventions like the one applied in this study.
Our findings are not surprising, as they conform to longer cycles of panic, skepticism, and integration described by existing studies of technology. Accounts of the momentous transformations and restructuring in people’s media consumption practices—from the printing press (McLuhan, 1962) to television (Meyrowitz, 1985) and the internet (Gitelman, 2008)—all include early stages of adoption in which new literacies are acquired organically and pre-existing literacies complement one another. People mainly learn to establish or at least question the veracity and authenticity of content in an organic way through exposure and ongoing engagement, so it is expected that a new form of deceptive media (Natale, 2024) will trigger widespread panics and skeptical reactions which in turn support dystopian journalistic narratives (Yadlin-Segal & Oppenheim, 2021) before people acquire the necessary literacy to make sense of them.
In comparison with previous cycles of deceptive media, such as the popularization of digital image manipulation, which could be mainly addressed through editorial policies and authorial responsibility (Pantti & Sirén, 2015), deepfakes and synthetic content are likely to become so pervasive and easy to create that verification requires high cognitive and fact-checking costs. In this scenario, people’s expectations of authenticity are likely to change, and content is assumed to be synthetic by default, with authenticity becoming the exception (Bajohr, 2023). The present study has examined Swiss attitudes in the early historical stages of deepfake circulation, and future studies could analyze the diminishing value of authenticity as synthetic media becomes more and more widespread.
Conclusion
This study advances research on deepfakes in three ways. First, it provides robust evidence that a brief, literacy intervention focusing on visual aspects does not improve overall discernment of high-quality deepfakes but also does not trigger generalized skepticism. Second, it identifies news media literacy and prior deepfake experience as factors that strengthen the impact of such interventions, highlighting the role of adjacent literacies and transfer learning. Third, it shows that even without measurable gains in accuracy, interventions can shape the cues people attend to when evaluating video content.
However, our study also has some limitations, particularly regarding the stimuli used. This resulted from a trade-off between creating a realistic scenario and maintaining a controlled experimental setting with minimal influencing factors. We used already existing short portrait videos (deepfakes and real) of internationally known politicians or celebrities (none of them Swiss) in a neutral or common setting without much visual background information (e.g., politicians sitting at a desk or on stage in front of a microphone, celebrity in a casual setting at home). Therefore, the video’s setting was very realistic and did not deliver much context, which was an advantage because it made the videos comparable and minimized the effects of prior knowledge about potentially well-known deepfakes. However, in reality, many deepfakes actually depict individuals in a highly controversial or surprising situation (e.g., Pope Francis wearing a Balenciaga-style white puffer jacket), providing context that may raise suspicion among users and improve the ability to discern deepfakes. The study also focused solely on the visual aspects of deepfakes and did not include sound. This approach helped minimize potential influencing factors in deepfake detection, ensuring a more controlled experimental setting. However, implausible or unrealistic statements, which often are at the core of deepfake disinformation (e.g., Ukrainian President Volodymyr Zelensky calling on his soldiers to lay down their weapons), typically affect deepfake detection (Hameleers et al., 2024).
Furthermore, as previously mentioned, we used only very high-quality deepfakes. This choice again addresses a realistic scenario: As deepfake technology advances, producing high-quality deepfakes will become increasingly easier. However, many deepfakes on the internet are still of low quality and are often referred to as cheapfakes. As cheapfakes were perceived as more credible than deepfakes of good quality in an experimental study by Hameleers (2024), whether the effectiveness of a literacy intervention differs when applied to deepfakes of varying quality, including cheapfakes, is a question for further research.
In addition, the study was conducted in a single country using deepfakes that were not specifically related to the Swiss context. One reason for this choice was the lack of publicly available deepfakes of Swiss politicians or celebrities. However, deepfakes created for disinformation or other harmful purposes are often designed to exploit specific contexts and influence targeted (regional) audiences. Indeed, our study shows that familiarity with the person has a positive effect on deepfake recognition. Therefore, it would be valuable to investigate whether an individual’s ability to detect (high-quality) deepfakes and the effect of a corresponding literacy intervention depend on whether local or foreign politicians or celebrities are depicted.
Supplemental Material
sj-pdf-1-jmq-10.1177_10776990251373088 – Supplemental material for The Short-Term Impact of an On-Site Literacy Intervention on Discerning Deepfake Videos Based on Visual Features
Supplemental material, sj-pdf-1-jmq-10.1177_10776990251373088 for The Short-Term Impact of an On-Site Literacy Intervention on Discerning Deepfake Videos Based on Visual Features by Daniel Vogler, Adrian Rauchfleisch and Gabriele de Seta in Journalism & Mass Communication Quarterly
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: D.V.’s research was funded by TA-SWISS, the Swiss Foundation for Technology Assessment. A.R.’s work was supported by the National Science and Technology Council, Taiwan (R.O.C.) (Grant No. 114-2628-H-002-007-) and by the Taiwan Social Resilience Research Center (Grant No. 114L9003) from the Higher Education Sprout Project by the Ministry of Education in Taiwan. G.d.S.’s work was supported by a Trond Mohn Foundation Starting Grant (TMS2024STG03).
Supplemental Material
Supplemental material is available in the online version of the article.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.