
Abstract
This study introduces the “framing element” method, an alternative approach to computational news framing detection. Rooted in a constructionist framing analysis framework, it identifies frames as packages of framing elements, including actors (individuals and organizations) and topics, extending beyond topic-focused methods in prior unsupervised analyses. Compared with latent Dirichlet allocation (LDA)- and Bidirectional Encoder Representations from Transformers (BERT)-based approaches on 1,300 U.S. gun violence news articles, this method addresses LDA’s limitations by focusing on high-level framing elements rather than keywords and is less labor-intensive than BERT-based supervised learning. Supporting both inductive and deductive analyses, it achieves comparable results to LDA while uncovering a previously unidentified gun violence frame.
Media framing has long been a prominent area in communication research (Gamson & Modigliani, 1989; Russell Neuman et al., 2014), examining the journalistic decisions of selecting and highlighting particular aspects of perceived reality to influence audiences’ attitudes, beliefs, and behaviors (Entman, 1993). Traditionally, quantitative framing analysis of media outlets was conducted through manual content analysis, a labor-intensive process of using deductive methods to categorize news corpus to discover the salient aspects reinforced by news framing (Guo et al., 2016; Riffe et al., 2014). With advancements in computer-assisted text analysis, computational communication scholars have developed and tested various approaches to identifying news frames with reduced human intervention to lower costs and eliminate bias in the manual categorization process (Guo et al., 2022; Waldherr et al., 2024; Walter & Ophir, 2019).
Research studies have examined multiple methods of identifying news frames with different levels of human intervention and arbitration, including dictionary-based, supervised, and unsupervised text analysis. Among these approaches, the unsupervised one requires the least amount of human intervention and has been widely used to explore the data as the first step (Nicholls & Culpepper, 2021). However, the two popular unsupervised approaches, topic modeling, and semantic network, have some limitations. While semantic analysis overly focuses on low-level linguistic components, such as word co-occurrence across articles, topic modeling often generates topics that are too narrow and specific, which researchers may mistakenly treat as frames (van Atteveldt et al., 2014; Walter & Ophir, 2019).
In this article, we discuss an alternative unsupervised method. Following Van Gorp’s (2010) constructive approach of treating recurring manifest linguistic devices as “framing elements,” previous studies have examined clusters of framing elements such as actors, sentiments, and actions as “frame packages,” or frames (Baden & Stalpouskaya, 2020; Vossen, 2020). Researchers who define frames this way also began to use computational methods to identify framing elements (Walter & Ophir, 2019). However, research of this kind only focused on framing elements as topics. Our proposed method (hereafter, the “framing element” method), based on a combination of computational techniques, automatically identifies frames as clusters of both topics and actors, defined as individual and organizational entities in the larger network.
To evaluate the performance of the framing element method, we compared it with widely used unsupervised methods, latent Dirichlet allocation (LDA) topic modeling (Nicholls & Culpepper, 2021; Walter & Ophir, 2019), and an established deep learning model, Bidirectional Encoder Representations from Transformers (BERT), based on 1,300 news articles about the gun violence issue in the United States. We conclude by discussing the advantages and disadvantages of the framing element method in comparison with the established LDA and BERT methods.
Literature Review
Conventional News Framing Analysis
According to Entman (1993, p. 53), framing is defined as selecting and emphasizing certain aspects of reality to make events, issues, and actors of agenda within news articles more salient, “in such a way as to promote a particular problem definition, casual interpretation, moral evaluation and/or treatment recommendation.” Previous studies on framing analysis are often conducted by manual content analysis based on deductive or inductive approaches. Deductive processes follow existing framing typologies identified from previous literature. For example, researchers have identified some generic frames that can be applied across time, space, and topics such as conflict, economic consequence, human impact, and morality (Semetko & Valkenburg, 2000). However, the deductive approach is limited due to researchers’ bias and failure to identify novel and issue-specific frames (Guo et al., 2016; Van Gorp, 2010). In contrast, an inductive frame analysis involves an iterative analysis of representative articles and mutual agreement between multiple human coders (Guo et al., 2022). Still, some level of subjectivity is unavoidable. Therefore, researchers advocated for a more systematic way of identifying frames (Van Gorp, 2010).
Given the challenges and inconsistencies of the former framing analysis approaches, Van Gorp (2010) proposes the idea of a “frame package,” which operationalizes a cultural repertoire of frames that are commonly selected by journalists for constructing news stories. He suggests that focusing on the quantifiable textual and visual evidence—the manifestation of framing elements, rather than the subjective full frame in a text, effectively reduces coders’ bias in content analysis. This “frame package” method successfully combines inductive and deductive approaches in framing analysis. For the inductive analysis, researchers should construct a repertoire of frame packages composed of framing devices that indicate distinct elements in news articles. Common framing devices include: “themes, subthemes, types of actors, actions, and setting, lines of reasoning, casual connections, contrasts, lexical choices, sources, qualification, statistics, charts, graphs, and appeals (emotional, logical, and ethical)” (Van Gorp, 2010, p. 90). Once researchers create an inventory of framing elements, they can use an inductive process to group these devices and construct frame packages. The deductive component of Van Gorp’s (2010) approach stems from the frame package validation and evaluation process. For instance, researchers would want to verify whether the constructed frame packages exist within representative articles and determine the weight of frame packages based on the number of framing elements contained in one article.
Previous studies have explored different framing elements for constructing frames. Gamson and Modigliani (1989) propose five framing devices: metaphors, catchphrases, visual images, depictions, and exemplars (i.e., historical examples from which lessons are drawn), that compose “media packages” (i.e., frame packages) 1 in nuclear power news. Pan and Kosicki (1993) also explore a constructivist approach for framing analysis by conceptualizing news text into quantifiable elements, including syntactical, script, thematic, and rhetorical structures.
Inspired by previous work, we aim to introduce a computational framing analysis method that leverages unsupervised learning to automatically group detectable framing elements for frame construction based on their co-occurrence across news articles on a shared issue. Our approach emphasizes framing elements that can be more readily captured and validated computationally, while preserving nuanced information in news articles and in the construction of frames as an initial step. Future extensions of this method will aim to include a richer repertoire of framing elements.
Specifically, we argue that actor attributes are an essential type of framing element for constructing and identifying newsframes, complementing the commonly used topic-based framing elements in previous unsupervised methods (Walter & Ophir, 2019). Frames are culturally resonant structures with symbolic significance, where stereotypes, values, archetypes, myths, and narratives intertwine (Van Gorp, 2010). While topics capture core news events, values are embodied by archetypes, stories are organized by character roles, and stereotypes are reflected in simplified characteristics attributed to groups of actors (Van Gorp, 2010).
There are existing generic frames that can be constructed by capturing relationships between actors. For instance, one of the most common generic frames, conflict, can be constructed from interactions among individuals, groups, or institutions in disagreement (Kang et al., 2019; Semetko & Valkenburg, 2000). Another frame, responsibility, is reflected by actors like governments, organizations, groups, or individuals to whom responsibility is assigned (Semetko & Valkenburg, 2000). If these frames were computationally constructed through unsupervised grouping of actors, the conflict frame would appear in a framing element network where edges form from the presence of disagreement among actors across articles. The responsibility frame, in turn, would emerge as clusters of accountable individual or organizational actors that frequently co-occur with impacted actors or incident-related topics, with edges indicating the presence of responsibility attribution.
In summary, to mitigate subjectivity from framing analysis in the conventional manual process, Van Gorp (2010) proposes a more systematic approach that operationalizes news frames as “frame packages,” a repertoire of quantifiable framing elements (i.e., framing devices), which is considered the constructivist approach to framing analysis. Previous studies have employed this constructive framing analysis by manually identifying different framing elements, such as metaphors, visual images, exemplars, and various syntactical and rhetorical structures (Gamson & Modigliani, 1989; Pan & Kosicki, 1993). Building on this prior work, our proposed method seeks to operationalize this constructivist approach computationally, starting with actors and topics, which are important framing elements and are comparatively easier to computationally detect and validate. Based on our work, future research could consider incorporating a broader range of framing elements (such as actors, actions, settings, sentiments, sources, statistics, and charts) through a similar automated pipeline.
Computational News Framing Analysis
Automating news framing detection has been an evolving yet contested area among mass communication scholars (Walter & Ophir, 2019). There are generally three broader categories of computational approaches for text analysis: (a) dictionary-based, (b) supervised machine learning, and (c) unsupervised machine learning. Each of these approaches involves different levels of human intervention and effort.
As one of the most widely used computational text analysis methods, the dictionary-based approach preserves a decent amount of human effort and subjectivity by relying on coding instruction. For instance, researchers need to construct a predefined list of words associated with a certain semantic category by deducting from the literature review or inducting from representative articles (Chan et al., 2020). Though researchers can also use off-the-shelf lexicons from the pre-developed toolkits, they might encounter lack-of-context dictionaries that are only designed for generic purposes. In particular, the validity and reliability of the method are compromised when scholars fail to validate dictionaries before transferring them to new contexts, or neglect to use tailored dictionaries for specific datasets (Boukes et al., 2020; González-Bailón & Paltoglou, 2015; van Atteveldt et al., 2021).
On the other hand, machine learning approaches detect patterns in news articles either from (a) supervised learning with training dataset labeled by human annotators or (b) data features within the unlabeled dataset (e.g., word occurrence or semantic network) that are automatically detected by unsupervised algorithms. In supervised learning, researchers will recruit human coders to provide “ground truth” labels to a sample of text data and predict the remaining unlabeled samples based on the model trained by the labeled data. Under the framing analysis context, researchers can propose a set of frames based on either the existing typologies from previous literature (such as generic frames) or issue-specific frames based on subject matter expertise. The advantage of this approach is that communication scholars can study large amounts of data from news articles with theoretical grounding by using the enduring frame typologies for better hypothesis testing. On the downside, this involves a labor-intensive and repetitive process of training human coders to arrive at satisfactory intercoder reliability and annotate a sufficient number of articles. This is especially true when the increasing number of training data can effectively improve the prediction accuracy of supervised learning models (Collingwood & Wilkerson, 2012).
When it comes to supervised learning algorithms for natural language processing (NLP), BERT has been found to outperform other models (Devlin et al., 2019; Guo et al., 2022). The transformer-based learning feature of the BERT model means that it has been trained on a large text corpus, including Wikipedia pages and books. It then generates an embedded vector format to represent sentences and would take the contextual information from the labeled dataset into consideration for better predictive accuracy (Devlin et al., 2019).
In comparison, unsupervised machine learning algorithms tremendously reduce the manual cost of dictionary construction and human annotation by utilizing algorithms to automatically learn the “hidden structure” of news articles (Guo et al., 2016). These hidden structures mirror the implicit associations that human coders identify in manual framing analysis, where reading between the lines reveals subtle messages and connections that evoke meaning without being explicitly stated. The unsupervised framing approach has been prominent in helping researchers conduct exploratory and preliminary analyses of large news datasets.
Among unsupervised methods, topic modeling and semantic networks are the two approaches commonly adopted by researchers. LDA-based topic modeling focuses on the occurrences of words across different articles. Setting n as the topic number, each article is viewed as a composite of n topics, with different topic proportions varied from 0% to 100% with the sum of proportions equal to 100%. Despite its popularity, using LDA topic modeling in news framing analysis leads to a false conceptualization of treating topics as frames (van Atteveldt et al., 2014; Walter & Ophir, 2020). While frames tend to be recurrent, generalizable, and comparable across settings (Akcakir et al., 2023; Goffman, 1974), topics are more contextual and commonly highlight the salience of events–instances reported in certain stories (Guo et al., 2022; Walter & Ophir, 2019). Falsely treating topics as frames may lead to the detected frames not being generalizable beyond the selected corpus (Guo et al., 2022).
The semantic network analysis usually treats low-level linguistic elements (e.g., words or phrases), as nodes. The edges are usually constructed by occurrences across articles with different weight measurements such as jaccard or cosine similarities as edges between those nodes. The method has its advantage in that it simulates the constructive approach of deriving frame packages from framing elements in a computational process. Additionally, it can adopt cutting-edge network sciences methods such as community detection algorithms to automatically detect the relationship between semantic elements for constructing news frames (Rubinov & Sporns, 2010). However, the method has its limitations due to over-reliance on low-level linguistic components, which can further limit the clustering result from generating theoretically relevant frame packages (van Atteveldt & Peng, 2018).
While the topic model LDA has been widely explored, semantic network analysis is an emerging area that demands more exploration (Walter & Ophir, 2019). The possibility of adding semantic networks in addition to other unsupervised text analysis methods is another interesting direction for computational researchers. In Walter and Ophir’s study (2019), they introduce an innovative, combined method called the Analysis of Topic Model Networks (ANTMN). This method identifies framing elements from topic modeling and uses community detection from network analysis to group framing elements into frame packages to represent frames for news articles. However, this unsupervised method overlooks other types of framing elements, focusing primarily on topics as the main type of framing element.
Established from Van Gorp’s (2010) constructionist framing analysis framework as discussed earlier, our proposed framing element approach identifies frames based on clusters of framing elements in news articles; particularly, we define framing elements as actors (including individual and organizational entities) and article-level topics extracted from news articles. Then, we apply community detection, an unsupervised approach to finding groups within a complex network (Girvan & Newman, 2002), to the framing elements network for constructing framing clusters, which are conceptualized as frames in this study. The method will be explained in detail in the following section. We will also assess the performance of the approach by comparing it with two other popular computational framing analysis methods, LDA and BERT approaches. Table 1 provides an additional systematic overview of the three methods, outlining their use cases (inductive or deductive), strengths, and weaknesses.
Comparison of BERT, LDA, and the Framing Element Approach for Framing Analysis.
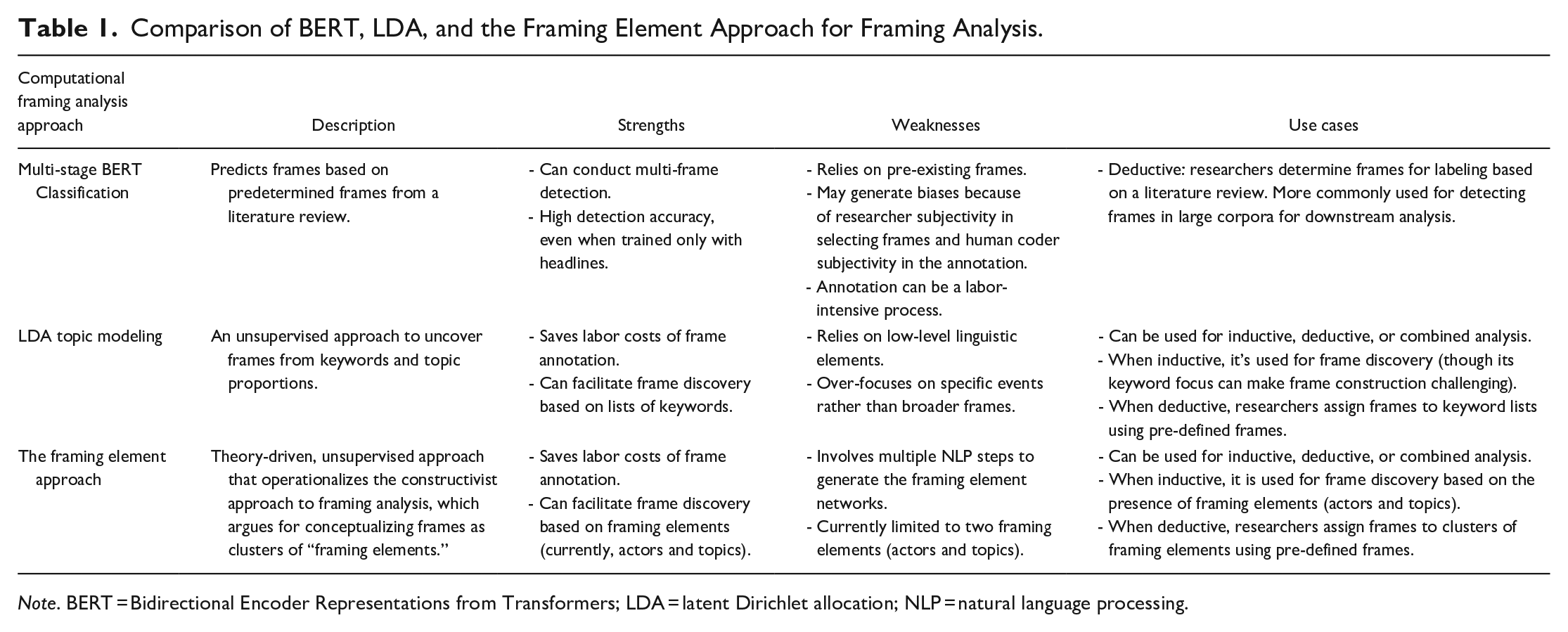
Note. BERT = Bidirectional Encoder Representations from Transformers; LDA = latent Dirichlet allocation; NLP = natural language processing.
We recognize that the LDA approach may seem like a compromise for method comparison, given its limitations as critiqued in previous studies (Akcakir et al., 2023; Guo et al., 2022; Walter & Ophir, 2019). Nevertheless, we selected LDA for comparison with the framing element approach because it remains one of the most commonly used unsupervised methods for framing analysis (Nicholls & Culpepper, 2021), and our proposed method is also an unsupervised approach. Additionally, the additive nature of our method (extending topics to include both actors and topics, and converting keywords to high-level semantics) makes it an interesting case for qualitatively assessing different operationalizations of framing and the implications of these differences. Therefore, beyond comparing accuracy performance in frame detection, we pay close attention to empirical evidence on how the use of keywords versus framing elements influences their different capacities in frame construction, detection, and discovery.
Methods
This research proposes an unsupervised framing analysis method of applying community detection from network analysis to entity-level and article topic-level framing elements that are detected in news articles using a combination of text analysis toolkits (spaCy, Dbpedia, and New York Times Tagger). Entity-level framing elements include both individual and organizational actors within each article, and the article topic-level framing element refers to the topic of each article. To evaluate the framing element approach, we compared results between community detection of the framing element network method, LDA topic modeling, and BERT supervised learning.
This study analyzes a sample of 2,900 gun violence news articles from major U.S. news websites in 2018, collected from the Crimson Hexagon’s ForSight (now BrandWatch) social media analytics platform using the following keywords: “gun,” “firearm,” “NRA,” “2nd amendment,” “second amendment,” “AR15,” “as- sault weapon,” “rifle,” “Brady act,” “Brady bill,” “mass shooting.” We employed manual content analysis to annotate the 2,900 news headlines, classifying them into relevant (N = 1,300) and irrelevant to gun violence issues in the United States. More information about the manual content analysis and the dataset can be found in Guo et al. (2022). We used the framing element method as well as the LDA topic modeling and BERT supervised learning to identify the dominant frames in the 1,300 news articles that have relevant headlines. Then we compared the results generated by the three methods, both qualitatively and quantitatively.
The Framing Element Approach: Community Detection of the Framing Element Network
Identifying Framing Elements
The first step of the framing element approach involves the detection of framing elements: operationalized as actors (individuals or organizations) and topics. Figure 1 provides a summary of how we detected framing elements based on the sample of 1,300 news articles on gun violence.

Flowchart of Detecting Framing Elements.
First, utilizing spaCy, a named entity recognition Python package, we extracted different types of actors (e.g., PERSON for person names and ORG for organizations) from each article. We then sought to understand who these persons are (e.g., politicians, educators) or what kind of organizations (e.g., political organizations, educational groups) are referred to. Using Wikipedia’s structured content database, Dbpedia (July 1, 2020, en, ttl, bzip2 version), we matched detected entities with their shortened English abstracts in Wikipedia (Dbpedia, 2019), 2 which allows us to detect their categories in the subsequent step. 3 To enhance the matching rate between detected entities and Wikipedia, we applied an off-the-shelf Wikipedia reference resolution tool, Wikifier (Brank et al., 2017), to the news corpus, which can solve the referencing challenge of matching detected entities with their corresponding Wikipedia package. 4 We were able to achieve matching rates of 52.19% for PERSON and 61.78% for ORG, respectively. To summarize, we identified two types of actors from the sample of news articles—persons and organizations; 57.5% of these actors are associated with a short description from Wikipedia that indicates the category of the actor.
Despite the detection rate being far from perfect, it is considered satisfactory since the remaining unmatched entities tend to involve less well-known individuals and organizations, which are less essential for reconstructing news frames. Among the PERSON entities, this might occur when the article references non-famous standby interviewees such as researchers, social workers, or spokespersons who do not have Wikipedia pages, making it challenging to determine their category using our current method. Similarly, the less-than-perfect ORG detection can be attributed to the mention of local organizations such as restaurants, clinics, and schools that lack Wikipedia pages. 5
Our next step is to examine the specific category (e.g., politics, health, economics) of these actors as well as the topic categories of the entire article. To do so, we implemented the New York Times (NYT) News Labeler from MIT Media Cloud, a news article taxonomic classifier tool trained on the NYT annotated corpus (Roberts et al., 2021; Rubinovitz, 2017), to label both our entity-level and article topic-level framing elements. The highest level of generality provided by the NYT News Labeler is the 600-category “general online descriptors (descriptors600),” which are “descriptive terms drawn from a normalized controlled vocabulary corresponding to subjects mentioned in the article” (Rubinovitz, 2017, p. 47), algorithmically assigned and manually verified by NYT staff. 6 To determine the categories of the Wikipedia-matched entities, we applied the NYT News Labeler to the entities’ Wikipedia abstracts and assigned the dominant topic detected as the category of these entities. To detect the topic-framing elements, we directly applied the NYT News Labeler to each article and recorded the top three dominant categories. Our final framing elements were composed of three types of elements, including two types of actors, individual actors (PERSON) and organizational actors (ORG), and article topics (TOPIC).
For the purpose of creating framing-element networks later, we re-categorized 600 News Labeler categories to 79 main categories for a more representative thematic categorization. We then replaced all the detected categories with their parental-level categories. Two communication researchers independently categorized 600 categories into major categories and then reached the final list. As a result, the framing elements within each article include all labeled entities, each with a category, and the top three topics of that article under the 79-category classification. That is, the maximum number of framing elements that can be detected is 237 (79 × 3), in which each of the 79 categories can be assigned to at most three framing element types, including PERSON, ORG, and TOPIC framing elements.
Developing Article Matrix
After all the framing elements are detected, our next step is to employ community detection to identify clusters composed of these elements. To do so, we would need to create a matrix, 7 in which each row represents a news article, and each column represents a framing element.
In his method, Van Gorp (2010) believes that “it is not necessary for a framing device to be frequently repeated in order to be capable of activating a frame” (p. 92). Therefore, instead of documenting the number of times each framing element is mentioned in the article, we just recorded the framing element’s presence (1 or 0). Doing so also to some extent addresses the limitation of the low Wikipedia detection rate mentioned above. Though some less-known actors cannot be detected, it may not affect the result as long as other actors in the same category are detected. Actors in the same category would be only counted once in the matrix. 8
In this step, we removed all framing elements that do not appear in any articles. In his constructive approach, Van Gorp (2010) argues that framing elements that only occasionally appear in text cause noise and lead content analysis to overcorrect framing element presence to reach satisfied intercoder reliability. Following this suggestion, we further removed framing elements that appeared less than five times to prevent our community detection from forcing the cluster formation based on rare framing elements. One hundred sixty-nine out of 237 framing elements remain.
We first reviewed the clustering results based on 169 framing elements with different numbers of frames, which did not produce satisfactory results due to the difficulty of assigning frames from too many elements. We then decided to combine ORG and PERSON into the same actor framing element if they share the same category to reduce the total number of framing elements. For instance, Government ORG and Government PERSON would be encoded to PERSON_ORG_government, and the element presence would be deducted to 1 after they are combined. The final analysis includes 86 framing elements. That is, the framing matrix includes 1,300 rows (i.e., the number of articles) and 86 columns (i.e., the number of framing elements).
Constructing Frames
Defining Edges
Based on the matrix, the next step is to create a network of framing elements. In this network, each node is a framing element and the edge (i.e., the relationship between framing elements) is first operationalized as a combination of co-occurrence between any two nodes across the news articles. Specifically, according to the framing matrix we developed, each framing element can be represented as a vector, indicating the element presence (1 or 0) in each news article. The occurrence weight of the edge between any two framing elements is the cosine similarity between the two occurrence vectors representing those elements.
Second, we also measured the edge based on the semantic similarity between the framing elements based on the BERT model. For example, a Healthcare_ORG framing element’s category “Healthcare” is semantically more similar to a Health insurance_ORG framing element’s category “Health insurance” than an Energy_ORG framing element’s category. Specifically, we converted the category text of each framing element into a numeric vector (word embedding) through BERT’s word vectorization function. The semantic weight of the edge between any two framing elements is the cosine similarity between the two BERT-assisted semantic vectors representing those elements.
Taken together, each framing element contains both its original occurrence vector and a BERT-assisted semantic vector, and each edge contains both an occurrence weight and a semantic weight. To clarify, our goal is to capture the relationship between framing elements by accounting for their co-occurrence across the articles as well as their semantic similarity. However, these two factors are not of equal importance in defining the edge. Thus, we computed the adjusted edge weight between framing elements by exploring different semantic weight adjustments from 0.1 to 1.0:1.0 indicating the semantic weight is equal to the occurrence weight in the framing element network. Through evaluating different levels of the semantic parameter (0.1–1.0), we detected that 0.1 weight barely conveys any semantic similarity between framing elements, and 1.0 weight overcounts the semantic meaning. As a result, we selected the semantic weight 0.5, which suggests the semantic similarity is counted as half of the weight of the co-occurrence factor.
Community Detection
Now that the nodes and edges of a network are defined, we then employed community detection techniques to identify clusters of framing elements as frames. SC (Spectral Clustering) and VEC (Community Discovery via NodeEmbedding) are two popular community detection algorithms in the network science community (Ding et al., 2017). While SC is a traditional concept that utilizes the eigenvectors of the Laplician matrix, VEC is based on the idea of random walks (Ding et al., 2017). In our case, SC performs better at reflecting the semantic information but is negatively impacted by the existence of one to two giant clusters in the clustering result. VEC on the other hand produces more evenly spread clusters, but only slightly considers the semantic information in edge weights.
Since semantic similarity between framing elements is an important factor to be considered in our research context, we selected the SC algorithm for our community detection and explored the number of clusters (i.e., frames) varied from 2 to 20. When the cluster number is below seven, some giant clusters will contain over 35 framing elements and disproportionately dominate the frame presence in the articles. A large number of framing elements in one cluster also leads to high variation in framing elements, which makes the cluster uninterpretable. However, any cluster number above 12 will produce primarily small clusters with only three to four framing elements. In doing so, even the most representative articles of a given cluster contain only one to two elements from the cluster. In other words, even the most representative articles are not illustrative for these small clusters as frames. Therefore, cluster numbers from 8 to 11 provide a balance between the appropriate cluster size and the comprehensiveness of each cluster in terms of the meaning. Through an iterative qualitative examination of clustered framing elements, we found that choosing 10 clusters produces the best result by providing the most coherent framing clusters. We labeled these 10 clusters based on their framing elements and researchers’ knowledge of gun violence frames (see Table A1).
Assigning Frames to Articles
To determine frame(s) for each individual news article, we normalized the framing cluster presence (i.e., framing elements in each cluster for each article) based on the maximum number of framing elements a cluster could contain across the entire corpus (normalized presence assignment). For example, if an article contains five framing elements from the Politics frame cluster and four framing elements from the Society/Culture frame cluster, and the maximum numbers of Politics and Society/Culture framing elements that appear in one article are 20 and 10, respectively, among in the entire corpus, the presence of the Politics frame and the Society/Culture frame in this article will be normalized to 25% and 40%, respectively. Since each framing cluster contains different numbers of framing elements, this normalization avoids overestimating the larger clusters and underestimating the smaller clusters.
LDA Unsupervised Topic Modeling
Following previous research (DiMaggio et al., 2013; van Atteveldt & Peng, 2018), we treated LDA topics, sets of frequency distributions of words, as frames for comparing three approaches under the framing analysis context. To prepare the LDA training corpus, we cleaned the datasets by removing punctuation, special characters, stop words, and numbers, and generated bigrams based on word frequency, while avoiding token unification (e.g., stemming or lemmatizing) for the LDA input. This decision aligns with previous research indicating that applying stemming or lemmatization negatively impacts topic stability (Schofield & Mimno, 2016; Walter & Ophir, 2020). We ran the LDA topic modeling package provided by Gensim on Python and fine-tuned our model parameter based on Rehurek and Sojkaon’s (2010) suggestion across the 1,300 articles. In LDA modeling, one way of selecting the appropriate number of topics is made at the researchers’ discretion, based on their preferred granularity (Guo et al., 2016). Guo et al.’s (2022) LDA analysis of gun violence framing tested 5, 10, and 15 topics, observing that redundant and nonsensical keyword lists appeared when topic numbers exceeded 15. Accordingly, we explored topic numbers from 8 to 15 for LDA, aligning with the range assessed in previous studies using similar datasets. We labeled the LDA results with gun violence frames based on the top 20 keywords detected by the LDA model for each topic. Again, because LDA generates topics rather than frames, we conceptualized these topics to their higher-level rhetoric frames. For instance, the topic with keywords related to a video game tournament was conceptualized as the Society and Culture frame. The nine LDA frames and their keywords can be found in Table A2.
The LDA algorithm estimates the topic proportion “theta” of each topic for each article (Blei, 2012). In other words, nine LDA topics will be ranked as the most dominant to the least dominant topic for each article based on their weights in those articles (e.g., Article 1: Topic 1 70%, Topic 2 20%, etc.). We treated this LDA topic proportion as the weight of each corresponding frame in the individual article.
BERT Supervised Learning
Frame Annotation
We used the BERT model as a supervised learning method, which means that we should first annotate a sample of articles to establish the ground truth frames for model training. Using manual content analysis, we annotated the headlines of the 1,300 relevant news articles based on the nine frames we identified according to the previous literature on gun violence. We then applied the trained classifier to all sentences in the article to predict the frame of each sentence and determine the article’s frames based on the proportion of sentences discussing each frame. This approach enables us to identify multiple frames, rather than a single frame, for each article—a challenge that has persisted in previous computational framing research (Akyürek et al., 2020; Guo et al., 2022; Liu et al., 2019).
Following the quantitative content analysis, we trained our human coders to detect up to two dominant frames in each headline based on the nine frames we proposed. The two human coders reached an acceptable level of Krippendorff intercoder reliability for each of the two frames (α = .90, .82) among the random sample of 200 article headlines. Out of the 1,300 relevant headlines, 319 were found to have two frames. The nine frames we identified contain both issue-specific frames that are commonly found in gun violence coverages (e.g., 2nd Amendment/Gun rights, Gun control/regulation, Mental health, School/Public space safety, and Race/Ethnicity) and generic frames (e.g., Politics, Public opinion, Economic consequences, and Society/Culture) to demonstrate the flexibility of each approach.
Modeling Training
We intended to use our annotated headlines as training sentences to predict the sentence frames in all articles. Recognizing that a good portion of sentences in news articles do not inherently contain any frames, we ran a multiclass prediction using the relevant 1,300 headlines based on the nine frames and 1,600 non-relevant headlines. We treated these 1,600 headlines as the “No frame” training sentences.
Using the 2,900 headlines as input and their frames as labels, we set the key training parameters for BERT as follows: learning rate = 10−5 and epochs = 4. We conducted a fivefold cross-validation to build a frame prediction model. This model reached a satisfactory accuracy level of 81.69% for 10 classes (nine gun violence frame classes and one “no frame” class). The precision and recall scores are 0.67 and 0.64, respectively. 9
Predicting Frames
We split all the articles into sentences using the Natural Language Toolkit package. We removed sentences with fewer than 20 characters, as we observed that if a sentence is too short it is not a valid sentence (the splitting method is not perfect) or it is too short to contain a sentence frame (e.g., “Sure!”). We then use the fine-turned BERT model to predict the frames of the remaining sentences.
Once the sentence frames were predicted, we aggregated them into article-level frames by counting the number of each sentence frame that appears in each article. We applied the majority vote rule to decide the two dominant frames for each article. The majority vote rule means that we picked the most common frames of the article as the first dominant frame, and the second most common frame as the second. This majority rule was applied to articles only without headlines because headlines were used for training sentence frames. To ensure a fair comparison, we did not want to mix annotated sentences (headlines) with predicted sentence frames for BERT when evaluating three methods.
Adjusting for the “No frame” class, we excluded all “No frame” sentence frames from any dominant frame detection. The rationale is that only sentences with labeled frames contribute to the understanding of the article-level frames; hence, sentences without any frames are excluded from the analysis. We ranked article frames using BERT supervised learning for each article based on our proposed nine frames, from the most dominant to the least dominant, determined by the proportion of sentence frames within each article.
An Additional Qualitative Comparison of Three Approaches
To compare the framing element approach, LDA modeling, and BERT, we conducted a follow-up qualitative analysis to examine their frame operationalization, performance, and resource usage. Regarding model performance, we highlighted the critical advantage of unsupervised over supervised approaches: the distinction between frame detection and frame discovery. Unlike supervised learning, whose predictive capabilities are constrained by a predefined set, unsupervised learning provides the flexibility to discover new frames not previously identified in the literature, while also aligning with predefined frames for frame detection.
We selected a random sample of 50 news articles, closely read them, and provided manual annotations for news frames, as well as recorded key actors in each article. While we referred to the nine gun violence frames identified by previous literature for ground truth annotation to explicitly evaluate the performance across different approaches, we also allowed for the possibility of discovering new frames when appropriate. For actor detection, we independently recorded the main actors from each article and then reviewed these recorded actors to assess their capacity to reflect the information of the article and their contribution to frame detection without the original content. We investigated both the predictive performance based on frame detection and intermediary elements such as sentence frames in BERT, keywords in LDA, and framing elements from the proposed approach, which could impact downstream performance. Together, we aim to assess the extent to which the three methods generated useful insights, retained article information, and provided recommendations under different contexts. The findings are discussed below.
Frame Operationalization
Both BERT and LDA approaches are established computational methods for frame analysis. The supervised learning model, BERT, operates as a deductive approach, predicting frames based on our predetermined nine frames. Due to its deductive nature, BERT is limited to frame detection and cannot be used for frame discovery since its target classes are predefined and its training data is manually annotated by humans. This manual annotation process could introduce bias when annotators are required to assign one of the nine frames, even when an article contains multiple frames.
In our BERT frame detection pipeline, instead of directly classifying news frames based on manual annotations at the article level, which is a time-consuming approach commonly done by previous computational communication scholars, we opted for a more flexible and resource-efficient method. We trained a sentence frame classifier based on annotated news headlines, applied the trained BERT model to all sentences in each article, and then used majority voting to determine the article frames. This multi-stage approach allowed us to train on a relatively large dataset (around 2,900 articles, including the “no frame” class) and facilitated multi-frame detection, a challenge in previous computational framing detections, for news articles. Multi-frame detection is a realistic relaxation from the singular frame constraint in previous computational approaches, as news articles on the same issue commonly contain more than one frame with varying weights. Despite being constrained by predefined frames, the multi-stage BERT classification operationalizes news frames as the proportion of relevant sentences discussing each gun violence frame, allowing for the flexibility of multiclass frame detection.
Previous studies have employed different approaches to operationalize LDA for frame detection. Some argue that with a relatively small number of LDA topics, each topic can be broad enough to serve as a news frame (Jacobi et al., 2016; Ylä-Anttila et al., 2022). Others suggest selecting a large number of LDA topics and then manually or automatically grouping them into fewer topic clusters using community detection algorithms (Walter & Ophir, 2019). We opted for the first LDA strategy by choosing relatively small topic numbers and identifying gun violence frames directly. This provides a more direct assessment of how replacing low-level linguistic elements, like keywords in LDA, with high-level semantics, such as framing elements, could potentially enhance unsupervised framing analysis through a more theory-driven approach.
Accordingly, our LDA implementation treats LDA topics (lists of keywords) as frames. Unlike the BERT approach, which is constrained by predefined frames, LDA has the flexibility to discover new frames during the frame labeling process. However, because its keyword-centric approach overemphasizes low-level linguistic elements, and the conveyed information becomes even sparser when LDA topics represent broad frames, it becomes challenging to discover and interpret unknown frames without predefined constraints.
The framing element method we proposed identifies clusters of framing elements as frames, operationalized as clusters of actors and topics in news articles. This construction is more theoretically aligned with the constructive approach to framing, which treats recurring manifest linguistic devices as “framing elements” that can include actors and subthemes (Baden & Stalpouskaya, 2020; Vossen, 2020).
Our framing element method is also a multi-stage approach that combines both pretrained models (various actor and topic detectors) and unsupervised training (community detection algorithms), allowing us to leverage greatly all the advancements being made in NLP off-the-shelf tools, as well as removing humans from the loop and potentially reducing bias in discovering new frames or annotating articles. We believe this multi-stage mixed-method approach could represent a methodological advancement over traditional computational approaches, given that previous scholars commonly observe multi-stage models to perform better than single-stage models (Nicholls & Culpepper, 2021).
In the current exploratory work, we are constructing framing elements as actors and topics. However, this proposed approach illustrates the potential to extend framing elements to broader categories such as actions, settings, or emotional and logical aspects, thereby making it more closely aligned with the conceptualization of news frames.
Performance
Among all the three methods, BERT achieved the best performance by having the highest retention of article information. Out of 50 analyzed news articles, BERT correctly predicted the article frames within the top two dominant frames with perfect accuracy. Additionally, in 40 out of 50 instances, BERT accurately predicted the top two frames for articles containing multiple frames in the correct order. This result is not surprising, as BERT has demonstrated impressive performance across various classification tasks in previous computational social science studies. Additionally, different from LDA and the framing element approach whose frame annotation is not constrained by any predefined frames, the supervised BERT model has a lot of shared understanding in terms of the predefined frame set, involving the annotation of 1,300 news headlines, giving it a huge information advantage over the other unsupervised approach. Therefore, BERT also achieved this level of accuracy at the cost of a labor-intensive process for training data annotation.
Comparing LDA with the framing element approach, although both achieved a comparable level of accuracy performance (with an accuracy of predicting the article frames within the top two dominant frames correctly at 84% for LDA and 80% for the framing element approach), they illustrated different strengths and weaknesses in keyword/framing element extraction, as well as in retaining article information. While LDA had a balanced performance across its nine frames, the framing element approach was particularly strong at identifying Economic consequence and Race/ethnicity frames. Both frames benefit from centering around the relationship between actors, with Race/ethnicity as a gun violence issue-specific frame identifying how gun issues relate to groups like ethnicity, religion, and terrorism actors, and Economic consequence as a generic framing describing the financial impact on individuals, groups, or organizations. Additionally, our method’s effectiveness in identifying these frames can be attributed to the semantic salience and coherence of economic and race-related actors (in contrast to the more diverse and localized spokespersons and organizations found in the Public Safety and Society/Culture frames), which makes it easier for our approach to detect relevant actors within these frame cluster. We expect the efficiency in detecting the generic Economic consequence frame to extend to issues beyond gun violence, given its actor-centered nature and the ease of its framing element detection. More broadly, the framing element method is likely to perform better in frames of other issues that meet these two conditions.
On the other hand, one weakness of LDA stems from its keyword-based emphasis: the LDA model has a disproportionately high tendency to assign high topic proportions to the Gun control/regulation frame because a large percentage of topic keywords overlapped with the theme of our dataset, which is gun violence. 10 This phenomenon with LDA has also been noted in other framing analysis studies, which observed that the method disproportionately overweights the Containment frame when analyzing COVID-19 news due to high keyword overlap with the underlying issue (Akcakir et al., 2023).
Beyond frame detection performance, one potential for frame discovery that we found from the proposed approach is that after clustering framing elements using the community detection algorithm, we identified a recurring frame for gun violence news that had been undiscovered by previous literature: “Political stance on gun control/regulation.” Although this new frame is usually hidden under the intersection of politics and gun regulation in both predefined frames and LDA-detected frames, during our thematic analysis of news articles, we encountered numerous articles discussing the gun violence issue through ideological or partisan debates on gun control. Five out of 50 articles were dominated by this new frame, while others mentioned it more briefly as part of multiple framing angles. We suggest that this frame discovery is possible because our framing elements approach highlights actors in articles. Specifically, partisan debates on gun control commonly mention various politicians and institutions from each party, making it well-suited for the proposed approach. This newly identified frame of gun violence also has its theoretical significance, corresponding to thematic framing, which emphasizes broader social and institutional solutions to an issue by highlighting a more general and abstract context, as opposed to episodic framing that focuses on individual stories and event-oriented reporting (Iyengar, 1991). We suggest that our approach’s focus on framing elements, such as actors and topics, makes it easier to detect thematic framing, whereas the keyword-focused nature of LDA makes such detection more challenging. The differences between the framing elements and keyword-focused approaches are discussed further below.
In addition to the comparison of frame prediction results, we also compared the keyword lists and framing element clusters for the LDA and the framing element approach to understand how different unsupervised methods operationalize frames differently. In the nine topic keyword lists generated by LDA, we observed that it has a high tendency to generate issue-specific topics, such as the Pittsburgh synagogue shooting event in 2018.
On the other hand, when identifying the main actors manually from the 50 articles, we first confirmed that we could roughly make implicit connections between these actors to make sense of the article. Additionally, it is promising to infer news frames from such information. For instance, in the article titled “Brett Kavanaugh: How could Trump’s new Supreme Court justice shape battles over abortion rights, gun control, and impeachment,” the main actors include political and government institutions (e.g., Supreme Court, Congress, National Security Agency), conservative political figures (e.g., President Trump, Republican senator Susan Collins, newly confirmed Supreme Court Justice Brett Kavanaugh), and other personnel and organizations (such as special counsel Robert Mueller investigating Russian interference, and Obama-era Environmental Protection Agency). These actors indicate that the article is framed around political stances and gun regulation based solely on the actors mentioned. Therefore, we have confirmed that framing element detection in our method pipeline has generally captured the most essential actors in the news articles. This further reassures us that even if some actor detections were lost in the previous Wikipedia matching step, these actors could still be non-famous interviewees (e.g., researchers, social workers, spokespersons) that do not significantly impact the reconstruction of frames from essential actors.
Investigating the intermediary components of both LDA and the framing element approach confirms our supposition that LDA would cause ambiguity if mass communication researchers attempted to use LDA topics as news frames. It is also in line with our expectation that, by generalizing low-level linguistic elements such as words to entities in the framing element method, we would be able to construct clusters that are closer to news frames rather than topics. A direct comparison can be drawn from the Public Opinion, Race/ethnicity, and Politics clusters we observed in both the framing element method and LDA results (see Tables A1 and A2). In the Public Opinion cluster, the LDA topic picks up the high occurrence of a specific incident, such as “synagogue” in this example. The framing element method, on the other hand, generalizes these words to Immigrant/Refugees PERSON actors. Additionally, this method also captures the intricacies of the Public Opinion frame by detecting celebrities’ opinions and responses under the Arts & Entertainment actors. For the Race/ethnicity cluster, while the LDA topic narrowly focuses on the police shootings of Black Americans, the framing element approach generates a broader Race/ethnicity frame that contains Race, Religion, Terrorism actors and organizations. Similarly, one of the Politics clusters in LDA focuses on President Trump making a visit to Pittsburgh, the framing element approach does not contain such event-centered clusters and includes more government, law and legislation actors in the Politics cluster. All these generalizations from the framing element approach help remove the bias toward event salience in news reporting.
Together, the qualitative comparison confirms the previous literature that the supervised method provides more accurate findings (Collingwood & Wilkerson, 2012). However, the supervised BERT model achieves this level of accuracy at the cost of a labor-intensive process, involving the annotation of 1,300 news headlines. The two unsupervised methods, the framing element approach and LDA, inform researchers of the potential media frames with less human intervention. While the LDA approach generates more narrowly focused topics than news frames, the framing element method is able to construct clusters that are closer to news frames rather than topics by generalizing low-level linguistic elements such as words to framing elements.
Resource Usage
Generally, the annotated data size required for training and testing a BERT model is not trivial and could be a major consideration for model selection. This constraint can sometimes be circumvented by finding off-the-shelf annotated datasets to train the model and then transfer it to the targeted task. However, the quality of such an approach greatly depends on the transferability and generalizability of the dataset. Another resource constraint for BERT is the deep learning computing infrastructure, which tends to be much faster when computed under the GPU CUDA framework rather than the CPU that most personal computers have access to, posing an accessibility constraint for communication scholars.
LDA does not require too many computational and infrastructural resources compared to BERT, but its performance greatly depends on researchers’ model tuning to find the hyperparameter sets that optimize the model performance. It can serve as a go-to exploratory step for finding frames for researchers who want to familiarize themselves with the “hidden structure” 11 of the text corpus.
Our proposed framing element approach may seem resource-consuming due to its multi-stage procedures in the framing element detection phase. However, we want to highlight that this complication arises because we are emphasizing doing it in the traditional NLP way to utilize various NLP toolkits. With the introduction of more advanced and off-the-shelf NLP tools like large language models (LLMs), we suspect that it will become much more attainable to get actor and topic detection through these conversational models and greatly simplify resource usage. Specifically, while researchers might hesitate to apply these generative models directly to frame detection due to their lack of explainability and nondeterminism—and because framing detection is a difficult reasoning task for these models—we can utilize LLMs for intermediate steps in detecting framing elements (e.g., actors, actions, settings, sentiments) in the corpus. The latter approach is particularly viable because such detections tend to be more rule-based and standardized in NLP, making it easier for researchers to verify performance either through human annotators or publicly available benchmark datasets. We view the incorporation of LLMs as a promising pathway to extend our approach to include a broader scope of framing elements that are theoretically important.
Comparison With Community Detection on Topic Networks
To directly assess the contribution of actor framing elements within the framing element network, we applied the same community detection procedure (SC algorithm, semantic weight 0.5, 2–20 clusters) to topic-only framing elements. The most coherent clustering result produced eight clusters, forming three major frame packages, Society, Politics, and School/Public space safety, while requiring five additional orphaned framing elements to be manually assigned (see Table A4).
Compared to the topic-and-actor network, the topic-only approach remained too sparse, as each article contained far fewer topics than actors, leading to uneven clusters, weak edges, orphaned elements, and fewer frame clusters. The absence of actor framing elements resulted in lower granularity, limiting the ability to capture both generic and issue-specific frames for gun violence news. Similar limitations have been observed in previous studies using community detection on LDA topic networks, which identified two frames for electoral politics and three for pandemic news (Walter & Ophir, 2019, 2020). Uneven clusters and orphaned elements were also observed in its application to multilingual COVID-19 news corpora (Akcakir et al., 2023).
Conclusion and Discussion
Computational framing research should emphasize the importance of formulating computational approaches based on rigorous theoretical conceptualization and operationalization. In this study, we adopted Van Gorp’s (2010) constructionist framing analysis as our theoretical framework, which explores the possibility of constructing frame packages from framing elements. We argue that actor framing elements, as essential components in understanding generic frames (such as conflicts and responsibilities frames), deserve more attention in framing analysis. Our proposed approach, community detection of the framing element network, identifies frames as clusters of framing elements including actors and topics in news articles. Further, we emphasize the differences between topics and frames. While topical phrases are most straightforward, rhetorical languages in framing are more subtle and complex, and hence require higher abstraction to actor level (Russell Neuman et al., 2014). Additionally, following Van Gorp’s (2010) deductive validation, our framing element method takes the weight of frame packages into account, examines the representative articles of each frame package, and assigns dominant frames to each article.
Based on a qualitative comparison of the framing element method and the other two popular computational methods to detect news frames—the LDA topic modeling and BERT, we first discuss different frame operationalization practices from both the traditional computational framing analysis approach and our proposed method. We highlight that our proposed method is more closely related to the conceptualization of constructionist framing analysis and can be easily extended to include a variety of other framing elements, while BERT is more likely to be constrained by predefined frames and LDA relies on low-level linguistic components that can be challenging for broader concepts like news frames. In terms of performance, we demonstrate that our proposed unsupervised approach cannot generate results as accurate as supervised approaches such as the one based on the BERT. Nevertheless, supervised approaches receive better performance at the cost of manual annotation, a labor-intensive process, and high computation resource usage.
We argue that the framing element approach preserves interpretability by unpacking the interconnected relationship between framing elements which can help researchers obtain an initial understanding of news frames in a large news data set, compared to the supervised learning approach (see Figure 2). For instance, our community detection result illustrates that the Race/Ethnicity cluster frame of gun violence news articles comprise multiple racial elements, including race, religion, and terrorism actors, while the Mental health frame emphasizes on the mental health concerns for children caused by gun violence incidents. We confirm the validity by first qualitatively examining the main actors in each article to see the capacity it can recover the information within each article, as well as reflecting the article frames, and observe the satisfactory discovery rate for these main actors from our framing element identification step. Additionally, we illustrate how the proposed method helps discover new frames beyond previous literature by identifying frames that are more centered around important figures and institutions, such as “Political stance on gun control/regulation.”
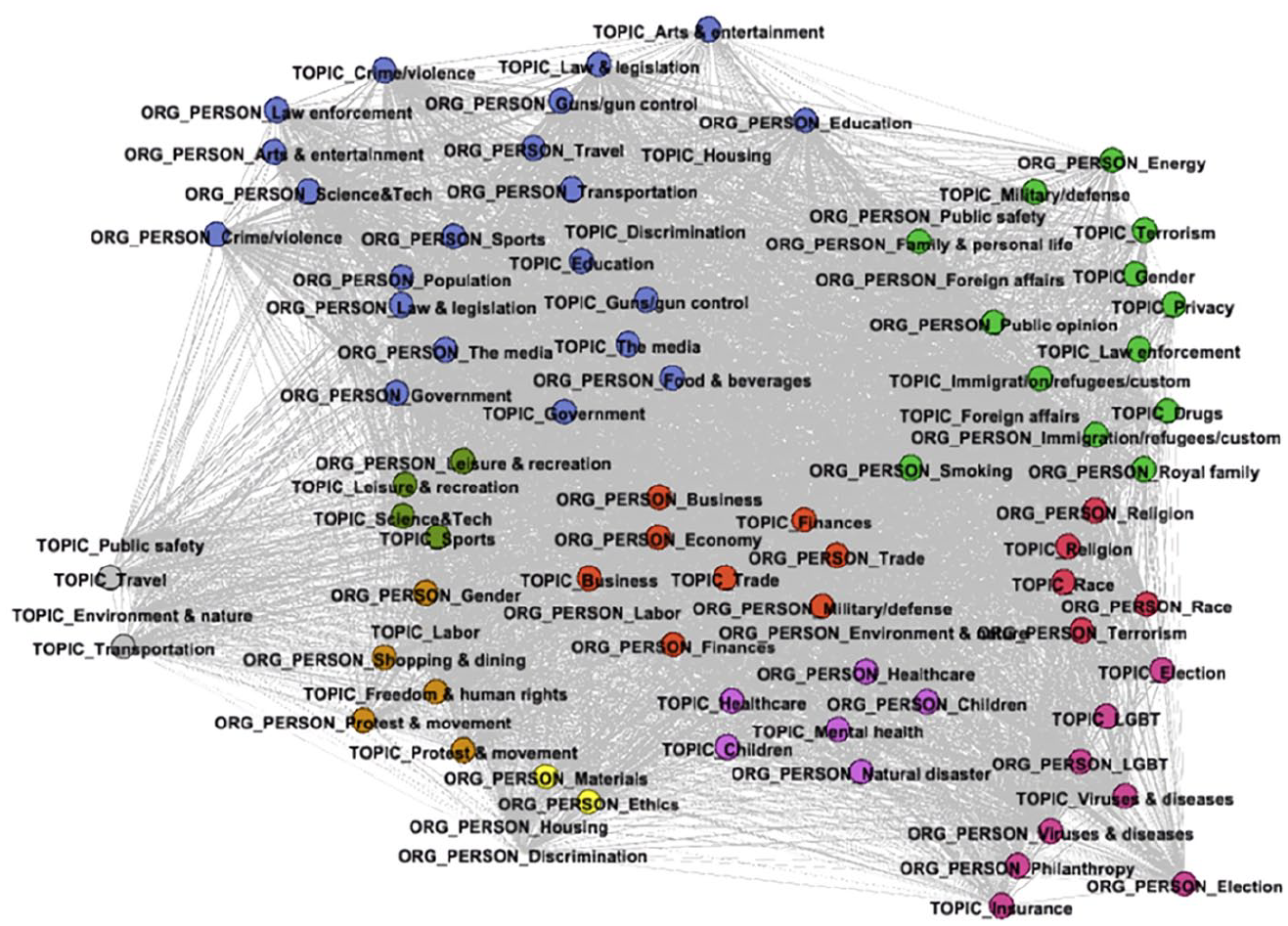
Community Detection of the Framing Element Network in Gun Violence News.
At the same time, the framing element approach has the potential to perform better than other unsupervised methods such as the LDA topic modeling examined here. Specifically, under the framing analysis context, the LDA model has a high tendency to generate issue-specific topics, which speaks to the concern raised in previous research that LDA would cause ambiguity if researchers attempted to use LDA topics as news frames (Maier et al., 2018). By generalizing low-level linguistic elements (i.e., words) to broader topics and actors as framing elements, the framing element method is able to construct clusters of framing elements that are closer to news frames, which are more generic and abstract than concrete topics. We suggest that our proposed method can be a promising approach to advance both deductive and inductive framing analysis for frame detection and discovery.
Taken together, our proposed method fulfills the theoretical promises outlined in the literature review. Inspired by Van Gorp’s (2010) theory, we automated a constructive approach to framing analysis by combining NLP and community detection. This approach circumvents limitations in the widely used unsupervised framing method, LDA, by focusing on high-level semantic concepts—specifically framing elements (such as actors and topics)—instead of the low-level keywords emphasized by LDA. Based on both qualitative and quantitative assessments, we found that the new method effectively discovers frames, including a novel gun violence frame, “Political stance on gun control/regulation,” aligned with thematic framing and not previously covered in the literature. Additionally, the new method achieved comparable results to LDA, excelling particularly in identifying frames with more salient actors (e.g., Economic consequence and Race/Ethnicity in gun violence news). Our unsupervised method more effectively reveals hidden structures—subtle relationships between framing elements—within a news corpus, simulating how human coders infer implicit connections among framing elements in traditional framing analysis. Directly assessing the additive contribution of actor framing elements, we find that a network with topic-only framing elements creates significantly sparser edges, resulting in weak edges, orphaned framing elements, and lower granularity compared to the proposed topic-and-actor network. Our proposed approach illustrates an automated pipeline for detecting and clustering framing elements, starting with actors and topics. This pipeline can be extended to broader categories of framing elements, allowing unsupervised framing analysis to benefit from the inclusion of more detailed data points.
Despite the methodological contribution, this study is limited in several aspects. First, the current approach demonstrates framing element detection and clustering using only two types of framing elements: actors and topics. However, the repertoire of framing elements could be extended to broader categories, which would likely enrich the construction of the framing element network and enhance researchers’ understanding of the relationships between different types of framing elements. We expect that future studies utilizing our proposed pipeline for incorporating additional framing elements could further advance the framing element approach in framing analysis. Secondly, we acknowledge the limitations of deriving insights from a single news issue, gun violence. Future studies interested in employing our method or comparing framing approaches for frame detection can extend to news issues with established frames in prior literature and relevance in multilingual, multinational, multimodal contexts, such as elections, pandemics, immigration, and climate change (Akcakir et al., 2023; Card et al., 2022; Geise & Xu, 2024; Guo et al., 2025; Walter & Ophir, 2019, 2020). Applying our method to inductive framing discovery may be particularly valuable for evolving issues like science and technology, and algorithmic bias (Jumle et al., 2024; Nah et al., 2024).
As previously acknowledged, we recognize that LDA may seem like a compromise for method comparison given its conceptual limitations. However, we chose to use it alongside our proposed approach because both are unsupervised learning methods, allowing us to conduct a qualitative, in-depth assessment of their differences in frame operationalization, detection, and discovery—beyond solely evaluating each method’s accuracy. We believe this empirical examination provides insights beyond addressing LDA’s conceptual limitations and further highlights how clusters of framing elements contribute to a more effective exploratory framing analysis than LDA’s keyword lists. Furthermore, similar to other computational framing analyses, we acknowledge that some degree of human reasoning and prior knowledge is typically required (Guo et al., 2022). In the framing element approach, while actors and topics are automatically grouped into frames, human reasoning remains necessary to interpret implicit connections between these elements. Although this process involves human input, the community detection of framing elements offers valuable insights by automatically revealing how certain elements frequently co-occur to form frames.
As it is based on Van Gorp’s (2010) constructionist approach, the framing element method faces similar limitations as those mentioned in his research. In particular, we have not taken into account the relative position of framing elements detected from articles, considering some framing element positions (such as the opening paragraph) may attract readers’ attention more easily than others. Additionally, choosing framing element presence rather than occurrence as a measurement, we do not explore how the relative frequency of each framing element within a frame package would affect the community detection and frame construction result. Lastly, different producers and providers of framing elements, such as journalists versus interviewees, might have different implications for news framing, which could serve as an interesting direction to explore in future analyses of computational framing.
We recommend researchers considering using the framing element approach as opposed to other unsupervised methods to explore large datasets because: (a) the framing element approach is theory-driven, avoiding the ambiguity of treating topics as frames, (b) it constructs frames based on high-level semantic concepts like actors and topics, avoiding reliance on uninterruptible low-level linguistic elements like LDA, and (c) it enables researchers to better understand the relationship between different types of framing elements, including actors and topics in news articles, and possibly discover new frames from the framing element network. However, given its limitations, researchers might not want to consider the results from the framing element approach for hypothesis testing other than for exploratory purposes or preliminary analysis of a large dataset. Researchers should consider the framing element approach as the first step for exploring the possible frames and the relationship between framing elements, whereas supervised methods should be used to further analyze the data or test hypotheses.
Footnotes
Appendix
Clusters of Framing Elements as Frames for the Topic-only Network.
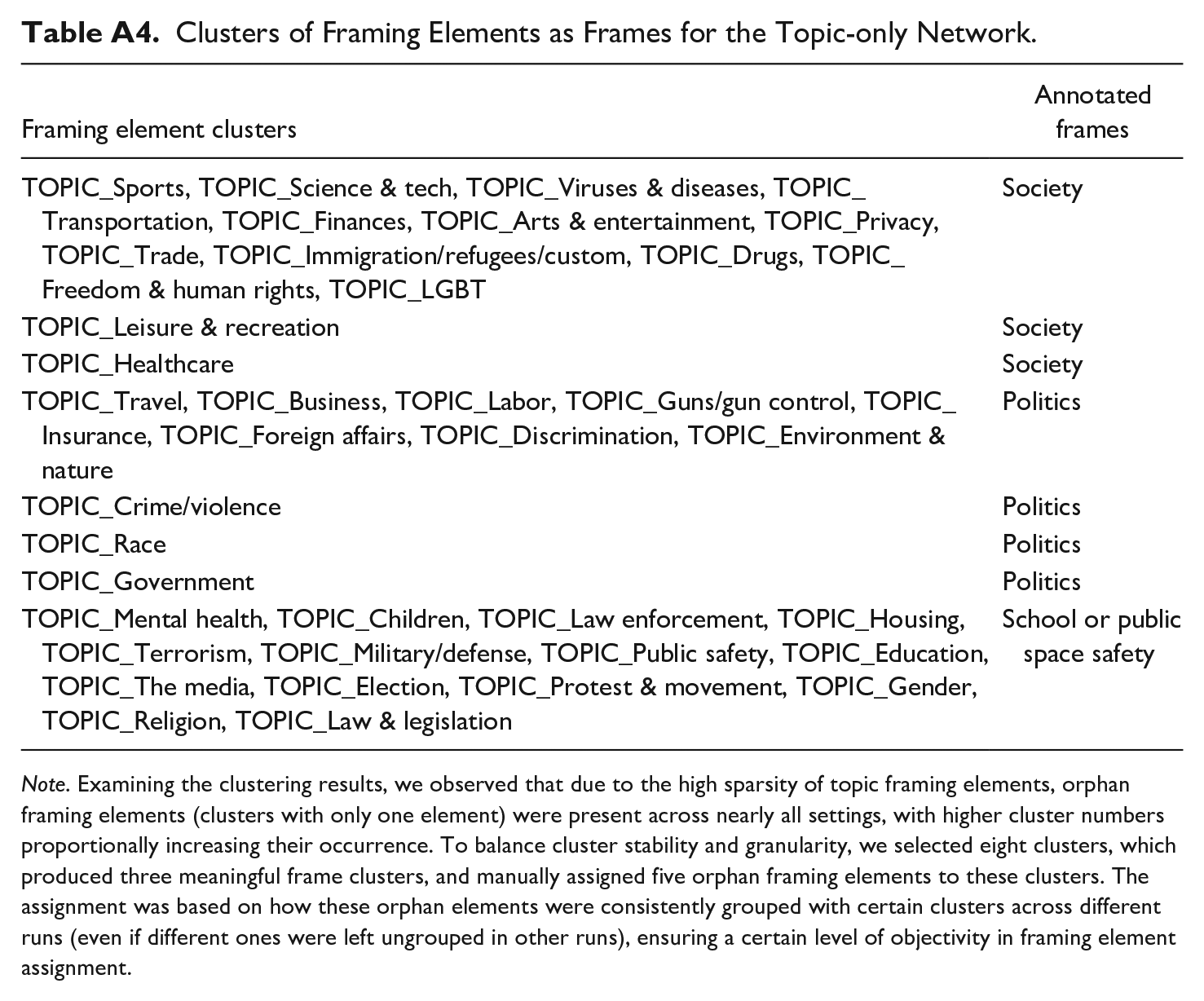
| Framing element clusters | Annotated frames |
|---|---|
| TOPIC_Sports, TOPIC_Science & tech, TOPIC_Viruses & diseases, TOPIC_Transportation, TOPIC_Finances, TOPIC_Arts & entertainment, TOPIC_Privacy, TOPIC_Trade, TOPIC_Immigration/refugees/custom, TOPIC_Drugs, TOPIC_Freedom & human rights, TOPIC_LGBT | Society |
| TOPIC_Leisure & recreation | Society |
| TOPIC_Healthcare | Society |
| TOPIC_Travel, TOPIC_Business, TOPIC_Labor, TOPIC_Guns/gun control, TOPIC_Insurance, TOPIC_Foreign affairs, TOPIC_Discrimination, TOPIC_Environment & nature | Politics |
| TOPIC_Crime/violence | Politics |
| TOPIC_Race | Politics |
| TOPIC_Government | Politics |
| TOPIC_Mental health, TOPIC_Children, TOPIC_Law enforcement, TOPIC_Housing, TOPIC_Terrorism, TOPIC_Military/defense, TOPIC_Public safety, TOPIC_Education, TOPIC_The media, TOPIC_Election, TOPIC_Protest & movement, TOPIC_Gender, TOPIC_Religion, TOPIC_Law & legislation | School or public space safety |
Note. Examining the clustering results, we observed that due to the high sparsity of topic framing elements, orphan framing elements (clusters with only one element) were present across nearly all settings, with higher cluster numbers proportionally increasing their occurrence. To balance cluster stability and granularity, we selected eight clusters, which produced three meaningful frame clusters, and manually assigned five orphan framing elements to these clusters. The assignment was based on how these orphan elements were consistently grouped with certain clusters across different runs (even if different ones were left ungrouped in other runs), ensuring a certain level of objectivity in framing element assignment.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the U.S. NSF under Grant 1838193.