
Abstract
The current study provides a new level of empirical evidence for the nature of ethnic stereotypes in news content by drawing on a sample of more than 3 million Dutch news items. The study’s findings demonstrate that universally accepted dimensions of stereotype content (i.e., low-status and high-threat attributes) can be replicated in news media content across a diverse set of ingroup and outgroup categories. Representations of minorities in newspapers have become progressively remote from factual integration outcomes, and are therefore rather an artifact of news production processes than a true reflection of what is actually happening in society.
News media have been accused of spreading stereotypes by repeatedly associating racial/ethnic outgroups with one-sided, biased attributes such as criminality and unemployment. Exposure to such stereotypical associations can contribute to the development of stereotypical beliefs by strengthening mental linkages between social groups and biased attributes (Arendt & Northup, 2015). Once established, these mental linkages can be activated by subsequent exposure to stereotypical media cues, and feed into racial/ethnic prejudice and discrimination on interpersonal and intergroup levels (Atwell Seate & Mastro, 2017; Matthes & Schmuck, 2017; Schieferdecker & Wessler, 2017). Hence, as mediated stereotypes may serve to justify today’s troubling levels of anti-immigrant attitudes and antipathy toward “others,” it is important to study the nature and strength of stereotypical associations in the media and trace the factors that account for variations in these representations.
Studies analyzing distorted media portrayals typically focus on a selective set of marginalized minorities as represented by a limited number of media outlets over a short period of time (Mutz & Goldman, 2016). Yet, the nature and strength of stereotypical associations in newspaper content are not without change. Given that the rise of polarizing political beliefs appears to have created a media climate where unfavorable beliefs toward “others” can be openly expressed and discussed Schemer, 2012), critical questions remain regarding the extent to which media stereotypes in diverse outlets are becoming more biased over time.
The large-scale investigation of over-time variation in mediated stereotypes is becoming accessible to communication scholars due to advances in the domain of computer-assisted analyses and the availability of so-called big data samples. For example, among researchers interested in the agenda-setting theory, computational approaches are rapidly becoming common (e.g., Guo & Vargo, 2015). Computational approaches are at the same time almost non-existent in the media-stereotyping literature (cf. Arendt & Karadas, 2017). An obvious explanation for this is that, until recently, such approaches have felt short in identifying stereotypes of social groups in mass-mediated content, as stereotypes are often subtle and therefore difficult to detect by computers. However, the use of shallow or deep neural networks for natural language processing, and in particular the use of word embeddings, have made it easier to accurately detect implicit bias in media texts, as is illustrated by recent empirical examples in the field of computational science (Bolukbasi et al., 2016a; Caliskan et al., 2017; Garg et al., 2018).
This study provides a new level of empirical evidence for the nature of ethnic stereotypes in newspaper content due to the combination of advanced automated methods and the analysis of all newspaper content in Dutch leading newspapers between 2000 and 2015 (N = 3,316,494 newspaper texts). The study’s approach is innovative in that it introduces the use of word embeddings to the media-stereotyping domain, herewith illustrating how this scholarship can move beyond frequently employed, but overly simplistic, bag-of-words approaches. The aim of our analysis is twofold. First, the study critically tests whether media depictions are in line with key theoretical notions of prejudice following predictions of the stereotype content model (SCM; Fiske et al., 2002). By testing universal dimensions of stereotype content in newspaper content among a large set of ingroup and outgroup categories, the study’s findings allow drawing more generalizable conclusions about the nature of stereotypical news content. Second, using time-series analysis, the study contrasts over-time variation in stereotype associations with real-world integration outcomes. As such, the study provides a critical test of the question of whether the content of news media has, over time, become more biased. In sum, the study allows sustaining claims regarding the nature of stereotypes in news media content while offering novel insights into the over-time development of news bias at a previously impossible scale.
The Measurement of Representations of Ethnic Groups in News Content
Previous empirical work in the media-stereotyping domain typically relies on human coding, which demands high financial and human resources and therefore does not easily scale across diverse ethnic groups, media outlets, and time periods. Computer-assisted approaches to content analyses, allowing for the fast and affordable analyses of large-scale samples, could potentially overcome these limitations. Yet, the analysis of ethnic bias in news messages requires a challenging level of complexity: To grasp subtle nuances in stereotypical news messages, fine-grained analyses are required. As a consequence, human coding has remained the dominant method to analyze stereotypes in media content.
The few studies that do employ automated methods typically rely on the top-down, relatively easy-to-apply, dictionary approach to measuring the co-occurrence of targets and attributes (Jacobs et al., 2018; Kroon et al., 2018; Ruigrok & van Atteveldt, 2007) such as the within-sentence or within-article co-occurrence of references to Muslims and terror. Among others, this approach has been used to identify linkages between immigration news content and crime, terrorism, and socioeconomic issues (Jacobs et al., 2018). An obvious limitation of such bag-of-words approaches is that contextual semantic information is not taken into consideration, herewith introducing limitations such as a loss of domain-contingent word meanings and grammatical functions (Grimmer & Stewart, 2013).
The use of word embeddings, which is rapidly becoming among the most popular methods in natural language processing, can overcome these limitations. Shortly put, word embeddings are based on the idea that linguistic terms can be accurately represented by contextual information. Word embeddings represent words in a vector space, where words are mapped to numeric vectors. Words with similar meanings are closer to each other in this vector space. Simply put, for each word its relationship to all other surrounding words is summed (Caliskan et al., 2017), the distance (i.e., cosine similarity scores) between vectors can be measured. This idea of distributional similarity is used to predict surrounding words, based on the thought that “[y]ou get to know a word by the company it keeps” (Firth, 1957, p. 11). The embedding models that result from this training algorithm can, for example, predict that man is to king as woman is to queen.
Yet, by capturing semantics, word embeddings inevitably reveal human bias (Bolukbasi et al., 2016a; Garg et al., 2018). By learning the meaning of words based on large training corpora of human communication, the resulting models inherently reflect implicit cultural dispositions, among which some are prejudiced, as “language itself contains recoverable and accurate imprints of our historic biases” (Caliskan et al., 2017). To illustrate, the close proximity of female to homemaker and man to programmer in a vector space reveals implicit gender bias (Bolukbasi et al., 2016a). As a consequence, in the general public discourse, the blind down-stream application of such machine learning techniques is often blamed for being biased, leading to headlines such as “Google’s Sentiment Analyzer Thinks Being Gay Is Bad” (Thompson, 2017). Yet, it is not Google who “thinks” being gay is bad, but—unfortunately—large parts of society: The algorithm has learned from billions of texts that gay and bad are associated in today’s discourse, no matter how offensive or unjust this is.
In this article, we turn around this criticism and make use of the fact that word embeddings pick up linguistic implicit biases. This idea is not new: Studies in the field of computational linguistics and artificial intelligence have successfully employed word embeddings to detect gender and ethnic bias in large samples of texts such as Web data and Google News (Bolukbasi et al., 2016a). More specifically, these studies document that embeddings accurately reflect human bias as measured by implicit association tests (Caliskan et al., 2017), and accurately capture sociological trends (Garg et al., 2018). Within the field of communication science, word embeddings have been used to measure sentiment (Rudkowsky et al., 2018). Yet, its application to detecting ethnic bias is virtually absent (cf. Arendt & Karadas, 2017; Leschke & Schwemmer, 2019). Accordingly, the current study introduces word embeddings as a much-promising method to measure the stereotypicality of media content to the field of communication science and illustrates its use by investigating the representation of diverse ethnic ingroups and outgroups in Dutch news articles.
Trait Dimensions of Mediated Stereotypical Associations: The SCM
News content of immigration and integration in the Netherlands has been described as turbulent (Bos et al., 2016), and characterized by strong negativity and threats (Vliegenthart & Roggeband, 2007). In particular, the assimilation frame has gained popularity over time in the immigration debate, while socioeconomic emancipation and multiculturalist perspectives have fallen behind (Duyvendak & Scholten, 2012; van Heerden et al., 2014). Overall, Dutch news media have been shown to frequently link immigration to issues of terrorism, crime, and the economy (Jacobs et al., 2018; Vliegenthart & Roggeband, 2007). Other than focusing on the frames or issues associated with immigration and integration, the current study focuses on stereotypical bias in representations of diverse ethnic minorities.
Drawing generalizable conclusions about news stereotypes is complex: The nature of stereotypical media content varies considerably across research contexts as well as the specific ethnicity under investigation (Mastro, 2009). As a consequence, the formulation of universal conclusions regarding the nature of racial stereotypic news messages remains a challenge. As prior scholarship typically considers media representations of a limited number of social groups, few universal assumptions can be offered regarding the nature of ethnic stereotypes in the media (Mastro, 2009). Regardless, recent evidence suggests that more generalizable assumptions regarding the nature of media stereotypes can be made following the predictions of the SCM (Kroon et al., 2018; Sink et al., 2018). The current study builds on this work to predict implicit stereotypicality in the context of media representations of ethnicity.
The SCM posits that two universal evaluative dimensions organize stereotype content—notably, warmth (e.g., good-hearted, benevolent) and competence (e.g., competent, intelligent; Fiske et al., 2002). The categorization of social groups as relatively high or low on warmth and competence defines how we think, feel, and behave toward “others.” The appraisal of social groups along the array of warmth and competence congregates into four distinct quadrants, each of which is associated with different social groups: low warmth and low competence (e.g., poor people, immigrants), low warmth and high competence (e.g., rich, Asians), high warmth and low competence (e.g., elderly, disabled), and high warmth and high competence (e.g., ingroup members and similar others; Fiske et al., 2002).
According to the SCM, warmth and competence attributions are rooted in intergroup relations related to competition and status (Cuddy et al., 2008; Fiske et al., 2007). Whether groups are viewed as cooperative or competitive is largely a question of intent: Are the group’s intentions helpful or harmful? Cooperative groups are thought to have helpful intentions, and trigger high-warmth perceptions (e.g., helpful, good-hearted). Competitive groups, on the contrary, are believed to have harmful intentions, which elicits low-warmth perceptions (e.g., harmful, and untrustworthy). The perceived status of social groups evaluates the ability of groups to control resources. High-status groups, viewed as capable of obtaining resources, are seen as competent (e.g., productive, intelligent). Low-status groups, on the contrary, are thought to be incapable of controlling resources and thus receive low-competence judgments (e.g., unproductive, not smart; Cuddy et al., 2008).
As prescribed by the SCM, the origins of warmth (i.e., threat, competitiveness) and competence (i.e., status) judgments are relevant in predicting intergroup bias on cognitive, emotional, and behavioral levels (Fiske et al., 2002). News media messages might be especially informative regarding the threat/competitiveness and status of ethnic ingroups and outgroups. In support of this claim, empirical studies have documented that news media tend to represent ethnic minorities in terms of threats to economic and social resources (Eberl et al., 2018), occupying low-status socioeconomic positions (Kroon et al., 2016). Accordingly, the current study focuses on indicators of threat and status in news media messages. We posit:
Over-Time Variation in Mediated Implicit Stereotypical Associations
Previous research adopting an over-time perspective on the presentation of minorities in the news tends to focus on the volume of coverage, rather than the way minority groups are portrayed. These studies generally conclude that differences in the visibility of migrant groups can be explained by real-world events such as terrorist attacks and elections (Eberl et al., 2018). The few studies that explicitly modeled the influence of time document considerable variation in the stereotypicality of media content. For example, U.S.-based scholarship indicates that Latino characters on prime-time TV are increasingly sexualized over the years (Tukachinsky et al., 2015). In the Netherlands and Flanders, evidence exists for an erratic over-time pattern of news coverage which relates immigration to crime and terrorism (Jacobs et al., 2018).
However, it remains an open empirical question to what extent media stereotypes of diverse ethnic ingroups and outgroups change over time, and if such changes are in sync with real-world developments. We expect that the stereotypicality of news media content about ethnic out-groups increase over time for the following reasons. First, news media content is likely to mirror increasingly unfavorable public perceptions about minority groups: As asserted by diverse sociologists, the shifting equilibrium between the host population and out-group members due to immigration influxes has amplified negative sentiments toward ethnic outgroups across Europe in the past decades (see Gorodzeisky & Semyonov, 2016). Owing in part to increased (perceived) fears of competition over socioeconomic resources, threat perceptions about minority groups have intensified (Erisen & Kentmen-Cin, 2017; Semyonov & Glikman, 2008). Media scholarship documents that these negative sentiments and threat perceptions are reproduced by news content about ethnic outgroups (Eberl et al., 2018). In addition, the rise of popular right across Europe represents a significant and important real-world trend that journalists logically cover. In doing so, however, news media messages may, to an increasing extent, offer a stage for right-wing politicians to voice anti-minority opinions and report on the anti-minority viewpoints put forward by such parties (Vliegenthart & Boomgaarden, 2007).
Following this argumentation, it can be expected that aggregated news media’s representation of ethnic groups is rather a product of public opinion and the political climate than a true reflection of actual, numerical integration outcomes. Contrasting the content of media coverage with real-world trends provides insight into the extent to which the unfolding of media representations diverges from factual real-world integration outcomes and herewith provides a true test of media bias. Previous scholarship that put such inter-reality comparisons to the test finds support for the bias hypothesis: Empirical evidence documents that negative media representations of marginalized groups diverge from real-world statistics (Dixon & Linz, 2000; Dixon & Williams, 2015; Jacobs et al., 2018). For example, Jacobs et al. (2018) find that news about immigration is largely unaffected by real-world figures such as crime and socioeconomic issues.
The available inter-reality comparisons tend not to consider over-time variation in media and real-world data, or rely on the involvement of general indicators without explicitly modeling the representation of minority groups among real-life statistics. The complex over-time interaction between news stereotypicality and the representation of diverse ethnic groups among real-world statistics, however, has remained unaddressed by previous media scholarship. The current study includes two real-world indicators that mirror high-threat and low-status stereotypes: criminality rates and the reception of social benefits. The following hypothesis and research question are formulated:
Method
Data preparation, model training, and subsequent analyses were conducted using Python. We used the Word2vec implementation provided by the gensim package (Mikolov, Corrado, et al., 2013; Mikolov, Yih, & Zweig, 2013; Řehůřek & Sojka, 2010). We then used R for hypothesis testing and for creating our final visualizations. Code used to train the models is available here: https://github.com/annekroon/mediabias.
Word embeddings are especially effective at solving word analogies, as they capture semantic word relations with mathematical relationships between vectors. The family of word-embedding techniques called Word2vec has gained popularity after its release in 2013 (Mikolov, Corrado, et al., 2013). This unsupervised machine-learning algorithm takes a large collection of documents as an input (think of hundreds of thousands of news articles, or all articles published on Wikipedia in a given language) and represents a word as a vector of weights across a set of k dimensions. In the current study, distributed weights across 100 dimensions are calculated for each word in the training corpus. Word2vec is a shallow neural network, in which the input layer (i.e., the features in the corpus that the model is trained on) is mapped on an intermediate hidden layer, which is then mapped on the output layer, in our case the vector space representations (for an introduction, see, e.g., Goldberg, 2017). We apply a continuous-bag-of-words model (CBOW), meaning that vector representations of each of the target words are learned from its context (i.e., its direct neighboring words). More specifically, in the current study, we look at vocabulary words occurring within five words of each other. In conclude, the final embedding model returns a distribution of weights over 100 dimensions for each word in our training corpus.
Thus, embedding models learn the meaning of words based on the context in which these words occur across its many occurrences in a training corpus (in the current study: newspaper articles). In this process, words that are similar are mapped (i.e., embedded) to nearby points in the vector space, sharing high cosine similarity values. Such neighboring words in a vector space can be synonyms or words that are used in comparable contextual or topical domains (Bolukbasi et al., 2016b). Intuitively, take the example of the word “cereal.” This word will likely occur in similar sentences that refer to “oats,” such as “I like to eat [cereal/oats] in the morning.” As a result, cereal and oats share semantic meaning, and will be close neighbors in the embeddings’ vector space.
Using word embeddings as a diagnostic tool for bias detection allows us to explicitly move beyond deductive, dictionary approaches that, for example, aim to count how often the word “immigrant” co-occurs with the word “terrorism.” Although such dictionary approaches are informative regarding the co-occurrence of stereotypical terms in specific news articles, they do not consider contextual information and neglect semantic meaning. Alternatively, word-embedding models necessarily encode bias present in the training corpus by learning word meaning based on the semantic context in which social and ethnic groups appear. Word-embedding models have therefore been referred to as an “AI stereotype catcher” (Greenwald, 2017), useful to identify largely implicit forms of bias that may arise even in the absence of blatant and explicit prejudiced accusations. Likewise, influential studies in the field of AI show that semantic nearness of social categories (e.g., man, woman) and attributes (e.g., programmer, nurse) replicate implicit bias as measured by implicit association tests (Caliskan et al., 2017; Garg et al., 2018).
Data and Training
The current study draws on the entire corpus of news articles that appeared in the five Dutch national newspapers with the highest circulation rate (de Volkskrant, NRC Handelsblad, Trouw, Algemeen Dagblad, De Telegraaf) from January 2000 up to and including December 2015 (N = 3,316,494 newspaper articles). The corpus includes the full range of article types available in these newspapers: news stories, but also op-eds, columns, and editorials. Of the newspapers in our sample, Algemeen Dagblad and De Telegraaf are often considered as tabloid-like, popular newspapers. On the contrary, de Volkskrant, NRC Handelsblad, and Trouw have generally been considered quality newspapers (Boukes & Vliegenthart, 2020; Roggeband & Vliegenthart, 2007). Especially the inclusion of tabloid-like newspapers might contribute to implicit bias in our corpus, as previous research indicates that European tabloid newspapers are more prone to represent ethnic minorities in stereotypical terms (Arendt, 2010; Kroon et al., 2016; Van Dijk, 2000). Covering several key events such as the aftermath of 9/11, the influx of immigrants and the rise of extreme right across Europe, newspaper content in the time frame under study is likely to resonate with a diverse range of sources, opinions, and arguments regarding ethnic minorities.
Model training was done in two steps. First, and to test our time-invariant hypotheses about the nature of media stereotypes, we train a single embedding model on the entire corpus. Second, and to allow testing of time-varying hypotheses, in a second step we trained word embeddings on consecutive years of the selected newspaper articles. The computer thus “learns” the meaning of words for each year separately, allowing for the detection of over-time variation in stereotypical associations. Thus, for each available year of news content, a single embedding model was trained (2000–2015), resulting in a set of 16 embedding models. To prepare our corpus for model training, we converted the entire text to lowercase sentences and removed numbers. Subsequently, each news article was split into sentences. Algorithmically, during model training, each sentence is processed to predict target words (e.g., “dog”) from source context words (i.e., neighboring words, for example, “I walk my ___ everyday”).
Accuracy of the embeddings
Several steps were taken to warrant the quality of the baseline embeddings model. First, we verified that references to target categories in our dataset are frequent (> 6K references, see Table 1), warranting the quality of the embeddings we are most interested in (Schnabel et al., 2015). Next, we perform a word analogy task (Mikolov, Yih, & Zweog, 2013; Pennington et al., 2014), which is among the most popular methods to evaluate the quality of word embeddings (Schnabel et al., 2015). This method is based on the idea that humans should be able to predict mathematical operations in a vector space: When given three words (a, b, c), knowing that a is to b as c is to d, one should be able to identify the target word d (Schnabel et al., 2015). The most-cited example that illustrates this principle is probably the task to complete the sentence “Man (a) is to king (b), as woman (c) is to _____.” The target word (d) that we are looking for is queen. We use this vector arithmetic to solve 1,424 analogies about common capitals and countries, family relations, and comparisons 1 , resulting in a mean accuracy of 66.62%. This is comparable to the quality of previously employed embeddings (Pennington et al., 2014).
Frequencies, High-Threat and Low-Status Associations Across Ethnic Categories.
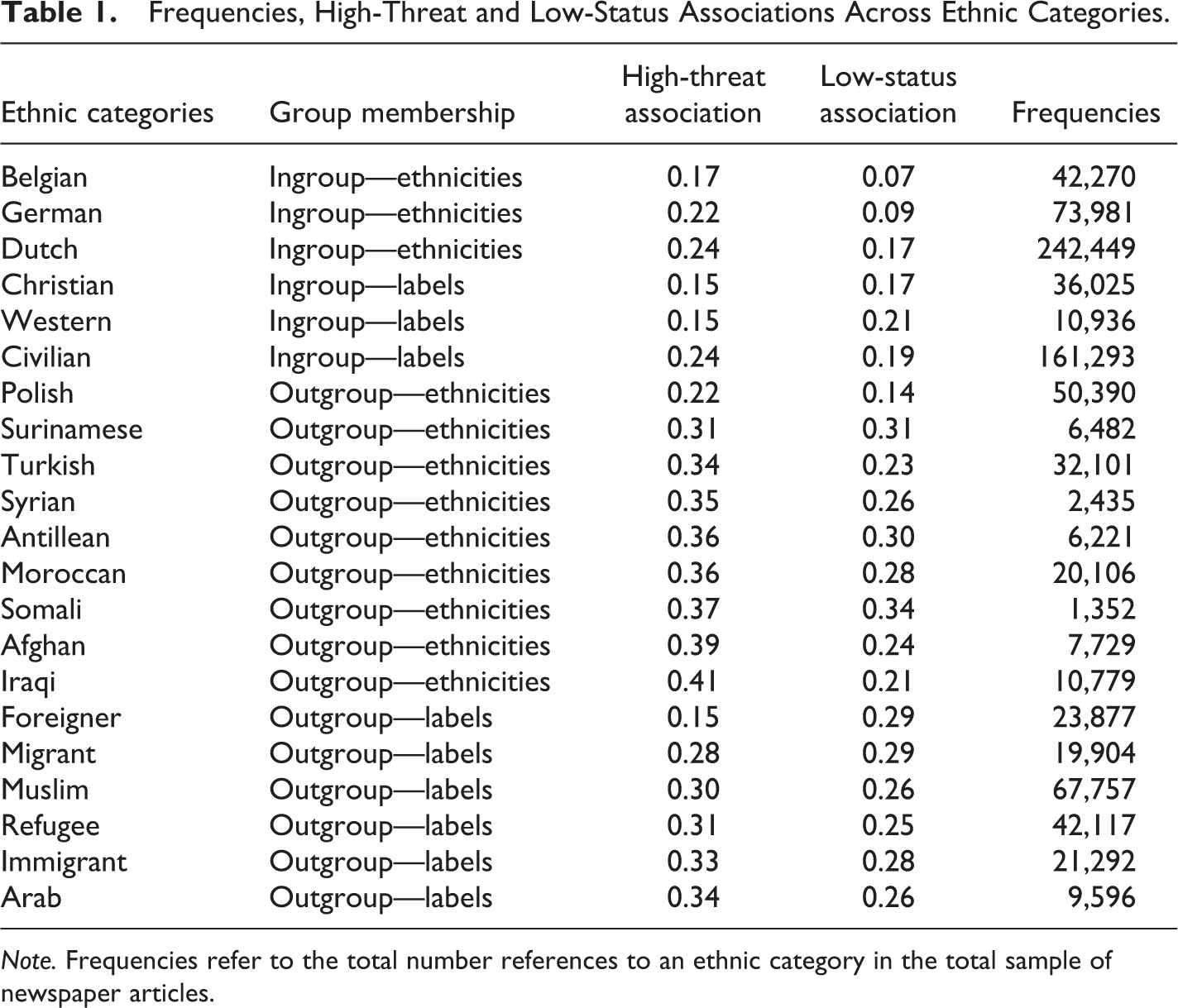
Note. Frequencies refer to the total number references to an ethnic category in the total sample of newspaper articles.
Attribute Word Lists Reflecting Low-Status and High-Threat Stereotypes
To measure low-status and high-threat associations, words tapping into these concepts need to be identified. We retrieve words capturing both concepts from the data under investigation, as this is most representative of the language and jargon used by journalists. We use a bottom-up approach to establish word lists using most similar scores retrieved from embeddings trained on the corpora of all news content per news outlet. In this way, we capture inter-media variation in most similar scores while maintaining large-scale accuracy benefits (Mikolov, Corrado, et al., 2013). For each ethnic category formulated in both singular and plural form (e.g., Moroccan and Moroccans), the 100 most-similar words in the vocabulary were retrieved. Most-similar words are words that are closest to the target word in the vector space.
The resulting word lists were subsequently manually revised and categorized by the authors as follows. We considered only words that carry a negative meaning and could, therefore, reveal a certain stereotype of an ethnic group. Negative words were categorized into two groups: high-threat indicators and low-status indicators, following the conceptualization put forward by Fiske et al. (2002). High-threat indicators were defined as words referring to hostility, deviance, threatening behavior or objects, criminal, and/or illegal activities (e.g., stealing, robberies, and murder). We also included words related to judicial authorities (e.g., policeman or cop), as we believe these words evoke associations with hostility and criminality. Low-status indicators were defined as words referring to low-social class, (un)intelligence, low education levels, unemployment, addiction, and/or homelessness. Words with a negative connotation that did not fit either of these categories were not included in the analysis. We excluded issue-specific words that are connected to foreign affairs, specific events or issues, and/or a selective set of ethnic categories (such as dictators, child soldiers, and radicalism), as we are explicitly interested in the general dimensions of stereotype content. During several rounds, the selection of words was critically debated and carefully revised by the authors. The final list of words capturing high-threat (N = 208 words) and low-status (N = 95 words) stereotypes are included in Appendices A and B.
Targets Word Lists Reflecting Ethnic Categories
A target word list is created capturing diverse ethnic categories. We included the eight largest non-western ethnic groups living in the Netherlands (i.e., Surinamese, Turkish, Syrian, Antillean, Moroccan, Somali, Afghan, and Iraqi). In addition, we included three large western ethnic groups living in the Netherlands (i.e., Belgian, German, Polish). Last, the Dutch were included. For reasons of completeness, labels often used in the news media to denote ethnic categories were also included (e.g., immigrants, foreigners—see below). For each ethnicity and each label both the singular and plural forms were included in the target word list (e.g., Moroccan, Moroccans, immigrant, immigrants). See Table 1 for an overview.
Variables Time-Invariant Prediction of Media Stereotypes
Ethnic categories and labels
In addition to the Dutch, we consider Germans and Belgians members of the ethnic ingroup, as they are geographically, linguistically, and culturally strongly related to the Netherlands. All other ethnicities are considered ethnic outgroups. Ethnic labels are also categorized as outgroup (i.e., foreigner, migrant, Muslim, refugee, immigrant, Arab) and ingroup (i.e., Christian, Western, Civilian) categories.
Implicit high-threat and low-status association strength
Using the baseline word-embedding model and the above-defined attribute and target word lists, the association strength between ethnic groups and stereotypical attributes must be computed. To this aim, a Python script was developed to retrieve similarity scores for all combinations of ethnic categories and the words representing respectively high threat and low status using the baseline word-embedding model. The script returns the cosine similarity for each pair. We calculate the average embedding distance between words representing ethnic groups and high-threat attributes. We also calculate the average embedding distance between words representing ethnic groups and words representing low-status stereotypes. Higher scores indicate stronger implicit associations.
Variables Time-Varying Prediction of Media Stereotypes
Group membership
For the dynamic analysis, we focus only on a small subset of the ethnic categories as real-world indicators were only available for these groups. Accordingly, we consider the four largest immigrant groups in the Netherlands as outgroups (i.e., Surinamese, Antillean, Turkish, Moroccan) and the Dutch as ingroup. A dummy variable is created differentiating between outgroup (1) and ingroup (0) category.
Implicit stereotype-association strength
Aiming to explain over-time variation in general patterns of implicit media bias, we do not differentiate between high-threat and low-status dimensions of stereotype content. 2 Instead, we assume that both dimensions represent negative stereotypical associations. More specifically, using the dynamic word-embedding models and the target and attribute word lists, we calculate the mean embedding distance for words representing ethnic groups and both high-threat and low-status attributes.
Year trend
Years received a value ranging from 1 (year 2005) to 11 (year 2015).
Real-life high-threat indicator: Criminality rates
The yearly share of registered suspects of crime by background was used as an indicator of the actual threat posed by different ethnic groups, obtained from Statistics Netherlands (M = 4.61, SD = 2.17).
Real-life low-status indicator: Unemployment benefits
The yearly share of unemployment benefits by background was used as an indicator of the actual social status of different ethnic groups, obtained from Statistics Netherlands (M = 3.05, SD = 0.95).
Demographic composition
As an indicator of demographic composition, we rely on the yearly share of the total population of the Netherlands by ethnic background, obtained from Statistics Netherlands (M = 9.15, SD = 0.35).
Analysis
To test our time-invariant hypotheses regarding the nature of media stereotypes (
Results
The Nature of Media Stereotypes: Implicit High-Threat and Low-Status Associations
The word-embedding model trained on the corpus of all news items was used to investigate high-treat and low-status associations across ingroups and outgroups. Figure 1 and Table 1 summarize the descriptive results. As can be seen, ingroup categories (in terms of both labels and ethnicities) are primarily situated in the neutral threat and neutral status quadrant of the figure. Notably, high-threat and low-status associations are relatively weak for Germans, Belgians, Christians, and the Dutch. Outgroup categories (both in terms of labels and ethnicities), on the contrary, are mostly situated in the high-threat, low-status quadrant of Figure 1. High-threat and low-status associations are especially strong for Antilleans, Moroccans, and Somalis. In addition, the label immigrant is strongly associated with high-threat and low-status portrayals. The Polish, however, are an exception—this outgroups scores relatively low on both dimensions of threat and low-status/social inferiority. Table 1 confirms that the association with low-status and high-trait stereotypes is lower for ingroups (i.e., ethnicities and labels) compared with outgroups (i.e., ethnicities and labels). These descriptive findings largely confirm the predictions put forward by SCM scholarship.
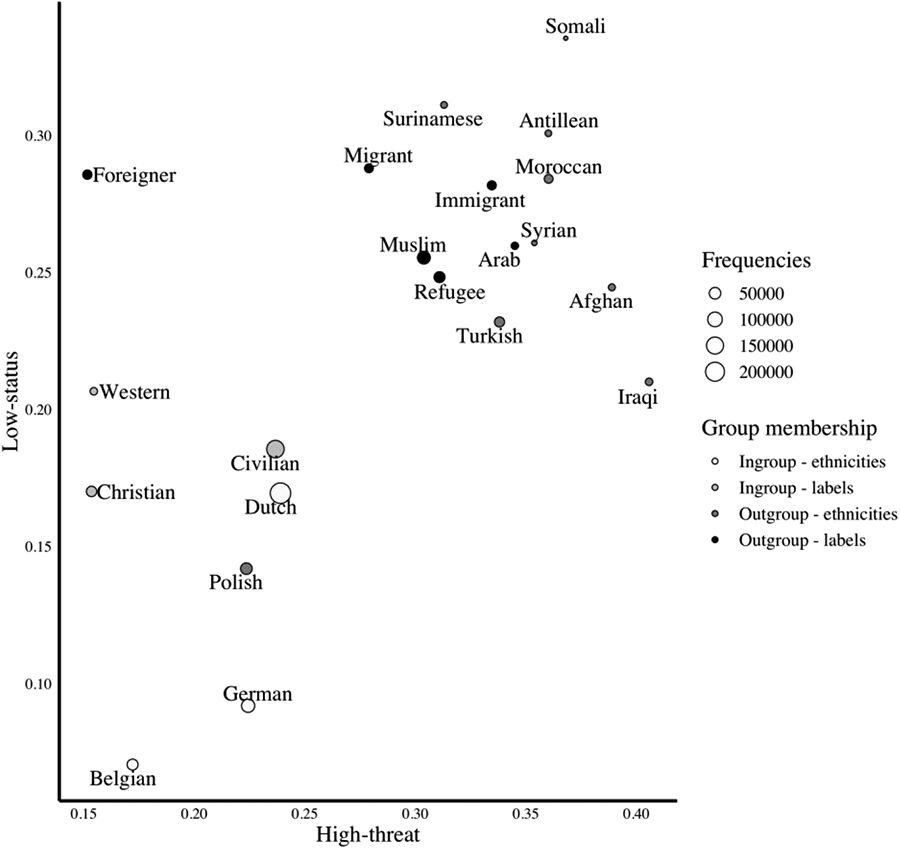
High-threat and low-status associations across ethnic categories and labels.
Next, we investigate whether descriptive differences in stereotype strength across group membership hold when testing for statistical significance. It was anticipated that news media implicitly associate outgroup ethnicities compared with ingroup members more strongly with high-threat stereotypes (
Time-Varying Prediction of Implicit Stereotype-Association Strength
Finally, we discuss the analysis explaining over-time variation in implicit stereotypical associations. Here, we use the word embeddings trained on consecutive years of news content (2005–2015). Figure 2 displays the over-time variation in the strength of implicit stereotype associations for the selected outgroup and ingroup categories. In support of our expectations, we see that generally, implicit stereotype-association strength increases over time for most of the ethnic outgroups. 3 Conversely, the association between the ethnic ingroup and implicit stereotype-association strength remains stable across time. Table 2 displays the results of the OLS-PCSE analysis. Model 1 shows the main effects of the predictor variables. The results show that, in agreement with our descriptive analysis, ethnic outgroups receive stronger stereotypical associations than the ethnic ingroups. Time does not exert a significant main effect on our dependent series. We do find positive effects of both the evolvement of criminality rates and unemployment benefits on the strength of implicit stereotypical associations. Finally, our control variable demographic composition does not significantly affect our outcome variable.
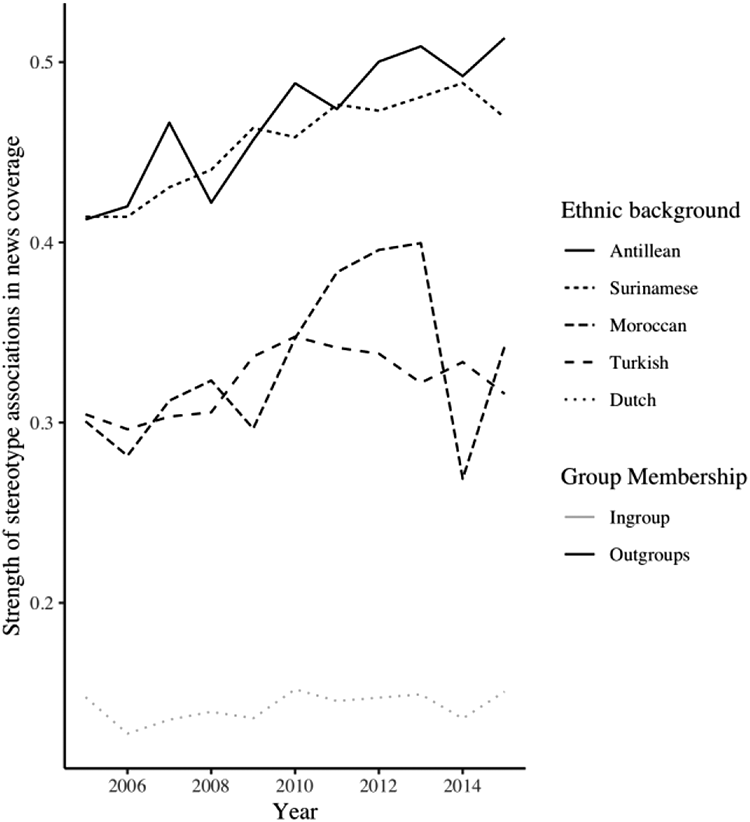
Over-time variation in stereotypical associations across group membership.
Time-Varying Prediction of Stereotype-Association Strength.
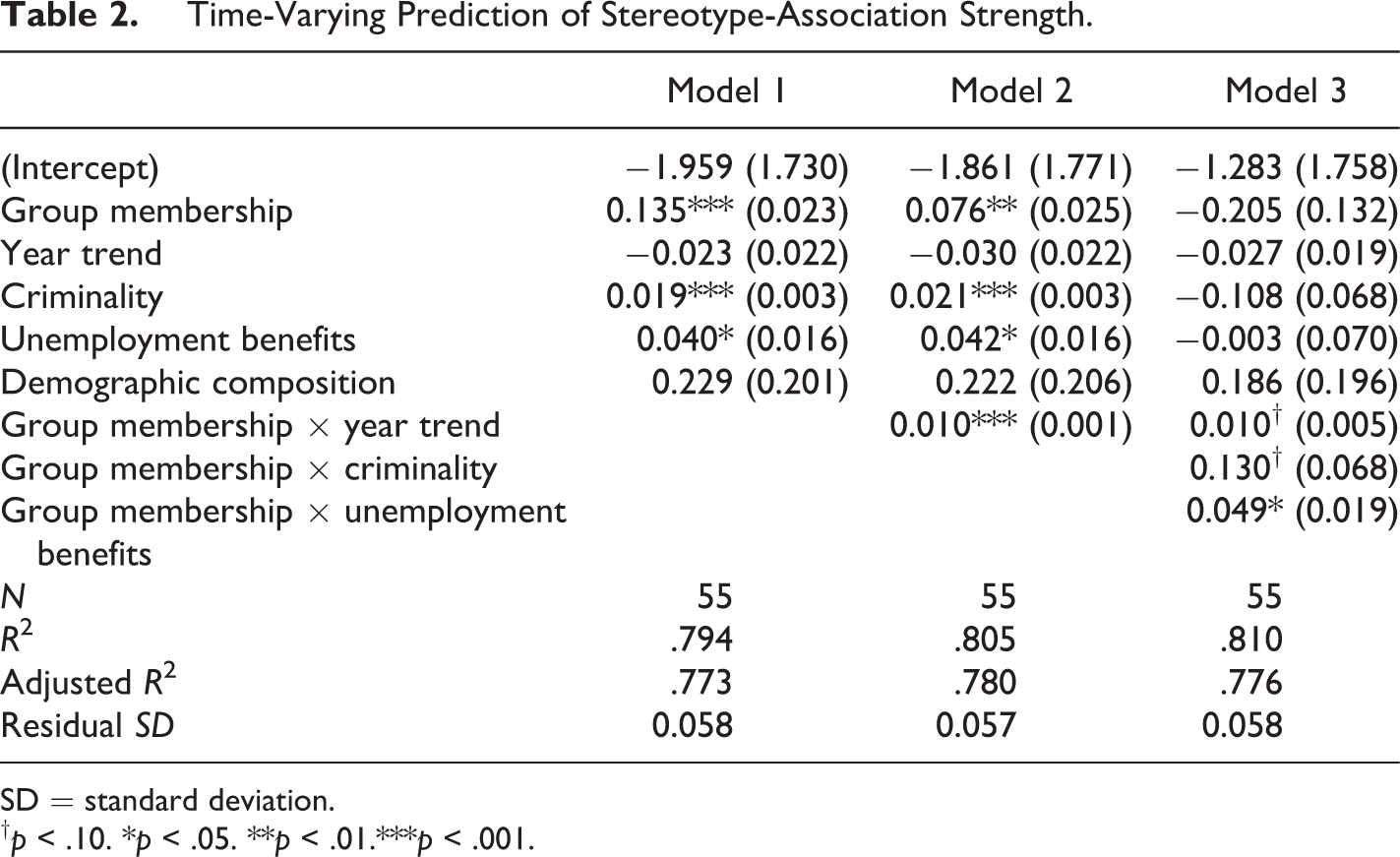
SD = standard deviation.
† p < .10. *p < .05. **p < .01.***p < .001.
It was anticipated that across time, implicit stereotype-association strength would increase for the ethnic outgroup, but not for the ethnic ingroup (
Last, we asked to what extent real-world integration outcomes (i.e., criminality rates and unemployment benefits) are related to the evolution of stereotype-association strength. To this end, we included interaction terms between group membership and the integration outcomes to our final model. The results indicate that the effects of criminality rates and the division of unemployment benefits on implicit stereotype-association strength in the news media are different for ingroup and outgroup categories. The inspection of the interaction terms reveals that the positive effect of criminality on implicit stereotype-association strength is stronger for the ethnic ingroup compared outgroups. More specifically, the representation among criminality rates matters for the news media portrayal of ethnic ingroups but not for ethnic outgroups: Regardless of the actual decreasing criminality rates among outgroups, evaluations of these groups in the media did not decline. Regarding the interaction between the share of unemployment benefits and group membership, a different pattern emerges: The positive effect of unemployment benefits on implicit stereotype-association strength is stronger for ethnic outgroups than for the ingroup. Raising unemployment benefits among ethnic outgroups results in stronger implicit stereotype associations, while this is not the case for ethnic ingroups. Figure 3 illustrates these findings by juxtaposing the evolution of the factual integration proxies and implicit stereotypical associations in news content across group membership.
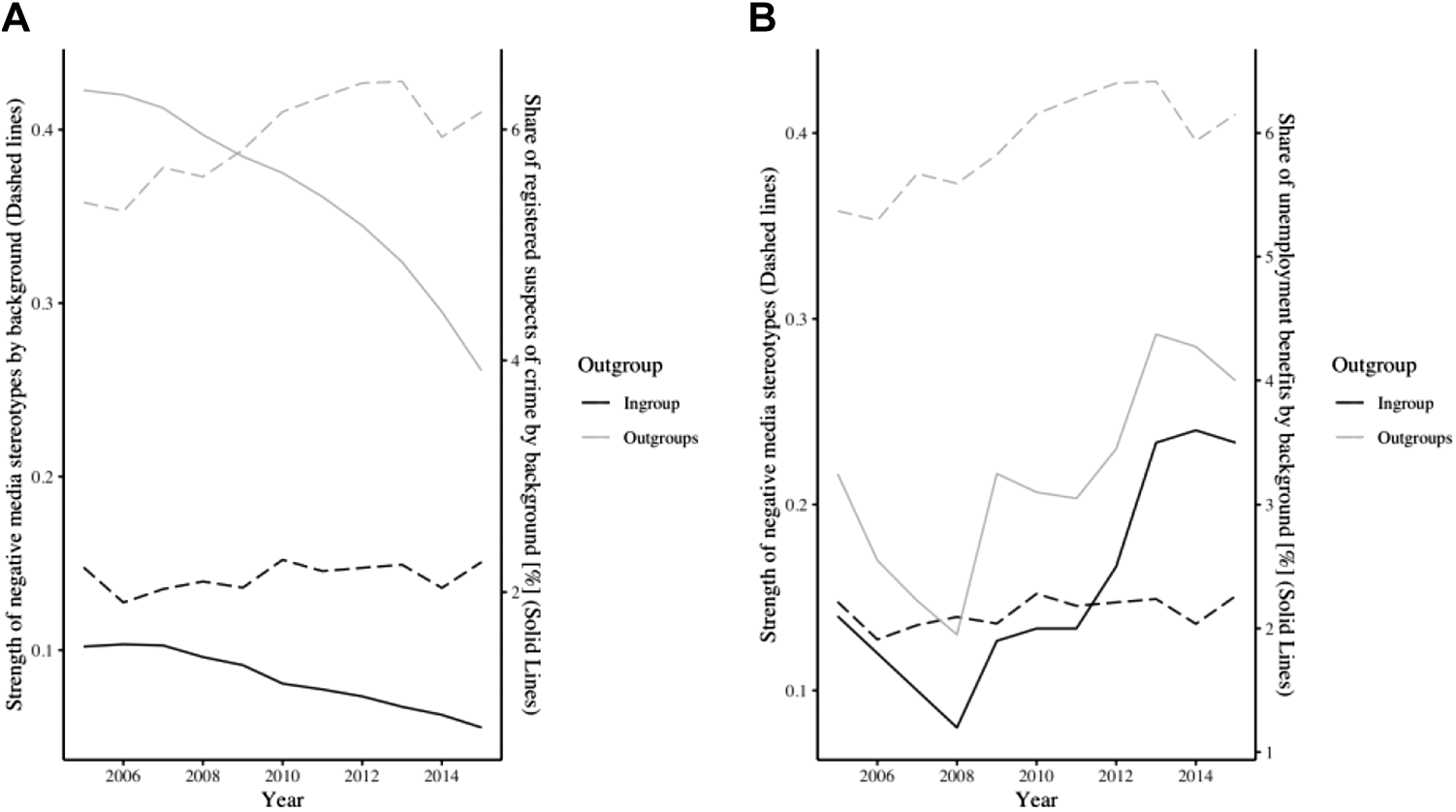
.Inter-reality comparison of integration outcomes and stereotype-association strength: (A) criminality and (B) unemployment benefits.
Discussion
The twofold aim of this study was to investigate universal dimensions of stereotype content in news content across a diverse set of ethnic ingroups and outgroups, and to trace the extent to which ethnic bias in news coverage has increased over time. To answer these questions, the current study introduces the use of word embeddings to the media-stereotyping scholarship as a promising method for detecting implicit bias in news content. Relying on an analysis of more than 3 million Dutch news articles, the current study finds strong support for the key dimensions of stereotype content as put forward by SCM scholarship (Fiske et al., 2002). In addition, the data show that, across time, content about ethnic outgroups has become progressively negative and remote from factual integration outcomes.
We first discuss our findings regarding the nature of media stereotypes. Importantly, the study shows that universally accepted dimensions of stereotype content as documented by an astounding body of psychological studies (see Cuddy et al., 2008, 2009) can be replicated using news media data. More specifically, the presented results show that news media portray ethnic outgroups in terms of fundamental dimensions explaining shared perceptions of societal groups: Compared with ethnic ingroups, news content proved to implicitly associate ethnic outgroups relatively strongly with low-status and high-threat stereotypes.
These results hold across a diverse set of ethnic subgroups. Implicit associations with low-status and high-threat stereotypes were significantly weaker for ethnic ingroups, defined as native citizens (i.e., the Dutch) as well as residents of immediate neighboring countries (i.e., Germans and Belgians). Ethnic outgroups from non-European soil received uniformly negative evaluations on both dimensions. Particularly, ethnic outgroups like Moroccans, Somali, and Antillean could uniformly be positioned in the high-threat, low-status quadrant of stereotype content. This indicates that news media portray immigrant subgroups largely in terms of dominant social perceptions about them (Fiske, 2012; Lee & Fiske, 2006). In sum, the findings are largely in line with predictions of the SCM (Fiske et al., 2002), and herewith offer strong support for the dual-dimensionality of stereotype content in newspaper content.
A few exceptions emerged. We found that implicit low-status and high-threat associations were weak for the Polish, the single European outgroup in our sample. This finding might be a reflection of the generally less pronounced negative attitudes toward European compared with non-European immigrants (Gorodzeisky & Semyonov, 2009). In addition, we found strong low-status but weak implicit threat associations for the generic label “foreigner,” revealing ambivalent stereotype content. Semantically, this generic label might comprise a range of people who are not perceived as threatening such as tourists or expats.
These findings have important societal ramifications. Status and threat indicators are core components of social judgments: Status informs individuals about the ability and competence of others—while perceived threat signals intentions—boiling down to the question whether “they” can be seen as friend or foe (Fiske et al., 2007). Consequently, low-status groups tend to be evaluated as incompetent, while threatening groups are judged as low in warmth. Especially in race-segregated societies, where close inter-racial contacts are the exception rather than the rule (Musterd, 2005), news media content is especially apt to inform individuals about the status and potential threat posed by ethnic outgroups. Our findings indicate that such mediated information is biased, and likely feeds into dominant ethnic stereotypes. This is especially problematic for groups that are frequently covered in Dutch news media such as Moroccans, Muslims, and immigrants in general.
Consequently, the widespread perception of ethnic outgroups in terms of low-status/low-competence and high-threat/low-warmth, which has been convincingly documented across diverse countries and cultures (Cuddy et al., 2008), seems to be—at least partly—rooted in the everyday news we consume. Such stereotypical perceptions are not inconsequential: SCM scholarship indicates that groups that are perceived as threatening and low in status are generally disliked, elicit feelings of pity and disgust, and tend to be excluded from diverse parts of society. Taken together, by spreading low-status and high-threat stereotypes of ethnic outgroups, news media might actively contribute to the maintenance of inequality and race-based exclusion in society.
Next, we discuss our findings regarding the over-time variation in media stereotypes. Our analysis shed light on long-term developments in real-world integration outcomes and implicit stereotype-association strength of the ethnic ingroup and major ethnic outgroups in the Netherlands. The results show that across time, negative associations show a slight upward trend for ethnic outgroups. In contrast, the evaluation of the ingroup remained relatively stable across time. By juxtaposing these findings to numeric integration outcomes, the study finds that across time, media representations of ethnic outgroups are becoming progressively remote from real-world statistics. First, the representation of ethnic outgroups among criminality rates (considered a proxy for the actual threat posed by these groups) decreased substantially during the studied time frame. Conversely, the implicit stereotype-association strength of ethnic outgroups displayed an opposite trend by becoming progressively stronger with time. Second, the over-time development of unemployment benefits (included as a proxy for actual social status) showed similar trends for ingroup and outgroup categories. However, increasing levels of unemployment benefits resulted in stronger implicit stereotype associations for outgroups, while this was not the case for ingroups. These results indicate that ethnic stereotypes in news content progressively diverge from real-world trends.
Importantly, these results indicate that the biased portrayal of ethnic minorities is rather an artifact of the news production process than a true reflection of what is actually happening in society. This conclusion is in line with previous studies that show that media content of ethnic minorities diverges from real-world data (Dixon & Linz, 2000; Jacobs et al., 2018). Based on a large-scale content analysis of Dutch media coverage on immigration, Jacobs et al. (2018) conclude that trends in immigration news develop remotely from trends in society. Our findings are in line with these conclusions. Several explanations for such a disconnected media reality can be offered. First, it might result from journalists’ tendency to report on specific newsworthy events, clearly demarcated in space and time, rather than general trends, which is evidenced by journalists’ reliance on episodic rather than thematic frames (Papacharissi & de Fatima Oliveira, 2008). Second, intensified negative sentiments regarding ethnic outgroups (Eberl et al., 2018), accelerated by the rise of the extreme right across Europe, seem to have permeated in the news content. Likewise, prevailing news values might have encouraged the production of news stories that focus on conflict: Reporters often find themselves writing about conflict when covering the immigration beat—especially regarding stories outside European/U.S. borders. Third and last, news media messages may, to an increasing extent, offer a stage for right-wing politicians to voice anti-minority opinions and report on the anti-minority viewpoints put forward by such parties (Boomgaarden & Vliegenthart, 2007). This means that, in their pursuit of offering balance news, journalists may find themselves chronicling the voice of those who might perpetuate stereotypes.
Following these considerations, an important question revolves around the notion of objectivity. More specifically, one may wonder how reporters can counteract biased news content. Although this question is not easily answered, we argue that it is important for reporters to be aware of structural inequalities and stereotypes on the societal level—and the possible impact hereof on the viewpoints of sources and the presumed newsworthiness of events. In this light, it is also important to consider which stories are not being told and which sources might not be cited to understand how bias seeps into the news.
The study makes the following methodological contributions. Importantly, the current study demonstrates the use of word embeddings to analyze subtle biases in large-scale mass-mediated texts. We have shown that word-embedding models, which are increasingly used in other fields, but new to communication science, are a promising opportunity for the detection of biases and stereotypes. In particular, they allow us to move beyond simplistic dictionary approaches that can measure if two words co-occur together, but not how similar they are. In sum, the here-reported findings are in line with recent scholarship that finds that human bias, as reflected in human language, can be accurately picked put up by word embeddings.
It should be noted that the tabloid-like newspapers in our sample could have contributed more strongly to the here-reported disparities in representations. Especially, anti-minority sentiment might resonate stronger in tabloid newspapers due to stronger affiliations with right-wing political parties (see Arendt, 2010; Kroon et al., 2016; Van Dijk, 2000). Finally, it is important to stress that our findings are the likely outcome of forces influencing the media agenda, such as routines, real-world events, and sources (Reese, 2001), rather than merely conscious or unconscious bias on the part of individual journalists.
Like all studies that employ new and innovative methods, ours has some limitations. Most notably, even though word embeddings have been successfully used before to quantify biases in texts (Bolukbasi et al., 2016a; Caliskan et al., 2017; Garg et al., 2018), we need more systematic validation studies. For instance, one could imagine that the ingroup is less often explicitly named but obvious for the reader from the context—an omission that might result in less quality word embeddings. Whether this is the case or not is an empirical question to be addressed in future work. In addition, by relying on large amounts of training data, this study did not answer the question of how and why bias exactly arises in our news corpora: It remains unclear which source types, topics, and articles mostly contribute to here-reported bias. Scholars are exploring the possibilities of tracing the origins of bias in embedding models back to the article level (Brunet et al., 2019). Future research could further explore such approaches, potentially combined with manual coding, to better understand how bias surfaces at the sentence or article level. Such a detailed, in-depth investigation of bias could be supplemented with journalists’ perspective on how and why such disparities in representations are encoded in news content. Last, the data used in this study provide merely insights into general representations in media content. Motives, reasons, and/or the presence of unconscious bias on the part of journalists cannot be inferred from the here-presented data.
In addition, our findings offer only support for the dual-dimensionality of stereotype content among ethnic outgroups, who are evaluated negatively on both dimensions. Future research should investigate the extent to which these dimensions are also useful to understand the portrayal of social groups receiving ambivalent stereotypes such as the elderly and disabled people (see Fiske et al., 2002).
Despite these limitations, the here-reported findings contribute to the formulation of universal dimensions of stereotype content, generalizable beyond specific ethnic categories. Moreover, the findings reveal that the biased portrayal of ethnic minorities is rather an artifact of news production processes than a true reflection of what is actually happening in society. A more thoughtful and accurate representation of minority groups in terms of the issues and topics associated with these groups may promote more favorable attitudes toward ethnic others, and pave the way for more inclusive societies.
Footnotes
Appendix A
Appendix B
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.