
Abstract
Intelligent tutoring systems (ITS) are designed to imitate human tutors by closing-the-loop between learners and tutoring agents. It is well-established that the cognitive factors of self-confidence and workload impact learners’ self-awareness of achievements and self-efficacy, which in turn enhances learning outcomes. However, little work has been done to operationalize these concepts in ITSs for psychomotor learning. In this work, the authors consider learners’ skill progression while repeatedly landing a quadrotor in a simulator. The landing simulator is enabled with automation assistance that can turn on or off; when on, the automation assistance augments the learner’s input to mimic an expert’s landing trajectory. The authors design an algorithm to calibrate learners’ self-confidence to their performance and compare it against learners’ who do not receive any assistance. Statistical analyses revealed that participants who received assistance according to the calibration algorithm demonstrated more self-efficacy and less fatigue than those who did not.
Introduction
Modern-day intelligent tutoring systems (ITSs) are designed to imitate human tutors and provide individualized feedback to learners (Woolf, 2008). This is usually accomplished by closing-the-loop between human models and tutoring agents. For example, in conventional learning contexts such as mathematics or computer programing, ITS agents are designed to respond to learners based on their self-confidence. The cognitive factors of self-confidence and workload impact the learner’s self-awareness of their achievements, or self-efficacy (Bandura et al., 1999). It is well-documented that increasing self-efficacy in students is associated with higher performance and motivation to continue learning (Bandura et al., 1999; Jungert & Rosander, 2010; Shuggi et al., 2019). However, developing ITSs may not be as straightforward for psychomotor learning because assessing an answer’s “correctness” in conventional learning contexts is not analogous to assessing how “correct” performance is in a psychomotor task (Neagu et al., 2021). Existing psychomotor learning ITSs face challenges including creating a knowledge space of the task, personalizing the agent to the learner’s characteristics, and maintaining learner motivation (Neagu et al., 2022).
In Yuh, Ortiz, Sommer-Kohrt, et al. (2024), we began tackling some of these challenges using a quadrotor landing simulator module (shown in Figure 1) that can be used to train a human to manually land a quadrotor. To improve the knowledge space of the task, the authors identified four learning stages associated with landing the quadrotor based on psychomotor learning theory (Dreyfus, 2004), the quadrotor state information, and eye gaze trajectories. From this, a rule-based classifier was developed using quadrotor and participant eye gaze trajectories. The learning stage classifier achieved an accuracy of 80.69%. Importantly, this classifier enables online assessment of users’ learning progression over multiple trials of quadrotor landings.

Quadrotor simulator module and controller.
Intelligence was introduced to the simulator module by creating an assistive mode in which the human’s input is augmented by automation designed to follow a human expert’s landing trajectory (Yuh et al., 2022; Yuh, Rabb, Thorpe, et al., 2024). However, this then introduces the question of when the learner should practice landing the quadrotor manually versus with automation assistance. Motivated by the role of human self-confidence in learning (Akbari & Sahibzada, 2020) as well as the impacts of self-efficacy on the learner’s motivation to learn (Dreyfus, 2004; McQuiggan et al., 2008), we designed an algorithm that makes this mode selection by calibrating the learner’s self-confidence to their performance (Yuh, Rabb, Thorpe, et al., 2024). We benchmarked this algorithm against a strategy with mode selections based solely on learner’s performance and showed statistically significant improvements in learning outcomes.
Despite these promising findings, the proposed psychomotor ITS designed to calibrate learners’ self-confidence via automation assistance has not been compared to the true baseline of human learning without any assistance. Therefore, our objective is to evaluate whether using automation that assists learners based on an algorithm designed to calibrate self-confidence to performance leads to improved learning outcomes in comparison to learners receiving no assistance. In this paper, we first define four learning stages in the context of the quadrotor landing simulator. Next, we describe the apparatus, procedure, and data collection in our experiment design. We follow this with a presentation and discussion of the statistical findings. Finally, we conclude with a summary of our contributions and the implications our findings have for future ITS design.
Learning Stages
In Yuh, Ortiz, Sommer-Kohrt, et al. (2024), the five-stage psychomotor learning theory model by Dreyfus (2004) is applied to the quadrotor landing simulator module using quadrotor state information and eye gaze trajectories. For the scope of this paper, eye gaze is not used because eye-tracking data was not collected. Additionally, eye-tracking may not be easily accessible or interpretable for all psychomotor tasks. The authors assume that most participants are unable to reach the expert (fifth) learning stage within 25 trials. Features of the quadrotor dynamics and landing types characterizing each learning stage are summarized in Table 1.
Learning Stage Descriptions in Terms of Quadrotor Dynamics and Feasible Landing Types adapted from Yuh, Ortiz, Sommer-Kohrt, et al. (2024).
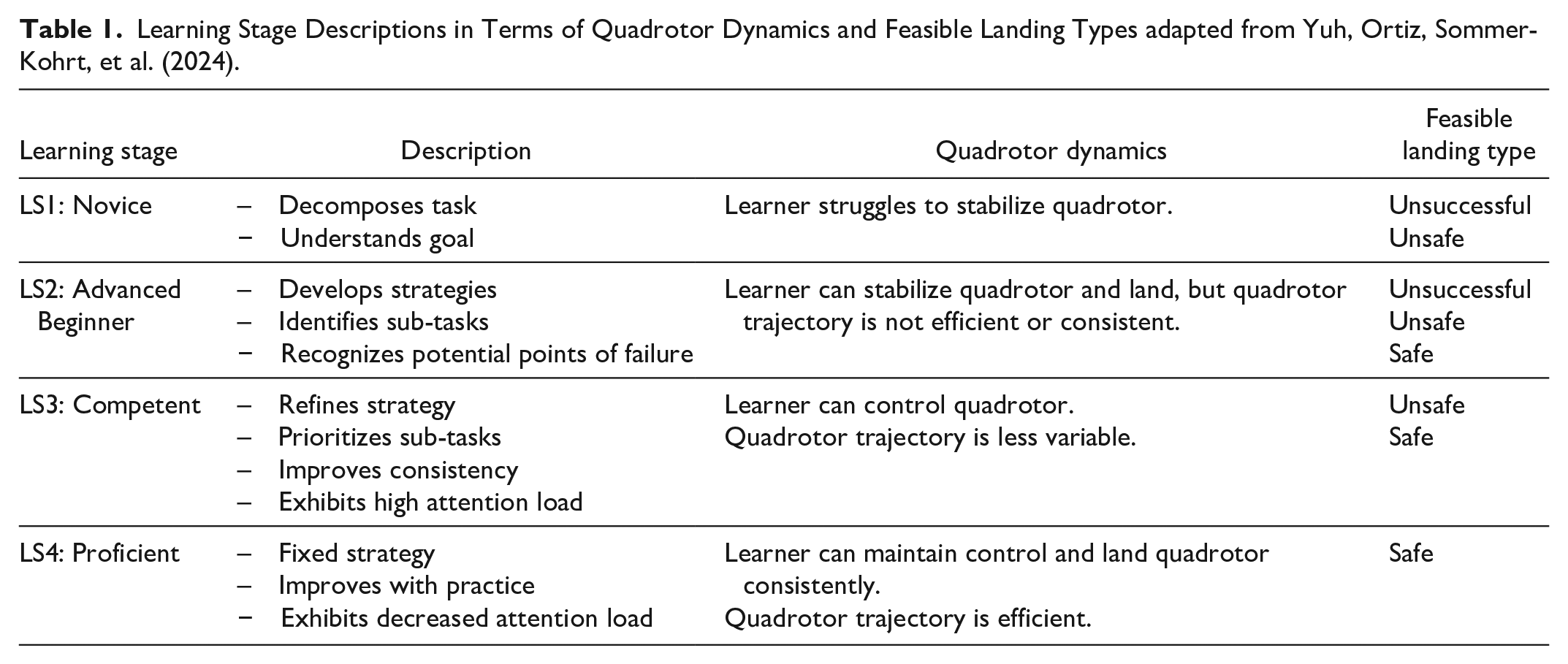
In learning stage 1 (LS1), the quadrotor trajectory is unstable and results in unsuccessful or unsafe landings. In learning stage 2 (LS2), the learner demonstrates more control over the quadrotor. Although the quadrotor position trajectory is not the most efficient, the learner can keep the quadrotor stable for most of the trial before crashing. In learning stage 3 (LS3), the learner maintains control over the quadrotor, resulting in a trajectory that is increasingly similar to an expert trajectory. Finally, in learning stage 4 (LS4), the learner can land the quadrotor consistently and efficiently. Example trajectories for each learning stage are provided in Figure 2.
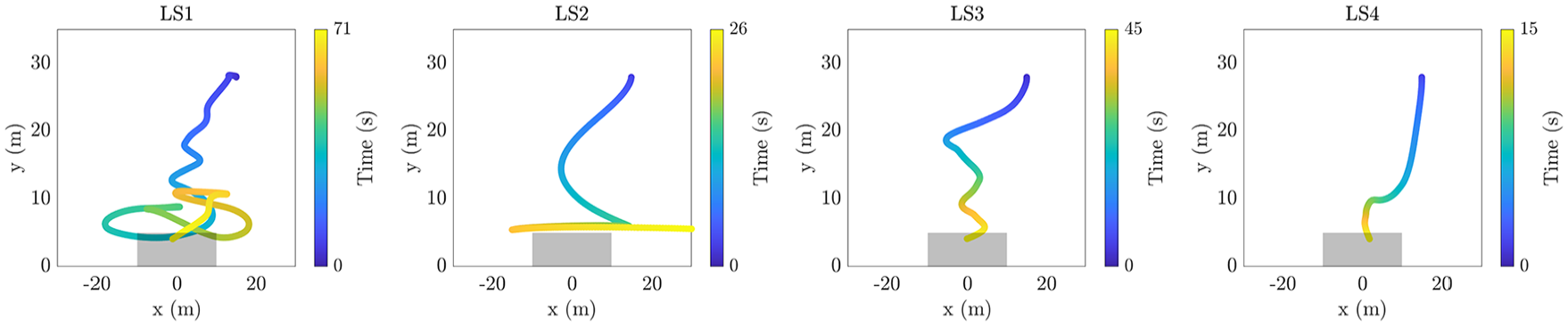
Examples of quadrotor trajectories categorized in learning stages 1 to 4. The landing pad is represented by a gray box.
Experimental Design
Apparatus
The quadrotor landing simulator was developed in Python 3.6.8 using Pygame 2.0.1. The simulator was originally developed by Byeon et al. (2021) and was adapted for this study. A Thrustmaster T. Hotas 4 joystick and throttle was used to control the quadrotor. The experimental platform is depicted in Figure 1.
Procedure
Prior to the 25 trials, participants are provided with instructions and a description of the experimental setup. Then, participants complete two 60-s tutorials to familiarize themselves with the simulator environment. The participants practice using the throttle by moving the quadrotor up and down and flying the quadrotor using both the throttle and joystick controls in the first and second tutorial, respectively.
Participants then complete 25 trials of landing the quadrotor, as depicted in Figure 3. After each trial, participants are shown their numerical performance score out of 1,000, the time taken to complete the trial, and the landing type (unsuccessful, unsafe, or safe). The performance score is designed specifically for the context of the quadrotor landing using gamification (Scheider et al., 2015). The participants must learn to land the quadrotor on the landing pad, while also satisfying landing speed and roll angle constraints (landing with a speed <5 m/s and a final roll angle between −10∘ and 10∘. Landing types are categorized as either unsuccessful, if they do not meet any of these criteria, unsafe if they meet just the landing pad criteria, and safe, if the landing constraints are also met. The reader is referred to Yuh, Ortiz, Sommer-Kohrt, et al. (2024) for additional details about the landing types and the design of the numerical scoring function.
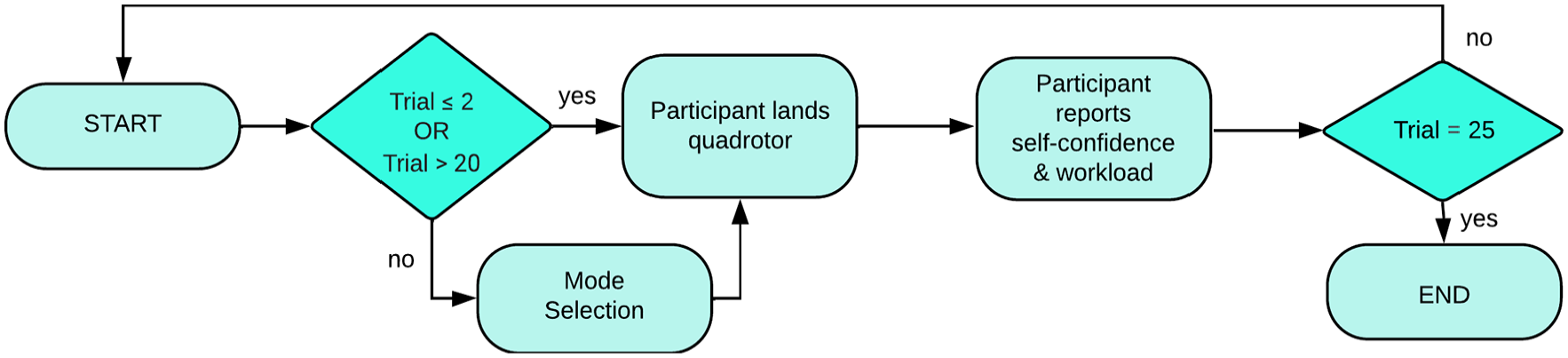
Flowchart of experiment. For the algorithm group, mode selection is based on the algorithm. For the manual group, all trials are completed in manual mode.
Participants self-report their self-confidence and mental demand on a scale of 0 to 100. Self-confidence is defined as “The confidence in oneself and one’s powers and abilities” to land the quadrotor. When prompting for mental demand self-reports, the following description of mental demand from the NASA Task Load Index (TLX) survey by (Hart & Staveland, 1988) is used: “How much mental and perceptual activity was required (e.g., thinking, deciding, calculating, remembering, looking, searching, etc.)? Was the task easy or demanding, simple or complex, exacting or forgiving?” To reduce the time participants spent on the survey portion of the experiment to avoid unqualified answers (Fowler & Cosenza, 2009), the full NASA TLX survey was not used. Mental demand is used to infer mental workload.
Participants are randomly assigned to two groups. The first group, known as the algorithm group, may receive automation assistance (which augments the participant’s input to the quadrotor controller) in trials 3 to 20 according to the mode selection algorithm designed to calibrate learners’ self-confidence to their performance shown in Figure 4. The participant is aware of when the automation assistance is on or off. Trials 21 to 25 are completed manually such that initial and final assessments of learning stage, performance, self-confidence, and mental demand in manual mode can be made for each participant. The second group, known as the manual group, completes all 25 trials manually so that the mode selection algorithm can be compared to the case in which learners are never provided with automation assistance. In addition to recording performance metrics and self-reported data, all trials are classified into learning stages 1 to 4 using the quadrotor position, velocity, and roll attitude states as well as the thrust force and roll attitude acceleration inputs.
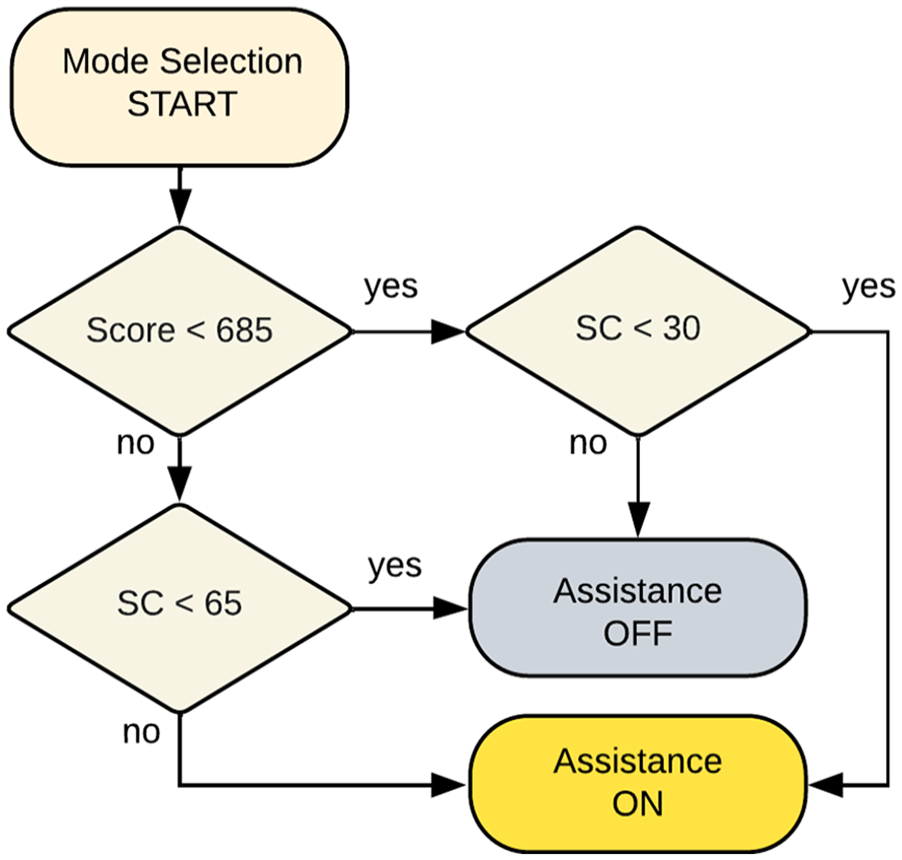
Mode selection for the algorithm group. Score and self-confidence (SC) thresholds are determined using 33% and 66% quantiles from prior launches of the experiment.
Data Collection
Quadrotor states and inputs are sampled at 30 Hz. After every trial, the performance score and landing type are assessed, and the participant’s self-confidence and mental workload are self-reported.
Participants
In total, 62 participants completed the study. Our analysis focuses on learners transitioning from novice (LS1) to proficient (LS4). Therefore, eight participants were removed because these participants already achieved LS3 and a safe landing manually within the first two trials in the quadrotor game or only achieved safe landings, meaning that these participants were too advanced in their skill. Among the remaining participants, 30 participants were removed due to never reaching LS3 and LS4. These participants never transitioned past the advanced beginner learning stage. This resulted in 24 participants split evenly between the algorithm (6 male, 6 female, mean age = 24.9 years) and manual (5 male, 7 female, mean age = 21.7 years) groups with participant ages ranging between 18 and 47 years. Each participant was compensated $20/hr. The Institutional Review Board at Purdue University approved the study.
Results and Discussion
To analyze how learning outcomes differ across the two groups of participants, we utilize independent t-tests to compare self-reported data, performance metrics, and achieved learning stages. This is followed by a regression analysis on self-reported self-confidence in both groups.
Independent t-Tests
In Table 2, differences in means of scores, self-confidence, number of LS1-LS4 classifications, and mean number of landing types in trials 21 to 25 are not significant. However, the mean mental workload in trials 21 to 25 is significantly lower for the algorithm group. In other words,
Independent t-Test Results Between the Algorithm and Manual Groups Including t-Value, Degrees of Freedom (DOF), p-Value, Significance (Sign.), Means, and Standard Deviations.
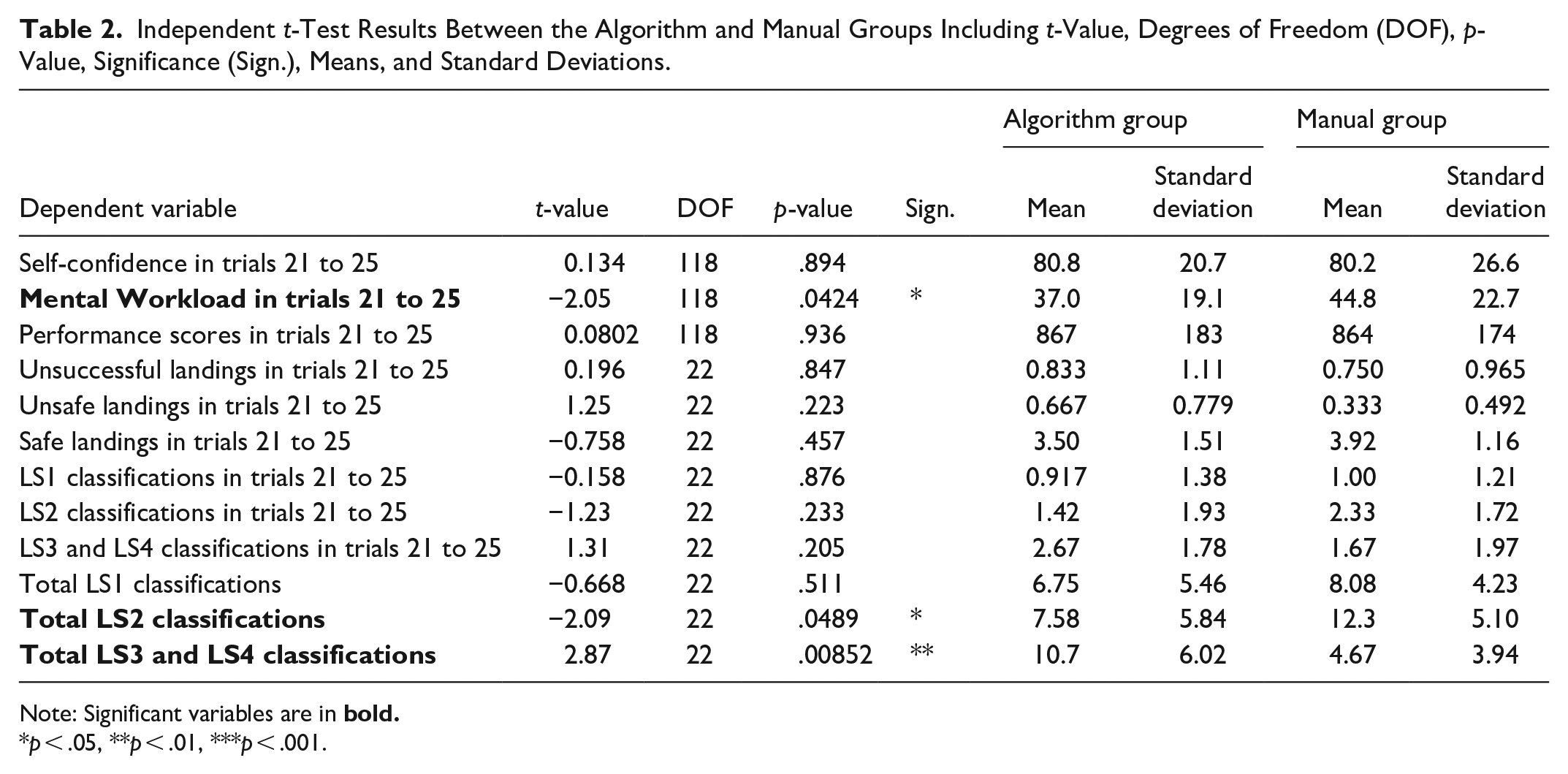
Note: Significant variables are in
p < .05, **p < .01, ***p < .001.
Multi-Variate Linear Regression Analysis
Multi-variate linear regression analyses were completed using self-confidence as the dependent variable and available feedback information (trial number, landing type, score, time taken per trial, and mental workload) as independent variables. A Bonferroni test was used to identify outliers in the data (Weisberg, 2005). Tables 3 and 4 show that performance feedback information has a significant impact on self-confidence for both groups. However, the ordinary R-squared values for the algorithm and manual groups were 0.624 and 0.278, respectively. This is important because the extent to which feedback information represented as independent variables explains the variation of self-confidence in the linear regression is better for the algorithm group than that of the manual group. In other words,
Coefficients, p-Values, and Significance (sign.) for Self-Confidence Regression Models for the Algorithm Group.
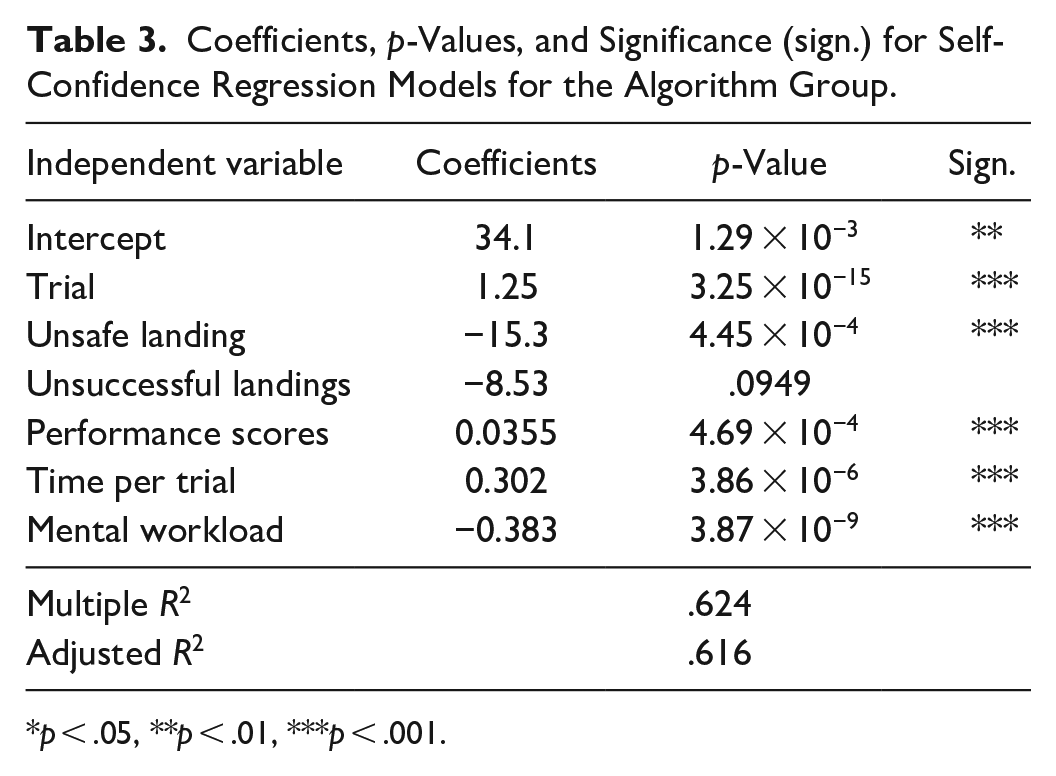
p < .05, **p < .01, ***p < .001.
Coefficients, p-Values, and Significance (Sign.) for Self-Confidence Regression Models for the Manual Group.
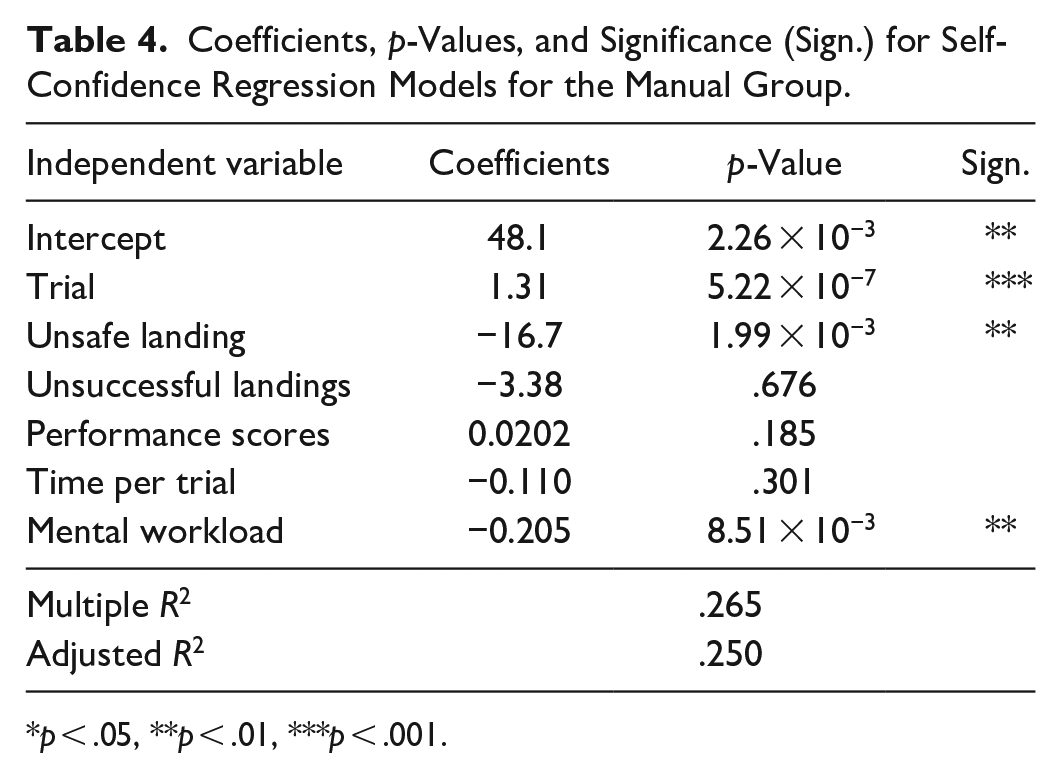
p < .05, **p < .01, ***p < .001.
Coefficients, p-Values, and Significance (Sign.) for Self-Confidence Regression Model with Assistance Independent Variable for the Algorithm Group.
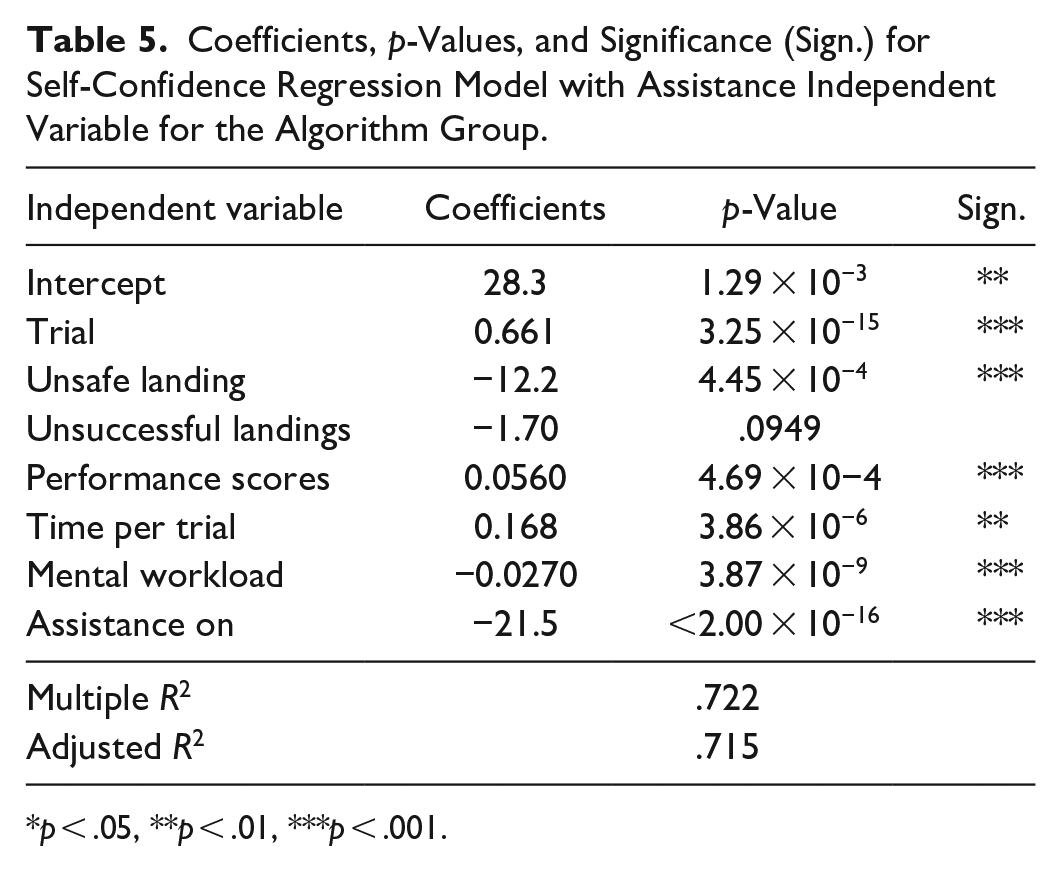
p < .05, **p < .01, ***p < .001.
Limitations
We recognize that the main limitation of this work is the sample sizes of the groups. To remedy this, the experiment should be extended beyond 25 trials in the future. The majority of the recruited participants who were removed from the dataset for not reaching LS3 could not achieve a safe landing within 25 trials. Given the difficulty of the quadrotor landing simulator, it is likely that these participants needed more trials to become proficient at the task. This would help increase the sample size within both the algorithm and manual group and improve the statistical power (Cohen, 1977).
Conclusion
In this work, our objective is to evaluate whether using automation that assists learners based on an algorithm designed to calibrate self-confidence to performance leads to improved learning outcomes in comparison to learners receiving no assistance. We evaluate the learning outcomes of the two groups using performance metrics, learning stage progression, and self-reports of self-confidence and mental workload.
Through statistical analyses, we found that participants who received assistance based on their self-reported self-confidence and performance in the quadrotor simulator demonstrated more self-efficacy and less fatigue than those who did not have access to assistance. This aligns with literature on human learning, in which it is recognized that cognitive factors such as self-confidence and workload play an integral role in a student’s self-efficacy and learning strategies, in turn, impacting their learning performance (Hayat et al., 2020). Furthermore, according to seminal self-efficacy literature, if human learners are more self-aware and realistic about their achievements, they are likely to experience future success (Bandura et al., 1999). Our algorithm for determining when to provide automation assistance in ITSs is a response to the challenge of personalizing assistance to learner characteristics and maintaining learner motivation (Neagu et al., 2020) and can be easily implemented in other psychomotor learning contexts where desirable performance and tutoring objectives are difficult to characterize quantitatively.
Footnotes
Acknowledgements
We thank Sooyung Byeon (Purdue University) for the initial development of the game platform and Jacob Hunter (Purdue University) for his help with data collection.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This material is based upon work supported by the National Science Foundation under Award No. 1836952. Any opinions, findings, and conclusions, or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.