
Abstract
Machine learning algorithms are becoming increasingly used in a variety of settings but are often black box in nature. Recent work has emphasized the need for algorithms to be more interpretable to end users, and calibrated classification models (CCMs) are one such type of model. CCMs provide more accurate confidence intervals to the end user, however little research has investigated how CCM confidence estimates and actual classification accuracy impact user performance. Therefore, the current study explored how expectations for machine learning algorithms and their actual behaviors influenced task performance and decision time. Results demonstrated that algorithms with high confidence and low classification accuracy led to the lowest performance and highest decision time in an image classification task. Limitations of the current study are discussed along with future research opportunities.
Keywords
Introduction
Artificial intelligence (AI) algorithms utilizing machine learning (ML) are often used in prediction tasks (Dick, 2019). A specific type of machine learning, convolutional neural networks (CNNs), frequently concern image classification and are commonly utilized across many domains (e.g., healthcare, Cho & Hung, 2023). Often, image classifiers utilize neural networks, which are modeled after human decision-making (Rawat & Wang, 2017). However, many of these classifiers are considered black-box models, which have been critiqued for not being easily interpretable or understandable to end-users (Guidotti et al., 2018; Hassija et al., 2024). Recent work has put forward novel methods to rectify these issues, such as explainable AI (XAI; Barredo Arrieta et al., 2020; Gunning, 2017) and calibrated classification models (CCMs; Bennette et al., 2020; Guo et al., 2017). With the widespread use of image classification in real-world decision-making, it is important that users appropriately trust these algorithms, which would lead to appropriate reliance (Lee & See, 2004), increasing performance efficiency.
As neural algorithms are often difficult to interpret, additional information could assist the user in gauging appropriate trust. In fact, Tomsett et al. (2020) stated that although AI/ML hold great promise as decision support systems, users must know the limitations of the algorithms to allow rapid trust. The authors proposed that algorithms should include explanations and uncertainty estimates to understand not only what the algorithm has learned, but also what it does not know.
Algorithms that make mistakes classified with high confidence can limit their adoption and lead to accidents in real-life decision-making tasks (Hendrycks & Gimpel, 2017). The authors note that low confidence decisions should instead be flagged for human intervention and present a remedy with the use of softmax probabilities to detect out-of-distribution (OOD) and incorrect examples. Prior work has expanded on this by deriving new OOD scores (DeVries & Taylor, 2018), using softmax distributions to improve OOD detection (Liang et al., 2018), and creating outlier exposures to improve deep anomaly detection (Hendrycks et al., 2019). In summary, this recent work has utilized OODs to gain more information about low confidence decisions and data outside of the training dataset. CCMs incorporate these OODs and include calibrated confidence estimates along with the predicted decision to provide additional information on how confident the algorithm is in its decision.
Classification decisions that are highly confident but incorrect not only concern safety (Hendrycks & Gimpel, 2017), but also influence the user. Algorithms that incorrectly classify an image with high confidence can be considered a negative unexpected behavior. Unexpected behaviors from autonomous systems lead to lowered trust and intentions to rely on the system (Lyons et al., 2023). Interestingly, other research has demonstrated unexpected behaviors had varying effects on trustworthiness and interaction with autonomous agents (Capiola et al., 2023). When unexpected behaviors were positive, the user chose to interact with the agent in the future. However, when the unexpected behavior was negative, users were less likely to choose to interact with the agent in the future and rated the agent as less trustworthy. Therefore, these prior findings suggest that if the unexpected behavior was negative, or highly confident and incorrect, users should trust the algorithm less. This could result in greater monitoring, which should increase decision time and decrease overall performance. Utilizing CCMs, the current study examined how task performance and decision time are impacted by differing levels of classification accuracy and algorithm confidence in an image classification task.
H1: Algorithms with high confidence and low classification accuracy will result in lower performance and higher decision time compared to all other algorithms.
Method
Participants
Participants were recruited on Amazon’s Mechanical Turk (MTurk) and had to be at least 18 years old, live in the United States, and speak fluent English. We leveraged CloudResearch (Litman et al., 2017), a platform that coordinates with MTurk and further refines participant selection. We restricted participants to those who had at least 100 human intelligence tasks (HITs) and at least a 95% approval rating. An a priori power analysis was performed in G*Power (Faul et al., 2009). The experimental design was a 2 (classification accuracy: high, low) by 2 (classification confidence: high, low) within- subjects design. Assuming a medium effect size (ƒ = 0.25) at 80% power (1 – β) and α = .05, we required 24 participants. The final sample (N = 23) used for analysis was 60.87% male, 73.91% white, and on average approximately 37.30 (SD = 12.36) years old. Participants were paid a base rate of $4.50 and could earn up to a $20 bonus (M = $17.35, SD = $2.45).
Task
The task consisted of participants monitoring the image classification decisions of four machine learning algorithms along with overriding any incorrect decisions. The testbed consisted of 15 images per page, and the images were either cats, dogs, or other small mammals (e.g., squirrels; see Figure 1). The algorithms were trained to classify images of cats and dogs. The algorithms’ decisions were written out underneath each image, and participants had the option to override and choose the correct decision from a dropdown list. The algorithms also had confidence levels for each binned image, split into high or low confidence. Green bordered images corresponded to high confidence (≥80% confident), while yellow bordered images represented low confidence (<80% confident).

Example trial (with answers) of the experimental task.
Procedure
After accepting the HIT on MTurk, participants were routed to the study page where they read the training slides. These slides introduced them to the task and gave relevant information regarding the machine learning algorithms.
Participants had to complete a training quiz following the slides to ensure that they understood the experiment. The experiment stated that the four algorithms performed well, but not perfectly, therefore the participants had to monitor and correct any decisions when needed. If the training quiz was successfully completed, the participants completed two practice rounds and four blocks of task rounds. To account for order effects, participants were randomly assigned an order to complete all four blocks. Each block consisted of a unique machine learning algorithm corresponding to a condition, and participants completed five rounds of the image classification task using each unique algorithm. Each round lasted 18 s, during which participants were assessed on their performance in the task. Participants started each block with $5.00 and were deducted $0.25 for each incorrectly classified image. Thus, participants could gain a total of $20.00 if all images were correctly classified. Images were considered correctly classified if the machine learning algorithm correctly binned an image or if the participant correctly overrode incorrectly binned images. Following each trial, participants were provided information on their overall performance and current bonus. After all blocks, participants responded to open-ended questions and demographic items and were thanked and compensated.
Manipulations
We manipulated classification accuracy (high, low) and confidence (high, low). Therefore, all images could be correctly or incorrectly classified and reflect high or low confidence in that decision. Low accuracy algorithms consisted of 66.7% accuracy per round (10/15 images correct), and high accuracy had 93.3% accuracy per round (14/15 images correct). We decided upon our low accuracy threshold by incorporating prior literature in human-machine teaming that considered low reliability between 60% and 70% (e.g., Dixon & Wickens, 2006, Dixon et al., 2007; Parasuraman & Manzey, 2010; Rice & McCarley, 2011). Low confidence algorithms displayed 33.3% of the images as yellow per round (5/15 images), and high confidence algorithms displayed 6.67% of the images as yellow per round (1/15 images). Each of the four algorithms corresponded to a unique aspect of the experimental design: low classification accuracy and low confidence, low classification accuracy and high confidence, high classification accuracy and low confidence, and high classification accuracy and high confidence. The ratio of animal type for incorrect decisions was maintained for all blocks (20% cat, 20% dog, and 60% other mammals). The incorrect images varied in position for each round and block to account for participant experience in the experiment. All remaining images were equally split between cats and dogs, which were marked highly confident and correctly classified.
Measures
Task Performance
Task performance was assessed by calculating the total number of correctly classified images on each round per block.
Decision Time
Decision time was assessed by calculating the number of milliseconds it took to classify the incorrect images on each round of each block.
Open-ended Responses
Participants were asked to freely write responses to four questions post-task about their interaction with, the accuracy of, the reliability of, and their strategy regarding the algorithms. An example item is “What strategy or strategies did you use to monitor each machine learning algorithm?”
Data Cleaning
To assure data quality, we incorporated multiple data cleaning procedures. Upon entering the HIT we included a CAPTCHA to prevent bots. The participants then had to pass the knowledge check by correctly answering four items after training. We assessed careless responding by including attention check items in the surveys (“For this item please select Disagree”; Ward & Pond, 2015) and flagging those participants who did not override any images for over half of the rounds. Based on these metrics, we removed the data for one participant, leaving us with a final sample of 23 participants
Results
Data were analyzed using linear mixed effects models in R with the lme4 package (Bates et al., 2015). Estimated marginal means (EMMs) and post hoc comparisons were calculated with emmeans (Lenth et al., 2023). Descriptive statistics can be found in Table 1. Detailed results can be found in Table 2 and all EMMs can be found in Table 3.
Descriptive Statistics for Study Variables.
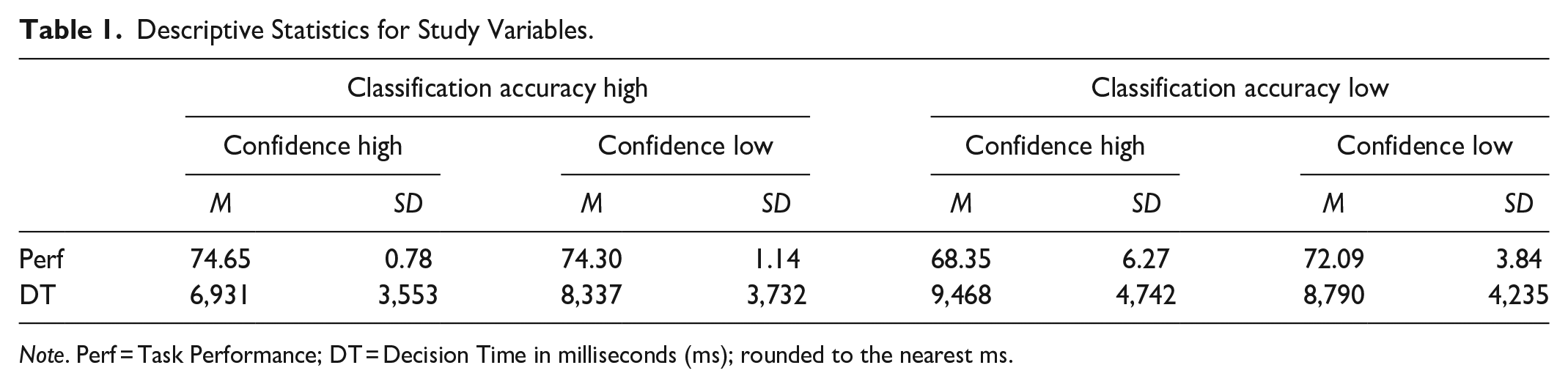
Note. Perf = Task Performance; DT = Decision Time in milliseconds (ms); rounded to the nearest ms.
Linear Mixed Effects Models for Task Performance and Decision Time.
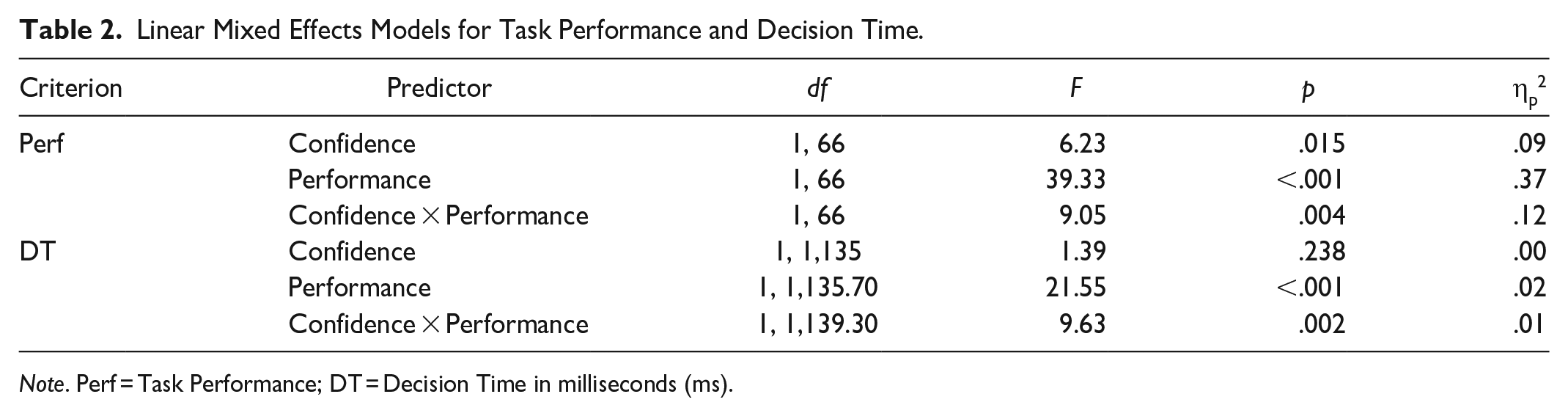
Note. Perf = Task Performance; DT = Decision Time in milliseconds (ms).
Estimated Marginal Means and Standard Errors for Study Variables.
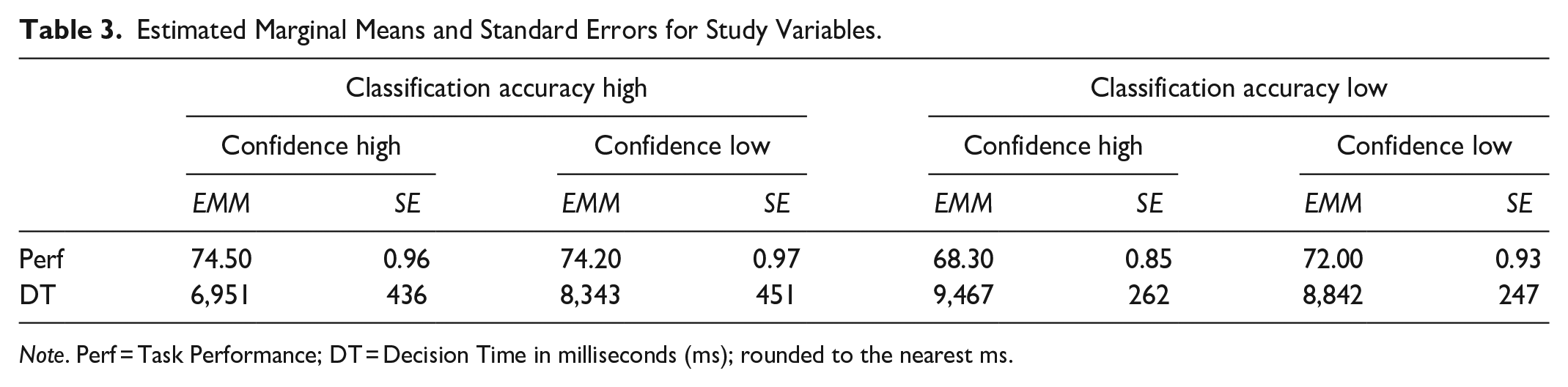
Note. Perf = Task Performance; DT = Decision Time in milliseconds (ms); rounded to the nearest ms.
Performance
There was a significant interaction of accuracy and confidence on performance, F(1, 66) = 9.05, p = .004, ηp2 = .12, qualifying the main effects of these manipulations. Post- hoc comparisons indicated that there were significant differences between algorithms of high confidence with high accuracy and high confidence with low accuracy, t(66) = 6.56, p < .001; high confidence with high accuracy and low confidence with low accuracy, t(66) = 2.67, p = .046; low confidence with high accuracy and high confidence with low accuracy, t(66) = 6.20, p < .001; and high confidence with low accuracy and low confidence with low accuracy, t(66) = −3.89, p = .001. See Figure 2.
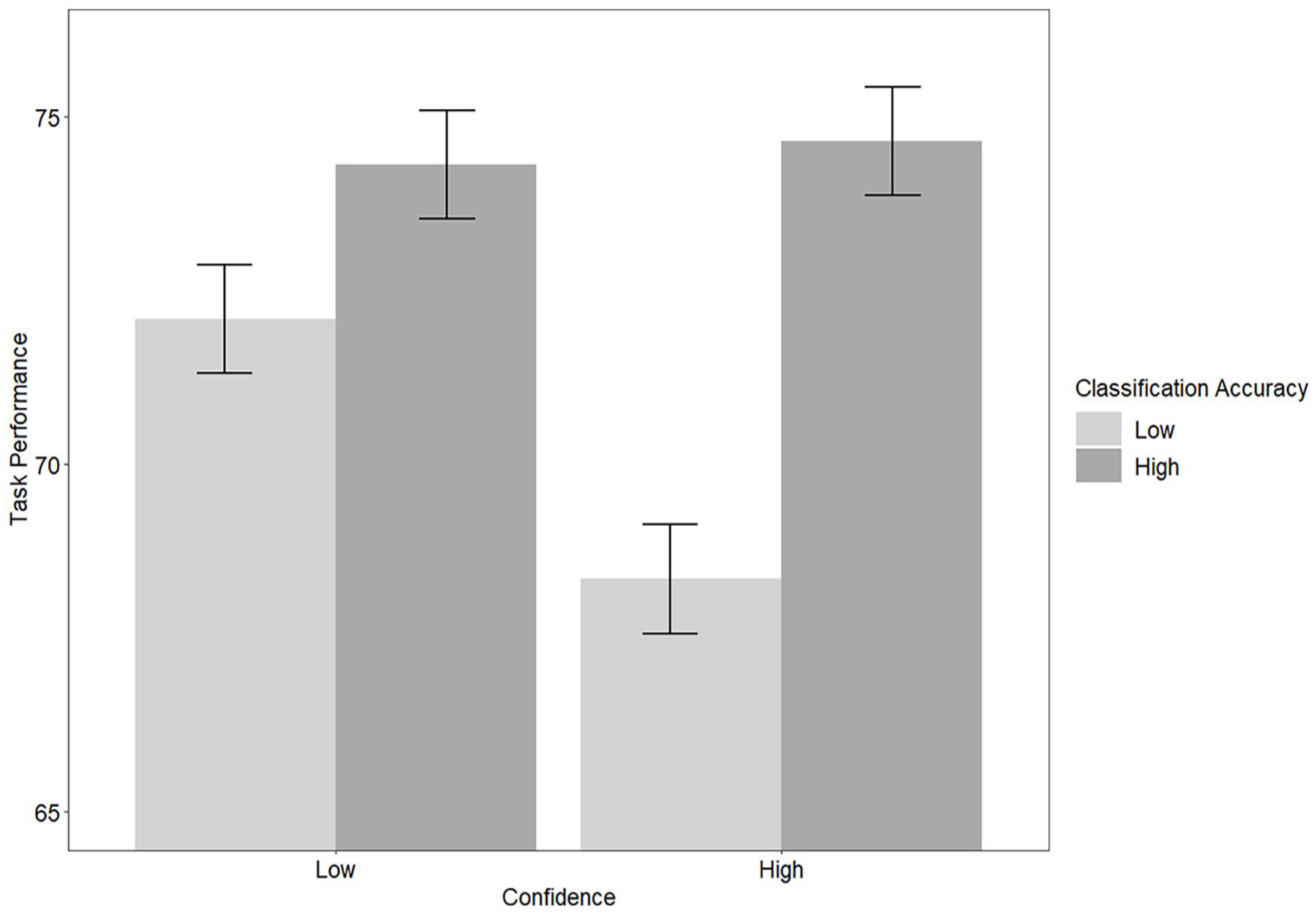
Classification accuracy and confidence on task performance.
Decision Time
There was a significant interaction of accuracy and confidence on decision time, F(1, 1,139.30) = 9.63, p = .002, ηp2 = 0.01, qualifying the main effect of performance. Post- hoc comparisons indicated that there were significant differences between algorithms of high confidence with high accuracy and high confidence with low accuracy, t(1,139) = −5.51, p < .001; and high confidence with high accuracy and low confidence with low accuracy, t(1,134) = −4.22, p < .001. See Figure 3. Together, results show support for H1.
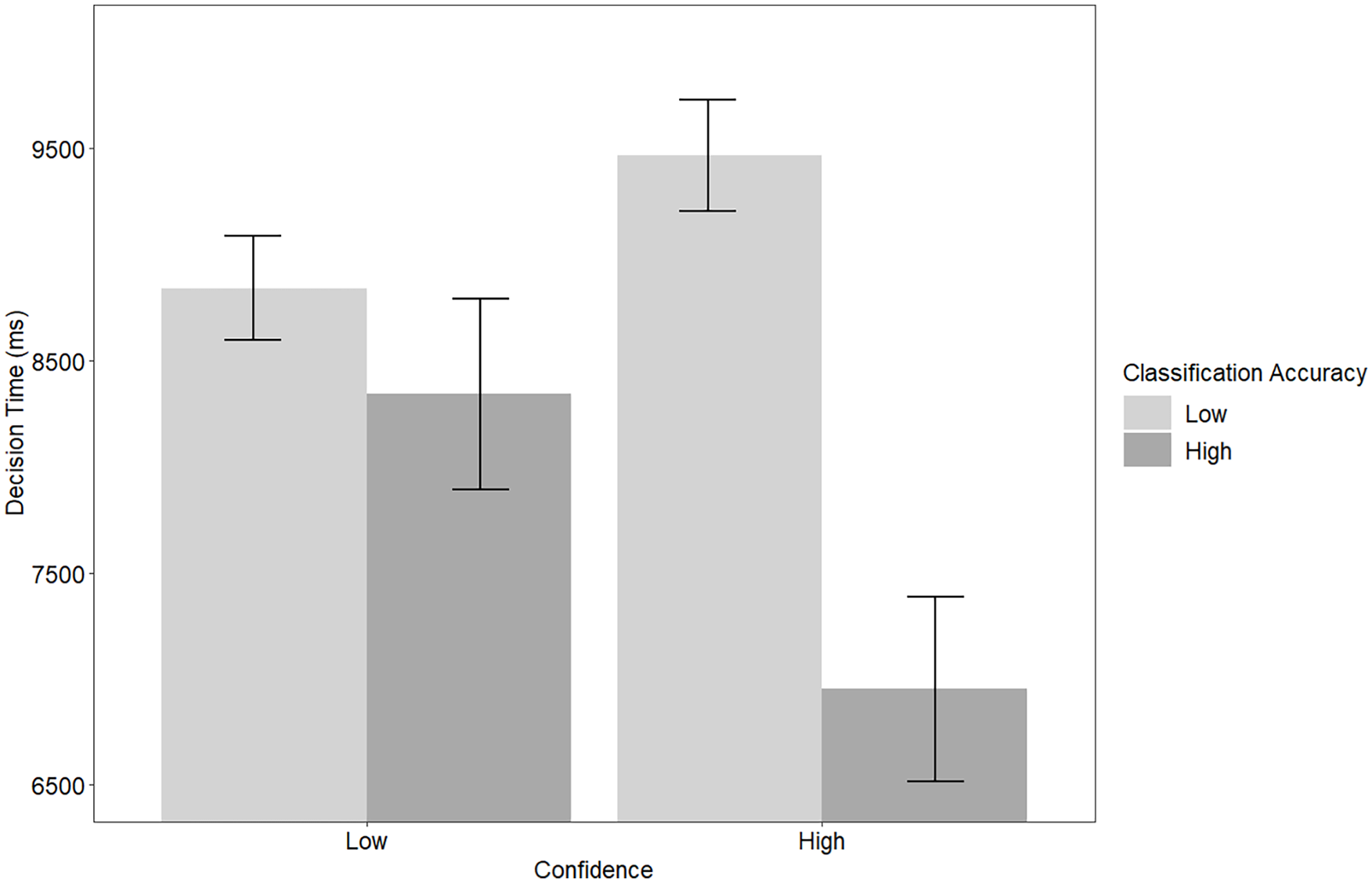
Classification accuracy and confidence on decision time.
Text Analysis
The qualitative data were analyzed to help explain the quantitative results and provide insight on participants’ perceptions. Multiple participants mentioned that two of the four algorithms were more useful than the other two, especially in terms of reliability and accuracy. For example, one participant wrote “Two of them were fairly accurate and only tended to have one mistake. The other two were very prone to mistakes and unreliable.” Participants also noted the differences in algorithms varied in terms of difficulty.
Participants stated that the most difficult block was the algorithm that was highly confident but low in accuracy. One participant stated, “The neon algorithm often labeled pictures wrong with greater certainty making reviewing its decisions more difficult.”
Participants also wrote about their strategy within the task, and most commonly they wrote about first checking the confidence estimates by the border color. Participants mentioned that they were less confident in yellow borders, but more confident in green borders because the algorithm was more confident. One participant wrote, “I was more confident in a green border, as the confidence of the algorithm was high. I tended to interact, check, and override yellow bordered images more, as this indicated a lower confidence, so I felt the need to double check.” Many participants would scan the rest of the images after checking the confidence level, indicating a lack of trust in the more confident decisions (e.g., “I felt the need to double-check all of the images because I didn’t trust the reliability of any of them. . .I looked at images that had a yellow border, indicating lower confidence first. Then I checked the other ones row by row”). Other participants mentioned just scanning each image and checking to see if the label and picture matched, “I simply went box by box and checked to see if the image matched up with its labelling. . .I did this in order to make sure I got all of the answers correct at the end of the round.” Overall, many participants mentioned that the algorithms varied and that they utilized the yellow borders, and many felt the need to double-check the algorithms’ decisions.
Discussion
AI utilizing ML algorithms are becoming more frequently used. However, for increased implementation, ML needs to be not only highly accurate, but also better understood by highlighting what they do not know (Tomsett et al., 2020).
CCMs incorporate decision confidence levels to provide more insight into how likely a decision is to be correct. Operators interacting with the ML can therefore better gage how much to rely on the algorithm and more accurately and quickly respond to potential errors. Overall, the current study demonstrated algorithms that do not appropriately inform users of errors led to decreased task performance and heightened decision time. In real-world situations, this could lead to potentially disastrous outcomes or not using the AI/ML, which would increase task loads of operators and slow down operations. Therefore, algorithms should not only be highly accurate, but also appropriately inform users of classification confidence, to increase efficiency.
Performance
Task performance was affected by both the algorithms’ classification accuracy and confidence. Overall, participants had comparable task performance regardless of confidence if paired with a high accuracy algorithm. When the algorithms performed well, participants did better in the task even if the algorithm did not flag low confidence decisions. On the other hand, when classification accuracy was low, participant performance depended on confidence. Algorithms that were highly confident but low in accuracy led to significantly lower task performance compared to all other conditions. These results were reflected in the thematic analyses which found participants had the most difficulty with the high confidence, low accuracy block, and that participants found this algorithm to be unreliable and not to be used in future tasks. This aligns with previous work stating that algorithms that are highly confident but incorrect lead to lower implementation and concern safety (Hendrycks & Gimpel, 2017). The lower task performance results emphasize this point by demonstrating that these negative unmet expectations make it more difficult for the operator to account for algorithm failures, leading to more incorrect decisions. This could prove especially concerning in high risk, real-world scenarios, leading to accidents or hazardous outcomes.
Decision Time
Decision time was impacted by the algorithms’ classification accuracy, such that decision time was lower when the algorithms correctly binned more images. However, this was qualified by an interaction: decision time was lowest when both accuracy and confidence were high, while decision time was the highest when confidence was high, but accuracy was low. Therefore, participants responded more quickly when expectations and behaviors positively matched. Monitoring the decisions less often demonstrates that participants had more trust in the algorithm (Muir & Moray, 1996), suggesting that positively met expectations led to the highest trust. This aligns with previous research on the relationship between trust and met expectations (Capiola et al., 2023; Lyons et al., 2023) and how negative unmet expectations lead to lower levels of behavioral trust (Capiola et al., 2023). Participant decision time was the highest when the algorithm was highly confident but had lower accuracy. Also, participants wrote they had lower trust in the algorithm because of its unreliability and difficulty, requiring they double-check its decisions.
Implications
The current work has implications for both designers and researchers. System designers should implement appropriate confidence levels along with accounting for high accuracy to increase performance and decrease the time it takes to interact with AI/ ML. This in turn would lend to operators having more time to devote to other tasks, thereby increasing productivity.
The present work demonstrates that appropriate confidence levels lead to fewer monitoring behaviors, suggesting the importance of trust in human machine learning interaction. Prior work has emphasized the importance of trust in algorithm use (Alarcon & Willis, 2023; Alarcon, Jessup, Meyer, et al., 2024; Alarcon, Jessup, Willis, et al., 2024), but researchers would do well to continue to investigate the impact of algorithm confidence and accuracy on trust.
Limitations and Future Research
A post-hoc examination of the testbed showed an error on one trial of the low accuracy with high confidence block. The algorithm mistakenly binned two images as correct, of which one was classified with high confidence and the other with low confidence. This meant participants were marked as incorrect, even if they successfully overrode the images. Later, participants were compensated for this error to account for the loss of bonus funds. This error could impact how participants interacted with that specific block in the task, and their perceptions of the algorithm. Therefore, future work plans to fix the error before examining trustworthiness metrics.
A second limitation was that the current study was a low-risk situation classifying animals. More high-risk image classification, such as medical diagnoses or threatening aircraft flyover, could impact how users interact with algorithms of varying confidence and accuracy. Along with higher levels of risk in the stimuli, higher risk regarding consequences could influence user perceptions and use. The current study implemented a time limit and a loss of bonus funds, but more high-risk stimuli and consequences, along with limited time, would be important to investigate.
A final limitation was the sample size of the current study. As previously mentioned, an a priori power analysis indicated that we needed 24 participants for appropriate power.
However, after cleaning the data, we were left with usable data for 23 participants. Due to this, we conducted a post-hoc power analysis and found that we were sufficiently powered for an effect size of ηp2 = .10. Therefore, we had sufficient power for the performance analysis, but lacked power for the decision time analysis. Future work would do well to examine the criteria of interest with an appropriately powered sample.
Conclusion
The current study investigated how varying levels of classification accuracy and confidence influenced performance and decision time in an image binning task. Results demonstrated the importance of appropriate confidence levels along with high accuracy to maximize performance and decrease time spent on monitoring and overriding the decisions. The incorporation of appropriate CCMs lend to improvement of human-AI/ML interactions and are imperative for the implementation of AI/ML. With the increase in AI/ML across various domains, the researchers advocate for the importance of calibrated confidence in AI/ML so that algorithms match in expectations and behaviors. In summary, accuracy is important for AI/ML, but if accuracy drops, the calibrated confidence levels would direct operators to potential errors, leading to better human machine learning interaction.
Footnotes
Acknowledgements
Distribution A. Approved for public release: distribution is unlimited. AFRL-2024-0482; cleared 20 Feb 2024. The views expressed are those of the authors and do not necessarily reflect the official policy or position of the Department of the Air Force, the Department of Defense, or the U.S. government.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported, in part, by the Air Force Research Laboratory (FA8650-20-D-6207) and the Air Force Office of Scientific Research (22RICOR001).