
Abstract
Crowd counting aims to estimate the number of individuals in images, and the use of multimodal data has been shown to significantly enhance counting accuracy. However, such approaches are highly sensitive to the loss or corruption of data from any single modality, leading to severe performance degradation. To address this limitation, a new problem setting—Modality-Reconfigurable Crowd Counting—is introduced, in which a model is required to maintain robust performance even when one of the input modalities (e.g., RGB or thermal) is perturbed or entirely unavailable. Modality reconfigurability is achieved through effective cross-modal information transfer, enabled by a Feature Patches Generator that leverages Margin Ranking Loss across multiple network layers to align and transfer discriminative features between modalities. Additionally, a Negative Knowledge Transfer Prevention module is incorporated to suppress misleading or detrimental cross-modal signals. State-of-the-art performance is demonstrated on RGB-T crowd counting benchmarks, with consistent accuracy maintained under both complete and degraded modality conditions.
Introduction
In recent years, rapid urbanization and population growth have led to dense gatherings in public spaces, posing significant challenges to public safety and epidemic control—as tragically illustrated by events such as the 2015 New Year’s Day stampede in Shanghai, China, and the 2022 Itaewon crowd crush in Seoul, South Korea. In response, crowd counting has attracted increasing research interest. The task involves estimating the number of individuals present in a given image, typically by generating a density map from the input. The total crowd count is obtained by integrating the values across this map, which simultaneously encodes spatial distribution information.
While extensive research has been devoted to crowd counting using RGB imagery,1–4 such approaches exhibit notable limitations under low-light conditions, as RGB data is highly sensitive to illumination variations. In contrast, thermal imaging captures heat radiation emitted by objects, with the human body serving as a consistent thermal source. This modality remains unaffected by ambient lighting and often enables clearer human detection in darkness, where interfering visual cues are absent. The widespread deployment of thermal sensors—accelerated by public safety initiatives and the global response to the COVID-19 pandemic—has further increased the accessibility of thermal data. Nevertheless, thermal images are not without drawbacks; their relatively low spatial resolution and susceptibility to confusion with non-human heat sources (e.g., vehicles or machinery) can impair counting accuracy in complex scenes.
To leverage the complementary strengths of RGB and thermal modalities, numerous multimodal crowd counting approaches have been proposed.5–10 These methods typically fuse multimodal features during both training and inference, yielding improved accuracy compared to unimodal counterparts. Despite their success, most existing frameworks rely on a critical yet often implicit assumption: all modalities are consistently available and reliable at inference time. In real-world deployments, especially in large-scale or outdoor environments, this assumption is frequently violated. Sensors may become unavailable or unreliable due to hardware malfunction, occlusion, adverse weather, thermal saturation, or severe illumination changes. Under such conditions, tightly coupled multimodal models often experience abrupt performance collapse, sometimes performing worse than unimodal baselines, thereby limiting their practical applicability.
To address this gap, a new problem setting—modality reconfigurable crowd counting—is introduced. This paradigm emphasizes the capability of a multimodal model to preserve accuracy and robustness even when one input modality is perturbed, corrupted, or entirely missing. The focus is placed on scenarios commonly encountered in real-world applications, such as lighting-induced RGB degradation or thermal sensor failure.
The proposed framework enables modality reconfigurability through a training strategy that exploits cross-modal complementarity without enforcing tight coupling during inference. A Feature Patches Generator is employed in conjunction with Margin Ranking Loss applied across multiple network layers to facilitate effective knowledge transfer between modalities. Crucially, feature extraction pathways for each modality remain independent, ensuring that inference can proceed using either modality alone when necessary. In the event of modality loss, the system seamlessly reconfigures to rely on the available input while retaining performance gains acquired during multimodal training. As a result, competitive counting accuracy is maintained under both complete and degraded input conditions.
Unlike prior multimodal crowd counting approaches that rely on tightly coupled fusion or modality recovery at inference time, the key novelty of this work lies in a modality-reconfigurable training paradigm that strengthens each unimodal branch through directional, performance-aware cross-modal supervision, while preserving strict modality independence during inference. This design enables robust deployment under missing or degraded modality conditions without requiring modality reconstruction or joint inference.
The main contributions of this work are summarized as follows: The problem of modality reconfigurable crowd counting is formally introduced, defined as the ability of a multimodal model to sustain performance despite external disturbances that compromise one input modality. A modality-reconfigurable training framework is proposed, which leverages cross-modal interactions to enhance individual modality representations while preserving inference-time flexibility. Experimental results on RGB-T crowd counting benchmarks demonstrate that, with the same backbone architecture, the incorporation of the proposed approach yields improved counting accuracy and robustness under varying environmental conditions, including missing or degraded modalities.
Related work
This section reviews prior work most closely related to the proposed approach, focusing on crowd counting and multimodal learning.
Crowd counting
Crowd counting has become a critical task in computer vision, with applications in public safety, traffic analysis, and urban planning. The evolution of methodologies can be broadly categorized into three paradigms: detection-based, regression-based, and density map estimation-based approaches.
Detection-based methods aim to identify and localize individuals before aggregating counts. Early efforts in this direction include,11–15 and the approach in 16 specifically targets sparse crowd counting in intelligent building environments. Additional detection frameworks have been explored in.17,18 While effective in low-density, unoccluded settings, these methods struggle significantly in crowded or heavily occluded scenes due to missed detections and overlapping instances.
Regression-based techniques were introduced to bypass explicit detection by mapping image features—either global or local—to a scalar crowd count. Representative works in this category include,1–4 which demonstrate improved efficiency over detection-based strategies. However, regression approaches provide no spatial information about crowd distribution, limiting their utility in applications requiring localization.
The current dominant framework is based on density map estimation, where a continuous map is generated such that the integral over the image yields the total count. This paradigm was pioneered in 1 and subsequently advanced by numerous studies. Multi-column architectures were introduced in,2,19 while context-aware modeling was explored in.20–22 Scale-adaptive networks were developed in,23,24 and attention mechanisms were incorporated in.25–27 Further improvements include hierarchical feature fusion,28–30 adversarial training,31,32 and transformer-based designs.33,34 Notably, spatially decomposable features were leveraged in 35 to enhance counting accuracy, and a weather-adaptive module was proposed in 36 to improve robustness under severe weather conditions. Despite their success with RGB imagery, these methods remain highly sensitive to lighting variations and often fail in dimly lit environments where reliable visual features are unavailable.
Multimodal learning
Multimodal learning seeks to enhance model performance by integrating complementary information from heterogeneous data sources. In crowd counting, this has motivated the use of modalities beyond RGB to overcome inherent limitations of visible-light imaging.
Depth-based crowd counting has been investigated in several works, including,37–39 which demonstrate the utility of geometric cues for person localization. However, depth sensors exhibit practical constraints in outdoor environments due to sunlight interference and limited effective range.
Thermal imaging has gained prominence due to its invariance to lighting conditions and strong response to human body heat. With the widespread deployment of infrared devices, thermal data has become increasingly accessible. RGB–thermal (RGB-T) crowd counting has been explored in,5–7 where fusion strategies such as cross-modal feature alignment and joint optimization are employed,8,10 Additional multimodal frameworks have been proposed in,40,41 and broader studies on multimodal representation learning include.42–45 These approaches consistently demonstrate that leveraging complementary features from multiple modalities improves both accuracy and robustness in complex scenes,9,46,47
Nevertheless, a common limitation across existing multimodal methods is their reliance on the simultaneous availability of all input modalities during inference. When one modality is missing or corrupted–due to sensor failure, occlusion, or environmental interference—the fused representation may degrade substantially, compromising real-world applicability. A large body of prior work focuses on recovering missing modalities or their latent representations. These approaches attempt to reconstruct unavailable inputs through modality imputation or modality generation, enabling multimodal models to operate under a complete-input assumption.48,49 Another line of research adopts model-level strategies to cope with missing modalities without explicitly reconstructing them.50–52
To further clarify the conceptual distinction from related multimodal robustness paradigms, Table 1 summarises key characteristics of missing-modality recovery, modality dropout, and cross-modal knowledge distillation in comparison with the proposed method.
Conceptual comparison of representative multimodal learning paradigms addressing missing or unreliable modalities.
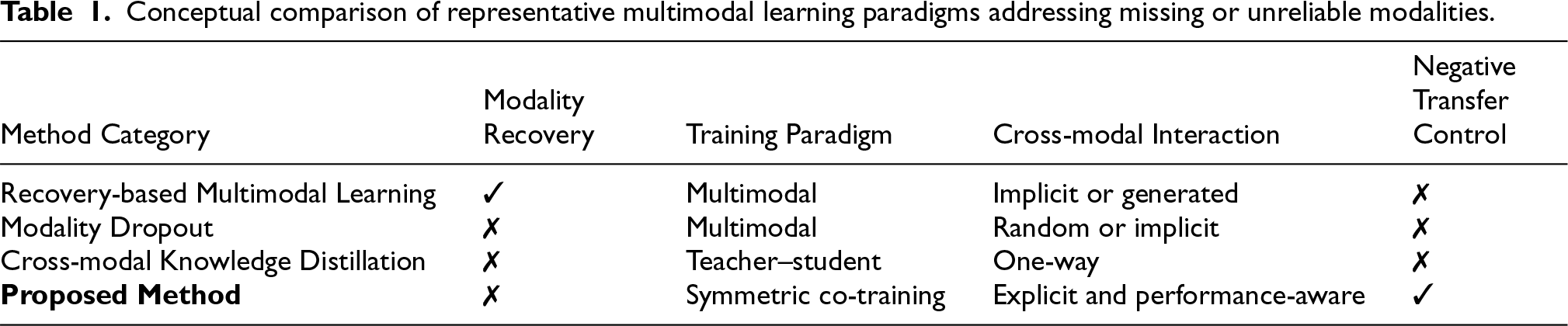
Conceptual comparison of representative multimodal learning paradigms addressing missing or unreliable modalities.
The present work addresses this gap by introducing modality reconfigurability: the proposed method does so by employing a structured information exchange mechanism and explicitly mitigating negative knowledge transfer, thereby enabling more robust unimodal performance under missing-modality conditions.
Despite the progress of existing RGB–thermal crowd counting methods, most approaches share a common assumption that all modalities are consistently available and reliable at inference time. When this assumption is violated, performance often degrades substantially, limiting practical deployment in real-world surveillance scenarios where sensor failure or degradation is common. To better contextualise the proposed approach, Table 2 provides a side-by-side comparison of representative RGB–thermal crowd counting methods, highlighting their core design principles and their limitations under missing-modality conditions. This comparison clarifies the key distinction between existing fusion-based approaches and the modality-reconfigurable paradigm adopted in this work.
Side-by-side comparison of representative RGB–thermal crowd counting methods and their main limitations under missing-modality scenarios.

The proposed framework, termed Modality-Reconfigurable Crowd Counting (MRCrowd), enables robust inference under partial modality availability by enhancing individual modality performance through controlled cross-modal interaction during training. Modality independence is preserved at inference time, while multimodal synergy is exploited during training via two key components: the Feature Patches Generator (FPG) and the Preventing Negative Knowledge Transfer (PNKT) module. The FPG facilitates cross-modal alignment through patch-level feature comparisons, while the PNKT module ensures that knowledge transfer occurs only in a beneficial direction. The total loss combines regression and Margin Ranking Loss terms, and gradients are backpropagated separately through each modality stream.
Multimodal feature extraction via feature patches generator
To enable effective cross-modal knowledge transfer, discriminative local features are extracted from intermediate network representations using the Feature Patches Generator (FPG), inspired by unsupervised feature augmentation techniques.
24
Given a feature map
As illustrated in Figures 1 and 2, a central region—referred to as the Center Select Block—is defined with height 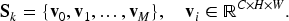
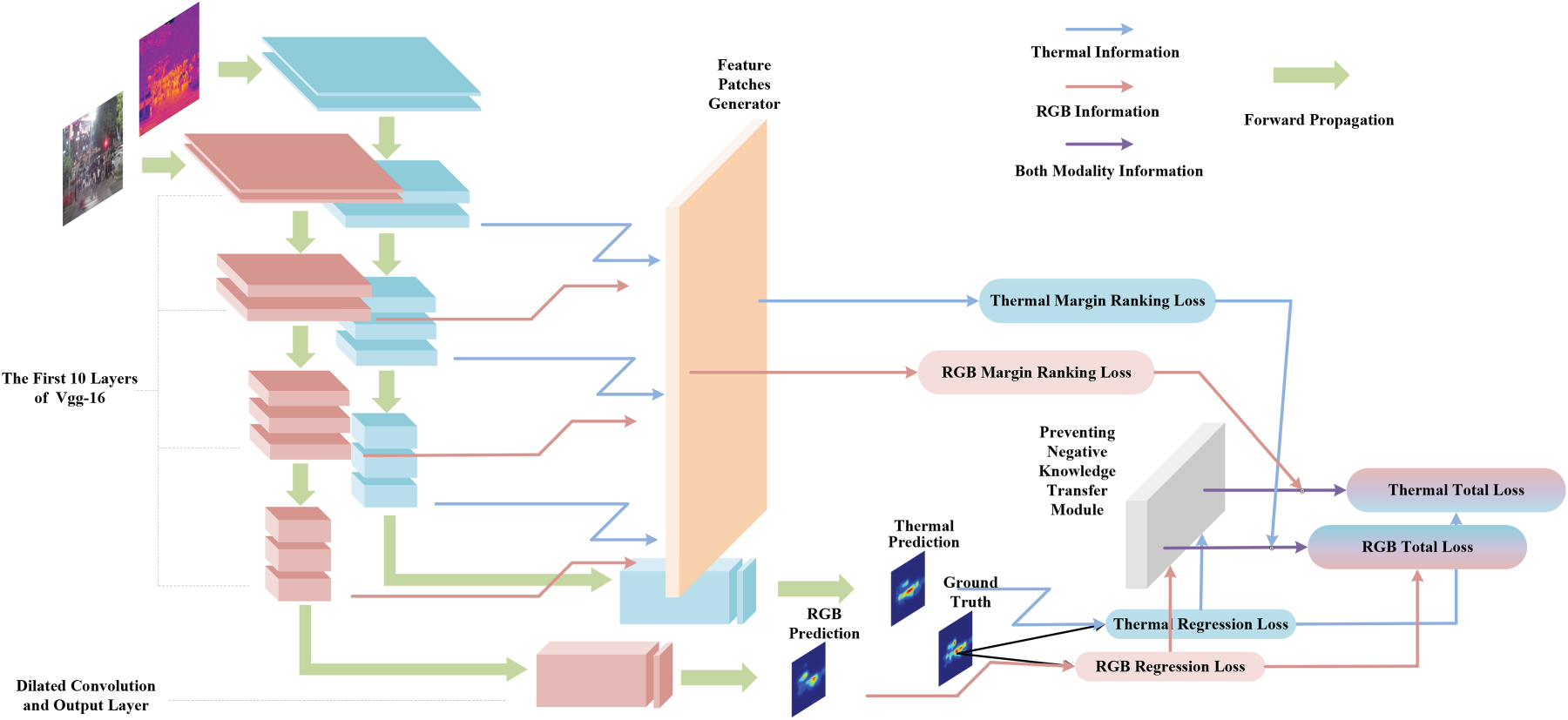
Overview of the proposed framework for modality-reconfigurable crowd counting. During training, feature maps from intermediate layers are processed by the Feature Patches Generator (FPG) to produce patch representations used in Margin Ranking Loss. The Preventing Negative Knowledge Transfer (PNKT) module computes adaptive parameters based on the regression losses of the RGB and thermal modalities, ensuring unidirectional knowledge transfer from the more accurate to the less accurate modality. The total loss—comprising regression and ranking terms—is backpropagated through each modality-specific network independently.
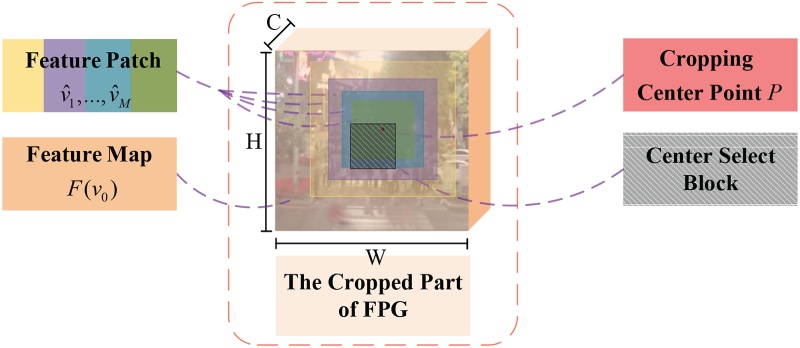
Detailed illustration of the Feature Patches Generator (FPG). A cropping center point is randomly selected within a central region of the feature map. Subsequently,
The complete procedure is formalized in Algorithm 1.

During training, the predictive accuracy of different modalities may vary due to scene-specific factors such as illumination or thermal interference. To prevent detrimental cross-modal influence, a Preventing Negative Knowledge Transfer (PNKT) module is employed to enforce unidirectional knowledge flow—from the more accurate modality to the less accurate one. The relative performance of the RGB and thermal modalities is quantified using the mean squared error (MSE), a standard regression loss. Let
The performance difference is defined as
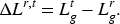
An adaptive weighting function 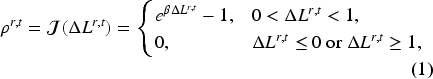
This mechanism prevents the less accurate modality from dominating the learning signal, thereby stabilizing convergence and avoiding negative transfer.
The total loss in MRCrowd integrates regression objectives with cross-modal feature alignment, enabling modality-reconfigurable learning. The framework consists of two parallel modality-specific backbones trained jointly. Feature maps from multiple intermediate layers are processed by the Feature Patches Generator (FPG) to produce patch sets
For each patch set 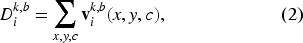
A Margin Ranking Loss is then applied to enforce ordinal consistency among patches: larger patches (which encompass more people) should yield higher count estimates than smaller, nested patches. Given a margin 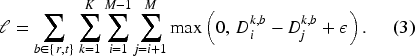
To enable controlled cross-modal interaction, the PNKT-generated weights 

Finally, the total loss for each modality combines its own regression loss with the complementarity term from the other modality:
During backpropagation, gradients of
This section presents the experimental setup, including the datasets, evaluation metrics, implementation details, and comparative results of the proposed method against existing approaches.
Datasets
Implementation details
The proposed framework was implemented using PyTorch. CSRNet
1
was adopted as the backbone architecture for both modality-specific branches. Stochastic Gradient Descent (SGD) was employed as the optimizer, with an initial learning rate of
The hyperparameters were configured as follows: the focusing parameter
For multimodal inference (denoted RGB+T), predictions were selected based on a brightness threshold applied to the input RGB image. If the average pixel intensity exceeded the threshold, the prediction from the RGB branch was used; otherwise, the thermal branch prediction was adopted. All other implementation details follow those of CSRNet. 1
Evaluation metrics
The performance was evaluated using Mean Absolute Error (MAE) and Root Mean Square Error (RMSE). Additionally, following the protocol in,
5
the Grid Average Mean Absolute Error (GAME)
53
was employed on the RGBT-CC dataset to assess spatially localized counting accuracy. These metrics are defined as:
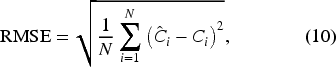
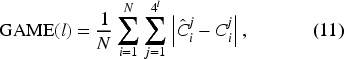
The modality reconfigurability of the proposed framework is evaluated under three conditions: (1) normal operation with both modalities available, (2) missing-modality scenarios, and (3) varying illumination conditions. All experiments are conducted on the RGBT-CC dataset.
1) Full-modality setting
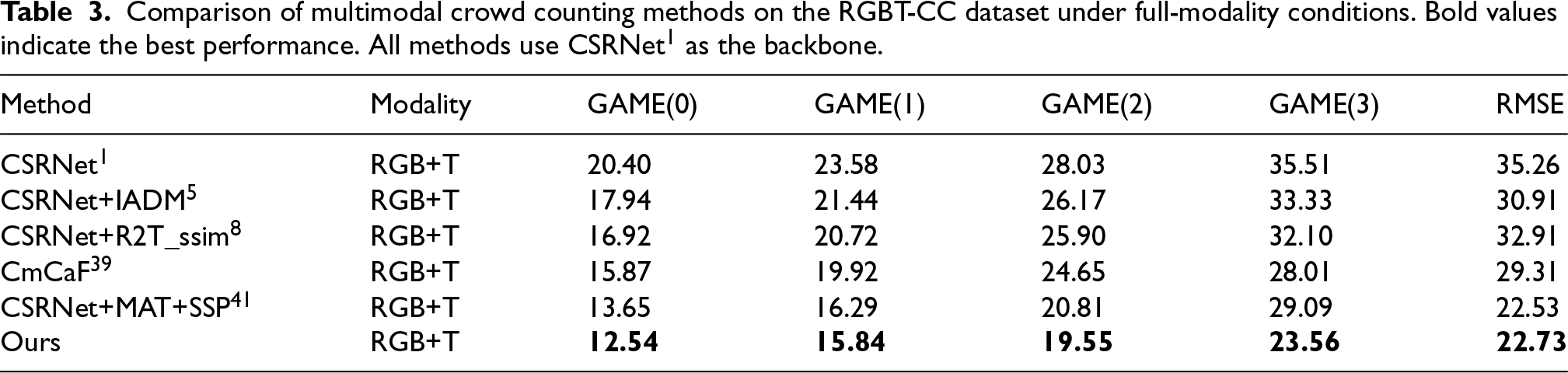
Under standard conditions—where both RGB and thermal inputs are available and no external perturbations are applied—the proposed method is compared against state-of-the-art multimodal approaches that share the same CSRNet backbone.
1
As shown in Table 3, the proposed framework achieves the lowest error across all metrics, with a GAME(0) of
Comparison of multimodal crowd counting methods on the RGBT-CC dataset under full-modality conditions. Bold values indicate the best performance. All methods use CSRNet
1
as the backbone.
Comparison of multimodal crowd counting methods on the RGBT-CC dataset under full-modality conditions. Bold values indicate the best performance. All methods use CSRNet 1 as the backbone.
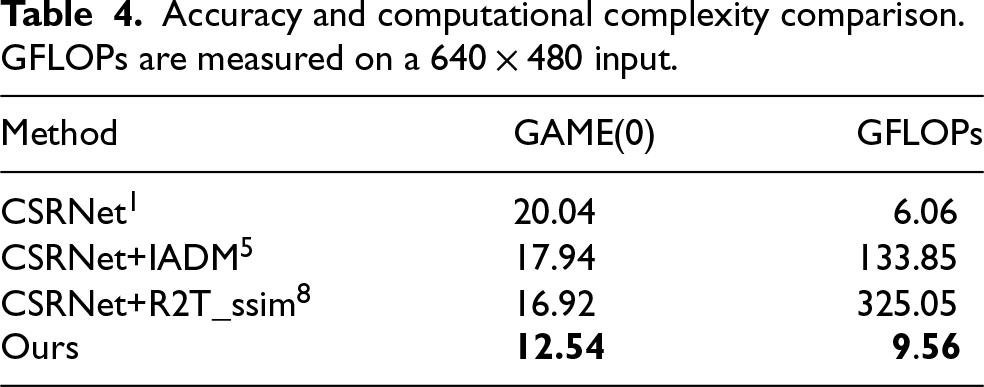
To assess computational efficiency, floating-point operations (FLOPs) are reported in Table 4, using a
Accuracy and computational complexity comparison. GFLOPs are measured on a
2) Missing-modality robustness
To evaluate robustness under partial input failure, we focus on failure patterns that most commonly arise in real-world multimodal sensing systems, where a modality may become unavailable or unreliable due to sensor malfunction, occlusion, or severe environmental interference. Accordingly, two representative failure modes are simulated: (i) replacing the unavailable modality with a zero tensor, which emulates a complete sensor dropout, and (ii) performing inference using only the available modality, corresponding to a unimodal fallback configuration.
Although these settings appear binary in form, they represent extreme yet practically meaningful endpoints of a broader spectrum of modality degradation. Importantly, the proposed framework does not rely on binary modality indicators during training. Instead, the Preventing Negative Knowledge Transfer (PNKT) mechanism continuously modulates cross-modal interaction based on regression loss differences, enabling adaptive learning behavior across varying degrees of modality reliability.
As shown in Table 5, conventional multimodal methods such as CSRNet+IADM suffer severe performance degradation when one modality becomes unreliable—particularly in the absence of RGB input—often performing worse than a unimodal CSRNet baseline. In contrast, the proposed framework maintains strong performance under both unimodal inference settings, achieving GAME(0) scores of 24.22 (RGB-only) and 13.30 (thermal-only), significantly outperforming all competing methods.
Modality reconfigurability evaluation on RGBT-CC under missing-modality conditions. ✓ indicates available modality; ✗ indicates missing. Bold values denote best results.
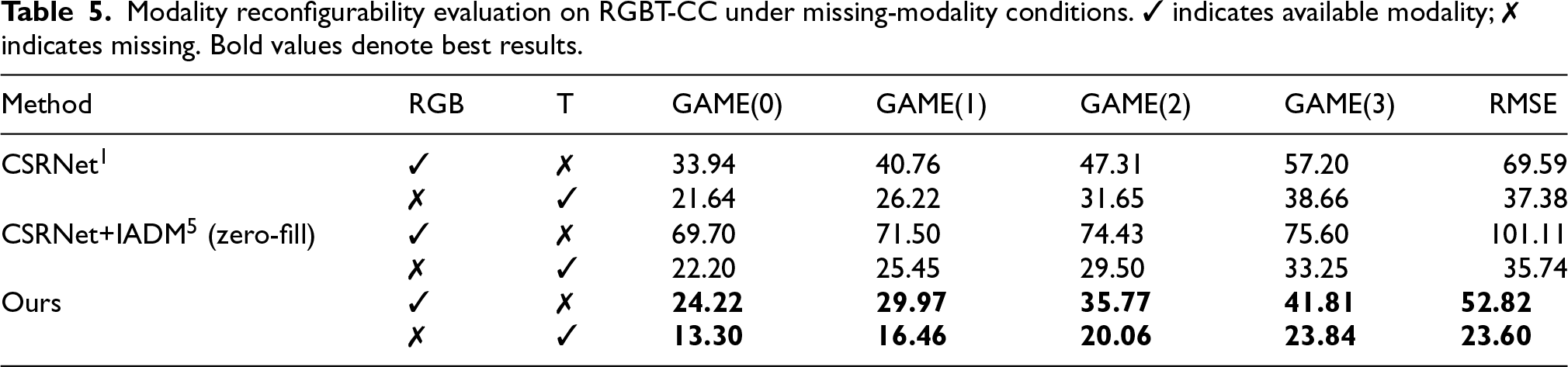
These results demonstrate that the proposed training strategy enables true modality reconfigurability: the model can seamlessly fall back to a single modality at inference time without performance collapse, while still benefiting from multimodal supervision during training. This behavior directly reflects robustness to partial and progressive modality degradation encountered in practical deployment scenarios.
3) Performance under varying illumination
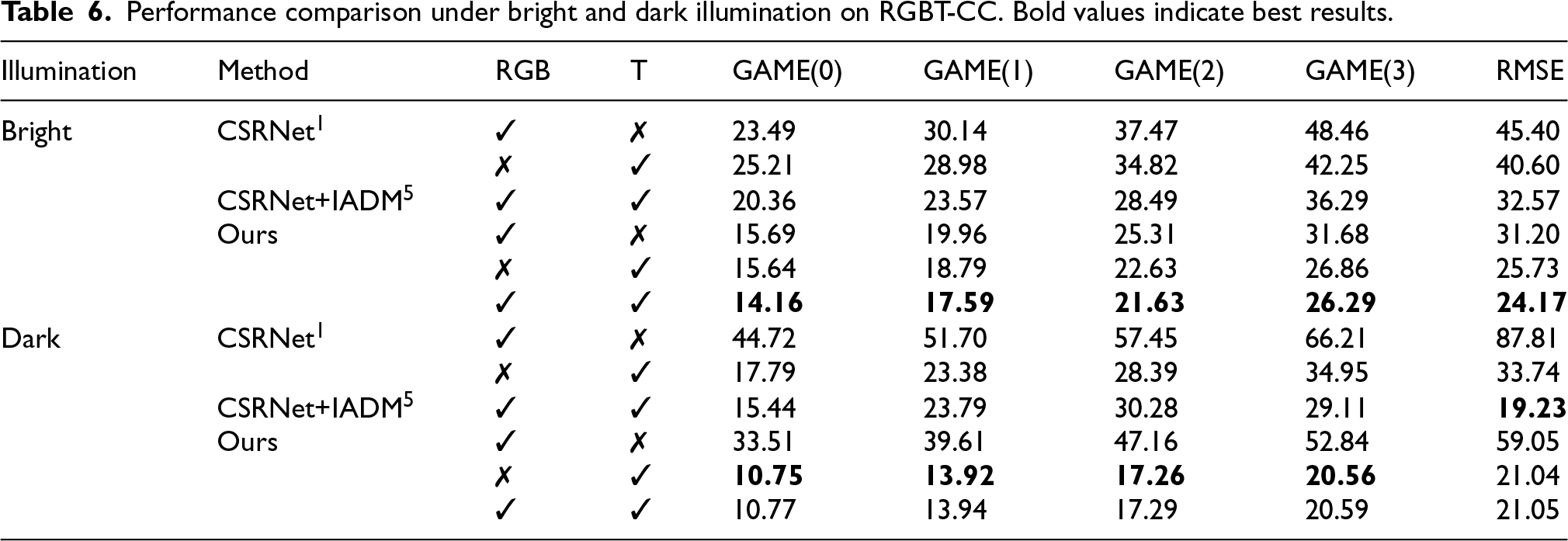
The dataset is partitioned into bright and dark subsets to assess illumination robustness. Results in Table 6 show that the proposed method consistently outperforms baselines in both conditions. Under bright lighting, the fused model achieves GAME(0)
Performance comparison under bright and dark illumination on RGBT-CC. Bold values indicate best results.
Qualitative results in Figure 3 further illustrate these advantages. In bright scenes with thermal interference (e.g., reflections from glass or car grills), the thermal modality produces spurious detections, while the RGB modality remains reliable. Conversely, in dark scenes, RGB features degrade, but thermal predictions remain accurate. The proposed framework leverages these complementary strengths during training, enabling robust unimodal inference when needed. In contrast, fixed-fusion methods like CSRNet+IADM fail to adapt, often misinterpreting thermal artifacts as people (highlighted in red boxes) or missing counts in low-light RGB inputs.
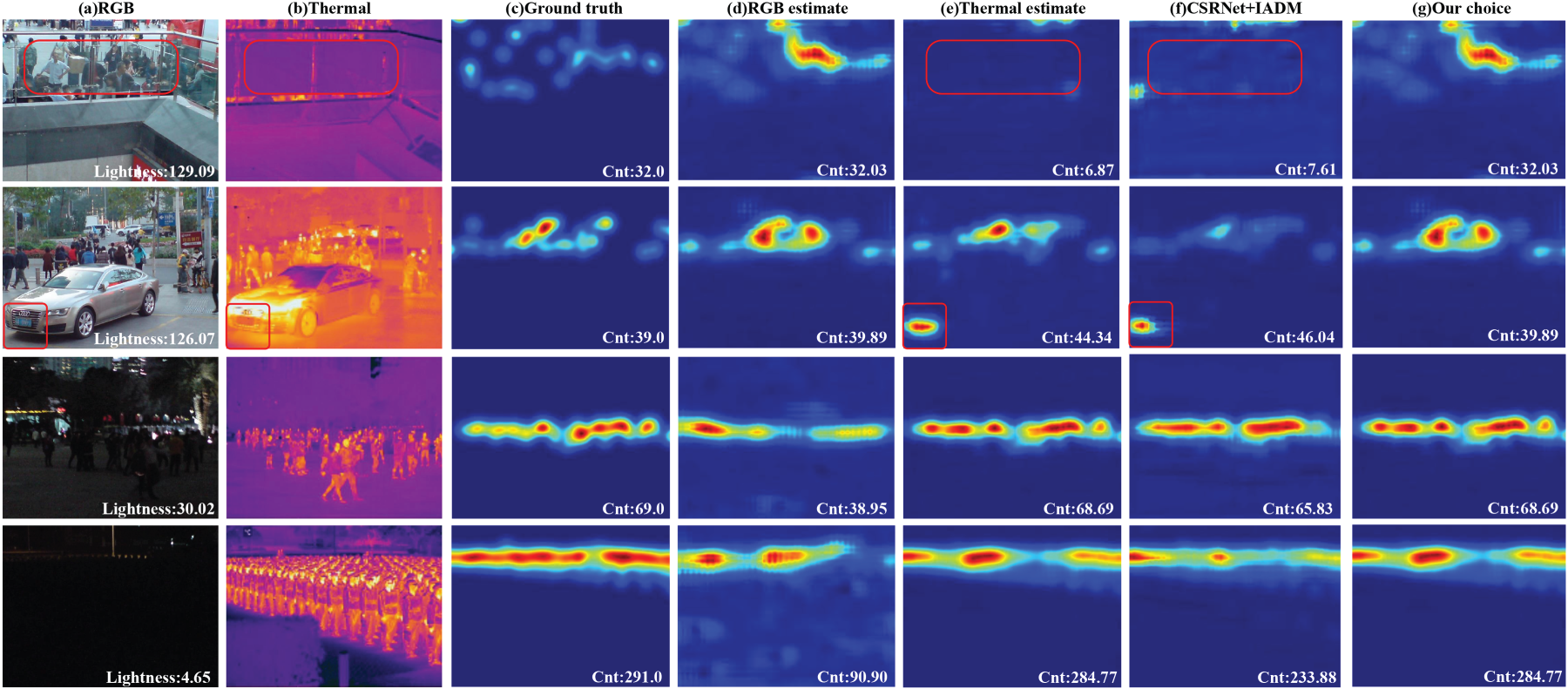
Visualization of density map predictions on RGBT-CC. Rows 1–3: bright scenes; rows 4–6: dark scenes. (a) RGB input, (b) thermal input, (c) ground truth, (d) RGB-only prediction, (e) thermal-only prediction, (f) CSRNet+IADM, 5 (g) proposed decision fusion. Red boxes indicate regions where thermal interference causes false positives in fixed-fusion methods.
The proposed method is further evaluated on the DroneRGBT dataset, which features aerial-view RGB–thermal image pairs. As shown in Table 7, the framework achieves MAE =
Results on droneRGBT dataset. Bold values indicate best performance.
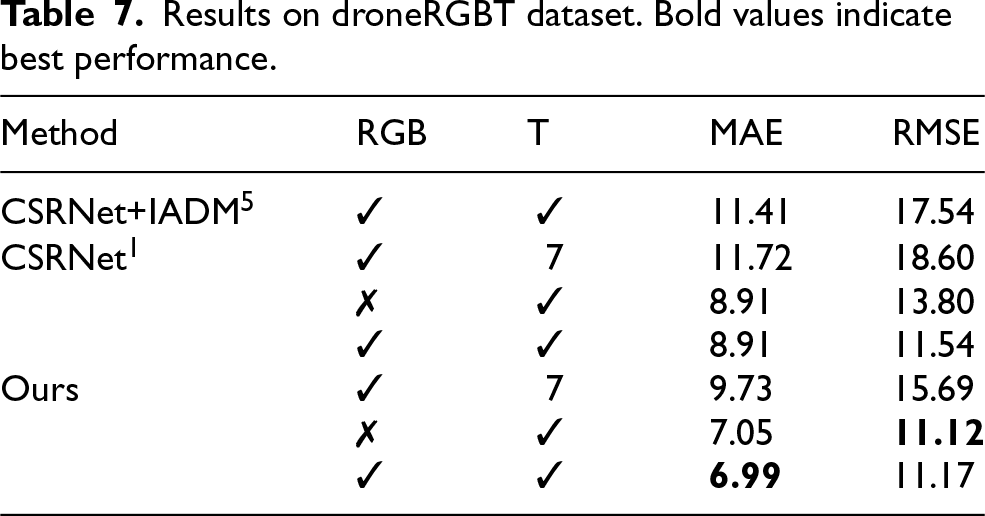
Results on droneRGBT dataset. Bold values indicate best performance.
Four ablation studies are conducted to evaluate the contribution of each component in the proposed framework. For consistency, all reported results correspond to the RGB modality and are evaluated on the RGBT-CC dataset.
1) Feature Patches Generator (FPG)
To assess the effectiveness of the Feature Patches Generator in enriching intermediate feature representations, an ablation variant was implemented in which raw feature maps from selected network layers were directly fed into the Margin Ranking Loss, bypassing the FPG. All other components remained unchanged. As shown in Table 8, the absence of patch-based augmentation leads to a measurable performance drop, confirming that the FPG effectively enhances cross-modal feature learning by providing multi-scale contextual information during training.
Ablation of core components (RGB modality, RGBT-CC).
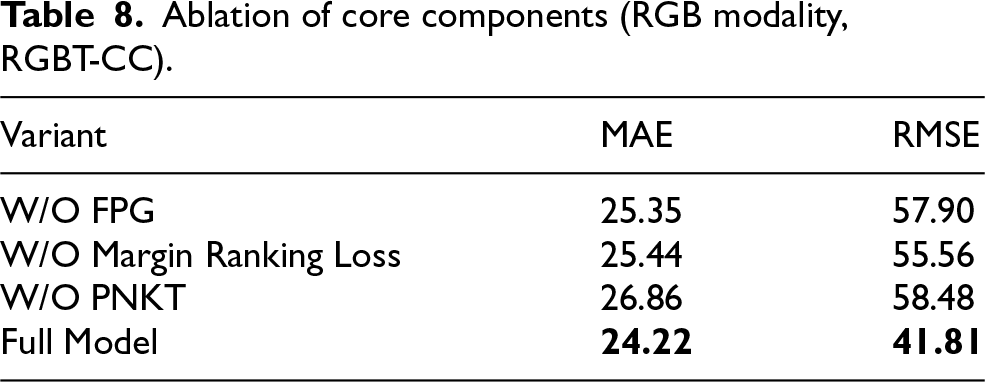
Ablation of core components (RGB modality, RGBT-CC).
2) Margin Ranking Loss
The utility of the Margin Ranking Loss was verified by replacing it with the standard mean squared error (MSE) loss commonly used in crowd counting. In this variant, the MSE loss was applied to the same feature patches generated by the FPG. Results in Table 8 indicate a degradation in counting accuracy, demonstrating that the ordinal constraint imposed by the Margin Ranking Loss is critical for effective feature-level knowledge transfer. Unlike regression-based losses, the ranking loss preserves relative crowd density relationships across spatial scales, enabling more informative cross-modal alignment.
3) PNKT module
To evaluate the role of the Preventing Negative Knowledge Transfer (PNKT) module, a variant was tested in which the adaptive weights
4) Feature map position
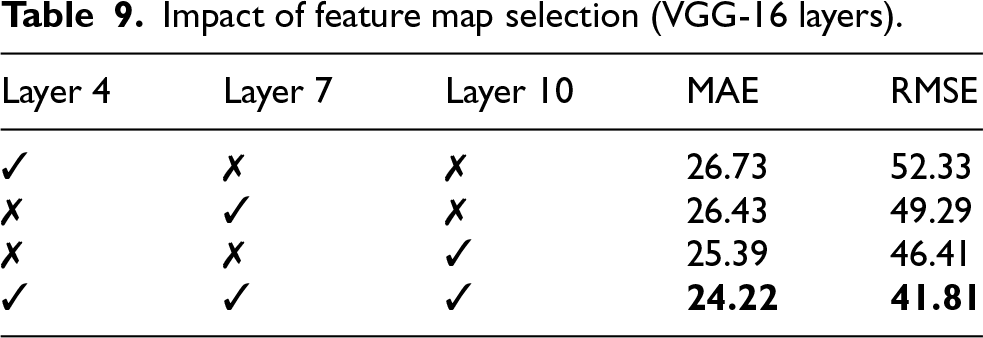
The impact of feature extraction depth was examined by selecting intermediate layers from different stages of the VGG-16 backbone. Three configurations were evaluated, corresponding to shallow, intermediate, and deep layers. Results in Table 9 show that deeper layers yield more discriminative representations, leading to improved performance. Furthermore, aggregating features from multiple layers consistently outperforms single-layer extraction, highlighting the benefit of multi-level semantic fusion.
Impact of feature map selection (VGG-16 layers).
5) Number of patches
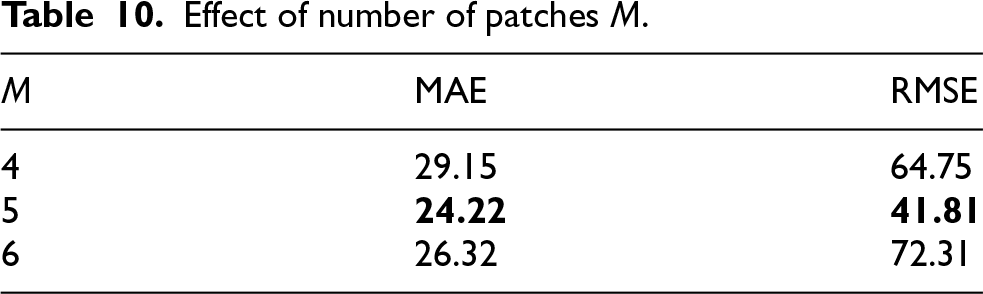
The influence of the number of generated patches
Effect of number of patches
The proposed training framework involves a weighting parameter
Sensitivity analysis of the knowledge transfer weight
on the RGBT-CC dataset.
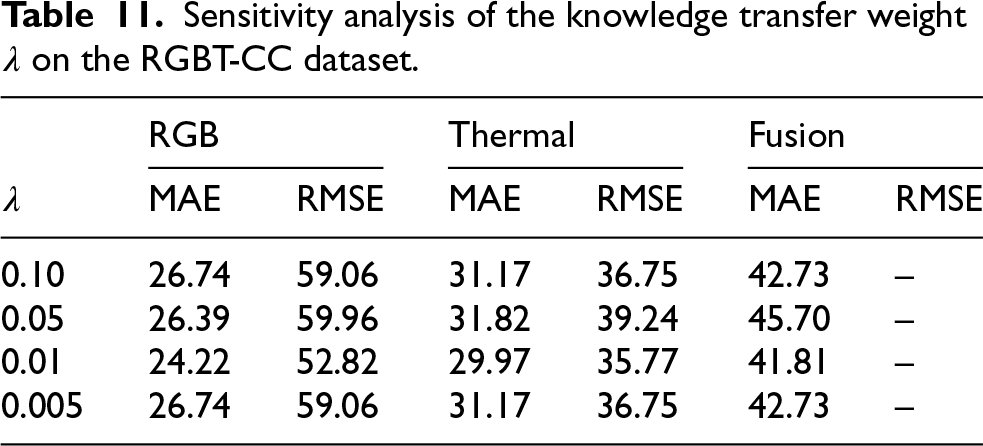
Sensitivity analysis of the knowledge transfer weight
The results indicate that the proposed method is not overly sensitive to the choice of
While this work primarily focuses on RGB–thermal crowd counting, the proposed modality-reconfigurable training strategy is not inherently tied to a specific sensor pairing. To provide additional evidence of generality, we evaluate the proposed framework on the ShanghaiTechRGBD dataset 54 using RGB and depth modalities. The same network architecture and training protocol are adopted, without any modality-specific modification. This experiment is intended to assess whether the proposed training paradigm can be transferred to a different multimodal setting, rather than to establish a new state of the art for RGB–depth crowd counting.
The quantitative results are reported in Table 12, where unimodal inference performance after multimodal training is also presented.
Performance on the shanghaiTechRGBD dataset.
54
“no need for two modalities” indicates unimodal inference after multimodal training.
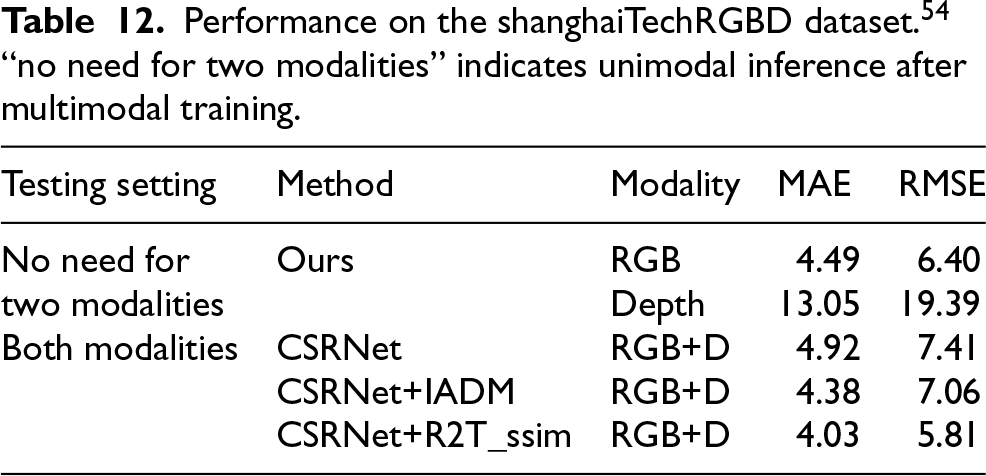
Performance on the shanghaiTechRGBD dataset. 54 “no need for two modalities” indicates unimodal inference after multimodal training.
These results suggest that the proposed modality-reconfigurable training strategy can be applied beyond RGB–thermal inputs, although more extensive evaluation on additional modalities and scenarios remains an important direction for future work.
In this work, a novel problem setting–modality reconfigurable crowd counting—is introduced, defined as the capability of a multimodal model to maintain robust counting performance when one input modality is missing, corrupted, or otherwise unavailable. To address the inherent fragility of existing multimodal approaches under partial-input conditions, a training framework is proposed that decouples cross-modal synergy during training from modality independence at inference.
During training, feature-level interactions between modalities are facilitated through a Feature Patches Generator (FPG), which produces multi-scale patch representations used in a Margin Ranking Loss to enforce ordinal consistency in crowd density estimates. Crucially, knowledge transfer between modalities is regulated by a Preventing Negative Knowledge Transfer (PNKT) module, which adaptively suppresses detrimental cross-modal signals based on relative regression performance. This mechanism enhances the representational capacity of each unimodal branch without introducing inference-time dependencies.
At test time, the system operates in a fully reconfigurable manner: either modality can be used independently, and a simple brightness-based decision rule enables dynamic selection between RGB and thermal predictions in multimodal deployment scenarios. Experimental results on two large-scale RGB–thermal crowd counting benchmarks–RGBT-CC and DroneRGBT–demonstrate that the proposed method achieves state-of-the-art accuracy under both complete and degraded modality conditions, thereby validating the effectiveness of the modality reconfigurability paradigm.
Footnotes
Acknowledgments
This work was supported in part by the Inner Mongolia Autonomous Region Science and Technology Breakthrough Project (2024KJTW0019), the National Natural Science Foundation of China (62301098), the Chongqing Postdoctoral Research Project Special Funding (2023CQBSHTBT004), Science and Technology Research Program of Chongqing Municipal Education Commission (KJQN202300618), Chongqing Postdoctoral Science Foundation Project (CSTB2023NSCQ-BHX0109) and the China Scholarship Council(202107000087), and the Jiangsu Distinguished Professor Programme.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.