
Abstract
When a platform has limited inventory, it is important to have a variety of products available for each customer while managing the remaining stock. To maximize revenue over the long term, the assortment policy needs to take into account the complex purchasing behavior of customers whose arrival orders and preferences may be unknown. We propose a data-driven approach for dynamic assortment planning that utilizes historical customer arrivals and transaction data. To address the challenge of online assortment customization, we use a Markov decision process framework and employ a model-free deep reinforcement learning (DRL) approach to solve the online assortment policy because of the computational challenge. Our method uses a specially designed deep neural network (DNN) model to create assortments while observing the inventory constraints, and an advantage actor-critic algorithm to update the parameters of the DNN model, with the help of a simulator built from the historical transaction data. To evaluate the effectiveness of our approach, we conduct simulations using both a synthetic data set generated with a pre-determined customer type distribution and ground-truth choice model, as well as a real-world data set. Our extensive experiments demonstrate that our approach produces significantly higher long-term revenue compared to some existing methods and remains robust under various practical conditions. We also demonstrate that our approach can be easily adapted to a more general problem that includes reusable products, where customers might return purchased items. In this setting, we find that our approach performs well under various usage time distributions.
Introduction
In online assortment customization, the platform develops a policy to offer products to diverse customers who arrive over time with the aim of maximizing total profits over a finite-time horizon (Bernstein et al., 2015; Chen et al., 2024; Golrezaei et al., 2014). Many online retail scenarios, including hotel bookings, show-ticket sales, and the sale of short-life-cycle products, involve presenting customers with various assortments from a limited inventory within a finite selling period. Our problem setting can be illustrated using the example of hotel booking, as shown in Figure 1. Different customers, represented by different colors, arrive one by one over time. When a customer arrives, the type is immediately revealed to the platform. The platform’s objective is to provide an assortment with a cardinality constraint, and the customer can choose to purchase from the offered set or leave without buying anything. If a hotel is chosen, the platform receives income from the sale and reduces the inventory count by one. If a customer chooses not to purchase, the platform earns zero revenue. During the selling horizon, the platform cannot display sold-out products, which is a standard requirement in retailing applications (Gallego et al., 2015). The objective of the platform is to maximize total revenue over the selling horizon by generating assortments sequentially.
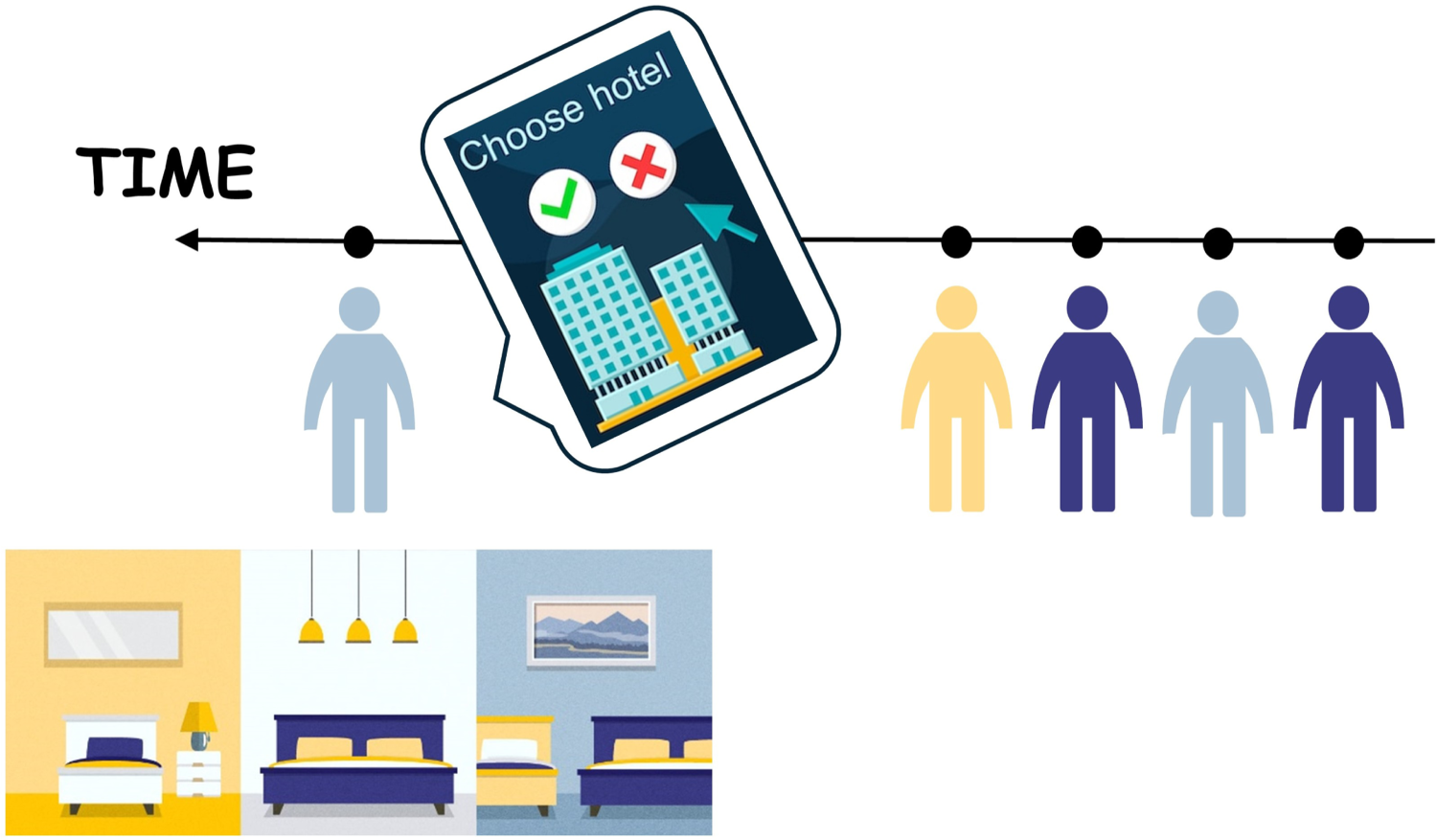
Online assortment customization with hotel booking as an example.
The input of our problem consists of historical arrival sequences and transaction data. However, the future customer arrival orders are unknown. To address this online optimization problem, assuming an adversarial pattern can be overly conservative and disregard historical arrival data. Conversely, fitting a stationary arrival pattern from data and assuming that different customer types arrive independently over time can result in an unrealistic assumption, as customer arrivals are typically random and follow a non-stationary pattern over time (Deng et al., 2022). The challenge of effectively utilizing historical arrival data in the online assortment optimization problem remains unresolved. The second challenge is to predict future customer choice behavior based on historical data. While researchers have put forth a variety of discrete choice models for such predictions, not all of them enable a tractable assortment optimization problem. Previous works on the online assortment customization problem usually assume a specific class of parametric choice models (Bernstein et al., 2015; Golrezaei et al., 2014; Gong et al., 2022; Rusmevichientong et al., 2020). However, the platform might find it challenging to select the appropriate choice model. A tractable parametric model may result in model misspecification, as real-world customer choice patterns are typically very complex. The model misspecification can propagate to the assortment decision and result in significant revenue losses. On the other hand, a comprehensive nonparametric choice model may lead to computational challenges. The final challenge to tackle concerns the limited inventory and the observation that assortment policies evolve over the selling period. Previous research has demonstrated that straightforward reservation strategies can enhance total revenue given certain assumptions about the underlying choice model (Golrezaei et al., 2014). However, a more tailored assortment strategy aimed at maximizing long-term revenue remains to be developed.
Considering these challenges, we propose a novel deep reinforcement learning (DRL) method to learn an assortment policy based on historical data. DRL, through its iterative interaction with the environment and progressive policy enhancement via trial and error, has proven to be an effective strategy for tackling real-world challenges associated with complex environmental dynamics in revenue management. Recent research in this area, including Oroojlooyjadid et al. (2022), Gijsbrechts et al. (2022), and Liu et al. (2024), demonstrates the tremendous power of DRL in outperforming state-of-the-art heuristics. For training our DRL agent, we construct a simulated environment where customers arrive according to historical arrival data and their choices are simulated based on a choice model, named the simulator, which is fitted on historical transaction data and exhibits high out-of-sample predictive accuracy. Subsequently, we interact with each customer by presenting assortments and observing their choices to iteratively enhance the assortment policy. Through our DRL agent’s interaction with this simulated environment, we continuously pose the simulated question: what would the revenue outcome have been if we had implemented an alternative assortment policy instead of the documented one? By leveraging responses from the simulated environment, our DRL agent learns to refine the current policy, ultimately aiming to maximize the total expected revenue. In particular, our approach belongs to the class of model-free reinforcement learning (RL), as the policy and value functions are approximated and solved without learning the environment explicitly. Our contributions can be summarized as follows.
First, to the best of our knowledge, this is the first study that solves the online assortment customization problem using DRL with general customer arrival processes and discrete choice models. Although DRL has been successful in various other applications, it is still challenging to apply to our problem, due to the unknown choice probabilities and the high-dimensional state and action spaces. This study not only provides a proof of concept that DRL, when adapted properly using the problem structure, can be a powerful tool for the online assortment customization problem, but also demonstrates the impressive performance against benchmarks in the literature.
Second, we propose several novel designs in the implementation of the RL algorithm. We develop a special architecture for the deep neural network (DNN) that combines Recurrent Neural Network (RNN) layers to effectively generate assortment decisions under two practical constraints: cardinality constraint and inventory constraint. The RNN sequentially selects products, naturally enforcing the cardinality constraint through a fixed number of selection steps and an “end-of-sequence” option, while inventory constraints are handled by dynamic masking of unavailable items. We also combine real-world sales data and a simulated environment to solve the issue of RL training demanding a large, sometimes unrealistic, number of transaction data. We adopt the advantage actor-critic (A2C) algorithm to update the parameters of the DNN that approximates the optimal assortment policy. Our framework is flexible to incorporate customer attributes for personalization and can be extended to settings with reusable products by augmenting the state with filtered past sales information.
Third, we conduct comprehensive numerical experiments to compare our approach with existing methods. We show that our method consistently matches or outperforms benchmark policies across various settings. The results offer several key insights. First, model misspecification, which happens when the fitted choice model does not reflect the actual customer behavior, can significantly reduce the performance of the learned assortment policy. Second, incorporating rich customer features yields significant revenue improvements. Overall, choosing the Markov chain (MC) choice model to fit the data, combined with the A2C algorithm, performs particularly well. It suggests that the MC choice model may strike a balance between complexity and tractability in RL algorithms. Finally, to support reproducibility and future research, we publicly release our code at https://github.com/Anonymous-Manuscript/DRL-assortment.
Section 2 provides a review of the related literature. Section 3 describes our problem setting in detail. Section 4 defines the MDP formulation of our problem and illustrates our model associated with its training algorithm. We present the numerical experiments in Section 5, including simulations based on a synthetical data set and a real-world transaction data set. More numerical experiments are included in the E-Companion, where we demonstrate the robustness and scalability of our approach. Section 6 concludes our article and provides several directions for future research.
Literature Review
Online Assortment Problem
Assortment optimization, which aims to choose the best assortment by solving a revenue maximization problem, is a well-studied topic in revenue management. Our work is closely related to several existing works about optimizing assortments with limited inventory for heterogeneous online arriving customers. Bernstein et al. (2015) consider a stochastic arrival order where the distribution of customer types is known, and the revenue maximization problem can be formulated as a dynamic program (DP). However, this formulation suffers from the notorious “curse of dimensionality” problem since we need high-dimensional state variables to record the remaining inventory of each product. They propose heuristics called
There are also several works relating to our extension where products are reusable. Under stochastic customer arrivals, the extra requirement of recording products that are currently in use makes the DP formulation even more intractable (Rusmevichientong et al., 2020). Rusmevichientong et al. (2020) propose a 1/2-approximation algorithm based on approximate dynamic programming. under the adversarial setting, the best algorithmic result is that the myopic policy is 1/2 competitive against the offline clairvoyant when the usage time of a product only depends on this particular product (Gong et al., 2022). Besides, Feng et al. (2024) prove that the aforementioned inventory-balancing algorithm is
The aforementioned works on online assortment customization are a special case of choice-based revenue management. A significant issue in this line of work is how to describe the choice probability of an alternative when faced with a specific assortment, and this is often captured by a specific choice model in the literature. Under the random utility maximization (RUM) principle, several choice models are proposed, including multinomial logit (MNL) choice model (McFadden et al., 1973), nested logit choice model, (Talluri et al., 2004) and MC choice model (Blanchet et al., 2016). Although they all have explanations for customer behaviors, they cannot capture irrational choices. Non-parametric models like rank list-based model (Farias et al., 2009) and tree-based choice model (Chen et al., 2019) are proposed on this account. Additionally, several studies have sought to improve empirical predictive performance by integrating neural networks with choice modeling, treating the problem as a multi-class classification task. Bentz and Merunka (2000) start this line of work. They propose a partially connected neural network with shared weights and Softmax outputs for predicting choice probabilities, and this tends to possess stronger predictive power than the widely used MNL choice model in their experiments. In recent years, a number of works follow up, for example, Han et al. (2022), Aouad and Désir (2022), Gabel and Timoshenko (2022), and Cai et al. (2022), extending the previous work to deep learning with different architectures in different application scenarios. Specifically, Gabel and Timoshenko (2022) propose a scalable deep-learning model in the coupon distribution context, and Cai et al. (2022) propose both feature-based and feature-free deep learning-based choice models. Although these neural choice models benefit from strong predictive performance, optimizing assortment based on them is hard due to their complex structure. Different from the literature on choice-based revenue management that assumes a specific choice model or a class of choice models, our approach is model-free. We fill the gap in choice-based revenue management literature to learn an assortment policy based on an arbitrary choice model. By learning a policy from a simulated environment built upon historical data, Our work provides a new data-driven approach in revenue management (Chen and Hu, 2023).
Deep RL
RL defines the process where a goal-driven decision-maker interacts with the environment sequentially (Sutton and Barto, 2018). Traditional RL methods like Q-learning (Watkins and Dayan, 1992) are adopted for problems where the environment can be simply modeled (Rana and Oliveira, 2014). In highly complex environments, DNNs are needed to act as function approximators, leading to DRL methods. DRL has made a huge success in recent years in the fields like games (Mnih et al., 2015) and traffic planning (Xie et al., 2023).
Thanks to cross-disciplinary research, many innovative technologies have been applied in the field of OR/OM (Choi et al., 2022). This includes the application of RL in classical OR/OM problems. By modeling these problems as Markov decision processes (MDPs), RL leads to long-term reward maximization. For MDP with large state space, tractable solutions are infeasible, and here DRL can be applied to learn a near-optimal policy. It has been shown that the performance of DRL beats conventional heuristics in many OR/OM applications. Bello et al. (2016) and Delarue et al. (2020) apply DRL in traditional combinatorial optimization problems, for example, the traveling salesman problem, KnapSack problem, and vehicle routing problem. More recently, Kokkodis and Ipeirotis (2021) adopt DRL in online labor markets; Green and Plunkett (2022) train a DRL agent to bargain optimally for both sides as platforms and buyers on eBay; Alomrani et al. (2022) leverage DRL for solving the online bipartite matching problem, and the DRL agent can be trained to choose one conjoint offline node to match once an online node arrives, with the goal of maximizing the total number of matches. In the field of revenue management (RM), Yang et al. (2022) leverage DRL to learn how to price and disclose the true information of fresh produce based on its current inventory and the remaining selling time; Liu (2023) develop DRL to learn a coupon targeting strategy; Oroojlooyjadid et al. (2022), Gijsbrechts et al. (2022), and Liu et al. (2024) train DRL agents for different inventory management tasks. Differently from the above problems in RM, the assortment problem is oriented to multiple products, and the substitution effects between products should be captured. While the actions in the above OR/OM applications are either to choose a particular node or to determine a specific value, the action in our problem is to choose a subset of products to offer once an online customer comes, which is more difficult because of its combinatorial nature.
DRL has also been adopted in the recommender system (RS); however, our work differs in both the problem it addresses and the methodology it employs. The RS literature typically studies repeated interactions with a single user (Xue et al., 2025) and uses RL to learn a policy that maps past recommendations and feedback to new ones to maximize engagement metrics. The major component to learn is the preference and internal state of a customer from past interactions. In contrast, the system dynamics in our application stem from the stochastic arrival of different customer types and the evolution of inventory as products are purchased over time. RL is used to learn the complex policy that depends on the combinatorial space of remaining inventory. From the perspective of methodology, Ie et al. (2019) develop a SlateQ algorithm based on DQN to propose recommendation sets. They learn a Q-value for each item and solve a static combinatorial optimization problem, where the Q-values are treated as the prices of each item. However, this optimization problem is only tractable under specific choice models such as the MNL choice model Rusmevichientong et al. (2010). The dependence of SlateQ on the MNL choice model results in a model misspecification problem, leading to poor performance in contexts where the MNL choice model is hard to capture real choice behavior. We compare our method with other methods in the literature in Table 1.
Comparison of our method with the ones in the literature.

Comparison of our method with the ones in the literature.
We consider an online assortment optimization problem in a finite selling horizon. Each horizon consists of
Let
The customer’s choice probability of type 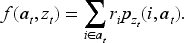
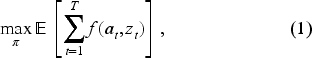
We solve this problem based on historical data, which provides two key types of information. First, we can infer the nonstationary arrival patterns. Since we have recorded customer arrivals by their types, one can fit the proportion of all the types and assume stationary arriving customer types, which leads to more tractable policies (Bernstein et al., 2015). We, on the other hand, allow for nonstationary arrivals of customer types that are directly extracted from the historical data. Second, historical transaction data captures customer preferences, including offered assortments and corresponding choices. Using this data, we can fit a choice model for each customer type
In this section, we describe our neural network architecture and the RL framework. Firstly, we formalize the online assortment customization problem as an MDP. Then we introduce our neural network model architecture. Lastly, we describe the actor-critic (A2C) training algorithm based on a simulator.
MDP Formulation
The online assortment customization problem can be formulated as a finite-horizon MDP, represented by
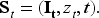
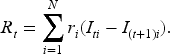
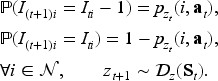
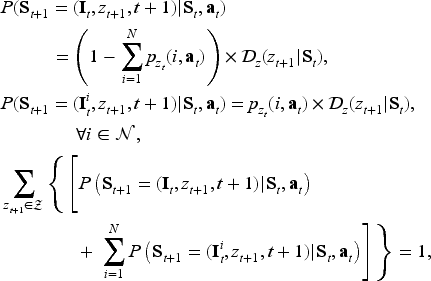
A policy 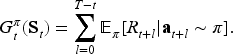
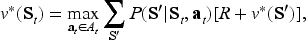
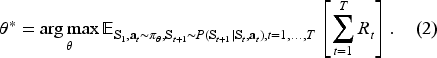
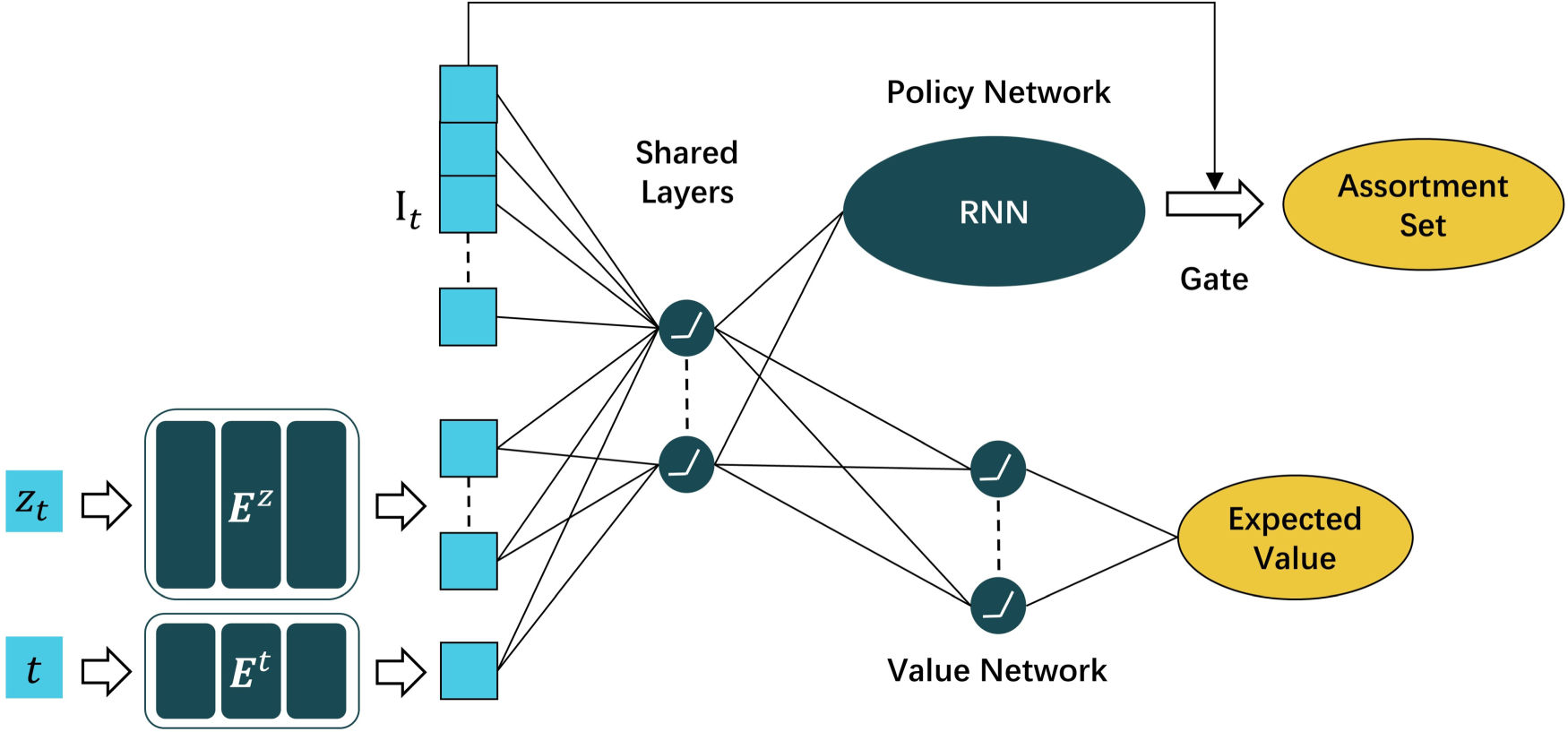
Our deep neural network (DNN) architecture.
We develop a DNN model to generate assortment and train it using the A2C algorithm (Konda and Tsitsiklis, 1999). There are three streams of the DRL method for policy learning. The value-based method, such as deep Q-learning (Mnih et al., 2015), keeps track of state-action value function
Figure 2 illustrates the architecture of our model. The input is the state vector, which contains information about both the products and the arriving customer. The inventory vector
The processed state vector is then passed through a multi-layer fully connected neural network, which models customer preferences across segments and accounts for the complex relationships among products. These relationships, including substitution and complementarity effects, are challenging to capture with parametric choice models. The output of these shared hidden layers, referred to as the “learned state”
Policy network.
Our framework can be extended to incorporate consumer features instead of relying on categorical customer types, to offer personalized assortments. To achieve this, the embedding matrix is replaced with a dense layer that processes a continuous consumer feature vector to output an embedded representation. This dense layer is trained jointly with the main neural network. Experiments on real-world data, where customer features are available, are presented in Section 5.2 to demonstrate the framework’s flexibility in capturing contextual information.
We conduct ablation studies in E-Companion EC.8, to evaluate the value of key components in our model. Specifically, we evaluate the value of the customer-type embedding matrix by analyzing the performance of an architecture that excludes it. The role of the value network is assessed similarly. Furthermore, we examine the effectiveness of the RNN-based policy network by comparing it to a policy network implemented with a standard multilayer perceptron (MLP), highlighting its advantages in capturing product correlations during assortment generation.
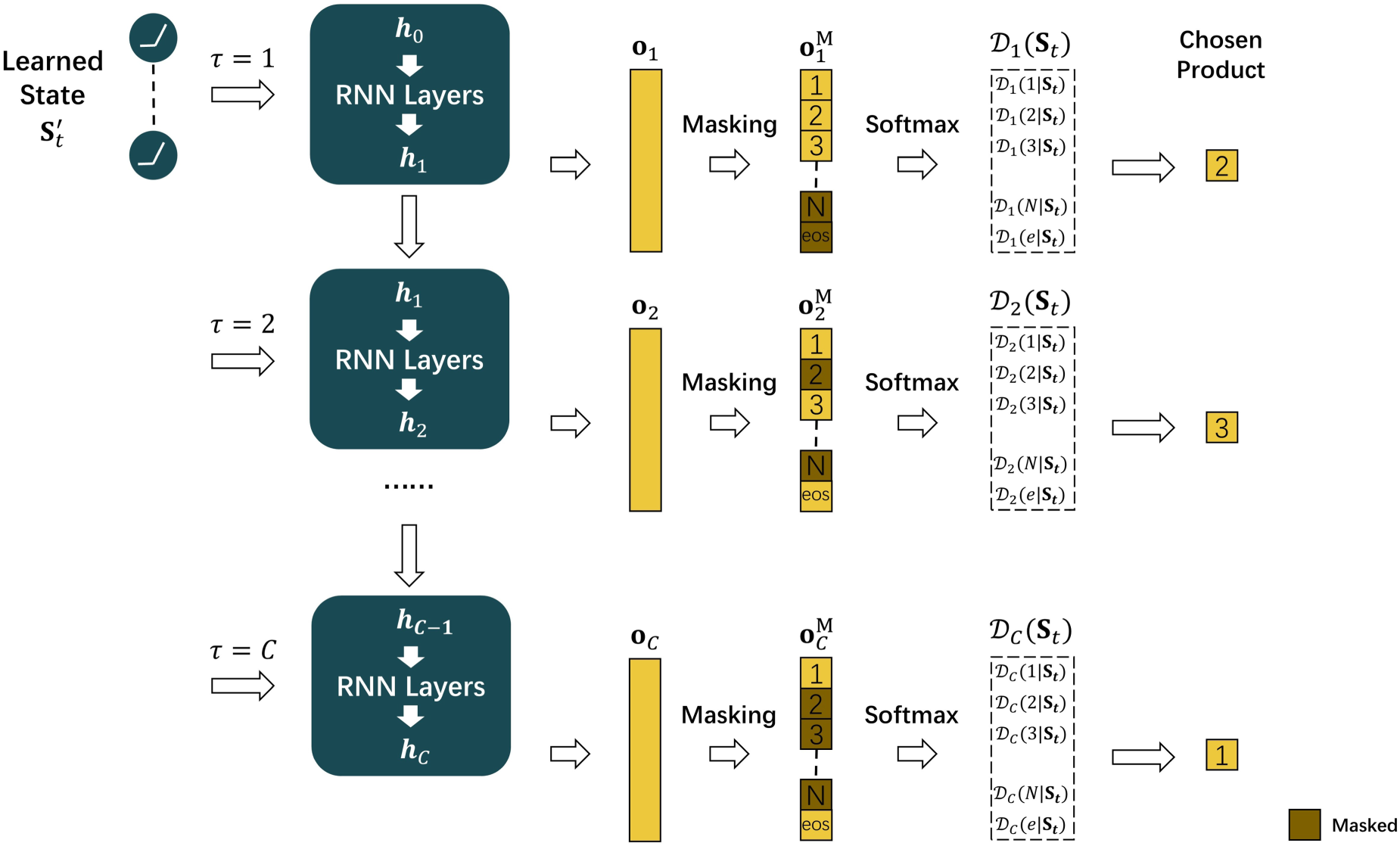
The policy network is designed to map the learned state
The first component of the policy network is an RNN, which sequentially maps the learned state 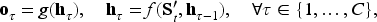
Each 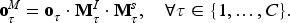
Applying the Softmax function to masked output vectors 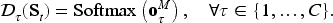
With distribution vectors 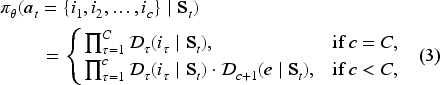
The RNN-based policy network has three key advantages. First, it effectively handles the high-dimensional action space, where the large number of possible assortments makes it impractical to directly output a one-hot vector indicating the assortment action. Second, the sequential selection process dynamically prioritizes products by their state-aware value (e.g., Product 2 in Figure 3 is selected first due to its highest inferred value) while implicitly capturing product correlations through the passing hidden states. Last, the cardinality constraint is naturally considered by constructing the “eos” decision and the
The DRL agent is data-hungry, requiring substantial data to learn accurate policy and value networks. However, in real-world applications, transaction data is often limited. To train the A2C algorithm, we construct a simulator using historical transaction data
Training Algorithm
We adopt the A2C algorithm to update our model by interacting with the constructed simulated environment. For a selling horizon with 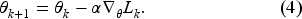
Value loss measures how well the value network estimates expected future reward at each time period. At time period 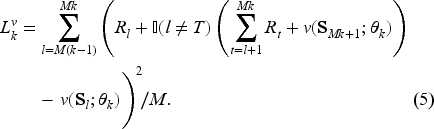
Policy loss measures how well the generated action performs. For the “good” actions, we want to increase the probability of being chosen. The norm advantage 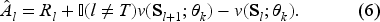
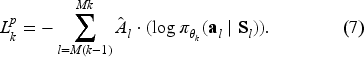
Entropy loss is used to ensure that we can explore more actions and avoid A2C converging to local optima. The entropy of time period 
The total loss function can be expressed as below:

The training process is detailed in Algorithm 1. Specifically, the first two inputs are based on historical data. The recorded historical arrival sequences,
In this section, we evaluate the performance of the proposed DRL approach through semi-synthetic numerical experiments. Section 5.1 presents simulations conducted on a synthetic data set, which is constructed based on a predefined customer arrival pattern and ground-truth choice model. First, we describe the construction of the simulation environment and the generation of synthetic transaction data in Section 5.1.1. The training and testing procedures for the DRL model are detailed in Section 5.1.2, while the criterion for selecting the simulator for training is outlined in Section 5.1.3. The main results of these simulations are provided in Section 5.1.4, while the interpretation of the results and more robustness checks are shown in E-Companion EC.6 and E-Companion EC.7. Section 5.2 presents a simulation based on a real-world hotel-booking data set, where we show our framework can be extended to capture customer attributes. The simulation results are presented in Section 5.2.1, with data preprocessing steps and simulator fitting deferred to E-Companion EC.9. Finally, numerical experiments extending our framework to a reusable product setting are discussed in E-Companion EC.11.
Below we introduce several existing approaches for the online assortment customization problem to compare with our approach.
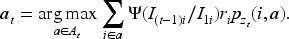
The implementation details of Myopic, Sub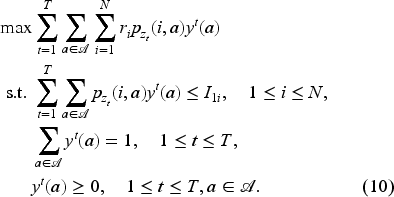
Simulation flowchart.
This LP upper bound assumes that the customer arrival order within a selling horizon is already known, which is why it is referred to as offline. The overall feasible set of assortment sets is denoted by
In the testing results presented below, the performance of our proposed method and all benchmarks is evaluated as a fraction of the offline LP upper bound, which is called the approximation ratio (short as “App Ratio”), providing a measure of how close each approach is to achieving optimality.
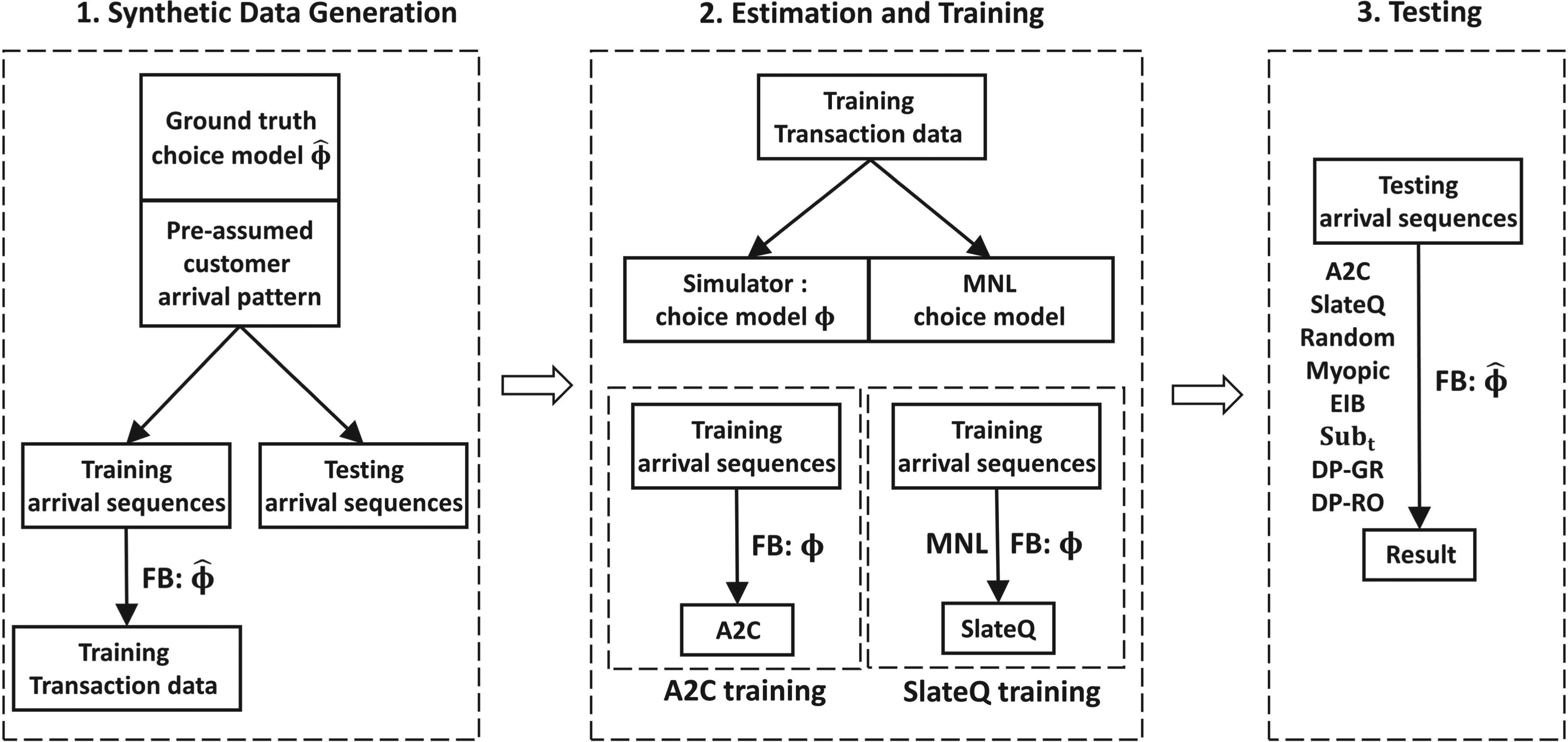
In this section, we simulate an environment where customers arrive following a predefined arrival pattern and provide feedback on offered assortments based on a realistic ground-truth choice model. The overall simulation process, including synthetic data generation, simulator estimation and training, and testing, is illustrated in Figure 4, with a detailed explanation for each part provided below.
Environment Construction and Transaction Data Generation
First, we describe the basic setup of the ground-truth environment. The environment consists of 10 products indexed by
Next, we introduce the ground-truth choice model, referred to as environment feedback function
Lastly, we describe the data generation process, which includes customer arrival sequences and transaction data. Based on the defined customer arrival pattern, we simulate synthetic arrival sequences for 500 selling horizons. The first 400 sequences, denoted as
The following sections will detail the processes of training, testing, and evaluating performance. In E-Companion EC.7, we conduct robustness checks by varying initial inventory levels and arrival patterns, as well as our scalability tests by transitioning from the basic scenario to those involving more products, diverse customer types, and an extended selling period. Additionally, we assess the robustness of our method by altering the ground-truth choice model to the latent class MNL (LC-MNL).
DRL Training and Testing
In this section, we outline our approach to preparing inputs for Algorithm 1, implementing benchmarks, and evaluating their performance throughout the testing sequences.
We first describe how to construct the simulated environment for training our DRL agent. The simulated environment serves two purposes: simulating type-specific customer arrivals in a sequence and modeling their choice behaviors. Specifically, customer arrival sequences are defined as 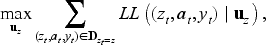
Once the simulated environment is built, Algorithm 1 is executed 40 times, each denoted as one training epoch, with the model update step set as
The non-DRL benchmarks (Myopic-MNL, Sub
All approaches are evaluated using the 100 testing arrival sequences
Out-of-Sample Log-Likelihood of Choice Models.
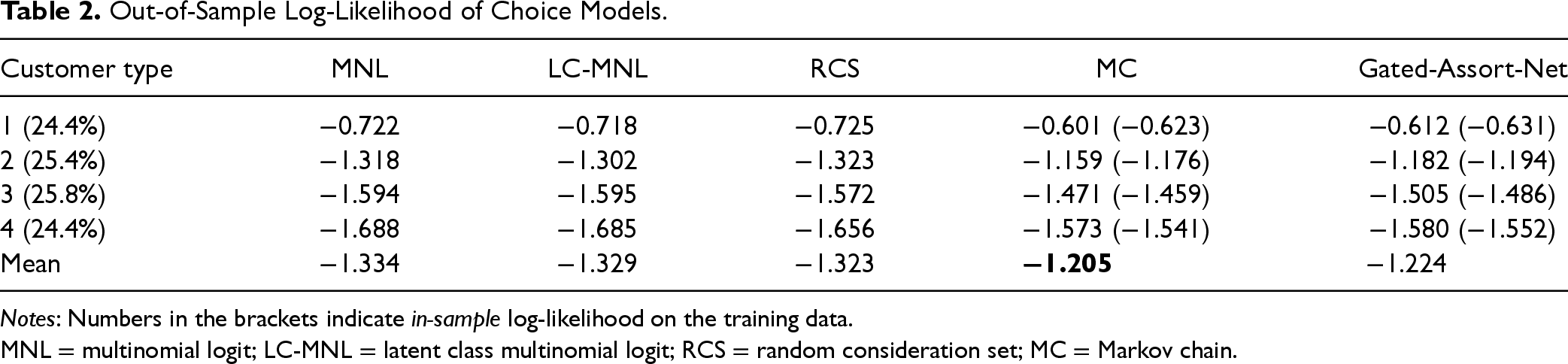
Out-of-Sample Log-Likelihood of Choice Models.
Notes: Numbers in the brackets indicate in-sample log-likelihood on the training data.
MNL = multinomial logit; LC-MNL = latent class multinomial logit; RCS = random consideration set; MC = Markov chain.
In this section, we compare the prediction ability of different choice models on the training transaction data, examine the impact of the simulator on the performance of our A2C method, and provide a criterion for selecting the simulator within our framework.
Different simulators exhibit varying abilities to fit the historical transaction data, leading to different levels of deviation from the ground-truth choice model. To evaluate these differences, we split the training transaction data into two parts: the training part (80%) and the testing part (20%). We fit all choice models on the training part, and use their log-likelihood on the testing part, named the out-of-sample log-likelihood, to compare their fitting performance, as suggested by Berbeglia et al. (2022). The results are summarized in Table 2. Each column in the table corresponds to a specific choice model, including MNL, LC-MNL, RCS, MC, and Gated-Assort-Net. Each row represents the fitting result for a particular customer type, with the proportion of each customer type displayed in the leftmost column. The last row provides the average performance of each choice model across all customer types. For the Gated-Assort-Net model, we save the version with the best in-sample log-likelihood during the 10-epoch training process. To assess potential over-fitting issue, we also report the best in-sample log-likelihood in brackets in the last two columns. The results show that MC achieves the best out-of-sample predictive performance overall, followed closely by Gated-Assort-Net, while LC-MNL, RCS, and MNL perform significantly worse. Moreover, for customer types 3 and 4, all choice models show lower log-likelihood values. This is probably a result of the increased size of the consideration sets for these customer types, which complicates capturing their behavior patterns. Additionally, both MC and Gated-Assort-Net model experience an overfitting problem with customer types 3 and 4, evidenced by their superior in-sample performance relative to their out-of-sample results, while the problem with MC is less severe.
Better out-of-sample performance indicates stronger predictive ability in unseen scenarios. Since accurate predictions for out-of-data choice scenarios are essential for effective learning in A2C through simulations, we recommend selecting the choice model with the best out-of-sample predictive performance as the simulator. To test this hypothesis, we train A2C agents using different choice models as simulators. Additionally, since the ground-truth choice model is available, we also train an A2C agent using the ground-truth choice model as the simulator. This allows us to quantify the optimality gap of our approach while isolating the impact of model misspecification in the simulator.
By comparing the performance of A2C agents trained with ground-truth and fitted choice models as simulators, as shown in Figure 5, we verify our criterion for simulator selection. The results show that A2C agents trained with MC and Gated-Assort-Net as simulators achieve the best performance, while those trained with LC-MNL, RCS, and MNL perform worse. This ranking aligns with the out-of-sample fitting performance of the choice models discussed earlier, validating our recommendation to use the choice model with the best out-of-sample predictive performance as the simulator. Furthermore, no significant performance difference is observed between A2C agents trained with MC and those trained with the ground-truth choice model as simulators, indicating that the MC model approximates the ground-truth choice model effectively and can reliably simulate choice scenarios. Finally, we observe that A2C agents trained with the ground-truth, MC, and Gated-Assort-Net simulators achieve near-optimal performance, with an approximation ratio larger than 0.97. In conclusion, we suggest selecting the choice model with the best out-of-sample performance in our framework to provide reliable feedback during the A2C training process.
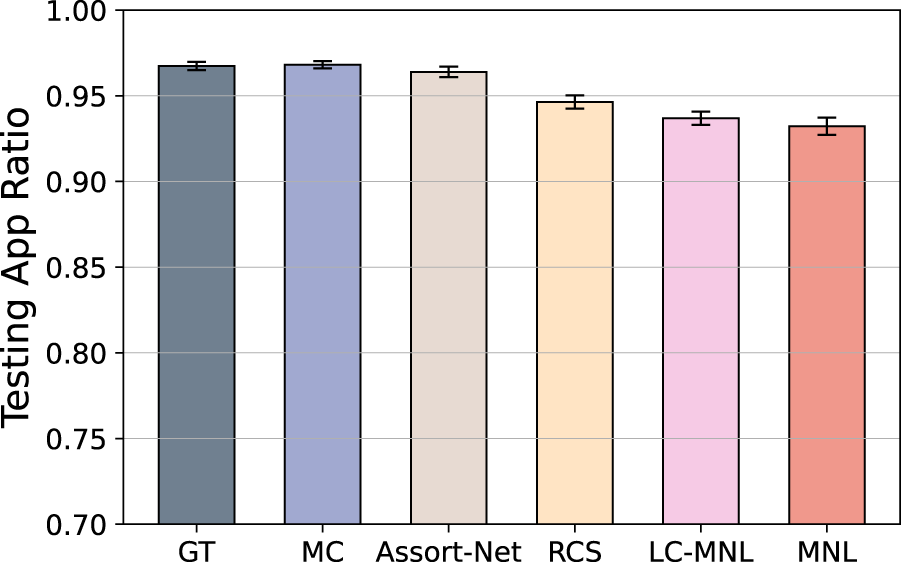
Testing results of advantage actor-critic (A2C) trained with six different simulators.
This section reports the testing results of different approaches under the basic setting.
Figure 6 presents the training curve of A2C and a comparison of the testing results across all approaches. In the left panel, the solid curve shows the mean validation result during the training process, with vertical lines indicating standard error across three training runs. The training stabilizes after around 15 epochs, with reduced variance across different initializations, suggesting the robustness of our method. In the right panel, each bar represents the mean approximation ratio of an approach, with black lines showing deviation across 10 testing runs. The results reveal several key insights. First, our A2C algorithm achieves a testing approximation ratio over 0.97 (right panel), outperforming all benchmarks. Note that this may differ from the validation results in the left panel due to discrepancies between the simulator used for validation and the ground-truth choice model used for testing. Among the benchmarks, DP-GR, DP-RO, and SlateQ achieve approximation ratios around 0.95, representing the best within this group. In contrast, the Random policy performs worst, with a mean ratio of 0.86, as expected due to its lack of learning from historical data. The Myopic policy improves upon Random by leveraging customer preferences, while EIB and Sub
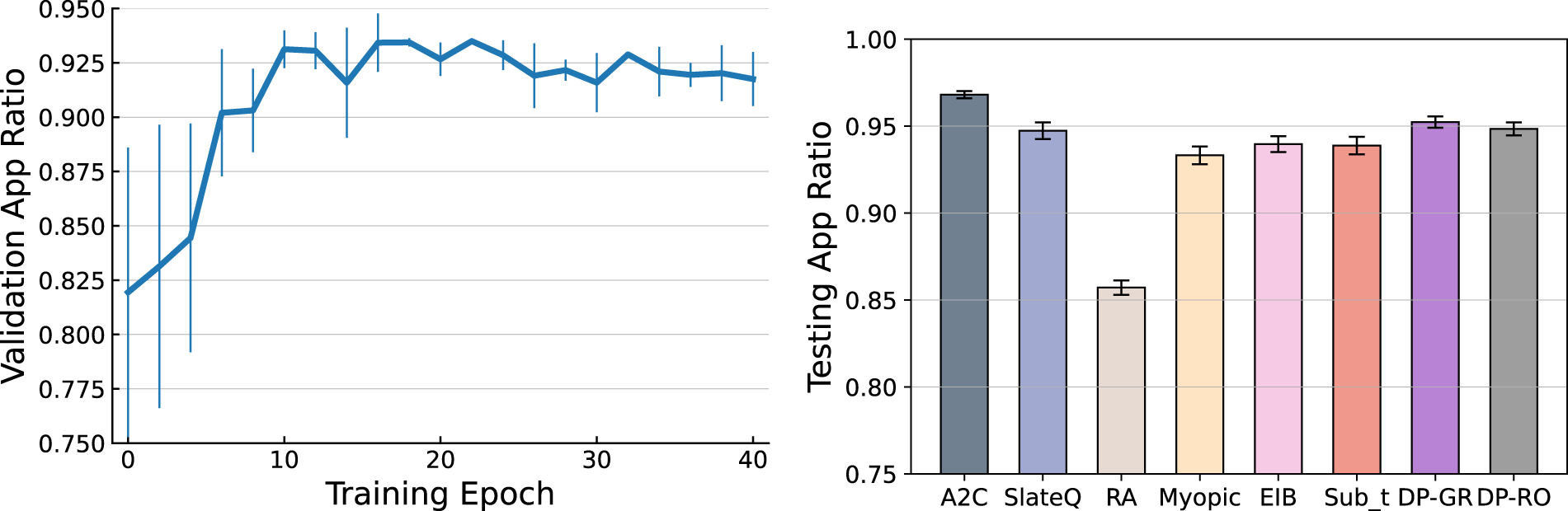
Training and testing results with the setting defined in Section 5.1.1.
Here we conduct simulations based on a real-world data set: Expedia 1 , which is a data set about hotel transactions, consisting of the customer search sessions, the recommended assortments, the attributes of products in the assortments, and the choices of these sessions. We choose this data set from a practical point of view that the total number of rooms is fixed in a time horizon. We extract a stream of customer arrival sequences and the transaction record of each arriving customer from this data set and manually set the initial inventory level of each hotel to construct the environment. Data pre-processing procedure is detailed in E-Companion EC.9.
The processed data set used in this section consists of 30 unique products and 4,272 search queries spanning 211 days. In E-Companion EC.7.2, we expand the data set to a case with 100 unique products to test scalability of our approach. Each search query comprises recommended products and the customer’s final choice. For each search query, we also observe six customer features, such as a weekend indicator, and six product features like the star rating of a hotel. Detailed description about product features and customer features is introduced in E-Companion Tables EC.8 and EC.9.
While our framework can adapt to a contextual setting by directly incorporating customer features, the benchmark methods require predefined customer types. Consequently, we apply K-means clustering to group customers into four types based on their features. Since the underlying choice model is unknown, our first step is to identify a ground-truth choice model by fitting various choice models to the transaction data and selecting the one with the best predictive performance. There are two classes of possible choice models. The first class is feature-based choice models, including MNL-feature and Gated-Assort-Net-feature, which take the feature vectors as input and output the choice probability of each product, while the second class is choice models which take product indexes without features as input and output probabilities. For the first class, we concatenate the six-dimensional feature vector of a certain product and the six-dimensional customer feature vector of a certain search query into a 12-dimensional feature vector of a certain product in a certain search query, to act as the input. We fit six choice models, including MNL-feature and Gated-Assort-Net-feature, and MNL, LC-MNL, MC, and Gated-Assort-Net, on the overall data set, which includes transaction data of all customer types. We also fit MNL, LC-MNL, MC, and Gated-Assort-Net models on transaction data of each clustered customer type. While fitting each choice model, we split the data into 80% training data for estimation and 20% testing data. Log-likelihood on testing data, named out-of-sample log-likelihood, is used to evaluate the predictive power of the models, with results summarized in Tables 3 and 4.
Log-likelihood of choice models fitted on overall data with all customer types.

Log-likelihood of choice models fitted on overall data with all customer types.
Notes: (1) In-sample and (2) out-of-sample.
MNL = multinomial logit; LC-MNL = latent class multinomial logit; MC = Markov chain.
Out-of-sample log-likelihood of choice models fitted on segmented data.
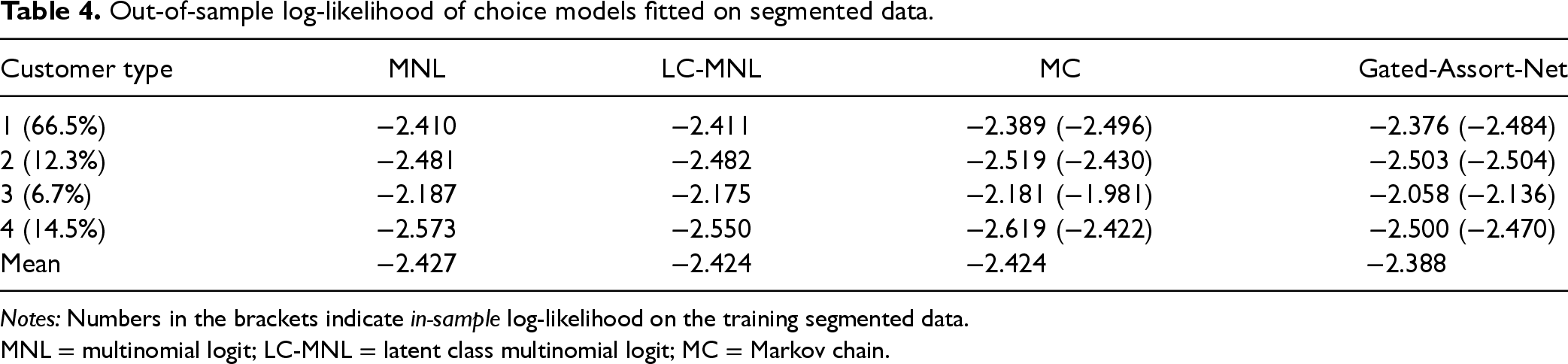
Notes: Numbers in the brackets indicate in-sample log-likelihood on the training segmented data.
MNL = multinomial logit; LC-MNL = latent class multinomial logit; MC = Markov chain.
We have the following observations. First, the Gated-Assort-Net-feature model achieves the best performance, illustrating the value of contextual information in predicting customer choices. However, the poor performance of the MNL-feature model may be caused by model misspecification, and the underlying nonlinear relationships between utility and features. Second, fitting choice models separately for each customer type performs worse than fitting a single model on the entire data set, suggesting that market segmentation is not always beneficial. With only 4,000 training samples, dividing them into smaller groups reduces data available per segment, weakening predictive power and causing overfitting, as seen in the in-sample versus out-of-sample performance gap for customer types 3 and 4 in Table 4. This highlights a trade-off between model accuracy and customization under limited data. Our A2C approach mitigates this by learning directly from a feature-based choice model fitted on the full data set, achieving both accurate modeling and effective personalization. Based on these results, we adopt the Gated-Assort-Net-feature model as the ground-truth choice model and use it as the simulator when training our A2C and SlateQ agents, to demonstrate our framework’s ability to handle contextual scenarios by directly incorporating customer features.
To evaluate the value of customer features, we compare two types of A2C agents. The first, referred to as A2C-F, takes a customer feature vector as input, followed by a fully connected embedding layer. The second, called A2C-T, uses a customer-type vector, which is pre-classified by K-means, as input, followed by an embedding matrix. Other benchmarks are implemented using MNL models fitted to the clustered customer types.
For training, we allocate customer sequences from the first 160 days and use the remaining 51 days for testing. The initial inventory level of each hotel is manually set to 5. We train our model for 40 epochs, with each epoch covering all 160 training customer sequences. After each epoch, we validate the current parameters of the model. The training process is repeated 3 times independently. Testing is conducted 10 times for each approach using the testing customer sequences to account for stochastic customer choice behavior.
The training and testing results are summarized in Figure 7. We can see that the performance of both A2C-F and A2C-T improve during training, demonstrating that our framework with either continuous customer feature or categorical customer type information is effective in policy learning. The deviation across three training results with different model initial parameters diminishes over time, indicating stable convergence for both agents. Interestingly, while A2C-T keeps improving in the first 20 epochs and stays stable afterwards, A2C-F consistently improves during training until it surpasses A2C-T in the last 20 training epochs, suggesting that incorporating finer-grained customer feature vectors enhances the agent’s ability to learn an effective policy.
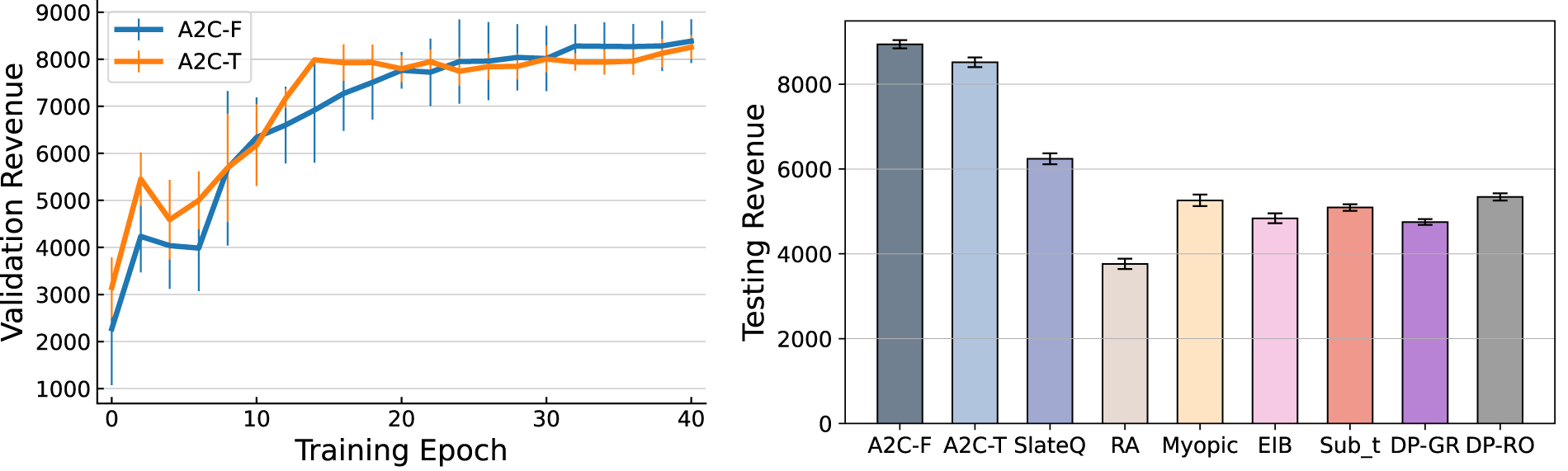
Training curve and testing result.
In testing, A2C-F achieves the highest revenue followed by A2C-T. Note that the only difference between these two agents lies in the granularity of the customer input: A2C-F utilizes detailed customer feature vectors, whereas A2C-T relies on pre-classified customer-type vectors. This comparison highlights the generality and flexibility of our framework in accommodating various levels of customer heterogeneity. The superior performance of A2C-F underscores its advantage in leveraging rich customer feature information, whereas A2C-T’s competitive results demonstrate the framework’s effectiveness in handling predefined customer types.
Among the benchmarks, SlateQ ranks third but significantly underperforms compared to A2C-F and A2C-T. Despite using the same Gated-Assort-Net-feature simulator, SlateQ’s reliance on the MNL choice model to guide actions introduces model misspecification issues, which hinder its performance. Of the remaining benchmarks, DP-RO achieves the best results but still lags behind SlateQ and the A2C agents. These findings demonstrate the challenges faced by MNL-based benchmarks, particularly as the number of products increases and customer behavior becomes more complex (e.g., context-dependent decision-making).
These findings confirm the efficacy of our A2C framework in tackling the challenge of modeling customer behavior and solving assortment optimization problem. The ability to accommodate both granular customer features and predefined customer types further underscores the flexibility and robustness of our approach. Similar trends are observed in the 100-product case, detailed in E-Companion EC.7.2, where the comparison between A2C-F and A2C-T is more evident.
We address the online assortment customization problem under inventory and cardinality constraints using a novel data-driven approach based on DRL. Departing from traditional methods that rely on specific choice models or their variants, our work proposes a generalizable framework that learns customized assortment policies through interactions with a simulated environment. This environment, constructed from historical transaction data, enables the DRL agent to trial assortment actions and observe purchasing outcomes through a feedback mechanism. Leveraging a specially designed DNN and the A2C training algorithm, our model learns an approximately optimal policy and extends to settings involving customer features and reusable products.
Our study contributes to the application of DRL in revenue management and demonstrates its potential through comprehensive numerical experiments. The key insights from our work are as follows:
We also admit that our work has limitations. One major constraint is its reliance on historical data for simulator construction. The effectiveness and adaptability of our approach depend on the quality, quantity, and representativeness of the data. Theoretical investigation of the relationship between data quality and model performance is an important future direction.
This study opens up several avenues for further research: first, future work can explore settings where customer choice depends on product positions within the assortment or across multiple pages due to space constraints (Abeliuk et al., 2016; Feldman and Segev, 2022). Integrating these behavioral effects into our framework can provide a more comprehensive solution for online platforms. Second, pricing is a critical lever to enhance revenue during the selling horizon. While prior research has addressed this issue under specific models like the MNL (Lei et al., 2022), extending our framework to jointly optimize assortment and pricing strategies is a promising direction. Finally, real-world settings often involve the introduction of new products and the discontinuation of existing ones. Addressing this dynamic through transfer learning, as explored by Oroojlooyjadid et al. (2022), could significantly enhance the adaptability of our approach.
Supplemental Material
sj-pdf-1-pao-10.1177_10591478251351737 - Supplemental material for Deep Reinforcement Learning for Online Assortment Customization: A Data-Driven Approach
Supplemental material, sj-pdf-1-pao-10.1177_10591478251351737 for Deep Reinforcement Learning for Online Assortment Customization: A Data-Driven Approach by Tao Li, Chenhao Wang, Yao Wang, Shaojie Tang and Ningyuan Chen in Production and Operations Management
Footnotes
Acknowledgments
We thank the department editor, the senior editor, and two anonymous referees whose comments substantially improved this article. Yao Wang is grateful for the support of the National Natural Science Foundation of China under Grant 12371513, and the Major Program of National Fund of Philosophy and Social Science of China under Grant 23&ZD135. This work was conducted while Tao Li was affiliated with Xi’an Jiaotong University, and the revisions were completed during his PhD at the Hong Kong University of Science and Technology.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Notes
How to cite this article
Li T, Wang C, Wang Y, Tang S, Chen N (2026) Deep Reinforcement Learning for Online Assortment Customization: A Data-Driven Approach. Production and Operations Management 35(2): 665–684.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.