
Abstract
Objectives
To systematically review the accuracy of artificial intelligence (AI)-based systems for grading of fundus images in diabetic retinopathy (DR) screening.
Methods
We searched MEDLINE, EMBASE, the Cochrane Library and the ClinicalTrials.gov from 1st January 2000 to 27th August 2021. Accuracy studies published in English were included if they met the pre-specified inclusion criteria. Selection of studies for inclusion, data extraction and quality assessment were conducted by one author with a second reviewer independently screening and checking 20% of titles. Results were analysed narratively.
Results
Forty-three studies evaluating 15 deep learning (DL) and 4 machine learning (ML) systems were included. Nine systems were evaluated in a single study each. Most studies were judged to be at high or unclear risk of bias in at least one QUADAS-2 domain. Sensitivity for referable DR and higher grades was ≥85% while specificity varied and was <80% for all ML systems and in 6/31 studies evaluating DL systems. Studies reported high accuracy for detection of ungradable images, but the latter were analysed and reported inconsistently. Seven studies reported that AI was more sensitive but less specific than human graders.
Conclusions
AI-based systems are more sensitive than human graders and could be safe to use in clinical practice but have variable specificity. However, for many systems evidence is limited, at high risk of bias and may not generalise across settings. Therefore, pre-implementation assessment in the target clinical pathway is essential to obtain reliable and applicable accuracy estimates.
Keywords
Background
Diabetic retinopathy (DR) is one of the most common complications of diabetes. Screening for DR aims to identify and monitor patients with more advanced forms of DR, so that treatment can be administered when it is most effective. 1 Furthermore, screening might have indirect benefits, by increasing patients’ awareness and motivation, leading to better management of diabetes and slower progression of DR.2–4 Diabetic eye screening programmes (DESP) are cost-effective relative to no screening 5 and data from epidemiological studies suggest that they are effective in reducing progression to proliferative DR (PDR) and preventing visual loss.6–8 However, they are costly to run and require a highly trained workforce and accessible diabetes and eye care services. Even well-established programmes, such as those in the UK, face challenges due to the increasing number of patients with diabetes. 9
In recent years, attempts to improve the efficiency of DESPs focused mainly on risk-stratified screening9,10 and the introduction of artificial intelligence (AI)-based automated retinal imaging assessment systems (ARIASs). In 2011, the first ARIASs were introduced in the Scottish and Portuguese DESPs to rule out DR prior to human grading. Given the large proportion of patients with normal images 11 and the low risk of the software missing clinically significant DR, both implementations were considered successful.12,13
However, despite the initial success and the increasing interest that followed the advent of deep learning (DL) algorithms, the introduction of ARIASs in clinical practice has been slower than expected and there are still concerns about the safety, cost-effectiveness and overall impact of AI-based screening. The current paper provides an up-to-date review of the accuracy and safety of ARIASs that are in the final stages of their clinical evaluation. It is based on the results from a larger project commissioned by the UK National Screening Committee (NSC) which, among its other components, included a systematic review of the accuracy of ARIASs. The review protocol was registered on PROSPERO (CRD42020200515) and any amendments are detailed and justified below.
Methods
We developed a search strategy combining free text and medical subject headings for ‘diabetic retinopathy’, ‘screening’ and ‘ARIAS’ (Supplemental material, Table S1) and searched MEDLINE (via OvidSp), EMBASE (via OvidSp), the Cochrane Library (CDSR and CENTRAL) and ClinicalTrials.gov (U.S. National Library of Medicine) from 1st January 2000 to 27th August 2021. In addition, we searched the reference lists of all included studies and relevant papers and contacted experts to check for additional titles.
English-language papers were included if they reported an evaluation of ARIAS in an external dataset (i.e. different from the one used for development); participants were ≥12 years of age; had type 1 or 2 diabetes; and underwent standard fundus photography to detect DR. The review was commissioned to inform a discussion on the use of ARIASs in the UK and, therefore, the original analysis published in the project's report 14 focused on studies applicable to the UK DESPs. The analysis presented here is not restricted to UK-relevant studies and has a slightly different focus: on the accuracy of ARIASs that are commercially available, licensed for clinical use or evaluated in a ‘clinically plausible dataset’ (defined as a dataset obtained from a well-characterised cohort of patients from the target population). When an evaluation in multiple datasets was reported, we included only the results from the most clinically relevant cohort. The other differences between the original and current analysis are as follows: (1) we excluded studies in which the ARIAS was used only as a decision aid in manual grading; (2) we excluded ARIASs evaluated only in publicly available datasets or poorly characterised datasets as those are more characteristic of the earlier stages of the evaluation process; (3) we excluded studies reporting accuracy at lesion level only or when no sensitivity and specificity estimates were reported or could be calculated from the published data; (4) we excluded conference abstracts or similar publications as those do not report study methods and results in sufficient detail.
Search results were imported into EndNote X8.2 (Thomas Reuters). A single reviewer carried out the screening of titles/abstracts and full text, with a second reviewer screening independently 20% of the titles at each level and resolving disagreements through discussion. This process was repeated for data extraction and methodological quality appraisal. The latter was carried out using the QUADAS-2 tool 15 and QUADAS-2C extension for comparative studies. 16 While in the original analysis applicability was assessed against the UK DESP, here we adopted broader criteria that reflect the variation across screening programmes (Tables S2 and S3). Given the small number of studies evaluating each ARIAS and the considerable clinical heterogeneity and high risk of bias, we summarised the results in tables and by plotting them in the Receiver Operating Characteristics (ROC) space and analysed them narratively. When not reported in the study, confidence intervals were recalculated from the accuracy estimates, prevalence and sample size. Review Manager 5.4.1 (The Cochrane Collaboration, 2020) was used to create the ROC plot and to calculate the confidence intervals around the sensitivity and specificity estimates.
Results
Our database searches identified 3309 records. Of those 854 were duplicates; 2455 were screened at title/abstract level and 387 were assessed at full text. The agreement (Cohen's kappa) between the reviewers who conducted the screening was 0.79 (titles/abstracts) and 0.83 (full text). Ultimately, 43 papers were included in the current analysis (Figure S1). Studies excluded at full text, with reasons for exclusion, are provided in Table S4.
Study characteristics
The studies evaluated 15 DL-based and 4 traditional machine learning (ML)-based systems11,17–27; both DL and ML versions of EyeArt were included. Two studies reported head-to-head comparison of more than one system.22,27 Nine systems were evaluated in a single study each; and only six were evaluated in ≥3 studies (Table S5). The populations from which the external datasets were drawn were from the following countries: Australia, Chile, China, Denmark, France, India, Italy, New Zealand, Poland, Portugal, Singapore, Spain, Thailand, the Netherlands, UK, USA and Zambia. Ten studies recruited participants prospectively, with another three28–30 implying, but not explicitly claiming, a prospective design. Seven studies compared head-to-head the accuracy of the system to that of human graders not involved in the reference grading.25,31–36 Only five studies were conducted independently from the developer/manufacturer22,27,29,37,38; and another one appeared to be an independent evaluation but without stating this explicitly 26 (Table 1).
Characteristics of the included studies.
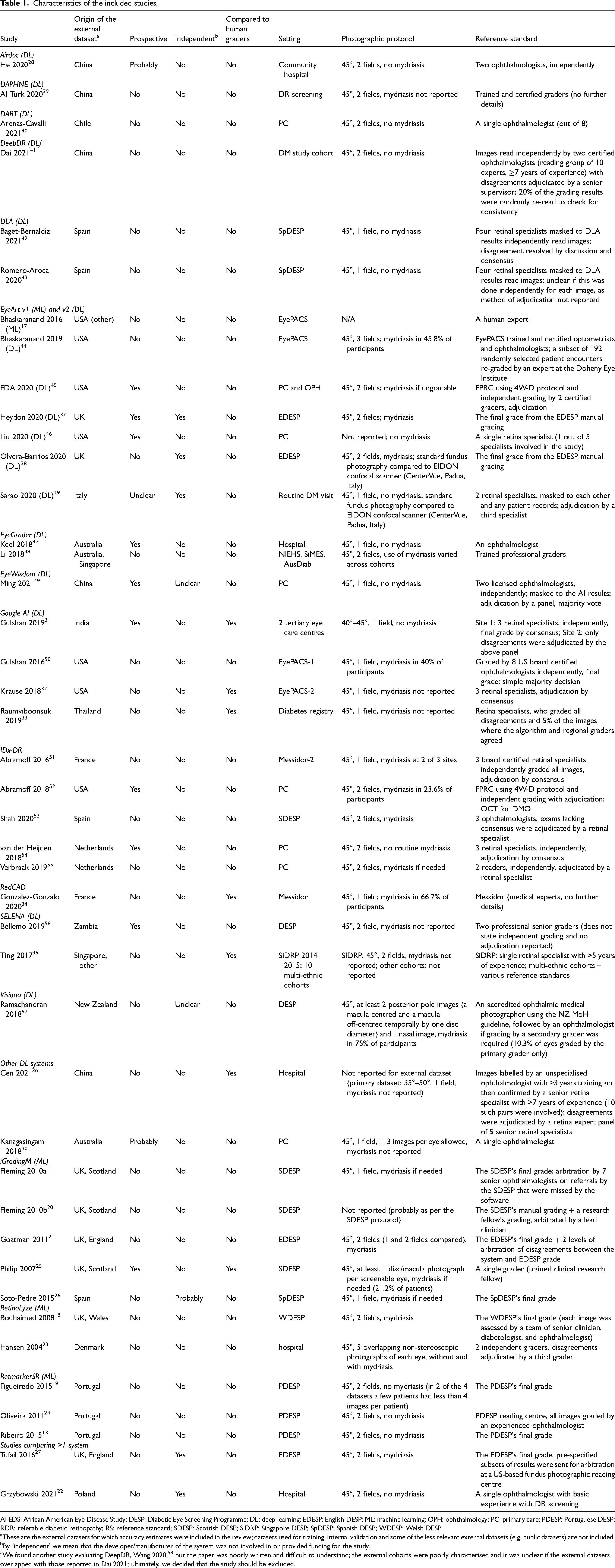
AFEDS: African American Eye Disease Study; DESP: Diabetic Eye Screening Programme; DL: deep learning; EDESP: English DESP; ML: machine learning; OPH: ophthalmology; PC: primary care; PDESP: Portuguese DESP; RDR: referable diabetic retinopathy; RS: reference standard; SDESP: Scottish DESP; SiDRP: Singapore DESP; SpDESP: Spanish DESP; WDESP: Welsh DESP.
These are the external datasets for which accuracy estimates were included in the review; datasets used for training, internal validation and some of the less relevant external datasets (e.g. public datasets) are not included.
By ‘independent’ we mean that the developer/manufacturer of the system was not involved in or provided funding for the study.
We found another study evaluating DeepDR, Wang 2020, 58 but the paper was poorly written and difficult to understand; the external cohorts were poorly characterised and it was unclear if the external datasets overlapped with those reported in Dai 2021; ultimately, we decided that the study should be excluded.
The sample size ranged from 83 23 to 107,001 participants. 44 Most of the studies included patients enrolled in DESPs or outpatient diabetes clinics. However, the inclusion criteria and patient characteristics varied considerably and were reported inconsistently. In particular, studies varied on patient age as an eligibility criterion (range ≥12 to >40 years of age), and with respect to the distribution of age, race/ethnicity, duration of diabetes and HbA1c level in the included patients. The prevalence of referable diabetic retinopathy (RDR) ranged from 1% 30 to 47% 29 suggesting considerable variation in the distribution of DR grades across study samples.
Methodological quality
The methodological quality of the included studies is summarised in Table 2. Only 11/43 studies were judged to be at low risk of bias in the patient selection domain and 29/43 and 26/43 in the reference standard and flow & timing domains, respectively. In contrast, all but four studies were found to be at low risk of bias in the index test domain. The main issues were failure to include a representative sample of the target population at patient and/or image level (e.g. convenience sampling, not reporting the method of sampling in sufficient detail or excluding images of low quality); failure to meet the reference standard criterion of at least two independent experts grading each image; and exclusion of technical failures from the analysis. Most of the studies were judged to be at low risk of applicability concerns across all three domains.
Methodological quality of included studies using the QUADAS-2 checklist.
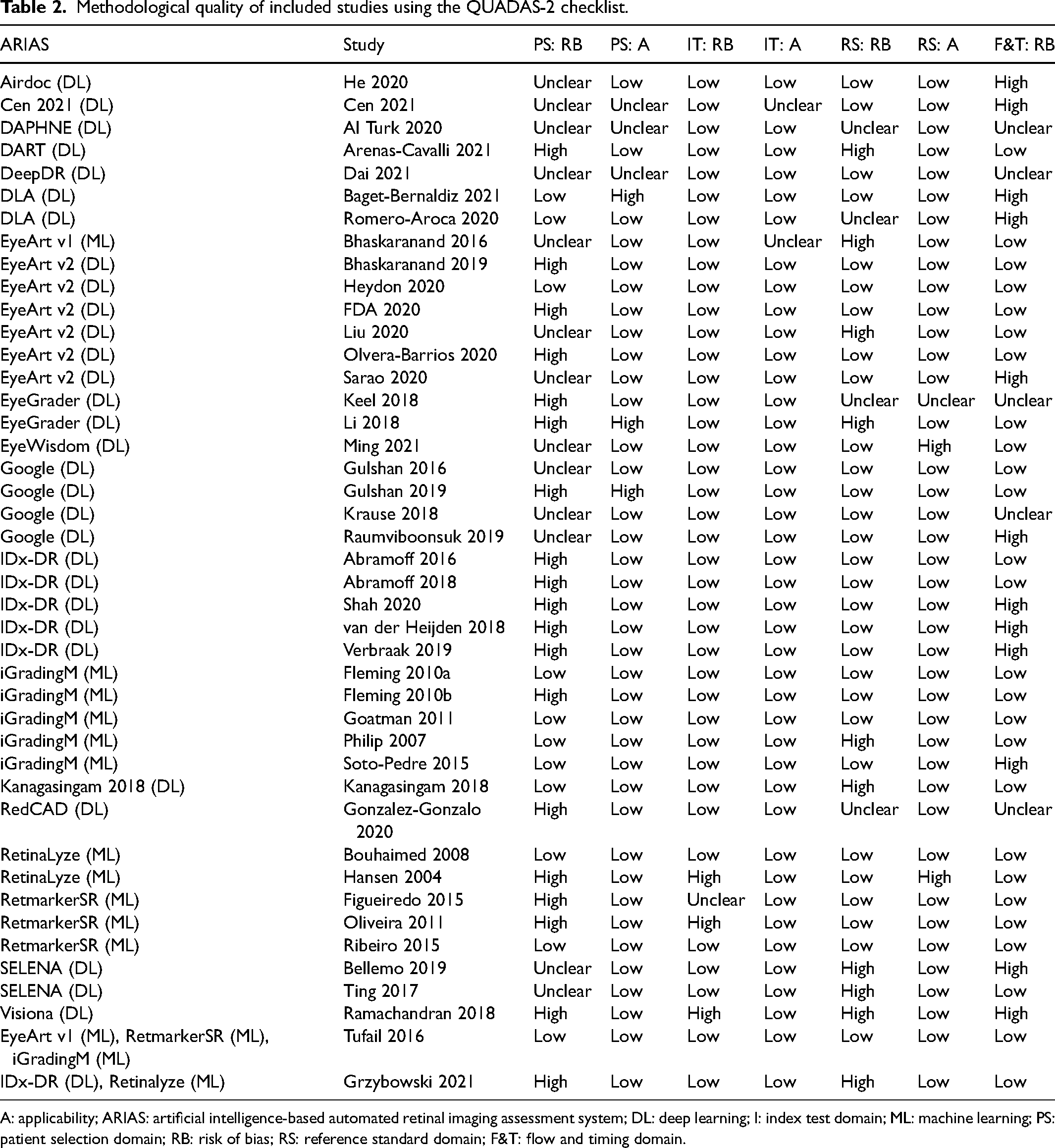
A: applicability; ARIAS: artificial intelligence-based automated retinal imaging assessment system; DL: deep learning; I: index test domain; ML: machine learning; PS: patient selection domain; RB: risk of bias; RS: reference standard domain; F&T: flow and timing domain.
Test accuracy of ARIASs
The results for RDR are summarised in Figure 1 and Table 3; Tables S6 and S7 detail sensitivity, specificity, and positive and negative predictive values arranged by prevalence of DR in the study samples. In addition, Table S8 details accuracy at other thresholds and factors affecting accuracy. RDR was commonly defined as a moderate or worse non-proliferative DR (NPDR) or diabetic macular oedema (DMO). All but two studies54,55 reported sensitivities ≥85%. Specificity estimates, on the other hand, varied widely ranging from 20% 27 to 100%. 42 All 13 studies evaluating ML systems reported specificities <80%, compared to only 6 of the 31 studies evaluating DL systems (Figure 1, Table 3).
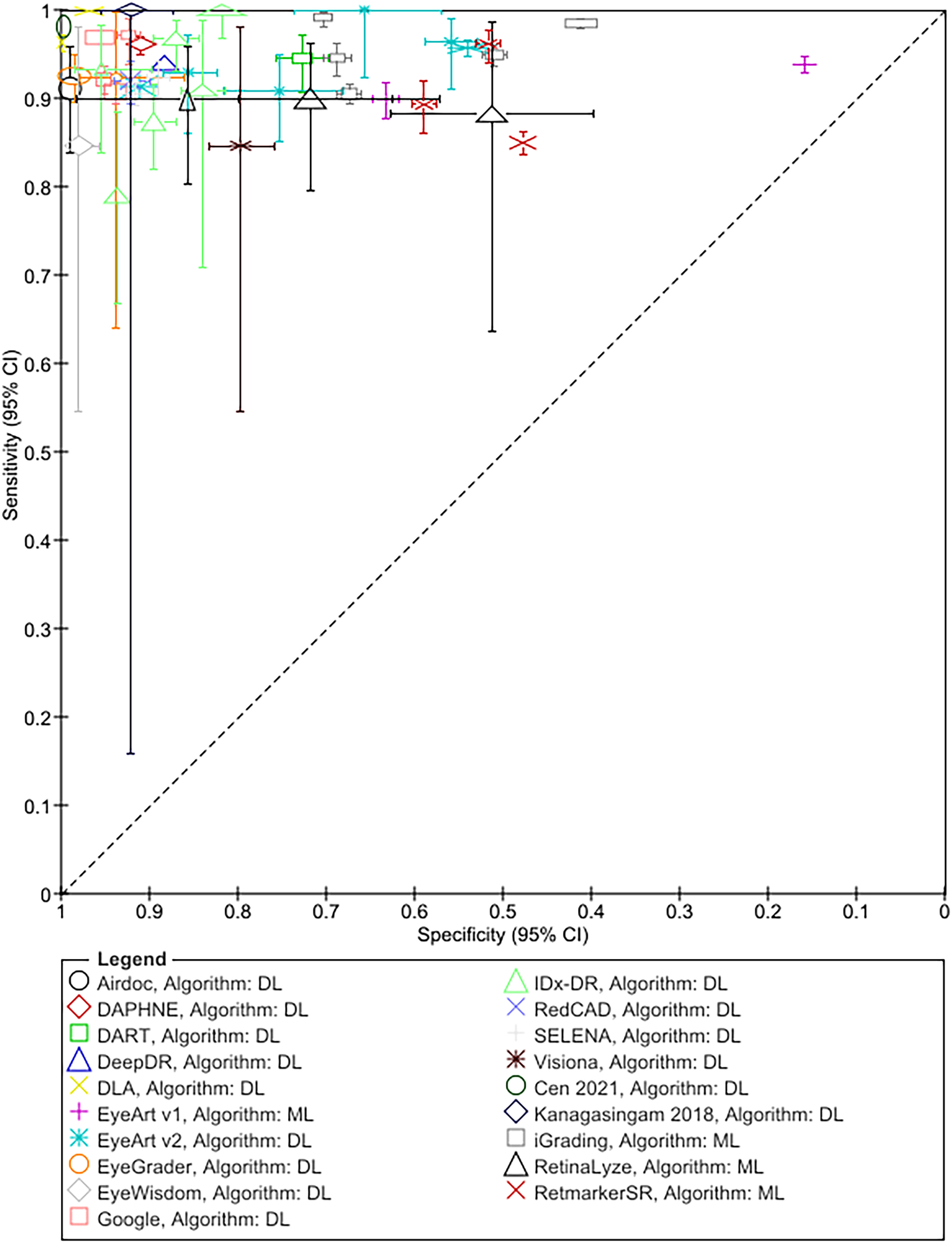
Summary ROC plot of study-level sensitivity and specificity by AI system (given the clinical and methodological variability across studies, the results should not be interpreted as an indication of the comparative accuracy of the systems).
Test accuracy for referable diabetic retinopathy.
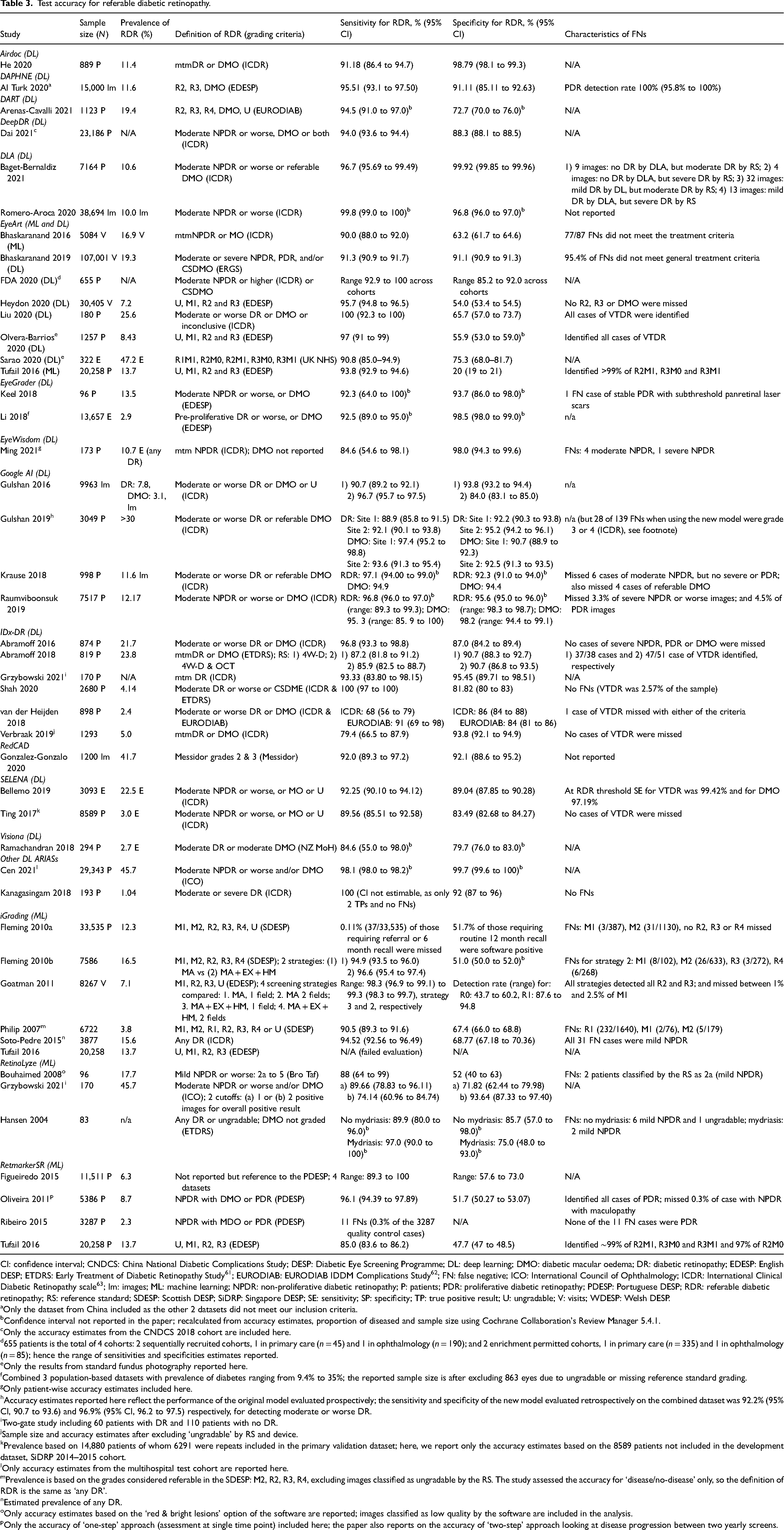
CI: confidence interval; CNDCS: China National Diabetic Complications Study; DESP: Diabetic Eye Screening Programme; DL: deep learning; DMO: diabetic macular oedema; DR: diabetic retinopathy; EDESP: English DESP; ETDRS: Early Treatment of Diabetic Retinopathy Study 61 ; EURODIAB: EURODIAB IDDM Complications Study 62 ; FN: false negative; ICO: International Council of Ophthalmology; ICDR: International Clinical Diabetic Retinopathy scale 63 ; Im: images; ML: machine learning; NPDR: non-proliferative diabetic retinopathy; P: patients; PDR: proliferative diabetic retinopathy; PDESP: Portuguese DESP; RDR: referable diabetic retinopathy; RS: reference standard; SDESP: Scottish DESP; SiDRP: Singapore DESP; SE: sensitivity; SP: specificity; TP: true positive result; U: ungradable; V: visits; WDESP: Welsh DESP.
Only the dataset from China included as the other 2 datasets did not meet our inclusion criteria.
Confidence interval not reported in the paper; recalculated from accuracy estimates, proportion of diseased and sample size using Cochrane Collaboration's Review Manager 5.4.1.
Only the accuracy estimates from the CNDCS 2018 cohort are included here.
655 patients is the total of 4 cohorts: 2 sequentially recruited cohorts, 1 in primary care (n = 45) and 1 in ophthalmology (n = 190); and 2 enrichment permitted cohorts, 1 in primary care (n = 335) and 1 in ophthalmology (n = 85); hence the range of sensitivities and specificities estimates reported.
Only the results from standard fundus photography reported here.
Combined 3 population-based datasets with prevalence of diabetes ranging from 9.4% to 35%; the reported sample size is after excluding 863 eyes due to ungradable or missing reference standard grading.
Only patient-wise accuracy estimates included here.
Accuracy estimates reported here reflect the performance of the original model evaluated prospectively; the sensitivity and specificity of the new model evaluated retrospectively on the combined dataset was 92.2% (95% CI, 90.7 to 93.6) and 96.9% (95% CI, 96.2 to 97.5) respectively, for detecting moderate or worse DR.
Two-gate study including 60 patients with DR and 110 patients with no DR.
Sample size and accuracy estimates after excluding ‘ungradable’ by RS and device.
Prevalence based on 14,880 patients of whom 6291 were repeats included in the primary validation dataset; here, we report only the accuracy estimates based on the 8589 patients not included in the development dataset, SiDRP 2014–2015 cohort.
Only accuracy estimates from the multihospital test cohort are reported here.
Prevalence is based on the grades considered referable in the SDESP: M2, R2, R3, R4, excluding images classified as ungradable by the RS. The study assessed the accuracy for ‘disease/no-disease’ only, so the definition of RDR is the same as ‘any DR’.
Estimated prevalence of any DR.
Only accuracy estimates based on the ‘red & bright lesions’ option of the software are reported; images classified as low quality by the software are included in the analysis.
Only the accuracy of ‘one-step’ approach (assessment at single time point) included here; the paper also reports on the accuracy of ‘two-step’ approach looking at disease progression between two yearly screens.
RDR covers a range of retinopathy grades, from moderate NPDR which usually requires only close monitoring, to PDR where urgent hospital assessment and treatment might be needed. Since the distribution of grades in the false negatives could vary, sensitivity estimates are insufficient to fully characterise the safety of the system. Hence, we also report the characteristics of the false negatives (Table 3) and the accuracy of the systems for detecting higher grades (Table S8). Most studies reported that at the RDR threshold no higher grades of DR were missed or their proportion was very small; and the sensitivity for higher grades was comparable or exceeded that for RDR. In addition, 13 of the 14 studies that investigated the accuracy of the systems for detecting any DR reported sensitivities ≥85% (Table S8).
Thirty-two studies provided data on ungradable images which were difficult to summarise due to inconsistent reporting. Overall, studies reported high detection rates for low-quality images (as determined by the reference standard) and failed to process only a small proportion of the images deemed gradable. There was some evidence that these aspects of the systems’ performance could be affected by a range of factors, such as differences in the imaging protocols27,45 and human behaviour 54 (Table S8).
Twenty-one studies investigated the impact of various factors on accuracy; they related to patient characteristics (age, sex, ethnicity/race, duration of diabetes and HbA1c); imaging protocol (camera type, number of fields and image resolution), algorithm (lesion types detected by ML systems, DL vs ML) and reference standard (grading criteria and method of adjudication) (Table S8). Only a small number of studies reported on each factor and the results varied across studies. Briefly, the studies reported that sex (6 studies) and mean HbA1c (3 studies) were not associated with accuracy, while age (7 studies), DL vs ML algorithm (1 study), duration of diabetes (1 study), grading criteria (1 study) and the method of adjudication (1 study) were. The rest of the results were inconsistent and varied across studies and systems.
Test accuracy of ARIASs compared to human graders
Seven studies conducted head-to-head comparison of the accuracy of human graders not involved in the reference grading to that of Google,31–33 Selena, 35 RetCAD, 34 DLP 36 and iGradingM 25 (Table 4). The number of graders was small (range 2-5), except for the study by Raumviboonsuk et al. which included 13 regional graders from the national screening programme in Thailand. 33 Across all studies ARIASs had higher sensitivity but lower specificity for RDR. In addition, Krause et al. reported that Google had higher sensitivity for referable DMO 32 ; and Ting et al. reported that Selena had higher sensitivity but lower specificity for vision-threatening DR. 35
Studies comparing directly (in the same sample) the test accuracy of ARIAS and human graders not involved in the reference grading.
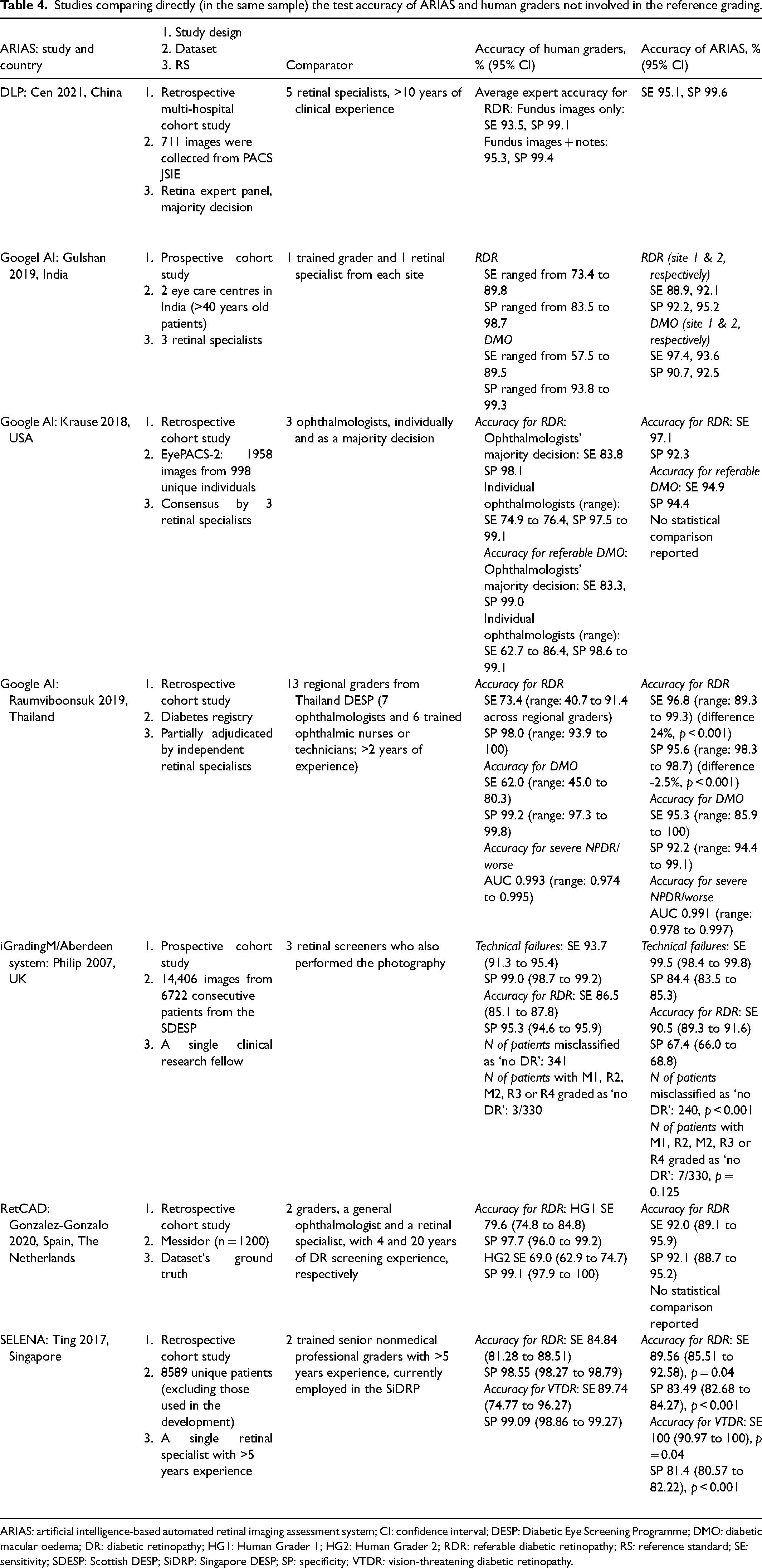
ARIAS: artificial intelligence-based automated retinal imaging assessment system; CI: confidence interval; DESP: Diabetic Eye Screening Programme; DMO: diabetic macular oedema; DR: diabetic retinopathy; HG1: Human Grader 1; HG2: Human Grader 2; RDR: referable diabetic retinopathy; RS: reference standard; SE: sensitivity; SDESP: Scottish DESP; SiDRP: Singapore DESP; SP: specificity; VTDR: vision-threatening diabetic retinopathy.
Discussion
The evaluation of the accuracy of AI-based medical tests goes through a number of stages. Prior to deployment, the systems should be evaluated in the target clinical pathway or a similar setting, so that the accuracy estimates could be used in clinical and policy decisions. 59 In the current paper, we reviewed the accuracy of ARIASs that have been approved for clinical use, are commercially available or have had at least one evaluation in a clinically plausible cohort of patients. Accuracy is the primary, albeit not the only, aspect of such systems’ performance. Unbiased and applicable evidence of acceptable accuracy should be the starting point when considering ARIASs for implementation in clinical practice.
We included 43 studies evaluating 15 DL-based and 4 traditional ML-based systems. Most studies reported sensitivity ≥85% for RDR, any DR and higher grades. At the RDR threshold no cases of proliferative/treatable disease were missed or their proportion was very small. Specificity estimates, on the other hand, varied considerably but, overall, DL systems had higher specificity than ML systems. Seven studies reported that ARIASs had higher sensitivities but lower specificities compared to human graders not involved in the reference grading. In addition, most studies reported high accuracy for detection of ungradable images as determined by the reference standard (also referred to as ‘imageability’), and a small proportion of cases where the system was unable to read an image classified as gradable by the reference standard (‘technical failure’).
The above results suggest that with respect to missing cases of severe or treatable disease, ARIASs could be safe to use in clinical practice provided the operational environment is similar to that in which the system has been evaluated. Limited data suggest that various factors could affect the accuracy of ARIASs for detection of DR and images of low quality as well as the proportion of technical failures. The variability in results indicates that such associations are likely to be system- and context-specific and should be investigated prior to deployment in the target clinical pathway.
Ultimately, the level of accuracy required will depend on the specific role of the system in the clinical pathway. For instance, when used in organised screening to rule out DR prior to manual grading (e.g. UK DESPs), lower specificity might not be an issue. Tufail et al. showed that in the English DESP, ARIASs with high sensitivity and specificity as low as 20% are still cost-effective both as a replacement of level 1 graders and when added to the existing clinical pathway prior to manual grading. 27 In addition, such programmes have well-established quality assurance systems that would allow monitoring and prompt action if there is a decline in the performance of ARIAS over time. Audit studies from Scotland and Portugal provide some real-life evidence that in such settings ARIASs with high sensitivity and relatively low specificity lead to a reduction in the human graders’ workload without compromising the safety of the screening programme.12,13
In settings where such quality controls are not readily available, low specificity (including technical failures) is likely to increase the number of unnecessary referrals and the associated costs. Of particular importance here are contextual and human factors as illustrated by van der Heijden et al. who assessed the accuracy of an ARIAS in a primary care setting in the Netherlands. The authors report a high number of referrals due to ‘insufficient quality’ because clinicians underutilised the ‘insufficient quality’ function of the system and preferred to make a referral instead of repeating the imaging using dilation. 54
Despite these promising results, the evidence base has several limitations. Firstly, most ARIASs were evaluated only in 1–2 studies and none of those evaluations were carried out independently from the developer/manufacturer of the system. The few systems evaluated in multiple studies provide evidence that the accuracy of ARIASs could be affected by multiple factors, especially in terms of specificity. This means that an evaluation in the target clinical pathway is necessary even when there is robust evidence of high performance from another context. Secondly, although the consistent high sensitivity across studies is reassuring, between-study comparison of alternative systems is not possible due to considerable differences in study design. For instance, 85% sensitivity when the reference standard involves a combination of mydriatic 4-wide field stereo retinal photography and optical coherence tomography is not the same as 85% sensitivity when the reference standard is based on the same standard 45° fundus photographs used with the index test. Thirdly, many of the studies were judged to be at high risk of bias in at least one QUADAS-2 domain. Of particular concern is the risk of selection bias, both at patient and image level, and the exclusion of ungradable images. This could lead to inflated accuracy estimates and decline in the system's performance when deployed in clinical practice. Detailed reporting of the selection process, both at patient and image level, and reporting of ungradable images in a way that makes it easier to evaluate their impact are highly desirable and will significantly improve the usability of the evidence.
Direct evaluation of the clinical effectiveness and overall impact of an ARIAS using randomised controlled trial (RCT) designs might not always be feasible. Hence, the importance of assessing the accuracy of the system in a representative dataset, both at patient and image level, and in real-life conditions. Such pre-implementation assessment should also provide evidence on other aspects of the system's performance, such as interoperability, reliability and acceptability. Then a linked evidence approach could be used to combine the evidence and estimate the clinical and cost-effectiveness of an ARIAS even in the absence of RCTs. 60
The following methodological limitations of the review should be acknowledged: we included only peer-reviewed, English-language journal articles; only 20% of the titles/abstracts and full texts were double-screened; only 20% of the extracted data and methodological quality decisions were verified by a second reviewer; some of the inclusion/exclusion criteria were modified after publication of the protocol.
Conclusion
Across systems and studies, ARIASs had ≥85% sensitivity for RDR and higher grades, higher than human graders, and could be safe to use in clinical practice (i.e. have a low risk of missing proliferative/treatable DR) provided the operational environment in the target clinical pathway is similar to that in which the system has been evaluated. The specificities were much more variable, even across studies evaluating the same system. Relatively low specificity might be acceptable when the system is used prior to manual grading in organised screening with established quality assurance protocols. In other settings, however, low specificity is likely to generate unnecessary referrals and incur additional costs. Since the accuracy and overall performance of ARIASs might be affected by a wide range of factors, including human behaviour, evaluation in the target clinical pathway prior to deployment is advisable. If an RCT is not feasible, the clinical and cost-effectiveness of the system relative to the current clinical pathway could be assessed using a linked evidence approach. This however will require not only unbiased and applicable accuracy estimates, but also evaluation of other aspects of the system's performance, such as interoperability, reliability and acceptability.
Supplemental Material
sj-docx-1-msc-10.1177_09691413221144382 - Supplemental material for Test accuracy of artificial intelligence-based grading of fundus images in diabetic retinopathy screening: A systematic review
Supplemental material, sj-docx-1-msc-10.1177_09691413221144382 for Test accuracy of artificial intelligence-based grading of fundus images in diabetic retinopathy screening: A systematic review by Zhivko Zhelev, Jaime Peters, Morwenna Rogers, Michael Allen, Goda Kijauskaite, Farah Seedat, Elizabeth Wilkinson and Christopher Hyde in Journal of Medical Screening
Footnotes
Acknowledgements
We would like to thank Jenny Lowe, University of Exeter Medical School, who helped with the retrieval of papers, and the UK NSC AI task group and the public who provided input to and commented on the original report.
Author contributions
ZZ, JP and MR drafted the protocol, with contribution from the other authors; MR developed the search strategy and conducted the searches; ZZ and JP carried out the selection of studies, data extraction and methodological quality assessment; CH, EW, MA, FS and GK provided advice and arbitration on the selection process, data extraction and methodological quality assessment; all authors contributed to the interpretation of results; ZZ wrote the original draft and the other authors revised the draft critically for important intellectual content and approved the final version of the paper. ZZ and JP directly accessed and verified the underlying data reported in the manuscript. All authors had full access to all the data in the study and had final responsibility for the decision to submit for publication. The UK NSC evidence team and AI task group were also involved in the review process and contributed to the final report and the current paper. The review process involved feedback from stakeholders and the public, as per standard UK NSC practice.
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship and/or publication of this article: All authors have completed the Unified Competing Interest form (available on request from the corresponding author). ZZ, JP, MR and MA declare no conflict of interest (except for the project grant received from the UK National Screening Committee); FS, CH and GK are members of the National Screening Committee, but declare no other conflict of interest; EW is a member of the National Diabetic Screening Advisory Board and President of the British Association of Retinal Screening and has received grants, consulting fees and payments from companies and organisations not directly related to this project.
Funding
The authors disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This review is part of a project funded by the UK National Screening Committee (ITT 4347). The project is an independent research supported also by the National Institute for Health and Care Research Applied Research Collaboration South West Peninsula. The views expressed in this publication are those of the author(s) and not necessarily those of the National Institute for Health and Care Research or the Department of Health and Social Care.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.