
Abstract
Objectives
To determine the agreement between artificial intelligence software (AI) and radiographers in assessing breast positioning criteria for mammograms from standard digital mammography and digital breast tomosynthesis.
Methods
Assessment of breast positioning was performed by AI and by four radiographers in pairs of two on 156 examinations of women screened in Bergen, April to September 2019, as part of BreastScreen Norway. Ten criteria were used; three for craniocaudal and seven for mediolateral-oblique view. The criteria evaluated the appearance of the nipple, breast rotation, pectoral muscle, inframammary fold and pectoral nipple line. Intraclass correlation and Cohen’s kappa coefficient (κ) were used to investigate the correlation and agreement between the radiographer’s assessments and AI.
Results
The intraclass correlation for the pectoral nipple line between the radiographers and AI was >0.92. A substantial to almost perfect agreement (κ > 0.69) was observed between the radiographers and AI on the nipple in profile criterion. We observed a slight to moderate agreement for the other criteria (κ = 0.06–0.52) and generally a higher agreement between the two pairs of radiographers (mean κ = 0.70) than between the radiographers and AI (mean κ = 0.41).
Conclusions
AI has great potential in evaluating breast position criteria in mammography by reducing subjectivity. However, varying agreement between radiographers and AI was observed. Standardized and evidence-based criteria for definitions, understandings and assessment methods are needed to reach optimal image quality in mammography.
Introduction
Consistent production of high-quality images is important in mammographic screening to achieve optimal visualisation of the breast tissue and detection of abnormalities associated with breast cancer. Image quality has shown to influence the rate of recall and screen-detected cancer, and consequently the sensitivity and specificity of screening.1,2 Several factors affect image quality, and breast positioning is one of the main contributors.
Image quality assessment can be performed directly at the screening examination or retrospectively, for quality assurance or for regular monitoring of image quality. The assessment includes evaluation of the positioning of the breast, how the breast is projected on the mammogram, and whether there is any movement blur, noise or other artefact in the image.3,4 Different systems for image quality assessment are available; either checklists with image quality statements, or classification systems, where several image quality statements are assessed and the images are classified based on the overall score.3–6 Commonly used systems include the ‘perfect, good, moderate, inadequate’ (PGMI) system and the ‘excellent, adequate, repeat’ (EAR) system.7,8 These two systems were developed for screen-film mammography, for which image quality was not possible to assess immediately at the screening examination.
BreastScreen Norway has used a modified version of the PGMI system for image quality assessment since the program started in 1996. The modification has been revised over the years, most recently in 2011. 9 However, PGMI classification is a time-consuming task, and only a sample of each radiographer’s images are reviewed and classified. Furthermore, performing image quality classification is subjective as the assessment differs between assessors, both for PGMI and for other classification systems, raising questions about the reliability and validity of these systems.10–13 In 2017, UK guidelines for mammographic screening stated that PGMI and EAR are no longer acceptable methods to assess image quality. 5 However, high-quality images are still a prerequisite in order to achieve a high sensitivity in diagnostic as well as screening mammography. An image quality assessment system that is reliable, valid and objective is therefore needed. As of today, most studies on image quality and positioning are based on screen-film or digital mammography (DM), and fewer on digital breast tomosynthesis (DBT).
In recent years, automated systems for image quality assessment using artificial intelligence (AI), have been developed.14–17 An AI system for image quality assessment would eliminate subjectivity and reduce time spent assessing image quality by the radiographers. Furthermore, having immediate image quality assessment at the screening before the woman leaves the screening unit could reduce recalls due to inadequate image quality. However, the development of automated systems relies on human observers to provide the reference standard for choice of image quality criteria and thresholds which will affect the results of the assessment. 18 Research is needed to investigate whether the AI systems for image quality assessment provide a valid and reliable measure of the criteria. In this study, we aimed to determine the agreement between an AI system and radiographers in assessing breast positioning criteria for DM and DBT.
Methods
We assessed breast positioning criteria from women attending the screening unit in Bergen, as part of BreastScreen Norway, which is a nationwide, population-based breast cancer screening program offering women aged 50–69 biennial two-view mammographic screening. 19 The Cancer Registry of Norway administers the program, while the screening examinations are performed at 26 stationary and four mobile screening units, organised under 17 breast centres across the country. Data collection as a part of BreastScreen Norway is regulated by the Cancer Registry Regulation and the Norwegian Health Registry Act §8, and data are stored at the Cancer Registry of Norway. The Regional Committee for Medical and Health Research Ethics (reference 2015/424) approved this study.
Study population
Mammograms from a random sample of 180 DM and 180 DBT screening examinations performed during the period from April to September 2019 were identified from the databases at the Cancer Registry of Norway and constituted the study population. All examinations were performed using GE Senographe Pristina 3 D Breast Tomosynthesis™ and consisted of two-view (craniocaudal, CC; and mediolateral oblique, MLO) screening examinations performed by 27 radiographers. Synthetic mammograms were used for assessing the breast positioning criteria of DBT examinations.
Assessment of breast positioning criteria
Assessments of breast positioning were performed manually and by the AI system. The manual assessment was performed over the course of two days on a weekend in October 2019 on two ‘picture archiving and communication system’ (PACS) stations in two separate rooms with two five-megapixel screens. A dedicated study radiographer at the screening centre in Bergen identified and made the examinations available in PACS before the assessment. The assessments of the DM screening examinations were performed on one of the PACS stations and the DBT examinations on the other.
Four radiographers performed the manual breast positioning assessment in pairs of two (R1 and R2). A fifth radiographer was available for arbitration if there were any disagreements. The radiographers were between 29 and 59 years old and had at least 3 years’ experience in mammographic screening. A pilot set of ten images was assessed in plenary before the assessment started to establish a common level of understanding of the breast positioning criteria and assessment methods. None of the radiographers participating in this study were involved in the development of the AI system. The pairs used one workday on each PACS station and recorded the results in a prepared spreadsheet. We aimed to assess as many images as possible during the available time slot and included all images except those of women with breast implants. We reached a total of 156 examinations, 79 (50.6%) performed using DM and 77 (49.4%) performed using DBT (Figure 1).
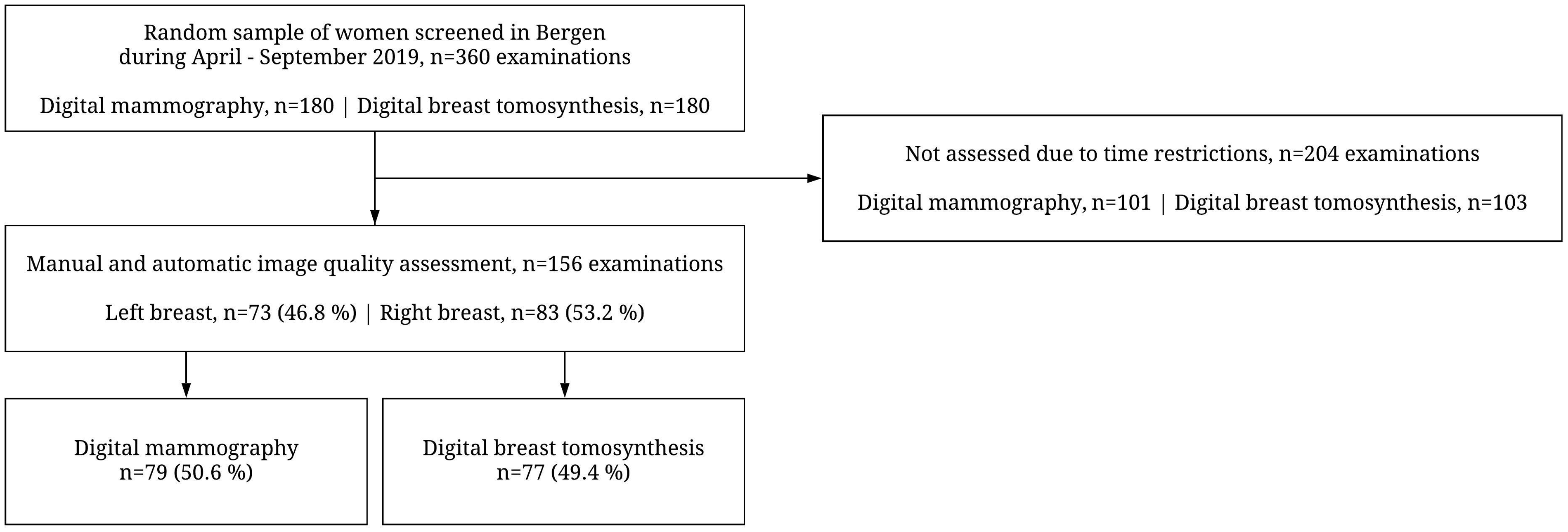
Flow chart of the study population.
The AI assessment was performed on all examinations included in the study population. Automated image processing software obtaining image information from the Digital Imaging and Communications in Medicine (DICOM) header and image pixel data (Volpara®Density™, Volpara Health Technologies Ltd., Wellington, NZ; algorithm version 1.5.5.1) was used.
Breast positioning criteria
Breast positioning was assessed using ten criteria; three for CC and seven for MLO view (Table 1). The breast positioning criteria were selected from the PGMI used in BreastScreen Norway 9 and criteria available from the AI system. The criteria included nipple in profile (both views), pectoral nipple line (both views), rotation of the breast (CC view), angle of pectoral muscle (MLO view), fold in pectoral muscle (MLO view), length of pectoral muscle to posterior nipple line (MLO view), shape of pectoral muscle (MLO view) and inframammary fold visibility (MLO view).
Breast positioning criteria, assessment methods for manual assessment of breast positioning and associated measurements.
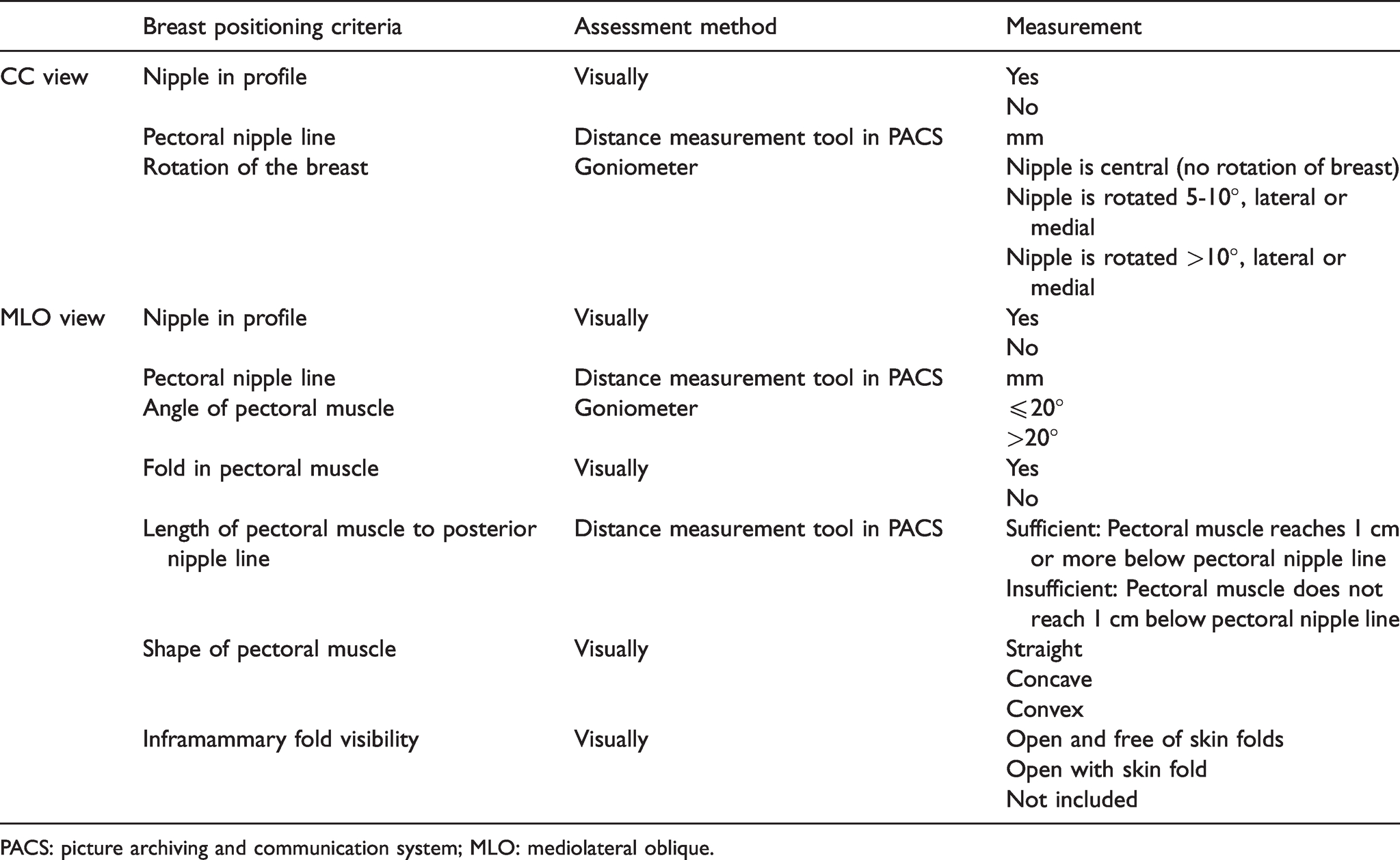
PACS: picture archiving and communication system; MLO: mediolateral oblique.
The pairs of radiographers reviewed the images and discussed the criteria to come to an agreement. A distance measurement tool in PACS was used to measure the pectoral nipple line, and length of the pectoral muscle to posterior nipple line. The pectoral nipple line in CC view was defined as the distance from the nipple to the image edge, independent of the pectoral muscle. For MLO view, the pectoral nipple line was defined as the distance from the nipple perpendicular to the anterior margin of the pectoral muscle (or the posterior image edge). An approximation of the pectoral line was drawn as a straight line, from the anterior to the superior end of the muscle in the image. The pectoral line and the corner of a piece of standard A4 paper were used to simplify drawing the perpendicular pectoral nipple line for the MLO view (Supplementary file 1). Measurement of the length of the pectoral muscle to the posterior nipple line used the perpendicular line created for the pectoral nipple line, i.e. whether the pectoral muscle reached 1 cm or more below this line. A goniometer was used to assess the rotation of the breast (CC) and the angle of the pectoral muscle (MLO). Rotation was measured as degrees between the midline of the breast at the posterior image edge and the position of the nipple, while the angle of the pectoral muscle was measured using the pectoral line and the posterior image edge.
Statistical analyses
Mean value and standard deviation (SD) were used to present the continuous variable pectoral nipple line and intraclass correlation (ICC) was used to investigate the correlation between R1, R2 and AI. ICC estimates and their 95% confidence interval (95% CI) were calculated based on a mean-rating absolute agreement and two-way random effects model. Correlation was interpreted according to the following distribution: <0.49, poor correlation; 0.50–0.74, moderate correlation; 0.75–0.89, good correlation; 0.90–1.0, excellent correlation. 20 All other variables were categorical and presented as percentages, and counted for each criterion by R1, R2 and AI. Further, they were presented as percentages and counted as agreement or disagreement between R1, R2 and AI. Cohen's kappa coefficient (κ) was used to quantify the agreement between R1, R2 and AI, and all groups together. The degree of agreement was determined according to the following distribution: <0, poor agreement; 0.0–0.20, slight agreement; 0.21–0.40, fair agreement; 0.41–0.60, moderate agreement; 0.61–0.80, substantial agreement; 0.81–1.0 almost perfect agreement. 21 Characteristics of the women screened, including mean values and 95% CI for age at screening (years), breast volume (cm3), fibroglandular volume (cm3), volumetric breast density (%), compression force (Newton), compression pressure (kilopascal), and compressed breast thickness (mm) are shown in Supplementary file 2. We found no statistically significant differences between the results for DM versus DBT, so all results are presented for DM and DBT combined. Results for DM and DBT, separately, are given in Supplementary files 3–6. Statistical analyses were performed using Stata version 16 (StataCorp, TX, USA).
Results
Pectoral nipple line (both views)
Mean length of the pectoral nipple line for CC view was 9.9 mm (SD = 2.4) for R1, 10.0 mm (SD = 2.4) for R2 and 10.8 mm (SD = 2.7) for AI (Table 2). For MLO view, mean length of the pectoral nipple line was 10.2 mm (SD = 2.6) for R1, 10.4 mm (SD = 2.6) for R2 and 11.4 mm (SD = 2.8) for AI (Table 2). ICC for the pectoral nipple line between R1 and AI and between R2 and AI was >0.92 for both views.
Mean value with standard deviation (SD) of the pectoral nipple line for CC and MLO view, by R1, R2 and AI and the intraclass correlation (ICC) with 95% confidence interval (95% CI) between R1, R2 and AI for CC and MLO view.
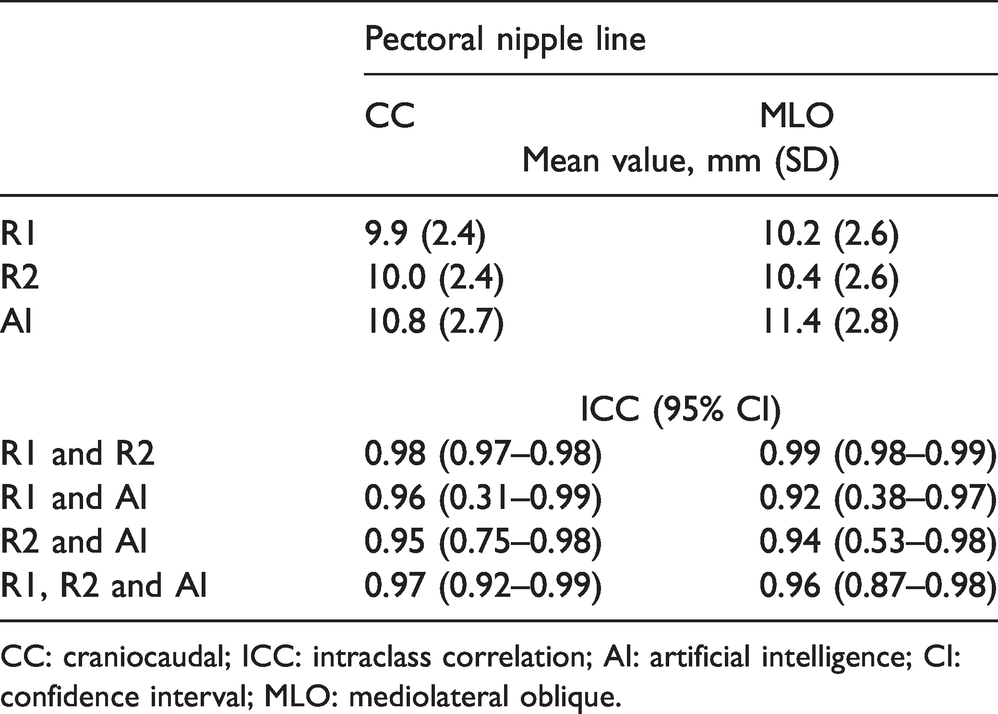
CC: craniocaudal; ICC: intraclass correlation; AI: artificial intelligence; CI: confidence interval; MLO: mediolateral oblique.
Nipple in profile (both views) and rotation of the breast (CC view)
The percentage of images with “nipple in profile” (yes) varied from 75.6% (118/156) to 83.3% (130/156) for CC and from 75.6% (118/156) to 84.6% (132/156) for MLO between R1, R2 and AI (Table 3). Substantial agreement was observed for R1 and AI, and R2 and AI for CC view (κ = 0.77 and 0.69, respectively). For MLO, the agreement was almost perfect for R1 and AI (κ = 0.83), and substantial for R2 and AI (κ = 0.72). The percentage of CC images with “central position of the nipple” (no rotation of the breast) varied between 35.9% (56/156) and 44.9% (70/156), while “nipple with a rotation” of 5°–10° varied between 19.2% (30/156) and 31.4% (49/156), and >10° varied between 24.4% (38/156) and 40.4% (63/156) (Table 3). Moderate agreement was observed between R1 and AI (κ = 0.52), and between R2 and AI (κ = 0.49).
Percentage (%) and proportion (n = out of 156 examinations) of nipple in profile for CC and MLO view, and rotation of the breast for CC view, by R1, R2 and AI, and the agreement, disagreement and Cohen’s Kappa value between R1, R2 and AI and in total.
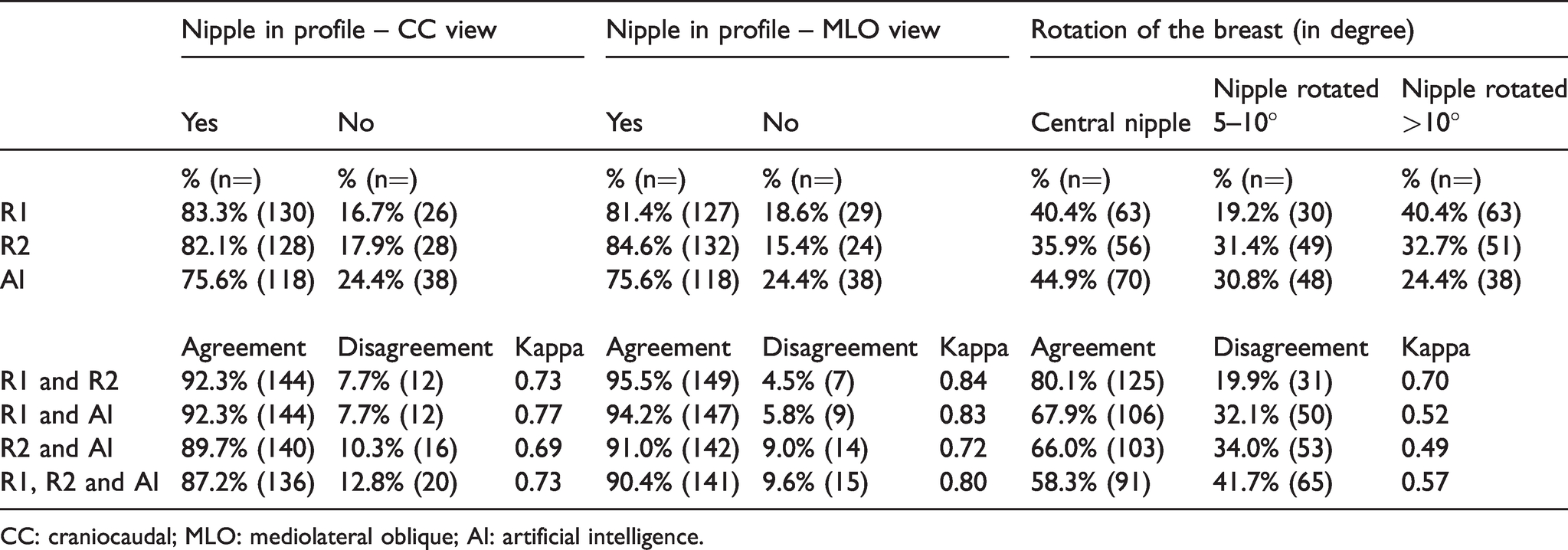
CC: craniocaudal; MLO: mediolateral oblique; AI: artificial intelligence.
Appearance of pectoral muscle and inframammary fold visibility (MLO view)
The percentage of images with a ≤ 20° “angle of the pectoral muscle” varied between 32.1% (50/156) and 41.7% (65/156) for R1, R2 and AI (Table 4). Fair agreement was observed between R1 and AI (κ = 0.25), and between R2 and AI (κ = 0.31). The variation in percentage of images with a “fold in the pectoral muscle” was between 12.8% (20/156) and 36.5% (57/156) between R1, R2 and AI (Table 4). The agreement between R1 and AI was fair (κ = 0.28), while it was slight for R2 and AI (κ = 0.18). The percentage of images with a “sufficient length of the pectoral muscle to posterior nipple line” varied between 62.2% (97/156) and 75.6% (118/156) between R1, R2 and AI (Table 4). Fair agreement was observed between R1 and AI (κ = 0.31), and between R2 and AI (κ = 0.27).
Percentage (%) and proportion (n = out of 156 examinations) of angle of pectoral muscle, fold in pectoral muscle and pectoral muscle to posterior nipple line for MLO view, by R1, R2 and AI, and the agreement, disagreement and Cohen’s Kappa value between R1, R2 and AI and in total.
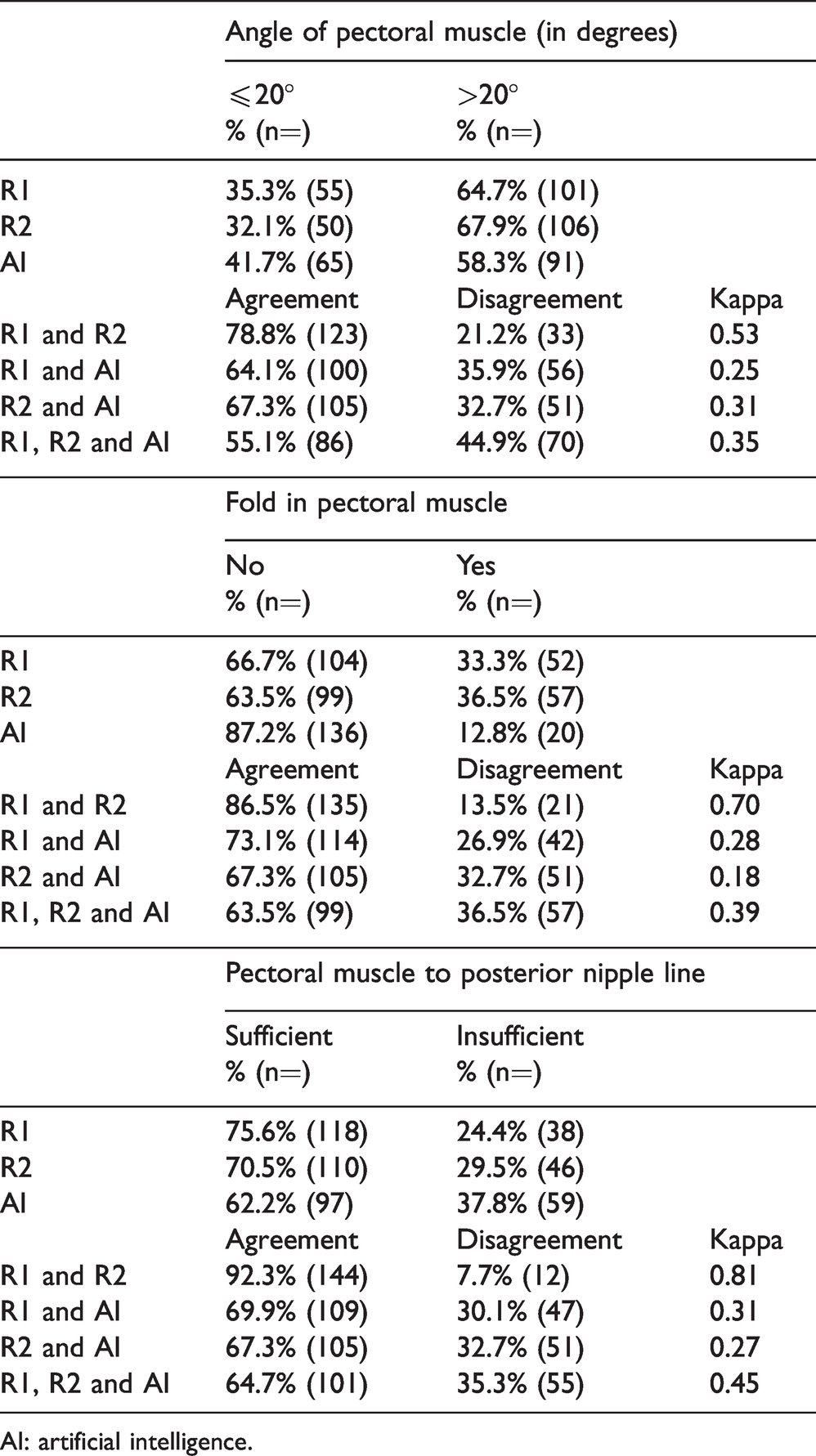
AI: artificial intelligence.
The percentage of images with a “straight pectoral muscle” varied from 71.8% (112/156) to 75.0% (117/156), while concave pectoral muscle varied from 16.0% (25/156) to 19.2% (30/156), and convex from 5.8% (9/156) to 12.2% (19/156) (Table 5). Slight agreement was observed between R1 and AI (κ = 0.06), and between R2 and AI (κ = 0.20). The percentage of images with an “inframammary fold that was open and free of skin folds” varied between 38.5% (60/156) and 53.8% (84/156) for R1, R2 and AI, while open with skin fold varied between 32.1% (50/156) and 41.0% (64/156), and inframammary fold not included in the image between 9.0% (14/156) and 20.5% (32/156) (Table 5). Fair agreement was observed between R1 and AI (κ = 0.34), and between R2 and AI (κ = 0.39).
Percentage (%) and proportion (n = out of 156 examinations) of shape of pectoral muscle and inframammary fold visibility for MLO view, by R1, R2 and AI, and the agreement, disagreement and Cohen’s Kappa value between each R1, R2 and AI and in total.
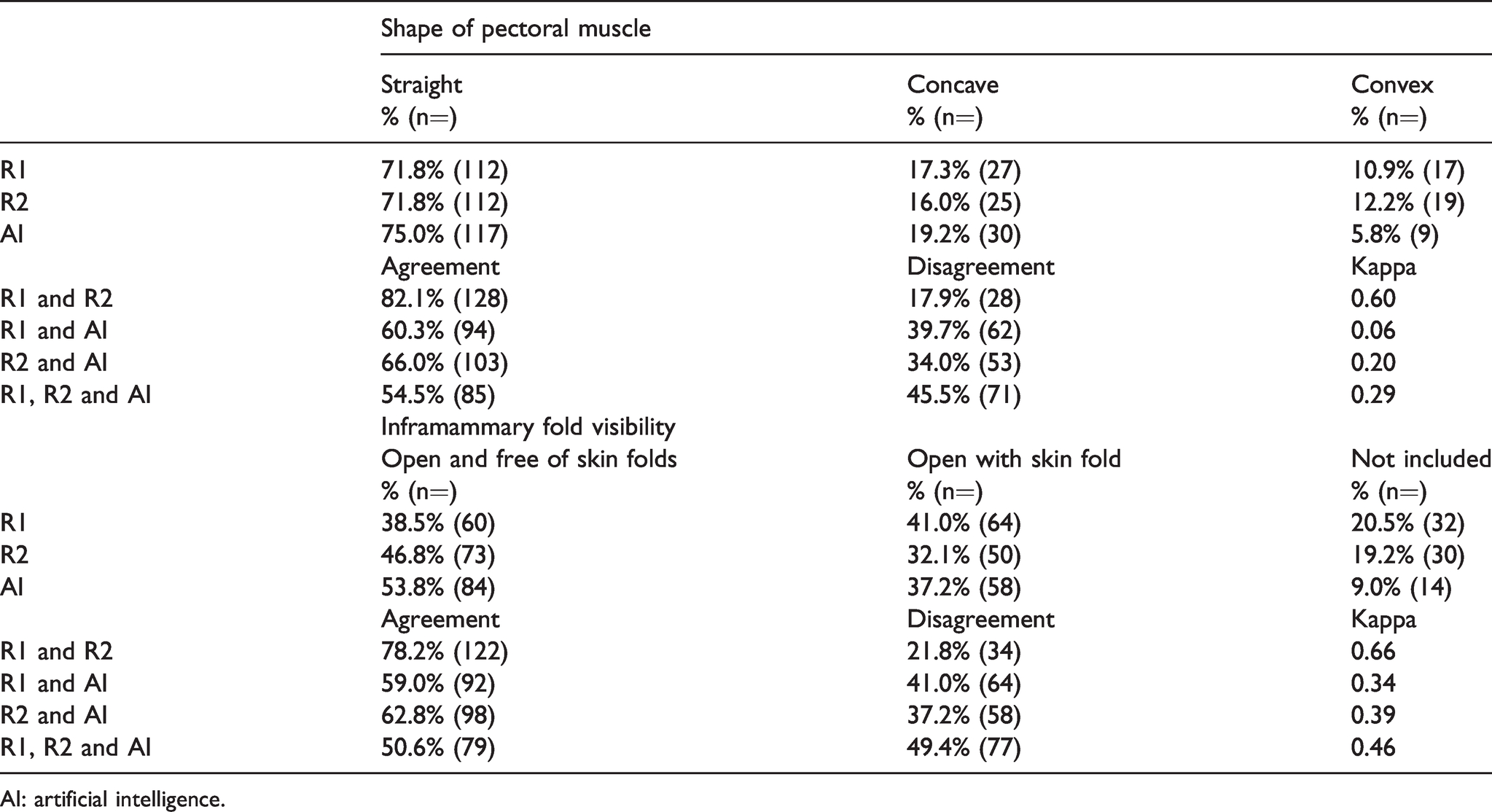
AI: artificial intelligence.
Discussion
This study aimed to determine the agreement between an AI system and radiographers in the assessment of breast positioning criteria. We observed a substantial to almost perfect agreement between AI and the radiographers for the nipple in profile criterion and an excellent correlation for pectoral nipple line. However, there was only a slight to moderate agreement for the other criteria, and generally a higher agreement between the two pairs of radiographers than between the radiographers and AI.
The reasons for the higher agreement and correlation for the criteria nipple in profile and pectoral nipple line, compared to the other criteria, are not obvious to the authors. Perhaps these criteria are simply easier to agree upon based on the appearance in the image – however, agreement between the pairs of radiographers was as high or even higher for other criteria. AI relies on premises set by humans to provide reference standards for the criteria. 18 In this case, premises were set by other radiographers than those participating in this study. It is possible that those who provided reference standards for this AI interpreted those two criteria in the same way as the radiographers in our study did. The lower agreement observed between the radiographers and AI on the other positioning criteria might reflect differences in the interpretation or definition of the criteria or the assessment methods. For instance, some criteria, like whether or not a skin fold is present, might be interpreted differently based on whether the fold is transparent and whether it covers any anatomy of interest. Furthermore, the assessment method will obviously impact on the agreement; for instance, how to assess rotation of the breast, pectoral nipple line, and criteria related to appearance of pectoral muscle.
The agreement between the two pairs of radiographers was generally higher than the agreement between R1 and AI, R2 and AI, and combined. A multi-centre study by Sharma et al. 22 evaluated agreement between one radiologist and nine radiographers in assessing positioning errors on 672 rejected DM examinations. The assessors were provided with similar criteria to those included in the present study. They reported slight to moderate agreement between the assessors (κ = 0.09–0.49), and thus the observed agreement between the radiographers in our study was higher than in their study. 22 The high agreement observed in our study could be due to the chosen method of using a plenary assessment of ten images before starting the assessment for the study and two radiographers discussing the criteria. However, we would argue that our results are promising when it comes to having a common understanding of breast positioning criteria and assessment methods. Our results support using training of radiographers to achieve a more uniform assessment, which could further lead to optimal mammographic positioning. 23
AI has great potential in mammographic screening by reducing the subjectivity in the image quality and breast positioning assessment among radiographers. An objective and reproducible assessment at the screening examination might reduce retakes due to preferences or opinions among the radiographers, and reduce recalls due to inadequate breast positioning. AI could also reduce the time radiographers spend assessing images, free up resources, and make the screening programs more efficient and cost-effective. However, if the radiographers do not understand, agree with or trust the performance of AI systems, these potential advantages could be lost. This highlights the need for a common understanding and definition of the criteria and assessment methods, in addition to transparency around how the AI systems work. In the future, AI may also have a significant impact on the radiologist’s screen reading. 24 If AI becomes the sole reader of a proportion of the mammograms in a screening program, it is particularly important that there is common understanding of adequate image quality and breast positioning to ensure reproducible imaging over time. Today, there is limited information available about how different AI systems work. Transparency seems to be crucial in the process of successfully adapting AI systems into clinical practice.
Several publications have emphasized the need for a reliable, valid and objective system of image quality assessment in mammography.11,13 The current systems for image quality assessment were developed in a different era, without the same technical and digital possibilities. Today, image quality can be assessed directly after every exposure, large and advanced detectors with better dynamic range are available, and there are many post-processing options. Thus, the relevance of the image criteria might have changed since the original criteria were identified. Furthermore, studies have raised questions regarding the achievability and relevance of some of the criteria used.2,12,25 The most recent attempts to improve systems for image quality assessment have, as far as we are aware, not reduced the subjectivity or lack of evidence.5,26 This highlights the importance of standardized and evidence-based criteria in systems for assessment of breast positioning in order to achieve uniform assessment and optimal image quality in mammography.
We assume that the criteria selected for this study impacted the results. Our study included fewer criteria than used in clinical practice in Norway 9 and in other studies. 26 For instance, we included three criteria for CC view; however, there is limited evidence and consistency about the choice of CC criteria. 27 Our study solely assessed breast positioning criteria, but other criteria related to blur, exposure and post-processing adequacy are also of importance for image quality. Furthermore, we only assessed selected positioning criteria and no overall image quality or technical errors. However, the choice of criteria was limited by available output from the AI system evaluated. Also, we excluded images of women with breast implants, which might represent a limitation of the study.
Conclusion
AI has great potential in image quality and breast positioning assessment in mammographic screening by reducing subjectivity. However, we observed varying agreement between the radiographers and AI for several breast positioning criteria, and there was higher agreement between the radiographers. Standardized and evidence-based definitions and assessment methods are needed to reach optimal image quality in mammography.
Supplemental Material
sj-pdf-1-msc-10.1177_0969141321998718 - Supplemental material for Assessment of breast positioning criteria in mammographic screening: Agreement between artificial intelligence software and radiographers
Supplemental material, sj-pdf-1-msc-10.1177_0969141321998718 for Assessment of breast positioning criteria in mammographic screening: Agreement between artificial intelligence software and radiographers by Gunvor G Waade, Anders Skyrud Danielsen, Åsne S Holen, Marthe Larsen, Berit Hanestad, Nina-Merete Hopland, Vanya Kalcheva and Solveig Hofvind in Journal of Medical Screening
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.