
Abstract
Artificial intelligence (AI) algorithms have been retrospectively evaluated as replacement for one radiologist in screening mammography double-reading; however, methods for resolving discordance between radiologists and AI in the absence of ‘real-world’ arbitration may underestimate cancer detection rate (CDR) and recall. In 108,970 consecutive screens from a population screening program (BreastScreen WA, Western Australia), 20,120 were radiologist/AI discordant without real-world arbitration. Recall probabilities were randomly assigned for these screens in 1000 simulations. Recall thresholds for screen-detected and interval cancers (sensitivity) and no cancer (false-positive proportion, FPP) were varied to calculate mean CDR and recall rate for the entire cohort. Assuming 100% sensitivity, the maximum CDR was 7.30 per 1000 screens. To achieve >95% probability that the mean CDR exceeded the screening program CDR (6.97 per 1000), interval cancer sensitivities ≥63% (at 100% screen-detected sensitivity) and ≥91% (at 80% screen-detected sensitivity) were required. Mean recall rate was relatively constant across sensitivity assumptions, but varied by FPP. FPP > 6.5% resulted in recall rates that exceeded the program estimate (3.38%). CDR improvements depend on a majority of interval cancers being detected in radiologist/AI discordant screens. Such improvements are likely to increase recall, requiring careful monitoring where AI is deployed for screen-reading.
Introduction
Population mammography screening programs have operated in many countries for decades based on evidence that screening reduces breast cancer deaths through early detection. Despite this success, 20–25% of breast cancers are missed at screening, many of which present symptomatically as ‘interval’ cancers between screening rounds. 1 Furthermore, most women (≥80%) recalled at screening do not have cancer (false positives),2,3 resulting in potential harms from unnecessary investigations and anxiety. 4 Coupled with these limitations, the practice of double-reading adopted by many screening programs (interpretation of mammograms by two independent readers, with discordance resolved by additional arbitrating reads or a consensus meeting) presents resourcing challenges for screening programs in the context of a global radiology workforce shortage. 5 Replacing one radiologist in double-reading with automated mammography interpretation by an artificial intelligence (AI) algorithm has the potential to identify interval cancers, reduce screening volume for radiologists and minimise false-positive recall.6,7
Evidence for AI as a reader replacement largely consists of retrospective cohort studies.3,7,8 Such studies pair AI with historical ‘real-world’ radiologist findings to estimate the cancer detection rate (CDR) (including detection of cancers that were screen-detected in practice, as well as interval cancers) and recall rate when AI is integrated into double-reading. A challenge in retrospective data is the resolution of discordance between the real-world reader and the AI, due to increased discordance relative to radiologist double-reading.3,7,8 Although some radiologist/AI discordant cases are likely to have had discordant findings by both initial real-world readers (and therefore an actual arbitration or consensus outcome), the absence of real-world arbitration is common. Arbitration of discordance may be simulated by applying the historical result of the second real-world read; however, this is likely to introduce biases that underestimate the contribution of AI to screen detection in practice (e.g. AI findings are unavailable to the arbitrating reader).3,9,10 To date, only one study investigating AI as a reader replacement has prospectively resolved discordance, but that study also has limitations resulting from AI findings informing consensus discussions in both the AI and no-AI arms. 11
To address the uncertainty associated with resolution of radiologist/AI discordance, we extend our large-scale, retrospective cohort study 3 to apply novel arbitration through statistical simulation. By applying plausible scenarios, we aim to estimate the potential that CDR and recall are underestimated in retrospective data, and to elucidate conditions required for CDR to exceed real-world double reading by radiologists.
Methods
The study cohort and data acquisition methods have been described previously.3,6 Briefly, 108,970 consecutive screening examinations from women aged 50–74 attending the population screening program in Western Australia, BreastScreen WA (BSWA), between November 2015 and December 2016 were included. The cohort was representative of women invited to screening in Australia. The double-reading screening decision (recall; no recall), decisions by individual radiologists (reader 1; reader 2; reader 3 arbitration for discordance), and the screening outcome for recalled cases (screen-detected cancer; no cancer) for real-world screening in the BSWA program were extracted from the Mammographic Screening Registry. Linkage to the WA Cancer Registry identified interval cancers diagnosed within the recommended screening interval (24 months for most women). A commercially available AI algorithm (DeepHealth, Saige-Q v2.0.0) 12 reinterpreted the mammograms and output a probability of malignancy for each screen, from which a binary recall/no recall decision was generated by applying a predefined threshold derived from an independent, external dataset. The replacement of one radiologist in double-reading was simulated by pairing recall decisions from reader 1 (which were undertaken independently from other readers) and the AI (Supplemental Figure 1). In our previous study, reader 1/AI discordance was arbitrated by the real-world reader 2. 3
In this study, we identified reader 1/AI discordant screens (N = 21,960). Of those, 20,120 (91.6%) did not have a real-world arbitration outcome (Supplemental Figure 1). For those screens, arbitration was simulated by first randomly generating a number uniformly distributed between 0 and 1 for each screen. If the random number exceeded a threshold probability, the case was deemed to be recalled. Random number generation was repeated to produce 1000 simulation datasets. Threshold probabilities were varied for screens with an outcome of screen-detected cancer (sensitivity; range 0.80–1.00), interval cancer (sensitivity; range 0.50–1.00) and no cancer (false-positive proportion, FPP; range 0.33–0.50). For 1840 reader 1/AI discordant screens with real-world arbitration, the recall decision from arbitration was used. In cases of reader 1/AI concordance, the agreed recall decision was applied. Mean CDRs (per 1000 screens) and recall rates (percentage) were computed for the entire cohort across the 1000 simulations, and 95% confidence intervals (CIs) were approximated from the 2.5th and 97.5th percentiles. Probabilities that the means were greater than the BSWA program CDR and recall, or the CDR and recall for integrated radiologist/AI reading reported in our previous study, were derived from the proportion of simulated estimates that exceeded those values. Analyses were undertaken in SAS 9.4 and R 4.0.4.
Results
The BSWA program (radiologist double-reading) CDR was 6.97 per 1000. In reader 1/AI discordant cases with real-world arbitration, the sensitivity of arbitration was (by definition) 1.00 for screen-detected cancer and 0.00 for interval cancer. In the most optimistic scenario for simulated arbitration of discordant cases without real-world arbitration (screen-detected sensitivity = 1.00, interval sensitivity = 1.00), the maximum possible CDR was 7.30 per 1000 (Table 1). CDR decreased linearly as the assumed sensitivities for screen-detected or interval cancer decreased (Figure 1). At maximum screen-detected sensitivity, interval sensitivities ≥0.67 and ≥0.63 resulted in ≥99% and ≥95% probability that the mean CDR was greater than the BSWA program estimate, respectively; to achieve these probabilities at screen-detected sensitivity of 0.80, interval sensitivities of ≥0.96 and ≥0.91 were required. At screen-detected sensitivity = 1.00, the mean CDR equalled the BSWA program CDR at interval sensitivity of 0.54; at screen-detected sensitivity = 0.80, CDR estimates were equal at interval sensitivity of 0.81. For all scenarios in Table 1, the mean CDR exceeded the CDR for integrated radiologist/AI reading from our previous study (6.37 per 1000) in 100% of simulations.
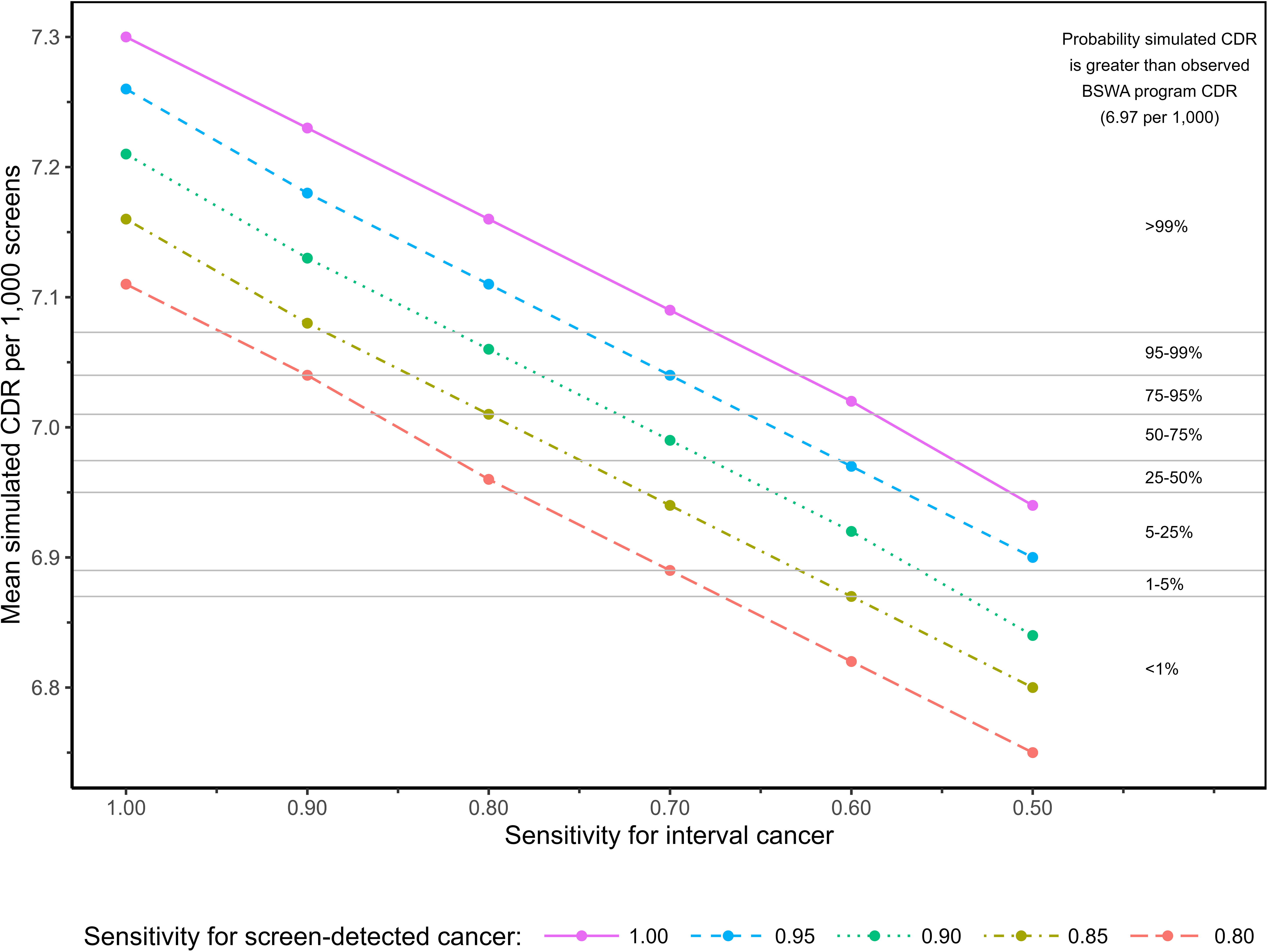
Probability that mean CDR exceeds BSWA CDR according to assumed sensitivity of arbitration for screen-detected and interval cancers in reader 1/AI discordant screens with no real-world arbitration.
Mean CDR according to assumed sensitivity of arbitration for screen-detected and interval cancers in reader 1/AI discordant screens with no real-world arbitration.
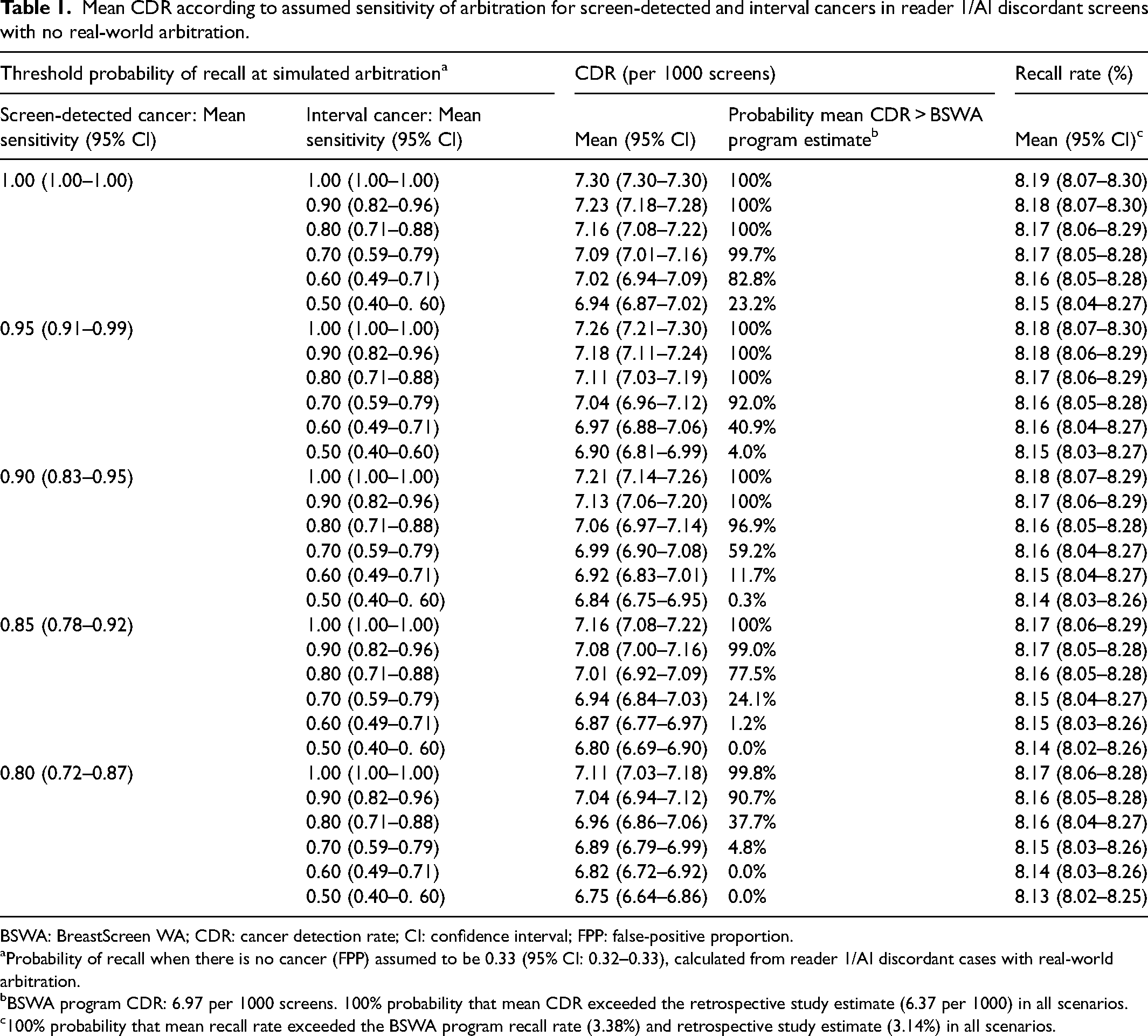
BSWA: BreastScreen WA; CDR: cancer detection rate; CI: confidence interval; FPP: false-positive proportion.
Probability of recall when there is no cancer (FPP) assumed to be 0.33 (95% CI: 0.32–0.33), calculated from reader 1/AI discordant cases with real-world arbitration.
BSWA program CDR: 6.97 per 1000 screens. 100% probability that mean CDR exceeded the retrospective study estimate (6.37 per 1000) in all scenarios.
100% probability that mean recall rate exceeded the BSWA program recall rate (3.38%) and retrospective study estimate (3.14%) in all scenarios.
Mean simulated recall rate was relatively insensitive to assumptions about sensitivity, but highly sensitive to the assumed FPP. In reader 1/AI discordant cases with real-world arbitration, the FPP was 0.33. When this proportion was applied to discordant cases without real-world arbitration, the mean recall rate was 8.13–8.19% in all scenarios tested, with 100% probability that this exceeded the BSWA program recall rate (3.38%) (Table 1). At an assumed FPP of 0.50, the mean recall rate increased to 11.29–11.35% (Supplemental Table 1). Assuming maximum values for sensitivity, the mean simulated recall rate equalled the BSWA recall rate at FPP = 0.065 (Supplemental Table 2).
Discussion
Retrospective studies can provide evidence about the utility of new health technologies and are an important intermediate step on the evaluation pathway. However, retrospective designs are inherently limited in the extent to which they can mimic the real-world settings in which technologies are implemented, particularly the complex interactions that can occur with humans. In the evaluation of AI as a replacement for one radiologist in screening mammography double-reading, retrospective studies encounter challenges in resolving discordance between radiologists and the AI, which is especially problematic given that AI can increase false-positives and therefore the need for arbitration relative to human double-reading.3,7,8 Our statistical simulations show a high probability that both CDR and recall are underestimated in retrospective studies where discordance is arbitrated by historical findings from a real-world second reader. This is likely due to biases such as AI findings being necessarily unavailable to the historical second reader, and inherently greater human-human agreement relative to AI-human agreement, potentially compounded by unblinding of first and second reader results. 3 Changes in reader experience from incorporating AI in screening workflow may exacerbate the underestimation of CDR. 3
Furthermore, in scenarios assuming high accuracy for arbitration (where real-world arbitration was unavailable), there was a high degree of certainty that the CDR for integrated radiologist/AI reading could exceed that for double-reading by humans. Importantly, any CDR increase is predicated on a majority of interval cancers being recalled by arbitration (≥63%, depending on the sensitivity for screen-detected cancers). In our study, the AI alone was positive in 98% of interval cancers in this subgroup, suggesting that a CDR increase is plausible if the AI findings are made available to the arbitrating reader. However, we found that an unrealistically low FPP for arbitration (<0.065) was required for our simulated recall rates to be lower than the program's actual estimate (i.e. > 93.5% of radiologist/AI false-positives would need to be ‘corrected’ by arbitration for a reduction in recall). Any gain in CDR associated with integrated radiologist/AI reading is therefore likely to be accompanied by an increase in recall; therefore, close monitoring of recall will be essential if AI is deployed as a reader in double-reading practice.
Early results from prospective trials of AI for a variety of breast cancer screening workflows have recently been reported with encouraging findings about AI's potential role.11,13,14 However, interval cancer ascertainment will require longer-term follow-up so this evidence base will continue to mature over time. In the interim, the results from retrospective studies, interpreted with appropriate caution and awareness of their limitations, can supplement the evidence from prospective trials to inform the further evaluation and monitoring of this technology.
Supplemental Material
sj-docx-1-msc-10.1177_09691413241262960 - Supplemental material for Simulated arbitration of discordance between radiologists and artificial intelligence interpretation of breast cancer screening mammograms
Supplemental material, sj-docx-1-msc-10.1177_09691413241262960 for Simulated arbitration of discordance between radiologists and artificial intelligence interpretation of breast cancer screening mammograms by M Luke Marinovich, William Lotter, Andrew Waddell and Nehmat Houssami in Journal of Medical Screening
Footnotes
Acknowledgements
The authors wish to thank Dr Elizabeth Wylie for contributing to the development and conduct of the BSWA cohort study, and commenting on an earlier version of this manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: MLM was supported by funding from a National Breast Cancer Foundation (NBCF) Investigator Initiated Research Scheme grant (grant number 2023/IIRS0028). NH was supported by the National Breast Cancer Foundation (NBCF) Chair in Breast Cancer Prevention program (EC-21-001) and by a National Health and Medical Research Council (NHMRC) Investigator (Leader) grant (grant number 1194410).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.