
Abstract
Objectives
Analysis of cancer screening effectiveness is challenging in part because of competing tests, which are additional screening tests that identify the condition of interest. For example, studies investigating screening with faecal occult blood tests to prevent colorectal cancer mortality need to consider the occurrence of screening colonoscopy. This paper compares analytic approaches to accounting for competing tests in analyses of cancer screening data.
Methods
We used simulations to compare bias and efficiency across approaches in different scenarios, quantify bias, and make recommendations for analyzing the effectiveness of a screening test in the presence of competing tests.
Results
Under all scenarios, the best performing approach for accommodating competing screening tests was censoring at the time of the competing screening test (range in bias across scenarios: −7.6% to 1.6%). Bias from other approaches ranged from 23.9% to 652.1%.
Conclusions
Censoring at the competing screening exam is the recommended approach for studying cancer screening effectiveness in the presence of competing tests. Censoring avoids confounding by prior competing test results and selection bias resulting from analyzing data on participants after they received a competing screening exam. Results from this study are broadly applicable to screening studies for other conditions, including other types of cancer.
Introduction
Much of what we know about cancer screening effectiveness comes from retrospective observational studies. Yet important methodological questions remain about how to use observational data to assess the effect of screening on cancer mortality. One particular analytic challenge is created by the availability of multiple screening modalities for most screen-detectable cancers. For example, colorectal cancer (CRC) is detectable by flexible sigmoidoscopy, faecal occult blood test (FOBT), or colonoscopy, and national clinical guidelines endorse all these preventive methods. 1 Breast cancer can be detected by digital and film mammography and magnetic resonance imaging. Cervical cancer screening methods include human papillomavirus and cytology testing. Many other conditions, including hearing loss and mild cognitive impairment, can be identified using more than one screening modality.
When multiple screening modalities are available for a particular cancer, the different tests are considered to be “competing”, because once a person has been screened with one modality, they are unlikely to be screened with another, at least for a period of time. Another factor that complicates the study of screening effectiveness is that certain test results (eg. cancer diagnosis) may be available in administrative databases, while others (eg. FOBT results, high-risk adenomas detected on colonoscopy) may not. This is a noted challenge in large population-based studies of screening. 2 Thus, analytic strategies need to be tailored to this limited set of data.
This paper examines observational data analysis approaches that account for competing screening tests and can be used with datasets that contain limited test results. We use CRC screening with the competing tests of FOBT and colonoscopy as an example to quantify and compare bias among approaches. This work adds to our understanding of the benefits and drawbacks of different analytic approaches to analyzing screening tests as they are used in real-world healthcare settings.
Methods
Our approach was to define several realistic but simple screening patterns and several possible analytic approaches for estimating the effectiveness of a screening test for reducing cancer mortality. More complex patterns can be extrapolated as combinations of the simple patterns we have investigated. We evaluated the bias and precision of the different approaches using a simulation study.
Screening patterns
Our example was a CRC screening study on FOBT effectiveness that considered colonoscopy to be a competing screening examination. We identified five possible simple screening patterns (Figure 1): (A) no screening at all; (B) receipt of only FOBT; (C) receipt of only screening colonoscopy; and (D) receipt of FOBT and then screening colonoscopy, or (E) receipt of screening colonoscopy and then FOBT.
Possible screening patterns for two competing screening modalities. FOBT, faecal occult blood test; Ti1 is the observed time of FOBT, the screening test of interest, and Ti2 the observed time of colonoscopy (a competing screening test for the same disease). Xi describes the observed screening pattern for person i, with Xi = (1(observed to use FOBT), 1(observed to use screening colonoscopy)) where 1is the indicator function which takes a value of 1 if the condition is satisfied.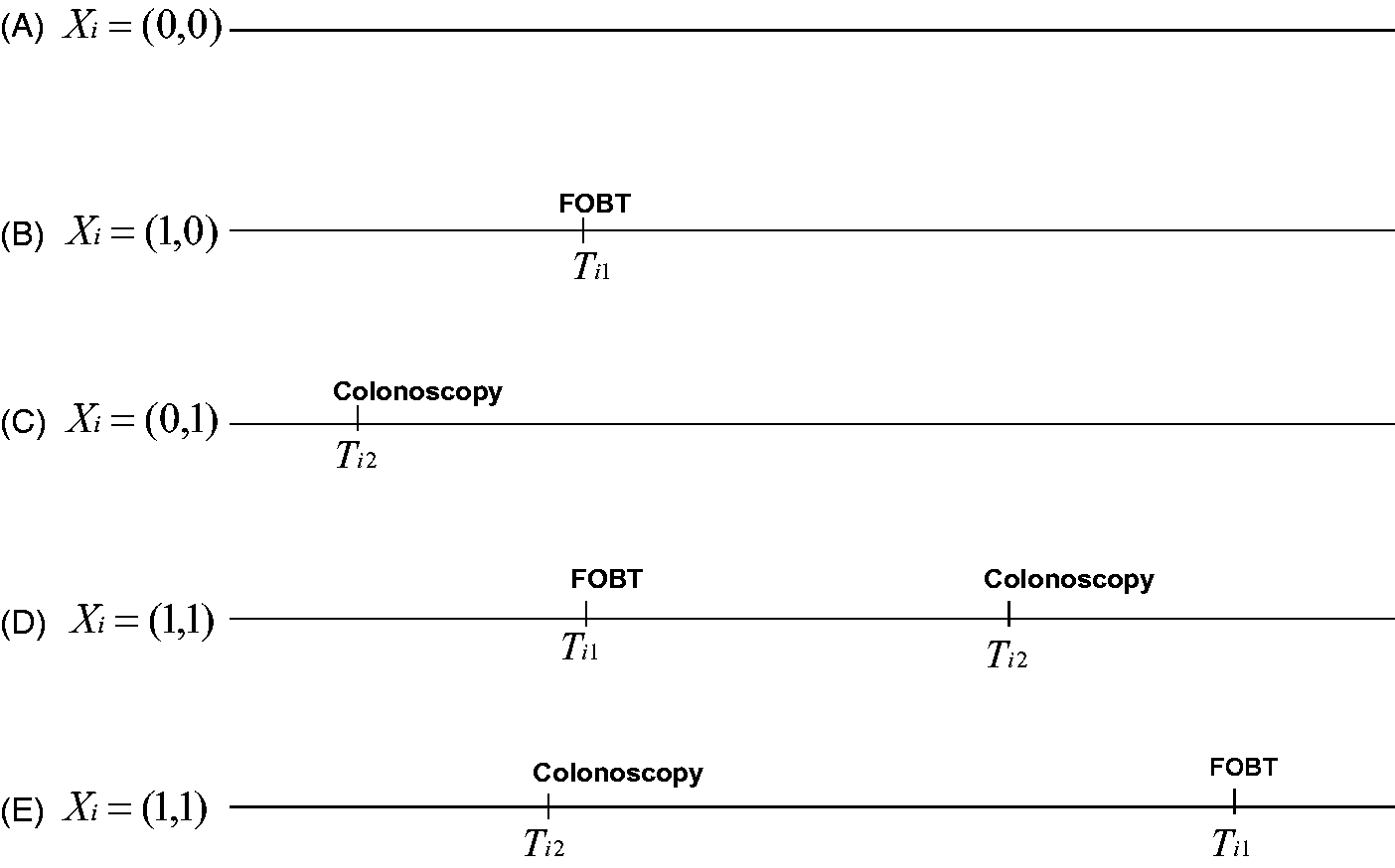
Analytic approaches
Approaches for Studying the Effectiveness of Screening Faecal Occult Blood Test (FOBT) in the Presence of Screening Colonoscopy.
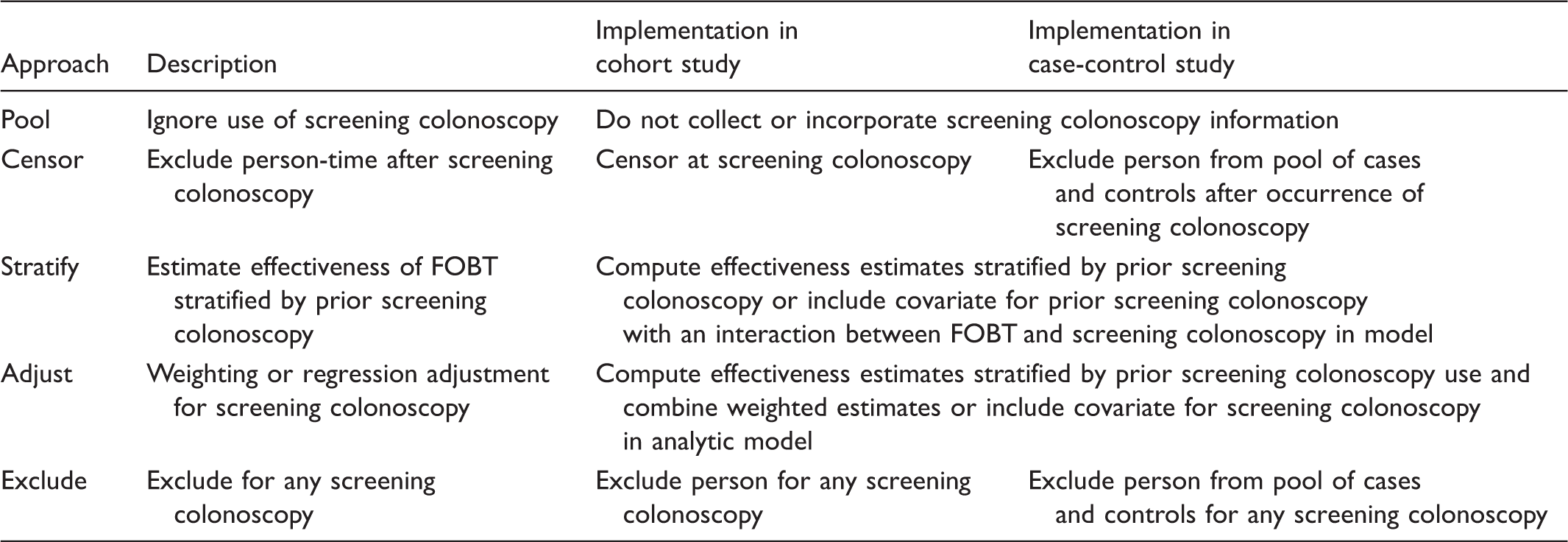
The first analytic decision is whether to account for the competing screening test at all. Not accounting for the competing test results in pooling people with and without screening colonoscopy when estimating FOBT effectiveness. Accounting for the competing screening test requires an approach for handling screening colonoscopy. In one approach, person-time following exposure to screening colonoscopy is excluded from estimates of FOBT effectiveness. In this approach, individuals are censored at the time of receipt of screening colonoscopy. In another approach, individuals are stratified by prior receipt of screening colonoscopy and data on the effectiveness of FOBT in the presence of competing screening colonoscopy are reported separately. Alternatively, standardized estimates are used to adjust for prior receipt of screening colonoscopy. Standardization is achieved by weighting the estimates of FOBT effectiveness in the presence and absence of screening colonoscopy by the proportion of people who receive and do not receive screening colonoscopy. A final approach is excluding data on people with screening colonoscopy.
To illustrate how the five analytic options could be implemented in practice, we describe estimators for the effectiveness of screening FOBT to reduce CRC mortality, assuming constant mortality rates within the effectiveness window (Appendix). Effectiveness was defined as the additive difference in mortality rate for screened compared with unscreened individuals. We defined the effectiveness window to be the period of person-time when a screening test might reduce mortality from the cancer of interest; this period might differ among tests for the same condition. We made the simplifying assumption that the effectiveness window was approximately equal to the time until a person was next due for screening (ie. the recommended screening interval), although this assumption probably resulted in an underestimate of the length of the effectiveness window. A longer interval would have increased the frequency with which competing tests could occur during the effectiveness window. The estimators illustrate how the approaches differ in events (the numerators) and persons or periods of person-time (the denominators). All approaches correspond to maximum likelihood estimators (MLEs) for the rates of exponentially distributed random variables over some period of person-time, except for the “exclude” approach (Table 1). This approach excluded both person-time and events using future information on use of the competing screening test, and does not correspond to an MLE. The exclude approach is therefore not necessarily a consistent estimator for the event rate. Moreover, although all other approaches corresponded to MLEs for event rates, these rates were not necessarily the rates in the general population—the target of inference—and thus may lead to biased effectiveness estimates.
Simulation study
Simulation study design
We conducted a simulation study to compare the bias and efficiency of alternative estimators of screening test effectiveness in the presence of a competing screening test. In simulations, the objective was to estimate the effectiveness of FOBT relative to no FOBT. Our measure of effectiveness was the difference in risk of cancer mortality for unscreened versus screened individuals during the effectiveness window. We simulated screening data over a period of 10 years, assuming the time to the first use of screening FOBT and colonoscopy were exponentially distributed.
Colonoscopy Screening Rates in Simulated Data.
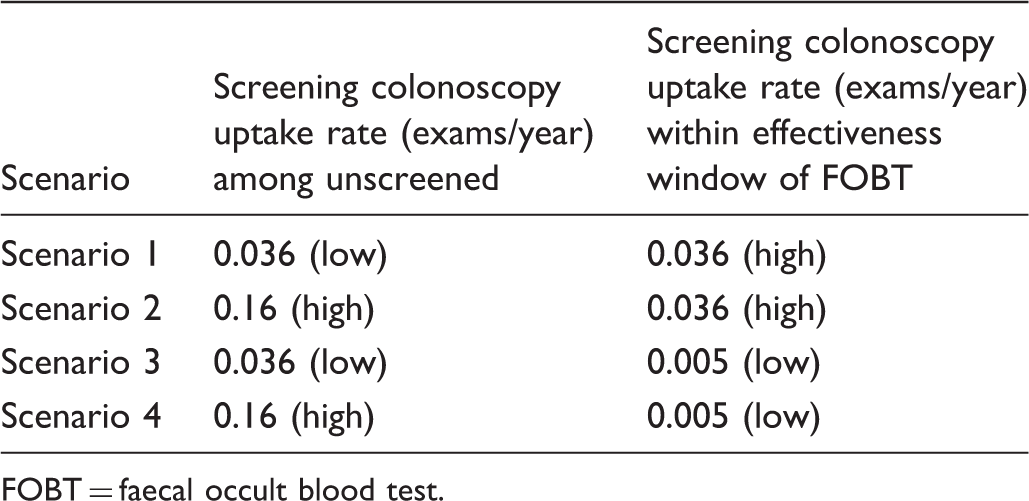
FOBT = faecal occult blood test.
The flow of simulated participants through the screening process is shown in Figure 2. Each oval represents a subset of the population with its CRC mortality rate indicated by λ. Arrows indicate the movement from one subgroup of the population into another, with rates of transition specified in exams per year or denoted by η. The entire population starts unscreened. Mortality from CRC in the absence of any screening was assumed to be 75 per 100,000 person-years for age ≥50 based on Surveillance, Epidemiology, and End Results programme (SEER) data from 1973 to 1993.
3
Our assumptions for screening test utilization rates,4–6 mortality rates,7–11 and probabilities for screening test results12,13 are in Figure 2. We assumed that, in the absence of other screening tests, biennial FOBT reduced mortality by 15% annually, and colonoscopy reduced the risk of CRC mortality by 31% annually. Mortality rates used in simulations were chosen to correspond to these mortality reductions, assuming exponentially distributed times to event. The CRC mortality rate in the population with negative colonoscopies was assumed to be very low based on reported CRC incidence following negative exams.10,11
Simulation of colorectal cancer screening and mortality outcomes. FOBT, faecal occult blood test; CSPY, colonoscopy; p-yrs, person-years; λ, mortality rate; η, rate of transition in exams per year; numbers in italics, probability; +, positive test findings (CRC or high risk adenoma); −, negative findings (no CRC or high risk adenoma); gray, information used to generate the simulated data but assumed unavailable when conducting analysis using observational administrative data.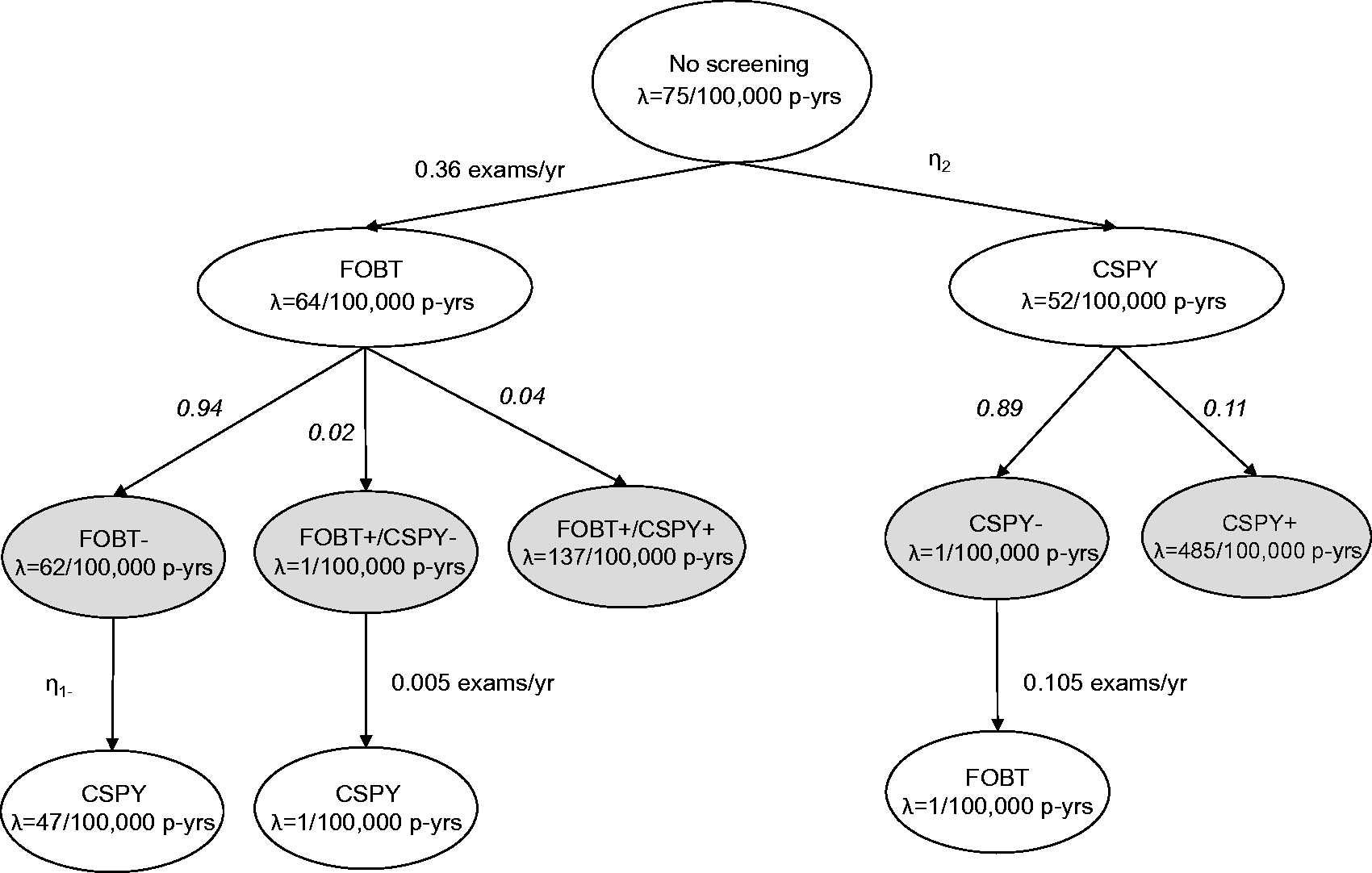
We assumed screening and choice of test were unrelated to CRC risk (ie. no confounding). For colonoscopy, screening test results were assumed to be definitive, and were therefore simulated as positive (CRC or high risk adenoma) or negative (no CRC or high risk adenoma) from a Bernoulli distribution. For FOBT, we assumed false-positive screening test results were possible, and hence simulated results (true positive, false positive, negative) from a multinomial distribution. Negative results were assumed to contain both true negatives and false negatives. We simulated subsequent mortality conditional on screening test results. Screening tests were assumed to reduce risk by lowering the mortality rate among individuals with true-positive test results. We computed overall mortality rates following a screening test, by averaging the mortality rate across individuals with differing screening test results, weighted by the frequency of screening test results. The conferred decrease in mortality risk was assumed to persist for two years following FOBT and 10 years following colonoscopy. All patients with false-positive FOBT results were assumed to receive diagnostic colonoscopy and experience a lower mortality rate associated with negative colonoscopy for 10 years following the examination. We assumed no further screening following a positive colonoscopy. Following negative colonoscopy, negative FOBT, or false-positive FOBT, we assumed that people could be screened with the other screening modality before being due again for screening. Time to death and time to uptake of the competing screening test were assumed to be exponentially distributed.
Simulated life histories were followed until the earliest of death, 10 years of follow-up, or two years after receipt of FOBT. This ensured that the data resembled what would be available in a cohort study in which participants were followed until death, for 10 years, or through the effective interval following a screening FOBT (ie. until the next recommended screening), whichever occurred first. Our simulation study thus focused on the effect of a single round of FOBT screening and not the effect of repeated screening.
Measures of comparison: Bias and standard errors
For each simulated dataset generated under the scenarios and using the assumptions described above, we estimated the FOBT effectiveness using the five analytic approaches described above and in Table 1. We computed absolute risk (AR) reduction as the difference between estimated mortality rates with and without FOBT screening. For each approach we summarized our findings using the average and standard error of the AR across all 1,000 simulated datasets; bias was estimated by taking the difference between the average AR and the true value (-11 per 100,000 person-years). Percent bias was computed as 100 times the ratio of bias divided by the true AR. Empirical standard errors were computed as the standard deviation of the estimated AR across the simulated datasets to estimate the variability of each approach.
Results
Bias, Empirical Standard Errors, and Percent Bias of Estimates for Attributable Risk of Mortality per 100,000 Person-years for Individuals Screened by FOBT Compared with Unscreened Individuals Based on Four Simulated Scenarios, Assuming a True Attributable Risk of -11 per 100,000 Person-years.
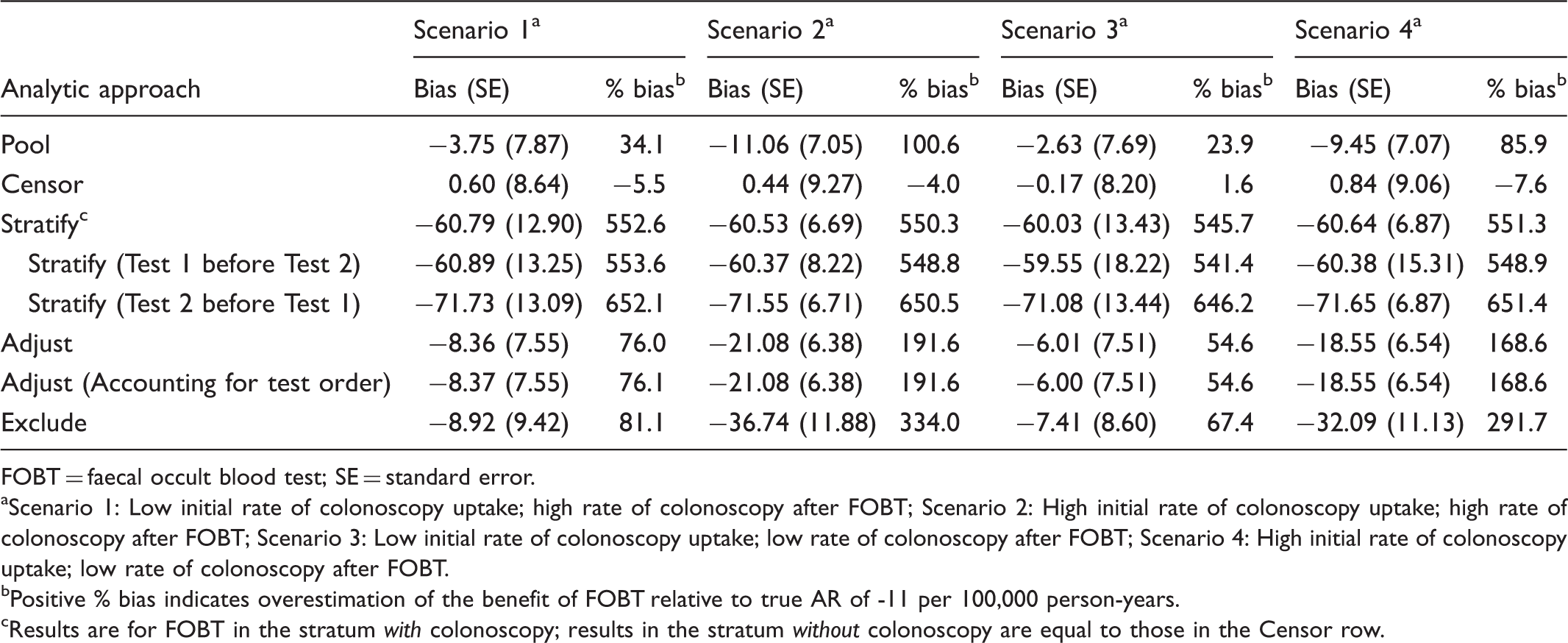
FOBT = faecal occult blood test; SE = standard error.
Scenario 1: Low initial rate of colonoscopy uptake; high rate of colonoscopy after FOBT; Scenario 2: High initial rate of colonoscopy uptake; high rate of colonoscopy after FOBT; Scenario 3: Low initial rate of colonoscopy uptake; low rate of colonoscopy after FOBT; Scenario 4: High initial rate of colonoscopy uptake; low rate of colonoscopy after FOBT.
Positive % bias indicates overestimation of the benefit of FOBT relative to true AR of -11 per 100,000 person-years.
Results are for FOBT in the stratum with colonoscopy; results in the stratum without colonoscopy are equal to those in the Censor row.
Discussion
We explored analytic approaches for evaluating the effectiveness of a screening test, when a competing screening modality might be used during the test’s effectiveness window. The best-performing approach for analyzing screening test effectiveness in the presence of a competing test was censoring at the time of the competing test. Simulation studies demonstrated that substantial bias occurs when other approaches were used. Based on our findings, we recommend censoring at the time of the competing screening test. In case-control studies, the censoring approach is equivalent to risk-set sampling, in which people are eligible to be cases or controls until they have a competing screening exam. While stratification by the competing screening exam may be intuitively appealing, for the reasons described below it produces biased estimates.
Results of a prior competing screening test act as a confounder because people who have a positive screening test result are not eligible to be screened again, so only those with a prior negative screening test result go on to receive the screening test of interest. If results of the prior competing screening test are available, traditional methods for handling confounding (eg. stratification or adjustment by prior test results) should be sufficient to eliminate bias. We focused on identifying the best analytic approach when data sources contain the occurrence of a competing screening test, but not results. For instance, in administrative data, information on cancer incidence and cancer mortality, but not individual test results, may be available. This is often the case in studies of CRC screening, where colonoscopy results are not available in administrative data. 2 In this scenario, stratification by the true confounder (results of a prior competing screening test) is impossible.
The occurrence of a competing screening test after the exam of interest (and during the effectiveness window of the test of interest) causes selection bias, because receipt of the competing test during the effectiveness window of the test of interest is related to the results of the test of interest. Only individuals with a negative result on the screening test of interest can subsequently receive the competing test. So, for example, FOBT will look beneficial when comparison is made between individuals with a negative FOBT result (low risk) and unscreened (average risk) individuals. Because this bias arises from stratification based on results of the test of interest, it is not remediable, even if results of the competing screening test (eg. colonoscopy) are known. In summary, biases that result from competing screening tests before and after the exam of interest occur because the only people screened with both tests are those whose first screening test result was negative; these people are at lower risk of mortality.
Our findings apply to competing screening tests, not diagnostic tests that are performed in response to signs or symptoms of disease. Censoring at diagnostic exams is not recommended, because these exams are often events along a causal pathway in which people are diagnosed with cancer before dying from it. Administrative data algorithms can help to identify test indication. 14 The question of how to study people who change screening regimens when they become due again for screening is different, and is not considered in this paper, which focuses on single rounds of screening.
Estimates of bias and precision are based on simulations to investigate five straightforward screening scenarios, with simplifying assumptions. This approach has several limitations. First, we investigated only two tests with five screening strategies. Real-world applications involve more complex combinations of tests. However, by considering only the test of interest and the first competing test to occur, more complicated strategies can be reduced to fit into our scenarios. Second, mortality rates were assumed to be constant, and the effect of screening tests was assumed to act on mortality via a step function, with risk immediately decreased following screening, then returning to its pre-screening value at the end of the effectiveness window. In reality, mortality rates and the effect of screening over the course of the effectiveness window are likely to be non-constant and the effectiveness window is likely to be longer than we assumed. Bias in situations with more complex mortality rates and screening effects might differ in magnitude from our findings. However, the basic pattern of bias and efficiency is expected to be the same across the five approaches. In spite of the simplicity of our simulations, our results provide guidance to researchers for estimating the comparative effectiveness of screening tests in the presence of competing screening tests, by describing the type of bias that may arise in different analytic approaches.
Our findings are broadly relevant to screening studies. However, understanding how to analyze real-world screening data is especially important for CRC studies because multiple screening modalities are common, and the comparative effectiveness of alternative regimens has primarily been examined using modeling.15,16 Nonetheless, similar issues are arising for studies of breast cancer screening with screening magnetic resonance imaging, ultrasound, and mammography all competing. The issue of analyzing data in the presence of competing screening tests is likely to become increasingly important with new emerging technologies and an emphasis on real-world comparative effectiveness studies using observational data. Our recommended analytic approach of censoring at the time of the competing screening test is straightforward, can be employed in both cohort and case-control studies, and is applicable to a variety of conditions that are detected by multiple screening modalities.
Footnotes
Acknowledgments
We thank Noel S Weiss (MD, DrPH) and V Paul Doria-Rose (DVM, PhD) for comments on early versions of the manuscript.
Declaration of conflicting interests
The authors have no conflicting interests to declare.
Funding
This work was supported by grants from the National Cancer Institute at the National Institutes of Health (UC2CA148576 to Buist and Doubeni; U54CA163261 to Rutter). The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Cancer Institute or the National Institutes of Health.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.