
Abstract
Propensity score estimation is often used as a preliminary step to estimate the average treatment effect with observational data. Nevertheless, misspecification of propensity score models undermines the validity of effect estimates in subsequent analyses. Prediction-based machine learning algorithms are increasingly used to estimate propensity scores to allow for more complex relationships between covariates. However, these approaches may not necessarily achieve covariates balancing. We propose a calibration-based method to better incorporate covariate balance properties in a general modeling framework. Specifically, we calibrate the loss function by adding a covariate imbalance penalty to standard parametric (e.g. logistic regressions) or machine learning models (e.g. neural networks). Our approach may mitigate the impact of model misspecification by explicitly taking into account the covariate balance in the propensity score estimation process. The empirical results show that the proposed method is robust to propensity score model misspecification. The integration of loss function calibration improves the balance of covariates and reduces the root-mean-square error of causal effect estimates. When the propensity score model is misspecified, the neural-network-based model yields the best estimator with less bias and smaller variance as compared to other methods considered.
Keywords
Introduction
In observational studies, the covariate distributions between treatment groups are usually imbalanced, which induces confounding bias when estimating the causal effect.1,2 Propensity score (PS), defined as the conditional probability of being treated given the covariates, 3 plays an essential role in causal inference. Because of the balancing property, the covariates and treatment are conditionally independent given the PS. 4 There are several PS methods to remove the confounding bias when estimating causal effect, including weighting, 5 stratification, 6 matching, 7 or regression adjustment. 8
The standard procedure for propensity score estimation is to fit a logistic regression model, check covariate balance, and re-fit the model until the balance is achieved. 6 However, there are significant drawbacks to this approach. Firstly, the parametric form of a logistic regression could be easily misspecified.9,10 It has been found that even under mild model misspecification, the logistic regression methods for PS estimation may fail and the performance of weighting methods including doubly robust estimator may be unsatisfactory. 11 Secondly, the logistic regression may fail to capture the complex non-linear relationship between covariates and the treatment. 12 Moreover, the iterative process is cumbersome, and people often skip this step, which leads to unreliable conclusions. 13
The goal of propensity score estimation is to balance covariates. Naïve PS estimation method such as a logistic regression may not achieve covariate balancing.
14
Empirical studies showed that the absolute standardized mean difference in covariates was strongly correlated with the bias of causal effect estimation,
15
but the prediction accuracy measure such as
Statistical or machine learning approaches are more flexible to incorporate non-linear relationships. 23 Prediction-based machine learning algorithms, such as bagging or boosting, 24 random forest, boosted classification and regression trees, 12 and neural networks are increasingly used to predict the propensity scores.15,16 However, these approaches may not necessarily achieve covariates balancing. 25 Incorporating covariate balance into the optimization process of machine learning methods can improve the estimation of causal effects.
Inspired by the dual characteristics of the PS which is the covariate balancing score and the conditional probability of treatment assignment, we calibrate the likelihood or loss function of a prediction model by adding a covariate-imbalance penalty. The calibrated loss function can take into account the prediction accuracy and covariate balance at the same time. This approach may mitigate the impact of misspecification of the PS model and thus improve the performance of the ATE estimator. Furthermore, we leverage the flexibility of machine learning methods by configuring the base model as either a logistic model or a neural network architecture.
The remainder of this article is organized as follows. In Section 2, we begin with a brief review of the traditional logistic regression PS model. Then we present the proposed methods where the loss function is calibrated by adding an imbalance score. Optimization and tuning parameter selection methods are introduced with a comprehensive algorithm. In Section 3, we assess the performance of the proposed methods in comparison with other PS estimation methods in the simulation study. In Section 4, we apply the proposed methods to a real study that examined the causal effect of the utilization of right heart catheterization in the intensive care unit on the hospital length of stay. We provide conclusions and discussions in Section 5.
Methods
Notation and model specification
Suppose there is a random sample of
The PS of receiving treatment of interest can be defined as
The logistic PS model can take the form of:

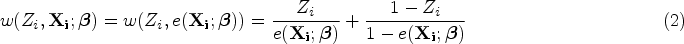
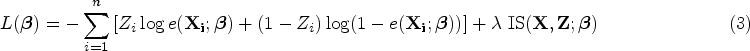

There are several ways to measure the difference between two covariate distributions, such as differences in moments (mean, variance, etc.), Kullback–Leibler (KL) divergence, and Kolmogorov–Smirnov (KS) test statistics.
30
Here we describe one commonly used measure for an IS, the absolute standardized difference in mean10,31,32:
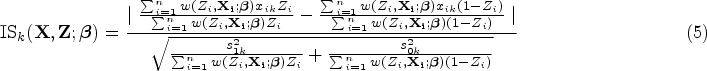
In fact, the logistic regression can be viewed as the most basic form of a neural network, comprising solely one input and output layer with a sigmoid function as the activation function, denoted by
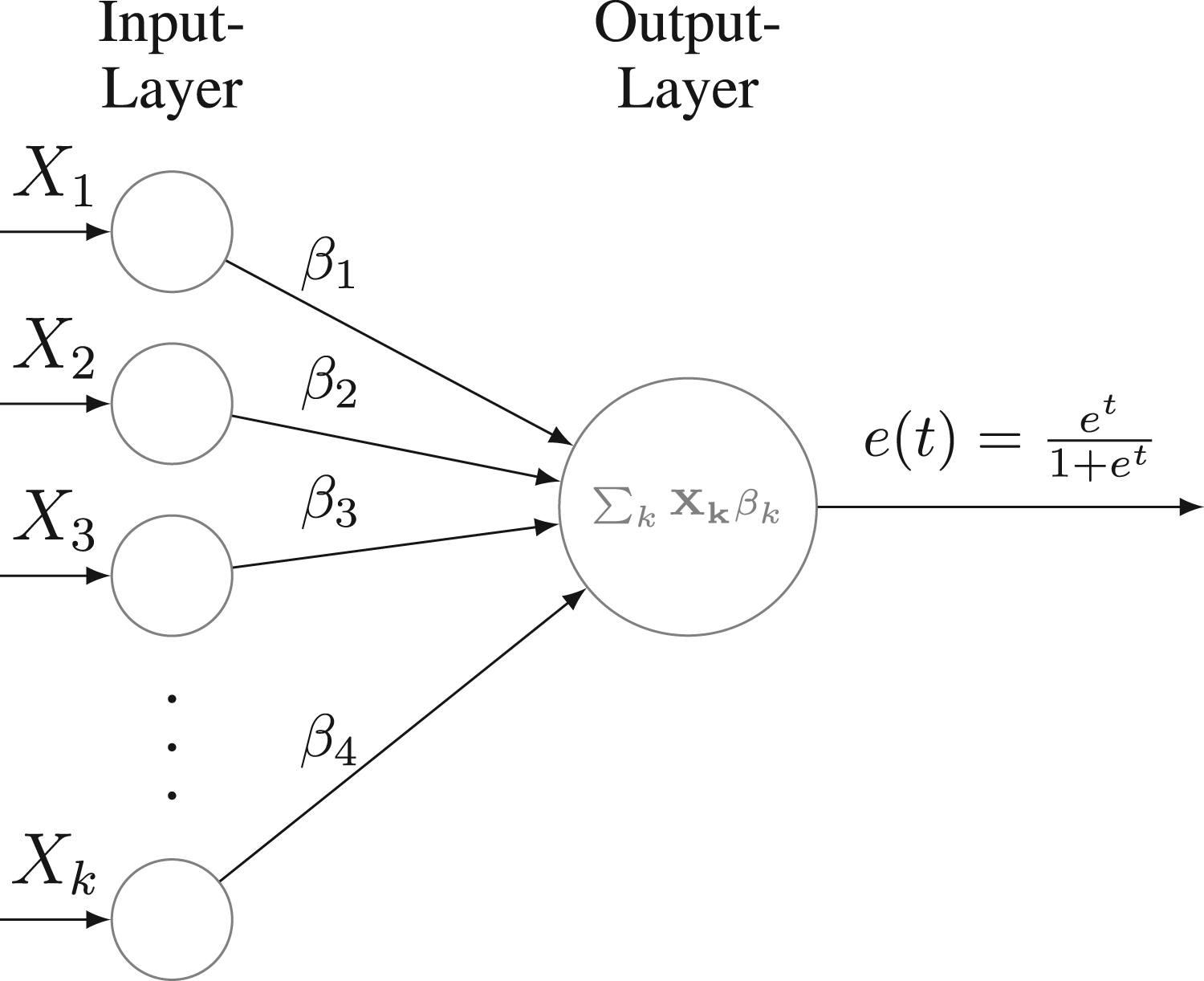
Neural network architecture for logistic regression.
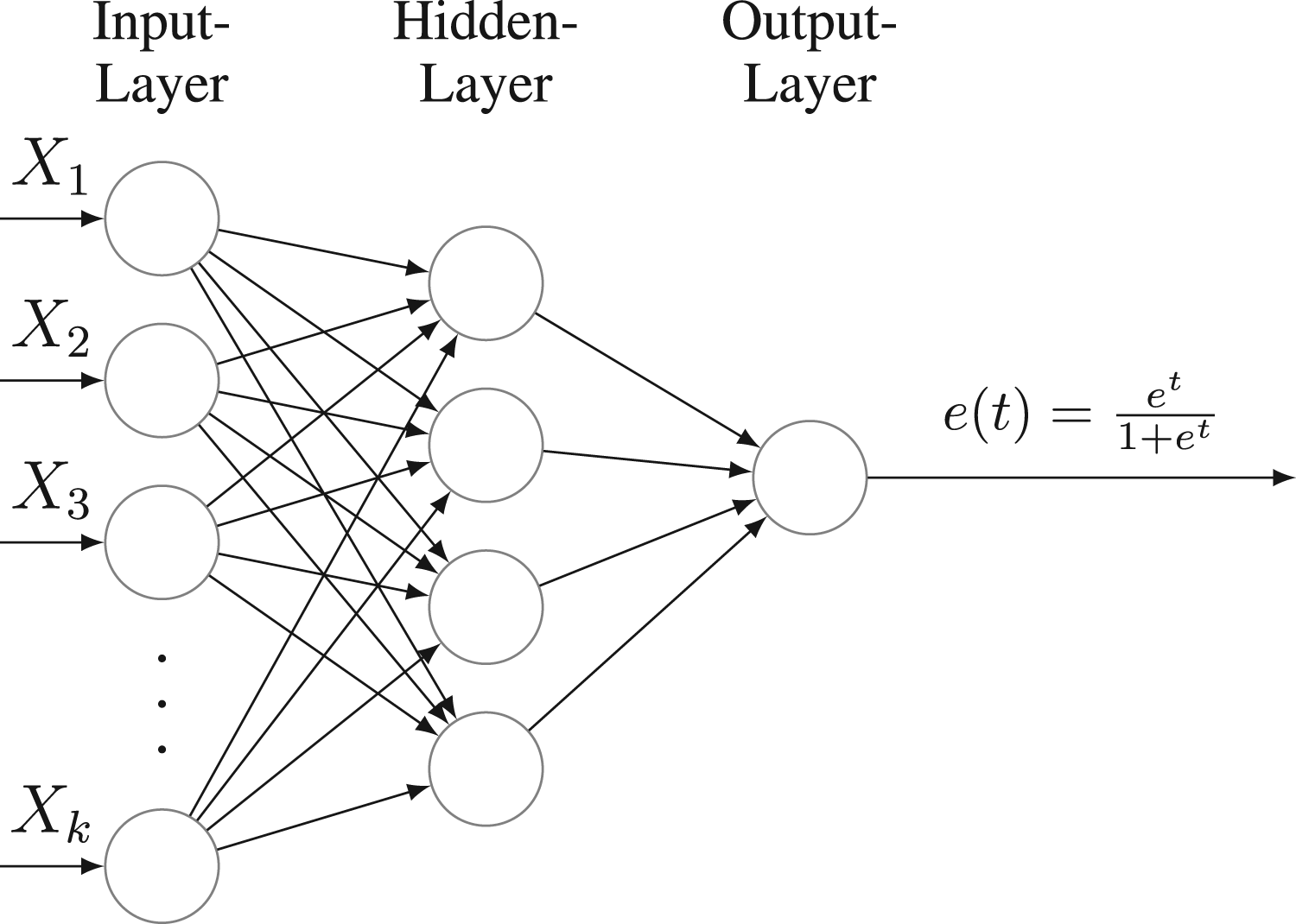
Neural network architecture with a hidden layer.
To minimize the calibrated loss function, we use Algorithm 1 described below to estimate the parameter
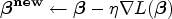
The initial values of the parameter

Tuning parameter
Since the objective of PS estimation is not to achieve perfect model fitting, the traditional tuning parameter selection methods that emphasize prediction accuracy cannot be applied. Several researchers suggested that using the covariate balance measures such as the absolute standardized difference as tuning parameter selection criteria worked better in ATE estimation.15,32,42,43 Motivated by this idea, we use grid search and select the tuning parameter
Cross-validation (CV) is widely recognized as an effective technique for parameter tuning.
44
In our context, the application of CV is also feasible, contingent upon available computational resources. It is important to note that if the
Simulation study
The simulation design introduced by Kang and Schafer 11 has become a widely adopted benchmark setting for evaluating the performance of PS methods.19,20 To test the robustness of our proposed method under model misspecification, we replicated this simulation setting and examined the empirical performance of the proposed method under different model misspecifications. In detail, we applied the calibrated loss function methods for PS estimation based on two base models, logistic regression and one-hidden-layer neural network in which the activation function is ReLU 45 for the hidden layer and the sigmoid function for the output layer.
Estimators of causal effect
In the following, we briefly reviewed three ATE estimators used in our simulation study. The first two were inverse probability weighting estimators that were proven to be an unbiased estimator when the PS model was correctly specified.
31
Horvitz–Thompson (HT) estimator
46
:
Hájek estimator (also called stabilized weights)
47
:
Doubly robust (DR) estimator
48
:
The DR estimator combines a PS model with an outcome model to yield a consistent estimator when one of the models is correctly specified.49–52
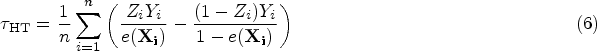
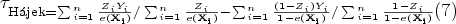
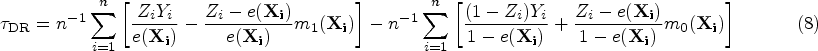
We first generated four latent pre-treatment covariates 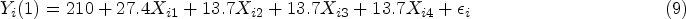
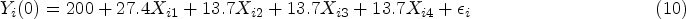
The true PS was generated with a logistic regression model:
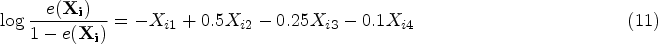




For each scenario, we conducted
The structure of the neural network in
Furthermore, we calculated the standardized mean difference in the weighted observed covariates
Table 1 presents the bias and RMSE of ATE estimation for different effect estimators under various PS estimation methods. We also reported the Monte Carlo standard error of bias and RMSE in Table 2. 53 Figure 3 shows the boxplots of ATE estimates across 1000 simulation runs, truncated at the 0.1th and 99.9th percentiles.
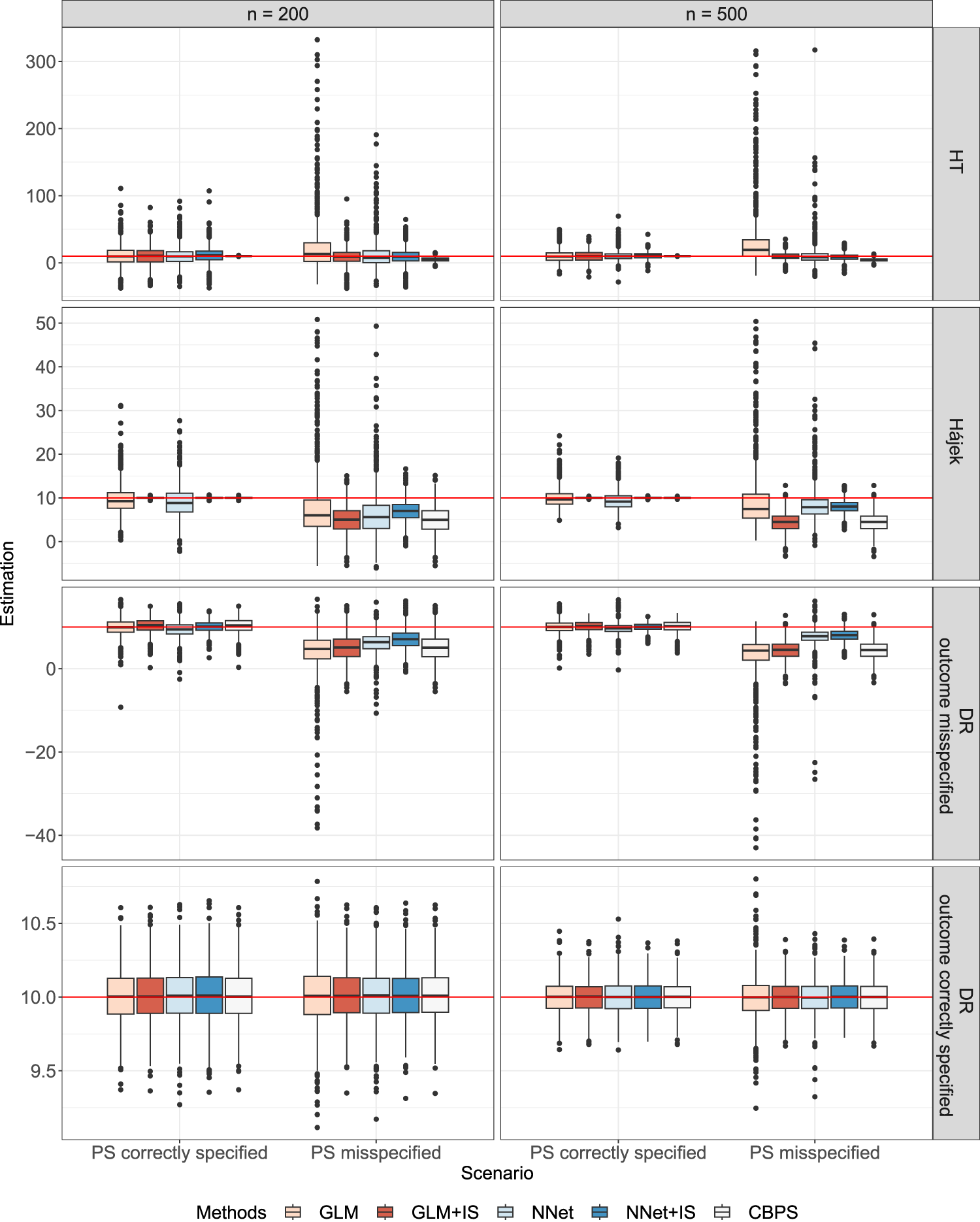
Boxplots of average treatment effect (ATE) estimates from
Performance of three average treatment effect estimators based on different propensity score estimation methods.
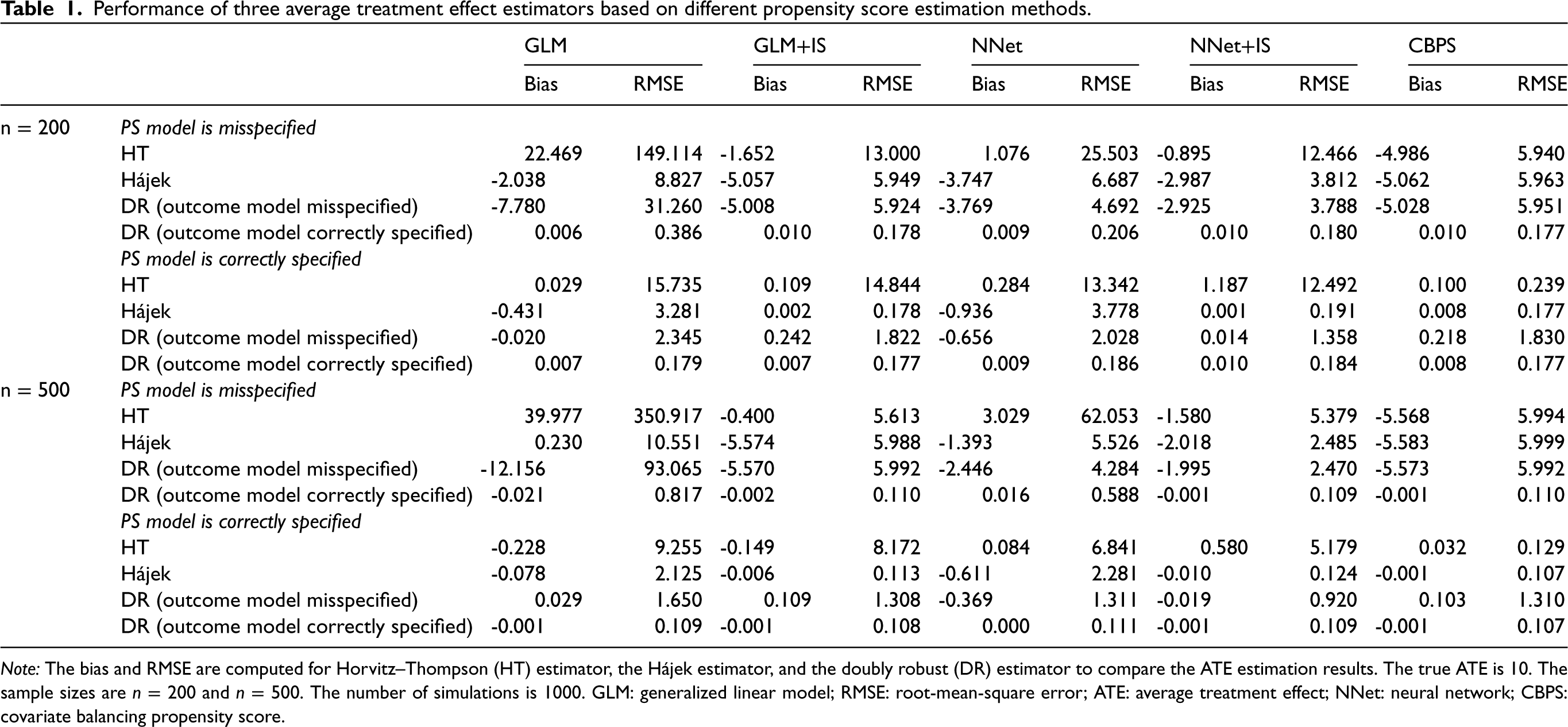
Note: The bias and RMSE are computed for Horvitz–Thompson (HT) estimator, the Hájek estimator, and the doubly robust (DR) estimator to compare the ATE estimation results. The true ATE is
Monte Carlo standard error (MCSE) for the performance measures of bias and RMSE. 53
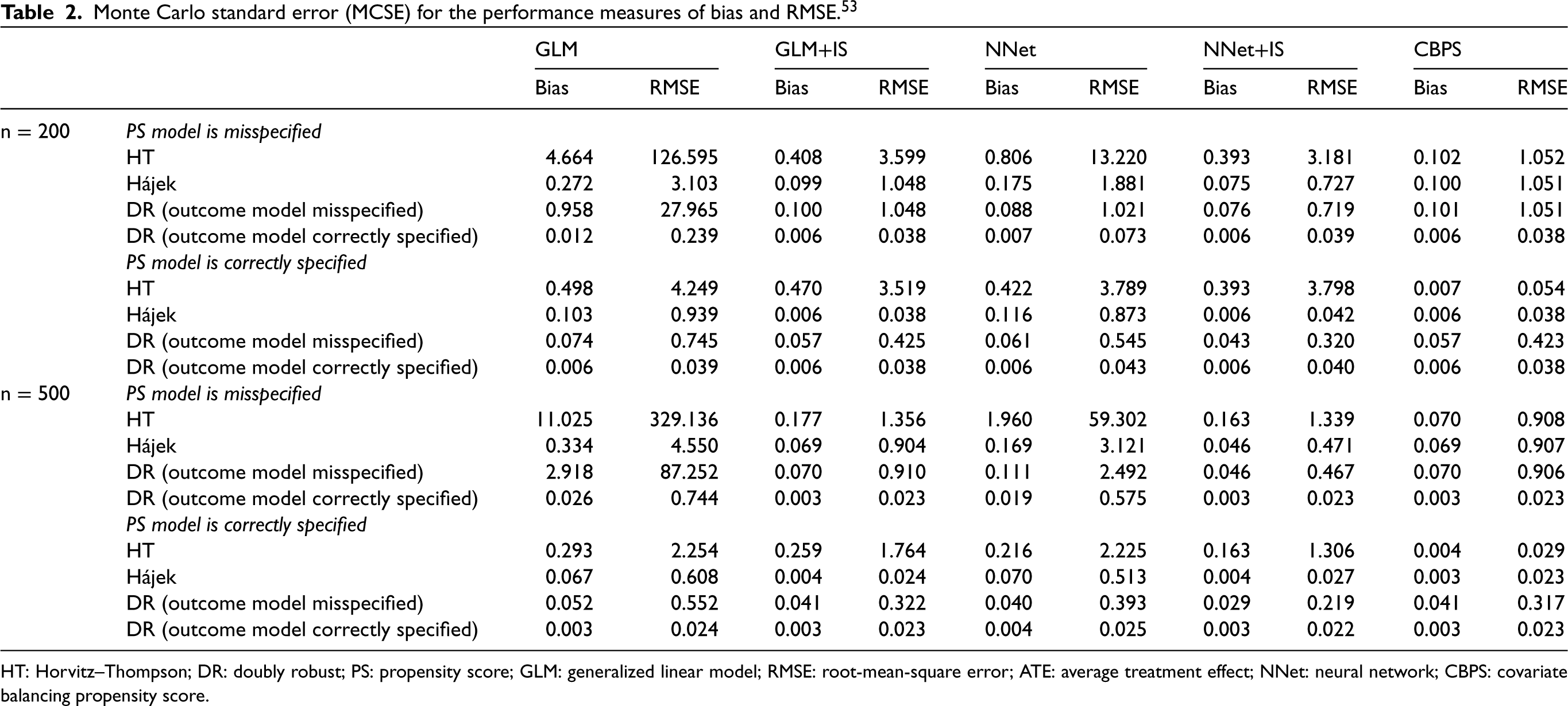
HT: Horvitz–Thompson; DR: doubly robust; PS: propensity score; GLM: generalized linear model; RMSE: root-mean-square error; ATE: average treatment effect; NNet: neural network; CBPS: covariate balancing propensity score.
When the PS model was misspecified, the proposed calibration methods for PS estimation (NNet+IS and GLM+IS) generally led to a smaller bias and RMSE in all ATE estimators when compared to the corresponding standard estimation methods (NNet and GLM). When the PS model was correctly specified, the bias was small for all ATE estimators, but our proposed methods (NNet+IS and GLM+IS) had lower RMSE compared with the original (NNet and GLM) methods. Overall, the NNet+IS method performed the best, resulting in the low bias and lowest RMSE for the Hájek or the DR estimator. The impact of sample size on RMSE depended on the PS model. When the PS model was correctly specified, the RMSE decreased with the increasing sample size for all PS methods. However, when the PS model was misspecified, only NNet+IS consistently led to a smaller RMSE of ATE with increasing sample sizes.
Under the simulated scenario, HT estimators appeared to have much larger RMSE and bias than the other estimators. The improvement in the HT estimators was especially substantial when the robust PS estimation methods were used under the misspecified PS model. Compared to the CBPS method, our proposed methods, especially the NNet+IS, resulted in much smaller biases in the HT estimator although the RMSEs were higher. For the Hájek estimator, the NNet+IS method reduced both the bias and RMSE, and the GLM+IS method reduced the RMSE whether PS was correctly specified or not. NNet+IS had overall the best performance in terms of the lowest bias and RMSE compared to other PS estimation methods including the CBPS.
For the DR estimator, when neither the PS model nor the outcome model was correctly misspecified, our robust PS methods, GLM+IS and NNet+IS, led to a moderate to significant reduction in the RMSE when compared to the original GLM and NNet methods. In addition, the flexible neural network (NNet) model appeared to perform better than the simple logistic regression (GLM) since it was more robust to the model misspecification. When either the PS model or outcome model was misspecified, we still observed improvement in DR estimates using our robust PS estimation methods. The NNet+IS method outperformed all other methods including the CBPS method in terms of the bias and RSME of DR estimates. This confirmed that even with the doubly robust property, the DR estimator can still benefit from the robust PS estimation methods in finite samples. When both models were correctly specified, all the PS methods gave similar results as expected, and the DR estimator had a smaller bias and variance than HT and Hájek estimators that did not use outcome models. For the scenario when the PS model was correctly specified, our proposed PS methods (GLM+IS and NNet+IS) resulted in more improvement in the bias and RSME for the Hájek estimator, and the DR estimator under the misspecified outcome model, but less improvement for the HT estimator and DR estimator under the correctly specified outcome model, when compared to the corresponding original methods (GLM and NNet). On the other hand, the CBPS performed the best when used with the HT estimator. Interestingly, the Hájek estimator even outperformed the DR estimator with a misspecified outcome model when GLM+IS or NNet+IS method was used. It appeared that the misspecification of the outcome model may still negatively affect the DR estimator even though the PS model was correctly specified in this scenario.
Figure 4 shows the boxplots of standardized mean difference in each covariate (observed or latent) when the PS model was misspecified using
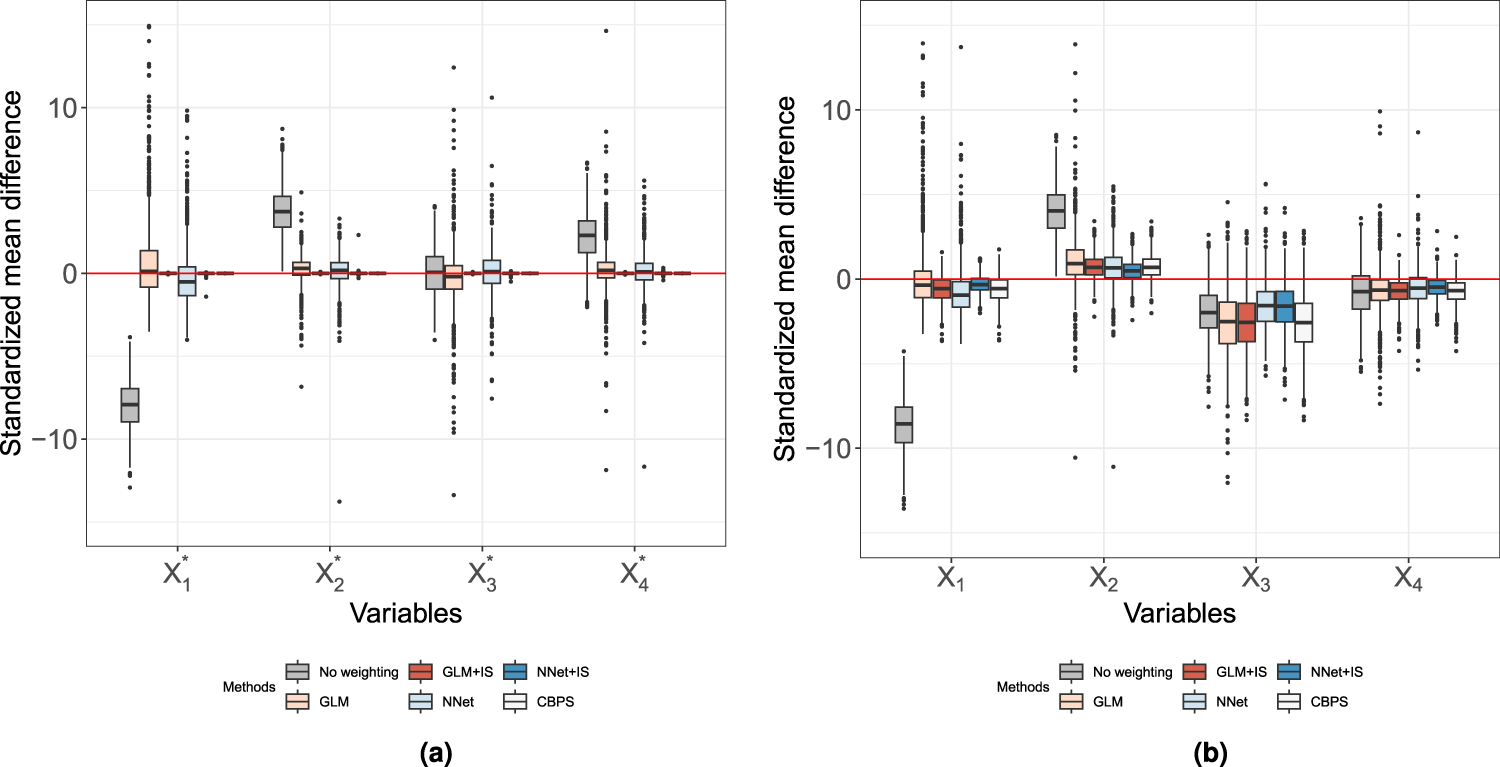
Propensity score (PS) weighted covariate balance under misspecified PS model. The sample size is
The mean absolute error (MAE), as a measurement of prediction performance of different PS estimation methods when the PS model is misspecified, was reported in Table 3. In this case, GLM and NNet have the smallest MAE of PS estimation when the sample size is 200 and 500, respectively. However, NNet+IS has the smallest bias of ATE estimation using the Hájek estimator regardless of the sample sizes as we shown in Table 2. These results were consistent with previous findings that the prediction error was not strongly related to the bias of ATE estimation.2,10,16
MAE of estimated PS for different estimation methods when PS model is misspecified.

Note: Mean absolute error (MAE) is defined as MAE =
We demonstrated our proposed PS methods using the right heart catheterization (RHC) dataset from Connors et al. 54 The objective of the analysis was to assess the effect of the utilization of RHC within the initial 24-hour period of care in the intensive care unit (ICU) on the hospital length of stay. The study cohort had 5734 patients in total, consisting of 2183 right heart catheterization users and 3551 non-users. The covariates identified by a panel of specialists in critical care included age, sex, race, years of education, income, medical insurance type, disease category, admission diagnosis, and other measurements.
In our analysis, we considered
Average effect of right heart catheterization on length of hospital stay (days).
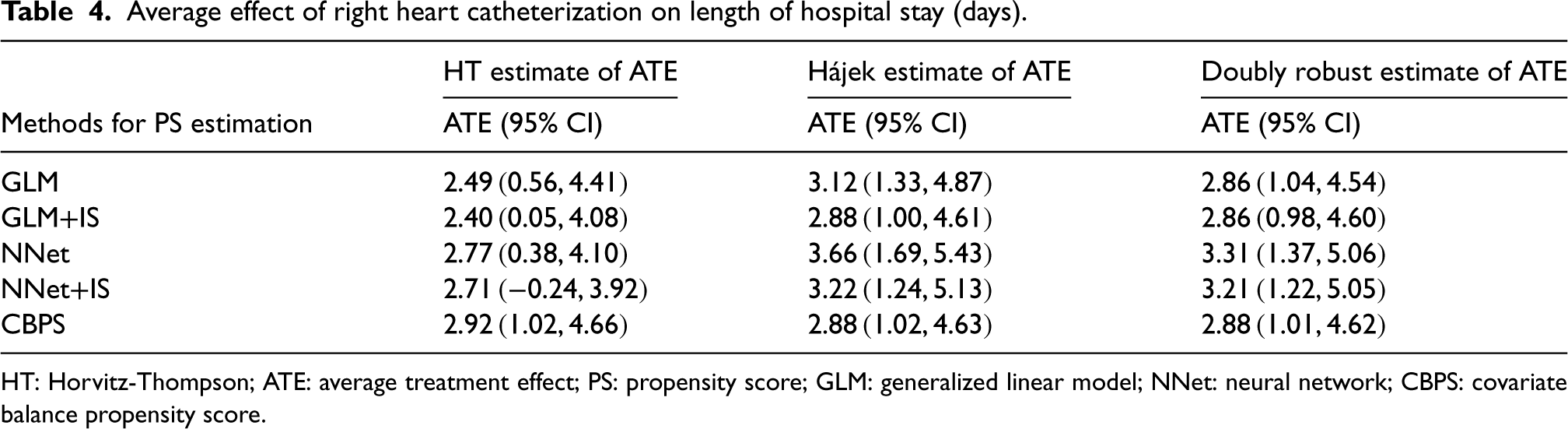
Average effect of right heart catheterization on length of hospital stay (days).
HT: Horvitz-Thompson; ATE: average treatment effect; PS: propensity score; GLM: generalized linear model; NNet: neural network; CBPS: covariate balance propensity score.
Overall, the Hájek and DR estimates of ATE were nearly identical when using calibrated loss approaches (i.e. GLM+IS and NNet+IS) or CBPS for PS estimation. In contrast, the HT estimates were consistently lower than the Hájek and DR estimates, with the exception of when CBPS was used for the PS estimation. Furthermore, the DR methods, whether calibrated or not, produced similar estimates. The calibrated Hájek estimators yielded estimates that closely aligned with those of the DR estimates. Furthermore, the ATE estimates were larger when the neural network base model (NNet or NNet+IS) was used to estimate PSs.
As shown in our simulation results, when the outcome model was correctly specified, the DR estimator would be much less biased than the Hájek estimator. In practice, the PS model may not be perfectly specified. Given the minimal difference between these two estimates in our analysis, we also expected the outcome model to be less likely to be specified correctly. Therefore, we thought the results from the NNet+IS method were more reliable given this method demonstrated the best performance in our simulation study under misspecification of both the PS and outcome models.
We also examined the covariate balance achieved by four PS estimation methods and an unweighted one using the standardized mean difference defined by Austin et al.13,55 (Figure 5). Most covariates can be better balanced via inverse PS weighting based on standard logistic regression and neural network methods and fall within the 0.1 threshold.
55
However, the standardized difference in means for some covariates fell out of the
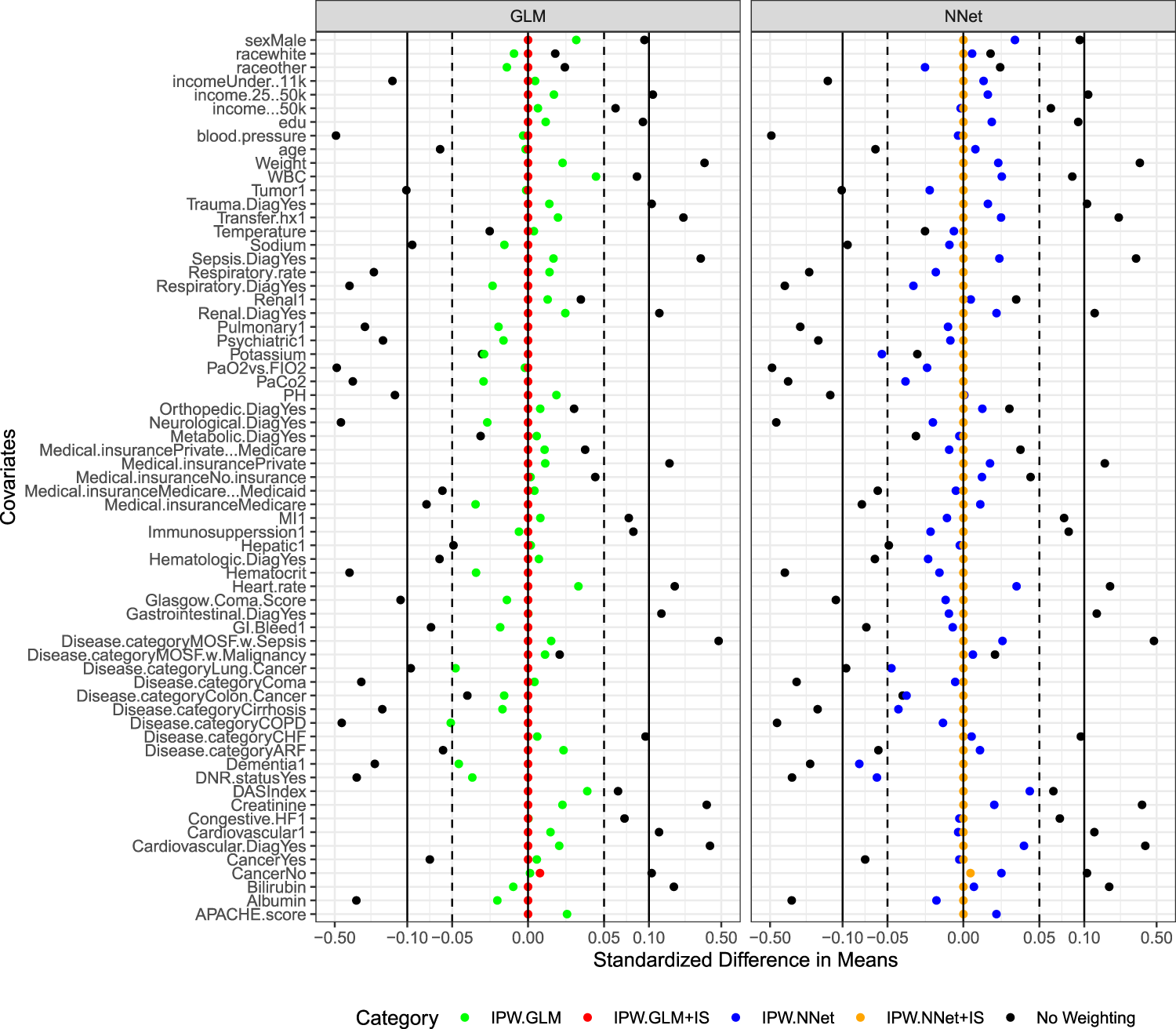
Standardized mean differences in inverse-propensity-score weighted covariate.
The dataset of Connors et al. 54 has been analyzed with various approaches, while each employing a slightly different set of covariates. We summarized the reported effect sizes of RHC use and our estimates in Figure 6. Notice that some published results did not provide the confidence interval for the estimated effect size. Comparing our results with those reported previously, the overall conclusions for all methods were consistent. However, the proposed method using neural network base model resulted in a larger effect of RHC on the length of stays than most of these reported except the one presented by Li et al. 22
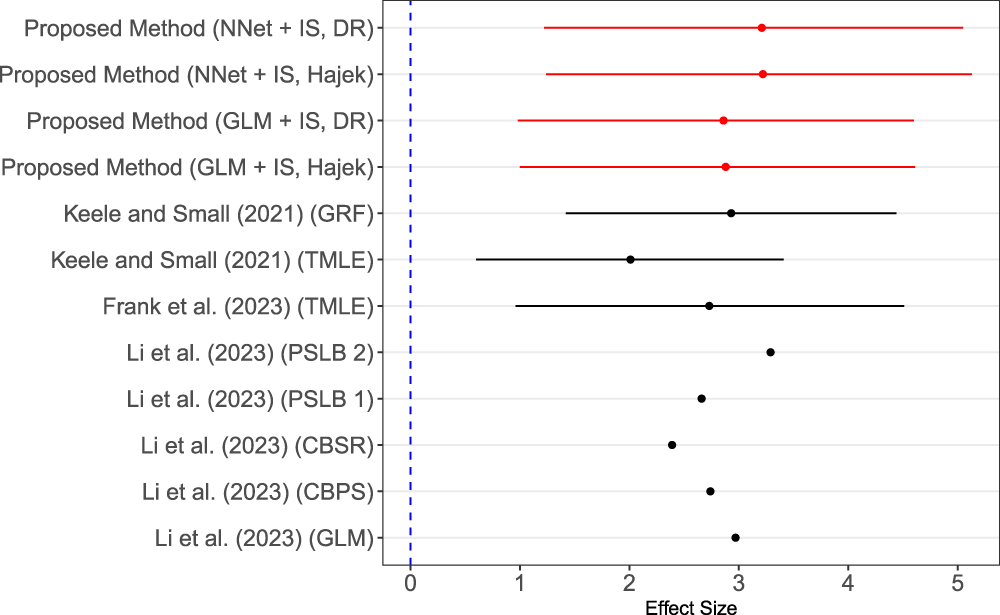
Forest plot of effect estimation given by multiple studies. Note: Keele and Small 58 used targeted maximum likelihood (TMLE) with super learner and also generalized regression trees (GRF). 58 Frank et al. 59 applied TMLE. 59 Li et al. 22 analyzed the right heart catheterization data with five methods including logistic regression, covariate balance propensity score (CBPS), covariate balancing scoring rules (CBSR), proposed propensity score with local balance 1 (PSLB 1), and proposed propensity score with local balance 2 (PSLB 2). 22
The significance of the proposed methods lies in the ability to address critical challenges associated with PS-based causal effect estimation, particularly in the context of the PS model misspecifications. A correctly specified PS model theoretically ensures balanced covariate distributions between treatment groups.2,3,60,61 Consequently, when the sample size is very large, the estimated PS could balance the covariates very well and the imbalance score penalty term is ignorable. When the sample size is limited, adding an imbalance penalty may correct the imbalance due to sampling variation so that increasing the precision. However, if the PS model is misspecified, the covariates may remain imbalanced even if the model accurately predicts treatment assignment. This misalignment can lead to biased estimates of the ATE. To address this issue, we developed robust PS estimation methods by calibrating the loss functions of predictive PS models. This adjustment considers the dual roles of PSs that the scores could predict the treatment and balance covariates. The proposed methods may improve upon prediction-focused methods when there is model misspecification due to complex, non-linear relationships among covariates. Our approach can mitigate bias and reduce RMSE in the estimation of the average treatment effect, particularly in scenarios involving model misspecifications.
As demonstrated in the simulation studies, when there was a model misspecification, prediction accuracy-based PS estimation methods such as logistic regression and neural network may result in large bias and variance in the ATE estimation. This problem was mainly driven by a small number of highly influential inverse probability weights that led to biased estimates and excessive variance. By adding a penalty term for covariates imbalance to the loss function, the proposed methods for PS estimation can achieve better covariate balance and eliminate the highly influential inverse probability weights, which led to a significant reduction in the bias and variance of ATE estimators. The proposed method also enables a better balance or even exact balance of observed covariates depending on the strength of the imbalance penalty. This type of balance shares similar spirits to the entropy balancing method 18 and the CBPS method, 20 both of which achieve exact balance.
The DR methods have been developed to address potential misspecifications in either the PS or outcome models. These methods can provide consistent estimates even if one of the two models is misspecified, provided the other model is correctly specified. However, it was reported that the DR estimator may not always outperform a single outcome model when both the PS and outcome models are slightly misspecified. 11 Through simulation studies (results not shown), we found that the DR estimator with NNet+IS as the PS model clearly outperformed the single misspecified outcome model, and the use of GLM+IS also showed improved performance. This highlights the ability of our proposed method in enhancing the DR estimator’s performance when both models are misspecified.
Our methods may help researchers avoid the ad hoc manipulation of estimated PSs or weights, such as trimming or truncating the weights. As shown in the simulation study, the PS estimation methods based on the calibrated loss function were more robust to model misspecification. In cases where either the PS model or the outcome model was correctly specified, the proposed calibrated version outperformed the prediction-based base model even for the DR estimator, especially in small sample sizes. When the PS model was correctly specified, the proposed methods could still reduce the variance in ATE estimation. In comparison to the logistic regression model, neural network model appeared to perform better under model misspecification. When the logistic regression was used as the prediction model for PS estimation, our proposed loss function calibration method and the CBPS method yielded very similar results for the Hájek and DR estimators. Both methods aim to optimize prediction and covariate balance at the same time. While the CBPS achieves covariate balancing within the framework of generalized method-of-moments, our approach is based on the calibrated loss function, which is more flexible to accommodate other covariate imbalance measures beyond marginal moments difference in each covariate. The penalty term to account for covariate imbalance can also vary across covariates depending on the strength of confounding effects. Lastly, our approach facilitates the use of other variable selection methods for predicting PS, such as least absolute shrinkage and selection operator (LASSO).
62
Specifically, when the dimension of covariates is high, an additional
The proposed approach offers several advantages. First, it is robust to mild to moderate model misspecification. Even if the PS model is misspecified, the covariate balance is still controlled to a certain degree. Second, it is user-friendly, reducing the need for the back-and-forth covariate-balance check and model refit. Third, the framework is flexible in the sense that a variety of prediction models can be chosen, from the logistic regression model to machine learning methods such as neural networks. The only modification required is a simple calibration of the loss function. Lastly, the robust estimates of the PSs can be seamlessly integrated with a wide range of standard causal effect estimation methods, such as inverse probability weighting, matching, and stratification methods. Although the proposed method primarily focuses on enhancing PS estimation, integrating neural networks or other non-parametric approaches for outcome modeling may further enhance the performance of DR estimators. This integration allows for more flexible modeling, especially when the true outcome model formulation is unclear and likely to be misspecified with parametric regression models. 63
In this article, we only consider a continuous outcome without censoring. However, extending our algorithms to other types of outcomes, such as binary and survival outcomes, is straightforward. Second, we investigated the most common scenario of a binary treatment in this work. Extensions to multi-level treatment groups warrant further study. While the proposed method is robust to misspecifications in the functional forms of the PS model, it still requires the absence of unmeasured confounding, as is the case with any observational study. Additionally, we apply an equal penalty to the imbalance across all covariates. In high-dimensional settings, confounder selection methods for causal inference are needed to help extend our proposed method to cases with high-dimensional covariates. 32 Moreover, achieving balance across all covariates may not always be feasible in high-dimensional settings. An outcome-assisted modeling approach motivated by Shortreed et al. 43 may be considered to adjust the level of penalty for each covariate imbalance depending on the strength of the covariate-outcome association.
Implementation and software
The computational complexity of a neural network primarily depends on the architecture of the network. We run our simulation studies on Intel Xeon E5-2680 v3 with a 2.50 GHz CPU and 270 GB RAM. It roughly took <40 seconds under a sample size of 200, and <50 seconds under a sample size of 500 to implement NNet+IS method for a given tuning parameter with a single thread. The large tuning parameter selection range and CV will also increase the computational complexity. We used PyTorch’s autograd package that offers automatic differentiation for all tensor operations, enabling efficient gradient computation even with the imbalance penalty term in the loss function. Our code enables parallel computing to reduce the computational time, which is extremely helpful when running on high-performance computing machines. We implement the simulation and the real data applications in R 4.2.1 and Python 3.11.4. The source codes are available to the public via GitHub https://github.com/ys3298/RobustPSviaLossCalibration.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article.