
Abstract
Joint modelling of longitudinal and time-to-event data is a method that recognizes the dependency between the two data types, and combines the two outcomes into a single model, which leads to more precise estimates. These models are applicable when individuals are followed over a period of time, generally to monitor the progression of a disease or a medical condition, and also when longitudinal covariates are available. Medical cost datasets are often also available in longitudinal scenarios, but these datasets usually arise from a complex sampling design rather than simple random sampling and such complex sampling design needs to be accounted for in the statistical analysis. Ignoring the sampling mechanism can lead to misleading conclusions. This article proposes a novel approach to the joint modelling of complex data by combining survey calibration with standard joint modelling. This is achieved by incorporating a new set of equations to calibrate the sampling weights for the survival model in a joint model setting. The proposed method is applied to data on anti-dementia medication costs and mortality in people with diagnosed dementia in New Zealand.
Introduction
Joint modelling of longitudinal and time-to-event data allows simultaneous modelling of a longitudinal variable and time-to-event process, by using sub-models to model each data type within a single model. 1 Joint models are useful when dealing with survival models with measurement error, partially missing time-dependent covariates, longitudinal models with informative dropouts, or survival process and longitudinal process that are associated via latent variables. 2 These models reduce bias in parameter estimates within a single study, which makes joint models useful and preferable to performing longitudinal or time-to-event analyses separately. 1 Slasor and Laird 3 demonstrated efficiency gains of 6.4% and 10.2% when using the joint piece-wise exponential joint model over the standard proportional hazards model in a simulation and clinical trial data, respectively.
Longitudinal data is composed of continuous or discrete repeated measures from particular individuals followed over a period of time. This sort of data is particularly useful for evaluating the relationship between risk factors and development of a disease, and the outcomes of treatments over time. 4 Time-to-event data records the length of time until the occurrence of a well-defined end-point of interest and is widely used in many statistical techniques such as Cox proportional hazards models. 5 Joint models allow us to deal with these two data types simultaneously by considering the dependency between them, using submodels that depend on each other. These models are applicable when individuals are followed over time, generally to observe the progression of a disease or a medical condition or death, and when longitudinal variables that are related to the time-to-event variable, such as monthly medical costs, are available.
Joint models are important as they provide more efficient estimates of the effects on the time-to-event variable, provide more efficient estimates of the effects of the longitudinal variables, and reduce bias in the estimates of the overall effects, that is, the effect on survival and the longitudinal variable. 6 One of the possible strategies that can be used in the joint modelling of longitudinal and survival data is to incorporate the longitudinal measurements directly into the Cox model as time-dependent covariates to perform Cox model analysis. However, because the longitudinal measurements are typically correlated between the same subject, this approach might lead to highly biased and inefficient estimates of the treatment effect. Tsiatis et al. 7 proposed the two-stage approach, in which a linear mixed model is fitted to the longitudinal data in the first stage and the fitted trajectory function is incorporated into the Cox model as a time-dependent covariate in the second stage but this approach still leads to potentially biased estimates. 6 Instead of using this approach, joint modelling of longitudinal and survival data can effectively remove this bias, by using individual-level random effects that account for both the association between the longitudinal and time-to-event outcomes, and the correlation between the longitudinal measurements in the longitudinal sub-model. 8 Therefore, joint models should be used as they do not lead to biased estimators.
Another challenge is that due to the increasing availability of electronic health records, increasingly more health services research questions are answered using secondary analysis of such national data sets, which are often obtained using complex sampling designs. Ignoring this design can result in severely biased estimates. 9 Therefore, the sampling design must be taken into account in the analysis. In complex samples, subjects are selected using sampling designs in which some subjects have higher or lower selection probabilities. Sampling weights are defined as the inverse of the selection probabilities. The weights can be interpreted as the number of individuals each individual represents in the population. These weights are used to multiply the log-likelihood contribution from each subject, accounting for the sampling design.
This article extends the pseudolikelihood approach to calibrated weights. The weights are calibrated to surrogates of the survival model influence functions. This is done by incorporating a new set of equations that calibrate the sampling weights. We use a two-phase design approach which has been previously used. 10 Our approach using weights calibrated to surrogates of the survival model influence functions results in more efficient estimates of the survival model parameters for variables that are available for the whole population.
Two-phase designs
In two-phase designs,
11
the first-phase sample (population) of size
Joint model of medical cost and mortality
A joint model of medical cost and survival can be a single model consisting of two or three sub-models. For example, assume a group of
Xu et al.
9
used the approach proposed by Liu et al.
15
to jointly model the cost
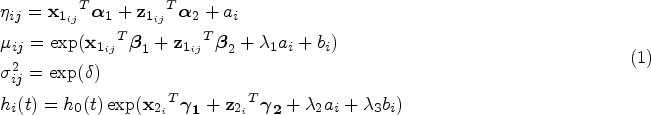
For a single individual
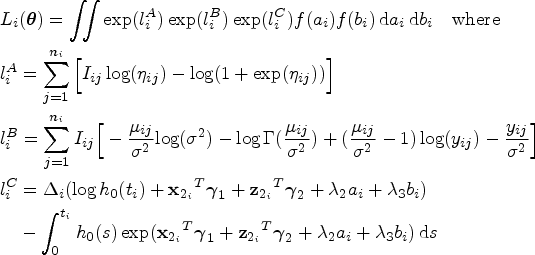
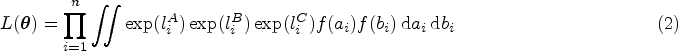

Recent literature in joint modelling has been based on the assumption that the data set was obtained via a SRS design, despite the fact that samples obtained from health records are usually complex. 9 To allow for the fact that data is collected using a complex sampling design, Xu et al. proposed an approach to incorporate sampling weights into the log-likelihoods.
To recognize the complex survey setting of the data, sampling weights


Deville and Särndal
21
proposed the theory of survey calibration (generalized raking), which uses calibrated weights to improve efficiency of estimators of totals from complex surveys, in cases where auxiliary variables for which the population total is known are available. The goal is to improve estimators of the form


Calibration performs well when estimating totals, and the auxiliary variables are strongly correlated with the study variable of interest.
21
Our parameter estimator is not a total, but we can express it asymptotically as total, with the help of influence functions (IFs) given by
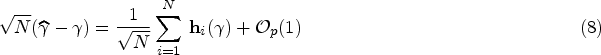
The dfbeta’s can be used as precise approximations of the IFs,
25
where dfbeta for individual
Use weighted regression models such as linear or logistic regression models to the phase-two sample, to predict the partially missing variables using variables known for all subjects. A separate prediction is required for each of the partially missing variables. Impute the partially missing variables for every subject at phase-one, using the prediction equation obtained. Fit a proportional hazards model to the phase-one data using the imputed values of partially missing variables. For individuals in the phase-two sample, the imputed values are used to ensure surrogates of the influence functions only depend on information available at phase-one. After the model is fitted, surrogates of the influence functions are obtained as dfbeta’s using the Calibrate the sampling weights using surrogates of the influence functions from the survival sub-model for the phase-two sample as auxiliary variables and zeroes as totals. We use raking calibration to guarantee positive adjusted weights. Obtain parameter estimates using log-pseudolikelihood with the resulting calibrated weights. That is, solving the equations:

Variance is estimated differently depending on the type of estimating equations used for parameter estimation. For unweighted log-likelihood, the variance is conveniently estimated with the usual negative Hessian matrix evaluated at the parameter estimates. For log-pseudolikelihood with sampling weights, we use a sandwich estimator, obtained from Taylor linearization:



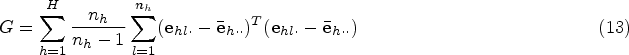


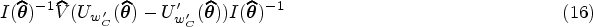
We conducted a simulation study to investigate the efficiency of the proposed estimators. This specific setting follows Xu et al., where phase 1 is used to generate values of a phase-one sample (finite population) from the joint model and phase 2 is used to select a phase-two sample from the phase-one sample. Automatic differentiation and Laplace approximation from the
At phase 1, the joint model used to generate the phase-one data set is given by
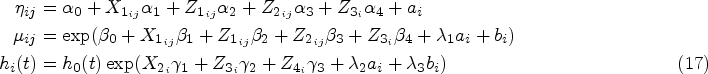
The fixed effect coefficients are set to
At phase 2, the phase-two sample is selected from the phase-one sample using a stratified cluster sampling design. Firstly, a simple random sample of two clusters is selected from each stratum. Then, individuals in each sampled cluster are selected by sampling with probability proportional to size (PPS) where the size measure is given by



In practice, true sampling weights may not always be available. Alternatively, Robins et al. 29 suggested using estimated sampling weights using a logistic regression model, as such estimated weights lead to efficiency gains even when the true sampling weights are available. We evaluate the performance of log-pseudolikelihood (IPW) and calibrated log-pseudolikelihood estimator using estimated sampling weights in place of true sampling weights. To estimate the sampling weights using logistic regression, information about all individuals in the phase-one sample is needed.
We conduct simulation studies using two sampling schemes based on estimated sampling weights in place of true sampling weights. While the phase-one data generation process is identical to the one previously used, phase-one variables
In the first scheme given by (21), the phase-two sample selection process is correctly accounted for by our weight estimation model. In the second scheme given by (22), the phase-two selection sample process is incorrectly accounted for by the weight estimation model, and the selection process involves an unmeasured phase-one variable ‘frailty’, which has a reasonably high bearing on phase-two sample selection, along with other known variables. The frailty variable is simulated from Bernoulli with
We use

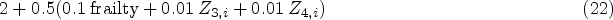
For the two scenarios, we use the same weight estimation model where sampling weights are estimated using logistic regression. In the logistic regression, the binary sampling indicator
Optimizing the joint likelihood of a joint model using the frequentist approach is challenging due to intractable integrals and a large number of parameters. To overcome this difficulty, we adopt a three-stage optimization approach to optimize the joint likelihood and obtain parameter estimates. Such approach requires compiling three separate C++ templates in
Step 1: The first step in the staged maximization is optimizing the joint calibrated log-pseudolikelihood of the logit model for the probability of having a positive medical cost, where random effects
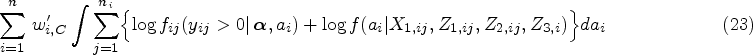
Step 2: The second step in the staged maximization involves prediction of the random effect
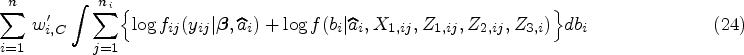
Step 3: The final step in the staged maximization is to use predicted random effects
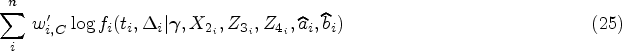
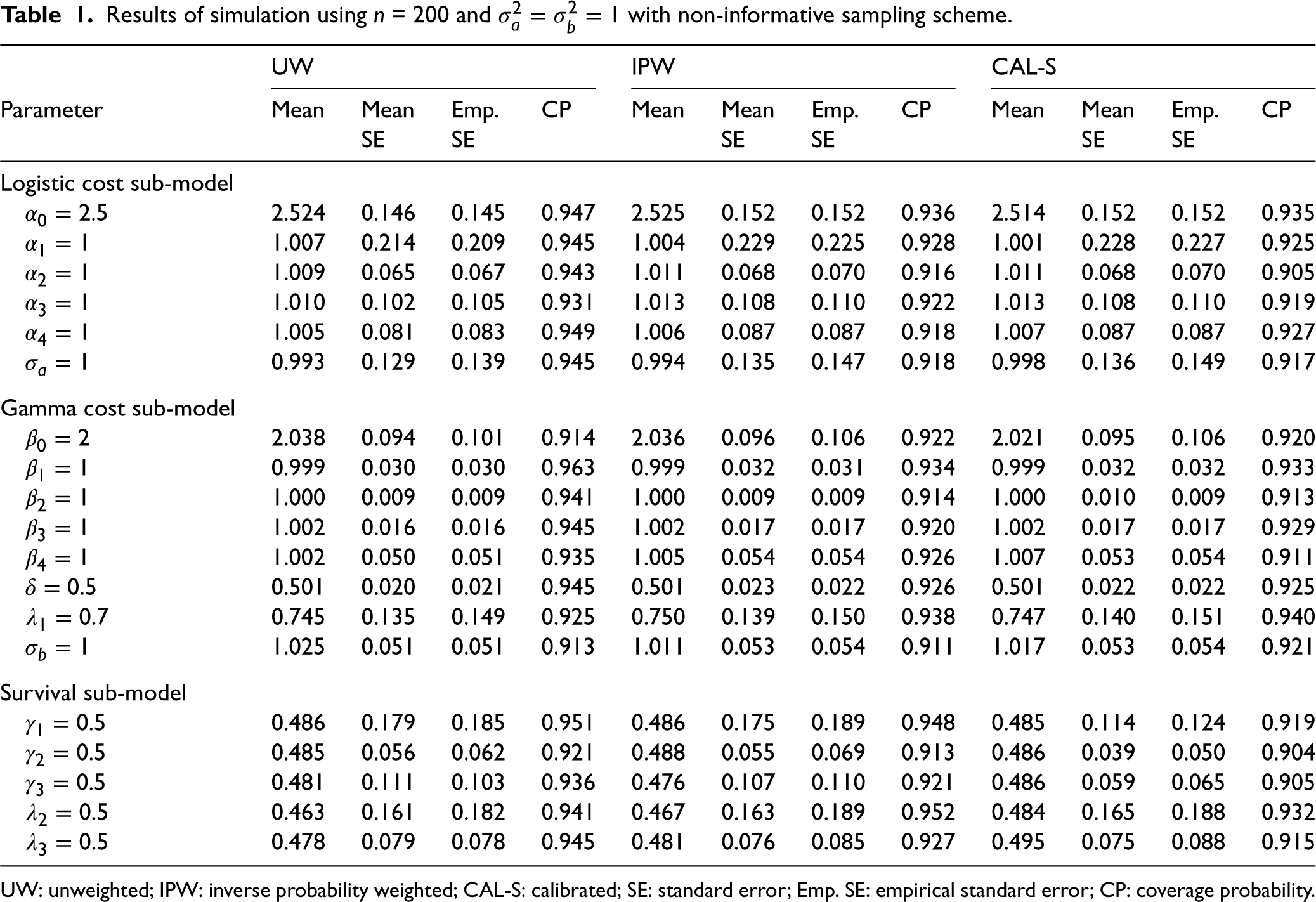
In the simulation study, the unweighted (UW), weighted (IPW) and calibrated (CAL-S) models are fit to the simulated data. The standard errors (SEs) are calculated as the square root of corresponding variance estimators as described in Section 5. Results are averaged and summarized across the 500 replicates. Results are shown in Tables 1 and 2 and provide information about the estimators in terms of SE, empirical standard error (Emp. SE) and coverage probability (CP). Tables 1 and 2 present the results from UW, IPW and CAL-S analyses using non-informative and outcome-dependent sampling schemes, respectively. IPW and CAL-S analyses in these tables are based on true sampling weights. Tables 3 and 4 present the results from UW, IPW and CAL-S analyses using different sampling schemes, respectively, using estimated weights for IPW and CAL-S analyses.
Results of simulation using
= 200 and
with non-informative sampling scheme.
Results of simulation using
UW: unweighted; IPW: inverse probability weighted; CAL-S: calibrated; SE: standard error; Emp. SE: empirical standard error; CP: coverage probability.
Results of simulation using
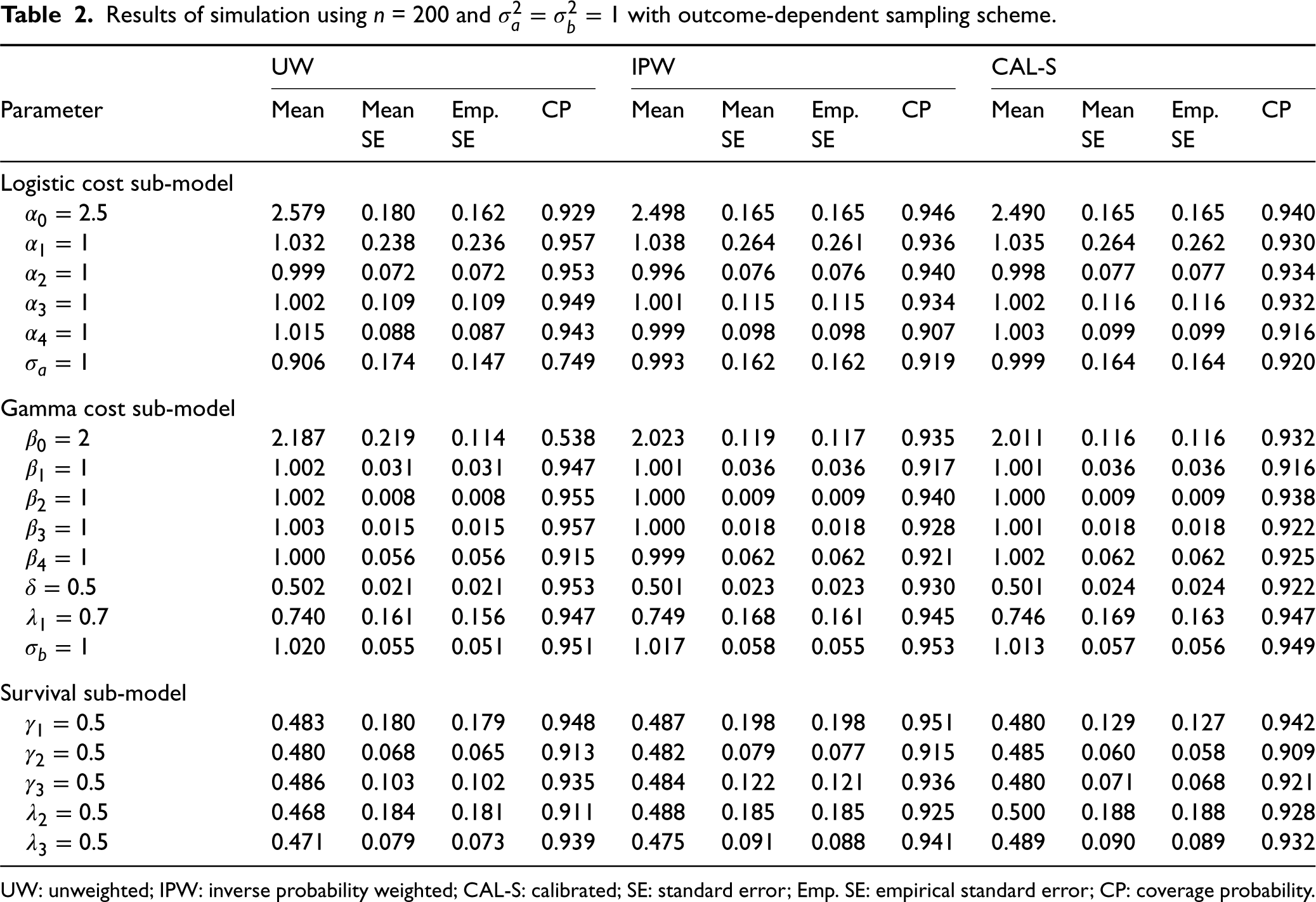
UW: unweighted; IPW: inverse probability weighted; CAL-S: calibrated; SE: standard error; Emp. SE: empirical standard error; CP: coverage probability.
Results of simulation using estimated sampling weights, where
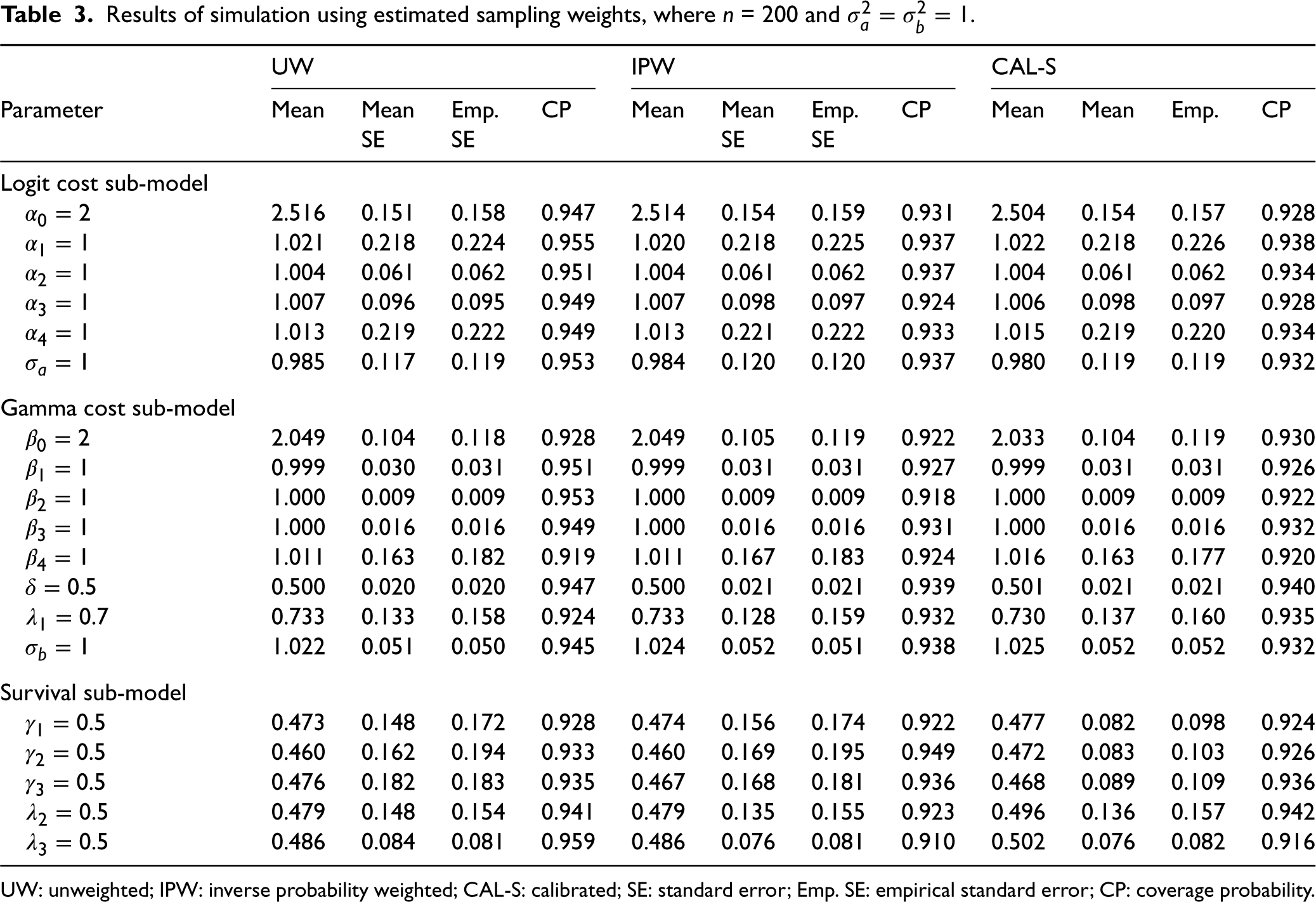
UW: unweighted; IPW: inverse probability weighted; CAL-S: calibrated; SE: standard error; Emp. SE: empirical standard error; CP: coverage probability.
Results of simulation using estimated sampling weights, where
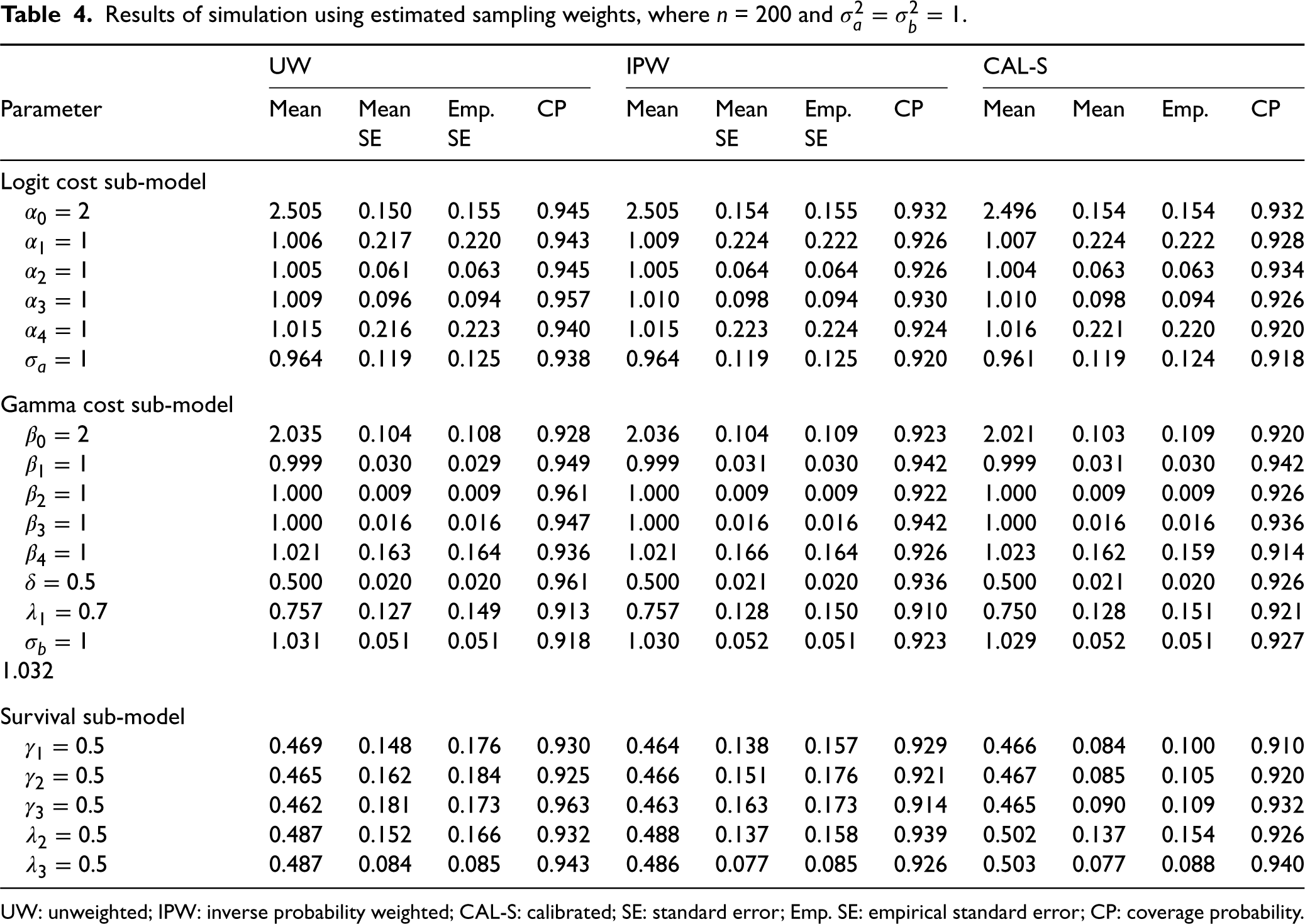
UW: unweighted; IPW: inverse probability weighted; CAL-S: calibrated; SE: standard error; Emp. SE: empirical standard error; CP: coverage probability.
Our simulation results in Table 1 show that when the sampling design is non-informative, using the unweighted log-likelihood (the standard maximum likelihood estimation) leads to a small finite sample bias. Using the log-pseudolikelihood also leads to unbiased results, with a slightly greater amount of variability of estimators. This indicates efficiency loss from multiplying the sampling weights by the individual likelihood contribution when there is no need to consider the sampling design, and is consistent with the result by Xu et al. As expected, Table 1 in the Supplemental Material shows that increasing the phase-two sample size
Our simulation results in Table 2 indicate that under the outcome-dependent sampling scheme, using the unweighted log-likelihood leads to biased estimates for model intercepts
Under both non-informative and outcome-dependent sampling scheme, calibration to surrogates of the survival model influence functions leads to significant efficiency gains for the parameter estimates (
Tables 3 and 4 show our simulation results where IPW and CAL-S analyses are based on estimated weights. The simulation studies in both tables are based on the identical weight estimation model, using sampling schemes (21) and (22), respectively. Tables 3 and 4 indicate that under both scenarios using estimated weights, as expected, pseudolikelihood estimator does not lead to significant efficiency gains or loss compared to the unweighted estimator. However, both unweighted and unweighted models lead to a small finite sample bias, even when the weight estimation model is incorrectly specified and does not correctly reflect the variables used in the phase-two sample selection.
Calibration to surrogates of the survival model influence functions under estimated weights leads to significant efficiency gains in the parameters estimates (
We conclude that calibration to surrogates of the influence functions from the survival model leads to significant efficiency gains for (
We apply our proposed method to jointly model anti-dementia medication costs and mortality in people with diagnosed dementia in New Zealand. We use an integrated dataset which was integrated from multiple datasets managed by Stats NZ Integrated Data Infrastructure (IDI) and interRAI.
Table 5 shows the phase-one and phase-two sample characteristics of the dementia data. For the phase-one sample, demographic information that includes age, gender and ethnicity is available, and for the phase-two sample, additional information that includes positive medication cost and mortality outcome is available. All phase-one sample individuals that are not included in the phase-two sample were not prescribed medications and are alive. In this application, mortality, its risk factors and determinants of anti-dementia medication costs are investigated for people with diagnosed dementia in New Zealand. The covariates of interest are age, gender, ethnicity, diabetes diagnosis, ADL (Activities of Daily Living) dependence and CPS (Cognitive Performance Scale). Many elderly, including those with diagnosed dementia, are disabled in one of more activities of daily living (ADL) such as bathing, eating and dressing. It is also of interest to evaluate the estimation of association parameters
Phase-one and phase-two sample characteristics of the dementia data.
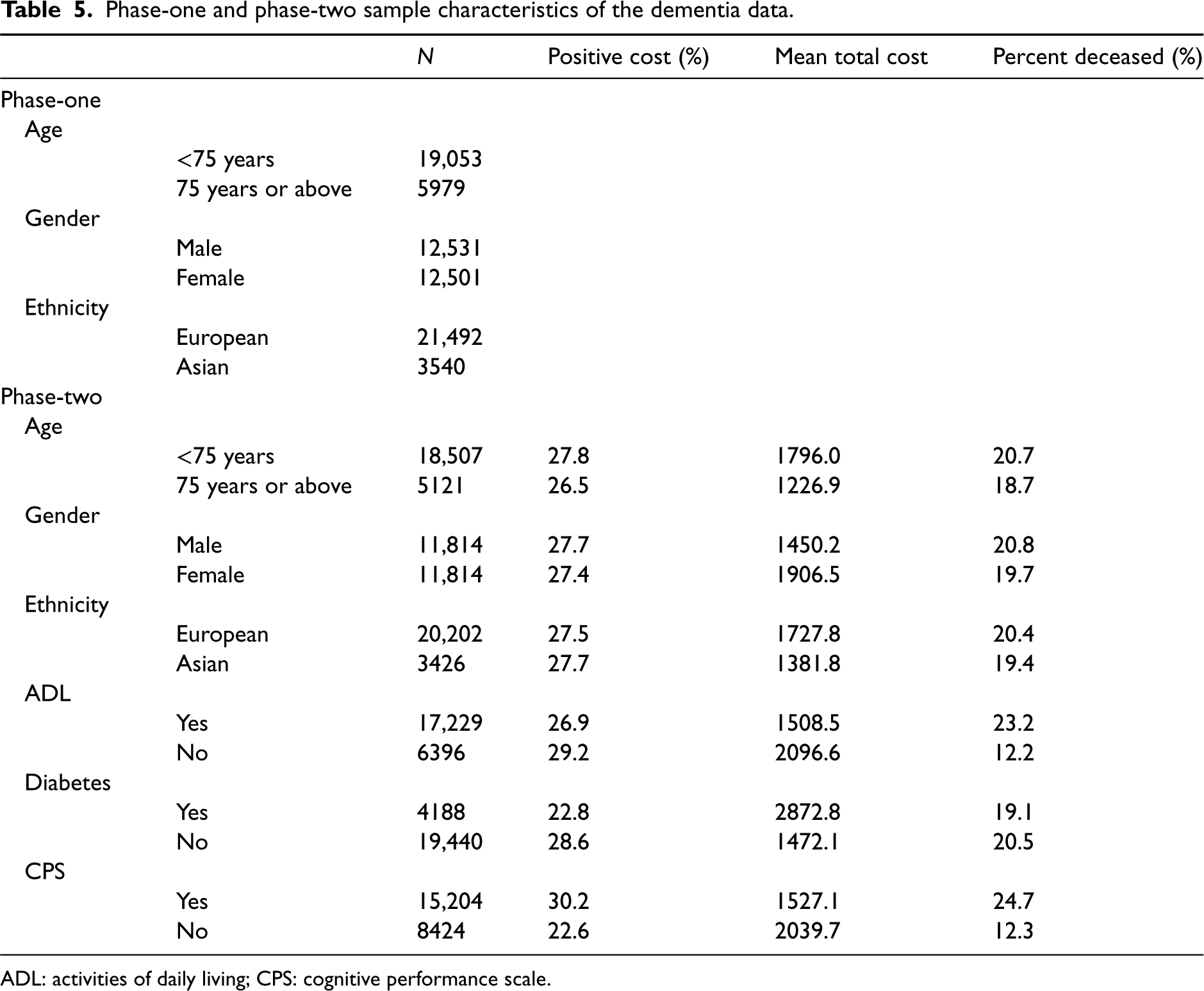
Phase-one and phase-two sample characteristics of the dementia data.
ADL: activities of daily living; CPS: cognitive performance scale.
In this application, true sampling weights are not available as there is no intervention in the phase-two sample selection and estimated weights and their calibrated weights are used to derive IPW and calibrated estimators, respectively. For calibration, we use ADL dependence, CPS and diabetes diagnosis as target variables, as they are only known in the phase-two sample, and demographics including age, gender and ethnicity as auxiliary variables, which are known in the phase-one sample.
The results in Table 6 show that dementia patients with higher CPS are more likely to use anti-dementia medication
Parameter estimates and SEs for dementia data using calibrated log-pseudolikelihood.
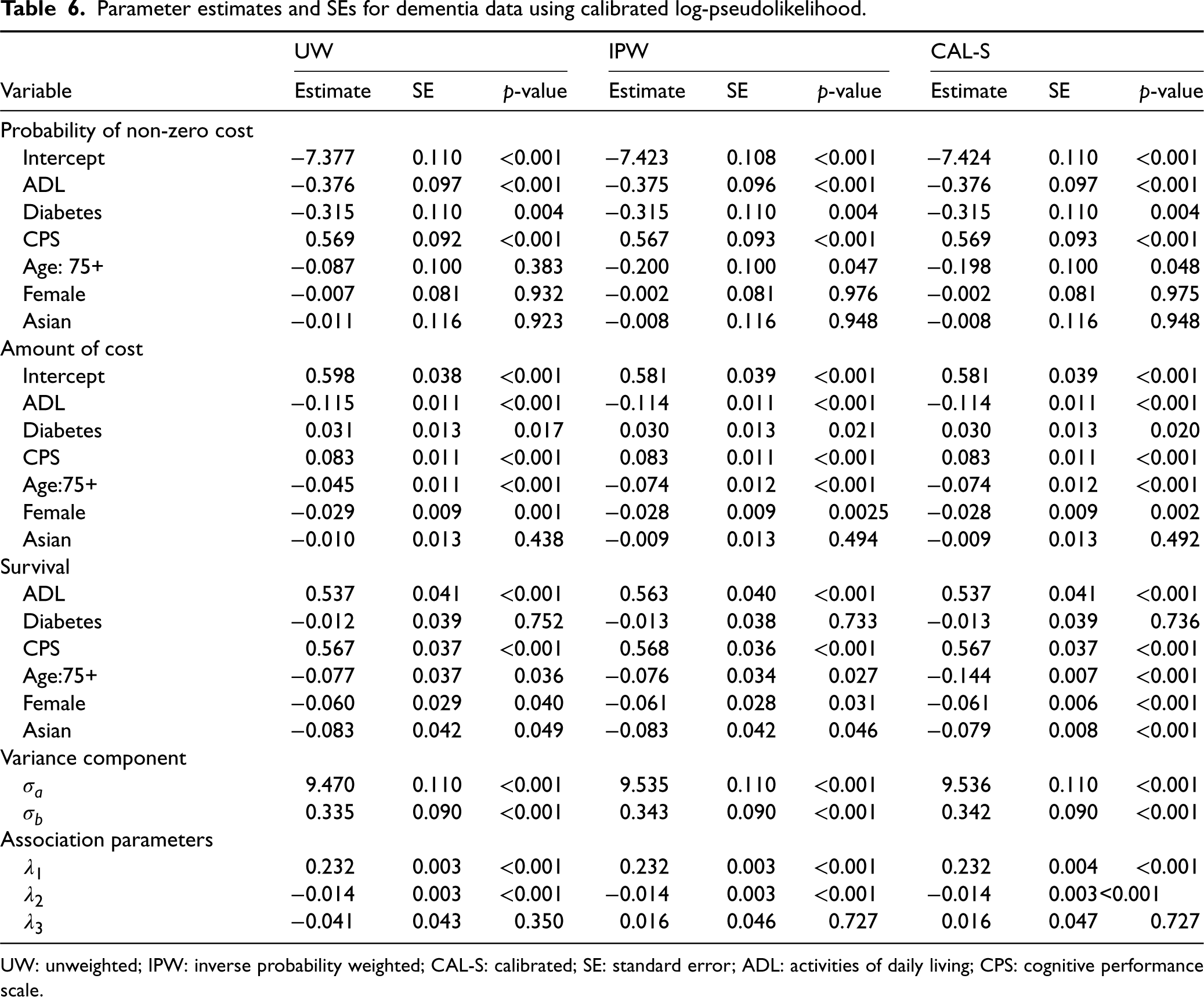
UW: unweighted; IPW: inverse probability weighted; CAL-S: calibrated; SE: standard error; ADL: activities of daily living; CPS: cognitive performance scale.
Patients who were 75 years old or younger were more likely to die compared to those older than 75 years old, which is consistent with previous findings that early onset dementia leads to higher mortality. 30 In addition, Asian ethnicity and being female were associated with lower mortality in dementia patients. There was no statistically significant differences in anti-dementia medication use between males and females which supports previous findings. 31
The estimated coefficient of the parameter
In all analyses,
As expected, calibration to surrogates of the survival model influence functions led to significant efficiency gains in the estimates of phase-one variables (age, gender and ethnicity) on mortality in the survival model. There were no efficiency gains in the estimates of phase-two variables, as the phase-one variables did not have a high correlation with the phase-two variables. This calibration methodology did not lead to any efficiency gains or loss in the parameters associated with the cost models. These results are expected based on our simulation studies where calibration to surrogates of the survival model influence functions only led to efficiency gains in the estimates of survival model parameters
Medical cost data are usually obtained using complex sampling designs rather than SRS and are characterized by right skewness and excessive proportion of zeros. These characteristics need to be reflected in the statistical analysis of medical cost data for valid statistical inference. In addition, medical cost is associated with survival as patients with a greater amount of medical cost are less likely to survive, and it is important that a joint model is used to analyse the two data types simultaneously to obtain more efficient parameter estimates compared to separate analysis of the two data types.
In this article, we extended the pseudolikelihood approach by Xu et al. to jointly model medical cost and mortality for complex surveys using survey calibration that modifies the sampling weights in a joint model setting. For calibration, we used surrogates by the influence functions from the survival sub-model fitted using imputed phase-one target variable and phase-one auxiliary variables. Such surrogates of the survival model influence functions were used to calibrate the sampling weights for the phase-two sample and estimate variances of the parameter estimates.
We showed that calibration to surrogates of the survival model influence functions led to efficiency gains for the parameters in the survival sub-model but not for the parameters in the cost sub-models, including the shared individual-level variable, despite the fact the sub-models are associated via shared random effects. This type of calibration is useful when the main interest is in making inferences about the survival model in a joint model setting, as we can gain significant efficiency gains for the survival model parameter estimates while accounting for the association between time-to-event and the longitudinal outcome variable. In order to make inferences about the survival model in a joint model setting, we recommend using calibration to surrogates of the survival model influence functions, for further efficiency gains.
A potential future work may be based on weight calibration in a joint model setting where the level of correlation between the longitudinal variable and survival is high, which leads to greater dependency between the sub-models. For potential application to real data where longitudinal and survival outcomes that are highly correlated are available, it may be of interest to investigate whether only using surrogates of the influence functions from the survival model can lead to efficiency gains in the longitudinal models.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802241236935 - Supplemental material for Weight calibration in the joint modelling of medical cost and mortality
Supplemental material, sj-pdf-1-smm-10.1177_09622802241236935 for Weight calibration in the joint modelling of medical cost and mortality by Seong Hoon Yoon, Alain Vandal and Claudia Rivera-Rodriguez in Statistical Methods in Medical Research
Footnotes
Acknowledgements
This work was supported in part by the University of Auckland doctoral scholarship (to the first author). The authors wish to acknowledge the use of New Zealand eScience Infrastructure (NeSI) high performance computing facilities, consulting support and/or training services as part of this research. New Zealand’s national facilities are provided by NeSI and funded jointly by NeSI’s collaborator institutions and through the Ministry of Business, Innovation & Employment’s Research Infrastructure programme. ![]() .
.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data availability
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.