
Abstract
Tailored meta-analysis uses setting-specific knowledge for the test positive rate and disease prevalence to constrain the possible values for a test's sensitivity and specificity. The constrained region is used to select those studies relevant to the setting for meta-analysis using an unconstrained bivariate random effects model (BRM). However, sometimes there may be no studies to aggregate, or the summary estimate may lie outside the plausible or “applicable” region. Potentially these shortcomings may be overcome by incorporating the constraints in the BRM to produce a constrained model. Using a penalised likelihood approach we developed an optimisation algorithm based on co-ordinate ascent and Newton-Raphson iteration to fit a constrained bivariate random effects model (CBRM) for meta-analysis. Using numerical examples based on simulation studies and real datasets we compared its performance with the BRM in terms of bias, mean squared error and coverage probability. We also determined the ‘closeness’ of the estimates to their true values using the Euclidian and Mahalanobis distances. The CBRM produced estimates which in the majority of cases had lower absolute mean bias and greater coverage probability than the BRM. The estimated sensitivities and specificity for the CBRM were, in general, closer to the true values than the BRM. For the two real datasets, the CBRM produced estimates which were in the applicable region in contrast to the BRM. When combining setting-specific data with test accuracy meta-analysis, a constrained model is more likely to yield a plausible estimate for the sensitivity and specificity in the practice setting than an unconstrained model.
Keywords
Introduction
Tailored meta-analysis1,2 has been introduced recently as a method to find a plausible estimate for a diagnostic test's performance in a specific clinical setting. Using routine data on the test positive rate, r and disease prevalence, p from the practice setting of interest an applicable region in receiver operating characteristic (ROC) space may be derived for the purpose of study selection. 1 Thus, local knowledge for the test in the practice enables a bounded region of plausible sensitivity-specificity pairs in ROC space to be drawn. This may be used to inform study selection by testing the compatibility of individual studies in terms of the reported sensitivity and specificity with those plausible for the setting of interest In general, once the studies have been selected for tailored meta-analysis, they are aggregated using the bivariate random-effects meta-analysis model as in the case of conventional meta-analysis.
However, tailored meta-analysis is not without shortcomings. In some cases, after ensuring compatibility with the applicable region, there may be too few studies to aggregate and even when there are enough studies it does not guarantee the summary estimate will be in the applicable region. Furthermore, a key feature of tailored meta-analysis is the imposing of constraints on a test's performance in order to define a bounded region in ROC space, yet these constraints are not incorporated in the fitting of the bivariate random-effects meta-analysis model.
Here we propose a constrained model in which the parameters to the bivariate random effects meta-analysis model are estimated as usual but subject to the constraints on the sensitivity and specificity as defined by a bounded region in ROC space. The model requires a different form of optimization and incorporates the Lagrangian in order to manage the constraints. As with the unconstrained bivariate random effects model (BRM), there is no closed-form to the likelihood function, 3 so no analytical solution to the Maximum Likelihood Estimate (MLE) exists, and numerical solutions are required.
Recently, it has been demonstrated that the BRM may be optimized using bespoke Newton-Raphson (NR) algorithms.3–5 The algorithms demonstrated favourable performance characteristics 3 when compared with the generic glmer function in the lme4 package in R. 6 For the constrained bivariate random effects model (CBRM) we propose a bespoke maximum likelihood algorithm based on NR iterations that optimizes the objective function using a coordinate ascent approach.
The importance of having good initial values for an NR algorithm is formally described by Kantorovich's theorem 7 and to this end the initial values for the five parameters are derived from analytical estimates.8,9 The CBRM is optimized using the penalty method. 10 This involves adding a penalty function, which penalises any violation of the constraints, to the objective function. 10 Thus, the constrained optimization problem is replaced by a sequence of unconstrained sub-problems where the solutions of the unconstrained problems ideally converge to the solution of the original constrained problem.
The impetus behind using a constrained model is to provide summary estimates for the test that are more specific to clinical practice than those provided by conventional meta-analysis. Although this seems plausible, it is important to establish this definitively and determine to what extent a constrained model in meta-analysis is better than conventional meta-analysis.
We develop this in the following sections. In section 2, we briefly describe the basis for deriving a constrained region in ROC space. Derivation of the constrained bivariate random-effects meta-analysis model is introduced in section 3. In section 4, the penalty-based algorithm is developed for the CBRM. In section 5, the CBRM and the BRM are compared using a simulation study and applying them to two real datasets from the literature. In section 6, we end with the discussion and conclusion.
Defining a constrained region in ROC space for a test
The logic which underpins the constrained region for a test's performance has been previously described in detail1,2 and is only outlined here. The accuracy of a test is usually established by comparing its classification with a reference standard. If s is the sensitivity and f is the false positive rate, where
A consequence of these equalities and inequalities is that local knowledge of r and p allows deductions to be made on what is permissible for the sensitivity and specificity. This is the basis for the constrained region in ROC space. The size of the region is dependent on the uncertainty in the estimates for r and p, and in general, the wider the confidence intervals the larger the region. Finally, to ensure the confidence intervals for r and p contain the true values, a minimum 99% confidence interval is usually chosen.1,11 This also means that the probability that the constrained region contains the true sensitivity and specificity for the test in the setting is greater than 99%.
Derivation of the constrained bivariate random-effects meta-analysis model
Similar to the BRM, the CBRM assumes a bivariate normal distribution for the logits of the sensitivity and specificity between studies. In addition, the model uses independent binomial distributions for the true positives, and true negatives within each study.
12
So the model is of the form:
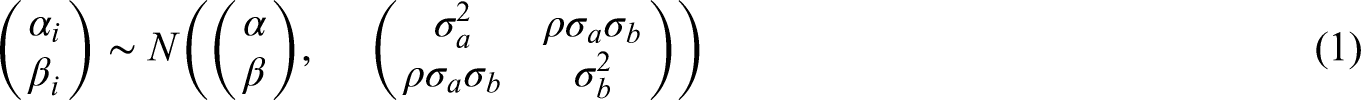


Thus the log-likelihood function of the bivariate generalized linear mixed effect model may be written as:
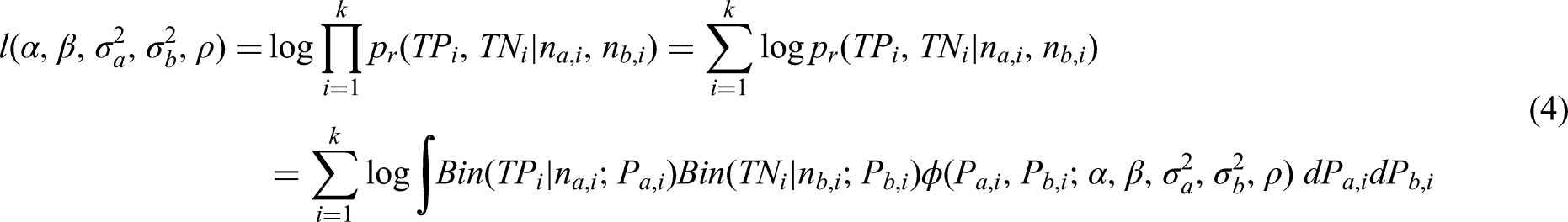
The adaptive multidimensional integration algorithms described in Genz and Malik 13 and Berntsen et al. 14 is used here to compute the double integration over the random effects in the log-likelihood function above, by using the R function adaptIntegrate within the package cubature. 15 So, in order to estimate the five parameters in the CBRM, we need to maximize the log-likelihood function defined in (4), subject to the constraints outlined in section 2 and defined algebraically below. The penalty methods can be used to solve a sequence of unconstrained nonlinear optimization problems whose solutions converge on the solution to the original constrained problem. Here we implement one of the most commonly used penalty functions, the quadratic-loss function.
Let
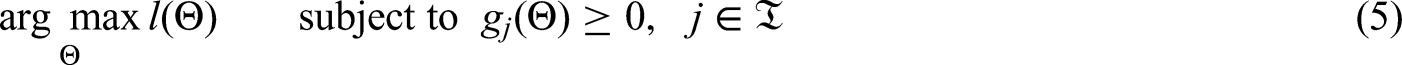
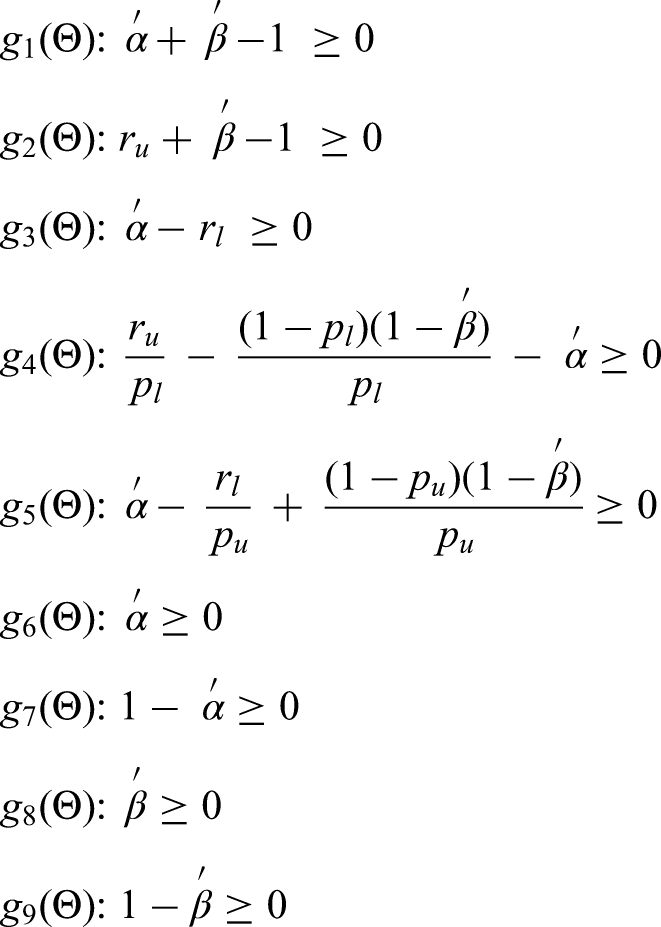
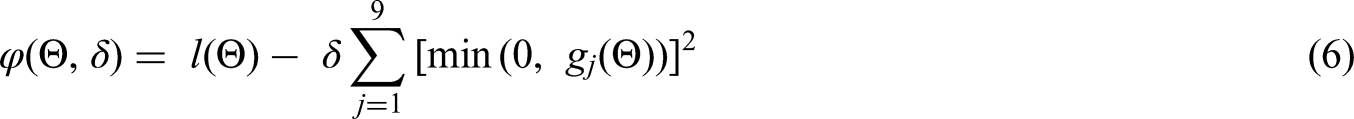
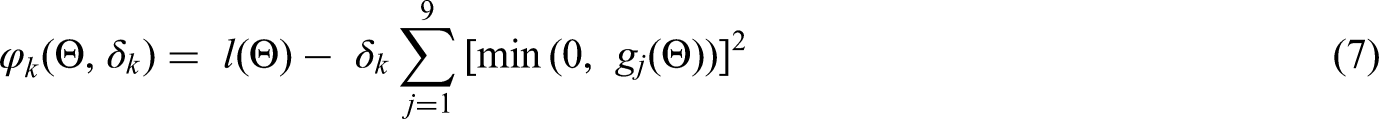
Algorithm 3.1 (penalty method for the CBRM):
Initialization: set
Maximization: Find an approximate maximizer
Convergence: Terminating when
Updating: Set new penalty parameter
Set new starting point to
The maximization step is an important element of the algorithm and this is dealt with in more detail in the next section. Note between iterations we increase
Recently, NR based algorithms have been reported for estimating the parameters in the BRM. 3 However, the algorithms may be computationally intensive and may, without appropriate initial values, lead to biased results in the final estimate due to convergence on local maxima. 16
Although the initial values may be derived using numerical methods, these are most efficiently estimated using analytical methods. Thus we may use analytical univariate weighted estimates for the initial values for
The co-ordinate ascent algorithm used here is also based on NR iteration. It starts with the initial estimates described, and then updates them repeatedly. At each iteration we start with estimating a single parameter whilst the other parameters remain fixed to their last estimated value. The value of the parameter that maximises the log-likelihood function along its axis is then chosen. The algorithm cycles through the other parameters until at the end of the iteration all five parameters have been updated.
Thus, we start with the initial estimate
Numerically, we can estimate each parameter separately using the NR method in the Get the first and second derivatives of the log likelihood function l w.r.t the underlying parameter to be estimated, lets say The Consider
As the coordinate ascent algorithm is based on NR, the theoretical importance of choosing good initial start values to ensure convergence has been previously described [7]. Based on the HO initial start, the following penalty algorithm may be used to estimate the parameters in the CBRM:
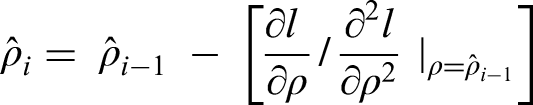
Algorithm 4.1 (penalty-based coordinate ascent algorithm for CBRM):
Initialization: set
Maximization: Find the coordinate ascent maximizer
Using the NR algorithm, to find
and
Convergence: Terminating when
set
Penalty Convergence: Terminating when
Updating: Set new penalty parameter
Set new starting point to
Although the algorithm can be computationally expensive, this may be controlled by applying large step changes to the penalty coefficient
Numerical examples
To evaluate the algorithm for the CBRM, we present a simulation study that compares it with another NR based algorithm for the BRM. 3 The performance characteristics are measured in terms of mean bias, mean squared error, coverage probability, and convergence probability. The ‘closeness’ of the estimates for the sensitivity and specificity to their true values are measured using the Euclidian and Mahalanobis distances. In addition, we apply the algorithm to two real data examples. The codes and analyses were conducted in R. 17
Simulated data examples
A simulation study was conducted to compare the CBRM with the BRM. For the simulated data, the parameters
For the
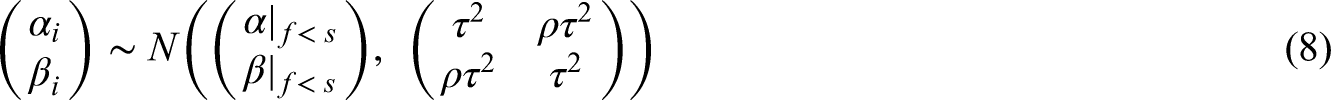
For the clinical setting of interest, one more study with overall sample size n was simulated to provide
The simulation study was conducted in two stages. For the first stage, the four parameters
For the second stage, we considered more extreme scenarios than in the first stage. In this stage, each scenario was a combination of the minimum or maximum of each parameter's values of the previous simulation. Thus we considered all 16 possible combinations between n = {50, 10000}, k = {5, 50},
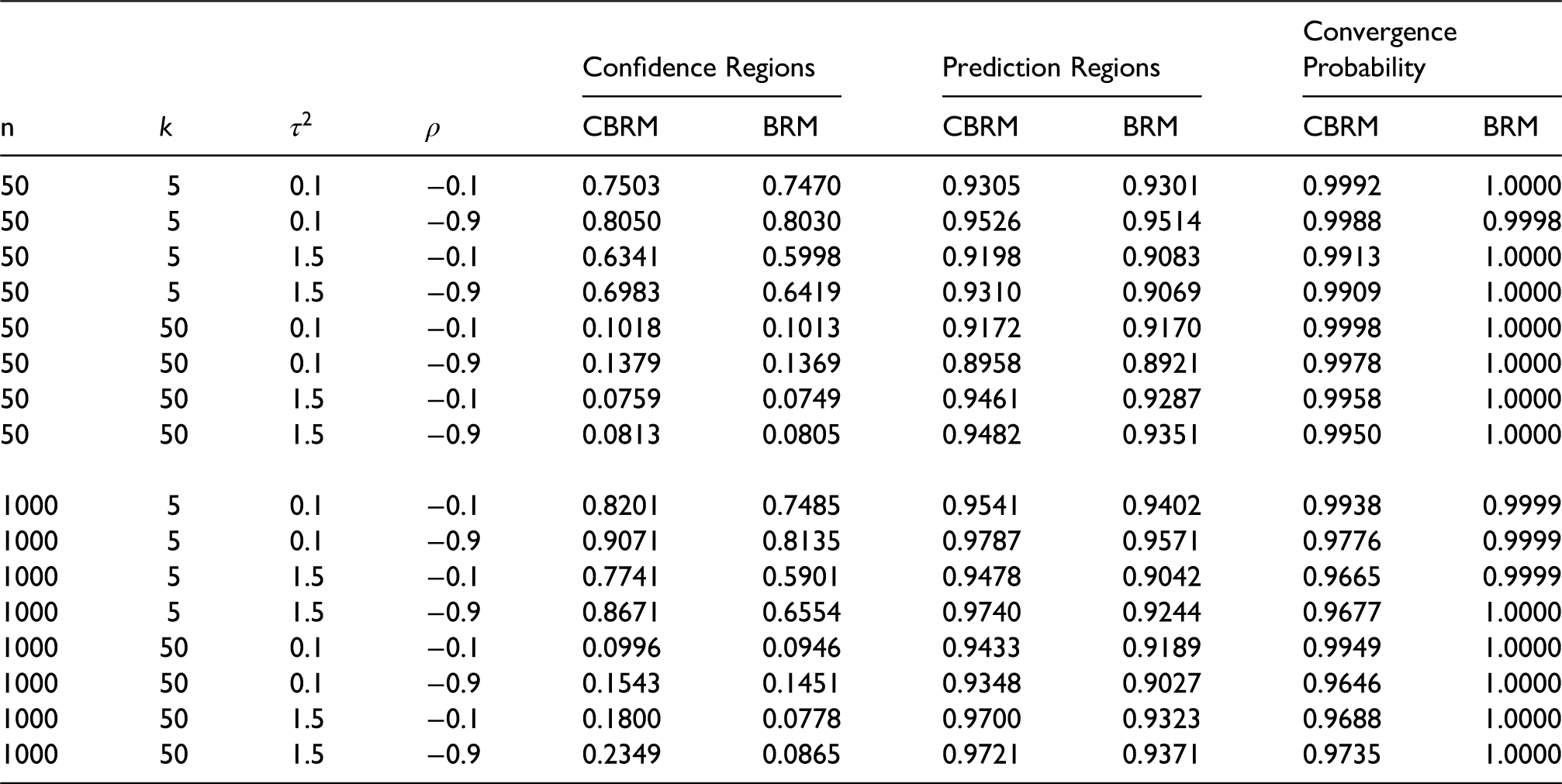
Table 1 provides the mean bias and the mean squared errors (MSE) for the estimated values of sensitivity and specificity for each scenario in the first stage. In all but one of the scenarios, the CBRM returns estimates for the sensitivity that have a lower absolute mean bias than the BRM. Similarly for the specificity, the CBRM returns estimates that have a lower absolute mean bias than the BRM in all but three of the scenarios. In general, for the MSE, the CBRM returns estimates that have a lower MSE than the BRM across all scenarios.
Mean bias and mean squared error of the estimated values of sensitivity and specificity for the CBRM and BRM based on10000 simulations for each of the scenarios.
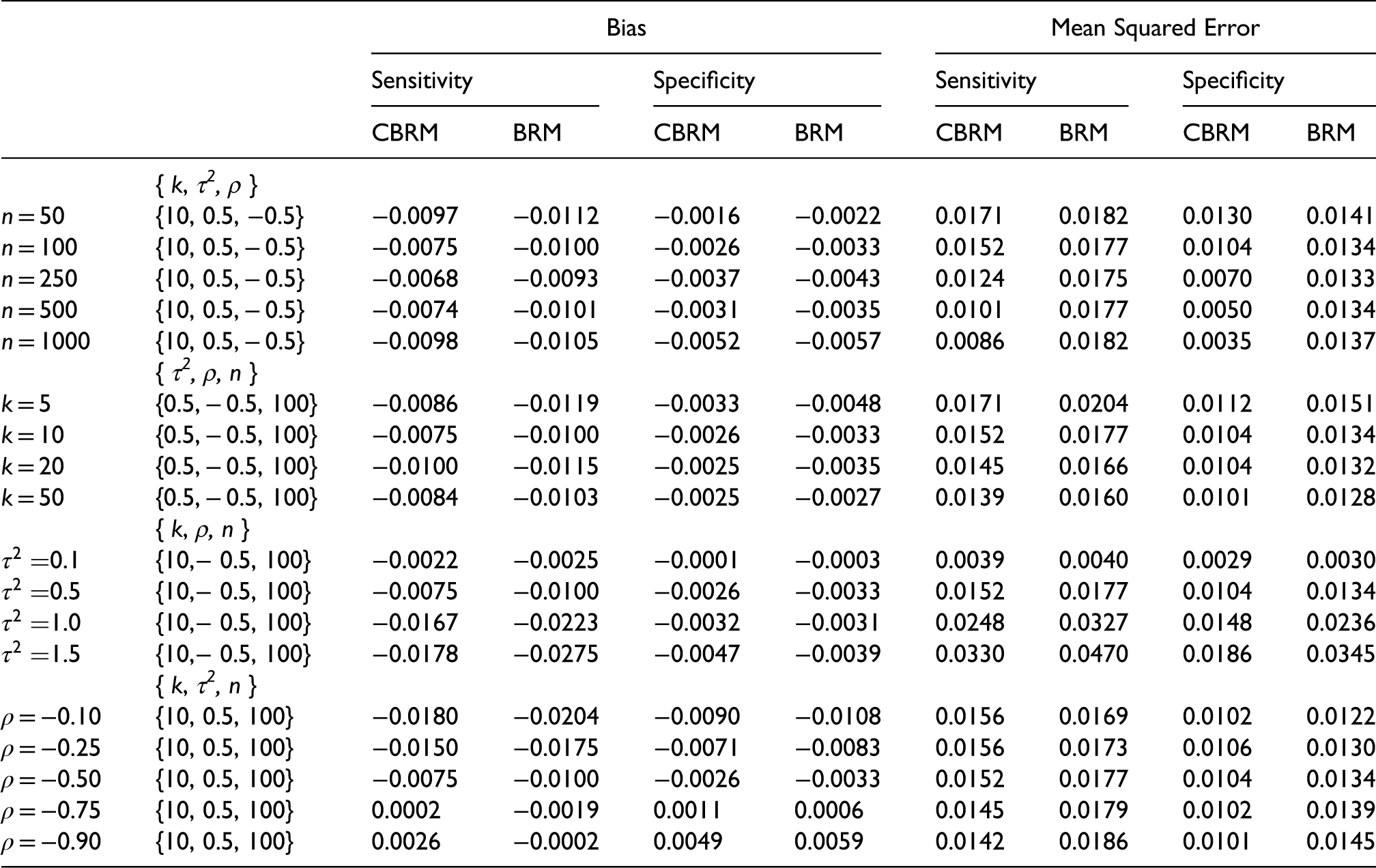
As expected, the differences in performance between the models in terms of the MSE are most pronounced for large n – as n increases the constrained region becomes more precise thus lowering the MSE for the CBRM.
From the same table we can see that, for both the CBRM and BRM, increasing the value of the variances
The mean bias and MSE for the between-study covariance matrix parameters are given in Table A1 and A2 of the Appendix. Table A1 gives the mean bias for the estimated values of
The prediction regions provide the region where we would expect to find the parameters
The coverage probability of the 95% confidence and prediction regions and the convergence probability for each scenario for the CBRM and BRM based on 10000 simulations.
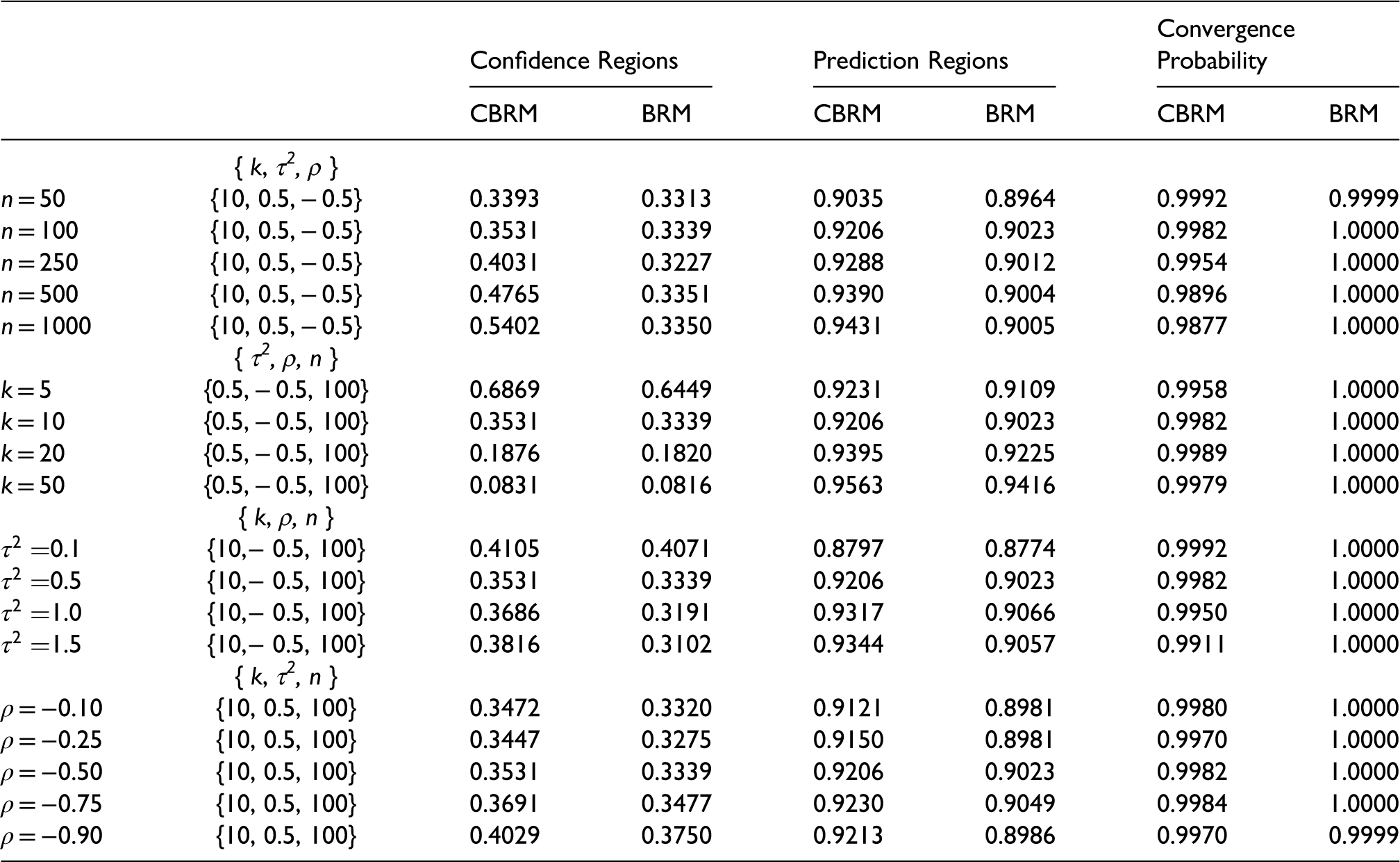
Clearly, for all scenarios, the CBRM returns higher coverage probabilities of the 95% confidence and prediction regions for
The BRM model is considered to have converged when the algorithm settles on a stable estimate before reaching a specific number of iterations. For the CBRM model to have converged, the sensitivity and specificity estimates must also satisfy the conditions in (5) and hence be located in the applicable region. The effect of this is seen in the last two columns of table 2 which show the probability of convergence for the CBRM to be slightly lower than the BRM.
As a measure of the deviation, we calculated the distance between the true values for the false positive rate and sensitivity
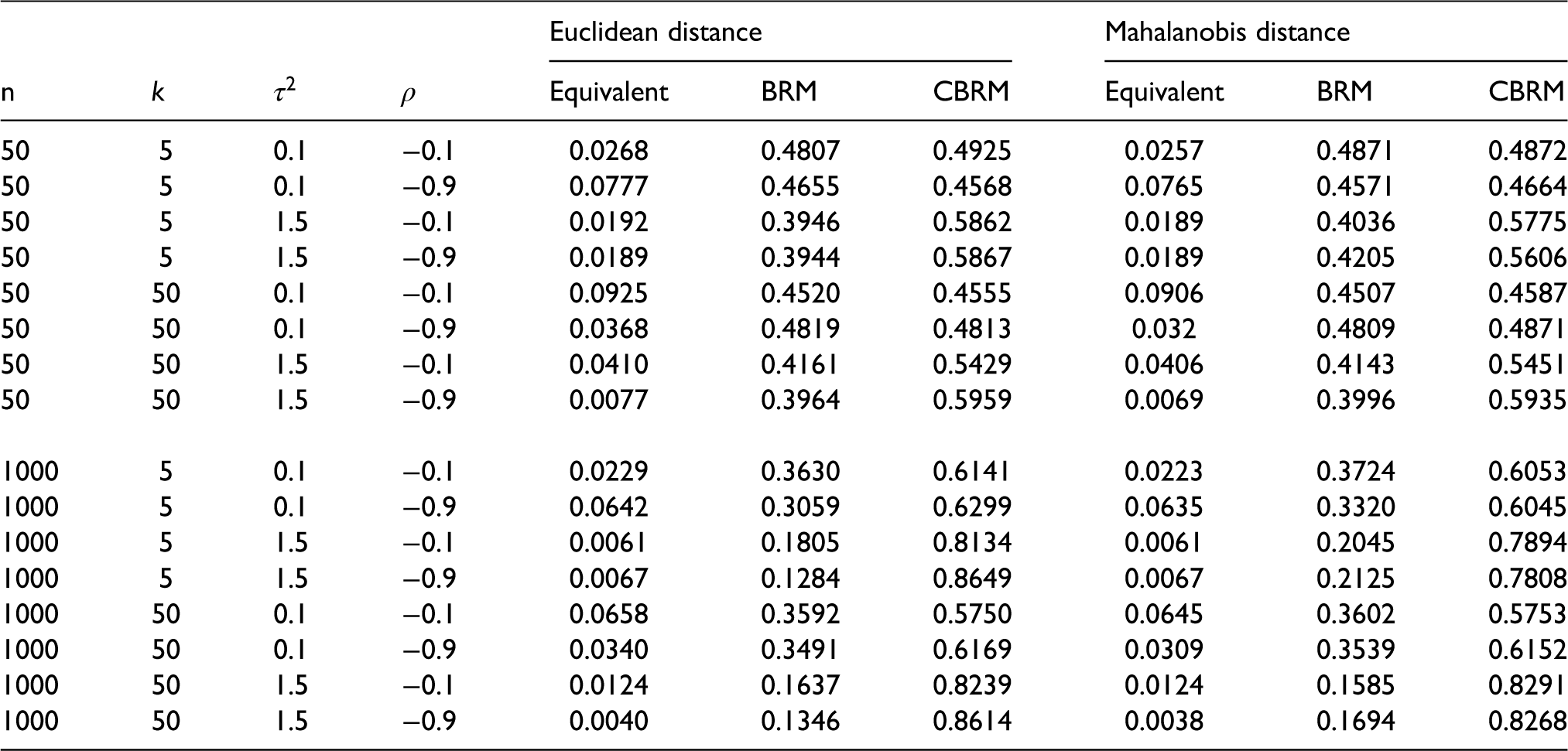
The distributions for the Euclidean distances are shown in figures A1, A2, A3 and A4 in the Appendix. It is clear for the CBRM that the lower quartile limit, median, upper quartile limit, 99.5 percentile and maximum are lower than the BRM. Whilst for some of the scenarios the difference between the CBRM and BRM is subtle, as the setting-specific sample size, n increases the difference in the medians in particular becomes more marked.
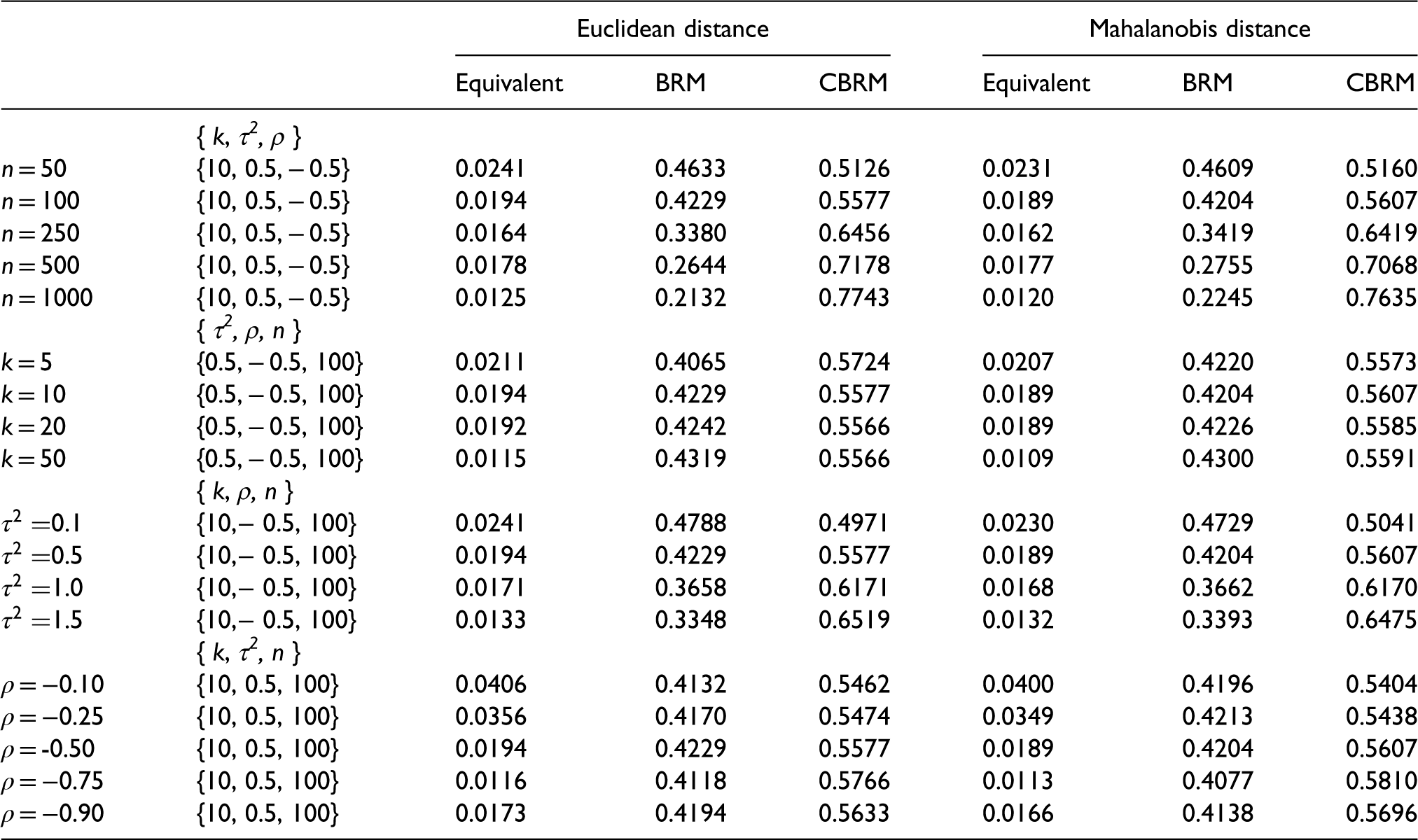
As a head to head comparison we considered which model was most likely to provide an estimate for
The probabilities of shortest distance between the estimated
For the second stage of the simulations, where we considered more extreme scenarios, the mean bias and the mean squared errors (MSE) for the estimated values of sensitivity and specificity are given in table 4. In all but three of the scenarios, the CBRM returns estimates for the specificity that have a lower absolute mean bias than the BRM. For the sensitivity, the CBRM returns estimates that have a lower absolute mean bias than the BRM in eight of the scenarios. In addition, for the MSE, the CBRM returns estimates that have a lower MSE than the BRM across all scenarios except four where they were equal. As with the stage 1 simulations, the most influential parameter is n, the sample size of the routine data collected from the setting of interest Thus, when n = 1000, the CBRM returns estimates for both sensitivity and specificity that have a lower MSE than the BRM over all the scenarios.
Mean bias and mean squared error of the estimated values of sensitivity and specificity for the CBRM and BRM based on10000 simulations for each of the 16 scenarios in stage 2.
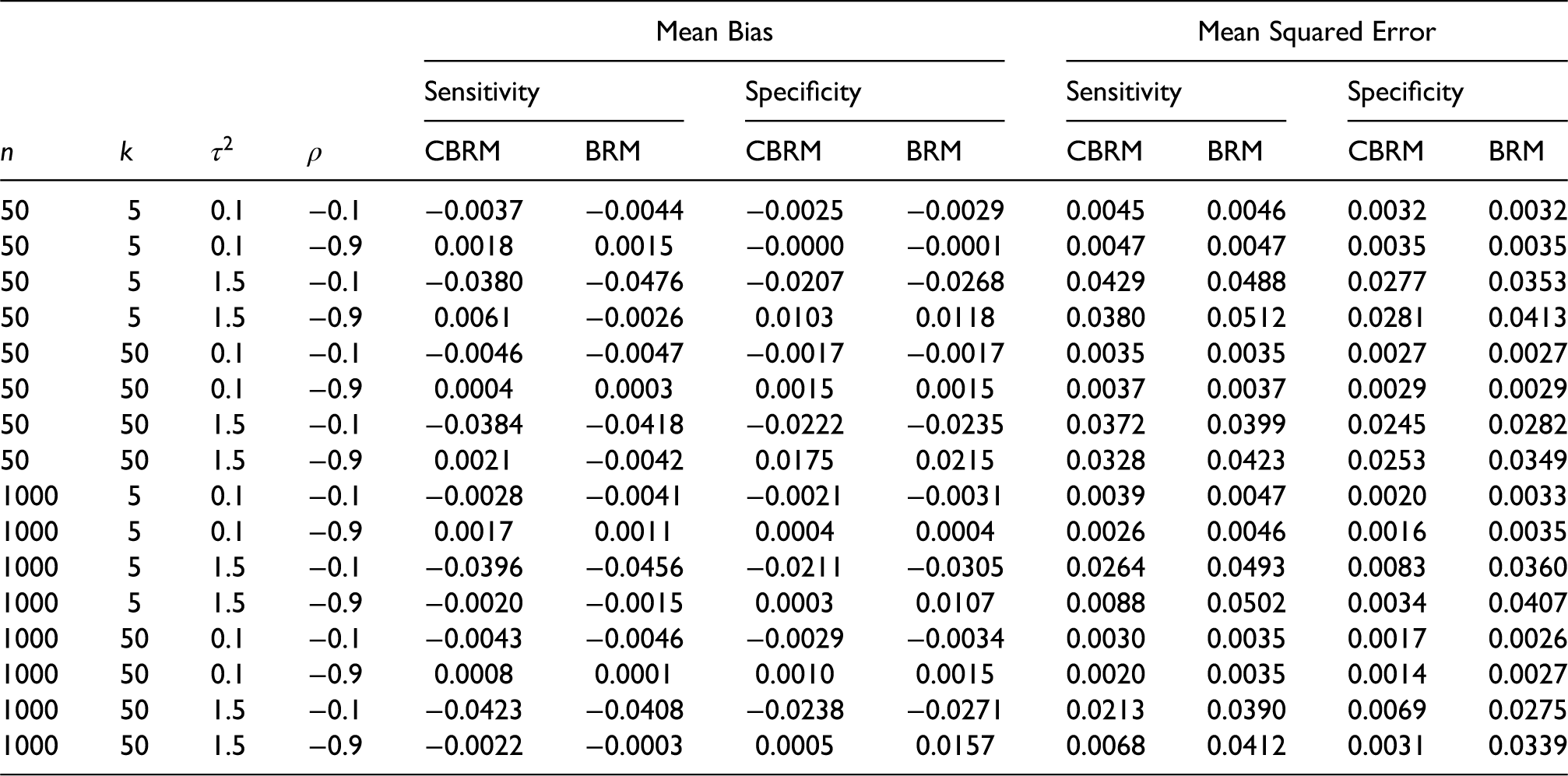
Table A3 and A4 gives the mean bias and MSE for the estimated values of
Table 5 gives the coverage probability of the 95% confidence and prediction regions and the convergence probability for the corresponding simulations. Again, for all scenarios, the CBRM returns higher coverage probabilities of the 95% confidence and prediction regions for
The coverage probability of the 95% confidence and prediction regions and the convergence probability for each of the 16 scenario for the CBRM and BRM based on10000 simulations.
From table 6, it can be clearly seen that the CBRM has the highest probabilities of shortest distance for all scenarios using the Mahalanobis distance metric and for all except one scenario using the Euclidean distance metric. Furthermore, the distributions for the Euclidean distances that are shown in figures A5, A6, A7 and A8 in the Appendix, illustrate that the CBRM's lower quartile limit, median, upper quartile limit, 99.5 percentile and maximum are lower than the BRM.
The probabilities of shortest distance between the estimated
Here, the CBRM algorithm is applied to two real meta-analysis datasets.2,20,21 In each meta-analysis, the CBRM parameters were estimated and compared with estimates for the parameters in the BRM.
The first meta-analysis evaluates the performance of computed tomography (CT) in detecting distant metastases. 20 There are 12 studies and the focus here will be on estimating the parameters in the CBRM using the penalty-based co-ordinate ascent algorithm and defining the applicable region for the 12 studies. The lower and upper limits of r are taken to be 0.24 and 0.4 respectively, while the lower and upper limits of p are taken to be 0.01 and 0.05 respectively.
The second meta-analysis evaluates the performance of Centor's criteria for diagnosing streptococcal infection in patients presenting to primary care with a sore throat. 21 There were nine studies included in the analysis. The upper and lower limits of r and p are based on data collected from a general practice setting and define an applicable region of feasible sensitivities and specificities for the setting in question. 2
Figures 1 and 2 illustrate the bivariate plots for the first and second meta-analysis respectively. In each case, it can be seen that the point estimate for the BRM lies outside of the constrained region. Since there is a less than 1% chance that the space outside the constrained region contains the true sensitivity and specificity for the test in the setting, the BRM estimates in these two cases are unlikely to be representative for the settings of interest
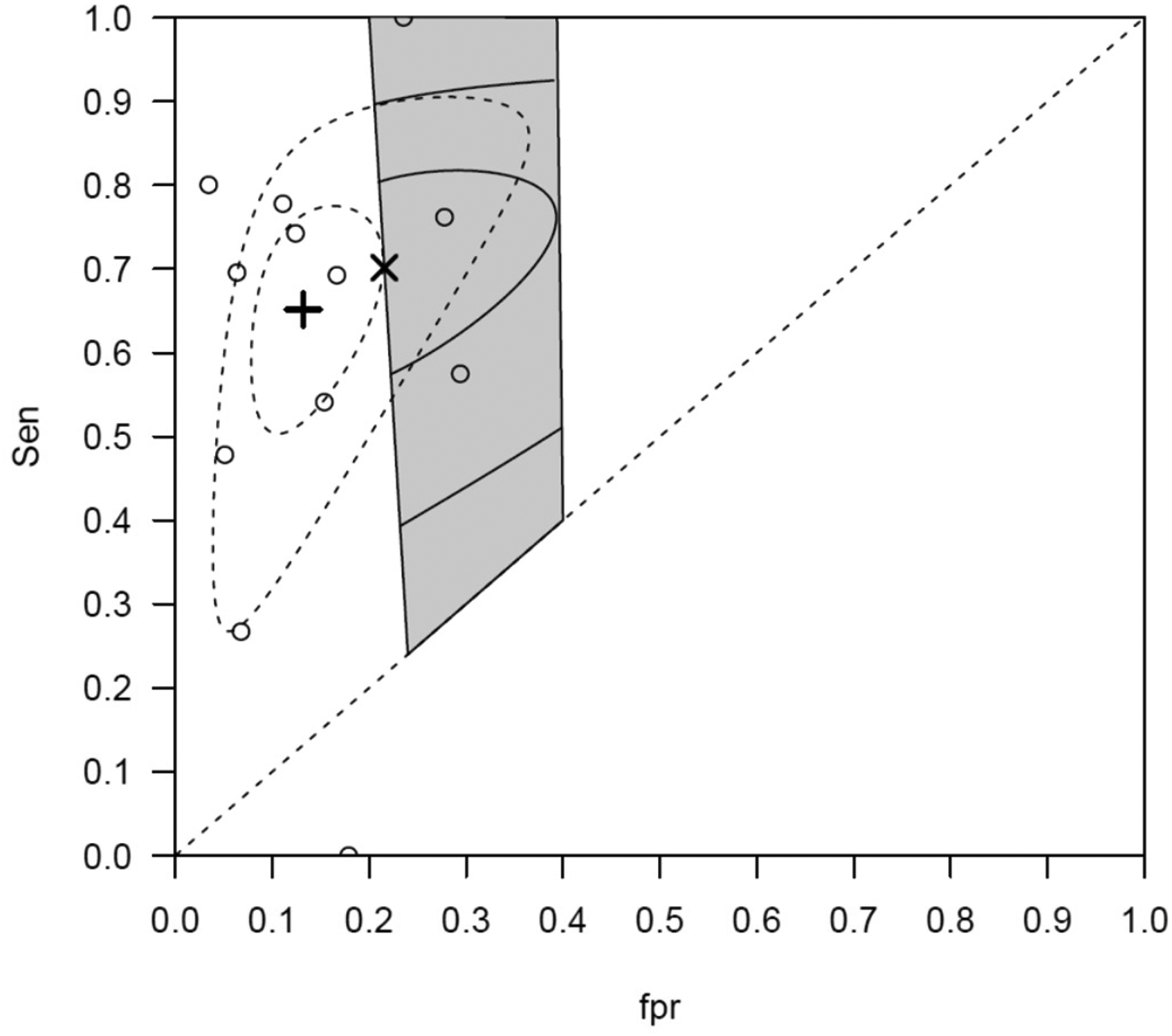
CT data: The studies are presented in circles ○. The grey shaded area represents the applicable region for the general practice. The summary estimate of BRM is represented by the
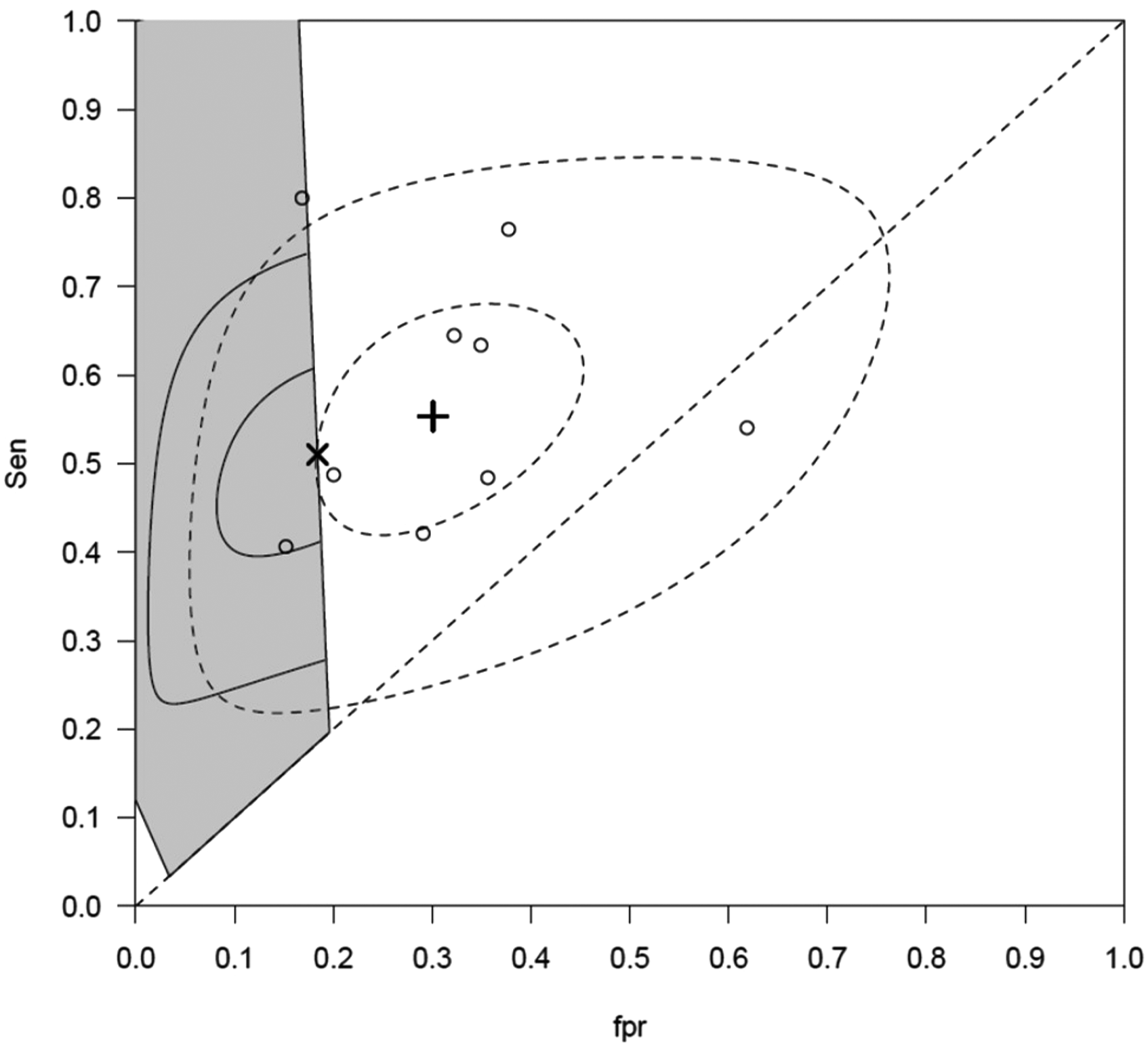
Centor data: The studies are presented in circles ○. The grey shaded area represents the applicable region for the general practice. The summary estimate of the BRM is represented by the
In contrast, the estimates for the CBRM lie on the boundaries of the respective constrained regions and therefore are strictly within the region and so are more likely to represent the setting of interest. Furthermore, in Figure 2 there are only two studies in the constrained region and it is likely there would have been too few studies to aggregate using a standard tailored meta-analysis approach. In table 7, the estimates for the five parameters for the CBRM algorithm and the BRM algorithm are given. It is clear the two models give different estimates for the two datasets.
Estimates for

Although meta-analysis, in general, has proved a successful tool in informing the evidence base on interventions, its role in summarising the performance of a test is more nuanced. For instance, the question of “how accurate is this test when applied to patients in our hospital?” is unlikely to be answered by a test accuracy meta-analysis. The presence of heterogeneity, a common feature in test accuracy meta-analyses, 11 ensures that in many cases the summary estimate is not representative of an individual clinical setting.
Ultimately this affects the extent in which we may use secondary research to assist diagnosis.
In order to improve the utility of meta-analysis in diagnostic prediction requires modifying the current approach. To this end tailored meta-analysis adapts conventional meta-analysis by incorporating evidence from the setting of interest to make it more relevant clinical practice. 2
Thus, the main objective of tailored meta-analysis is to find a plausible estimate for a diagnostic test's performance through defining an applicable region based on data collected from the clinical setting. 2 Specifically, an estimate for the local test positive rate and local prevalence allows a plausible estimate for the test performance in the setting of interest to be derived from the meta-analysis. Potentially this could improve diagnostic prediction.
In previous analyses the constrained ‘applicable region’ has been used to select only those studies that are deemed relevant for the setting.1,2,18 leading to some of the studies to be excluded from the meta-analysis. As a result this may lead to a loss of information. In contrast, the constrained model proposed here, includes all of the studies. The resulting model presents a challenging nonlinear constrained optimization problem which, like the BRM, has no closed form for the likelihood function.
In order to derive the maximum likelihood estimate, we have developed a penalty-based algorithm for estimating the parameters in the CBRM. It starts with analytical estimates of the initial values for a Newton-Raphson based coordinate ascent algorithm used to maximize the penalty function. The algorithm continues by updating the penalty parameter and the starting point until convergence is achieved.
Based on the simulation study and the two previously published test accuracy reviews, the algorithm is capable of providing plausible estimates for the parameters in the constrained bivariate random effects model. This contrasts the unconstrained approach where for the two real examples the summary estimates for the sensitivity and specificity were both outside the constrained region.
Measuring the validity of estimates produced by meta-analysis models is an area of active research where the methods usually incorporate ‘leave-one-out’ or leave-k-out’ cross-validation techniques. 22 Although the statistical basis for these is well developed, they tend to apply to univariate models. 22 Here, through simulation studies, we used the Euclidean and Mahalanobis distance metrics to measure the ‘closeness’ of the model estimates for the sensitivity and specificity with their true values. These studies demonstrated that compared with the BRM, the CBRM is more likely to provide a point estimate for the sensitivity and specificity which is closer to the true values for a new study setting. They also showed that the CBRM is more likely to estimate a prediction region to capture the true sensitivity and specificity for a new study.
However, the model is not without limitations. Previous research has demonstrated the effects of outlier studies on the BRM and proposed methods for dealing with outliers and providing robust estimates for the model's main parameters.23,24 Although not investigated here, outlier studies could also affect the estimates of the CBRM and future research could investigate incorporating methods for dealing with outliers in the CBRM.
Both models are essentially generalized mixed models and a Maximum Likelihood (ML) approach to estimating the parameters was implemented. Other approaches such as the Restricted Maximum Likelihood (REML) have been used in linear mixed models as they provide bias-corrected estimates for the variances. However, REML approaches to generalized linear models are less well developed and some packages such as lme4 do not implement them on this basis. 6 Nonetheless, it is clear that a ML approach to the BRM (and CBRM) underestimates the variance suggesting research into other approaches is needed for these models.
The penalty method is not the only approach that could be used to optimize the CBRM. Other numerical nonlinear optimization algorithms such as the barrier method or augmented Lagrangian method could be used 10 and like the penalty method, these need to be evaluated for the constrained model over a range of simulated examples. Potentially, any improvements on the computation time or mean-squared error may give the methods priority over the penalty method.
Furthermore, other NR based approaches may be used such as the expected Fisher Information matrix, 25 which provides a positive definite Hessian matrix. This has the advantage of generating an estimate for each of the five parameters simultaneously at each iteration and could potentially save on computational time.
Although the benefits of using specific quantitative information from clinical practice to augment meta-analysis have already been demonstrated the methods used so far have focussed on modifying study selection. Here we have proposed a constrained model that incorporates all the studies and guarantees that the summary estimate for the sensitivity and specificity is located in a plausible or applicable region for the practice setting. As such, it has the potential to improve diagnostic decision-making in practice.
Supplemental Material
sj-docx-1-smm-10.1177_09622802211065157 - Supplemental material for On estimating a constrained bivariate random effects model for meta-analysis of test accuracy studies
Supplemental material, sj-docx-1-smm-10.1177_09622802211065157 for On estimating a constrained bivariate random effects model for meta-analysis of test accuracy studies by Mohammed Baragilly and Brian Harvey Willis in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article
Funding
BHW was supported by funding from a Medical Research Council Clinician Scientist award (MR/N007999/1)
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.