
Abstract
A bivariate generalised linear mixed model is often used for meta-analysis of test accuracy studies. The model is complex and requires five parameters to be estimated. As there is no closed form for the likelihood function for the model, maximum likelihood estimates for the parameters have to be obtained numerically. Although generic functions have emerged which may estimate the parameters in these models, they remain opaque to many. From first principles we demonstrate how the maximum likelihood estimates for the parameters may be obtained using two methods based on Newton–Raphson iteration. The first uses the profile likelihood and the second uses the Observed Fisher Information. As convergence may depend on the proximity of the initial estimates to the global maximum, each algorithm includes a method for obtaining robust initial estimates. A simulation study was used to evaluate the algorithms and compare their performance with the generic generalised linear mixed model function glmer from the lme4 package in R before applying them to two meta-analyses from the literature. In general, the two algorithms had higher convergence rates and coverage probabilities than glmer. Based on its performance characteristics the method of profiling is recommended for fitting the bivariate generalised linear mixed model for meta-analysis.
1 Introduction
Meta-analysis may be used to aggregate data from multiple primary studies to produce summary estimates. The most common type of model used in meta-analysis involves aggregating data where a single outcome measure is used to summarise the effect measure. Such univariate modelling approaches have yielded notable successes for meta-analysis where the results have helped inform medical decisions on treatments of life threatening diseases.1,2
In the case of meta-analysis of test accuracy studies, the picture is complicated by there being, in general, two outcomes of interest that are correlated. The modelling approach taken in this instance is to assume the study-level parameters for the outcomes follow a bivariate normal distribution.3,4 Although, after a suitable transformation, we may assume the observed data within studies to be normally distributed, 3 this is an approximation and they are more accurately modelled by assuming binomial distributions. 4 Thus, to aggregate the data from test accuracy studies, a bivariate generalised linear mixed model is used. Note it is more commonly labelled a bivariate random effects model (BRM) 3 and this will be the term which will be adopted here when referring to the model.
As with many complex models of this nature, there is no closed form to the likelihood function for the model, so it is not possible to express the maximum likelihood estimates (MLEs) for the parameters analytically and numerical solutions are required. Although some packages are capable of providing maximum likelihood estimates for the parameters in the BRM, they tend to be generic packages in which the algorithms are not readily accessible and are not necessarily optimised for this model. For example, the glmer function from the lme4 package in R5 and NLMIXED in SAS6 are used to fit a range of generalised linear and non-linear models and are not specifically written for estimating the parameters in the BRM. Thus, an algorithm which is expressly written and optimised to fit the BRM has the potential for better performance characteristics than that of a generic function. It also needs to be transparent in order to facilitate understanding and reproducibility.
Here we develop two different optimisation approaches based on Newton–Raphson methods, 7 specifically to derive the maximum likelihood estimates for the parameters in the BRM. To demonstrate how this may be done from first principles, the theory and steps behind the optimisation are described explicitly, and the R code is provided in the online Appendix. We conduct a simulation study to evaluate the two algorithms and compare their performances with that of a generic function from a standard package, namely, the glmer function in the lme4 package in R. 5 We then apply the algorithms to two case examples.
The paper is organised as follows. In section 2, we describe the theory in detail that underpins the bivariate random effects model used in test accuracy meta-analyses. In section 3, the optimisation methods in generic packages that may be used to fit the BRM are described. In section 4, the theory behind deriving maximum likelihood estimates in the BRM is explained in detail. In sections 5 and 6, the method of Profiling 8 and the Observed Fisher Information using robust initial parameter values (OFIRIV) are developed for the BRM. In section 7, these methods are compared using a simulation study and applying them to two case examples from the literature. Finally, in section 8, we end with the discussion.
2 Statistical methodology
A test's performance is traditionally summarised in terms of its sensitivity (the proportion of patients with disease who test positive) and specificity (the proportion of patients without disease who test negative). The two are also correlated being affected by the position of the threshold for a positive test result: as the threshold increases, the sensitivity decreases and the specificity increases. This effect is summarised by a receiver operating characteristic (ROC) curve which plots the different sensitivity–specificity pairs for each test threshold. 9
An early attempt to incorporate such an effect in meta-analysis was made by Moses and colleagues, 10 who produced a Summary ROC (SROC) curve using simple linear regression. The model does capture variation between studies due to a changing threshold but other sources of variation are largely ignored. For the purpose of translation into practice, a summary point is usually more desirable but a valid point estimate is not readily provided by this model.
Attempts to overcome these limitations3,4 have led to the proposing of hierarchical models.3,4,11 Van Houwelingen
12
applied a bivariate random effects model to meta-analysis which was later taken up by Reitsma,
3
who applied it to test accuracy meta-analyses. This model allows a summary point for the sensitivity and specificity in ROC space to be estimated. An alternative approach as proposed by Rutter and Gatsonis
9
leads to a Hierarchical Summary Receiver Operating Characteristic (HSROC) curve, although a summary point may be derived from this model. Here we will focus on the bivariate random effects model for test accuracy studies. The model is a mixed model and assumes a bivariate normal distribution of the form


Thus, the five parameters
For a test accuracy review with k studies, let


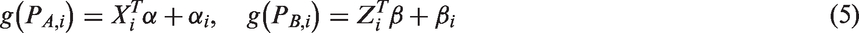
The parameters of the bivariate generalised linear mixed effect model may be estimated by maximising the likelihood function. The log-likelihood function,
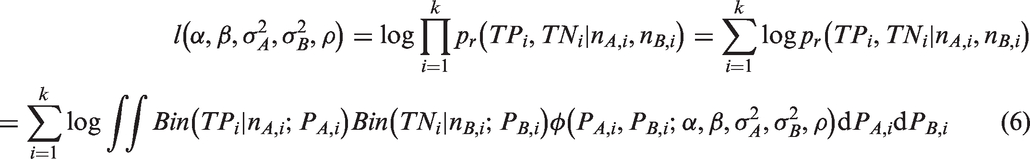
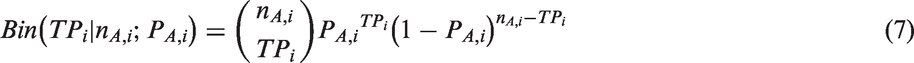
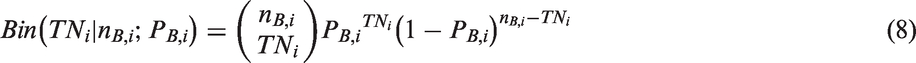
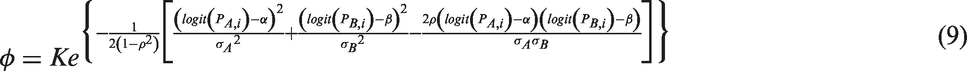
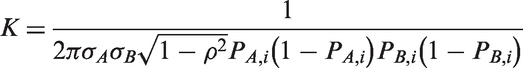
From inspecting the log likelihood function in equation (6), it can be seen that it involves a double integration over the random effects and there is no closed form so it cannot be solved analytically. In order to get a solution to the integral, we have to use numerical optimisation methods such as the Laplacian approximation or the adaptive Gaussian quadrature 14 to evaluate this integral. Before proceeding to derive the maximum likelihood estimates of the BRM using methods based on the Newton-Raphson algorithm, 7 we will briefly describe the optimisation approaches used in two generic packages.
3 Optimisation methods used in generic packages
Both the glmer function in the lme4 package in R5 and the NLMIXED function in SAS6 are generic functions that have been developed to optimise a range of generalised mixed and non-linear mixed models. As such they may be used to provide estimates for the bivariate generalised linear mixed model or BRM. Both use a Cholesky parameterisation of the models being optimised.5,6
Briefly, one of the issues in estimating the parameters in any generalised mixed model is that the covariance matrix of random effects, Σ(θ), may be singular and thus its inverse may not exist. In some cases, this may be overcome by re-formulating the objective function. Thus, for random effects vector V, Σ(θ) may be re-formulated in terms of a relative covariance factor Λ(θ), for a variance component θ, allowing V to be expressed as the product Λ(θ)U, where U is a spherical random effects vector. Taking this approach, the likelihood function may be written in terms of sparse Cholesky factors and finding the maximum likelihood is transformed into finding the penalised least squares.5,15 By writing the likelihood in terms of sparse Cholesky factors, the problem may be reformulated so that the resulting matrix is not singular even when Σ(θ) is singular. 15
This is the approach taken in the glmer function in the lme4 package in R5 and the initial values of θ for the sparse Cholesky factors are taken to be 1 on the diagonal and 0 for off diagonal elements. 16
The default numerical optimisation algorithms used in glmer are the Nelder–Mead and the Bounded Optimisation By Quadratic Approximation (BOBYQA). 17 The Nelder–Mead method is a derivative-free optimisation (DFO) algorithm 18 introduced as a means of optimising functions when the derivatives are not available or unknown. It starts with a simplex (a generalisation of a triangle to n dimensions) so that a function of n variables is evaluated at n + 1 points. The values of the function at these points are ranked and by geometric transformations (reflection, contraction, and expansion) the point where the function is largest is replaced with a point where the function is smaller. This gives a new simplex and the process continues until convergence.
The BOBYQA algorithm is a sophisticated algorithm and one of several due to Powell which is derivative free. 19 Essentially it is based on using a quadratic model to locally approximate the objective function, F, over a trust region. After k iterations, the coefficients of the quadratic model Q k are obtained by constraining Q k to interpolate F at a fixed number of points – these are the interpolation conditions. The sub-problem is to find d k such that xk + dk minimises Q k over the trust region. If xk + dk improves on the current iterate x k , then this becomes the new iterate x k+1 and the trust region and quadratic model Q k are updated. If it is not an improvement, then an alternative iteration algorithm is used to identify d k so that it ensures linear independence in the interpolation conditions. Broadly, this process continues until convergence.
Other derivative approaches may be used to fit the bivariate model as is the case with NLMIXED function in SAS. For instance NLMIXED, as used by some authors,4,20 tends to be fitted using the default dual quasi-Newton algorithm. 6 Thus, for a symmetrical, positive definite matrix B(k) which satisfies the secant condition, B(k) is chosen so that it may be updated according to B(k+1) = B(k) + A(k) (where A(k) is a matrix which is easily estimated) whilst still preserving symmetry, positive definiteness and the secant condition. The Broyden, Fletcher, Goldfarb, and Shanno (BFGS) formula 21 provides one approach where these conditions are satisfied and this is applied to the Cholesky factor of the approximate Hessian as the default method in the NLMIXED function.
For the purpose of comparison with the Newton–Raphson algorithms that follow, we focussed on glmer in R which is open source and readily available. 22
4 Maximum likelihood estimations for bivariate model using NR algorithm
Here we demonstrate two different numerical methods for deriving maximum likelihood estimates (MLE) for the parameters in the bivariate random effects model used in test accuracy meta-analysis. They are both based on the Newton–Raphson (NR) algorithm, 7 perhaps, one of the most common numerical methods used in optimisation. The NR algorithm is an iterative method for finding the roots of a differentiable function that generates a sequence of estimates which usually come increasingly close to the optimal solution. The algorithm is based on successive approximations to the solution, using Taylor's theorem to approximate the equation. It may be applied to both one-dimensional and higher dimensional problems by replacing the derivative with the gradient, and the reciprocal of the second derivative with the inverse of the Hessian matrix (see below).23,24
In essence, the task of maximum likelihood estimation may be reduced to a one of finding the roots to the derivatives of the log likelihood function, that is, finding


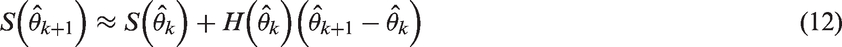
Since

In order to calculate the derivatives in equations (10) and (11) numerically, one can use the simple approximation to the first order derivative in five dimensions with respect to the underlying estimated parameter. Suppose it is
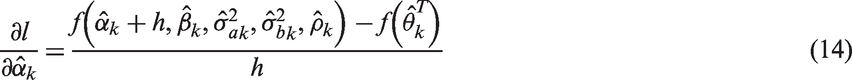
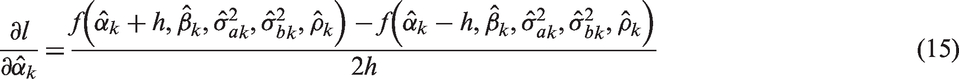
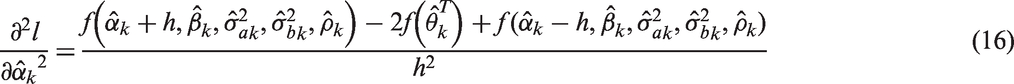
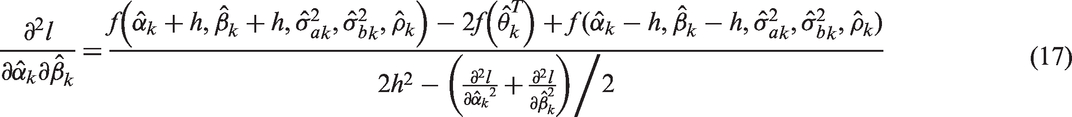
We can calculate the other elements in equations (10) and (11), in a similar fashion to those shown in equations (14) to (17). Alternatively one may use the ready-made functions in R, grad and hessian, in the package numDeriv. 25
The double integration over the random effects in the log likelihood function in equation (6) is computed using the adaptive multidimensional integration algorithms described in Genz and Malik 26 and Berntsen et al. 27 It is written in C and may be accessed via the R wrapper cubature. 28 We can use the function adaptIntegrate (within cubature) to perform adaptive multidimensional integration of vector-valued integrands over hypercubes, and get a solution to the integral in equation (6) and then estimate the five parameters in the BRM.
The first algorithm uses the profile of the log likelihood equation 6 in equation (6) to estimate the five unknown parameters in equation (9) by starting with what may be called ‘robust initial values’. The robust initial values are starting values that are sufficiently close to the actual values of the parameters so they increase both the chances and the speed of convergence. The second algorithm is based on the observed Fisher information matrix 8 where similar to the first algorithm, robust initial values provide the starting point to the algorithm before updating the observed Fisher information matrix.
5 The method of profiling
In order to explain the method of profiling,8,29 suppose that only two parameters α and β need to be estimated and that
Lindstrom and Bates 31 pointed out that optimising the profile log-likelihood usually requires fewer iterations, the derivatives are somewhat simpler, and the convergence is more consistent. In addition, they have also encountered examples where the NR algorithm failed to converge when optimising the likelihood (which includes a variance term) but was able to optimise the profile likelihood with ease.
It is often difficult to determine whether an algorithm has converged upon a ‘local’ maximum instead of the ‘global’ maximum32,33 but many objective functions will have local maxima either due to the shape of the underlying function or due to noise introduced by the data. One approach to overcome this is to choose multiple initial values randomly and select the maximum these yield. 33 Here a more systematic approach is taken, where the data from the studies help define a feasible space for the global maximum and an equally spaced grid is overlaid on the space.34,35 This is then used as the basis for a maximum likelihood approach in determining robust initial values. It represents the first phase of the algorithm. In the second phase, we update the estimations continuously, using the last estimated values, until we get the convergence.
The profile log likelihood algorithm for estimating the parameters in bivariate model:
5.1 Initial estimate phase: we can derive an initial estimate of the nuisance parameters ( 5.1a. Using the minimum and maximum of α and β across all the studies as bounds, and using the delta-method to estimate the range of 5.1b. Construct combinations of all the possible values of ( 5.1c. As previously, construct combinations of all the possible values of ( 5.1d. Following the same procedure, initial estimates for 5.2. The updating phase: based on the initial estimate 5.3. While
Although the algorithm is straightforward, compared with the observed Fisher information algorithm below, it is more computationally expensive and is likely to be more time consuming as a result. In particular, the second phase involves several iterations, as the NR algorithm is applied to each of the five parameters individually in each update until convergence is achieved. Moreover, the log likelihood function is evaluated over many different possible combinations of the parameters' values.
6 Observed Fisher information with robust initial values (OFIRIV)
Although the method of profiling circumvents the local maximum problem by generating robust initial parameter values, it is computationally expensive. In contrast, the observed Fisher information is more efficient than the method of profiling but without appropriate starting values there is still the risk of it converging on a local maximum.
Here the approach of ascertaining robust initial parameter values is combined with an algorithm based on the observed Fisher information. 8 This has the potential of improving on the previous algorithm by increasing the computational efficiency.
Thus, the algorithm is as follows:
6.1. Initial estimate phase: get an initial estimate 6.2. Updating phase: the next steps use the observed Fisher information matrix
8
to update the estimates for the parameters in the BRM. 6.2a. Let 6.2b. Calculate the score statistic 6.2c. Estimate 6.2d. Check whether 6.2e. While
To ensure stability of the algorithm, we may control for jumps in individual components of the parameter vector between iterations and redirect the algorithm to the robust initial value for the component. For example, if the difference
Other criteria may be used for terminating the iteration. Recall that obtaining the maximum likelihood estimate is equivalent to finding the roots to the score statistic
Compared to the profile log likelihood algorithm, this algorithm consumes less time than the former and is computationally more straightforward. Furthermore, once the Hessian matrix has been estimated at the initial step, (
It is well known that the choice of initial values can be important in the speed of convergence, the ability of the algorithm to find a global maximum, and the ability to converge at all.36, 37 However, specifically for Newton–Raphson-based methods, Kantorovich's theorem provides the theoretical underpinning for the importance of the choice of initial values and the success of convergence. 38 Essentially around the start point, the behaviour of the Jacobian of the function and its inverse have to meet certain conditions on continuity and boundedness if the algorithm is to converge.
Here we applied a grid across a bounded space for the parameters 29 before taking a maximum likelihood approach to generate robust initial values for the parameters. However, there is no guarantee the algorithm with robust initial values will produce parameter estimates that uniquely maximises the log-likelihood. Whilst the choice of robust initial values may lower the risk of the algorithm converging on a local maximum, 39 it cannot eliminate this risk. Essentially identifying the global maximum is still a heuristic process no matter what initial values are chosen.
Furthermore when the data are noisy, rather than converging on a local maximum, the algorithms may fail to converge at all. Generally, this occurs when one or more elements in the score function or Hessian returns an infinity, the absolute value of the correlation exceeds 1, or a negative variance begins to emerge. To cope with these types of situation, we may reset the variable responsible to either the value in a previous iteration or to the initial value. If this occurs in the initial value estimate phase, the resetting of the variable may involve setting the value on the grid that maximises the likelihood. If the correlation is the problem variable in the initial estimate phase, the Pearson correlation coefficient for the observed data may be used. These measures allow the algorithm to proceed on a slightly modified trajectory. Both algorithms discussed in this and the preceding section accommodate these scenarios in this way.
An alternative approach for obtaining the MLEs of the parameters is to transform all or part of the model in order to facilitate convergence. This is used by the two generic packages as discussed in section 3.
7 Numerical examples
In this section, the two algorithms are evaluated through a simulated study before applying them to two real case examples. In each case, they are compared with the glmer function from the package lme4 in R,5 which has been previously validated. All analyses were conducted in R22 and the code for each of the algorithms appears in the online appendices.
7.1 Simulation study
For the simulation study, the true values of the five parameters were set to:
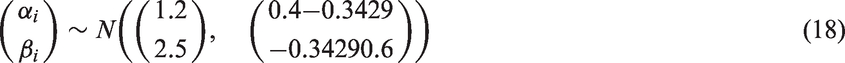
This provides the study-specific sensitivity,
For each of the three algorithms (including glmer) the BRM was applied to 10,000 simulated data sets of size k = 10 and then k = 20. The results were compared using the convergence rate, mean squared error (MSE), average relative error (ARE), mean bias and coverage probability.
The convergence rates calculated from 10,000 simulations for each method at k = 10 and 20.

MSE of the estimated values of the five parameters for the different methods at k = 10 and 20 based on converged samples from 10,000 simulations. The values in bold refer to the lowest MSE between all the methods.

ARE of the estimated values of the five parameters for the different methods at k = 10 and 20 based on converged samples from 10,000 simulations.

Note: The values in bold refer to the ARE between all the methods.
Mean bias of the estimated values of the five parameters for the different methods at k = 10 and 20 based on converged samples from 10,000 simulations.

Note: The values in bold refer to the lowest absolute bias between all the methods.
The coverage probability of the 95% confidence regions for
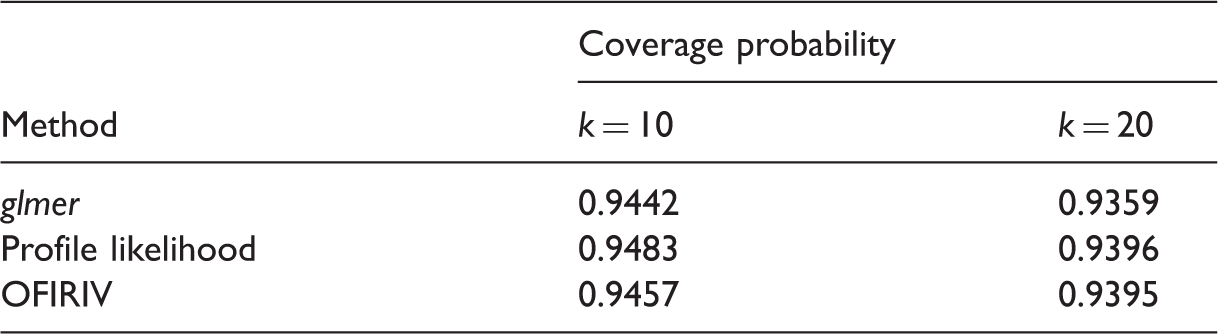
It is clear that the different methods are comparable across a number of statistics. However, the glmer function does have a substantially lower convergence rates than the other two algorithms. Thus based on its superior convergence rate and coverage probability, the profile likelihood is recommended as the method of choice for estimating the parameters for the bivariate random effects model in meta-analysis.
To illustrate the contrasting performance, three examples where glmer failed to converge are compared with the profile likelihood and the OFIRIV algorithms which did converge. The three simulated data sets are based on 10 studies and may be found in the online Appendix. For the first example, glmer's failure to converge was due to it calculating an inconsistent gradient value in some iterations (max|grad| = 0.0105486). For this example, the profile likelihood estimates of (
In the second example, glmer returned a NAN for the correlation coefficient and two warning messages. The first was that it was unable to evaluate a scaled gradient and the second that there was a degenerate Hessian matrix with negative eigenvalues. The profile likelihood estimates of (
In the third example, glmer failed to converge due to producing a correlation coefficient
7.2 Real data examples
In this section, the three algorithms described are applied to two previously published test accuracy reviews.41,42 For each of these reviews, the five parameters in the BRM in equation (6) were estimated by the three algorithms and their performances compared.
7.2.1 Computed tomography of the distant metastasis
The first review evaluated the accuracy of several imaging modalities in detecting cancer including 98 studies published between 1990 and 2009. 41 Here the focus will be on the accuracy of computed tomography (CT) in identifying distant metastases where there were 12 relevant studies. The data may be found in the supplementary materials of Chen et al. 13
The estimation results (in logit space) based on the different algorithms for the CT dataset.

Note: For glmer this is the number of iterations of the Nelder–Mead algorithm.
Estimates for α, β,
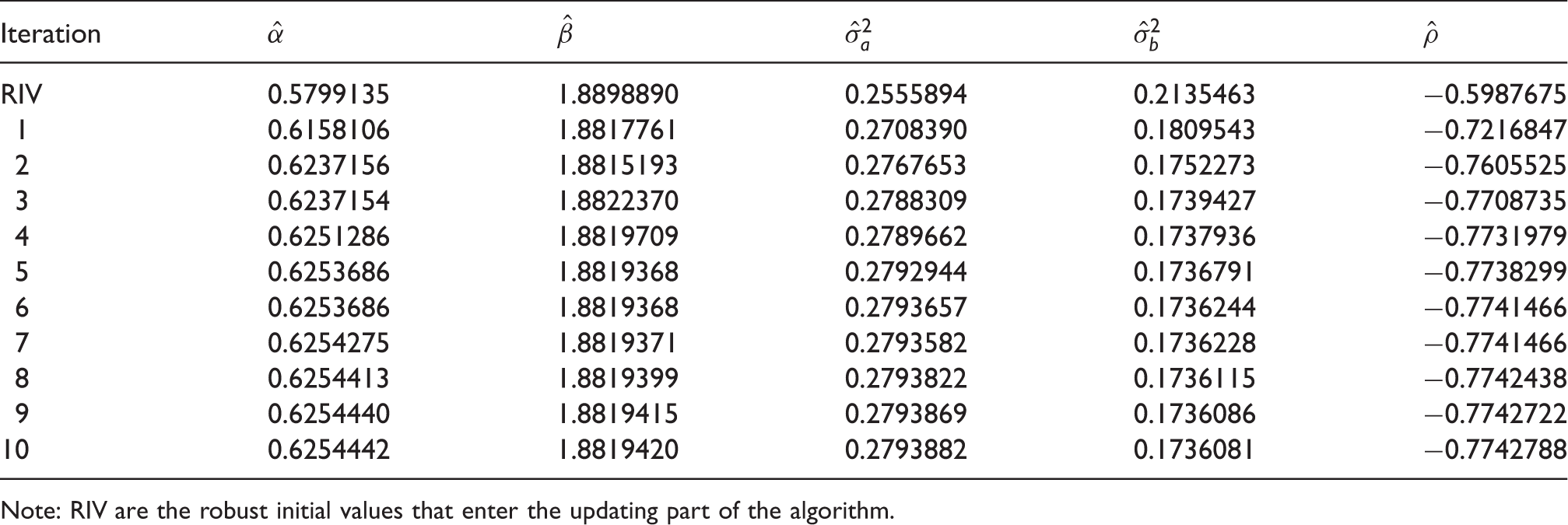
Note: RIV are the robust initial values that enter the updating part of the algorithm.
Estimates for α, β,
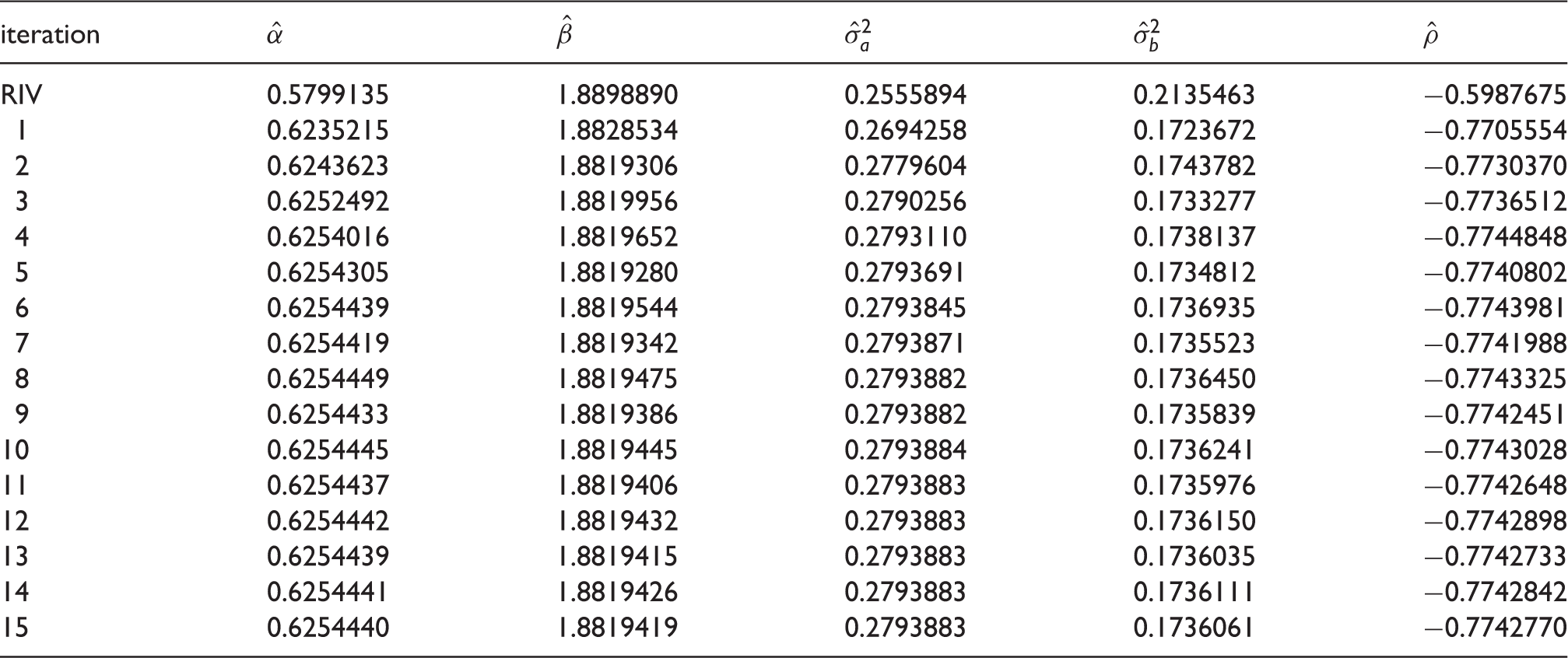
The estimation results (in logit space) based on the different algorithms for the PHQ-9 dataset.42

Note: For glmer this is the number of iterations of the Nelder–Mead algorithm.
Also of note is the behaviour of each algorithm which shows smooth changes between iterations without any wild fluctuations. This is because the algorithms start with robust initial values that are sufficiently close to the real value of the parameters thereby increasing the stability of the algorithms.
7.2.2 Screening for depression based on the PHQ-9
The second dataset used is a review which evaluated the accuracy of the Patient Health Questionnaire (PHQ-9) in screening for depression. The PHQ-9 consists of nine questions and is a recognised screening tool for depression. Willis and Hyde 42 conducted a meta-analysis which evaluated its accuracy and the data used here may be found in the supplemental appendix. 42 There were 10 included studies.
For each algorithm, Table 6 gives the estimated values of the five parameters for the PHQ-9 data and the number of iterations needed for convergence. Like the previous example, the OFIRIV algorithm and profile log likelihood algorithm give results that are close to those from the glmer function. Although the OFIRIV executes more iterations than the profile likelihood before convergence is attained, it still executes far fewer than the glmer function.
8 Discussion
Meta-analysis is integral to evidence synthesis providing a means of summarising research from multiple primary studies. Its widespread uptake has coincided with developments in the meta-analysis methods used, progressing from fixed effects methods 43 to including study-specific random effects, 44 and from univariate outcomes 44 to using multivariate outcomes. 45
This has increased the complexity of the type of models used and the optimisation methods needed to estimate the unknown parameters. The most common model used in test accuracy meta-analyses is a bivariate generalised linear mixed model, and is often referred to as the bivariate random effects model (BRM). The complexity of this model lies with the need to perform a double integration over the random effects and an integrand which is a binomial-normal mixture distribution. Having no closed form, numerical methods are required to estimate the parameters of interest. Although generic functions such as glmer in the lme4 package in R5 and NLMIXED in SAS6 may be used to fit the BRM, they remain ‘black boxes’ to the vast majority of users.
Here we have demonstrated from first principles how maximum likelihood estimates may be derived using Newton–Raphson-based approaches to provide estimates for the parameters of interest in the BRM used in test accuracy meta-analyses. In this respect, the proposed algorithms appear to have received little attention in the literature.
Both the method of profiling and the Observed Fisher Information matrix algorithm perform well and give accurate estimates for the five unknown parameters of the BRM. However, without suitable modifications, they still have the potential to breakdown either by converging on biased estimates, the so-called ‘local maxima problem’, 39 or not converge at all.
One way to address the local maxima problem is to choose the initial values for the parameters more carefully. Here we get robust initial values by first using the data to derive a grid across a feasible space of values for the parameters. Then each parameter is estimated independently based on values of the other parameters that maximise the log likelihood function with respect to the parameter being estimated. This method is aimed at providing initial values which are close to the true values for the parameters to increase the chances of converging on these true values.
The second issue is that the algorithm may fail to converge at all, particularly when there are noisy data. There may be a number of reasons for this, including difficulty in calculating the partial second derivatives in the Hessian matrix due to their being a very small rate of change or that an inverse for the Hessian matrix may not exist. The correlation may become out of bounds or one or more of the variances may take on negative values. Essentially this represents a recurring challenge for multi-parameter models – how to ensure the optimisation algorithm reliably converges on an accurate estimate.
To deal with this, some authors advocate transforming the model to an alternative parameterisation such as those used by the generic packages discussed earlier. For example, the model may be transformed so that the covariance matrix or Hessian matrix remains positive definite throughout successive iterations. Whilst this offers a substantial improvement, for the glmer function at least, it does not lead to convergence in all cases. This was clearly demonstrated by the simulation study.
Another approach is to monitor the iterative process for aberrant parameter estimates or function values and reset to a value from a previous iteration when this occurs. For example, when a parameter estimate strays out of the space of feasible values, or a derivative becomes infinite. This recognises there may be many trajectories that converge on a stable estimate and resetting the current estimate of a parameter may move the algorithm onto a different trajectory. This was the method used in both the profile likelihood and the OFIRIV algorithms and the convergence rates were 100% and close to 100%, respectively.
Both algorithms developed in this study perform better than the glmer function in terms of convergence and coverage probability whilst being comparable in other performance characteristics such as mean squared error, mean bias and average relative error. However, due to its superior convergence rate and coverage probability, we recommend the method of profiling over the OFIRIV.
Furthermore the OFIRIV and method of profile algorithms benefit from having been developed specifically to estimate the parameters in the BRM, in contrast to the glmer function which is designed to fit a range of different models. Perhaps this indicates that as the models get more sophisticated, algorithms which are specifically optimised for the task may become more important.
Other Newton–Raphson-based approaches are possible, such as the method of scoring which uses the expected Fisher information matrix. 46 In principle, this method should improve the stability of the algorithm by ensuring the Hessian matrix is positive definite. However, for the BRM it involves two integrations, one over the random effects and the other to estimate the expectation of the Hessian matrix and technically this is not straight forward as well as being computationally time-consuming.
Although the focus here has been on developing algorithms which estimated the sensitivity and specificity in a BRM, the same approach could easily be extended to estimating parameters when study-level covariates are included in the BRM. Such meta-regression analyses are common place when investigating heterogeneity between studies and may improve the potential validity of any estimates. 47 Equally the algorithms could be applied to recently developed tailored models which augment the applicability of test accuracy research by combining meta-analyses with routine data.48,49
The study does have some limitations. Although the OFIRIV and method of profiling algorithms demonstrate high performance characteristics and compare favourably with the one of the generic functions in R, a more extensive investigation is required to firmly establish their utility and limitations. This would involve evaluating them over a greater variety of cases, including examples with sparse data. 50
Many of the functions used to fit the BRM invoke generic optimisation methods5,6 that are used to fit other models. For example, glmer uses Nelder–Mead 18 and BOBYQA 19 and NLMIXED uses a dual quasi-Newton algorithm 6 as the default algorithm across all types of models. One of the conclusions which may be drawn from this study is that it may be for the BRM a more specific optimisation approach would overcome some of the convergence issues that have been previously reported in other studies. 50 This could be investigated using simulated examples over a range of optimisation algorithms.
The emphasis here has been to be explicit in the methods used to fit the bivariate random effects model and demonstrate how this may be done from first principles using the open source programming language R. 22 However, as an interpretative language, R is slow for such models and the code may take several minutes to run. The computational time could be significantly improved by translating the algorithms into a low-level compiled language such as C.
In summary, we have developed two algorithms based on Newton–Raphson methods to fit specifically the bivariate random effects model used in meta-analysis of test accuracy studies. From a simulation study, it was demonstrated that both algorithms had higher convergence rates and coverage probability than those from the glmer function whilst having similar performance characteristics in other measures. Overall the profile likelihood approach had the best performance characteristics for fitting the bivariate random effects model out of the three methods. Future research should focus on improving the computational time of these algorithms.
Supplemental Material
Supplemental Material1 - Supplemental material for Maximum likelihood estimation based on Newton–Raphson iteration for the bivariate random effects model in test accuracy meta-analysis
Supplemental material, Supplemental Material1 for Maximum likelihood estimation based on Newton–Raphson iteration for the bivariate random effects model in test accuracy meta-analysis by Brian H Willis, Mohammed Baragilly and Dyuti Coomar in Statistical Methods in Medical Research
Supplemental Material
Supplemental Material2 - Supplemental material for Maximum likelihood estimation based on Newton–Raphson iteration for the bivariate random effects model in test accuracy meta-analysis
Supplemental material, Supplemental Material2 for Maximum likelihood estimation based on Newton–Raphson iteration for the bivariate random effects model in test accuracy meta-analysis by Brian H Willis, Mohammed Baragilly and Dyuti Coomar in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: BHW was supported by funding from a Medical Research Council Clinician Scientist award (MR/N007999/1).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.