
Abstract
Meta-analytic methods may be used to combine evidence from different sources of information. Quite commonly, the normal–normal hierarchical model (NNHM) including a random-effect to account for between-study heterogeneity is utilized for such analyses. The same modeling framework may also be used to not only derive a combined estimate, but also to borrow strength for a particular study from another by deriving a shrinkage estimate. For instance, a small-scale randomized controlled trial could be supported by a non-randomized study, e.g. a clinical registry. This would be particularly attractive in the context of rare diseases. We demonstrate that a meta-analysis still makes sense in this extreme case, effectively based on a synthesis of only two studies, as illustrated using a recent trial and a clinical registry in Creutzfeld-Jakob disease. Derivation of a shrinkage estimate within a Bayesian random-effects meta-analysis may substantially improve a given estimate even based on only a single additional estimate while accounting for potential effect heterogeneity between the studies. Alternatively, inference may equivalently be motivated via a model specification that does not require a common overall mean parameter but considers the treatment effect in one study, and the difference in effects between the studies. The proposed approach is quite generally applicable to combine different types of evidence originating, e.g. from meta-analyses or individual studies. An application of this more general setup is provided in immunosuppression following liver transplantation in children.
Keywords
1 Introduction
In clinical research of orphan diseases, one of the major problems is often the recruitment of a sufficient number of subjects to perform a meaningful clinical trial. Examples include neuromyelitis optica, 1 myocarditis, 2 and Creutzfeld-Jakob disease (CJD). 3 In such cases, it may be possible to gain some power by using more sophisticated trial designs, and it is often desirable to be able to formally utilize additional information external to the actual trial, which may be implemented via the use of informative prior distributions in the eventual analysis. 4 The external information could be in the form of related studies or elicited expert opinion. 5 For instance, in the context of a small-scale randomized controlled trial in idiopathic nephrotic syndrome in children, a rare condition, Thall et al. 6 recently proposed the elicitation of expert opinions on response probabilities based on the bins-and-chips approach. 7
When considering external evidence, the obvious danger is that a too simplistic approach may lead to a “naïve” pooling of initially separate data. For example, while data from non-randomized studies (e.g. clinical registries) may undoubtedly contribute complementing information to a randomized clinical trial, one may want to prevent a complete mixing of both types of data, which would in a sense also invalidate the original randomization. Rather it seems desirable to stratify the analysis for the different sources by explicitly allowing for potential heterogeneity between data sets, which then implicitly downweights the impact on one another. Here the weights depend on the observed similarity of estimates, also known as dynamic borrowing of information. 8 The eventual analysis then may refer explicitly to the outcome of the randomized trial, and not to some overall average, as generally more weight is placed on evidence from randomized controlled trials.
A simple approach originally proposed by Pocock 9 was recently implemented by Schoenfeld et al., 10 who investigated the use of adult data to support the analysis of a paediatric trial, and who utilized a variance component of known (elicited) magnitude to account for heterogeneity between the two studies' estimates. A closely related approach is implemented in the normal-normal hierarchical model (NNHM) that is commonly utilized in random-effects meta-analysis; the difference essentially is that heterogeneity is treated as an unknown for which a prior distribution may be specified. Technically, inference on the study of primary interest is done by investigating the corresponding shrinkage estimate. The contribution of information from additional studies then may readily be evaluated by considering the corresponding meta-analytic-predictive (MAP) prior.11,12 The NNHM is readily generalized (and in fact most commonly used) for combining more than two studies; such an approach may e.g. be used to extrapolate information from early-phase studies in the approval process. 12 In the case of two studies, the NNHM can also be shown to be to some extent equivalent to a similar, more general model specification as we will explain below.
While the interpretation of parameters within the familiar NNHM context is straightforward and with the inclusion of an unknown heterogeneity parameter it is intended that evidence from separate studies is sufficiently loosely connected to provide a robust estimation framework, it is not obvious to what extent this approach actually improves estimates in the extreme case of only two studies or more generally two data sources. Here we develop a suitable statistical hierarchical model to include two sources of data, e.g. two studies or meta-analyses. Within the proposed model, we describe a shrinkage estimator and inference methods including posterior predictive p-values. Furthermore, the value of this approach in the particular case of only two studies is evaluated in simulations.
The manuscript is organized as follows. In the next section, we present the statistical model and, in particular, shrinkage estimation and inference. The following sections are dedicated to a simulation study investigating the operating characteristics of the proposed methodology and an application in CJD. Motivated by a meta-analysis investigating the effect of immunosuppression in paediatric liver transplantation patients, we extend the shrinkage applications to more general settings considering two data sources, e.g. two meta-analyses, rather than two studies. Finally, we close with some conclusions and a brief discussion.
2 Statistical model and shrinkage estimation
2.1 The normal–normal hierarchical model
The most commonly used model for random-effects meta-analysis is the normal-normal hierarchical model (NNHM). This model is applicable for the joint analysis of several (k) real-valued effect measurements y
i
that have individual standard errors σ
i
associated (

The θ
i
then may be more or less similar across measurements; at the study level, a certain amount of heterogeneity is anticipated by introducing another variance component τ and assuming

2.2 Shrinkage estimation
Quite commonly, the main interest lies in determining the overall effect μ. When the aim of the analysis is to provide a basis for planning a new study, it may also be of interest to predict a future outcome
If the heterogeneity τ was zero, then the model would reduce to the fixed-effect model, and all estimates y
i
would effectively relate to the same parameter (
2.3 The Bayesian approach to meta-analysis
The inference problems within the NNHM may be approached using frequentist or Bayesian methods.13–15,21,22 A Bayesian approach has proven especially useful in cases where large-sample asymptotics do not apply, 23 e.g. for the analysis of few studies 20 or even only two studies. 24 Here, we will follow a Bayesian approach and investigate its properties in some more detail.
Within the NNHM we have several unknowns; first the study-specific effects θ
i
, whose hyperprior is given through Equation (2). For the overall mean effect μ, it is often convenient to use a non-informative (improper) uniform prior. The heterogeneity
The heterogeneity τ is usually considered a nuisance parameter, while the primary interest is in inferring the overall effect (μ), a prediction (
2.4 Posterior predictive p-values
Posterior predictive p-values are conceptually closely related to “classical” p-values, and were originally developed in the context of model checking.16,27,28 The definition is relatively straightforward; like a classical p-value, it is based on a null hypothesis H0 and a pre-specified (“test-”) statistic or “discrepancy variable”
Similarly to the usual p-values, this means a comparison against values of the statistic amongst data sets that might have occurred conditioning on the observed data as well as the null hypothesis. Technically, posterior predictive p-values are often easily computed using Monte Carlo sampling, which here means first drawing parameter values from the intersection of the parameters' posterior distribution and null hypothesis, then drawing a data set
The test statistic to be used needs to be pre-specified. For instance, an obvious choice for the overall effect μ may be the posterior probability of a non-beneficial effect, i.e.

The null hypothesis then is usually specified for a certain parameter as one- or two-sided. Accordingly, the test statistic's relevant distribution (or the sampling scheme, in case of MCMC computation) as well as the statistic's rejection region is affected. Computation of posterior predictive p-values is also implemented in the
2.5 The reference model as an alternative variation of the NNHM
When meta-analyzing a pair of estimates, the common NNHM may sometimes be hard to motivate, as an exchangeable model of both estimates θ
i
centered around a common mean value μ may seem inappropriate. Consider for example the joint analysis of randomized and observational data; reference to a common mean parameter μ or identical variances
Suppose that the prior for the effect μ in the NNHM is given by an (improper) uniform distribution, and that the heterogeneity prior is defined through a density



The reference model parametrisation of the problem is different here in that the two observables y
i
are treated asymmetrically. The first one (y1) measures the parameter α (the reference) “directly”, while the second one (y2) includes an additional offset with variance
As has been pointed out by Neuenschwander et al.,
30
the model may also be regarded as a special case of Pocock's bias model, or the model underlying the commensurate prior. In both instances, for the case of k = 2 studies, the discrepancy between the two underlying parameters (here:
3 Dependency of the shrinkage estimate on the observed heterogeneity
In the following, we investigate the effect of varying the input data on the resulting shrinkage estimates. The setup is similar to the one also adopted in the subsequent simulation study; we consider the case of two estimates (y1 and y2) with standard errors
Figure 1 (top panel) illustrates the effect on the shrinkage estimate and the corresponding 95% credible interval. One can see how the estimate (posterior median of θ1) moves (mostly) in concordance with the second estimate (y2) and that the resulting interval is narrowest when y1 and y2 are in close agreement. For larger differences, the estimated heterogeneity increases, less borrowing of information takes place, the interval widens and the estimate of θ1 is less attracted towards y2. Eventually the shrinkage interval exhibits a certain degree of robustness and barely changes with increasing difference. This robustness feature may be explained by the fact that implicitly the meta-analysis is equivalent to an analysis of the first study using the MAP-prior based on the second study.
11
The prior derived via the hierarchical model from the first study then is rather vague and heavy-tailed, leading to the robust behaviour.
32
Effect of varying the difference between quoted estimates (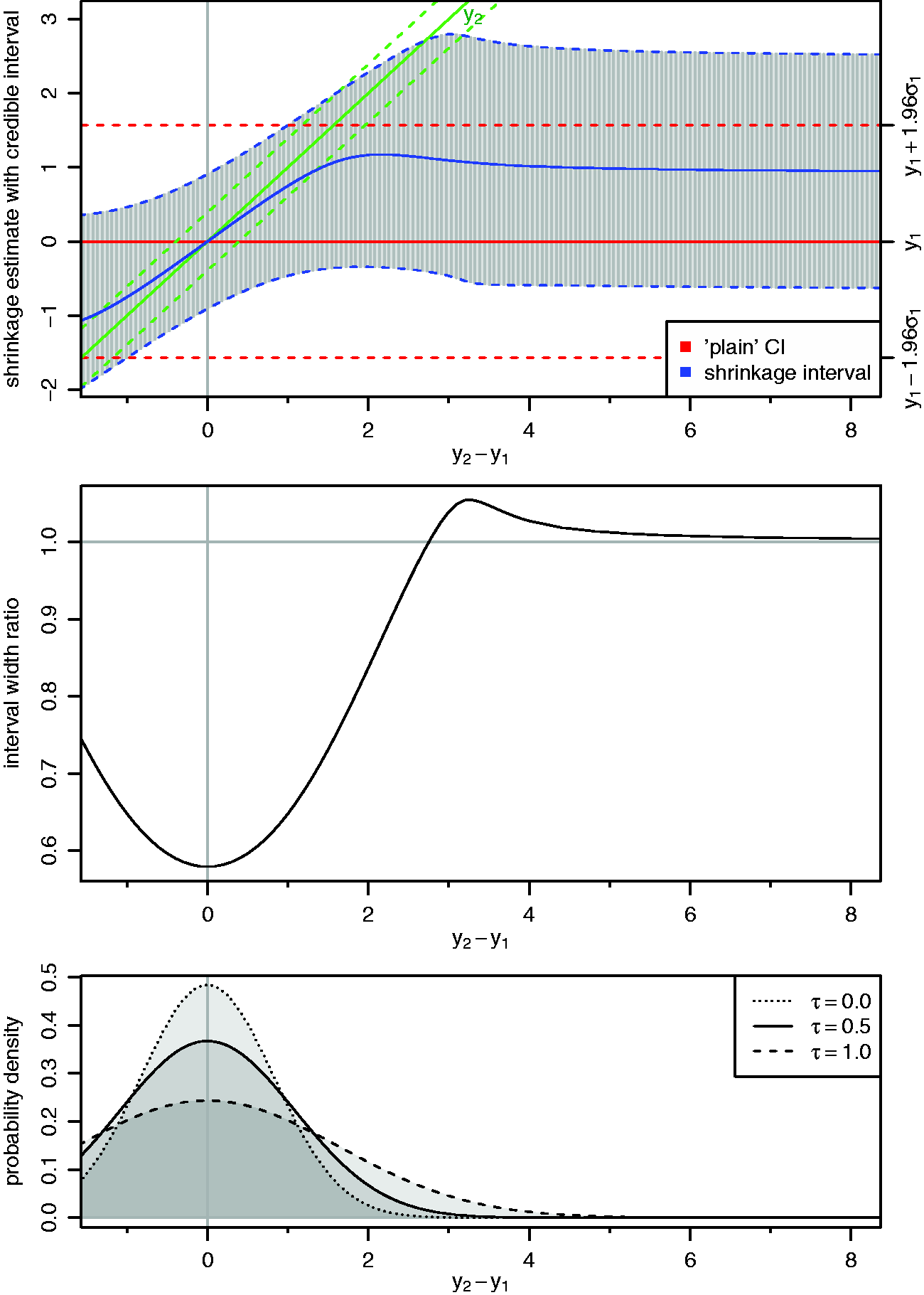
The middle panel shows that the shrinkage interval is shorter than the “plain” interval (
The scenario shown here is where we would in fact expect the greatest gain from considering the second estimate (y2) in estimating θ1, since the second estimate's error is much smaller than the first (
4 Simulation study
4.1 Setup
The simulations shown in the following are based on the NNHM, and since binary endpoints are very common in meta-analysis applications,
33
the setup is motivated by a scenario featuring a log-OR endpoint. If a study of size n
i
results in a contingency table as an outcome, this may be converted into a log-OR that is associated with an approximate standard error of
We can compare the resulting precision by comparing the 95% shrinkage interval width δ
i
with the original confidence interval width and considering the relative width
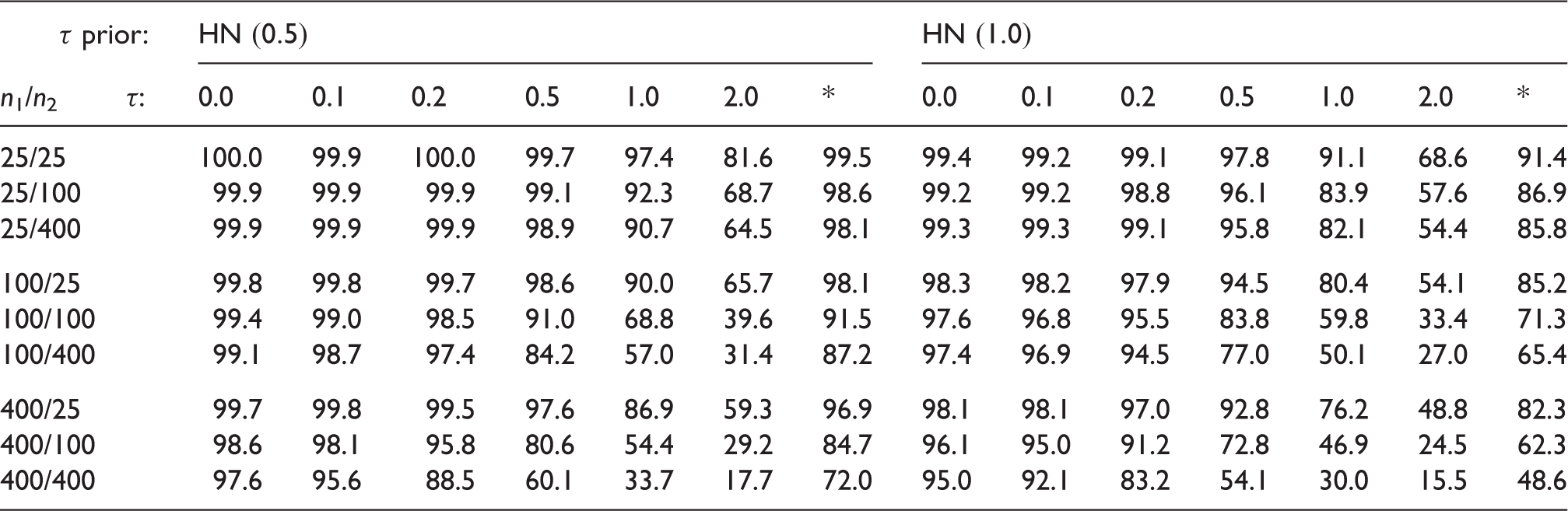
4.2 Coverage
Coverage (%) of shrinkage intervals for estimation of the first study's mean parameter (θ1).
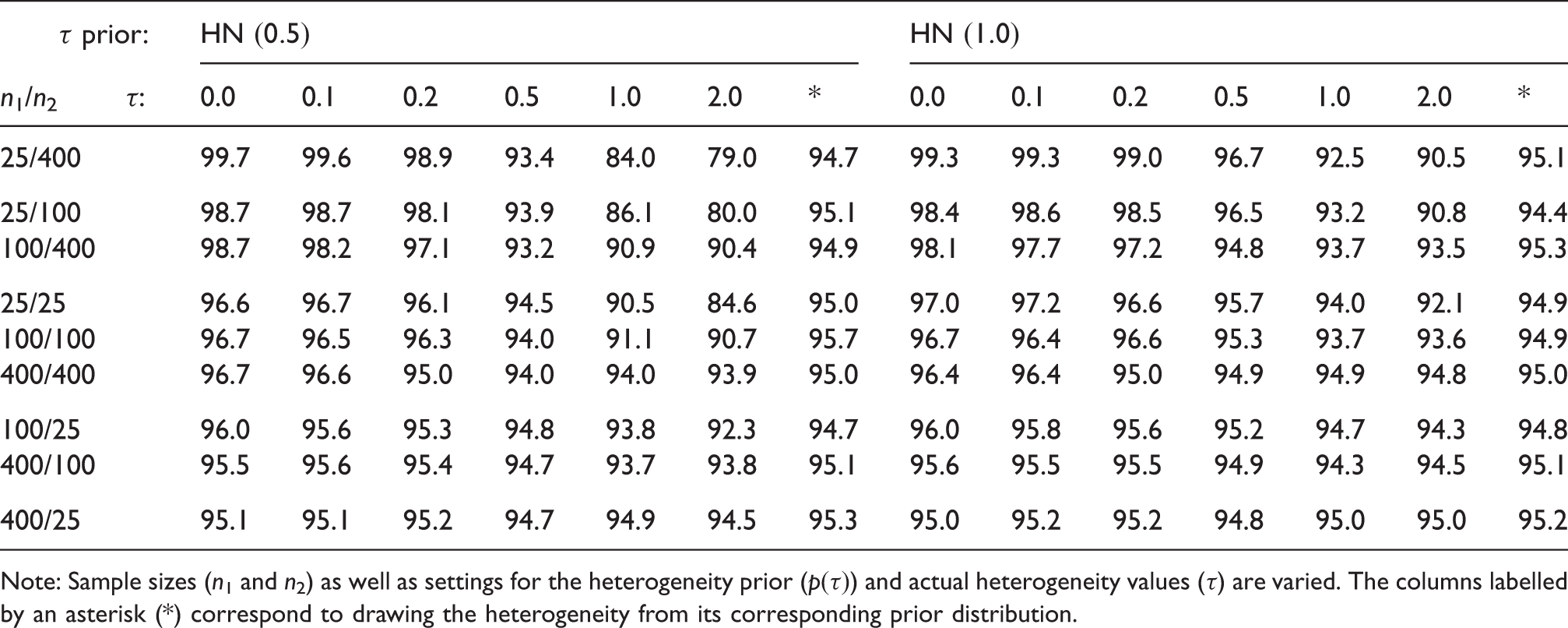
Note: Sample sizes (n1 and n2) as well as settings for the heterogeneity prior (
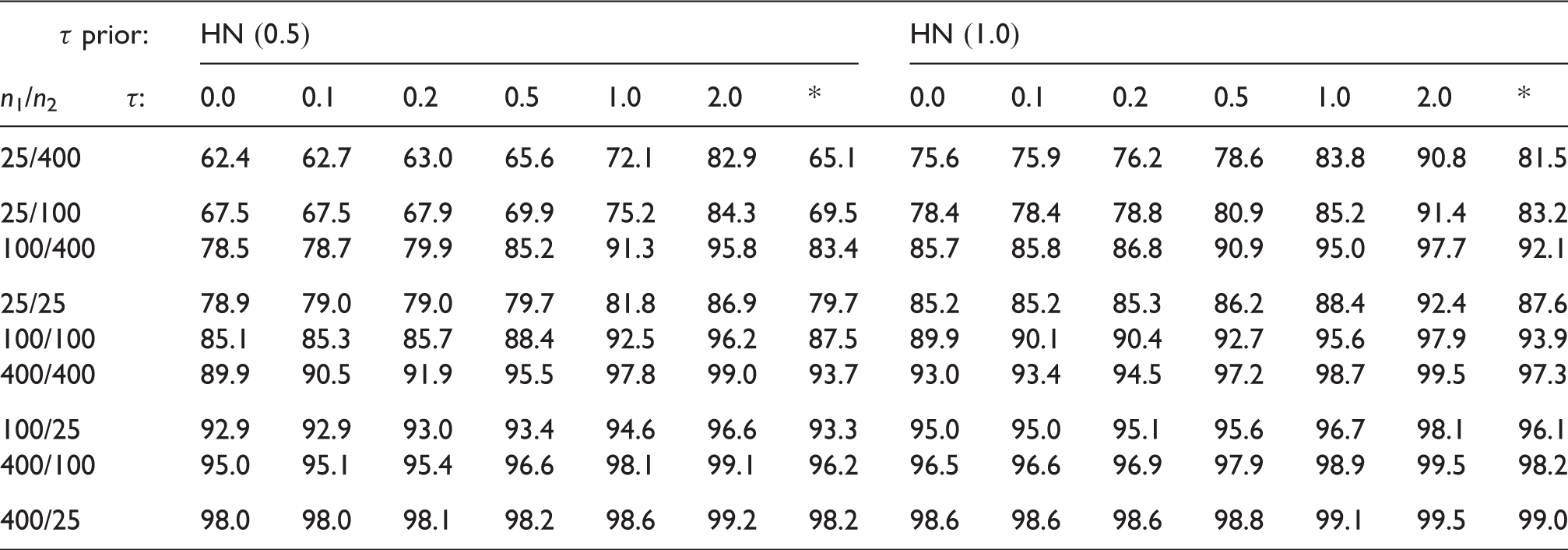
4.3 Interval length and effective sample size gain
Mean width (%) of shrinkage intervals (for θ1) relative to original “plain” CI based only on y1 and σ1.
Gain (%) in effective sample size when using the shrinkage estimate, relative to the original CI.
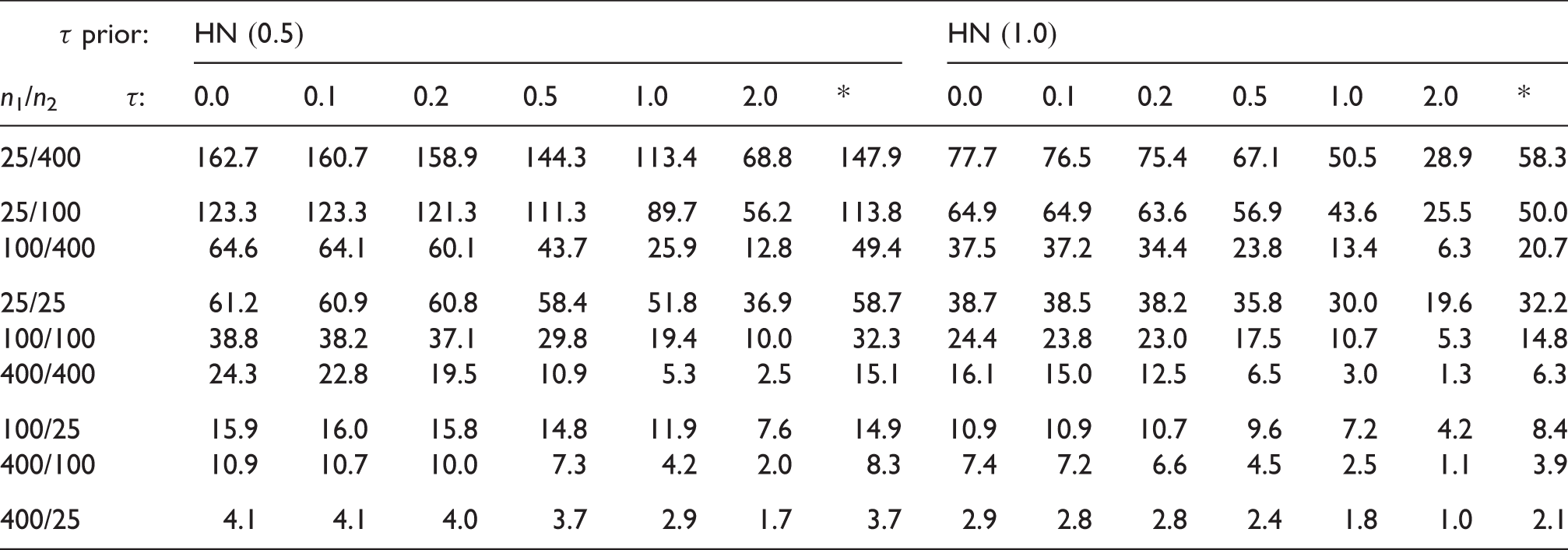
4.4 Fraction of shortened intervals
4.5 Implications for practical application
The previous sections illustrate the process of shrinkage estimation within the NNHM framework and investigate the potential benefits. Across a range of realistic settings, the method exhibits sensible and robust behaviour, and despite the seemingly pathological outset of synthesizing only two estimates, the expected information gain may still be substantial. In the following, we will illustrate the approach by applying it in two examplary cases, one based on two studies (one randomized, one observational), and one based on two estimates from meta-analyses of different types of studies.
5 An application in Creutzfeld-Jakob disease
With a prevalence of 1 in
Varges et al.
3
studied the use of doxycycline, an antiprion agent, in early CJD. They conducted a double-blind randomised placebo-controlled trial that failed to recruit the originally planned number of patients and was terminated prematurely with only n = 12 patients (seven on doxycycline and five on placebo). Additionally, data were available from an observational study of n = 88 patients including 55 patients who received doxycycline. The primary endpoint was all-cause mortality which was analyzed using Cox proportional hazard regressions. In the case of the randomized controlled trial, the model included only the factor treatment as independent variable whereas the analysis of the observational data in addition was stratified by propensity scores. The observed log hazard ratios (standard errors) were −0.173 (0.631) and −0.499 (0.249) in the randomized controlled trial and the observational study, respectively. Varges et al. performed a random-effects meta-analysis to estimate the overall (pooled) effect μ using standard frequentist methodology. They reported a combined hazard ratio of 0.633 with 95% confidence interval of
Now suppose primary interest was in the ‘randomized’ effect, but one is willing to utilize external observational evidence as supporting information. We may now apply the shrinkage estimation approach. Figure 2 shows the estimated logarithmic hazard ratios based on obervational and randomized data along with the derived mean estimate (μ). The two shrinkage estimates are also shown next to the original (quoted) estimates. For the randomized trial, the updated credible interval covers the range of [ Forest plot for the CJD example (log-HR outcome). The shrinkage interval for the log-HR based on randomized evidence here is [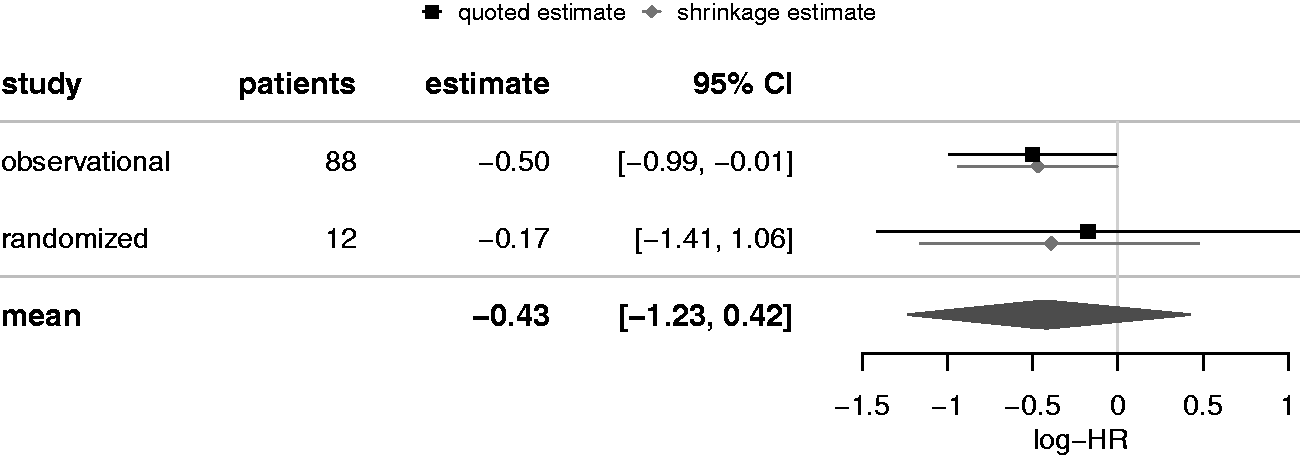
From two studies, there is only very little to be learned about the between-study heterogeneity τ. 24 The prior median heterogeneity was at 0.34, which a posteriori is slightly reduced to 0.28; the posterior 95% quantile is at 0.85 instead of 0.98. Note that while the estimates for the overall mean and the shrinkage estimate do not differ much in this particular case, their interpretations are quite different. The R code to reproduce the calculations for this example is provided in Appendix 1.
6 Beyond two studies: more general shrinkage applications
So far we have described shrinkage estimation mostly in terms of “studies” and corresponding parameter estimates. However, the method may be applied more widely. Estimates do not need to come from studies, these could also originate from different types of evidence, for example, from two meta-analyses, or from a meta-analysis and a single study.
If the NNHM is fitted to the results of meta-analyses, then this adds another hierarchical level to the model. In the spirit of a bias allowance model framework, 38 in addition to between-study variability, the variability between study types is considered as a separate variance component. Especially in the context of normal models39,40 and when interest is in main effects, 41 application of a one-stage model simultaneously including all hierarchy levels may in many cases not lead to substantially different results from a simpler two-stage approach in which data at the study-level are combined first, and summaries are subsequently combined in a second stage. 42 This way, inference is substantially simplified, and standard meta-analysis software can be used.
Consider the example of a meta-analysis investigating the effect of immunosuppression in paediatric patients, where the outcome of interest is the occurrence of acute rejection (AR) events that the therapy is supposed to prevent. 43 Only two randomized trials are available, but in addition four observational studies reported on the effect. One may not expect to see identical effects in both types of studies, but the discrepancy between them will be limited. A meta-analysis of the two randomized trials may then profit from considering the outcomes of the four observational trials in addition, leading to a particular kind of extrapolation approach. 44
Figure 3 shows the example data. In both sets of studies we see similar effects, the negative combined estimates of the log-odds-ratio indicate a successful prevention of AR events, and the two associated credible intervals are mostly overlapping. After combining the two sets of studies separately, we may now perform a meta-analysis of the resulting two combined estimates (in all cases using uniform priors for effects and HN(0.5) priors for heterogeneities). The shrinkage estimate for the mean effect in the randomized studies then provides an estimate for the randomized effect that is also informed by the observational evidence, while allowing for heterogeneity (at a second level) between both types of estimates. Note that in this context the shrinkage estimate then does not refer to a single study, but to one of the meta-analysis estimates that are combined here. The shrinkage estimate is shown at the very bottom of Figure 3. Compared to the original estimate based only on the two randomized trials, the shrinkage estimate is, in concordance with the observational evidence, slightly more moderate (at a lower absolute log-OR). Consideration of the additional evidence also gains precision: the shrinkage interval is 25% shorter than the original interval.
Illustration of a more general shrinkage application. The two sources of evidence themselves here are meta-analyses of observational and randomized studies. The combined randomized estimate may then borrow information from the observational studies' evidence. The two combined estimates are again meta-analysed to yield a shrinkage interval for the randomized effect.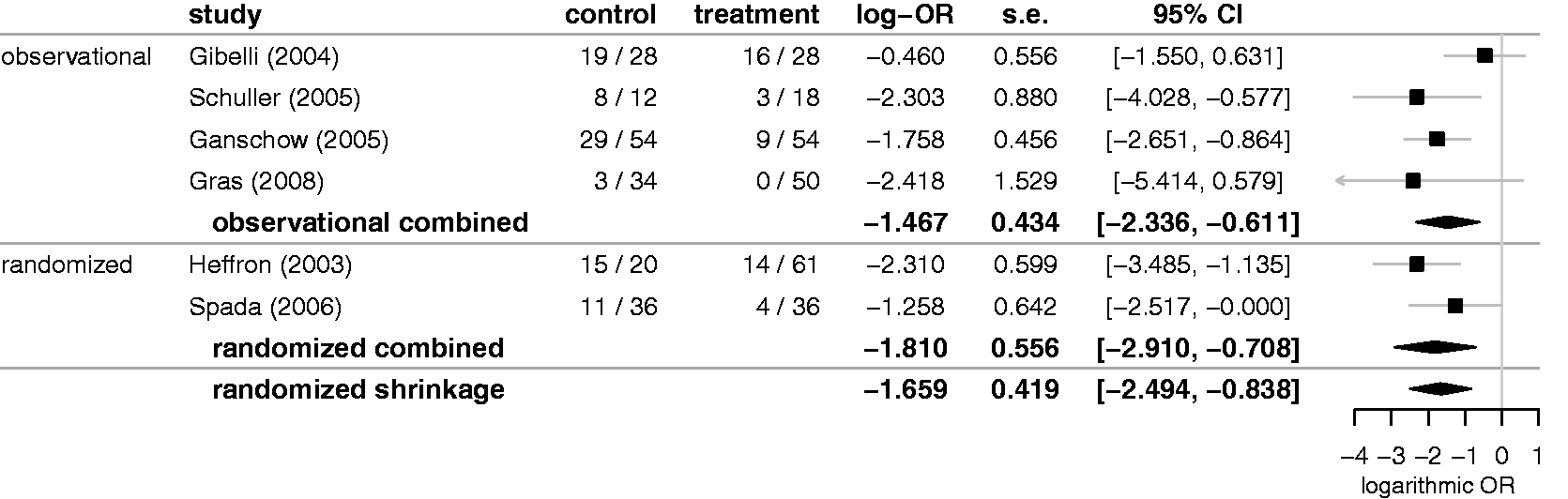
For the shrinkage estimate, we get a posterior probability of
7 Discussion
Use of the NNHM to consider external information via shrinkage estimation provides a transparent procedure based on well-defined parameters and a common model framework. The NNHM may readily be generalized, for example, to more studies, more levels of hierarchy, or the inclusion of regression parameters. The amount of information considered may be explicated by noting that a joint analysis is equivalent to the use of a meta-analytic-predictive (MAP) prior. 11 At the same time, heavy tails of the MAP prior ensure a certain degree of robustness of the shrinkage estimate in case of prior-data conflicts. 32 The simulations demonstrate that the gain in precision may be greater than expected, and substantial especially in cases where the external data are associated with equal or less uncertainty than the data that are of primary interest. The possible precision gain may allow the conduct and evaluation of trials in circumstances where otherwise evidence would be too sparse, or it may generally enable to allocate resources more efficiently.
In the spirit of the reference model parametrization outlined above, the institution of an “overall mean” μ is not necessary. In many cases, when the data to be synthesized are of differing natures, the idea of a “central” mean parameter might be hard to motivate; what is relevant here is that the two estimates are modeled as being connected via an uncertain normally distributed offset. Normality here especially implies symmetry, i.e. the displacement between the two does not have a preferred direction; over- or under-estimation of one another are equally likely, so that a priori no systematic bias is assumed. Availability of this alternative motivation broadens the range of applicability of meta-analytic methods.
As usual, the user needs to be aware of the limits of the applicability of the model, which here in particular means that the normality assumptions should be plausible. 45 These assumptions might be challenged, for example, when estimates are based on count data suffering from small-sample or rare-event problems, in which case more specific models may be more appropriate. 46 We also make the implicit assumption that patient populations are sufficiently similar to allow for a meaningful comparison. Furthermore, analyses of non-randomized studies may need to be adjusted for confounding,47,48 as was also done in the CJD example.
Although frequentist analyses still dominate clinical trials, examples of Bayesian analyses are emerging. A recent application is the trial by Laptook et al. 49 in newborns with hypoxic-ischemic encephalopathy, a form of brain damage resulting from an insufficient supply of oxygen to the brain. The authors used the Bayesian framework to interpret their results in the light of different choices of priors that they termed “neutral”, “skeptical” and “optimistic”. 50 In this regard, it differs from our proposal as we advocate the use of external data to inform the prior. The connection to common meta-analysis methods then helps motivating the choice of model details. Sensitivity analyses could be performed in our setting by varying the prior on the between-trial heterogeneity τ, for example, by varying the scale parameter of the half-normal prior.
Although not assessed in the simulations here, the performance of frequentist shrinkage BLUP estimators is likely to be unsatisfactory when dealing with only two studies. The reason lies in the underestimation of the between-study heterogeneity with a high likelihood of the variance estimate resulting in zero, and the challenge to incorporate the uncertaintly in the estimation of the heterogeneity in the inference.20,24,51 A Bayesian alternative was described here and shown in simulations to have satisfactory properties under practically relevant scenarios. Therefore, the approach described here adds to the tool box of practicing statisticians. The proposed Bayesian approach can easily be implemented using the R package
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research has received funding from the EU's 7th Framework Programme for research, technological development and demonstration under grant agreement number FP HEALTH 2013-602144 with project title (acronym) “Innovative methodology for small populations research” (InSPiRe).