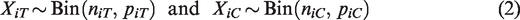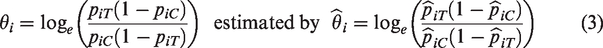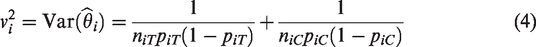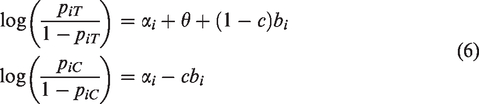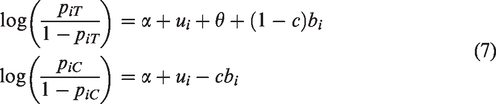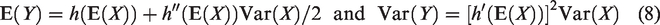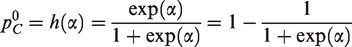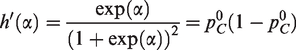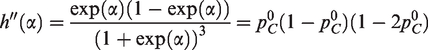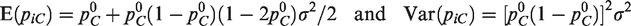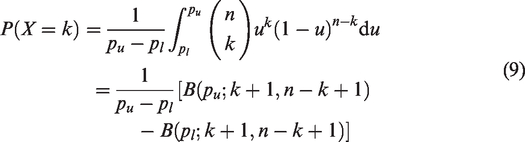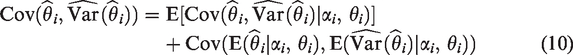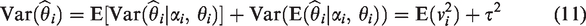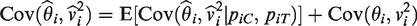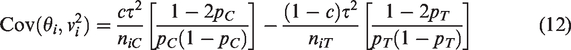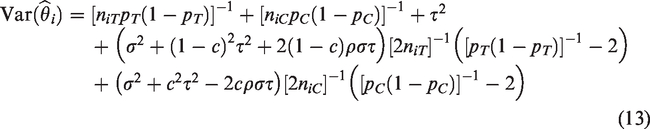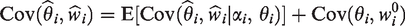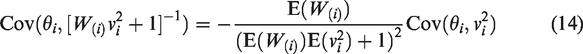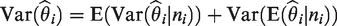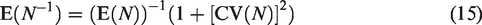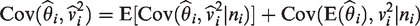Contemporary statistical publications rely on simulation to evaluate performance of new methods and compare them with established methods. In the context of random-effects meta-analysis of log-odds-ratios, we investigate how choices in generating data affect such conclusions. The choices we study include the overall log-odds-ratio, the distribution of probabilities in the control arm, and the distribution of study-level sample sizes. We retain the customary normal distribution of study-level effects. To examine the impact of the components of simulations, we assess the performance of the best available inverse–variance–weighted two-stage method, a two-stage method with constant sample-size-based weights, and two generalized linear mixed models. The results show no important differences between fixed and random sample sizes. In contrast, we found differences among data-generation models in estimation of heterogeneity variance and overall log-odds-ratio. This sensitivity to design poses challenges for use of simulation in choosing methods of meta-analysis.
Many methodological publications in applied statistics develop a new method, illustrate it in examples, and evaluate its performance by simulation. Our interest lies in methods for meta-analysis (MA). For meta-analysis of odds ratios, we demonstrate how researchers’ choices of simulation design can affect conclusions on the comparative merits of various methods.
Presentations of meta-analysis methods usually include assumptions about the behavior of the estimates from the individual studies. For example, a generic 2-stage random-effects model relates the observed effect sizes yi (i =1, …, K) to the overall effect μ in the model
where represent random variation in the underlying study-level effects, the represent random variation within the studies, and the δi and the are independent. From the yi and their estimated variances, , the two-stage method estimates μ and also . Such a model can serve as a basis for analysis and also as the basis for generating data as part of a simulation study. The analysis model and the data-generation model may differ, however. For example, when the measure of effect is the log-odds-ratio, the data-generation model produces more-basic study-level data (such as numbers of events in the two arms, as shown in Section 2), from which yi and are calculated, and the popular inverse–variance–weighted methods build on equation (1). On the other hand, other methods, such as generalized linear models, build on the likelihood for the distributions in the data-generation model. In order to study the impact of choices among data-generation models – our primary interest – our simulations use several analysis models and methods based on them.
For a particular method, one can regard a measure of performance, such as the bias of a point estimator or the coverage of an interval estimator, as a function of variables that describe the meta-analysis and its setting. By a combination of analysis and, mainly, simulation, one aims to evaluate that function and describe its behavior. The variables include the number of studies, the study-level sample sizes, the extent of imbalance of the arm-level sample sizes, the overall effect, the between-study variance of the effect (for a random-effects method), and the arm-level variances within the studies (if the effect is continuous); and the relation of the performance measure to the variables usually involves nonlinearities and interactions. Thus, the design of a simulation has important implications for accuracy in evaluating the function, for estimating those relations, and, especially, for relevance of the results to practice.
The conventional meta-analysis of odds ratios from K studies involves 2K binomial variables, for and j = C or T (for the Control or Treatment arm). The random-effects model assumes that for and an indicator zij taking on values 0 (for Control) and 1 (for Treatment). In this notation, and .
A design specifies a systematic collection of situations involving the number of studies, K; the sample sizes, nij; the control-arm probabilities, piC, or, equivalently, their logits, αi; the overall log-odds-ratio, θ; and the between-study variance, . For each situation the simulation uses M replications, where M is typically large, say 10,000.
For simplicity, we consider equal arm-level sample sizes, ; some studies use a random allocation ratio centered at a given percentage, q. Studies vary in how they specify the ni. Choices include setting with the same value in all M replications, using a fixed set of ni (not all equal), and using some distribution (typically normal or uniform) to generate a new set of ni in each replication.
Similarly, the piC or their logits αi can be fixed or generated from some distribution. Again, normal and uniform distributions are the typical choices.
For most studies use a few selected values or an equally spaced set, such as = 0, 0.1, …, 1, though some generate randomly.1 Some studies specify values of the heterogeneity measure I2 and obtain values of indirectly.
In Section 2, we review approaches for generating log-odds-ratios and control-arm probabilities, and consider their statistical consequences. For two-stage methods of meta-analysis, which use the studies’ sample log-odds-ratios and their estimated variances, the relation between the estimates and their inverse-variance weights can produce bias. Section 3 examines this complication analytically, for fixed study-level sample sizes. Section 4 discusses approaches for generating sample sizes randomly and analyzes their impact. In Section 5 we study, by simulation, how various choices in generating data affect comparative merits of several established meta-analytic methods in estimating the between-study variance and the overall log-odds-ratio θ. The methods we study include the best available two-stage methods for MA: the Mandel-Paule estimator of and the corresponding inverse–variance–weighted estimator of θ with a confidence interval based on the normal distribution. We also consider the performance of two GLMM methods and a two-stage estimator of θ with constant sample-size-based weights whose confidence interval is based on the t distribution. Section 6 describes and summarizes the results. Discussion, in Section 7, offers concluding remarks. Appendices 1 and 2 provide technical details for Section 3. Additional figures are provided in online Supplemental material.
2 Generation of log-odds-ratios and control-arm probabilities
Consider K studies that used a particular individual-level binary outcome. Each study reports XiT and XiC, the numbers of events in the niT subjects in the Treatment arm and the niC subjects in the Control arm, for . It is customary to treat XiT and XiC as independent binomial variables
The log-odds-ratio for Study i is
The (conditional, given pij and nij) variance of , derived by the delta method, is
estimated by substituting for pij. (In analyses, we follow the particular method’s procedure for calculating .)
Under the binomial-normal random-effects model (REM), the true study-level effects, θi, follow a normal distribution
For analysis, the resulting logistic mixed-effects model belongs to the class of generalized linear mixed models (GLMMs).2,3 Kuss,1 Jackson et al.,4 and Bakbergenuly and Kulinskaya5 review these GLMM methods.
In practice, piC and piT vary among studies in a variety of ways, not necessarily described by any particular distribution. Almost all analyses and simulations use the binomial-normal REM for the relation between piT and piC. Simulations can treat the piC as constant (e.g. at a sequence of values) or sample them from a distribution, either directly (usually from a uniform distribution or a more general beta distribution; Section 2.2 discusses beta and beta-binomial models) or indirectly, by generating (usually from a Gaussian distribution).
For reference, Table 1 lists the various data-generation models considered in more detail later.
Summary of data-generation models for log-odds-ratio.
Data-
Study-level
Fraction of
generation
Intercept
random
random effect
model
αi or
effects bi
in Control arm (c)
FIM1
fixed αi
0
FIM2
fixed αi
1/2
RIM1
0
RIM2
1/2
URIM1
piC uniform
0
FIM1F
fixed αi
N/A
RIM1F
N/A
URIM1F
piC uniform
N/A
Note: In the fixed-intercept models, and . In the random-intercept models, and .
2.1 Models with fixed and random intercepts
We consider two fixed-intercepts random-effects models (FIM1 and FIM2, Section 2.1.1) and two random-intercept random-effects models (RIM1 and RIM2, Section 2.1.2) as in Bakbergenuly and Kulinskaya.5 These models are equivalent to Models 2 and 4 (for FIM) and Models 3 and 5 (for RIM), respectively, of Jackson et al.4 Briefly, the FIMs include fixed control-arm effects (log-odds of the control-arm probabilities), and the RIMs replace these fixed effects with random effects.
Under the fixed-effect (common-effect) model, and . Still, the control-arm effects can be either fixed or random, resulting in two fixed-effect models: the fixed-intercepts fixed-effect model FIM1F, and the random-intercept fixed-effect model RIM1F. Random-intercept fixed-effect models were considered by Kuss1 and Piaget-Rossel and Taffé.6 However, GLMMs with random θi are traditional in meta-analysis.
2.1.1 Fixed-intercepts models (FIM1 and FIM2)
The fixed-intercepts models assume fixed effects for the studies’ control arms and allow heterogeneity in odds ratios among studies. (We follow Rice et al.7 in using the plural form for fixed intercepts that differ among the studies.) Given the binomial distributions in the two arms (equation (2)), the model is ()
where the αi are the fixed control-arm effects, θ is the overall log-odds-ratio, and the are random effects. Under FIM1, c =0, resulting in higher variance in the treatment arm. Under FIM2, c =1/2, splitting the random effect bi equally between the two equations and yielding equal variance in the two arms. When , these two models become a fixed-intercepts fixed-effect model, FIM1F.
An analysis has to estimate the fixed study-specific intercepts αi (usually regarded as nuisance parameters), along with θ and . In a logistic mixed-effects regression, these K +2 parameters are estimated iteratively, using marginal quasi-likelihood, penalized quasi-likelihood, or a first- or second-order-expansion approximation. Jackson et al.4 demonstrate that inference using FIM2 is preferable, even though they generate data from FIM1.
2.1.2 Random-intercept models (RIM1 and RIM2)
As K becomes large, it may be inconvenient, even problematic, for analysis to have a separate αi for each study. One can replace those fixed intercepts with random intercepts , centered at α:
As before, θ is the overall log-odds-ratio, and . RIM1 and RIM2 correspond to c =0 and 1/2, respectively. Now the , and ui and bi can be correlated: . (If this bivariate normal distribution is not correct, however, estimates of θ will be biased.8) Under RIM1, heterogeneity of log-odds is represented in the control arms by the variance and in the treatment arms by . Typically, ρ is taken as zero in simulation. The standard two-stage random-effects analysis model, which works with the sample log-odds-ratios, involves only a single between-study variance, . Turner et al.2 point out that ρ should be estimated. Estimation of α, θ, and ρ is similar to estimation of the parameters in the fixed-intercept model.2 Again, RIM2 is preferable to RIM1 for inference.
When , these two models become a random-intercept fixed-effect model, denoted by RIM1F.
The vast majority of simulation studies use FIM1 or RIM1 for data generation, both for standard two-stage methods of MA and when studying performance of GLMMs, even when they use FIM2 or RIM2 for inference. Examples include Sidik and Jonkman,9 Platt et al.,10 Bakbergenuly and Kulinskaya,5 and Cheng et al.11 for FIM, and Abo-Zaid et al.12 ( and 1.5), Kosmidis et al.13 (), and Jackson et al.4 (Settings 1 to 12) () for RIM.
Langan et al.14 use a somewhat more complicated simulation scheme, which either fixes the average within-study probabilities (at .5, .05, and .001) or generates them from , and then derives the values of piC and piT from the values of and θi, the latter normally distributed as in equation (5). Thus, piC satisfies the equation . So has a share of the variance, making this a version of FIM2 or RIM2.
2.1.3 Moments of the control-arm probability under RIM
The Gaussian random-intercept models generate the control-arm probabilities, piC, indirectly: has a normal distribution centered at . On the probability scale, where , the distribution is unimodal and skewed to the right when . Thus, simulations from RIM involve, on average, higher control-arm probabilities than corresponding simulations from FIM, though the median control-arm probability is the same. (In FIM1, the distribution has a single value: .) To aid in comparing FIM and RIM, we evaluate the mean and variance of this distribution; we use the standard delta method.
For a transformed random variable
For and , we have
The derivatives of at α are
and
Hence
The mean probability increases with the variance, , of the normal distribution of ui. For , say, the mean is .100 when , but it increases to .109 for and to .136 for . Therefore, simulations from FIM and RIM are not quite equivalent.
2.2 Non-Gaussian random-intercept models
Other distributions besides the Gaussian can serve as a mixing distribution for control-arm probabilities.
In Bayesian analysis, the beta distributions are conjugate priors for a binomial, so they are a natural choice for a mixing distribution. The result is a marginal beta-binomial distribution in the control arm. In meta-analysis a beta-binomial model1,15 usually assumes beta-binomial distributions in both arms. However, Bakbergenuly and Kulinskaya15 showed that the standard RE method does not perform well when the data come from a beta-binomial model. Therefore, we would not use a RIM with beta-generated probabilities.
We are not aware of any simulation studies that intentionally used a beta distribution for control-arm probabilities. However, the Beta(1,1) distribution is the same as , and a popular choice is a uniform distribution on an interval, . Viechtbauer,16 Sidik and Jonkman,17 and Nagashima et al.18 (Set iii) generated the piC from in combination with the Gaussian REM. Similarly, Jackson et al.4 (Setting 13) generated the piC from . All these studies add a uniform distribution of control-arm probabilities to the FIM1 setting, producing a random-intercept model that we denote by URIM1. This model retains the normal distribution of the θi.
Piaget-Rossel and Taffé6 used a fixed-effect model with , URIM1F in our nomenclature, with . Piaget-Rossel19 used the same distribution for the piC and uniformly distributed log-odds-ratios, .
If and , then X has the discrete uniform distribution . More generally, when , the probabilities for the numbers of successes are
where denotes the incomplete beta function. To examine the effects on the performance of the MA methods, our simulations include uniform distributions of control-arm probabilities.
3 Variances and covariances of estimated log-odds-ratios and their weights
Traditional one-size-fits-all meta-analysis proceeds in two stages: obtain the study-level estimates and their estimated variances (or standard errors) and then estimate the overall effect as a weighted mean with inverse-variance weights. One of its main faults is that it ignores the variability of the estimated variances. As a result, the variance of the overall effect is underestimated.20 Additionally, a relation between the estimated study-level effects and their estimated variances may lead to bias in the estimate of the overall effect. In this section, we explore these relations for the log-odds-ratio and its variance and inverse-variance weight. We also demonstrate that the relation varies with the data-generation mechanism. In particular, the sample log-odds-ratio and its estimated variance can be almost independent under FIM2 and RIM2 when θ = 0. Because the calculations are somewhat easier, we first examine the relation to the estimated variance and then turn to the relation to the inverse-variance weight.
3.1 Relation of sample log-odds-ratio and its estimated variance
The data-generation mechanisms for the random-effects model generate the piC and piT and then generate XiC and XiT, according to equation (2). Thus, to obtain the covariance between and , we apply the law of total covariance
In the process, to show the full effect of the data-generating mechanism, we also obtain , using the more-familiar law of total variance
In equation (10), the covariance of the conditional expectations is just because and (to first order) . Thus, we need to calculate and take its expectation. Conditioning on αi and θi, in equation (6) and equation (7), is equivalent to conditioning on piC and piT. Therefore, we can rewrite equation (10) as (shortening to )
The first term in the above equation accounts for the binomial variation (of order ) in and in , given piC and piT, whereas the second term accounts for the variation of its expected value and variance from random effects, of order 1 in model (7). Therefore, the first, binomial term is of smaller order () than the second term (the covariance of the expected moments) and can be neglected in a calculation to order .
To calculate the covariance of θi and , we assume, for simplicity, that ui and bi are independent in RIM1 and RIM2. Then, defining and , to order
In particular, when c =1/2, θ = 0 and niT = niC, .
After some algebra, we also obtain, to order ,
The binomial variance component is inflated by allowing random effects/random intercepts. The extent of the inflation involves , and c.
3.2 Relation of sample log-odds-ratio and its weight
We can write the IV weights as , where is independent of and of . Similarly, let . We are interested in . Again using the law of total covariance
where . The first term of the covariance is of a smaller order than the second, so to order , .
Expanding and taking into account the independence of from θi and , we have
where .
Equations (12) to (14) show that the choice of θ, the choice of pC (through α), the choice of FIM versus RIM (through ), the choice of fixed-effect versus random-effects model (through ), and the choice of FIM1/RIM1 versus FIM2/RIM2 (through c) all affect the covariances between and their estimated weights, and result in varying biases in the estimated overall effect. In particular, when , and c =1/2, the covariance is zero, so the and their estimated weights are almost independent, making the standard IV estimate of the overall effect unbiased when generated from FIM2/RIM2. On the other hand, the sign of the bias of the depends on the sign of , and the bias increases with an increase in when generated from FIM1/RIM1.
4 Generation of sample sizes
Several authors5,11 use constant study-level sample sizes, either equal or unequal, in all replications. More often, however, authors generate sample sizes from a uniform or normal distribution. Jackson et al.4 use (mostly with niC = niT) sample sizes from discrete U(50, 500). Langan et al.14 use either constant and equal sample sizes within and across studies, or sample sizes from and ; Sidik and Jonkman17 use , and Abo-Zaid et al.12 use and . Viechtbauer16 generates study-level sample sizes () from ( is the variance) with . In an extensive simulation study for sparse data, Kuss1 uses FIM1F and FIM1 along with a large number of fitting methods. He generates both the number of studies K and their sample sizes n from log-normal distributions: with mean 0.65 and standard deviation 1.2 for rather small K, with log-normal mean 3.05 and log-normal standard deviation 0.97 for larger K, and with log-normal mean 4.615 and log-normal standard deviation 1.1 for sample sizes. He applies the ceiling function to the generated number and adds 1, and he limits the number of studies to a maximum of 100.
In general, if mutually independent random variables Yi have a common distribution , and is independent of the Yi, the sum has a compound distribution.21 A binomial distribution with probability p and a random number of trials is a compound Bernoulli distribution. The first two moments of such a distribution are and . This variance is larger than the variance of the distribution. Therefore, random generation of sample sizes produces an overdispersed binomial (compound Bernoulli) distribution for the control arm, and may also inflate, though in a more complicated way, the variance in the treatment arm.
In particular, when , the variance . And when .
4.1 Variances and covariances of estimated log-odds-ratios and their weights for random sample sizes
To calculate the variance of when sample sizes are random, we again use the law of total variance
The second term is , and the first term is obtained by substituting and in equation (13).
Using the delta method
where the coefficient of variation, , is the ratio of the standard deviation of N to its mean. Therefore, to order , random generation of sample sizes inflates the variance of if and only if the coefficient of variation of the distribution of sample sizes is of order 1. In the simulations of Viechtbauer,16 where , so the variance is not inflated. In contrast, generating sample sizes from would result in and would inflate variance. (Use of such a combination of mean and variance, however, is unlikely to produce realistic sets of sample sizes, and the probability of generating a negative sample size exceeds 2%.)
The variance of a uniform distribution on an interval of width Δ centered at n0 is , and its CV is . Therefore, is of order 1 whenever the width of the interval is of the same order as its center. Hence, variance is inflated in the simulations by Jackson,4 Langan et al.,14 Sidik and Jonkman,17 and Abo-Zaid et al.,12 who all use wide intervals for n.
Similarly, we use the law of total covariance to calculate the covariance between and
The second term is zero, as , which does not depend on ni. So is obtained by substituting and in equation (12), and the covariances are affected only when is of order 1.
5 Design of simulations
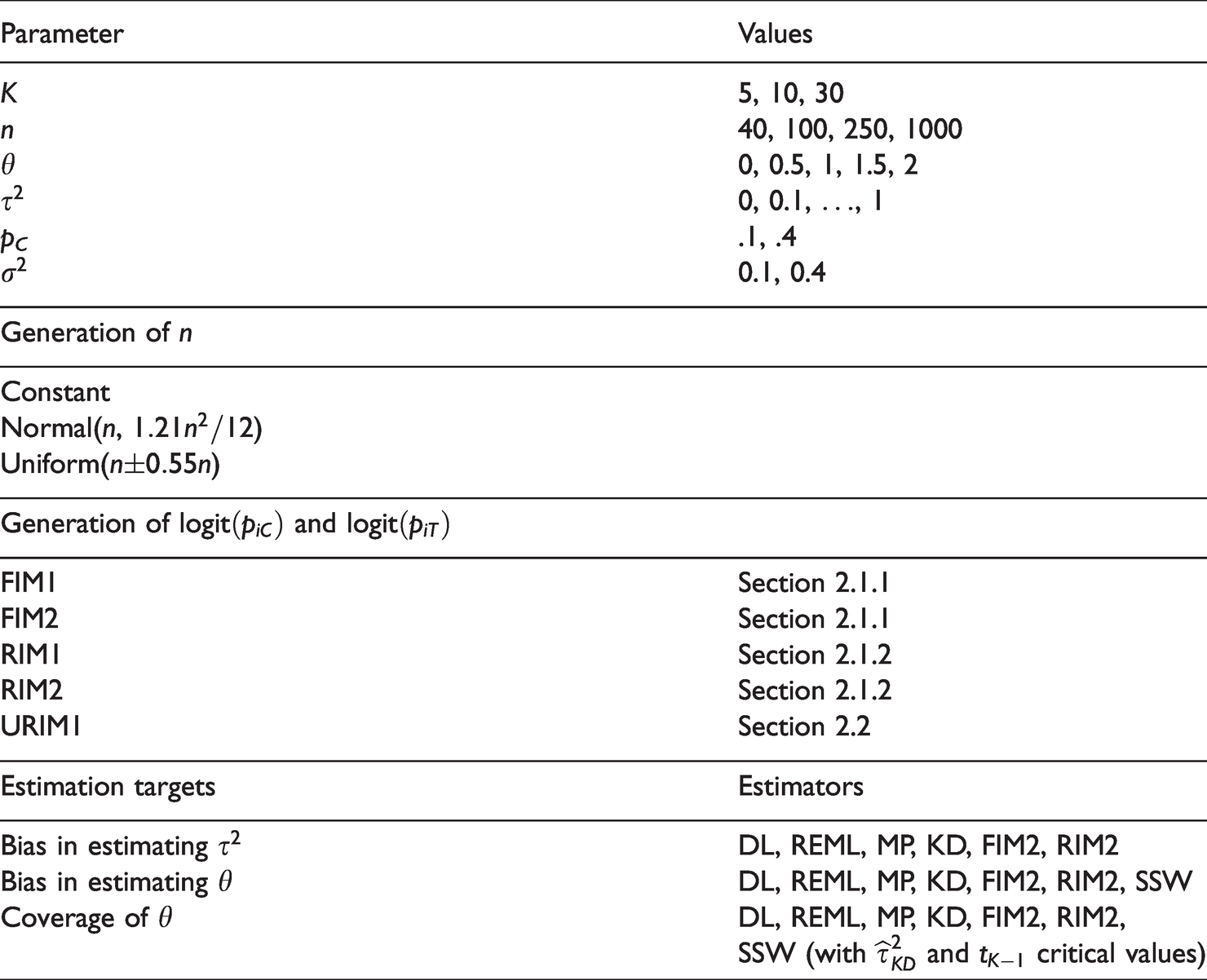
Our simulations keep the arm-level sample sizes equal in the K (= 5, 10, 30) studies. The control-arm probability . For the log-odds-ratios θi, we use equation (5) with θ = 0, 0.5, 1, 1.5, and 2 and = 0, 0.1, …, 1. We vary two components of the data-generating mechanism: the model (at five levels: FIM1, FIM2, RIM1, RIM2, and URIM1) and the arm-level sample sizes, n, centered at 40, 100, 250, and 1000 (constant, normally distributed, or uniformly distributed). We also vary the variance for RIM.
We keep the control-arm probabilities piC and the log-odds-ratios θi independent (i.e. ρ = 0 in the RIMs).
To make the normal and uniform distributions of sample sizes comparable, we center them at the same value n and equate their variances. If a normal distribution has variance , a uniform distribution with the same variance has interval width . We set , resulting in and a squared CV of 0.101. Therefore, by equation (15), our simulations with random n inflate variances and covariances by 10% in comparison with simulations with fixed n. Wider intervals of n would inflate variances more, but in generating sample sizes from a corresponding normal distribution, we want negative sample sizes to have reasonably small probability. For our choice of Δn this probability is .0008. Unfortunately, we were still getting a small number of values below zero out of thousands of simulated values, so we additionally truncate the n values generated from a normal distribution at 10. Truncation happens with probability .009.
Similarly, for control-arm probabilities, even though using a normal distribution on the logit shifts the mean value of the control-arm probability, as discussed in Section 2.1.3, we can have equal variances on the probability scale by taking in comparator simulations.
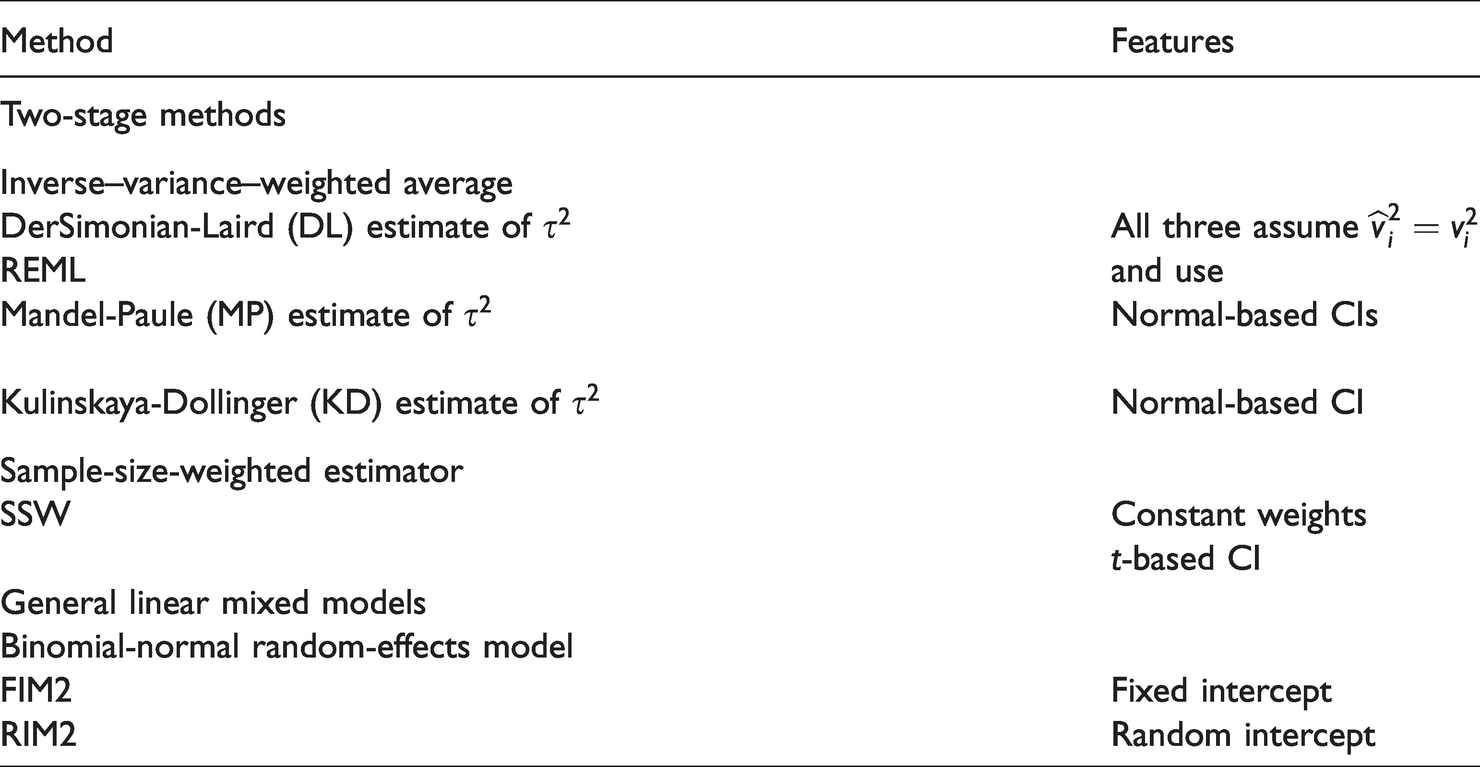
For each generated dataset, we use a number of the two-stage methods for log-odds-ratio, including the best available method:22,23 MP estimation of with corresponding inverse–variance–weighted estimation of θ and a confidence interval based on the normal distribution. We also consider the performance of the GLMM methods based on FIM2 and RIM2 as implemented in metafor.4,5,24 Finally, we include a weighted-average estimator of θ whose weights depend only on the studies’ arm-level sample sizes: .22 We refer to this sample-size-weighted estimator as SSW. The accompanying confidence interval is based on the t distribution with degrees of freedom. Table 2 lists the analysis methods.
Summary of methods for meta-analysis of log-odds-ratios in our simulations.
Method
Features
Two-stage methods
Inverse–variance–weighted average
DerSimonian-Laird (DL) estimate of
All three assume
REML
and use
Mandel-Paule (MP) estimate of
Normal-based CIs
Kulinskaya-Dollinger (KD) estimate of
Normal-based CI
Sample-size-weighted estimator
SSW
Constant weights
t-based CI
General linear mixed models
Binomial-normal random-effects model
FIM2
Fixed intercept
RIM2
Random intercept
For each combination of the parameters and a data-generating mechanism, we generated data for 1000 simulated meta-analyses.
Table 3 shows the components of the simulations. For completeness we included the DerSimonian-Laird (DL), restricted maximum-likelihood (REML), MP, and Kulinskaya-Dollinger (KD) estimators of with the corresponding inverse–variance–weighted estimators of θ and confidence intervals with critical values from the normal distribution. Bakbergenuly et al.22 studied those inverse–variance–weighted estimators in detail. The results for the other IV-weighted estimators under the five data-generation mechanisms are similar to those for the Mandel-Paule estimator, so we do not include them in Section 6. Our preprints25,26 give the full details. Among the estimators, FIM2 and RIM2 denote the estimators in the corresponding GLMMs.
Components of the simulations.
Parameter
Values
K
5, 10, 30
n
40, 100, 250, 1000
θ
0, 0.5, 1, 1.5, 2
0, 0.1, …, 1
pC
.1, .4
0.1, 0.4
Generation of n
Constant
Normal(n, )
Uniform()
Generation of and
FIM1
Section 2.1.1
FIM2
Section 2.1.1
RIM1
Section 2.1.2
RIM2
Section 2.1.2
URIM1
Section 2.2
Estimation targets
Estimators
Bias in estimating
DL, REML, MP, KD, FIM2, RIM2
Bias in estimating θ
DL, REML, MP, KD, FIM2, RIM2, SSW
Coverage of θ
DL, REML, MP, KD, FIM2, RIM2,
SSW (with and critical values)
6 Results of the simulations
In the figures that accompany the summaries of results, each plot shows a trace of a measure of the performance of an estimator (bias or coverage) for each of the five data-generation mechanisms. The horizontal variable is . A row corresponds to a value of n (usually 40 or 100) and a combination of values of other parameters (e.g. pC and or θ). The figures illustrate the important patterns in the full sets of figures.25,26 These preprints contain full simulation results for constant, normally distributed, and uniformly distributed sample sizes n.
As it turned out, the three methods of generating sample sizes produced essentially the same results. For two illustrative examples, compare the third and fourth rows of Figures 1 and 2. Thus, with those exceptions, the plots in the figures come from the results for constant n.
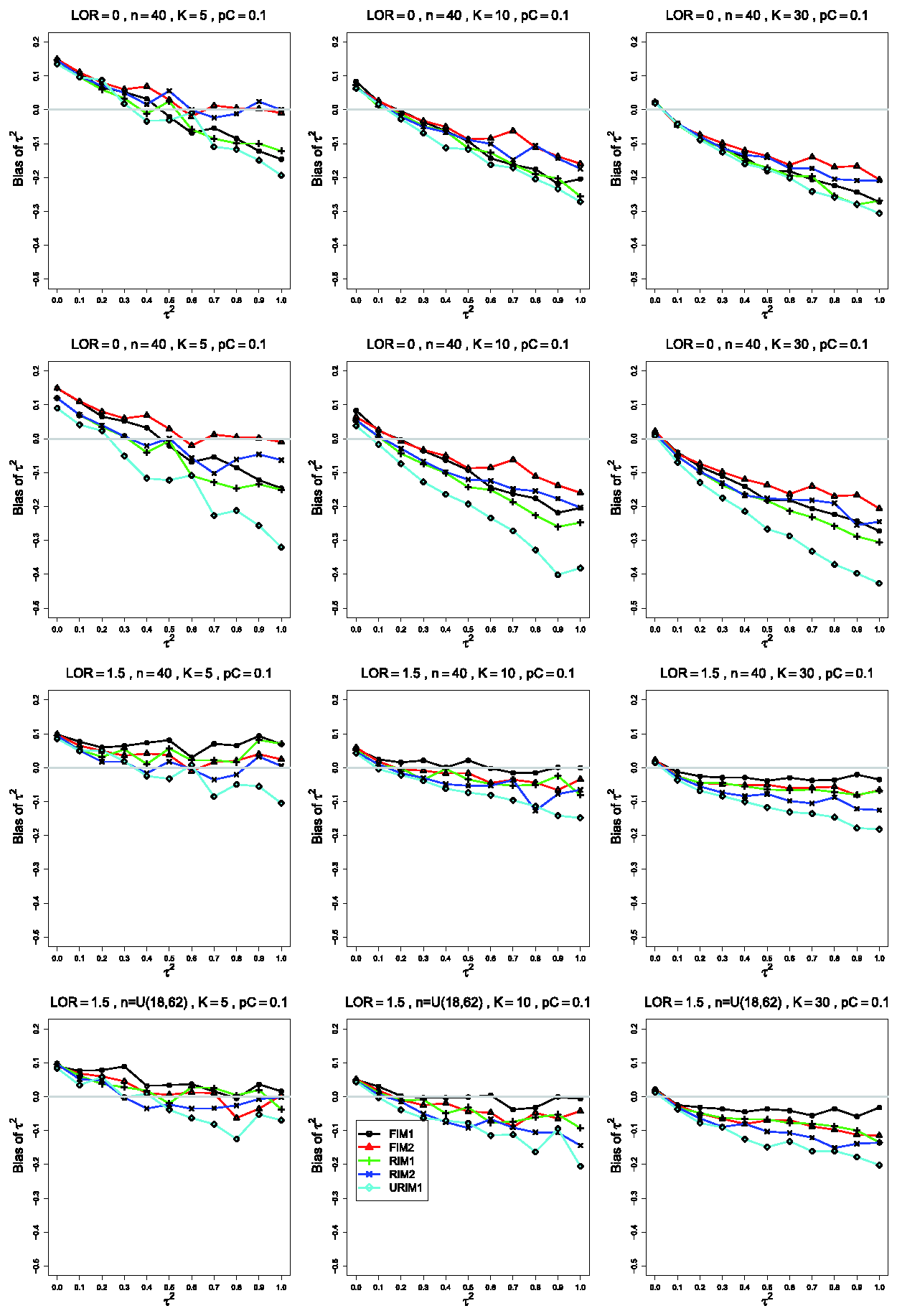
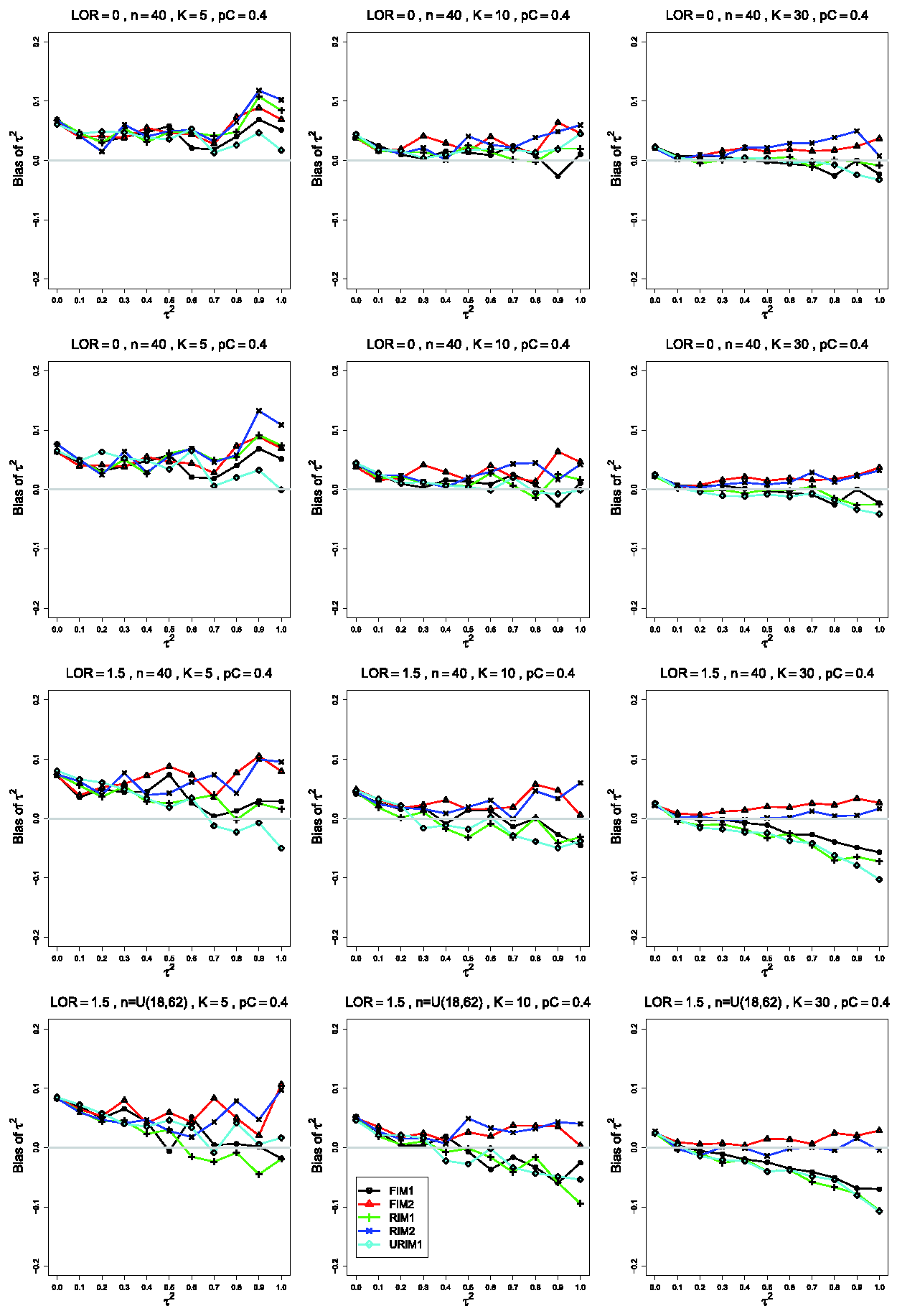
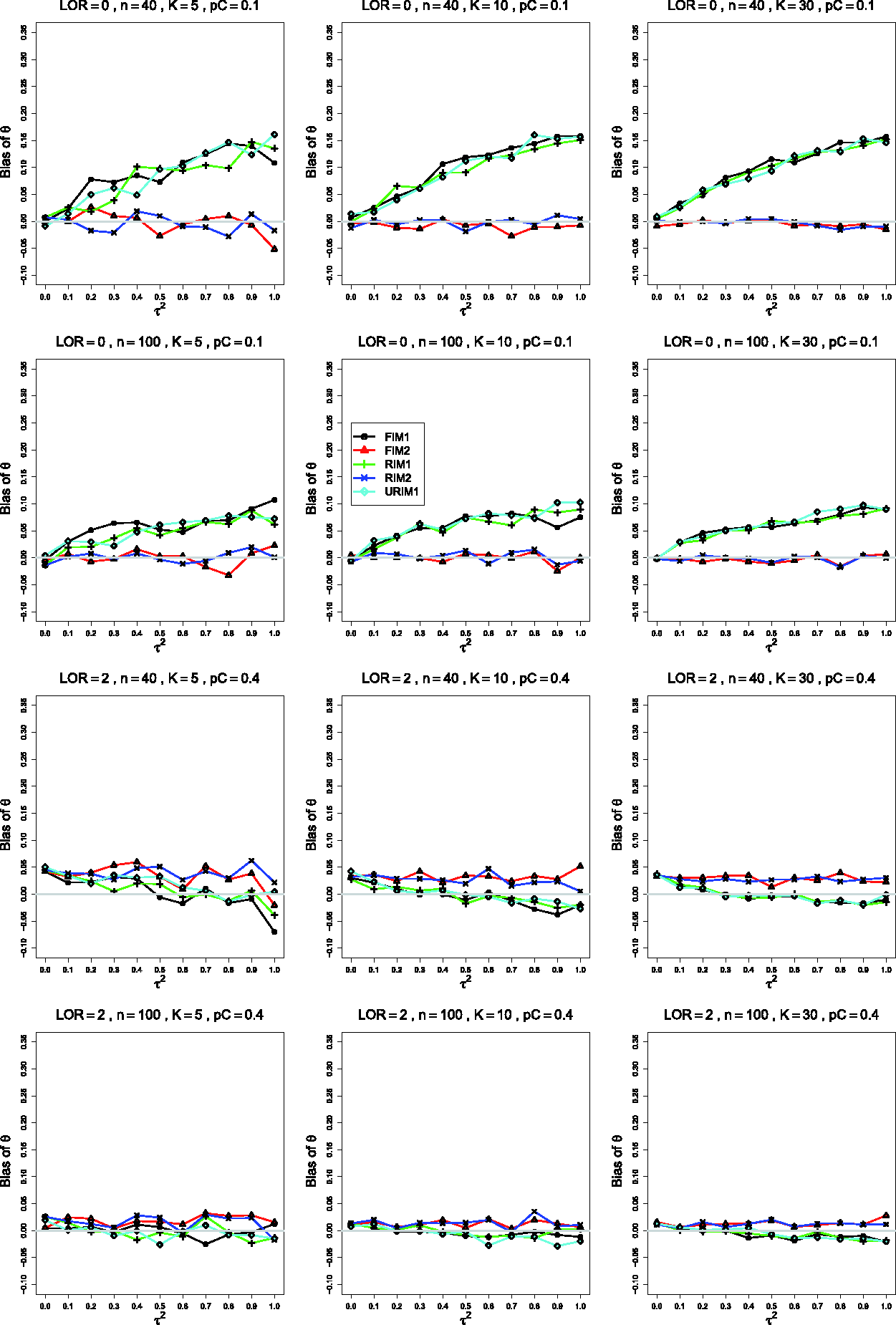
Bias in estimating the between-studies variance, , by for , θ = 0, (top row); θ = 0, (second row); (bottom two rows). Sample sizes are constant n =40 in the top three rows and uniformly distributed in the bottom row. The data-generation mechanisms are FIM1 (circle), FIM2 (triangle), RIM1 (plus), RIM2 (cross), and URIM1 (diamond). Light gray line at 0.
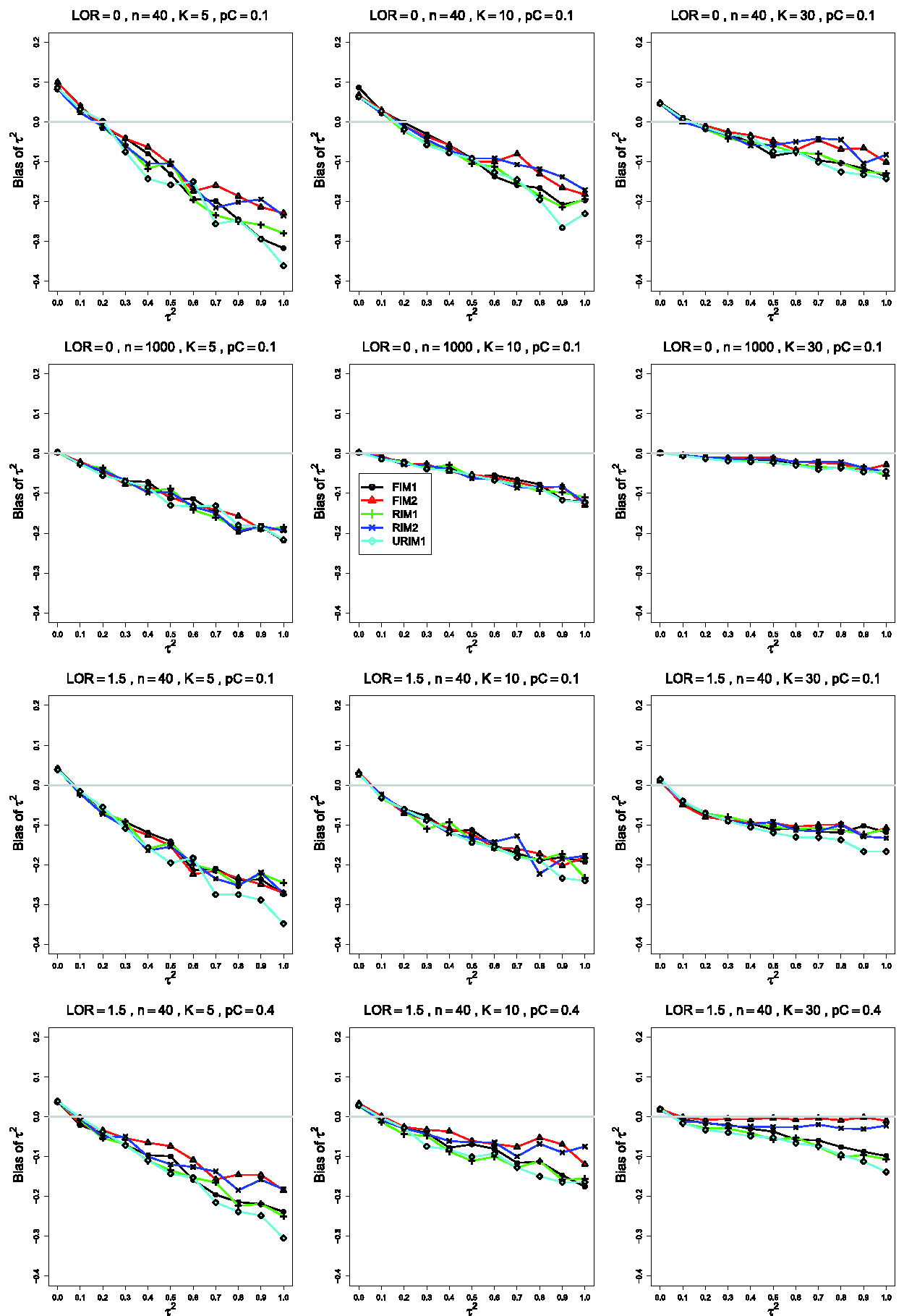
Bias in estimating the between-studies variance, , by for , θ = 0, (top row); θ = 0, (second row); (bottom two rows). Sample sizes are constant n =40 in the top three rows and uniformly distributed in the bottom row. The data-generation mechanisms are FIM1 (circle), FIM2 (triangle), RIM1 (plus), RIM2 (cross), and URIM1 (diamond). Light gray line at 0.
If the five data-generation mechanisms produce the same results, their traces in a plot coincide (except for minor variation). We focus on systematic departures from this null pattern (e.g. the traces separate into two groups). The specific performance measure may be important (e.g. an estimator has substantially greater bias when the data are generated by a certain mechanism). We generally give performance less emphasis, however, because our primary goal is to examine the consequences for inference of the choice of a data-generating method. Bakbergenuly et al.22 have studied in detail the performance under FIM1 of the estimators other than the GLMM estimators based on FIM2 and RIM2.
6.1 Bias of
The estimated bias of often varies among the data-generation mechanisms. In the most common single pattern, the traces versus form two clusters: one for FIM2 and RIM2 and another for FIM1, RIM1, and URIM1, as shown in the first row of Figure 1. When and , separations tend to become clearer as K increases, and they are most evident when K =30. As n increases, the traces flatten and coalesce around 0 bias, becoming essentially flat when . As θ increases, the traces for FIM2 and RIM2 merge with the others and then emerge below them, and the whole set of traces flattens toward 0.
Changing only pC, from .1 to .4 (Figure 2), produces traces that stay near 0. Groupings are not consistently visible. As θ increases, the reversal observed when (particularly when n =40 and K =30) does not occur. Instead, the separation between the traces for FIM2 and RIM2 and those for FIM1, RIM1, and URIM1 increases because the latter mechanisms produce larger negative bias as increases.
When the simulations use instead of , the most noticeable differences (when and and, especially, K =30) are substantially larger negative bias under URIM1 (compare the first two rows of Figure 1) and greater separation among the traces for the other mechanisms. The trace for URIM1 approaches the others as θ increases (compare the second and third rows of Figure 1). This change in produces little change in the patterns for .
Turning from the data-generation mechanisms to the bias, when and θ = 0, has positive bias for small to moderate values of and substantial negative bias when , increasing in . FIM1, RIM1 and URIM1 produce larger negative bias than FIM2 and RIM2 when n =40. When sample sizes increase to n =100, FIM2 and RIM2 have positive bias for , whereas for K =30, FIM2 and RIM2 have almost no bias. Differences between data-generation mechanisms disappear by n =250.
Negative bias at large decreases with increasing θ. When , K =5, and n =40, has a small positive bias, especially under RIM1, decreasing in K. For K =30, FIM1 produces almost no bias, and other mechanisms result in small negative bias. Bias is almost absent when .
When and θ = 0, has a small positive bias, somewhat increasing for larger . RIM2 and FIM2 produce somewhat more bias than the other mechanisms. When and , FIM2 and RIM2 produce almost no bias for K =30, and the rest produce negative bias for large . For , FIM2 and RIM2 produce positive bias, and FIM1, RIM1, and URIM1 produce positive bias for small to moderate values of and negative bias for large values.
6.2 Bias of the estimators ofin the FIM2 and RIM2 GLMMs
Having used the FIM2 and RIM2 data-generation mechanisms, we examine the performance of the estimators in those GLMMs (in this section and in Sections 6.4 and 6.7).
6.2.1 Bias of
For the bias of , departures of the traces from the null pattern generally occur when n =40 and occasionally when n =100. In the most common departure, at larger , the traces for FIM1, RIM1, and URIM1 form one group, and those for FIM2 and RIM2 form another, closer to 0, as in the first row of Figure 3. This pattern tends to become clearer as K increases; it occurs more often when K =30 than when K =10 or K =5.
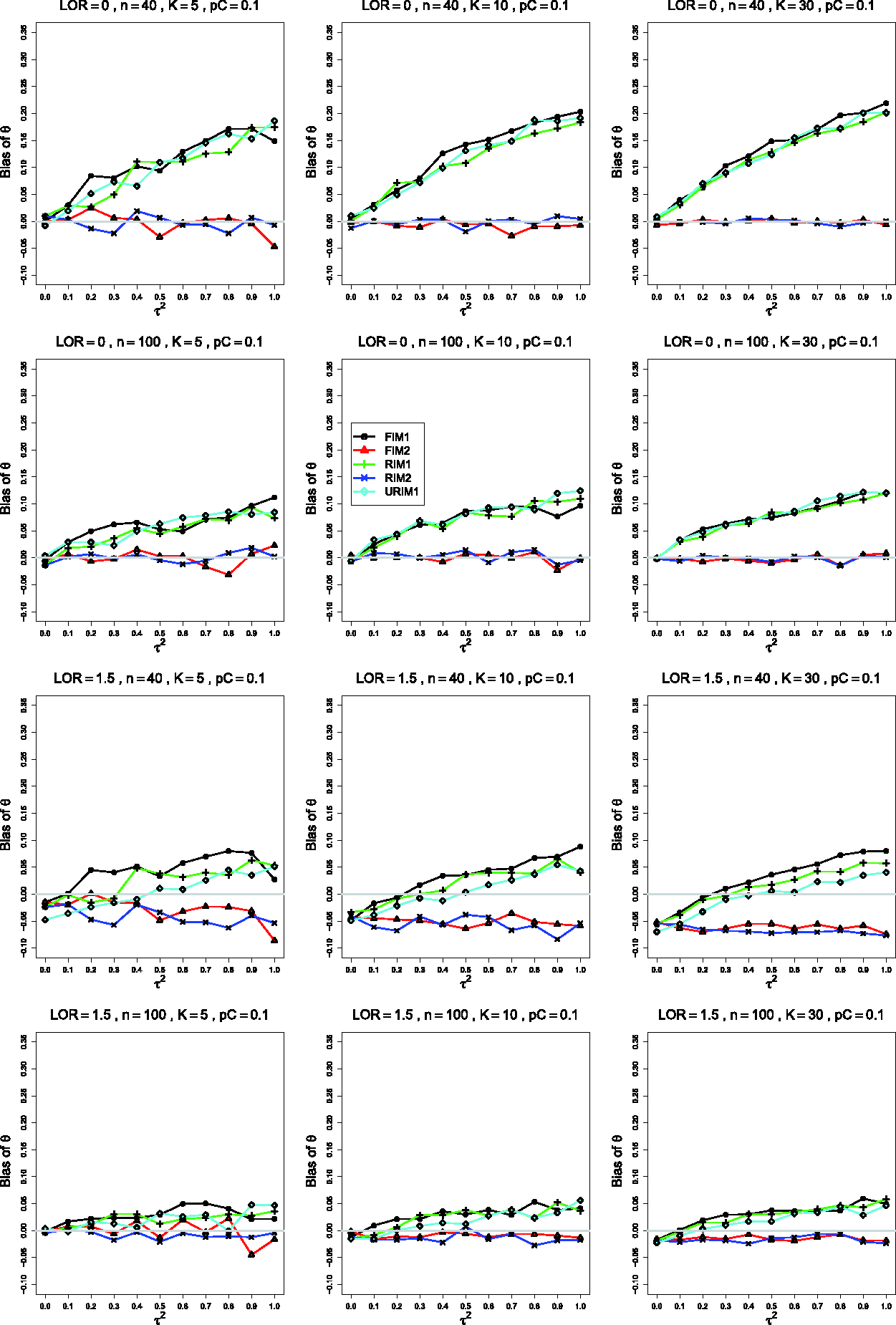
Bias of the estimator of the between-studies variance in the FIM2 GLMM for , θ = 0 (top two rows); (third row); (bottom row); constant sample sizes n =40 in rows 1, 3 and 4, and n =1000 in row 2. The data-generation mechanisms are FIM1 (circle), FIM2 (triangle), RIM1 (plus), RIM2 (cross), and URIM1 (diamond). Light gray line at 0.
The separation between FIM2 and RIM2 and FIM1, RIM1, and URIM1 tends to be clearer when than when (compare the third and fourth rows of Figure 3), and when than when . When , the traces tend to be closer together as θ increases, but increasing θ has the opposite effect when .
In some situations, particularly when , n =40, K =5, and is larger, the trace for URIM1 is visibly lower than the other traces (as in the third row of Figure 3).
The bias of under FIM2 and RIM2 relative to the other mechanisms (e.g. in the plot for K =30 in the fourth row of Figure 3) is consistent with fitting the same GLMM that generated the data and with the fact that FIM2 is a submodel of RIM2.
Except at small has negative bias, increasing with (as in the first row of Figure 3, where the bias exceeds –20% when ) but decreasing as K increases. The bias remains large when θ is larger. It is worst when K =5, even for n =1000 (second row of Figure 3). When n =40 and K =30 and (but not when ), is almost unbiased under FIM2 and RIM2 (compare the third and fourth rows of Figure 3).
6.2.2 Bias of
In summarizing the traces of the bias of , pC and n play a larger role than for . The pattern in which FIM2 and RIM2 form a group, above the rest (FIM1, RIM1, and URIM1), is readily evident whenever , and it extends to smaller (as in the fourth row of Figure 4). In addition to n =40 the pattern is generally present when n =100.
Bias of the estimator of the between-studies variance in the RIM2 GLMM for , θ = 0 (top two rows); (third row); (bottom row); constant sample sizes n =40 in rows 1, 3 and 4, and n =1000 in row 2. The data-generation mechanisms are FIM1 (circle), FIM2 (triangle), RIM1 (plus), RIM2 (cross), and URIM1 (diamond). Light gray line at 0.
If , the same pattern is visible when , θ = 0, K =30, and n is 100 and 250. When θ is larger and n =40, however, the traces follow a different, three-group pattern: FIM1 > RIM1/URIM1 > FIM2/RIM2 (as in the third row of Figure 4).
Contrary to what one might expect, the trace for RIM2 is not always closest to 0; indeed, it is sometimes fairly far from 0, particularly when K <30 (as in the third and fourth rows of Figure 4).
Similar to has substantial negative bias when K =5 or K =10. When K =30, is nearly unbiased under RIM2 and FIM2, particularly when .
6.3 Bias of
The other IV-weighted estimators of θ have bias patterns similar to those of .
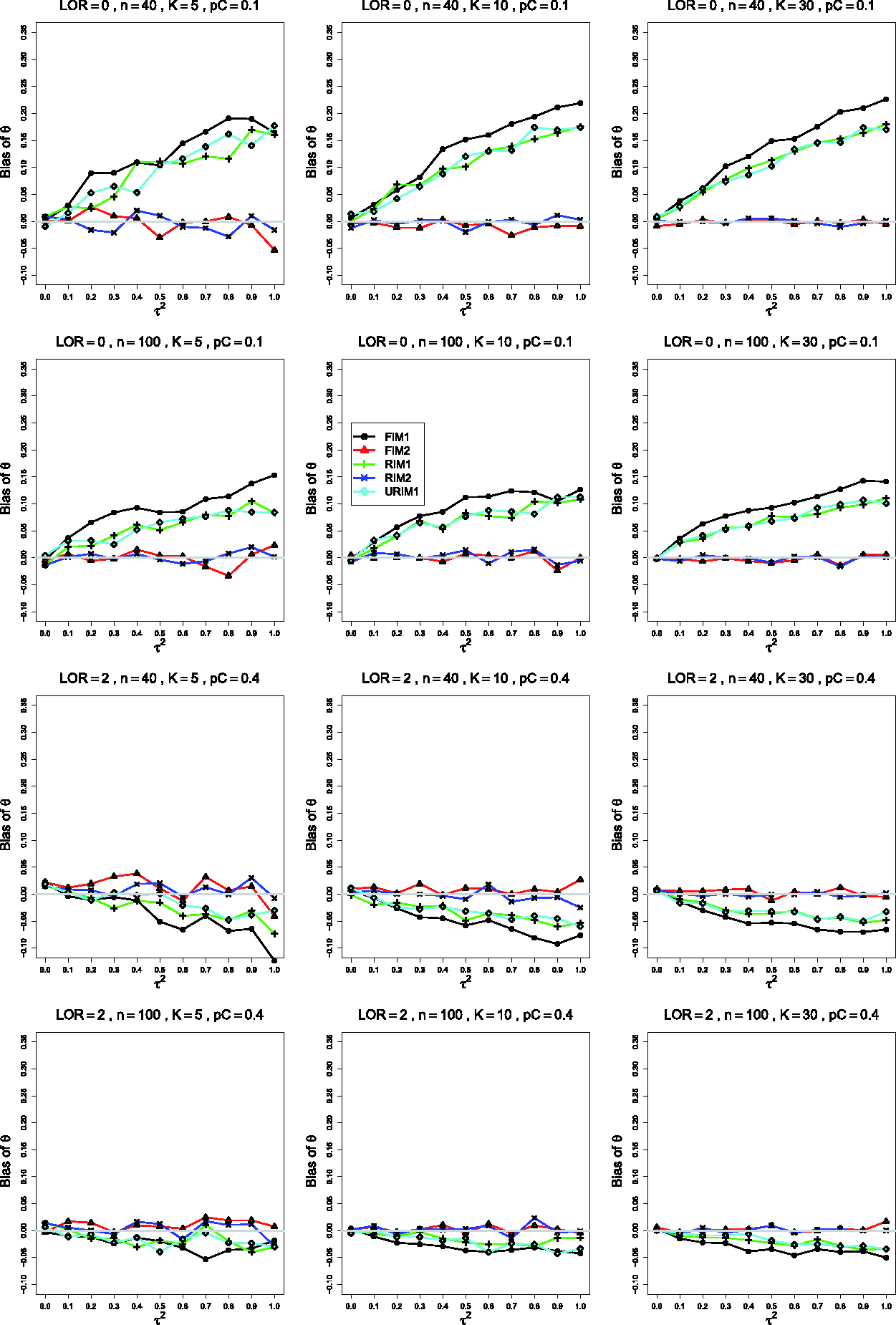
In the traces for the bias of , the patterns divide most clearly on pC. When , no plot for shows the null pattern, whereas when , departures from the null pattern are rare, occurring mainly when n =40 and K =30.
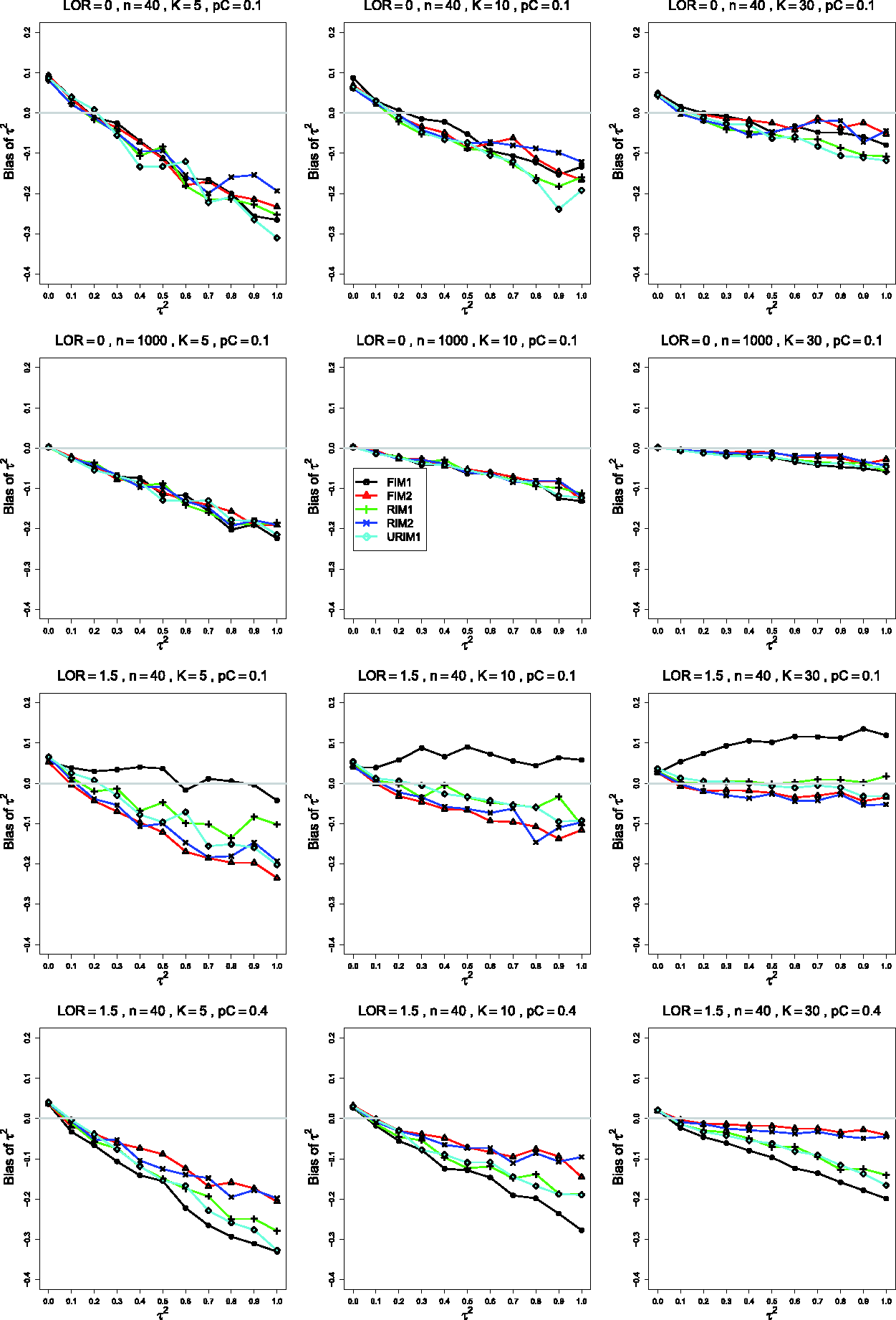
The first three rows of Figure 5 illustrate the behavior when . The traces for FIM2 and RIM2 form one group, in which the bias does not vary with ; and those for FIM1, RIM1, and URIM1 form a second group, in which the bias increases with . Under FIM2 and RIM2 is essentially unbiased when θ = 0 (as in the first row of Figure 5); but when , its bias is roughly −0.05 when n =40 (as in the third row of Figure 5), decreasing to nearly 0 when n =100. As n increases, the traces for FIM1, RIM1, and URIM1 flatten and also approach 0.
Bias in estimating the overall log-odds-ratio, θ, by for (top three rows); pC = .4, (bottom row), and constant sample sizes . Top two rows: θ = 0; bottom two rows: . The data-generation mechanisms are FIM1 (circle), FIM2 (triangle), RIM1 (plus), RIM2 (cross), and URIM1 (diamond). Light gray line at 0.
The fourth row of Figure 5 illustrates a situation, when , in which, for K =30, is nearly unbiased under FIM2 and RIM2 and has some negative bias under FIM1, RIM1, and URIM1, particularly when is larger. Other such situations involve θ = 0 or, mainly, θ = 2. Ordinarily, however, is essentially unbiased under all five data-generation mechanisms.
6.4 Bias of the estimators of θ in the FIM2 and RIM2 GLMMs
For the bias of and , the patterns of the traces in Figures 6 and 7 strongly resemble those for . When , both estimators are essentially unbiased under FIM2 and RIM2, except for bias of + 0.01 to + 0.03 in when and n =40. The behavior of the other group differs more clearly between and : when n =40 and n =100, usually has greater bias under FIM1 than under RIM1 or URIM1. (The plots for show a suggestion of this behavior.)
When , both and are usually unbiased under all five data-generation mechanisms. The exceptions arise mainly when n =40 (especially when K =30). When θ = 0, the traces for FIM1, RIM1, and URIM1 rise to around 0.02; when or θ = 2, those traces drop to around −0.02 or lower.
6.5 Bias of the SSW estimator of θ
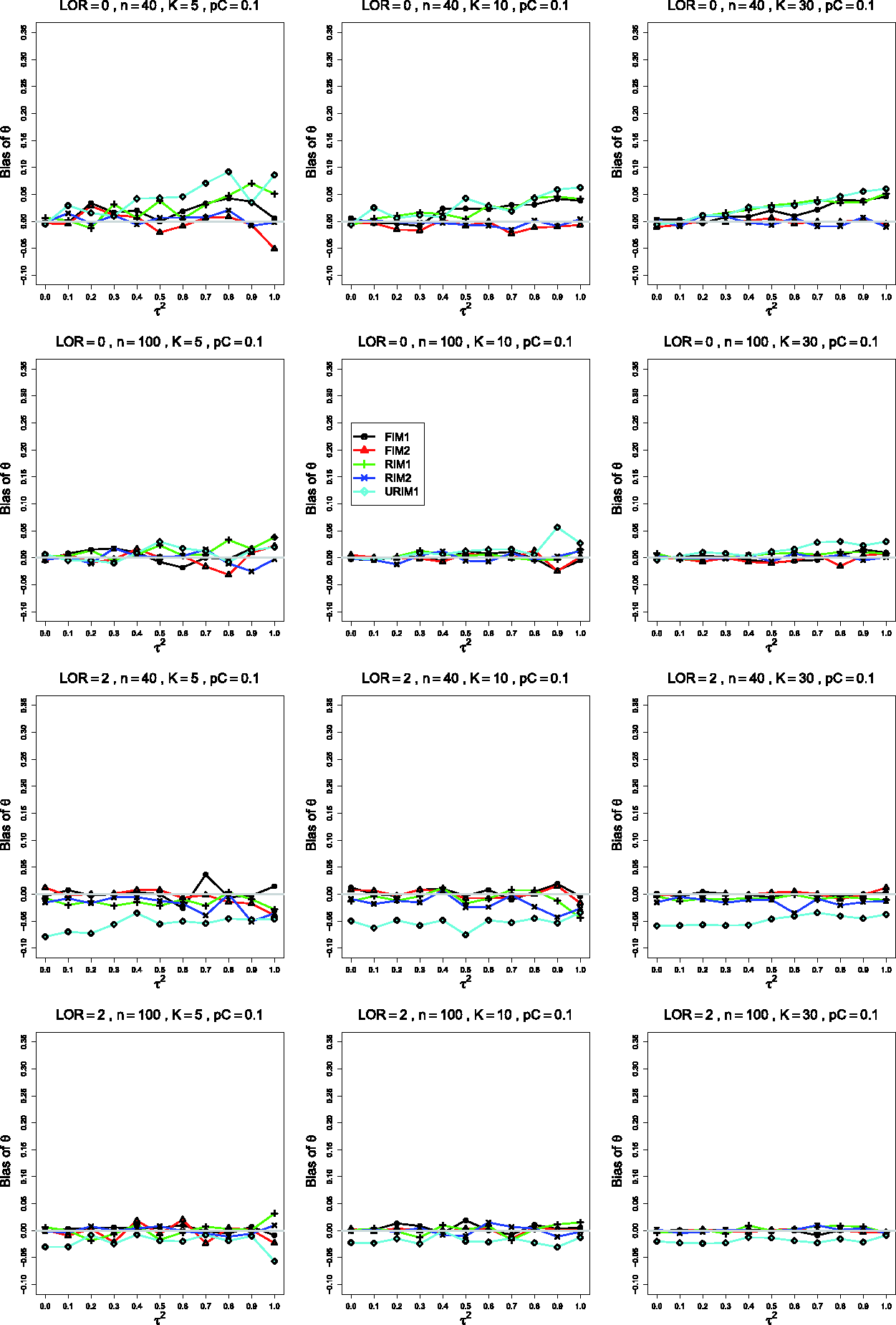
Only a few situations show bias in . Those involve . When θ = 0, n =40, and K =10 and 30, the traces for FIM1, RIM1, and URIM1 are positive, rising to around 0.05 as increases to 1 (first row of Figure 8).
A different pattern arises when θ = 2 and ; the trace for URIM1 is low, around −0.05 when n =40 (and K =5, 10, and 30) and around −0.02 when n =100 and K =30, shown in the third and fourth rows of Figure 8.
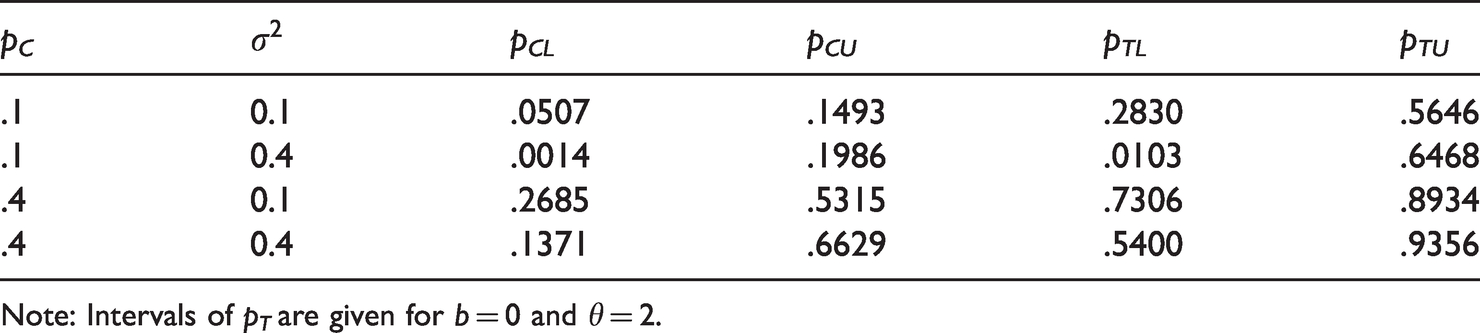
An explanation for this bias is that URIM1 may quite often produce extremely low or extremely high probabilities, as shown in Table 4. These probabilities may be even more extreme when is large. Then the relevant binomial distributions produce more zero or n values. Adding 0.5 to these data introduces the observed biases. This does not happen when because then the probabilities are far enough from 0 and 1.
Lower and upper bounds for piC (pCL and pCU) and for piT (pTL and pTU) values under URIM1.
pC
pCL
pCU
pTL
pTU
.1
0.1
.0507
.1493
.2830
.5646
.1
0.4
.0014
.1986
.0103
.6468
.4
0.1
.2685
.5315
.7306
.8934
.4
0.4
.1371
.6629
.5400
.9356
Note: Intervals of pT are given for b =0 and θ = 2.
6.6 Coverage of the confidence interval for θ centered at
The 95% confidence interval for θ centered at uses normal critical values. The coverage of the confidence intervals based on the other IV-weighted estimators of θ has similar patterns.
With few exceptions, the patterns of the traces for coverage of the confidence interval based on are similar for and . When K =5, all five start together above .95 at . For they decrease and then level off below .95 (as illustrated in Figure S1 in the Supplementary Material). As K increases, that level approaches .95, but increasing n has the opposite effect, producing coverage like that shown in the second row of Figure S1. Exceptions occur when θ = 0 and 0.5, , n =40, and K =10 and 30. Beyond a certain the traces separate into two groups; FIM2 and RIM2 level off around .95, and FIM1, RIM1, and URIM1 continue to decrease. Other, similar exceptions occur when θ = 0, , n =100, and K =30 and perhaps when θ = 2, , n =40, and K =30.
6.7 Coverage of the confidence intervals for θ from the FIM2 and RIM2 GLMMs
The coverage of the 95% confidence interval accompanying generally resembles that of the confidence interval based on (compare Figure S2 and Figure S1). The main difference is that for all values of θ, the traces in the plot for n =40 and K =30 separate into the two groups (as illustrated in the first row of Figure S2).
The coverage of the confidence interval accompanying has a surprising feature: When and n =40, the traces for the five data-generation mechanisms often differ substantially (as in the first and third rows of Figure S3). Coverage may be close to .95 when , but it can decline to .60 and below when . Coverage under FIM2 generally exceeds .90, and it improves as θ increases. When or , coverage of θ is similar to that from the FIM2 GLMM.
6.8 Coverage of the confidence interval centered at the SSW estimator of θ
In all situations in our simulations, the traces for the coverage of the confidence interval centered at follow the null pattern. This favorable result makes it easy to summarize the coverage itself.
Coverage of the SSW interval exceeds .95 for small values of . When , n =40, and K =5, coverage is still too high at (first row of Figure S4); this excess decreases somewhat when (third row of Figure S4). It decreases when K =10, and coverage is close to nominal when K =30. Coverage approaches nominal for lower values of as the sample size increases. For n =1000, coverage is above nominal only at (second and fourth rows of Figure S4). Coverage does not depend on or θ.
6.9 Summary
Our simulations explored two main components of design: the data-generation mechanism and the distribution of study-level sample sizes. As we mentioned earlier, the second of these had essentially no impact on bias of estimators of , bias of estimators of θ, or coverage of confidence intervals for θ.
The five data-generation mechanisms often produced different results for at least one of those measures of performance. In the most frequent pattern, FIM2 and RIM2 yield similar results, and FIM1, RIM1, and URIM1 also yield results that are similar but different from those of FIM2 and RIM2. In some situations, URIM1 stands apart (e.g., for the bias of and the bias of ), and so does FIM1 (for the bias of and the bias of ). For K =30 Figure S3 shows a particularly unusual pattern, in which the traces for the five data-generation mechanisms are mostly separate.
In summary, except for the coverage of the SSW confidence interval and, in most situations, the bias of , the choice of data-generation mechanism affects the results. These differences can complicate the process of integrating results from separate simulation studies.
7 Discussion
With the advent of powerful computers, the typical methodology paper in applied statistics has a standard structure. It proposes a new method, sometimes but not necessarily provides a mathematical derivation of its properties, and then uses simulation to demonstrate, usually successfully, that the new method is superior to previous methods.
Using methods for meta-analysis of odds ratios as an example, we aimed to compare various ways of generating data in simulations. In the literature, we identified five methods of generating odds ratios. We combined them with three methods of generating sample sizes, and we derived the statistical properties of inverse–variance–weighted estimators of the overall log-odds-ratio, θ, under these methods of data generation. In particular, we derived, to order , the biases and the variances of the inverse–variance–weighted estimators of θ.
We simulated data from the combinations of data-generation mechanism and sample-sizes method, and we compared the resulting estimates of the performance in estimating and θ of four methods of meta-analysis: inverse–variance weighting (represented by the Mandel-Paule method), the FIM2 and RIM2 GLMMs, and SSW (for θ only). Our results show that the properties of various methods and the recommendations on their use greatly depend on the data-generation mechanism.
Our theoretical derivations showed that, under FIM1/RIM1/URIM1, the IV-weighted estimators of θ should have positive bias for small values of and negative bias for . On the other hand, under FIM2/RIM2 these estimators should be approximately unbiased when θ = 0. Our simulations (Figure 5) confirmed these findings.
Importantly, results of our simulations also show very similar behavior for the FIM2 and RIM2 GLMM estimators of θ (Figures 6 and 7). This finding is not very astonishing. Regardless of the hype that concerns use of GLMMs in meta-analysis, GLMs (and GLMMs) are asymptotic methods. The maximum-likelihood equations used in GLMs for binary data (Section 4.4 in McCullagh and Nelder27) are weighted-least-squares equations with inverse–variance weights. For this reason, the GLMMs result in quite considerable biases in meta-analysis of odds-ratios, as demonstrated by our simulations and by Bakbergenuly and Kulinskaya.5
Bias of the estimator of the overall log-odds-ratio, θ, in the FIM2 GLMM when , constant sample sizes , and and θ = 0 (top two rows) or and θ = 2 (bottom two rows). The data-generation mechanisms are FIM1 (circle), FIM2 (triangle), RIM1 (plus), RIM2 (cross), and URIM1 (diamond). Light gray line at 0.
Bias of the estimator of the overall log-odds-ratio, θ, in the RIM2 GLMM when , constant sample sizes , and and θ = 0 (top two rows) or and θ = 2 (bottom two rows). The data-generation mechanisms are FIM1 (circle), FIM2 (triangle), RIM1 (plus), RIM2 (cross), and URIM1 (diamond). Light gray line at 0.
The SSW estimator of θ had considerably less bias, but even for this estimator the data-generation mechanism mattered, as URIM1 produced more-biased results (Figure 8).
Bias of the SSW estimator of the overall log-odds-ratio, θ, for , , and constant sample sizes . Top two rows, θ = 0; bottom two rows, θ = 2. The data-generation mechanisms are FIM1 (circle), FIM2 (triangle), RIM1 (plus), RIM2 (cross), and URIM1 (diamond). Light gray line at 0.
Differences in the behavior of moment-based estimators of such as under various data-generation mechanisms (Figures 1 and 2) have the same explanation as those for estimators of θ. These estimators are derived from the Q statistic, which is affected by the correlation between the effects and the weights.
Even though wider, t-based confidence intervals17,28,29 would somewhat improve coverage of θ, differences in coverage are due perhaps more to the centering of the intervals at very biased estimators. These biases are so large that they obscured the results of inflated variance in RIM methods. We also did not observe differences associated with random generation of sample sizes, perhaps because we used relatively tight intervals for them.
Finally, an interesting question is whether particular estimation methods work better when the data are generated exactly from the assumed model. Counterintuitively, the answer is no. In the majority of our simulations, generation under FIM2/RIM2 resulted in better estimation by all methods. But the RIM2 GLMM produced confidence intervals for θ that had much better coverage when the data were generated under FIM2, and really bad coverage otherwise.
What method(s) of meta-analysis should be used in practice, where we can never be certain of the true data-generating mechanism? In estimating θ, SSW provides the lowest biases and coverage that is correct but rather conservative and appears to be robust to the data-generation mechanism. This advantage will be shared by other methods that use constant weights.
As a more robust alternative in the two-stage random-effects model, Henmi and Copas30 and, independently, Stanley and Doucouliagos31 use an inverse–variance–weighted fixed-effect (FE) estimator as the center of the CI for θ. Our results show that the FE estimator of θ is also biased and will be affected by the simulation method.
Our findings are not surprising when put in a wider context. In pursuit of the effect of interest, we often neglect nuisance parameters that are sometimes only implicitly present in our models. However, when the sufficient statistics include these nuisance parameters, their distribution matters. Different distribution assumptions for the nuisance parameters should and do result in different properties of the estimators of interest. This influence directly parallels the effects of choice of prior distribution on the properties of the increasingly common Bayesian variants of the two-stage and GLM meta-analytic methods.8,32,33 One solution may be to try to develop minimax procedures that would minimize possible biases. Another solution is the use of procedures that are robust to a wide class of distributions for nuisance parameters.
We demonstrated substantial effects of data-generating mechanisms on the inference in meta-analysis of odds-ratios. These complications are not restricted to binary data, and they make it difficult to rely on any single simulation in choosing methods. Careful, resourceful effort may lead to a battery of designs that, collectively, approximates the mechanisms underlying the data in actual meta-analyses. In any event, simulations should be designed with the awareness of the possible effects of design choices, and quite a few recommendations may need to be revised.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802211013065 - Supplemental material for Exploring consequences of simulation design for apparent performance of methods of meta-analysis
Supplemental material, sj-pdf-1-smm-10.1177_09622802211013065 for Exploring consequences of simulation design for apparent performance of methods of meta-analysis by Elena Kulinskaya, David C. Hoaglin and Ilyas Bakbergenuly in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Economic and Social Research Council [grant number ES/L011859/1].
Data availability statement
Our full simulation results are available in Kulinskaya et al.25,26
ORCID iD
Elena Kulinskaya
Supplemental material
Supplemental material for this article is available online.
References
1.
KussO.Statistical methods for meta-analyses including information from studies without any events—add nothing to nothing and succeed nevertheless.Stat Med2015;
34: 1097–1116.
2.
TurnerRMOmarRZYangM, et al.
A multilevel model framework for meta-analysis of clinical trials with binary outcomes. Stat Med2000;
19: 3417–3432.
3.
StijnenTHamzaTHÖzdemirP.Random effects meta-analysis of event outcome in the framework of the generalized linear mixed model with applications in sparse data.Stat Med2010;
29: 3046–3067.
4.
JacksonDLawMStijnenT, et al.
A comparison of seven random-effects models for meta-analyses that estimate the summary odds ratio.Stat Med2018;
37: 1059–1085.
5.
BakbergenulyIKulinskayaE.Meta-analysis of binary outcomes via generalized linear mixed models: a simulation study.BMC Med Res Methodol2018;
18: 70.
6.
Piaget-RosselRTafféP.A pseudo-likelihood approach for the meta-analysis of homogeneous treatment effects: exploiting the information contained in single-arm and double-zero studies. J Stat: Adv Theory Appl2019;
21: 91–117.
7.
RiceKHigginsJPTLumleyT.A re-evaluation of fixed effect(s) meta-analysis. J Royal Stat Soc: Series A (Stat Soc)2018;
181: 205–227.
8.
DiasSSuttonAJAdesAE, et al.
Evidence synthesis for decision making 2: A generalized linear modeling framework for pairwise and network meta-analysis of randomized controlled trials.Med Decis Mak2013;
33: 607–617.
9.
SidikKJonkmanJN.A simple confidence interval for meta-analysis.Stat Med2002;
21: 3153–3159.
10.
PlattRWLerouxBGBreslowN.Generalized linear mixed models for meta-analysis. Stat Med1999;
18: 643–654.
11.
ChengJPullenayegumEMarshallJK, et al.
Impact of including or excluding both-armed zero-event studies on using standard meta-analysis methods for rare event outcome: a simulation study.BMJ Open2016;
6: e010983.
12.
Abo-ZaidGGuoBDeeksJJ, et al.
Individual participant data meta-analyses should not ignore clustering.J Clin Epidemiol2013;
66: 865–873.
13.
KosmidisIGuoloAVarinC.Improving the accuracy of likelihood-based inference in meta-analysis and meta-regression. Biometrika2017;
104: 489–496.
14.
LanganDHigginsJPTJacksonD, et al.
A comparison of heterogeneity variance estimators in simulated random-effects meta-analyses.Res Synthesis Meth2019;
10: 83–98.
15.
BakbergenulyIKulinskayaE.Beta-binomial model for meta-analysis of odds ratios.Stat Med2017;
36: 1715–1734.
16.
ViechtbauerW.Confidence intervals for the amount of heterogeneity in meta-analysis.Stat Med2007;
26: 37–52.
17.
SidikKJonkmanJN.A comparison of heterogeneity variance estimators in combining results of studies. Stat Med2007;
26: 1964–1981.
18.
NagashimaKNomaHFurukawaTA.Prediction intervals for random-effects meta-analysis: a confidence distribution approach.Stat Meth Med Res2019;
28: 1689–1702.
LiYShiLRothH.The bias of the commonly-used estimate of variance in meta-analysis. Commun Stat Theory Meth1994;
23: 1063–1085.
21.
GrubbströmRWTangO.The moments and central moments of a compound distribution. Eur J Operation Res2006;
170: 106–119.
22.
BakbergenulyIHoaglinDCKulinskayaE.Methods for estimating between-study variance and overall effect in meta-analysis of odds-ratios. Res Synthesis Meth2020;
11: 426–442.
23.
VeronikiAAJacksonDViechtbauerW, et al.
Methods to estimate the between-study variance and its uncertainty in meta-analysis.Res Synthesis Meth2016;
7: 55–79.
24.
ViechtbauerW.Conducting meta-analyses in R with the metafor package. J Stat Software2010;
36: 3.
25.
KulinskayaEHoaglinDCBakbergenulyI. Exploring consequences of simulation design for apparent performance of statistical methods. 1: Results from simulations with constant sample sizes, 2020. eprint arXiv: 2006.16638 [stat.ME].
26.
KulinskayaEHoaglinDCBakbergenulyI. Exploring consequences of simulation design for apparent performance of statistical methods. 2: Results from simulations with normally and uniformly distributed sample sizes. eprint arXiv: 2007.05354 [stat.ME].
HartungJKnappG.A refined method for the meta-analysis of controlled clinical trials with binary outcome.Stat Med2001;
20: 3875–3889.
29.
RöverCKnappGFriedeT.Hartung-Knapp-Sidik-Jonkman approach and its modification for random-effects meta-analysis with few studies.BMC Med Res Methodol2015;
15: 99.
30.
HenmiMCopasJB.Confidence intervals for random effects meta-analysis and robustness to publication bias. Stat Med2010;
29: 2969–2983.
31.
StanleyTDDoucouliagosH.Neither fixed nor random: weighted least squares meta-analysis.Stat Med2015;
34: 2116–2127.
32.
FriedeTRöverCWandelS, et al.
Meta-analysis of few small studies in orphan diseases.Res Synthesis Meth2017;
8: 79–91.
33.
TurnerRMJacksonDWeiY, et al.
Predictive distributions for between-study heterogeneity and simple methods for their application in Bayesian meta-analysis. Stat Med2015;
34: 984–998.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.